Kubernetes: Defining log-driver and log-opt when specifying pod in RC and Pod
We need to be able to define the following options when specifying the pod definition in RC and Pod
--log-driver= Logging driver for container
--log-opt=[] Log driver options
These options should be settable at container level and have been introduced with Docker 1.8.
Since docker client lib support both options as well adding those options to the pod definition is now doable.
 ejemba
ejemba
All 117 comments
/cc @kubernetes/rh-cluster-infra
 timothysc
on 13 Oct 2015
timothysc
on 13 Oct 2015
Hmm, I think we'll probably want to be able to set this cluster-wide as a default, and then maybe allow specific pod definitions to override.
cc @sosiouxme @smarterclayton @liggitt @jwhonce @jcantrill @bparees @jwforres
 ncdc
on 13 Oct 2015
ncdc
on 13 Oct 2015
Can you describe how you would leverage this on a per container basis (use case)? We traditionally do not expose Docker specific options directly in containers unless they can be cleanly abstracted across runtimes. Knowing how you would want to use this will help justify it.
 smarterclayton
on 13 Oct 2015
smarterclayton
on 13 Oct 2015
Note that docker logs still only support json-file and journald drivers, though I imagine that list could expand.
Perhaps what users would actually want is a selection of defined log writing endpoints, not exposure to the logging driver details.
 sosiouxme
on 13 Oct 2015
sosiouxme
on 13 Oct 2015
@ncdc @smarterclayton I agree with both of you, after reconsidering our use case in internal, it turns out that
- Our primary need is to protect our nodes. We send the logs to a log server but if it fails, logs fallback on docker internal logs. In such case, to prevent node saturation we need a cluster wide behaviour for docker log
- Exposing specific docker options in the pod/Rc definitions is not a good idea as @smarterclayton suggested it. We also agree with an abstraction allowing definition of high level log behaviour if possible
- Another option is making change on kubelet configuration files and code to handle such log behavior
ejemba
on 13 Oct 2015
The changes to the salt templates to make this a default should not be
terribly difficult. It's really just proper daemon configuration (and
dealing with any changes to log aggregation via fluentd by virtue of
selecting a different source)
On Tue, Oct 13, 2015 at 10:55 AM, Epo Jemba [email protected]
wrote:
@ncdc https://github.com/ncdc @smarterclayton
https://github.com/smarterclayton I agree with both of you, after
reconsidering our use case in internal, it turns out that
- Our primary need is to protect our nodes. We send the logs to a log
server but if it fails, logs fallback on docker internal logs. In such
case, to prevent node saturation we need a cluster wide behaviour for
docker log- Exposing specific docker options in the pod/Rc definitions is not a
good idea as @smarterclayton https://github.com/smarterclayton
suggested it. We also agree with an abstraction allowing definition of high
level log behaviour if possible- Another option is making change on kubelet configuration files and
code to handle such log behavior—
Reply to this email directly or view it on GitHub
https://github.com/kubernetes/kubernetes/issues/15478#issuecomment-147740136
.
smarterclayton
on 13 Oct 2015
:thumbsup:
Note that there are now 9 logging drivers. What's the consensus on getting this one in?
 halr9000
on 12 May 2016
halr9000
on 12 May 2016
+1
 briangebala
on 18 May 2016
briangebala
on 18 May 2016
In case anyone isn't aware, you can define the default log driver on a per-node basis with a flag to the Docker daemon (--log-driver). In my environment, I set the driver to journald this way. I struggle to think of a use-case for overriding this on a per-container basis to be honest.
 obeattie
on 18 May 2016
obeattie
on 18 May 2016
Most clustering will not want their logs going "out-of-band", so what is the feature enablement that this would provide.
Also, from an ops perspective it looks like a loss of control. Currently we set the defaults and configure a logging stack to aggregate.
timothysc
on 18 May 2016
+1 on this.
Not being able to control how docker logging is handled implies that the only sane logging option is using the tools shipped with k8s, which is an incredible limitation.
@timothysc here our use-case. We have a complex dynamic infrastructure (~100 machines) with a lot of existing services running on them, with our own logstash to gather logs. Well, we are now trying to move our services, one by one, to k8s and to me there seems to be no clean way to integrate logging between our existing infrastructure and containers clustered on k8s.
K8S is extremely opinionated on how you gather logs. This might be great for whoever is starting from scratch on a simple infrastructure. For everyone else working on complex infrastructures which would not mind to dive deep and to implement a custom logging mechanism, there is simply not way to do it at the moment, which is quite frustrating.
Hopefully, it makes sense.
 jnardiello
on 23 May 2016
jnardiello
on 23 May 2016
So in your scenario logs are truly "per application", but you have to
ensure the underlying host supports those logs? That's the concern we're
discussing here - either we do cluster level, or node level, but if we do
pod level, then the scheduler would have to be aware of what log drivers
are present where. As much as possible we try to avoid that.
On Mon, May 23, 2016 at 10:50 AM, Jacopo Nardiello <[email protected]
wrote:
+1 on this.
Not being able to control how docker logging is handled implies that the
only sane logging option is using the tools shipped with k8s, which is an
incredible limitation.@timothysc https://github.com/timothysc here our use-case. We have a
complex dynamic infrastructure (~100 machines) with a lot of existing
services running on them, with our own logstash to gather logs. Well, we
are now trying to move our services, one by one, to k8s and to me there
seems to be no clean way to integrate logging between our existing
infrastructure and containers clustered on k8s.K8S is extremely opinionated on how you gather logs. This might be great
for whoever is starting from scratch on a simple infrastructure. For
everyone else working on complex infrastructures which would not mind to
dive deep and to implement a custom logging mechanism, there is simply not
way to do it at the moment, which is quite frustrating.Hopefully, it makes sense.
—
You are receiving this because you were mentioned.
Reply to this email directly or view it on GitHub
https://github.com/kubernetes/kubernetes/issues/15478#issuecomment-221002545
smarterclayton
on 23 May 2016
@smarterclayton I do understand about your concerns and they are well placed. I'm not sure if the whole cluster has to be aware of the existence of pod-level logging, what I think we should do is giving the option to log pod stdout/stderr somewhere (a file based on their current pod name?) so that anyone willing to implement their custom solution, would have a persisted place where to get the content. This opens up a HUGE chapter though as logrotation is not trivial.
These are just my two cents, but we can't pretend that real-world complex scenarios just give up their existing logging infrastructure.
jnardiello
on 26 May 2016
Are you specifying custom log options per application? How many different
sets of log options would you have per cluster? If there are small sets of
config, an option would be to support an annotation on pods that is
correlated to node level config that offers a number of "standard log
options". I.e. at kubelet launch time define a "log mode X" (which defines
custom log options and driver), and the pod would specify "
pod.alpha.kubernetes.io/log.mode=X".
Yet another option would be that we expose a way to let deployers have the
opportunity to mutate the container definition immediately before we start
the container. That's harder today because we'd have to serialize the
docker def out to an intermediate format, execute it, and then run it
again, but potentially easier in the future.
Finally, we could expose key value pairs on the container interface that
are passed to the container engine directly, offer no API guarantees for
them, and ensure PodSecurityPolicy can regulate those options. That would
be the escape hatch for callers, but we wouldn't be able to provide any
guarantee those would continue to work across releases.
On Thu, May 26, 2016 at 5:34 AM, Jacopo Nardiello [email protected]
wrote:
@smarterclayton https://github.com/smarterclayton I do understand about
your concerns and they are well placed. I'm not sure if the whole cluster
has to be aware of the existence of pod-level logging, what I think we
should do is giving the option to log pod stdout/stderr somewhere (a file
based on their current pod name?) so that anyone willing to implement their
custom solution, would have a persisted place where to get the content.
This opens up a HUGE chapter though as logrotation is not trivial.These are just my two cents, but we can't pretend that real-world complex
scenarios just give up their existing logging infrastructure.—
You are receiving this because you were mentioned.
Reply to this email directly or view it on GitHub
https://github.com/kubernetes/kubernetes/issues/15478#issuecomment-221823732
smarterclayton
on 26 May 2016
@smarterclayton have you seen https://github.com/kubernetes/kubernetes/issues/24677#issuecomment-220735829
ncdc
on 26 May 2016
No, thanks. Moving discussion there.
On Thu, May 26, 2016 at 11:23 AM, Andy Goldstein [email protected]
wrote:
@smarterclayton https://github.com/smarterclayton have you seen #24677
(comment)
https://github.com/kubernetes/kubernetes/issues/24677#issuecomment-220735829—
You are receiving this because you were mentioned.
Reply to this email directly or view it on GitHub
https://github.com/kubernetes/kubernetes/issues/15478#issuecomment-221903781
smarterclayton
on 26 May 2016
Hi there,
I think this is an important feature that should be considered for kubernetes.
Enabling the use of Docker's log driver can solve some non-trivial problems.
I would say that logging to disk is an anti-pattern. Logs are inherently "state", and should preferably not be saved to disk. Shipping the logs directly from a container to a repository solves many problems.
Setting the log driver would mean that the kubectl logs command can not show anything anymore.
While that feature is "nice to have" - the feature won't be needed when the logs are available from a different source.
Docker already has log drivers for google cloud (gcplogs) and Amazon (awslogs). While it is possible to set them on the Docker daemon itself, that has many drawbacks. By being able to set the two docker options:
--log-driver= Logging driver for container
--log-opt=[] Log driver options
It would be possible to send along labels (for gcplogs) or awslogs-group (for awslogs)
specific to a pod. That would make it easy to find the logs at the other end.
I have been reading up on how people are handling logs in kubernetes. Many seem to set up some elaborate scrapers that forward the logs to central systems. Being able to set the log driver will make that unnecessary - freeing up time to work on more interesting things :)
 pbthorste
on 30 Nov 2016
pbthorste
on 30 Nov 2016
I can also add that some people, including me, want to perform docker logs rotation via '--log-opt max-size' option on JSON logging driver (which is native to docker) instead of setting up logrotate on the host. So, even exposing just the '--log-opt' option would be greatly appreciated
 daniilyar
on 12 Dec 2016
daniilyar
on 12 Dec 2016
I have modified the k8s, when creating container configuration LogConfig.
 barnettZQG
on 12 Dec 2016
barnettZQG
on 12 Dec 2016
+1
Using docker log driver for centralized log collection looks much simpler then creating symbolic links for log files, mounting them to a special fluentd container, tailing them and managing log rotation.
 defat
on 27 Dec 2016
defat
on 27 Dec 2016
Use case for per container configuration: I want to log elsewhere or differently for containers I deploy and I don't care about (or want to change) the log driver for the standard containers necessary to run Kubernetes.
There you go. Please make this happen.
 et304383
on 12 Jan 2017
et304383
on 12 Jan 2017
Another idea is, where all the containers still forward logs into the same endpoint, but you can at least set different fields values for different docker containers on your log server.
This would work for the gelf docker driver, if we could ensure docker containers created by Kubernetes are custom labelled. Meaning: some of a Pod fields could be forwarded as docker container labels. (Maybe this is already possible but I don't know how to achieve that).
Example without Kubernetes, only with docker daemon and gelf driver. Have docker daemon configured with: --log-driver=gelf --log-opt labels=env,label2 and create a docker container:
docker run -dti --label env=testing --label label2=some_value alpine:3.4 /bin/sh -c "while true; do date; sleep 2; done"
and another docker container:
docker run -dti --label env=production --label label2=some_value alpine:3.4 /bin/sh -c "while true; do date; sleep 2; done"
This way, on Graylog, you can differenciate between env=production and env=testing containers.
Currently I use such docker daemon options:
--log-driver=gelf --log-opt gelf-address=udp://graylog.example.com:12201 --log-opt tag=k8s-testing --log-opt labels=io.kubernetes.pod.namespace,io.kubernetes.container.name,io.kubernetes.pod.name
 xmik
on 12 Jan 2017
xmik
on 12 Jan 2017
@xmik , just what to confirm it is an existing feature or your proposal regarding
Currently I use such docker daemon options:
--log-driver=gelf --log-opt gelf-address=udp://graylog.example.com:12201 --log-opt tag=k8s-testing --log-opt labels=io.kubernetes.pod.namespace,io.kubernetes.container.name,io.kubernetes.pod.name
 stainboy
on 26 Jan 2017
stainboy
on 26 Jan 2017
Those docker daemon options I currently use, already work. Kubernetes already sets some labels for each docker container. For example, when running docker inspect on kube-apiserver container:
"Labels": {
"io.kubernetes.container.hash": "4959a3f5",
"io.kubernetes.container.name": "kube-apiserver",
"io.kubernetes.container.ports": "[{\"name\":\"https\",\"hostPort\":6443,\"containerPort\":6443,\"protocol\":\"TCP\"},{\"name\":\"local\",\"hostPort\":8080,\"containerPort\":8080,\"protocol\":\"TCP\"}]",
"io.kubernetes.container.restartCount": "1",
"io.kubernetes.container.terminationMessagePath": "/dev/termination-log",
"io.kubernetes.pod.name": "kube-apiserver-k8s-production-master-1",
"io.kubernetes.pod.namespace": "kube-system",
"io.kubernetes.pod.terminationGracePeriod": "30",
"io.kubernetes.pod.uid": "a47396d9dae12c81350569f56aea562e"
}
Hence, those docker daemon options work.
However, I think it is not possible now to make Kubernetes set custom labels on a docker container basing on Pod spec. So e.g. --log-driver=gelf --log-opt labels=env,label2 does not work.
xmik
on 26 Jan 2017
Are there any news on this front? Having the ability to specify the labels and then take advantage of --log-opt labels<> would be pretty good!
 beldpro-ci
on 18 Mar 2017
beldpro-ci
on 18 Mar 2017
@portante @jcantrill Just to capture it here because we discussed it, here is the use case that we were thinking this might be useful for:
When the log recording pods starts encountering and logging errors the infra that gathers those errors will grab them and feed them back to the recording mechanism which in turn throws and logs more errors.
This feedback loop can be avoided by using filtering mechanisms but that is a bit brittle. Using a different logging driver to record to a file and have rotation options seems like it would be a good solution.
 pweil-
on 31 Mar 2017
pweil-
on 31 Mar 2017
My 2 cents.
Current solutions to logging inside k8s are (AFAIK):
- sidecar container sending logs somewhere
- replication controller sending all logs somewhere
- the container itself sending logs somewhere
Sidecar container seems kind of overkill for me. The replication controller strategy seems good, but it mix logs of containers from all deployments, and some users might now want that, and may instead want to log each app to a different thing. For this cases, the last option works best IMHO, but creates a lot of code replicated in all containers (eg: install and setup logentries daemon).
This all would be way easier if we had access to log-driver flags, so each deployment would define how it should be logged, using docker native features.
I can try to implement that, but will probably need some help - as I'm not familiar to kubernetes codebase.
 caarlos0
on 17 May 2017
caarlos0
on 17 May 2017
once multi tenancy becomes more of a thing, it will be harder to solve properly.
Each namespace may be a different tenant so logs from each should not necessarily be aggregated, but allowed to be sent to tenant specified locations.
I can think of a few ways of doing this:
- make a new volume type, container-logs. This allows a daemonset launched by a particular namespace to access just the logs from its own containers. They can then send the logs with whatever log shipper of choice to whichever storage daemon of choice.
- Modify one of(or more) of the log shippers, such as fluentd-bit to read the namespace the pod is in, and redirect logs from each pod to a further log shipper running in that namespace as a service. Such as fluentd. This again allows the namespace to configure its own log shipper to push to whatever log backend they want to support.
 kfox1111
on 17 May 2017
kfox1111
on 17 May 2017
@caarlos0 @kfox1111 I agree with your points. This is a complex topic, as it requires coordination of instrumentation, storage, node and maybe even more teams. I suggest having a proposal for the overall logging architecture laid out first and then discuss the changed to this consistent view. I expect for this proposal to appear in a month or so, bringing order and figuring out all problems mentioned.
 crassirostris
on 17 May 2017
crassirostris
on 17 May 2017
@crassirostris I'm not sure I understand: if we just allow log-driver et al, we don't have to deal with storage or any of that, right?
Is just docker sendings its STDOUT to whatever log driver is set up in a container basis, right? We kind of pass the responsibility down to the container... seems like a pretty simple solution to me - but, as I said, I don't know the codebase, so maybe I'm just plain wrong...
caarlos0
on 17 May 2017
The issue is the log-driver in docker doesn't add any of the k8s metadata that makes consuming the logs later actually useful. :/
kfox1111
on 17 May 2017
@kfox1111 hmm, makes sense...
but, what if the user only wants the "application" logs, not kubernetes logs, not docker logs, just the app running inside the container logs?
In that case, seems to me, log-driver would work...
caarlos0
on 17 May 2017
@caarlos0 It may have some implications, e.g. kubelet makes some assumptions about logging format to server kubectl logs.
But all things aside, log-driver per se is Docker-specific and might not work for other runtimes, that's the main reason not to include it in the API.
crassirostris
on 17 May 2017
@crassirostris that makes sense...
since this feature will not be added (as described in the issue), maybe this issue should be closed (or edited or whatever)?
caarlos0
on 17 May 2017
@caarlos0 However, we definitely want to make the logging set up more flexible and transparent. Your feedback will be appreciated on the proposal!
crassirostris
on 17 May 2017
stdout logging from containers is currently handled out-of-band within Kubernetes. We are currently rely on non-Kubernetes solutions to handle logging, or privileged containers that jail-break Kubernetes to get access to the out-of-band logging. Container run-time logging is different per run-time (docker, rkt, Windows), so picking any one, like Docker --log-driver is creating future baggage.
I suggest we need the kubelet to bring log streams back in-band. Define or pick a minimal JSON or XML log format, that collects stdout lines from each container, add a minimal cluster+namespace+pod+container metadata, so the log source is identified within Kubernetes space, and direct the stream to a Kubernetes Service+Port. Users are free to provide whatever log consumption Service they like. Maybe Kubernetes will provide one reference/default Service that implements the 'kubectl logs' support.
Without a logging consumption Service specified, logs will be discarded and not hit disk at all. Streaming the logs elsewhere, or writing to persistent storage and rotating, all that is the responsibility/decision of the Service.
The kubelet container runtime wrapper does the minimum to extract the stdout from each container runtime, and bring it back in-band for k8s self-hosted Service(s) to consume and process.
The container spec in the Deployment or Pod would optionally specify the target Service and Port for stdout logging. Adding k8s metadata for cluster+namespace+pod+container would be optional (so the choice of raw/untouched or with metadata). Users would be free to aggregate all logs to one place, or aggregate by tenant, or namespace, or application.
The nearest to this now is to run a Service that uses 'kubectl logs -f' to stream container logs for each container via the API server. That's doesn't sound very efficient or scalable. This proposal would allow more efficient direct steaming from container runtime wrapper direct to Service or Pod, with optimizations like preferring logging Deployment or Daemonset Pods on the same node and the container generating the logs.
I am proposing Kubernetes should do the minimum to efficiently bring container run-time logs in-band, for any self-hosted, homogeneous or heterogeneous logging solutions we with to create within Kubernetes space.
What do people think?
 whereisaaron
on 18 May 2017
whereisaaron
on 18 May 2017
@whereisaaron I really would like not to have this discussion now, when we don't have all details around the logging ecosystem in one place.
E.g. I see network and machine problems disrupting the log flow, but again, I don't want to discuss it just yet. How about we discuss this later, when proposal is ready? Does it seem reasonable for you?
crassirostris
on 18 May 2017
Certainly @crassirostris. Please let us know here when the proposal is ready to check out.
whereisaaron
on 20 May 2017
/sig scalability
 kargakis
on 10 Jun 2017
kargakis
on 10 Jun 2017
Although both --log-driverand --log-opt are options for the Docker daemon and not k8s features, it would be nice to specify them in the k8s pod spec for:
- per-pod log driver and not a single node-level log driver
- different types of app-specific log drivers (fluentd, syslog, journald, splunk) on the same node
- set
--log-optto configure log rotation for a pod - per-pod
--log-optsettings and not a single node-level--log-opt
AFAIK, none of the above can be set at the pod-level in the k8s pod spec today.
 vhosakot
on 13 Dec 2017
vhosakot
on 13 Dec 2017
@vhosakot none of the above can be set at any level in Kubernetes, because those are not Kubernetes concepts
crassirostris
on 13 Dec 2017
@crassirostris exactly! :)
If k8s does everything that Docker does at the pod-level/container-level, won't it be easy for users? Why make users use Docker at all for few pod-level/container-level stuff?
And, a k8s lover not a Docker fan may ask the same question.
vhosakot
on 13 Dec 2017
@vhosakot Point is, there's a number of other container runtimes that can be used with K8s, but --log-opt exists only in Docker. Creating such option on the K8s level would be intentionally leaking the abstraction. I don't think this is the way we want to go. If an option exists, it should be supported by all container runtimes, ideally be a part of CRI
I'm not saying that there won't be such option, I'm saying it won't be a direct route to Docker
crassirostris
on 13 Dec 2017
@crassirostris True, sounds like it comes down to if k8s should do what CRI does/allows at the pod-level/container-level, not Docker-specific.
vhosakot
on 13 Dec 2017
Yup, absolutely correct
crassirostris
on 13 Dec 2017
Although i'm late to this discussion and i have an interest in seeing this feature implemented, I would argue that there is a trade-off between having a pretty design and having a straight-forward way of setting up a sane and uniform logging solution for the cluster. Yes, having this feature implemented would expose docker internal , which is a big no no , but at the same time i could bet good money that the majority of K8S users use docker as the underlying container tech and docker does come with a very comprehensive list of log drivers.
 gabriel-tincu
on 19 Dec 2017
gabriel-tincu
on 19 Dec 2017
@gabriel-tincu I'm currently not convinced that the original FR is worth the trouble
docker does come with a very comprehensive list of log drivers
You can set up logging on Docker level during the K8s deployment step and use any of these log drivers, without leaking this information to K8s. The only thing you cannot do today is set up those options per-container/per-pod (actually, you can have a setup with dedicated nodes & use node selector), but I'm not sure it's a big limitation.
crassirostris
on 19 Dec 2017
@crassirostris I agree that you can set that up __before__ setting up the environment, but if there's a way to actively update the docker log driver after the environment is already setup then it eludes me at the moment
gabriel-tincu
on 12 Jan 2018
@gabriel-tincu @vhosakot the direct interface that used to existing between k8s and Docker back in the 'olden day' of >=1.5 is deprecated and I believe the code totally removed now. Everything between the kubelet and the run-times like Docker (or the others like rkt, cri-o, runc, lxd) goes through CRI. There are lots of container runtimes now and Docker itself is likely to be deprecated and removed soon in favor of cri-containerd+containerd.
http://blog.kubernetes.io/2017/11/containerd-container-runtime-options-kubernetes.html
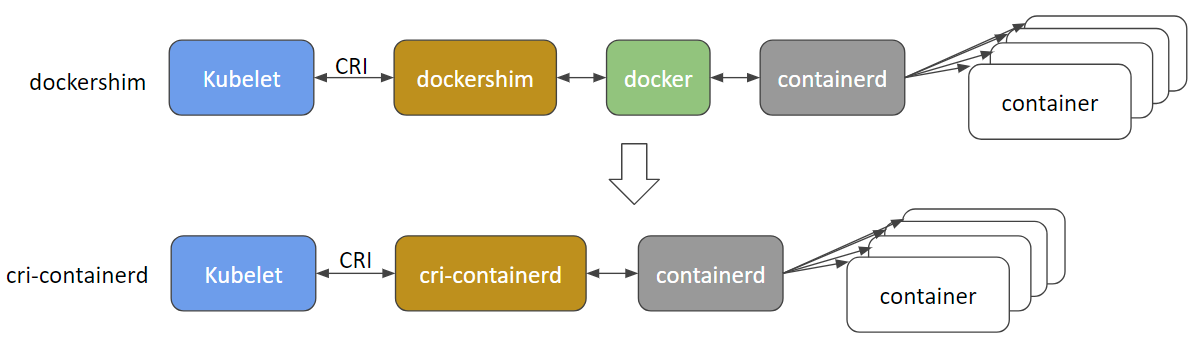
@crassirostris any movement on a proposal, that might have the possibility of in-band container logging?
whereisaaron
on 12 Jan 2018
CRI container log is file based (https://github.com/kubernetes/community/blob/master/contributors/design-proposals/node/kubelet-cri-logging.md), and the log path is explicitly defined:
/var/log/pods/PodUID/ContainerName/RestartCount.log
In most of the docker logging drivers https://docs.docker.com/config/containers/logging/configure/#supported-logging-drivers, I think for cluster environment, the most important ones are the drivers ingesting container log into cluster logging management system, such as splunk, awslogs, gcplogs etc.
In the case of CRI, no "docker log driver" should be used. People can run a daemonset to ingest container logs from the CRI container log directory into wherever they want. They can use fluentd or even write a daemonset by themselves.
If more metadata is needed, we can think about dropping a metadata file, extend the file path or let the daemonset get metadata from apiserver. There is ongoing discussion about this https://github.com/kubernetes/kubernetes/issues/58638
 Random-Liu
on 22 Feb 2018
Random-Liu
on 22 Feb 2018
Issues go stale after 90d of inactivity.
Mark the issue as fresh with /remove-lifecycle stale.
Stale issues rot after an additional 30d of inactivity and eventually close.
If this issue is safe to close now please do so with /close.
Send feedback to sig-testing, kubernetes/test-infra and/or fejta.
/lifecycle stale
 fejta-bot
on 23 May 2018
fejta-bot
on 23 May 2018
Stale issues rot after 30d of inactivity.
Mark the issue as fresh with /remove-lifecycle rotten.
Rotten issues close after an additional 30d of inactivity.
If this issue is safe to close now please do so with /close.
Send feedback to sig-testing, kubernetes/test-infra and/or fejta.
/lifecycle rotten
/remove-lifecycle stale
fejta-bot
on 22 Jun 2018
/remove-lifecycle rotten
 iavael
on 25 Jun 2018
iavael
on 25 Jun 2018
any updates on this? so how has anyone running k8s with Docker containers settled logging to some backend like AWS CloudWatch?
 bryan831
on 4 Jul 2018
bryan831
on 4 Jul 2018
@bryan831 it is popular to collect the k8s container log files using fluentd or similar and aggregate them into your choice of back-end, CloudWatch, StackDriver, Elastisearch etc.
There are off-the-shelf Helm charts for e.g. fluentd+CloudWatch, fluentd+Elastisearch, fluent-bit->fluentd->your choice, Datadog and probably other combinations if you poke around.
whereisaaron
on 4 Jul 2018
Issues go stale after 90d of inactivity.
Mark the issue as fresh with /remove-lifecycle stale.
Stale issues rot after an additional 30d of inactivity and eventually close.
If this issue is safe to close now please do so with /close.
Send feedback to sig-testing, kubernetes/test-infra and/or fejta.
/lifecycle stale
fejta-bot
on 2 Oct 2018
It would be nice to be able to customize Docker --log-opt options. In my case, I would like to use a tag such as '--log-opt tag="{{.ImageName}}/{{.Name}}/{{.ID}}"' to emit ImageName to the logs so that I know which container version are logs coming from. (Reference : https://docs.docker.com/config/containers/logging/log_tags/)
 pmahalwar-intertrust
on 26 Oct 2018
pmahalwar-intertrust
on 26 Oct 2018
/remove-lifecycle stale
pmahalwar-intertrust
on 26 Oct 2018
@pmahalwar-intertrust you can pass the same --log-opt to the docker daemon, which will affect all your containers ...
 nrobert13
on 26 Oct 2018
nrobert13
on 26 Oct 2018
@pmahalwar-intertrust the logs collected from containerd by kubernetes already includes extensive metadata, include any labels you have applied to the container. If you collect it with fluentd you'll get all the metadata e.g. as in the log entry below.
{
"log": " - [] - - [25/Oct/2018:06:29:48 +0000] \"GET /nginx_status/format/json HTTP/1.1\" 200 9250 \"-\" \"Go-http-client/1.1\" 118 0.000 [internal] - - - - 5eb73997a372badcb4e3d993ceb44cd9\n",
"stream": "stdout",
"docker": {
"container_id": "3657e1d9a86e629d0dccefec0c3c7624eaf0c4a11f60f53c5045ec0839c37f06"
},
"kubernetes": {
"container_name": "nginx-ingress-controller",
"namespace_name": "ingress",
"pod_name": "nginx-ingress-dev-controller-69c644f7f5-vs8vw",
"pod_id": "53514ad6-d0f4-11e8-a04c-02c433fc5820",
"labels": {
"app": "nginx-ingress",
"component": "controller",
"pod-template-hash": "2572009391",
"release": "nginx-ingress-dev"
},
"host": "ip-172-29-21-204.us-east-2.compute.internal",
"master_url": "https://10.3.0.1:443/api",
"namespace_id": "e262510b-180a-11e8-b763-0a0386e3402c"
},
"kubehost": "ip-172-29-21-204.us-east-2.compute.internal"
}
Is there still no plan to support these features?
--log-driver= Logging driver for container
--log-opt=[] Log driver options
 lifubang
on 8 Nov 2018
lifubang
on 8 Nov 2018
Hi @lifubang I can't speak to anyone's plans, but the daemon that supported those features, dockerd is no longer part of Kubernetes (see discussion above covering that).
You can still optionally install it if you want to, so you might be able to do that in order use the old dockerd log drivers. That option is discussed here:
https://kubernetes.io/blog/2018/05/24/kubernetes-containerd-integration-goes-ga/
But using a dedicated logging service like fluentd is the suggested approach. You can deploy it globally for your cluster or per-Pod as a sidecar. Logging in Kubernetes is discussed here:
https://kubernetes.io/docs/concepts/cluster-administration/logging/
whereisaaron
on 8 Nov 2018
I highly recommend fluentd as described by @whereisaaron
As far as this feature request being worked on... the kubernetes architectural roadmap has logging under the "Ecosystem" section of things that are not really "part of" kubernetes so I doubt such a feature is going to ever be natively supported.
https://github.com/kubernetes/community/blob/master/contributors/devel/architectural-roadmap.md#summarytldr
 taylorshaulis
on 8 Nov 2018
taylorshaulis
on 8 Nov 2018
I strongly recommend against using fluentd as it has several bugs that can make your life h*ll when running k8s
in_tail prevents docker from removing container https://github.com/fluent/fluentd/issues/1680.
in_tail removes untracked file position during startup phase. It means the content of pos_file is growing until restart and can eat up a ton of cpu scanning through it when you tails lots of files with dynamic path setting.
https://github.com/fluent/fluentd/issues/1126.
 roffe
on 6 Dec 2018
roffe
on 6 Dec 2018
Issues go stale after 90d of inactivity.
Mark the issue as fresh with /remove-lifecycle stale.
Stale issues rot after an additional 30d of inactivity and eventually close.
If this issue is safe to close now please do so with /close.
Send feedback to sig-testing, kubernetes/test-infra and/or fejta.
/lifecycle stale
fejta-bot
on 21 Mar 2019
Thanks for your experience @roffe. fluent/fluentd#1680 was an issue back about k8s 1.5 and we didn't use 'in_tail' back then for that reason. Since k8s moved to containerd logging it doesn't seem to be still a thing? We haven't seen any detectable impact from fluent/fluentd#1126.
You recommended against fluentd. What would you recommend instead? What do you personally use instead of fluentd for log aggregation with k8s metadata?
whereisaaron
on 21 Mar 2019
Stale issues rot after 30d of inactivity.
Mark the issue as fresh with /remove-lifecycle rotten.
Rotten issues close after an additional 30d of inactivity.
If this issue is safe to close now please do so with /close.
Send feedback to sig-testing, kubernetes/test-infra and/or fejta.
/lifecycle rotten
fejta-bot
on 20 Apr 2019
Rotten issues close after 30d of inactivity.
Reopen the issue with /reopen.
Mark the issue as fresh with /remove-lifecycle rotten.
Send feedback to sig-testing, kubernetes/test-infra and/or fejta.
/close
fejta-bot
on 20 May 2019
@fejta-bot: Closing this issue.
In response to this:
Rotten issues close after 30d of inactivity.
Reopen the issue with/reopen.
Mark the issue as fresh with/remove-lifecycle rotten.Send feedback to sig-testing, kubernetes/test-infra and/or fejta.
/close
Instructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes/test-infra repository.
 k8s-ci-robot
on 20 May 2019
k8s-ci-robot
on 20 May 2019
This shouldn't have been closed, should it?
The feature request still make sense to me as I'm looking to set the log-opts per pod (without setting it on the daemon or use logrotate)...
 yzargari
on 27 Aug 2019
yzargari
on 27 Aug 2019
I'm fairly certain that supporting docker specific configuration options from inside k8s is not a good idea. As previously mentioned a fluentd daemonset or fluenbit side car are current options. I prefer the sidecar as it's far more secure.
 coffeepac
on 29 Aug 2019
coffeepac
on 29 Aug 2019
@whereisaaron did you found a logging solution for K8s@containerd?
 loxal
on 11 Sep 2019
loxal
on 11 Sep 2019
are --log-driver , --log-opt still not supported?
I'm trying to find a way to forward logs from single pod to Splunk. any ideas?
 sariel1212
on 15 Sep 2019
sariel1212
on 15 Sep 2019
@sariel1212 for a single pod I recommend including a side car container in your pod that is only the splunk forwarding agent. You can share an emptydir volume between all containers in the pod and have the application container(s) write their logs to the shared emptydir. Then have the splunk forwarder container read from that volume and forward them.
coffeepac
on 16 Sep 2019
If you should want to collect to Splunk for your whole cluster @sariel1212, there is an official Splunk helm chart to deploy fluentd with the Splunk HEC fluentd plug-in to collect node logs, container log, and control plane logs, plus Kubernetes objects, and Kubernetes cluster metrics. For one Pod @coffeepac's suggestion of a sidecar with a shared emptydir is a good approach.
whereisaaron
on 16 Sep 2019
It's pretty terrible that there's still no way for a cluster owner to use Docker log drivers after all this time.
I was able to get setup very quickly with Docker-Compose (simulating my K8s cluster) to pipe all stdout/err to my log aggregated service.
Trying to do this in Kubenetes? From this thread it looks like I'm going to have to augment the code for every microservice! Not good.
 ashleydavis
on 24 Sep 2019
ashleydavis
on 24 Sep 2019
Hi @ashleydavis, dockerd was deprecated in Kubernetes so there is no point introducing support for something that is no longer part of Kubernetes. Though you can still install it in addition to Kubernetes. Here is the background:
https://kubernetes.io/blog/2018/05/24/kubernetes-containerd-integration-goes-ga/
You don't need to augment containers unless you want to, Kubernetes natively streams stdout/stderr logs for every container automatically. You just need to deploy one container on each node (a DaemonSet) to collect and send those log streams to your choice(s) of aggregation service. It is very easy.
https://docs.fluentd.org/container-deployment/kubernetes
The are lots of ready-made fluentd+backend container images and sample configurations for back aggregation back-ends here:
https://github.com/fluent/fluentd-kubernetes-daemonset
If you are using DataDog they have their own agent to install instead or as well as fluentd:
https://docs.datadoghq.com/integrations/kubernetes/
In general docker tended to kitchen sink, with logging and log plug-ins, and swarm, and runtime tools, build tools, networking, and file system mounting, etc. all in one daemon process. Kubernetes generally prefers loosely coupled containers/processes doing one task each and communicating via APIs. So it is a bit of a different style to get used to.
whereisaaron
on 24 Sep 2019
Thanks for the detailed response. I'm definitely going to look into this.
With dockerd deprecated does that mean I can't deploy Docker images to Kubernetes in the future?
ashleydavis
on 24 Sep 2019
@ashleydavis you can certainly keep using 'Docker' images (even without dockerd present), and you can keep deploying dockerd on your Kubernetes nodes for your own purposes (like in docker-in-docker builds) if you want. The core parts of docker have been extracted and standardised as 'OCI containers' and the containerd run-time.
https://www.opencontainers.org/
https://containerd.io/
Both Docker and Kubernetes are now based on these shared standards.
https://blog.docker.com/2017/08/what-is-containerd-runtime/
https://kubernetes.io/blog/2018/05/24/kubernetes-containerd-integration-goes-ga/
whereisaaron
on 24 Sep 2019
Thanks, I'm learning so much.
I just created a microservice that I called Loggy. The intention was for it to be sent logs by the Docker log driver and then forward them (via webhook) to Slack.
You can see the code here: https://github.com/artlife-solutions/loggy/blob/master/src/index.ts
It's pretty simple, receive a log and forward it via HTTP POST to Slack.
What's the quickest way to adapt this so that I can collect and aggregate logs from my pods?
ashleydavis
on 24 Sep 2019
@ashleydavis you could Build a container image with that micro-service in it, then either
Deploy it you cluster as Deployment with a Service that all containers on your cluster could then send to (using the Service's cluster DNS name).
Deploy it as an addition 'sidecar' container in your Deployment. Containers in the same Pod share private access to the same
localhostso the application container can send to your micro-service container sidecar onlocalhost:12201. Alternatively, containers in the same Pod can share a volume for shared log files or named pipes.
This is getting off-topic here and not everyone will want this, so perhaps go research some examples on Github and hit some Slack channels for advice.
https://github.com/ramitsurana/awesome-kubernetes
https://slack.k8s.io/
https://kubernetes.io/
whereisaaron
on 24 Sep 2019
Sounds good thanks. I was just hoping not to have to change existing services. I'd just like to capture their stdout/error. Anyway to do that?
The promise of Docker log drivers was simplicity. Is there any simple way to do this?
ashleydavis
on 24 Sep 2019
Sure @ashleydavis, deploy your cluster, deploy fluentd, and bang, you’re done 😺. Every application you deploy will have its stdout/stderr shipped to your favorite aggregator. 👍
whereisaaron
on 24 Sep 2019
After investing some time into K8s and logging I have setup a nice ELK stack without explicit GELF configuration. Please take a look at https://www.elastic.co/guide/en/beats/filebeat/current/running-on-kubernetes.html
My setup is Filebeat that pipes the logs to Logstash that filters & extracts and pipes their stuff into Elasticsearch. With Kibana I can view the logs and aggregate data.
loxal
on 24 Sep 2019
I would also love to support logging to the operating system's native syslog file, for example: on Ubuntu I can write logs to /var/log/syslog, which is managed by logrotate out of the box.
With swarm / compose, I can do this:
version: '3.3'
services:
mysql:
image: mysql:5.7
logging:
driver: syslog
options:
tag: mysql
Using an emtpyDir volume is fine, however, long running pods are at risk of filling the volume unless you add an additional process that rotate / truncate the log files. I do not agree with this additional complexity when the OS is already handling the rotation of /var/log/syslog.
I do agree that using sidecars for some deployments is a great idea (I already do this for some of my deployments), however, everyone's environment is different.
 jsirianni
on 5 Dec 2019
jsirianni
on 5 Dec 2019
Using an emtpyDir volume is fine
Be careful with them -- they are managed by Kubernetes and their lifetime isn't controlled by you. If a pod is evicted and rescheduled to another node -- logs will be lost. If you update a pod and its uid changes, it won't use the old volume but rather create a new one and removes the old one.
 php-coder
on 5 Dec 2019
php-coder
on 5 Dec 2019
@jsirianni not all systems are running syslog which means there would have to be some per-node annotation on what facilities are available to ensure a given pod's needs are met. docker compose gets to make that assumption because its running locally only.
coffeepac
on 6 Dec 2019
@coffeepac Just because the nodes might not have syslog does not mean the operator should not have the option. If I intend to use syslog, I would make sure my worker nodes have syslog.
jsirianni
on 6 Dec 2019
I feel this issue should be reopened as there is still enough use cases for this feature.
/reopen
 saiyam1814
on 27 Feb 2020
saiyam1814
on 27 Feb 2020
@saiyam1814: Reopened this issue.
In response to this:
I feel this issue should be reopened as there is still enough use cases for this feature.
/reopen
Instructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes/test-infra repository.
k8s-ci-robot
on 27 Feb 2020
Personally, I still think Kubernetes should support Docker log drivers or some other simple built-in way to configure logging.
I've been told many times that setting up logging is easy on Kubernetes, but now having been through the process of setting up my own logging aggregation system I can say that it truly is not simple.
I've written a blog post on the simplest way to hand-roll your own log aggregation system for Kubernetes: http://www.the-data-wrangler.com/kubernetes-log-aggregation/
Hopefully my blog post will help others figure out their own strategy.
It shouldn't be so difficult, but this is where we are at.
ashleydavis
on 27 Feb 2020
Sure we need a way to consume Docker logs directly from stdout and stderr, instead of use log files. There are some security issues to use the Docker path to log files, because you can access to other logs in the host system.
Can we implement the Docker log-driver ? 👍
 Tetragramato
on 2 Mar 2020
Tetragramato
on 2 Mar 2020
Configuring docker log drivers on a container-in-a-pod level (where the pod is in customer control) would enable redirecting logs with the gelf driver directly to a graylog service/pod (which is also in customer control) instead of having to collect them from files on the host with another immediate service (which is more management overhead and a worse break of abstraction level than using the gelf log driver) or by customer's pods accessing the container logs directory on the host.
Therefore I would love to see this feature implemented in kubernetes.
 blubberdiblub
on 10 Mar 2020
blubberdiblub
on 10 Mar 2020
It would helpful to make sure we do something like https://github.com/cri-o/cri-o/pull/1605, where we disconnect the log stream interpretation from the log drivers so that container behavior can't effect how the drivers work.
 portante
on 10 Mar 2020
portante
on 10 Mar 2020
Rotten issues close after 30d of inactivity.
Reopen the issue with /reopen.
Mark the issue as fresh with /remove-lifecycle rotten.
Send feedback to sig-testing, kubernetes/test-infra and/or fejta.
/close
fejta-bot
on 9 Apr 2020
@fejta-bot: Closing this issue.
In response to this:
Rotten issues close after 30d of inactivity.
Reopen the issue with/reopen.
Mark the issue as fresh with/remove-lifecycle rotten.Send feedback to sig-testing, kubernetes/test-infra and/or fejta.
/close
Instructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes/test-infra repository.
k8s-ci-robot
on 9 Apr 2020
Function still needs to be implemented
/reopen
 M0rdecay
on 9 Apr 2020
M0rdecay
on 9 Apr 2020
@M0rdecay: You can't reopen an issue/PR unless you authored it or you are a collaborator.
In response to this:
Function still needs to be implemented
/reopen
Instructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes/test-infra repository.
k8s-ci-robot
on 9 Apr 2020
@M0rdecay: You can't reopen an issue/PR unless you authored it or you are a collaborator.
Okay, i understood
M0rdecay
on 9 Apr 2020
Even aws ecs has this functionality where one can set the docker logging driver.
In our environment, we have created a separate index with a unique token for each container service.
"logConfiguration": {
"logDriver": "splunk",
"options": {
"splunk-format": "raw",
"splunk-insecureskipverify": "true",
"splunk-token": "xxxxx-xxxxxxx-xxxxx-xxxxxxx-xxxxxx",
"splunk-url": "https://xxxxx.splunk-heavyforwarderxxx.com",
"tag": "{{.Name}}/{{.ID}}",
"splunk-verify-connection": "false",
"mode": "non-blocking"
}
}
But didn't find anything like this in k8s. It should be there in the pod definition itself.
 arshadsiddique-jfl
on 10 Aug 2020
arshadsiddique-jfl
on 10 Aug 2020
The options still need to be implemented
/reopen
ejemba
on 10 Aug 2020
@ejemba: Reopened this issue.
In response to this:
The options still need to be implemented
/reopen
Instructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes/test-infra repository.
k8s-ci-robot
on 10 Aug 2020
/sig node
/remove-sig instrumentation
 logicalhan
on 26 Aug 2020
logicalhan
on 26 Aug 2020
/remove-sig scalability
logicalhan
on 26 Aug 2020
@logicalhan: Those labels are not set on the issue: sig/
In response to this:
/remove-sig scalability
Instructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes/test-infra repository.
k8s-ci-robot
on 26 Aug 2020
Any progress with it?
I was looking specifically for an ability to setup pods' containers to log into the external logstash, specifying docker's gelf log-driver. Setting it by default for all the containers in /etc/docker/daemon.json seems to be an overhead.
 freehck
on 16 Sep 2020
freehck
on 16 Sep 2020
Rotten issues close after 30d of inactivity.
Reopen the issue with /reopen.
Mark the issue as fresh with /remove-lifecycle rotten.
Send feedback to sig-testing, kubernetes/test-infra and/or fejta.
/close
fejta-bot
on 16 Oct 2020
@fejta-bot: Closing this issue.
In response to this:
Rotten issues close after 30d of inactivity.
Reopen the issue with/reopen.
Mark the issue as fresh with/remove-lifecycle rotten.Send feedback to sig-testing, kubernetes/test-infra and/or fejta.
/close
Instructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes/test-infra repository.
k8s-ci-robot
on 16 Oct 2020
/reopen
 andreswebs
on 2 Nov 2020
andreswebs
on 2 Nov 2020
@andreswebs: You can't reopen an issue/PR unless you authored it or you are a collaborator.
In response to this:
/reopen
Instructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes/test-infra repository.
k8s-ci-robot
on 2 Nov 2020
/reopen
ejemba
on 3 Nov 2020
@ejemba: Reopened this issue.
In response to this:
/reopen
Instructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes/test-infra repository.
k8s-ci-robot
on 3 Nov 2020
@ejemba: This issue is currently awaiting triage.
If a SIG or subproject determines this is a relevant issue, they will accept it by applying the triage/accepted label and provide further guidance.
The triage/accepted label can be added by org members by writing /triage accepted in a comment.
Instructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes/test-infra repository.
k8s-ci-robot
on 3 Nov 2020
I would really like this feature to be implemented. I am currently migrating workloads from Rancher 1.x clusters to Rancher 2.x clusters which run k8s. We have a deployment which sets the log-driver and log-opt parameters in the docker-compose configuration.
I dont want to have to configure one specific host to use the gelf driver globally and tag the pod with a label and host with a label.
 bananflugan
on 4 Nov 2020
bananflugan
on 4 Nov 2020
Seems like we should change CRI-O to specify that both container log streams (stdout / stderr) are collected in a raw form, and the when reading the raw for later we can apply different interpretations of the log byte stream then.
portante
on 13 Nov 2020
Rotten issues close after 30d of inactivity.
Reopen the issue with /reopen.
Mark the issue as fresh with /remove-lifecycle rotten.
Send feedback to sig-testing, kubernetes/test-infra and/or fejta.
/close
fejta-bot
on 13 Dec 2020
@fejta-bot: Closing this issue.
In response to this:
Rotten issues close after 30d of inactivity.
Reopen the issue with/reopen.
Mark the issue as fresh with/remove-lifecycle rotten.Send feedback to sig-testing, kubernetes/test-infra and/or fejta.
/close
Instructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes/test-infra repository.
k8s-ci-robot
on 13 Dec 2020
Related issues
 sjenning
·
3Comments
sjenning
·
3Comments
 arun-gupta
·
3Comments
arun-gupta
·
3Comments
 cooligc
·
3Comments
cooligc
·
3Comments
 ttripp
·
3Comments
ttripp
·
3Comments
 zetaab
·
3Comments
zetaab
·
3Comments
Most helpful comment
Hi there,
I think this is an important feature that should be considered for kubernetes.
Enabling the use of Docker's log driver can solve some non-trivial problems.
I would say that logging to disk is an anti-pattern. Logs are inherently "state", and should preferably not be saved to disk. Shipping the logs directly from a container to a repository solves many problems.
Setting the log driver would mean that the kubectl logs command can not show anything anymore.
While that feature is "nice to have" - the feature won't be needed when the logs are available from a different source.
Docker already has log drivers for google cloud (gcplogs) and Amazon (awslogs). While it is possible to set them on the Docker daemon itself, that has many drawbacks. By being able to set the two docker options:
--log-driver= Logging driver for container
--log-opt=[] Log driver options
It would be possible to send along labels (for gcplogs) or awslogs-group (for awslogs)
specific to a pod. That would make it easy to find the logs at the other end.
I have been reading up on how people are handling logs in kubernetes. Many seem to set up some elaborate scrapers that forward the logs to central systems. Being able to set the log driver will make that unnecessary - freeing up time to work on more interesting things :)