Kubernetes: Определение драйвера журнала и log-opt при указании модуля в RC и Pod
Нам нужно иметь возможность определять следующие параметры при указании определения модуля в RC и Pod
--log-driver = Драйвер записи для контейнера
--log-opt = [] Параметры драйвера журнала
Эти параметры должны быть установлены на уровне контейнера и были введены в Docker 1.8.
Поскольку клиентская библиотека docker поддерживает оба параметра, теперь можно добавить эти параметры в определение модуля.
 ejemba
ejemba
Все 117 Комментарий
/ cc @ kubernetes / rh-кластер-инфра
 timothysc
13 окт. 2015
timothysc
13 окт. 2015
Хм, я думаю, мы, вероятно, захотим установить это значение по умолчанию для всего кластера, а затем, возможно, разрешить переопределение определенных определений модуля.
cc @sosiouxme @smarterclayton @liggitt @jwhonce @jcantrill @bparees @jwforres
 ncdc
13 окт. 2015
ncdc
13 окт. 2015
Можете ли вы описать, как бы вы могли использовать это для каждого контейнера (вариант использования)? Мы традиционно не предоставляем конкретные параметры Docker непосредственно в контейнерах, если они не могут быть четко абстрагированы во время выполнения. Знание того, как вы хотели бы это использовать, поможет оправдать это.
 smarterclayton
13 окт. 2015
smarterclayton
13 окт. 2015
Обратите внимание, что журналы докеров по-прежнему поддерживают только драйверы json-file и journald, хотя я предполагаю, что этот список может расшириться.
Возможно, на самом деле пользователям действительно нужен выбор определенных конечных точек записи журнала, а не доступ к сведениям о драйвере ведения журнала.
 sosiouxme
13 окт. 2015
sosiouxme
13 окт. 2015
@ncdc @smarterclayton Я согласен с вами обоими, после пересмотра нашего
- Наша основная потребность - защитить наши узлы. Мы отправляем журналы на сервер журналов, но в случае сбоя записывает резервные копии во внутренние журналы докеров. В таком случае, чтобы предотвратить насыщение узлов, нам нужно поведение для всего кластера для журнала докеров.
- Предоставление определенных параметров докеров в определениях pod / Rc - не лучшая идея, как предложил @smarterclayton . Мы также согласны с абстракцией, позволяющей определять поведение журнала высокого уровня, если это возможно.
- Другой вариант - внести изменения в файлы конфигурации и код kubelet для обработки такого поведения журнала.
ejemba
13 окт. 2015
Изменения в шаблонах соли, чтобы сделать это значение по умолчанию, не должны быть
ужасно сложно. На самом деле это просто правильная конфигурация демона (и
обработка любых изменений в агрегации журналов через fluentd в силу
выбор другого источника)
Во вторник, 13 октября 2015 г., в 10:55, Epo Jemba [email protected]
написал:
@ncdc https://github.com/ncdc @smarterclayton
https://github.com/smarterclayton Я согласен с вами обоими, после
пересматривая наш вариант использования во внутреннем, оказывается, что
- Наша основная потребность - защитить наши узлы. Отправляем логи в лог
сервер, но в случае сбоя регистрирует откат во внутренних журналах докера. В таком
случае, чтобы предотвратить насыщение узлов, нам нужно поведение в масштабе всего кластера для
журнал докеров- Предоставление определенных параметров докера в определениях pod / Rc не является
хорошая идея как @smarterclayton https://github.com/smarterclayton
предложил это. Мы также согласны с абстракцией, допускающей определение высокого
уровень поведения журнала, если возможно- Другой вариант - внести изменения в файлы конфигурации kubelet и
код для обработки такого поведения журнала-
Ответьте на это письмо напрямую или просмотрите его на GitHub
https://github.com/kubernetes/kubernetes/issues/15478#issuecomment -147740136
.
smarterclayton
13 окт. 2015
:пальцы вверх:
Обратите внимание, что теперь существует 9 драйверов регистрации . Каков консенсус по поводу этого?
 halr9000
12 мая 2016
halr9000
12 мая 2016
+1
 briangebala
18 мая 2016
briangebala
18 мая 2016
Если кто-то не знает, вы можете определить драйвер журнала по умолчанию для каждого узла с помощью флага для демона Docker ( --log-driver ). В своей среде я таким образом установил для драйвера значение journald . Честно говоря, мне сложно придумать вариант использования для переопределения этого для каждого контейнера.
 obeattie
18 мая 2016
obeattie
18 мая 2016
Большинство кластеров не хотят, чтобы их журналы выходили «за пределы диапазона», так что какие функции это даст?
Кроме того, с точки зрения эксплуатации это выглядит как потеря контроля. В настоящее время мы устанавливаем значения по умолчанию и настраиваем стек журналов для агрегирования.
timothysc
18 мая 2016
+1 по этому поводу.
Невозможность контролировать ведение журнала докеров подразумевает, что единственный разумный вариант ведения журнала - это использование инструментов, поставляемых с k8s, что является невероятным ограничением.
@timothysc вот наш пример использования. У нас есть сложная динамическая инфраструктура (~ 100 машин) с множеством существующих сервисов, работающих на них, с нашим собственным logstash для сбора журналов. Что ж, сейчас мы пытаемся перенести наши службы один за другим на k8s, и мне кажется, что нет чистого способа интегрировать ведение журнала между нашей существующей инфраструктурой и контейнерами, кластеризованными на k8s.
K8S крайне категорично относится к тому, как вы собираете журналы. Это может быть отличным вариантом для тех, кто начинает с нуля простую инфраструктуру. Для всех остальных, работающих со сложной инфраструктурой, которые не прочь бы углубиться и реализовать собственный механизм ведения журнала, в настоящий момент просто нет способа сделать это, что довольно неприятно.
Надеюсь, в этом есть смысл.
 jnardiello
23 мая 2016
jnardiello
23 мая 2016
Таким образом, в вашем сценарии журналы действительно предназначены для каждого приложения, но вы должны
убедиться, что базовый хост поддерживает эти журналы? Это беспокойство, которое мы
обсуждая здесь - либо мы делаем уровень кластера, либо уровень узла, но если мы делаем
уровень модуля, тогда планировщик должен знать, какие драйверы журнала
присутствуют где. По возможности мы стараемся этого избегать.
В понедельник, 23 мая 2016 г., в 10:50, Якопо Нардиелло < [email protected]
написал:
+1 по этому поводу.
Отсутствие возможности контролировать ведение журнала докеров означает, что
Единственная разумная возможность ведения журнала - это использование инструментов, поставляемых с k8s, что является
невероятное ограничение.@timothysc https://github.com/timothysc здесь наш пример использования. У нас есть
сложная динамическая инфраструктура (~ 100 машин) с большим количеством существующих
сервисы, работающие на них, с нашим собственным logstash для сбора журналов. Ну мы
теперь пытаются перенести наши сервисы один за другим на k8s, а мне там
кажется, нет чистого способа интегрировать ведение журнала между нашими существующими
инфраструктура и контейнеры сгруппированы на k8s.K8S крайне категорично относится к тому, как вы собираете журналы. Это могло бы быть здорово
для тех, кто начинает с нуля на простой инфраструктуре. Для
все остальные, работающие над сложной инфраструктурой, были бы не против
погрузиться глубоко и реализовать собственный механизм ведения журнала, просто нет
способ сделать это в настоящий момент, что довольно расстраивает.Надеюсь, в этом есть смысл.
-
Вы получаете это, потому что вас упомянули.
Ответьте на это письмо напрямую или просмотрите его на GitHub
https://github.com/kubernetes/kubernetes/issues/15478#issuecomment -221002545
smarterclayton
23 мая 2016
@smarterclayton Я понимаю, что вас беспокоит, и у них все в порядке. Я не уверен, что весь кластер должен знать о существовании ведения журнала на уровне модуля, что, я думаю, мы должны сделать, так это дать возможность где-то регистрировать модуль stdout / stderr (файл, основанный на их текущем имени модуля?) так что любой желающий реализовать свое собственное решение будет иметь постоянное место, где можно получить контент. Это открывает ОГРОМНУЮ главу, хотя логротация - нетривиальная задача.
Это всего лишь мои два цента, но мы не можем делать вид, что в реальных сложных сценариях просто отказываются от существующей инфраструктуры ведения журналов.
jnardiello
26 мая 2016
Указываете ли вы настраиваемые параметры журнала для каждого приложения? Сколько разных
будут ли у вас наборы параметров журнала для каждого кластера? Если есть небольшие наборы
config, можно было бы поддерживать аннотацию к модулям, которая
коррелирован с конфигурацией уровня узла, которая предлагает ряд "стандартных журналов"
options ". Т.е. во время запуска kubelet определите" режим журнала X "(который определяет
настраиваемые параметры журнала и драйвер), а модуль укажет "
pod.alpha.kubernetes.io/log.mode=X ".
Еще один вариант - предоставить разработчикам возможность
возможность изменить определение контейнера непосредственно перед тем, как мы начнем
контейнер. Сегодня это сложнее, потому что нам пришлось бы сериализовать
docker def out в промежуточный формат, выполните его, а затем запустите
снова, но потенциально проще в будущем.
Наконец, мы можем предоставить пары ключ-значение в интерфейсе контейнера, который
передаются непосредственно в движок контейнера, не дают никаких гарантий API для
их, и убедитесь, что PodSecurityPolicy может регулировать эти параметры. Это было бы
быть аварийным выходом для звонящих, но мы не сможем предоставить никаких
гарантировать, что они будут продолжать работать во всех выпусках.
26 мая 2016 г., в 5:34, Якопо Нардиелло [email protected]
написал:
@smarterclayton https://github.com/smarterclayton Я понимаю насчет
ваши заботы, и они хорошо размещены. Я не уверен, что весь кластер
должен знать о существовании ведения журнала на уровне модуля, что, как я думаю, мы
следует сделать, это дать возможность где-нибудь регистрировать pod stdout / stderr (файл
на основе их текущего имени модуля?), так что любой желающий реализовать свои
индивидуальное решение, будет постоянное место, где можно получить контент.
Это открывает ОГРОМНУЮ главу, хотя логротация - нетривиальная задача.Это всего лишь мои два цента, но мы не можем притворяться, что это сложный реальный мир.
сценарии просто отказываются от существующей инфраструктуры ведения журналов.-
Вы получаете это, потому что вас упомянули.
Ответьте на это письмо напрямую или просмотрите его на GitHub
https://github.com/kubernetes/kubernetes/issues/15478#issuecomment -221823732
smarterclayton
26 мая 2016
@smarterclayton вы видели https://github.com/kubernetes/kubernetes/issues/24677#issuecomment -220735829
ncdc
26 мая 2016
Нет, спасибо. Перенос обсуждения туда.
26 мая 2016 г., в 11:23, Энди Голдштейн [email protected]
написал:
@smarterclayton https://github.com/smarterclayton вы видели # 24677
(комментарий)
https://github.com/kubernetes/kubernetes/issues/24677#issuecomment -220735829-
Вы получаете это, потому что вас упомянули.
Ответьте на это письмо напрямую или просмотрите его на GitHub
https://github.com/kubernetes/kubernetes/issues/15478#issuecomment -221903781
smarterclayton
26 мая 2016
Всем привет,
Я считаю, что это важная особенность, которую следует учитывать кубернетам.
Включение использования драйвера журнала Docker может решить некоторые нетривиальные проблемы.
Я бы сказал, что запись на диск - это антипаттерн. Журналы по своей сути являются «состояниями» и желательно не сохранять на диск. Доставка журналов непосредственно из контейнера в репозиторий решает многие проблемы.
Установка драйвера журнала будет означать, что команда kubectl logs больше ничего не может отображать.
Хотя эту функцию «приятно иметь», она не понадобится, если журналы доступны из другого источника.
В Docker уже есть драйверы журналов для Google Cloud (gcplogs) и Amazon (awslogs). Хотя их можно установить на самом демоне Docker, у этого есть много недостатков. Имея возможность установить два параметра докера:
--log-driver = Драйвер записи для контейнера
--log-opt = [] Параметры драйвера журнала
Можно было бы отправлять метки (для gcplogs) или awslogs-group (для awslogs)
специфичен для стручка. Это упростило бы поиск журналов на другом конце.
Я читал о том, как люди обрабатывают журналы в кубернетах. Многие, кажется, устанавливают сложные скребки, которые пересылают журналы в центральные системы. Возможность установить драйвер журнала сделает это ненужным - высвободив время для работы над более интересными вещами :)
 pbthorste
30 нояб. 2016
pbthorste
30 нояб. 2016
Я также могу добавить, что некоторые люди, в том числе я, хотят выполнить ротацию журналов докеров с помощью параметра --log-opt max-size в драйвере ведения журнала JSON (который является родным для докера) вместо настройки logrotate на хосте. Таким образом, мы будем очень благодарны даже за использование только опции '--log-opt'.
 daniilyar
12 дек. 2016
daniilyar
12 дек. 2016
Я изменил k8s при создании конфигурации контейнера LogConfig.
 barnettZQG
12 дек. 2016
barnettZQG
12 дек. 2016
+1
Использование драйвера журнала Docker для централизованного сбора журналов выглядит намного проще, чем создание символических ссылок для файлов журналов, их монтирование в специальный контейнер fluentd, их отслеживание и управление ротацией журналов.
 defat
27 дек. 2016
defat
27 дек. 2016
Вариант использования конфигурации для каждого контейнера: я хочу вести журнал в другом месте или по-другому для развертываемых мной контейнеров, и меня не волнует (или я хочу изменить) драйвер журнала для стандартных контейнеров, необходимых для запуска Kubernetes.
Вот и все. Пожалуйста, сделай это.
 et304383
12 янв. 2017
et304383
12 янв. 2017
Другая идея заключается в том, что все контейнеры по-прежнему пересылают журналы в одну и ту же конечную точку, но вы можете, по крайней мере, установить разные значения полей для разных контейнеров докеров на своем сервере журналов.
Это сработало бы для драйвера докера gelf, если бы мы могли гарантировать, что контейнеры докеров, созданные Kubernetes, имеют индивидуальную маркировку. Значение: некоторые поля пода могут быть перенаправлены как ярлыки контейнера докеров. (Возможно, это уже возможно, но я не знаю, как этого добиться).
Пример без Kubernetes, только с docker daemon и драйвером gelf. Настройте демон докера с помощью: --log-driver=gelf --log-opt labels=env,label2 и создайте контейнер докера:
docker run -dti --label env=testing --label label2=some_value alpine:3.4 /bin/sh -c "while true; do date; sleep 2; done"
и еще один докер-контейнер:
docker run -dti --label env=production --label label2=some_value alpine:3.4 /bin/sh -c "while true; do date; sleep 2; done"
Таким образом, в Graylog вы можете различать контейнеры env=production и env=testing .
В настоящее время я использую такие параметры демона докеров:
--log-driver=gelf --log-opt gelf-address=udp://graylog.example.com:12201 --log-opt tag=k8s-testing --log-opt labels=io.kubernetes.pod.namespace,io.kubernetes.container.name,io.kubernetes.pod.name
 xmik
12 янв. 2017
xmik
12 янв. 2017
@xmik , что подтвердить, что это уже существующая функция или ваше предложение относительно
В настоящее время я использую такие параметры демона докеров:
--log-driver=gelf --log-opt gelf-address=udp://graylog.example.com:12201 --log-opt tag=k8s-testing --log-opt labels=io.kubernetes.pod.namespace,io.kubernetes.container.name,io.kubernetes.pod.name
 stainboy
26 янв. 2017
stainboy
26 янв. 2017
Те параметры демона докеров, которые я сейчас использую, уже работают. Kubernetes уже устанавливает несколько меток для каждого контейнера докеров. Например, при запуске docker inspect в контейнере kube-apiserver:
"Labels": {
"io.kubernetes.container.hash": "4959a3f5",
"io.kubernetes.container.name": "kube-apiserver",
"io.kubernetes.container.ports": "[{\"name\":\"https\",\"hostPort\":6443,\"containerPort\":6443,\"protocol\":\"TCP\"},{\"name\":\"local\",\"hostPort\":8080,\"containerPort\":8080,\"protocol\":\"TCP\"}]",
"io.kubernetes.container.restartCount": "1",
"io.kubernetes.container.terminationMessagePath": "/dev/termination-log",
"io.kubernetes.pod.name": "kube-apiserver-k8s-production-master-1",
"io.kubernetes.pod.namespace": "kube-system",
"io.kubernetes.pod.terminationGracePeriod": "30",
"io.kubernetes.pod.uid": "a47396d9dae12c81350569f56aea562e"
}
Следовательно, эти параметры демона докеров работают.
Однако я думаю, что сейчас невозможно заставить Kubernetes устанавливать пользовательские метки для контейнера докеров на основе спецификации Pod. Так, например, --log-driver=gelf --log-opt labels=env,label2 не работает.
xmik
26 янв. 2017
Есть какие-нибудь новости по этому поводу? Было бы неплохо иметь возможность указывать метки, а затем использовать --log-opt labels<> !
 beldpro-ci
18 мар. 2017
beldpro-ci
18 мар. 2017
@portante @jcantrill Просто чтобы зафиксировать это здесь, потому что мы это обсуждали, вот пример использования, для которого, как мы думали, это может быть полезно:
Когда модули записи журнала начинают обнаруживать и регистрировать ошибки, инфраструктура, которая собирает эти ошибки, захватывает их и передает их обратно в механизм записи, который, в свою очередь, выдает и регистрирует больше ошибок.
Этого цикла обратной связи можно избежать, используя механизмы фильтрации, но это немного хрупко. Использование другого драйвера ведения журнала для записи в файл и возможности ротации кажется хорошим решением.
 pweil-
31 мар. 2017
pweil-
31 мар. 2017
Мои 2 цента.
Текущие решения для входа в k8s (AFAIK):
- контейнер с коляской отправляет журналы куда-то
- контроллер репликации отправляет куда-то все логи
- сам контейнер куда-то отправляет логи
Контейнер с коляской мне кажется излишним. Стратегия контроллера репликации кажется хорошей, но она смешивает журналы контейнеров из всех развертываний, и некоторые пользователи теперь могут захотеть этого, а вместо этого могут захотеть регистрировать каждое приложение для разных вещей. В этом случае последний вариант работает лучше всего, IMHO, но создает много кода, реплицированного во всех контейнерах (например: установка и настройка демона журналов).
Все это было бы намного проще, если бы у нас был доступ к флагам log-driver , поэтому каждое развертывание определяло бы, как оно должно регистрироваться, используя собственные функции докеров.
Я могу попытаться реализовать это, но, вероятно, мне понадобится помощь - поскольку я не знаком с кодовой базой kubernetes.
 caarlos0
17 мая 2017
caarlos0
17 мая 2017
как только многопользовательская аренда станет более распространенной, ее будет сложнее решить должным образом.
Каждое пространство имен может относиться к разному арендатору, поэтому журналы от каждого из них не обязательно должны быть агрегированы, их следует разрешить отправлять в указанные арендатором местоположения.
Я могу придумать несколько способов сделать это:
- создать новый тип тома, контейнер-журналы. Это позволяет демону, запускаемому определенным пространством имен, получать доступ только к журналам из его собственных контейнеров. Затем они могут отправить журналы любым отправителем журналов по выбору любому демону хранилища.
- Измените один из (или несколько) отправителей журналов, например fluentd-bit, для чтения пространства имен, в котором находится модуль, и перенаправьте журналы из каждого модуля другому отправителю журналов, работающему в этом пространстве имен в качестве службы. Например, fluentd. Это снова позволяет пространству имен настраивать собственный отправитель журналов для отправки в любой серверный модуль журналов, который они хотят поддерживать.
 kfox1111
17 мая 2017
kfox1111
17 мая 2017
@ caarlos0 @ kfox1111 Я согласен с вашим мнением. Это сложная тема, поскольку она требует координации инструментовки, хранилища, узла и, возможно, даже большего числа команд. Я предлагаю сначала изложить предложение по общей архитектуре журналирования, а затем обсудить изменение этого согласованного представления. Я ожидаю, что это предложение появится примерно через месяц, наведя порядок и решив все упомянутые проблемы.
 crassirostris
17 мая 2017
crassirostris
17 мая 2017
@crassirostris Я не уверен, что понимаю: если мы просто разрешим log-driver и др., нам не придется иметь дело с хранилищем или чем-то в этом роде, верно?
Докер просто отправляет свой STDOUT в любой драйвер журнала, настроенный на основе контейнера, верно? Мы как бы передаем ответственность контейнеру ... кажется мне довольно простым решением, но, как я уже сказал, я не знаю кодовую базу, так что, возможно, я просто ошибаюсь ...
caarlos0
17 мая 2017
Проблема в том, что драйвер журнала в докере не добавляет никаких метаданных k8s, что делает последующее использование журналов действительно полезным. : /
kfox1111
17 мая 2017
@ kfox1111 хм, имеет смысл ...
но что, если пользователю нужны только журналы «приложения», а не журналы кубернетов, не журналы докеров, а только приложение, работающее внутри журналов контейнера?
В таком случае, как мне кажется, log-driver сработает ...
caarlos0
17 мая 2017
@ caarlos0 Это может иметь некоторые последствия, например, kubelet делает некоторые предположения о формате записи в журналы kubectl сервера.
Но помимо всего прочего, log-driver per se зависит от Docker и может не работать для других сред выполнения, что является основной причиной не включать его в API.
crassirostris
17 мая 2017
@crassirostris, что имеет смысл ...
поскольку эта функция не будет добавлена (как описано в проблеме), возможно, эту проблему следует закрыть (или отредактировать, или что-то еще)?
caarlos0
17 мая 2017
@ caarlos0 Однако мы определенно хотим сделать настройку ведения журнала более гибкой и прозрачной. Мы будем благодарны за ваш отзыв о предложении!
crassirostris
17 мая 2017
В настоящее время ведение журнала stdout из контейнеров осуществляется вне канала в Kubernetes. В настоящее время мы полагаемся на решения, не относящиеся к Kubernetes, для обработки журналов или привилегированные контейнеры, которые взламывают Kubernetes, чтобы получить доступ к внеполосному журналированию. Ведение журнала во время выполнения контейнера различается в зависимости от времени выполнения (docker, rkt, Windows), поэтому выбор любого из них, например Docker --log-driver, создает будущий багаж.
Я предлагаю, чтобы нам понадобился кубелет, чтобы вернуть потоки журналов в полосу. Определите или выберите минимальный формат журнала JSON или XML, который собирает строки стандартного вывода из каждого контейнера, добавьте минимальный кластер + пространство имен + pod + метаданные контейнера, чтобы источник журнала был идентифицирован в пространстве Kubernetes, и направьте поток в Kubernetes Service + Порт. Пользователи могут предоставлять любую услугу потребления журналов, которая им нравится. Возможно, Kubernetes предоставит одну справочную службу / службу по умолчанию, которая реализует поддержку журналов kubectl.
Если служба потребления журналов не указана,
Оболочка времени выполнения контейнера kubelet делает минимум для извлечения stdout из каждой среды выполнения контейнера и возврата его обратно в канал для автономных сервисов k8s для использования и обработки.
В спецификации контейнера в Deployment или Pod можно указать целевую службу и порт для ведения журнала stdout. Добавление метаданных k8s для кластера + пространства имен + pod + контейнера будет необязательным (поэтому выбор необработанных / нетронутых или с метаданными). Пользователи смогут объединить все журналы в одном месте или по арендатору, пространству имен или приложению.
Ближайшим к этому сейчас является запуск службы, которая использует kubectl logs -f для потоковой передачи журналов контейнера для каждого контейнера через сервер API. Звучит не очень эффективно или масштабируемо. Это предложение обеспечит более эффективную прямую передачу из оболочки среды выполнения контейнера непосредственно в службу или модуль с такими оптимизациями, как предпочтение ведения журнала развертывания или модулей Daemonset на том же узле и контейнера, генерирующего журналы.
Я предлагаю Kubernetes делать минимум для эффективного переноса журналов времени выполнения контейнера внутри канала для любых автономных, однородных или гетерогенных решений для ведения журналов, которые мы создаем в пространстве Kubernetes.
Что думают люди?
 whereisaaron
18 мая 2017
whereisaaron
18 мая 2017
@whereisaaron Мне бы очень хотелось не обсуждать это сейчас, когда у нас нет всех деталей экосистемы журналирования в одном месте.
Например, я вижу проблемы с сетью и машиной, нарушающие поток журнала, но, опять же, я пока не хочу это обсуждать. Как насчет того, чтобы обсудить это позже, когда предложение будет готово? Вам это кажется разумным?
crassirostris
18 мая 2017
Конечно @crassirostris. Пожалуйста, дайте нам знать здесь, когда предложение будет готово к проверке.
whereisaaron
20 мая 2017
/ sig масштабируемость
 kargakis
10 июн. 2017
kargakis
10 июн. 2017
Хотя и --log-driver и --log-opt являются параметрами для демона Docker, а не функциями k8s, было бы неплохо указать их в спецификации модуля k8s для:
- драйвер журнала для каждого модуля, а не драйвер журнала на уровне отдельного узла
- различные типы драйверов журналов для конкретных приложений (fluentd, syslog, journald, splunk) на одном узле
- установите
--log-optчтобы настроить ротацию журналов для модуля - для пакета
--log-optнастроек, а не одного уровня--log-opt
AFAIK, сегодня ничего из вышеперечисленного не может быть установлено на уровне модуля в спецификации модуля k8s.
 vhosakot
13 дек. 2017
vhosakot
13 дек. 2017
@vhosakot: ничего из вышеперечисленного нельзя установить на любом уровне в Kubernetes, потому что это не концепции Kubernetes.
crassirostris
13 дек. 2017
@crassirostris именно так! :)
Если k8s будет делать все, что делает Docker на уровне пода / контейнера, разве это не будет легко для пользователей? Зачем вообще заставлять пользователей использовать Docker для нескольких вещей на уровне пода / контейнера?
И любитель k8s, но не фанат Docker, может задать тот же вопрос.
vhosakot
13 дек. 2017
@vhosakot Дело в том, что есть ряд других сред выполнения контейнеров, которые можно использовать с K8s, но --log-opt существует только в Docker. Создание такой опции на уровне K8s означало бы намеренную утечку абстракции. Я не думаю, что мы хотим идти по этому пути. Если опция существует, она должна поддерживаться всеми средами выполнения контейнеров, в идеале быть частью CRI.
Я не говорю, что такого варианта не будет, я говорю, что это не будет прямой путь к Docker
crassirostris
13 дек. 2017
@crassirostris Верно, похоже, все сводится к тому, должен ли k8s делать то, что CRI делает / позволяет на уровне пода / контейнера, а не специфично для Docker.
vhosakot
13 дек. 2017
Ага, абсолютно правильно
crassirostris
13 дек. 2017
Хотя я опаздываю к этому обсуждению и мне интересно, чтобы эта функция была реализована, я бы сказал, что существует компромисс между красивым дизайном и простым способом создания разумного и единообразного решения для ведения журнала. для кластера. Да, реализация этой функции приведет к открытию внутреннего докера, что является большим нет, но в то же время я могу поспорить, что большинство пользователей K8S используют докер в качестве базовой технологии контейнера, и докер поставляется с очень полным списком драйверов журналов.
 gabriel-tincu
19 дек. 2017
gabriel-tincu
19 дек. 2017
@ gabriel-tincu В настоящее время я не уверен, что оригинальный FR стоит усилий
docker поставляется с очень полным списком драйверов журналов
Вы можете настроить ведение журнала на уровне Docker на этапе развертывания K8s и использовать любой из этих драйверов журнала, не передавая эту информацию в K8s. Единственное, что вы не можете сделать сегодня, - это настроить эти параметры для каждого контейнера / модуля (на самом деле, вы можете настроить выделенные узлы и использовать селектор узлов), но я не уверен, что это большое ограничение.
crassirostris
19 дек. 2017
@crassirostris Я согласен с тем, что вы можете настроить это __before__, настраивая среду, но если есть способ активно обновить драйвер журнала докеров после того, как среда уже настроена, тогда он ускользает от меня в данный момент
gabriel-tincu
12 янв. 2018
@ gabriel-tincu @vhosakot прямой интерфейс, который существовал между k8s и Docker еще в «старые времена»> = 1.5, устарел, и я считаю, что сейчас код полностью удален. Все между kubelet и средами выполнения, такими как Docker (или другими, такими как rkt, cri-o, runc, lxd), проходит через CRI. Сейчас существует множество сред выполнения контейнеров, и сам Docker, скорее всего, будет устаревшим и скоро будет удален в пользу cri-containerd + containerd .
http://blog.kubernetes.io/2017/11/containerd-container-runtime-options-kubernetes.html
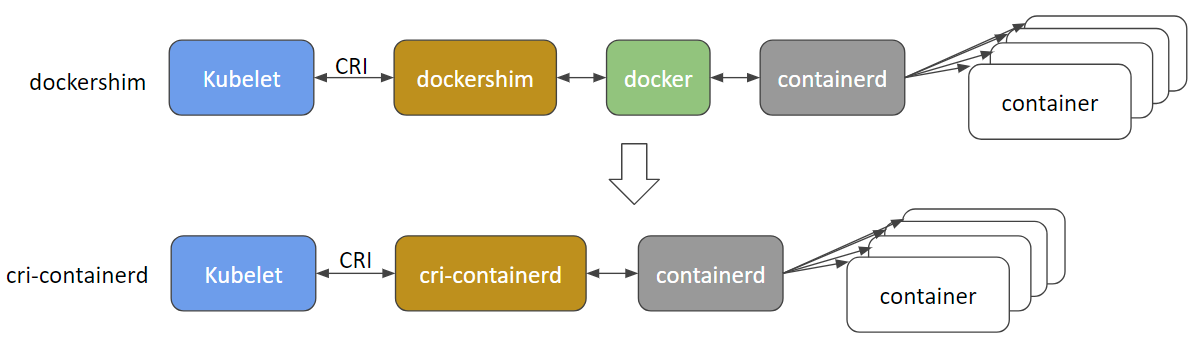
@crassirostris любое движение по предложению, которое может иметь возможность внутриполосного ведения журнала контейнера?
whereisaaron
12 янв. 2018
Журнал контейнера CRI основан на файлах (https://github.com/kubernetes/community/blob/master/contributors/design-proposals/node/kubelet-cri-logging.md), а путь к журналу определен явно:
/var/log/pods/PodUID/ContainerName/RestartCount.log
В большинстве драйверов ведения журнала докеров https://docs.docker.com/config/containers/logging/configure/#supported -logging-drivers, я думаю, для кластерной среды наиболее важными из них являются драйверы, которые загружают журнал контейнера в кластер. система управления журналами, например splunk , awslogs , gcplogs и т. д.
В случае CRI не следует использовать «драйвер журнала докеров». Люди могут запускать демон для загрузки журналов контейнеров из каталога журналов контейнера CRI в любое место. Они могут использовать fluentd или даже сами написать демонсет.
Если требуются дополнительные метаданные, мы можем подумать об удалении файла метаданных, удлинить путь к файлу или позволить демону получать метаданные от apiserver. По этому поводу продолжается обсуждение https://github.com/kubernetes/kubernetes/issues/58638
 Random-Liu
22 февр. 2018
Random-Liu
22 февр. 2018
Проблемы устаревают после 90 дней бездействия.
Отметьте проблему как новую с помощью /remove-lifecycle stale .
Устаревшие выпуски гниют после дополнительных 30 дней бездействия и в конечном итоге закрываются.
Если сейчас можно безопасно закрыть эту проблему, сделайте это с помощью /close .
Отправьте отзыв в sig-testing, kubernetes / test-infra и / или fejta .
/ жизненный цикл устаревший
 fejta-bot
23 мая 2018
fejta-bot
23 мая 2018
Старые выпуски гниют после 30 дней бездействия.
Отметьте проблему как новую с помощью /remove-lifecycle rotten .
Гнилые проблемы закрываются после дополнительных 30 дней бездействия.
Если сейчас можно безопасно закрыть эту проблему, сделайте это с помощью /close .
Отправьте отзыв в sig-testing, kubernetes / test-infra и / или fejta .
/ жизненный цикл гнилой
/ remove-жизненный цикл устаревший
fejta-bot
22 июн. 2018
/ remove-lifecycle гнилой
 iavael
25 июн. 2018
iavael
25 июн. 2018
какие-нибудь обновления по этому поводу? Итак, как кто-то, использующий k8s с контейнерами Docker, установил ведение журнала в какой-то бэкэнд, например AWS CloudWatch?
 bryan831
4 июл. 2018
bryan831
4 июл. 2018
@ bryan831 популярно собирать файлы журнала контейнера k8s с помощью fluentd или аналогичного средства и объединять их в серверную часть, CloudWatch, StackDriver, Elastisearch и т. д. по вашему выбору.
Существуют готовые диаграммы Helm, например, для fluentd + CloudWatch , fluentd + Elastisearch , fluent-bit-> fluentd-> на ваш выбор , Datadog и, возможно, других комбинаций, если вы копаетесь.
whereisaaron
4 июл. 2018
Проблемы устаревают после 90 дней бездействия.
Отметьте проблему как новую с помощью /remove-lifecycle stale .
Устаревшие выпуски гниют после дополнительных 30 дней бездействия и в конечном итоге закрываются.
Если сейчас можно безопасно закрыть эту проблему, сделайте это с помощью /close .
Отправьте отзыв в sig-testing, kubernetes / test-infra и / или fejta .
/ жизненный цикл устаревший
fejta-bot
2 окт. 2018
Было бы неплохо иметь возможность настраивать параметры Docker --log-opt. В моем случае я хотел бы использовать такой тег, как '--log-opt tag = "{{. ImageName}} / {{. Name}} / {{. ID}}"', чтобы отправлять ImageName в журналы. чтобы я знал, из какой версии контейнера берутся журналы. (Ссылка: https://docs.docker.com/config/containers/logging/log_tags/)
 pmahalwar-intertrust
26 окт. 2018
pmahalwar-intertrust
26 окт. 2018
/ remove-жизненный цикл устаревший
pmahalwar-intertrust
26 окт. 2018
@ pmahalwar-intertrust вы можете передать тот же параметр --log-opt демону docker, который повлияет на все ваши контейнеры ...
 nrobert13
26 окт. 2018
nrobert13
26 окт. 2018
@ pmahalwar-intertrust журналы, собранные с containerd помощью kubernetes, уже включают обширные метаданные, включая любые метки, которые вы применили к контейнеру. Если вы соберете его с помощью fluentd вы получите все метаданные, например, как в записи журнала ниже.
{
"log": " - [] - - [25/Oct/2018:06:29:48 +0000] \"GET /nginx_status/format/json HTTP/1.1\" 200 9250 \"-\" \"Go-http-client/1.1\" 118 0.000 [internal] - - - - 5eb73997a372badcb4e3d993ceb44cd9\n",
"stream": "stdout",
"docker": {
"container_id": "3657e1d9a86e629d0dccefec0c3c7624eaf0c4a11f60f53c5045ec0839c37f06"
},
"kubernetes": {
"container_name": "nginx-ingress-controller",
"namespace_name": "ingress",
"pod_name": "nginx-ingress-dev-controller-69c644f7f5-vs8vw",
"pod_id": "53514ad6-d0f4-11e8-a04c-02c433fc5820",
"labels": {
"app": "nginx-ingress",
"component": "controller",
"pod-template-hash": "2572009391",
"release": "nginx-ingress-dev"
},
"host": "ip-172-29-21-204.us-east-2.compute.internal",
"master_url": "https://10.3.0.1:443/api",
"namespace_id": "e262510b-180a-11e8-b763-0a0386e3402c"
},
"kubehost": "ip-172-29-21-204.us-east-2.compute.internal"
}
Нет ли еще планов по поддержке этих функций?
--log-driver = Драйвер записи для контейнера
--log-opt = [] Параметры драйвера журнала
 lifubang
8 нояб. 2018
lifubang
8 нояб. 2018
Привет, @lifubang, я не могу говорить о чьих-либо планах, но демон, поддерживающий эти функции, dockerd больше не является частью Kubernetes (см. Обсуждение выше, посвященное этому).
Вы по-прежнему можете установить его, если хотите, так что вы можете сделать это, чтобы использовать старые драйверы журналов dockerd . Этот вариант обсуждается здесь:
https://kubernetes.io/blog/2018/05/24/kubernetes-containerd-integration-goes-ga/
Но рекомендуется использовать специализированную службу ведения журнала, например fluentd . Вы можете развернуть его глобально для своего кластера или для каждого модуля в качестве дополнительного компонента. Здесь обсуждается вход в Kubernetes:
https://kubernetes.io/docs/concepts/cluster-administration/logging/
whereisaaron
8 нояб. 2018
Я настоятельно рекомендую fluentd, как описано @whereisaaron
Что касается этого запроса функции, над которым работает ... в архитектурной дорожной карте кубернетов в разделе «Экосистема» ведется запись вещей, которые на самом деле не являются «частью» кубернетов, поэтому я сомневаюсь, что такая функция когда-либо будет изначально поддерживаться.
https://github.com/kubernetes/community/blob/master/contributors/devel/architectural-roadmap.md#summarytldr
 taylorshaulis
8 нояб. 2018
taylorshaulis
8 нояб. 2018
Я настоятельно не рекомендую использовать fluentd, поскольку в нем есть несколько ошибок, которые могут испортить вашу жизнь при использовании k8s.
in_tail не позволяет докеру удалить контейнер https://github.com/fluent/fluentd/issues/1680.
in_tail удаляет неотслеживаемую позицию файла на этапе запуска. Это означает, что содержимое pos_file увеличивается до перезапуска и может съесть тонну сканирования процессора, когда вы отслеживаете множество файлов с настройкой динамического пути.
https://github.com/fluent/fluentd/issues/1126.
 roffe
6 дек. 2018
roffe
6 дек. 2018
Проблемы устаревают после 90 дней бездействия.
Отметьте проблему как новую с помощью /remove-lifecycle stale .
Устаревшие выпуски гниют после дополнительных 30 дней бездействия и в конечном итоге закрываются.
Если сейчас можно безопасно закрыть эту проблему, сделайте это с помощью /close .
Отправьте отзыв в sig-testing, kubernetes / test-infra и / или fejta .
/ жизненный цикл устаревший
fejta-bot
21 мар. 2019
Спасибо за ваш опыт @roffe. fluent / fluentd # 1680 был проблемой в k8s 1.5, и по этой причине мы тогда не использовали in_tail. Поскольку k8s перешел на ведение журнала containerd , похоже, что это не так? Мы не наблюдали заметного воздействия fluent / fluentd # 1126.
Вы рекомендовали против fluentd . Что бы вы порекомендовали вместо этого? Что вы лично используете вместо fluentd для агрегирования логов с метаданными k8s?
whereisaaron
21 мар. 2019
Старые выпуски гниют после 30 дней бездействия.
Отметьте проблему как новую с помощью /remove-lifecycle rotten .
Гнилые проблемы закрываются после дополнительных 30 дней бездействия.
Если сейчас можно безопасно закрыть эту проблему, сделайте это с помощью /close .
Отправьте отзыв в sig-testing, kubernetes / test-infra и / или fejta .
/ жизненный цикл гнилой
fejta-bot
20 апр. 2019
Гнилые проблемы закрываются после 30 дней бездействия.
Повторно откройте проблему с помощью /reopen .
Отметьте проблему как новую с помощью /remove-lifecycle rotten .
Отправьте отзыв в sig-testing, kubernetes / test-infra и / или fejta .
/близко
fejta-bot
20 мая 2019
@ fejta-bot: Закрытие этого вопроса.
В ответ на это :
Гнилые проблемы закрываются после 30 дней бездействия.
Повторно откройте проблему с помощью/reopen.
Отметьте проблему как новую с помощью/remove-lifecycle rotten.Отправьте отзыв в sig-testing, kubernetes / test-infra и / или fejta .
/близко
Инструкции по взаимодействию со мной с помощью PR-комментариев доступны здесь . Если у вас есть вопросы или предложения, связанные с моим поведением, отправьте сообщение о проблеме в репозиторий kubernetes / test-infra .
 k8s-ci-robot
20 мая 2019
k8s-ci-robot
20 мая 2019
Это не должно было быть закрыто, не так ли?
Запрос функции по-прежнему имеет для меня смысл, поскольку я хочу установить параметры журнала для каждого модуля (без настройки его на демоне или использования logrotate) ...
 yzargari
27 авг. 2019
yzargari
27 авг. 2019
Я почти уверен, что поддержка конкретных параметров конфигурации докеров изнутри k8s - не лучшая идея. Как уже упоминалось ранее, текущими вариантами являются fluentd daemonset или fluenbit side car. Я предпочитаю коляску, так как она намного безопаснее.
 coffeepac
29 авг. 2019
coffeepac
29 авг. 2019
@whereisaaron вы нашли решение для ведения логов для
 loxal
11 сент. 2019
loxal
11 сент. 2019
--log-driver, --log-opt все еще не поддерживаются?
Я пытаюсь найти способ пересылать журналы из одного модуля в Splunk. Любые идеи?
 sariel1212
15 сент. 2019
sariel1212
15 сент. 2019
@ sariel1212 для одного модуля Я рекомендую включить в ваш модуль боковой автомобильный контейнер, который является только агентом пересылки splunk. Вы можете совместно использовать том emptydir между всеми контейнерами в модуле и позволить контейнеру (контейнерам) приложения записывать свои журналы в общий каталог emptydir. Затем попросите контейнер пересылки splunk считывать с этого тома и пересылать их.
coffeepac
16 сент. 2019
Если вы хотите собирать в Splunk для всего кластера @ sariel1212 , существует официальная диаграмма Splunk helm для развертывания fluentd с плагином Splunk HEC fluentd для сбора журналы узлов, журнал контейнеров и журналы уровня управления, а также объекты Kubernetes и метрики кластера Kubernetes. Для одного Pod @coffeepac предложение
whereisaaron
16 сент. 2019
Довольно ужасно, что владелец кластера все еще не может использовать драйверы журнала Docker после всего этого времени.
Мне удалось очень быстро настроить Docker-Compose (имитирующий мой кластер K8s), чтобы передать все stdout / err в мою агрегированную службу журналов.
Пытаетесь сделать это в Кубенетесе? Судя по этой теме, мне придется дополнить код для каждого микросервиса! Нехорошо.
 ashleydavis
24 сент. 2019
ashleydavis
24 сент. 2019
Привет, @ashleydavis , dockerd устарел в Kubernetes, поэтому нет смысла вводить поддержку для чего-то, что больше не является частью Kubernetes. Хотя вы все равно можете установить его в дополнение к Kubernetes. Вот предыстория:
https://kubernetes.io/blog/2018/05/24/kubernetes-containerd-integration-goes-ga/
Вам не нужно дополнять контейнеры, если вы этого не хотите, Kubernetes автоматически выполняет потоковую передачу журналов stdout / stderr для каждого контейнера. Вам просто нужно развернуть один контейнер на каждом узле ( DaemonSet ), чтобы собирать и отправлять эти потоки журналов в выбранную вами службу агрегации. Это очень просто.
https://docs.fluentd.org/container-deployment/kubernetes
Здесь есть много готовых fluentd + образов бэкэнд-контейнеров и примеров конфигураций для бэкэндов бэкэнд-агрегации:
https://github.com/fluent/fluentd-kubernetes-daemonset
Если вы используете DataDog, вместо него нужно установить собственный агент или fluentd :
https://docs.datadoghq.com/integrations/kubernetes/
В общем, docker имел тенденцию к kitchen sink , с модулями ведения журналов и журналов, а также с инструментами swarm и времени выполнения, инструментами сборки, сетью, монтированием файловой системы и т. Д. - все в одном процессе демона. Kubernetes обычно предпочитает слабосвязанные контейнеры / процессы, каждый из которых выполняет одну задачу и взаимодействует через API. Так что это немного другой стиль, к которому нужно привыкнуть.
whereisaaron
24 сент. 2019
Спасибо за подробный ответ. Я обязательно займусь этим.
Если dockerd устарел, означает ли это, что я не могу развертывать образы Docker в Kubernetes в будущем?
ashleydavis
24 сент. 2019
@ashleydavis, вы, безусловно, можете продолжать использовать образы Docker (даже без dockerd ), и вы можете продолжать развертывать dockerd на своих узлах Kubernetes для своих собственных целей (например, в docker-in-docker builds), если хотите. Основные части докера были извлечены и стандартизированы как «контейнеры OCI» и среда выполнения containerd .
https://www.opencontainers.org/
https://containerd.io/
И Docker, и Kubernetes теперь основаны на этих общих стандартах.
https://blog.docker.com/2017/08/what-is-containerd-runtime/
https://kubernetes.io/blog/2018/05/24/kubernetes-containerd-integration-goes-ga/
whereisaaron
24 сент. 2019
Спасибо, я так много учусь.
Я только что создал микросервис, который назвал Loggy. Предполагалось, что он будет отправлять журналы драйвером журнала Docker, а затем пересылать их (через веб-перехватчик) в Slack.
Вы можете увидеть код здесь: https://github.com/artlife-solutions/loggy/blob/master/src/index.ts
Это довольно просто: получите журнал и отправьте его через HTTP POST в Slack.
Какой самый быстрый способ адаптировать это, чтобы я мог собирать и объединять журналы из своих модулей?
ashleydavis
24 сент. 2019
@ashleydavis вы можете создать образ контейнера с этим микросервисом в нем, а затем либо
Разверните его в кластере как Развертывание со службой, в которую все контейнеры в вашем кластере могут затем отправлять (используя DNS-имя кластера службы ).
Разверните его как дополнительный контейнер «sidecar» в своем развертывании . Контейнеры в одном Pod совместно используют частный доступ к одному и тому же
localhostпоэтому контейнер приложения может отправлять в ваш сопроводительный файл контейнера микрослужб наlocalhost:12201. В качестве альтернативы контейнеры в одном Pod могут совместно использовать том для общих файлов журналов или именованных каналов.
Здесь это становится не по теме, и не всем это захочется, поэтому, возможно, изучите несколько примеров на Github и обратитесь за советом по некоторым
https://github.com/ramitsurana/awesome-kubernetes
https://slack.k8s.io/
https://kubernetes.io/
whereisaaron
24 сент. 2019
Звучит хорошо, спасибо. Я просто надеялся, что мне не придется менять существующие службы. Я просто хотел бы зафиксировать их стандартный вывод / ошибку. Как бы то ни было, чтобы это сделать?
Драйверы журналов Docker обещали простоту. Есть какой-нибудь простой способ сделать это?
ashleydavis
24 сент. 2019
Конечно, @ashleydavis , разверните свой кластер, разверните fluentd и бац, готово 😺. Каждое развертываемое вами приложение будет иметь свой стандартный вывод / стандартный поток, отправленный вашему любимому агрегатору. 👍
whereisaaron
24 сент. 2019
Потратив некоторое время на K8s и ведя журнал, я установил хороший стек ELK без явной конфигурации GELF . Взгляните на https://www.elastic.co/guide/en/beats/filebeat/current/running-on-kubernetes.html.
Моя установка - это Filebeat, который передает журналы в Logstash, который фильтрует, извлекает и передает их данные в Elasticsearch. С помощью Kibana я могу просматривать журналы и сводные данные.
loxal
24 сент. 2019
Я также хотел бы поддержать ведение журнала в собственный файл системного журнала операционной системы, например: в Ubuntu я могу записывать журналы в /var/log/syslog , что управляется logrotate из коробки.
С помощью swarm / compose я могу сделать это:
version: '3.3'
services:
mysql:
image: mysql:5.7
logging:
driver: syslog
options:
tag: mysql
Использование тома emtpyDir - это нормально, однако долго работающие поды рискуют заполнить том, если вы не добавите дополнительный процесс, который вращает / усекает файлы журнала. Я не согласен с этой дополнительной сложностью, когда ОС уже обрабатывает ротацию / var / log / syslog.
Я согласен с тем, что использование боковых тележек для некоторых развертываний - отличная идея (я уже делаю это для некоторых своих развертываний), однако среда у всех разная.
 jsirianni
5 дек. 2019
jsirianni
5 дек. 2019
Использование тома emtpyDir в порядке
Будьте осторожны с ними - ими управляет Kubernetes, и вы не контролируете их время жизни. Если модуль исключен и перенесен на другой узел, журналы будут потеряны. Если вы обновите модуль и его uid изменится, он не будет использовать старый том, а создаст новый и удалит старый.
 php-coder
5 дек. 2019
php-coder
5 дек. 2019
@jsirianni не все системы используют системный журнал, а это означает, что для каждого узла должна быть аннотация о том, какие средства доступны, чтобы обеспечить удовлетворение потребностей данного модуля. docker compose делает это предположение, потому что он работает только локально.
coffeepac
6 дек. 2019
@coffeepac Тот факт, что узлы могут не иметь системного
jsirianni
6 дек. 2019
Я считаю, что эту проблему следует открыть повторно, поскольку для этой функции еще достаточно вариантов использования.
/ повторно открыть
 saiyam1814
27 февр. 2020
saiyam1814
27 февр. 2020
@ saiyam1814 : Повторно
В ответ на это :
Я считаю, что эту проблему следует открыть повторно, поскольку для этой функции еще достаточно вариантов использования.
/ повторно открыть
Инструкции по взаимодействию со мной с помощью PR-комментариев доступны здесь . Если у вас есть вопросы или предложения, связанные с моим поведением, отправьте сообщение о проблеме в репозиторий kubernetes / test-infra .
k8s-ci-robot
27 февр. 2020
Лично я по-прежнему считаю, что Kubernetes должен поддерживать драйверы журнала Docker или какой-либо другой простой встроенный способ настройки ведения журнала.
Мне много раз говорили, что настроить ведение журнала в Kubernetes легко, но теперь, пройдя через процесс настройки моей собственной системы агрегации журналов, я могу сказать, что это действительно непросто.
Я написал сообщение в блоге о простейшем способе создания собственной системы агрегирования журналов для Kubernetes: http://www.the-data-wrangler.com/kubernetes-log-aggregation/
Надеюсь, мой пост в блоге поможет другим понять их собственную стратегию.
Это не должно быть так сложно, но вот где мы находимся.
ashleydavis
27 февр. 2020
Конечно, нам нужен способ использования журналов Docker непосредственно из stdout и stderr, вместо использования файлов журналов. Есть некоторые проблемы с безопасностью использования пути Docker для файлов журналов, потому что вы можете получить доступ к другим журналам в хост-системе.
Можем ли мы реализовать драйвер журнала Docker? 👍
 Tetragramato
2 мар. 2020
Tetragramato
2 мар. 2020
Настройка драйверов журнала докеров на уровне контейнера в модуле (где модуль находится под контролем клиента) позволит перенаправить журналы с помощью драйвера gelf непосредственно в службу / модуль серого журнала (который также находится под контролем клиента. ) вместо того, чтобы собирать их из файлов на хосте с помощью другой немедленной службы (что требует больших затрат на управление и худшего нарушения уровня абстракции, чем при использовании драйвера журнала gelf ) или модулями клиента, обращающимися к каталогу журналов контейнера на хосте.
Поэтому мне бы хотелось, чтобы эта функция была реализована в кубернетах.
 blubberdiblub
10 мар. 2020
blubberdiblub
10 мар. 2020
Было бы полезно убедиться, что мы делаем что-то вроде https://github.com/cri-o/cri-o/pull/1605 , где мы отключаем интерпретацию потока журнала от драйверов журнала, чтобы поведение контейнера не могло повлиять на то, как драйверы работают.
 portante
10 мар. 2020
portante
10 мар. 2020
Гнилые проблемы закрываются после 30 дней бездействия.
Повторно откройте проблему с помощью /reopen .
Отметьте проблему как новую с помощью /remove-lifecycle rotten .
Отправьте отзыв в sig-testing, kubernetes / test-infra и / или fejta .
/близко
fejta-bot
9 апр. 2020
@ fejta-bot: Закрытие этого вопроса.
В ответ на это :
Гнилые проблемы закрываются после 30 дней бездействия.
Повторно откройте проблему с помощью/reopen.
Отметьте проблему как новую с помощью/remove-lifecycle rotten.Отправьте отзыв в sig-testing, kubernetes / test-infra и / или fejta .
/близко
Инструкции по взаимодействию со мной с помощью PR-комментариев доступны здесь . Если у вас есть вопросы или предложения, связанные с моим поведением, отправьте сообщение о проблеме в репозиторий kubernetes / test-infra .
k8s-ci-robot
9 апр. 2020
Функцию еще нужно реализовать
/ повторно открыть
 M0rdecay
9 апр. 2020
M0rdecay
9 апр. 2020
@ M0rdecay : Вы не можете повторно открыть выпуск / PR, если не являетесь его автором или соавтором.
В ответ на это :
Функцию еще нужно реализовать
/ повторно открыть
Инструкции по взаимодействию со мной с помощью PR-комментариев доступны здесь . Если у вас есть вопросы или предложения, связанные с моим поведением, отправьте сообщение о проблеме в репозиторий kubernetes / test-infra .
k8s-ci-robot
9 апр. 2020
@ M0rdecay : Вы не можете повторно открыть выпуск / PR, если не являетесь его автором или соавтором.
Хорошо я понял
M0rdecay
9 апр. 2020
Даже aws ecs имеет эту функцию, где можно установить драйвер ведения журнала докеров.
В нашей среде мы создали отдельный индекс с уникальным токеном для каждой контейнерной службы.
"logConfiguration": {
"logDriver": "splunk",
"параметры": {
"splunk-format": "raw",
"splunk-insecureskipverify": "правда",
"splunk-token": "xxxxx-xxxxxxx-xxxxx-xxxxxxx-xxxxxx",
"splunk-url": " https://xxxxx.splunk-heavyforwarderxxx.com ",
"тег": "{{.Name}} / {{. ID}}",
"splunk-verify-connection": "ложь",
«режим»: «неблокирующий»
}
}
Но в k8s ничего подобного не нашел. Это должно быть в самом определении модуля.
 arshadsiddique-jfl
10 авг. 2020
arshadsiddique-jfl
10 авг. 2020
Параметры еще предстоит реализовать
/ повторно открыть
ejemba
10 авг. 2020
@ejemba : Повторно
В ответ на это :
Параметры еще предстоит реализовать
/ повторно открыть
Инструкции по взаимодействию со мной с помощью PR-комментариев доступны здесь . Если у вас есть вопросы или предложения, связанные с моим поведением, отправьте сообщение о проблеме в репозиторий kubernetes / test-infra .
k8s-ci-robot
10 авг. 2020
/ sig узел
/ remove-sig инструментарий
 logicalhan
26 авг. 2020
logicalhan
26 авг. 2020
/ remove-sig масштабируемость
logicalhan
26 авг. 2020
@logicalhan : Эти ярлыки не установлены для проблемы: sig/
В ответ на это :
/ remove-sig масштабируемость
Инструкции по взаимодействию со мной с помощью PR-комментариев доступны здесь . Если у вас есть вопросы или предложения, связанные с моим поведением, отправьте сообщение о проблеме в репозиторий kubernetes / test-infra .
k8s-ci-robot
26 авг. 2020
Есть ли в этом прогресс?
Я специально искал возможность настроить контейнеры подов для входа во внешний logstash, указав драйвер журнала docker gelf. Установка его по умолчанию для всех контейнеров в /etc/docker/daemon.json кажется накладными расходами.
 freehck
16 сент. 2020
freehck
16 сент. 2020
Гнилые проблемы закрываются после 30 дней бездействия.
Повторно откройте проблему с помощью /reopen .
Отметьте проблему как новую с помощью /remove-lifecycle rotten .
Отправьте отзыв в sig-testing, kubernetes / test-infra и / или fejta .
/близко
fejta-bot
16 окт. 2020
@ fejta-bot: Закрытие этого вопроса.
В ответ на это :
Гнилые проблемы закрываются после 30 дней бездействия.
Повторно откройте проблему с помощью/reopen.
Отметьте проблему как новую с помощью/remove-lifecycle rotten.Отправьте отзыв в sig-testing, kubernetes / test-infra и / или fejta .
/близко
Инструкции по взаимодействию со мной с помощью PR-комментариев доступны здесь . Если у вас есть вопросы или предложения, связанные с моим поведением, отправьте сообщение о проблеме в репозиторий kubernetes / test-infra .
k8s-ci-robot
16 окт. 2020
/ повторно открыть
 andreswebs
2 нояб. 2020
andreswebs
2 нояб. 2020
@andreswebs : Вы не можете повторно открыть проблему / PR, если не являетесь автором или соавтором.
В ответ на это :
/ повторно открыть
Инструкции по взаимодействию со мной с помощью PR-комментариев доступны здесь . Если у вас есть вопросы или предложения, связанные с моим поведением, отправьте сообщение о проблеме в репозиторий kubernetes / test-infra .
k8s-ci-robot
2 нояб. 2020
/ повторно открыть
ejemba
3 нояб. 2020
@ejemba : Повторно
В ответ на это :
/ повторно открыть
Инструкции по взаимодействию со мной с помощью PR-комментариев доступны здесь . Если у вас есть вопросы или предложения, связанные с моим поведением, отправьте сообщение о проблеме в репозиторий kubernetes / test-infra .
k8s-ci-robot
3 нояб. 2020
@ejemba : Эта проблема в настоящее время ожидает сортировки.
Если SIG или подпроект определят, что это актуальная проблема, они примут ее, применив метку triage/accepted и предоставят дальнейшие инструкции.
Метка triage/accepted может быть добавлена участниками организации, написав /triage accepted в комментарии.
Инструкции по взаимодействию со мной с помощью PR-комментариев доступны здесь . Если у вас есть вопросы или предложения, связанные с моим поведением, отправьте сообщение о проблеме в репозиторий kubernetes / test-infra .
k8s-ci-robot
3 нояб. 2020
Я бы очень хотел, чтобы эта функция была реализована. В настоящее время я переношу рабочие нагрузки с кластеров Rancher 1.x на кластеры Rancher 2.x, на которых работает k8s. У нас есть развертывание, которое устанавливает параметры log-driver и log-opt в конфигурации docker-compose.
Я не хочу настраивать один конкретный хост для глобального использования драйвера gelf и помечать модуль меткой, а хост - меткой.
 bananflugan
4 нояб. 2020
bananflugan
4 нояб. 2020
Похоже, мы должны изменить CRI-O, чтобы указать, что оба потока журнала контейнера (stdout / stderr) собираются в необработанной форме, а при чтении необработанного файла для последующего использования мы можем применить различные интерпретации потока байтов журнала.
portante
13 нояб. 2020
Гнилые проблемы закрываются после 30 дней бездействия.
Повторно откройте проблему с помощью /reopen .
Отметьте проблему как новую с помощью /remove-lifecycle rotten .
Отправьте отзыв в sig-testing, kubernetes / test-infra и / или fejta .
/близко
fejta-bot
13 дек. 2020
@ fejta-bot: Закрытие этого вопроса.
В ответ на это :
Гнилые проблемы закрываются после 30 дней бездействия.
Повторно откройте проблему с помощью/reopen.
Отметьте проблему как новую с помощью/remove-lifecycle rotten.Отправьте отзыв в sig-testing, kubernetes / test-infra и / или fejta .
/близко
Инструкции по взаимодействию со мной с помощью PR-комментариев доступны здесь . Если у вас есть вопросы или предложения, связанные с моим поведением, отправьте сообщение о проблеме в репозиторий kubernetes / test-infra .
k8s-ci-robot
13 дек. 2020
Смежные вопросы
 sanjana-bhat
·
3Комментарии
sanjana-bhat
·
3Комментарии
 mml
·
3Комментарии
mml
·
3Комментарии
 jason-riddle
·
3Комментарии
jason-riddle
·
3Комментарии
 rhohubbuild
·
3Комментарии
rhohubbuild
·
3Комментарии
 zetaab
·
3Комментарии
zetaab
·
3Комментарии
Самый полезный комментарий
Всем привет,
Я считаю, что это важная особенность, которую следует учитывать кубернетам.
Включение использования драйвера журнала Docker может решить некоторые нетривиальные проблемы.
Я бы сказал, что запись на диск - это антипаттерн. Журналы по своей сути являются «состояниями» и желательно не сохранять на диск. Доставка журналов непосредственно из контейнера в репозиторий решает многие проблемы.
Установка драйвера журнала будет означать, что команда kubectl logs больше ничего не может отображать.
Хотя эту функцию «приятно иметь», она не понадобится, если журналы доступны из другого источника.
В Docker уже есть драйверы журналов для Google Cloud (gcplogs) и Amazon (awslogs). Хотя их можно установить на самом демоне Docker, у этого есть много недостатков. Имея возможность установить два параметра докера:
--log-driver = Драйвер записи для контейнера
--log-opt = [] Параметры драйвера журнала
Можно было бы отправлять метки (для gcplogs) или awslogs-group (для awslogs)
специфичен для стручка. Это упростило бы поиск журналов на другом конце.
Я читал о том, как люди обрабатывают журналы в кубернетах. Многие, кажется, устанавливают сложные скребки, которые пересылают журналы в центральные системы. Возможность установить драйвер журнала сделает это ненужным - высвободив время для работы над более интересными вещами :)