增强说明
- 单行增强说明(可作为发行说明):Kubelet 组件,用于协调 Kubernetes 中不同组件的细粒度硬件资源分配。
- 主要联系人(受让人): @klueska
- 负责的 SIG:sig-node
- 设计提案链接(社区仓库): https :
- KEP 公关: https :
- KEP: https :
- 链接到 e2e 和/或单元测试:N/A Yet
- 审阅者 -(对于 LGTM)建议有 2 个以上的审阅者(至少一位来自代码区域 OWNERS 文件)同意进行审阅。 多家公司审稿人优先: @ConnorDoyle @balajismaniam
- 批准人(可能来自 SIG/增强所属领域): @ derekwaynecarr @ConnorDoyle
- 增强目标(哪个目标等于哪个里程碑):
- Alpha 发布目标 (xy):v1.16
- Beta 发布目标 (xy):v1.18
- 稳定释放目标 (xy)
 lmdaly
lmdaly
所有159条评论
/sig 节点
/种类特征
抄送@ConnorDoyle @balajismaniam @nolancon
lmdaly
于 2019-01-17
我可以在向 Borg 学习的基础上为这个设计提供帮助。 因此,将我视为审阅者/批准者。
 vishh
于 2019-02-04
vishh
于 2019-02-04
我可以在向 Borg 学习的基础上为这个设计提供帮助。 因此,将我视为审阅者/批准者。
是否有任何关于此功能在 borg 中如何工作的公共文档?
 jeremyeder
于 2019-02-11
jeremyeder
于 2019-02-11
与 NUMA AFAIK 无关。
2019 年 2 月 11 日星期一上午 7:50,Jeremy Eder < [email protected]写道:
我可以在向 Borg 学习的基础上为这个设计提供帮助。 所以算我一个
作为审稿人/审批人。是否有任何关于此功能在 borg 中如何工作的公共文档?
—
您收到此消息是因为您发表了评论。
直接回复本邮件,在GitHub上查看
https://github.com/kubernetes/enhancements/issues/693#issuecomment-462378195 ,
或静音线程
https://github.com/notifications/unsubscribe-auth/AGvIKPfanjb9Q5DxXAiBgv9C6Y809JX0ks5vMZFZgaJpZM4aE3uz
.
vishh
于 2019-02-11
仅供参考@claurence
这个跟踪问题和 KEP (https://github.com/kubernetes/enhancements/pull/781) 没有及时赶上 v1.14 增强功能冻结和延长的截止日期。 我很感激您在截止日期前打开这些文件,但它们似乎没有得到足够的审查或签署。 这将需要通过异常过程。
在我们决定这是否值得例外之前,我倾向于搁置与此增强相关的所有 PR。
参考: https :
 spiffxp
于 2019-02-24
spiffxp
于 2019-02-24
/cc @jiayingz @dchen1107
 jiayingz
于 2019-02-25
jiayingz
于 2019-02-25
@lmdaly我看到你们都在描述中列出了 1.14 作为 alpha 里程碑 - 因为没有合并的可实现 KEP 这个问题不会被跟踪 1.14 - 如果有意图将它包含在该版本中,请提交例外请求。
 claurence
于 2019-02-27
claurence
于 2019-02-27
@lmdaly我看到你们都在描述中列出了 1.14 作为 alpha 里程碑 - 因为没有合并的可实现 KEP 这个问题不会被跟踪 1.14 - 如果有意图将它包含在该版本中,请提交例外请求。
@claurence KEP 现在已合并(KEP 之前已合并到社区存储库中。这只是根据新指南将其移至新的增强存储库),我们是否仍需要提交异常请求以跟踪此问题1.14?
lmdaly
于 2019-03-05
虽然在通读了设计和 WIP PR 之后,我担心当前的实现并不像我们在https://github.com/kubernetes/enhancements/pull/781 中提出的原始拓扑设计那样通用
我在这里留下了一些评论以供进一步讨论: https :
 resouer
于 2019-03-11
resouer
于 2019-03-11
当前的实现不是通用的
对此也有同样的担忧:) 其他的怎么样,例如设备之间的链接(GPU 的 nvlinke)?
 k82cn
于 2019-03-20
k82cn
于 2019-03-20
@resouer @k82cn最初的提议仅涉及调整 CPU 管理器和设备管理器做出的决定,以确保设备与容器运行的 CPU 接近。 满足设备间关联性不是该提案的目标。
但是,如果当前的实现阻止了将来添加设备间关联性,那么一旦我了解它是如何做到的,我很乐意更改实现,
lmdaly
于 2019-03-25
我认为我在当前实现中看到的主要问题以及支持设备间关联的能力如下:
要支持设备间关联,您通常需要首先确定您希望将哪些设备分配给容器 _before_ 决定您希望容器具有的套接字关联。
例如,对于 Nvidia GPU,为了实现最佳连接,您首先需要找到并分配具有最多连接 NVLINK 的 GPU 集_before_ 确定该集具有的套接字关联。
从我目前的提案中可以看出,假设这些操作以相反的顺序发生,即在分配设备之前决定套接字关联。
 klueska
于 2019-04-05
klueska
于 2019-04-05
这不一定是真的@klueska。 如果拓扑提示被扩展为编码点对点设备拓扑,则设备管理器在报告套接字关联时可以考虑这一点。 换句话说,跨设备拓扑不需要泄漏到设备管理器的范围之外。 这看起来可行吗?
 ConnorDoyle
于 2019-04-05
ConnorDoyle
于 2019-04-05
也许我不知何故对流程感到困惑。 我是这样理解的:
1) 在初始化时,设备插件(不是devicemanager )用topologymanager注册自己,以便它可以在以后发出回调。
2) 当 pod 被提交时,kubelet 调用lifecycle.PodAdmitHandler上的topologymanager 。
3) lifecycle.PodAdmitHandler GetTopologyHints在每个注册的设备插件上调用
4) 然后合并这些提示以生成与 pod 关联的合并的TopologyHint
5) 如果它决定接纳 pod,它从lifecycle.PodAdmitHandler成功返回,将 pod 的合并TopologyHint存储在本地状态存储中
6)在未来的某一时刻, cpumanager和devicemanager调用GetAffinity(pod)的topology经理检索TopologyHint关联与豆荚
7) cpumanager使用这个 TopologyHint` 来分配一个 CPU
8) devicemanager使用这个 TopologyHint` 来分配一组设备
9) Pod 的初始化继续...
如果这是正确的,我想我正在为设备插件报告其TopologyHints和devicemanager进行实际分配的时间点之间发生的事情而苦苦挣扎。
如果这些提示旨在对分配的“首选项”进行编码,那么我认为您所说的是具有更像的结构:
type TopologyHints struct {
hints []struct {
SocketID int
DeviceIDs []int
}
}
我们不仅传递套接字关联首选项列表,还传递这些套接字关联首选项如何与可分配的 GPU 首选项配对。
如果这是您正在考虑的方向,那么我认为我们可以让它发挥作用,但我们需要以某种方式在cpumanager和devicemanager之间进行协调,以确保它们“接受”相同在进行分配时提示。
有没有什么东西可以让我已经错过了?
klueska
于 2019-04-05
@克鲁斯卡
我认为会发生什么,对您的流程进行一些_次要_更正是:
在初始化时,设备插件用
devicemanager注册自己,以便它可以在以后发出回调。lifecycle.PodAdmitHandler在 Kubelet 中的每个拓扑感知组件上调用GetTopologyHints,目前devicemanager和cpumanager。
在这种情况下,将在 Kubelet 中表示为拓扑感知的是cpumanager和devicemanager 。 拓扑管理器仅用于协调拓扑感知组件之间的分配。
为了这:
但是我们需要以某种方式在 cpumanager 和 devicemanager 之间进行协调,以确保它们在进行分配时“接受”相同的提示。
这就是引入topologymanager本身的目的。 从早期的草稿之一,
这些组件应该协调以避免交叉 NUMA 分配。 与这种协调相关的问题很棘手; 跨域请求,例如“与分配的 NIC 在同一 NUMA 节点上的独占核心”涉及 CNI 和 CPU 管理器。 如果 CPU 管理器首先选择,它可能会在没有可用 NIC 的 NUMA 节点上选择一个内核,反之亦然。
 eloyekunle
于 2019-04-06
eloyekunle
于 2019-04-06
我知道了。
所以devicemanager和cpumanager都实现了GetTopologyHints()并调用了GetAffinity() ,避免了topologymanager与任何底层设备插件的方向交互. 更仔细地查看代码,我发现devicemanager只是将控制权委托给插件以帮助填充TopologyHints ,无论如何这最终更有意义。
回到我提出的原始问题/问题....
从 Nvidia 的角度来看,我认为我们可以通过这个提议的流程使一切正常,假设更多信息被添加到TopologyHints结构(以及设备插件接口)以在未来报告点对点链接信息.
然而,我认为以SocketMask作为广告套接字关联的主要数据结构可能会限制我们在不破坏现有接口的情况下在未来使用点对点信息扩展TopologyHints能力。 主要原因是(至少在 Nvidia GPU 的情况下)首选插槽取决于最终将实际分配哪些 GPU。
例如,考虑下图,当尝试将 2 个 GPU 分配给具有最佳连接性的 Pod 时:
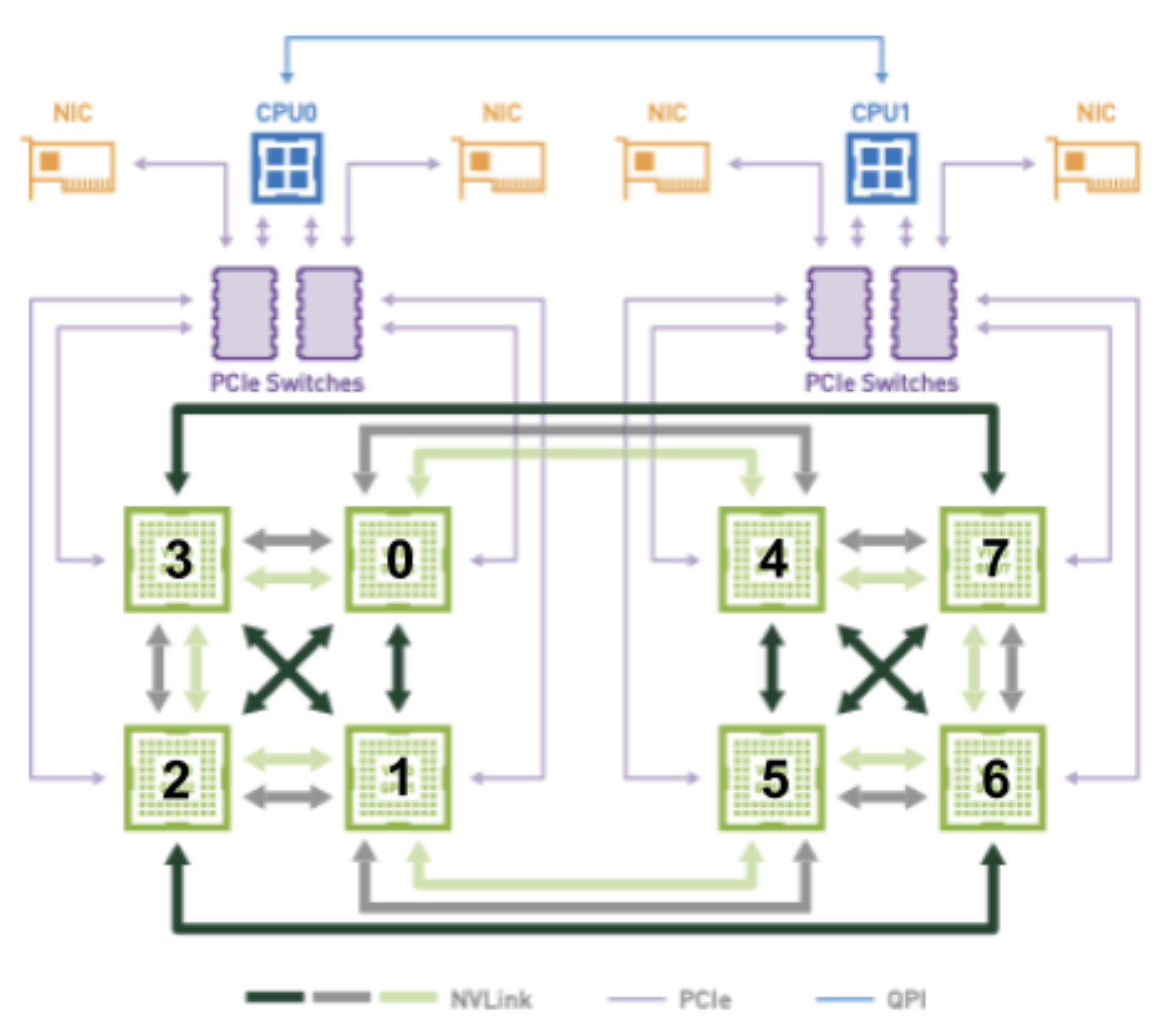
(2, 3) 和 (6, 7) 的 GPU 组合都有 2 个 NVLINK 并驻留在相同的 PCIe 总线上。 因此,当尝试将 2 个 GPU 分配给一个 Pod 时,它们应该被视为平等的候选者。 但是,根据选择的组合,显然会首选不同的套接字,因为 (2, 3) 连接到套接字 0,而 (6, 7) 连接到套接字 1。
此信息将需要以某种方式编码在TopologyHints结构中,以便devicemanager可以最终执行这些所需的分配之一(即topologymanager合并提示中的任何一个向下)。 同样,首选设备分配和首选套接字之间的依赖关系需要在TopologyHints编码,以便cpumanager可以从正确的套接字分配 CPU。
对于此示例,特定于 Nvidia GPU 的潜在解决方案如下所示:
type TopologyHint struct {
SocketID int
DeviceIDs []int
}
type TopologyHints []TopologyHint
devicemanagerhints := &TopologyHints{
{SocketID: 0, DeviceIDs: []int{2, 3}},
{SocketID: 1, DeviceIDs: []int{6, 7}},
}
cpumanagerhints := &TopologyHints{
{SocketID: 1},
}
当devicemanager和cpumanager稍后调用GetAffinity()时, topologymanager将合并这些提示以返回{SocketID: 1, DeviceIDs: []int{6, 7}}作为首选提示。
虽然这可能会或可能不会为所有加速器提供足够通用的解决方案,但将SocketMask TopologyHints结构中的SocketMask替换
请注意, GetTopologyHints()仍然返回TopologyHints ,而GetAffinity()已被修改为返回单个TopologyHint而不是TopologyHints 。
type TopologyHint struct {
SocketID int
}
type TopologyHints []TopologyHint
&TopologyHints{
{SocketID: 0},
{SocketID: 1},
}
type HintProvider interface {
GetTopologyHints(pod v1.Pod, container v1.Container) TopologyHints
}
type Store interface {
GetAffinity(podUID string, containerName string) TopologyHint
}
想法?
klueska
于 2019-04-09
@klueska也许我遗漏了一些东西,但我认为不需要将 NV Link GPU 的设备 ID 填充到 TopologyManager。
如果设备插件 API 被扩展为允许设备像@ConnorDoyle建议的那样发回有关点对点设备连接的信息,那么设备管理器将能够基于此发回套接字信息。
在您的示例中devicemanagerhints可能是设备插件发送回设备管理器的信息。 然后设备管理器将套接字信息发送回 TopologyManager,TopologyManager 存储选择的套接字提示。
在分配时,设备管理器调用 GetAffinity 来获取所需的套接字分配(在这种情况下假设套接字为 1),使用此信息和设备插件发回的信息,它可以看到它应该在套接字 1 上分配设备( 6,7) 因为它们是 NV Link 设备。
这是有道理的还是我遗漏了什么?
lmdaly
于 2019-04-10
感谢您抽出时间与我澄清这一点。 我一定误解了@ConnorDoyle的原始建议:
如果拓扑提示被扩展为编码点对点设备拓扑,则设备管理器在报告套接字关联时可以考虑这一点。
我认为这是想直接使用点对点信息扩展TopologyHints结构。
这听起来像是您建议只需要扩展设备插件 API 以向devicemanager提供点对点信息,以便它可以使用此信息通知SocketMask在TopologyHints结构中设置,每当GetTopologyHints()被调用。
我认为这会起作用,只要设备插件的 API 扩展旨在为我们提供类似于我在上面的示例中概述的信息,并且devicemanager被扩展为在 pod 准入和设备之间存储此信息分配时间。
现在我们在 Nvidia 有一个定制的解决方案,它修补我们的kubelet基本上按照你的建议去做(除了我们不向设备插件做出任何决定—— devicemanager已使 GPU 感知并自行制定基于拓扑的 GPU 分配决策)。
我们只是想确保无论采取什么长期解决方案,我们都可以在未来删除这些自定义补丁。 现在我对这里的流程如何运作有了更好的了解,我看不到任何会阻碍我们的东西。
再次感谢您花时间澄清一切。
klueska
于 2019-04-10
你好@lmdaly ,我是 1.15 的增强负责人。 这个功能会在 1.15 中从 alpha/beta/stable 阶段毕业吗? 请让我知道,以便可以正确跟踪并添加到电子表格中。
编码开始后,请列出此问题中所有相关的 k/k PR,以便正确跟踪它们。
 kacole2
于 2019-04-12
kacole2
于 2019-04-12
此功能将有自己的功能门,并且是 alpha 版。
/里程碑 1.15
 derekwaynecarr
于 2019-04-12
derekwaynecarr
于 2019-04-12
@derekwaynecarr :提供的里程碑对于此存储库无效。 此存储库中的里程碑:[ keps-beta , keps-ga , v1.14 , v1.15 ]
使用/milestone clear清除里程碑。
在回答这个:
此功能将有自己的功能门,并且是 alpha 版。
/里程碑 1.15
此处提供了有关使用 PR 评论与我互动的说明。 如果您对我的行为有任何疑问或建议,请针对kubernetes/test-infra存储库提出问题。
 k8s-ci-robot
于 2019-04-12
k8s-ci-robot
于 2019-04-12
/里程碑 v1.15
derekwaynecarr
于 2019-04-12
/分配@lmdaly
 justaugustus
于 2019-04-28
lmdaly
于 2019-04-29
justaugustus
于 2019-04-28
lmdaly
于 2019-04-29
@lmdaly
https://github.com/kubernetes/kubernetes/issues/72828
我和我的团队考虑测试 numa 敏感应用程序的拓扑管理器。
所以,我们有一些问题。
在 PR 之上,这些是拓扑管理器的完整实现吗?
它现在是否经过测试或稳定?
 bg-chun
于 2019-05-15
bg-chun
于 2019-05-15
@bg-chun 我们在 Nvidia 也在做同样的事情。 我们已将这些 WIP PR 拉入我们的内部堆栈,并围绕它为 CPU/GPU 构建了拓扑感知分配策略。 在这样做的过程中,我们发现了一些问题,并对这些 PR 给出了一些具体的反馈。
有关更多详细信息,请参阅此处的讨论主题:
https://kubernetes.slack.com/archives/C0BP8PW9G/p1556371768035800
klueska
于 2019-05-15
嘿, @lmdaly我是 v1.15 文档发布影子。
我看到您的目标是针对 1.15 版本的此增强功能的 alpha 版本。 这是否需要任何新文档(或修改)?
友情提示,我们正在寻找在 5 月 30 日星期四之前提交的针对 k/website(分支 dev-1.15)的 PR。 如果它是完整文档的开始,那就太好了,但即使是占位符 PR 也是可以接受的。 如果您有任何问题,请告诉我! 😄
 daminisatya
于 2019-05-18
daminisatya
于 2019-05-18
@lmdaly只是一个友好的提醒,我们正在寻找在 5 月 30 日星期四之前针对 k/website(分支 dev-1.15)的 PR。 如果它是完整文档的开始,那就太好了,但即使是占位符 PR 也是可以接受的。 如果您有任何问题,请告诉我! 😄
daminisatya
于 2019-05-27
嗨@lmdaly 。 代码冻结时间为 2019 年 5 月 30 日星期四@ EOD PST 。 发布的所有增强功能都必须是代码完整的,包括测试,并打开文档 PR。
将查看https://github.com/kubernetes/kubernetes/issues/72828以查看是否全部合并。
如果您知道这会滑倒,请回复并告诉我们。 谢谢!
kacole2
于 2019-05-28
@daminisatya我已经推送了 doc PR。 https://github.com/kubernetes/website/pull/14572
让我知道它是否正确完成以及是否需要完成任何其他项目。 感谢您的提醒!
lmdaly
于 2019-05-28
谢谢@lmdaly ✨
daminisatya
于 2019-05-29
嗨@lmdaly ,今天是 1.15 发布周期的代码冻结。 仍然有相当多的 k/k PR 尚未从您的跟踪问题https://github.com/kubernetes/kubernetes/issues/72828 中合并1.15 Enhancement Tracking Sheet 中被标记为 At Risk 。 今天 EOD PST 将合并这些内容吗? 在此之后,里程碑中将只允许发布阻止问题和 PR,但有例外。
kacole2
于 2019-05-30
/里程碑清除
kacole2
于 2019-06-03
嗨@lmdaly @derekwaynecarr ,我是 1.16 增强负责人。 这个功能会在 1.16 中从 alpha/beta/stable 阶段毕业吗? 请告诉我,以便将其添加到1.16 跟踪电子表格中。 如果不是即将毕业,我会将其从里程碑中删除并更改跟踪标签。
一旦编码开始或已经开始,请在本期列出所有相关的 k/k PR,以便正确跟踪它们。
里程碑日期是 Enhancement Freeze 7/30 和 Code Freeze 8/29。
谢谢你。
kacole2
于 2019-07-09
lmdaly
于 2019-07-17
同意这将在 1.16 的 alpha 中登陆,我们将关闭之前在 1.15 合并的 kep 中开始和捕获的工作。
derekwaynecarr
于 2019-07-30
嗨@lmdaly ,我是 v1.16 文档发布影子。
此增强功能是否需要任何新文档(或修改)?
友情提示,我们正在寻找 8 月 23 日星期五到期的针对 k/website(分支 dev-1.16)的 PR。 如果它是完整文档的开始,那就太好了,但即使是占位符 PR 也是可以接受的。 如果您有任何问题,请告诉我!
谢谢!
 VineethReddy02
于 2019-08-01
VineethReddy02
于 2019-08-01
文档公关: https :
lmdaly
于 2019-08-07
@lmdaly拓扑管理器会提供任何信息或 API 来告诉用户给定 pod 的 NUMA 配置吗?
 mJace
于 2019-08-15
mJace
于 2019-08-15
@mJace通过 pod 的 kubectl 描述可见的东西?
lmdaly
于 2019-08-15
@lmdaly是的, kubectl describe很好。 或者一些api来返回相关信息。
因为我们正在开发一个服务来为 pod 提供一些拓扑相关的信息,比如 pod 的 cpu pinning 状态,以及它的 pass-throughed VF 的 numa 节点。
并且一些像 weave scope 这样的监控工具可以调用 api 来做一些花哨的工作。
例如,管理员可以判断 VNF 是否处于正确的 numa 配置下。
只是想知道拓扑管理器是否会涵盖这一部分。
或者如果拓扑管理器计划支持这种功能,我们可以做任何工作。
mJace
于 2019-08-15
@mJace好的,所以目前拓扑管理器没有这样的 API。 我认为这没有优先级,因为 CPU 和设备管理器无法查看实际分配给 pod 的内容。
所以我认为最好就此展开讨论,看看我们可以为用户提供什么样的观点。
lmdaly
于 2019-08-15
我明白了,我以为 CPU 和设备管理器能够看到这些信息。
也许 cadvisor 是提供这些信息的好角色。
因为基本上 cadvisor 通过ps ls获取容器信息,如 PID 等。
和我们查看容器拓扑相关信息的方式是一样的。
我将在 cadvisor 中实现它并为它创建一个 pr。
mJace
于 2019-08-15
我在 cadvisor 中创建了一个相关的问题。
https://github.com/google/cadvisor/issues/2290
mJace
于 2019-08-16
/分配
 khenidak
于 2019-08-24
khenidak
于 2019-08-24
+1 @mJace cadvisor 提案。
要在容器内使用带有CPU Manager和Topology Manager的 DPDK 库,解析容器的 cpu 关联,然后将其传递给 dpdk 库,DPDK 库的线程固定都需要两者。
有关更多详细信息,如果容器的 cgroup cpuset 子系统中不允许使用 cpus,则调用sched_setaffinity以在 cpus 上锁定进程将被过滤掉。
DPDK lib 使用pthread_setaffinity_np进行线程固定,而pthread_setaffinity_np是sched_setaffinity的线程级包装器。
而 Kubernetes 的 CPU Manager 在容器的 cgroup cpuset 子系统上设置了独占的 cpus。
bg-chun
于 2019-08-26
@bg-chun 我将 cadvisor 的变化理解为服务于不同的目的:监控。 根据您的要求,可以通过解析“/proc/self/status”中的“Cpus_Allowed”或“Cpus_Allowed_List”来从容器内部读取分配的 CPU。 这种方法对你有用吗?
ConnorDoyle
于 2019-08-26
/proc/*/status 中的@ConnorDoyle信息如Cpus_Allowed受sched_setaffinity 。 因此,如果应用程序设置了某些内容,它将是 Cgroup 的cpuset控制器真正允许的内容的子集。
 kad
于 2019-08-26
kad
于 2019-08-26
@kad ,我建议容器内的启动器找出 cpu id 值以传递给 DPDK 程序的方法。 所以这发生在设置线程级关联之前。
ConnorDoyle
于 2019-08-26
@康纳道尔
谢谢你的建议,我会考虑的。
我的计划是部署 tiny-rest-api 服务器来告诉 dpdk-container 的独占 CPU 分配信息。
关于变化,我还没有看到 cadvisor 的变化,我只看到了提案。
该提案在目标中说able to tell if there is any cpu affinity set for the container. ,在未来工作中说to tell if there is any cpu affinity set for the container processes. 。
阅读提案后,我只是认为如果 cadvisor 能够解析 cpu pinning 信息并且 kubelet 将其作为环境变量(例如status.podIP 、 metadata.name和limits.cpu传递到容器中,那就太好
这就是我离开 +1 的主要原因。
bg-chun
于 2019-08-26
@bg-chun 你可以在 cadvisor 查看我的第一个公关
https://github.com/google/cadvisor/pull/2291
我已经完成了一些类似的功能。
https://github.com/mJace/numacc
但不确定在 cadvisor 中实现它的正确方法是什么
这就是为什么我只创建一个具有一项新功能的 PR -> 显示 PSR。
mJace
于 2019-08-26
但不确定在 cadvisor 中实现它的正确方法是什么
也许我们可以根据该提案讨论这个问题? 如果您认为需要此功能:)
mJace
于 2019-08-26
@lmdaly 1.16 的代码冻结时间是 8 月 29 日星期四。 我们将跟踪https://github.com/kubernetes/kubernetes/issues/72828以获取剩余的 k/k PR
kacole2
于 2019-08-26
@kacole2此功能所需的所有 PR 已合并或在合并队列中。
lmdaly
于 2019-08-30
嘿@lmdaly - 1.17 增强功能在这里。 我想检查一下,看看您是否认为此增强功能会在 1.17 中升级为 alpha/beta/stable?
目前的发布时间表是:
- 9 月 23 日,星期一 - 发布周期开始
- 10 月 15 日,星期二,EOD PST - 增强功能冻结
- 太平洋标准时间 11 月 14 日星期四,EOD - 代码冻结
- 11 月 19 日,星期二 - 必须完成和审查文档
- 12 月 9 日星期一 - Kubernetes 1.17.0 发布
如果您这样做,请列出本期所有相关的 k/k PR,以便正确跟踪它们。 👍
谢谢!
/里程碑清除
 mrbobbytables
于 2019-09-22
mrbobbytables
于 2019-09-22
@lmdaly是否有直接与 RDMA 讨论的 GPU 链接?
 nickolaev
于 2019-09-25
nickolaev
于 2019-09-25
@nickolaev ,我们也在研究这个用例。 我们确实开始了一些关于如何做到这一点的内部思考,但我们很乐意就此进行合作。
 moshe010
于 2019-09-25
moshe010
于 2019-09-25
@moshe010 @nickolaev @lmdaly ,我们也在研究这个与 RDMA 和 GPU 直接相关的用例。 我们愿意就此进行合作。 可以围绕这个开始一个线程/讨论吗?
 Deepthidharwar
于 2019-09-25
Deepthidharwar
于 2019-09-25
你好! 我有一个关于 NTM 和调度程序的问题。 据我了解,调度程序不了解 NUMA,并且可以更喜欢节点,因为所需的 NUMA 上没有资源(cpu、内存和设备)。 因此拓扑管理器将拒绝该节点上的资源分配。 这是真的吗?
 LilyaBu
于 2019-09-25
LilyaBu
于 2019-09-25
@nickolaev @Deepthidharwar ,我将使用用例开始谷歌文档,我们可以将讨论转移到它。 下周我会发布一些东西。 如果你觉得没问题。
moshe010
于 2019-09-25
我真的很高兴看到这个功能。 我们还需要单个 NUMA 节点中的 CPU、Hugepage、SRIOV-VF 和其他硬件资源。
但是hugepage并没有通过设备插件实现为标量资源,这个特性需要改变k8s中的hugepage特性吗?
@iamneha
 andyzheung
于 2019-09-26
andyzheung
于 2019-09-26
@ConnorDoyle只是为了确认,此功能需要来自 cpu 管理器和设备管理器的拓扑提示? 我在 1.16 上对其进行了测试,但没有奏效,似乎它只是从 cpu 管理器那里得到提示,而没有从设备端得到提示。
 jianzzha
于 2019-09-26
jianzzha
于 2019-09-26
@ConnorDoyle这里有更多细节:
https://gist.githubusercontent.com/jianzzha/c2a66a2514c178cca76a432029ff3387/raw/264f13dfcd06f1f80c48c113aa235fab7c33d81e/hyper%2520threading%25
jianzzha
于 2019-09-26
@jianzzha ,您使用的是什么设备插件? 例如,如果您使用 SR-IOV 设备插件,您需要确保它报告 NUMA 节点,请参阅 [1]
moshe010
于 2019-09-26
@andyzheung目前正在讨论巨大的页面集成,并已在过去两周的 sig-node 会议上提出。 以下是一些相关链接:
https://docs.google.com/presentation/d/1H5xhCjgCZJjdTm-mGUFwqoz8XmoVd8xTCwJ1AfVR_54/edit?usp=sharing
https://github.com/kubernetes/enhancements/pull/1245
https://github.com/kubernetes/enhancements/pull/1199
@jianzzha关于设备插件没有给出提示。 您的插件是否已更新以报告有关它枚举的设备的 NUMA 信息? 需要将此字段添加到设备消息https://github.com/kubernetes/kubernetes/blob/master/pkg/kubelet/apis/deviceplugin/v1beta1/api.proto#L100
klueska
于 2019-09-26
多谢你们。 固定并现在工作。
jianzzha
于 2019-09-26
@克鲁斯卡
关于 nvidia-gpu-device-plugin..
我只能看到一个活动PR(WIP)来更新拓扑管理器的 nvidia-gpu-device-plugin。
是否会更新 nvidia-gpu-divice-plugin 以提供上述 PR 的拓扑提示? 或者有什么我想念的吗?
bg-chun
于 2019-09-26
@bg-chun 是的,应该是。 刚刚联系了作者。 如果他在第二天左右没有回来,我会自己更新插件。
klueska
于 2019-09-26
@bg-chun @klueska我已经更新了补丁。
 carmark
于 2019-09-27
carmark
于 2019-09-27
@klueska @carmark
感谢您的更新和通知。
我将在我的工作区中向用户介绍 sr-iov-plugin update 和 gpu-plugin update。
bg-chun
于 2019-09-27
我会建议下一个版本的增强功能。
它基本上消除了“仅当 Pod 处于保证 QoS 中时才会发生拓扑对齐”的限制。
这种限制使我目前无法使用拓扑管理器,因为我不想从 K8s 中要求独占 CPU,但是我想对齐来自多个池(例如 GPU + SR)的多个设备的插槽-IOV VF 等)
如果我的工作负载对内存不敏感,或者不想限制其内存使用(保证 QoS 的另一个标准),该怎么办?
将来,当希望大页面也能对齐时,此限制将更加限制 IMO。
是否有任何反对单独对齐“可对齐”资源的论据? 当然,如果使用独占 CPU,让我们只从 CPU 管理器收集提示,但如果用户需要设备具有套接字信息,我们或者当用户要求大页面等时从内存管理器收集提示。
无论是这样,或者如果 Pod 启动期间不必要的额外计算负载是一个问题,可能会带回原始的 Pod 级配置标志来控制是否发生对齐(我很惊讶地看到在实现过程中被废弃)
 Levovar
于 2019-09-30
Levovar
于 2019-09-30
我会建议下一个版本的增强功能。
它基本上消除了“仅当 Pod 处于保证 QoS 中时才会发生拓扑对齐”的限制。
这是我们 1.17 待办事项列表中的第 8 项:
https://docs.google.com/document/d/1YTUvezTLGmVtEF3KyLOX3FzfSDw9w0zB-s2Tj6PNzLA/edit#heading =h.xnehh6metosd
是否有任何反对单独对齐“可对齐”资源的论据? 当然,如果使用独占 CPU,让我们只从 CPU 管理器收集提示,但如果用户需要设备具有套接字信息,我们或者当用户要求大页面等时从内存管理器收集提示。
您是否提议有一种机制来选择性地告诉 kubelet 哪些资源要对齐,哪些不对齐(即我想对齐 CPU 和 GPU 分配,但不是我的大页面分配)。 我认为没有人会完全反对这一点,但是如果我们继续将对齐指定为节点级别的标志,那么用于有选择地决定对齐哪些资源以及不对齐哪些资源的界面可能会变得过于繁琐。
无论是这样,或者如果 Pod 启动期间不必要的额外计算负载是一个问题,可能会带回原始的 Pod 级配置标志来控制是否发生对齐(我很惊讶地看到在实现过程中被废弃)
对 pod 级别标志的支持不足以保证提出更新 pod 规范的提案。 对我来说,将这个决定推到 pod 级别是有意义的,因为有些 pod 需要/想要对齐,而有些则不需要,但并不是每个人都同意。
klueska
于 2019-09-30
+1 用于删除拓扑对齐的 QoS 类限制(我将其添加到列表中:smiley:)。 我不明白@Levovar要求在每个资源的基础上启用拓扑,只是我们应该对齐给定容器使用的所有可对齐资源。
据我所知,KEP 中从来没有用于选择加入拓扑的 Pod 级字段。 最初不引入它的理由与隐含独占内核的理由相同——Kubernetes 作为一个项目希望在节点级性能管理方面自由地解释 pod 规范。 我知道这种立场让社区的一些成员不满意,但我们总是可以再次提出这个话题。 为少数用户启用高级功能与为大多数用户调节认知负荷之间存在天然的紧张关系。
ConnorDoyle
于 2019-10-01
IMO 在设计的早期阶段至少有一个 Pod 级别的标志,如果我没记错的话,但它大约是 1.13 :D
我个人对一直尝试调整所有资源都没有意见,但“回到过去”通常会有社区反对会延迟启动或所有 Pod 的调度决策的功能,无论是否他们真的需要增强,或者不需要。
所以我只是想“预先解决”这些问题,我想到了两个选项:根据某些标准预先确定资源组的对齐方式(对 CPU 来说容易定义,对其他人来说更难); 或引入一些配置标志。
但是,如果现在没有反对通用增强功能的反击,我对此非常满意:)
Levovar
于 2019-10-01
@mrbobbytables我们计划在 1.17 中将TopologyManager升级到beta 。 跟踪问题在这里: https :
klueska
于 2019-10-03
@bg-chun @klueska我已经更新了补丁。
补丁合并:
https://github.com/NVIDIA/k8s-device-plugin/commit/cc0aad87285b573127add4e487b13434a61ba0d6
使用补丁创建新版本:
https://github.com/NVIDIA/k8s-device-plugin/releases/tag/1.0.0-beta2
klueska
于 2019-10-03
v1.17 的跟踪测试版
derekwaynecarr
于 2019-10-04
太棒了,谢谢
/stage 测试版
mrbobbytables
于 2019-10-06
@lmdaly
我是 v1.17 文档影子之一。
此增强功能(或为 v1.17 计划的工作)是否需要任何新文档(或对现有文档的修改)? 如果没有,您能否更新 1.17 增强跟踪表(或让我知道,我会这样做)
如果是这样,只是一个友好的提醒,我们正在寻找一个在 11 月 8 日星期五到期的针对 k/website(分支 dev-1.17)的 PR,它此时可以只是一个占位符 PR。 如果您有任何问题,请告诉我!
谢谢!
VineethReddy02
于 2019-10-21
lmdaly
于 2019-10-23
https://github.com/kubernetes/enhancements/pull/1340
伙计们,我打开 KEP 更新 PR 为拓扑管理器添加一个内置节点标签( beta.kubernetes.io/topology )。
标签将公开节点的策略。
我认为当同一集群中有多个策略的节点时,将 pod 调度到特定节点会很有帮助。
我可以要求审查吗?
bg-chun
于 2019-10-28
嗨@lmdaly @derekwaynecarr
来自 1.17 增强团队的 Jeremy 在这里👋。 您能否列出为此而进行的 k/k PR,以便我们跟踪它们? 我看到#83492 被合并了,但看起来还有一些相关的问题挂在整体跟踪项目上。 我们将于 11 月 14 日接近 Code Freeze,因此我们想在此之前了解情况如何! 非常感谢!
 jeremyrickard
于 2019-11-04
jeremyrickard
于 2019-11-04
@jeremyrickard这是上面提到的 1.17 的跟踪问题: https :
klueska
于 2019-11-04
@lmdaly @derekwaynecarr
友情提示,我们正在为 11 月 8 日星期五到期的 k/website(branch dev-1.17)文档寻找占位符 PR。 我们只剩下 2 天的截止日期了。
daminisatya
于 2019-11-06
文档公关在这里顺便说一句: https :
lmdaly
于 2019-11-08
@klueska我看到一些工作升级到 1.18。 您是否仍打算在 1.17 中将其升级为 Beta 版,还是将其保持为 Alpha 版但会发生变化?
jeremyrickard
于 2019-11-13
没关系,我在https://github.com/kubernetes/kubernetes/issues/85093中看到,您现在将在 1.18 中跳转到测试版,而不是作为 1.17 的一部分。 您是否希望我们将此作为对 alpha 版本的重大更改进行跟踪,作为 1.17 里程碑@klueska 的一部分? 或者只是将毕业推迟到1.18?
jeremyrickard
于 2019-11-13
/里程碑 v1.18
jeremyrickard
于 2019-11-15
嘿@klueska
1.18 增强团队签到! 你还打算在 1.18 升级到测试版吗? 如果您的 KEP 需要任何更新,则增强冻结将在 1 月 28 日进行,而代码冻结将在 3 月 5 日进行。
谢谢!
jeremyrickard
于 2020-01-07
是的。
klueska
于 2020-01-07
@klueska感谢您的更新! 更新跟踪表。
jeremyrickard
于 2020-01-07
@klueska在审查此版本的 KEP 时,我们注意到缺少测试计划。 为了在版本中升级到测试版,需要添加测试计划。 我现在将把它从里程碑中删除,但是如果您提交异常请求并将测试计划添加到 KEP,我们可以将它添加回来。 为迟到的通知道歉。
jeremyrickard
于 2020-01-29
/里程碑清除
jeremyrickard
于 2020-01-29
@vpickard请看上面
klueska
于 2020-01-29
 vpickard
于 2020-01-29
vpickard
于 2020-01-29
@jeremyrickard有没有测试计划模板可以指给我参考?
vpickard
于 2020-01-29
@vpickard你可以看看:
https://github.com/kubernetes/enhancements/blob/master/keps/sig-storage/20190530-pv-health-monitor.md#test -plan
和
https://github.com/kubernetes/enhancements/blob/master/keps/sig-storage/20200120-skip-permission-change.md#test -plan
包括单元测试和 e2e 测试的概述。
如果您有任何显示在测试网格中的内容,最好包括在内。
jeremyrickard
于 2020-01-29
例外被批准。
/里程碑 v1.18
jeremyrickard
于 2020-01-30
@jeremyrickard合并测试计划: https :
klueska
于 2020-02-04
嗨@klueska @vpickard ,友情提醒, Code Freeze将于 3 月 5 日星期四生效。
能否请您链接所有 k/k PR 或任何其他应针对此增强功能进行跟踪的 PR?
谢谢 :)
 palnabarun
于 2020-02-05
palnabarun
于 2020-02-05
嗨@palnabarun
1.18 的跟踪问题:
https://github.com/kubernetes/kubernetes/issues/85093
当前开放的 PR:
https://github.com/kubernetes/kubernetes/pull/87758 (已批准,剥落测试)
https://github.com/kubernetes/kubernetes/pull/87759 (WIP)
https://github.com/kubernetes/kubernetes/pull/87650 (已审核,需要批准)
https://github.com/kubernetes/kubernetes/pull/87645(e2e测试 PR,需要审批)
@vpickard你能添加我错过的任何 e2e PR。
谢谢
 nolancon
于 2020-02-05
nolancon
于 2020-02-05
感谢@nolancon在这里链接 PR 和保护伞问题。 我已将 PR 添加到跟踪表中。
palnabarun
于 2020-02-05
嗨@palnabarun , @nolancon ,
一些与 E2E 测试相关的额外开放 PR:
https://github.com/kubernetes/test-infra/pull/16062 (需要审核通过)
https://github.com/kubernetes/test-infra/pull/16037 (需要审核通过)
vpickard
于 2020-02-06
感谢@vpickard的额外更新。 :)
palnabarun
于 2020-02-09
你好@lmdaly我是
此增强(或 v1.18 计划的工作)是否需要任何新文档(或对现有文档的修改)? 如果没有,您能否更新 1.18 增强跟踪表(或让我知道,我会这样做)
如果是这样,只是一个友好的提醒,我们正在寻找一个在 2 月 28 日星期五到期的针对 k/website (branch dev-1.18) 的 PR,此时它可以只是一个占位符 PR。 如果您有任何问题,请告诉我!
 irvifa
于 2020-02-09
irvifa
于 2020-02-09
嗨@irvifa ,感谢您的
谢谢。
nolancon
于 2020-02-10
嗨@nolancon感谢您的迅速回复,我现在将状态更改为占位符 PR..谢谢!
irvifa
于 2020-02-10
@palnabarun仅供参考,我已将此 PR https://github.com/kubernetes/kubernetes/pull/87759拆分为两个 PR,以简化审查过程。 第二个在这里https://github.com/kubernetes/kubernetes/pull/87983并且也需要被跟踪。 谢谢。
nolancon
于 2020-02-10
@nolancon感谢您的更新。
我看到一些 PR 仍在等待合并。 我想看看你是否需要发布团队的帮助来让审阅者和批准者加入 PR。 如果您需要任何东西,请告诉我们。
仅供参考,我们非常接近3 月 5 日的 Code Freeze
palnabarun
于 2020-02-27
@nolancon感谢您的更新。
我看到一些 PR 仍在等待合并。 我想看看你是否需要发布团队的帮助来让审阅者和批准者加入 PR。 如果您需要任何东西,请告诉我们。
仅供参考,我们非常接近3 月 5 日的 Code Freeze
@palnabarun 还有一个更新, https://github.com/kubernetes/kubernetes/pull/87983现已关闭,无需跟踪。 所需的更改包含在原始 PR https://github.com/kubernetes/kubernetes/pull/87759 中,正在审查中。
nolancon
于 2020-02-27
@nolancon酷。 我也在跟踪您在上面分享的保护伞跟踪器问题。 :)
palnabarun
于 2020-02-27
嗨@nolancon ,这提醒我们距离3 月 5 日的 Code Freeze仅两天
通过 Code Freeze,所有相关 PR 都应该合并,否则您需要提交例外请求。
palnabarun
于 2020-03-03
嗨@nolancon ,
今天 EOD 是代码冻结。
你认为https://github.com/kubernetes/kubernetes/pull/87650会在截止日期前得到审查吗?
如果没有,请提交例外请求。
palnabarun
于 2020-03-05
嗨@nolancon ,
今天 EOD 是代码冻结。
你认为kubernetes/kubernetes#87650会在截止日期前被审核吗?
如果没有,请提交例外请求。
嗨@palnabarun ,过去几天取得了很大进展,我们有信心在代码冻结之前获得所有批准和合并。 如果没有,我将提交例外请求。
澄清一下,EOD 是指太平洋标准时间下午 5 点还是午夜? 谢谢
nolancon
于 2020-03-05
澄清一下,EOD 是指太平洋标准时间下午 5 点还是午夜? 谢谢
太平洋标准时间下午 5 点。
jeremyrickard
于 2020-03-05
PR 已获批准,但缺少 sig-node 需要添加以进行合并的里程碑。 我已经 ping 了它们,希望它能够解开并且你不需要例外。 =)
 kikisdeliveryservice
于 2020-03-05
kikisdeliveryservice
于 2020-03-05
这个 kep 的所有 PR 似乎已经合并(并在截止日期前批准),我已经更新了我们的增强跟踪表。 :微笑:
kikisdeliveryservice
于 2020-03-06
/里程碑清除
(随着里程碑完成,从 v1.18 里程碑中删除此增强问题)
palnabarun
于 2020-04-29
嗨@nolancon @lmdaly ,这里是 1.19 的增强阴影。 在 1.19 中有任何计划吗?
 johnbelamaric
于 2020-05-04
johnbelamaric
于 2020-05-04
1.19 唯一计划的增强功能是:
https://github.com/kubernetes/enhancements/pull/1121
其余的工作将根据需要进行代码重构/错误修复。
反正有没有把这个问题的所有者改为我而不是@lmdaly?
klueska
于 2020-05-04
谢谢,我会更新联系方式。
/里程碑 v1.19
johnbelamaric
于 2020-05-04
/分配@klueska
/取消分配@lmdaly
 pires
于 2020-05-06
pires
于 2020-05-06
嗨,凯文。 最近 KEP 格式发生了变化,上周也合并了 #1620,在 KEP 模板中添加了生产准备审查问题。 如果可能,请花时间重新格式化您的 KEP 并回答添加到模板中的问题。 这些问题的答案将有助于操作员使用该功能并对其进行故障排除(尤其是现阶段的监控部分)。 谢谢!
johnbelamaric
于 2020-05-13
@克鲁斯卡^^
johnbelamaric
于 2020-05-13
@derekwaynecarr @klueska @johnbelamaric
我还计划在 1.19 rel 上添加新的拓扑策略。
但它还没有得到所有者和维护者的审查。
(如果在 1.19 中似乎很难制作,请告诉我。)
- KEP 更新 PR: https :
- kubelet 公关:WIP
bg-chun
于 2020-05-13
嗨@klueska 👋 1.19 文档阴影在这里! 为 1.19 计划的这项增强工作是否需要对文档进行新增或修改?
友情提示,如果需要对文档进行新的/修改,在 6 月 12 日星期五之前需要针对 k/website(分支dev-1.19 )的占位符 PR。
 annajung
于 2020-05-21
annajung
于 2020-05-21
嗨@klueska希望你做得很好,再次检查以查看是否需要文档。 你能确认吗?
annajung
于 2020-05-27
嗨@annajung。 有 2 个待定的增强功能都需要更改文档:
1121
1752
我们仍在决定这些是否会进入 1.19 或被推到 1.20。 如果我们决定将它们保留到 1.19,我一定会在 6 月 12 日之前为文档创建一个占位符 PR。
klueska
于 2020-05-29
伟大的! 感谢您的更新,我会相应地更新跟踪表! 一旦占位符 PR 完成,请告诉我。 谢谢!
annajung
于 2020-05-30
@lmdaly @ConnorDoyle
我希望这里是提问和提供反馈的正确地方。
我在 k8s 集群 v1.17 上打开了TopologyManager和CPUManager 。
他们的政策是best-effort和static
这是我的 Pod 的资源
resources:
requests:
cpu: 2
intel.com/sriov_pool_a: '1'
limits:
cpu: 2
intel.com/sriov_pool_a: '1'
sriov_pool_a 的 PF 在 NUMA 节点 0 中,所以我希望我的 pod 也应该在 NUMA 节点 0 的 CPU 上运行。
但是我发现我的 pod 进程正在 NUMA 节点 1 的 CPU 上运行。
此外,根据taskset -p <pid>的结果,没有设置 cpu 关联掩码。
有什么不对? 我希望容器应该为 numa 节点 0 的 cpu 设置 cpu 关联掩码。
是否有任何示例或测试可以让我知道我的TopoloyManager是否正常工作?
mJace
于 2020-06-04
@annajung Placeholder docs PR 添加: https :
klueska
于 2020-06-09
嗨@klueska ,
为了跟进周一发送给 k-dev 的电子邮件,我想让您知道 Code Freeze 已延长至 7 月 9 日星期四。 你可以在这里看到修改后的时间表: https :
我们希望届时所有 PR 都能合并。 请让我知道,如果你有任何问题。 😄
最好的,
克尔斯滕
kikisdeliveryservice
于 2020-06-18
嗨@klueska ,下一个截止日期即将到来的友好提醒。
请记住填写您的占位符文档 PR 并在 7 月 6 日星期一之前准备好进行审核。
annajung
于 2020-06-22
谢谢@annajung 。 由于代码冻结现在已移至 7 月 9 日,是否也将文档日期提前? 如果我们创建了文档,但该功能没有及时(或以与文档建议的形式略有不同的形式),会发生什么情况?
klueska
于 2020-06-23
嗨@klueska ,这是一个很好的观点! 随着新的发布日期,所有文档的截止日期也被推迟了一周,但我认为你有一个有效的观点。 让我联系发布的文档负责人并回复您! 感谢您指出这一点!
annajung
于 2020-06-24
嗨@klueska ,再次感谢您提请我们注意。 与发布的文档日期混淆了。 正如您所提到的,“PR 准备好审查”应该在代码冻结之后出现,并且已经在过去的版本中出现。
但是,在与发布团队交谈后,我们决定保留 1.19 版本的日期,将“PR 准备审查”作为软截止日期。 文档团队将非常灵活,并与您/其他可能需要额外时间以确保文档与代码同步的人一起工作。 虽然“PR 准备审查”截止日期不会强制执行,但“PR 审查并阅读以合并”将是。
希望这有助于解决您的疑虑! 如果您还有其他问题,请告诉我!
另外,只是一个日期的友好提醒:
“文档截止日期 - 准备审查的 PR”将于 7 月 6 日到期
“文档完成 - 所有 PR 已审核并准备合并”将于 7 月 16 日到期
annajung
于 2020-06-24
嗨@klueska :wave: -- 1.19 增强功能在这里,
您能否在此处链接到所有实施 PR,以便发布团队可以跟踪它们? :slightly_smiling_face:
谢谢你。
palnabarun
于 2020-06-28
@palnabarun
PR 跟踪https://github.com/kubernetes/enhancements/pull/1121可以在以下位置找到:
https://github.com/kubernetes/kubernetes/pull/92665
不幸的是,增强功能 #1752 不会被纳入发布版本,因此没有 PR 可以跟踪它。
klueska
于 2020-06-30
嗨@klueska :wave:,我看到你提到的两个 PR(https://github.com/kubernetes/enhancements/pull/1121 和 https://github.com/kubernetes/enhancements/pull/1752)参考相同的增强。 由于https://github.com/kubernetes/enhancements/pull/1752扩展了 Beta 版毕业要求,并且不会将其纳入发布版,我们是否可以假设 1.19 中没有预期的进一步更改?
谢谢你。 :slightly_smiling_face:
Code Freeze 从太平洋标准时间 7 月 9 日星期四开始
palnabarun
于 2020-07-06
@palnabarun这是#92665 的后续 PR,应该在今天或明天登陆: https :
在那之后,这个版本应该没有更多的 PR,等待不可预见的错误。
klueska
于 2020-07-06
惊人的! 谢谢你的更新。 :+1:
palnabarun
于 2020-07-06
@annajung https://github.com/kubernetes/website/pull/21607现在可以审查了。
klueska
于 2020-07-06
恭喜@klueska kubernetes/kubernetes#92794 终于合并了,我会相应更新追踪表😄
kikisdeliveryservice
于 2020-07-11
/里程碑清除
(随着里程碑完成,从 v1.19 里程碑中删除此增强问题)
kikisdeliveryservice
于 2020-09-12
嗨@klueska
增强功能在这里。 有没有计划在 1.20 毕业?
谢谢!
克尔斯滕
kikisdeliveryservice
于 2020-09-13
没有计划让它毕业,但是有一个 PR 应该在 1.20 中与此增强相关:
https://github.com/kubernetes/kubernetes/pull/92967
klueska
于 2020-09-16
即使它没有在 1.20 中毕业,请继续将相关的 PR 链接到这个问题,就像你刚刚所做的那样。
kikisdeliveryservice
于 2020-09-16
@kikisdeliveryservice你能帮助理解这个过程吗? 拓扑管理器功能未在 1.20 中毕业,但新功能将添加到其中并正在开发中: https: //github.com/kubernetes/enhancements/pull/1752 k/k: https://github。 com/kubernetes/kubernetes/pull/92967。 这是我们需要与发布团队一起跟踪的事情吗? 它可以简化跟踪 1.20 或其他正在跟踪的文档更新的过程。
这种变化是附加的,所以没有太多理由称它为 beta2 或其他东西。
反映额外功能未在 1.19 中发布的现实的相关凹凸 PR: https :
 SergeyKanzhelev
于 2020-10-27
SergeyKanzhelev
于 2020-10-27
拓扑管理器 Web 文档更新 PR 以包含范围功能: https :
 k-wiatrzyk
于 2020-10-29
k-wiatrzyk
于 2020-10-29
相信可以用1.20跟踪,不一定要毕业。 @kikisdeliveryservice如果这不正确,请加入。 作为 1.20 版本的一部分,我将跟踪共享的 k/web 站点,直到我听到其他消息。
annajung
于 2020-10-29
嗨@SergeyKanzhelev
纵观历史,事实并非如此。 有人告诉我,这不会在上面毕业,这很好,也是为什么这个 KEP 未被跟踪。 但是,此增强功能(增强团队不知道)最近被 @k-wiatrzyk 重新定位为 1.20 测试版(https://github.com/kubernetes/enhancements/pull/1950)。
如果您想利用发布流程:增强跟踪、成为发布里程碑的一部分并让文档团队跟踪此/将文档包含在 1.20 版本中,则应尽快提交增强例外请求。
kikisdeliveryservice
于 2020-10-30
该功能已合并到(预先存在的)KEP(在增强截止日期之前)。
https://github.com/kubernetes/enhancements/pull/1752
在它的实施中,PR 已经是里程碑的一部分。
https://github.com/kubernetes/kubernetes/pull/92967
我不知道还有更多事情要做。
我们需要向谁提出例外,具体是为了什么?
klueska
于 2020-10-30
嗨@klueska ,您引用的公关已于 6 月合并,以便将测试版添加到 1.19 中的 kep: https : #beta -v119
1.20 的增强截止日期是 10 月 6 日,但更改,将测试版移至 1.20 并删除对 1.19 的引用已于 3 天前通过https://github.com/kubernetes/enhancements/pull/1950合并
您可以在此处找到发送异常请求的说明: https :
kikisdeliveryservice
于 2020-10-30
抱歉,我仍然对我们将申请例外的内容感到困惑。
我很高兴这样做,我只是不确定要包含什么。
“节点拓扑管理器”功能已在 1.18 中升级为测试版。
它不会在 1.20 中升级到 GA(它仍处于测试阶段)。
为 1.20 合并的 PR(即 kubernetes/kubernetes#92967)是对拓扑管理器现有代码的改进,但它与 alpha/beta/ga 等状态方面的“颠簸”无关。
klueska
于 2020-10-30
我已经发送了一封例外邮件,因为截止日期是今天(以防万一): https :
k-wiatrzyk
于 2020-11-02
@kikisdeliveryservice @klueska @annajung
例外呼吁已获批准,您可以在此处找到确认信息: https :
k-wiatrzyk
于 2020-11-04
感谢 @k-wiatrzyk 和@klueska更新了跟踪表。
抄送: @annajung
kikisdeliveryservice
于 2020-11-05
嘿@k-wiatrzyk @klueska
看起来 kubernetes/kubernetes#92967 已获批准,但需要 rebase。
只是提醒一下, Code Freeze将于 11 月 12日例外。
最好的,
克尔斯滕
kikisdeliveryservice
于 2020-11-11
PR 合并,更新表 - 是的! :smile_cat:
kikisdeliveryservice
于 2020-11-12
相关问题
 xing-yang
·
13评论
xing-yang
·
13评论
 wojtek-t
·
12评论
wojtek-t
·
12评论
 AndiLi99
·
13评论
AndiLi99
·
13评论
 robscott
·
11评论
justaugustus
·
3评论
robscott
·
11评论
justaugustus
·
3评论
最有用的评论
这个 kep 的所有 PR 似乎已经合并(并在截止日期前批准),我已经更新了我们的增强跟踪表。 :微笑: