Xgboost: Panggilan untuk kontribusi: meningkatkan kinerja CPU multi-core 'hist'
Sudah waktunya menangani gajah di ruangan: kinerja pada CPU multi-core.
Deskripsi masalah
Saat ini, algoritme penumbuh pohon hist ( tree_method=hist ) berskala buruk pada CPU multi-core: untuk beberapa set data, kinerja menurun seiring dengan bertambahnya jumlah utas . Masalah ini ditemukan oleh @ Laurae2 's Gradient Boosting Benchmark ( GitHub repo ).
Perilaku penskalaan adalah sebagai berikut untuk set data Bosch :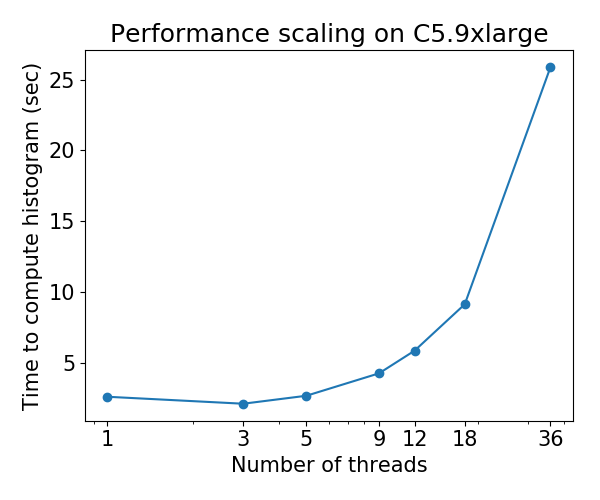
Panggilan untuk Kontribusi
Saya telah mengidentifikasi hambatan kinerja dari algoritma 'hist' dan memasukkannya ke dalam repositori kecil: hcho3 / xgboost-fast-hist-perf-lab . Anda dapat mencoba meningkatkan kinerja dengan merevisi src / build_hist.cc .
Beberapa ide
- Ubah tata letak matriks data dari CSR ke tata letak lain seperti ellpack
- Cobalah untuk mendistribusikan pekerjaan secara lebih merata di antara utas pekerja. Ketidakseimbangan kerja disebabkan oleh pola matriks data yang jarang dan tidak teratur.
- Kelompokkan fitur pelengkap bersama-sama, skenario umum untuk data one-hot-encoded.
 hcho3
hcho3
Semua 44 komentar
@ Laurae2 Terima kasih telah mempersiapkan benchmark GBT. Sangat membantu dalam mengidentifikasi titik masalah.
hcho3
pada 19 Okt 2018
@ hcho3 Apakah OpenMP guided schedule membantu load balancing? Jika demikian, ellpack tidak akan berguna.
 trivialfis
pada 24 Okt 2018
trivialfis
pada 24 Okt 2018
Dugaan saya adalah bahwa alokasi statis pekerjaan menggunakan ellpack akan mencapai beban kerja yang seimbang dengan overhead yang lebih rendah dari mode OpenMP guided atau dynamic . Dengan dynamic , Anda mendapatkan overhead runtime untuk menjaga antrian pencurian pekerjaan
hcho3
pada 24 Okt 2018
mungkin sedikit di luar topik, apakah kita memiliki hasil benchmark approx ?
Kami menemukan percepatan sub-optimal dengan multi-threading di lingkungan internal kami ... ingin melihat data orang lain
 CodingCat
pada 24 Okt 2018
CodingCat
pada 24 Okt 2018
@CodingCat Paket patokan tertaut hanya menggunakan hist . Apakah approx menunjukkan penurunan performa seperti hist (misalnya 36 thread lebih lambat dari 3 thread)?
hcho3
pada 24 Okt 2018
@ hcho3 karena keterbatasan dalam cluster kami, kami hanya dapat menguji hingga 8 utas ... tetapi kami menemukan speedup yang sangat terbatas membandingkan 8 hingga 4 .....
CodingCat
pada 24 Okt 2018
@ CodingCat Maksud Anda 8 utas berjalan lebih lambat dari 4?
hcho3
pada 24 Okt 2018
@CodingCat approx memiliki penskalaan yang sangat buruk sehingga saya bahkan tidak ingin mencoba membandingkannya. Itu bahkan tidak berskala dengan benar pada laptop 4 inti saya (3,6 GHz), oleh karena itu saya bahkan tidak membayangkan dengan 64 atau 72 utas.
@ hcho3 Saya akan melihatnya menggunakan repositori Anda dengan VTune nanti.
Bagi mereka yang ingin mendapatkan performa mendetail di VTune, Anda dapat menggunakan yang berikut ini untuk ditambahkan ke header:
#include <ittnotify.h> // Intel Instrumentation and Tracing Technology
Tambahkan yang berikut ini sebelum apa yang ingin Anda lacak di luar loop (ganti nama string / variabel):
__itt_resume();
__itt_domain* domain = __itt_domain_create("MyDomain");
__itt_string_handle* task = __itt_string_handle_create("MyTask");
__itt_task_begin(domain, __itt_null, __itt_null, task);
Tambahkan yang berikut ini setelah apa yang ingin Anda lacak di luar loop (ganti nama string / variabel):
__itt_task_end(domain);
__itt_pause();
Dan mulai proyek dengan VTune dengan parameter yang benar untuk jumlah utas. Mulai eksekusi dengan instrumentasi yang dijeda untuk melakukan analisis kinerja.
 Laurae2
pada 24 Okt 2018
Laurae2
pada 24 Okt 2018
@ hcho3 tidak lebih lambat, tetapi mungkin hanya 15-% speedup dengan 4 utas lagi ... (jika saya melakukan lebih banyak eksperimen, saya akan curiga hasilnya bahkan akan menyatu .....
CodingCat
pada 24 Okt 2018
@ Laurae2 sepertinya saya bukan satu-satunya
CodingCat
pada 24 Okt 2018
@ hcho3 Saya akan mencoba memberi Anda beberapa hasil penskalaan sebelum akhir minggu ini jika tidak ada yang melakukannya pada exact , approx dan hist , semuanya dengan depth=6 , saat melakukan e26b5d6.
Saya baru-baru ini memigrasi server komputasi saya, dan saya melakukan benchmark baru di Bosch pada mesin baru dengan 3,7 GHz semua turbo / 36 core / 72 utas / bandwidth RAM 80 GBps minggu ini.
Laurae2
pada 24 Okt 2018
Pembaru fast_hist seharusnya lebih cepat untuk xgboost terdistribusi. @CodingCat Saya terkejut tidak ada yang mencoba menambahkan panggilan AllReduce sehingga berfungsi dalam mode terdistribusi.
 RAMitchell
pada 24 Okt 2018
RAMitchell
pada 24 Okt 2018
@RAMitchell Saya cukup baru ketika saya menulis fast_hist updater, jadi tidak ada dukungan mode terdistribusi. Saya ingin mendapatkannya setelah rilis 0.81.
hcho3
pada 24 Okt 2018
@ Laurae2 FYI, saya menjalankan rangkaian benchmark Anda pada mesin C5.9xlarge dan hasil untuk XGBoost hist tampaknya konsisten dengan hasil Anda sebelumnya. Saya dapat memberikan nomornya jika Anda mau.
hcho3
pada 24 Okt 2018
@ Laurae2 Juga, saya memiliki akses ke mesin EC2. Jika Anda memiliki skrip yang ingin Anda jalankan pada instans EC2, beri tahu saya.
hcho3
pada 24 Okt 2018
@RAMitchell Saya cukup baru ketika saya menulis fast_hist updater, jadi tidak ada dukungan mode terdistribusi. Saya ingin mendapatkannya setelah rilis 0.81.
@ hcho3 jika Anda tidak keberatan, saya dapat mengambil tantangan untuk mendapatkan algoritme histogram yang lebih cepat didistribusikan, saat ini saya setengah waktu dalam pekerjaan Uber saya dan tahun depan mungkin memiliki lebih banyak waktu di xgboost
CodingCat
pada 29 Okt 2018
@CodingCat Bagus sekali, terima kasih! Beri tahu saya jika Anda memiliki pertanyaan tentang kode 'hist'.
hcho3
pada 29 Okt 2018
@CodingCat FYI, saya berencana untuk menambahkan tes unit untuk updater 'hist' segera setelah rilis 0.81. Itu akan membantu ketika harus menambahkan dukungan terdistribusi.
hcho3
pada 29 Okt 2018
@ hcho3 @CodingCat approx tampaknya telah dihapus dalam sebulan terakhir, apakah ini perilaku yang diharapkan?
https://github.com/dmlc/xgboost/commit/70d208d68c3a32aaa4fcd6aa456f286a4da5912f#diff -53a3a623be5ce5a351a89012c7b03a31 (PR https://github.com/dmlc/xgboost/pull/3395 telah menghapus tree_method = approx ? hasil antara perkiraan dan bukan ...
Laurae2
pada 29 Okt 2018
@ Laurae2 Sepertinya refactor menghapus pesan INFO tentang approx yang dipilih. Jika tidak, approx seharusnya masih tersedia.
hcho3
pada 29 Okt 2018
@ Laurae2 Sebenarnya, Anda benar. Meskipun approx masih dalam basis kode, untuk beberapa alasan ia tidak dipanggil bahkan ketika tree_method=approx disetel. Saya akan menyelidiki bug ini secepatnya.
hcho3
pada 29 Okt 2018
Masalah # 3840 telah diajukan. Rilis 0.81 tidak akan dirilis hingga ini diperbaiki.
hcho3
pada 29 Okt 2018
@ hcho3 Saya menemukan sesuatu yang sangat aneh di server saya dengan histogram cepat, saya akan memberi tahu Anda hasilnya jika besok penghitungan benchmark selesai (kita berbicara tentang efisiensi negatif yang sangat besar dari histogram cepat, ini sangat besar, saya mencoba untuk mengukurnya tetapi berharap tidak terlalu lama).
Untuk perkiraan, efisiensi yang buruk jauh lebih baik dari yang diharapkan, tetapi saya tidak berharap itu berlaku untuk komputer mana pun (mungkin itu menjadi lebih baik dengan generasi CPU Intel yang lebih baru = frekuensi RAM yang lebih tinggi?). Saya akan memposting data setelah histogram cepat selesai di server saya.
Sebagai informasi, saya menggunakan dataset Bosch dengan 477 fitur (fitur dengan nilai yang hilang kurang dari 5%).
Mencapai lebih dari 3000 jam waktu CPU ... (setidaknya server saya digunakan dengan baik untuk sementara waktu) selanjutnya bagi saya adalah melihat https://github.com/hcho3/xgboost-fast-hist-perf- lab / blob / master / src / build_hist.cc dengan Intel VTune.
@ hcho3 Jika Anda mau, saya dapat memberikan skrip R benchmark saya setelah server saya selesai melakukan komputasi. Saya menjalankan dengan depth=8 dan nrounds=50 , untuk semua tree_method=exact , tree_method=approx (dengan updater=grow_histmaker,prune solusi, sebelum # 3849), dan tree_method=hist , dari 1 hingga 72 utas. Ini mungkin mengungkap hal-hal yang lebih menarik untuk dikerjakan (dan Anda juga dapat mengujinya di AWS).
Laurae2
pada 1 Nov 2018
Silakan lihat hasil awal di bawah ini, berjalan 7 kali ke hasil rata-rata. Pastikan untuk mengklik untuk melihat lebih baik. Meja sintetis disediakan. Berbeda dengan pertunjukan plot, CPU tidak disematkan.
Bagannya jelas tampak jauh berbeda dari yang saya persiapkan ... (karena betapa aneh perilakunya, saya menjalankan kembali ini dengan UMA aktif (NUMA nonaktif)). Nanti saya akan memeriksa dengan Intel VTune.
Perangkat keras dan perangkat lunak:
- CPU: Dual Xeon Gold 6154, 3,7 GHz semua turbo, 2x 18 core / 36 utas
- RAM: 4x 64GB RAM DDR4 2666 MHz (saluran ganda, kira-kira bandwidth 80 GBps)
- BIOS: NUMA aktif, Sub NUMA pengelompokan nonaktif
- Sistem Operasi: Pop_OS! 18.10
- Gubernur: kinerja
- Kernel: 4.18.0-10
- Tanda kernel:
pti=off spectre_v2=off spec_store_bypass_disable=off l1tf=off noibrs noibpb nopti no_stf_barrier - Penyusun: gcc 8.2.0
- R: 3.5.1 dikompilasi dengan gcc 8.2.0 dan dengan Intel MKL
- flag kompilasi tambahan di R:
-O3 -mtune=native
Perlindungan Meltdown / Spectre:
laurae@laurae-compute:~$ head /sys/devices/system/cpu/vulnerabilities/*
==> /sys/devices/system/cpu/vulnerabilities/l1tf <==
Mitigation: PTE Inversion; VMX: vulnerable
==> /sys/devices/system/cpu/vulnerabilities/meltdown <==
Vulnerable
==> /sys/devices/system/cpu/vulnerabilities/spec_store_bypass <==
Vulnerable
==> /sys/devices/system/cpu/vulnerabilities/spectre_v1 <==
Mitigation: __user pointer sanitization
==> /sys/devices/system/cpu/vulnerabilities/spectre_v2 <==
Vulnerable
| Benang | Tepat (efisiensi) | Approx (efisiensi) | Hist (efisiensi) |
| ---: | ---: | ---: | ---: |
| 1 | 1367 d (100%) | 1702 d (100%) | 69,9 d (100%) |
| 2 | 758,7 d (180%) | 881.0d (193%) | 52,5 d (133%) |
| 4 | 368,6 d (371%) | 445.6 d (382%) | 31,7 d (221%) |
| 6 | 241,5 d (566%) | 219,6 d (582%) | 24,1 d (290%) |
| 9 | 160,4 d (852%) | 194,4 d (875%) | 23,1 d (303%) |
| 18 | 86,3 d (1583%) | 106,3 d (1601%) | 24,2 d (289%) |
| 27 | 66,4 d (2059%) | 80,2 d (2122%) | 63.6 d (110%) |
| 36 | 52,9 d (2586%) | 60,0 d (2837%) | 55,2 d (127%) |
| 54 | 215,4 d (635%) | 289,5 d (588%) | 343.0s (20%) |
| 72 | 218,9 d (624%) | 295.6 d (576%) | 1237,2 d (6%) |
xgboost Kecepatan yang tepat:
xgboost Efisiensi yang tepat:
xgboost Perkiraan kecepatan:
xgboost Perkiraan efisiensi:
xgboost Kecepatan histogram:
xgboost Efisiensi histogram:
Laurae2
pada 3 Nov 2018
Sepertinya ada masalah dengan banyak soket.
RAMitchell
pada 3 Nov 2018
@RAMitchell Tampaknya menjadi masalah dengan ketersediaan node NUMA, saya dapat mereplikasi masalah ini (dengan hasil yang jauh lebih buruk dengan lebih sedikit utas selama pelatihan) menggunakan Sub NUMA Clustering (2 soket = 4 node NUMA daripada 1 soket = 2 node NUMA ).

xgboost seperti kebanyakan mesin pembelajaran alg tidak memiliki pengoptimalan untuk menangani node NUMA. Tapi itu akan menjadi masalah kedua. Oleh karena itu, mereka tidak sesuai untuk lingkungan multi-soket atau ketika node NUMA tersedia melalui COD (Cluster on Die) atau SNC (Sub NUMA Clustering), dan hyperthreading membuat ketidakseimbangan beban kerja menjadi masalah besar bagi mereka.
Masalah 1 adalah tentang degradasi besar kinerja multithread dalam mode hist xgboost (masalah ini).
Masalah 2 adalah tentang pengoptimalan NUMA (masalah lain untuk dibuka).
Laurae2
pada 4 Nov 2018
Berikut adalah hasil dengan NUMA dinonaktifkan. Saya memasangkan hasil dengan NUMA diaktifkan untuk perbandingan. Juga menambahkan 71 utas untuk menampilkan kinerja sebelum CPU kewalahan dengan penjadwal kernel di 72 utas (lebih banyak sumber daya yang dibutuhkan daripada yang tersedia).
Tarif UMA jauh lebih baik daripada NUMA untuk multithreading, ini adalah hasil yang diharapkan dari interleaving memori pada proses non-NUMA aware.
Waktu waktu:
| Benang | Tepat
NUMA | Tepat
UMA | Approx
NUMA | Approx
UMA | Hist
NUMA | Hist
UMA |
| ---: | ---: | ---: | ---: | ---: | ---: | ---: |
| 1 | 1367-an | 1667-an | 1702-an | 1792-an | 69,9 d | 85.6 d |
| 2 | 758.7s | 810.3s | 881.0s | 909.0s | 52,5 d | 54.1d |
| 4 | 368.6s | 413.0s | 445.6s | 452.9 d | 31,7 d | 36.2 d |
| 6 | 241,5 d | 273.8s | 219.6s | 302,4 d | 24.1d | 30,5 d |
| 9 | 160,4 d | 182,8 d | 194,4 d | 202,5 d | 23.1d | 28,3 d |
| 18 | 86,3 d | 94,4 d | 106,3 d | 105,8 d | 24.2d | 31.2d |
| 27 | 66,4 d | 66,4 d | 80,2 d | 73.6 d | 63.6 d | 37,5 d |
| 36 | 52,9 d | 52,7 d | 60.0d | 59,4 d | 55.2d | 43,5 d |
| 54 | 215,4 d | 49,2 d | 289,5 d | 58,5 d | 343.0s | 57,4 d |
| 71 | 218.3 d | 47.01d | 295,9 d | 56,5 d | 1238.2s | 71,5 d |
| 72 | 218.9 d | 49.0d | 295.6s | 58.6 d | 1237.2s | 79.1d |
Tabel efisiensi:
| Benang | Tepat
NUMA | Tepat
UMA | Approx
NUMA | Approx
UMA | Hist
NUMA | Hist
UMA |
| ---: | ---: | ---: | ---: | ---: | ---: | ---: |
| 1 | 100% | 100% | 100% | 100% | 100% | 100% |
| 2 | 180% | 206% | 193% | 197% | 133% | 158% |
| 4 | 371% | 404% | 382% | 396% | 221% | 236% |
| 6 | 566% | 609% | 582% | 593% | 290% | 280% |
| 9 | 852% | 912% | 875% | 885% | 303% | 302% |
| 18 | 1583% | 1766% | 1601% | 1694% | 289% | 274% |
| 27 | 2059% | 2510% | 2122% | 2436% | 110% | 229% |
| 36 | 2586% | 3162% | 2837% | 3017% | 127% | 197% |
| 54 | 635% | 3384% | 588% | 3065% | 20% | 149% |
| 71 | 626% | 3545% | 575% | 3172% | 6% | 120% |
| 72 | 624% | 3401% | 576% | 3059% | 6% | 108% |
Mode UMA.
xgboost Kecepatan yang tepat:
xgboost Efisiensi yang tepat:
xgboost Perkiraan kecepatan:
xgboost Perkiraan efisiensi:
xgboost Kecepatan histogram:
xgboost Efisiensi histogram:
Laurae2
pada 4 Nov 2018
Seperti yang dikomentari di https://github.com/dmlc/xgboost/pull/3957#issuecomment -453815876, saya menguji komit a2dc929 (sebelum peningkatan CPU) dan 5f151c5 (pasca peningkatan CPU).
Saya menguji menggunakan server Dual Xeon 6154 saya (kompiler gcc, bukan Intel), menggunakan Bosch untuk 500 iterasi, eta 0,10, dan kedalaman 8, dengan 3 kali berjalan masing-masing untuk 1 hingga 72 utas. Kami melihat peningkatan kinerja sekitar hingga 50% (1/3 lebih cepat) untuk beban kerja multithread pada kinerja puncak.
Berikut adalah hasil untuk sebelum # 3957 (commit a2dc929):

Berikut adalah hasil untuk # 3957 (commit 5f151c5):

Dengan menggunakan kurva efisiensi, kami melihat peningkatan skalabilitas 50% (ini tidak berarti masalah terselesaikan: kami masih harus memperbaikinya, jika kami bisa - idealnya, jika kami dapat mencapai kisaran 1000-2000% itu akan menjadi gila-gilaan. Bagus).
Kurva efisiensi a2dc929:

Kurva efisiensi 5f151c5:

Laurae2
pada 15 Jan 2019
Terima kasih @ Laurae2 , saya akan melanjutkan dan memasang pin pada masalah ini, sehingga masalah ini selalu berada di atas pelacak masalah. Memang ada lebih banyak pekerjaan yang harus dilakukan.
hcho3
pada 16 Jan 2019
@ hcho3 @SmirnovEgorRu Saya melihat regresi kinerja CPU kecil pada beban kerja singlethreaded pada 100% data padat dengan komit 5f151c5 yang menimbulkan penalti 10% -15% secara keseluruhan saat melakukan penyetelan hyperparameter pada X core x 1 xgboost thread.
Berikut adalah contoh 50 juta baris x 100 kolom data padat acak (gcc 8), membutuhkan setidaknya 256GB RAM untuk melatihnya dengan benar dari Python / R, dijalankan 3 kali (6 hari).
Komit a2dc929:

Komit 5f151c5:

Meskipun mereka menghasilkan kinerja multithread yang sangat mirip, kinerja singlethreaded dihantam oleh pelatihan yang lebih lambat ( peningkatan @SmirnovEgorRu masih berskala lebih cepat, mencapai efisiensi 500% casing 50M x 100 ini pada 11 utas vs 13 utas sebelumnya).
Tidak termasuk waktu pembuatan gmat, kami memiliki untuk singlethread pada 50M x 100:
| Komit | Total | waktu gmat | Melatih waktu |
| : --- | ---: | ---: | ---: |
| a2dc929 | 2926-an | 816-an | 2109 d |
| 5f151c5 | (+ 13%) 3316 d | (~%) 817 d | (+ 18%) 2499 d |
Laurae2
pada 26 Jan 2019
@ hcho3 @ Laurae2 Umumnya Hyper-threading hanya membantu dalam kasus algoritme yang terikat Core, tidak ada algoritme yang terikat memori.
HT membantu memuat pipeline CPU dengan instruksi lebih lanjut untuk eksekusi. Jika sebagian besar instruksi menunggu eksekusi instruksi sebelumnya (terikat latensi) - HT benar-benar dapat membantu, dalam beberapa beban kerja tertentu saya mengamati percepatan hingga 1,5x kali.
Namun, jika aplikasi Anda menghabiskan sebagian besar waktu untuk bekerja dengan memori (terikat memori) - HT membuat lebih buruk. 2 hyper-threads berbagi satu cpu-cache dan saling menggantikan informasi yang berguna. Akibatnya, kami melihat penurunan kinerja.
Gradient Boosting - algoritma terikat memori. Penggunaan HT seharusnya tidak membawa peningkatan kinerja dalam kasus apa pun dan percepatan maksimum Anda karena versi threading vs 1thread dibatasi oleh jumlah inti perangkat keras. Jadi menurut saya lebih baik mengukur kinerja pada CPU tanpa HT.
Bagaimana dengan NUMA - Saya mengamati masalah yang sama pada implementasi DAAL. Ini membutuhkan kontrol penggunaan memori oleh setiap inti. Saya akan melihatnya di masa depan.
Bagaimana dengan perlambatan kecil pada 1 utas - saya akan menyelidikinya. Saya pikir - memperbaiki itu mudah.
@ hcho3 Saat ini saya sedang mengerjakan bagian pengoptimalan berikutnya. Saya berharap saya akan siap untuk permintaan tarik baru dalam waktu dekat.
 SmirnovEgorRu
pada 30 Jan 2019
SmirnovEgorRu
pada 30 Jan 2019
@SmirnovEgorRu Sekali lagi terima kasih atas usaha Anda. Untuk diketahui, baru-baru ini ada diskusi tentang peningkatan jumlah paralelisme dengan melakukan ekspansi node level-bijaksana: # 4077.
hcho3
pada 30 Jan 2019
@ Laurae2 Setelah kita menggabungkan # 3957, # 4310, dan # 4529, dapatkah kita berasumsi bahwa masalah penskalaan telah diselesaikan? Efek NUMA mungkin masih bermasalah.
hcho3
pada 5 Jul 2019
@ hcho3 Saya akan memasang kembali nanti untuk memeriksa, tetapi dari apa yang saya perhatikan ada regresi kinerja di lingkungan produksi (terutama # 3957 menyebabkan lebih dari 30x pelambatan).
Saya juga akan memeriksa hasil performa dengan @szilard .
Buka contoh: https://github.com/szilard/GBM-perf/issues/9
Laurae2
pada 5 Jul 2019
Penskalaan multicore dan sebenarnya juga masalah NUMA telah diperbaiki secara luas:
Multicore:

Sangat menonjol peningkatan pada data yang lebih kecil (0,1 juta baris)


Lebih detail di sini:
https://github.com/szilard/GBM-perf#multi -core-scaling-cpu
https://github.com/szilard/GBM-perf/issues/29#issuecomment -689713624
Selain itu, masalah NUMA sebagian besar telah diatasi:



 szilard
pada 17 Sep 2020
szilard
pada 17 Sep 2020
@szilard Terima kasih banyak telah meluangkan waktu untuk melakukan benchmark! Dan kabar baik bahwa XGBoost telah meningkat dalam penskalaan kinerja CPU.
hcho3
pada 17 Sep 2020
Ya, kerja bagus semua orang di utas ini karena telah menyelesaikan ini.
szilard
pada 17 Sep 2020
FYI, berikut adalah waktu pelatihan pada baris 1M pada EC2 r4.16xlarge (2 soket dengan masing-masing 16c + 16HT) pada 1, 16 (1so & tanpa HT) dan 64 (semua) core untuk versi xgboost yang berbeda:

szilard
pada 17 Sep 2020
@szilard , terima kasih banyak atas analisisnya! Senang mendengar bahwa pengoptimalan berfungsi.
PS Di atas saya melihat bahwa XGB 1.2 memiliki beberapa regresi terhadap versi 1.1. Ini info yang sangat menarik, izinkan saya mengklarifikasi ini. Itu tidak diharapkan untukku.
SmirnovEgorRu
pada 18 Sep 2020
@szilard , jika topik ini menarik bagi Anda - beberapa latar belakang dan hasil pengoptimalan CPU tersedia di blog ini:
https://medium.com/intel-analytics-software/new-optimizations-for-cpu-in-xgboost-1-1-81144ea21115
SmirnovEgorRu
pada 18 Sep 2020
Terima kasih @SmirnovEgorRu untuk pengoptimalan Anda dan untuk tautan ke entri blog (saya tidak melihat entri ini sebelumnya).
Agar lebih mudah untuk mereproduksi nomor saya dan mendapatkan yang baru di masa depan dan atau perangkat keras lainnya, saya membuat Dockerfile terpisah untuk ini:
https://github.com/szilard/GBM-perf/tree/master/analysis/xgboost_cpu_by_version
Anda harus mengatur id inti CPU untuk soket pertama, tanpa inti hyper threaded (mis. 0-15 pada r4.16xlarge, yang memiliki 2 soket, masing-masing 16c + 16HT) dan versi xgboost:
VER=v1.2.0
CORES_1SO_NOHT=0-15 ## set physical core ids on first socket, no hyperthreading
sudo docker build --build-arg CACHE_DATE=$(date +%Y-%m-%d) --build-arg VER=$VER -t gbmperf_xgboost_cpu_ver .
sudo docker run --rm -e CORES_1SO_NOHT=$CORES_1SO_NOHT gbmperf_xgboost_cpu_ver
Mungkin perlu menjalankan skrip beberapa kali, waktu pelatihan pada semua inti biasanya menunjukkan variabilitas yang agak lebih tinggi, tidak yakin apakah karena lingkungan virtualisasi (EC2) atau karena NUMA.
szilard
pada 18 Sep 2020
Hasil pada c5.metal yang memiliki frekuensi lebih tinggi dan core lebih banyak daripada r4.16xlarge yang telah saya gunakan dalam benchmark:
https://github.com/szilard/GBM-perf/issues/41
TLDR: xgboost memanfaatkan lebih banyak core yang lebih cepat dan lebih banyak dibandingkan libs lain. 👍
szilard
pada 21 Sep 2020
Saya bertanya-tanya tentang ini:

percepatan dari 1 hingga 24 core untuk xgboost lebih kecil untuk data yang lebih besar (10 juta baris, panel di sebelah kanan) daripada untuk data yang lebih kecil (1 juta baris, panel di kolom tengah). Apakah ini semacam peningkatan cache hit atau sesuatu yang tidak dimiliki libs lain?
szilard
pada 21 Sep 2020
Berikut beberapa hasil pada AMD:
https://github.com/szilard/GBM-perf/issues/42
Sepertinya pengoptimalan xgboost bekerja dengan baik pada AMD juga.
szilard
pada 21 Sep 2020
Masalah terkait
trivialfis
·
3Komentar
 mhnamaki
·
3Komentar
mhnamaki
·
3Komentar
 uasthana15
·
4Komentar
uasthana15
·
4Komentar
 nicoJiang
·
4Komentar
nicoJiang
·
4Komentar
 wenbo5565
·
3Komentar
wenbo5565
·
3Komentar
Komentar yang paling membantu
Penskalaan multicore dan sebenarnya juga masalah NUMA telah diperbaiki secara luas:
Multicore:
Sangat menonjol peningkatan pada data yang lebih kecil (0,1 juta baris)
Lebih detail di sini:
https://github.com/szilard/GBM-perf#multi -core-scaling-cpu
https://github.com/szilard/GBM-perf/issues/29#issuecomment -689713624
Selain itu, masalah NUMA sebagian besar telah diatasi: