部屋の中の象、つまりマルチコアCPUでのパフォーマンスに取り組む時が来ました。
問題の説明
現在、 histツリー成長アルゴリズム( tree_method=hist )は、マルチコアCPUでのスケーリングが不十分です。一部のデータセットでは、スレッド数が増えると@ Laurae2のGradientBoosting Benchmark ( GitHub repo )によって発見されました。
Boschデータセットのスケーリング動作は次のとおりです。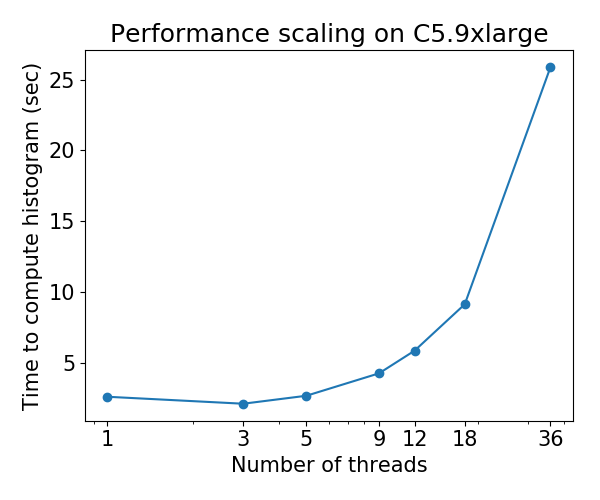
寄付を呼びかける
'hist'アルゴリズムのパフォーマンスのボトルネックを特定し、それを小さなリポジトリhcho3 / xgboost-fast-hist-perf-labに配置しました。 src / build_hist.ccを修正することで、パフォーマンスの向上を試みることができます。
いくつかのアイデア
 hcho3
hcho3
全てのコメント44件
@ Laurae2GBTベンチマークをご用意いただきありがとうございます。 問題のある場所を特定するのに役立ちました。
hcho3
2018年10月19日
@ hcho3 OpenMP guidedスケジュールは負荷分散に役立ちますか? もしそうなら、ellpackはあまり役に立ちません。
 trivialfis
2018年10月24日
trivialfis
2018年10月24日
私の推測では、ellpackを使用した作業の静的割り当ては、OpenMPのguidedまたはdynamicモードよりも低いオーバーヘッドでバランスの取れたワークロードを実現します。 dynamic 、作業を盗むキューを維持するための実行時のオーバーヘッドが発生します
hcho3
2018年10月24日
少し話題から外れているかもしれませんが、 approxベンチマーク結果はありますか?
内部環境でのマルチスレッドによる次善のスピードアップを見つけました...他の人のデータを見たい
 CodingCat
2018年10月24日
CodingCat
2018年10月24日
@CodingCatリンクされたベンチマークスイートはhistのみを使用します。 approxはhistようなパフォーマンスの低下を示していますか(たとえば、36スレッドは3スレッドより遅い)?
hcho3
2018年10月24日
@ hcho3クラスターの制限により、最大8つのスレッドでしかテストできません...しかし、8と4 ....を比較すると非常に限られたスピードアップが見られます。
CodingCat
2018年10月24日
@CodingCat 8つのスレッドの実行速度が4より遅いということですか?
hcho3
2018年10月24日
@CodingCat approxスケーリングが非常に悪いため、ベンチマークを試してみたくありませんでした。 私の4コアラップトップ(3.6 GHz)でも適切にスケーリングされないため、64スレッドまたは72スレッドでは想像もできません。
@ hcho3後で、VTuneでリポジトリを使用して確認します。
VTuneで詳細なパフォーマンスを取得したい場合は、以下を使用してヘッダーに追加できます。
#include <ittnotify.h> // Intel Instrumentation and Tracing Technology
ループの外側で追跡するものの前に以下を追加します(文字列/変数の名前を変更します)。
__itt_resume();
__itt_domain* domain = __itt_domain_create("MyDomain");
__itt_string_handle* task = __itt_string_handle_create("MyTask");
__itt_task_begin(domain, __itt_null, __itt_null, task);
ループの外側で追跡するものの後に以下を追加します(文字列/変数の名前を変更します)。
__itt_task_end(domain);
__itt_pause();
そして、スレッド数の正しいパラメーターを使用してVTuneでプロジェクトを開始します。 パフォーマンス分析を行うために、インストルメンテーションを一時停止して実行可能ファイルを起動します。
 Laurae2
2018年10月24日
Laurae2
2018年10月24日
@ hcho3遅くはありませんが、スレッドが4つ増えると、おそらく15%のスピードアップになります...(さらに実験を行うと、結果が収束するのではないかと思います.....
CodingCat
2018年10月24日
@ Laurae2は私だけではないようです
CodingCat
2018年10月24日
@ hcho3 exact 、 approx 、 hist 、すべてdepth=6誰も実行しない場合は、今週の終わりまでにスケーリング結果を取得しようとします。
最近、コンピューティングサーバーを移行しました。今週は、すべてターボ/ 36コア/ 72スレッド/ 80 GBpsRAM帯域幅の3.7GHzの新しいマシンでBoschの新しいベンチマークを再実行しています。
Laurae2
2018年10月24日
fast_histアップデータは、分散xgboostの方がはるかに高速である必要があります。 @CodingCat AllReduce呼び出しを追加しようとした人がいないので、分散モードで動作することに驚いています。
 RAMitchell
2018年10月24日
RAMitchell
2018年10月24日
@RAMitchell fast_histアップデータを作成したときはかなり新しいので、分散モードのサポートがありません。 0.81リリース後に入手したいのですが。
hcho3
2018年10月24日
@ Laurae2参考までに、ベンチマークスイートをC5.9xlargeマシンで実行しましたが、XGBoost hist結果は以前の結果と一致しているようです。 よろしければ番号をお付けします。
hcho3
2018年10月24日
@ Laurae2また、EC2マシンにアクセスできます。 EC2インスタンスで実行したいスクリプトがある場合は、お知らせください。
hcho3
2018年10月24日
@RAMitchell fast_histアップデータを作成したときはかなり新しいので、分散モードのサポートがありません。 0.81リリース後に入手したいのですが。
@ hcho3よろしければ、分散型のより高速なヒストグラムアルゴリズムを取得するために挑戦することができます。現在、Uberの仕事でハーフタイムを過ごしており、来年はxgboostにもっと時間がかかる可能性があります。
CodingCat
2018年10月29日
@CodingCatそれは素晴らしいことです、ありがとう! 'hist'コードについて質問がある場合はお知らせください。
hcho3
2018年10月29日
@CodingCat参考までに、0.81リリースの直後に「hist」アップデーターの単体テストを追加する予定です。 分散サポートを追加する場合は、これが役立つはずです。
hcho3
2018年10月29日
@ hcho3 @CodingCat approxは先月削除されたようですが、予想される動作ですか?
https://github.com/dmlc/xgboost/commit/70d208d68c3a32aaa4fcd6aa456f286a4da5912f#diff -53a3a623be5ce5a351a89012c7b03a31(PR https://github.com/dmlc/xgboost/pull/3395がtree_method = approxを削除しましたか?およそと非およその間の結果...
Laurae2
2018年10月29日
@ Laurae2リファクタリングにより、 approxが選択されているというINFOメッセージが削除されたようです。 それ以外の場合は、 approxは引き続き使用できます。
hcho3
2018年10月29日
@ Laurae2実は、あなたは正しいです。 approxはまだコードベースにありますが、何らかの理由でtree_method=approxが設定されていても呼び出されません。 このバグをできるだけ早く調査します。
hcho3
2018年10月29日
問題#3840が提出されました。 これが修正されるまで、リリース0.81はリリースされません。
hcho3
2018年10月29日
@ hcho3高速ヒストグラムを使用してサーバー上で非常に奇妙なものを見つけました。明日ベンチマーク計算が終了したら、結果をお知らせします(高速ヒストグラムの非常に大きな負の効率について話しているので、私が試しているのは非常に大きいです。それを測定しますが、長くなりすぎないことを願っています)。
およそ、効率の悪さは予想よりもはるかに優れていますが、どのコンピューターにも当てはまるとは思いません(新しいIntel CPU世代= RAM周波数が高いほど良くなるのではないでしょうか?)。 サーバーで高速ヒストグラムが終了したら、データを投稿します。
参考までに、私は477個の機能(5%未満の欠損値を持つ機能)を備えたBoschデータセットを使用しています。
3000時間以上のCPU時間に達しました...(少なくとも私のサーバーはしばらくの間有効に使用されています)次に私はhttps://github.com/hcho3/xgboost-fast-hist-perf-を見ていき使用した
@ hcho3必要に応じて、サーバーの計算が終了したら、ベンチマークRスクリプトを提供できます。 depth=8とnrounds=50 、すべてのtree_method=exact 、 tree_method=approx ( updater=grow_histmaker,prune回避策、#3849より前)、およびtree_method=hist 、1から72スレッド。 取り組むべきもっと興味深いものが見つかるかもしれません(そしてAWSでもテストできるでしょう)。
Laurae2
2018年11月01日
以下の予備的な結果を参照してください。平均結果まで7回実行されました。 よく見るにはクリックしてください。 提供される合成テーブル。 プロットが示すのとは異なり、CPUは固定されていません。
チャートは明らかに私が準備したものとはかなり異なっているように見えます...(動作がいかに奇妙であるため、UMAをオン(NUMAをオフ)にしてこれを再実行しています)。 後でIntelVTuneで確認します。
ハードウェアとソフトウェア:
- CPU:デュアルXeon Gold 6154、3.7 GHzオールターボ、2x18コア/ 36スレッド
- RAM:4x 64GB RAM DDR4 2666 MHz(デュアルチャネル、約80 GBps帯域幅)
- BIOS:NUMAオン、サブNUMAクラスタリングオフ
- オペレーティングシステム:Pop_OS! 18.10
- 知事:パフォーマンス
- カーネル:4.18.0-10
- カーネルフラグ:
pti=off spectre_v2=off spec_store_bypass_disable=off l1tf=off noibrs noibpb nopti no_stf_barrier - コンパイラ:gcc 8.2.0
- R:3.5.1をgcc8.2.0およびIntelMKLでコンパイル
- Rの追加のコンパイルフラグ:
-O3 -mtune=native
メルトダウン/スペクタープロテクション:
laurae@laurae-compute:~$ head /sys/devices/system/cpu/vulnerabilities/*
==> /sys/devices/system/cpu/vulnerabilities/l1tf <==
Mitigation: PTE Inversion; VMX: vulnerable
==> /sys/devices/system/cpu/vulnerabilities/meltdown <==
Vulnerable
==> /sys/devices/system/cpu/vulnerabilities/spec_store_bypass <==
Vulnerable
==> /sys/devices/system/cpu/vulnerabilities/spectre_v1 <==
Mitigation: __user pointer sanitization
==> /sys/devices/system/cpu/vulnerabilities/spectre_v2 <==
Vulnerable
| スレッド| 正確(効率)| おおよそ(効率)| 履歴(効率)|
| ---:| ---:| ---:| ---:|
| 1 | 1367秒(100%)| 1702秒(100%)| 69.9秒(100%)|
| 2 | 758.7秒(180%)| 881.0秒(193%)| 52.5秒(133%)|
| 4 | 368.6秒(371%)| 445.6秒(382%)| 31.7秒(221%)|
| 6 | 241.5秒(566%)| 219.6秒(582%)| 24.1秒(290%)|
| 9 | 160.4秒(852%)| 194.4秒(875%)| 23.1秒(303%)|
| 18 | 86.3秒(1583%)| 106.3秒(1601%)| 24.2秒(289%)|
| 27 | 66.4秒(2059%)| 80.2秒(2122%)| 63.6秒(110%)|
| 36 | 52.9秒(2586%)| 60.0秒(2837%)| 55.2秒(127%)|
| 54 | 215.4秒(635%)| 289.5秒(588%)| 343.0秒(20%)|
| 72 | 218.9秒(624%)| 295.6秒(576%)| 1237.2秒(6%)|
xgboost正確な速度:
xgboost正確な効率:
xgboostおおよその速度:
xgboostおおよその効率:
xgboostヒストグラム速度:
xgboostヒストグラムの効率:
Laurae2
2018年11月03日
複数のソケットに問題があるようです。
RAMitchell
2018年11月03日
@RAMitchell NUMAノードの可用性に問題があるようです。サブNUMAクラスタリング(1ソケット= 2NUMAノードではなく2ソケット= 2 NUMAノード)を使用して、この問題を再現できます(トレーニング中のスレッドが少なくなると、結果がさらに悪化します)。 )。

ほとんどの機械学習アルゴリズムと同様に、xgboostにはNUMAノードを処理するための最適化がありません。 しかし、それは2番目の問題になります。 したがって、これらはマルチソケット環境や、NUMAノードがCOD(Cluster on Die)またはSNC(Sub NUMA Clustering)を介して利用できる場合には適切ではなく、ハイパースレッディングによってワークロードの不均衡が大きなペナルティになります。
問題1は、xgboost histモードでのマルチスレッドパフォーマンスの大幅な低下に関するものです(この問題)。
問題2は、NUMAの最適化に関するものです(別の問題を開く必要があります)。
Laurae2
2018年11月04日
NUMAを無効にした場合の結果は次のとおりです。 比較のためにNUMAを有効にして結果をペアにしました。 また、CPUが72スレッドでカーネルスケジューラに圧倒される前のパフォーマンスを示すために71スレッドを追加しました(使用可能なリソースよりも多くのリソースが必要です)。
UMAは、マルチスレッドに関してNUMAよりもはるかに優れています。これは、NUMAに対応していないプロセスでのメモリインターリーブの予想される結果です。
時間時間:
| スレッド| 正確
NUMA | 正確
UMA | 約
NUMA | 約
UMA | 履歴
NUMA | 履歴
UMA |
| ---:| ---:| ---:| ---:| ---:| ---:| ---:|
| 1 | 1367年代| 1667年代| 1702年代| 1792年代| 69.9秒| 85.6秒|
| 2 | 758.7秒| 810.3秒| 881.0s | 909.0s | 52.5秒| 54.1秒|
| 4 | 368.6秒| 413.0秒| 445.6秒| 452.9秒| 31.7秒| 36.2秒|
| 6 | 241.5秒| 273.8秒| 219.6秒| 302.4秒| 24.1秒| 30.5秒|
| 9 | 160.4秒| 182.8秒| 194.4秒| 202.5秒| 23.1秒| 28.3秒|
| 18 | 86.3秒| 94.4秒| 106.3秒| 105.8秒| 24.2秒| 31.2秒|
| 27 | 66.4秒| 66.4秒| 80.2秒| 73.6秒| 63.6秒| 37.5秒|
| 36 | 52.9秒| 52.7秒| 60.0秒| 59.4秒| 55.2秒| 43.5秒|
| 54 | 215.4秒| 49.2秒| 289.5秒| 58.5秒| 343.0秒| 57.4秒|
| 71 | 218.3秒| 47.01秒| 295.9秒| 56.5秒| 1238.2s | 71.5秒|
| 72 | 218.9秒| 49.0秒| 295.6秒| 58.6秒| 1237.2s | 79.1秒|
効率表:
| スレッド| 正確
NUMA | 正確
UMA | 約
NUMA | 約
UMA | 履歴
NUMA | 履歴
UMA |
| ---:| ---:| ---:| ---:| ---:| ---:| ---:|
| 1 | 100%| 100%| 100%| 100%| 100%| 100%|
| 2 | 180%| 206%| 193%| 197%| 133%| 158%|
| 4 | 371%| 404%| 382%| 396%| 221%| 236%|
| 6 | 566%| 609%| 582%| 593%| 290%| 280%|
| 9 | 852%| 912%| 875%| 885%| 303%| 302%|
| 18 | 1583%| 1766%| 1601%| 1694%| 289%| 274%|
| 27 | 2059%| 2510%| 2122%| 2436%| 110%| 229%|
| 36 | 2586%| 3162%| 2837%| 3017%| 127%| 197%|
| 54 | 635%| 3384%| 588%| 3065%| 20%| 149%|
| 71 | 626%| 3545%| 575%| 3172%| 6%| 120%|
| 72 | 624%| 3401%| 576%| 3059%| 6%| 108%|
UMAモード。
xgboost正確な速度:
xgboost正確な効率:
xgboostおおよその速度:
xgboostおおよその効率:
xgboostヒストグラム速度:
xgboostヒストグラムの効率:
Laurae2
2018年11月04日
https://github.com/dmlc/xgboost/pull/3957#issuecomment -453815876でコメントされているように、コミットa2dc929(CPUの改善前)と5f151c5(CPUの改善後)をテストしました。
Dual Xeon 6154サーバー(Intelではなくgccコンパイラ)を使用して、Boschを500回の反復、eta 0.10、深さ8でテストし、1〜72スレッドでそれぞれ3回実行しました。 ピークパフォーマンスでマルチスレッドワークロードのパフォーマンスが最大約50%(1/3高速)向上することがわかります。
#3957(commit a2dc929)より前の結果は次のとおりです。

#3957(commit 5f151c5)の結果は次のとおりです。

効率曲線を使用すると、スケーラビリティが50%向上することがわかります(これは、問題が解決されたことを意味するわけではありません。可能であれば、それでも改善する必要があります。理想的には、めちゃくちゃになる1000〜2000%の範囲に到達できる場合です。すごい)。
a2dc929の効率曲線:

5f151c5の効率曲線:

Laurae2
2019年01月15日
@ Laurae2に感謝します。この問題をピン留めして、常に問題追跡システムの最上位に表示されるようにします。 やるべきことは確かにもっとあります。
hcho3
2019年01月16日
@ hcho3 @SmirnovEgorRu Xコアx 1 xgboostスレッドでハイパーパラメーター調整を行うと、コミット5f151c5で全体的に10%〜15%のペナルティが発生する、100%高密度データのシングルスレッドワークロードで小さなCPUパフォーマンスの低下が見られます。
これは、5000万行x 100列のランダムな高密度データ(gcc 8)の例であり、Python / Rから適切にトレーニングするには少なくとも256GBのRAMが必要で、3回(6日)実行されます。
a2dc929をコミットします:

5f151c5をコミットします:

それらは非常に類似したマルチスレッドパフォーマンスにつながりますが、シングルスレッドパフォーマンスはより遅いトレーニングによって打撃を受けます( @SmirnovEgorRuの改善はさらに速くスケーリングし、この50M x 100の場合、11スレッドで500%の効率に達しますが、以前は13スレッドでした)。
gmatの作成時間を除いて、50M x100のシングルスレッドの場合は次のようになります。
| コミット| 合計| gmat時間| 電車の時間|
| :--- | ---:| ---:| ---:|
| a2dc929 | 2926年代| 816s | 2109秒|
| 5f151c5 | (+ 13%)3316秒| (〜%)817秒| (+ 18%)2499s |
Laurae2
2019年01月26日
@ hcho3 @ Laurae2一般に、ハイパースレッディングはコアバウンドアルゴリズムの場合にのみ役立ち、
HTは、実行のためのより多くの命令によってCPUのパイプラインをロードするのに役立ちます。 ほとんどの命令が前の命令の実行を待つ場合(レイテンシーバウンド)-HTは本当に役立ちます。特定のワークロードでは、最大1.5倍のスピードアップが見られました。
ただし、アプリケーションがほとんどの時間をメモリの操作(メモリバウンド)に費やしている場合、HTはさらに悪化します。 2つのハイパースレッドが1つのCPUキャッシュを共有し、有用な情報を相互に置き換えます。 その結果、パフォーマンスが低下します。
勾配ブースティング-メモリバウンドアルゴリズム。 HTを使用してもパフォーマンスが向上することはなく、1スレッドバージョンと比較したスレッドによる最大速度の向上は、ハードウェアコアの数によって制限されます。 したがって、HTを使用せずにCPUのパフォーマンスを測定する方がよいと思います。
NUMAについてはどうですか?DAALの実装でも同じ問題が発生しました。 各コアによるメモリ使用量の制御が必要です。 将来的に見ていきます。
1つのスレッドでの小さな速度低下はどうですか?調査します。 修正は簡単だと思います。
@ hcho3現在、私は最適化の次の部分に取り組んでいます。 近い将来、新しいプルリクエストの準備ができていることを願っています。
 SmirnovEgorRu
2019年01月30日
SmirnovEgorRu
2019年01月30日
@SmirnovEgorRuお疲れ様でした。 参考までに、レベルごとのノード拡張を実行することによって並列処理の量を増やすことについての最近の議論がありました:#4077。
hcho3
2019年01月30日
@ Laurae2 #3957、#4310、および#4529で統合したので、スケーリングの問題が解決されたと想定できますか? NUMAの影響はまだ問題がある可能性があります。
hcho3
2019年07月05日
@ hcho3後で確認するために再ベンチングしますが、実稼働環境でパフォーマンスの低下があったことに気づきました(特に、#3957が30倍以上の速度低下を引き起こしました)。
@szilardでもパフォーマンス結果を確認します。
オープンな例: https :
Laurae2
2019年07月05日
マルチコアスケーリングと実際にはNUMAの問題も大幅に改善されました。
マルチコア:

小さいデータ(0.1M行)での非常に顕著な改善


詳細はこちら:
https://github.com/szilard/GBM-perf#multi -core-scaling-cpu
https://github.com/szilard/GBM-perf/issues/29#issuecomment -689713624
また、 NUMAの問題は大幅に軽減されました。



 szilard
2020年09月17日
szilard
2020年09月17日
@szilardベンチマークに時間を
hcho3
2020年09月17日
ええ、これを達成してくれたこのスレッドのみんな素晴らしい仕事。
szilard
2020年09月17日
参考までに、さまざまなバージョンのxgboostの1、16(1so&no HT)および64(すべて)コアのEC2 r4.16xlarge(それぞれ16c + 16HTの2つのソケット)の1M行でのトレーニング時間は次のとおりです。

szilard
2020年09月17日
@szilard 、分析ありがとうございます! 最適化が機能すると聞いてうれしいです。
上記のPSXGB1.2には1.1バージョンに対していくらかのリグレッションがあることがわかります。 非常に興味深い情報です。これを明確にしましょう。 それは私には期待されていません。
SmirnovEgorRu
2020年09月18日
@szilard 、このトピックがあなたにとって興味深いものである場合
https://medium.com/intel-analytics-software/new-optimizations-for-cpu-in-xgboost-1-1-81144ea21115
SmirnovEgorRu
2020年09月18日
最適化作業とブログ投稿へのリンクをありがとう@SmirnovEgorRu (私は以前にこの投稿を見ませんでした)。
自分の番号を簡単に再現し、将来新しい番号やその他のハードウェアを入手しやすくするために、次のために別のDockerfileを作成しました。
https://github.com/szilard/GBM-perf/tree/master/analysis/xgboost_cpu_by_version
最初のソケットのCPUコアIDを設定する必要があります。ハイパースレッディングコアは設定せず(たとえば、2つのソケットを備えたr4.16xlargeの0-15、それぞれ16c + 16HT)、xgboostバージョンを設定します。
VER=v1.2.0
CORES_1SO_NOHT=0-15 ## set physical core ids on first socket, no hyperthreading
sudo docker build --build-arg CACHE_DATE=$(date +%Y-%m-%d) --build-arg VER=$VER -t gbmperf_xgboost_cpu_ver .
sudo docker run --rm -e CORES_1SO_NOHT=$CORES_1SO_NOHT gbmperf_xgboost_cpu_ver
スクリプトを数回実行する価値があるかもしれません。すべてのコアでのトレーニング時間は通常、仮想化環境(EC2)によるものか、NUMAによるものかはわかりませんが、多少高い変動性を示します。
szilard
2020年09月18日
ベンチマークで使用しているr4.16xlargeよりも高い周波数と多くのコアを持つc5.metalでの結果:
https://github.com/szilard/GBM-perf/issues/41
TLDR:xgboostは、他のライブラリと比較して、より高速でより多くのコアを最大限に活用します。 👍
szilard
2020年09月21日
私はこれについて疑問に思います:

xgboostの1コアから24コアへのスピードアップは、小さいデータ(100万行、中央の列のパネル)よりも大きいデータ(1000万行、右側のパネル)の方が小さくなります。 これは、キャッシュヒットの増加のようなものですか、それとも他のライブラリにはないものですか?
szilard
2020年09月21日
szilard
2020年09月21日
関連する問題
 mhnamaki
·
3コメント
mhnamaki
·
3コメント
 matthewmav
·
3コメント
matthewmav
·
3コメント
 pplonski
·
3コメント
pplonski
·
3コメント
 hx364
·
3コメント
hx364
·
3コメント
 vkuznet
·
3コメント
vkuznet
·
3コメント
最も参考になるコメント
マルチコアスケーリングと実際にはNUMAの問題も大幅に改善されました。
マルチコア:
小さいデータ(0.1M行)での非常に顕著な改善
詳細はこちら:
https://github.com/szilard/GBM-perf#multi -core-scaling-cpu
https://github.com/szilard/GBM-perf/issues/29#issuecomment -689713624
また、 NUMAの問題は大幅に軽減されました。