Xgboost: Призыв к участию: улучшите производительность многоядерного процессора "hist"
Пришло время заняться «слоном в комнате»: производительностью на многоядерных процессорах.
Описание проблемы
В настоящее время алгоритм роста дерева hist ( tree_method=hist ) плохо масштабируется на многоядерных процессорах: для некоторых наборов данных производительность ухудшается по мере увеличения количества потоков . Эта проблема была обнаружена с помощью теста Gradient Boosting Benchmark @ Laurae2 (репозиторий GitHub ).
Для набора данных Bosch характер масштабирования следующий: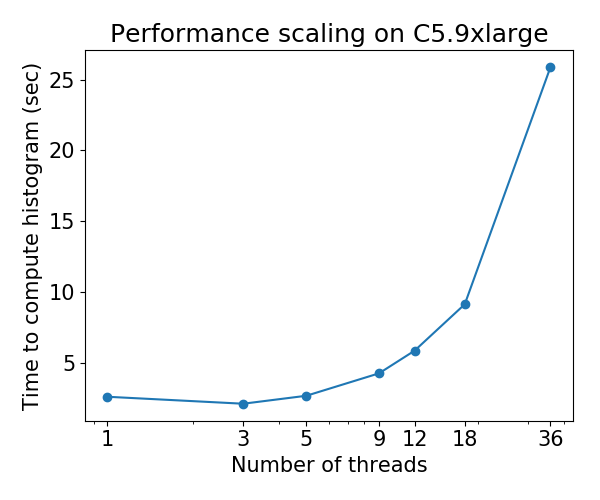
Призыв к участию
Я выявил узкое место в производительности алгоритма hist и поместил его в небольшой репозиторий: hcho3 / xgboost-fast-hist-perf-lab . Вы можете попытаться повысить производительность, отредактировав src / build_hist.cc .
Некоторые идеи
- Измените макет матрицы данных с CSR на другие макеты, такие как ellpack
- Постарайтесь более равномерно распределить работу между рабочими потоками. Несбалансированность работы вызвана нерегулярными разреженными структурами матрицы данных.
- Сгруппируйте дополнительные функции вместе, общий сценарий для данных с горячим кодированием.
 hcho3
hcho3
Все 44 Комментарий
@ Laurae2 Спасибо за подготовку теста GBT. Это помогло определить проблемное место.
hcho3
19 окт. 2018
@ hcho3 Помогает ли OpenMP guided schedule балансировать нагрузку? В таком случае ellpack будет не очень полезен.
 trivialfis
24 окт. 2018
trivialfis
24 окт. 2018
Я предполагаю, что статическое распределение работы с использованием ellpack позволит достичь сбалансированной рабочей нагрузки с меньшими накладными расходами, чем режим guided или dynamic в OpenMP. С dynamic вы получаете накладные расходы времени выполнения на поддержку очереди кражи работы
hcho3
24 окт. 2018
может быть немного не по теме, есть ли у нас результаты тестов approx ?
Мы обнаруживаем неоптимальное ускорение многопоточности в нашей внутренней среде ... хотим посмотреть на данные других
 CodingCat
24 окт. 2018
CodingCat
24 окт. 2018
@CodingCat Связанный набор тестов использует только hist . Показывает ли approx снижение производительности, например hist (например, 36 потоков медленнее, чем 3 потока)?
hcho3
24 окт. 2018
@ hcho3 из-за ограничений в нашем кластере мы можем тестировать только до 8 потоков ... но мы находим очень ограниченное ускорение по сравнению с 8 до 4 .....
CodingCat
24 окт. 2018
@CodingCat Вы имеете в виду, что 8 потоков работают медленнее, чем 4?
hcho3
24 окт. 2018
@CodingCat approx имеет настолько плохое масштабирование, что я даже не хотел тестировать его. Он даже не масштабируется должным образом на моем 4-ядерном ноутбуке (3,6 ГГц), поэтому я даже не представляю себе 64 или 72 потока.
@ hcho3 Я посмотрю на это позже, используя ваш репозиторий с VTune.
Для тех, кто хочет получить подробную информацию о производительности в VTune, можно добавить в заголовок следующее:
#include <ittnotify.h> // Intel Instrumentation and Tracing Technology
Добавьте следующее перед тем, что вы хотите отслеживать вне цикла (переименуйте строки / переменные):
__itt_resume();
__itt_domain* domain = __itt_domain_create("MyDomain");
__itt_string_handle* task = __itt_string_handle_create("MyTask");
__itt_task_begin(domain, __itt_null, __itt_null, task);
Добавьте следующее после того, что вы хотите отслеживать вне цикла (переименуйте строки / переменные):
__itt_task_end(domain);
__itt_pause();
И запускаем проект с VTune с правильными параметрами количества потоков. Запустите исполняемый файл с приостановленным инструментарием, чтобы провести анализ производительности.
 Laurae2
24 окт. 2018
Laurae2
24 окт. 2018
@ hcho3 он не медленнее, но, возможно, только на 15% ускорение с еще 4 потоками ... (если я проведу больше экспериментов, я подозреваю, что результаты даже сойдутся ...
CodingCat
24 окт. 2018
@ Laurae2 похоже, что я не единственный
CodingCat
24 окт. 2018
@ hcho3 Я постараюсь предоставить вам результаты масштабирования до конца этой недели, если никто не делает этого с exact , approx и hist , все с depth=6 , при фиксации e26b5d6.
Я недавно перенес свой вычислительный сервер и на этой неделе повторно выполняю новые тесты на Bosch на новой машине с 3,7 ГГц в режиме турбо / 36 ядер / 72 потока / 80 ГБ / с.
Laurae2
24 окт. 2018
Программа обновления fast_hist должна быть намного быстрее для распределенного xgboost. @CodingCat Я удивлен, что никто не пытался добавить вызовы AllReduce, поэтому он работает в распределенном режиме.
 RAMitchell
24 окт. 2018
RAMitchell
24 окт. 2018
@RAMitchell Я был
hcho3
24 окт. 2018
@ Laurae2 К вашему сведению, я запустил ваш набор тестов на машине C5.9xlarge, и результаты для XGBoost hist похоже, согласуются с вашими предыдущими результатами. Я могу назвать цифры, если хотите.
hcho3
24 окт. 2018
@ Laurae2 Кроме того, у меня есть доступ к машинам EC2. Если у вас есть сценарий, который вы хотите запустить на экземпляре EC2, дайте мне знать.
hcho3
24 окт. 2018
@RAMitchell Я был
@ hcho3, если вы не возражаете, я могу принять вызов, чтобы получить алгоритм распределенной более быстрой гистограммы, в настоящее время я использую его половину своего рабочего времени в Uber, а в следующем году, возможно, будет больше времени на xgboost
CodingCat
29 окт. 2018
@CodingCat Было бы здорово, спасибо! Сообщите мне, если у вас возникнут вопросы по поводу кода "hist".
hcho3
29 окт. 2018
@CodingCat К вашему сведению, я планирую добавить модульные тесты для средства обновления «hist» вскоре после выпуска 0.81. Это должно помочь, когда дело доходит до добавления распределенной поддержки.
hcho3
29 окт. 2018
@ hcho3 @CodingCat approx похоже, был удален за последний месяц, это ожидаемое поведение?
https://github.com/dmlc/xgboost/commit/70d208d68c3a32aaa4fcd6aa456f286a4da5912f#diff -53a3a623be5ce5a351a89012c7b03a31 $ (PR https://github.com/dmlc/models) tree_method = approx get_digital #xgull #xgull результаты между ок. и не прибл ...
Laurae2
29 окт. 2018
@ Laurae2 Похоже, рефакторинг удалил информационное сообщение о approx . В противном случае approx все еще должен быть доступен.
hcho3
29 окт. 2018
@ Laurae2 На самом деле вы правы. Несмотря на то, что approx все еще находится в базе кода, по какой-то причине он не вызывается, даже если установлен tree_method=approx . Я исследую эту ошибку как можно скорее.
hcho3
29 окт. 2018
Зарегистрирован выпуск № 3840. Релиз 0.81 не будет выпущен, пока это не будет исправлено.
hcho3
29 окт. 2018
@ hcho3 Я нахожу что-то очень странное на своем сервере с быстрой гистограммой, я дам вам знать результаты, если завтра расчет теста завершится (мы говорим об огромной отрицательной эффективности быстрой гистограммы, она настолько огромна, что я пытаюсь чтобы измерить его, но надеюсь, что он не станет слишком длинным).
Примерно низкая эффективность намного лучше, чем ожидалось, но я не ожидаю, что это будет правдой для любого компьютера (может быть, лучше с новым поколением процессоров Intel = более высокая частота ОЗУ?). Я отправлю данные, как только гистограмма на моем сервере закончится.
Для информации я использую набор данных Bosch с 477 функциями (функции с отсутствующими значениями менее 5%).
Достигнуто более 3000 часов процессорного времени ... (по крайней мере, мой сервер какое-то время используется для хорошего использования), следующим для меня будет https://github.com/hcho3/xgboost-fast-hist-perf- lab / blob / master / src / build_hist.cc с Intel VTune.
@ hcho3 Если хотите, я могу предоставить вам свой depth=8 и nrounds=50 для всех tree_method=exact , tree_method=approx (с обходным путем updater=grow_histmaker,prune , до # 3849) и tree_method=hist , от 1 до 72 потоков. Это может открыть больше интересных вещей для работы (и вы также сможете протестировать это на AWS).
Laurae2
1 нояб. 2018
Пожалуйста, посмотрите предварительные результаты ниже, проведено 7 раз для получения средних результатов. Обязательно нажмите, чтобы лучше просмотреть. Предоставляется синтетический стол. В отличие от графиков, процессоры не были закреплены.
Диаграммы явно кажутся отличными от тех, к которым я был подготовлен ... (из-за того, насколько странно поведение, я повторно запускаю это с включенным UMA (NUMA выключенным)). Позже проверю с Intel VTune.
Железо и софт:
- Процессор: Dual Xeon Gold 6154, 3,7 ГГц полностью турбо, 2x 18 ядер / 36 потоков
- Оперативная память: 4x 64 ГБ RAM DDR4 2666 МГц (двухканальная, пропускная способность около 80 ГБ / с)
- BIOS: NUMA включено, кластеризация Sub NUMA выключена
- Операционная система: Pop_OS! 18.10
- Губернатор: производительность
- Ядро: 4.18.0-10
- Флаги ядра:
pti=off spectre_v2=off spec_store_bypass_disable=off l1tf=off noibrs noibpb nopti no_stf_barrier - Компилятор: gcc 8.2.0
- R: 3.5.1 скомпилирован с gcc 8.2.0 и с Intel MKL
- дополнительные флаги компиляции в R:
-O3 -mtune=native
Защита от Meltdown / Spectre:
laurae@laurae-compute:~$ head /sys/devices/system/cpu/vulnerabilities/*
==> /sys/devices/system/cpu/vulnerabilities/l1tf <==
Mitigation: PTE Inversion; VMX: vulnerable
==> /sys/devices/system/cpu/vulnerabilities/meltdown <==
Vulnerable
==> /sys/devices/system/cpu/vulnerabilities/spec_store_bypass <==
Vulnerable
==> /sys/devices/system/cpu/vulnerabilities/spectre_v1 <==
Mitigation: __user pointer sanitization
==> /sys/devices/system/cpu/vulnerabilities/spectre_v2 <==
Vulnerable
| Темы | Точная (эффективность) | Приблизительно (КПД) | Hist (эффективность) |
| ---: | ---: | ---: | ---: |
| 1 | 1367-е годы (100%) | 1702-е годы (100%) | 69,9 с (100%) |
| 2 | 758,7 с (180%) | 881,0 с (193%) | 52,5 сек (133%) |
| 4 | 368,6 сек (371%) | 445,6 сек (382%) | 31,7 с (221%) |
| 6 | 241,5 сек (566%) | 219,6 сек (582%) | 24,1 с (290%) |
| 9 | 160,4 с (852%) | 194,4 сек. (875%) | 23,1 с (303%) |
| 18 | 86,3 сек (1583%) | 106,3 сек (1601%) | 24,2 с (289%) |
| 27 | 66,4 с (2059%) | 80,2 с (2122%) | 63,6 с (110%) |
| 36 | 52,9 с (2586%) | 60,0 с (2837%) | 55,2 с (127%) |
| 54 | 215,4 сек. (635%) | 289,5 сек (588%) | 343,0 с (20%) |
| 72 | 218,9 сек (624%) | 295,6 сек (576%) | 1237,2 с (6%) |
xgboost Точная скорость:
xgboost Точная эффективность:
xgboost Приблизительная скорость:
xgboost Приблизительная эффективность:
xgboost Скорость гистограммы:
Эффективность гистограммы xgboost:
Laurae2
3 нояб. 2018
Похоже, проблема с несколькими сокетами.
RAMitchell
3 нояб. 2018
@RAMitchell Кажется, проблема с доступностью узлов NUMA, я могу воспроизвести эту проблему (с гораздо худшим результатом с меньшим количеством потоков во время обучения), используя кластеризацию Sub NUMA (2 сокета = 4 узла NUMA вместо 1 сокета = 2 узла NUMA ).

xgboost, как и большинство алгоритмов машинного обучения, не имеет оптимизации для обработки узлов NUMA. Но это будет вторая проблема. Следовательно, они не подходят для среды с несколькими сокетами или когда узлы NUMA доступны через COD (Cluster on Die) или SNC (Sub NUMA Clustering), а гиперпоточность делает дисбаланс рабочей нагрузки огромным штрафом для них.
Проблема 1 связана с огромным ухудшением многопоточной производительности в режиме xgboost hist (эта проблема).
Проблема 2 касается оптимизации NUMA (еще одна проблема, которую необходимо открыть).
Laurae2
4 нояб. 2018
Вот результаты с отключенным NUMA. Я соединил результаты с включенным NUMA для сравнения. Также добавлен 71 поток, чтобы продемонстрировать производительность, прежде чем ЦП будет перегружен планировщиком ядра на 72 потока (требуется больше ресурсов, чем доступно).
UMA намного лучше, чем NUMA для многопоточности, это ожидаемый результат чередования памяти в процессе, не поддерживающем NUMA.
Время время:
| Темы | Точный
NUMA | Точный
UMA | Приблизительно
NUMA | Приблизительно
UMA | Hist
NUMA | Hist
UMA |
| ---: | ---: | ---: | ---: | ---: | ---: | ---: |
| 1 | 1367-е | 1667-е | 1702-е | 1792-е | 69,9 с | 85,6 с |
| 2 | 758,7 с | 810,3 с | 881.0 с | 909.0 с | 52,5 с | 54,1 с |
| 4 | 368,6 с | 413.0 с | 445,6 с | 452,9 с | 31,7 с | 36,2 с |
| 6 | 241,5 с | 273,8 с | 219,6 с | 302,4 с | 24,1 с | 30,5 с |
| 9 | 160,4 с | 182,8 с | 194,4 с | 202,5 с | 23,1 с | 28,3 с |
| 18 | 86,3 с | 94,4 с | 106,3 с | 105,8 с | 24,2 с | 31,2 с |
| 27 | 66,4 с | 66,4 с | 80,2 с | 73,6 с | 63,6 с | 37,5 с |
| 36 | 52,9 с | 52,7 с | 60.0 с | 59,4 с | 55,2 с | 43,5 с |
| 54 | 215,4 с | 49,2 с | 289,5 с | 58,5 с | 343,0 с | 57,4 с |
| 71 | 218,3 с | 47.01 с | 295,9 с | 56,5 с | 1238.2 с | 71,5 с |
| 72 | 218,9 с | 49,0 с | 295,6 с | 58,6 с | 1237.2 с | 79,1 с |
Таблица эффективности:
| Темы | Точный
NUMA | Точный
UMA | Приблизительно
NUMA | Приблизительно
UMA | Hist
NUMA | Hist
UMA |
| ---: | ---: | ---: | ---: | ---: | ---: | ---: |
| 1 | 100% | 100% | 100% | 100% | 100% | 100% |
| 2 | 180% | 206% | 193% | 197% | 133% | 158% |
| 4 | 371% | 404% | 382% | 396% | 221% | 236% |
| 6 | 566% | 609% | 582% | 593% | 290% | 280% |
| 9 | 852% | 912% | 875% | 885% | 303% | 302% |
| 18 | 1583% | 1766% | 1601% | 1694% | 289% | 274% |
| 27 | 2059% | 2510% | 2122% | 2436% | 110% | 229% |
| 36 | 2586% | 3162% | 2837% | 3017% | 127% | 197% |
| 54 | 635% | 3384% | 588% | 3065% | 20% | 149% |
| 71 | 626% | 3545% | 575% | 3172% | 6% | 120% |
| 72 | 624% | 3401% | 576% | 3059% | 6% | 108% |
Режим UMA.
xgboost Точная скорость:
xgboost Точная эффективность:
xgboost Приблизительная скорость:
xgboost Приблизительная эффективность:
xgboost Скорость гистограммы:
Эффективность гистограммы xgboost:
Laurae2
4 нояб. 2018
Как прокомментировано в https://github.com/dmlc/xgboost/pull/3957#issuecomment -453815876, я тестировал коммиты a2dc929 (улучшение до ЦП) и 5f151c5 (улучшение после ЦП).
Я тестировал свой сервер Dual Xeon 6154 (компилятор gcc, а не Intel), используя Bosch для 500 итераций, eta 0.10 и depth 8, с 3 запусками каждый для от 1 до 72 потоков. Мы замечаем увеличение производительности примерно на 50% (на 1/3 быстрее) для многопоточных рабочих нагрузок при максимальной производительности.
Вот результаты до # 3957 (фиксация a2dc929):

Вот результаты для # 3957 (коммит 5f151c5):

Используя кривые эффективности, мы видим увеличение масштабируемости на 50% (это не означает, что проблема решена: нам все еще нужно ее улучшить, если мы можем - в идеале, если мы сможем выйти на диапазон 1000-2000%, что было бы безумно. отличный).
Кривая эффективности a2dc929:

Кривая эффективности 5f151c5:

Laurae2
15 янв. 2019
Спасибо @ Laurae2 , я продолжу и
hcho3
16 янв. 2019
@ hcho3 @SmirnovEgorRu Я вижу небольшую регрессию производительности процессора при однопоточных рабочих нагрузках на 100% плотных данных с фиксацией 5f151c5, что влечет за собой штраф в 10-15% в целом при настройке гиперпараметров на ядрах X x 1 поток xgboost.
Вот пример случайных плотных данных 50M строк x 100 столбцов (gcc 8), требуется не менее 256 ГБ ОЗУ для правильного обучения из Python / R, запускается 3 раза (6 дней).
Зафиксируйте a2dc929:

Зафиксируйте 5f151c5:

Хотя они приводят к очень схожей многопоточной производительности, однопоточная производительность снижается из-за более медленного обучения ( улучшения @SmirnovEgorRu по -прежнему масштабируются быстрее, достигая в этом случае 50M x 100 500% эффективности при 11 потоках против 13 потоков ранее).
Исключая время создания gmat, у нас есть для однопоточного на 50M x 100:
| Зафиксировать | Итого | гмат время | Время поезда |
| : --- | ---: | ---: | ---: |
| a2dc929 | 2926s | 816s | 2109-е |
| 5f151c5 | (+ 13%) 3316с | (~%) 817 с | (+ 18%) 2499-е |
Laurae2
26 янв. 2019
@ hcho3 @ Laurae2 Обычно Hyper-threading помогает только в случае алгоритмов с привязкой к ядру , без алгоритма с привязкой к памяти.
HT помогает загружать конвейер процессора большим количеством инструкций для выполнения. Если большинство инструкций ждут выполнения предыдущих инструкций (ограничение задержки) - HT действительно может помочь, в некоторых конкретных рабочих нагрузках я наблюдал ускорение до 1,5 раза.
Однако, если ваше приложение тратит большую часть времени на работу с памятью (привязанной к памяти), HT делает еще хуже. 2 гиперпотока используют один cpu-cache и заменяют друг друга полезной информацией. В результате мы видим снижение производительности.
Gradient Boosting - алгоритм ограничения памяти. Использование HT ни в коем случае не должно приводить к повышению производительности, а максимальное ускорение за счет потоковой передачи по сравнению с однопоточной версией ограничено количеством аппаратных ядер. Так что, на мой взгляд, лучше измерять производительность на CPU без HT.
Что касается NUMA - я наблюдал те же проблемы при реализации DAAL. Это требует контроля использования памяти каждым ядром. Я посмотрю на это в будущем.
Насчет небольшого замедления на 1 потоке - разберусь. Думаю - исправить легко.
@ hcho3 В данный момент я работаю над следующей частью оптимизаций. Надеюсь, в ближайшем будущем я буду готов к новому запросу.
 SmirnovEgorRu
30 янв. 2019
SmirnovEgorRu
30 янв. 2019
@SmirnovEgorRu Еще раз спасибо за ваши усилия. К вашему сведению, недавно была дискуссия об увеличении степени параллелизма путем выполнения поэтапного расширения узлов: # 4077.
hcho3
30 янв. 2019
@ Laurae2 Теперь, когда мы объединили # 3957, # 4310 и # 4529, можем ли мы предположить, что проблема масштабирования решена? Эффекты NUMA все еще могут быть проблематичными.
hcho3
5 июл. 2019
@ hcho3 Я перейду позже, чтобы проверить, но из того, что я мог заметить, наблюдались падения производительности в производственных средах (особенно # 3957, вызывающий более чем 30-кратное замедление).
Я также проверю результаты производительности с помощью @szilard .
Открытый пример: https://github.com/szilard/GBM-perf/issues/9
Laurae2
5 июл. 2019
Масштабирование многоядерных процессоров, а также проблема NUMA были значительно улучшены:
Многоядерный:

Очень заметное улучшение для небольших данных (0,1 млн строк)


Подробнее здесь:
https://github.com/szilard/GBM-perf#multi -core-scaling-cpu
https://github.com/szilard/GBM-perf/issues/29#issuecomment -689713624
Также проблема NUMA была в значительной степени смягчена:



 szilard
17 сент. 2020
szilard
17 сент. 2020
@szilard Спасибо, что
hcho3
17 сент. 2020
Да, все участники этой ветки проделали огромную работу.
szilard
17 сент. 2020
К вашему сведению, вот время обучения для 1M строк на EC2 r4.16xlarge (2 сокета по 16c + 16HT каждый) на 1, 16 (1so & no HT) и 64 (все) ядрах для разных версий xgboost:

szilard
17 сент. 2020
@szilard ,
PS Выше я вижу, что XGB 1.2 имеет некоторый регресс по сравнению с версией 1.1. Это очень интересная информация, позвольте мне уточнить. Для меня этого не ждут.
SmirnovEgorRu
18 сент. 2020
@szilard , если эта тема вам интересна - некоторая предыстория и результаты оптимизации процессора доступны в этом блоге:
https://medium.com/intel-analytics-software/new-optimizations-for-cpu-in-xgboost-1-1-81144ea21115
SmirnovEgorRu
18 сент. 2020
Спасибо @SmirnovEgorRu за вашу работу по оптимизации и за ссылку на сообщение в блоге (раньше я не видел этот пост).
Чтобы было легче воспроизводить мои числа и получать новые в будущем или другое оборудование, я сделал для этого отдельный Dockerfile:
https://github.com/szilard/GBM-perf/tree/master/analysis/xgboost_cpu_by_version
Вам нужно будет установить идентификаторы ядра процессора для первого сокета, без гиперпоточных ядер (например, 0-15 на r4.16xlarge, который имеет 2 сокета, 16c + 16HT каждый) и версию xgboost:
VER=v1.2.0
CORES_1SO_NOHT=0-15 ## set physical core ids on first socket, no hyperthreading
sudo docker build --build-arg CACHE_DATE=$(date +%Y-%m-%d) --build-arg VER=$VER -t gbmperf_xgboost_cpu_ver .
sudo docker run --rm -e CORES_1SO_NOHT=$CORES_1SO_NOHT gbmperf_xgboost_cpu_ver
Возможно, стоит запустить скрипт несколько раз, время обучения на всех ядрах обычно несколько более изменчиво, не уверен, из-за среды виртуализации (EC2) или из-за NUMA.
szilard
18 сент. 2020
Результаты на c5.metal, который имеет более высокую частоту и больше ядер, чем r4.16xlarge, которые я использовал в тесте:
https://github.com/szilard/GBM-perf/issues/41
TL; DR: xgboost максимально использует более быстрые и новые ядра по сравнению с другими библиотеками. 👍
szilard
21 сент. 2020
Мне интересно вот что:

ускорение с 1 до 24 ядер для xgboost меньше для больших данных (10 миллионов строк, панели справа), чем для меньших данных (1 миллион строк, панели в среднем столбце). Это какое-то увеличенное количество попаданий в кеш или что-то, чего нет в других библиотеках?
szilard
21 сент. 2020
Вот некоторые результаты по AMD:
https://github.com/szilard/GBM-perf/issues/42
Похоже, оптимизация xgboost отлично работает и на AMD.
szilard
21 сент. 2020
Смежные вопросы
 pplonski
·
3Комментарии
pplonski
·
3Комментарии
 choushishi
·
3Комментарии
choushishi
·
3Комментарии
 wenbo5565
·
3Комментарии
wenbo5565
·
3Комментарии
 Str1ker17
·
3Комментарии
Str1ker17
·
3Комментарии
 nicoJiang
·
4Комментарии
nicoJiang
·
4Комментарии
Самый полезный комментарий
Масштабирование многоядерных процессоров, а также проблема NUMA были значительно улучшены:
Многоядерный:
Очень заметное улучшение для небольших данных (0,1 млн строк)
Подробнее здесь:
https://github.com/szilard/GBM-perf#multi -core-scaling-cpu
https://github.com/szilard/GBM-perf/issues/29#issuecomment -689713624
Также проблема NUMA была в значительной степени смягчена: