Kubernetes: Mendefinisikan log-driver dan log-opt saat menentukan pod di RC dan Pod
Kita harus dapat mendefinisikan opsi berikut saat menentukan definisi pod di RC dan Pod
--log-driver= Logging driver untuk kontainer
--log-opt=[] Log opsi driver
Opsi ini harus dapat diatur pada level container dan telah diperkenalkan dengan Docker 1.8.
Karena lib klien buruh pelabuhan mendukung kedua opsi serta menambahkan opsi tersebut ke definisi pod sekarang dapat dilakukan.
 ejemba
ejemba
Semua 117 komentar
/ cc @ kubernetes / rh-cluster-infra
 timothysc
pada 13 Okt 2015
timothysc
pada 13 Okt 2015
Hmm, saya pikir kita mungkin ingin dapat mengatur seluruh cluster ini sebagai default, dan kemudian mungkin mengizinkan definisi pod tertentu untuk ditimpa.
cc @sosiouxme @smarterclayton @liggitt @jwhonce @jcantrill @bparees @jwforres
 ncdc
pada 13 Okt 2015
ncdc
pada 13 Okt 2015
Bisakah Anda menjelaskan bagaimana Anda akan memanfaatkan ini berdasarkan per wadah (kasus penggunaan)? Kami secara tradisional tidak mengekspos opsi khusus Docker secara langsung dalam wadah kecuali mereka dapat diabstraksikan dengan bersih di seluruh runtime. Mengetahui bagaimana Anda ingin menggunakan ini akan membantu membenarkannya.
 smarterclayton
pada 13 Okt 2015
smarterclayton
pada 13 Okt 2015
Perhatikan bahwa log buruh pelabuhan masih hanya mendukung file json dan driver journald, meskipun saya membayangkan daftar itu dapat berkembang.
Mungkin yang sebenarnya diinginkan pengguna adalah pilihan titik akhir penulisan log yang ditentukan, bukan paparan detail driver logging.
 sosiouxme
pada 13 Okt 2015
sosiouxme
pada 13 Okt 2015
@ncdc @smarterclayton Saya setuju dengan Anda berdua, setelah mempertimbangkan kembali use case kami di internal, ternyata
- Kebutuhan utama kami adalah untuk melindungi node kami. Kami mengirim log ke server log tetapi jika gagal, log fallback pada log internal buruh pelabuhan. Dalam kasus seperti itu, untuk mencegah kejenuhan node, kita memerlukan perilaku luas cluster untuk log buruh pelabuhan
- Mengekspos opsi buruh pelabuhan tertentu dalam definisi pod/Rc bukanlah ide yang baik seperti yang disarankan oleh @smarterclayton . Kami juga setuju dengan abstraksi yang memungkinkan definisi perilaku log tingkat tinggi jika memungkinkan
- Pilihan lain adalah membuat perubahan pada file konfigurasi kubelet dan kode untuk menangani perilaku log tersebut
ejemba
pada 13 Okt 2015
Perubahan pada templat garam untuk menjadikan ini sebagai default seharusnya tidak
sangat sulit. Ini benar-benar konfigurasi daemon yang tepat (dan
berurusan dengan perubahan apa pun pada agregasi log melalui fasih berdasarkan
memilih sumber yang berbeda)
Pada Tue, 13 Oktober 2015 di 10:55, Epo Jemba [email protected]
menulis:
@ncdc https://github.com/ncdc @smarterclayton
https://github.com/smarterclayton Saya setuju dengan Anda berdua, setelah
mempertimbangkan kembali kasus penggunaan kami di internal, ternyata
- Kebutuhan utama kami adalah untuk melindungi node kami. Kami mengirim log ke log
server tetapi jika gagal, log fallback pada log internal buruh pelabuhan. Sedemikian
kasus, untuk mencegah saturasi node kita memerlukan perilaku cluster yang luas untuk
log buruh pelabuhan- Mengekspos opsi buruh pelabuhan tertentu dalam definisi pod/Rc bukanlah
ide bagus sebagai @smarterclayton https://github.com/smarterclayton
menyarankan itu. Kami juga setuju dengan abstraksi yang memungkinkan definisi high
perilaku log level jika memungkinkan- Pilihan lain adalah membuat perubahan pada file konfigurasi kubelet dan
kode untuk menangani perilaku log seperti itu—
Balas email ini secara langsung atau lihat di GitHub
https://github.com/kubernetes/kubernetes/issues/15478#issuecomment -147740136
.
smarterclayton
pada 13 Okt 2015
:jempolan:
Perhatikan bahwa sekarang ada 9 driver logging . Apa konsensus untuk memasukkan yang ini?
 halr9000
pada 12 Mei 2016
halr9000
pada 12 Mei 2016
+1
 briangebala
pada 18 Mei 2016
briangebala
pada 18 Mei 2016
Jika ada yang tidak mengetahuinya, Anda dapat menentukan driver log default pada basis per-node dengan flag ke daemon Docker ( --log-driver ). Di lingkungan saya, saya mengatur driver ke journald dengan cara ini. Saya berjuang untuk memikirkan kasus penggunaan untuk mengesampingkan ini berdasarkan per-kontainer untuk jujur.
 obeattie
pada 18 Mei 2016
obeattie
pada 18 Mei 2016
Sebagian besar pengelompokan tidak ingin log mereka "out-of-band", jadi apa pengaktifan fitur yang akan disediakan ini.
Juga, dari perspektif ops sepertinya kehilangan kendali. Saat ini kami menetapkan default dan mengonfigurasi tumpukan logging untuk digabungkan.
timothysc
pada 18 Mei 2016
+1 pada ini.
Tidak dapat mengontrol bagaimana docker logging ditangani menyiratkan bahwa satu-satunya opsi logging yang waras adalah menggunakan alat yang dikirimkan dengan k8s, yang merupakan batasan yang luar biasa.
@timothysc di sini kasus penggunaan kami. Kami memiliki infrastruktur dinamis yang kompleks (~100 mesin) dengan banyak layanan yang berjalan di dalamnya, dengan logstash kami sendiri untuk mengumpulkan log. Nah, kami sekarang mencoba untuk memindahkan layanan kami, satu per satu, ke k8s dan bagi saya tampaknya tidak ada cara yang bersih untuk mengintegrasikan logging antara infrastruktur kami yang ada dan container yang dikelompokkan di k8s.
K8S sangat berpendirian tentang cara Anda mengumpulkan log. Ini mungkin bagus untuk siapa pun yang memulai dari awal dengan infrastruktur sederhana. Untuk semua orang yang bekerja pada infrastruktur kompleks yang tidak keberatan menyelam lebih dalam dan menerapkan mekanisme logging kustom, tidak ada cara untuk melakukannya saat ini, yang cukup membuat frustrasi.
Semoga masuk akal.
 jnardiello
pada 23 Mei 2016
jnardiello
pada 23 Mei 2016
Jadi dalam log skenario Anda benar-benar "per aplikasi", tetapi Anda harus
memastikan Host yang mendasarinya mendukung log itu? Itulah kekhawatiran kami
diskusikan di sini - apakah kami melakukan level cluster, atau level node, tetapi jika kami melakukannya
tingkat pod, maka penjadwal harus mengetahui driver log apa
hadir dimana. Sebisa mungkin kita berusaha menghindarinya.
Pada Senin, 23 Mei 2016 pukul 10:50, Jacopo Nardiello < [email protected]
menulis:
+1 pada ini.
Tidak dapat mengontrol bagaimana docker logging ditangani menyiratkan bahwa
satu-satunya opsi logging yang waras adalah menggunakan alat yang dikirimkan dengan k8s, yang merupakan
batasan yang luar biasa.@timothysc https://github.com/timothysc di sini kasus penggunaan kami. Kita punya sebuah
infrastruktur dinamis yang kompleks (~100 mesin) dengan banyak yang sudah ada
layanan yang berjalan pada mereka, dengan logstash kami sendiri untuk mengumpulkan log. Nah, kami
sekarang mencoba untuk memindahkan layanan kami, satu per satu, ke k8s dan ke saya di sana
tampaknya tidak ada cara yang bersih untuk mengintegrasikan logging antara yang ada
infrastruktur dan kontainer berkerumun di k8s.K8S sangat berpendirian tentang cara Anda mengumpulkan log. Ini mungkin bagus
untuk siapa pun yang memulai dari awal dengan infrastruktur sederhana. Untuk
semua orang bekerja pada infrastruktur kompleks yang tidak keberatan
menyelam lebih dalam dan untuk menerapkan mekanisme logging kustom, tidak ada
cara untuk melakukannya saat ini, yang cukup membuat frustrasi.Semoga masuk akal.
—
Anda menerima ini karena Anda disebutkan.
Balas email ini secara langsung atau lihat di GitHub
https://github.com/kubernetes/kubernetes/issues/15478#issuecomment -221002545
smarterclayton
pada 23 Mei 2016
@smarterclayton Saya mengerti tentang kekhawatiran Anda dan mereka ditempatkan dengan baik. Saya tidak yakin apakah seluruh cluster harus mengetahui keberadaan logging tingkat pod, yang menurut saya harus kita lakukan adalah memberikan opsi untuk mencatat pod stdout/stderr di suatu tempat (file berdasarkan nama pod mereka saat ini?) sehingga siapa pun yang ingin menerapkan solusi khusus mereka, akan memiliki tempat yang tetap untuk mendapatkan konten. Ini membuka bab BESAR karena logrotasi tidak sepele.
Ini hanya dua sen saya, tetapi kami tidak dapat berpura-pura bahwa skenario kompleks dunia nyata hanya menyerahkan infrastruktur logging yang ada.
jnardiello
pada 26 Mei 2016
Apakah Anda menentukan opsi log khusus per aplikasi? Berapa banyak yang berbeda?
set opsi log yang akan Anda miliki per cluster? Jika ada set kecil
config, opsinya adalah mendukung anotasi pada pod yaitu
berkorelasi dengan konfigurasi tingkat simpul yang menawarkan sejumlah "log standar"
options". Yaitu pada waktu peluncuran kubelet, tentukan "log mode X" (yang mendefinisikan
opsi log kustom dan driver), dan pod akan menentukan "
pod.alpha.kubernetes.io/log.mode=X".
Namun opsi lain adalah kami mengekspos cara untuk membiarkan penyebar memiliki
kesempatan untuk mengubah definisi wadah segera sebelum kita mulai
wadah. Itu lebih sulit hari ini karena kita harus membuat cerita bersambung
docker def out ke format perantara, jalankan, lalu jalankan
lagi, tetapi berpotensi lebih mudah di masa depan.
Akhirnya, kita dapat mengekspos pasangan nilai kunci pada antarmuka kontainer yang
diteruskan ke mesin kontainer secara langsung, tidak menawarkan jaminan API untuk
mereka, dan memastikan PodSecurityPolicy dapat mengatur opsi tersebut. Itu akan
menjadi pintu keluar bagi penelepon, tetapi kami tidak akan dapat menyediakannya
menjamin mereka akan terus bekerja di seluruh rilis.
Pada Kam, 26 Mei 2016 pukul 05.34, Jacopo Nardiello [email protected]
menulis:
@smarterclayton https://github.com/smarterclayton Saya mengerti tentang
kekhawatiran Anda dan mereka ditempatkan dengan baik. Saya tidak yakin apakah seluruh cluster
harus menyadari keberadaan logging tingkat pod, apa yang saya pikir kita
yang harus dilakukan adalah memberikan opsi untuk mencatat pod stdout/stderr di suatu tempat (file
berdasarkan nama pod mereka saat ini?) sehingga siapa pun yang mau mengimplementasikan
solusi khusus, akan memiliki tempat yang bertahan untuk mendapatkan konten.
Ini membuka bab BESAR karena logrotasi tidak sepele.Ini hanya dua sen saya, tapi kita tidak bisa berpura-pura kompleks dunia nyata itu
skenario hanya menyerahkan infrastruktur logging yang ada.—
Anda menerima ini karena Anda disebutkan.
Balas email ini secara langsung atau lihat di GitHub
https://github.com/kubernetes/kubernetes/issues/15478#issuecomment -221823732
smarterclayton
pada 26 Mei 2016
@smarterclayton pernahkah Anda melihat https://github.com/kubernetes/kubernetes/issues/24677#issuecomment -220735829
ncdc
pada 26 Mei 2016
Tidak, terima kasih. Memindahkan diskusi ke sana.
Pada Kamis, 26 Mei 2016 pukul 11:23, Andy Goldstein [email protected]
menulis:
@smarterclayton https://github.com/smarterclayton apakah Anda sudah melihat #24677
(komentar)
https://github.com/kubernetes/kubernetes/issues/24677#issuecomment -220735829—
Anda menerima ini karena Anda disebutkan.
Balas email ini secara langsung atau lihat di GitHub
https://github.com/kubernetes/kubernetes/issues/15478#issuecomment -221903781
smarterclayton
pada 26 Mei 2016
Hai, yang di sana,
Saya pikir ini adalah fitur penting yang harus dipertimbangkan untuk kubernetes.
Mengaktifkan penggunaan driver log Docker dapat memecahkan beberapa masalah non-sepele.
Saya akan mengatakan bahwa masuk ke disk adalah anti-pola. Log secara inheren "status", dan sebaiknya tidak disimpan ke disk. Pengiriman log langsung dari wadah ke repositori memecahkan banyak masalah.
Menyetel driver log berarti perintah kubectl logs tidak dapat menampilkan apa pun lagi.
Meskipun fitur tersebut "bagus untuk dimiliki" - fitur tersebut tidak akan diperlukan jika log tersedia dari sumber yang berbeda.
Docker sudah memiliki driver log untuk google cloud (gcplogs) dan Amazon (awslogs). Meskipun dimungkinkan untuk mengaturnya di daemon Docker itu sendiri, itu memiliki banyak kelemahan. Dengan dapat mengatur dua opsi buruh pelabuhan:
--log-driver= Logging driver untuk kontainer
--log-opt=[] Log opsi driver
Dimungkinkan untuk mengirim bersama label (untuk gcplogs) atau awslogs-group (untuk awslogs)
khusus untuk sebuah pod. Itu akan memudahkan untuk menemukan log di ujung yang lain.
Saya telah membaca tentang bagaimana orang menangani log di kubernetes. Banyak yang tampaknya menyiapkan beberapa pencakar rumit yang meneruskan log ke sistem pusat. Mampu mengatur driver log akan membuat itu tidak perlu - membebaskan waktu untuk mengerjakan hal-hal yang lebih menarik :)
 pbthorste
pada 30 Nov 2016
pbthorste
pada 30 Nov 2016
Saya juga dapat menambahkan bahwa beberapa orang, termasuk saya, ingin melakukan rotasi log buruh pelabuhan melalui opsi '--log-opt max-size' pada driver logging JSON (yang asli dari buruh pelabuhan) alih-alih mengatur logrotate pada Host. Jadi, bahkan hanya mengekspos opsi '--log-opt' akan sangat dihargai
 daniilyar
pada 12 Des 2016
daniilyar
pada 12 Des 2016
Saya telah memodifikasi k8s, saat membuat konfigurasi kontainer LogConfig.
 barnettZQG
pada 12 Des 2016
barnettZQG
pada 12 Des 2016
+1
Menggunakan driver log buruh pelabuhan untuk pengumpulan log terpusat terlihat jauh lebih sederhana daripada membuat tautan simbolis untuk file log, memasangnya ke wadah fasih khusus, membuntutinya, dan mengelola rotasi log.
 defat
pada 27 Des 2016
defat
pada 27 Des 2016
Use case untuk konfigurasi per container: Saya ingin login di tempat lain atau berbeda untuk container yang saya gunakan dan saya tidak peduli (atau ingin mengubah) driver log untuk container standar yang diperlukan untuk menjalankan Kubernetes.
Ini dia. Tolong buat ini terjadi.
 et304383
pada 12 Jan 2017
et304383
pada 12 Jan 2017
Ide lain adalah, di mana semua wadah masih meneruskan log ke titik akhir yang sama, tetapi Anda setidaknya dapat menetapkan nilai bidang yang berbeda untuk wadah buruh pelabuhan yang berbeda di server log Anda.
Ini akan bekerja untuk driver buruh pelabuhan gelf, jika kita dapat memastikan wadah buruh pelabuhan yang dibuat oleh Kubernetes diberi label khusus. Artinya: beberapa bidang Pod dapat diteruskan sebagai label wadah buruh pelabuhan. (Mungkin ini sudah mungkin tetapi saya tidak tahu bagaimana mencapainya).
Contoh tanpa Kubernetes, hanya dengan daemon docker dan driver gelf. Konfigurasikan daemon buruh pelabuhan dengan: --log-driver=gelf --log-opt labels=env,label2 dan buat wadah buruh pelabuhan:
docker run -dti --label env=testing --label label2=some_value alpine:3.4 /bin/sh -c "while true; do date; sleep 2; done"
dan wadah buruh pelabuhan lainnya:
docker run -dti --label env=production --label label2=some_value alpine:3.4 /bin/sh -c "while true; do date; sleep 2; done"
Dengan cara ini, di Graylog, Anda dapat membedakan antara container env=production dan env=testing .
Saat ini saya menggunakan opsi daemon buruh pelabuhan seperti:
--log-driver=gelf --log-opt gelf-address=udp://graylog.example.com:12201 --log-opt tag=k8s-testing --log-opt labels=io.kubernetes.pod.namespace,io.kubernetes.container.name,io.kubernetes.pod.name
 xmik
pada 12 Jan 2017
xmik
pada 12 Jan 2017
@xmik , apa yang harus mengkonfirmasi itu adalah fitur yang ada atau proposal Anda tentang
Saat ini saya menggunakan opsi daemon buruh pelabuhan seperti:
--log-driver=gelf --log-opt gelf-address=udp://graylog.example.com:12201 --log-opt tag=k8s-testing --log-opt labels=io.kubernetes.pod.namespace,io.kubernetes.container.name,io.kubernetes.pod.name
 stainboy
pada 26 Jan 2017
stainboy
pada 26 Jan 2017
Opsi daemon buruh pelabuhan yang saat ini saya gunakan, sudah berfungsi. Kubernetes telah menetapkan beberapa label untuk setiap container buruh pelabuhan. Misalnya, saat menjalankan docker inspect pada wadah kube-apiserver:
"Labels": {
"io.kubernetes.container.hash": "4959a3f5",
"io.kubernetes.container.name": "kube-apiserver",
"io.kubernetes.container.ports": "[{\"name\":\"https\",\"hostPort\":6443,\"containerPort\":6443,\"protocol\":\"TCP\"},{\"name\":\"local\",\"hostPort\":8080,\"containerPort\":8080,\"protocol\":\"TCP\"}]",
"io.kubernetes.container.restartCount": "1",
"io.kubernetes.container.terminationMessagePath": "/dev/termination-log",
"io.kubernetes.pod.name": "kube-apiserver-k8s-production-master-1",
"io.kubernetes.pod.namespace": "kube-system",
"io.kubernetes.pod.terminationGracePeriod": "30",
"io.kubernetes.pod.uid": "a47396d9dae12c81350569f56aea562e"
}
Oleh karena itu, opsi daemon buruh pelabuhan itu berfungsi.
Namun, saya pikir sekarang tidak mungkin untuk membuat Kubernetes menetapkan label khusus pada wadah buruh pelabuhan berdasarkan spesifikasi Pod. Jadi misalnya --log-driver=gelf --log-opt labels=env,label2 tidak berfungsi.
xmik
pada 26 Jan 2017
Apakah ada berita di depan ini? Memiliki kemampuan untuk menentukan label dan kemudian memanfaatkan --log-opt labels<> akan cukup bagus!
 beldpro-ci
pada 18 Mar 2017
beldpro-ci
pada 18 Mar 2017
@portante @jcantrill Hanya untuk menangkapnya di sini karena kami membahasnya, berikut adalah kasus penggunaan yang kami pikir ini mungkin berguna untuk:
Ketika pod perekaman log mulai menemukan dan mencatat kesalahan, infra yang mengumpulkan kesalahan tersebut akan mengambilnya dan memasukkannya kembali ke mekanisme perekaman yang pada gilirannya akan melempar dan mencatat lebih banyak kesalahan.
Loop umpan balik ini dapat dihindari dengan menggunakan mekanisme penyaringan tetapi itu agak rapuh. Menggunakan driver logging yang berbeda untuk merekam ke file dan memiliki opsi rotasi sepertinya itu akan menjadi solusi yang baik.
 pweil-
pada 31 Mar 2017
pweil-
pada 31 Mar 2017
2 sen saya.
Solusi saat ini untuk masuk ke dalam k8 adalah (AFAIK):
- kontainer sespan mengirim log ke suatu tempat
- pengontrol replikasi mengirim semua log ke suatu tempat
- wadah itu sendiri mengirim log ke suatu tempat
Wadah sespan tampaknya agak berlebihan bagi saya. Strategi pengontrol replikasi tampaknya bagus, tetapi menggabungkan log wadah dari semua penerapan, dan beberapa pengguna sekarang mungkin menginginkannya, dan mungkin ingin mencatat setiap aplikasi ke hal yang berbeda. Untuk kasus ini, opsi terakhir berfungsi paling baik IMHO, tetapi membuat banyak kode yang direplikasi di semua wadah (mis.: instal dan atur daemon logentries).
Ini semua akan jauh lebih mudah jika kita memiliki akses ke flag log-driver , jadi setiap penerapan akan menentukan bagaimana itu harus dicatat, menggunakan fitur asli buruh pelabuhan.
Saya dapat mencoba mengimplementasikannya, tetapi mungkin memerlukan bantuan - karena saya tidak terbiasa dengan basis kode kubernetes.
 caarlos0
pada 17 Mei 2017
caarlos0
pada 17 Mei 2017
begitu multi tenancy menjadi lebih dari satu hal, akan lebih sulit untuk diselesaikan dengan benar.
Setiap namespace mungkin penyewa yang berbeda sehingga log dari masing-masing tidak harus dikumpulkan, tetapi diizinkan untuk dikirim ke lokasi yang ditentukan penyewa.
Saya dapat memikirkan beberapa cara untuk melakukan ini:
- buat tipe volume baru, container-logs. Ini memungkinkan daemonset yang diluncurkan oleh namespace tertentu untuk mengakses hanya log dari wadahnya sendiri. Mereka kemudian dapat mengirim log dengan pengirim log pilihan apa pun ke daemon penyimpanan pilihan mana pun.
- Ubah salah satu (atau lebih) pengirim log, seperti fasih-bit untuk membaca namespace tempat pod berada, dan mengalihkan log dari setiap pod ke pengirim log lebih lanjut yang berjalan di namespace itu sebagai layanan. Seperti fasih. Ini sekali lagi memungkinkan namespace untuk mengonfigurasi pengirim lognya sendiri untuk mendorong ke backend log apa pun yang ingin mereka dukung.
 kfox1111
pada 17 Mei 2017
kfox1111
pada 17 Mei 2017
@caarlos0 @kfox1111 Saya setuju dengan poin Anda. Ini adalah topik yang kompleks, karena memerlukan koordinasi instrumentasi, penyimpanan, node, dan bahkan mungkin lebih banyak tim. Saya menyarankan agar proposal untuk arsitektur logging keseluruhan ditata terlebih dahulu dan kemudian mendiskusikan perubahan ke tampilan yang konsisten ini. Saya berharap proposal ini muncul dalam sebulan atau lebih, menertibkan dan mencari tahu semua masalah yang disebutkan.
 crassirostris
pada 17 Mei 2017
crassirostris
pada 17 Mei 2017
@crassirostris Saya tidak yakin saya mengerti: jika kami mengizinkan log-driver dkk, kami tidak harus berurusan dengan penyimpanan atau semacamnya, kan?
Apakah hanya buruh pelabuhan yang mengirimkan STDOUT-nya ke driver log apa pun yang diatur dalam basis wadah, bukan? Kami agak menyerahkan tanggung jawab ke wadah ... sepertinya solusi yang cukup sederhana bagi saya - tetapi, seperti yang saya katakan, saya tidak tahu basis kode, jadi mungkin saya benar-benar salah ...
caarlos0
pada 17 Mei 2017
Masalahnya adalah log-driver di buruh pelabuhan tidak menambahkan metadata k8s apa pun yang membuat penggunaan log nanti benar-benar berguna. :/
kfox1111
pada 17 Mei 2017
@kfox1111 hmm, masuk akal...
tetapi, bagaimana jika pengguna hanya menginginkan log "aplikasi", bukan log kubernetes, bukan log buruh pelabuhan, hanya aplikasi yang berjalan di dalam log kontainer?
Dalam hal ini, menurut saya, log-driver akan bekerja...
caarlos0
pada 17 Mei 2017
@caarlos0 Ini mungkin memiliki beberapa implikasi, misalnya kubelet membuat beberapa asumsi tentang format logging ke server kubectl logs.
Tetapi selain semua hal, log-driver per se adalah khusus Docker dan mungkin tidak berfungsi untuk runtime lain, itulah alasan utama untuk tidak memasukkannya ke dalam API.
crassirostris
pada 17 Mei 2017
@crassirostris itu masuk akal...
karena fitur ini tidak akan ditambahkan (seperti yang dijelaskan dalam masalah), mungkin masalah ini harus ditutup (atau diedit atau apa pun)?
caarlos0
pada 17 Mei 2017
@caarlos0 Namun, kami pasti ingin membuat pengaturan logging lebih fleksibel dan transparan. Umpan balik Anda akan dihargai pada proposal!
crassirostris
pada 17 Mei 2017
stdout logging dari container saat ini ditangani out-of-band dalam Kubernetes. Saat ini kami mengandalkan solusi non-Kubernetes untuk menangani logging, atau container istimewa yang melakukan jailbreak pada Kubernetes untuk mendapatkan akses ke logging out-of-band. Logging run-time container berbeda per run-time (docker, rkt, Windows), jadi memilih salah satu, seperti Docker --log-driver membuat bagasi di masa mendatang.
Saya sarankan kita membutuhkan kubelet untuk mengembalikan aliran log in-band. Tentukan atau pilih format log JSON atau XML minimal, yang mengumpulkan baris stdout dari setiap container, tambahkan metadata cluster+namespace+pod+container minimal, sehingga sumber log diidentifikasi dalam ruang Kubernetes, dan mengarahkan aliran ke Kubernetes Service+ Pelabuhan. Pengguna bebas untuk menyediakan Layanan konsumsi log apa pun yang mereka suka. Mungkin Kubernetes akan menyediakan satu referensi/Layanan default yang mengimplementasikan dukungan 'kubectl logs'.
Tanpa Layanan konsumsi logging yang ditentukan, log akan dibuang dan tidak mengenai disk sama sekali . Streaming log di tempat lain, atau menulis ke penyimpanan terus-menerus dan berputar, semua itu adalah tanggung jawab/keputusan Layanan.
Pembungkus runtime container kubelet melakukan minimum untuk mengekstrak stdout dari setiap runtime container, dan membawanya kembali ke dalam band untuk digunakan dan diproses oleh Layanan yang dihosting sendiri oleh k8s.
Spesifikasi container di Deployment atau Pod secara opsional akan menentukan Service dan Port target untuk stdout logging. Menambahkan metadata k8s untuk cluster+namespace+pod+container akan menjadi opsional (jadi pilihan mentah/tidak tersentuh atau dengan metadata). Pengguna akan bebas untuk menggabungkan semua log ke satu tempat, atau menggabungkan berdasarkan penyewa, atau namespace, atau aplikasi.
Yang terdekat dengan ini sekarang adalah menjalankan Layanan yang menggunakan 'kubectl logs -f' untuk mengalirkan log kontainer untuk setiap kontainer melalui server API. Itu tidak terdengar sangat efisien atau terukur. Proposal ini akan memungkinkan steaming langsung yang lebih efisien dari pembungkus runtime container langsung ke Service atau Pod, dengan pengoptimalan seperti memilih Deployment logging atau Pod Daemonset pada node yang sama dan container yang menghasilkan log.
Saya mengusulkan Kubernetes harus melakukan yang minimum untuk secara efisien membawa log run-time container in-band, untuk setiap solusi logging yang dihosting sendiri, homogen atau heterogen yang kami buat dalam ruang Kubernetes.
Apa yang orang pikirkan?
 whereisaaron
pada 18 Mei 2017
whereisaaron
pada 18 Mei 2017
@whereisaaron Saya benar-benar ingin tidak membahas ini sekarang, ketika kami tidak memiliki semua detail seputar ekosistem logging di satu tempat.
Misalnya saya melihat masalah jaringan dan mesin mengganggu aliran log, tetapi sekali lagi, saya tidak ingin membahasnya dulu. Bagaimana kalau kita membahasnya nanti, ketika proposal sudah siap? Apakah itu tampak masuk akal bagi Anda?
crassirostris
pada 18 Mei 2017
Tentu saja @crassirostris. Harap beri tahu kami di sini jika proposal siap untuk diperiksa.
whereisaaron
pada 20 Mei 2017
/ tanda skalabilitas
 kargakis
pada 10 Jun 2017
kargakis
pada 10 Jun 2017
Meskipun --log-driver dan --log-opt keduanya adalah opsi untuk daemon Docker dan bukan fitur k8s, akan lebih baik untuk menentukannya dalam spesifikasi pod k8s untuk:
- driver log per-pod dan bukan driver log level node tunggal
- berbagai jenis driver log khusus aplikasi (fluentd, syslog, journald, splunk) pada node yang sama
- set
--log-optuntuk mengonfigurasi rotasi log untuk sebuah pod - per-pod
--log-optdan bukan tingkat simpul tunggal--log-opt
AFAIK, tidak satu pun di atas yang dapat disetel pada level pod dalam spesifikasi pod k8s hari ini.
 vhosakot
pada 13 Des 2017
vhosakot
pada 13 Des 2017
@vhosakot tidak satu pun di atas dapat diatur pada level mana pun di Kubernetes, karena itu bukan konsep Kubernetes
crassirostris
pada 13 Des 2017
@crassirostris tepatnya! :)
Jika k8s melakukan semua yang dilakukan Docker di level pod/level container, bukankah akan mudah bagi pengguna? Mengapa membuat pengguna menggunakan Docker sama sekali untuk beberapa hal tingkat pod/tingkat wadah?
Dan, pecinta k8s bukan penggemar Docker mungkin menanyakan pertanyaan yang sama.
vhosakot
pada 13 Des 2017
@vhosakot Intinya adalah, ada sejumlah runtime container lain yang dapat digunakan dengan K8, tetapi --log-opt hanya ada di Docker. Membuat opsi seperti itu pada level K8 akan dengan sengaja membocorkan abstraksi. Saya tidak berpikir ini adalah cara yang kita inginkan. Jika ada opsi, itu harus didukung oleh semua runtime container, idealnya menjadi bagian dari CRI
Saya tidak mengatakan bahwa tidak akan ada opsi seperti itu, saya mengatakan itu tidak akan menjadi rute langsung ke Docker
crassirostris
pada 13 Des 2017
@crassirostris Benar, sepertinya itu tergantung pada apakah k8s harus melakukan apa yang dilakukan/diizinkan CRI di tingkat pod/tingkat wadah, bukan khusus Docker.
vhosakot
pada 13 Des 2017
Yup, benar sekali
crassirostris
pada 13 Des 2017
Meskipun saya terlambat untuk diskusi ini dan saya tertarik untuk melihat fitur ini diimplementasikan, saya berpendapat bahwa ada trade-off antara memiliki desain yang cantik dan memiliki cara langsung untuk menyiapkan solusi logging yang waras dan seragam. untuk klaster. Ya, menerapkan fitur ini akan mengekspos docker internal , yang merupakan masalah besar, tidak, tetapi pada saat yang sama saya dapat bertaruh banyak uang bahwa mayoritas pengguna K8S menggunakan docker sebagai teknologi kontainer yang mendasarinya dan buruh pelabuhan memang datang dengan daftar yang sangat komprehensif dari driver log.
 gabriel-tincu
pada 19 Des 2017
gabriel-tincu
pada 19 Des 2017
@gabriel-tincu Saat ini saya tidak yakin bahwa FR asli sepadan dengan masalahnya
buruh pelabuhan memang datang dengan daftar driver log yang sangat lengkap
Anda dapat mengatur logging pada level Docker selama langkah penerapan K8 dan menggunakan salah satu driver log ini, tanpa membocorkan informasi ini ke K8. Satu-satunya hal yang tidak dapat Anda lakukan hari ini adalah mengatur opsi tersebut per-wadah/per-pod (sebenarnya, Anda dapat memiliki pengaturan dengan node khusus & menggunakan pemilih node), tapi saya tidak yakin itu batasan besar.
crassirostris
pada 19 Des 2017
@crassirostris Saya setuju bahwa Anda dapat mengaturnya __before__ mengatur lingkungan, tetapi jika ada cara untuk secara aktif memperbarui driver log buruh pelabuhan setelah lingkungan sudah diatur maka itu menghindari saya saat ini
gabriel-tincu
pada 12 Jan 2018
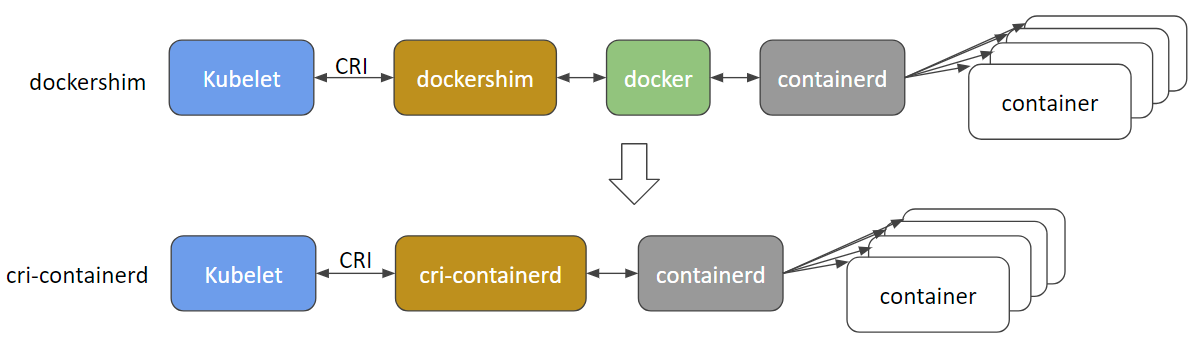
@gabriel-tincu @vhosakot antarmuka langsung yang dulu ada antara k8s dan Docker di 'masa lalu' >=1.5 sudah usang dan saya yakin kodenya benar-benar dihapus sekarang. Segala sesuatu antara kubelet dan run-time seperti Docker (atau yang lainnya seperti rkt, cri-o, runc, lxd) melewati CRI. Ada banyak runtime kontainer sekarang dan Docker sendiri kemungkinan akan ditinggalkan dan segera dihapus demi cri-containerd + containerd .
http://blog.kubernetes.io/2017/11/containerd-container-runtime-options-kubernetes.html
@crassirostris ada gerakan pada proposal, yang mungkin memiliki kemungkinan logging kontainer in-band?
whereisaaron
pada 12 Jan 2018
Log kontainer CRI berbasis file (https://github.com/kubernetes/community/blob/master/contributors/design-proposals/node/kubelet-cri-logging.md), dan jalur log didefinisikan secara eksplisit:
/var/log/pods/PodUID/ContainerName/RestartCount.log
Di sebagian besar driver logging buruh pelabuhan https://docs.docker.com/config/containers/logging/configure/#supported -logging-drivers , saya pikir untuk lingkungan cluster, yang paling penting adalah driver yang menelan log kontainer ke dalam cluster sistem manajemen logging, seperti splunk , awslogs , gcplogs dll.
Dalam kasus CRI, "driver log buruh pelabuhan" tidak boleh digunakan. Orang dapat menjalankan daemonset untuk menyerap log kontainer dari direktori log kontainer CRI ke mana pun mereka mau. Mereka dapat menggunakan fasih atau bahkan menulis daemonset sendiri.
Jika lebih banyak metadata diperlukan, kita dapat memikirkan untuk menghapus file metadata, memperluas jalur file, atau membiarkan daemonset mendapatkan metadata dari apiserver. Ada diskusi yang sedang berlangsung tentang ini https://github.com/kubernetes/kubernetes/issues/58638
 Random-Liu
pada 22 Feb 2018
Random-Liu
pada 22 Feb 2018
Masalah menjadi basi setelah 90 hari tidak aktif.
Tandai masalah sebagai baru dengan /remove-lifecycle stale .
Masalah basi membusuk setelah 30 hari tambahan tidak aktif dan akhirnya ditutup.
Jika masalah ini aman untuk ditutup sekarang, silakan lakukan dengan /close .
Kirim umpan balik ke sig-testing, kubernetes/test-infra dan/atau fejta .
/siklus hidup basi
 fejta-bot
pada 23 Mei 2018
fejta-bot
pada 23 Mei 2018
Masalah basi membusuk setelah 30 hari tidak aktif.
Tandai masalah sebagai baru dengan /remove-lifecycle rotten .
Masalah busuk ditutup setelah 30 hari tambahan tidak aktif.
Jika masalah ini aman untuk ditutup sekarang, silakan lakukan dengan /close .
Kirim umpan balik ke sig-testing, kubernetes/test-infra dan/atau fejta .
/siklus hidup busuk
/hapus siklus hidup basi
fejta-bot
pada 22 Jun 2018
/hapus-siklus hidup busuk
 iavael
pada 25 Jun 2018
iavael
pada 25 Jun 2018
ada update tentang ini? jadi bagaimana orang yang menjalankan k8s dengan wadah Docker menyelesaikan logging ke beberapa backend seperti AWS CloudWatch?
 bryan831
pada 4 Jul 2018
bryan831
pada 4 Jul 2018
@bryan831 sangat populer untuk mengumpulkan file log kontainer k8s menggunakan fasih atau serupa dan menggabungkannya ke dalam pilihan back-end, CloudWatch, StackDriver, Elastisearch, dll.
Ada bagan Helm yang tersedia untuk misalnya fasih+CloudWatch , fasih+Elastisearch , fasih-bit->fluentd->pilihan Anda , Datadog dan mungkin kombinasi lain jika Anda melihat-lihat.
whereisaaron
pada 4 Jul 2018
Masalah menjadi basi setelah 90 hari tidak aktif.
Tandai masalah sebagai baru dengan /remove-lifecycle stale .
Masalah basi membusuk setelah 30 hari tambahan tidak aktif dan akhirnya ditutup.
Jika masalah ini aman untuk ditutup sekarang, silakan lakukan dengan /close .
Kirim umpan balik ke sig-testing, kubernetes/test-infra dan/atau fejta .
/siklus hidup basi
fejta-bot
pada 2 Okt 2018
Akan menyenangkan untuk dapat menyesuaikan opsi Docker --log-opt. Dalam kasus saya, saya ingin menggunakan tag seperti '--log-opt tag="{{.ImageName}}/{{.Name}}/{{.ID}}"' untuk memancarkan ImageName ke log sehingga saya tahu dari versi kontainer mana log berasal. (Referensi: https://docs.docker.com/config/containers/logging/log_tags/)
 pmahalwar-intertrust
pada 26 Okt 2018
pmahalwar-intertrust
pada 26 Okt 2018
/hapus siklus hidup basi
pmahalwar-intertrust
pada 26 Okt 2018
@pmahalwar-intertrust Anda dapat meneruskan --log-opt yang sama ke daemon buruh pelabuhan, yang akan memengaruhi semua wadah Anda ...
 nrobert13
pada 26 Okt 2018
nrobert13
pada 26 Okt 2018
@pmahalwar-intertrust log yang dikumpulkan dari containerd oleh kubernetes sudah menyertakan metadata yang ekstensif, termasuk label apa pun yang telah Anda terapkan ke container. Jika Anda mengumpulkannya dengan fluentd Anda akan mendapatkan semua metadata misalnya seperti pada entri log di bawah ini.
{
"log": " - [] - - [25/Oct/2018:06:29:48 +0000] \"GET /nginx_status/format/json HTTP/1.1\" 200 9250 \"-\" \"Go-http-client/1.1\" 118 0.000 [internal] - - - - 5eb73997a372badcb4e3d993ceb44cd9\n",
"stream": "stdout",
"docker": {
"container_id": "3657e1d9a86e629d0dccefec0c3c7624eaf0c4a11f60f53c5045ec0839c37f06"
},
"kubernetes": {
"container_name": "nginx-ingress-controller",
"namespace_name": "ingress",
"pod_name": "nginx-ingress-dev-controller-69c644f7f5-vs8vw",
"pod_id": "53514ad6-d0f4-11e8-a04c-02c433fc5820",
"labels": {
"app": "nginx-ingress",
"component": "controller",
"pod-template-hash": "2572009391",
"release": "nginx-ingress-dev"
},
"host": "ip-172-29-21-204.us-east-2.compute.internal",
"master_url": "https://10.3.0.1:443/api",
"namespace_id": "e262510b-180a-11e8-b763-0a0386e3402c"
},
"kubehost": "ip-172-29-21-204.us-east-2.compute.internal"
}
Apakah masih belum ada rencana untuk mendukung fitur ini?
--log-driver= Logging driver untuk kontainer
--log-opt=[] Log opsi driver
 lifubang
pada 8 Nov 2018
lifubang
pada 8 Nov 2018
Hai @lifubang Saya tidak dapat berbicara dengan rencana siapa pun, tetapi daemon yang mendukung fitur-fitur itu, dockerd bukan lagi bagian dari Kubernetes (lihat diskusi di atas yang membahas itu).
Anda masih dapat menginstalnya secara opsional jika Anda mau, jadi Anda mungkin dapat melakukannya untuk menggunakan driver log dockerd . Opsi itu dibahas di sini:
https://kubernetes.io/blog/2018/05/24/kubernetes-containerd-integration-goes-ga/
Tetapi menggunakan layanan pencatatan khusus seperti fluentd adalah pendekatan yang disarankan. Anda dapat menerapkannya secara global untuk cluster atau per-Pod Anda sebagai sidecar. Masuk ke Kubernetes dibahas di sini:
https://kubernetes.io/docs/concepts/cluster-administration/logging/
whereisaaron
pada 8 Nov 2018
Saya sangat merekomendasikan fasih seperti yang dijelaskan oleh @whereisaaron
Sejauh permintaan fitur ini sedang dikerjakan... peta jalan arsitektur kubernetes telah masuk di bawah bagian "Ekosistem" dari hal-hal yang sebenarnya bukan "bagian dari" kubernet jadi saya ragu fitur seperti itu akan pernah didukung secara asli.
https://github.com/kubernetes/community/blob/master/contributors/devel/architectural-roadmap.md#summarytldr
 taylorshaulis
pada 8 Nov 2018
taylorshaulis
pada 8 Nov 2018
Saya sangat menyarankan untuk tidak menggunakan fasih karena memiliki beberapa bug yang dapat membuat hidup Anda kacau saat menjalankan k8s
in_tail mencegah buruh pelabuhan menghapus wadah https://github.com/fluent/fluentd/issues/1680 .
in_tail menghapus posisi file yang tidak terlacak selama fase startup. Itu berarti konten pos_file tumbuh hingga restart dan dapat memakan banyak pemindaian cpu melaluinya ketika Anda mengekor banyak file dengan pengaturan jalur dinamis.
https://github.com/fluent/fluentd/issues/1126.
 roffe
pada 6 Des 2018
roffe
pada 6 Des 2018
Masalah menjadi basi setelah 90 hari tidak aktif.
Tandai masalah sebagai baru dengan /remove-lifecycle stale .
Masalah basi membusuk setelah 30 hari tambahan tidak aktif dan akhirnya ditutup.
Jika masalah ini aman untuk ditutup sekarang, silakan lakukan dengan /close .
Kirim umpan balik ke sig-testing, kubernetes/test-infra dan/atau fejta .
/siklus hidup basi
fejta-bot
pada 21 Mar 2019
Terima kasih atas pengalamannya @roffe. fasih/fluentd#1680 adalah masalah kembali tentang k8s 1.5 dan kami tidak menggunakan 'in_tail' saat itu karena alasan itu. Sejak k8s pindah ke containerd logging sepertinya tidak ada masalah? Kami belum melihat dampak yang dapat dideteksi dari fasih/fasih#1126.
Anda merekomendasikan terhadap fluentd . Apa yang akan Anda rekomendasikan? Apa yang Anda gunakan secara pribadi daripada fluentd untuk agregasi log dengan metadata k8s?
whereisaaron
pada 21 Mar 2019
Masalah basi membusuk setelah 30 hari tidak aktif.
Tandai masalah sebagai baru dengan /remove-lifecycle rotten .
Masalah busuk ditutup setelah 30 hari tambahan tidak aktif.
Jika masalah ini aman untuk ditutup sekarang, silakan lakukan dengan /close .
Kirim umpan balik ke sig-testing, kubernetes/test-infra dan/atau fejta .
/siklus hidup busuk
fejta-bot
pada 20 Apr 2019
Masalah busuk ditutup setelah 30 hari tidak aktif.
Buka kembali masalah dengan /reopen .
Tandai masalah sebagai baru dengan /remove-lifecycle rotten .
Kirim umpan balik ke sig-testing, kubernetes/test-infra dan/atau fejta .
/Menutup
fejta-bot
pada 20 Mei 2019
@fejta-bot: Menutup masalah ini.
Menanggapi hal ini :
Masalah busuk ditutup setelah 30 hari tidak aktif.
Buka kembali masalah dengan/reopen.
Tandai masalah sebagai baru dengan/remove-lifecycle rotten.Kirim umpan balik ke sig-testing, kubernetes/test-infra dan/atau fejta .
/Menutup
Instruksi untuk berinteraksi dengan saya menggunakan komentar PR tersedia di sini . Jika Anda memiliki pertanyaan atau saran terkait dengan perilaku saya, silakan ajukan masalah pada repositori kubernetes/test-infra .
 k8s-ci-robot
pada 20 Mei 2019
k8s-ci-robot
pada 20 Mei 2019
Ini seharusnya tidak ditutup, bukan?
Permintaan fitur masih masuk akal bagi saya karena saya ingin mengatur log-opts per pod (tanpa mengaturnya di daemon atau menggunakan logrotate)...
 yzargari
pada 27 Agu 2019
yzargari
pada 27 Agu 2019
Saya cukup yakin bahwa mendukung opsi konfigurasi khusus buruh pelabuhan dari dalam k8s bukanlah ide yang baik. Seperti yang disebutkan sebelumnya, daemonset fasih atau mobil samping fluenbit adalah opsi saat ini. Saya lebih suka sespan karena jauh lebih aman.
 coffeepac
pada 29 Agu 2019
coffeepac
pada 29 Agu 2019
@whereisaaron apakah Anda menemukan solusi logging untuk K8s@containerd?
 loxal
pada 11 Sep 2019
loxal
pada 11 Sep 2019
apakah --log-driver , --log-opt masih belum didukung?
Saya mencoba menemukan cara untuk meneruskan log dari pod tunggal ke Splunk. ada ide?
 sariel1212
pada 15 Sep 2019
sariel1212
pada 15 Sep 2019
@sariel1212 untuk satu pod, saya sarankan menyertakan wadah mobil samping di pod Anda yang hanya merupakan agen penerusan splunk. Anda dapat berbagi volume emptydir di antara semua container di dalam pod dan meminta container aplikasi menulis lognya ke emptydir yang dibagikan. Kemudian minta wadah splunk forwarder membaca dari volume itu dan meneruskannya.
coffeepac
pada 16 Sep 2019
Jika Anda ingin mengumpulkan ke Splunk untuk seluruh cluster Anda @sariel1212 , ada bagan helm Splunk resmi untuk menyebarkan fluentd dengan plug-in Splunk HEC fluentd untuk dikumpulkan log node, log container, dan log bidang kontrol, ditambah objek Kubernetes, dan metrik cluster Kubernetes. Untuk satu saran Pod @coffeepac tentang sespan dengan emptydir bersama adalah pendekatan yang baik.
whereisaaron
pada 16 Sep 2019
Sangat mengerikan bahwa masih tidak ada cara bagi pemilik cluster untuk menggunakan driver log Docker setelah sekian lama.
Saya bisa mendapatkan pengaturan dengan sangat cepat dengan Docker-Compose (mensimulasikan cluster K8s saya) untuk menyalurkan semua stdout/err ke layanan agregat log saya.
Mencoba melakukan ini di Kubenetes? Dari utas ini sepertinya saya harus menambah kode untuk setiap layanan mikro! Tidak baik.
 ashleydavis
pada 24 Sep 2019
ashleydavis
pada 24 Sep 2019
Hai @ashleydavis , dockerd tidak digunakan lagi di Kubernetes jadi tidak ada gunanya memperkenalkan dukungan untuk sesuatu yang bukan lagi bagian dari Kubernetes. Meskipun Anda masih dapat menginstalnya selain Kubernetes. Berikut adalah latar belakangnya:
https://kubernetes.io/blog/2018/05/24/kubernetes-containerd-integration-goes-ga/
Anda tidak perlu menambah container kecuali Anda menginginkannya, Kubernetes secara native mengalirkan log stdout/stderr untuk setiap container secara otomatis. Anda hanya perlu men-deploy satu container pada setiap node (a DaemonSet ) untuk mengumpulkan dan mengirim aliran log tersebut ke layanan agregasi pilihan Anda. Ini sangat mudah.
https://docs.fluentd.org/container-deployment/kubernetes
Ada banyak fluentd +gambar container backend yang sudah jadi dan contoh konfigurasi untuk back-end agregasi belakang di sini:
https://github.com/fluent/fluentd-kubernetes-daemonset
Jika Anda menggunakan DataDog, mereka memiliki agen sendiri untuk diinstal atau juga fluentd :
https://docs.datadoghq.com/integrations/kubernetes/
Secara umum docker cenderung kitchen sink , dengan logging dan plug-in log, dan swarm, dan alat runtime, alat pembangunan, jaringan, dan pemasangan sistem file, dll. Semua dalam satu proses daemon. Kubernetes umumnya lebih menyukai wadah/proses yang digabungkan secara longgar, masing-masing melakukan satu tugas dan berkomunikasi melalui API. Jadi ini adalah gaya yang sedikit berbeda untuk membiasakan diri.
whereisaaron
pada 24 Sep 2019
Terima kasih atas respon yang mendetail. Saya pasti akan menyelidiki ini.
Dengan dockerd yang tidak digunakan lagi, apakah itu berarti saya tidak dapat menerapkan gambar Docker ke Kubernetes di masa mendatang?
ashleydavis
pada 24 Sep 2019
@ashleydavis Anda pasti dapat terus menggunakan gambar 'Docker' (bahkan tanpa dockerd ), dan Anda dapat terus menggunakan dockerd pada node Kubernetes Anda untuk tujuan Anda sendiri (seperti di docker-in-docker membangun) jika Anda mau. Bagian inti dari buruh pelabuhan telah diekstraksi dan distandarisasi sebagai 'wadah OCI' dan run-time containerd .
https://www.opencontainers.org/
https://containerd.io/
Baik Docker dan Kubernetes sekarang didasarkan pada standar bersama ini.
https://blog.docker.com/2017/08/what-is-containerd-runtime/
https://kubernetes.io/blog/2018/05/24/kubernetes-containerd-integration-goes-ga/
whereisaaron
pada 24 Sep 2019
Terima kasih, saya belajar banyak.
Saya baru saja membuat layanan mikro yang saya sebut Loggy. Tujuannya adalah untuk mengirimkan log oleh driver log Docker dan kemudian meneruskannya (melalui webhook) ke Slack.
Anda dapat melihat kodenya di sini: https://github.com/artlife-solutions/loggy/blob/master/src/index.ts
Ini cukup sederhana, terima log dan teruskan melalui HTTP POST ke Slack.
Apa cara tercepat untuk mengadaptasi ini sehingga saya dapat mengumpulkan dan menggabungkan log dari pod saya?
ashleydavis
pada 24 Sep 2019
@ashleydavis Anda dapat membuat gambar wadah dengan layanan mikro di dalamnya, lalu
Terapkan cluster Anda sebagai Deployment dengan Layanan yang kemudian dapat dikirim oleh semua kontainer di cluster Anda (menggunakan nama DNS cluster Layanan ).
Terapkan sebagai wadah 'sespan' tambahan di Deployment Anda. Kontainer dalam Pod yang sama berbagi akses pribadi ke
localhostsehingga kontainer aplikasi dapat mengirim ke sidecar kontainer layanan mikro Anda dilocalhost:12201. Atau, container dalam Pod yang sama dapat berbagi volume untuk file log bersama atau pipa bernama.
Ini keluar dari topik di sini dan tidak semua orang menginginkan ini, jadi mungkin cari beberapa contoh di Github dan kunjungi beberapa saluran Slack untuk mendapatkan saran.
https://github.com/ramitsurana/awesome-kubernetes
https://slack.k8s.io/
https://kubernetes.io/
whereisaaron
pada 24 Sep 2019
Kedengarannya bagus terima kasih. Saya hanya berharap tidak perlu mengubah layanan yang ada. Saya hanya ingin menangkap stdout/error mereka. Pokoknya untuk melakukan itu?
Janji driver log Docker adalah kesederhanaan. Apakah ada cara sederhana untuk melakukan ini?
ashleydavis
pada 24 Sep 2019
Tentu @ashleydavis , deploy cluster Anda, deploy fluentd , dan bang, selesai . Setiap aplikasi yang Anda terapkan akan mengirimkan stdout/stderr ke agregator favorit Anda. 👍
whereisaaron
pada 24 Sep 2019
Setelah menginvestasikan beberapa waktu ke dalam K8 dan masuk, saya telah menyiapkan tumpukan ELK yang bagus https://www.elastic.co/guide/en/beats/filebeat/current/running-on-kubernetes.html
Pengaturan saya adalah Filebeat yang menyalurkan log ke Logstash yang memfilter & mengekstrak dan menyalurkan barang-barang mereka ke Elasticsearch. Dengan Kibana saya dapat melihat log dan data agregat.
loxal
pada 24 Sep 2019
Saya juga ingin mendukung logging ke file syslog asli sistem operasi, misalnya: di Ubuntu saya dapat menulis log ke /var/log/syslog , yang dikelola oleh logrotate di luar kotak.
Dengan swarm/compose, saya bisa melakukan ini:
version: '3.3'
services:
mysql:
image: mysql:5.7
logging:
driver: syslog
options:
tag: mysql
Menggunakan volume emtpyDir baik-baik saja, namun, pod yang berjalan lama berisiko mengisi volume kecuali Anda menambahkan proses tambahan yang memutar / memotong file log. Saya tidak setuju dengan kerumitan tambahan ini ketika OS sudah menangani rotasi /var/log/syslog.
Saya setuju bahwa menggunakan sidecars untuk beberapa penerapan adalah ide bagus (saya sudah melakukan ini untuk beberapa penerapan saya), namun, lingkungan setiap orang berbeda.
 jsirianni
pada 5 Des 2019
jsirianni
pada 5 Des 2019
Menggunakan volume emtpyDir baik-baik saja
Hati-hati dengan mereka -- mereka dikelola oleh Kubernetes dan masa hidup mereka tidak dikendalikan oleh Anda. Jika sebuah pod dikeluarkan dan dijadwal ulang ke node lain -- log akan hilang. Jika Anda memperbarui pod dan uidnya berubah, itu tidak akan menggunakan volume lama melainkan membuat yang baru dan menghapus yang lama.
 php-coder
pada 5 Des 2019
php-coder
pada 5 Des 2019
@jsirianni tidak semua sistem menjalankan syslog yang berarti harus ada beberapa anotasi per-node pada fasilitas apa yang tersedia untuk memastikan kebutuhan pod tertentu terpenuhi. docker compose dapat membuat asumsi itu karena hanya berjalan secara lokal.
coffeepac
pada 6 Des 2019
@coffeepac Hanya karena node mungkin tidak memiliki syslog tidak berarti operator tidak memiliki opsi. Jika saya bermaksud menggunakan syslog, saya akan memastikan node pekerja saya memiliki syslog.
jsirianni
pada 6 Des 2019
Saya merasa masalah ini harus dibuka kembali karena masih ada cukup banyak kasus penggunaan untuk fitur ini.
/buka kembali
 saiyam1814
pada 27 Feb 2020
saiyam1814
pada 27 Feb 2020
@saiyam1814 :
Menanggapi hal ini :
Saya merasa masalah ini harus dibuka kembali karena masih ada cukup banyak kasus penggunaan untuk fitur ini.
/buka kembali
Instruksi untuk berinteraksi dengan saya menggunakan komentar PR tersedia di sini . Jika Anda memiliki pertanyaan atau saran terkait dengan perilaku saya, silakan ajukan masalah pada repositori kubernetes/test-infra .
k8s-ci-robot
pada 27 Feb 2020
Secara pribadi, saya masih berpikir Kubernetes harus mendukung driver log Docker atau cara bawaan sederhana lainnya untuk mengonfigurasi logging.
Saya telah diberitahu berkali-kali bahwa pengaturan logging itu mudah di Kubernetes, tetapi sekarang setelah melalui proses pengaturan sistem agregasi logging saya sendiri, saya dapat mengatakan bahwa itu benar-benar tidak sederhana.
Saya telah menulis posting blog tentang cara paling sederhana untuk menjalankan sistem agregasi log Anda sendiri untuk Kubernetes: http://www.the-data-wrangler.com/kubernetes-log-aggregation/
Semoga posting blog saya akan membantu orang lain mengetahui strategi mereka sendiri.
Seharusnya tidak terlalu sulit, tetapi di sinilah kita berada.
ashleydavis
pada 27 Feb 2020
Tentu kita memerlukan cara untuk menggunakan log Docker langsung dari stdout dan stderr, daripada menggunakan file log. Ada beberapa masalah keamanan untuk menggunakan jalur Docker untuk mencatat file, karena Anda dapat mengakses log lain di sistem host.
Bisakah kita mengimplementasikan driver log Docker? 👍
 Tetragramato
pada 2 Mar 2020
Tetragramato
pada 2 Mar 2020
Mengonfigurasi driver log buruh pelabuhan pada level container-in-a-pod (di mana pod berada dalam kendali pelanggan) akan memungkinkan pengalihan log dengan driver gelf langsung ke layanan/pod graylog (yang juga berada dalam kendali pelanggan ) daripada harus mengumpulkannya dari file di Host dengan layanan langsung lainnya (yang lebih banyak biaya manajemen dan tingkat abstraksi yang lebih buruk daripada menggunakan driver log gelf ) atau dengan pod pelanggan yang mengakses direktori log kontainer pada tuan rumah.
Oleh karena itu saya akan senang melihat fitur ini diimplementasikan di kubernetes.
 blubberdiblub
pada 10 Mar 2020
blubberdiblub
pada 10 Mar 2020
Akan sangat membantu untuk memastikan bahwa kami melakukan sesuatu seperti https://github.com/cri-o/cri-o/pull/1605 , di mana kami memutuskan interpretasi aliran log dari driver log sehingga perilaku kontainer tidak dapat memengaruhi caranya para pengemudi bekerja.
 portante
pada 10 Mar 2020
portante
pada 10 Mar 2020
Masalah busuk ditutup setelah 30 hari tidak aktif.
Buka kembali masalah dengan /reopen .
Tandai masalah sebagai baru dengan /remove-lifecycle rotten .
Kirim umpan balik ke sig-testing, kubernetes/test-infra dan/atau fejta .
/Menutup
fejta-bot
pada 9 Apr 2020
@fejta-bot: Menutup masalah ini.
Menanggapi hal ini :
Masalah busuk ditutup setelah 30 hari tidak aktif.
Buka kembali masalah dengan/reopen.
Tandai masalah sebagai baru dengan/remove-lifecycle rotten.Kirim umpan balik ke sig-testing, kubernetes/test-infra dan/atau fejta .
/Menutup
Instruksi untuk berinteraksi dengan saya menggunakan komentar PR tersedia di sini . Jika Anda memiliki pertanyaan atau saran terkait dengan perilaku saya, silakan ajukan masalah pada repositori kubernetes/test-infra .
k8s-ci-robot
pada 9 Apr 2020
Fungsi masih perlu diimplementasikan
/buka kembali
 M0rdecay
pada 9 Apr 2020
M0rdecay
pada 9 Apr 2020
@M0rdecay : Anda tidak dapat membuka kembali masalah/PR kecuali Anda yang menulisnya atau Anda adalah kolaborator.
Menanggapi hal ini :
Fungsi masih perlu diimplementasikan
/buka kembali
Instruksi untuk berinteraksi dengan saya menggunakan komentar PR tersedia di sini . Jika Anda memiliki pertanyaan atau saran terkait dengan perilaku saya, silakan ajukan masalah pada repositori kubernetes/test-infra .
k8s-ci-robot
pada 9 Apr 2020
@M0rdecay : Anda tidak dapat membuka kembali masalah/PR kecuali Anda yang menulisnya atau Anda adalah kolaborator.
Oke, saya mengerti
M0rdecay
pada 9 Apr 2020
Bahkan aws ecs memiliki fungsi ini di mana seseorang dapat mengatur driver logging buruh pelabuhan.
Di lingkungan kami, kami telah membuat indeks terpisah dengan token unik untuk setiap layanan kontainer.
"logKonfigurasi": {
"logDriver": "splunk",
"pilihan": {
"splunk-format": "mentah",
"splunk-insecureskipverify": "benar",
"splunk-token": "xxxxx-xxxxxxx-xxxxx-xxxxxxx-xxxxxx",
"splunk-url": " https://xxxxx.splunk-heavyforwarderxxx.com ",
"tag": "{{.Nama}}/{{.ID}}",
"splunk-verify-connection": "false",
"mode": "tanpa pemblokiran"
}
}
Tetapi tidak menemukan yang seperti ini di k8s. Itu harus ada di definisi pod itu sendiri.
 arshadsiddique-jfl
pada 10 Agu 2020
arshadsiddique-jfl
pada 10 Agu 2020
Opsi masih perlu diterapkan
/buka kembali
ejemba
pada 10 Agu 2020
@ejemba :
Menanggapi hal ini :
Opsi masih perlu diterapkan
/buka kembali
Instruksi untuk berinteraksi dengan saya menggunakan komentar PR tersedia di sini . Jika Anda memiliki pertanyaan atau saran terkait dengan perilaku saya, silakan ajukan masalah pada repositori kubernetes/test-infra .
k8s-ci-robot
pada 10 Agu 2020
/ tanda tangan simpul
/ hapus-sig instrumentasi
 logicalhan
pada 26 Agu 2020
logicalhan
pada 26 Agu 2020
/hapus-sig skalabilitas
logicalhan
pada 26 Agu 2020
@logicalhan : Label-label itu tidak disetel pada masalah: sig/
Menanggapi hal ini :
/hapus-sig skalabilitas
Instruksi untuk berinteraksi dengan saya menggunakan komentar PR tersedia di sini . Jika Anda memiliki pertanyaan atau saran terkait dengan perilaku saya, silakan ajukan masalah pada repositori kubernetes/test-infra .
k8s-ci-robot
pada 26 Agu 2020
Ada kemajuan dengannya?
Saya mencari secara khusus kemampuan untuk mengatur wadah pod untuk masuk ke logstash eksternal, menentukan driver log gelf buruh pelabuhan. Menyetelnya secara default untuk semua wadah di /etc/docker/daemon.json tampaknya menjadi overhead.
 freehck
pada 16 Sep 2020
freehck
pada 16 Sep 2020
Masalah busuk ditutup setelah 30 hari tidak aktif.
Buka kembali masalah dengan /reopen .
Tandai masalah sebagai baru dengan /remove-lifecycle rotten .
Kirim umpan balik ke sig-testing, kubernetes/test-infra dan/atau fejta .
/Menutup
fejta-bot
pada 16 Okt 2020
@fejta-bot: Menutup masalah ini.
Menanggapi hal ini :
Masalah busuk ditutup setelah 30 hari tidak aktif.
Buka kembali masalah dengan/reopen.
Tandai masalah sebagai baru dengan/remove-lifecycle rotten.Kirim umpan balik ke sig-testing, kubernetes/test-infra dan/atau fejta .
/Menutup
Instruksi untuk berinteraksi dengan saya menggunakan komentar PR tersedia di sini . Jika Anda memiliki pertanyaan atau saran terkait dengan perilaku saya, silakan ajukan masalah pada repositori kubernetes/test-infra .
k8s-ci-robot
pada 16 Okt 2020
/buka kembali
 andreswebs
pada 2 Nov 2020
andreswebs
pada 2 Nov 2020
@andreswebs : Anda tidak dapat membuka kembali masalah/PR kecuali Anda yang menulisnya atau Anda adalah kolaborator.
Menanggapi hal ini :
/buka kembali
Instruksi untuk berinteraksi dengan saya menggunakan komentar PR tersedia di sini . Jika Anda memiliki pertanyaan atau saran terkait dengan perilaku saya, silakan ajukan masalah pada repositori kubernetes/test-infra .
k8s-ci-robot
pada 2 Nov 2020
/buka kembali
ejemba
pada 3 Nov 2020
@ejemba :
Menanggapi hal ini :
/buka kembali
Instruksi untuk berinteraksi dengan saya menggunakan komentar PR tersedia di sini . Jika Anda memiliki pertanyaan atau saran terkait dengan perilaku saya, silakan ajukan masalah pada repositori kubernetes/test-infra .
k8s-ci-robot
pada 3 Nov 2020
@ejemba : Masalah ini sedang menunggu triase.
Jika SIG atau subproyek menentukan bahwa ini adalah masalah yang relevan, mereka akan menerimanya dengan menerapkan label triage/accepted dan memberikan panduan lebih lanjut.
Label triage/accepted dapat ditambahkan oleh anggota org dengan menulis /triage accepted di komentar.
Instruksi untuk berinteraksi dengan saya menggunakan komentar PR tersedia di sini . Jika Anda memiliki pertanyaan atau saran terkait dengan perilaku saya, silakan ajukan masalah pada repositori kubernetes/test-infra .
k8s-ci-robot
pada 3 Nov 2020
Saya sangat ingin fitur ini diterapkan. Saat ini saya memigrasikan beban kerja dari cluster Rancher 1.x ke cluster Rancher 2.x yang menjalankan k8s. Kami memiliki penerapan yang menetapkan parameter log-driver dan log-opt dalam konfigurasi docker-compose.
Saya tidak ingin harus mengonfigurasi satu Host tertentu untuk menggunakan driver gelf secara global dan memberi tag pada pod dengan label dan Host dengan label.
 bananflugan
pada 4 Nov 2020
bananflugan
pada 4 Nov 2020
Sepertinya kita harus mengubah CRI-O untuk menentukan bahwa kedua aliran log kontainer (stdout / stderr) dikumpulkan dalam bentuk mentah, dan saat membaca mentah untuk nanti kita dapat menerapkan interpretasi yang berbeda dari aliran byte log.
portante
pada 13 Nov 2020
Masalah busuk ditutup setelah 30 hari tidak aktif.
Buka kembali masalah dengan /reopen .
Tandai masalah sebagai baru dengan /remove-lifecycle rotten .
Kirim umpan balik ke sig-testing, kubernetes/test-infra dan/atau fejta .
/Menutup
fejta-bot
pada 13 Des 2020
@fejta-bot: Menutup masalah ini.
Menanggapi hal ini :
Masalah busuk ditutup setelah 30 hari tidak aktif.
Buka kembali masalah dengan/reopen.
Tandai masalah sebagai baru dengan/remove-lifecycle rotten.Kirim umpan balik ke sig-testing, kubernetes/test-infra dan/atau fejta .
/Menutup
Instruksi untuk berinteraksi dengan saya menggunakan komentar PR tersedia di sini . Jika Anda memiliki pertanyaan atau saran terkait dengan perilaku saya, silakan ajukan masalah pada repositori kubernetes/test-infra .
k8s-ci-robot
pada 13 Des 2020
Masalah terkait
 broady
·
3Komentar
broady
·
3Komentar
 errordeveloper
·
3Komentar
errordeveloper
·
3Komentar
 rhohubbuild
·
3Komentar
rhohubbuild
·
3Komentar
 ddysher
·
3Komentar
ddysher
·
3Komentar
 arun-gupta
·
3Komentar
arun-gupta
·
3Komentar
Komentar yang paling membantu
Hai, yang di sana,
Saya pikir ini adalah fitur penting yang harus dipertimbangkan untuk kubernetes.
Mengaktifkan penggunaan driver log Docker dapat memecahkan beberapa masalah non-sepele.
Saya akan mengatakan bahwa masuk ke disk adalah anti-pola. Log secara inheren "status", dan sebaiknya tidak disimpan ke disk. Pengiriman log langsung dari wadah ke repositori memecahkan banyak masalah.
Menyetel driver log berarti perintah kubectl logs tidak dapat menampilkan apa pun lagi.
Meskipun fitur tersebut "bagus untuk dimiliki" - fitur tersebut tidak akan diperlukan jika log tersedia dari sumber yang berbeda.
Docker sudah memiliki driver log untuk google cloud (gcplogs) dan Amazon (awslogs). Meskipun dimungkinkan untuk mengaturnya di daemon Docker itu sendiri, itu memiliki banyak kelemahan. Dengan dapat mengatur dua opsi buruh pelabuhan:
--log-driver= Logging driver untuk kontainer
--log-opt=[] Log opsi driver
Dimungkinkan untuk mengirim bersama label (untuk gcplogs) atau awslogs-group (untuk awslogs)
khusus untuk sebuah pod. Itu akan memudahkan untuk menemukan log di ujung yang lain.
Saya telah membaca tentang bagaimana orang menangani log di kubernetes. Banyak yang tampaknya menyiapkan beberapa pencakar rumit yang meneruskan log ke sistem pusat. Mampu mengatur driver log akan membuat itu tidak perlu - membebaskan waktu untuk mengerjakan hal-hal yang lebih menarik :)