Xgboost: Call for Contribution: Verbesserung der Multi-Core-CPU-Leistung von 'hist'
Es ist an der Zeit, den Elefanten im Raum anzugehen: Leistung auf Multi-Core-CPUs.
Problembeschreibung
Derzeit lässt sich der hist ( tree_method=hist ) auf Mehrkern-CPUs schlecht skalieren: Bei einigen Datensätzen verschlechtert sich die Leistung, wenn die Anzahl der Threads erhöht wird . Dieses Problem wurde von @ Laurae2s Gradient Boosting Benchmark ( GitHub Repo ) entdeckt.
Das Skalierungsverhalten für den Bosch-Datensatz ist wie folgt: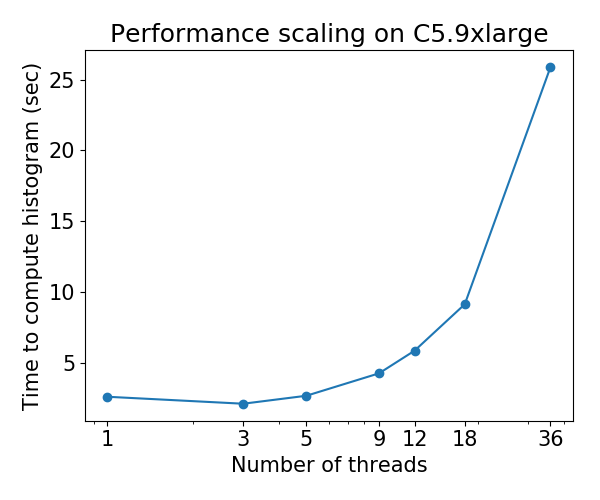
Aufforderung zur Einreichung von Beiträgen
Ich habe den Leistungsengpass des 'hist'-Algorithmus identifiziert und in ein kleines Repository gestellt: hcho3 / xgboost-fast-hist-perf-lab . Sie können versuchen, die Leistung zu verbessern, indem Sie src / build_hist.cc überarbeiten .
Einige Ideen
- Ändern Sie das Datenmatrix-Layout von CSR in andere Layouts wie Ellpack
- Versuchen Sie, die Arbeit gleichmäßiger auf die Arbeitsthreads zu verteilen. Das Arbeitsungleichgewicht wird durch unregelmäßige, spärliche Muster der Datenmatrix verursacht.
- Gruppieren Sie komplementäre Funktionen, ein gängiges Szenario für One-Hot-codierte Daten.
 hcho3
hcho3
Alle 44 Kommentare
@ Laurae2 Vielen Dank, dass Sie den GBT-Benchmark vorbereitet haben. Es war hilfreich bei der Identifizierung des Problempunkts.
hcho3
am 19. Okt. 2018
@ hcho3 Hilft OpenMP guided Zeitplan beim Lastenausgleich? In diesem Fall ist das Ellpack nicht sehr nützlich.
 trivialfis
am 24. Okt. 2018
trivialfis
am 24. Okt. 2018
Ich vermute, dass die statische Zuweisung von Arbeit mit Ellpack eine ausgeglichene Arbeitslast mit einem geringeren Overhead als der OpenMP-Modus guided oder dynamic von OpenMP erreichen würde. Mit dynamic Sie Laufzeitaufwand für die Aufrechterhaltung der Warteschlange zum Stehlen von Arbeit
hcho3
am 24. Okt. 2018
Vielleicht etwas abseits des Themas. Haben wir Benchmark-Ergebnisse von approx ?
Wir finden die suboptimale Beschleunigung durch Multithreading in unserer internen Umgebung heraus ... möchten die Daten anderer betrachten
 CodingCat
am 24. Okt. 2018
CodingCat
am 24. Okt. 2018
@CodingCat Die verknüpfte Benchmark-Suite verwendet nur hist . Zeigt approx eine Leistungsverschlechterung wie hist (z. B. 36 Threads langsamer als 3 Threads)?
hcho3
am 24. Okt. 2018
@ hcho3 Aufgrund der Einschränkung in unserem Cluster können wir nur mit bis zu 8 Threads testen ... aber wir finden eine sehr begrenzte Beschleunigung im Vergleich von 8 zu 4 .....
CodingCat
am 24. Okt. 2018
@CodingCat Du meinst 8 Threads laufen langsamer als 4?
hcho3
am 24. Okt. 2018
@CodingCat approx hat eine so schlechte Skalierung, dass ich nicht einmal versuchen wollte, sie zu vergleichen. Auf meinem 4-Core-Laptop (3,6 GHz) lässt es sich nicht einmal richtig skalieren, daher stelle ich mir das mit 64 oder 72 Threads nicht einmal vor.
@ hcho3 Ich werde es mir später in Ihrem Repository mit VTune ansehen.
Für diejenigen, die eine detaillierte Leistung in VTune erhalten möchten, kann Folgendes zum Header hinzugefügt werden:
#include <ittnotify.h> // Intel Instrumentation and Tracing Technology
Fügen Sie vor dem, was Sie außerhalb einer Schleife verfolgen möchten, Folgendes hinzu (benennen Sie die Zeichenfolgen / Variablen um):
__itt_resume();
__itt_domain* domain = __itt_domain_create("MyDomain");
__itt_string_handle* task = __itt_string_handle_create("MyTask");
__itt_task_begin(domain, __itt_null, __itt_null, task);
Fügen Sie nach dem, was Sie außerhalb einer Schleife verfolgen möchten, Folgendes hinzu (benennen Sie die Zeichenfolgen / Variablen um):
__itt_task_end(domain);
__itt_pause();
Starten Sie mit VTune ein Projekt mit den richtigen Parametern für die Anzahl der Threads. Starten Sie die ausführbare Datei mit angehaltener Instrumentierung, um eine Leistungsanalyse durchzuführen.
 Laurae2
am 24. Okt. 2018
Laurae2
am 24. Okt. 2018
@ hcho3 es ist nicht langsamer, aber vielleicht nur 15% schneller mit 4 weiteren Threads ... (wenn ich mehr Experimente durchführe, würde ich vermuten, dass die Ergebnisse sogar konvergieren würden .....
CodingCat
am 24. Okt. 2018
@ Laurae2 sieht so aus, als wäre ich nicht der einzige
CodingCat
am 24. Okt. 2018
@ hcho3 Ich werde versuchen, Ihnen vor Ende dieser Woche einige Skalierungsergebnisse zu liefern, wenn niemand dies mit exact , approx und hist tut, alle mit depth=6 , beim Festschreiben von e26b5d6.
Ich habe kürzlich meinen Computerserver migriert und mache diese Woche neue Benchmarks für Bosch auf einem neuen Computer mit 3,7 GHz, allen Turbo / 36 Kernen / 72 Threads / 80 GBit / s RAM-Bandbreite.
Laurae2
am 24. Okt. 2018
Der fast_hist-Updater sollte für verteiltes xgboost viel schneller sein. @CodingCat Ich bin überrascht, dass niemand versucht hat, AllReduce-Aufrufe hinzuzufügen, damit es im verteilten Modus funktioniert.
 RAMitchell
am 24. Okt. 2018
RAMitchell
am 24. Okt. 2018
@ RAMitchell Ich war ziemlich neu, als ich den fast_hist-Updater schrieb, daher fehlt ihm die Unterstützung für den verteilten Modus. Ich würde es gerne nach der Veröffentlichung von 0.81 erreichen.
hcho3
am 24. Okt. 2018
@ Laurae2 FYI, ich habe Ihre Benchmark-Suite auf einem C5.9xlarge-Computer ausgeführt und die Ergebnisse für XGBoost hist scheinen mit Ihren vorherigen Ergebnissen übereinzustimmen. Ich kann die Zahlen aufstellen, wenn Sie möchten.
hcho3
am 24. Okt. 2018
@ Laurae2 Außerdem habe ich Zugriff auf EC2-Maschinen. Wenn Sie ein Skript haben, das Sie auf einer EC2-Instanz ausführen möchten, lassen Sie es mich wissen.
hcho3
am 24. Okt. 2018
@ RAMitchell Ich war ziemlich neu, als ich den fast_hist-Updater schrieb, daher fehlt ihm die Unterstützung für den verteilten Modus. Ich würde es gerne nach der Veröffentlichung von 0.81 erreichen.
@ hcho3 Wenn es Ihnen nichts ausmacht, kann ich mich der Herausforderung stellen, den verteilten, schnelleren Histogramm-Algorithmus zu erhalten. Ich bin derzeit in meinem Uber-Job zur Hälfte damit beschäftigt und habe nächstes Jahr möglicherweise mehr Zeit für xgboost
CodingCat
am 29. Okt. 2018
@CodingCat Das wäre toll, danke! Lassen Sie mich wissen, wenn Sie Fragen zum 'hist'-Code haben.
hcho3
am 29. Okt. 2018
@CodingCat FYI, ich plane, bald nach der Veröffentlichung von 0.81 Unit-Tests für den 'hist'-Updater hinzuzufügen. Das sollte helfen, wenn es darum geht, verteilten Support hinzuzufügen.
hcho3
am 29. Okt. 2018
@ hcho3 @CodingCat approx scheint im letzten Monat entfernt worden zu sein. Ist dies ein erwartetes Verhalten?
https://github.com/dmlc/xgboost/commit/70d208d68c3a32aaa4fcd6aa456f286a4da5912f#diff -53a3a623be5ce5a351a89012c7b03a31 (PR https://github.com/dmlc/xgboost/pull/3395 entfernt tree_method = approx ?) => immer gleich Ergebnisse zwischen ca. und nicht ca.
Laurae2
am 29. Okt. 2018
@ Laurae2 Der Refactor hat approx . Andernfalls sollte approx noch verfügbar sein.
hcho3
am 29. Okt. 2018
@ Laurae2 Eigentlich hast du recht. Obwohl sich approx noch in der Codebasis befindet, wird es aus irgendeinem Grund nicht aufgerufen, selbst wenn tree_method=approx ist. Ich werde diesen Fehler so schnell wie möglich untersuchen.
hcho3
am 29. Okt. 2018
Die Ausgabe Nr. 3840 wurde eingereicht. Release 0.81 wird erst veröffentlicht, wenn dies behoben ist.
hcho3
am 29. Okt. 2018
@ hcho3 Ich
Für ungefähr ist die schlechte Effizienz viel besser als erwartet, aber ich erwarte nicht, dass dies für jeden Computer zutrifft (vielleicht wird es mit einer neueren Intel-CPU-Generation besser = höhere RAM-Frequenz?). Ich werde die Daten veröffentlichen, sobald das schnelle Histogramm auf meinem Server beendet ist.
Zur Information verwende ich einen Bosch-Datensatz mit 477 Funktionen (Funktionen mit weniger als 5% fehlenden Werten).
Über 3000 Stunden CPU-Zeit erreicht ... (zumindest mein Server wird für eine Weile gut genutzt) Als nächstes werde ich https://github.com/hcho3/xgboost-fast-hist-perf- lab / blob / master / src / build_hist.cc mit Intel VTune.
@ hcho3 Wenn Sie möchten, kann ich Ihnen mein Benchmark-R-Skript zur Verfügung stellen, sobald mein Server die Datenverarbeitung abgeschlossen hat. Ich lief mit depth=8 und nrounds=50 für alle tree_method=exact , tree_method=approx (mit updater=grow_histmaker,prune Workaround vor # 3849) und tree_method=hist , von 1 bis 72 Threads. Möglicherweise werden interessantere Dinge entdeckt, an denen gearbeitet werden muss (und Sie können sie auch auf AWS testen).
Laurae2
am 1. Nov. 2018
Bitte beachten Sie die vorläufigen Ergebnisse unten, lief 7 Mal zu durchschnittlichen Ergebnissen. Stellen Sie sicher, dass Sie auf klicken, um eine bessere Ansicht zu erhalten. Synthetischer Tisch zur Verfügung gestellt. Im Gegensatz zu den Plots wurden die CPUs nicht fixiert.
Die Diagramme scheinen sich deutlich von denen zu unterscheiden, auf die ich vorbereitet war ... (aufgrund des seltsamen Verhaltens führe ich dies mit aktivierter UMA (NUMA aus) erneut aus). Später werde ich mich bei Intel VTune erkundigen.
Hardware und Software:
- CPU: Dual Xeon Gold 6154, 3,7 GHz alle Turbo, 2x 18 Kerne / 36 Threads
- RAM: 4x 64 GB RAM DDR4 2666 MHz (Zweikanal, ca. 80 GBit / s Bandbreite)
- BIOS: NUMA ein, Sub-NUMA-Clustering aus
- Betriebssystem: Pop_OS! 18.10
- Gouverneur: Leistung
- Kernel: 4.18.0-10
- Kernel-Flags:
pti=off spectre_v2=off spec_store_bypass_disable=off l1tf=off noibrs noibpb nopti no_stf_barrier - Compiler: gcc 8.2.0
- R: 3.5.1 kompiliert mit gcc 8.2.0 und mit Intel MKL
- zusätzliche Kompilierungsflags in R:
-O3 -mtune=native
Meltdown / Spectre-Schutz:
laurae@laurae-compute:~$ head /sys/devices/system/cpu/vulnerabilities/*
==> /sys/devices/system/cpu/vulnerabilities/l1tf <==
Mitigation: PTE Inversion; VMX: vulnerable
==> /sys/devices/system/cpu/vulnerabilities/meltdown <==
Vulnerable
==> /sys/devices/system/cpu/vulnerabilities/spec_store_bypass <==
Vulnerable
==> /sys/devices/system/cpu/vulnerabilities/spectre_v1 <==
Mitigation: __user pointer sanitization
==> /sys/devices/system/cpu/vulnerabilities/spectre_v2 <==
Vulnerable
| Themen | Genau (Effizienz) | Ca. (Effizienz) | Hist (Effizienz) |
| ---: | ---: | ---: | ---: |
| 1 | 1367s (100%) | 1702s (100%) | 69,9 s (100%) |
| 2 | 758,7 s (180%) | 881,0 s (193%) | 52,5 s (133%) |
| 4 | 368,6 s (371%) | 445,6 s (382%) | 31,7 s (221%) |
| 6 | 241,5 s (566%) | 219,6 s (582%) | 24,1 s (290%) |
| 9 | 160,4 s (852%) | 194,4 s (875%) | 23,1 s (303%) |
| 18 | 86,3 s (1583%) | 106,3 s (1601%) | 24,2 s (289%) |
| 27 | 66,4 s (2059%) | 80,2 s (2122%) | 63,6 s (110%) |
| 36 | 52,9 s (2586%) | 60,0 s (2837%) | 55,2 s (127%) |
| 54 | 215,4 s (635%) | 289,5 s (588%) | 343,0 s (20%) |
| 72 | 218,9 s (624%) | 295,6 s (576%) | 1237,2 s (6%) |
xgboost Genaue Geschwindigkeit:
xgboost Genaue Effizienz:
xgboost Ungefähre Geschwindigkeit:
xgboost Ungefähre Effizienz:
xgboost Histogrammgeschwindigkeit:
Effizienz des xgboost-Histogramms:
Laurae2
am 3. Nov. 2018
Sieht nach einem Problem mit mehreren Steckdosen aus.
RAMitchell
am 3. Nov. 2018
@RAMitchell Scheint ein Problem mit der Verfügbarkeit von NUMA-Knoten zu sein. Ich kann dieses Problem (mit einem viel schlechteren Ergebnis mit weniger Threads während des Trainings) mithilfe von Sub-NUMA-Clustering (2 Sockets = 4 NUMA-Knoten anstelle von 1 Socket = 2 NUMA-Knoten) replizieren ).

xgboost hat wie die meisten Algen für maschinelles Lernen keine Optimierung für den Umgang mit NUMA-Knoten. Aber das wäre eine zweite Ausgabe. Daher sind sie weder für Umgebungen mit mehreren Sockets geeignet, noch wenn NUMA-Knoten über COD (Cluster on Die) oder SNC (Sub-NUMA-Clustering) verfügbar sind, und Hyperthreading macht das Ungleichgewicht der Arbeitslast zu einer enormen Belastung für sie.
In Problem 1 geht es um die enorme Verschlechterung der Multithread-Leistung im xgboost-Hist-Modus (dieses Problem).
In Ausgabe 2 geht es um die NUMA-Optimierung (ein weiteres zu öffnendes Problem).
Laurae2
am 4. Nov. 2018
Hier sind die Ergebnisse mit deaktiviertem NUMA. Ich habe die Ergebnisse mit NUMA gepaart, das zum Vergleich aktiviert ist. Außerdem wurden 71 Threads hinzugefügt, um die Leistung zu demonstrieren, bevor die CPU mit 72 Threads vom Kernel-Scheduler überfordert wird (mehr Ressourcen erforderlich als verfügbar).
UMA ist beim Multithreading weitaus besser als NUMA. Dies ist ein erwartetes Ergebnis der Speicherverschachtelung bei einem nicht NUMA-fähigen Prozess.
Zeit Zeit:
| Themen | Genau
NUMA | Genau
UMA | Ca.
NUMA | Ca.
UMA | Hist
NUMA | Hist
UMA |
| ---: | ---: | ---: | ---: | ---: | ---: | ---: |
| 1 | 1367er Jahre | 1667er Jahre | 1702s | 1792s | 69,9s | 85,6s |
| 2 | 758,7s | 810,3s | 881.0s | 909.0s | 52,5s | 54,1s |
| 4 | 368,6s | 413,0s | 445,6s | 452,9s | 31,7s | 36,2 s |
| 6 | 241,5 s | 273,8s | 219,6s | 302,4s | 24.1s | 30,5 s |
| 9 | 160,4s | 182,8s | 194,4s | 202,5s | 23.1s | 28,3s |
| 18 | 86,3s | 94,4s | 106,3s | 105,8s | 24,2 s | 31,2 s |
| 27 | 66,4s | 66,4s | 80,2s | 73,6s | 63,6s | 37,5 s |
| 36 | 52,9s | 52,7s | 60,0s | 59,4s | 55,2 s | 43,5 s |
| 54 | 215,4s | 49,2 s | 289,5 s | 58,5s | 343.0s | 57,4s |
| 71 | 218,3s | 47.01s | 295,9s | 56,5s | 1238,2s | 71,5s |
| 72 | 218,9s | 49,0 s | 295,6s | 58,6s | 1237,2s | 79,1s |
Effizienz-Tabelle:
| Themen | Genau
NUMA | Genau
UMA | Ca.
NUMA | Ca.
UMA | Hist
NUMA | Hist
UMA |
| ---: | ---: | ---: | ---: | ---: | ---: | ---: |
| 1 | 100% | 100% | 100% | 100% | 100% | 100% |
| 2 | 180% | 206% | 193% | 197% | 133% | 158% |
| 4 | 371% | 404% | 382% | 396% | 221% | 236% |
| 6 | 566% | 609% | 582% | 593% | 290% | 280% |
| 9 | 852% | 912% | 875% | 885% | 303% | 302% |
| 18 | 1583% | 1766% | 1601% | 1694% | 289% | 274% |
| 27 | 2059% | 2510% | 2122% | 2436% | 110% | 229% |
| 36 | 2586% | 3162% | 2837% | 3017% | 127% | 197% |
| 54 | 635% | 3384% | 588% | 3065% | 20% | 149% |
| 71 | 626% | 3545% | 575% | 3172% | 6% | 120% |
| 72 | 624% | 3401% | 576% | 3059% | 6% | 108% |
UMA-Modus.
xgboost Genaue Geschwindigkeit:
xgboost Genaue Effizienz:
xgboost Ungefähre Geschwindigkeit:
xgboost Ungefähre Effizienz:
xgboost Histogrammgeschwindigkeit:
Effizienz des xgboost-Histogramms:
Laurae2
am 4. Nov. 2018
Wie in https://github.com/dmlc/xgboost/pull/3957#issuecomment -453815876 kommentiert, habe ich die Commits a2dc929 (vor der CPU-Verbesserung) und 5f151c5 (nach der CPU-Verbesserung) getestet.
Ich habe mit meinem Dual Xeon 6154-Server (gcc-Compiler, nicht Intel) mit Bosch für 500 Iterationen, eta 0,10 und Tiefe 8, mit jeweils 3 Läufen für 1 bis 72 Threads getestet. Wir stellen eine Leistungssteigerung von bis zu 50% (1/3 schneller) für Multithread-Workloads bei maximaler Leistung fest.
Hier sind die Ergebnisse für vor # 3957 (Commit a2dc929):

Hier sind die Ergebnisse für # 3957 (Commit 5f151c5):

Anhand der Effizienzkurven sehen wir eine Erhöhung der Skalierbarkeit um 50% (dies bedeutet nicht, dass das Problem gelöst ist: Wir müssen es noch verbessern, wenn wir können - im Idealfall, wenn wir den Bereich von 1000 bis 2000% erreichen können, der wahnsinnig wäre großartig).
Wirkungsgradkurve von a2dc929:

Wirkungsgradkurve von 5f151c5:

Laurae2
am 15. Jan. 2019
Danke @ Laurae2 , ich werde dieses Problem
hcho3
am 16. Jan. 2019
@ hcho3 @SmirnovEgorRu Ich
Hier ist ein Beispiel für zufällig dichte Daten mit 50 Millionen Zeilen x 100 Spalten (gcc 8), für deren ordnungsgemäßes Training mindestens 256 GB RAM aus Python / R erforderlich sind und die dreimal (6 Tage) ausgeführt werden.
Commit a2dc929:

Commit 5f151c5:

Obwohl sie zu einer sehr ähnlichen Multithread-Leistung führen, wird die Singlethread-Leistung durch ein langsameres Training beeinträchtigt (die Verbesserungen von
Mit Ausnahme der Gmat-Erstellungszeit haben wir für Singlethread auf 50M x 100:
| Commit | Gesamt | gmat Zeit | Zugzeit |
| : --- | ---: | ---: | ---: |
| a2dc929 | 2926s | 816s | 2109s |
| 5f151c5 | (+ 13%) 3316s | (~%) 817s | (+ 18%) 2499s |
Laurae2
am 26. Jan. 2019
@ hcho3 @ Laurae2 Im Allgemeinen hilft Hyper-Threading nur bei Core-gebundenen Algorithmen, nicht bei speichergebundenen Algorithmen.
HT hilft beim Laden der CPU-Pipeline durch weitere Anweisungen zur Ausführung. Wenn die meisten Anweisungen auf die Ausführung vorheriger Anweisungen warten (Latenzzeit gebunden) - HT kann wirklich helfen. Bei bestimmten Workloads habe ich eine bis zu 1,5-fache Beschleunigung beobachtet.
Wenn Ihre Anwendung jedoch die meiste Zeit mit der Arbeit mit Speicher verbringt (speichergebunden), wird HT noch schlimmer. 2 Hyper-Threads teilen sich einen CPU-Cache und verdrängen sich gegenseitig nützliche Informationen. Als Ergebnis sehen wir einen Leistungsabfall.
Gradient Boosting - speichergebundener Algorithmus. Die Verwendung von HT sollte in keinem Fall zu einer Leistungsverbesserung führen, und Ihre maximale Beschleunigung aufgrund von Threading im Vergleich zur 1thread-Version ist durch die Anzahl der Hardwarekerne begrenzt. Daher ist es meiner Meinung nach besser, die Leistung auf einer CPU ohne HT zu messen.
Was ist mit NUMA? Ich habe die gleichen Probleme bei der DAAL-Implementierung beobachtet. Es erfordert die Kontrolle der Speichernutzung durch jeden Kern. Ich werde es mir in Zukunft ansehen.
Was ist mit einer kleinen Verlangsamung von 1 Thread - ich werde es untersuchen. Ich denke - Fix ist einfach.
@ hcho3 Im Moment arbeite ich am nächsten Teil der Optimierungen. Ich hoffe, dass ich in naher Zukunft für neue Pull-Anfragen bereit bin.
 SmirnovEgorRu
am 30. Jan. 2019
SmirnovEgorRu
am 30. Jan. 2019
@ SmirnovEgorRu Nochmals vielen Dank für Ihre Bemühungen. Zu Ihrer Information, es gab kürzlich eine Diskussion über die Erhöhung der Parallelität durch die Durchführung einer stufenweisen Knotenerweiterung: # 4077.
hcho3
am 30. Jan. 2019
@ Laurae2 Können wir nach der Zusammenführung von # 3957, # 4310 und # 4529 davon ausgehen, dass das Skalierungsproblem behoben wurde? Die Auswirkungen von NUMA können weiterhin problematisch sein.
hcho3
am 5. Juli 2019
@ hcho3 Ich werde später erneut prüfen, um zu überprüfen, aber
Ich werde die Leistungsergebnisse auch mit @szilard überprüfen.
Offenes Beispiel: https://github.com/szilard/GBM-perf/issues/9
Laurae2
am 5. Juli 2019
Die Multicore-Skalierung und tatsächlich auch das NUMA-Problem wurden in der Tat stark verbessert:
Multicore:

Sehr bemerkenswert die Verbesserung bei kleineren Daten (0,1 Millionen Zeilen)


Weitere Details hier:
https://github.com/szilard/GBM-perf#multi -core-scaling-cpu
https://github.com/szilard/GBM-perf/issues/29#issuecomment -689713624
Auch das NUMA- Problem wurde weitgehend gemildert:



 szilard
am 17. Sept. 2020
szilard
am 17. Sept. 2020
@szilard Vielen Dank, dass Sie sich die Zeit genommen haben, den Benchmark
hcho3
am 17. Sept. 2020
Ja, großartige Arbeit, alle in diesem Thread, die dies erreicht haben.
szilard
am 17. Sept. 2020
Zu Ihrer Information, hier sind die Trainingszeiten für 1M-Reihen auf EC2 r4.16xlarge (2 Sockel mit jeweils 16c + 16HT) auf 1, 16 (1so & no HT) und 64 (alle) Kernen für verschiedene Versionen von xgboost:

szilard
am 17. Sept. 2020
@szilard , vielen Dank für die Analyse! Gut zu hören, dass die Optimierungen funktionieren.
PS Oben sehe ich, dass XGB 1.2 eine gewisse Regression gegenüber der Version 1.1 aufweist. Es ist eine sehr interessante Information, lassen Sie mich das klarstellen. Es wird für mich nicht erwartet.
SmirnovEgorRu
am 18. Sept. 2020
@szilard , wenn dieses Thema für Sie interessant ist - einige Hintergrundinformationen und Ergebnisse der CPU-Optimierungen finden Sie in diesem Blog:
https://medium.com/intel-analytics-software/new-optimizations-for-cpu-in-xgboost-1-1-81144ea21115
SmirnovEgorRu
am 18. Sept. 2020
Vielen Dank an @SmirnovEgorRu für Ihre Optimierungsarbeit und für den Link zum Blog-Beitrag (diesen Beitrag habe ich vorher noch nicht gesehen).
Um meine Nummern einfacher zu reproduzieren und in Zukunft neue und / oder andere Hardware zu erhalten, habe ich eine separate Docker-Datei dafür erstellt:
https://github.com/szilard/GBM-perf/tree/master/analysis/xgboost_cpu_by_version
Sie müssen die CPU-Kern-IDs für den ersten Socket, keine Hyper-Threaded-Kerne (z. B. 0-15 auf r4.16xlarge mit 2 Sockeln, jeweils 16c + 16HT) und die xgboost-Version festlegen:
VER=v1.2.0
CORES_1SO_NOHT=0-15 ## set physical core ids on first socket, no hyperthreading
sudo docker build --build-arg CACHE_DATE=$(date +%Y-%m-%d) --build-arg VER=$VER -t gbmperf_xgboost_cpu_ver .
sudo docker run --rm -e CORES_1SO_NOHT=$CORES_1SO_NOHT gbmperf_xgboost_cpu_ver
Es könnte sich lohnen, das Skript mehrmals auszuführen. Die Trainingszeiten auf allen Kernen weisen normalerweise eine etwas höhere Variabilität auf, nicht sicher, ob dies auf die Virtualisierungsumgebung (EC2) oder auf NUMA zurückzuführen ist.
szilard
am 18. Sept. 2020
Ergebnisse auf c5.metal mit höherer Frequenz und mehr Kernen als r4.16xlarge, die ich im Benchmark verwendet habe:
https://github.com/szilard/GBM-perf/issues/41
TLDR: xgboost nutzt schnellere und mehr Kerne im Vergleich zu anderen Bibliotheken. 👍
szilard
am 21. Sept. 2020
Ich frage mich allerdings darüber:

Die Beschleunigung von 1 auf 24 Kerne für xgboost ist für die größeren Daten (10 Millionen Zeilen, Felder rechts) kleiner als für kleinere Daten (1 Million Zeilen, Felder in der mittleren Spalte). Ist dies eine Art erhöhter Cache-Treffer oder etwas, das andere Bibliotheken nicht haben?
szilard
am 21. Sept. 2020
Hier sind einige Ergebnisse zu AMD:
https://github.com/szilard/GBM-perf/issues/42
Anscheinend funktionieren die xgboost-Optimierungen auch bei AMD hervorragend.
szilard
am 21. Sept. 2020
Verwandte Themen
 nicoJiang
·
4Kommentare
nicoJiang
·
4Kommentare
 matthewmav
·
3Kommentare
matthewmav
·
3Kommentare
 choushishi
·
3Kommentare
choushishi
·
3Kommentare
 uasthana15
·
4Kommentare
uasthana15
·
4Kommentare
 Str1ker17
·
3Kommentare
Str1ker17
·
3Kommentare
Hilfreichster Kommentar
Die Multicore-Skalierung und tatsächlich auch das NUMA-Problem wurden in der Tat stark verbessert:
Multicore:
Sehr bemerkenswert die Verbesserung bei kleineren Daten (0,1 Millionen Zeilen)
Weitere Details hier:
https://github.com/szilard/GBM-perf#multi -core-scaling-cpu
https://github.com/szilard/GBM-perf/issues/29#issuecomment -689713624
Auch das NUMA- Problem wurde weitgehend gemildert: