Kubernetes: Definieren von Log-Treiber und Log-Opt beim Angeben von Pod in RC und Pod
Wir müssen in der Lage sein, die folgenden Optionen zu definieren, wenn wir die Pod-Definition in RC und Pod festlegen
--log-driver= Logging-Treiber für Container
--log-opt=[] Treiberoptionen protokollieren
Diese Optionen sollten auf Container-Ebene einstellbar sein und wurden mit Docker 1.8 eingeführt.
Da die Docker-Client-Bibliothek beide Optionen unterstützt, ist das Hinzufügen dieser Optionen zur Pod-Definition jetzt machbar.
 ejemba
ejemba
Alle 117 Kommentare
/cc @ kubernetes / rh-cluster-infra
 timothysc
am 13. Okt. 2015
timothysc
am 13. Okt. 2015
Hmm, ich denke, wir sollten dies wahrscheinlich clusterweit als Standard festlegen und dann möglicherweise zulassen, dass bestimmte Pod-Definitionen überschrieben werden.
cc @sosiouxme @smarterclayton @liggitt @jwhonce @jcantrill @bparees @jwforres
 ncdc
am 13. Okt. 2015
ncdc
am 13. Okt. 2015
Können Sie beschreiben, wie Sie dies auf Containerbasis nutzen würden (Anwendungsfall)? Wir stellen Docker-spezifische Optionen traditionell nicht direkt in Containern zur Verfügung, es sei denn, sie können über Laufzeiten hinweg sauber abstrahiert werden. Wenn Sie wissen, wie Sie dies verwenden möchten, können Sie dies rechtfertigen.
 smarterclayton
am 13. Okt. 2015
smarterclayton
am 13. Okt. 2015
Beachten Sie, dass Docker-Protokolle immer noch nur Json-Datei- und Journald-Treiber unterstützen, obwohl ich mir vorstellen kann, dass diese Liste erweitert werden könnte.
Was die Benutzer vielleicht tatsächlich wollen, ist eine Auswahl definierter Endpunkte für das Schreiben von Protokollen und nicht die Offenlegung der Details des Protokollierungstreibers.
 sosiouxme
am 13. Okt. 2015
sosiouxme
am 13. Okt. 2015
@ncdc @smarterclayton Ich stimme euch beiden zu, nachdem wir unseren Anwendungsfall intern noch einmal überdacht haben, stellt sich heraus, dass
- Unser primäres Bedürfnis besteht darin, unsere Knoten zu schützen. Wir senden die Protokolle an einen Protokollserver, aber wenn dies fehlschlägt, werden die Protokolle auf die internen Docker-Protokolle zurückgesetzt. In einem solchen Fall benötigen wir ein Cluster-weites Verhalten für das Docker-Log, um eine Knotensättigung zu verhindern
- Das Freigeben bestimmter Docker-Optionen in den Pod/Rc-Definitionen ist keine gute Idee, wie @smarterclayton vorgeschlagen hat. Wir stimmen auch einer Abstraktion zu, die die Definition von High-Level-Log-Verhalten ermöglicht, wenn möglich
- Eine andere Möglichkeit besteht darin, Änderungen an Kubelet-Konfigurationsdateien und -Code vorzunehmen, um ein solches Protokollverhalten zu handhaben
ejemba
am 13. Okt. 2015
Die Änderungen an den Salt-Vorlagen, um dies als Standard festzulegen, sollten nicht sein
furchtbar schwierig. Es ist wirklich nur die richtige Daemon-Konfiguration (und
Umgang mit Änderungen an der Log-Aggregation über fluentd aufgrund von
Auswahl einer anderen Quelle)
Am Dienstag, 13. Oktober 2015 um 10:55 Uhr, Epo Jemba [email protected]
schrieb:
@ncdc https://github.com/ncdc @smarterclayton
https://github.com/smarterclayton Ich stimme euch beiden zu, nachdem
Wenn wir unseren Anwendungsfall intern überdenken, stellt sich heraus, dass
- Unser primäres Bedürfnis besteht darin, unsere Knoten zu schützen. Wir senden die Protokolle an ein Protokoll
Server, aber wenn es fehlschlägt, protokolliert Fallback auf Docker-internen Protokollen. In solch
Um eine Knotensättigung zu verhindern, benötigen wir ein clusterweites Verhalten für
Docker-Log- Das Freigeben bestimmter Docker-Optionen in den Pod/Rc-Definitionen ist nicht möglich
gute Idee als @smarterclayton https://github.com/smarterclayton
schlug es vor. Wir stimmen auch einer Abstraktion zu, die die Definition von hoch . erlaubt
Level-Log-Verhalten, wenn möglich- Eine andere Möglichkeit besteht darin, Änderungen an Kubelet-Konfigurationsdateien vorzunehmen und
Code, um ein solches Log-Verhalten zu handhaben—
Antworten Sie direkt auf diese E-Mail oder zeigen Sie sie auf GitHub an
https://github.com/kubernetes/kubernetes/issues/15478#issuecomment -147740136
.
smarterclayton
am 13. Okt. 2015
:Daumen hoch:
Beachten Sie, dass es jetzt 9 Protokollierungstreiber gibt . Wie ist der Konsens darüber, diesen hier zu bekommen?
 halr9000
am 12. Mai 2016
halr9000
am 12. Mai 2016
+1
 briangebala
am 18. Mai 2016
briangebala
am 18. Mai 2016
Falls es jemand nicht weiß, können Sie den Standardprotokolltreiber auf Knotenbasis mit einem Flag für den Docker-Daemon ( --log-driver ) definieren. In meiner Umgebung habe ich den Treiber auf diese Weise auf journald . Um ehrlich zu sein, fällt es mir schwer, mir einen Anwendungsfall vorzustellen, um dies auf Containerbasis zu überschreiben.
 obeattie
am 18. Mai 2016
obeattie
am 18. Mai 2016
Die meisten Cluster werden nicht wollen, dass ihre Logs "out-of-band" werden, also was wäre die Feature-Aktivierung, die dies bieten würde.
Außerdem sieht es aus der Sicht des Betriebs nach einem Kontrollverlust aus. Derzeit legen wir die Standardeinstellungen fest und konfigurieren einen Logging-Stack zum Aggregieren.
timothysc
am 18. Mai 2016
+1 dazu.
Nicht in der Lage zu sein, die Handhabung der Docker-Protokollierung zu kontrollieren, bedeutet, dass die einzige vernünftige Protokollierungsoption die Verwendung der mit k8s gelieferten Tools ist, was eine unglaubliche Einschränkung darstellt.
@timothysc hier unser Anwendungsfall. Wir haben eine komplexe dynamische Infrastruktur (~100 Maschinen) mit vielen bestehenden Diensten, die darauf laufen, mit unseren eigenen logstash zum Sammeln von Protokollen. Nun, wir versuchen jetzt, unsere Dienste nacheinander auf k8s zu verschieben, und mir scheint es keine saubere Möglichkeit zu geben, die Protokollierung zwischen unserer bestehenden Infrastruktur und auf k8s geclusterten Containern zu integrieren.
K8S ist sehr eigensinnig, wie Sie Protokolle sammeln. Dies könnte großartig sein für alle, die mit einer einfachen Infrastruktur bei Null anfangen. Für alle anderen, die an komplexen Infrastrukturen arbeiten und denen es nichts ausmacht, tief einzutauchen und einen benutzerdefinierten Protokollierungsmechanismus zu implementieren, gibt es derzeit einfach keine Möglichkeit, dies zu tun, was ziemlich frustrierend ist.
Hoffentlich macht es Sinn.
 jnardiello
am 23. Mai 2016
jnardiello
am 23. Mai 2016
In Ihrem Szenario sind Protokolle also wirklich "pro Anwendung", aber Sie müssen
Sicherstellen, dass der zugrunde liegende Host diese Protokolle unterstützt? Das ist unsere Sorge
diskutieren hier - entweder wir tun Cluster-Ebene oder Knoten-Ebene, aber wenn wir es tun
Pod-Ebene, dann müsste der Scheduler wissen, welche Log-Treiber
sind wo vorhanden. Das versuchen wir so gut es geht zu vermeiden.
Am Mo, 23. Mai 2016 um 10:50 Uhr, Jacopo Nardiello < [email protected]
schrieb:
+1 dazu.
Nicht in der Lage zu sein zu kontrollieren, wie die Docker-Protokollierung gehandhabt wird, bedeutet, dass die
Die einzige vernünftige Protokollierungsoption verwendet die mit k8s gelieferten Tools, was eine
unglaubliche Einschränkung.@timothysc https://github.com/timothysc hier unser Anwendungsfall. Wir haben ein
komplexe dynamische Infrastruktur (~100 Maschinen) mit vielen vorhandenen
Dienste, die darauf ausgeführt werden, mit unserem eigenen Logstash zum Sammeln von Protokollen. Also, wir
versuchen jetzt, unsere Dienste nacheinander auf k8s und auf mich zu verschieben
scheint kein sauberer Weg zu sein, die Protokollierung zwischen unseren bestehenden zu integrieren
Infrastruktur und Container auf k8s geclustert.K8S ist sehr eigensinnig, wie Sie Protokolle sammeln. Das könnte toll sein
für alle, die mit einer einfachen Infrastruktur bei Null anfangen. Zum
alle anderen, die an komplexen Infrastrukturen arbeiten, denen das nichts ausmacht
tief einzutauchen und einen benutzerdefinierten Logging-Mechanismus zu implementieren, gibt es einfach nicht
wie man es im Moment macht, was ziemlich frustrierend ist.Hoffentlich macht es Sinn.
—
Sie erhalten dies, weil Sie erwähnt wurden.
Antworten Sie direkt auf diese E-Mail oder zeigen Sie sie auf GitHub an
https://github.com/kubernetes/kubernetes/issues/15478#issuecomment -221002545
smarterclayton
am 23. Mai 2016
@smarterclayton Ich verstehe Ihre Bedenken und sie sind gut platziert. Ich bin mir nicht sicher, ob der gesamte Cluster sich der Protokollierung auf Pod-Ebene bewusst sein muss. Ich denke, wir sollten die Option geben, pod stdout/stderr irgendwo zu protokollieren (eine Datei basierend auf ihrem aktuellen Pod-Namen?) damit jeder, der bereit ist, seine benutzerdefinierte Lösung zu implementieren, einen dauerhaften Ort hat, an dem er den Inhalt erhält. Dies öffnet jedoch ein RIESIGES Kapitel, da Logrotation nicht trivial ist.
Dies sind nur meine zwei Cent, aber wir können nicht so tun, als würden komplexe Szenarien der realen Welt einfach ihre vorhandene Protokollierungsinfrastruktur aufgeben.
jnardiello
am 26. Mai 2016
Geben Sie benutzerdefinierte Protokolloptionen pro Anwendung an? Wie viele verschiedene
Sätze von Protokolloptionen würden Sie pro Cluster haben? Wenn es kleine Sätze von gibt
config, eine Option wäre, eine Anmerkung auf Pods zu unterstützen, die ist
korreliert mit der Konfiguration auf Knotenebene, die eine Reihe von "Standardprotokollen" bietet
Optionen". Dh zum Startzeitpunkt von Kubelet definieren Sie einen "Log-Modus X" (der definiert
benutzerdefinierte Protokolloptionen und Treiber) und der Pod würde "
pod.alpha.kubernetes.io/log.mode=X".
Eine weitere Option wäre, dass wir einen Weg aufzeigen, den Deployers die Möglichkeit zu geben, die
Möglichkeit, die Containerdefinition unmittelbar vor dem Start zu mutieren
der Kontainer. Das ist heute schwieriger, weil wir die serialisieren müssten
docker def in ein Zwischenformat aus, führe es aus und führe es dann aus
wieder, aber möglicherweise in Zukunft einfacher.
Schließlich könnten wir Schlüssel-Wert-Paare auf der Container-Schnittstelle verfügbar machen, die
werden direkt an die Container-Engine übergeben, bieten keine API-Garantien für
und stellen Sie sicher, dass PodSecurityPolicy diese Optionen regulieren kann. Das würde
die Fluchtluke für Anrufer sein, aber wir könnten keine bieten
garantieren, dass diese weiterhin über mehrere Releases hinweg funktionieren.
Am Do, 26. Mai 2016 um 5:34 Uhr, Jacopo Nardiello [email protected]
schrieb:
@smarterclayton https://github.com/smarterclayton Ich verstehe davon
Ihre Anliegen und sie sind gut platziert. Ich bin mir nicht sicher, ob der ganze Cluster
muss sich der Existenz von Pod-Level-Logging bewusst sein, was ich denke, dass wir
tun sollte, ist die Möglichkeit zu geben, pod stdout/stderr irgendwo zu loggen (eine Datei
basierend auf ihrem aktuellen Pod-Namen?), damit jeder, der bereit ist, ihre
benutzerdefinierte Lösung, einen dauerhaften Ort haben, an dem der Inhalt abgerufen werden kann.
Dies öffnet jedoch ein RIESIGES Kapitel, da Logrotation nicht trivial ist.Das sind nur meine zwei Cent, aber wir können diesen Komplex der realen Welt nicht vortäuschen
Szenarien geben einfach ihre vorhandene Protokollierungsinfrastruktur auf.—
Sie erhalten dies, weil Sie erwähnt wurden.
Antworten Sie direkt auf diese E-Mail oder zeigen Sie sie auf GitHub an
https://github.com/kubernetes/kubernetes/issues/15478#issuecomment -221823732
smarterclayton
am 26. Mai 2016
@smarterclayton hast du gesehen https://github.com/kubernetes/kubernetes/issues/24677#issuecomment -220735829
ncdc
am 26. Mai 2016
Nein danke. Bewegende Diskussion dorthin.
Am Do, 26. Mai 2016 um 11:23 Uhr, Andy Goldstein [email protected]
schrieb:
@smarterclayton https://github.com/smarterclayton hast du #24677 gesehen?
(Kommentar)
https://github.com/kubernetes/kubernetes/issues/24677#issuecomment -220735829—
Sie erhalten dies, weil Sie erwähnt wurden.
Antworten Sie direkt auf diese E-Mail oder zeigen Sie sie auf GitHub an
https://github.com/kubernetes/kubernetes/issues/15478#issuecomment -221903781
smarterclayton
am 26. Mai 2016
Hi,
Ich denke, dies ist ein wichtiges Feature, das für Kubernetes in Betracht gezogen werden sollte.
Das Aktivieren der Verwendung des Protokolltreibers von Docker kann einige nicht triviale Probleme lösen.
Ich würde sagen, dass die Protokollierung auf die Festplatte ein Anti-Muster ist. Protokolle sind von Natur aus "Status" und sollten vorzugsweise nicht auf der Festplatte gespeichert werden. Der direkte Versand der Protokolle von einem Container an ein Repository löst viele Probleme.
Das Setzen des Log-Treibers würde bedeuten, dass der Befehl kubectl logs nichts mehr anzeigen kann.
Obwohl diese Funktion "nice to have" ist, wird die Funktion nicht benötigt, wenn die Protokolle von einer anderen Quelle verfügbar sind.
Docker verfügt bereits über Protokolltreiber für Google Cloud (gcplogs) und Amazon (awslogs). Es ist zwar möglich, sie auf dem Docker-Daemon selbst zu setzen, aber das hat viele Nachteile. Indem Sie die beiden Docker-Optionen einstellen können:
--log-driver= Logging-Treiber für Container
--log-opt=[] Treiberoptionen protokollieren
Es wäre möglich Labels (für gcplogs) oder awslogs-group (für awslogs) mitzuschicken
spezifisch für einen Pod. Das würde es leicht machen, die Protokolle am anderen Ende zu finden.
Ich habe gelesen, wie Leute mit Logs in Kubernetes umgehen. Viele scheinen einige aufwendige Schaber einzurichten, die die Stämme an zentrale Systeme weiterleiten. Die Möglichkeit, den Protokolltreiber einzustellen, macht dies überflüssig - so bleibt Zeit, um an interessanteren Dingen zu arbeiten :)
 pbthorste
am 30. Nov. 2016
pbthorste
am 30. Nov. 2016
Ich kann auch hinzufügen, dass einige Leute, einschließlich mir, eine Docker-Log-Rotation über die Option '--log-opt max-size' im JSON-Logging-Treiber (der für Docker nativ ist) durchführen möchten, anstatt logrotate auf dem Host einzurichten. Es wäre also sehr wünschenswert, auch nur die Option '--log-opt' freizugeben
 daniilyar
am 12. Dez. 2016
daniilyar
am 12. Dez. 2016
Ich habe die k8s beim Erstellen der Containerkonfiguration LogConfig geändert.
 barnettZQG
am 12. Dez. 2016
barnettZQG
am 12. Dez. 2016
+1
Die Verwendung des Docker-Protokolltreibers für die zentralisierte Protokollsammlung sieht viel einfacher aus, als symbolische Links für Protokolldateien zu erstellen, sie in einen speziellen fließenden Container einzubinden, sie zu verfolgen und die Protokollrotation zu verwalten.
 defat
am 27. Dez. 2016
defat
am 27. Dez. 2016
Anwendungsfall für die Konfiguration pro Container: Ich möchte mich für Container, die ich bereitstelle, an anderer Stelle oder anders protokollieren, und ich kümmere mich nicht um den Protokolltreiber für die Standardcontainer, die zum Ausführen von Kubernetes erforderlich sind (oder möchte ihn ändern).
Da gehst du. Bitte lassen Sie dies geschehen.
 et304383
am 12. Jan. 2017
et304383
am 12. Jan. 2017
Eine andere Idee ist, dass alle Container weiterhin Protokolle an denselben Endpunkt weiterleiten, Sie jedoch zumindest unterschiedliche Feldwerte für verschiedene Docker-Container auf Ihrem Protokollserver
Dies würde für den gelf-Docker-Treiber funktionieren, wenn wir sicherstellen könnten, dass von Kubernetes erstellte Docker-Container benutzerdefinierte beschriftet sind. Bedeutung: Einige Pod-Felder könnten als Docker-Container-Labels weitergeleitet werden. (Vielleicht ist das schon möglich, aber ich weiß nicht, wie ich das erreichen soll).
Beispiel ohne Kubernetes, nur mit Docker-Daemon und Gelf-Treiber. Lassen Sie den Docker-Daemon konfigurieren mit: --log-driver=gelf --log-opt labels=env,label2 und erstellen Sie einen Docker-Container:
docker run -dti --label env=testing --label label2=some_value alpine:3.4 /bin/sh -c "while true; do date; sleep 2; done"
und ein weiterer Docker-Container:
docker run -dti --label env=production --label label2=some_value alpine:3.4 /bin/sh -c "while true; do date; sleep 2; done"
Auf diese Weise können Sie auf Graylog zwischen env=production und env=testing Containern unterscheiden.
Derzeit verwende ich solche Docker-Daemon-Optionen:
--log-driver=gelf --log-opt gelf-address=udp://graylog.example.com:12201 --log-opt tag=k8s-testing --log-opt labels=io.kubernetes.pod.namespace,io.kubernetes.container.name,io.kubernetes.pod.name
 xmik
am 12. Jan. 2017
xmik
am 12. Jan. 2017
@xmik , nur was zu bestätigen ist eine vorhandene Funktion oder Ihr Vorschlag bezüglich
Derzeit verwende ich solche Docker-Daemon-Optionen:
--log-driver=gelf --log-opt gelf-address=udp://graylog.example.com:12201 --log-opt tag=k8s-testing --log-opt labels=io.kubernetes.pod.namespace,io.kubernetes.container.name,io.kubernetes.pod.name
 stainboy
am 26. Jan. 2017
stainboy
am 26. Jan. 2017
Diese Docker-Daemon-Optionen, die ich derzeit verwende, funktionieren bereits. Kubernetes legt bereits einige Labels für jeden Docker-Container fest. Wenn Sie beispielsweise docker inspect auf dem kube-apiserver-Container ausführen:
"Labels": {
"io.kubernetes.container.hash": "4959a3f5",
"io.kubernetes.container.name": "kube-apiserver",
"io.kubernetes.container.ports": "[{\"name\":\"https\",\"hostPort\":6443,\"containerPort\":6443,\"protocol\":\"TCP\"},{\"name\":\"local\",\"hostPort\":8080,\"containerPort\":8080,\"protocol\":\"TCP\"}]",
"io.kubernetes.container.restartCount": "1",
"io.kubernetes.container.terminationMessagePath": "/dev/termination-log",
"io.kubernetes.pod.name": "kube-apiserver-k8s-production-master-1",
"io.kubernetes.pod.namespace": "kube-system",
"io.kubernetes.pod.terminationGracePeriod": "30",
"io.kubernetes.pod.uid": "a47396d9dae12c81350569f56aea562e"
}
Daher funktionieren diese Docker-Daemon-Optionen.
Ich denke jedoch, dass es jetzt nicht möglich ist, Kubernetes benutzerdefinierte Labels für einen Docker-Container basierend auf der Pod-Spezifikation festzulegen. Also zB --log-driver=gelf --log-opt labels=env,label2 funktioniert nicht.
xmik
am 26. Jan. 2017
Gibt es diesbezüglich Neuigkeiten? Die Möglichkeit, die Labels anzugeben und dann --log-opt labels<> wäre ziemlich gut!
 beldpro-ci
am 18. März 2017
beldpro-ci
am 18. März 2017
@portante @jcantrill Nur um es hier festzuhalten, weil wir es besprochen haben, hier ist der Anwendungsfall, für den wir dachten, dass dies nützlich sein könnte:
Wenn die Log-Aufzeichnungs-Pods auf Fehler stoßen und diese protokollieren, wird das Infra, das diese Fehler sammelt, sie erfassen und an den Aufzeichnungsmechanismus zurücksenden, der wiederum weitere Fehler auslöst und protokolliert.
Diese Rückkopplungsschleife kann durch den Einsatz von Filtermechanismen vermieden werden, aber das ist etwas spröde. Die Verwendung eines anderen Protokollierungstreibers zum Aufzeichnen in eine Datei und mit Rotationsoptionen scheint eine gute Lösung zu sein.
 pweil-
am 31. März 2017
pweil-
am 31. März 2017
Meine 2 Cent.
Aktuelle Lösungen für die Protokollierung in k8s sind (AFAIK):
- Sidecar-Container, der Protokolle irgendwo sendet
- Replikationscontroller sendet alle Protokolle irgendwohin
- der Container selbst sendet Logs irgendwohin
Sidecar-Container scheint mir etwas übertrieben zu sein. Die Strategie des Replikationscontrollers scheint gut zu sein, aber sie mischt Protokolle von Containern aus allen Bereitstellungen, und einige Benutzer möchten dies möglicherweise jetzt und möchten stattdessen jede App für eine andere Sache protokollieren. Für diese Fälle funktioniert die letzte Option IMHO am besten, erzeugt aber viel Code, der in allen Containern repliziert wird (zB: install and setup logentries daemon).
Dies alles wäre viel einfacher, wenn wir Zugriff auf log-driver Flags hätten, sodass jede Bereitstellung mithilfe von Docker-nativen Funktionen definieren würde, wie sie protokolliert werden soll.
Ich kann versuchen, das zu implementieren, brauche aber wahrscheinlich etwas Hilfe - da ich mit der Kubernetes-Codebase nicht vertraut bin.
 caarlos0
am 17. Mai 2017
caarlos0
am 17. Mai 2017
Sobald Multi-Tenancy immer mehr an Bedeutung gewinnt, wird es schwieriger, sie richtig zu lösen.
Jeder Namespace kann ein anderer Mandant sein, daher sollten Protokolle von jedem nicht unbedingt aggregiert werden, sondern dürfen an vom Mandanten angegebene Speicherorte gesendet werden.
Ich kann mir einige Möglichkeiten vorstellen, dies zu tun:
- Erstellen Sie einen neuen Datenträgertyp, container-logs. Dadurch kann ein Daemonset, das von einem bestimmten Namespace gestartet wird, nur auf die Protokolle seiner eigenen Container zugreifen. Sie können die Protokolle dann mit einem beliebigen Protokollversender ihrer Wahl an einen beliebigen Speicher-Daemon senden.
- Ändern Sie einen (oder mehrere) der Protokollversender, z. B. fluentd-bit, um den Namespace zu lesen, in dem sich der Pod befindet, und leiten Sie Protokolle von jedem Pod an einen weiteren Protokollversender um, der in diesem Namespace als Dienst ausgeführt wird. Wie fließend. Dies ermöglicht es dem Namespace wiederum, seinen eigenen Log-Shipper so zu konfigurieren, dass er an jedes Log-Back-End sendet, das er unterstützen möchte.
 kfox1111
am 17. Mai 2017
kfox1111
am 17. Mai 2017
@caarlos0 @kfox1111 Ich stimme Ihren Punkten zu. Dies ist ein komplexes Thema, da es die Koordination von Instrumentierung, Speicher, Knoten und vielleicht noch mehr Teams erfordert. Ich schlage vor, zuerst einen Vorschlag für die gesamte Logging-Architektur zu erstellen und dann die Änderung zu dieser konsistenten Ansicht zu diskutieren. Ich erwarte, dass dieser Vorschlag in einem Monat oder so erscheint, um Ordnung zu schaffen und alle erwähnten Probleme herauszufinden.
 crassirostris
am 17. Mai 2017
crassirostris
am 17. Mai 2017
@crassirostris Ich bin mir nicht sicher, ob ich das verstehe: Wenn wir nur log-driver usw. zulassen, müssen wir uns nicht um die Speicherung oder
Sendet Docker einfach seinen STDOUT an jeden Protokolltreiber, der auf Containerbasis eingerichtet ist, oder? Wir geben die Verantwortung irgendwie auf den Container ab... scheint mir eine ziemlich einfache Lösung zu sein - aber wie gesagt, ich kenne die Codebasis nicht, also liege ich vielleicht einfach falsch...
caarlos0
am 17. Mai 2017
Das Problem ist, dass der Protokolltreiber im Docker keine der k8s-Metadaten hinzufügt, die das spätere Verbrauchen der Protokolle tatsächlich nützlich machen. :/
kfox1111
am 17. Mai 2017
@kfox1111 hmm, macht Sinn...
Aber was ist, wenn der Benutzer nur die "Anwendungsprotokolle" möchte, keine Kubernetes-Protokolle, keine Docker-Protokolle, sondern nur die App, die in den Container-Protokollen ausgeführt wird?
In diesem Fall scheint mir log-driver zu funktionieren...
caarlos0
am 17. Mai 2017
@caarlos0 Es kann einige Auswirkungen haben, z. B. macht kubelet einige Annahmen über das Protokollierungsformat für Server-kubectl-Protokolle.
Abgesehen davon ist log-driver per se Docker-spezifisch und funktioniert möglicherweise nicht für andere Laufzeiten, das ist der Hauptgrund, es nicht in die API aufzunehmen.
crassirostris
am 17. Mai 2017
@crassirostris das macht Sinn...
da diese Funktion nicht hinzugefügt wird (wie in der Ausgabe beschrieben), sollte diese Ausgabe vielleicht geschlossen (oder bearbeitet oder was auch immer) werden?
caarlos0
am 17. Mai 2017
@caarlos0 Wir wollen das Logging-
crassirostris
am 17. Mai 2017
Die stdout-Protokollierung von Containern wird derzeit in Kubernetes out-of-band gehandhabt. Wir verlassen uns derzeit auf Nicht-Kubernetes-Lösungen, um das Logging zu handhaben, oder auf privilegierte Container, die Kubernetes jailbreaken, um Zugriff auf das Out-of-Band-Logging zu erhalten. Die Protokollierung der Container-Laufzeit ist je nach Laufzeit (docker, rkt, Windows) unterschiedlich, so dass die Auswahl eines beliebigen Typs wie Docker --log-driver zukünftiges Gepäck erzeugt.
Ich schlage vor, wir brauchen das Kubelet, um Log-Streams wieder in-Band zu bringen. Definieren oder wählen Sie ein minimales JSON- oder XML-Protokollformat, das Standardzeilen aus jedem Container sammelt, fügen Sie ein minimales Cluster+Namespace+Pod+Container-Metadaten hinzu, damit die Protokollquelle innerhalb des Kubernetes-Bereichs identifiziert wird, und leiten Sie den Stream an einen Kubernetes-Dienst+ Hafen. Es steht den Benutzern frei, einen beliebigen Protokollverbrauchsdienst bereitzustellen. Vielleicht stellt Kubernetes einen Referenz-/Standarddienst bereit, der die Unterstützung von 'kubectl logs' implementiert.
Ohne Angabe eines Protokollierungsverbrauchsdienstes werden Protokolle verworfen und nicht auf die Festplatte übertragen . Das Streamen der Protokolle an anderer Stelle oder das Schreiben in den dauerhaften Speicher und das Rotieren liegen in der Verantwortung/Entscheidung des Dienstes.
Der kubelet-Container-Laufzeit-Wrapper tut das Minimum, um den stdout aus jeder Container-Laufzeit zu extrahieren und ihn in-Band zurückzubringen, damit die selbstgehosteten k8s-Dienste konsumiert und verarbeitet werden können.
Die Containerspezifikation im Deployment oder Pod würde optional den Zieldienst und Port für die Standardprotokollierung angeben. Das Hinzufügen von k8s-Metadaten für Cluster+Namespace+Pod+Container wäre optional (also die Wahl zwischen roh/unberührt oder mit Metadaten). Benutzern steht es frei, alle Protokolle an einem Ort zusammenzufassen oder nach Mandant, Namespace oder Anwendung zusammenzufassen.
Der nächste Schritt ist jetzt, einen Dienst auszuführen, der 'kubectl logs -f' verwendet, um Container-Logs für jeden Container über den API-Server zu streamen. Das klingt nicht sehr effizient oder skalierbar. Dieser Vorschlag würde ein effizienteres direktes Steaming vom Container-Laufzeit-Wrapper direkt zum Dienst oder Pod ermöglichen, mit Optimierungen wie der Bevorzugung der Protokollierung von Deployment- oder Daemonset-Pods auf demselben Knoten und dem Container, der die Protokolle generiert.
Ich schlage vor, dass Kubernetes das Minimum tun sollte, um Container-Laufzeitprotokolle effizient in Band zu bringen, für alle selbstgehosteten, homogenen oder heterogenen Protokollierungslösungen, die wir innerhalb des Kubernetes-Raums erstellen.
Was denken die Leute?
 whereisaaron
am 18. Mai 2017
whereisaaron
am 18. Mai 2017
@whereisaaron Ich möchte diese Diskussion jetzt wirklich nicht führen, wenn wir nicht alle Details rund um das Logging-Ökosystem an einem Ort haben.
ZB sehe ich Netzwerk- und Maschinenprobleme, die den Protokollfluss stören, aber ich möchte noch nicht darauf eingehen. Wie wäre es, wenn wir das später besprechen, wenn der Vorschlag fertig ist? Erscheint Ihnen das vernünftig?
crassirostris
am 18. Mai 2017
Auf jeden Fall @crassirostris. Bitte teilen Sie uns hier mit, wann der Vorschlag zur Prüfung bereit ist.
whereisaaron
am 20. Mai 2017
/ Sig-Skalierbarkeit
 kargakis
am 10. Juni 2017
kargakis
am 10. Juni 2017
Obwohl sowohl --log-driver als auch --log-opt Optionen für den Docker-Daemon und keine k8s-Funktionen sind, wäre es schön, sie in der k8s-Pod-Spezifikation anzugeben für:
- Pro-Pod-Protokolltreiber und kein einzelner Protokolltreiber auf Knotenebene
- verschiedene Arten von App-spezifischen Protokolltreibern (fluentd, syslog, journald, splunk) auf demselben Knoten
- setze
--log-opt, um die Log-Rotation für einen Pod zu konfigurieren - pro Pod
--log-optEinstellungen und nicht eine einzelne Knotenebene--log-opt
AFAIK, keines der oben genannten kann heute auf Pod-Ebene in der k8s-Pod-Spezifikation eingestellt werden.
 vhosakot
am 13. Dez. 2017
vhosakot
am 13. Dez. 2017
@vhosakot keines der oben genannten kann in Kubernetes auf einer beliebigen Ebene festgelegt werden, da dies keine Kubernetes-Konzepte sind
crassirostris
am 13. Dez. 2017
@crassirostris genau! :)
Wenn k8s alles macht, was Docker auf Pod-Ebene/Container-Ebene macht, wird es dann für Benutzer nicht einfach sein? Warum sollten Benutzer Docker überhaupt für einige Dinge auf Pod- / Container-Ebene verwenden?
Und ein k8s-Liebhaber, kein Docker-Fan, kann die gleiche Frage stellen.
vhosakot
am 13. Dez. 2017
@vhosakot Point ist, es gibt eine Reihe anderer Container-Laufzeiten, die mit K8s verwendet werden können, aber --log-opt existiert nur in Docker. Die Schaffung einer solchen Option auf K8s-Ebene würde absichtlich die Abstraktion durchsickern lassen. Ich glaube nicht, dass dies der Weg ist, den wir gehen wollen. Falls eine Option existiert, sollte diese von allen Container-Laufzeiten unterstützt werden, idealerweise ein Teil von CRI
Ich sage nicht, dass es eine solche Option nicht geben wird, ich sage, es wird kein direkter Weg zu Docker geben
crassirostris
am 13. Dez. 2017
@crassirostris Stimmt, es hört sich so an, als ob k8s das tun soll, was CRI auf Pod-Ebene/Container-Ebene tut/zulässt, nicht Docker-spezifisch.
vhosakot
am 13. Dez. 2017
Ja, absolut richtig
crassirostris
am 13. Dez. 2017
Obwohl ich zu spät zu dieser Diskussion bin und ein Interesse daran habe, diese Funktion implementiert zu sehen, würde ich argumentieren, dass es einen Kompromiss zwischen einem hübschen Design und einer einfachen Möglichkeit gibt, eine vernünftige und einheitliche Protokollierungslösung einzurichten für den Cluster. Ja, die Implementierung dieser Funktion würde docker internal aufdecken, was ein großes Nein ist, aber gleichzeitig kann ich gut darauf wetten, dass die Mehrheit der K8S-Benutzer Docker als zugrunde liegende Containertechnologie verwenden und Docker mit einer sehr umfassenden Liste geliefert wird von Log-Treibern.
 gabriel-tincu
am 19. Dez. 2017
gabriel-tincu
am 19. Dez. 2017
@gabriel-tincu Ich bin derzeit nicht davon überzeugt, dass die ursprüngliche FR die Mühe wert ist
docker wird mit einer sehr umfassenden Liste von Protokolltreibern geliefert
Sie können die Protokollierung auf Docker-Ebene während des K8s-Bereitstellungsschritts einrichten und einen dieser Protokolltreiber verwenden, ohne diese Informationen an K8s weiterzugeben. Das einzige, was Sie heute nicht tun können, ist, diese Optionen pro Container/pro-Pod einzurichten (eigentlich können Sie ein Setup mit dedizierten Knoten haben und den Knotenselektor verwenden), aber ich bin mir nicht sicher, ob dies eine große Einschränkung ist.
crassirostris
am 19. Dez. 2017
@crassirostris Ich stimme zu, dass Sie dies __vor__ dem Einrichten der Umgebung einrichten können, aber wenn es eine Möglichkeit gibt, den Docker-Protokolltreiber aktiv zu aktualisieren, nachdem die Umgebung bereits eingerichtet ist, entgeht mir dies im Moment
gabriel-tincu
am 12. Jan. 2018
@gabriel-tincu @vhosakot die direkte Schnittstelle, die in den "alten Tagen" von >=1.5 zwischen k8s und Docker existierte, ist veraltet und ich glaube, der Code wurde jetzt vollständig entfernt. Alles zwischen dem Kubelet und den Laufzeiten wie Docker (oder den anderen wie rkt, cri-o, runc, lxd) läuft durch CRI. Es gibt jetzt viele Container-Laufzeiten und Docker selbst wird wahrscheinlich veraltet sein und bald zugunsten von cri-containerd + containerd .
http://blog.kubernetes.io/2017/11/containerd-container-runtime-options-kubernetes.html
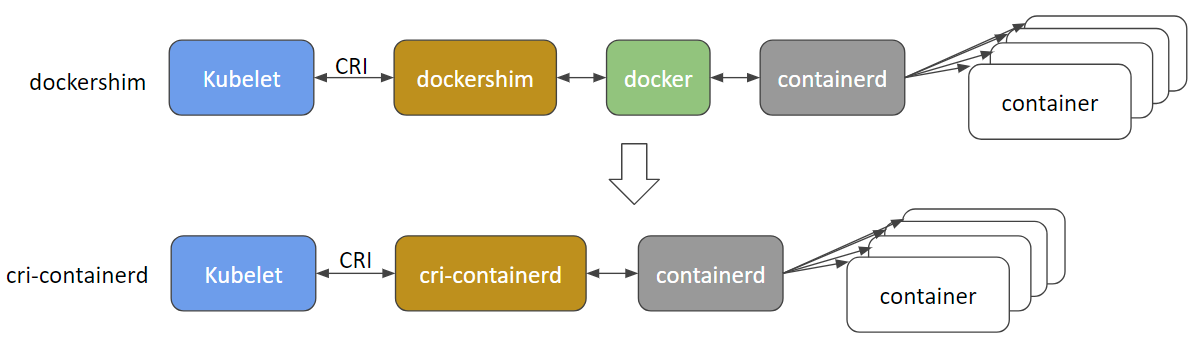
@crassirostris irgendeine Bewegung zu einem Vorschlag, der die Möglichkeit der In-Band-Container-Protokollierung hat?
whereisaaron
am 12. Jan. 2018
Das CRI-Container-Log ist dateibasiert (https://github.com/kubernetes/community/blob/master/contributors/design-proposals/node/kubelet-cri-logging.md), und der Log-Pfad ist explizit definiert:
/var/log/pods/PodUID/ContainerName/RestartCount.log
In den meisten Docker-Logging-Treibern https://docs.docker.com/config/containers/logging/configure/#supported -logging-drivers, denke ich, sind die Treiber für die Cluster-Umgebung die wichtigsten, die das Container-Log in den Cluster aufnehmen Protokollierungsverwaltungssystem, wie splunk , awslogs , gcplogs usw.
Bei CRI sollte kein "Docker-Log-Treiber" verwendet werden. Benutzer können einen Daemonset ausführen, um Container-Logs aus dem CRI-Container-Log-Verzeichnis aufzunehmen, wo immer sie wollen. Sie können fluentd verwenden oder sogar selbst ein Daemonset schreiben.
Wenn mehr Metadaten benötigt werden, können wir darüber nachdenken, eine Metadatendatei zu löschen, den Dateipfad zu erweitern oder dem Daemonset Metadaten vom apiserver holen zu lassen. Darüber wird laufend diskutiert https://github.com/kubernetes/kubernetes/issues/58638
 Random-Liu
am 22. Feb. 2018
Random-Liu
am 22. Feb. 2018
Die Probleme veralten nach 90 Tagen Inaktivität.
Markieren Sie das Problem mit /remove-lifecycle stale .
Veraltete Ausgaben verrotten nach weiteren 30 Tagen Inaktivität und werden schließlich geschlossen.
Wenn dieses Problem jetzt sicher geschlossen werden kann, tun Sie dies bitte mit /close .
Senden Sie Feedback an sig-testing, kubernetes/test-infra und/oder fejta .
/Lebenszyklus veraltet
 fejta-bot
am 23. Mai 2018
fejta-bot
am 23. Mai 2018
Abgestandene Ausgaben verrotten nach 30 Tagen Inaktivität.
Markieren Sie das Problem mit /remove-lifecycle rotten .
Faule Probleme werden nach weiteren 30 Tagen Inaktivität geschlossen.
Wenn dieses Problem jetzt sicher geschlossen werden kann, tun Sie dies bitte mit /close .
Senden Sie Feedback an sig-testing, kubernetes/test-infra und/oder fejta .
/Lebenszyklus faul
/Entferne-Lebenszyklus veraltet
fejta-bot
am 22. Juni 2018
/remove-lifecycle faul
 iavael
am 25. Juni 2018
iavael
am 25. Juni 2018
irgendwelche Updates dazu? Wie also hat jemand, der k8s mit Docker-Containern ausführt, die Protokollierung in einem Back-End wie AWS CloudWatch erledigt?
 bryan831
am 4. Juli 2018
bryan831
am 4. Juli 2018
@bryan831 Es ist beliebt, die k8s-Container-Protokolldateien mit fluentd oder ähnlichem zu sammeln und sie in einem Back-End Ihrer Wahl, CloudWatch, StackDriver, Elastisearch usw.
Es gibt Standard-Helm-Charts für zB fluentd+CloudWatch , fluentd+Elastisearch , fluent-bit->fluentd->Ihre Wahl , Datadog und wahrscheinlich andere Kombinationen, wenn Sie
whereisaaron
am 4. Juli 2018
Die Probleme veralten nach 90 Tagen Inaktivität.
Markieren Sie das Problem mit /remove-lifecycle stale .
Veraltete Ausgaben verrotten nach weiteren 30 Tagen Inaktivität und werden schließlich geschlossen.
Wenn dieses Problem jetzt sicher geschlossen werden kann, tun Sie dies bitte mit /close .
Senden Sie Feedback an sig-testing, kubernetes/test-infra und/oder fejta .
/Lebenszyklus veraltet
fejta-bot
am 2. Okt. 2018
Es wäre schön, Docker --log-opt-Optionen anpassen zu können. In meinem Fall möchte ich ein Tag wie '--log-opt tag="{{.ImageName}}/{{.Name}}/{{.ID}}"' verwenden, um ImageName an die Protokolle auszugeben damit ich weiß, aus welcher Containerversion die Protokolle stammen. (Referenz: https://docs.docker.com/config/containers/logging/log_tags/)
 pmahalwar-intertrust
am 26. Okt. 2018
pmahalwar-intertrust
am 26. Okt. 2018
/Entferne-Lebenszyklus veraltet
pmahalwar-intertrust
am 26. Okt. 2018
@pmahalwar-intertrust können Sie das gleiche --log-opt an den Docker-Daemon übergeben, was sich auf alle Ihre Container auswirkt ...
 nrobert13
am 26. Okt. 2018
nrobert13
am 26. Okt. 2018
@pmahalwar-intertrust die von kubernetes von containerd gesammelten Protokolle enthalten bereits umfangreiche Metadaten, einschließlich aller Labels, die Sie auf den Container angewendet haben. Wenn Sie es mit fluentd sammeln, erhalten Sie alle Metadaten wie im Log-Eintrag unten.
{
"log": " - [] - - [25/Oct/2018:06:29:48 +0000] \"GET /nginx_status/format/json HTTP/1.1\" 200 9250 \"-\" \"Go-http-client/1.1\" 118 0.000 [internal] - - - - 5eb73997a372badcb4e3d993ceb44cd9\n",
"stream": "stdout",
"docker": {
"container_id": "3657e1d9a86e629d0dccefec0c3c7624eaf0c4a11f60f53c5045ec0839c37f06"
},
"kubernetes": {
"container_name": "nginx-ingress-controller",
"namespace_name": "ingress",
"pod_name": "nginx-ingress-dev-controller-69c644f7f5-vs8vw",
"pod_id": "53514ad6-d0f4-11e8-a04c-02c433fc5820",
"labels": {
"app": "nginx-ingress",
"component": "controller",
"pod-template-hash": "2572009391",
"release": "nginx-ingress-dev"
},
"host": "ip-172-29-21-204.us-east-2.compute.internal",
"master_url": "https://10.3.0.1:443/api",
"namespace_id": "e262510b-180a-11e8-b763-0a0386e3402c"
},
"kubehost": "ip-172-29-21-204.us-east-2.compute.internal"
}
Gibt es noch keinen Plan, diese Funktionen zu unterstützen?
--log-driver= Logging-Treiber für Container
--log-opt=[] Treiberoptionen protokollieren
 lifubang
am 8. Nov. 2018
lifubang
am 8. Nov. 2018
Hallo @lifubang Ich kann nicht zu den Plänen von irgendjemandem sprechen, aber der Daemon, der diese Funktionen unterstützt, dockerd ist nicht mehr Teil von Kubernetes (siehe die Diskussion oben darüber).
Sie können es immer noch optional installieren, wenn Sie möchten, also können Sie dies möglicherweise tun, um die alten dockerd Protokolltreiber zu verwenden. Diese Option wird hier diskutiert:
https://kubernetes.io/blog/2018/05/24/kubernetes-containerd-integration-goes-ga/
Aber die Verwendung eines dedizierten Protokollierungsdienstes wie fluentd ist der empfohlene Ansatz. Sie können es global für Ihren Cluster oder pro Pod als Sidecar bereitstellen. Das Logging in Kubernetes wird hier besprochen:
https://kubernetes.io/docs/concepts/cluster-administration/logging/
whereisaaron
am 8. Nov. 2018
Ich empfehle fluentd wie von @whereisaaron beschrieben
Soweit an dieser Feature-Anfrage gearbeitet wird ... die Kubernetes-Architektur-Roadmap enthält unter dem Abschnitt "Ökosystem" eine Protokollierung von Dingen, die nicht wirklich "Teil von" Kubernetes sind, daher bezweifle ich, dass ein solches Feature jemals nativ unterstützt wird.
https://github.com/kubernetes/community/blob/master/contributors/devel/architectural-roadmap.md#summarytldr
 taylorshaulis
am 8. Nov. 2018
taylorshaulis
am 8. Nov. 2018
Ich rate dringend davon ab, fluentd zu verwenden, da es mehrere Fehler enthält, die Ihr Leben beim Ausführen von k8s zum Höllenfeuer machen können
in_tail verhindert, dass Docker den Container https://github.com/fluent/fluentd/issues/1680 entfernt.
in_tail entfernt nicht verfolgte Dateipositionen während der Startphase. Dies bedeutet, dass der Inhalt von pos_file bis zum Neustart anwächst und eine Menge CPU-Scannen durch ihn auffressen kann, wenn Sie viele Dateien mit dynamischen Pfadeinstellungen überwachen.
https://github.com/fluent/fluentd/issues/1126.
 roffe
am 6. Dez. 2018
roffe
am 6. Dez. 2018
Die Probleme veralten nach 90 Tagen Inaktivität.
Markieren Sie das Problem mit /remove-lifecycle stale .
Veraltete Ausgaben verrotten nach weiteren 30 Tagen Inaktivität und werden schließlich geschlossen.
Wenn dieses Problem jetzt sicher geschlossen werden kann, tun Sie dies bitte mit /close .
Senden Sie Feedback an sig-testing, kubernetes/test-infra und/oder fejta .
/Lebenszyklus veraltet
fejta-bot
am 21. März 2019
Danke für deine Erfahrung @roffe. fluent/fluentd#1680 war damals ein Problem bei k8s 1.5 und wir haben 'in_tail' damals aus diesem Grund nicht verwendet. Seit k8s auf containerd Logging umgezogen ist, scheint es immer noch nichts zu geben? Wir haben keine erkennbaren Auswirkungen von fluent/fluentd#1126 gesehen.
Sie haben gegen fluentd empfohlen. Was würden Sie stattdessen empfehlen? Was verwenden Sie persönlich anstelle von fluentd für die Protokollaggregation mit k8s-Metadaten?
whereisaaron
am 21. März 2019
Abgestandene Ausgaben verrotten nach 30 Tagen Inaktivität.
Markieren Sie das Problem mit /remove-lifecycle rotten .
Faule Probleme werden nach weiteren 30 Tagen Inaktivität geschlossen.
Wenn dieses Problem jetzt sicher geschlossen werden kann, tun Sie dies bitte mit /close .
Senden Sie Feedback an sig-testing, kubernetes/test-infra und/oder fejta .
/Lebenszyklus faul
fejta-bot
am 20. Apr. 2019
Faule Probleme werden nach 30 Tagen Inaktivität geschlossen.
Öffnen Sie das Problem erneut mit /reopen .
Markieren Sie das Problem mit /remove-lifecycle rotten .
Senden Sie Feedback an sig-testing, kubernetes/test-infra und/oder fejta .
/nah dran
fejta-bot
am 20. Mai 2019
@fejta-bot: Schließe dieses Problem.
Als Antwort darauf :
Faule Probleme werden nach 30 Tagen Inaktivität geschlossen.
Öffnen Sie das Problem erneut mit/reopen.
Markieren Sie das Problem mit/remove-lifecycle rotten.Senden Sie Feedback an sig-testing, kubernetes/test-infra und/oder fejta .
/nah dran
Anleitungen zur Interaktion mit mir über PR-Kommentare finden Sie hier . Wenn Sie Fragen oder Vorschläge zu meinem Verhalten haben, reichen Sie bitte ein Problem gegen das
 k8s-ci-robot
am 20. Mai 2019
k8s-ci-robot
am 20. Mai 2019
Das hätte nicht geschlossen werden sollen, oder?
Die Funktionsanfrage macht für mich immer noch Sinn, da ich die Log-Opts pro Pod festlegen möchte (ohne sie auf dem Daemon einzustellen oder logrotate zu verwenden) ...
 yzargari
am 27. Aug. 2019
yzargari
am 27. Aug. 2019
Ich bin mir ziemlich sicher, dass die Unterstützung von Docker-spezifischen Konfigurationsoptionen von innerhalb von k8s keine gute Idee ist. Wie bereits erwähnt, sind ein fließend Daemonset oder ein Fluenbit-Seitenwagen aktuelle Optionen. Ich bevorzuge den Beiwagen, da er viel sicherer ist.
 coffeepac
am 29. Aug. 2019
coffeepac
am 29. Aug. 2019
@whereisaaron hast du eine Logging-Lösung für K8s@containerd gefunden?
 loxal
am 11. Sept. 2019
loxal
am 11. Sept. 2019
werden --log-driver , --log-opt immer noch nicht unterstützt?
Ich versuche, eine Möglichkeit zu finden, Protokolle von einem einzelnen Pod an Splunk weiterzuleiten. irgendwelche Ideen?
 sariel1212
am 15. Sept. 2019
sariel1212
am 15. Sept. 2019
@sariel1212 für einen einzelnen Pod empfehle ich, einen Seitenwagen-Container in Ihren Pod aufzunehmen, der nur der Splunk-Spediteur ist. Sie können ein leeres Verzeichnis für alle Container im Pod freigeben und die Anwendungscontainer (s) ihre Protokolle in das freigegebene leere Verzeichnis schreiben lassen. Lassen Sie dann den Splunk-Forwarder-Container aus diesem Volume lesen und leiten Sie sie weiter.
coffeepac
am 16. Sept. 2019
Wenn Sie für Ihren gesamten Cluster @sariel1212 nach Splunk sammeln offizielles Splunk helm Diagramm zum Bereitstellen von fluentd mit dem Splunk HEC fluentd Plug-in zum Sammeln Node-Logs, Container-Logs und Control Plane-Logs sowie Kubernetes-Objekte und Kubernetes-Cluster-Metriken. Für einen ist der Vorschlag von Pod @coffeepac eines
whereisaaron
am 16. Sept. 2019
Es ist ziemlich schrecklich, dass es für einen Clusterbesitzer nach all dieser Zeit immer noch keine Möglichkeit gibt, Docker-Protokolltreiber zu verwenden.
Ich konnte mit Docker-Compose (das mein K8s-Cluster simulierte) sehr schnell die Einrichtung durchführen, um alle stdout/err an meinen log-aggregierten Dienst weiterzuleiten.
Versuchen Sie dies in Kubenetes zu tun? Aus diesem Thread sieht es so aus, als müsste ich den Code für jeden Microservice erweitern! Nicht gut.
 ashleydavis
am 24. Sept. 2019
ashleydavis
am 24. Sept. 2019
Hallo @ashleydavis , dockerd wurde in Kubernetes veraltet, daher macht es keinen Sinn, Unterstützung für etwas einzuführen, das nicht mehr Teil von Kubernetes ist. Sie können es jedoch weiterhin zusätzlich zu Kubernetes installieren. Hier der Hintergrund:
https://kubernetes.io/blog/2018/05/24/kubernetes-containerd-integration-goes-ga/
Sie müssen Container nicht erweitern, es sei denn, Sie möchten, Kubernetes streamt nativ stdout/stderr-Protokolle für jeden Container automatisch. Sie müssen nur einen Container auf jedem Knoten bereitstellen (ein DaemonSet ), um diese Log-Streams zu sammeln und an einen Aggregationsdienst Ihrer Wahl zu senden. Es ist sehr leicht.
https://docs.fluentd.org/container-deployment/kubernetes
Hier gibt es viele fertige fluentd +Back-End-Container-Images und Beispielkonfigurationen für Back-Aggregation-Back-Ends:
https://github.com/fluent/fluentd-kubernetes-daemonset
Wenn Sie DataDog verwenden, müssen sie stattdessen ihren eigenen Agenten installieren oder zusätzlich fluentd :
https://docs.datadoghq.com/integrations/kubernetes/
Im Allgemeinen tendierte docker zu kitchen sink , mit Logging- und Log-Plug-Ins, Schwarm- und Laufzeit-Tools, Build-Tools, Netzwerk- und Dateisystem-Mounting usw. alles in einem Daemon-Prozess. Kubernetes bevorzugt im Allgemeinen lose gekoppelte Container/Prozesse, die jeweils eine Aufgabe ausführen und über APIs kommunizieren. Es ist also ein etwas anderer Stil, an den man sich gewöhnen muss.
whereisaaron
am 24. Sept. 2019
Danke für die ausführliche Antwort. Ich werde das auf jeden Fall prüfen.
Bedeutet das, dass Dockerd veraltet ist, in Zukunft keine Docker-Images in Kubernetes bereitstellen kann?
ashleydavis
am 24. Sept. 2019
@ashleydavis Sie können sicherlich weiterhin 'Docker'-Images verwenden (auch ohne dockerd vorhanden), und Sie können dockerd für Ihre eigenen Zwecke auf Ihren Kubernetes-Knoten bereitstellen (wie in Docker-in-Docker baut), wenn Sie möchten. Die Kernteile von Docker wurden extrahiert und als 'OCI-Container' und die containerd Laufzeit standardisiert.
https://www.opencontainers.org/
https://containerd.io/
Sowohl Docker als auch Kubernetes basieren nun auf diesen gemeinsamen Standards.
https://blog.docker.com/2017/08/what-is-containerd-runtime/
https://kubernetes.io/blog/2018/05/24/kubernetes-containerd-integration-goes-ga/
whereisaaron
am 24. Sept. 2019
Danke, ich lerne so viel.
Ich habe gerade einen Microservice erstellt, den ich Loggy genannt habe. Die Absicht war es, Logs vom Docker-Log-Treiber zu senden und diese dann (per Webhook) an Slack weiterzuleiten.
Sie können den Code hier sehen: https://github.com/artlife-solutions/loggy/blob/master/src/index.ts
Es ist ziemlich einfach, ein Protokoll zu erhalten und es per HTTP POST an Slack weiterzuleiten.
Wie kann ich dies am schnellsten anpassen, damit ich Protokolle von meinen Pods sammeln und aggregieren kann?
ashleydavis
am 24. Sept. 2019
@ashleydavis Sie könnten ein Container-Image mit diesem
Stellen Sie Ihren Cluster als Bereitstellung mit einem Dienst bereit, an den alle Container in Ihrem Cluster dann senden können (unter Verwendung des Cluster-DNS-Namens des
Stellen Sie es als zusätzlichen 'Sidecar'-Container in Ihrem Deployment bereit . Container im selben Pod teilen sich privaten Zugriff auf dasselbe
localhostsodass der Anwendungscontainer auflocalhost:12201an Ihren Micro-Service-Container-Sidecar senden kann. Alternativ können Container im selben Pod ein Volume für freigegebene Protokolldateien oder Named Pipes gemeinsam nutzen.
Dies wird hier nicht mehr zum Thema und nicht jeder wird dies wollen, also recherchiere vielleicht ein paar Beispiele auf Github und Slack-Kanälen nach Ratschlägen.
https://github.com/ramitsurana/awesome-kubernetes
https://slack.k8s.io/
https://kubernetes.io/
whereisaaron
am 24. Sept. 2019
Klingt gut. Danke. Ich hatte nur gehofft, bestehende Dienste nicht ändern zu müssen. Ich möchte nur ihren stdout/error erfassen. Wie auch immer, das zu tun?
Das Versprechen der Docker-Protokolltreiber war Einfachheit. Gibt es eine einfache Möglichkeit, dies zu tun?
ashleydavis
am 24. Sept. 2019
Klar @ashleydavis , stellen Sie Ihren Cluster fluentd bereit und fertig, fertig . Für jede Anwendung, die Sie bereitstellen, wird stdout/stderr an Ihren bevorzugten Aggregator gesendet. 👍
whereisaaron
am 24. Sept. 2019
Nachdem ich einige Zeit in K8s und Logging investiert habe, habe ich einen schönen ELK-Stack ohne explizite GELF-Konfiguration aufgebaut . Bitte werfen Sie einen Blick auf https://www.elastic.co/guide/en/beats/filebeat/current/running-on-kubernetes.html
Mein Setup ist Filebeat, das die Protokolle an Logstash weiterleitet, das ihre Inhalte filtert und extrahiert und an Elasticsearch weiterleitet. Mit Kibana kann ich die Protokolle anzeigen und Daten aggregieren.
loxal
am 24. Sept. 2019
Ich würde auch gerne die Protokollierung in der systemeigenen Syslog-Datei des Betriebssystems unterstützen, zum Beispiel: Unter Ubuntu kann ich Protokolle in /var/log/syslog schreiben, die von logrotate out-of-the-box verwaltet werden.
Mit swarm/compose kann ich das machen:
version: '3.3'
services:
mysql:
image: mysql:5.7
logging:
driver: syslog
options:
tag: mysql
Die Verwendung eines emtpyDir-Volumes ist in Ordnung, jedoch besteht die Gefahr, dass Pods mit langer Laufzeit das Volume füllen, es sei denn, Sie fügen einen zusätzlichen Prozess hinzu, der die Protokolldateien rotiert / abschneidet. Ich bin mit dieser zusätzlichen Komplexität nicht einverstanden, wenn das Betriebssystem bereits die Rotation von /var/log/syslog handhabt.
Ich stimme zu, dass die Verwendung von Sidecars für einige Bereitstellungen eine großartige Idee ist (ich mache dies bereits für einige meiner Bereitstellungen), jedoch ist die Umgebung jedes Einzelnen anders.
 jsirianni
am 5. Dez. 2019
jsirianni
am 5. Dez. 2019
Die Verwendung eines emtpyDir-Volumes ist in Ordnung
Seien Sie vorsichtig mit ihnen – sie werden von Kubernetes verwaltet und ihre Lebensdauer wird nicht von Ihnen kontrolliert. Wenn ein Pod entfernt und auf einen anderen Knoten verschoben wird, gehen die Protokolle verloren. Wenn Sie einen Pod aktualisieren und sich seine Uid ändert, wird nicht das alte Volume verwendet, sondern ein neues erstellt und das alte entfernt.
 php-coder
am 5. Dez. 2019
php-coder
am 5. Dez. 2019
@jsirianni nicht alle Systeme führen syslog aus, was bedeutet, dass es eine Anmerkung pro Knoten geben müsste, welche Einrichtungen verfügbar sind, um sicherzustellen, dass die Anforderungen eines bestimmten Pods erfüllt werden. Docker Compose muss diese Annahme treffen, da es nur lokal ausgeführt wird.
coffeepac
am 6. Dez. 2019
@coffeepac Nur weil die Knoten möglicherweise kein Syslog haben, bedeutet dies nicht, dass der Operator keine Option haben sollte. Wenn ich beabsichtige, Syslog zu verwenden, würde ich sicherstellen, dass meine Worker-Knoten über Syslog verfügen.
jsirianni
am 6. Dez. 2019
Ich bin der Meinung, dass dieses Problem erneut geöffnet werden sollte, da es noch genügend Anwendungsfälle für diese Funktion gibt.
/wieder öffnen
 saiyam1814
am 27. Feb. 2020
saiyam1814
am 27. Feb. 2020
@saiyam1814 : Dieses Problem wurde erneut geöffnet.
Als Antwort darauf :
Ich bin der Meinung, dass dieses Problem erneut geöffnet werden sollte, da es noch genügend Anwendungsfälle für diese Funktion gibt.
/wieder öffnen
Anleitungen zur Interaktion mit mir über PR-Kommentare finden Sie hier . Wenn Sie Fragen oder Vorschläge zu meinem Verhalten haben, reichen Sie bitte ein Problem gegen das
k8s-ci-robot
am 27. Feb. 2020
Ich persönlich denke immer noch, dass Kubernetes Docker-Protokolltreiber oder eine andere einfache integrierte Möglichkeit zur Konfiguration der Protokollierung unterstützen sollte.
Mir wurde oft gesagt, dass das Einrichten der Protokollierung auf Kubernetes einfach ist, aber nachdem ich jetzt mein eigenes Protokollierungsaggregationssystem eingerichtet habe, kann ich sagen, dass es wirklich nicht einfach ist.
Ich habe einen Blogbeitrag über die einfachste Möglichkeit geschrieben, Ihr eigenes Log-Aggregationssystem für Kubernetes zu erstellen: http://www.the-data-wrangler.com/kubernetes-log-aggregation/
Hoffentlich hilft mein Blogbeitrag anderen, ihre eigene Strategie zu finden.
Es sollte nicht so schwer sein, aber hier sind wir.
ashleydavis
am 27. Feb. 2020
Natürlich brauchen wir eine Möglichkeit, Docker-Protokolle direkt von stdout und stderr zu verwenden, anstatt Protokolldateien zu verwenden. Es gibt einige Sicherheitsprobleme, den Docker-Pfad für Protokolldateien zu verwenden, da Sie auf andere Protokolle im Hostsystem zugreifen können.
Können wir den Docker-Log-Treiber implementieren? 👍
 Tetragramato
am 2. März 2020
Tetragramato
am 2. März 2020
Die Konfiguration von Docker-Protokolltreibern auf Container-in-a-Pod-Ebene (wo der Pod unter Kundenkontrolle steht) würde die Umleitung von Protokollen mit dem gelf Treiber direkt an einen Graylog-Dienst/-Pod (der sich ebenfalls unter Kundenkontrolle befindet) ermöglichen ), anstatt sie mit einem anderen Sofortdienst aus Dateien auf dem Host sammeln zu müssen (was mehr Verwaltungsaufwand und eine schlimmere Unterbrechung der Abstraktionsebene bedeutet als die Verwendung des gelf Protokolltreibers) oder indem die Pods des Kunden auf das Container-Protokollverzeichnis zugreifen auf dem Wirt.
Daher würde ich diese Funktion gerne in Kubernetes implementiert sehen.
 blubberdiblub
am 10. März 2020
blubberdiblub
am 10. März 2020
Es wäre hilfreich, sicherzustellen, dass wir etwas wie https://github.com/cri-o/cri-o/pull/1605 tun, wo wir die Log-Stream-Interpretation von den Log-Treibern trennen, damit das Containerverhalten nicht beeinflussen kann, wie die Treiber funktionieren.
 portante
am 10. März 2020
portante
am 10. März 2020
Faule Probleme werden nach 30 Tagen Inaktivität geschlossen.
Öffnen Sie das Problem erneut mit /reopen .
Markieren Sie das Problem mit /remove-lifecycle rotten .
Senden Sie Feedback an sig-testing, kubernetes/test-infra und/oder fejta .
/nah dran
fejta-bot
am 9. Apr. 2020
@fejta-bot: Schließe dieses Problem.
Als Antwort darauf :
Faule Probleme werden nach 30 Tagen Inaktivität geschlossen.
Öffnen Sie das Problem erneut mit/reopen.
Markieren Sie das Problem mit/remove-lifecycle rotten.Senden Sie Feedback an sig-testing, kubernetes/test-infra und/oder fejta .
/nah dran
Anleitungen zur Interaktion mit mir über PR-Kommentare finden Sie hier . Wenn Sie Fragen oder Vorschläge zu meinem Verhalten haben, reichen Sie bitte ein Problem gegen das
k8s-ci-robot
am 9. Apr. 2020
Funktion muss noch implementiert werden
/wieder öffnen
 M0rdecay
am 9. Apr. 2020
M0rdecay
am 9. Apr. 2020
@M0rdecay : Sie können ein Problem/eine PR nicht erneut öffnen, es sei denn, Sie haben es verfasst oder sind ein Mitarbeiter.
Als Antwort darauf :
Funktion muss noch implementiert werden
/wieder öffnen
Anleitungen zur Interaktion mit mir über PR-Kommentare finden Sie hier . Wenn Sie Fragen oder Vorschläge zu meinem Verhalten haben, reichen Sie bitte ein Problem gegen das
k8s-ci-robot
am 9. Apr. 2020
@M0rdecay : Sie können ein Problem/eine PR nicht erneut öffnen, es sei denn, Sie haben es verfasst oder sind ein Mitarbeiter.
OK habe verstanden
M0rdecay
am 9. Apr. 2020
Sogar aws ecs hat diese Funktionalität, bei der man den Docker-Logging-Treiber einstellen kann.
In unserer Umgebung haben wir für jeden Containerdienst einen separaten Index mit einem eindeutigen Token erstellt.
"logConfiguration": {
"logDriver": "splunk",
"Optionen": {
"splunk-format": "roh",
"splunk-insecureskipverify": "wahr",
"splunk-token": "xxxxx-xxxxxxx-xxxxx-xxxxxxx-xxxxxx",
"splunk-url": " https://xxxxx.splunk-heavyforwarderxxx.com ",
"tag": "{{.Name}}/{{.ID}}",
"splunk-verify-connection": "falsch",
"mode": "non-blocking"
}
}
Habe aber nichts dergleichen in k8s gefunden. Es sollte in der Pod-Definition selbst vorhanden sein.
 arshadsiddique-jfl
am 10. Aug. 2020
arshadsiddique-jfl
am 10. Aug. 2020
Die Optionen müssen noch umgesetzt werden
/wieder öffnen
ejemba
am 10. Aug. 2020
@ejemba : Dieses Problem wurde erneut geöffnet.
Als Antwort darauf :
Die Optionen müssen noch umgesetzt werden
/wieder öffnen
Anleitungen zur Interaktion mit mir über PR-Kommentare finden Sie hier . Wenn Sie Fragen oder Vorschläge zu meinem Verhalten haben, reichen Sie bitte ein Problem gegen das
k8s-ci-robot
am 10. Aug. 2020
/sig-Knoten
/ Entfernen-Sig-Instrumentierung
 logicalhan
am 26. Aug. 2020
logicalhan
am 26. Aug. 2020
/Sig-Skalierbarkeit entfernen
logicalhan
am 26. Aug. 2020
@logicalhan : Diese Labels sind nicht für das Problem festgelegt: sig/
Als Antwort darauf :
/Sig-Skalierbarkeit entfernen
Anleitungen zur Interaktion mit mir über PR-Kommentare finden Sie hier . Wenn Sie Fragen oder Vorschläge zu meinem Verhalten haben, reichen Sie bitte ein Problem gegen das
k8s-ci-robot
am 26. Aug. 2020
Gibt es Fortschritte damit?
Ich habe speziell nach einer Möglichkeit gesucht, Pods-Container so einzurichten, dass sie sich beim externen Logstash anmelden und den gelf-Log-Treiber von Docker angeben. Die Standardeinstellung für alle Container in /etc/docker/daemon.json scheint ein Overhead zu sein.
 freehck
am 16. Sept. 2020
freehck
am 16. Sept. 2020
Faule Probleme werden nach 30 Tagen Inaktivität geschlossen.
Öffnen Sie das Problem erneut mit /reopen .
Markieren Sie das Problem mit /remove-lifecycle rotten .
Senden Sie Feedback an sig-testing, kubernetes/test-infra und/oder fejta .
/nah dran
fejta-bot
am 16. Okt. 2020
@fejta-bot: Schließe dieses Problem.
Als Antwort darauf :
Faule Probleme werden nach 30 Tagen Inaktivität geschlossen.
Öffnen Sie das Problem erneut mit/reopen.
Markieren Sie das Problem mit/remove-lifecycle rotten.Senden Sie Feedback an sig-testing, kubernetes/test-infra und/oder fejta .
/nah dran
Anleitungen zur Interaktion mit mir über PR-Kommentare finden Sie hier . Wenn Sie Fragen oder Vorschläge zu meinem Verhalten haben, reichen Sie bitte ein Problem gegen das
k8s-ci-robot
am 16. Okt. 2020
/wieder öffnen
 andreswebs
am 2. Nov. 2020
andreswebs
am 2. Nov. 2020
@andreswebs : Sie können ein Problem/eine PR nicht erneut öffnen, es sei denn, Sie haben es verfasst oder sind ein Mitarbeiter.
Als Antwort darauf :
/wieder öffnen
Anleitungen zur Interaktion mit mir über PR-Kommentare finden Sie hier . Wenn Sie Fragen oder Vorschläge zu meinem Verhalten haben, reichen Sie bitte ein Problem gegen das
k8s-ci-robot
am 2. Nov. 2020
/wieder öffnen
ejemba
am 3. Nov. 2020
@ejemba : Dieses Problem wurde erneut geöffnet.
Als Antwort darauf :
/wieder öffnen
Anleitungen zur Interaktion mit mir über PR-Kommentare finden Sie hier . Wenn Sie Fragen oder Vorschläge zu meinem Verhalten haben, reichen Sie bitte ein Problem gegen das
k8s-ci-robot
am 3. Nov. 2020
@ejemba : Dieses Problem wartet derzeit auf eine Prüfung.
Wenn eine SIG oder ein Teilprojekt feststellt, dass dies ein relevantes Problem ist, akzeptiert sie dies durch Anbringen des Labels triage/accepted und bietet weitere Anleitungen.
Das Label triage/accepted kann von Organisationsmitgliedern hinzugefügt werden, indem sie /triage accepted in einen Kommentar schreiben.
Anleitungen zur Interaktion mit mir über PR-Kommentare finden Sie hier . Wenn Sie Fragen oder Vorschläge zu meinem Verhalten haben, reichen Sie bitte ein Problem gegen das
k8s-ci-robot
am 3. Nov. 2020
Ich würde mir sehr wünschen, dass diese Funktion implementiert wird. Ich migriere derzeit Workloads von Rancher 1.x-Clustern zu Rancher 2.x-Clustern, auf denen k8s ausgeführt wird. Wir haben eine Bereitstellung, die die Parameter log-driver und log-opt in der docker-compose-Konfiguration festlegt.
Ich möchte nicht einen bestimmten Host konfigurieren müssen, um den Gelf-Treiber global zu verwenden und den Pod mit einem Label und den Host mit einem Label zu versehen.
 bananflugan
am 4. Nov. 2020
bananflugan
am 4. Nov. 2020
Anscheinend sollten wir CRI-O ändern, um anzugeben, dass beide Container-Log-Streams (stdout / stderr) in einer Rohform gesammelt werden, und wenn wir das Rohformat für später lesen, können wir dann verschiedene Interpretationen des Log-Byte-Streams anwenden.
portante
am 13. Nov. 2020
Faule Probleme werden nach 30 Tagen Inaktivität geschlossen.
Öffnen Sie das Problem erneut mit /reopen .
Markieren Sie das Problem mit /remove-lifecycle rotten .
Senden Sie Feedback an sig-testing, kubernetes/test-infra und/oder fejta .
/nah dran
fejta-bot
am 13. Dez. 2020
@fejta-bot: Schließe dieses Problem.
Als Antwort darauf :
Faule Probleme werden nach 30 Tagen Inaktivität geschlossen.
Öffnen Sie das Problem erneut mit/reopen.
Markieren Sie das Problem mit/remove-lifecycle rotten.Senden Sie Feedback an sig-testing, kubernetes/test-infra und/oder fejta .
/nah dran
Anleitungen zur Interaktion mit mir über PR-Kommentare finden Sie hier . Wenn Sie Fragen oder Vorschläge zu meinem Verhalten haben, reichen Sie bitte ein Problem gegen das
k8s-ci-robot
am 13. Dez. 2020
Verwandte Themen
 Seb-Solon
·
3Kommentare
Seb-Solon
·
3Kommentare
 ddysher
·
3Kommentare
ddysher
·
3Kommentare
 zetaab
·
3Kommentare
zetaab
·
3Kommentare
 broady
·
3Kommentare
broady
·
3Kommentare
 alexferl
·
3Kommentare
alexferl
·
3Kommentare
Hilfreichster Kommentar
Hi,
Ich denke, dies ist ein wichtiges Feature, das für Kubernetes in Betracht gezogen werden sollte.
Das Aktivieren der Verwendung des Protokolltreibers von Docker kann einige nicht triviale Probleme lösen.
Ich würde sagen, dass die Protokollierung auf die Festplatte ein Anti-Muster ist. Protokolle sind von Natur aus "Status" und sollten vorzugsweise nicht auf der Festplatte gespeichert werden. Der direkte Versand der Protokolle von einem Container an ein Repository löst viele Probleme.
Das Setzen des Log-Treibers würde bedeuten, dass der Befehl kubectl logs nichts mehr anzeigen kann.
Obwohl diese Funktion "nice to have" ist, wird die Funktion nicht benötigt, wenn die Protokolle von einer anderen Quelle verfügbar sind.
Docker verfügt bereits über Protokolltreiber für Google Cloud (gcplogs) und Amazon (awslogs). Es ist zwar möglich, sie auf dem Docker-Daemon selbst zu setzen, aber das hat viele Nachteile. Indem Sie die beiden Docker-Optionen einstellen können:
--log-driver= Logging-Treiber für Container
--log-opt=[] Treiberoptionen protokollieren
Es wäre möglich Labels (für gcplogs) oder awslogs-group (für awslogs) mitzuschicken
spezifisch für einen Pod. Das würde es leicht machen, die Protokolle am anderen Ende zu finden.
Ich habe gelesen, wie Leute mit Logs in Kubernetes umgehen. Viele scheinen einige aufwendige Schaber einzurichten, die die Stämme an zentrale Systeme weiterleiten. Die Möglichkeit, den Protokolltreiber einzustellen, macht dies überflüssig - so bleibt Zeit, um an interessanteren Dingen zu arbeiten :)