Kubernetes: Necesita un comando kubectl simple para ver el uso de recursos del clúster
Los usuarios se tropiezan con los pods que no pueden programar debido a la deficiencia de recursos. Puede ser difícil saber cuándo un pod está pendiente porque aún no se ha iniciado o porque el clúster no tiene espacio para programarlo. http://kubernetes.io/v1.1/docs/user-guide/compute-resources.html#monitoring -compute-resource-use ayuda, pero no es tan detectable (tiendo a probar un 'get' en un pod en pendiente primero, y solo después de esperar un rato y verlo 'atascado' en pendiente, uso 'describir' para darme cuenta de que es un problema de programación).
Esto también se complica porque los pods del sistema se encuentran en un espacio de nombres que está oculto. Los usuarios olvidan que esos pods existen y 'cuentan contra' los recursos del clúster.
Hay varias soluciones posibles de repente, no sé cuál sería ideal:
1) Desarrollar un nuevo estado de pod que no sea Pendiente para representar "intentó programar y falló por falta de recursos".
2) Haga que kubectl obtenga po o kubectl obtenga po -o = wide muestre una columna para detallar por qué hay algo pendiente (tal vez el container.state que es Waiting en este caso, o el event.message más reciente).
3) Cree un nuevo comando kubectl para describir más fácilmente los recursos. Me estoy imaginando un "uso de kubectl" que brinda una descripción general de la CPU y Mem del clúster total, por CPU y Mem por nodo y el uso de cada pod / contenedor. Aquí incluiríamos todos los pods, incluidos los del sistema. Esto puede ser útil a largo plazo junto con programadores más complejos, o cuando su clúster tiene suficientes recursos pero ningún nodo los tiene (diagnosticando el problema de 'no hay agujeros lo suficientemente grandes').
 goltermann
goltermann
Todos 88 comentarios
Algo parecido a (2) parece razonable, aunque la gente de UX lo sabría mejor que yo.
(3) parece vagamente relacionado con # 15743 pero no estoy seguro de que estén lo suficientemente cerca como para combinarse.
 davidopp
en 20 nov. 2015
davidopp
en 20 nov. 2015
Además del caso anterior, sería bueno ver qué uso de recursos estamos obteniendo.
kubectl utilization requests podría mostrarse (tal vez kubectl util o kubectl usage sean mejores / más cortos):
cores: 4.455/5 cores (89%)
memory: 20.1/30 GiB (67%)
...
En este ejemplo, las solicitudes de contenedor agregadas son 4.455 núcleos y 20.1 GiB y hay 5 núcleos y 30GiB en total en el clúster.
 chrishiestand
en 16 sept. 2016
chrishiestand
en 16 sept. 2016
Hay:
$ kubectl top nodes
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
cluster1-k8s-master-1 312m 15% 1362Mi 68%
cluster1-k8s-node-1 124m 12% 233Mi 11%
 xmik
en 19 dic. 2016
xmik
en 19 dic. 2016
Utilizo el siguiente comando para obtener una vista rápida del uso de recursos. Es la forma más sencilla que encontré.
kubectl describe nodes
 ozbillwang
en 11 ene. 2017
ozbillwang
en 11 ene. 2017
Si hubiera una manera de "formatear" la salida de kubectl describe nodes , no me importaría escribir un script para resumir todas las solicitudes / límites de recursos del nodo.
 tonglil
en 20 ene. 2017
tonglil
en 20 ene. 2017
aquí está mi truco kubectl describe nodes | grep -A 2 -e "^\\s*CPU Requests"
 from-nibly
en 2 feb. 2017
from-nibly
en 2 feb. 2017
@ de-nely gracias, justo lo que estaba buscando
 jredl-va
en 25 may. 2017
jredl-va
en 25 may. 2017
Sí, esto es mío:
$ cat bin/node-resources.sh
#!/bin/bash
set -euo pipefail
echo -e "Iterating...\n"
nodes=$(kubectl get node --no-headers -o custom-columns=NAME:.metadata.name)
for node in $nodes; do
echo "Node: $node"
kubectl describe node "$node" | sed '1,/Non-terminated Pods/d'
echo
done
@goltermann No hay etiquetas sig sobre este tema. Agregue una etiqueta de firma por:
(1) mencionando una firma: @kubernetes/sig-<team-name>-misc
(2) especificando la etiqueta manualmente: /sig <label>
_Nota: el método (1) activará una notificación al equipo. Puedes encontrar la lista de equipos aquí ._
 k8s-github-robot
en 1 jun. 2017
k8s-github-robot
en 1 jun. 2017
@ kubernetes / sig-cli-misc
 kargakis
en 10 jun. 2017
kargakis
en 10 jun. 2017
Puede usar el siguiente comando para encontrar el porcentaje de utilización de cpu de sus nodos
alias util='kubectl get nodes | grep node | awk '\''{print $1}'\'' | xargs -I {} sh -c '\''echo {} ; kubectl describe node {} | grep Allocated -A 5 | grep -ve Event -ve Allocated -ve percent -ve -- ; echo '\'''
Note: 4000m cores is the total cores in one node
alias cpualloc="util | grep % | awk '{print \$1}' | awk '{ sum += \$1 } END { if (NR > 0) { result=(sum**4000); printf result/NR \"%\n\" } }'"
$ cpualloc
3.89358%
Note: 1600MB is the total cores in one node
alias memalloc='util | grep % | awk '\''{print $3}'\'' | awk '\''{ sum += $1 } END { if (NR > 0) { result=(sum*100)/(NR*1600); printf result/NR "%\n" } }'\'''
$ memalloc
24.6832%
 alok87
en 5 jul. 2017
alok87
en 5 jul. 2017
@tomfotherby alias util='kubectl get nodes | grep node | awk '\''{print $1}'\'' | xargs -I {} sh -c '\''echo {} ; kubectl describe node {} | grep Allocated -A 5 | grep -ve Event -ve Allocated -ve percent -ve -- ; echo '\'''
alok87
en 21 jul. 2017
@ alok87 - Gracias por sus alias. En mi caso, esto es lo que funcionó para mí dado que usamos bash y m3.large tipos de instancia (2 cpu, memoria de 7.5G).
alias util='kubectl get nodes --no-headers | awk '\''{print $1}'\'' | xargs -I {} sh -c '\''echo {} ; kubectl describe node {} | grep Allocated -A 5 | grep -ve Event -ve Allocated -ve percent -ve -- ; echo '\'''
# Get CPU request total (we x20 because because each m3.large has 2 vcpus (2000m) )
alias cpualloc='util | grep % | awk '\''{print $1}'\'' | awk '\''{ sum += $1 } END { if (NR > 0) { print sum/(NR*20), "%\n" } }'\'''
# Get mem request total (we x75 because because each m3.large has 7.5G ram )
alias memalloc='util | grep % | awk '\''{print $5}'\'' | awk '\''{ sum += $1 } END { if (NR > 0) { print sum/(NR*75), "%\n" } }'\'''
$util
ip-10-56-0-178.ec2.internal
CPU Requests CPU Limits Memory Requests Memory Limits
960m (48%) 2700m (135%) 630Mi (8%) 2034Mi (27%)
ip-10-56-0-22.ec2.internal
CPU Requests CPU Limits Memory Requests Memory Limits
920m (46%) 1400m (70%) 560Mi (7%) 550Mi (7%)
ip-10-56-0-56.ec2.internal
CPU Requests CPU Limits Memory Requests Memory Limits
1160m (57%) 2800m (140%) 972Mi (13%) 3976Mi (53%)
ip-10-56-0-99.ec2.internal
CPU Requests CPU Limits Memory Requests Memory Limits
804m (40%) 794m (39%) 824Mi (11%) 1300Mi (17%)
cpualloc
48.05 %
$ memalloc
9.95333 %
 tomfotherby
en 25 jul. 2017
tomfotherby
en 25 jul. 2017
https://github.com/kubernetes/kubernetes/issues/17512#issuecomment -267992922 kubectl top muestra el uso , no la asignación. La asignación es lo que causa el problema insufficient CPU . Hay mucha confusión en este tema sobre la diferencia.
AFAICT, no hay una manera fácil de obtener un informe de la asignación de CPU de nodo por pod, ya que las solicitudes son por contenedor en la especificación. E incluso entonces, es difícil ya que .spec.containers[*].requests puede tener o no los campos limits / requests (en mi experiencia)
 nfirvine
en 30 ago. 2017
nfirvine
en 30 ago. 2017
/ cc @mysterikkit
 misterikkit
en 2 ene. 2018
misterikkit
en 2 ene. 2018
Entrar en esta fiesta de scripts de shell. Tengo un clúster más antiguo que ejecuta la CA con la reducción de escala deshabilitada. Escribí este script para determinar aproximadamente cuánto puedo reducir el clúster cuando comienza a aumentar en sus límites de ruta de AWS:
#!/bin/bash
set -e
KUBECTL="kubectl"
NODES=$($KUBECTL get nodes --no-headers -o custom-columns=NAME:.metadata.name)
function usage() {
local node_count=0
local total_percent_cpu=0
local total_percent_mem=0
local readonly nodes=$@
for n in $nodes; do
local requests=$($KUBECTL describe node $n | grep -A2 -E "^\\s*CPU Requests" | tail -n1)
local percent_cpu=$(echo $requests | awk -F "[()%]" '{print $2}')
local percent_mem=$(echo $requests | awk -F "[()%]" '{print $8}')
echo "$n: ${percent_cpu}% CPU, ${percent_mem}% memory"
node_count=$((node_count + 1))
total_percent_cpu=$((total_percent_cpu + percent_cpu))
total_percent_mem=$((total_percent_mem + percent_mem))
done
local readonly avg_percent_cpu=$((total_percent_cpu / node_count))
local readonly avg_percent_mem=$((total_percent_mem / node_count))
echo "Average usage: ${avg_percent_cpu}% CPU, ${avg_percent_mem}% memory."
}
usage $NODES
Produce resultados como:
ip-REDACTED.us-west-2.compute.internal: 38% CPU, 9% memory
...many redacted lines...
ip-REDACTED.us-west-2.compute.internal: 41% CPU, 8% memory
ip-REDACTED.us-west-2.compute.internal: 61% CPU, 7% memory
Average usage: 45% CPU, 15% memory.
 negz
en 21 feb. 2018
negz
en 21 feb. 2018
También hay una opción de pod en el comando superior:
kubectl top pod
 ylogx
en 21 feb. 2018
ylogx
en 21 feb. 2018
@ylogx https://github.com/kubernetes/kubernetes/issues/17512#issuecomment -326089708
nfirvine
en 21 feb. 2018
Mi forma de obtener la asignación, en todo el clúster:
$ kubectl get po --all-namespaces -o=jsonpath="{range .items[*]}{.metadata.namespace}:{.metadata.name}{'\n'}{range .spec.containers[*]} {.name}:{.resources.requests.cpu}{'\n'}{end}{'\n'}{end}"
Produce algo como:
kube-system:heapster-v1.5.0-dc8df7cc9-7fqx6
heapster:88m
heapster-nanny:50m
kube-system:kube-dns-6cdf767cb8-cjjdr
kubedns:100m
dnsmasq:150m
sidecar:10m
prometheus-to-sd:
kube-system:kube-dns-6cdf767cb8-pnx2g
kubedns:100m
dnsmasq:150m
sidecar:10m
prometheus-to-sd:
kube-system:kube-dns-autoscaler-69c5cbdcdd-wwjtg
autoscaler:20m
kube-system:kube-proxy-gke-cluster1-default-pool-cd7058d6-3tt9
kube-proxy:100m
kube-system:kube-proxy-gke-cluster1-preempt-pool-57d7ff41-jplf
kube-proxy:100m
kube-system:kubernetes-dashboard-7b9c4bf75c-f7zrl
kubernetes-dashboard:50m
kube-system:l7-default-backend-57856c5f55-68s5g
default-http-backend:10m
kube-system:metrics-server-v0.2.0-86585d9749-kkrzl
metrics-server:48m
metrics-server-nanny:5m
kube-system:tiller-deploy-7794bfb756-8kxh5
tiller:10m
 shtouff
en 4 mar. 2018
shtouff
en 4 mar. 2018
Esto es raro. Quiero saber cuándo estoy en o acercándome a la capacidad de asignación. Parece una función bastante básica de un clúster. Ya sea una estadística que muestre un porcentaje alto o un error textual ... ¿cómo lo saben otras personas? ¿Usar siempre el ajuste de escala automático en una plataforma en la nube?
 kierenj
en 13 mar. 2018
kierenj
en 13 mar. 2018
Soy el autor de https://github.com/dpetzold/kube-resource-explorer/ a la dirección # 3. Aquí hay algunos resultados de muestra:
$ ./resource-explorer -namespace kube-system -reverse -sort MemReq
Namespace Name CpuReq CpuReq% CpuLimit CpuLimit% MemReq MemReq% MemLimit MemLimit%
--------- ---- ------ ------- -------- --------- ------ ------- -------- ---------
kube-system event-exporter-v0.1.7-5c4d9556cf-kf4tf 0 0% 0 0% 0 0% 0 0%
kube-system kube-proxy-gke-project-default-pool-175a4a05-mshh 100m 10% 0 0% 0 0% 0 0%
kube-system kube-proxy-gke-project-default-pool-175a4a05-bv59 100m 10% 0 0% 0 0% 0 0%
kube-system kube-proxy-gke-project-default-pool-175a4a05-ntfw 100m 10% 0 0% 0 0% 0 0%
kube-system kube-dns-autoscaler-244676396-xzgs4 20m 2% 0 0% 10Mi 0% 0 0%
kube-system l7-default-backend-1044750973-kqh98 10m 1% 10m 1% 20Mi 0% 20Mi 0%
kube-system kubernetes-dashboard-768854d6dc-jh292 100m 10% 100m 10% 100Mi 3% 300Mi 11%
kube-system kube-dns-323615064-8nxfl 260m 27% 0 0% 110Mi 4% 170Mi 6%
kube-system fluentd-gcp-v2.0.9-4qkwk 100m 10% 0 0% 200Mi 7% 300Mi 11%
kube-system fluentd-gcp-v2.0.9-jmtpw 100m 10% 0 0% 200Mi 7% 300Mi 11%
kube-system fluentd-gcp-v2.0.9-tw9vk 100m 10% 0 0% 200Mi 7% 300Mi 11%
kube-system heapster-v1.4.3-74b5bd94bb-fz8hd 138m 14% 138m 14% 301856Ki 11% 301856Ki 11%
 dpetzold
en 2 may. 2018
dpetzold
en 2 may. 2018
@shtouff
root<strong i="7">@debian9</strong>:~# kubectl get po -n chenkunning-84 -o=jsonpath="{range .items[*]}{.metadata.namespace}:{.metadata.name}{'\n'}{range .spec.containers[*]} {.name}:{.resources.requests.cpu}{'\n'}{end}{'\n'}{end}"
error: error parsing jsonpath {range .items[*]}{.metadata.namespace}:{.metadata.name}{'\n'}{range .spec.containers[*]} {.name}:{.resources.requests.cpu}{'\n'}{end}{'\n'}{end}, unrecognized character in action: U+0027 '''
root<strong i="8">@debian9</strong>:~# kubectl version
Client Version: version.Info{Major:"1", Minor:"6+", GitVersion:"v1.6.7-beta.0+$Format:%h$", GitCommit:"bb053ff0cb25a043e828d62394ed626fda2719a1", GitTreeState:"dirty", BuildDate:"2017-08-26T09:34:19Z", GoVersion:"go1.8", Compiler:"gc", Platform:"linux/amd64"}
Server Version: version.Info{Major:"1", Minor:"6+", GitVersion:"v1.6.7-beta.0+$Format:84c3ae0384658cd40c1d1e637f5faa98cf6a965c$", GitCommit:"3af2004eebf3cbd8d7f24b0ecd23fe4afb889163", GitTreeState:"clean", BuildDate:"2018-04-04T08:40:48Z", GoVersion:"go1.8.1", Compiler:"gc", Platform:"linux/amd64"}
 harryge00
en 22 may. 2018
harryge00
en 22 may. 2018
@ harryge00 : U + 0027 es una cita
nfirvine
en 22 may. 2018
@nfirvine ¡Gracias! He resuelto el problema usando:
kubectl get pods -n my-ns -o=jsonpath='{range .items[*]}{.metadata.name}{"\t"}{.spec.containers[0].resources.limits.cpu} {"\n"}{end}' |awk '{sum+=$2 ; print $0} END{print "sum=",sum}'
Funciona para espacios de nombres cuyos pods solo contienen 1 contenedor cada uno.
harryge00
en 25 may. 2018
@xmik Oye, estoy usando k8 1.7 y ejecutando hepaster. Cuando ejecuto $ kubectl top nodes --heapster-namespace = kube-system, me muestra "error: las métricas aún no están disponibles". ¿Alguna pista para abordar el error?
 abushoeb
en 5 jun. 2018
abushoeb
en 5 jun. 2018
@abushoeb :
No creo queEditar: esta bandera es compatible, tenías razón: https://github.com/kubernetes/kubernetes/issues/44540#issuecomment -362882035.kubectl topadmita la bandera:--heapster-namespace.- Si ves el "error: las métricas aún no están disponibles", debes verificar la implementación de heapster. ¿Qué dicen sus registros? ¿Está bien el servicio de heapster, los puntos finales no son
<none>? Verifique este último con un comando como:kubectl -n kube-system describe svc/heapster
xmik
en 5 jun. 2018
@xmik, tienes razón, el heapster no se configuró correctamente. Muchas gracias. Está funcionando ahora. ¿Sabe si hay alguna forma de obtener información sobre el uso de la GPU en tiempo real? Este comando superior solo proporciona el uso de CPU y memoria.
abushoeb
en 5 jun. 2018
No lo se. :(
xmik
en 5 jun. 2018
@abushoeb Me
 avgKol
en 21 jun. 2018
avgKol
en 21 jun. 2018
@avgKol comprueba primero la implementación de tu heapster. En mi caso, no se implementó correctamente. Una forma de verificarlo es acceder a las métricas a través del comando CURL como curl -L http://heapster-pod-ip:heapster-service-port/api/v1/model/metrics/ . Si no muestra métricas, verifique el pod y los registros del heapster. También se puede acceder a las métricas de Hepster a través de un navegador web como este .
abushoeb
en 22 jun. 2018
Si alguien está interesado, creé una herramienta para generar HTML estático para el uso de recursos (y costos) de Kubernetes: https://github.com/hjacobs/kube-resource-report
 hjacobs
en 18 jul. 2018
hjacobs
en 18 jul. 2018
@hjacobs Me gustaría usar esa herramienta pero no soy un fanático de instalar / usar paquetes de Python. ¿Te importaría empaquetarlo como una imagen de Docker?
tonglil
en 18 jul. 2018
@tonglil, el proyecto es bastante temprano, pero mi plan es tener una imagen de Docker lista para usar, incl. servidor web con el que puedes hacer kubectl apply -f .. .
hjacobs
en 18 jul. 2018
Esto es lo que funcionó para mí:
kubectl get nodes -o=jsonpath="{range .items[*]}{.metadata.name}{'\t'}{.status.allocatable.memory}{'\t'}{.status.allocatable.cpu}{'\n'}{end}"
Muestra la salida como:
ip-192-168-101-177.us-west-2.compute.internal 251643680Ki 32
ip-192-168-196-254.us-west-2.compute.internal 251643680Ki 32
 arun-gupta
en 12 sept. 2018
arun-gupta
en 12 sept. 2018
@tonglil, una imagen de Docker ahora está disponible: https://github.com/hjacobs/kube-resource-report
hjacobs
en 13 sept. 2018
Los problemas se vuelven obsoletos después de 90 días de inactividad.
Marque el problema como nuevo con /remove-lifecycle stale .
Los problemas obsoletos se pudren después de 30 días adicionales de inactividad y finalmente se cierran.
Si es seguro cerrar este problema ahora, hágalo con /close .
Envíe sus comentarios a sig-testing, kubernetes / test-infra y / o fejta .
/ ciclo de vida obsoleto
 fejta-bot
en 17 dic. 2018
fejta-bot
en 17 dic. 2018
/ remove-lifecycle stale
Más o menos cada mes, mi búsqueda en Google me lleva de nuevo a este problema. Hay formas de obtener las estadísticas que necesito con cadenas largas de jq , o con paneles de Grafana con un montón de cálculos ... pero sería _ tan_ bueno si hubiera un comando como:
# kubectl utilization cluster
cores: 19.255/24 cores (80%)
memory: 16.4/24 GiB (68%)
# kubectl utilization [node name]
cores: 3.125/4 cores (78%)
memory: 2.1/4 GiB (52%)
(similar a lo que @chrishiestand mencionó anteriormente en el hilo).
A menudo, estoy construyendo y destruyendo unas pocas docenas de clústeres de prueba por semana, y prefiero no tener que crear automatización o agregar algunos alias de shell para poder ver "si pongo tantos servidores allí y lanzo estas aplicaciones sobre ellos, cuál es mi utilización / presión general ".
Especialmente para clústeres más pequeños / más esotéricos, no quiero configurar la escala automática a la luna (generalmente por razones de dinero), pero necesito saber si tengo suficiente sobrecarga para manejar eventos menores de escala automática de pod.
 geerlingguy
en 30 dic. 2018
geerlingguy
en 30 dic. 2018
Una solicitud adicional: me gustaría poder ver el uso de recursos sumado por espacio de nombres (como mínimo; por Implementación / etiqueta también sería útil), para poder enfocar mis esfuerzos de recorte de recursos averiguando qué espacios de nombres valen concentrandose en.
 evankanderson
en 1 ene. 2019
evankanderson
en 1 ene. 2019
Hice un pequeño complemento kubectl-view-utilization , que proporciona la funcionalidad descrita por @geerlingguy . La instalación a través del administrador de complementos de krew está disponible. Esto está implementado en BASH y necesita awk y bc.
Con el marco del complemento kubectl, esto podría abstraerse por completo de las herramientas principales.
 etopeter
en 13 ene. 2019
etopeter
en 13 ene. 2019
Me alegro de que otros también se hayan enfrentado a este desafío. Creé Kube Eagle (un exportador de Prometheus) que me ayudó a obtener una mejor visión general de los recursos del clúster y, en última instancia, me permitió utilizar mejor los recursos de hardware disponibles:
https://github.com/google-cloud-tools/kube-eagle

 weeco
en 3 mar. 2019
weeco
en 3 mar. 2019
Este es un script de Python para obtener la utilización real del nodo en formato de tabla.
https://github.com/amelbakry/kube-node-utilization
Utilización del nodo de Kubernetes ..........
+ ------------------------------------------------ + -------- + -------- +
| NodeName | CPU | Memoria |
+ ------------------------------------------------ + -------- + -------- +
| ip-176-35-32-139.eu-central-1.compute.internal | 13,49% | 60,87% |
| ip-176-35-26-21.eu-central-1.compute.internal | 5,89% | 15,10% |
| ip-176-35-9-122.eu-central-1.compute.internal | 8,08% | 65,51% |
| ip-176-35-22-243.eu-central-1.compute.internal | 6,29% | 19,28% |
+ ------------------------------------------------ + -------- + -------- +
 amelbakry
en 24 abr. 2019
amelbakry
en 24 abr. 2019
Para mí, al menos @amelbakry, es la utilización a nivel de clúster lo que es importante: "¿necesito agregar más máquinas?" / "¿Debería eliminar algunas máquinas?" / "¿Debería esperar que el clúster se amplíe pronto?" ..
kierenj
en 25 abr. 2019
¿Qué pasa con el uso de almacenamiento efímero? ¿Alguna idea de cómo obtenerlo de todas las vainas?
Y para ser útil, mis sugerencias:
kubectl get pods -o json -n kube-system | jq -r '.items[] | .metadata.name + " \n Req. RAM: " + .spec.containers[].resources.requests.memory + " \n Lim. RAM: " + .spec.containers[].resources.limits.memory + " \n Req. CPU: " + .spec.containers[].resources.requests.cpu + " \n Lim. CPU: " + .spec.containers[].resources.limits.cpu + " \n Req. Eph. DISK: " + .spec.containers[].resources.requests["ephemeral-storage"] + " \n Lim. Eph. DISK: " + .spec.containers[].resources.limits["ephemeral-storage"] + "\n"'
...
kube-proxy-xlmjt
Req. RAM: 32Mi
Lim. RAM: 256Mi
Req. CPU: 100m
Lim. CPU:
Req. Eph. DISK: 100Mi
Lim. Eph. DISK: 512Mi
...
echo "\nRAM Requests TOTAL:" && kubectl describe namespace kube-system | grep 'requests.memory' && echo "\nRAM Requests:\n" && kubectl get pods -o json -n kube-system | jq -r '.items[] | .spec.containers[].resources.requests.memory + " | " + .metadata.name'
echo "\nRAM Limits TOTAL:" && kubectl describe namespace kube-system | grep 'limits.memory' && echo "\nRAM Limits:\n" && kubectl get pods -o json -n kube-system | jq -r '.items[] | .spec.containers[].resources.limits.memory + " | " + .metadata.name'
echo "\nCPU Requests TOTAL:" && kubectl describe namespace kube-system | grep 'requests.cpu' && echo "\nCPU Requests:\n" && kubectl get pods -o json -n kube-system | jq -r '.items[] | .spec.containers[].resources.requests.cpu + " | " + .metadata.name'
echo "\nCPU Limits TOTAL:" && kubectl describe namespace kube-system | grep 'limits.cpu' && echo "\nCPU Limits:\n" && kubectl get pods -o json -n kube-system | jq -r '.items[] | .spec.containers[].resources.limits.cpu + " | " + .metadata.name'
echo "\nEph. DISK Requests TOTAL:" && kubectl describe namespace kube-system | grep 'requests.ephemeral-storage' && echo "\nEph. DISK Requests:\n" && kubectl get pods -o json -n kube-system | jq -r '.items[] | .spec.containers[].resources.requests["ephemeral-storage"] + " | " + .metadata.name'
echo "\nEph. DISK Limits TOTAL:" && kubectl describe namespace kube-system | grep 'limits.ephemeral-storage' && echo "\nEph. DISK Limits:\n" && kubectl get pods -o json -n kube-system | jq -r '.items[] | .spec.containers[].resources.limits["ephemeral-storage"] + " | " + .metadata.name'
RAM Requests TOTAL:
requests.memory 3504Mi 16Gi
RAM Requests:
64Mi | aws-alb-ingress-controller-6b569b448c-jzj6f
...
 kivagant-ba
en 25 abr. 2019
kivagant-ba
en 25 abr. 2019
@ kivagant-ba puede probar este fragmento para obtener métricas de pod por nodo, puede obtener todos los nodos como
https://github.com/amelbakry/kube-node-utilization
def get_pod_metrics_per_node (nodo):
pod_metrics = "/api/v1/pods?fieldSelector=spec.nodeName%3D" + nodo
response = api_client.call_api (pod_metrics,
'GET', auth_settings = ['BearerToken'],
response_type = 'json', _preload_content = Falso)
respuesta = json.loads (respuesta [0] .data.decode ('utf-8'))
respuesta de retorno
amelbakry
en 25 abr. 2019
@kierenj Creo que el componente cluster-autoscaler basado en qué nube se está ejecutando Kubernetes debería manejar la capacidad. No estoy seguro si esta es tu pregunta.
amelbakry
en 25 abr. 2019
Los problemas se vuelven obsoletos después de 90 días de inactividad.
Marque el problema como nuevo con /remove-lifecycle stale .
Los problemas obsoletos se pudren después de 30 días adicionales de inactividad y finalmente se cierran.
Si es seguro cerrar este problema ahora, hágalo con /close .
Envíe sus comentarios a sig-testing, kubernetes / test-infra y / o fejta .
/ ciclo de vida obsoleto
fejta-bot
en 30 jul. 2019
/ remove-lifecycle stale
Yo, como muchos otros, sigo volviendo aquí, durante años, para obtener el truco que necesitamos para administrar los clústeres a través de CLI (por ejemplo, AWS ASG)
 eduncan911
en 28 ago. 2019
eduncan911
en 28 ago. 2019
@etopeter Gracias por un complemento CLI tan genial. Amo la simplicidad de la misma. ¿Algún consejo sobre cómo comprender mejor los números y su significado exacto?
 demisx
en 28 ago. 2019
demisx
en 28 ago. 2019
Si alguien puede usarlo aquí, hay un script que descargará los límites actuales de pods.
kubectl get pods --all-namespaces -o=jsonpath="{range .items[*]}{.metadata.namespace}:{.metadata.name}{'\n'}\
{'.spec.nodeName -'} {.spec.nodeName}{'\n'}\
{range .spec.containers[*]}\
{'requests.cpu -'} {.resources.requests.cpu}{'\n'}\
{'limits.cpu -'} {.resources.limits.cpu}{'\n'}\
{'requests.memory -'} {.resources.requests.memory}{'\n'}\
{'limits.memory -'} {.resources.limits.memory}{'\n'}\
{'\n'}{end}\
{'\n'}{end}"
Salida de ejemplo
...
kube- sistema: addon-http-application-routing-nginx-ingress-controller-6bq49l7
.spec.nodeName - aks-agentpool-84550961-0
request.cpu -
limites.cpu -
peticiones.memoria -
Limites.memory -
kube- sistema: coredns-696c4d987c-pjht8
.spec.nodeName - aks-agentpool-84550961-0
peticiones.cpu - 100 m
limites.cpu -
peticiones.memoria - 70Mi
Limites.memory - 170Mi
kube- sistema: coredns-696c4d987c-rtkl6
.spec.nodeName - aks-agentpool-84550961-2
peticiones.cpu - 100 m
limites.cpu -
peticiones.memoria - 70Mi
Limites.memory - 170Mi
kube- sistema: coredns-696c4d987c-zgcbp
.spec.nodeName: aks-agentpool-84550961-1
peticiones.cpu - 100 m
limites.cpu -
peticiones.memoria - 70Mi
Limites.memory - 170Mi
kube- sistema: coredns-autoscaler-657d77ffbf-7t72x
.spec.nodeName - aks-agentpool-84550961-2
request.cpu - 20m
limites.cpu -
peticiones.memoria - 10Mi
Limites.memory -
kube- sistema: coredns-autoscaler-657d77ffbf-zrp6m
.spec.nodeName - aks-agentpool-84550961-0
request.cpu - 20m
limites.cpu -
peticiones.memoria - 10Mi
Limites.memory -
kube- sistema: kube-proxy-57nw5
.spec.nodeName: aks-agentpool-84550961-1
peticiones.cpu - 100 m
limites.cpu -
peticiones.memoria -
Limites.memory -
...
 Spaceman1861
en 2 sept. 2019
Spaceman1861
en 2 sept. 2019
@ Spaceman1861 ¿ podrías mostrar un ejemplo?
eduncan911
en 2 sept. 2019
@ eduncan911 hecho
Spaceman1861
en 2 sept. 2019
Me resulta más fácil leer la salida en formato de tabla, así (esto muestra solicitudes en lugar de límites):
kubectl get pods -o custom-columns=NAME:.metadata.name,"CPU(cores)":.spec.containers[*].resources.requests.cpu,"MEMORY(bytes)":.spec.containers[*].resources.requests.memory --all-namespaces
Salida de muestra:
NAME CPU(cores) MEMORY(bytes)
pod1 100m 128Mi
pod2 100m 128Mi,128Mi
 lentzi90
en 2 sept. 2019
lentzi90
en 2 sept. 2019
@ lentzi90 solo para su información: puede mostrar columnas personalizadas similares en Kubernetes Web View ("kubectl para la web"), demostración: https://kube-web-view.demo.j-serv.de/clusters/local/namespaces/ default / pods? join = metrics; customcols = CPU + Requests = join (% 27,% 20% 27,% 20spec.containers [ ] .resources.requests.cpu)% 3BMemory + Requests = join (% 27,% 20% 27,% 20spec.containers [ ] .resources.requests.memory)
Documentos sobre columnas personalizadas: https://kube-web-view.readthedocs.io/en/latest/features.html#listing -resources
hjacobs
en 2 sept. 2019
Oooo shiny @hjacobs Me gusta eso.
Spaceman1861
en 2 sept. 2019
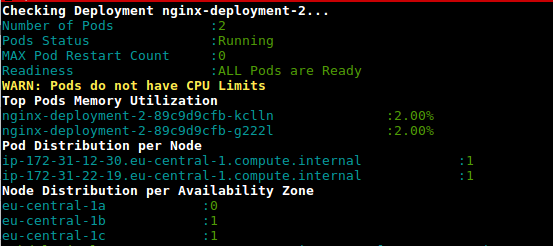
Este es un script (deployment-health.sh) para obtener la utilización de los pods en la implementación según el uso y los límites configurados
https://github.com/amelbakry/kubernetes-scripts
amelbakry
en 2 sept. 2019
Inspirado por las respuestas de @ lentzi90 y @ylogx , he creado un gran script propio que muestra el uso real de recursos ( kubectl top pods ) y las solicitudes y límites de recursos:
join -a1 -a2 -o 0,1.2,1.3,2.2,2.3,2.4,2.5, -e '<none>' <(kubectl top pods) <(kubectl get pods -o custom-columns=NAME:.metadata.name,"CPU_REQ(cores)":.spec.containers[*].resources.requests.cpu,"MEMORY_REQ(bytes)":.spec.containers[*].resources.requests.memory,"CPU_LIM(cores)":.spec.containers[*].resources.limits.cpu,"MEMORY_LIM(bytes)":.spec.containers[*].resources.limits.memory) | column -t -s' '
ejemplo de salida:
NAME CPU(cores) MEMORY(bytes) CPU_REQ(cores) MEMORY_REQ(bytes) CPU_LIM(cores) MEMORY_LIM(bytes)
xxxxx-847dbbc4c-c6twt 20m 110Mi 50m 150Mi 150m 250Mi
xxx-service-7b6b9558fc-9cq5b 19m 1304Mi 1 <none> 1 <none>
xxxxxxxxxxxxxxx-hook-5d585b449b-zfxmh 0m 46Mi 200m 155M 200m 155M
Aquí está el alias para que use kstats en su terminal:
alias kstats='join -a1 -a2 -o 0,1.2,1.3,2.2,2.3,2.4,2.5, -e '"'"'<none>'"'"' <(kubectl top pods) <(kubectl get pods -o custom-columns=NAME:.metadata.name,"CPU_REQ(cores)":.spec.containers[*].resources.requests.cpu,"MEMORY_REQ(bytes)":.spec.containers[*].resources.requests.memory,"CPU_LIM(cores)":.spec.containers[*].resources.limits.cpu,"MEMORY_LIM(bytes)":.spec.containers[*].resources.limits.memory) | column -t -s'"'"' '"'"
PD: he probado scripts solo en mi mac, para linux y windows puede requerir algunos cambios
 alikhil
en 25 sept. 2019
alikhil
en 25 sept. 2019
Este es un script (deployment-health.sh) para obtener la utilización de los pods en la implementación según el uso y los límites configurados
https://github.com/amelbakry/kubernetes-scripts
@amelbakry Recibo el siguiente error al intentar ejecutarlo en una Mac:
Failed to execute process './deployment-health.sh'. Reason:
exec: Exec format error
The file './deployment-health.sh' is marked as an executable but could not be run by the operating system.
Woops,
"#!" debe ser la primera línea. En su lugar, intente "bash
./deployment-health.sh "para solucionar el problema.
/Charles
PD. PR abrió para solucionar el problema
El miércoles, 25 de septiembre de 2019 a las 10:19 a. M. Dmitri Moore [email protected]
escribió:
Este es un script (deployment-health.sh) para obtener la utilización de los pods
en implementación según el uso y los límites configurados
https://github.com/amelbakry/kubernetes-scripts@amelbakry https://github.com/amelbakry Estoy obteniendo lo siguiente
error al intentar ejecutarlo en una Mac:Error al ejecutar el proceso './deployment-health.sh'. Razón:
exec: error de formato de Exec
El archivo './deployment-health.sh' está marcado como ejecutable, pero el sistema operativo no pudo ejecutarlo.-
Estás recibiendo esto porque estás suscrito a este hilo.
Responda a este correo electrónico directamente, véalo en GitHub
https://github.com/kubernetes/kubernetes/issues/17512?email_source=notifications&email_token=AACA3TODQEUPWK3V3UY3SF3QLOMSFA5CNFSM4BUXCUG2YY3PNVWWK3TUL52HS4DFVDVREXWJWKNM86 ,
o silenciar el hilo
https://github.com/notifications/unsubscribe-auth/AACA3TOPOBIWXFX2DAOT6JDQLOMSFANCNFSM4BUXCUGQ
.
 cgthayer
en 25 sept. 2019
cgthayer
en 25 sept. 2019
@cgthayer Es posible que desee aplicar esa corrección de relaciones públicas a nivel mundial. Además, cuando ejecuté los scripts en MacOs Mojave, aparecieron un montón de errores, incluidos los nombres de zona específicos de la UE que no uso. Parece que estos guiones se han escrito para un proyecto específico.
demisx
en 2 oct. 2019
Aquí hay una versión modificada de join ex. que también hace totales de columnas.
oc_ns_pod_usage () {
# show pod usage for cpu/mem
ns="$1"
usage_chk3 "$ns" || return 1
printf "$ns\n"
separator=$(printf '=%.0s' {1..50})
printf "$separator\n"
output=$(join -a1 -a2 -o 0,1.2,1.3,2.2,2.3,2.4,2.5, -e '<none>' \
<(kubectl top pods -n $ns) \
<(kubectl get -n $ns pods -o custom-columns=NAME:.metadata.name,"CPU_REQ(cores)":.spec.containers[*].resources.requests.cpu,"MEMORY_REQ(bytes)":.spec.containers[*].resources.requests.memory,"CPU_LIM(cores)":.spec.containers[*].resources.limits.cpu,"MEMORY_LIM(bytes)":.spec.containers[*].resources.limits.memory))
totals=$(printf "%s" "$output" | awk '{s+=$2; t+=$3; u+=$4; v+=$5; w+=$6; x+=$7} END {print s" "t" "u" "v" "w" "x}')
printf "%s\n%s\nTotals: %s\n" "$output" "$separator" "$totals" | column -t -s' '
printf "$separator\n"
}
Ejemplo
$ oc_ns_pod_usage ls-indexer
ls-indexer
==================================================
NAME CPU(cores) MEMORY(bytes) CPU_REQ(cores) MEMORY_REQ(bytes) CPU_LIM(cores) MEMORY_LIM(bytes)
ls-indexer-f5-7cd5859997-qsfrp 15m 741Mi 1 1000Mi 2 2000Mi
ls-indexer-f5-7cd5859997-sclvg 15m 735Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-4b7j2 92m 1103Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-5xj5l 88m 1124Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-6vvl2 92m 1132Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-85f66 85m 1151Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-924jz 96m 1124Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-g6gx8 119m 1119Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-hkhnt 52m 819Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-hrsrs 51m 1122Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-j4qxm 53m 885Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-lxlrb 83m 1215Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-mw6rt 86m 1131Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-pbdf8 95m 1115Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-qk9bm 91m 1141Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-sdv9r 54m 1194Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-t67v6 75m 1234Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-tkxs2 88m 1364Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-v6jl2 53m 747Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-wkqr7 53m 838Mi 1 1000Mi 2 2000Mi
ls-indexer-metricbeat-74d89d7d85-jp8qc 190m 1191Mi 1 1000Mi 2 2000Mi
ls-indexer-metricbeat-74d89d7d85-jv4bv 192m 1162Mi 1 1000Mi 2 2000Mi
ls-indexer-metricbeat-74d89d7d85-k4dcd 194m 1144Mi 1 1000Mi 2 2000Mi
ls-indexer-metricbeat-74d89d7d85-n46tz 192m 1155Mi 1 1000Mi 2 2000Mi
ls-indexer-packetbeat-db98f6fdf-8x446 35m 1198Mi 1 1000Mi 2 2000Mi
ls-indexer-packetbeat-db98f6fdf-gmxxd 22m 1203Mi 1 1000Mi 2 2000Mi
ls-indexer-syslog-5466bc4d4f-gzxw8 27m 1125Mi 1 1000Mi 2 2000Mi
ls-indexer-syslog-5466bc4d4f-zh7st 29m 1153Mi 1 1000Mi 2 2000Mi
==================================================
Totals: 2317 30365 28 28000 56 56000
==================================================
 slmingol
en 21 oct. 2019
slmingol
en 21 oct. 2019
¿Y qué es uses_chk3?
 cristifalcas
en 25 oct. 2019
cristifalcas
en 25 oct. 2019
También me gustaría compartir mis herramientas ;-) kubectl-view-allocations: kubectl plugin para listar asignaciones (cpu, memoria, gpu, ... X solicitado, límite, asignable, ...). , la solicitud es bienvenida.
Lo hice porque me gustaría proporcionar a mis usuarios (internos) una forma de ver "quién asigna qué". De forma predeterminada, se muestran todos los recursos, pero en el siguiente ejemplo solo solicito el recurso con "gpu" en el nombre.
> kubectl-view-allocations -r gpu
Resource Requested %Requested Limit %Limit Allocatable Free
nvidia.com/gpu 7 58% 7 58% 12 5
├─ node-gpu1 1 50% 1 50% 2 1
│ └─ xxxx-784dd998f4-zt9dh 1 1
├─ node-gpu2 0 0% 0 0% 2 2
├─ node-gpu3 0 0% 0 0% 2 2
├─ node-gpu4 1 50% 1 50% 2 1
│ └─ aaaa-1571819245-5ql82 1 1
├─ node-gpu5 2 100% 2 100% 2 0
│ ├─ bbbb-1571738839-dfkhn 1 1
│ └─ bbbb-1571738888-52c4w 1 1
└─ node-gpu6 2 100% 2 100% 2 0
├─ bbbb-1571738688-vlxng 1 1
└─ cccc-1571745684-7k6bn 1 1
próxima (s) versión (s):
- permitirá ocultar el nivel (nodo, grupo) o elegir cómo agrupar (por ejemplo, para proporcionar una descripción general con solo recursos)
- instalación a través de curl, krew, brew, ... (actualmente los binarios están disponibles en la sección de lanzamientos de github)
Gracias a kubectl-view-utilization por la inspiración, pero agregar soporte a otros recursos fue para muchos copiar / pegar o difícil de hacer para mí en bash (de manera genérica).
 davidB
en 25 oct. 2019
davidB
en 25 oct. 2019
aquí está mi truco
kubectl describe nodes | grep -A 2 -e "^\\s*CPU Requests"
Esto ya no funciona :(
 libudas
en 28 nov. 2019
libudas
en 28 nov. 2019
Prueba kubectl describe node | grep -A5 "Allocated"
 MostafaGazar
en 28 nov. 2019
MostafaGazar
en 28 nov. 2019
Actualmente, este es el cuarto problema más solicitado por aprobación, pero sigue siendo priority/backlog .
Estaría feliz de intentarlo si alguien pudiera indicarme la dirección correcta o si pudiéramos finalizar una propuesta. Creo que la UX de la herramienta de kubectl .
 alexkreidler
en 1 dic. 2019
alexkreidler
en 1 dic. 2019
Usando los siguientes comandos: kubectl top nodes & kubectl describe node no obtenemos resultados consistentes
Por ejemplo, con el primero, la CPU (núcleos) son 1064 m, pero este resultado no se puede obtener con el segundo (1480 m):
kubectl top nodes
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
abcd-p174e23ea5qa4g279446c803f82-abc-node-0 1064m 53% 6783Mi 88%
kubectl describe node abcd-p174e23ea5qa4g279446c803f82-abc-node-0
...
Resource Requests Limits
-------- -------- ------
cpu 1480m (74%) 1300m (65%)
memory 2981486848 (37%) 1588314624 (19%)
¿Alguna idea sobre cómo obtener la CPU (núcleos) sin usar kubectl top nodes ?
 smpar
en 18 dic. 2019
smpar
en 18 dic. 2019
También me gustaría compartir mis herramientas ;-) kubectl-view-allocations: kubectl plugin para listar asignaciones (cpu, memoria, gpu, ... X solicitado, límite, asignable, ...). , la solicitud es bienvenida.
Lo hice porque me gustaría proporcionar a mis usuarios (internos) una forma de ver "quién asigna qué". De forma predeterminada, se muestran todos los recursos, pero en el siguiente ejemplo solo solicito el recurso con "gpu" en el nombre.
> kubectl-view-allocations -r gpu Resource Requested %Requested Limit %Limit Allocatable Free nvidia.com/gpu 7 58% 7 58% 12 5 ├─ node-gpu1 1 50% 1 50% 2 1 │ └─ xxxx-784dd998f4-zt9dh 1 1 ├─ node-gpu2 0 0% 0 0% 2 2 ├─ node-gpu3 0 0% 0 0% 2 2 ├─ node-gpu4 1 50% 1 50% 2 1 │ └─ aaaa-1571819245-5ql82 1 1 ├─ node-gpu5 2 100% 2 100% 2 0 │ ├─ bbbb-1571738839-dfkhn 1 1 │ └─ bbbb-1571738888-52c4w 1 1 └─ node-gpu6 2 100% 2 100% 2 0 ├─ bbbb-1571738688-vlxng 1 1 └─ cccc-1571745684-7k6bn 1 1próxima (s) versión (s):
* will allow to hide (node, pod) level or to choose how to group, (eg to provide an overview with only resources) * installation via curl, krew, brew, ... (currently binary are available under the releases section of github)Gracias a kubectl-view-utilization por la inspiración, pero agregar soporte a otros recursos fue para muchos copiar / pegar o difícil de hacer para mí en bash (de manera genérica).
Hola David, sería bueno si proporcionaras más binarios compilados para nuevas distribuciones. En Ubuntu 16.04 obtenemos
kubectl-view-allocations: /lib/x86_64-linux-gnu/libc.so.6: no se encontró la versión 'GLIBC_2.25' (requerida por kubectl-view-allocations)
dpkg -l |grep glib
ii libglib2.0-0: amd64 2.48.2-0ubuntu4.4
 omerfsen
en 12 ene. 2020
omerfsen
en 12 ene. 2020
@omerfsen, ¿puedes probar la nueva versión kubectl-view-allocations y comentar la versión del ticket
davidB
en 15 ene. 2020
Mi forma de obtener la asignación, en todo el clúster:
$ kubectl get po --all-namespaces -o=jsonpath="{range .items[*]}{.metadata.namespace}:{.metadata.name}{'\n'}{range .spec.containers[*]} {.name}:{.resources.requests.cpu}{'\n'}{end}{'\n'}{end}"Produce algo como:
kube-system:heapster-v1.5.0-dc8df7cc9-7fqx6 heapster:88m heapster-nanny:50m kube-system:kube-dns-6cdf767cb8-cjjdr kubedns:100m dnsmasq:150m sidecar:10m prometheus-to-sd: kube-system:kube-dns-6cdf767cb8-pnx2g kubedns:100m dnsmasq:150m sidecar:10m prometheus-to-sd: kube-system:kube-dns-autoscaler-69c5cbdcdd-wwjtg autoscaler:20m kube-system:kube-proxy-gke-cluster1-default-pool-cd7058d6-3tt9 kube-proxy:100m kube-system:kube-proxy-gke-cluster1-preempt-pool-57d7ff41-jplf kube-proxy:100m kube-system:kubernetes-dashboard-7b9c4bf75c-f7zrl kubernetes-dashboard:50m kube-system:l7-default-backend-57856c5f55-68s5g default-http-backend:10m kube-system:metrics-server-v0.2.0-86585d9749-kkrzl metrics-server:48m metrics-server-nanny:5m kube-system:tiller-deploy-7794bfb756-8kxh5 tiller:10m
de lejos, la mejor respuesta aquí.
 abelal83
en 31 ene. 2020
abelal83
en 31 ene. 2020
Inspirado por los scripts anteriores, creé el siguiente script para ver el uso, las solicitudes y los límites:
join -1 2 -2 2 -a 1 -a 2 -o "2.1 0 1.3 2.3 2.5 1.4 2.4 2.6" -e '<wait>' \
<( kubectl top pods --all-namespaces | sort --key 2 -b ) \
<( kubectl get pods --all-namespaces -o custom-columns=NAMESPACE:.metadata.namespace,NAME:.metadata.name,"CPU_REQ(cores)":.spec.containers[*].resources.requests.cpu,"MEMORY_REQ(bytes)":.spec.containers[*].resources.requests.memory,"CPU_LIM(cores)":.spec.containers[*].resources.limits.cpu,"MEMORY_LIM(bytes)":.spec.containers[*].resources.limits.memory | sort --key 2 -b ) \
| column -t -s' '
Debido a que el script de shell join espera una lista ordenada, los scripts dados anteriormente me fallaron.
Como resultado, verá el uso actual desde arriba y desde la implementación las solicitudes y los límites de (aquí) todos los espacios de nombres:
NAMESPACE NAME CPU(cores) CPU_REQ(cores) CPU_LIM(cores) MEMORY(bytes) MEMORY_REQ(bytes) MEMORY_LIM(bytes)
kube-system aws-node-2jzxr 18m 10m <none> 41Mi <none> <none>
kube-system aws-node-5zn6w <wait> 10m <none> <wait> <none> <none>
kube-system aws-node-h8cc5 20m 10m <none> 42Mi <none> <none>
kube-system aws-node-h9n4f 0m 10m <none> 0Mi <none> <none>
kube-system aws-node-lz5fn 17m 10m <none> 41Mi <none> <none>
kube-system aws-node-tpmxr 20m 10m <none> 39Mi <none> <none>
kube-system aws-node-zbkkh 23m 10m <none> 47Mi <none> <none>
cluster-autoscaler cluster-autoscaler-aws-cluster-autoscaler-5db55fbcf8-mdzkd 1m 100m 500m 9Mi 300Mi 500Mi
cluster-autoscaler cluster-autoscaler-aws-cluster-autoscaler-5db55fbcf8-q9xs8 39m 100m 500m 75Mi 300Mi 500Mi
kube-system coredns-56b56b56cd-bb26t 6m 100m <none> 11Mi 70Mi 170Mi
kube-system coredns-56b56b56cd-nhp58 6m 100m <none> 11Mi 70Mi 170Mi
kube-system coredns-56b56b56cd-wrmxv 7m 100m <none> 12Mi 70Mi 170Mi
gitlab-runner-l gitlab-runner-l-gitlab-runner-6b8b85f87f-9knnx 3m 100m 200m 10Mi 128Mi 256Mi
gitlab-runner-m gitlab-runner-m-gitlab-runner-6bfd5d6c84-t5nrd 7m 100m 200m 13Mi 128Mi 256Mi
gitlab-runner-mda gitlab-runner-mda-gitlab-runner-59bb66c8dd-bd9xw 4m 100m 200m 17Mi 128Mi 256Mi
gitlab-runner-ops gitlab-runner-ops-gitlab-runner-7c5b85dc97-zkb4c 3m 100m 200m 12Mi 128Mi 256Mi
gitlab-runner-pst gitlab-runner-pst-gitlab-runner-6b8f9bf56b-sszlr 6m 100m 200m 20Mi 128Mi 256Mi
gitlab-runner-s gitlab-runner-s-gitlab-runner-6bbccb9b7b-dmwgl 50m 100m 200m 27Mi 128Mi 512Mi
gitlab-runner-shared gitlab-runner-shared-gitlab-runner-688d57477f-qgs2z 3m <none> <none> 15Mi <none> <none>
kube-system kube-proxy-5b65t 15m 100m <none> 19Mi <none> <none>
kube-system kube-proxy-7qsgh 12m 100m <none> 24Mi <none> <none>
kube-system kube-proxy-gn2qg 13m 100m <none> 23Mi <none> <none>
kube-system kube-proxy-pz7fp 15m 100m <none> 18Mi <none> <none>
kube-system kube-proxy-vdjqt 15m 100m <none> 23Mi <none> <none>
kube-system kube-proxy-x4xtp 19m 100m <none> 15Mi <none> <none>
kube-system kube-proxy-xlpn7 0m 100m <none> 0Mi <none> <none>
metrics-server metrics-server-5875c7d795-bj7cq 5m 200m 500m 29Mi 200Mi 500Mi
metrics-server metrics-server-5875c7d795-jpjjn 7m 200m 500m 29Mi 200Mi 500Mi
gitlab-runner-s runner-heq8ujaj-project-10386-concurrent-06t94f <wait> 200m,100m 200m,200m <wait> 200Mi,128Mi 500Mi,500Mi
gitlab-runner-s runner-heq8ujaj-project-10386-concurrent-10lpn9j 1m 200m,100m 200m,200m 12Mi 200Mi,128Mi 500Mi,500Mi
gitlab-runner-s runner-heq8ujaj-project-10386-concurrent-11jrxfh <wait> 200m,100m 200m,200m <wait> 200Mi,128Mi 500Mi,500Mi
gitlab-runner-s runner-heq8ujaj-project-10386-concurrent-129hpvl 1m 200m,100m 200m,200m 12Mi 200Mi,128Mi 500Mi,500Mi
gitlab-runner-s runner-heq8ujaj-project-10386-concurrent-13kswg8 1m 200m,100m 200m,200m 12Mi 200Mi,128Mi 500Mi,500Mi
gitlab-runner-s runner-heq8ujaj-project-10386-concurrent-15qhp5w <wait> 200m,100m 200m,200m <wait> 200Mi,128Mi 500Mi,500Mi
Notable: puede ordenar el consumo de CPU con, por ejemplo:
| awk 'NR<2{print $0;next}{print $0| "sort --key 3 --numeric -b --reverse"}
Esto funciona en Mac; no estoy seguro, si también funciona en Linux (debido a unir, ordenar, etc.).
Con suerte, alguien puede usar esto hasta que kubectl tenga una buena vista de eso.
 stefanjacobs
en 11 feb. 2020
stefanjacobs
en 11 feb. 2020
Tengo una buena experiencia con kube-capacity .
Ejemplo:
kube-capacity --util
NODE CPU REQUESTS CPU LIMITS CPU UTIL MEMORY REQUESTS MEMORY LIMITS MEMORY UTIL
* 560m (28%) 130m (7%) 40m (2%) 572Mi (9%) 770Mi (13%) 470Mi (8%)
example-node-1 220m (22%) 10m (1%) 10m (1%) 192Mi (6%) 360Mi (12%) 210Mi (7%)
example-node-2 340m (34%) 120m (12%) 30m (3%) 380Mi (13%) 410Mi (14%) 260Mi (9%)
 eyalev
en 18 feb. 2020
eyalev
en 18 feb. 2020
Para que esta herramienta sea realmente útil, debe detectar todos los complementos de dispositivos de Kubernetes implementados en el clúster y mostrar el uso de todos ellos. CPU / Mem definitivamente no es suficiente. También hay GPU, TPU (para aprendizaje automático), Intel QAT y probablemente más que no conozco. También, ¿qué pasa con el almacenamiento? Debería poder ver fácilmente lo que se solicitó y lo que se usa (idealmente también en términos de iops).
 boniek83
en 9 abr. 2020
boniek83
en 9 abr. 2020
@ boniek83 , es por eso que creé kubectl-view-allocations , porque necesito listar GPU, ... cualquier comentario (sobre el proyecto github) es bienvenido. Tengo curiosidad por saber si detecta TPU (debería hacerlo si figura como recursos de un nodo)
davidB
en 9 abr. 2020
@ boniek83 , es por eso que creé kubectl-view-allocations , porque necesito listar GPU, ... cualquier comentario (sobre el proyecto github) es bienvenido. Tengo curiosidad por saber si detecta TPU (debería hacerlo si figura como recursos de un nodo)
Soy consciente de su herramienta y, para mi propósito, es la mejor que está disponible actualmente. ¡Gracias por hacerlo!
Intentaré que prueben los TPU después de Pascua. Sería útil si estos datos estuvieran disponibles en formato de aplicación web con gráficos bonitos para no tener que dar acceso a kubernetes a los científicos de datos. Solo quieren saber quién está consumiendo los recursos y nada más :)
boniek83
en 9 abr. 2020
Dado que ninguna de las herramientas y scripts anteriores se ajusta a mis necesidades (y este problema aún está abierto :(), pirateé mi propia variante:
https://github.com/eht16/kube-cargo-load
Proporciona una descripción general rápida de los POD en un clúster y muestra sus solicitudes y límites de memoria configurados y el uso real de la memoria. La idea es tener una idea de la relación entre los límites de memoria configurados y el uso real.
 eht16
en 13 abr. 2020
eht16
en 13 abr. 2020
¿Cómo podemos obtener registros de volcados de memoria de los pods?
Las vainas a menudo se cuelgan,
 RahulRatan07
en 26 abr. 2020
RahulRatan07
en 26 abr. 2020
kubectl describe nodesOkubectl top nodes, ¿cuál se debe considerar para calcular la utilización de recursos del clúster?- También por qué hay diferencia entre estos 2 resultados.
¿Hay alguna explicación lógica para esto todavía?
 hmsvigle
en 27 abr. 2020
hmsvigle
en 27 abr. 2020
/ tipo de característica
 brianpursley
en 29 abr. 2020
brianpursley
en 29 abr. 2020
Todos los comentarios y trucos con nodos funcionaron bien para mí. También necesito algo para una vista más alta para realizar un seguimiento de ... ¡como la suma de recursos por grupo de nodos!
 prathameshd9
en 30 abr. 2020
prathameshd9
en 30 abr. 2020
Hola,
Quiero registrar el uso de la CPU y la memoria de un pod, cada 5 minutos durante un período de tiempo. Luego usaría estos datos para crear un gráfico en Excel. ¿Algunas ideas? Gracias
 rajjar123456
en 18 jul. 2020
rajjar123456
en 18 jul. 2020
Hola,
Me alegra ver que Google nos señaló a todos este problema :-) (un poco decepcionado de que todavía esté abierto después de casi 5 años). Gracias por todos los recortes de shell y otras herramientas.
 yceoshda
en 28 jul. 2020
yceoshda
en 28 jul. 2020
Hack simple y rápido:
$ kubectl describe nodes | grep 'Name:\| cpu\| memory'
Name: XXX-2-wke2
cpu 1552m (77%) 2402m (120%)
memory 2185Mi (70%) 3854Mi (123%)
Name: XXX-2-wkep
cpu 1102m (55%) 1452m (72%)
memory 1601Mi (51%) 2148Mi (69%)
Name: XXX-2-wkwz
cpu 852m (42%) 1352m (67%)
memory 1125Mi (36%) 3624Mi (116%)
 SerheyDolgushev
en 5 ago. 2020
SerheyDolgushev
en 5 ago. 2020
Hack simple y rápido:
$ kubectl describe nodes | grep 'Name:\| cpu\| memory' Name: XXX-2-wke2 cpu 1552m (77%) 2402m (120%) memory 2185Mi (70%) 3854Mi (123%) Name: XXX-2-wkep cpu 1102m (55%) 1452m (72%) memory 1601Mi (51%) 2148Mi (69%) Name: XXX-2-wkwz cpu 852m (42%) 1352m (67%) memory 1125Mi (36%) 3624Mi (116%)Los complementos del dispositivo no están allí. Ellos deberían ser. Estos dispositivos también son recursos.
boniek83
en 5 ago. 2020
¡Hola!
Creé este script y lo comparto contigo.
https://github.com/Sensedia/open-tools/blob/master/scripts/listK8sHardwareResources.sh
Este script tiene una compilación de algunas de las ideas que compartiste aquí. El script se puede incrementar y puede ayudar a otras personas a obtener las métricas de forma más sencilla.
¡Gracias por compartir los consejos y los comandos!
 aeciopires
en 7 ago. 2020
aeciopires
en 7 ago. 2020
Para mi caso de uso, terminé escribiendo un simple complemento kubectl que enumera los límites / reservas de CPU / RAM para los nodos en una tabla. También verifica el consumo actual de CPU / RAM de la vaina (como kubectl top pods ), pero ordena la salida por CPU en orden descendente.
Es más una cosa de conveniencia que cualquier otra cosa, pero tal vez alguien más lo encuentre útil también.
 laurybueno
en 9 ago. 2020
laurybueno
en 9 ago. 2020
Vaya, ¿qué hilo tan grande y aún no hay una solución adecuada del equipo de Kubernetes para calcular correctamente el uso general actual de la CPU de todo un clúster?
 denissabramovs
en 20 sept. 2020
denissabramovs
en 20 sept. 2020
Para aquellos que buscan ejecutar esto en minikube, primero habilite el complemento del servidor de métricas
minikube addons enable metrics-server
y luego ejecuta el comando
kubectl top nodes
 raul1991
en 16 oct. 2020
raul1991
en 16 oct. 2020
Si está usando Krew :
kubectl krew install resource-capacity
kubectl resource-capacity
NODE CPU REQUESTS CPU LIMITS MEMORY REQUESTS MEMORY LIMITS
* 16960m (35%) 18600m (39%) 26366Mi (14%) 3100Mi (1%)
ip-10-0-138-176.eu-north-1.compute.internal 2460m (31%) 4200m (53%) 567Mi (1%) 784Mi (2%)
ip-10-0-155-49.eu-north-1.compute.internal 2160m (27%) 2200m (27%) 4303Mi (14%) 414Mi (1%)
ip-10-0-162-84.eu-north-1.compute.internal 3860m (48%) 3900m (49%) 8399Mi (27%) 414Mi (1%)
ip-10-0-200-101.eu-north-1.compute.internal 2160m (27%) 2200m (27%) 4303Mi (14%) 414Mi (1%)
ip-10-0-231-146.eu-north-1.compute.internal 2160m (27%) 2200m (27%) 4303Mi (14%) 414Mi (1%)
ip-10-0-251-167.eu-north-1.compute.internal 4160m (52%) 3900m (49%) 4491Mi (14%) 660Mi (2%)
 benjick
en 14 nov. 2020
benjick
en 14 nov. 2020
Temas relacionados
 Seb-Solon
·
3Comentarios
Seb-Solon
·
3Comentarios
 zetaab
·
3Comentarios
zetaab
·
3Comentarios
 tbchj
·
3Comentarios
tbchj
·
3Comentarios
 jadhavnitind
·
3Comentarios
jadhavnitind
·
3Comentarios
 ttripp
·
3Comentarios
ttripp
·
3Comentarios
Comentario más útil
Hay: