Kubernetes: Precisa de um comando kubectl simples para ver o uso de recursos do cluster
Os usuários estão sendo confundidos por pods que não conseguem agendar devido a deficiências de recursos. Pode ser difícil saber quando um pod está pendente porque ele ainda não foi inicializado ou porque o cluster não tem espaço para programá-lo. http://kubernetes.io/v1.1/docs/user-guide/compute-resources.html#monitoring -compute-resource-usage ajuda, mas não é tão detectável (eu tendo a tentar um 'get' em um pod em pendente primeiro, e só depois de esperar um pouco e ver que ele está "preso" em pendente, devo usar "descrever" para perceber que é um problema de agendamento).
Isso também é complicado porque os pods do sistema estão em um namespace oculto. Os usuários esquecem que esses pods existem e 'contam contra' os recursos do cluster.
Existem várias soluções possíveis de improviso, não sei qual seria o ideal:
1) Desenvolva um novo estado de pod diferente de Pendente para representar "tentou agendar e falhou por falta de recursos".
2) Faça com que kubectl get po ou kubectl get po -o = wide exiba uma coluna para detalhar porque algo está pendente (talvez o container.state que está Esperando neste caso ou o event.message mais recente).
3) Crie um novo comando kubectl para descrever os recursos com mais facilidade. Estou imaginando um "uso de kubectl" que dá uma visão geral da CPU e Mem total do cluster, por CPU e Mem de nó e o uso de cada pod / contêiner. Aqui incluiríamos todos os pods, incluindo os do sistema. Isso pode ser útil a longo prazo junto com agendadores mais complexos, ou quando seu cluster tem recursos suficientes, mas nenhum nó tem (diagnosticando o problema 'sem buracos grandes o suficiente').
 goltermann
goltermann
Todos 88 comentários
Algo na linha de (2) parece razoável, embora o pessoal de UX saiba mais do que eu.
(3) parece vagamente relacionado a # 15743, mas não tenho certeza se eles são próximos o suficiente para combinar.
 davidopp
em 20 nov. 2015
davidopp
em 20 nov. 2015
Além do caso acima, seria bom ver a utilização de recursos que estamos obtendo.
kubectl utilization requests pode mostrar (talvez kubectl util ou kubectl usage sejam melhores / mais curtos):
cores: 4.455/5 cores (89%)
memory: 20.1/30 GiB (67%)
...
Neste exemplo, as solicitações de contêiner agregado são 4,455 núcleos e 20,1 GiB e há 5 núcleos e 30 GiB no total no cluster.
 chrishiestand
em 16 set. 2016
chrishiestand
em 16 set. 2016
Há:
$ kubectl top nodes
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
cluster1-k8s-master-1 312m 15% 1362Mi 68%
cluster1-k8s-node-1 124m 12% 233Mi 11%
 xmik
em 19 dez. 2016
xmik
em 19 dez. 2016
Eu uso o comando abaixo para obter uma visão rápida do uso de recursos. É a maneira mais simples que encontrei.
kubectl describe nodes
 ozbillwang
em 11 jan. 2017
ozbillwang
em 11 jan. 2017
Se houvesse uma maneira de "formatar" a saída de kubectl describe nodes , eu não me importaria em criar um script para resumir todas as solicitações / limites de recursos do nó.
 tonglil
em 20 jan. 2017
tonglil
em 20 jan. 2017
aqui está meu hack kubectl describe nodes | grep -A 2 -e "^\\s*CPU Requests"
 from-nibly
em 2 fev. 2017
from-nibly
em 2 fev. 2017
@de-nìvel obrigado, exatamente o que eu estava procurando
 jredl-va
em 25 mai. 2017
jredl-va
em 25 mai. 2017
Sim, este é o meu:
$ cat bin/node-resources.sh
#!/bin/bash
set -euo pipefail
echo -e "Iterating...\n"
nodes=$(kubectl get node --no-headers -o custom-columns=NAME:.metadata.name)
for node in $nodes; do
echo "Node: $node"
kubectl describe node "$node" | sed '1,/Non-terminated Pods/d'
echo
done
@goltermann Não há rótulos de assinatura neste assunto. Adicione um rótulo de assinatura por:
(1) mencionando um sig: @kubernetes/sig-<team-name>-misc
(2) especificando o rótulo manualmente: /sig <label>
_Nota: o método (1) irá disparar uma notificação para a equipe. Você pode encontrar a lista de times aqui ._
 k8s-github-robot
em 1 jun. 2017
k8s-github-robot
em 1 jun. 2017
@ kubernetes / sig-cli-misc
 kargakis
em 10 jun. 2017
kargakis
em 10 jun. 2017
Você pode usar o comando abaixo para encontrar a porcentagem de processamento de seus nós
alias util='kubectl get nodes | grep node | awk '\''{print $1}'\'' | xargs -I {} sh -c '\''echo {} ; kubectl describe node {} | grep Allocated -A 5 | grep -ve Event -ve Allocated -ve percent -ve -- ; echo '\'''
Note: 4000m cores is the total cores in one node
alias cpualloc="util | grep % | awk '{print \$1}' | awk '{ sum += \$1 } END { if (NR > 0) { result=(sum**4000); printf result/NR \"%\n\" } }'"
$ cpualloc
3.89358%
Note: 1600MB is the total cores in one node
alias memalloc='util | grep % | awk '\''{print $3}'\'' | awk '\''{ sum += $1 } END { if (NR > 0) { result=(sum*100)/(NR*1600); printf result/NR "%\n" } }'\'''
$ memalloc
24.6832%
 alok87
em 5 jul. 2017
alok87
em 5 jul. 2017
@tomfotherby alias util='kubectl get nodes | grep node | awk '\''{print $1}'\'' | xargs -I {} sh -c '\''echo {} ; kubectl describe node {} | grep Allocated -A 5 | grep -ve Event -ve Allocated -ve percent -ve -- ; echo '\'''
alok87
em 21 jul. 2017
@ alok87 - Obrigado por seus apelidos. No meu caso, isso é o que funcionou para mim, visto que usamos os tipos de instância bash e m3.large (2 cpu, 7,5 G de memória).
alias util='kubectl get nodes --no-headers | awk '\''{print $1}'\'' | xargs -I {} sh -c '\''echo {} ; kubectl describe node {} | grep Allocated -A 5 | grep -ve Event -ve Allocated -ve percent -ve -- ; echo '\'''
# Get CPU request total (we x20 because because each m3.large has 2 vcpus (2000m) )
alias cpualloc='util | grep % | awk '\''{print $1}'\'' | awk '\''{ sum += $1 } END { if (NR > 0) { print sum/(NR*20), "%\n" } }'\'''
# Get mem request total (we x75 because because each m3.large has 7.5G ram )
alias memalloc='util | grep % | awk '\''{print $5}'\'' | awk '\''{ sum += $1 } END { if (NR > 0) { print sum/(NR*75), "%\n" } }'\'''
$util
ip-10-56-0-178.ec2.internal
CPU Requests CPU Limits Memory Requests Memory Limits
960m (48%) 2700m (135%) 630Mi (8%) 2034Mi (27%)
ip-10-56-0-22.ec2.internal
CPU Requests CPU Limits Memory Requests Memory Limits
920m (46%) 1400m (70%) 560Mi (7%) 550Mi (7%)
ip-10-56-0-56.ec2.internal
CPU Requests CPU Limits Memory Requests Memory Limits
1160m (57%) 2800m (140%) 972Mi (13%) 3976Mi (53%)
ip-10-56-0-99.ec2.internal
CPU Requests CPU Limits Memory Requests Memory Limits
804m (40%) 794m (39%) 824Mi (11%) 1300Mi (17%)
cpualloc
48.05 %
$ memalloc
9.95333 %
 tomfotherby
em 25 jul. 2017
tomfotherby
em 25 jul. 2017
https://github.com/kubernetes/kubernetes/issues/17512#issuecomment -267992922 kubectl top mostra o uso , não a alocação. A alocação é o que causa o problema insufficient CPU . Há muita confusão nesta edição sobre a diferença.
AFAICT, não há uma maneira fácil de obter um relatório de alocação de CPU do nó por pod, uma vez que as solicitações são por contêiner na especificação. E mesmo assim, é difícil porque .spec.containers[*].requests pode ou não ter os campos limits / requests (em minha experiência)
 nfirvine
em 30 ago. 2017
nfirvine
em 30 ago. 2017
/ cc @mysterikkit
 misterikkit
em 2 jan. 2018
misterikkit
em 2 jan. 2018
Entrando nesta festa de script de shell. Eu tenho um cluster mais antigo executando o CA com redução de escala desabilitada. Eu escrevi este script para determinar aproximadamente o quanto posso reduzir o cluster quando ele começa a aumentar seus limites de rota AWS:
#!/bin/bash
set -e
KUBECTL="kubectl"
NODES=$($KUBECTL get nodes --no-headers -o custom-columns=NAME:.metadata.name)
function usage() {
local node_count=0
local total_percent_cpu=0
local total_percent_mem=0
local readonly nodes=$@
for n in $nodes; do
local requests=$($KUBECTL describe node $n | grep -A2 -E "^\\s*CPU Requests" | tail -n1)
local percent_cpu=$(echo $requests | awk -F "[()%]" '{print $2}')
local percent_mem=$(echo $requests | awk -F "[()%]" '{print $8}')
echo "$n: ${percent_cpu}% CPU, ${percent_mem}% memory"
node_count=$((node_count + 1))
total_percent_cpu=$((total_percent_cpu + percent_cpu))
total_percent_mem=$((total_percent_mem + percent_mem))
done
local readonly avg_percent_cpu=$((total_percent_cpu / node_count))
local readonly avg_percent_mem=$((total_percent_mem / node_count))
echo "Average usage: ${avg_percent_cpu}% CPU, ${avg_percent_mem}% memory."
}
usage $NODES
Produz resultados como:
ip-REDACTED.us-west-2.compute.internal: 38% CPU, 9% memory
...many redacted lines...
ip-REDACTED.us-west-2.compute.internal: 41% CPU, 8% memory
ip-REDACTED.us-west-2.compute.internal: 61% CPU, 7% memory
Average usage: 45% CPU, 15% memory.
 negz
em 21 fev. 2018
negz
em 21 fev. 2018
Também existe a opção de pod no comando superior:
kubectl top pod
 ylogx
em 21 fev. 2018
ylogx
em 21 fev. 2018
@ylogx https://github.com/kubernetes/kubernetes/issues/17512#issuecomment -326089708
nfirvine
em 21 fev. 2018
Minha maneira de obter a alocação, em todo o cluster:
$ kubectl get po --all-namespaces -o=jsonpath="{range .items[*]}{.metadata.namespace}:{.metadata.name}{'\n'}{range .spec.containers[*]} {.name}:{.resources.requests.cpu}{'\n'}{end}{'\n'}{end}"
Ele produz algo como:
kube-system:heapster-v1.5.0-dc8df7cc9-7fqx6
heapster:88m
heapster-nanny:50m
kube-system:kube-dns-6cdf767cb8-cjjdr
kubedns:100m
dnsmasq:150m
sidecar:10m
prometheus-to-sd:
kube-system:kube-dns-6cdf767cb8-pnx2g
kubedns:100m
dnsmasq:150m
sidecar:10m
prometheus-to-sd:
kube-system:kube-dns-autoscaler-69c5cbdcdd-wwjtg
autoscaler:20m
kube-system:kube-proxy-gke-cluster1-default-pool-cd7058d6-3tt9
kube-proxy:100m
kube-system:kube-proxy-gke-cluster1-preempt-pool-57d7ff41-jplf
kube-proxy:100m
kube-system:kubernetes-dashboard-7b9c4bf75c-f7zrl
kubernetes-dashboard:50m
kube-system:l7-default-backend-57856c5f55-68s5g
default-http-backend:10m
kube-system:metrics-server-v0.2.0-86585d9749-kkrzl
metrics-server:48m
metrics-server-nanny:5m
kube-system:tiller-deploy-7794bfb756-8kxh5
tiller:10m
 shtouff
em 4 mar. 2018
shtouff
em 4 mar. 2018
Isso é estranho. Quero saber quando estou na capacidade de alocação ou quase chegando. Parece uma função bastante básica de um cluster. Quer se trate de uma estatística que mostra uma alta% ou de um erro textual ... como outras pessoas sabem disso? Sempre use o escalonamento automático em uma plataforma de nuvem?
 kierenj
em 13 mar. 2018
kierenj
em 13 mar. 2018
Eu escrevi https://github.com/dpetzold/kube-resource-explorer/ para o endereço # 3. Aqui está um exemplo de saída:
$ ./resource-explorer -namespace kube-system -reverse -sort MemReq
Namespace Name CpuReq CpuReq% CpuLimit CpuLimit% MemReq MemReq% MemLimit MemLimit%
--------- ---- ------ ------- -------- --------- ------ ------- -------- ---------
kube-system event-exporter-v0.1.7-5c4d9556cf-kf4tf 0 0% 0 0% 0 0% 0 0%
kube-system kube-proxy-gke-project-default-pool-175a4a05-mshh 100m 10% 0 0% 0 0% 0 0%
kube-system kube-proxy-gke-project-default-pool-175a4a05-bv59 100m 10% 0 0% 0 0% 0 0%
kube-system kube-proxy-gke-project-default-pool-175a4a05-ntfw 100m 10% 0 0% 0 0% 0 0%
kube-system kube-dns-autoscaler-244676396-xzgs4 20m 2% 0 0% 10Mi 0% 0 0%
kube-system l7-default-backend-1044750973-kqh98 10m 1% 10m 1% 20Mi 0% 20Mi 0%
kube-system kubernetes-dashboard-768854d6dc-jh292 100m 10% 100m 10% 100Mi 3% 300Mi 11%
kube-system kube-dns-323615064-8nxfl 260m 27% 0 0% 110Mi 4% 170Mi 6%
kube-system fluentd-gcp-v2.0.9-4qkwk 100m 10% 0 0% 200Mi 7% 300Mi 11%
kube-system fluentd-gcp-v2.0.9-jmtpw 100m 10% 0 0% 200Mi 7% 300Mi 11%
kube-system fluentd-gcp-v2.0.9-tw9vk 100m 10% 0 0% 200Mi 7% 300Mi 11%
kube-system heapster-v1.4.3-74b5bd94bb-fz8hd 138m 14% 138m 14% 301856Ki 11% 301856Ki 11%
 dpetzold
em 2 mai. 2018
dpetzold
em 2 mai. 2018
@shtouff
root<strong i="7">@debian9</strong>:~# kubectl get po -n chenkunning-84 -o=jsonpath="{range .items[*]}{.metadata.namespace}:{.metadata.name}{'\n'}{range .spec.containers[*]} {.name}:{.resources.requests.cpu}{'\n'}{end}{'\n'}{end}"
error: error parsing jsonpath {range .items[*]}{.metadata.namespace}:{.metadata.name}{'\n'}{range .spec.containers[*]} {.name}:{.resources.requests.cpu}{'\n'}{end}{'\n'}{end}, unrecognized character in action: U+0027 '''
root<strong i="8">@debian9</strong>:~# kubectl version
Client Version: version.Info{Major:"1", Minor:"6+", GitVersion:"v1.6.7-beta.0+$Format:%h$", GitCommit:"bb053ff0cb25a043e828d62394ed626fda2719a1", GitTreeState:"dirty", BuildDate:"2017-08-26T09:34:19Z", GoVersion:"go1.8", Compiler:"gc", Platform:"linux/amd64"}
Server Version: version.Info{Major:"1", Minor:"6+", GitVersion:"v1.6.7-beta.0+$Format:84c3ae0384658cd40c1d1e637f5faa98cf6a965c$", GitCommit:"3af2004eebf3cbd8d7f24b0ecd23fe4afb889163", GitTreeState:"clean", BuildDate:"2018-04-04T08:40:48Z", GoVersion:"go1.8.1", Compiler:"gc", Platform:"linux/amd64"}
 harryge00
em 22 mai. 2018
harryge00
em 22 mai. 2018
@ harryge00 : U + 0027 é uma citação ondulada, provavelmente um problema de copiar e colar
nfirvine
em 22 mai. 2018
@nfirvine Obrigado! Resolvi o problema usando:
kubectl get pods -n my-ns -o=jsonpath='{range .items[*]}{.metadata.name}{"\t"}{.spec.containers[0].resources.limits.cpu} {"\n"}{end}' |awk '{sum+=$2 ; print $0} END{print "sum=",sum}'
Ele funciona para namespaces cujos pods contêm apenas 1 contêiner cada.
harryge00
em 25 mai. 2018
@xmik Ei, estou usando k8 1.7 e executando o hepaster. Quando executo $ kubectl top nodes --heapster-namespace = kube-system, ele me mostra "erro: as métricas ainda não estão disponíveis". Alguma pista para resolver o erro?
 abushoeb
em 5 jun. 2018
abushoeb
em 5 jun. 2018
@abushoeb :
Não acho queEditar: este sinalizador é compatível, você estava certo: https://github.com/kubernetes/kubernetes/issues/44540#issuecomment -362882035.kubectl topsuporte a bandeira:--heapster-namespace.- Se você vir "erro: as métricas ainda não estão disponíveis", você deve verificar a implantação do heapster. O que dizem seus logs? O serviço do heapster está ok, os endpoints não são
<none>? Verifique o último com um comando como:kubectl -n kube-system describe svc/heapster
xmik
em 5 jun. 2018
@xmik você está certo, o heapster não foi configurado corretamente. Muito obrigado. Está funcionando agora. Você sabe se existe uma maneira de obter informações de uso da GPU em tempo real? Este comando superior fornece apenas o uso da CPU e da memória.
abushoeb
em 5 jun. 2018
Eu não sei disso. :(
xmik
em 5 jun. 2018
@abushoeb Estou recebendo o mesmo erro "erro: métricas ainda não disponíveis". Como você consertou isso?
 avgKol
em 21 jun. 2018
avgKol
em 21 jun. 2018
@avgKol verifique sua implantação de heapster primeiro. No meu caso, ele não foi implantado corretamente. Uma maneira de verificar isso é acessar as métricas por meio do comando CURL, como curl -L http://heapster-pod-ip:heapster-service-port/api/v1/model/metrics/ . Se não mostrar métricas, verifique o pod e os registros do heapster. As métricas do hepster também podem ser acessadas por meio de um navegador da web como este .
abushoeb
em 22 jun. 2018
Se alguém estiver interessado, criei uma ferramenta para gerar HTML estático para uso de recursos do Kubernetes (e custos): https://github.com/hjacobs/kube-resource-report
 hjacobs
em 18 jul. 2018
hjacobs
em 18 jul. 2018
@hjacobs Eu gostaria de usar essa ferramenta, mas não sou um fã de instalar / usar pacotes Python. Importa-se de empacotá-lo como uma imagem docker?
tonglil
em 18 jul. 2018
@tonglil, o projeto está bem no início, mas meu plano é ter uma imagem do Docker pronta para usar, incl. servidor web com o qual você pode apenas fazer kubectl apply -f .. .
hjacobs
em 18 jul. 2018
Aqui está o que funcionou para mim:
kubectl get nodes -o=jsonpath="{range .items[*]}{.metadata.name}{'\t'}{.status.allocatable.memory}{'\t'}{.status.allocatable.cpu}{'\n'}{end}"
Ele mostra a saída como:
ip-192-168-101-177.us-west-2.compute.internal 251643680Ki 32
ip-192-168-196-254.us-west-2.compute.internal 251643680Ki 32
 arun-gupta
em 12 set. 2018
arun-gupta
em 12 set. 2018
@tonglil, uma imagem Docker está agora disponível: https://github.com/hjacobs/kube-resource-report
hjacobs
em 13 set. 2018
Os problemas ficam obsoletos após 90 dias de inatividade.
Marque o problema como novo com /remove-lifecycle stale .
Problemas obsoletos apodrecem após 30 dias adicionais de inatividade e, eventualmente, fecham.
Se este problema puder ser encerrado agora, faça-o com /close .
Envie feedback para sig-testing, kubernetes / test-infra e / ou fejta .
/ lifecycle stale
 fejta-bot
em 17 dez. 2018
fejta-bot
em 17 dez. 2018
/ remove-lifecycle stale
A cada mês, mais ou menos, meu Google me leva de volta a esse problema. Existem maneiras de obter as estatísticas de que preciso com strings jq longas ou com painéis Grafana com um monte de cálculos ... mas seria _tão_ bom se houvesse um comando como:
# kubectl utilization cluster
cores: 19.255/24 cores (80%)
memory: 16.4/24 GiB (68%)
# kubectl utilization [node name]
cores: 3.125/4 cores (78%)
memory: 2.1/4 GiB (52%)
(semelhante ao que @chrishiestand mencionou anteriormente no tópico).
Muitas vezes estou construindo e destruindo algumas dezenas de clusters de teste por semana e prefiro não ter que construir automação ou adicionar alguns aliases de shell para ser capaz de apenas ver "se eu colocar tantos servidores lá fora e jogar fora esses aplicativos sobre eles, qual é a minha utilização / pressão geral ".
Especialmente para clusters menores / mais esotéricos, não quero configurar o escalonamento automático para a lua (geralmente por motivos financeiros), mas preciso saber se tenho sobrecarga suficiente para lidar com eventos de escalonamento automático menores.
 geerlingguy
em 30 dez. 2018
geerlingguy
em 30 dez. 2018
Uma solicitação adicional - eu gostaria de ser capaz de ver o uso de recursos somados por namespace (no mínimo; por implantação / rótulo também seria útil), para que eu possa concentrar meus esforços de corte de recursos descobrindo quais namespaces valem concentrando-se.
 evankanderson
em 1 jan. 2019
evankanderson
em 1 jan. 2019
Fiz um pequeno plugin kubectl-view-usage , que fornece a funcionalidade @geerlingguy descrita. A instalação através do gerenciador de plugins do krew está disponível. Isso é implementado em BASH e precisa de awk e bc.
Com a estrutura do plugin kubectl, isso pode ser completamente abstraído das ferramentas principais.
 etopeter
em 13 jan. 2019
etopeter
em 13 jan. 2019
Estou feliz que outros também estivessem enfrentando esse desafio. Eu criei o Kube Eagle (um exportador prometheus) que me ajudou a obter uma melhor visão geral dos recursos do cluster e, finalmente, me permitiu utilizar melhor os recursos de hardware disponíveis:
https://github.com/google-cloud-tools/kube-eagle

 weeco
em 3 mar. 2019
weeco
em 3 mar. 2019
Este é um script Python para obter a utilização real do nó em formato de tabela
https://github.com/amelbakry/kube-node-utilization
Utilização do nó do Kubernetes ..........
+ ------------------------------------------------ + -------- + -------- +
| NodeName | CPU | Memória |
+ ------------------------------------------------ + -------- + -------- +
| ip-176-35-32-139.eu-central-1.compute.internal | 13,49% | 60,87% |
| ip-176-35-26-21.eu-central-1.compute.internal | 5,89% | 15,10% |
| ip-176-35-9-122.eu-central-1.compute.internal | 8,08% | 65,51% |
| ip-176-35-22-243.eu-central-1.compute.internal | 6,29% | 19,28% |
+ ------------------------------------------------ + -------- + -------- +
 amelbakry
em 24 abr. 2019
amelbakry
em 24 abr. 2019
Para mim, pelo menos @amelbakry , é a utilização no nível do cluster que é importante: "eu preciso adicionar mais máquinas?" / "devo remover algumas máquinas?" / "devo esperar que o cluster seja ampliado em breve?" ..
kierenj
em 25 abr. 2019
E quanto ao uso de armazenamento efêmero? Alguma ideia de como obtê-lo de todos os pods?
E para ser útil, minhas dicas:
kubectl get pods -o json -n kube-system | jq -r '.items[] | .metadata.name + " \n Req. RAM: " + .spec.containers[].resources.requests.memory + " \n Lim. RAM: " + .spec.containers[].resources.limits.memory + " \n Req. CPU: " + .spec.containers[].resources.requests.cpu + " \n Lim. CPU: " + .spec.containers[].resources.limits.cpu + " \n Req. Eph. DISK: " + .spec.containers[].resources.requests["ephemeral-storage"] + " \n Lim. Eph. DISK: " + .spec.containers[].resources.limits["ephemeral-storage"] + "\n"'
...
kube-proxy-xlmjt
Req. RAM: 32Mi
Lim. RAM: 256Mi
Req. CPU: 100m
Lim. CPU:
Req. Eph. DISK: 100Mi
Lim. Eph. DISK: 512Mi
...
echo "\nRAM Requests TOTAL:" && kubectl describe namespace kube-system | grep 'requests.memory' && echo "\nRAM Requests:\n" && kubectl get pods -o json -n kube-system | jq -r '.items[] | .spec.containers[].resources.requests.memory + " | " + .metadata.name'
echo "\nRAM Limits TOTAL:" && kubectl describe namespace kube-system | grep 'limits.memory' && echo "\nRAM Limits:\n" && kubectl get pods -o json -n kube-system | jq -r '.items[] | .spec.containers[].resources.limits.memory + " | " + .metadata.name'
echo "\nCPU Requests TOTAL:" && kubectl describe namespace kube-system | grep 'requests.cpu' && echo "\nCPU Requests:\n" && kubectl get pods -o json -n kube-system | jq -r '.items[] | .spec.containers[].resources.requests.cpu + " | " + .metadata.name'
echo "\nCPU Limits TOTAL:" && kubectl describe namespace kube-system | grep 'limits.cpu' && echo "\nCPU Limits:\n" && kubectl get pods -o json -n kube-system | jq -r '.items[] | .spec.containers[].resources.limits.cpu + " | " + .metadata.name'
echo "\nEph. DISK Requests TOTAL:" && kubectl describe namespace kube-system | grep 'requests.ephemeral-storage' && echo "\nEph. DISK Requests:\n" && kubectl get pods -o json -n kube-system | jq -r '.items[] | .spec.containers[].resources.requests["ephemeral-storage"] + " | " + .metadata.name'
echo "\nEph. DISK Limits TOTAL:" && kubectl describe namespace kube-system | grep 'limits.ephemeral-storage' && echo "\nEph. DISK Limits:\n" && kubectl get pods -o json -n kube-system | jq -r '.items[] | .spec.containers[].resources.limits["ephemeral-storage"] + " | " + .metadata.name'
RAM Requests TOTAL:
requests.memory 3504Mi 16Gi
RAM Requests:
64Mi | aws-alb-ingress-controller-6b569b448c-jzj6f
...
 kivagant-ba
em 25 abr. 2019
kivagant-ba
em 25 abr. 2019
@ kivagant-ba você pode tentar este snipt para obter métricas de pod por nó, você pode obter todos os nós, como
https://github.com/amelbakry/kube-node-utilization
def get_pod_metrics_per_node (nó):
pod_metrics = "/api/v1/pods?fieldSelector=spec.nodeName%3D" + node
resposta = api_client.call_api (pod_metrics,
'GET', auth_settings = ['BearerToken'],
response_type = 'json', _preload_content = False)
resposta = json.loads (resposta [0] .data.decode ('utf-8'))
resposta de retorno
amelbakry
em 25 abr. 2019
@kierenj Acho que o componente de autoescalador de cluster com base no qual o Cloud Kubernetes está sendo executado deve lidar com a capacidade. não tenho certeza se esta é a sua pergunta.
amelbakry
em 25 abr. 2019
Os problemas ficam obsoletos após 90 dias de inatividade.
Marque o problema como novo com /remove-lifecycle stale .
Problemas obsoletos apodrecem após 30 dias adicionais de inatividade e, eventualmente, fecham.
Se este problema puder ser encerrado agora, faça-o com /close .
Envie feedback para sig-testing, kubernetes / test-infra e / ou fejta .
/ lifecycle stale
fejta-bot
em 30 jul. 2019
/ remove-lifecycle stale
Eu, como muitos outros, continuo voltando aqui - há anos - para obter o hack de que precisamos para gerenciar os clusters via CLI (por exemplo, AWS ASGs)
 eduncan911
em 28 ago. 2019
eduncan911
em 28 ago. 2019
@etopeter Obrigado por um plugin CLI tão legal. Ame a simplicidade disso. Algum conselho sobre como entender melhor os números e seu significado exato?
 demisx
em 28 ago. 2019
demisx
em 28 ago. 2019
Se alguém puder encontrar uso dele, aqui está um script que descartará os limites atuais dos pods.
kubectl get pods --all-namespaces -o=jsonpath="{range .items[*]}{.metadata.namespace}:{.metadata.name}{'\n'}\
{'.spec.nodeName -'} {.spec.nodeName}{'\n'}\
{range .spec.containers[*]}\
{'requests.cpu -'} {.resources.requests.cpu}{'\n'}\
{'limits.cpu -'} {.resources.limits.cpu}{'\n'}\
{'requests.memory -'} {.resources.requests.memory}{'\n'}\
{'limits.memory -'} {.resources.limits.memory}{'\n'}\
{'\n'}{end}\
{'\n'}{end}"
Saída de exemplo
...
kube- system: addon-http-application-routing-nginx-ingress-controller-6bq49l7
.spec.nodeName - aks-agentpool-84550961-0
request.cpu -
limites.cpu -
solicitações.memória -
limites.memória -
sistema kube
.spec.nodeName - aks-agentpool-84550961-0
request.cpu - 100m
limites.cpu -
solicitações.memória - 70Mi
limites.memória - 170Mi
sistema kube
.spec.nodeName - aks-agentpool-84550961-2
request.cpu - 100m
limites.cpu -
solicitações.memória - 70Mi
limites.memória - 170Mi
sistema kube
.spec.nodeName - aks-agentpool-84550961-1
request.cpu - 100m
limites.cpu -
solicitações.memória - 70Mi
limites.memória - 170Mi
sistema kube
.spec.nodeName - aks-agentpool-84550961-2
request.cpu - 20m
limites.cpu -
solicitações.memória - 10Mi
limites.memória -
sistema kube
.spec.nodeName - aks-agentpool-84550961-0
request.cpu - 20m
limites.cpu -
solicitações.memória - 10Mi
limites.memória -
sistema kube
.spec.nodeName - aks-agentpool-84550961-1
request.cpu - 100m
limites.cpu -
solicitações.memória -
limites.memória -
...
 Spaceman1861
em 2 set. 2019
Spaceman1861
em 2 set. 2019
@ Spaceman1861 você poderia mostrar um exemplo de saída?
eduncan911
em 2 set. 2019
@ eduncan911 feito
Spaceman1861
em 2 set. 2019
Acho mais fácil ler a saída em formato de tabela, como este (mostra solicitações em vez de limites):
kubectl get pods -o custom-columns=NAME:.metadata.name,"CPU(cores)":.spec.containers[*].resources.requests.cpu,"MEMORY(bytes)":.spec.containers[*].resources.requests.memory --all-namespaces
Saída de amostra:
NAME CPU(cores) MEMORY(bytes)
pod1 100m 128Mi
pod2 100m 128Mi,128Mi
 lentzi90
em 2 set. 2019
lentzi90
em 2 set. 2019
@ lentzi90 apenas para sua informação: você pode mostrar colunas personalizadas semelhantes no Kubernetes Web View ("kubectl para a web"), demo: https://kube-web-view.demo.j-serv.de/clusters/local/namespaces/ default / pods? join = metrics; customcols = CPU + Requests = join (% 27,% 20% 27,% 20spec.containers [ ] .resources.requests.cpu)% 3BMemory + Requests = join (% 27,% 20% 27,% 20spec.containers [ ]
Documentos em colunas personalizadas: https://kube-web-view.readthedocs.io/en/latest/features.html#listing -resources
hjacobs
em 2 set. 2019
Oooo brilhante @hjacobs eu gosto disso.
Spaceman1861
em 2 set. 2019
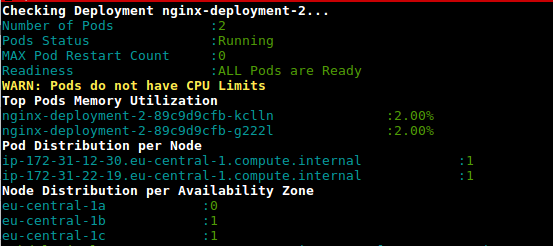
Este é um script (deployment-health.sh) para obter a utilização dos pods na implantação com base no uso e nos limites configurados
https://github.com/amelbakry/kubernetes-scripts
amelbakry
em 2 set. 2019
Inspirado pelas respostas de @ lentzi90 e @ylogx , criei um grande script que mostra o uso real de recursos ( kubectl top pods ) e solicitações e limites de recursos:
join -a1 -a2 -o 0,1.2,1.3,2.2,2.3,2.4,2.5, -e '<none>' <(kubectl top pods) <(kubectl get pods -o custom-columns=NAME:.metadata.name,"CPU_REQ(cores)":.spec.containers[*].resources.requests.cpu,"MEMORY_REQ(bytes)":.spec.containers[*].resources.requests.memory,"CPU_LIM(cores)":.spec.containers[*].resources.limits.cpu,"MEMORY_LIM(bytes)":.spec.containers[*].resources.limits.memory) | column -t -s' '
exemplo de saída:
NAME CPU(cores) MEMORY(bytes) CPU_REQ(cores) MEMORY_REQ(bytes) CPU_LIM(cores) MEMORY_LIM(bytes)
xxxxx-847dbbc4c-c6twt 20m 110Mi 50m 150Mi 150m 250Mi
xxx-service-7b6b9558fc-9cq5b 19m 1304Mi 1 <none> 1 <none>
xxxxxxxxxxxxxxx-hook-5d585b449b-zfxmh 0m 46Mi 200m 155M 200m 155M
Aqui está o alias para você usar apenas kstats em seu terminal:
alias kstats='join -a1 -a2 -o 0,1.2,1.3,2.2,2.3,2.4,2.5, -e '"'"'<none>'"'"' <(kubectl top pods) <(kubectl get pods -o custom-columns=NAME:.metadata.name,"CPU_REQ(cores)":.spec.containers[*].resources.requests.cpu,"MEMORY_REQ(bytes)":.spec.containers[*].resources.requests.memory,"CPU_LIM(cores)":.spec.containers[*].resources.limits.cpu,"MEMORY_LIM(bytes)":.spec.containers[*].resources.limits.memory) | column -t -s'"'"' '"'"
PS Eu testei scripts apenas no meu mac, para linux e windows pode requerer algumas mudanças
 alikhil
em 25 set. 2019
alikhil
em 25 set. 2019
Este é um script (deployment-health.sh) para obter a utilização dos pods na implantação com base no uso e nos limites configurados
https://github.com/amelbakry/kubernetes-scripts
@amelbakry Estou recebendo o seguinte erro ao tentar executá-lo em um Mac:
Failed to execute process './deployment-health.sh'. Reason:
exec: Exec format error
The file './deployment-health.sh' is marked as an executable but could not be run by the operating system.
Woops,
"#!" precisa ser a primeira linha. Em vez disso, tente "bash
./deployment-health.sh "para solucionar o problema.
/ charles
PS. PR aberto para corrigir o problema
Na quarta-feira, 25 de setembro de 2019 às 10:19 Dmitri Moore [email protected]
escreveu:
Este é um script (deployment-health.sh) para obter a utilização dos pods
na implantação com base no uso e limites configurados
https://github.com/amelbakry/kubernetes-scripts@amelbakry https://github.com/amelbakry Estou recebendo o seguinte
erro ao tentar executá-lo em um Mac:Falha ao executar o processo './deployment-health.sh'. Razão:
exec: erro de formato de execução
O arquivo './deployment-health.sh' está marcado como um executável, mas não pode ser executado pelo sistema operacional.-
Você está recebendo isto porque está inscrito neste tópico.
Responda a este e-mail diretamente, visualize-o no GitHub
https://github.com/kubernetes/kubernetes/issues/17512?email_source=notifications&email_token=AACA3TODQEUPWK3V3UY3SF3QLOMSFA5CNFSM4BUXCUG2YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOD7SVHRQ#issuecomment-535122886 ,
ou silenciar o tópico
https://github.com/notifications/unsubscribe-auth/AACA3TOPOBIWXFX2DAOT6JDQLOMSFANCNFSM4BUXCUGQ
.
 cgthayer
em 25 set. 2019
cgthayer
em 25 set. 2019
@cgthayer Você pode querer aplicar essa correção de RP globalmente. Além disso, quando executei os scripts no MacOs Mojave, vários erros apareceram, incluindo nomes de zona específicos da UE que não uso. Parece que esses scripts foram escritos para um projeto específico.
demisx
em 2 out. 2019
Aqui está uma versão modificada do ex de junção. que também faz totais de colunas.
oc_ns_pod_usage () {
# show pod usage for cpu/mem
ns="$1"
usage_chk3 "$ns" || return 1
printf "$ns\n"
separator=$(printf '=%.0s' {1..50})
printf "$separator\n"
output=$(join -a1 -a2 -o 0,1.2,1.3,2.2,2.3,2.4,2.5, -e '<none>' \
<(kubectl top pods -n $ns) \
<(kubectl get -n $ns pods -o custom-columns=NAME:.metadata.name,"CPU_REQ(cores)":.spec.containers[*].resources.requests.cpu,"MEMORY_REQ(bytes)":.spec.containers[*].resources.requests.memory,"CPU_LIM(cores)":.spec.containers[*].resources.limits.cpu,"MEMORY_LIM(bytes)":.spec.containers[*].resources.limits.memory))
totals=$(printf "%s" "$output" | awk '{s+=$2; t+=$3; u+=$4; v+=$5; w+=$6; x+=$7} END {print s" "t" "u" "v" "w" "x}')
printf "%s\n%s\nTotals: %s\n" "$output" "$separator" "$totals" | column -t -s' '
printf "$separator\n"
}
Exemplo
$ oc_ns_pod_usage ls-indexer
ls-indexer
==================================================
NAME CPU(cores) MEMORY(bytes) CPU_REQ(cores) MEMORY_REQ(bytes) CPU_LIM(cores) MEMORY_LIM(bytes)
ls-indexer-f5-7cd5859997-qsfrp 15m 741Mi 1 1000Mi 2 2000Mi
ls-indexer-f5-7cd5859997-sclvg 15m 735Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-4b7j2 92m 1103Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-5xj5l 88m 1124Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-6vvl2 92m 1132Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-85f66 85m 1151Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-924jz 96m 1124Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-g6gx8 119m 1119Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-hkhnt 52m 819Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-hrsrs 51m 1122Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-j4qxm 53m 885Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-lxlrb 83m 1215Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-mw6rt 86m 1131Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-pbdf8 95m 1115Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-qk9bm 91m 1141Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-sdv9r 54m 1194Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-t67v6 75m 1234Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-tkxs2 88m 1364Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-v6jl2 53m 747Mi 1 1000Mi 2 2000Mi
ls-indexer-filebeat-7858f56c9-wkqr7 53m 838Mi 1 1000Mi 2 2000Mi
ls-indexer-metricbeat-74d89d7d85-jp8qc 190m 1191Mi 1 1000Mi 2 2000Mi
ls-indexer-metricbeat-74d89d7d85-jv4bv 192m 1162Mi 1 1000Mi 2 2000Mi
ls-indexer-metricbeat-74d89d7d85-k4dcd 194m 1144Mi 1 1000Mi 2 2000Mi
ls-indexer-metricbeat-74d89d7d85-n46tz 192m 1155Mi 1 1000Mi 2 2000Mi
ls-indexer-packetbeat-db98f6fdf-8x446 35m 1198Mi 1 1000Mi 2 2000Mi
ls-indexer-packetbeat-db98f6fdf-gmxxd 22m 1203Mi 1 1000Mi 2 2000Mi
ls-indexer-syslog-5466bc4d4f-gzxw8 27m 1125Mi 1 1000Mi 2 2000Mi
ls-indexer-syslog-5466bc4d4f-zh7st 29m 1153Mi 1 1000Mi 2 2000Mi
==================================================
Totals: 2317 30365 28 28000 56 56000
==================================================
 slmingol
em 21 out. 2019
slmingol
em 21 out. 2019
E o que é usage_chk3?
 cristifalcas
em 25 out. 2019
cristifalcas
em 25 out. 2019
Também gostaria de compartilhar minhas ferramentas ;-) kubectl-view-alocations: plug-in kubectl para listar as alocações (cpu, memória, gpu, ... X solicitado, limite, alocável, ...). , os pedidos são bem-vindos.
Fiz isso porque gostaria de fornecer aos meus usuários (internos) uma maneira de ver "quem aloca o quê". Por padrão, todos os recursos são exibidos, mas no exemplo a seguir, solicito apenas o recurso com "gpu" no nome.
> kubectl-view-allocations -r gpu
Resource Requested %Requested Limit %Limit Allocatable Free
nvidia.com/gpu 7 58% 7 58% 12 5
├─ node-gpu1 1 50% 1 50% 2 1
│ └─ xxxx-784dd998f4-zt9dh 1 1
├─ node-gpu2 0 0% 0 0% 2 2
├─ node-gpu3 0 0% 0 0% 2 2
├─ node-gpu4 1 50% 1 50% 2 1
│ └─ aaaa-1571819245-5ql82 1 1
├─ node-gpu5 2 100% 2 100% 2 0
│ ├─ bbbb-1571738839-dfkhn 1 1
│ └─ bbbb-1571738888-52c4w 1 1
└─ node-gpu6 2 100% 2 100% 2 0
├─ bbbb-1571738688-vlxng 1 1
└─ cccc-1571745684-7k6bn 1 1
próxima (s) versão (ões):
- permitirá ocultar (nó, pod) nível ou escolher como agrupar (por exemplo, fornecer uma visão geral apenas com recursos)
- instalação via curl, krew, brew, ... (atualmente binários estão disponíveis na seção de lançamentos do github)
Obrigado a kubectl-view-usage pela inspiração, mas adicionar suporte a outros recursos era muito difícil de copiar / colar ou fazer no bash (de uma forma genérica).
 davidB
em 25 out. 2019
davidB
em 25 out. 2019
aqui está meu hack
kubectl describe nodes | grep -A 2 -e "^\\s*CPU Requests"
Isso não funciona mais :(
 libudas
em 28 nov. 2019
libudas
em 28 nov. 2019
Experimente kubectl describe node | grep -A5 "Allocated"
 MostafaGazar
em 28 nov. 2019
MostafaGazar
em 28 nov. 2019
Este é atualmente o quarto problema mais solicitado pelos polegares, mas ainda é priority/backlog .
Eu ficaria feliz em tentar fazer isso se alguém pudesse me indicar a direção certa ou se pudéssemos finalizar uma proposta. Eu acho que a UX da ferramenta de kubectl .
 alexkreidler
em 1 dez. 2019
alexkreidler
em 1 dez. 2019
Usando os seguintes comandos: kubectl top nodes & kubectl describe node não obtemos resultados consistentes
Por exemplo, com o primeiro, a CPU (núcleos) tem 1064m, mas este resultado não pode ser obtido com o segundo (1480m):
kubectl top nodes
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
abcd-p174e23ea5qa4g279446c803f82-abc-node-0 1064m 53% 6783Mi 88%
kubectl describe node abcd-p174e23ea5qa4g279446c803f82-abc-node-0
...
Resource Requests Limits
-------- -------- ------
cpu 1480m (74%) 1300m (65%)
memory 2981486848 (37%) 1588314624 (19%)
Alguma ideia sobre como obter a CPU (núcleos) sem usar o kubectl top nodes ?
 smpar
em 18 dez. 2019
smpar
em 18 dez. 2019
Também gostaria de compartilhar minhas ferramentas ;-) kubectl-view-alocations: plug-in kubectl para listar as alocações (cpu, memória, gpu, ... X solicitado, limite, alocável, ...). , os pedidos são bem-vindos.
Fiz isso porque gostaria de fornecer aos meus usuários (internos) uma maneira de ver "quem aloca o quê". Por padrão, todos os recursos são exibidos, mas no exemplo a seguir, solicito apenas o recurso com "gpu" no nome.
> kubectl-view-allocations -r gpu Resource Requested %Requested Limit %Limit Allocatable Free nvidia.com/gpu 7 58% 7 58% 12 5 ├─ node-gpu1 1 50% 1 50% 2 1 │ └─ xxxx-784dd998f4-zt9dh 1 1 ├─ node-gpu2 0 0% 0 0% 2 2 ├─ node-gpu3 0 0% 0 0% 2 2 ├─ node-gpu4 1 50% 1 50% 2 1 │ └─ aaaa-1571819245-5ql82 1 1 ├─ node-gpu5 2 100% 2 100% 2 0 │ ├─ bbbb-1571738839-dfkhn 1 1 │ └─ bbbb-1571738888-52c4w 1 1 └─ node-gpu6 2 100% 2 100% 2 0 ├─ bbbb-1571738688-vlxng 1 1 └─ cccc-1571745684-7k6bn 1 1próxima (s) versão (ões):
* will allow to hide (node, pod) level or to choose how to group, (eg to provide an overview with only resources) * installation via curl, krew, brew, ... (currently binary are available under the releases section of github)Obrigado a kubectl-view-usage pela inspiração, mas adicionar suporte a outros recursos era muito difícil de copiar / colar ou fazer no bash (de uma forma genérica).
Olá David, seria bom se você fornecesse mais binários compilados para novas distribuições. No Ubuntu 16.04 temos
kubectl-view-alocations: /lib/x86_64-linux-gnu/libc.so.6: versão `GLIBC_2.25 'não encontrada (exigido por kubectl-view-alocations)
dpkg -l |grep glib
ii libglib2.0-0: amd64 2.48.2-0ubuntu4.4
 omerfsen
em 12 jan. 2020
omerfsen
em 12 jan. 2020
@omerfsen, você pode tentar a nova versão kubectl-view-alocations e comentar na versão do tíquete
davidB
em 15 jan. 2020
Minha maneira de obter a alocação, em todo o cluster:
$ kubectl get po --all-namespaces -o=jsonpath="{range .items[*]}{.metadata.namespace}:{.metadata.name}{'\n'}{range .spec.containers[*]} {.name}:{.resources.requests.cpu}{'\n'}{end}{'\n'}{end}"Ele produz algo como:
kube-system:heapster-v1.5.0-dc8df7cc9-7fqx6 heapster:88m heapster-nanny:50m kube-system:kube-dns-6cdf767cb8-cjjdr kubedns:100m dnsmasq:150m sidecar:10m prometheus-to-sd: kube-system:kube-dns-6cdf767cb8-pnx2g kubedns:100m dnsmasq:150m sidecar:10m prometheus-to-sd: kube-system:kube-dns-autoscaler-69c5cbdcdd-wwjtg autoscaler:20m kube-system:kube-proxy-gke-cluster1-default-pool-cd7058d6-3tt9 kube-proxy:100m kube-system:kube-proxy-gke-cluster1-preempt-pool-57d7ff41-jplf kube-proxy:100m kube-system:kubernetes-dashboard-7b9c4bf75c-f7zrl kubernetes-dashboard:50m kube-system:l7-default-backend-57856c5f55-68s5g default-http-backend:10m kube-system:metrics-server-v0.2.0-86585d9749-kkrzl metrics-server:48m metrics-server-nanny:5m kube-system:tiller-deploy-7794bfb756-8kxh5 tiller:10m
de longe a melhor resposta aqui.
 abelal83
em 31 jan. 2020
abelal83
em 31 jan. 2020
Inspirado nos scripts acima, criei o seguinte script para visualizar o uso, solicitações e limites:
join -1 2 -2 2 -a 1 -a 2 -o "2.1 0 1.3 2.3 2.5 1.4 2.4 2.6" -e '<wait>' \
<( kubectl top pods --all-namespaces | sort --key 2 -b ) \
<( kubectl get pods --all-namespaces -o custom-columns=NAMESPACE:.metadata.namespace,NAME:.metadata.name,"CPU_REQ(cores)":.spec.containers[*].resources.requests.cpu,"MEMORY_REQ(bytes)":.spec.containers[*].resources.requests.memory,"CPU_LIM(cores)":.spec.containers[*].resources.limits.cpu,"MEMORY_LIM(bytes)":.spec.containers[*].resources.limits.memory | sort --key 2 -b ) \
| column -t -s' '
Como o script de shell join espera uma lista ordenada, os scripts fornecidos acima falharam para mim.
Você vê como resultado o uso atual do topo e da implantação as solicitações e os limites de (aqui) todos os namespaces:
NAMESPACE NAME CPU(cores) CPU_REQ(cores) CPU_LIM(cores) MEMORY(bytes) MEMORY_REQ(bytes) MEMORY_LIM(bytes)
kube-system aws-node-2jzxr 18m 10m <none> 41Mi <none> <none>
kube-system aws-node-5zn6w <wait> 10m <none> <wait> <none> <none>
kube-system aws-node-h8cc5 20m 10m <none> 42Mi <none> <none>
kube-system aws-node-h9n4f 0m 10m <none> 0Mi <none> <none>
kube-system aws-node-lz5fn 17m 10m <none> 41Mi <none> <none>
kube-system aws-node-tpmxr 20m 10m <none> 39Mi <none> <none>
kube-system aws-node-zbkkh 23m 10m <none> 47Mi <none> <none>
cluster-autoscaler cluster-autoscaler-aws-cluster-autoscaler-5db55fbcf8-mdzkd 1m 100m 500m 9Mi 300Mi 500Mi
cluster-autoscaler cluster-autoscaler-aws-cluster-autoscaler-5db55fbcf8-q9xs8 39m 100m 500m 75Mi 300Mi 500Mi
kube-system coredns-56b56b56cd-bb26t 6m 100m <none> 11Mi 70Mi 170Mi
kube-system coredns-56b56b56cd-nhp58 6m 100m <none> 11Mi 70Mi 170Mi
kube-system coredns-56b56b56cd-wrmxv 7m 100m <none> 12Mi 70Mi 170Mi
gitlab-runner-l gitlab-runner-l-gitlab-runner-6b8b85f87f-9knnx 3m 100m 200m 10Mi 128Mi 256Mi
gitlab-runner-m gitlab-runner-m-gitlab-runner-6bfd5d6c84-t5nrd 7m 100m 200m 13Mi 128Mi 256Mi
gitlab-runner-mda gitlab-runner-mda-gitlab-runner-59bb66c8dd-bd9xw 4m 100m 200m 17Mi 128Mi 256Mi
gitlab-runner-ops gitlab-runner-ops-gitlab-runner-7c5b85dc97-zkb4c 3m 100m 200m 12Mi 128Mi 256Mi
gitlab-runner-pst gitlab-runner-pst-gitlab-runner-6b8f9bf56b-sszlr 6m 100m 200m 20Mi 128Mi 256Mi
gitlab-runner-s gitlab-runner-s-gitlab-runner-6bbccb9b7b-dmwgl 50m 100m 200m 27Mi 128Mi 512Mi
gitlab-runner-shared gitlab-runner-shared-gitlab-runner-688d57477f-qgs2z 3m <none> <none> 15Mi <none> <none>
kube-system kube-proxy-5b65t 15m 100m <none> 19Mi <none> <none>
kube-system kube-proxy-7qsgh 12m 100m <none> 24Mi <none> <none>
kube-system kube-proxy-gn2qg 13m 100m <none> 23Mi <none> <none>
kube-system kube-proxy-pz7fp 15m 100m <none> 18Mi <none> <none>
kube-system kube-proxy-vdjqt 15m 100m <none> 23Mi <none> <none>
kube-system kube-proxy-x4xtp 19m 100m <none> 15Mi <none> <none>
kube-system kube-proxy-xlpn7 0m 100m <none> 0Mi <none> <none>
metrics-server metrics-server-5875c7d795-bj7cq 5m 200m 500m 29Mi 200Mi 500Mi
metrics-server metrics-server-5875c7d795-jpjjn 7m 200m 500m 29Mi 200Mi 500Mi
gitlab-runner-s runner-heq8ujaj-project-10386-concurrent-06t94f <wait> 200m,100m 200m,200m <wait> 200Mi,128Mi 500Mi,500Mi
gitlab-runner-s runner-heq8ujaj-project-10386-concurrent-10lpn9j 1m 200m,100m 200m,200m 12Mi 200Mi,128Mi 500Mi,500Mi
gitlab-runner-s runner-heq8ujaj-project-10386-concurrent-11jrxfh <wait> 200m,100m 200m,200m <wait> 200Mi,128Mi 500Mi,500Mi
gitlab-runner-s runner-heq8ujaj-project-10386-concurrent-129hpvl 1m 200m,100m 200m,200m 12Mi 200Mi,128Mi 500Mi,500Mi
gitlab-runner-s runner-heq8ujaj-project-10386-concurrent-13kswg8 1m 200m,100m 200m,200m 12Mi 200Mi,128Mi 500Mi,500Mi
gitlab-runner-s runner-heq8ujaj-project-10386-concurrent-15qhp5w <wait> 200m,100m 200m,200m <wait> 200Mi,128Mi 500Mi,500Mi
Digno de nota: você pode classificar o consumo de CPU com, por exemplo:
| awk 'NR<2{print $0;next}{print $0| "sort --key 3 --numeric -b --reverse"}
Isso funciona no Mac - não tenho certeza se funciona no Linux também (por causa de join, sort, etc ...).
Felizmente, alguém pode usar isso até que o kubectl tenha uma boa visão disso.
 stefanjacobs
em 11 fev. 2020
stefanjacobs
em 11 fev. 2020
Tenho uma boa experiência com capacidade kube .
Exemplo:
kube-capacity --util
NODE CPU REQUESTS CPU LIMITS CPU UTIL MEMORY REQUESTS MEMORY LIMITS MEMORY UTIL
* 560m (28%) 130m (7%) 40m (2%) 572Mi (9%) 770Mi (13%) 470Mi (8%)
example-node-1 220m (22%) 10m (1%) 10m (1%) 192Mi (6%) 360Mi (12%) 210Mi (7%)
example-node-2 340m (34%) 120m (12%) 30m (3%) 380Mi (13%) 410Mi (14%) 260Mi (9%)
 eyalev
em 18 fev. 2020
eyalev
em 18 fev. 2020
Para que essa ferramenta seja realmente útil, ela deve detectar todos os plug-ins de dispositivos kubernetes implantados no cluster e mostrar o uso de todos eles. CPU / Mem definitivamente não é suficiente. Há também GPUs, TPUs (para aprendizado de máquina), Intel QAT e provavelmente mais que eu não conheço. E quanto ao armazenamento? Devo ser capaz de ver facilmente o que foi solicitado e o que é usado (de preferência em termos de iops também).
 boniek83
em 9 abr. 2020
boniek83
em 9 abr. 2020
@ boniek83 , É por isso que criei kubectl-view-alocações , porque preciso listar a GPU, ... qualquer feedback (sobre o projeto do github) é bem
davidB
em 9 abr. 2020
@ boniek83 , É por isso que criei kubectl-view-alocações , porque preciso listar a GPU, ... qualquer feedback (sobre o projeto do github) é bem
Conheço a sua ferramenta e, para mim, é a melhor que existe atualmente. Obrigado por fazer isso!
Vou tentar testar os TPUs depois da Páscoa. Seria útil se esses dados estivessem disponíveis no formato de aplicativo da web com gráficos bonitos, para que eu não tivesse que dar acesso ao kubernetes para cientistas de dados. Eles só querem saber quem está consumindo recursos e nada mais :)
boniek83
em 9 abr. 2020
Como nenhuma das ferramentas e scripts acima atendem às minhas necessidades (e esse problema ainda está aberto :(), eu hackeei minha própria variante:
https://github.com/eht16/kube-cargo-load
Ele fornece uma visão geral rápida dos PODs em um cluster e mostra suas solicitações e limites de memória configurados e o uso real de memória. A ideia é obter uma imagem da proporção entre os limites de memória configurados e o uso real.
 eht16
em 13 abr. 2020
eht16
em 13 abr. 2020
Como podemos obter logs de despejo de memória dos pods?
Os pods costumam travar,
 RahulRatan07
em 26 abr. 2020
RahulRatan07
em 26 abr. 2020
kubectl describe nodesORkubectl top nodes, qual deles deve ser considerado para calcular a utilização de recursos do cluster?- Também porque há diferença entre esses 2 resultados.
Existe alguma explicação lógica para isso?
 hmsvigle
em 27 abr. 2020
hmsvigle
em 27 abr. 2020
/ tipo recurso
 brianpursley
em 29 abr. 2020
brianpursley
em 29 abr. 2020
Todos os comentários e hacks com nós funcionaram bem para mim. Eu também preciso de algo para uma visão superior para acompanhar ... como a soma de recursos por pool de nós!
 prathameshd9
em 30 abr. 2020
prathameshd9
em 30 abr. 2020
Oi,
Quero registrar o uso da CPU e da memória de um pod, a cada 5 minutos durante um determinado período. Em seguida, usaria esses dados para criar um gráfico no Excel. Alguma ideia? Obrigado
 rajjar123456
em 18 jul. 2020
rajjar123456
em 18 jul. 2020
Oi,
Estou feliz em ver que o Google apontou todos nós para este problema :-) (um pouco desapontado por ainda estar aberto depois de quase 5 anos). Obrigado por todos os recortes de shell e outras ferramentas.
 yceoshda
em 28 jul. 2020
yceoshda
em 28 jul. 2020
Hack simples e rápido:
$ kubectl describe nodes | grep 'Name:\| cpu\| memory'
Name: XXX-2-wke2
cpu 1552m (77%) 2402m (120%)
memory 2185Mi (70%) 3854Mi (123%)
Name: XXX-2-wkep
cpu 1102m (55%) 1452m (72%)
memory 1601Mi (51%) 2148Mi (69%)
Name: XXX-2-wkwz
cpu 852m (42%) 1352m (67%)
memory 1125Mi (36%) 3624Mi (116%)
 SerheyDolgushev
em 5 ago. 2020
SerheyDolgushev
em 5 ago. 2020
Hack simples e rápido:
$ kubectl describe nodes | grep 'Name:\| cpu\| memory' Name: XXX-2-wke2 cpu 1552m (77%) 2402m (120%) memory 2185Mi (70%) 3854Mi (123%) Name: XXX-2-wkep cpu 1102m (55%) 1452m (72%) memory 1601Mi (51%) 2148Mi (69%) Name: XXX-2-wkwz cpu 852m (42%) 1352m (67%) memory 1125Mi (36%) 3624Mi (116%)Os plug-ins do dispositivo não estão lá. Eles deveriam ser. Esses dispositivos também são recursos.
boniek83
em 5 ago. 2020
Olá!
Eu criei este script e compartilho com você.
https://github.com/Sensedia/open-tools/blob/master/scripts/listK8sHardwareResources.sh
Este script contém uma compilação de algumas das ideias que você compartilhou aqui. O script pode ser incrementado e pode ajudar outras pessoas a obter as métricas de forma mais simples.
Obrigado por compartilhar as dicas e comandos!
 aeciopires
em 7 ago. 2020
aeciopires
em 7 ago. 2020
Para o meu caso de uso, acabei escrevendo um plug-in kubectl simples que lista limites / reservas de CPU / RAM para nós em uma tabela. Ele também verifica o consumo atual de CPU / RAM do pod (como kubectl top pods ), mas ordenando a saída por CPU em ordem decrescente.
É mais uma coisa conveniente do que qualquer outra coisa, mas talvez outra pessoa também ache útil.
 laurybueno
em 9 ago. 2020
laurybueno
em 9 ago. 2020
Uau, que thread enorme e ainda nenhuma solução adequada da equipe do kubernetes para calcular corretamente o uso geral atual da CPU de um cluster inteiro?
 denissabramovs
em 20 set. 2020
denissabramovs
em 20 set. 2020
Para quem deseja executar isso no minikube, primeiro habilite o complemento do servidor de métricas
minikube addons enable metrics-server
e então execute o comando
kubectl top nodes
 raul1991
em 16 out. 2020
raul1991
em 16 out. 2020
Se você estiver usando o Krew :
kubectl krew install resource-capacity
kubectl resource-capacity
NODE CPU REQUESTS CPU LIMITS MEMORY REQUESTS MEMORY LIMITS
* 16960m (35%) 18600m (39%) 26366Mi (14%) 3100Mi (1%)
ip-10-0-138-176.eu-north-1.compute.internal 2460m (31%) 4200m (53%) 567Mi (1%) 784Mi (2%)
ip-10-0-155-49.eu-north-1.compute.internal 2160m (27%) 2200m (27%) 4303Mi (14%) 414Mi (1%)
ip-10-0-162-84.eu-north-1.compute.internal 3860m (48%) 3900m (49%) 8399Mi (27%) 414Mi (1%)
ip-10-0-200-101.eu-north-1.compute.internal 2160m (27%) 2200m (27%) 4303Mi (14%) 414Mi (1%)
ip-10-0-231-146.eu-north-1.compute.internal 2160m (27%) 2200m (27%) 4303Mi (14%) 414Mi (1%)
ip-10-0-251-167.eu-north-1.compute.internal 4160m (52%) 3900m (49%) 4491Mi (14%) 660Mi (2%)
 benjick
em 14 nov. 2020
benjick
em 14 nov. 2020
Questões relacionadas
 montanaflynn
·
3Comentários
montanaflynn
·
3Comentários
 cooligc
·
3Comentários
cooligc
·
3Comentários
 chowyu08
·
3Comentários
chowyu08
·
3Comentários
 theothermike
·
3Comentários
theothermike
·
3Comentários
 tbchj
·
3Comentários
tbchj
·
3Comentários
Comentários muito úteis
Há: