Kubernetes: Need simple kubectl command to see cluster resource usage
Users are getting tripped up by pods not being able to schedule due to resource deficiencies. It can be hard to know when a pod is pending because it just hasn't started up yet, or because the cluster doesn't have room to schedule it. http://kubernetes.io/v1.1/docs/user-guide/compute-resources.html#monitoring-compute-resource-usage helps, but isn't that discoverable (I tend to try a 'get' on a pod in pending first, and only after waiting a while and seeing it 'stuck' in pending, do I use 'describe' to realize it's a scheduling problem).
This is also complicated by system pods being in a namespace that is hidden. Users forget that those pods exist, and 'count against' cluster resources.
There are several possible fixes offhand, I don't know what would be ideal:
1) Develop a new pod state other than Pending to represent "tried to schedule and failed for lack of resources".
2) Have kubectl get po or kubectl get po -o=wide display a column to detail why something is pending (perhaps the container.state that is Waiting in this case, or the most recent event.message).
3) Create a new kubectl command to more easily describe resources. I'm imagining a "kubectl usage" that gives an overview of total cluster CPU and Mem, per node CPU and Mem and each pod/container's usage. Here we would include all pods, including system ones. This might be useful long term alongside more complex schedulers, or when your cluster has enough resources but no single node does (diagnosing the 'no holes large enough' problem).
 goltermann
goltermann
All 88 comments
Something along the lines of (2) seems reasonable, though the UX folks would know better than me.
(3) seems vaguely related to #15743 but I'm not sure they're close enough to combine.
 davidopp
on 20 Nov 2015
davidopp
on 20 Nov 2015
In addition to the case above, it would be nice to see what resource utilization we're getting.
kubectl utilization requests might show (maybe kubectl util or kubectl usage are better/shorter):
cores: 4.455/5 cores (89%)
memory: 20.1/30 GiB (67%)
...
In this example, the aggregate container requests are 4.455 cores and 20.1 GiB and there are 5 cores and 30GiB total in the cluster.
 chrishiestand
on 16 Sep 2016
chrishiestand
on 16 Sep 2016
There is:
$ kubectl top nodes
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
cluster1-k8s-master-1 312m 15% 1362Mi 68%
cluster1-k8s-node-1 124m 12% 233Mi 11%
 xmik
on 19 Dec 2016
xmik
on 19 Dec 2016
I use below command to get a quick view for the resource usage. It is the simplest way I found.
kubectl describe nodes
 ozbillwang
on 11 Jan 2017
ozbillwang
on 11 Jan 2017
If there was a way to "format" the output of kubectl describe nodes, I wouldn't mind scripting my way to summarize all node's resource requests/limits.
 tonglil
on 20 Jan 2017
tonglil
on 20 Jan 2017
here is my hack kubectl describe nodes | grep -A 2 -e "^\\s*CPU Requests"
 from-nibly
on 2 Feb 2017
from-nibly
on 2 Feb 2017
@from-nibly thanks, just what i was looking for
 jredl-va
on 25 May 2017
jredl-va
on 25 May 2017
Yup, this is mine:
$ cat bin/node-resources.sh
#!/bin/bash
set -euo pipefail
echo -e "Iterating...\n"
nodes=$(kubectl get node --no-headers -o custom-columns=NAME:.metadata.name)
for node in $nodes; do
echo "Node: $node"
kubectl describe node "$node" | sed '1,/Non-terminated Pods/d'
echo
done
@goltermann There are no sig labels on this issue. Please add a sig label by:
(1) mentioning a sig: @kubernetes/sig-<team-name>-misc
(2) specifying the label manually: /sig <label>
_Note: method (1) will trigger a notification to the team. You can find the team list here._
 k8s-github-robot
on 1 Jun 2017
k8s-github-robot
on 1 Jun 2017
@kubernetes/sig-cli-misc
 kargakis
on 10 Jun 2017
kargakis
on 10 Jun 2017
You can use the below command to find the percentage cpu utlisation of your nodes
alias util='kubectl get nodes | grep node | awk '\''{print $1}'\'' | xargs -I {} sh -c '\''echo {} ; kubectl describe node {} | grep Allocated -A 5 | grep -ve Event -ve Allocated -ve percent -ve -- ; echo '\'''
Note: 4000m cores is the total cores in one node
alias cpualloc="util | grep % | awk '{print \$1}' | awk '{ sum += \$1 } END { if (NR > 0) { result=(sum**4000); printf result/NR \"%\n\" } }'"
$ cpualloc
3.89358%
Note: 1600MB is the total cores in one node
alias memalloc='util | grep % | awk '\''{print $3}'\'' | awk '\''{ sum += $1 } END { if (NR > 0) { result=(sum*100)/(NR*1600); printf result/NR "%\n" } }'\'''
$ memalloc
24.6832%
 alok87
on 5 Jul 2017
alok87
on 5 Jul 2017
@tomfotherby alias util='kubectl get nodes | grep node | awk '\''{print $1}'\'' | xargs -I {} sh -c '\''echo {} ; kubectl describe node {} | grep Allocated -A 5 | grep -ve Event -ve Allocated -ve percent -ve -- ; echo '\'''
alok87
on 21 Jul 2017
@alok87 - Thanks for your aliases. In my case, this is what worked for me given that we use bash and m3.large instance types (2 cpu , 7.5G memory).
alias util='kubectl get nodes --no-headers | awk '\''{print $1}'\'' | xargs -I {} sh -c '\''echo {} ; kubectl describe node {} | grep Allocated -A 5 | grep -ve Event -ve Allocated -ve percent -ve -- ; echo '\'''
# Get CPU request total (we x20 because because each m3.large has 2 vcpus (2000m) )
alias cpualloc='util | grep % | awk '\''{print $1}'\'' | awk '\''{ sum += $1 } END { if (NR > 0) { print sum/(NR*20), "%\n" } }'\'''
# Get mem request total (we x75 because because each m3.large has 7.5G ram )
alias memalloc='util | grep % | awk '\''{print $5}'\'' | awk '\''{ sum += $1 } END { if (NR > 0) { print sum/(NR*75), "%\n" } }'\'''
$util
ip-10-56-0-178.ec2.internal
CPU Requests CPU Limits Memory Requests Memory Limits
960m (48%) 2700m (135%) 630Mi (8%) 2034Mi (27%)
ip-10-56-0-22.ec2.internal
CPU Requests CPU Limits Memory Requests Memory Limits
920m (46%) 1400m (70%) 560Mi (7%) 550Mi (7%)
ip-10-56-0-56.ec2.internal
CPU Requests CPU Limits Memory Requests Memory Limits
1160m (57%) 2800m (140%) 972Mi (13%) 3976Mi (53%)
ip-10-56-0-99.ec2.internal
CPU Requests CPU Limits Memory Requests Memory Limits
804m (40%) 794m (39%) 824Mi (11%) 1300Mi (17%)
cpualloc
48.05 %
$ memalloc
9.95333 %
 tomfotherby
on 25 Jul 2017
tomfotherby
on 25 Jul 2017
https://github.com/kubernetes/kubernetes/issues/17512#issuecomment-267992922 kubectl top shows usage, not allocation. Allocation is what causes the insufficient CPU problem. There's a ton of confusion in this issue about the difference.
AFAICT, there's no easy way to get a report of node CPU allocation by pod, since requests are per container in the spec. And even then, it's difficult since .spec.containers[*].requests may or may not have the limits/requests fields (in my experience)
 nfirvine
on 30 Aug 2017
nfirvine
on 30 Aug 2017
/cc @misterikkit
 misterikkit
on 2 Jan 2018
misterikkit
on 2 Jan 2018
Getting in on this shell scripting party. I have an older cluster running the CA with scale down disabled. I wrote this script to determine roughly how much I can scale down the cluster when it starts to bump up on its AWS route limits:
#!/bin/bash
set -e
KUBECTL="kubectl"
NODES=$($KUBECTL get nodes --no-headers -o custom-columns=NAME:.metadata.name)
function usage() {
local node_count=0
local total_percent_cpu=0
local total_percent_mem=0
local readonly nodes=$@
for n in $nodes; do
local requests=$($KUBECTL describe node $n | grep -A2 -E "^\\s*CPU Requests" | tail -n1)
local percent_cpu=$(echo $requests | awk -F "[()%]" '{print $2}')
local percent_mem=$(echo $requests | awk -F "[()%]" '{print $8}')
echo "$n: ${percent_cpu}% CPU, ${percent_mem}% memory"
node_count=$((node_count + 1))
total_percent_cpu=$((total_percent_cpu + percent_cpu))
total_percent_mem=$((total_percent_mem + percent_mem))
done
local readonly avg_percent_cpu=$((total_percent_cpu / node_count))
local readonly avg_percent_mem=$((total_percent_mem / node_count))
echo "Average usage: ${avg_percent_cpu}% CPU, ${avg_percent_mem}% memory."
}
usage $NODES
Produces output like:
ip-REDACTED.us-west-2.compute.internal: 38% CPU, 9% memory
...many redacted lines...
ip-REDACTED.us-west-2.compute.internal: 41% CPU, 8% memory
ip-REDACTED.us-west-2.compute.internal: 61% CPU, 7% memory
Average usage: 45% CPU, 15% memory.
 negz
on 21 Feb 2018
negz
on 21 Feb 2018
There is also pod option in top command:
kubectl top pod
 ylogx
on 21 Feb 2018
ylogx
on 21 Feb 2018
@ylogx https://github.com/kubernetes/kubernetes/issues/17512#issuecomment-326089708
nfirvine
on 21 Feb 2018
My way to obtain the allocation, cluster-wide:
$ kubectl get po --all-namespaces -o=jsonpath="{range .items[*]}{.metadata.namespace}:{.metadata.name}{'\n'}{range .spec.containers[*]} {.name}:{.resources.requests.cpu}{'\n'}{end}{'\n'}{end}"
It produces something like:
kube-system:heapster-v1.5.0-dc8df7cc9-7fqx6
heapster:88m
heapster-nanny:50m
kube-system:kube-dns-6cdf767cb8-cjjdr
kubedns:100m
dnsmasq:150m
sidecar:10m
prometheus-to-sd:
kube-system:kube-dns-6cdf767cb8-pnx2g
kubedns:100m
dnsmasq:150m
sidecar:10m
prometheus-to-sd:
kube-system:kube-dns-autoscaler-69c5cbdcdd-wwjtg
autoscaler:20m
kube-system:kube-proxy-gke-cluster1-default-pool-cd7058d6-3tt9
kube-proxy:100m
kube-system:kube-proxy-gke-cluster1-preempt-pool-57d7ff41-jplf
kube-proxy:100m
kube-system:kubernetes-dashboard-7b9c4bf75c-f7zrl
kubernetes-dashboard:50m
kube-system:l7-default-backend-57856c5f55-68s5g
default-http-backend:10m
kube-system:metrics-server-v0.2.0-86585d9749-kkrzl
metrics-server:48m
metrics-server-nanny:5m
kube-system:tiller-deploy-7794bfb756-8kxh5
tiller:10m
 shtouff
on 4 Mar 2018
shtouff
on 4 Mar 2018
This is weird. I want to know when I'm at or nearing allocation capacity. It seems a pretty basic function of a cluster. Whether it's a statistic that shows a high % or textual error... how do other people know this? Just always use autoscaling on a cloud platform?
 kierenj
on 13 Mar 2018
kierenj
on 13 Mar 2018
I authored https://github.com/dpetzold/kube-resource-explorer/ to address #3. Here is some sample output:
$ ./resource-explorer -namespace kube-system -reverse -sort MemReq
Namespace Name CpuReq CpuReq% CpuLimit CpuLimit% MemReq MemReq% MemLimit MemLimit%
--------- ---- ------ ------- -------- --------- ------ ------- -------- ---------
kube-system event-exporter-v0.1.7-5c4d9556cf-kf4tf 0 0% 0 0% 0 0% 0 0%
kube-system kube-proxy-gke-project-default-pool-175a4a05-mshh 100m 10% 0 0% 0 0% 0 0%
kube-system kube-proxy-gke-project-default-pool-175a4a05-bv59 100m 10% 0 0% 0 0% 0 0%
kube-system kube-proxy-gke-project-default-pool-175a4a05-ntfw 100m 10% 0 0% 0 0% 0 0%
kube-system kube-dns-autoscaler-244676396-xzgs4 20m 2% 0 0% 10Mi 0% 0 0%
kube-system l7-default-backend-1044750973-kqh98 10m 1% 10m 1% 20Mi 0% 20Mi 0%
kube-system kubernetes-dashboard-768854d6dc-jh292 100m 10% 100m 10% 100Mi 3% 300Mi 11%
kube-system kube-dns-323615064-8nxfl 260m 27% 0 0% 110Mi 4% 170Mi 6%
kube-system fluentd-gcp-v2.0.9-4qkwk 100m 10% 0 0% 200Mi 7% 300Mi 11%
kube-system fluentd-gcp-v2.0.9-jmtpw 100m 10% 0 0% 200Mi 7% 300Mi 11%
kube-system fluentd-gcp-v2.0.9-tw9vk 100m 10% 0 0% 200Mi 7% 300Mi 11%
kube-system heapster-v1.4.3-74b5bd94bb-fz8hd 138m 14% 138m 14% 301856Ki 11% 301856Ki 11%
 dpetzold
on 2 May 2018
dpetzold
on 2 May 2018
@shtouff
root@debian9:~# kubectl get po -n chenkunning-84 -o=jsonpath="{range .items[*]}{.metadata.namespace}:{.metadata.name}{'\n'}{range .spec.containers[*]} {.name}:{.resources.requests.cpu}{'\n'}{end}{'\n'}{end}"
error: error parsing jsonpath {range .items[*]}{.metadata.namespace}:{.metadata.name}{'\n'}{range .spec.containers[*]} {.name}:{.resources.requests.cpu}{'\n'}{end}{'\n'}{end}, unrecognized character in action: U+0027 '''
root@debian9:~# kubectl version
Client Version: version.Info{Major:"1", Minor:"6+", GitVersion:"v1.6.7-beta.0+$Format:%h$", GitCommit:"bb053ff0cb25a043e828d62394ed626fda2719a1", GitTreeState:"dirty", BuildDate:"2017-08-26T09:34:19Z", GoVersion:"go1.8", Compiler:"gc", Platform:"linux/amd64"}
Server Version: version.Info{Major:"1", Minor:"6+", GitVersion:"v1.6.7-beta.0+$Format:84c3ae0384658cd40c1d1e637f5faa98cf6a965c$", GitCommit:"3af2004eebf3cbd8d7f24b0ecd23fe4afb889163", GitTreeState:"clean", BuildDate:"2018-04-04T08:40:48Z", GoVersion:"go1.8.1", Compiler:"gc", Platform:"linux/amd64"}
 harryge00
on 22 May 2018
harryge00
on 22 May 2018
@harryge00: U+0027 is a curly quote, probably a copy-paste problem
nfirvine
on 22 May 2018
@nfirvine Thanks! I have solved problem by using:
kubectl get pods -n my-ns -o=jsonpath='{range .items[*]}{.metadata.name}{"\t"}{.spec.containers[0].resources.limits.cpu} {"\n"}{end}' |awk '{sum+=$2 ; print $0} END{print "sum=",sum}'
It works for namespaces whose pods only containing 1 container each.
harryge00
on 25 May 2018
@xmik Hey, I'm using k8 1.7 and running hepaster. When I run $ kubectl top nodes --heapster-namespace=kube-system, it shows me "error: metrics not available yet". Any clue for tackling the error?
 abushoeb
on 5 Jun 2018
abushoeb
on 5 Jun 2018
@abushoeb:
I don't thinkEdit: this flag is supported, you were right: https://github.com/kubernetes/kubernetes/issues/44540#issuecomment-362882035 .kubectl topsupports flag:--heapster-namespace.- If you see "error: metrics not available yet", then you should check heapster deployment. What its logs say? Is the heapster service ok, endpoints are not
<none>? Check the latter with a command like:kubectl -n kube-system describe svc/heapster
xmik
on 5 Jun 2018
@xmik you are right, the heapster wasn't configured properly. Thanks a lot. It's working now. Do you know if there is a way to get real-time GPU usage information? This top command only gives CPU and Memory usage.
abushoeb
on 5 Jun 2018
I don't know that. :(
xmik
on 5 Jun 2018
@abushoeb I am getting the same error "error: metrics not available yet" . How did you fix it?
 avgKol
on 21 Jun 2018
avgKol
on 21 Jun 2018
@avgKol check you heapster deployment first. In my case, it was not deployed properly. One way to check it is to access metrics via CURL command like curl -L http://heapster-pod-ip:heapster-service-port/api/v1/model/metrics/. If it doesn't show metrics then check the heapster pod and logs. The hepster metrics can be accessed via a web browser too like this.
abushoeb
on 22 Jun 2018
If anybody is interested, I created a tool to generate static HTML for Kubernetes resource usage (and costs): https://github.com/hjacobs/kube-resource-report
 hjacobs
on 18 Jul 2018
hjacobs
on 18 Jul 2018
@hjacobs I would like to use that tool but not a fan of installing/using python packages. Mind packaging it up as a docker image?
tonglil
on 18 Jul 2018
@tonglil the project is pretty early, but my plan is to have an out-of-the-box ready Docker image incl. webserver which you can just do kubectl apply -f .. with.
hjacobs
on 18 Jul 2018
Here is what worked for me:
kubectl get nodes -o=jsonpath="{range .items[*]}{.metadata.name}{'\t'}{.status.allocatable.memory}{'\t'}{.status.allocatable.cpu}{'\n'}{end}"
It shows output as:
ip-192-168-101-177.us-west-2.compute.internal 251643680Ki 32
ip-192-168-196-254.us-west-2.compute.internal 251643680Ki 32
 arun-gupta
on 12 Sep 2018
arun-gupta
on 12 Sep 2018
@tonglil a Docker image is now available: https://github.com/hjacobs/kube-resource-report
hjacobs
on 13 Sep 2018
Issues go stale after 90d of inactivity.
Mark the issue as fresh with /remove-lifecycle stale.
Stale issues rot after an additional 30d of inactivity and eventually close.
If this issue is safe to close now please do so with /close.
Send feedback to sig-testing, kubernetes/test-infra and/or fejta.
/lifecycle stale
 fejta-bot
on 17 Dec 2018
fejta-bot
on 17 Dec 2018
/remove-lifecycle stale
Every month or so, my Googling leads me back to this issue. There are ways of getting the statistics I need with long jq strings, or with Grafana dashboards with a bunch of calculations... but it would be _so_ nice if there were a command like:
# kubectl utilization cluster
cores: 19.255/24 cores (80%)
memory: 16.4/24 GiB (68%)
# kubectl utilization [node name]
cores: 3.125/4 cores (78%)
memory: 2.1/4 GiB (52%)
(similar to what @chrishiestand mentioned way earlier in the thread).
I am often building and destroying a few dozen test clusters per week, and I'd rather not have to build automation or add in some shell aliases to be able to just see "if I put this many servers out there, and toss these apps on them, what is my overall utilization/pressure".
Especially for smaller / more esoteric clusters, I don't want to set up autoscale-to-the-moon (usually for money reasons), but do need to know if I have enough overhead to handle minor pod autoscaling events.
 geerlingguy
on 30 Dec 2018
geerlingguy
on 30 Dec 2018
One additional request -- I'd like to be able to see summed resource usage by namespace (at a minimum; by Deployment/label would also be useful), so I can focus my resource-trimming efforts by figuring out which namespaces are worth concentrating on.
 evankanderson
on 1 Jan 2019
evankanderson
on 1 Jan 2019
I made a small plugin kubectl-view-utilization, that provides functionality @geerlingguy described. Installation via krew plugin manager is available. This is implemented in BASH and it needs awk and bc.
With kubectl plugin framework this could be completely abstracted away from core tools.
 etopeter
on 13 Jan 2019
etopeter
on 13 Jan 2019
I am glad others were also facing this challenge. I created Kube Eagle (a prometheus exporter) which helped me gaining a better overview of cluster resources and ultimately let me better utilize the available hardware resources:
https://github.com/google-cloud-tools/kube-eagle

 weeco
on 3 Mar 2019
weeco
on 3 Mar 2019
This is a python script to get the actual node utilization in table format
https://github.com/amelbakry/kube-node-utilization
Kubernetes Node Utilization..........
+------------------------------------------------+--------+--------+
| NodeName | CPU | Memory |
+------------------------------------------------+--------+--------+
| ip-176-35-32-139.eu-central-1.compute.internal | 13.49% | 60.87% |
| ip-176-35-26-21.eu-central-1.compute.internal | 5.89% | 15.10% |
| ip-176-35-9-122.eu-central-1.compute.internal | 8.08% | 65.51% |
| ip-176-35-22-243.eu-central-1.compute.internal | 6.29% | 19.28% |
+------------------------------------------------+--------+--------+
 amelbakry
on 24 Apr 2019
amelbakry
on 24 Apr 2019
For me at least @amelbakry it's cluster-level utilisation that's important: "do I need to add more machines?" / "should I remove some machines?" / "should I expect the cluster to scale up soon?" ..
kierenj
on 25 Apr 2019
What about ephemeral storage usage? Any ideas how to get it from all pods?
And to be useful, my hints:
kubectl get pods -o json -n kube-system | jq -r '.items[] | .metadata.name + " \n Req. RAM: " + .spec.containers[].resources.requests.memory + " \n Lim. RAM: " + .spec.containers[].resources.limits.memory + " \n Req. CPU: " + .spec.containers[].resources.requests.cpu + " \n Lim. CPU: " + .spec.containers[].resources.limits.cpu + " \n Req. Eph. DISK: " + .spec.containers[].resources.requests["ephemeral-storage"] + " \n Lim. Eph. DISK: " + .spec.containers[].resources.limits["ephemeral-storage"] + "\n"'
...
kube-proxy-xlmjt
Req. RAM: 32Mi
Lim. RAM: 256Mi
Req. CPU: 100m
Lim. CPU:
Req. Eph. DISK: 100Mi
Lim. Eph. DISK: 512Mi
...
echo "\nRAM Requests TOTAL:" && kubectl describe namespace kube-system | grep 'requests.memory' && echo "\nRAM Requests:\n" && kubectl get pods -o json -n kube-system | jq -r '.items[] | .spec.containers[].resources.requests.memory + " | " + .metadata.name'
echo "\nRAM Limits TOTAL:" && kubectl describe namespace kube-system | grep 'limits.memory' && echo "\nRAM Limits:\n" && kubectl get pods -o json -n kube-system | jq -r '.items[] | .spec.containers[].resources.limits.memory + " | " + .metadata.name'
echo "\nCPU Requests TOTAL:" && kubectl describe namespace kube-system | grep 'requests.cpu' && echo "\nCPU Requests:\n" && kubectl get pods -o json -n kube-system | jq -r '.items[] | .spec.containers[].resources.requests.cpu + " | " + .metadata.name'
echo "\nCPU Limits TOTAL:" && kubectl describe namespace kube-system | grep 'limits.cpu' && echo "\nCPU Limits:\n" && kubectl get pods -o json -n kube-system | jq -r '.items[] | .spec.containers[].resources.limits.cpu + " | " + .metadata.name'
echo "\nEph. DISK Requests TOTAL:" && kubectl describe namespace kube-system | grep 'requests.ephemeral-storage' && echo "\nEph. DISK Requests:\n" && kubectl get pods -o json -n kube-system | jq -r '.items[] | .spec.containers[].resources.requests["ephemeral-storage"] + " | " + .metadata.name'
echo "\nEph. DISK Limits TOTAL:" && kubectl describe namespace kube-system | grep 'limits.ephemeral-storage' && echo "\nEph. DISK Limits:\n" && kubectl get pods -o json -n kube-system | jq -r '.items[] | .spec.containers[].resources.limits["ephemeral-storage"] + " | " + .metadata.name'
RAM Requests TOTAL:
requests.memory 3504Mi 16Gi
RAM Requests:
64Mi | aws-alb-ingress-controller-6b569b448c-jzj6f
...
 kivagant-ba
on 25 Apr 2019
kivagant-ba
on 25 Apr 2019
@kivagant-ba you can try this snipt to get pod metrics per node, you can get all nodes like
https://github.com/amelbakry/kube-node-utilization
def get_pod_metrics_per_node(node):
pod_metrics = "/api/v1/pods?fieldSelector=spec.nodeName%3D" + node
response = api_client.call_api(pod_metrics,
'GET', auth_settings=['BearerToken'],
response_type='json', _preload_content=False)
response = json.loads(response[0].data.decode('utf-8'))
return response
amelbakry
on 25 Apr 2019
@kierenj I think the cluster-autoscaler component based on which cloud kubernetes is running should handle the capacity. not sure if this is your question.
amelbakry
on 25 Apr 2019
Issues go stale after 90d of inactivity.
Mark the issue as fresh with /remove-lifecycle stale.
Stale issues rot after an additional 30d of inactivity and eventually close.
If this issue is safe to close now please do so with /close.
Send feedback to sig-testing, kubernetes/test-infra and/or fejta.
/lifecycle stale
fejta-bot
on 30 Jul 2019
/remove-lifecycle stale
I, like many others, keep coming back here - for years - to get the hack we need to manage the clusters via CLI (e.g. AWS ASGs)
 eduncan911
on 28 Aug 2019
eduncan911
on 28 Aug 2019
@etopeter Thank you for such a cool CLI plugin. Love the simplicity of it. Any advice on how to better understand the numbers and their exact meaning?
 demisx
on 28 Aug 2019
demisx
on 28 Aug 2019
If anyone can find use of it here is a script that will dump current limits of pods.
kubectl get pods --all-namespaces -o=jsonpath="{range .items[*]}{.metadata.namespace}:{.metadata.name}{'\n'}\
{'.spec.nodeName -'} {.spec.nodeName}{'\n'}\
{range .spec.containers[*]}\
{'requests.cpu -'} {.resources.requests.cpu}{'\n'}\
{'limits.cpu -'} {.resources.limits.cpu}{'\n'}\
{'requests.memory -'} {.resources.requests.memory}{'\n'}\
{'limits.memory -'} {.resources.limits.memory}{'\n'}\
{'\n'}{end}\
{'\n'}{end}"
Example output
...
kube-system:addon-http-application-routing-nginx-ingress-controller-6bq49l7
.spec.nodeName - aks-agentpool-84550961-0
requests.cpu -
limits.cpu -
requests.memory -
limits.memory -
kube-system:coredns-696c4d987c-pjht8
.spec.nodeName - aks-agentpool-84550961-0
requests.cpu - 100m
limits.cpu -
requests.memory - 70Mi
limits.memory - 170Mi
kube-system:coredns-696c4d987c-rtkl6
.spec.nodeName - aks-agentpool-84550961-2
requests.cpu - 100m
limits.cpu -
requests.memory - 70Mi
limits.memory - 170Mi
kube-system:coredns-696c4d987c-zgcbp
.spec.nodeName - aks-agentpool-84550961-1
requests.cpu - 100m
limits.cpu -
requests.memory - 70Mi
limits.memory - 170Mi
kube-system:coredns-autoscaler-657d77ffbf-7t72x
.spec.nodeName - aks-agentpool-84550961-2
requests.cpu - 20m
limits.cpu -
requests.memory - 10Mi
limits.memory -
kube-system:coredns-autoscaler-657d77ffbf-zrp6m
.spec.nodeName - aks-agentpool-84550961-0
requests.cpu - 20m
limits.cpu -
requests.memory - 10Mi
limits.memory -
kube-system:kube-proxy-57nw5
.spec.nodeName - aks-agentpool-84550961-1
requests.cpu - 100m
limits.cpu -
requests.memory -
limits.memory -
...
 Spaceman1861
on 2 Sep 2019
Spaceman1861
on 2 Sep 2019
@Spaceman1861 could you show an example outout?
eduncan911
on 2 Sep 2019
@eduncan911 done
Spaceman1861
on 2 Sep 2019
I find it easier to read the output in table format, like this (this shows requests instead of limits):
kubectl get pods -o custom-columns=NAME:.metadata.name,"CPU(cores)":.spec.containers[*].resources.requests.cpu,"MEMORY(bytes)":.spec.containers[*].resources.requests.memory --all-namespaces
Sample output:
NAME CPU(cores) MEMORY(bytes)
pod1 100m 128Mi
pod2 100m 128Mi,128Mi
 lentzi90
on 2 Sep 2019
lentzi90
on 2 Sep 2019
@lentzi90 just FYI: you can show similar custom columns in Kubernetes Web View ("kubectl for the web"), demo: https://kube-web-view.demo.j-serv.de/clusters/local/namespaces/default/pods?join=metrics;customcols=CPU+Requests=join(%27,%20%27,%20spec.containers[].resources.requests.cpu)%3BMemory+Requests=join(%27,%20%27,%20spec.containers[].resources.requests.memory)
Docs on custom columns: https://kube-web-view.readthedocs.io/en/latest/features.html#listing-resources
hjacobs
on 2 Sep 2019
Oooo shiny @hjacobs I like that.
Spaceman1861
on 2 Sep 2019
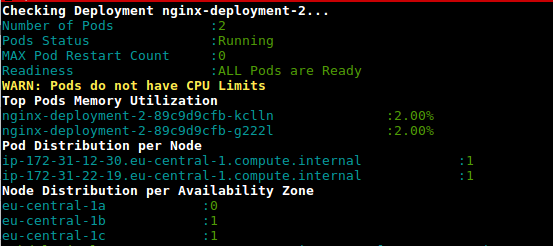
This is a script (deployment-health.sh) to get the utilization of the pods in deployment based on the usage and configured limits
https://github.com/amelbakry/kubernetes-scripts
amelbakry
on 2 Sep 2019
Inspired by the answers of @lentzi90 and @ylogx, I have created own big script which shows actual resource usage (kubectl top pods) and resource requests and limits:
join -a1 -a2 -o 0,1.2,1.3,2.2,2.3,2.4,2.5, -e '<none>' <(kubectl top pods) <(kubectl get pods -o custom-columns=NAME:.metadata.name,"CPU_REQ(cores)":.spec.containers[*].resources.requests.cpu,"MEMORY_REQ(bytes)":.spec.containers[*].resources.requests.memory,"CPU_LIM(cores)":.spec.containers[*].resources.limits.cpu,"MEMORY_LIM(bytes)":.spec.containers[*].resources.limits.memory) | column -t -s' '
output example:
NAME CPU(cores) MEMORY(bytes) CPU_REQ(cores) MEMORY_REQ(bytes) CPU_LIM(cores) MEMORY_LIM(bytes)
xxxxx-847dbbc4c-c6twt 20m 110Mi 50m 150Mi 150m 250Mi
xxx-service-7b6b9558fc-9cq5b 19m 1304Mi 1 <none> 1 <none>
xxxxxxxxxxxxxxx-hook-5d585b449b-zfxmh 0m 46Mi 200m 155M 200m 155M
Here is the alias for you to just use kstats in your terminal:
alias kstats='join -a1 -a2 -o 0,1.2,1.3,2.2,2.3,2.4,2.5, -e '"'"'<none>'"'"' <(kubectl top pods) <(kubectl get pods -o custom-columns=NAME:.metadata.name,"CPU_REQ(cores)":.spec.containers[*].resources.requests.cpu,"MEMORY_REQ(bytes)":.spec.containers[*].resources.requests.memory,"CPU_LIM(cores)":.spec.containers[*].resources.limits.cpu,"MEMORY_LIM(bytes)":.spec.containers[*].resources.limits.memory) | column -t -s'"'"' '"'"
P.S. I've tested scripts only on my mac, for linux and windows it may require some changes
 alikhil
on 25 Sep 2019
alikhil
on 25 Sep 2019
This is a script (deployment-health.sh) to get the utilization of the pods in deployment based on the usage and configured limits
https://github.com/amelbakry/kubernetes-scripts
@amelbakry I am getting the following error trying to execute it on a Mac:
Failed to execute process './deployment-health.sh'. Reason:
exec: Exec format error
The file './deployment-health.sh' is marked as an executable but could not be run by the operating system.
Woops,
"#!" needs to be the very first line. Instead try "bash
./deployment-health.sh" to work around the issue.
/charles
PS. PR opened to fix the issue
On Wed, Sep 25, 2019 at 10:19 AM Dmitri Moore notifications@github.com
wrote:
This is a script (deployment-health.sh) to get the utilization of the pods
in deployment based on the usage and configured limits
https://github.com/amelbakry/kubernetes-scripts@amelbakry https://github.com/amelbakry I am getting the following
error trying to execute it on a Mac:Failed to execute process './deployment-health.sh'. Reason:
exec: Exec format error
The file './deployment-health.sh' is marked as an executable but could not be run by the operating system.—
You are receiving this because you are subscribed to this thread.
Reply to this email directly, view it on GitHub
https://github.com/kubernetes/kubernetes/issues/17512?email_source=notifications&email_token=AACA3TODQEUPWK3V3UY3SF3QLOMSFA5CNFSM4BUXCUG2YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOD7SVHRQ#issuecomment-535122886,
or mute the thread
https://github.com/notifications/unsubscribe-auth/AACA3TOPOBIWXFX2DAOT6JDQLOMSFANCNFSM4BUXCUGQ
.
 cgthayer
on 25 Sep 2019
cgthayer
on 25 Sep 2019
@cgthayer You might want to apply that PR fix globally. Also, when I ran the scripts on MacOs Mojave, a bunch of errors showed up, including EU specific zone names which I don't use. Looks like these scripts have been written for a specific project.
demisx
on 2 Oct 2019
Here's a modified version of the join ex. which does totals of columns as well.
oc_ns_pod_usage () {
# show pod usage for cpu/mem
ns="$1"
usage_chk3 "$ns" || return 1
printf "$ns\n"
separator=$(printf '=%.0s' {1..50})
printf "$separator\n"
output=$(join -a1 -a2 -o 0,1.2,1.3,2.2,2.3,2.4,2.5, -e '<none>' \
<(kubectl top pods -n $ns) \
<(kubectl get -n $ns pods -o custom-columns=NAME:.metadata.name,"CPU_REQ(cores)":.spec.containers[*].resources.requests.cpu,"MEMORY_REQ(bytes)":.spec.containers[*].resources.requests.memory,"CPU_LIM(cores)":.spec.containers[*].resources.limits.cpu,"MEMORY_LIM(bytes)":.spec.containers[*].resources.limits.memory))
totals=$(printf "%s" "$output" | awk '{s+=$2; t+=$3; u+=$4; v+=$5; w+=$6; x+=$7} END {print s" "t" "u" "v" "w" "x}')
printf "%s\n%s\nTotals: %s\n" "$output" "$separator" "$totals" | column -t -s' '
printf "$separator\n"
}
Example
$ oc_ns_pod_usage ls-indexer
ls-indexer
==================================================
NAME CPU(cores) MEMORY(bytes) CPU_REQ(cores) MEMORY_REQ(bytes) CPU_LIM(cores) MEMORY_LIM(bytes)
ls-indexer-f5-7cd5859997-qsfrp 15m 741Mi 1 1000Mi 2 2000Mi
ls-indexer-f5-7cd5859997-sclvg 15m 735Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-4b7j2 92m 1103Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-5xj5l 88m 1124Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-6vvl2 92m 1132Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-85f66 85m 1151Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-924jz 96m 1124Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-g6gx8 119m 1119Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-hkhnt 52m 819Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-hrsrs 51m 1122Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-j4qxm 53m 885Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-lxlrb 83m 1215Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-mw6rt 86m 1131Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-pbdf8 95m 1115Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-qk9bm 91m 1141Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-sdv9r 54m 1194Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-t67v6 75m 1234Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-tkxs2 88m 1364Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-v6jl2 53m 747Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-wkqr7 53m 838Mi 1 1000Mi 2 2000Mi
ls-indexer-metricbeat-74d89d7d85-jp8qc 190m 1191Mi 1 1000Mi 2 2000Mi
ls-indexer-metricbeat-74d89d7d85-jv4bv 192m 1162Mi 1 1000Mi 2 2000Mi
ls-indexer-metricbeat-74d89d7d85-k4dcd 194m 1144Mi 1 1000Mi 2 2000Mi
ls-indexer-metricbeat-74d89d7d85-n46tz 192m 1155Mi 1 1000Mi 2 2000Mi
ls-indexer-packetbeat-db98f6fdf-8x446 35m 1198Mi 1 1000Mi 2 2000Mi
ls-indexer-packetbeat-db98f6fdf-gmxxd 22m 1203Mi 1 1000Mi 2 2000Mi
ls-indexer-syslog-5466bc4d4f-gzxw8 27m 1125Mi 1 1000Mi 2 2000Mi
ls-indexer-syslog-5466bc4d4f-zh7st 29m 1153Mi 1 1000Mi 2 2000Mi
==================================================
Totals: 2317 30365 28 28000 56 56000
==================================================
 slmingol
on 21 Oct 2019
slmingol
on 21 Oct 2019
And what is usage_chk3?
 cristifalcas
on 25 Oct 2019
cristifalcas
on 25 Oct 2019
I would like to also share my tools ;-) kubectl-view-allocations: kubectl plugin to list allocations (cpu, memory, gpu,... X requested, limit, allocatable,...)., request are welcome.
I made it because I would like to provide to my (internal) users a way to see "who allocates what". By default every resources are displayed, but in the following sample I only request resource with "gpu" in name.
> kubectl-view-allocations -r gpu
Resource Requested %Requested Limit %Limit Allocatable Free
nvidia.com/gpu 7 58% 7 58% 12 5
├─ node-gpu1 1 50% 1 50% 2 1
│ └─ xxxx-784dd998f4-zt9dh 1 1
├─ node-gpu2 0 0% 0 0% 2 2
├─ node-gpu3 0 0% 0 0% 2 2
├─ node-gpu4 1 50% 1 50% 2 1
│ └─ aaaa-1571819245-5ql82 1 1
├─ node-gpu5 2 100% 2 100% 2 0
│ ├─ bbbb-1571738839-dfkhn 1 1
│ └─ bbbb-1571738888-52c4w 1 1
└─ node-gpu6 2 100% 2 100% 2 0
├─ bbbb-1571738688-vlxng 1 1
└─ cccc-1571745684-7k6bn 1 1
coming version(s):
- will allow to hide (node, pod) level or to choose how to group, (eg to provide an overview with only resources)
- installation via curl, krew, brew, ... (currently binary are available under the releases section of github)
Thanks to kubectl-view-utilization for the inspiration, but adding support to other resources was to many copy/paste or hard to do for me in bash (for a generic way).
 davidB
on 25 Oct 2019
davidB
on 25 Oct 2019
here is my hack
kubectl describe nodes | grep -A 2 -e "^\\s*CPU Requests"
This doesn't work anymore :(
 libudas
on 28 Nov 2019
libudas
on 28 Nov 2019
Give kubectl describe node | grep -A5 "Allocated" a try
 MostafaGazar
on 28 Nov 2019
MostafaGazar
on 28 Nov 2019
This is currently the 4th highest requested issue by thumbs up, but still is priority/backlog.
I'd be happy to take a stab at this if someone could point me in the right direction or if we could finalize a proposal. I think the UX of @davidB's tool is awesome, but this really belongs in the core kubectl.
 alexkreidler
on 1 Dec 2019
alexkreidler
on 1 Dec 2019
Using the following comands: kubectl top nodes & kubectl describe node we do not get consistent results
For example with the first one the CPU(cores) are 1064m but this result cannot be fetched with the second one(1480m):
kubectl top nodes
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
abcd-p174e23ea5qa4g279446c803f82-abc-node-0 1064m 53% 6783Mi 88%
kubectl describe node abcd-p174e23ea5qa4g279446c803f82-abc-node-0
...
Resource Requests Limits
-------- -------- ------
cpu 1480m (74%) 1300m (65%)
memory 2981486848 (37%) 1588314624 (19%)
Any idea about getting the CPU(cores) without using the kubectl top nodes ?
 smpar
on 18 Dec 2019
smpar
on 18 Dec 2019
I would like to also share my tools ;-) kubectl-view-allocations: kubectl plugin to list allocations (cpu, memory, gpu,... X requested, limit, allocatable,...)., request are welcome.
I made it because I would like to provide to my (internal) users a way to see "who allocates what". By default every resources are displayed, but in the following sample I only request resource with "gpu" in name.
> kubectl-view-allocations -r gpu Resource Requested %Requested Limit %Limit Allocatable Free nvidia.com/gpu 7 58% 7 58% 12 5 ├─ node-gpu1 1 50% 1 50% 2 1 │ └─ xxxx-784dd998f4-zt9dh 1 1 ├─ node-gpu2 0 0% 0 0% 2 2 ├─ node-gpu3 0 0% 0 0% 2 2 ├─ node-gpu4 1 50% 1 50% 2 1 │ └─ aaaa-1571819245-5ql82 1 1 ├─ node-gpu5 2 100% 2 100% 2 0 │ ├─ bbbb-1571738839-dfkhn 1 1 │ └─ bbbb-1571738888-52c4w 1 1 └─ node-gpu6 2 100% 2 100% 2 0 ├─ bbbb-1571738688-vlxng 1 1 └─ cccc-1571745684-7k6bn 1 1coming version(s):
* will allow to hide (node, pod) level or to choose how to group, (eg to provide an overview with only resources) * installation via curl, krew, brew, ... (currently binary are available under the releases section of github)Thanks to kubectl-view-utilization for the inspiration, but adding support to other resources was to many copy/paste or hard to do for me in bash (for a generic way).
Hello David it would be nice if you provide more compiled binary for new distributions. On Ubuntu 16.04 we get
kubectl-view-allocations: /lib/x86_64-linux-gnu/libc.so.6: version `GLIBC_2.25' not found (required by kubectl-view-allocations)
dpkg -l |grep glib
ii libglib2.0-0:amd64 2.48.2-0ubuntu4.4
 omerfsen
on 12 Jan 2020
omerfsen
on 12 Jan 2020
@omerfsen can you try the new version kubectl-view-allocations and comment into the ticket version `GLIBC_2.25' not found #14 ?
davidB
on 15 Jan 2020
My way to obtain the allocation, cluster-wide:
$ kubectl get po --all-namespaces -o=jsonpath="{range .items[*]}{.metadata.namespace}:{.metadata.name}{'\n'}{range .spec.containers[*]} {.name}:{.resources.requests.cpu}{'\n'}{end}{'\n'}{end}"It produces something like:
kube-system:heapster-v1.5.0-dc8df7cc9-7fqx6 heapster:88m heapster-nanny:50m kube-system:kube-dns-6cdf767cb8-cjjdr kubedns:100m dnsmasq:150m sidecar:10m prometheus-to-sd: kube-system:kube-dns-6cdf767cb8-pnx2g kubedns:100m dnsmasq:150m sidecar:10m prometheus-to-sd: kube-system:kube-dns-autoscaler-69c5cbdcdd-wwjtg autoscaler:20m kube-system:kube-proxy-gke-cluster1-default-pool-cd7058d6-3tt9 kube-proxy:100m kube-system:kube-proxy-gke-cluster1-preempt-pool-57d7ff41-jplf kube-proxy:100m kube-system:kubernetes-dashboard-7b9c4bf75c-f7zrl kubernetes-dashboard:50m kube-system:l7-default-backend-57856c5f55-68s5g default-http-backend:10m kube-system:metrics-server-v0.2.0-86585d9749-kkrzl metrics-server:48m metrics-server-nanny:5m kube-system:tiller-deploy-7794bfb756-8kxh5 tiller:10m
by far the best answer here.
 abelal83
on 31 Jan 2020
abelal83
on 31 Jan 2020
Inspired by the scripts above I created the following script to view the usage, requests and limits:
join -1 2 -2 2 -a 1 -a 2 -o "2.1 0 1.3 2.3 2.5 1.4 2.4 2.6" -e '<wait>' \
<( kubectl top pods --all-namespaces | sort --key 2 -b ) \
<( kubectl get pods --all-namespaces -o custom-columns=NAMESPACE:.metadata.namespace,NAME:.metadata.name,"CPU_REQ(cores)":.spec.containers[*].resources.requests.cpu,"MEMORY_REQ(bytes)":.spec.containers[*].resources.requests.memory,"CPU_LIM(cores)":.spec.containers[*].resources.limits.cpu,"MEMORY_LIM(bytes)":.spec.containers[*].resources.limits.memory | sort --key 2 -b ) \
| column -t -s' '
Because the join shell script expects a sorted list, the scripts given above failed for me.
You see as a result the current usage from top and from the deployment the requests and the limits of (here) all namespaces:
NAMESPACE NAME CPU(cores) CPU_REQ(cores) CPU_LIM(cores) MEMORY(bytes) MEMORY_REQ(bytes) MEMORY_LIM(bytes)
kube-system aws-node-2jzxr 18m 10m <none> 41Mi <none> <none>
kube-system aws-node-5zn6w <wait> 10m <none> <wait> <none> <none>
kube-system aws-node-h8cc5 20m 10m <none> 42Mi <none> <none>
kube-system aws-node-h9n4f 0m 10m <none> 0Mi <none> <none>
kube-system aws-node-lz5fn 17m 10m <none> 41Mi <none> <none>
kube-system aws-node-tpmxr 20m 10m <none> 39Mi <none> <none>
kube-system aws-node-zbkkh 23m 10m <none> 47Mi <none> <none>
cluster-autoscaler cluster-autoscaler-aws-cluster-autoscaler-5db55fbcf8-mdzkd 1m 100m 500m 9Mi 300Mi 500Mi
cluster-autoscaler cluster-autoscaler-aws-cluster-autoscaler-5db55fbcf8-q9xs8 39m 100m 500m 75Mi 300Mi 500Mi
kube-system coredns-56b56b56cd-bb26t 6m 100m <none> 11Mi 70Mi 170Mi
kube-system coredns-56b56b56cd-nhp58 6m 100m <none> 11Mi 70Mi 170Mi
kube-system coredns-56b56b56cd-wrmxv 7m 100m <none> 12Mi 70Mi 170Mi
gitlab-runner-l gitlab-runner-l-gitlab-runner-6b8b85f87f-9knnx 3m 100m 200m 10Mi 128Mi 256Mi
gitlab-runner-m gitlab-runner-m-gitlab-runner-6bfd5d6c84-t5nrd 7m 100m 200m 13Mi 128Mi 256Mi
gitlab-runner-mda gitlab-runner-mda-gitlab-runner-59bb66c8dd-bd9xw 4m 100m 200m 17Mi 128Mi 256Mi
gitlab-runner-ops gitlab-runner-ops-gitlab-runner-7c5b85dc97-zkb4c 3m 100m 200m 12Mi 128Mi 256Mi
gitlab-runner-pst gitlab-runner-pst-gitlab-runner-6b8f9bf56b-sszlr 6m 100m 200m 20Mi 128Mi 256Mi
gitlab-runner-s gitlab-runner-s-gitlab-runner-6bbccb9b7b-dmwgl 50m 100m 200m 27Mi 128Mi 512Mi
gitlab-runner-shared gitlab-runner-shared-gitlab-runner-688d57477f-qgs2z 3m <none> <none> 15Mi <none> <none>
kube-system kube-proxy-5b65t 15m 100m <none> 19Mi <none> <none>
kube-system kube-proxy-7qsgh 12m 100m <none> 24Mi <none> <none>
kube-system kube-proxy-gn2qg 13m 100m <none> 23Mi <none> <none>
kube-system kube-proxy-pz7fp 15m 100m <none> 18Mi <none> <none>
kube-system kube-proxy-vdjqt 15m 100m <none> 23Mi <none> <none>
kube-system kube-proxy-x4xtp 19m 100m <none> 15Mi <none> <none>
kube-system kube-proxy-xlpn7 0m 100m <none> 0Mi <none> <none>
metrics-server metrics-server-5875c7d795-bj7cq 5m 200m 500m 29Mi 200Mi 500Mi
metrics-server metrics-server-5875c7d795-jpjjn 7m 200m 500m 29Mi 200Mi 500Mi
gitlab-runner-s runner-heq8ujaj-project-10386-concurrent-06t94f <wait> 200m,100m 200m,200m <wait> 200Mi,128Mi 500Mi,500Mi
gitlab-runner-s runner-heq8ujaj-project-10386-concurrent-10lpn9j 1m 200m,100m 200m,200m 12Mi 200Mi,128Mi 500Mi,500Mi
gitlab-runner-s runner-heq8ujaj-project-10386-concurrent-11jrxfh <wait> 200m,100m 200m,200m <wait> 200Mi,128Mi 500Mi,500Mi
gitlab-runner-s runner-heq8ujaj-project-10386-concurrent-129hpvl 1m 200m,100m 200m,200m 12Mi 200Mi,128Mi 500Mi,500Mi
gitlab-runner-s runner-heq8ujaj-project-10386-concurrent-13kswg8 1m 200m,100m 200m,200m 12Mi 200Mi,128Mi 500Mi,500Mi
gitlab-runner-s runner-heq8ujaj-project-10386-concurrent-15qhp5w <wait> 200m,100m 200m,200m <wait> 200Mi,128Mi 500Mi,500Mi
Noteworthy: You can sort over CPU consumption with e.g.:
| awk 'NR<2{print $0;next}{print $0| "sort --key 3 --numeric -b --reverse"}
This works on Mac - I am not sure, if it works on Linux, too (because of join, sort, etc...).
Hopefully, someone can use this till kubectl gets a good view for that.
 stefanjacobs
on 11 Feb 2020
stefanjacobs
on 11 Feb 2020
I have a good experience with kube-capacity.
Example:
kube-capacity --util
NODE CPU REQUESTS CPU LIMITS CPU UTIL MEMORY REQUESTS MEMORY LIMITS MEMORY UTIL
* 560m (28%) 130m (7%) 40m (2%) 572Mi (9%) 770Mi (13%) 470Mi (8%)
example-node-1 220m (22%) 10m (1%) 10m (1%) 192Mi (6%) 360Mi (12%) 210Mi (7%)
example-node-2 340m (34%) 120m (12%) 30m (3%) 380Mi (13%) 410Mi (14%) 260Mi (9%)
 eyalev
on 18 Feb 2020
eyalev
on 18 Feb 2020
In order for this tool to be truly useful it should detect all kubernetes device plugins deployed on cluster and show usage for all of them. CPU/Mem is definetly not enough. There's also GPUs, TPUs (for machine learning), Intel QAT and probably more I don't know about. Also what about storage? I should be able to easily see what was requested and what is used (ideally in terms of iops as well).
 boniek83
on 9 Apr 2020
boniek83
on 9 Apr 2020
@boniek83 , It's why I created kubectl-view-allocations, because I need to list GPU,... any feedback (on the github project) are welcomes. I curious to know if it detects TPU (it should if it is listed as a Node's resources)
davidB
on 9 Apr 2020
@boniek83 , It's why I created kubectl-view-allocations, because I need to list GPU,... any feedback (on the github project) are welcomes. I curious to know if it detects TPU (it should if it is listed as a Node's resources)
I'm aware of your tool and, for my purpose, it is the best that is currently available. Thanks for making it!
I will try to get TPUs tested after Easter. It would be helpful if this data would be available in web app format with pretty graphs so I wouldn't have to give any access to kubernetes to data scientists. They only want to know who is eating away resources and nothing more :)
boniek83
on 9 Apr 2020
Since none of the tools and scripts above fit my needs (and this issue is still open :( ), I hacked my own variant:
https://github.com/eht16/kube-cargo-load
It provides a quick overview of PODs in a cluster and shows their configured memory requests and limits and the actual memory usage. The idea is to get a picture of the ratio between configured memory limits and actual usage.
 eht16
on 13 Apr 2020
eht16
on 13 Apr 2020
How can we get memory dumps logs of the pods?
Pods are often getting hung,
 RahulRatan07
on 26 Apr 2020
RahulRatan07
on 26 Apr 2020
kubectl describe nodesORkubectl top nodes, which one should be considered to calculate cluster resource utilization ?- Also Why there is difference between these 2 results.
Is there any logical explanation this yet ?
 hmsvigle
on 27 Apr 2020
hmsvigle
on 27 Apr 2020
/kind feature
 brianpursley
on 29 Apr 2020
brianpursley
on 29 Apr 2020
All the comments and hacks with nodes worked well for me. I also need something for a higher view to keep track of..like sum of resources per node pool !
 prathameshd9
on 30 Apr 2020
prathameshd9
on 30 Apr 2020
hi,
I want to log the cpu and memory usage for a pod , every 5 mins over a period of time. I would then use this data to create a graph in excel. Any ideas? Thanks
 rajjar123456
on 18 Jul 2020
rajjar123456
on 18 Jul 2020
Hi,
I'm happy to see that Google pointed all of us to this issue :-) (a bit disappointed that it's still open after almost 5y.) Thanks for all the shell snips and other tools.
 yceoshda
on 28 Jul 2020
yceoshda
on 28 Jul 2020
Simple and quick hack:
$ kubectl describe nodes | grep 'Name:\| cpu\| memory'
Name: XXX-2-wke2
cpu 1552m (77%) 2402m (120%)
memory 2185Mi (70%) 3854Mi (123%)
Name: XXX-2-wkep
cpu 1102m (55%) 1452m (72%)
memory 1601Mi (51%) 2148Mi (69%)
Name: XXX-2-wkwz
cpu 852m (42%) 1352m (67%)
memory 1125Mi (36%) 3624Mi (116%)
 SerheyDolgushev
on 5 Aug 2020
SerheyDolgushev
on 5 Aug 2020
Simple and quick hack:
$ kubectl describe nodes | grep 'Name:\| cpu\| memory' Name: XXX-2-wke2 cpu 1552m (77%) 2402m (120%) memory 2185Mi (70%) 3854Mi (123%) Name: XXX-2-wkep cpu 1102m (55%) 1452m (72%) memory 1601Mi (51%) 2148Mi (69%) Name: XXX-2-wkwz cpu 852m (42%) 1352m (67%) memory 1125Mi (36%) 3624Mi (116%)Device plugins are not there. They should be. Such devices are resources as well.
boniek83
on 5 Aug 2020
Hello!
I created this script and share it with you.
https://github.com/Sensedia/open-tools/blob/master/scripts/listK8sHardwareResources.sh
This script has a compilation of some of the ideas you shared here. The script can be incremented and can help other people get the metrics more simply.
Thanks for sharing the tips and commands!
 aeciopires
on 7 Aug 2020
aeciopires
on 7 Aug 2020
For my use case, I ended up writing a simple kubectl plugin that lists CPU/RAM limits/reservations for nodes in a table. It also checks current pod CPU/RAM consumption (like kubectl top pods), but ordering output by CPU in descending order.
Its more of a convenience thing than anything else, but maybe someone else will find it useful too.
 laurybueno
on 9 Aug 2020
laurybueno
on 9 Aug 2020
Whoa, what a huge thread and still no proper solution from kubernetes team to properly calculate current overall cpu usage of a whole cluster?
 denissabramovs
on 20 Sep 2020
denissabramovs
on 20 Sep 2020
For those looking to run this on minikube , first enable the metric server add-on
minikube addons enable metrics-server
and then run the command
kubectl top nodes
 raul1991
on 16 Oct 2020
raul1991
on 16 Oct 2020
If you're using Krew:
kubectl krew install resource-capacity
kubectl resource-capacity
NODE CPU REQUESTS CPU LIMITS MEMORY REQUESTS MEMORY LIMITS
* 16960m (35%) 18600m (39%) 26366Mi (14%) 3100Mi (1%)
ip-10-0-138-176.eu-north-1.compute.internal 2460m (31%) 4200m (53%) 567Mi (1%) 784Mi (2%)
ip-10-0-155-49.eu-north-1.compute.internal 2160m (27%) 2200m (27%) 4303Mi (14%) 414Mi (1%)
ip-10-0-162-84.eu-north-1.compute.internal 3860m (48%) 3900m (49%) 8399Mi (27%) 414Mi (1%)
ip-10-0-200-101.eu-north-1.compute.internal 2160m (27%) 2200m (27%) 4303Mi (14%) 414Mi (1%)
ip-10-0-231-146.eu-north-1.compute.internal 2160m (27%) 2200m (27%) 4303Mi (14%) 414Mi (1%)
ip-10-0-251-167.eu-north-1.compute.internal 4160m (52%) 3900m (49%) 4491Mi (14%) 660Mi (2%)
 benjick
on 14 Nov 2020
benjick
on 14 Nov 2020
Related issues
 tbchj
·
3Comments
tbchj
·
3Comments
 alexferl
·
3Comments
alexferl
·
3Comments
 Seb-Solon
·
3Comments
Seb-Solon
·
3Comments
 mml
·
3Comments
mml
·
3Comments
 ddysher
·
3Comments
ddysher
·
3Comments
Most helpful comment
There is: