Kubernetes: Definindo log-driver e log-opt ao especificar pod em RC e Pod
Precisamos ser capazes de definir as seguintes opções ao especificar a definição do pod em RC e Pod
--log-driver = Driver de registro para contêiner
--log-opt = [] Opções de driver de log
Essas opções devem ser configuráveis no nível do contêiner e foram introduzidas com o Docker 1.8.
Como a lib do cliente docker suporta ambas as opções, também é possível adicionar essas opções à definição do pod.
 ejemba
ejemba
Todos 117 comentários
/ cc @ kubernetes / rh-cluster-infra
 timothysc
em 13 out. 2015
timothysc
em 13 out. 2015
Hmm, acho que provavelmente queremos ser capazes de definir isso em todo o cluster como um padrão e, em seguida, talvez permitir que definições específicas de pod sejam substituídas.
cc @sosiouxme @smarterclayton @liggitt @jwhonce @jcantrill @bparees @jwforres
 ncdc
em 13 out. 2015
ncdc
em 13 out. 2015
Você pode descrever como alavancaria isso por contêiner (caso de uso)? Tradicionalmente, não expomos opções específicas do Docker diretamente em contêineres, a menos que possam ser abstraídas de forma limpa nos tempos de execução. Saber como você gostaria de usar isso ajudará a justificá-lo.
 smarterclayton
em 13 out. 2015
smarterclayton
em 13 out. 2015
Observe que os logs do docker ainda suportam apenas drivers de arquivo json e journald, embora eu imagine que a lista possa se expandir.
Talvez o que os usuários realmente desejem é uma seleção de pontos de extremidade de gravação de log definidos, não exposição aos detalhes do driver de log.
 sosiouxme
em 13 out. 2015
sosiouxme
em 13 out. 2015
@ncdc @smarterclayton Concordo com vocês dois, depois de reconsiderar nosso caso de uso interno, descobri que
- Nossa necessidade primária é proteger nossos nós. Enviamos os logs para um servidor de log, mas se ele falhar, os logs serão substituídos nos logs internos do docker. Nesse caso, para evitar a saturação do nó, precisamos de um comportamento amplo do cluster para docker log
- Expor opções específicas do docker nas definições de pod / Rc não é uma boa ideia, como @smarterclayton sugeriu. Também concordamos com uma abstração que permite a definição de comportamento de log de alto nível, se possível
- Outra opção é fazer alterações nos arquivos de configuração do kubelet e no código para lidar com esse comportamento de registro
ejemba
em 13 out. 2015
As mudanças nos modelos salt para torná-lo um padrão não devem ser
terrivelmente difícil. É realmente apenas a configuração adequada do daemon (e
lidar com quaisquer mudanças na agregação de log via fluentd em virtude de
selecionando uma fonte diferente)
Na terça, 13 de outubro de 2015 às 10:55, Epo Jemba [email protected]
escreveu:
@ncdc https://github.com/ncdc @smarterclayton
https://github.com/smarterclayton Concordo com vocês dois, depois
reconsiderando nosso caso de uso interno, descobriu-se que
- Nossa necessidade primária é proteger nossos nós. Enviamos os logs para um log
servidor, mas se falhar, registra o fallback nos logs internos do docker. Em tal
caso, para evitar a saturação do nó, precisamos de um comportamento de todo o cluster para
docker log- Expor opções específicas do docker nas definições de pod / Rc não é um
boa ideia como @smarterclayton https://github.com/smarterclayton
sugeriu. Também concordamos com uma abstração que permite a definição de alta
nível de comportamento do registro, se possível- Outra opção é fazer alterações nos arquivos de configuração kubelet e
código para lidar com esse comportamento de log-
Responda a este e-mail diretamente ou visualize-o no GitHub
https://github.com/kubernetes/kubernetes/issues/15478#issuecomment -147740136
.
smarterclayton
em 13 out. 2015
:afirmativo:
Observe que agora existem 9 drivers de registro . Qual é o consenso sobre como conseguir isso?
 halr9000
em 12 mai. 2016
halr9000
em 12 mai. 2016
+1
 briangebala
em 18 mai. 2016
briangebala
em 18 mai. 2016
Caso ninguém saiba, você pode definir o driver de log padrão por nó com um sinalizador para o daemon do Docker ( --log-driver ). Em meu ambiente, eu defino o driver como journald desta forma. Para ser honesto, tenho dificuldade em pensar em um caso de uso para substituir isso por contêiner.
 obeattie
em 18 mai. 2016
obeattie
em 18 mai. 2016
A maioria dos clusters não vai querer que seus logs fiquem "fora da banda", então qual é a ativação de recursos que isso forneceria.
Além disso, da perspectiva das operações, parece uma perda de controle. Atualmente, definimos os padrões e configuramos uma pilha de registro para agregar.
timothysc
em 18 mai. 2016
+1 sobre isso.
Não ser capaz de controlar como o registro do docker é tratado implica que a única opção de registro lógico é usar as ferramentas fornecidas com o k8s, o que é uma limitação incrível.
@timothysc aqui nosso caso de uso. Temos uma infraestrutura dinâmica complexa (~ 100 máquinas) com muitos serviços existentes em execução nelas, com nossos próprios logstash para coletar logs. Bem, agora estamos tentando mover nossos serviços, um por um, para k8s e, para mim, parece não haver uma maneira limpa de integrar o log entre nossa infraestrutura existente e os contêineres agrupados em k8s.
K8S é extremamente opinativo sobre como você coleta logs. Isso pode ser ótimo para quem está começando do zero em uma infraestrutura simples. Para todos os outros que trabalham em infraestruturas complexas que não se importariam em mergulhar fundo e implementar um mecanismo de registro personalizado, simplesmente não há maneira de fazer isso no momento, o que é bastante frustrante.
Felizmente, faz sentido.
 jnardiello
em 23 mai. 2016
jnardiello
em 23 mai. 2016
Portanto, em seu cenário, os registros são verdadeiramente "por aplicativo", mas você deve
garantir que o host subjacente suporte esses logs? Essa é a nossa preocupação
discutindo aqui - ou fazemos nível de cluster ou nível de nó, mas se fizermos
nível de pod, então o agendador teria que estar ciente de quais drivers de log
estão presentes onde. Tanto quanto possível, tentamos evitar isso.
Na segunda-feira, 23 de maio de 2016 às 10:50, Jacopo Nardiello < [email protected]
escreveu:
+1 sobre isso.
Não ser capaz de controlar como o registro do docker é tratado implica que o
apenas a opção de registro lógico está usando as ferramentas fornecidas com o k8s, que é um
limitação incrível.@timothysc https://github.com/timothysc aqui nosso caso de uso. Nós temos uma
infraestrutura dinâmica complexa (~ 100 máquinas) com muitas
serviços em execução neles, com nosso próprio logstash para coletar logs. Bem, nós
agora estão tentando mover nossos serviços, um por um, para k8s e para mim lá
parece não haver uma maneira limpa de integrar o registro entre nossos
infraestrutura e contêineres agrupados em k8s.K8S é extremamente opinativo sobre como você coleta logs. Isso pode ser ótimo
para quem está começando do zero em uma infraestrutura simples. Para
todos os outros trabalhando em infraestruturas complexas que não se importariam em
mergulhar fundo e implementar um mecanismo de registro personalizado, simplesmente não há
maneira de fazer isso no momento, o que é bastante frustrante.Felizmente, faz sentido.
-
Você está recebendo isso porque foi mencionado.
Responda a este e-mail diretamente ou visualize-o no GitHub
https://github.com/kubernetes/kubernetes/issues/15478#issuecomment -221002545
smarterclayton
em 23 mai. 2016
@smarterclayton Eu entendo suas preocupações e eles estão bem colocados. Não tenho certeza se todo o cluster deve estar ciente da existência de registro em nível de pod, o que acho que devemos fazer é dar a opção de registrar pod stdout / stderr em algum lugar (um arquivo baseado no nome do pod atual?) de modo que qualquer pessoa disposta a implementar sua solução personalizada teria um local permanente para obter o conteúdo. Isso abre um capítulo ENORME, pois a logrotação não é trivial.
Esses são apenas meus dois centavos, mas não podemos fingir que cenários complexos do mundo real simplesmente desistem de sua infraestrutura de registro existente.
jnardiello
em 26 mai. 2016
Você está especificando opções de log personalizadas por aplicativo? Quantos diferentes
conjuntos de opções de log que você teria por cluster? Se houver pequenos conjuntos de
config, uma opção seria oferecer suporte a uma anotação em pods que é
correlacionada à configuração de nível de nó que oferece uma série de "log padrão
opções ". Ou seja, no momento do lançamento do kubelet, defina um" modo de registro X "(que define
opções de log e driver personalizados), e o pod especificaria "
pod.alpha.kubernetes.io/log.mode=X ".
Outra opção seria expor uma maneira de permitir que os implantadores tenham
oportunidade de alterar a definição do contêiner imediatamente antes de começarmos
o contêiner. Isso é mais difícil hoje porque teríamos que serializar o
docker def out para um formato intermediário, execute-o e, em seguida, execute-o
novamente, mas potencialmente mais fácil no futuro.
Finalmente, poderíamos expor pares de valores-chave na interface do contêiner que
são passados para o mecanismo de contêiner diretamente, não oferecem garantias de API para
eles e garantir que a PodSecurityPolicy possa regular essas opções. Isso iria
ser a saída de emergência para os chamadores, mas não seríamos capazes de fornecer qualquer
garantir que eles continuem a funcionar em todas as versões.
Em quinta-feira, 26 de maio de 2016 às 5h34, Jacopo Nardiello [email protected]
escreveu:
@smarterclayton https://github.com/smarterclayton Eu entendo sobre
suas preocupações e eles estão bem colocados. Não tenho certeza se todo o cluster
deve estar ciente da existência de registro em nível de pod, o que eu acho que
deve fazer é dar a opção de registrar o pod stdout / stderr em algum lugar (um arquivo
com base no nome do pod atual?) para que qualquer pessoa disposta a implementar
solução personalizada, teria um local persistente onde obter o conteúdo.
Isso abre um capítulo ENORME, pois a logrotação não é trivial.Estes são apenas meus dois centavos, mas não podemos fingir que o complexo do mundo real
os cenários simplesmente desistem de sua infraestrutura de registro existente.-
Você está recebendo isso porque foi mencionado.
Responda a este e-mail diretamente ou visualize-o no GitHub
https://github.com/kubernetes/kubernetes/issues/15478#issuecomment -221823732
smarterclayton
em 26 mai. 2016
@smarterclayton você viu https://github.com/kubernetes/kubernetes/issues/24677#issuecomment -220735829
ncdc
em 26 mai. 2016
Não, obrigado. Movendo a discussão lá.
Na quinta-feira, 26 de maio de 2016 às 11h23, Andy Goldstein [email protected]
escreveu:
@smarterclayton https://github.com/smarterclayton você viu # 24677
(Comente)
https://github.com/kubernetes/kubernetes/issues/24677#issuecomment -220735829-
Você está recebendo isso porque foi mencionado.
Responda a este e-mail diretamente ou visualize-o no GitHub
https://github.com/kubernetes/kubernetes/issues/15478#issuecomment -221903781
smarterclayton
em 26 mai. 2016
Olá,
Acho que esse é um recurso importante que deve ser considerado para o kubernetes.
Habilitar o uso do driver de log do Docker pode resolver alguns problemas não triviais.
Eu diria que o registro no disco é um anti-padrão. Os logs são inerentemente "estado" e, de preferência, não devem ser salvos no disco. Enviar os logs diretamente de um contêiner para um repositório resolve muitos problemas.
Definir o driver de log significaria que o comando kubectl logs não mostraria mais nada.
Embora esse recurso seja "bom ter", ele não será necessário quando os logs estiverem disponíveis em uma fonte diferente.
O Docker já tem drivers de log para google cloud (gcplogs) e Amazon (awslogs). Embora seja possível defini-los no próprio daemon do Docker, isso tem muitas desvantagens. Ao ser capaz de definir as duas opções do docker:
--log-driver = Driver de registro para contêiner
--log-opt = [] Opções de driver de log
Seria possível enviar etiquetas (para gcplogs) ou awslogs-group (para awslogs)
específico para um pod. Isso tornaria mais fácil encontrar os logs na outra extremidade.
Tenho lido sobre como as pessoas estão lidando com registros no kubernetes. Muitos parecem instalar alguns raspadores elaborados que encaminham as toras para sistemas centrais. Ser capaz de definir o driver de log tornará isso desnecessário - liberando tempo para trabalhar em coisas mais interessantes :)
 pbthorste
em 30 nov. 2016
pbthorste
em 30 nov. 2016
Também posso acrescentar que algumas pessoas, inclusive eu, desejam executar a rotação de logs do docker por meio da opção '--log-opt max-size' no driver de log JSON (que é nativo do docker) em vez de configurar o logrotate no host. Assim, mesmo expondo apenas a opção '--log-opt' seria muito apreciado
 daniilyar
em 12 dez. 2016
daniilyar
em 12 dez. 2016
Eu modifiquei o k8s, ao criar o LogConfig de configuração de contêiner.
 barnettZQG
em 12 dez. 2016
barnettZQG
em 12 dez. 2016
+1
Usar o driver docker log para coleta de log centralizada parece muito mais simples do que criar links simbólicos para arquivos de log, montando-os em um contêiner fluentd especial, acompanhando-os e gerenciando a rotação do log.
 defat
em 27 dez. 2016
defat
em 27 dez. 2016
Caso de uso para configuração por contêiner: quero registrar em outro lugar ou de forma diferente para contêineres que implanto e não me importo (ou quero mudar) o driver de registro para os contêineres padrão necessários para executar o Kubernetes.
Ai está. Por favor, faça isso acontecer.
 et304383
em 12 jan. 2017
et304383
em 12 jan. 2017
Outra ideia é que todos os contêineres ainda encaminhem logs para o mesmo ponto de extremidade, mas você pode pelo menos definir valores de campos diferentes para contêineres docker diferentes em seu servidor de log.
Isso funcionaria para o driver docker gelf, se pudéssemos garantir que os contêineres docker criados pelo Kubernetes sejam rotulados de forma personalizada. Significado: alguns dos campos de um pod podem ser encaminhados como rótulos de contêiner do docker. (Talvez isso já seja possível, mas não sei como fazer).
Exemplo sem Kubernetes, apenas com docker daemon e driver gelf. Configure o daemon do docker com: --log-driver=gelf --log-opt labels=env,label2 e crie um contêiner do docker:
docker run -dti --label env=testing --label label2=some_value alpine:3.4 /bin/sh -c "while true; do date; sleep 2; done"
e outro contêiner docker:
docker run -dti --label env=production --label label2=some_value alpine:3.4 /bin/sh -c "while true; do date; sleep 2; done"
Desta forma, no Graylog, você pode diferenciar entre env=production e env=testing contêineres.
Atualmente, eu uso essas opções de daemon do docker:
--log-driver=gelf --log-opt gelf-address=udp://graylog.example.com:12201 --log-opt tag=k8s-testing --log-opt labels=io.kubernetes.pod.namespace,io.kubernetes.container.name,io.kubernetes.pod.name
 xmik
em 12 jan. 2017
xmik
em 12 jan. 2017
@xmik , apenas o que confirmar se é um recurso existente ou sua proposta a respeito
Atualmente, eu uso essas opções de daemon do docker:
--log-driver=gelf --log-opt gelf-address=udp://graylog.example.com:12201 --log-opt tag=k8s-testing --log-opt labels=io.kubernetes.pod.namespace,io.kubernetes.container.name,io.kubernetes.pod.name
 stainboy
em 26 jan. 2017
stainboy
em 26 jan. 2017
Essas opções do daemon do docker que uso atualmente já funcionam. O Kubernetes já define alguns rótulos para cada contêiner do docker. Por exemplo, ao executar docker inspect no contêiner kube-apiserver:
"Labels": {
"io.kubernetes.container.hash": "4959a3f5",
"io.kubernetes.container.name": "kube-apiserver",
"io.kubernetes.container.ports": "[{\"name\":\"https\",\"hostPort\":6443,\"containerPort\":6443,\"protocol\":\"TCP\"},{\"name\":\"local\",\"hostPort\":8080,\"containerPort\":8080,\"protocol\":\"TCP\"}]",
"io.kubernetes.container.restartCount": "1",
"io.kubernetes.container.terminationMessagePath": "/dev/termination-log",
"io.kubernetes.pod.name": "kube-apiserver-k8s-production-master-1",
"io.kubernetes.pod.namespace": "kube-system",
"io.kubernetes.pod.terminationGracePeriod": "30",
"io.kubernetes.pod.uid": "a47396d9dae12c81350569f56aea562e"
}
Portanto, essas opções de daemon do docker funcionam.
No entanto, acho que agora não é possível fazer o Kubernetes definir rótulos personalizados em um contêiner do docker com base nas especificações do pod. Portanto, por exemplo, --log-driver=gelf --log-opt labels=env,label2 não funciona.
xmik
em 26 jan. 2017
Há alguma novidade nesta frente? Ter a capacidade de especificar os rótulos e, em seguida, aproveitar --log-opt labels<> seria muito bom!
 beldpro-ci
em 18 mar. 2017
beldpro-ci
em 18 mar. 2017
@portante @jcantrill Apenas para capturá-lo aqui porque o discutimos, aqui está o caso de uso para o qual pensamos que poderia ser útil:
Quando os pods de gravação de log começarem a encontrar e registrar erros, o infra que reúne esses erros os pegará e os enviará de volta ao mecanismo de gravação que, por sua vez, lança e registra mais erros.
Este ciclo de feedback pode ser evitado usando mecanismos de filtragem, mas isso é um pouco frágil. Usar um driver de log diferente para gravar em um arquivo e ter opções de rotação parece ser uma boa solução.
 pweil-
em 31 mar. 2017
pweil-
em 31 mar. 2017
Meus 2 centavos.
As soluções atuais para registro dentro de k8s são (AFAIK):
- contêiner de sidecar enviando registros para algum lugar
- controlador de replicação enviando todos os logs para algum lugar
- o próprio contêiner enviando logs para algum lugar
O contêiner de sidecar parece meio exagero para mim. A estratégia do controlador de replicação parece boa, mas mistura logs de contêineres de todas as implantações, e alguns usuários podem agora querer isso e, em vez disso, registrar cada aplicativo em uma coisa diferente. Para esses casos, a última opção funciona melhor IMHO, mas cria uma grande quantidade de código replicado em todos os contêineres (por exemplo: instalar e configurar daemon de logentries).
Tudo isso seria muito mais fácil se tivéssemos acesso aos sinalizadores log-driver , de modo que cada implantação definiria como deveria ser registrada, usando recursos nativos do docker.
Posso tentar implementar isso, mas provavelmente precisarei de ajuda - já que não estou familiarizado com a base de código do kubernetes.
 caarlos0
em 17 mai. 2017
caarlos0
em 17 mai. 2017
quando a multilocação se tornar mais comum, será mais difícil resolvê-la adequadamente.
Cada namespace pode ser um locatário diferente, portanto, os logs de cada um não devem ser necessariamente agregados, mas podem ser enviados a locais especificados pelo locatário.
Posso pensar em algumas maneiras de fazer isso:
- faça um novo tipo de volume, contêiner-logs. Isso permite que um daemonset iniciado por um determinado namespace acesse apenas os logs de seus próprios contêineres. Eles podem então enviar os logs com qualquer remetente de log de sua escolha para qualquer daemon de armazenamento de escolha.
- Modifique um (ou mais) dos remetentes de log, como fluentd-bit para ler o namespace em que o pod está, e redirecione os logs de cada pod para outro remetente de log em execução nesse namespace como um serviço. Como fluentd. Isso novamente permite que o namespace configure seu próprio remetente de log para enviar para qualquer back-end de log que eles desejam oferecer suporte.
 kfox1111
em 17 mai. 2017
kfox1111
em 17 mai. 2017
@ caarlos0 @ kfox1111 concordo com seus pontos. Este é um tema complexo, pois requer coordenação de instrumentação, armazenamento, nó e talvez até mais equipes. Eu sugiro ter uma proposta para a arquitetura de registro geral apresentada primeiro e, em seguida, discutir a mudança para esta visão consistente. Espero que essa proposta apareça em mais ou menos um mês, trazendo ordem e resolvendo todos os problemas mencionados.
 crassirostris
em 17 mai. 2017
crassirostris
em 17 mai. 2017
@crassirostris Não tenho certeza se entendi: se apenas permitirmos log-driver et al, não teremos que lidar com armazenamento ou nada disso, certo?
O docker está apenas enviando seu STDOUT para qualquer driver de log configurado em uma base de contêiner, certo? Nós meio que passamos a responsabilidade para o contêiner ... parece uma solução muito simples para mim - mas, como eu disse, não conheço a base de código, então talvez eu esteja simplesmente errado ...
caarlos0
em 17 mai. 2017
O problema é que o driver de log no docker não adiciona nenhum dos metadados do k8s que torna o consumo dos logs mais tarde realmente útil. : /
kfox1111
em 17 mai. 2017
@ kfox1111 hmm, faz sentido ...
mas, e se o usuário quiser apenas os logs do "aplicativo", não os logs do kubernetes, nem os logs do docker, apenas o aplicativo em execução nos logs do contêiner?
Nesse caso, parece-me que log-driver funcionaria ...
caarlos0
em 17 mai. 2017
@ caarlos0 Pode ter algumas implicações, por exemplo, o kubelet faz algumas suposições sobre o formato de log para os logs do kubectl do servidor.
Mas, deixando as coisas de lado, log-driver per se é específico do Docker e pode não funcionar para outros tempos de execução, esse é o principal motivo para não incluí-lo na API.
crassirostris
em 17 mai. 2017
@crassirostris isso faz sentido ...
uma vez que este recurso não será adicionado (conforme descrito no problema), talvez este problema deva ser fechado (ou editado ou qualquer outra coisa)?
caarlos0
em 17 mai. 2017
@ caarlos0 No entanto, definitivamente queremos tornar a configuração de registro mais flexível e transparente. Agradecemos seu feedback sobre a proposta!
crassirostris
em 17 mai. 2017
O registro stdout de contêineres atualmente é tratado fora de banda no Kubernetes. No momento, contamos com soluções não Kubernetes para lidar com o registro, ou contêineres privilegiados que desbloqueiam o Kubernetes para obter acesso ao registro fora de banda. O registro em tempo de execução do contêiner é diferente por tempo de execução (docker, rkt, Windows), portanto, escolher qualquer um, como Docker --log-driver, é criar uma bagagem futura.
Eu sugiro que precisamos do kubelet para trazer os fluxos de registro de volta dentro da banda. Defina ou escolha um formato de registro JSON ou XML mínimo, que colete linhas stdout de cada contêiner, adicione um cluster + namespace + pod + metadados do contêiner mínimo, para que a fonte de registro seja identificada dentro do espaço Kubernetes e direcione o fluxo para um serviço Kubernetes + Porta. Os usuários são livres para fornecer qualquer serviço de consumo de log de sua preferência. Talvez o Kubernetes forneça um serviço de referência / padrão que implemente o suporte a 'logs de kubectl'.
Sem um serviço de consumo de registro especificado, os registros serão descartados e nem chegarão ao disco . Transmitir os logs em outro lugar, ou gravar em armazenamento persistente e rotativo, tudo isso é responsabilidade / decisão do Serviço.
O wrapper de tempo de execução do contêiner kubelet faz o mínimo para extrair o stdout de cada tempo de execução do contêiner e trazê-lo de volta dentro da banda para o (s) serviço (s) auto-hospedado k8s consumir e processar.
A especificação do contêiner na implantação ou pod especifica opcionalmente o serviço e a porta de destino para o registro stdout. Adicionar metadados k8s para cluster + namespace + pod + container seria opcional (então a escolha de bruto / intocado ou com metadados). Os usuários seriam livres para agregar todos os logs a um local, ou agregá-los por locatário, namespace ou aplicativo.
O mais próximo disso agora é executar um serviço que usa 'kubectl logs -f' para transmitir logs de contêiner para cada contêiner por meio do servidor de API. Isso não parece muito eficiente ou escalonável. Esta proposta permitiria uma transmissão direta mais eficiente do wrapper de tempo de execução do contêiner direto para o serviço ou pod, com otimizações como a preferência de implantação de registro ou pods de Daemonset no mesmo nó e o contêiner que gera os registros.
Estou propondo que o Kubernetes deve fazer o mínimo para trazer registros de tempo de execução do contêiner dentro da banda, para qualquer solução de registro auto-hospedada, homogênea ou heterogênea que possamos criar no espaço do Kubernetes.
O que as pessoas pensam?
 whereisaaron
em 18 mai. 2017
whereisaaron
em 18 mai. 2017
@whereisaaron Eu realmente gostaria de não ter essa discussão agora, quando não temos todos os detalhes sobre o ecossistema madeireiro em um só lugar.
Por exemplo, vejo problemas de rede e máquina interrompendo o fluxo de log, mas, novamente, não quero discutir isso ainda. Que tal discutirmos isso mais tarde, quando a proposta estiver pronta? Parece razoável para você?
crassirostris
em 18 mai. 2017
Certamente @crassirostris. Informe-nos aqui quando a proposta estiver pronta para check-out.
whereisaaron
em 20 mai. 2017
escalabilidade / sig
 kargakis
em 10 jun. 2017
kargakis
em 10 jun. 2017
Embora --log-driver e --log-opt sejam opções para o daemon do Docker e não recursos do k8s, seria bom especificá-los nas especificações do pod k8s para:
- driver de log por pod e não um único driver de log no nível do nó
- diferentes tipos de drivers de log específicos do aplicativo (fluentd, syslog, journald, splunk) no mesmo nó
- defina
--log-optpara configurar a rotação de registro para um pod - configurações por pod
--log-opte não um único nível de nó--log-opt
AFAIK, nenhuma das opções acima pode ser definida no nível do pod na especificação do pod k8s hoje.
 vhosakot
em 13 dez. 2017
vhosakot
em 13 dez. 2017
@vhosakot nenhuma das opções acima pode ser definida em qualquer nível no Kubernetes, porque esses não são conceitos do Kubernetes
crassirostris
em 13 dez. 2017
@crassirostris exatamente! :)
Se o k8s fizer tudo o que o Docker faz no nível de pod / contêiner, não será fácil para os usuários? Por que fazer os usuários usarem o Docker para poucas coisas no nível de pod / contêiner?
E, um amante do K8s e não um fã do Docker pode fazer a mesma pergunta.
vhosakot
em 13 dez. 2017
@vhosakot Point é, há vários outros tempos de execução de contêiner que podem ser usados com K8s, mas --log-opt existe apenas no Docker. Criar tal opção no nível K8s seria intencionalmente vazar a abstração. Não acho que este seja o caminho que queremos seguir. Se houver uma opção, ela deve ser compatível com todos os tempos de execução do contêiner, de preferência, fazer parte do CRI
Não estou dizendo que não haverá essa opção, estou dizendo que não será uma rota direta para o Docker
crassirostris
em 13 dez. 2017
@crassirostris Verdadeiro, parece que tudo se resume a se o k8s deve fazer o que o CRI faz / permite no nível de pod / contêiner, não específico do Docker.
vhosakot
em 13 dez. 2017
Sim, absolutamente correto
crassirostris
em 13 dez. 2017
Embora eu esteja atrasado para esta discussão e tenha interesse em ver esse recurso implementado, eu diria que há uma compensação entre ter um design bonito e ter uma maneira direta de configurar uma solução de registro sã e uniforme para o cluster. Sim, ter esse recurso implementado exporia o docker interno, o que é um grande não, mas ao mesmo tempo eu poderia apostar um bom dinheiro que a maioria dos usuários do K8S usa o docker, pois a tecnologia de contêiner subjacente e o docker vêm com uma lista muito abrangente de drivers de log.
 gabriel-tincu
em 19 dez. 2017
gabriel-tincu
em 19 dez. 2017
@ gabriel-tincu Atualmente não estou convencido de que o FR original valha a pena
docker vem com uma lista muito abrangente de drivers de registro
Você pode configurar o log no nível do Docker durante a etapa de implantação do K8s e usar qualquer um desses drivers de log, sem vazar essas informações para o K8s. A única coisa que você não pode fazer hoje é configurar essas opções por contêiner / por pod (na verdade, você pode ter uma configuração com nós dedicados e usar seletor de nó), mas não tenho certeza se é uma grande limitação.
crassirostris
em 19 dez. 2017
@crassirostris Eu concordo que você pode configurar isso __antes__ configurando o ambiente, mas se houver uma maneira de atualizar ativamente o driver do docker log depois que o ambiente já estiver configurado, então não consigo entender no momento
gabriel-tincu
em 12 jan. 2018
@ gabriel-tincu @vhosakot a interface direta que existia entre o k8s e o Docker nos 'tempos antigos' de> = 1.5 está obsoleta e acredito que o código foi totalmente removido agora. Tudo entre o kubelet e os tempos de execução, como o Docker (ou os outros como rkt, cri-o, runc, lxd), passa pelo CRI. Existem muitos tempos de execução de contêiner agora e o próprio Docker provavelmente será descontinuado e removido em breve em favor de cri-containerd + containerd .
http://blog.kubernetes.io/2017/11/containerd-container-runtime-options-kubernetes.html
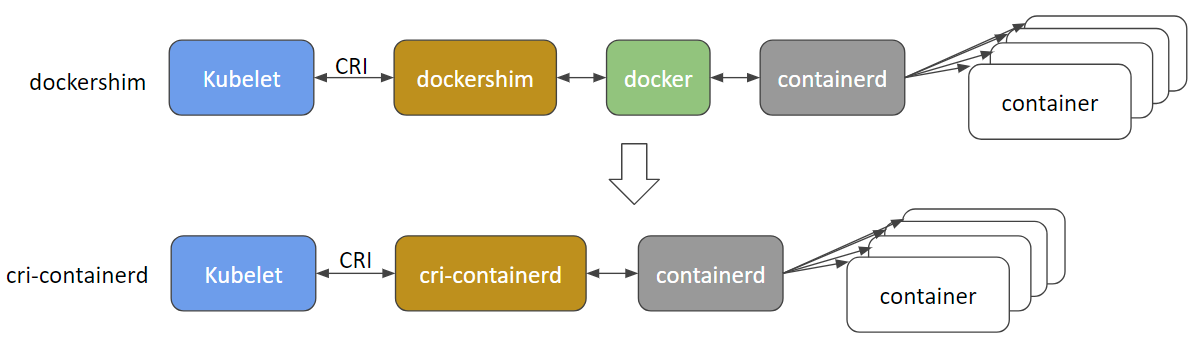
@crassirostris algum movimento em uma proposta, que possa ter a possibilidade de log de contêineres em banda?
whereisaaron
em 12 jan. 2018
O log do contêiner CRI é baseado em arquivo (https://github.com/kubernetes/community/blob/master/contributors/design-proposals/node/kubelet-cri-logging.md), e o caminho do log é definido explicitamente:
/var/log/pods/PodUID/ContainerName/RestartCount.log
Na maioria dos drivers de registro do docker https://docs.docker.com/config/containers/logging/configure/#supported -logging-drivers, acho que para o ambiente de cluster, os mais importantes são os drivers que ingerem log de contêiner no cluster sistema de gerenciamento de registro, como splunk , awslogs , gcplogs etc.
No caso de CRI, nenhum "driver docker log" deve ser usado. As pessoas podem executar um daemonset para ingerir logs de contêiner do diretório de log de contêiner CRI para onde quiserem. Eles podem usar fluentd ou até mesmo escrever um daemonset por si próprios.
Se mais metadados forem necessários, podemos pensar em descartar um arquivo de metadados, estender o caminho do arquivo ou deixar o daemonset obter metadados do apiserver. Há uma discussão em andamento sobre isso https://github.com/kubernetes/kubernetes/issues/58638
 Random-Liu
em 22 fev. 2018
Random-Liu
em 22 fev. 2018
Os problemas ficam obsoletos após 90 dias de inatividade.
Marque o problema como novo com /remove-lifecycle stale .
Problemas obsoletos apodrecem após 30 dias adicionais de inatividade e, eventualmente, fecham.
Se for seguro encerrar este problema agora, faça-o com /close .
Envie feedback para sig-testing, kubernetes / test-infra e / ou fejta .
/ lifecycle stale
 fejta-bot
em 23 mai. 2018
fejta-bot
em 23 mai. 2018
Problemas obsoletos apodrecem após 30 dias de inatividade.
Marque o problema como novo com /remove-lifecycle rotten .
Problemas podres são encerrados após 30 dias adicionais de inatividade.
Se for seguro encerrar este problema agora, faça-o com /close .
Envie feedback para sig-testing, kubernetes / test-infra e / ou fejta .
/ lifecycle podre
/ remove-lifecycle stale
fejta-bot
em 22 jun. 2018
/ remove-lifecycle podre
 iavael
em 25 jun. 2018
iavael
em 25 jun. 2018
alguma atualização sobre isso? então, como alguém executando k8s com contêineres Docker estabeleceu o registro em algum back-end como o AWS CloudWatch?
 bryan831
em 4 jul. 2018
bryan831
em 4 jul. 2018
@ bryan831 é comum coletar os arquivos de log do contêiner k8s usando fluentd ou semelhante e agregá-los em sua escolha de back-end, CloudWatch, StackDriver, Elastisearch etc.
Existem gráficos do Helm disponíveis no mercado para, por exemplo, fluentd + CloudWatch , fluentd + Elastisearch , fluent-bit-> fluentd-> sua escolha , Datadog e provavelmente outras combinações, se você vasculhar.
whereisaaron
em 4 jul. 2018
Os problemas ficam obsoletos após 90 dias de inatividade.
Marque o problema como novo com /remove-lifecycle stale .
Problemas obsoletos apodrecem após 30 dias adicionais de inatividade e, eventualmente, fecham.
Se for seguro encerrar este problema agora, faça-o com /close .
Envie feedback para sig-testing, kubernetes / test-infra e / ou fejta .
/ lifecycle stale
fejta-bot
em 2 out. 2018
Seria bom poder personalizar as opções --log-opt do Docker. No meu caso, gostaria de usar uma tag como '--log-opt tag = "{{. ImageName}} / {{. Name}} / {{. ID}}"' para emitir ImageName para os registros para que eu saiba de qual versão do contêiner vêm os registros. (Referência: https://docs.docker.com/config/containers/logging/log_tags/)
 pmahalwar-intertrust
em 26 out. 2018
pmahalwar-intertrust
em 26 out. 2018
/ remove-lifecycle stale
pmahalwar-intertrust
em 26 out. 2018
@ pmahalwar-intertrust você pode passar o mesmo --log-opt para o daemon do docker, o que afetará todos os seus contêineres ...
 nrobert13
em 26 out. 2018
nrobert13
em 26 out. 2018
@ pmahalwar-intertrust os logs coletados de containerd pelo kubernetes já incluem metadados extensos, incluindo todos os rótulos que você aplicou ao contêiner. Se você coletar com fluentd você obterá todos os metadados, por exemplo, como na entrada de registro abaixo.
{
"log": " - [] - - [25/Oct/2018:06:29:48 +0000] \"GET /nginx_status/format/json HTTP/1.1\" 200 9250 \"-\" \"Go-http-client/1.1\" 118 0.000 [internal] - - - - 5eb73997a372badcb4e3d993ceb44cd9\n",
"stream": "stdout",
"docker": {
"container_id": "3657e1d9a86e629d0dccefec0c3c7624eaf0c4a11f60f53c5045ec0839c37f06"
},
"kubernetes": {
"container_name": "nginx-ingress-controller",
"namespace_name": "ingress",
"pod_name": "nginx-ingress-dev-controller-69c644f7f5-vs8vw",
"pod_id": "53514ad6-d0f4-11e8-a04c-02c433fc5820",
"labels": {
"app": "nginx-ingress",
"component": "controller",
"pod-template-hash": "2572009391",
"release": "nginx-ingress-dev"
},
"host": "ip-172-29-21-204.us-east-2.compute.internal",
"master_url": "https://10.3.0.1:443/api",
"namespace_id": "e262510b-180a-11e8-b763-0a0386e3402c"
},
"kubehost": "ip-172-29-21-204.us-east-2.compute.internal"
}
Ainda não há um plano para oferecer suporte a esses recursos?
--log-driver = Driver de registro para contêiner
--log-opt = [] Opções de driver de log
 lifubang
em 8 nov. 2018
lifubang
em 8 nov. 2018
Olá @lifubang, não posso falar sobre os planos de ninguém, mas o daemon que suportava esses recursos, dockerd não faz mais parte do Kubernetes (consulte a discussão acima).
Você ainda pode instalá-lo opcionalmente se quiser, então você pode fazer isso para usar os antigos dockerd drivers de log. Essa opção é discutida aqui:
https://kubernetes.io/blog/2018/05/24/kubernetes-containerd-integration-goes-ga/
Mas usar um serviço de registro dedicado como fluentd é a abordagem sugerida. Você pode implantá-lo globalmente para seu cluster ou por pod como um arquivo secundário. O registro no Kubernetes é discutido aqui:
https://kubernetes.io/docs/concepts/cluster-administration/logging/
whereisaaron
em 8 nov. 2018
Eu recomendo altamente fluentd conforme descrito por @whereisaaron
No que diz respeito a esta solicitação de recurso sendo trabalhada ... o roteiro arquitetônico do kubernetes tem registro na seção "Ecossistema" de coisas que não são realmente "parte" do kubernetes, então duvido que tal recurso venha a ter suporte nativo.
https://github.com/kubernetes/community/blob/master/contributors/devel/architectural-roadmap.md#summarytldr
 taylorshaulis
em 8 nov. 2018
taylorshaulis
em 8 nov. 2018
Eu recomendo fortemente contra o uso do fluentd, pois ele tem vários bugs que podem tornar sua vida difícil ao executar o k8s
in_tail evita que o docker remova o contêiner https://github.com/fluent/fluentd/issues/1680.
in_tail remove a posição do arquivo não rastreado durante a fase de inicialização. Isso significa que o conteúdo de pos_file está crescendo até a reinicialização e pode consumir uma tonelada de varredura da CPU quando você controla muitos arquivos com configuração de caminho dinâmico.
https://github.com/fluent/fluentd/issues/1126.
 roffe
em 6 dez. 2018
roffe
em 6 dez. 2018
Os problemas ficam obsoletos após 90 dias de inatividade.
Marque o problema como novo com /remove-lifecycle stale .
Problemas obsoletos apodrecem após 30 dias adicionais de inatividade e, eventualmente, fecham.
Se for seguro encerrar este problema agora, faça-o com /close .
Envie feedback para sig-testing, kubernetes / test-infra e / ou fejta .
/ lifecycle stale
fejta-bot
em 21 mar. 2019
Obrigado pela sua experiência @roffe. fluent / fluentd # 1680 era um problema por volta do k8s 1.5 e não usávamos 'in_tail' naquela época por esse motivo. Desde que k8s mudou para containerd log não parece ser ainda uma coisa? Não vimos nenhum impacto detectável do fluent / fluentd # 1126.
Você recomendou contra fluentd . O que você recomendaria em vez disso? O que você usa pessoalmente em vez de fluentd para agregação de log com metadados k8s?
whereisaaron
em 21 mar. 2019
Problemas obsoletos apodrecem após 30 dias de inatividade.
Marque o problema como novo com /remove-lifecycle rotten .
Problemas podres são encerrados após 30 dias adicionais de inatividade.
Se for seguro encerrar este problema agora, faça-o com /close .
Envie feedback para sig-testing, kubernetes / test-infra e / ou fejta .
/ lifecycle podre
fejta-bot
em 20 abr. 2019
Problemas podres são encerrados após 30 dias de inatividade.
Reabra o problema com /reopen .
Marque o problema como novo com /remove-lifecycle rotten .
Envie feedback para sig-testing, kubernetes / test-infra e / ou fejta .
/fechar
fejta-bot
em 20 mai. 2019
@ fejta-bot: Fechando este problema.
Em resposta a isso :
Problemas podres são encerrados após 30 dias de inatividade.
Reabra o problema com/reopen.
Marque o problema como novo com/remove-lifecycle rotten.Envie feedback para sig-testing, kubernetes / test-infra e / ou fejta .
/fechar
Instruções para interagir comigo usando comentários de RP estão disponíveis aqui . Se você tiver dúvidas ou sugestões relacionadas ao meu comportamento, registre um problema no repositório kubernetes / test-infra .
 k8s-ci-robot
em 20 mai. 2019
k8s-ci-robot
em 20 mai. 2019
Isso não deveria ter sido fechado, deveria?
A solicitação de recurso ainda faz sentido para mim, pois estou tentando definir as opções de log por pod (sem configurá-lo no daemon ou usar logrotate) ...
 yzargari
em 27 ago. 2019
yzargari
em 27 ago. 2019
Tenho quase certeza de que o suporte a opções de configuração específicas do docker de dentro do k8s não é uma boa ideia. Como mencionado anteriormente, um daemonset fluentd ou um side car fluenbit são as opções atuais. Eu prefiro o sidecar porque é muito mais seguro.
 coffeepac
em 29 ago. 2019
coffeepac
em 29 ago. 2019
@whereisaaron você encontrou uma solução de registro para K8s @ containerd?
 loxal
em 11 set. 2019
loxal
em 11 set. 2019
--log-driver, --log-opt ainda não são suportados?
Estou tentando encontrar uma maneira de encaminhar os logs de um único pod para o Splunk. alguma ideia?
 sariel1212
em 15 set. 2019
sariel1212
em 15 set. 2019
@ sariel1212 para um único pod, eu recomendo incluir um contêiner de carro lateral em seu pod que é apenas o agente de despacho da splunk. Você pode compartilhar um volume emptydir entre todos os contêineres no pod e fazer com que os contêineres do aplicativo gravem seus registros no emptydir compartilhado. Em seguida, faça com que o contêiner do encaminhador de splunk leia esse volume e os encaminhe.
coffeepac
em 16 set. 2019
Se você deseja coletar no Splunk para todo o seu cluster @ sariel1212 , há um gráfico Splunk helm oficial para implantar fluentd com o plug-in Splunk HEC fluentd para coletar logs de nó, log de contêiner e logs de plano de controle, além de objetos Kubernetes e métricas de cluster Kubernetes. Para um Pod @coffeepac , a sugestão de um sidecar com um emptydir compartilhado é uma boa abordagem.
whereisaaron
em 16 set. 2019
É terrível que ainda não haja uma maneira de um proprietário de cluster usar drivers de log do Docker depois de todo esse tempo.
Consegui configurar muito rapidamente com o Docker-Compose (simulando meu cluster K8s) para canalizar todos os stdout / err para meu serviço agregado de log.
Quer fazer isso no Kubenetes? A partir deste tópico, parece que terei que aumentar o código para cada microsserviço! Não é bom.
 ashleydavis
em 24 set. 2019
ashleydavis
em 24 set. 2019
Olá @ashleydavis , dockerd tornou-se obsoleto no Kubernetes, portanto, não faz sentido introduzir suporte para algo que não faz mais parte do Kubernetes. Embora você ainda possa instalá-lo além do Kubernetes. Aqui está o pano de fundo:
https://kubernetes.io/blog/2018/05/24/kubernetes-containerd-integration-goes-ga/
Você não precisa aumentar os contêineres, a menos que queira. O Kubernetes transmite nativamente os registros stdout / stderr para cada contêiner automaticamente. Você só precisa implantar um contêiner em cada nó (um DaemonSet ) para coletar e enviar esses fluxos de log para sua (s) escolha (ões) de serviço de agregação. Isso é muito fácil.
https://docs.fluentd.org/container-deployment/kubernetes
Existem muitas imagens prontas de fluentd + contêiner de back-end e configurações de amostra para back-ends de agregação de volta aqui:
https://github.com/fluent/fluentd-kubernetes-daemonset
Se você estiver usando DataDog, eles têm seu próprio agente para instalar, ou também fluentd :
https://docs.datadoghq.com/integrations/kubernetes/
Em geral, docker tendia a kitchen sink , com log e plug-ins de log, e enxame e ferramentas de tempo de execução, ferramentas de construção, rede e montagem de sistema de arquivos, etc. tudo em um processo daemon. O Kubernetes geralmente prefere contêineres / processos fracamente acoplados, realizando uma tarefa cada e se comunicando por meio de APIs. Portanto, é um estilo um pouco diferente para se acostumar.
whereisaaron
em 24 set. 2019
Obrigado pela resposta detalhada. Definitivamente vou investigar isso.
Com o dockerd obsoleto, isso significa que não posso implantar imagens do Docker no Kubernetes no futuro?
ashleydavis
em 24 set. 2019
@ashleydavis, você certamente pode continuar usando imagens do 'Docker' (mesmo sem dockerd presente) e pode continuar implantando dockerd em seus nós do Kubernetes para seus próprios fins (como no docker-in-docker compilações) se você quiser. As partes principais do docker foram extraídas e padronizadas como 'contêineres OCI' e o tempo de execução containerd .
https://www.opencontainers.org/
https://containerd.io/
Tanto o Docker quanto o Kubernetes agora são baseados nesses padrões compartilhados.
https://blog.docker.com/2017/08/what-is-containerd-runtime/
https://kubernetes.io/blog/2018/05/24/kubernetes-containerd-integration-goes-ga/
whereisaaron
em 24 set. 2019
Obrigado, estou aprendendo muito.
Acabei de criar um microsserviço que chamei de Loggy. A intenção era que ele enviasse os logs pelo driver de log do Docker e depois os encaminhasse (via webhook) para o Slack.
Você pode ver o código aqui: https://github.com/artlife-solutions/loggy/blob/master/src/index.ts
É muito simples, receber um log e encaminhá-lo via HTTP POST para o Slack.
Qual é a maneira mais rápida de adaptar isso para que eu possa coletar e agregar registros de meus pods?
ashleydavis
em 24 set. 2019
@ashleydavis você poderia construir uma imagem de contêiner com aquele micro-serviço nele, então
Implante-o em cluster como implantação com um serviço para o qual todos os contêineres do cluster podem enviar (usando o nome DNS do cluster do serviço ).
Implante-o como um contêiner de 'arquivo secundário' adicional em sua implantação . Os contêineres no mesmo pod compartilham acesso privado ao mesmo
localhostpara que o contêiner do aplicativo possa enviar para o arquivo secundário do contêiner de microsserviço emlocalhost:12201. Como alternativa, os contêineres no mesmo pod podem compartilhar um volume para arquivos de log compartilhados ou canais nomeados.
Isso está saindo do assunto aqui e nem todo mundo vai querer isso, então talvez vá pesquisar alguns exemplos no Github e acessar alguns canais do Slack para obter conselhos.
https://github.com/ramitsurana/awesome-kubernetes
https://slack.k8s.io/
https://kubernetes.io/
whereisaaron
em 24 set. 2019
Parece bom, obrigado. Eu só esperava não ter que mudar os serviços existentes. Eu gostaria apenas de capturar seu stdout / erro. Como fazer isso?
A promessa dos drivers de log do Docker era a simplicidade. Existe alguma maneira simples de fazer isso?
ashleydavis
em 24 set. 2019
Claro @ashleydavis , implante seu cluster, implante fluentd e pronto, pronto 😺. Cada aplicativo que você implantar terá seu stdout / stderr enviado para seu agregador favorito. 👍
whereisaaron
em 24 set. 2019
Depois de investir algum tempo em K8s e registro, configurei uma boa pilha ELK sem configuração GELF explícita . Dê uma olhada em https://www.elastic.co/guide/en/beats/filebeat/current/running-on-kubernetes.html
Minha configuração é o Filebeat, que canaliza os logs para o Logstash, que filtra, extrai e canaliza seu material para o Elasticsearch. Com Kibana posso visualizar os logs e agregar dados.
loxal
em 24 set. 2019
Eu também adoraria dar suporte ao registro no arquivo syslog nativo do sistema operacional, por exemplo: no Ubuntu, posso escrever registros em /var/log/syslog , que é gerenciado por logrotate pronto para uso.
Com enxame / composição, posso fazer isso:
version: '3.3'
services:
mysql:
image: mysql:5.7
logging:
driver: syslog
options:
tag: mysql
Não há problema em usar um volume emtpyDir; no entanto, os pods de longa execução correm o risco de encher o volume, a menos que você adicione um processo adicional que gire / trunque os arquivos de log. Não concordo com essa complexidade adicional quando o sistema operacional já está lidando com a rotação de / var / log / syslog.
Eu concordo que usar sidecars para algumas implantações é uma ótima ideia (eu já faço isso para algumas das minhas implantações), no entanto, o ambiente de cada pessoa é diferente.
 jsirianni
em 5 dez. 2019
jsirianni
em 5 dez. 2019
Usar um volume emtpyDir é bom
Tenha cuidado com eles - eles são gerenciados pelo Kubernetes e sua vida útil não é controlada por você. Se um pod for removido e reprogramado para outro nó, os logs serão perdidos. Se você atualizar um pod e seu uid mudar, ele não usará o volume antigo, mas criará um novo e removerá o antigo.
 php-coder
em 5 dez. 2019
php-coder
em 5 dez. 2019
@jsirianni nem todos os sistemas estão executando o syslog, o que significa que deve haver alguma anotação por nó sobre quais recursos estão disponíveis para garantir que as necessidades de um determinado pod sejam atendidas. docker compose faz essa suposição porque está sendo executado apenas localmente.
coffeepac
em 6 dez. 2019
@coffeepac Só porque os nós podem não ter syslog, não significa que o operador não deve ter a opção. Se pretendo usar o syslog, certifico-me de que meus nós de trabalho tenham syslog.
jsirianni
em 6 dez. 2019
Acho que esse problema deve ser reaberto, pois ainda há casos de uso suficientes para esse recurso.
/reabrir
 saiyam1814
em 27 fev. 2020
saiyam1814
em 27 fev. 2020
@ saiyam1814 : Este problema foi reaberto.
Em resposta a isso :
Acho que esse problema deve ser reaberto, pois ainda há casos de uso suficientes para esse recurso.
/reabrir
Instruções para interagir comigo usando comentários de RP estão disponíveis aqui . Se você tiver dúvidas ou sugestões relacionadas ao meu comportamento, registre um problema no repositório kubernetes / test-infra .
k8s-ci-robot
em 27 fev. 2020
Pessoalmente, ainda acho que o Kubernetes deve oferecer suporte a drivers de registro do Docker ou alguma outra forma integrada simples de configurar o registro.
Disseram-me muitas vezes que configurar o registro é fácil no Kubernetes, mas agora, tendo passado pelo processo de configuração do meu próprio sistema de agregação de registro, posso dizer que realmente não é simples.
Escrevi uma postagem no blog sobre a maneira mais simples de criar manualmente seu próprio sistema de agregação de registros para o Kubernetes: http://www.the-data-wrangler.com/kubernetes-log-aggregation/
Espero que minha postagem no blog ajude outros a descobrirem suas próprias estratégias.
Não deveria ser tão difícil, mas é aqui que estamos.
ashleydavis
em 27 fev. 2020
Claro, precisamos de uma maneira de consumir logs do Docker diretamente de stdout e stderr, em vez de usar arquivos de log. Existem alguns problemas de segurança para usar o caminho do Docker para arquivos de log, porque você pode acessar outros logs no sistema host.
Podemos implementar o driver de log do Docker? 👍
 Tetragramato
em 2 mar. 2020
Tetragramato
em 2 mar. 2020
Configurar drivers de registro do docker em um nível de container-in-a-pod (onde o pod está no controle do cliente) permitiria o redirecionamento de registros com o driver gelf diretamente para um serviço / pod graylog (que também está no controle do cliente ) em vez de ter que coletá-los de arquivos no host com outro serviço imediato (que é mais sobrecarga de gerenciamento e uma quebra de nível de abstração pior do que usar o driver de log gelf ) ou pelos pods do cliente acessando o diretório de registros do contêiner no host.
Portanto, eu adoraria ver esse recurso implementado no kubernetes.
 blubberdiblub
em 10 mar. 2020
blubberdiblub
em 10 mar. 2020
Seria útil ter certeza de fazer algo como https://github.com/cri-o/cri-o/pull/1605 , onde desconectamos a interpretação do fluxo de log dos drivers de log para que o comportamento do contêiner não possa afetar como os motoristas trabalham.
 portante
em 10 mar. 2020
portante
em 10 mar. 2020
Problemas podres são encerrados após 30 dias de inatividade.
Reabra o problema com /reopen .
Marque o problema como novo com /remove-lifecycle rotten .
Envie feedback para sig-testing, kubernetes / test-infra e / ou fejta .
/fechar
fejta-bot
em 9 abr. 2020
@ fejta-bot: Fechando este problema.
Em resposta a isso :
Problemas podres são encerrados após 30 dias de inatividade.
Reabra o problema com/reopen.
Marque o problema como novo com/remove-lifecycle rotten.Envie feedback para sig-testing, kubernetes / test-infra e / ou fejta .
/fechar
Instruções para interagir comigo usando comentários de RP estão disponíveis aqui . Se você tiver dúvidas ou sugestões relacionadas ao meu comportamento, registre um problema no repositório kubernetes / test-infra .
k8s-ci-robot
em 9 abr. 2020
A função ainda precisa ser implementada
/reabrir
 M0rdecay
em 9 abr. 2020
M0rdecay
em 9 abr. 2020
@ M0rdecay : Você não pode reabrir uma edição / RP a menos que seja o autor ou um colaborador.
Em resposta a isso :
A função ainda precisa ser implementada
/reabrir
Instruções para interagir comigo usando comentários de RP estão disponíveis aqui . Se você tiver dúvidas ou sugestões relacionadas ao meu comportamento, registre um problema no repositório kubernetes / test-infra .
k8s-ci-robot
em 9 abr. 2020
@ M0rdecay : Você não pode reabrir uma edição / RP a menos que seja o autor ou um colaborador.
Ok entendi
M0rdecay
em 9 abr. 2020
Até mesmo o aws ecs tem essa funcionalidade em que se pode definir o driver de registro do docker.
Em nosso ambiente, criamos um índice separado com um token exclusivo para cada serviço de contêiner.
"logConfiguration": {
"logDriver": "splunk",
"opções": {
"formato splunk": "raw",
"splunk-insecureskipverify": "true",
"splunk-token": "xxxxx-xxxxxxx-xxxxx-xxxxxxx-xxxxxx",
"splunk-url": " https://xxxxx.splunk-heavyforwarderxxx.com ",
"tag": "{{.Name}} / {{. ID}}",
"splunk-verify-connection": "false",
"modo": "sem bloqueio"
}
}
Mas não encontrei nada parecido com isso em k8s. Deve estar lá na própria definição do pod.
 arshadsiddique-jfl
em 10 ago. 2020
arshadsiddique-jfl
em 10 ago. 2020
As opções ainda precisam ser implementadas
/reabrir
ejemba
em 10 ago. 2020
@ejemba : Reabriu este problema.
Em resposta a isso :
As opções ainda precisam ser implementadas
/reabrir
Instruções para interagir comigo usando comentários de RP estão disponíveis aqui . Se você tiver dúvidas ou sugestões relacionadas ao meu comportamento, registre um problema no repositório kubernetes / test-infra .
k8s-ci-robot
em 10 ago. 2020
nó / sig
/ remove-sig instrumentação
 logicalhan
em 26 ago. 2020
logicalhan
em 26 ago. 2020
escalabilidade / remove-sig
logicalhan
em 26 ago. 2020
@logicalhan : Esses rótulos não são definidos para o problema: sig/
Em resposta a isso :
escalabilidade / remove-sig
Instruções para interagir comigo usando comentários de RP estão disponíveis aqui . Se você tiver dúvidas ou sugestões relacionadas ao meu comportamento, registre um problema no repositório kubernetes / test-infra .
k8s-ci-robot
em 26 ago. 2020
Algum progresso com isso?
Eu estava procurando especificamente por uma capacidade de configurar contêineres de pods para fazer login no logstash externo, especificando o driver de registro gelf do docker. Configurá-lo por padrão para todos os contêineres em /etc/docker/daemon.json parece ser uma sobrecarga.
 freehck
em 16 set. 2020
freehck
em 16 set. 2020
Problemas podres são encerrados após 30 dias de inatividade.
Reabra o problema com /reopen .
Marque o problema como novo com /remove-lifecycle rotten .
Envie feedback para sig-testing, kubernetes / test-infra e / ou fejta .
/fechar
fejta-bot
em 16 out. 2020
@ fejta-bot: Fechando este problema.
Em resposta a isso :
Problemas podres são encerrados após 30 dias de inatividade.
Reabra o problema com/reopen.
Marque o problema como novo com/remove-lifecycle rotten.Envie feedback para sig-testing, kubernetes / test-infra e / ou fejta .
/fechar
Instruções para interagir comigo usando comentários de RP estão disponíveis aqui . Se você tiver dúvidas ou sugestões relacionadas ao meu comportamento, registre um problema no repositório kubernetes / test-infra .
k8s-ci-robot
em 16 out. 2020
/reabrir
 andreswebs
em 2 nov. 2020
andreswebs
em 2 nov. 2020
@andreswebs : Você não pode reabrir uma edição / RP a menos que seja o autor ou um colaborador.
Em resposta a isso :
/reabrir
Instruções para interagir comigo usando comentários de RP estão disponíveis aqui . Se você tiver dúvidas ou sugestões relacionadas ao meu comportamento, registre um problema no repositório kubernetes / test-infra .
k8s-ci-robot
em 2 nov. 2020
/reabrir
ejemba
em 3 nov. 2020
@ejemba : Reabriu este problema.
Em resposta a isso :
/reabrir
Instruções para interagir comigo usando comentários de RP estão disponíveis aqui . Se você tiver dúvidas ou sugestões relacionadas ao meu comportamento, registre um problema no repositório kubernetes / test-infra .
k8s-ci-robot
em 3 nov. 2020
@ejemba : Este problema está aguardando a triagem.
Se um SIG ou subprojeto determinar que esta é uma questão relevante, eles o aceitarão aplicando o rótulo triage/accepted e fornecerão mais orientações.
O rótulo triage/accepted pode ser adicionado por membros da organização escrevendo /triage accepted em um comentário.
Instruções para interagir comigo usando comentários de RP estão disponíveis aqui . Se você tiver dúvidas ou sugestões relacionadas ao meu comportamento, registre um problema no repositório kubernetes / test-infra .
k8s-ci-robot
em 3 nov. 2020
Eu realmente gostaria que esse recurso fosse implementado. Atualmente, estou migrando cargas de trabalho de clusters Rancher 1.x para clusters Rancher 2.x que executam k8s. Temos uma implantação que define os parâmetros log-driver e log-opt na configuração docker-compose.
Não quero ter que configurar um host específico para usar o driver gelf globalmente e marcar o pod com um rótulo e o host com um rótulo.
 bananflugan
em 4 nov. 2020
bananflugan
em 4 nov. 2020
Parece que devemos alterar o CRI-O para especificar que ambos os fluxos de log do contêiner (stdout / stderr) são coletados em uma forma bruta e, ao ler a matéria bruta para mais tarde, podemos aplicar diferentes interpretações do fluxo de bytes do log.
portante
em 13 nov. 2020
Problemas podres são encerrados após 30 dias de inatividade.
Reabra o problema com /reopen .
Marque o problema como novo com /remove-lifecycle rotten .
Envie feedback para sig-testing, kubernetes / test-infra e / ou fejta .
/fechar
fejta-bot
em 13 dez. 2020
@ fejta-bot: Fechando este problema.
Em resposta a isso :
Problemas podres são encerrados após 30 dias de inatividade.
Reabra o problema com/reopen.
Marque o problema como novo com/remove-lifecycle rotten.Envie feedback para sig-testing, kubernetes / test-infra e / ou fejta .
/fechar
Instruções para interagir comigo usando comentários de RP estão disponíveis aqui . Se você tiver dúvidas ou sugestões relacionadas ao meu comportamento, registre um problema no repositório kubernetes / test-infra .
k8s-ci-robot
em 13 dez. 2020
Questões relacionadas
 rhohubbuild
·
3Comentários
rhohubbuild
·
3Comentários
 ddysher
·
3Comentários
ddysher
·
3Comentários
 broady
·
3Comentários
broady
·
3Comentários
 tbchj
·
3Comentários
tbchj
·
3Comentários
 jason-riddle
·
3Comentários
jason-riddle
·
3Comentários
Comentários muito úteis
Olá,
Acho que esse é um recurso importante que deve ser considerado para o kubernetes.
Habilitar o uso do driver de log do Docker pode resolver alguns problemas não triviais.
Eu diria que o registro no disco é um anti-padrão. Os logs são inerentemente "estado" e, de preferência, não devem ser salvos no disco. Enviar os logs diretamente de um contêiner para um repositório resolve muitos problemas.
Definir o driver de log significaria que o comando kubectl logs não mostraria mais nada.
Embora esse recurso seja "bom ter", ele não será necessário quando os logs estiverem disponíveis em uma fonte diferente.
O Docker já tem drivers de log para google cloud (gcplogs) e Amazon (awslogs). Embora seja possível defini-los no próprio daemon do Docker, isso tem muitas desvantagens. Ao ser capaz de definir as duas opções do docker:
--log-driver = Driver de registro para contêiner
--log-opt = [] Opções de driver de log
Seria possível enviar etiquetas (para gcplogs) ou awslogs-group (para awslogs)
específico para um pod. Isso tornaria mais fácil encontrar os logs na outra extremidade.
Tenho lido sobre como as pessoas estão lidando com registros no kubernetes. Muitos parecem instalar alguns raspadores elaborados que encaminham as toras para sistemas centrais. Ser capaz de definir o driver de log tornará isso desnecessário - liberando tempo para trabalhar em coisas mais interessantes :)