Xgboost: Appel à contribution: améliorer les performances du processeur multicœur de 'hist'
Il est temps de s'attaquer à l'éléphant dans la salle: les performances sur les processeurs multicœurs.
Description du problème
Actuellement, l'algorithme d'arborescence hist ( tree_method=hist ) évolue mal sur les processeurs multicœurs: pour certains ensembles de données, les performances se détériorent à mesure que le nombre de threads augmente . Ce problème a été découvert par le Gradient Boosting Benchmark de @ Laurae2 ( GitHub ).
Le comportement de mise à l'échelle est le suivant pour l' ensemble de données Bosch :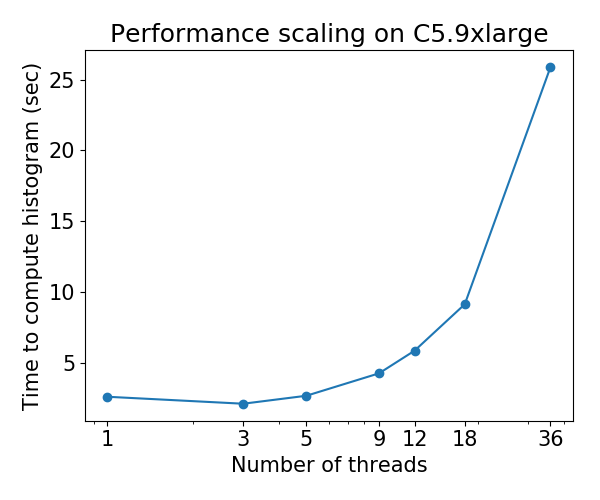
Appel à contribution
J'ai identifié le goulot d'étranglement des performances de l'algorithme «hist» et je l'ai mis dans un petit référentiel: hcho3 / xgboost-fast-hist-perf-lab . Vous pouvez essayer d'améliorer les performances en révisant src / build_hist.cc .
Quelques idées
- Changer la disposition de la matrice de données de CSR à d'autres dispositions telles que ellpack
- Essayez de répartir le travail plus équitablement entre les threads de travail. Le déséquilibre de travail est causé par des modèles irréguliers clairsemés de la matrice de données.
- Regroupez les fonctionnalités complémentaires, un scénario commun pour les données codées à chaud.
 hcho3
hcho3
Tous les 44 commentaires
@ Laurae2 Merci d'avoir préparé le benchmark GBT. Cela a été utile pour identifier le problème.
hcho3
le 19 oct. 2018
@ hcho3 OpenMP guided schedule aide-t-il à équilibrer la charge? Si tel est le cas, l'ellpack ne sera pas très utile.
 trivialfis
le 24 oct. 2018
trivialfis
le 24 oct. 2018
Je suppose que l'allocation statique du travail à l'aide d'ellpack permettrait d'obtenir une charge de travail équilibrée avec une surcharge inférieure au mode guided ou dynamic d'OpenMP. Avec dynamic , vous obtenez une surcharge d'exécution pour maintenir la file d'attente de vol de travail
hcho3
le 24 oct. 2018
pourrait être un peu hors sujet, avons-nous des résultats de référence de approx ?
Nous découvrons l'accélération sous-optimale avec le multi-threading dans notre environnement interne ... nous voulons regarder les données des autres
 CodingCat
le 24 oct. 2018
CodingCat
le 24 oct. 2018
@CodingCat La suite de benchmark liée utilise uniquement hist . Est-ce que approx montre une dégradation des performances comme hist (par exemple 36 threads plus lents que 3 threads)?
hcho3
le 24 oct. 2018
@ hcho3 en raison de la limitation de notre cluster, nous ne pouvons tester qu'avec jusqu'à 8 threads ... mais nous trouvons une accélération très limitée comparant 8 à 4 .....
CodingCat
le 24 oct. 2018
@CodingCat Vous voulez dire que 8 threads fonctionnent plus lentement que 4?
hcho3
le 24 oct. 2018
@CodingCat approx a une mise à l'échelle si pauvre que je ne voulais même pas essayer de le comparer. Il ne s'adapte même pas correctement sur mon ordinateur portable à 4 cœurs (3,6 GHz), donc je n'imagine même pas avec 64 ou 72 threads.
@ hcho3 Je vais y jeter un œil en utilisant votre référentiel avec VTune plus tard.
Pour ceux qui souhaitent obtenir des performances détaillées dans VTune, on peut utiliser ce qui suit pour ajouter à l'en-tête:
#include <ittnotify.h> // Intel Instrumentation and Tracing Technology
Ajoutez ce qui suit avant ce que vous souhaitez suivre en dehors d'une boucle (renommez les chaînes / variables):
__itt_resume();
__itt_domain* domain = __itt_domain_create("MyDomain");
__itt_string_handle* task = __itt_string_handle_create("MyTask");
__itt_task_begin(domain, __itt_null, __itt_null, task);
Ajoutez ce qui suit après ce que vous souhaitez suivre en dehors d'une boucle (renommez les chaînes / variables):
__itt_task_end(domain);
__itt_pause();
Et démarrez un projet avec VTune avec les paramètres corrects pour le nombre de threads. Démarrez l'exécutable avec une instrumentation en pause pour effectuer une analyse des performances.
 Laurae2
le 24 oct. 2018
Laurae2
le 24 oct. 2018
@ hcho3 ce n'est pas plus lent, mais peut-être seulement 15% d'accélération avec 4 threads supplémentaires ... (si je mène plus d'expériences, je soupçonnerais que les résultats convergeraient même .....
CodingCat
le 24 oct. 2018
@ Laurae2 semble que je ne suis pas la seule
CodingCat
le 24 oct. 2018
@ hcho3 J'essaierai de vous obtenir des résultats de mise à l'échelle avant la fin de cette semaine si personne ne le fait sur exact , approx et hist , le tout avec depth=6 , lors du commit e26b5d6.
J'ai récemment migré mon serveur de calcul, et je refais de nouveaux benchmarks sur Bosch sur une nouvelle machine avec 3,7 GHz tout turbo / 36 cœurs / 72 threads / 80 GBps de bande passante de RAM cette semaine.
Laurae2
le 24 oct. 2018
Le programme de mise à jour fast_hist devrait être beaucoup plus rapide pour xgboost distribué. @CodingCat Je suis surpris que personne n'ait essayé d'ajouter des appels AllReduce pour qu'il fonctionne en mode distribué.
 RAMitchell
le 24 oct. 2018
RAMitchell
le 24 oct. 2018
@RAMitchell J'étais assez nouveau lorsque j'ai écrit le programme de mise à jour fast_hist, il manque donc de support en mode distribué. J'aimerais y arriver après la version 0.81.
hcho3
le 24 oct. 2018
@ Laurae2 FYI, j'ai exécuté votre suite de benchmark sur une machine C5.9xlarge et les résultats pour XGBoost hist semblent être cohérents avec vos résultats précédents. Je peux mettre les chiffres si vous le souhaitez.
hcho3
le 24 oct. 2018
@ Laurae2 J'ai également accès aux machines EC2. Si vous souhaitez exécuter un script sur une instance EC2, faites-le moi savoir.
hcho3
le 24 oct. 2018
@RAMitchell J'étais assez nouveau lorsque j'ai écrit le programme de mise à jour fast_hist, il manque donc de support en mode distribué. J'aimerais y arriver après la version 0.81.
@ hcho3 si cela ne vous dérange pas, je peux relever le défi pour obtenir l'algorithme d'histogramme plus rapide distribué, je suis actuellement à mi-temps dans mon travail Uber et l'année prochaine pourrait avoir plus de temps sur xgboost
CodingCat
le 29 oct. 2018
@CodingCat Ce serait génial, merci! Faites-moi savoir si vous avez des questions sur le code «hist».
hcho3
le 29 oct. 2018
@CodingCat FYI, je prévois d'ajouter des tests unitaires pour le programme de mise à jour 'hist' peu de temps après la version 0.81. Cela devrait aider lorsqu'il s'agit d'ajouter un support distribué.
hcho3
le 29 oct. 2018
@ hcho3 @CodingCat approx semble avoir été supprimé le mois dernier, est-ce un comportement attendu?
https://github.com/dmlc/xgboost/commit/70d208d68c3a32aaa4fcd6aa456f286a4da5912f#diff -53a3a623be5ce5a351a89012c7b03a31 (PR https://githubull.com/dmlc/xgbo tree_method = approx suppression =
Laurae2
le 29 oct. 2018
@ Laurae2 On dirait que le refactor a supprimé un message INFO concernant la sélection de approx . Sinon, approx devrait toujours être disponible.
hcho3
le 29 oct. 2018
@ Laurae2 En fait, vous avez raison. Même si approx est toujours dans la base de code, pour une raison quelconque, il n'est pas appelé même lorsque tree_method=approx est défini. J'étudierai ce bug dès que possible.
hcho3
le 29 oct. 2018
Le problème # 3840 a été déposé. La version 0.81 ne sera pas publiée tant que cela ne sera pas corrigé.
hcho3
le 29 oct. 2018
@ hcho3 Je trouve quelque chose de très étrange sur mon serveur avec un histogramme rapide, je vous ferai savoir les résultats si demain le calcul de référence se termine (nous parlons d'énorme efficacité négative de l'histogramme rapide, c'est tellement énorme que j'essaye pour le mesurer mais j'espère qu'il ne sera pas trop long).
Pendant environ, le faible rendement est bien meilleur que prévu, mais je ne m'attends pas à ce que ce soit vrai pour aucun ordinateur (peut-être que cela s'améliore avec la nouvelle génération de processeurs Intel = une fréquence de RAM plus élevée?). Je publierai les données une fois l'histogramme rapide terminé sur mon serveur.
Pour information, j'utilise un ensemble de données Bosch avec 477 fonctionnalités (les fonctionnalités avec moins de 5% de valeurs manquantes).
Atteint plus de 3000 heures de temps CPU ... (au moins mon serveur est utilisé à bon escient pendant un certain temps), la prochaine pour moi sera de regarder https://github.com/hcho3/xgboost-fast-hist-perf- lab / blob / master / src / build_hist.cc avec Intel VTune.
@ hcho3 Si vous le souhaitez, je peux vous fournir mon script de référence R une fois que mon serveur a terminé le calcul. J'ai couru avec depth=8 et nrounds=50 , pour tout tree_method=exact , tree_method=approx (avec updater=grow_histmaker,prune solution tree_method=hist , de 1 à 72 fils. Cela peut révéler des éléments plus intéressants sur lesquels travailler (et vous pourrez également le tester sur AWS).
Laurae2
le 1 nov. 2018
Veuillez consulter les résultats préliminaires ci-dessous. Assurez-vous de cliquer pour mieux voir. Table synthétique fournie. Contrairement aux représentations graphiques, les processeurs n'étaient pas épinglés.
Les graphiques semblent clairement très différents de ceux pour lesquels j'étais préparé ... (en raison de l'étrange du comportement, je réexécute avec UMA activé (NUMA désactivé)). Plus tard, je vérifierai avec Intel VTune.
Matériel et logiciel:
- Processeur: Dual Xeon Gold 6154, 3,7 GHz tout turbo, 2x 18 cœurs / 36 threads
- RAM: 4x 64 Go de RAM DDR4 2666 MHz (double canal, bande passante d'environ 80 Go / s)
- BIOS: NUMA activé, clustering Sub NUMA désactivé
- Système d'exploitation: Pop_OS! 18.10
- Gouverneur: performance
- Noyau: 4.18.0-10
- Drapeaux du noyau:
pti=off spectre_v2=off spec_store_bypass_disable=off l1tf=off noibrs noibpb nopti no_stf_barrier - Compilateur: gcc 8.2.0
- R: 3.5.1 compilé avec gcc 8.2.0 et avec Intel MKL
- indicateurs de compilation supplémentaires dans R:
-O3 -mtune=native
Protections Meltdown / Spectre:
laurae@laurae-compute:~$ head /sys/devices/system/cpu/vulnerabilities/*
==> /sys/devices/system/cpu/vulnerabilities/l1tf <==
Mitigation: PTE Inversion; VMX: vulnerable
==> /sys/devices/system/cpu/vulnerabilities/meltdown <==
Vulnerable
==> /sys/devices/system/cpu/vulnerabilities/spec_store_bypass <==
Vulnerable
==> /sys/devices/system/cpu/vulnerabilities/spectre_v1 <==
Mitigation: __user pointer sanitization
==> /sys/devices/system/cpu/vulnerabilities/spectre_v2 <==
Vulnerable
| Threads | Exact (efficacité) | Approx (efficacité) | Hist (efficacité) |
| ---: | ---: | ---: | ---: |
| 1 | 1367s (100%) | 1702s (100%) | 69,9s (100%) |
| 2 | 758,7s (180%) | 881,0s (193%) | 52,5 s (133%) |
| 4 | 368,6s (371%) | 445,6s (382%) | 31,7s (221%) |
| 6 | 241,5s (566%) | 219,6s (582%) | 24,1s (290%) |
| 9 | 160,4s (852%) | 194,4s (875%) | 23,1s (303%) |
| 18 | 86,3s (1583%) | 106,3s (1601%) | 24,2s (289%) |
| 27 | 66,4s (2059%) | 80,2s (2122%) | 63,6s (110%) |
| 36 | 52,9s (2586%) | 60,0s (2837%) | 55,2s (127%) |
| 54 | 215,4s (635%) | 289,5s (588%) | 343,0s (20%) |
| 72 | 218,9s (624%) | 295,6s (576%) | 1237,2s (6%) |
xgboost Vitesse exacte:
xgboost Efficacité exacte:
xgboost Vitesse approximative:
xgboost Efficacité approximative:
Vitesse de l'histogramme xgboost:
Efficacité de l'histogramme xgboost:
Laurae2
le 3 nov. 2018
Cela ressemble à un problème avec plusieurs sockets.
RAMitchell
le 3 nov. 2018
@RAMitchell Semble être un problème avec la disponibilité des nœuds NUMA, je peux répliquer ce problème (avec un résultat bien pire avec moins de threads pendant la formation) en utilisant le clustering Sub NUMA (2 sockets = 4 nœuds NUMA au lieu de 1 socket = 2 nœuds NUMA ).

xgboost, comme la plupart des algorithmes d'apprentissage automatique, n'a pas d'optimisation pour la gestion des nœuds NUMA. Mais ce serait un deuxième problème. Par conséquent, ils ne sont pas appropriés pour un environnement multi-socket ni lorsque les nœuds NUMA sont disponibles via COD (Cluster on Die) ou SNC (Sub NUMA Clustering), et l'hyperthreading fait du déséquilibre de la charge de travail une énorme pénalité pour eux.
Le problème 1 concernerait l'énorme dégradation des performances multithread en mode d'hist xgboost (ce problème).
Le problème 2 concernerait l'optimisation NUMA (un autre problème à ouvrir).
Laurae2
le 4 nov. 2018
Voici les résultats avec NUMA désactivé. J'ai associé les résultats avec NUMA activé pour comparaison. Ajout de 71 threads pour présenter les performances avant que le processeur ne soit submergé par le planificateur du noyau à 72 threads (plus de ressources requises que disponibles).
UMA est bien meilleur que NUMA pour le multithreading, c'est un résultat attendu de l'entrelacement de la mémoire sur un processus non compatible NUMA.
Temps temps:
| Threads | Exact
NUMA | Exact
UMA | Environ
NUMA | Environ
UMA | Hist
NUMA | Hist
UMA |
| ---: | ---: | ---: | ---: | ---: | ---: | ---: |
| 1 | 1367s | 1667s | 1702s | 1792s | 69,9s | 85,6s |
| 2 | 758,7s | 810.3s | 881,0s | 909,0s | 52,5s | 54.1s |
| 4 | 368,6s | 413,0s | 445,6s | 452,9s | 31,7s | 36.2s |
| 6 | 241,5s | 273.8s | 219,6s | 302.4s | 24.1s | 30,5s |
| 9 | 160,4s | 182.8s | 194,4s | 202,5s | 23.1s | 28,3s |
| 18 | 86,3s | 94,4s | 106,3s | 105,8s | 24.2s | 31.2s |
| 27 | 66,4s | 66,4s | 80.2s | 73,6s | 63,6s | 37,5s |
| 36 | 52,9s | 52,7s | 60,0s | 59,4s | 55.2s | 43,5s |
| 54 | 215,4s | 49.2s | 289,5s | 58,5s | 343,0s | 57,4s |
| 71 | 218,3s | 47.01s | 295,9s | 56,5s | 1238.2s | 71,5s |
| 72 | 218,9s | 49,0s | 295,6s | 58,6s | 1237.2s | 79.1s |
Tableau d'efficacité:
| Threads | Exact
NUMA | Exact
UMA | Environ
NUMA | Environ
UMA | Hist
NUMA | Hist
UMA |
| ---: | ---: | ---: | ---: | ---: | ---: | ---: |
| 1 | 100% | 100% | 100% | 100% | 100% | 100% |
| 2 | 180% | 206% | 193% | 197% | 133% | 158% |
| 4 | 371% | 404% | 382% | 396% | 221% | 236% |
| 6 | 566% | 609% | 582% | 593% | 290% | 280% |
| 9 | 852% | 912% | 875% | 885% | 303% | 302% |
| 18 | 1583% | 1766% | 1601% | 1694% | 289% | 274% |
| 27 | 2059% | 2510% | 2122% | 2436% | 110% | 229% |
| 36 | 2586% | 3162% | 2837% | 3017% | 127% | 197% |
| 54 | 635% | 3384% | 588% | 3065% | 20% | 149% |
| 71 | 626% | 3545% | 575% | 3172% | 6% | 120% |
| 72 | 624% | 3401% | 576% | 3059% | 6% | 108% |
Mode UMA.
xgboost Vitesse exacte:
xgboost Efficacité exacte:
xgboost Vitesse approximative:
xgboost Efficacité approximative:
Vitesse de l'histogramme xgboost:
Efficacité de l'histogramme xgboost:
Laurae2
le 4 nov. 2018
Comme commenté dans https://github.com/dmlc/xgboost/pull/3957#issuecomment -453815876, j'ai testé les commits a2dc929 (amélioration pré-CPU) et 5f151c5 (amélioration post CPU).
J'ai testé en utilisant mon serveur Dual Xeon 6154 (compilateur gcc, pas Intel), en utilisant Bosch pour 500 itérations, eta 0.10, et profondeur 8, avec 3 exécutions chacune pour 1 à 72 threads. Nous remarquons une augmentation des performances d'environ 50% (1/3 plus rapide) pour les charges de travail multithread à des performances optimales.
Voici les résultats pour avant # 3957 (commit a2dc929):

Voici les résultats pour # 3957 (commit 5f151c5):

En utilisant les courbes d'efficacité, nous voyons l'augmentation de 50% de l'évolutivité (cela ne signifie pas que le problème est résolu: nous devons encore l'améliorer, si nous le pouvons - idéalement, si nous pouvons atteindre la plage de 1000 à 2000%, ce serait insensé génial).
Courbe d'efficacité de a2dc929:

Courbe d'efficacité de 5f151c5:

Laurae2
le 15 janv. 2019
Merci @ Laurae2 , je vais continuer et épingler ce problème afin qu'il soit toujours au top du suivi des problèmes. Il y a en effet encore du travail à faire.
hcho3
le 16 janv. 2019
@ hcho3 @SmirnovEgorRu Je constate une petite régression des performances du processeur sur les charges de travail à thread unique sur des données 100% denses avec le commit 5f151c5 qui entraîne une pénalité globale de 10% à 15% lors du réglage des hyperparamètres sur X cœurs x 1 thread xgboost.
Voici un exemple de 50M lignes x 100 colonnes de données denses aléatoires (gcc 8), nécessite au moins 256 Go de RAM pour l'entraîner correctement à partir de Python / R, exécutez 3 fois (6 jours).
Commit a2dc929:

Commit 5f151c5:

Bien qu'elles conduisent à des performances multithreads très similaires, les performances en fil simple sont affectées par un entraînement plus lent (les améliorations de @SmirnovEgorRu évoluent toujours plus rapidement, atteignant dans ce cas 50M x 100 500% d'efficacité à 11 threads contre 13 threads auparavant).
En excluant le temps de création de gmat, nous avons pour le fil unique sur 50M x 100:
| Commit | Total | temps gmat | Temps de train |
| : --- | ---: | ---: | ---: |
| a2dc929 | 2926s | 816s | 2109s |
| 5f151c5 | (+ 13%) 3316s | (~%) 817s | (+ 18%) 2499s |
Laurae2
le 26 janv. 2019
@ hcho3 @ Laurae2 Généralement, l'hyper-threading n'aide que dans le cas d'algorithmes liés au noyau, pas d'algorithme lié à la mémoire.
HT aide à charger le pipeline de CPU par plus d'instructions pour l'exécution. Si la plupart des instructions attendent l'exécution des instructions précédentes (liées à la latence) - HT peut vraiment aider, dans certaines charges de travail spécifiques, j'ai observé une accélération jusqu'à 1,5 fois.
Cependant, si votre application passe le plus clair de son temps à travailler avec la mémoire (liée à la mémoire), HT est encore pire. 2 hyper-threads partagent un cpu-cache et se déplacent mutuellement des informations utiles. En conséquence, nous constatons une dégradation des performances.
Gradient Boosting - algorithme lié à la mémoire. L'utilisation de HT ne devrait en aucun cas améliorer les performances et votre accélération maximale due au threading par rapport à la version à 1 thread est limitée par le nombre de cœurs matériels. Donc, à mon avis, mieux vaut mesurer les performances sur CPU sans HT.
Qu'en est-il de NUMA - J'ai observé les mêmes problèmes lors de la mise en œuvre de DAAL. Cela nécessite le contrôle de l'utilisation de la mémoire par chaque cœur. Je l'examinerai à l'avenir.
Qu'en est-il du petit ralentissement sur 1 thread - je vais l'étudier. Je pense que la solution est facile.
@ hcho3 En ce moment, je travaille sur la partie suivante des optimisations. J'espère que je serai prêt pour une nouvelle pull-request dans un proche avenir.
 SmirnovEgorRu
le 30 janv. 2019
SmirnovEgorRu
le 30 janv. 2019
@SmirnovEgorRu Merci encore pour vos efforts. Pour info, il y a eu une discussion récente sur l'augmentation du parallélisme en effectuant une expansion de nœud par niveau: # 4077.
hcho3
le 30 janv. 2019
@ Laurae2 Maintenant que nous avons fusionné dans # 3957, # 4310 et # 4529, pouvons-nous supposer que le problème de mise à l'échelle a été résolu? Les effets de NUMA peuvent encore être problématiques.
hcho3
le 5 juil. 2019
@ hcho3 Je reviendrai plus tard pour vérifier, mais d'après ce que j'ai pu remarquer, il y avait des régressions de performances sur les environnements de production (en particulier # 3957 provoquant un ralentissement plus de 30x).
Je vérifierai également les résultats de performance avec @szilard .
Exemple ouvert: https://github.com/szilard/GBM-perf/issues/9
Laurae2
le 5 juil. 2019
La mise à l'échelle multicœur et en fait aussi le problème NUMA a été largement amélioré:
Multicœur:

Amélioration très notable sur les données plus petites (0,1 million de lignes)


Plus de détails ici:
https://github.com/szilard/GBM-perf#multi -core-scaling-cpu
https://github.com/szilard/GBM-perf/issues/29#issuecomment -689713624
Le problème du NUMA a également été largement atténué:



 szilard
le 17 sept. 2020
szilard
le 17 sept. 2020
@szilard Merci beaucoup d'avoir pris le temps de faire le benchmark! Et c'est une excellente nouvelle que XGBoost ait amélioré la mise à l'échelle des performances du processeur.
hcho3
le 17 sept. 2020
Ouais, excellent travail à tous sur ce fil pour avoir accompli cela.
szilard
le 17 sept. 2020
Pour info, voici les temps de formation sur 1M lignes sur EC2 r4.16xlarge (2 sockets avec 16c + 16HT chacune) sur 1, 16 (1so & no HT) et 64 (tous) cœurs pour différentes versions de xgboost:

szilard
le 17 sept. 2020
@szilard , merci beaucoup pour l'analyse! C'est bien d'entendre que les optimisations fonctionnent.
PS Ci-dessus, je vois que XGB 1.2 a une certaine régression par rapport à la version 1.1. C'est une information très intéressante, permettez-moi de clarifier cela. Ce n'est pas prévu pour moi.
SmirnovEgorRu
le 18 sept. 2020
@szilard , si ce sujet vous intéresse - quelques informations générales et les résultats des optimisations du processeur sont disponibles dans ce blog:
https://medium.com/intel-analytics-software/new-optimizations-for-cpu-in-xgboost-1-1-81144ea21115
SmirnovEgorRu
le 18 sept. 2020
Merci @SmirnovEgorRu pour votre travail d'optimisation et pour le lien vers l'article de blog (je n'avais pas vu cet article auparavant)
Pour être plus facile de reproduire mes numéros et d'en obtenir de nouveaux à l'avenir et / ou d'autres matériels, j'ai créé un Dockerfile séparé pour cela:
https://github.com/szilard/GBM-perf/tree/master/analysis/xgboost_cpu_by_version
Vous devrez définir les identifiants de cœur du processeur pour le premier socket, pas de cœurs hyper threadés (par exemple 0-15 sur r4.16xlarge, qui a 2 sockets, 16c + 16HT chacun) et la version xgboost:
VER=v1.2.0
CORES_1SO_NOHT=0-15 ## set physical core ids on first socket, no hyperthreading
sudo docker build --build-arg CACHE_DATE=$(date +%Y-%m-%d) --build-arg VER=$VER -t gbmperf_xgboost_cpu_ver .
sudo docker run --rm -e CORES_1SO_NOHT=$CORES_1SO_NOHT gbmperf_xgboost_cpu_ver
Cela peut valoir la peine d'exécuter le script plusieurs fois, les temps de formation sur tous les cœurs montrent généralement une variabilité un peu plus élevée, je ne sais pas si à cause de l'environnement de virtualisation (EC2) ou à cause de NUMA.
szilard
le 18 sept. 2020
Résultats sur c5.metal qui a une fréquence plus élevée et plus de cœurs que r4.16xlarge que j'utilise dans le benchmark:
https://github.com/szilard/GBM-perf/issues/41
TLDR: xgboost tire le meilleur parti de cœurs plus rapides et plus nombreux par rapport aux autres bibliothèques. 👍
szilard
le 21 sept. 2020
Je me demande cependant à ce sujet:

l'accélération de 1 à 24 cœurs pour xgboost est plus petite pour les données plus volumineuses (10M lignes, panneaux à droite) que pour les données plus petites (1M lignes, panneaux dans la colonne du milieu). Est-ce une sorte d'augmentation des accès au cache ou quelque chose que les autres bibliothèques n'ont pas?
szilard
le 21 sept. 2020
Voici quelques résultats sur AMD:
https://github.com/szilard/GBM-perf/issues/42
On dirait que les optimisations de xgboost fonctionnent également très bien sur AMD.
szilard
le 21 sept. 2020
Questions connexes
 uasthana15
·
4Commentaires
uasthana15
·
4Commentaires
 pplonski
·
3Commentaires
pplonski
·
3Commentaires
 ivannz
·
3Commentaires
ivannz
·
3Commentaires
 choushishi
·
3Commentaires
choushishi
·
3Commentaires
 hx364
·
3Commentaires
hx364
·
3Commentaires
Commentaire le plus utile
La mise à l'échelle multicœur et en fait aussi le problème NUMA a été largement amélioré:
Multicœur:
Amélioration très notable sur les données plus petites (0,1 million de lignes)
Plus de détails ici:
https://github.com/szilard/GBM-perf#multi -core-scaling-cpu
https://github.com/szilard/GBM-perf/issues/29#issuecomment -689713624
Le problème du NUMA a également été largement atténué: