Xgboost: Convocatoria de contribución: mejorar el rendimiento de la CPU multinúcleo de 'hist'
Ya es hora de abordar el elefante en la sala: rendimiento en CPU de varios núcleos.
Descripción del problema
Actualmente, el algoritmo de crecimiento de árboles hist ( tree_method=hist ) se escala mal en CPU de varios núcleos: para algunos conjuntos de datos, el rendimiento se deteriora a medida que aumenta la cantidad de subprocesos . Este problema fue descubierto por Gradient Boosting Benchmark de @ Laurae2 ( repositorio de GitHub ).
El comportamiento de escala es el siguiente para el conjunto de datos de Bosch :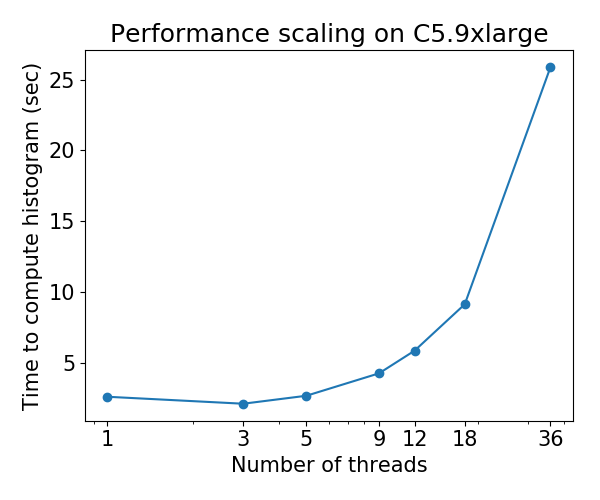
Convocatoria de contribución
Identifiqué el cuello de botella de rendimiento del algoritmo 'hist' y lo puse en un pequeño repositorio: hcho3 / xgboost-fast-hist-perf-lab . Puede intentar mejorar el rendimiento revisando src / build_hist.cc .
Algunas ideas
- Cambie el diseño de la matriz de datos de CSR a otros diseños como ellpack
- Intente distribuir el trabajo de manera más equitativa entre los subprocesos de trabajo. El desequilibrio de trabajo es causado por patrones dispersos irregulares de la matriz de datos.
- Agrupe funciones complementarias, un escenario común para datos codificados en caliente.
 hcho3
hcho3
Todos 44 comentarios
@ Laurae2 Gracias por preparar el índice de referencia de GBT. Ha sido útil para identificar el lugar del problema.
hcho3
en 19 oct. 2018
@ hcho3 ¿El guided ayuda a equilibrar la carga? Si es así, el ellpack no será muy útil.
 trivialfis
en 24 oct. 2018
trivialfis
en 24 oct. 2018
Supongo que la asignación estática de trabajo usando ellpack lograría una carga de trabajo equilibrada con una sobrecarga menor que el modo guided o dynamic de OpenMP. Con dynamic , obtiene una sobrecarga de tiempo de ejecución para mantener la cola de robo de trabajo
hcho3
en 24 oct. 2018
podría ser un poco fuera de tema, ¿tenemos resultados de referencia de approx ?
Descubrimos la aceleración subóptima con subprocesos múltiples en nuestro entorno interno ... queremos ver los datos de otros
 CodingCat
en 24 oct. 2018
CodingCat
en 24 oct. 2018
@CodingCat La suite de referencia vinculada solo usa hist . ¿ approx muestra una degradación del rendimiento como hist (por ejemplo, 36 subprocesos más lentos que 3 subprocesos)?
hcho3
en 24 oct. 2018
@ hcho3 debido a la limitación en nuestro clúster, podemos probar solo con hasta 8 subprocesos ... pero encontramos una aceleración muy limitada comparando 8 a 4 .....
CodingCat
en 24 oct. 2018
@CodingCat ¿
hcho3
en 24 oct. 2018
@CodingCat approx tiene un escalado tan pobre que ni siquiera quería probarlo. Ni siquiera se escala correctamente en mi computadora portátil de 4 núcleos (3.6 GHz), por lo tanto, ni siquiera me imagino con 64 o 72 subprocesos.
@ hcho3 Lo veré usando su repositorio con VTune más tarde.
Para aquellos que desean obtener un rendimiento detallado en VTune, pueden usar lo siguiente para agregar al encabezado:
#include <ittnotify.h> // Intel Instrumentation and Tracing Technology
Agregue lo siguiente antes de lo que desea rastrear fuera de un bucle (cambie el nombre de las cadenas / variables):
__itt_resume();
__itt_domain* domain = __itt_domain_create("MyDomain");
__itt_string_handle* task = __itt_string_handle_create("MyTask");
__itt_task_begin(domain, __itt_null, __itt_null, task);
Agregue lo siguiente después de lo que desea rastrear fuera de un bucle (cambie el nombre de las cadenas / variables):
__itt_task_end(domain);
__itt_pause();
Y comience un proyecto con VTune con los parámetros correctos para el número de subprocesos. Inicie el ejecutable con instrumentación en pausa para realizar análisis de rendimiento.
 Laurae2
en 24 oct. 2018
Laurae2
en 24 oct. 2018
@ hcho3 no es más lento, pero tal vez solo un 15% de aceleración con 4 subprocesos más ... (si realizo más experimentos, sospecho que los resultados incluso convergerían ...
CodingCat
en 24 oct. 2018
@ Laurae2 parece que no soy el único
CodingCat
en 24 oct. 2018
@ hcho3 Intentaré obtener algunos resultados de escalado antes del final de esta semana si nadie lo hace en exact , approx y hist , todos con depth=6 , al confirmar e26b5d6.
Recientemente migré mi servidor de cómputo, y esta semana estoy rehaciendo nuevos puntos de referencia en Bosch en una nueva máquina con 3,7 GHz, todos turbo / 36 núcleos / 72 subprocesos / 80 GBps de ancho de banda de RAM.
Laurae2
en 24 oct. 2018
El actualizador fast_hist debería ser mucho más rápido para xgboost distribuido. @CodingCat Me sorprende que nadie haya intentado agregar llamadas AllReduce para que funcione en modo distribuido.
 RAMitchell
en 24 oct. 2018
RAMitchell
en 24 oct. 2018
@RAMitchell Era bastante nuevo cuando escribí el actualizador fast_hist, por lo que carece de soporte para el modo distribuido. Me gustaría llegar a él después del lanzamiento 0.81.
hcho3
en 24 oct. 2018
@ Laurae2 FYI, ejecuté su suite de referencia en una máquina C5.9xlarge y los resultados para XGBoost hist parecen ser consistentes con sus resultados anteriores. Puedo poner los números si lo desea.
hcho3
en 24 oct. 2018
@ Laurae2 Además, tengo acceso a máquinas EC2. Si tiene un script que le gustaría ejecutar en una instancia EC2, hágamelo saber.
hcho3
en 24 oct. 2018
@RAMitchell Era bastante nuevo cuando escribí el actualizador fast_hist, por lo que carece de soporte para el modo distribuido. Me gustaría llegar a él después del lanzamiento 0.81.
@ hcho3, si no le importa, puedo aceptar el desafío de obtener el algoritmo de histograma distribuido más rápido, actualmente estoy medio tiempo en él en mi trabajo de Uber y el próximo año puede tener más tiempo en xgboost
CodingCat
en 29 oct. 2018
@CodingCat ¡ Eso sería genial, gracias! Avíseme si tiene alguna pregunta sobre el código 'hist'.
hcho3
en 29 oct. 2018
@CodingCat FYI, planeo agregar pruebas unitarias para el actualizador 'hist' poco después del lanzamiento 0.81. Eso debería ayudar cuando se trata de agregar soporte distribuido.
hcho3
en 29 oct. 2018
@ hcho3 @CodingCat approx parece haber sido eliminado en el último mes, ¿es un comportamiento esperado?
https://github.com/dmlc/xgboost/commit/70d208d68c3a32aaa4fcd6aa456f286a4da5912f#diff -53a3a623be5ce5a351a89012c7b03a31 (PR https://github.com/dmlc/x tree_method = approx 195 tree_method = approx 195 / se quitó
Laurae2
en 29 oct. 2018
@ Laurae2 Parece que el refactor eliminó un mensaje INFO sobre la selección de approx . De lo contrario, approx aún debería estar disponible.
hcho3
en 29 oct. 2018
@ Laurae2 En realidad, tienes razón. Aunque approx todavía está en la base de código, por alguna razón no se invoca incluso cuando se establece tree_method=approx . Investigaré este error lo antes posible.
hcho3
en 29 oct. 2018
Se presentó el número 3840. La versión 0.81 no se lanzará hasta que esto se solucione.
hcho3
en 29 oct. 2018
@ hcho3 Estoy encontrando algo muy extraño en mi servidor con histograma rápido, les haré saber los resultados si mañana finaliza el cálculo de referencia (estamos hablando de una enorme eficiencia negativa del histograma rápido, es tan grande que lo estoy intentando para medirlo pero espero que no sea demasiado largo).
Aproximadamente, la baja eficiencia es mucho mejor de lo esperado, pero no espero que sea cierto para ninguna computadora (¿tal vez mejore con la nueva generación de CPU Intel = mayor frecuencia de RAM?). Publicaré los datos una vez que finalice el histograma rápido en mi servidor.
Para obtener información, estoy usando un conjunto de datos de Bosch con 477 características (las características con menos del 5% de valores perdidos).
Alcanzado más de 3000 horas de tiempo de CPU ... (al menos mi servidor se utiliza para un buen uso por un tiempo) lo siguiente para mí será ver https://github.com/hcho3/xgboost-fast-hist-perf- lab / blob / master / src / build_hist.cc con Intel VTune.
@ hcho3 Si lo desea, puedo proporcionarle mi script R de referencia una vez que mi servidor termine de computar. Ejecuté con depth=8 y nrounds=50 , para todos los tree_method=exact , tree_method=approx (con updater=grow_histmaker,prune solución alternativa, antes de # 3849) y tree_method=hist , de 1 a 72 hilos. Puede descubrir cosas más interesantes en las que trabajar (y también podrá probarlo en AWS).
Laurae2
en 1 nov. 2018
Consulte los resultados preliminares a continuación, ejecutados 7 veces para promediar los resultados. Asegúrese de hacer clic para ver mejor. Se proporciona mesa sintética. A diferencia de los programas de gráficos, las CPU no se fijaron.
Los gráficos claramente parecen muy diferentes a los que estaba preparado para ... (debido a lo extraño que es el comportamiento, estoy volviendo a ejecutar esto con UMA activado (NUMA desactivado)). Más tarde lo comprobaré con Intel VTune.
Hardware y software:
- CPU: Dual Xeon Gold 6154, 3,7 GHz todo turbo, 2x 18 núcleos / 36 hilos
- RAM: 4x 64GB RAM DDR4 2666 MHz (doble canal, aproximadamente 80 GBps de ancho de banda)
- BIOS: NUMA activado, agrupación sub NUMA desactivada
- Sistema operativo: Pop_OS! 18.10
- Gobernador: desempeño
- Núcleo: 4.18.0-10
- Banderas del núcleo:
pti=off spectre_v2=off spec_store_bypass_disable=off l1tf=off noibrs noibpb nopti no_stf_barrier - Compilador: gcc 8.2.0
- R: 3.5.1 compilado con gcc 8.2.0 y con Intel MKL
- banderas de compilación adicionales en R:
-O3 -mtune=native
Protecciones Meltdown / Spectre:
laurae@laurae-compute:~$ head /sys/devices/system/cpu/vulnerabilities/*
==> /sys/devices/system/cpu/vulnerabilities/l1tf <==
Mitigation: PTE Inversion; VMX: vulnerable
==> /sys/devices/system/cpu/vulnerabilities/meltdown <==
Vulnerable
==> /sys/devices/system/cpu/vulnerabilities/spec_store_bypass <==
Vulnerable
==> /sys/devices/system/cpu/vulnerabilities/spectre_v1 <==
Mitigation: __user pointer sanitization
==> /sys/devices/system/cpu/vulnerabilities/spectre_v2 <==
Vulnerable
| Hilos | Exacto (eficiencia) | Aprox. (Eficiencia) | Hist (eficiencia) |
| ---: | ---: | ---: | ---: |
| 1 | 1367s (100%) | 1702 (100%) | 69,9 s (100%) |
| 2 | 758,7 s (180%) | 881,0 s (193%) | 52,5 s (133%) |
| 4 | 368,6 s (371%) | 445,6 s (382%) | 31,7 s (221%) |
| 6 | 241,5 s (566%) | 219,6 s (582%) | 24,1 s (290%) |
| 9 | 160,4 s (852%) | 194,4 s (875%) | 23,1 s (303%) |
| 18 | 86,3 s (1583%) | 106,3 s (1601%) | 24,2 s (289%) |
| 27 | 66,4 s (2059%) | 80,2 s (2122%) | 63,6 s (110%) |
| 36 | 52,9 s (2586%) | 60,0 s (2837%) | 55,2 s (127%) |
| 54 | 215,4 s (635%) | 289,5 s (588%) | 343,0 s (20%) |
| 72 | 218,9 s (624%) | 295,6 s (576%) | 1237,2 s (6%) |
xgboost Velocidad exacta:
xgboost Eficiencia exacta:
xgboost Velocidad aproximada:
xgboost Eficiencia aproximada:
xgboost Velocidad del histograma:
Eficiencia del histograma xgboost:
Laurae2
en 3 nov. 2018
Parece un problema con varios sockets.
RAMitchell
en 3 nov. 2018
@RAMitchell Parece ser un problema con la disponibilidad de los nodos NUMA, puedo replicar este problema (con un resultado mucho peor con menos subprocesos durante el entrenamiento) usando Sub NUMA Clustering (2 sockets = 4 nodos NUMA en lugar de 1 socket = 2 nodos NUMA ).

xgboost, como la mayoría de los algoritmos de aprendizaje automático, no tiene optimización para manejar nodos NUMA. Pero ese sería un segundo problema. Por lo tanto, no son apropiados para entornos de múltiples sockets ni cuando los nodos NUMA están disponibles a través de COD (Cluster on Die) o SNC (Sub NUMA Clustering), y el hyperthreading hace que el desequilibrio de la carga de trabajo sea una gran penalización para ellos.
El problema 1 se trataría de la enorme degradación del rendimiento de subprocesos múltiples en el modo xgboost hist (este problema).
El problema 2 sería sobre la optimización de NUMA (otro problema por abrir).
Laurae2
en 4 nov. 2018
Estos son los resultados con NUMA deshabilitado. Emparejé los resultados con NUMA habilitado para comparar. También se agregaron 71 subprocesos para mostrar el rendimiento antes de que la CPU se abrume con el programador del kernel en 72 subprocesos (se requieren más recursos de los disponibles).
A UMA le va mucho mejor que a NUMA para subprocesos múltiples, este es un resultado esperado del entrelazado de memoria en un proceso no compatible con NUMA.
Tiempo tiempo:
| Hilos | Exacto
NUMA | Exacto
UMA | Aprox.
NUMA | Aprox.
UMA | Hist
NUMA | Hist
UMA |
| ---: | ---: | ---: | ---: | ---: | ---: | ---: |
| 1 | 1367s | 1667s | 1702s | 1792s | 69,9s | 85,6s |
| 2 | 758,7s | 810,3s | 881.0s | 909.0s | 52,5s | 54,1s |
| 4 | 368,6s | 413.0s | 445,6s | 452,9s | 31,7s | 36,2s |
| 6 | 241,5s | 273,8s | 219,6s | 302,4s | 24,1s | 30,5 s |
| 9 | 160,4s | 182,8s | 194,4s | 202,5s | 23,1s | 28,3 s |
| 18 | 86,3s | 94,4s | 106,3s | 105,8s | 24,2s | 31,2s |
| 27 | 66,4s | 66,4s | 80,2s | 73,6s | 63,6s | 37,5s |
| 36 | 52,9s | 52,7s | 60,0s | 59,4s | 55,2s | 43,5s |
| 54 | 215,4s | 49,2s | 289,5s | 58,5s | 343.0s | 57,4s |
| 71 | 218,3s | 47.01s | 295,9s | 56,5s | 1238.2s | 71,5s |
| 72 | 218,9s | 49,0s | 295,6s | 58,6s | 1237.2s | 79,1s |
Tabla de eficiencia:
| Hilos | Exacto
NUMA | Exacto
UMA | Aprox.
NUMA | Aprox.
UMA | Hist
NUMA | Hist
UMA |
| ---: | ---: | ---: | ---: | ---: | ---: | ---: |
| 1 | 100% | 100% | 100% | 100% | 100% | 100% |
| 2 | 180% | 206% | 193% | 197% | 133% | 158% |
| 4 | 371% | 404% | 382% | 396% | 221% | 236% |
| 6 | 566% | 609% | 582% | 593% | 290% | 280% |
| 9 | 852% | 912% | 875% | 885% | 303% | 302% |
| 18 | 1583% | 1766% | 1601% | 1694% | 289% | 274% |
| 27 | 2059% | 2510% | 2122% | 2436% | 110% | 229% |
| 36 | 2586% | 3162% | 2837% | 3017% | 127% | 197% |
| 54 | 635% | 3384% | 588% | 3065% | 20% | 149% |
| 71 | 626% | 3545% | 575% | 3172% | 6% | 120% |
| 72 | 624% | 3401% | 576% | 3059% | 6% | 108% |
Modo UMA.
xgboost Velocidad exacta:
xgboost Eficiencia exacta:
xgboost Velocidad aproximada:
xgboost Eficiencia aproximada:
xgboost Velocidad del histograma:
Eficiencia del histograma xgboost:
Laurae2
en 4 nov. 2018
Como se comentó en https://github.com/dmlc/xgboost/pull/3957#issuecomment -453815876, probé las confirmaciones a2dc929 (mejora previa a la CPU) y 5f151c5 (mejora posterior a la CPU).
Probé usando mi servidor Dual Xeon 6154 (compilador gcc, no Intel), usando Bosch para 500 iteraciones, eta 0.10 y profundidad 8, con 3 ejecuciones cada una para 1 a 72 subprocesos. Observamos un aumento del rendimiento de aproximadamente un 50% (1/3 más rápido) para cargas de trabajo multiproceso con el máximo rendimiento.
Aquí están los resultados para antes del # 3957 (comete a2dc929):

Aquí están los resultados para # 3957 (cometer 5f151c5):

Usando las curvas de eficiencia, vemos un aumento del 50% en la escalabilidad (esto no significa que el problema esté resuelto: todavía tenemos que mejorarlo, si podemos, idealmente, si podemos llegar al rango de 1000-2000%, sería una locura estupendo).
Curva de eficiencia de a2dc929:

Curva de eficiencia de 5f151c5:

Laurae2
en 15 ene. 2019
Gracias @ Laurae2 , seguiré adelante y
hcho3
en 16 ene. 2019
@ hcho3 @SmirnovEgorRu Veo una pequeña regresión del rendimiento de la CPU en cargas de trabajo de un solo subproceso en datos 100% densos con el compromiso 5f151c5 que incurre en una penalización del 10% -15% en general al realizar el ajuste de hiperparámetros en X núcleos x 1 hilo xgboost.
Aquí hay un ejemplo de 50 millones de filas x 100 columnas de datos densos aleatorios (gcc 8), requiere al menos 256 GB de RAM para entrenarlo correctamente desde Python / R, ejecutar 3 veces (6 días).
Confirmar a2dc929:

Confirmar 5f151c5:

Aunque conducen a un rendimiento multiproceso muy similar, el rendimiento de un solo hilo se ve afectado por un entrenamiento más lento (las mejoras de @SmirnovEgorRu aún escalan más rápido, alcanzando en este caso de 50M x 100 una eficiencia del 500% en 11 hilos frente a 13 hilos antes).
Excluyendo el tiempo de creación de gmat, tenemos para un solo hilo en 50M x 100:
| Comprometerse | Total | tiempo gmat | Hora del tren |
| : --- | ---: | ---: | ---: |
| a2dc929 | 2926s | 816s | 2109s |
| 5f151c5 | (+ 13%) 3316s | (~%) 817s | (+ 18%) 2499s |
Laurae2
en 26 ene. 2019
@ hcho3 @ Laurae2 Generalmente, Hyper-threading solo ayuda en el caso de algoritmos vinculados al núcleo, no algoritmos vinculados a la memoria.
HT ayuda a cargar la canalización de la CPU mediante más instrucciones de ejecución. Si la mayoría de las instrucciones esperan la ejecución de las instrucciones anteriores (ligada a la latencia), HT realmente puede ayudar, en algunas cargas de trabajo específicas observé una aceleración de hasta 1.5 veces.
Sin embargo, si su aplicación pasa la mayor parte del tiempo trabajando con la memoria (limitada a la memoria), HT lo empeora aún más. 2 hiperprocesos comparten un caché de cpu y desplazan información útil entre sí. Como resultado, vemos una degradación del rendimiento.
Gradient Boosting: algoritmo vinculado a la memoria. El uso de HT no debería mejorar el rendimiento en ningún caso y su aceleración máxima debido al subproceso frente a la versión de 1 subproceso está limitada por la cantidad de núcleos de hardware. Entonces, mi opinión es mejor medir el rendimiento en la CPU sin HT.
¿Qué pasa con NUMA? Observé los mismos problemas en la implementación de DAAL. Requiere el control del uso de la memoria por cada núcleo. Lo miraré en el futuro.
¿Qué pasa con una pequeña desaceleración en 1 hilo? Lo investigaré. Creo que arreglarlo es fácil.
@ hcho3 En este momento estoy trabajando en la siguiente parte de optimizaciones. Espero estar listo para una nueva solicitud de extracción en un futuro próximo.
 SmirnovEgorRu
en 30 ene. 2019
SmirnovEgorRu
en 30 ene. 2019
@SmirnovEgorRu Gracias nuevamente por su esfuerzo. Para su información, hubo una discusión reciente sobre el aumento de la cantidad de paralelismo al realizar una expansión de nodo a nivel: # 4077.
hcho3
en 30 ene. 2019
@ Laurae2 Ahora que nos fusionamos en # 3957, # 4310 y # 4529, ¿podemos asumir que el problema de escala se ha resuelto? Los efectos de NUMA aún pueden ser problemáticos.
hcho3
en 5 jul. 2019
@ hcho3 Volveré a buscar más tarde para verificar, pero por lo que pude notar, hubo regresiones de rendimiento en los entornos de producción (especialmente # 3957, lo que causa una desaceleración de más de 30 veces).
También comprobaré los resultados de rendimiento con @szilard .
Ejemplo abierto: https://github.com/szilard/GBM-perf/issues/9
Laurae2
en 5 jul. 2019
La escala multinúcleo y, de hecho, también el problema de NUMA se ha mejorado en gran medida:
Multinúcleo:

Muy notable la mejora en datos más pequeños (0.1M filas)


Más detalles aquí:
https://github.com/szilard/GBM-perf#multi -core-scaling-cpu
https://github.com/szilard/GBM-perf/issues/29#issuecomment -689713624
Además, el problema de NUMA se ha mitigado en gran medida:



 szilard
en 17 sept. 2020
szilard
en 17 sept. 2020
@szilard ¡ Muchas gracias por tomarse el tiempo para hacer el benchmark! Y es una gran noticia que XGBoost haya mejorado en la escala de rendimiento de la CPU.
hcho3
en 17 sept. 2020
Sí, gran trabajo a todos en este hilo por haber logrado esto.
szilard
en 17 sept. 2020
Para su información, aquí están los tiempos de entrenamiento en filas de 1M en EC2 r4.16xlarge (2 sockets con 16c + 16HT cada uno) en 1, 16 (1so y sin HT) y 64 (todos) núcleos para diferentes versiones de xgboost:

szilard
en 17 sept. 2020
@szilard , ¡muchas gracias por el análisis! Es bueno saber que las optimizaciones funcionan.
PS Arriba veo que XGB 1.2 tiene cierta regresión contra la versión 1.1. Es una información muy interesante, déjame aclarar esto. No se espera de mí.
SmirnovEgorRu
en 18 sept. 2020
@szilard , si este tema es interesante para usted, algunos antecedentes y resultados de las optimizaciones de la CPU están disponibles en este blog:
https://medium.com/intel-analytics-software/new-optimizations-for-cpu-in-xgboost-1-1-81144ea21115
SmirnovEgorRu
en 18 sept. 2020
Gracias @SmirnovEgorRu por su trabajo de optimización y por el enlace a la publicación del blog (no vi esta publicación antes).
Para que sea más fácil reproducir mis números y obtener nuevos en el futuro u otro hardware, hice un Dockerfile separado para esto:
https://github.com/szilard/GBM-perf/tree/master/analysis/xgboost_cpu_by_version
Deberá configurar los ID del núcleo de la CPU para el primer socket, sin núcleos hiperprocesados (por ejemplo, 0-15 en r4.16xlarge, que tiene 2 sockets, 16c + 16HT cada uno) y la versión xgboost:
VER=v1.2.0
CORES_1SO_NOHT=0-15 ## set physical core ids on first socket, no hyperthreading
sudo docker build --build-arg CACHE_DATE=$(date +%Y-%m-%d) --build-arg VER=$VER -t gbmperf_xgboost_cpu_ver .
sudo docker run --rm -e CORES_1SO_NOHT=$CORES_1SO_NOHT gbmperf_xgboost_cpu_ver
Puede que valga la pena ejecutar el script varias veces, los tiempos de entrenamiento en todos los núcleos suelen mostrar una variabilidad algo mayor, no estoy seguro si debido al entorno de virtualización (EC2) o debido a NUMA.
szilard
en 18 sept. 2020
Resultados en c5.metal que tiene una frecuencia más alta y más núcleos que r4.16xlarge que he estado usando en el punto de referencia:
https://github.com/szilard/GBM-perf/issues/41
TLDR: xgboost aprovecha al máximo los núcleos más rápidos y más rápidos frente a otras bibliotecas. 👍
szilard
en 21 sept. 2020
Me pregunto sobre esto:

la aceleración de 1 a 24 núcleos para xgboost es menor para los datos más grandes (10 millones de filas, paneles a la derecha) que para datos más pequeños (1 millón de filas, paneles en la columna central). ¿Se trata de algún tipo de aumento de los accesos al caché o algo que otras bibliotecas no tienen?
szilard
en 21 sept. 2020
Aquí hay algunos resultados sobre AMD:
https://github.com/szilard/GBM-perf/issues/42
Parece que las optimizaciones de xgboost también funcionan muy bien en AMD.
szilard
en 21 sept. 2020
Temas relacionados
 nicoJiang
·
4Comentarios
nicoJiang
·
4Comentarios
 hx364
·
3Comentarios
hx364
·
3Comentarios
 XiaoxiaoWang87
·
3Comentarios
XiaoxiaoWang87
·
3Comentarios
 choushishi
·
3Comentarios
choushishi
·
3Comentarios
 matthewmav
·
3Comentarios
matthewmav
·
3Comentarios
Comentario más útil
La escala multinúcleo y, de hecho, también el problema de NUMA se ha mejorado en gran medida:
Multinúcleo:
Muy notable la mejora en datos más pequeños (0.1M filas)
Más detalles aquí:
https://github.com/szilard/GBM-perf#multi -core-scaling-cpu
https://github.com/szilard/GBM-perf/issues/29#issuecomment -689713624
Además, el problema de NUMA se ha mitigado en gran medida: