Kubernetes: Définition de log-driver et log-opt lors de la spécification du pod dans RC et Pod
Nous devons pouvoir définir les options suivantes lors de la spécification de la définition du pod dans RC et Pod
--log-driver= Pilote de journalisation pour le conteneur
--log-opt=[] Options du pilote de journal
Ces options doivent être paramétrables au niveau du conteneur et ont été introduites avec Docker 1.8.
Étant donné que la bibliothèque cliente docker prend en charge les deux options, il est désormais possible d'ajouter ces options à la définition du pod.
 ejemba
ejemba
Tous les 117 commentaires
/ cc @ kubernetes / rh-cluster-infra
 timothysc
le 13 oct. 2015
timothysc
le 13 oct. 2015
Hmm, je pense que nous voudrons probablement pouvoir définir ce cluster par défaut, puis peut-être autoriser le remplacement de définitions de pods spécifiques.
cc @sosiouxme @smarterclayton @liggitt @jwhonce @jcantrill @bparees @jwforres
 ncdc
le 13 oct. 2015
ncdc
le 13 oct. 2015
Pouvez-vous décrire comment vous en tireriez parti par conteneur (cas d'utilisation) ? Traditionnellement, nous n'exposons pas les options spécifiques à Docker directement dans les conteneurs, à moins qu'elles ne puissent être clairement abstraites entre les environnements d'exécution. Savoir comment vous voudriez l'utiliser vous aidera à le justifier.
 smarterclayton
le 13 oct. 2015
smarterclayton
le 13 oct. 2015
Notez que les journaux docker ne prennent toujours en charge que les pilotes json-file et journald, même si j'imagine que cette liste pourrait s'allonger.
Peut-être que ce que les utilisateurs voudraient réellement, c'est une sélection de points de terminaison d'écriture de journal définis, et non une exposition aux détails du pilote de journalisation.
 sosiouxme
le 13 oct. 2015
sosiouxme
le 13 oct. 2015
@ncdc @smarterclayton Je suis d'accord avec vous deux, après avoir reconsidéré notre cas d'utilisation en interne, il s'avère que
- Notre besoin principal est de protéger nos nœuds. Nous envoyons les journaux à un serveur de journaux, mais en cas d'échec, les journaux se replient sur les journaux internes de Docker. Dans ce cas, pour éviter la saturation des nœuds, nous avons besoin d'un comportement à l'échelle du cluster pour le journal docker
- Exposer des options de docker spécifiques dans les définitions de pod/Rc n'est pas une bonne idée comme l' a suggéré
- Une autre option consiste à modifier les fichiers de configuration et le code de kubelet pour gérer un tel comportement de journal
ejemba
le 13 oct. 2015
Les modifications apportées aux modèles de sel pour en faire une valeur par défaut ne doivent pas être
terriblement difficile. C'est vraiment juste une bonne configuration de démon (et
traiter toute modification apportée à l'agrégation de journaux via fluentd en vertu de
sélection d'une autre source)
Le Mar 13 Oct 2015 à 10h55, Epo Jemba [email protected]
a écrit:
@ncdc https://github.com/ncdc @smarterclayton
https://github.com/smarterclayton Je suis d'accord avec vous deux, après
en revenant sur notre cas d'utilisation en interne, il s'avère que
- Notre besoin principal est de protéger nos nœuds. Nous envoyons les journaux à un journal
serveur mais s'il échoue, les journaux se replient sur les journaux internes de docker. Dans un tel
cas, pour éviter la saturation des nœuds, nous avons besoin d'un comportement à l'échelle du cluster pour
journal docker- L'exposition d'options docker spécifiques dans les définitions pod/Rc n'est pas une
bonne idée comme @smarterclayton https://github.com/smarterclayton
l'a suggéré. Nous sommes également d'accord avec une abstraction permettant de définir
comportement du journal de niveau si possible- Une autre option consiste à modifier les fichiers de configuration de kubelet et
code pour gérer un tel comportement de journal-
Répondez directement à cet e-mail ou consultez-le sur GitHub
https://github.com/kubernetes/kubernetes/issues/15478#issuecomment -147740136
.
smarterclayton
le 13 oct. 2015
:pouces vers le haut:
Notez qu'il existe désormais 9 pilotes de journalisation . Quel est le consensus sur l'introduction de celui-ci?
 halr9000
le 12 mai 2016
halr9000
le 12 mai 2016
+1
 briangebala
le 18 mai 2016
briangebala
le 18 mai 2016
Au cas où quelqu'un ne le sache pas, vous pouvez définir le pilote de journal par défaut par nœud avec un indicateur pour le démon Docker ( --log-driver ). Dans mon environnement, j'ai défini le pilote sur journald cette façon. Pour être honnête, j'ai du mal à penser à un cas d'utilisation pour remplacer cela par conteneur.
 obeattie
le 18 mai 2016
obeattie
le 18 mai 2016
La plupart des clusters ne voudront pas que leurs journaux soient "hors bande", alors quelle est l'activation des fonctionnalités que cela fournirait.
De plus, du point de vue des opérations, cela ressemble à une perte de contrôle. Actuellement, nous définissons les valeurs par défaut et configurons une pile de journalisation à agréger.
timothysc
le 18 mai 2016
+1 à ce sujet.
Ne pas pouvoir contrôler la façon dont la journalisation Docker est gérée implique que la seule option de journalisation saine utilise les outils fournis avec k8s, ce qui est une limitation incroyable.
@timothysc voici notre cas d'utilisation. Nous avons une infrastructure dynamique complexe (~100 machines) avec de nombreux services existants qui s'exécutent dessus, avec notre propre logstash pour collecter les journaux. Eh bien, nous essayons maintenant de déplacer nos services, un par un, vers k8 et il me semble qu'il n'y a pas de moyen propre d'intégrer la journalisation entre notre infrastructure existante et les conteneurs regroupés sur k8.
K8S est extrêmement avisé sur la façon dont vous collectez les journaux. Cela peut être génial pour quiconque part de zéro sur une infrastructure simple. Pour tous ceux qui travaillent sur des infrastructures complexes qui n'hésiteraient pas à plonger profondément et à mettre en œuvre un mécanisme de journalisation personnalisé, il n'y a tout simplement aucun moyen de le faire pour le moment, ce qui est assez frustrant.
Espérons que cela ait du sens.
 jnardiello
le 23 mai 2016
jnardiello
le 23 mai 2016
Donc, dans votre scénario, les journaux sont vraiment "par application", mais vous devez
s'assurer que l'hôte sous-jacent prend en charge ces journaux ? C'est la préoccupation que nous sommes
discuter ici - soit nous faisons au niveau du cluster, soit au niveau du nœud, mais si nous le faisons
au niveau du pod, le planificateur devrait savoir quels pilotes de journal
sont présents où. Dans la mesure du possible, nous essayons d'éviter cela.
Le lundi 23 mai 2016 à 10h50, Jacopo Nardiello < [email protected]
a écrit:
+1 à ce sujet.
Ne pas pouvoir contrôler la façon dont la journalisation Docker est gérée implique que le
seule option de journalisation saine utilise les outils fournis avec k8s, qui est un
limite incroyable.@timothysc https://github.com/timothysc voici notre cas d'utilisation. Nous avons un
infrastructure dynamique complexe (~100 machines) avec beaucoup de
services exécutés sur eux, avec notre propre logstash pour collecter les journaux. Bien nous
essayons maintenant de déplacer nos services, un par un, vers k8s et vers moi là-bas
ne semble pas être un moyen propre d'intégrer la journalisation entre nos
infrastructure et conteneurs regroupés sur k8.K8S est extrêmement avisé sur la façon dont vous collectez les journaux. Cela pourrait être génial
pour celui qui part de zéro sur une infrastructure simple. Pour
tous les autres travaillant sur des infrastructures complexes qui n'hésiteraient pas à
plonger profondément et mettre en œuvre un mécanisme de journalisation personnalisé, il n'y a tout simplement pas
façon de le faire pour le moment, ce qui est assez frustrant.Espérons que cela ait du sens.
-
Vous recevez ceci parce que vous avez été mentionné.
Répondez directement à cet e-mail ou consultez-le sur GitHub
https://github.com/kubernetes/kubernetes/issues/15478#issuecomment -221002545
smarterclayton
le 23 mai 2016
@smarterclayton Je comprends vos préoccupations et elles sont bien placées. Je ne sais pas si l'ensemble du cluster doit être conscient de l'existence de la journalisation au niveau du pod, ce que je pense que nous devrions faire est de donner la possibilité de consigner le pod stdout/stderr quelque part (un fichier basé sur leur nom de pod actuel ?) afin que toute personne désireuse de mettre en œuvre sa solution personnalisée ait un endroit persistant où obtenir le contenu. Cela ouvre un chapitre ÉNORME, car la logrotation n'est pas triviale.
Ce ne sont que mes deux cents, mais nous ne pouvons pas prétendre que les scénarios complexes du monde réel abandonnent simplement leur infrastructure de journalisation existante.
jnardiello
le 26 mai 2016
Spécifiez-vous des options de journal personnalisées par application ? Combien de différents
ensembles d'options de journal auriez-vous par cluster ? S'il y a de petits ensembles de
config, une option serait de prendre en charge une annotation sur les pods qui est
corrélé à la configuration au niveau du nœud qui offre un certain nombre de « journal standard
options". C'est-à-dire au lancement de kubelet définir un "log mode X" (qui définit
options de journal personnalisées et pilote), et le pod spécifierait "
pod.alpha.kubernetes.io/log.mode=X".
Une autre option serait que nous exposions un moyen de permettre aux déployeurs d'avoir le
possibilité de muter la définition du conteneur juste avant de commencer
le conteneur. C'est plus difficile aujourd'hui parce qu'il faudrait sérialiser le
docker def vers un format intermédiaire, exécutez-le, puis exécutez-le
encore, mais potentiellement plus facile à l'avenir.
Enfin, nous pourrions exposer des paires clé-valeur sur l'interface du conteneur qui
sont transmis directement au moteur de conteneur, n'offrent aucune garantie API pour
et s'assurer que PodSecurityPolicy peut réguler ces options. Qui serait
être la sortie de secours pour les appelants, mais nous ne serions pas en mesure de fournir
garantir que ceux-ci continueraient à fonctionner dans toutes les versions.
Le jeu. 26 mai 2016 à 5h34, Jacopo Nardiello [email protected]
a écrit:
@smarterclayton https://github.com/smarterclayton Je comprends
vos préoccupations et ils sont bien placés. Je ne sais pas si l'ensemble du cluster
doit être conscient de l'existence de la journalisation au niveau des pods, ce que je pense que nous
devrait faire est de donner la possibilité de consigner pod stdout/stderr quelque part (un fichier
en fonction de leur nom de pod actuel ?) afin que toute personne souhaitant mettre en œuvre son
solution personnalisée, aurait un endroit persistant où obtenir le contenu.
Cela ouvre un chapitre ÉNORME, car la logrotation n'est pas triviale.Ce ne sont que mes deux cents, mais nous ne pouvons pas prétendre que le complexe du monde réel
les scénarios abandonnent simplement leur infrastructure de journalisation existante.-
Vous recevez ceci parce que vous avez été mentionné.
Répondez directement à cet e-mail ou consultez-le sur GitHub
https://github.com/kubernetes/kubernetes/issues/15478#issuecomment-221823732
smarterclayton
le 26 mai 2016
@smarterclayton avez-vous vu https://github.com/kubernetes/kubernetes/issues/24677#issuecomment -220735829
ncdc
le 26 mai 2016
Non merci. Discussion émouvante là-bas.
Le jeu. 26 mai 2016 à 11h23, Andy Goldstein [email protected]
a écrit:
@smarterclayton https://github.com/smarterclayton avez-vous vu #24677
(commenter)
https://github.com/kubernetes/kubernetes/issues/24677#issuecomment -220735829-
Vous recevez ceci parce que vous avez été mentionné.
Répondez directement à cet e-mail ou consultez-le sur GitHub
https://github.com/kubernetes/kubernetes/issues/15478#issuecomment -221903781
smarterclayton
le 26 mai 2016
Salut,
Je pense que c'est une fonctionnalité importante qui devrait être prise en compte pour kubernetes.
L'activation de l'utilisation du pilote de journal de Docker peut résoudre certains problèmes non triviaux.
Je dirais que la journalisation sur disque est un anti-modèle. Les journaux sont intrinsèquement « étatiques » et ne doivent de préférence pas être enregistrés sur le disque. L'expédition des journaux directement d'un conteneur vers un référentiel résout de nombreux problèmes.
La définition du pilote de journal signifierait que la commande kubectl logs ne peut plus rien afficher.
Bien que cette fonctionnalité soit "agréable à avoir" - la fonctionnalité ne sera pas nécessaire lorsque les journaux sont disponibles à partir d'une source différente.
Docker dispose déjà de pilotes de journal pour google cloud (gcplogs) et Amazon (awslogs). Bien qu'il soit possible de les définir sur le démon Docker lui-même, cela présente de nombreux inconvénients. En pouvant définir les deux options du docker :
--log-driver= Pilote de journalisation pour le conteneur
--log-opt=[] Options du pilote de journal
Il serait possible d'envoyer des étiquettes (pour gcplogs) ou awslogs-group (pour awslogs)
spécifique à un pod. Cela faciliterait la recherche des journaux à l'autre extrémité.
J'ai lu comment les gens gèrent les journaux dans kubernetes. Beaucoup semblent mettre en place des grattoirs élaborés qui transmettent les journaux aux systèmes centraux. Pouvoir configurer le pilote de journal rendra cela inutile - libérant du temps pour travailler sur des choses plus intéressantes :)
 pbthorste
le 30 nov. 2016
pbthorste
le 30 nov. 2016
Je peux également ajouter que certaines personnes, dont moi, souhaitent effectuer une rotation des journaux docker via l'option '--log-opt max-size' sur le pilote de journalisation JSON (qui est natif de docker) au lieu de configurer logrotate sur l'hôte. Ainsi, même exposer uniquement l'option '--log-opt' serait grandement apprécié
 daniilyar
le 12 déc. 2016
daniilyar
le 12 déc. 2016
J'ai modifié les k8s, lors de la création de la configuration du conteneur LogConfig.
 barnettZQG
le 12 déc. 2016
barnettZQG
le 12 déc. 2016
+1
L'utilisation du pilote de journal docker pour la collecte centralisée des journaux semble beaucoup plus simple que la création de liens symboliques pour les fichiers journaux, leur montage dans un conteneur fluentd spécial, leur suivi et la gestion de la rotation des journaux.
 defat
le 27 déc. 2016
defat
le 27 déc. 2016
Cas d'utilisation pour la configuration par conteneur : je souhaite me connecter ailleurs ou différemment pour les conteneurs que je déploie et je ne me soucie pas (ou je souhaite modifier) le pilote de journal pour les conteneurs standard nécessaires à l'exécution de Kubernetes.
Voilà. Veuillez faire en sorte que cela se produise.
 et304383
le 12 janv. 2017
et304383
le 12 janv. 2017
Une autre idée est que tous les conteneurs transmettent toujours
Cela fonctionnerait pour le pilote docker gelf, si nous pouvions nous assurer que les conteneurs docker créés par Kubernetes sont étiquetés de manière personnalisée. Signification : certains des champs d'un pod peuvent être transférés en tant qu'étiquettes de conteneur Docker. (C'est peut-être déjà possible mais je ne sais pas comment y parvenir).
Exemple sans Kubernetes, uniquement avec le démon docker et le pilote gelf. Configurez le démon docker avec : --log-driver=gelf --log-opt labels=env,label2 et créez un conteneur docker :
docker run -dti --label env=testing --label label2=some_value alpine:3.4 /bin/sh -c "while true; do date; sleep 2; done"
et un autre conteneur docker :
docker run -dti --label env=production --label label2=some_value alpine:3.4 /bin/sh -c "while true; do date; sleep 2; done"
De cette façon, sur Graylog, vous pouvez différencier les conteneurs env=production et env=testing .
Actuellement, j'utilise ces options de démon docker :
--log-driver=gelf --log-opt gelf-address=udp://graylog.example.com:12201 --log-opt tag=k8s-testing --log-opt labels=io.kubernetes.pod.namespace,io.kubernetes.container.name,io.kubernetes.pod.name
 xmik
le 12 janv. 2017
xmik
le 12 janv. 2017
@xmik , juste de quoi confirmer qu'il s'agit d'une fonctionnalité existante ou de votre proposition concernant
Actuellement, j'utilise ces options de démon docker :
--log-driver=gelf --log-opt gelf-address=udp://graylog.example.com:12201 --log-opt tag=k8s-testing --log-opt labels=io.kubernetes.pod.namespace,io.kubernetes.container.name,io.kubernetes.pod.name
 stainboy
le 26 janv. 2017
stainboy
le 26 janv. 2017
Les options du démon docker que j'utilise actuellement fonctionnent déjà. Kubernetes définit déjà des étiquettes pour chaque conteneur Docker. Par exemple, lors de l'exécution de docker inspect sur le conteneur kube-apiserver :
"Labels": {
"io.kubernetes.container.hash": "4959a3f5",
"io.kubernetes.container.name": "kube-apiserver",
"io.kubernetes.container.ports": "[{\"name\":\"https\",\"hostPort\":6443,\"containerPort\":6443,\"protocol\":\"TCP\"},{\"name\":\"local\",\"hostPort\":8080,\"containerPort\":8080,\"protocol\":\"TCP\"}]",
"io.kubernetes.container.restartCount": "1",
"io.kubernetes.container.terminationMessagePath": "/dev/termination-log",
"io.kubernetes.pod.name": "kube-apiserver-k8s-production-master-1",
"io.kubernetes.pod.namespace": "kube-system",
"io.kubernetes.pod.terminationGracePeriod": "30",
"io.kubernetes.pod.uid": "a47396d9dae12c81350569f56aea562e"
}
Par conséquent, ces options de démon docker fonctionnent.
Cependant, je pense qu'il n'est pas possible maintenant de faire en sorte que Kubernetes définisse des étiquettes personnalisées sur un conteneur Docker en se basant sur les spécifications de Pod. Ainsi, par exemple, --log-driver=gelf --log-opt labels=env,label2 ne fonctionne pas.
xmik
le 26 janv. 2017
Y a-t-il des nouvelles sur ce front? Avoir la possibilité de spécifier les étiquettes et de profiter ensuite de --log-opt labels<> serait plutôt bien !
 beldpro-ci
le 18 mars 2017
beldpro-ci
le 18 mars 2017
@portante @jcantrill Juste pour le capturer ici parce que nous en avons discuté, voici le cas d'utilisation pour lequel nous pensions que cela pourrait être utile :
Lorsque les modules d'enregistrement de journaux commencent à rencontrer et à enregistrer des erreurs, l'infra qui rassemble ces erreurs les récupère et les renvoie au mécanisme d'enregistrement qui à son tour génère et enregistre davantage d'erreurs.
Cette boucle de rétroaction peut être évitée en utilisant des mécanismes de filtrage mais c'est un peu fragile. L'utilisation d'un autre pilote de journalisation pour enregistrer dans un fichier et avoir des options de rotation semble être une bonne solution.
 pweil-
le 31 mars 2017
pweil-
le 31 mars 2017
Mes 2 cents.
Les solutions actuelles pour se connecter à l'intérieur des k8 sont (pour autant que je sache) :
- conteneur side-car envoyant des journaux quelque part
- contrôleur de réplication envoyant tous les journaux quelque part
- le conteneur lui-même envoie des logs quelque part
Le conteneur side-car me semble un peu exagéré. La stratégie du contrôleur de réplication semble bonne, mais elle mélange les journaux de conteneurs de tous les déploiements, et certains utilisateurs peuvent maintenant le souhaiter, et peuvent plutôt vouloir enregistrer chaque application sur un élément différent. Pour ce cas, la dernière option fonctionne le mieux à mon humble avis, mais crée beaucoup de code répliqué dans tous les conteneurs (par exemple: install and setup logentries daemon).
Tout cela serait beaucoup plus facile si nous avions accès aux indicateurs log-driver , donc chaque déploiement définirait comment il doit être enregistré, en utilisant les fonctionnalités natives de Docker.
Je peux essayer de l'implémenter, mais j'aurai probablement besoin d'aide - car je ne connais pas la base de code kubernetes.
 caarlos0
le 17 mai 2017
caarlos0
le 17 mai 2017
une fois que la multilocation deviendra plus une chose, il sera plus difficile à résoudre correctement.
Chaque espace de noms peut être un locataire différent, donc les journaux de chacun ne doivent pas nécessairement être agrégés, mais autorisés à être envoyés aux emplacements spécifiés par le locataire.
Je peux penser à plusieurs façons de le faire:
- créer un nouveau type de volume, container-logs. Cela permet à un démon lancé par un espace de noms particulier d'accéder uniquement aux journaux de ses propres conteneurs. Ils peuvent ensuite envoyer les journaux avec n'importe quel expéditeur de journaux de leur choix au démon de stockage de leur choix.
- Modifiez un (ou plusieurs) des expéditeurs de journaux, comme fluentd-bit pour lire l'espace de noms dans lequel se trouve le pod, et redirigez les journaux de chaque pod vers un autre expéditeur de journaux s'exécutant dans cet espace de noms en tant que service. Comme fluentd. Cela permet à nouveau à l'espace de noms de configurer son propre expéditeur de journaux pour le pousser vers le backend de journal qu'il souhaite prendre en charge.
 kfox1111
le 17 mai 2017
kfox1111
le 17 mai 2017
@caarlos0 @kfox1111 Je suis d'accord avec vos points. Il s'agit d'un sujet complexe, car il nécessite la coordination de l'instrumentation, du stockage, des nœuds et peut-être même d'autres équipes. Je suggère d'abord de présenter une proposition pour l'architecture de journalisation globale, puis de discuter de la modification de cette vue cohérente. Je m'attends à ce que cette proposition apparaisse dans un mois environ, mettant de l'ordre et résolvant tous les problèmes mentionnés.
 crassirostris
le 17 mai 2017
crassirostris
le 17 mai 2017
@cassirostris Je ne suis pas sûr de comprendre : si nous log-driver et al, nous n'avons pas à nous soucier du stockage ou de tout cela, n'est-ce pas ?
Docker envoie-t-il simplement son STDOUT à n'importe quel pilote de journal configuré dans un conteneur, n'est-ce pas ? Nous passons en quelque sorte la responsabilité au conteneur... me semble être une solution assez simple - mais, comme je l'ai dit, je ne connais pas la base de code, alors peut-être que je me trompe tout simplement...
caarlos0
le 17 mai 2017
Le problème est que le pilote de journal dans docker n'ajoute aucune des métadonnées k8s qui rendent la consommation des journaux plus tard réellement utile. :/
kfox1111
le 17 mai 2017
@kfox1111 hmm, c'est logique...
mais, que se passe-t-il si l'utilisateur ne veut que les journaux "d'application", pas les journaux kubernetes, pas les journaux docker, juste l'application s'exécutant dans les journaux du conteneur ?
Dans ce cas, il me semble que log-driver fonctionnerait...
caarlos0
le 17 mai 2017
@caarlos0 Cela peut avoir des implications, par exemple kubelet fait des hypothèses sur le format de journalisation dans les journaux kubectl du serveur.
Mais toutes choses mises à part, log-driver soi est spécifique à Docker et peut ne pas fonctionner pour d'autres environnements d'exécution, c'est la principale raison de ne pas l'inclure dans l'API.
crassirostris
le 17 mai 2017
@cassirostris qui a du sens...
puisque cette fonctionnalité ne sera pas ajoutée (comme décrit dans le problème), peut-être que ce problème devrait être fermé (ou modifié ou autre) ?
caarlos0
le 17 mai 2017
@caarlos0 Cependant, nous souhaitons absolument rendre la configuration de la journalisation plus flexible et transparente. Vos commentaires seront appréciés sur la proposition!
crassirostris
le 17 mai 2017
La journalisation stdout à partir des conteneurs est actuellement gérée hors bande dans Kubernetes. Nous comptons actuellement sur des solutions non Kubernetes pour gérer la journalisation, ou sur des conteneurs privilégiés qui jailbreakent Kubernetes pour accéder à la journalisation hors bande. La journalisation de l'exécution du conteneur est différente selon l'exécution (docker, rkt, Windows), donc en choisir une, comme Docker --log-driver, crée un futur bagage.
Je suggère que nous ayons besoin du kubelet pour ramener les flux de journaux dans la bande. Définissez ou choisissez un format de journal JSON ou XML minimal, qui collecte les lignes stdout de chaque conteneur, ajoutez un cluster minimal + espace de noms + pod + métadonnées de conteneur, de sorte que la source du journal soit identifiée dans l'espace Kubernetes et dirigez le flux vers un service Kubernetes + Port. Les utilisateurs sont libres de fournir le service de consommation de journaux qu'ils souhaitent. Peut-être que Kubernetes fournira un service de référence/par défaut qui implémente la prise en charge des « journaux kubectl ».
Sans un service de consommation de journalisation spécifié, les journaux seront supprimés et n'atteindront pas du tout le disque . Diffuser les journaux ailleurs, ou écrire sur un stockage persistant et en rotation, tout cela relève de la responsabilité/décision du Service.
L'encapsuleur d'exécution de conteneur kubelet fait le minimum pour extraire le stdout de chaque environnement d'exécution de conteneur et le ramener dans la bande pour que le ou les services auto-hébergés k8s soient consommés et traités.
La spécification de conteneur dans le déploiement ou le pod spécifierait éventuellement le service et le port cibles pour la journalisation stdout. L'ajout de métadonnées k8s pour cluster+namespace+pod+container serait facultatif (donc le choix de raw/untouched ou avec des métadonnées). Les utilisateurs seraient libres de regrouper tous les journaux en un seul endroit, ou de les regrouper par locataire, espace de noms ou application.
Le plus proche de cela maintenant est d'exécuter un service qui utilise 'kubectl logs -f' pour diffuser les journaux de conteneur pour chaque conteneur via le serveur API. Cela ne semble pas très efficace ou évolutif. Cette proposition permettrait une diffusion directe plus efficace du wrapper d'exécution du conteneur directement vers le service ou le pod, avec des optimisations telles que la préférence pour la journalisation du déploiement ou des pods Daemonset sur le même nœud et le conteneur générant les journaux.
Je propose que Kubernetes fasse le minimum pour apporter efficacement les journaux d'exécution des conteneurs dans la bande, pour toutes les solutions de journalisation auto-hébergées, homogènes ou hétérogènes que nous créons dans l'espace Kubernetes.
Qu'en pensent les gens ?
 whereisaaron
le 18 mai 2017
whereisaaron
le 18 mai 2017
@whereisaaron J'aimerais vraiment ne pas avoir cette discussion maintenant, alors que nous n'avons pas tous les détails sur l'écosystème de l'exploitation forestière en un seul endroit.
Par exemple, je vois des problèmes de réseau et de machine perturber le flux de journaux, mais encore une fois, je ne veux pas en discuter pour l'instant. Et si nous discutions de cela plus tard, lorsque la proposition sera prête ? Cela vous semble-t-il raisonnable ?
crassirostris
le 18 mai 2017
Certainement @cassirostris. S'il vous plaît laissez-nous savoir ici lorsque la proposition est prête à être vérifiée.
whereisaaron
le 20 mai 2017
/ évolutivité sig
 kargakis
le 10 juin 2017
kargakis
le 10 juin 2017
Bien que --log-driver et --log-opt soient des options pour le démon Docker et non pour les fonctionnalités de k8s, il serait bien de les spécifier dans la spécification du pod k8s pour :
- pilote de journal par pod et non un seul pilote de journal au niveau du nœud
- différents types de pilotes de journal spécifiques à l'application (fluentd, syslog, journald, splunk) sur le même nœud
- définir
--log-optpour configurer la rotation des journaux pour un pod - par pod
--log-optparamètres et pas un seul niveau--log-optnœud
AFAIK, aucun des éléments ci-dessus ne peut être défini au niveau du pod dans la spécification du pod k8s aujourd'hui.
 vhosakot
le 13 déc. 2017
vhosakot
le 13 déc. 2017
@vhosakot aucun de ce qui précède ne peut être défini à n'importe quel niveau dans Kubernetes, car ce ne sont pas des concepts Kubernetes
crassirostris
le 13 déc. 2017
@cassirostris exactement ! :)
Si k8s fait tout ce que Docker fait au niveau du pod/du conteneur, ne sera-t-il pas facile pour les utilisateurs ? Pourquoi obliger les utilisateurs à utiliser Docker pour peu de choses au niveau des pods/conteneurs ?
Et, un amateur de k8s et non un fan de Docker peut se poser la même question.
vhosakot
le 13 déc. 2017
@vhosakot Point est qu'il existe un certain nombre d'autres environnements d'exécution de conteneurs qui peuvent être utilisés avec K8, mais --log-opt n'existe que dans Docker. Créer une telle option au niveau K8 serait une fuite intentionnelle de l'abstraction. Je ne pense pas que ce soit la voie que nous voulons suivre. Si une option existe, elle doit être prise en charge par tous les environnements d'exécution de conteneur, idéalement faire partie du CRI
Je ne dis pas qu'il n'y aura pas une telle option, je dis que ce ne sera pas une route directe vers Docker
crassirostris
le 13 déc. 2017
@cassirostris Vrai, on dirait qu'il s'agit de savoir si k8s doit faire ce que CRI fait/autorise au niveau du pod/au niveau du conteneur, et non spécifique à Docker.
vhosakot
le 13 déc. 2017
Oui, tout à fait correct
crassirostris
le 13 déc. 2017
Bien que je sois en retard dans cette discussion et que j'aie intérêt à voir cette fonctionnalité implémentée, je dirais qu'il y a un compromis entre avoir un joli design et avoir un moyen simple de mettre en place une solution de journalisation saine et uniforme pour le cluster. Oui, la mise en œuvre de cette fonctionnalité exposerait docker internal , ce qui est un gros non non , mais en même temps, je pourrais parier beaucoup d'argent que la majorité des utilisateurs de K8S utilisent docker car la technologie de conteneur sous-jacente et docker vient avec une liste très complète des pilotes de journal.
 gabriel-tincu
le 19 déc. 2017
gabriel-tincu
le 19 déc. 2017
@gabriel-tincu Je ne suis actuellement pas convaincu que le FR original en vaille la peine
docker est livré avec une liste très complète de pilotes de journal
Vous pouvez configurer la journalisation au niveau Docker pendant l'étape de déploiement de K8s et utiliser l'un de ces pilotes de journal, sans divulguer ces informations à K8s. La seule chose que vous ne pouvez pas faire aujourd'hui est de configurer ces options par conteneur/par pod (en fait, vous pouvez avoir une configuration avec des nœuds dédiés et utiliser un sélecteur de nœud), mais je ne suis pas sûr que ce soit une grande limitation.
crassirostris
le 19 déc. 2017
@cassirostris Je suis d'accord pour dire que vous pouvez configurer cela __avant__ la configuration de l'environnement, mais s'il existe un moyen de mettre à jour activement le pilote de journal docker une fois que l'environnement est déjà configuré, cela m'échappe pour le moment
gabriel-tincu
le 12 janv. 2018
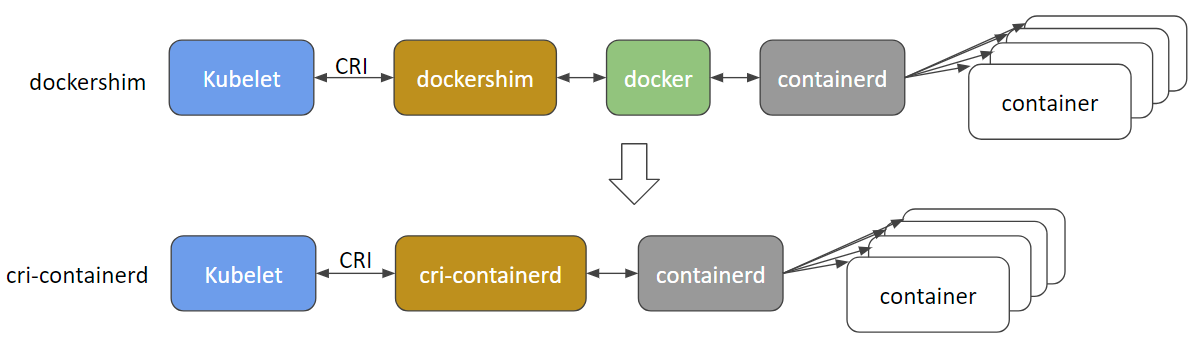
@gabriel-tincu @vhosakot l'interface directe qui existait entre k8s et Docker à l'époque de >=1.5 est obsolète et je pense que le code est totalement supprimé maintenant. Tout entre le kubelet et les run-times comme Docker (ou les autres comme rkt, cri-o, runc, lxd) passe par CRI. Il existe actuellement de nombreux environnements d'exécution de conteneurs et Docker lui-même sera probablement obsolète et bientôt supprimé au profit de cri-containerd + containerd .
http://blog.kubernetes.io/2017/11/containerd-container-runtime-options-kubernetes.html
@cassirostris tout mouvement sur une proposition, qui pourrait avoir la possibilité d'une journalisation de conteneurs intrabande ?
whereisaaron
le 12 janv. 2018
Le journal du conteneur CRI est basé sur un fichier (https://github.com/kubernetes/community/blob/master/contributors/design-proposals/node/kubelet-cri-logging.md) et le chemin du journal est explicitement défini :
/var/log/pods/PodUID/ContainerName/RestartCount.log
Dans la plupart des pilotes de journalisation docker https://docs.docker.com/config/containers/logging/configure/#supported -logging-drivers, je pense que pour l'environnement de cluster, les plus importants sont les pilotes ingérant le journal du conteneur dans le cluster système de gestion de journalisation, tel que splunk , awslogs , gcplogs etc.
Dans le cas de CRI, aucun "pilote de journal docker" ne doit être utilisé. Les utilisateurs peuvent exécuter un ensemble de démons pour ingérer les journaux de conteneurs à partir du répertoire des journaux de conteneurs CRI où ils le souhaitent. Ils peuvent utiliser fluentd ou même écrire un démon par eux-mêmes.
Si plus de métadonnées sont nécessaires, nous pouvons penser à supprimer un fichier de métadonnées, étendre le chemin du fichier ou laisser le démon obtenir les métadonnées d'apiserver. Il y a une discussion en cours à ce sujet https://github.com/kubernetes/kubernetes/issues/58638
 Random-Liu
le 22 févr. 2018
Random-Liu
le 22 févr. 2018
Les problèmes deviennent obsolètes après 90 jours d'inactivité.
Marquez le problème comme récent avec /remove-lifecycle stale .
Les problèmes périmés pourrissent après 30 jours supplémentaires d'inactivité et finissent par se fermer.
Si ce problème peut être résolu en toute sécurité maintenant, veuillez le faire avec /close .
Envoyez vos commentaires à sig-testing, kubernetes/test-infra et/ou fejta .
/cycle de vie périmé
 fejta-bot
le 23 mai 2018
fejta-bot
le 23 mai 2018
Les problèmes périmés pourrissent après 30 jours d'inactivité.
Marquez le problème comme récent avec /remove-lifecycle rotten .
Les problèmes pourris se ferment après 30 jours supplémentaires d'inactivité.
Si ce problème peut être résolu en toute sécurité maintenant, veuillez le faire avec /close .
Envoyez vos commentaires à sig-testing, kubernetes/test-infra et/ou fejta .
/cycle de vie pourri
/supprimer le cycle de vie périmé
fejta-bot
le 22 juin 2018
/remove-lifecycle pourri
 iavael
le 25 juin 2018
iavael
le 25 juin 2018
des mises à jour à ce sujet ? Alors, comment quelqu'un qui exécute des k8 avec des conteneurs Docker a-t-il réglé la journalisation sur un backend comme AWS CloudWatch ?
 bryan831
le 4 juil. 2018
bryan831
le 4 juil. 2018
@ bryan831 il est
Il existe des graphiques Helm prêts à l'emploi pour, par exemple, fluentd+Elastisearch , fluent-bit->fluentd->votre choix , Datadog et probablement d'autres combinaisons si vous fouillez.
whereisaaron
le 4 juil. 2018
Les problèmes deviennent obsolètes après 90 jours d'inactivité.
Marquez le problème comme récent avec /remove-lifecycle stale .
Les problèmes périmés pourrissent après 30 jours supplémentaires d'inactivité et finissent par se fermer.
Si ce problème peut être résolu en toute sécurité maintenant, veuillez le faire avec /close .
Envoyez vos commentaires à sig-testing, kubernetes/test-infra et/ou fejta .
/cycle de vie périmé
fejta-bot
le 2 oct. 2018
Ce serait bien de pouvoir personnaliser les options Docker --log-opt. Dans mon cas, je voudrais utiliser une balise telle que '--log-opt tag="{{.ImageName}}/{{.Name}}/{{.ID}}"' pour émettre ImageName dans les journaux afin que je sache de quelle version du conteneur proviennent les journaux. (Référence : https://docs.docker.com/config/containers/logging/log_tags/)
 pmahalwar-intertrust
le 26 oct. 2018
pmahalwar-intertrust
le 26 oct. 2018
/supprimer le cycle de vie périmé
pmahalwar-intertrust
le 26 oct. 2018
@pmahalwar-intertrust vous pouvez passer le même --log-opt au démon docker, ce qui affectera tous vos conteneurs ...
 nrobert13
le 26 oct. 2018
nrobert13
le 26 oct. 2018
@pmahalwar-intertrust les journaux collectés à partir de containerd par kubernetes incluent déjà des métadonnées étendues, incluent toutes les étiquettes que vous avez appliquées au conteneur. Si vous le collectez avec fluentd vous obtiendrez toutes les métadonnées, par exemple comme dans l'entrée de journal ci-dessous.
{
"log": " - [] - - [25/Oct/2018:06:29:48 +0000] \"GET /nginx_status/format/json HTTP/1.1\" 200 9250 \"-\" \"Go-http-client/1.1\" 118 0.000 [internal] - - - - 5eb73997a372badcb4e3d993ceb44cd9\n",
"stream": "stdout",
"docker": {
"container_id": "3657e1d9a86e629d0dccefec0c3c7624eaf0c4a11f60f53c5045ec0839c37f06"
},
"kubernetes": {
"container_name": "nginx-ingress-controller",
"namespace_name": "ingress",
"pod_name": "nginx-ingress-dev-controller-69c644f7f5-vs8vw",
"pod_id": "53514ad6-d0f4-11e8-a04c-02c433fc5820",
"labels": {
"app": "nginx-ingress",
"component": "controller",
"pod-template-hash": "2572009391",
"release": "nginx-ingress-dev"
},
"host": "ip-172-29-21-204.us-east-2.compute.internal",
"master_url": "https://10.3.0.1:443/api",
"namespace_id": "e262510b-180a-11e8-b763-0a0386e3402c"
},
"kubehost": "ip-172-29-21-204.us-east-2.compute.internal"
}
N'y a-t-il toujours pas de plan pour prendre en charge ces fonctionnalités ?
--log-driver= Pilote de journalisation pour le conteneur
--log-opt=[] Options du pilote de journal
 lifubang
le 8 nov. 2018
lifubang
le 8 nov. 2018
Salut @lifubang, je ne peux parler des plans de personne, mais le démon qui prend en charge ces fonctionnalités, dockerd ne fait plus partie de Kubernetes (voir la discussion ci-dessus à ce sujet).
Vous pouvez toujours l'installer si vous le souhaitez, vous pourrez donc le faire afin d'utiliser les anciens pilotes de journal dockerd . Cette option est discutée ici :
https://kubernetes.io/blog/2018/05/24/kubernetes-containerd-integration-goes-ga/
Mais l'utilisation d'un service de journalisation dédié comme fluentd est l'approche suggérée. Vous pouvez le déployer globalement pour votre cluster ou par Pod en tant que side-car. La connexion à Kubernetes est abordée ici :
https://kubernetes.io/docs/concepts/cluster-administration/logging/
whereisaaron
le 8 nov. 2018
Je recommande fortement fluentd comme décrit par @whereisaaron
En ce qui concerne cette demande de fonctionnalité en cours de traitement... la feuille de route architecturale de kubernetes contient une journalisation dans la section "Écosystème" de choses qui ne font pas vraiment "partie de" kubernetes, donc je doute qu'une telle fonctionnalité soit jamais prise en charge nativement.
https://github.com/kubernetes/community/blob/master/contributors/devel/architectural-roadmap.md#summarytldr
 taylorshaulis
le 8 nov. 2018
taylorshaulis
le 8 nov. 2018
Je déconseille fortement d'utiliser fluentd car il contient plusieurs bogues qui peuvent vous rendre la vie impossible lorsque vous exécutez k8s
in_tail empêche docker de supprimer le conteneur https://github.com/fluent/fluentd/issues/1680.
in_tail supprime la position du fichier non suivi pendant la phase de démarrage. Cela signifie que le contenu de pos_file augmente jusqu'au redémarrage et peut consommer une tonne de processeurs en le parcourant lorsque vous suivez de nombreux fichiers avec un paramètre de chemin dynamique.
https://github.com/fluent/fluentd/issues/1126.
 roffe
le 6 déc. 2018
roffe
le 6 déc. 2018
Les problèmes deviennent obsolètes après 90 jours d'inactivité.
Marquez le problème comme récent avec /remove-lifecycle stale .
Les problèmes périmés pourrissent après 30 jours supplémentaires d'inactivité et finissent par se fermer.
Si ce problème peut être résolu en toute sécurité maintenant, veuillez le faire avec /close .
Envoyez vos commentaires à sig-testing, kubernetes/test-infra et/ou fejta .
/cycle de vie périmé
fejta-bot
le 21 mars 2019
Merci pour votre expérience @roffe. fluent/fluentd#1680 était un problème à propos de k8s 1.5 et nous n'avons pas utilisé 'in_tail' à l'époque pour cette raison. Depuis que k8s est passé à la journalisation containerd cela ne semble plus être une chose ? Nous n'avons vu aucun impact détectable de fluent/fluentd#1126.
Vous avez recommandé contre fluentd . Que recommanderiez-vous à la place ? Qu'utilisez-vous personnellement au lieu de fluentd pour l'agrégation de journaux avec les métadonnées k8s ?
whereisaaron
le 21 mars 2019
Les problèmes périmés pourrissent après 30 jours d'inactivité.
Marquez le problème comme récent avec /remove-lifecycle rotten .
Les problèmes pourris se ferment après 30 jours supplémentaires d'inactivité.
Si ce problème peut être résolu en toute sécurité maintenant, veuillez le faire avec /close .
Envoyez vos commentaires à sig-testing, kubernetes/test-infra et/ou fejta .
/cycle de vie pourri
fejta-bot
le 20 avr. 2019
Les problèmes pourris se ferment après 30 jours d'inactivité.
Rouvrez le problème avec /reopen .
Marquez le problème comme récent avec /remove-lifecycle rotten .
Envoyez vos commentaires à sig-testing, kubernetes/test-infra et/ou fejta .
/proche
fejta-bot
le 20 mai 2019
@fejta-bot : Fermeture de ce problème.
En réponse à ceci :
Les problèmes pourris se ferment après 30 jours d'inactivité.
Rouvrez le problème avec/reopen.
Marquez le problème comme récent avec/remove-lifecycle rotten.Envoyez vos commentaires à sig-testing, kubernetes/test-infra et/ou fejta .
/proche
Les instructions pour interagir avec moi à l'aide des commentaires de relations publiques sont disponibles ici . Si vous avez des questions ou des suggestions concernant mon comportement, veuillez signaler un problème dans le
 k8s-ci-robot
le 20 mai 2019
k8s-ci-robot
le 20 mai 2019
Cela n'aurait pas dû être fermé, n'est-ce pas ?
La demande de fonctionnalité a toujours du sens pour moi car je cherche à définir les options de journalisation par pod (sans le définir sur le démon ni utiliser logrotate) ...
 yzargari
le 27 août 2019
yzargari
le 27 août 2019
Je suis à peu près certain que la prise en charge des options de configuration spécifiques à Docker depuis l'intérieur de k8 n'est pas une bonne idée. Comme mentionné précédemment, un démonset fluentd ou un side-car fluenbit sont des options actuelles. Je préfère le side-car car il est beaucoup plus sûr.
 coffeepac
le 29 août 2019
coffeepac
le 29 août 2019
@oùisaaron avez-vous trouvé une solution de journalisation pour K8s@containerd ?
 loxal
le 11 sept. 2019
loxal
le 11 sept. 2019
les --log-driver , --log-opt ne sont-ils toujours pas pris en charge ?
J'essaie de trouver un moyen de transférer les journaux d'un seul pod vers Splunk. des idées?
 sariel1212
le 15 sept. 2019
sariel1212
le 15 sept. 2019
@ sariel1212 pour un seul pod, je recommande d'inclure un conteneur de side-car dans votre pod qui n'est que l'agent de transport de splunk. Vous pouvez partager un volume emptydir entre tous les conteneurs du pod et demander au(x) conteneur(s) d'application d'écrire leurs journaux dans le emptydir partagé. Ensuite, faites lire le conteneur du redirecteur splunk à partir de ce volume et transférez-le.
coffeepac
le 16 sept. 2019
Si vous souhaitez collecter sur Splunk pour l'ensemble de votre cluster @sariel1212 , il existe un graphique officiel Splunk helm pour déployer fluentd avec le plug-in Splunk HEC fluentd à collecter les journaux de nœud, le journal de conteneur et les journaux de plan de contrôle, ainsi que les objets Kubernetes et les métriques de cluster Kubernetes. Pour un Pod @coffeepac, la suggestion d'un side-car avec un répertoire vide partagé est une bonne approche.
whereisaaron
le 16 sept. 2019
C'est assez terrible qu'il n'y ait toujours aucun moyen pour un propriétaire de cluster d'utiliser les pilotes de journal Docker après tout ce temps.
J'ai pu configurer très rapidement avec Docker-Compose (simulant mon cluster K8s) pour diriger toutes les sorties stdout/err vers mon service agrégé de journaux.
Vous essayez de le faire dans Kubenetes ? D'après ce fil, il semble que je vais devoir augmenter le code pour chaque microservice ! Pas bon.
 ashleydavis
le 24 sept. 2019
ashleydavis
le 24 sept. 2019
Salut @ashleydavis , dockerd était obsolète dans Kubernetes, il ne sert donc à rien d'introduire la prise en charge de quelque chose qui ne fait plus partie de Kubernetes. Bien que vous puissiez toujours l'installer en plus de Kubernetes. Voici le fond :
https://kubernetes.io/blog/2018/05/24/kubernetes-containerd-integration-goes-ga/
Vous n'avez pas besoin d'augmenter les conteneurs, sauf si vous le souhaitez, Kubernetes diffuse automatiquement les journaux stdout/stderr pour chaque conteneur. Il vous suffit de déployer un conteneur sur chaque nœud (un DaemonSet ) pour collecter et envoyer ces flux de journaux à votre ou vos choix de service d'agrégation. C'est très facile.
https://docs.fluentd.org/container-deployment/kubernetes
Il existe de nombreuses images de conteneur fluentd + backend prêtes à l'emploi et des exemples de configurations pour les back-ends d'agrégation arrière ici :
https://github.com/fluent/fluentd-kubernetes-daemonset
Si vous utilisez DataDog, ils ont leur propre agent à installer à la place ou en plus de fluentd :
https://docs.datadoghq.com/integrations/kubernetes/
En général, docker avait tendance à kitchen sink , avec des plug-ins de journalisation et de journalisation, et des outils d'essaim et d'exécution, des outils de construction, la mise en réseau et le montage du système de fichiers, etc. le tout dans un processus démon. Kubernetes préfère généralement les conteneurs/processus faiblement couplés effectuant une tâche chacun et communiquant via des API. C'est donc un style un peu différent auquel s'habituer.
whereisaaron
le 24 sept. 2019
Merci pour la réponse détaillée. Je vais certainement me renseigner là-dessus.
Avec dockerd déprécié, cela signifie-t-il que je ne pourrai plus déployer d'images Docker sur Kubernetes à l'avenir ?
ashleydavis
le 24 sept. 2019
@ashleydavis, vous pouvez certainement continuer à utiliser les images 'Docker' (même sans dockerd présent), et vous pouvez continuer à déployer dockerd sur vos nœuds Kubernetes à vos propres fins (comme dans docker-in-docker builds) si vous le souhaitez. Les parties principales de docker ont été extraites et standardisées en tant que « conteneurs OCI » et en tant que containerd exécution.
https://www.opencontainers.org/
https://containerd.io/
Docker et Kubernetes sont désormais basés sur ces normes partagées.
https://blog.docker.com/2017/08/what-is-containerd-runtime/
https://kubernetes.io/blog/2018/05/24/kubernetes-containerd-integration-goes-ga/
whereisaaron
le 24 sept. 2019
Merci, j'apprends tellement.
Je viens de créer un microservice que j'ai appelé Loggy. L'intention était que les journaux soient envoyés par le pilote de journal Docker, puis transmis (via un webhook) à Slack.
Vous pouvez voir le code ici : https://github.com/artlife-solutions/loggy/blob/master/src/index.ts
C'est assez simple, recevez un journal et transférez-le via HTTP POST à Slack.
Quel est le moyen le plus rapide d'adapter cela afin que je puisse collecter et agréger les journaux de mes pods ?
ashleydavis
le 24 sept. 2019
@ashleydavis, vous pouvez créer une image de conteneur avec ce micro-service, puis soit
Déployez-le dans votre cluster en tant que déploiement avec un service auquel tous les conteneurs de votre cluster pourraient ensuite envoyer (en utilisant le nom DNS du cluster du service ).
Déployez-le en tant que conteneur "side-car" supplémentaire dans votre Deployment . Les conteneurs d'un même pod partagent un accès privé au même
localhostafin que le conteneur d'application puisse envoyer à votre side-car de conteneur de micro-services surlocalhost:12201. Alternativement, les conteneurs du même pod peuvent partager un volume pour les fichiers journaux partagés ou les canaux nommés.
Cela devient hors sujet ici et tout le monde ne le voudra pas, alors peut-être cherchez-vous des exemples sur Github et accédez à certaines chaînes Slack pour obtenir des conseils.
https://github.com/ramitsurana/awesome-kubernetes
https://slack.k8s.io/
https://kubernetes.io/
whereisaaron
le 24 sept. 2019
Ça sonne bien merci. J'espérais juste ne pas avoir à changer les services existants. Je voudrais juste capturer leur stdout/error. De toute façon faire ça ?
La promesse des pilotes de journal Docker était la simplicité. Y a-t-il un moyen simple de le faire ?
ashleydavis
le 24 sept. 2019
Bien sûr @ashleydavis , déployez votre cluster, déployez fluentd , et bang, vous avez terminé 😺. Chaque application que vous déployez aura son stdout/stderr expédié à votre agrégateur préféré. ??
whereisaaron
le 24 sept. 2019
Après avoir investi du temps dans K8 et connecté, j'ai configuré une belle pile ELK sans configuration GELF explicite . Veuillez consulter https://www.elastic.co/guide/en/beats/filebeat/current/running-on-kubernetes.html
Ma configuration est Filebeat qui dirige les journaux vers Logstash qui filtre et extrait et dirige leurs données vers Elasticsearch. Avec Kibana, je peux afficher les journaux et agréger les données.
loxal
le 24 sept. 2019
J'aimerais également prendre en charge la journalisation dans le fichier syslog natif du système d'exploitation, par exemple : sur Ubuntu, je peux écrire des journaux dans /var/log/syslog , qui est géré par logrotate prêt à l'emploi.
Avec swarm/compose, je peux faire ceci :
version: '3.3'
services:
mysql:
image: mysql:5.7
logging:
driver: syslog
options:
tag: mysql
L'utilisation d'un volume emtpyDir convient, cependant, les pods de longue durée risquent de remplir le volume à moins que vous n'ajoutiez un processus supplémentaire qui fait pivoter/tronque les fichiers journaux. Je ne suis pas d'accord avec cette complexité supplémentaire alors que le système d'exploitation gère déjà la rotation de /var/log/syslog.
Je suis d'accord pour dire que l'utilisation de side-cars pour certains déploiements est une excellente idée (je le fais déjà pour certains de mes déploiements), cependant, l'environnement de chacun est différent.
 jsirianni
le 5 déc. 2019
jsirianni
le 5 déc. 2019
L'utilisation d'un volume emtpyDir est très bien
Soyez prudent avec eux - ils sont gérés par Kubernetes et leur durée de vie n'est pas contrôlée par vous. Si un pod est expulsé et reprogrammé vers un autre nœud, les journaux seront perdus. Si vous mettez à jour un pod et que son uid change, il n'utilisera pas l'ancien volume mais en créera plutôt un nouveau et supprimera l'ancien.
 php-coder
le 5 déc. 2019
php-coder
le 5 déc. 2019
@jsirianni tous les systèmes
coffeepac
le 6 déc. 2019
@coffeepac Ce n'est pas parce que les nœuds peuvent ne pas avoir de syslog que l'opérateur ne devrait pas avoir l'option. Si j'ai l'intention d'utiliser syslog, je m'assurerais que mes nœuds de travail ont syslog.
jsirianni
le 6 déc. 2019
Je pense que ce problème devrait être rouvert car il y a encore suffisamment de cas d'utilisation pour cette fonctionnalité.
/rouvrir
 saiyam1814
le 27 févr. 2020
saiyam1814
le 27 févr. 2020
@saiyam1814 : A
En réponse à ceci :
Je pense que ce problème devrait être rouvert car il y a encore suffisamment de cas d'utilisation pour cette fonctionnalité.
/rouvrir
Les instructions pour interagir avec moi à l'aide des commentaires de relations publiques sont disponibles ici . Si vous avez des questions ou des suggestions concernant mon comportement, veuillez signaler un problème dans le
k8s-ci-robot
le 27 févr. 2020
Personnellement, je pense toujours que Kubernetes devrait prendre en charge les pilotes de journal Docker ou un autre moyen intégré simple pour configurer la journalisation.
On m'a dit à plusieurs reprises que la configuration de la journalisation est facile sur Kubernetes, mais maintenant que j'ai mis en place mon propre système d'agrégation de journalisation, je peux dire que ce n'est vraiment pas simple.
J'ai écrit un article de blog sur le moyen le plus simple de créer manuellement votre propre système d'agrégation de journaux pour Kubernetes : http://www.the-data-wrangler.com/kubernetes-log-aggregation/
J'espère que mon article de blog aidera les autres à comprendre leur propre stratégie.
Cela ne devrait pas être si difficile, mais c'est là où nous en sommes.
ashleydavis
le 27 févr. 2020
Bien sûr, nous avons besoin d'un moyen de consommer les journaux Docker directement à partir de stdout et stderr, au lieu d'utiliser des fichiers journaux. L'utilisation du chemin Docker pour les fichiers journaux pose certains problèmes de sécurité, car vous pouvez accéder à d'autres journaux dans le système hôte.
Pouvons-nous implémenter le pilote de journal Docker ? ??
 Tetragramato
le 2 mars 2020
Tetragramato
le 2 mars 2020
La configuration des pilotes de journal docker au niveau du conteneur dans un pod (où le pod est sous le contrôle du client) permettrait de rediriger les journaux avec le pilote gelf directement vers un service/pod graylog (qui est également sous le contrôle du client ) au lieu d'avoir à les collecter à partir de fichiers sur l'hôte avec un autre service immédiat (ce qui représente plus de frais de gestion et une rupture de niveau d'abstraction pire que l'utilisation du pilote de journal gelf ) ou par les pods du client accédant au répertoire des journaux du conteneur sur l'hôte.
Par conséquent, j'aimerais voir cette fonctionnalité implémentée dans kubernetes.
 blubberdiblub
le 10 mars 2020
blubberdiblub
le 10 mars 2020
Il serait utile de s'assurer que nous faisons quelque chose comme https://github.com/cri-o/cri-o/pull/1605 , où nous déconnectons l'interprétation du flux de journal des pilotes de journal afin que le comportement du conteneur ne puisse pas affecter la façon dont les chauffeurs fonctionnent.
 portante
le 10 mars 2020
portante
le 10 mars 2020
Les problèmes pourris se ferment après 30 jours d'inactivité.
Rouvrez le problème avec /reopen .
Marquez le problème comme récent avec /remove-lifecycle rotten .
Envoyez vos commentaires à sig-testing, kubernetes/test-infra et/ou fejta .
/proche
fejta-bot
le 9 avr. 2020
@fejta-bot : Fermeture de ce problème.
En réponse à ceci :
Les problèmes pourris se ferment après 30 jours d'inactivité.
Rouvrez le problème avec/reopen.
Marquez le problème comme récent avec/remove-lifecycle rotten.Envoyez vos commentaires à sig-testing, kubernetes/test-infra et/ou fejta .
/proche
Les instructions pour interagir avec moi à l'aide des commentaires de relations publiques sont disponibles ici . Si vous avez des questions ou des suggestions concernant mon comportement, veuillez signaler un problème dans le
k8s-ci-robot
le 9 avr. 2020
La fonction doit encore être implémentée
/rouvrir
 M0rdecay
le 9 avr. 2020
M0rdecay
le 9 avr. 2020
@M0rdecay : Vous ne pouvez pas rouvrir un problème/RP à moins que vous ne l'ayez créé ou que vous soyez un collaborateur.
En réponse à ceci :
La fonction doit encore être implémentée
/rouvrir
Les instructions pour interagir avec moi à l'aide des commentaires de relations publiques sont disponibles ici . Si vous avez des questions ou des suggestions concernant mon comportement, veuillez signaler un problème dans le
k8s-ci-robot
le 9 avr. 2020
@M0rdecay : Vous ne pouvez pas rouvrir un problème/RP à moins que vous ne l'ayez créé ou que vous soyez un collaborateur.
Bon j'ai compris
M0rdecay
le 9 avr. 2020
Même aws ecs a cette fonctionnalité où l'on peut définir le pilote de journalisation docker.
Dans notre environnement, nous avons créé un index distinct avec un jeton unique pour chaque service de conteneur.
"logConfiguration": {
"logDriver": "splunk",
"options": {
"splunk-format": "raw",
"splunk-insecureskipverify": "true",
"splunk-token": "xxxxx-xxxxxxx-xxxxx-xxxxxxx-xxxxxx",
"splunk-url": " https://xxxxx.splunk-heavyforwarderxxx.com ",
"tag": "{{.Name}}/{{.ID}}",
"splunk-verify-connection": "false",
"mode": "non bloquant"
}
}
Mais je n'ai rien trouvé de tel dans k8s. Cela devrait être là dans la définition du pod elle-même.
 arshadsiddique-jfl
le 10 août 2020
arshadsiddique-jfl
le 10 août 2020
Les options doivent encore être mises en œuvre
/rouvrir
ejemba
le 10 août 2020
@ejemba : Réouverture de ce problème.
En réponse à ceci :
Les options doivent encore être mises en œuvre
/rouvrir
Les instructions pour interagir avec moi à l'aide des commentaires de relations publiques sont disponibles ici . Si vous avez des questions ou des suggestions concernant mon comportement, veuillez signaler un problème dans le
k8s-ci-robot
le 10 août 2020
/ nœud de signature
/ instrumentation remove-sig
 logicalhan
le 26 août 2020
logicalhan
le 26 août 2020
/remove-sig évolutivité
logicalhan
le 26 août 2020
@logicalhan : Ces étiquettes ne sont pas définies sur le problème : sig/
En réponse à ceci :
/remove-sig évolutivité
Les instructions pour interagir avec moi à l'aide des commentaires de relations publiques sont disponibles ici . Si vous avez des questions ou des suggestions concernant mon comportement, veuillez signaler un problème dans le
k8s-ci-robot
le 26 août 2020
Des progrès avec ?
Je cherchais spécifiquement une possibilité de configurer les conteneurs des pods pour se connecter au logstash externe, en spécifiant le pilote de journal gelf de docker. Le définir par défaut pour tous les conteneurs dans /etc/docker/daemon.json semble être une surcharge.
 freehck
le 16 sept. 2020
freehck
le 16 sept. 2020
Les problèmes pourris se ferment après 30 jours d'inactivité.
Rouvrez le problème avec /reopen .
Marquez le problème comme récent avec /remove-lifecycle rotten .
Envoyez vos commentaires à sig-testing, kubernetes/test-infra et/ou fejta .
/proche
fejta-bot
le 16 oct. 2020
@fejta-bot : Fermeture de ce problème.
En réponse à ceci :
Les problèmes pourris se ferment après 30 jours d'inactivité.
Rouvrez le problème avec/reopen.
Marquez le problème comme récent avec/remove-lifecycle rotten.Envoyez vos commentaires à sig-testing, kubernetes/test-infra et/ou fejta .
/proche
Les instructions pour interagir avec moi à l'aide des commentaires de relations publiques sont disponibles ici . Si vous avez des questions ou des suggestions concernant mon comportement, veuillez signaler un problème dans le
k8s-ci-robot
le 16 oct. 2020
/rouvrir
 andreswebs
le 2 nov. 2020
andreswebs
le 2 nov. 2020
@andreswebs : Vous ne pouvez pas rouvrir un problème/RP à moins que vous ne l'ayez créé ou que vous soyez un collaborateur.
En réponse à ceci :
/rouvrir
Les instructions pour interagir avec moi à l'aide des commentaires de relations publiques sont disponibles ici . Si vous avez des questions ou des suggestions concernant mon comportement, veuillez signaler un problème dans le
k8s-ci-robot
le 2 nov. 2020
/rouvrir
ejemba
le 3 nov. 2020
@ejemba : Réouverture de ce problème.
En réponse à ceci :
/rouvrir
Les instructions pour interagir avec moi à l'aide des commentaires de relations publiques sont disponibles ici . Si vous avez des questions ou des suggestions concernant mon comportement, veuillez signaler un problème dans le
k8s-ci-robot
le 3 nov. 2020
@ejemba : Ce problème est actuellement en attente de tri.
Si un SIG ou un sous-projet détermine qu'il s'agit d'un problème pertinent, il l'acceptera en appliquant le label triage/accepted et fournira des conseils supplémentaires.
L'étiquette triage/accepted peut être ajoutée par les membres de l'organisation en écrivant /triage accepted dans un commentaire.
Les instructions pour interagir avec moi à l'aide des commentaires de relations publiques sont disponibles ici . Si vous avez des questions ou des suggestions concernant mon comportement, veuillez signaler un problème dans le
k8s-ci-robot
le 3 nov. 2020
J'aimerais vraiment que cette fonctionnalité soit implémentée. Je migre actuellement des charges de travail des clusters Rancher 1.x vers des clusters Rancher 2.x qui exécutent k8. Nous avons un déploiement qui définit les paramètres log-driver et log-opt dans la configuration docker-compose.
Je ne veux pas avoir à configurer un hôte spécifique pour utiliser le pilote gelf globalement et marquer le pod avec une étiquette et l'hôte avec une étiquette.
 bananflugan
le 4 nov. 2020
bananflugan
le 4 nov. 2020
Il semble que nous devrions modifier CRI-O pour spécifier que les deux flux de journaux de conteneur (stdout / stderr) sont collectés sous une forme brute, et que lors de la lecture du brut pour plus tard, nous pouvons appliquer différentes interprétations du flux d'octets de journal.
portante
le 13 nov. 2020
Les problèmes pourris se ferment après 30 jours d'inactivité.
Rouvrez le problème avec /reopen .
Marquez le problème comme récent avec /remove-lifecycle rotten .
Envoyez vos commentaires à sig-testing, kubernetes/test-infra et/ou fejta .
/proche
fejta-bot
le 13 déc. 2020
@fejta-bot : Fermeture de ce problème.
En réponse à ceci :
Les problèmes pourris se ferment après 30 jours d'inactivité.
Rouvrez le problème avec/reopen.
Marquez le problème comme récent avec/remove-lifecycle rotten.Envoyez vos commentaires à sig-testing, kubernetes/test-infra et/ou fejta .
/proche
Les instructions pour interagir avec moi à l'aide des commentaires de relations publiques sont disponibles ici . Si vous avez des questions ou des suggestions concernant mon comportement, veuillez signaler un problème dans le
k8s-ci-robot
le 13 déc. 2020
Questions connexes
 montanaflynn
·
3Commentaires
montanaflynn
·
3Commentaires
 theothermike
·
3Commentaires
theothermike
·
3Commentaires
 sjenning
·
3Commentaires
sjenning
·
3Commentaires
 tbchj
·
3Commentaires
tbchj
·
3Commentaires
 mml
·
3Commentaires
mml
·
3Commentaires
Commentaire le plus utile
Salut,
Je pense que c'est une fonctionnalité importante qui devrait être prise en compte pour kubernetes.
L'activation de l'utilisation du pilote de journal de Docker peut résoudre certains problèmes non triviaux.
Je dirais que la journalisation sur disque est un anti-modèle. Les journaux sont intrinsèquement « étatiques » et ne doivent de préférence pas être enregistrés sur le disque. L'expédition des journaux directement d'un conteneur vers un référentiel résout de nombreux problèmes.
La définition du pilote de journal signifierait que la commande kubectl logs ne peut plus rien afficher.
Bien que cette fonctionnalité soit "agréable à avoir" - la fonctionnalité ne sera pas nécessaire lorsque les journaux sont disponibles à partir d'une source différente.
Docker dispose déjà de pilotes de journal pour google cloud (gcplogs) et Amazon (awslogs). Bien qu'il soit possible de les définir sur le démon Docker lui-même, cela présente de nombreux inconvénients. En pouvant définir les deux options du docker :
--log-driver= Pilote de journalisation pour le conteneur
--log-opt=[] Options du pilote de journal
Il serait possible d'envoyer des étiquettes (pour gcplogs) ou awslogs-group (pour awslogs)
spécifique à un pod. Cela faciliterait la recherche des journaux à l'autre extrémité.
J'ai lu comment les gens gèrent les journaux dans kubernetes. Beaucoup semblent mettre en place des grattoirs élaborés qui transmettent les journaux aux systèmes centraux. Pouvoir configurer le pilote de journal rendra cela inutile - libérant du temps pour travailler sur des choses plus intéressantes :)