Enhancements: Node Topology Manager
Enhancement Description
- One-line enhancement description (can be used as a release note): Kubelet component to coordinate fine-grained hardware resource assignments for different components in Kubernetes.
- Primary contact (assignee): @klueska
- Responsible SIGs: sig-node
- Design proposal link (community repo): https://github.com/kubernetes/community/pull/1680
- KEP PR: https://github.com/kubernetes/enhancements/pull/781
- KEP: https://github.com/kubernetes/enhancements/blob/master/keps/sig-node/0035-20190130-topology-manager.md
- Link to e2e and/or unit tests: N/A Yet
- Reviewer(s) - (for LGTM) recommend having 2+ reviewers (at least one from code-area OWNERS file) agreed to review. Reviewers from multiple companies preferred: @ConnorDoyle @balajismaniam
- Approver (likely from SIG/area to which enhancement belongs): @derekwaynecarr @ConnorDoyle
- Enhancement target (which target equals to which milestone):
- Alpha release target (x.y): v1.16
- Beta release target (x.y): v1.18
- Stable release target (x.y)
 lmdaly
lmdaly
All 159 comments
/sig node
/kind feature
cc @ConnorDoyle @balajismaniam @nolancon
lmdaly
on 17 Jan 2019
I can help inform this design based on learning from Borg. So count me in as a reviewer/approver.
 vishh
on 4 Feb 2019
vishh
on 4 Feb 2019
I can help inform this design based on learning from Borg. So count me in as a reviewer/approver.
Is there any public documentation on how this feature works in borg?
 jeremyeder
on 11 Feb 2019
jeremyeder
on 11 Feb 2019
Not about NUMA AFAIK.
On Mon, Feb 11, 2019, 7:50 AM Jeremy Eder <[email protected] wrote:
I can help inform this design based on learning from Borg. So count me in
as a reviewer/approver.Is there any public documentation on how this feature works in borg?
—
You are receiving this because you commented.
Reply to this email directly, view it on GitHub
https://github.com/kubernetes/enhancements/issues/693#issuecomment-462378195,
or mute the thread
https://github.com/notifications/unsubscribe-auth/AGvIKPfanjb9Q5DxXAiBgv9C6Y809JX0ks5vMZFZgaJpZM4aE3uz
.
vishh
on 11 Feb 2019
FYI @claurence
This tracking issue and KEP (https://github.com/kubernetes/enhancements/pull/781) did not make it in time for the v1.14 enhancements freeze nor the extended deadline. I appreciate that you opened these before the deadlines, but they didn't seem to get sufficient review or sign off. This will need to go through the exception process.
Until we decide whether this is worth the exception, I'm inclined to put a hold on all PR's associated with this enhancement.
 spiffxp
on 24 Feb 2019
spiffxp
on 24 Feb 2019
/cc @jiayingz @dchen1107
 jiayingz
on 25 Feb 2019
jiayingz
on 25 Feb 2019
@lmdaly I see y'all are have 1.14 listed in the description as the alpha milestone - since there wasn't a merged implementable KEP this issue is not being tracked for 1.14 - if there are intentions for it to be included in that release please submit an exception request.
 claurence
on 27 Feb 2019
claurence
on 27 Feb 2019
@lmdaly I see y'all are have 1.14 listed in the description as the alpha milestone - since there wasn't a merged implementable KEP this issue is not being tracked for 1.14 - if there are intentions for it to be included in that release please submit an exception request.
@claurence the KEP is now merged (KEP had been previously merged in the community repo. this was just to move it to the new enhancements repo as per the new guidelines), do we still need to submit an exception request to get this issue tracked for 1.14?
lmdaly
on 5 Mar 2019
While after reading the design & WIP PRs througoutly, I have concerns that the current implementation is not generic as the original topology design we proposed in https://github.com/kubernetes/enhancements/pull/781. This one currently reads more like NUMA topology in node level.
I left some comments for further discussion here: https://github.com/kubernetes/kubernetes/pull/74345#discussion_r264387724
 resouer
on 11 Mar 2019
resouer
on 11 Mar 2019
the current implementation is not generic
Share the same concern about on that :) How about others, e.g. links between device (nvlinke for GPU)?
 k82cn
on 20 Mar 2019
k82cn
on 20 Mar 2019
@resouer @k82cn The initial proposal deals only with aligning the decisions made by cpu manager and device manager to ensure proximity of devices with the cpu the container runs on. Satisfying the inter-device affinity was a non-goal of the proposal.
If however, the current implementation is blocking the addition of inter-device affinity in the future then I am happy to change the implementation once I get an understanding of how it is doing so,
lmdaly
on 25 Mar 2019
I think the main issue I see with the current implementation and the ability to support inter-device affinity is the following:
To support inter-device affinity you normally need to first figure out which devices you would like to allocate to a container _before_ deciding what socket affinity you would like the container to have.
For example, with Nvidia GPUs, for optimal connectivity, you first need to find and allocate the set of GPUs with the most connected NVLINKs _before_ determining what socket affinity that set has.
From what I can tell in the current proposal, the assumption is that these operations happen in reverse order, i.e. the socket affinity is decided before doing the allocation of devices.
 klueska
on 5 Apr 2019
klueska
on 5 Apr 2019
That’s not necessarily true @klueska. If the topology hints were extended to encode point-to-point device topology, the Device Manager could consider that when reporting socket affinity. In other words, cross device topology wouldn’t need to leak out of the scope of the device manager. Does that seem feasible?
 ConnorDoyle
on 5 Apr 2019
ConnorDoyle
on 5 Apr 2019
Maybe I'm confused about the flow somehow. This is how I understand it:
1) At initialization, device plugins (not the devicemanager) register themselves with the topologymanager so it can issue callbacks on it at a later time.
2) When a pod is submitted the kubelet calls the lifecycle.PodAdmitHandler on the topologymanager.
3) The lifecycle.PodAdmitHandler calls GetTopologyHints on each registered device plugin
4) It then merges these hints to produce a consolidated TopologyHint associated with the pod
5) If it decided to admit the pod, it returns successfully from lifecycle.PodAdmitHandler storing the consolidated TopologyHint for the pod in a local state store
6) At some point in the future, the cpumanager and the devicemanager call GetAffinity(pod) on the topology manager to retrieve the TopologyHint associated with the pod
7) The cpumanager uses this TopologyHint` to allocate a CPU
8) The devicemanager uses this TopologyHint` to allocate a set of devices
9) Initialization of the pod continues...
If this is correct, I guess I'm struggling with what happens between the point in time when the device plugin reports its TopologyHints and the time when the devicemanager does the actual allocation.
If these hints are meant to encode "preferences" for allocation, then I think what you are saying is to have a structure more like:
type TopologyHints struct {
hints []struct {
SocketID int
DeviceIDs []int
}
}
Where we not only pass a list of socket affinity preferences, but how those socket affinity preferences pair with allocatable GPU preferences.
If this is the direction you are thinking, then I think we could make it work, but we would need to somehow coordinate between the cpumanager and the devicemanager to make sure they "accepted" the same hint when making their allocations.
Is there something in place that allows this already that I missed?
klueska
on 5 Apr 2019
@klueska
I think what happens, making some _minor_ corrections to your flow is:
At initialization, device plugins register themselves with the
devicemanagerso it can issue callbacks on it at a later time.The
lifecycle.PodAdmitHandlercallsGetTopologyHintson each topology-aware component in the Kubelet, currentlydevicemanagerandcpumanager.
In this case, what will be represented as topology-aware in the Kubelet are the cpumanager and the devicemanager. The topology manager is only intended to coordinate allocations between topology-aware components.
For this:
but we would need to somehow coordinate between the cpumanager and the devicemanager to make sure they "accepted" the same hint when making their allocations.
This is what the topologymanager itself was introduced to achieve. From one of the earlier drafts,
These components should coordinate in order to avoid cross NUMA assignments. The problems related to this coordination are tricky; cross domain requests such as “An exclusive core on the same NUMA node as the assigned NIC” involves both CNI and the CPU manager. If the CPU manager picks first, it may select a core on a NUMA node without an available NIC and vice-versa.
 eloyekunle
on 6 Apr 2019
eloyekunle
on 6 Apr 2019
I see.
So the devicemanager and cpumanager both implement GetTopologyHints() as well as call GetAffinity(), avoiding direction interaction from the topologymanager with any underlying device plugins. Looking more closely at the code, I see that the devicemanager simply delegates control to the plugins to help fill in TopologyHints, which makes more sense in the end anyway.
Circling back to the original question / issue I raised though....
From Nvidia's perspective, I think we can make everything work with this proposed flow, assuming more information is added to the TopologyHints struct (and consequently the device plugin interface) to report point-to-point link information in the future.
However, I think starting with a SocketMask as the primary data structure for advertising socket affinity may limit our ability to expand TopologyHints with point-to-point information in the future without breaking the existing interface. The primary reason being that (at least in the case of Nvidia GPUs) the preferred socket depends on which GPUs are actually going to be allocated in the end.
For example, consider the figure below, when attempting to allocate 2 GPUs to a pod with optimal connectivity:
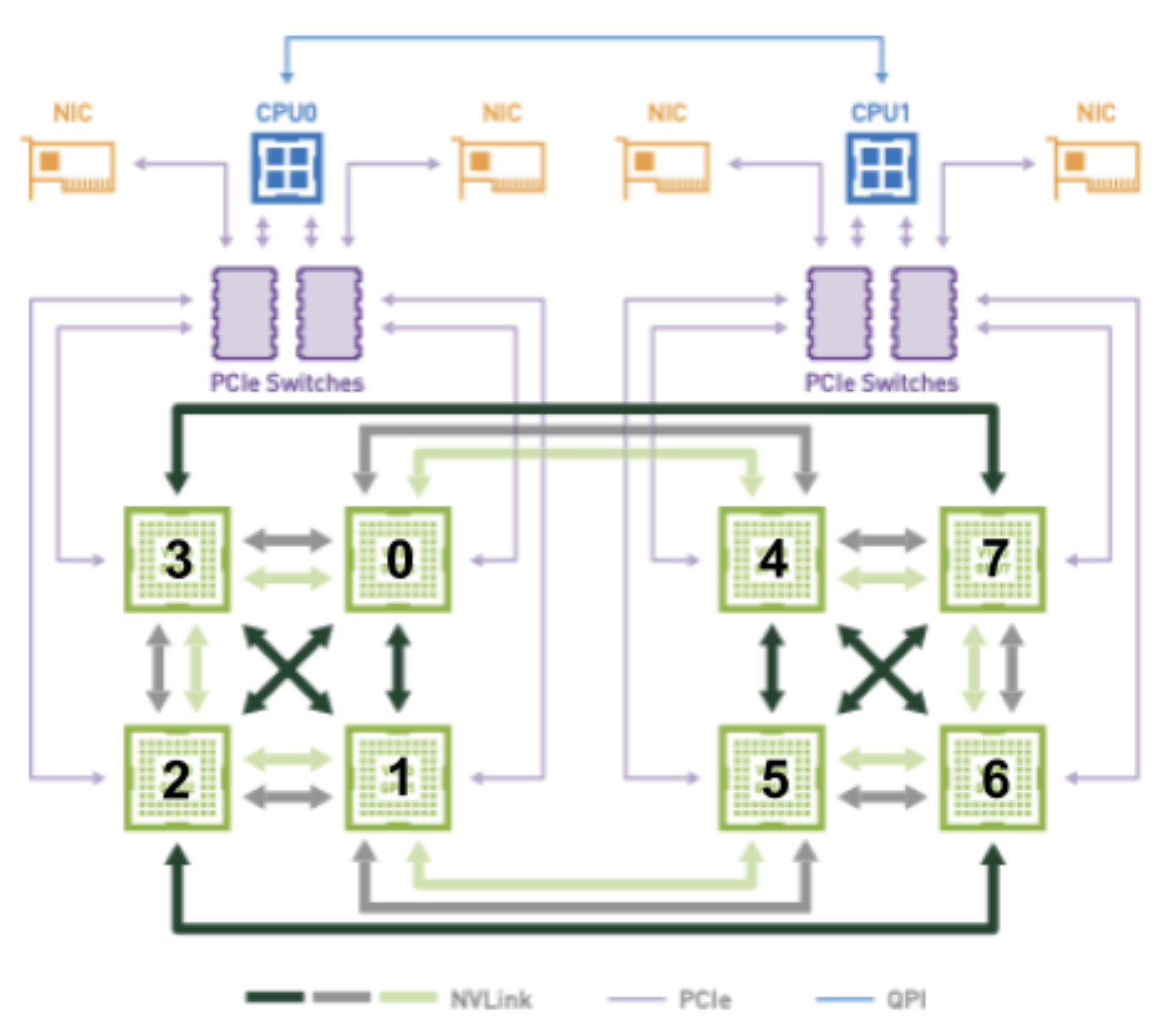
The GPU combinations of (2, 3) and (6, 7) both have 2 NVLINKs and reside on the same PCIe bus. They should therefore be considered equal candidates when attempting to allocate 2 GPUs to a pod. Depending on which combination is chosen, however, a different socket will obviously be preferred as (2, 3) is connected to socket 0 and (6, 7) is connected to socket 1.
This information will somehow need to be encoded in the TopologyHints struct so that the devicemanager can perform one of these desired allocations in the end (i.e. whichever one the topologymanager consolidates the hints down to). Likewise, the dependency between the preferred device allocations and the preferred socket will need to be encoded in TopologyHints so that the cpumanager can allocate CPUs from the correct socket.
A potential solution specific to Nvidia GPUs for this example would look something like:
type TopologyHint struct {
SocketID int
DeviceIDs []int
}
type TopologyHints []TopologyHint
devicemanagerhints := &TopologyHints{
{SocketID: 0, DeviceIDs: []int{2, 3}},
{SocketID: 1, DeviceIDs: []int{6, 7}},
}
cpumanagerhints := &TopologyHints{
{SocketID: 1},
}
Where the topologymanager would consolidate these hints to return {SocketID: 1, DeviceIDs: []int{6, 7}} as the preferred hint when the devicemanager and cpumanager later call GetAffinity().
While this may or may not provide a generic enough solution for all accelerators, replacing SocketMask in the TopologyHints struct with something structured more like the following would allow us to expand each individual hint with more fields in the future:
Note that GetTopologyHints() still return TopologyHints, while GetAffinity()has been modified to return a single TopologyHint rather than TopologyHints.
type TopologyHint struct {
SocketID int
}
type TopologyHints []TopologyHint
&TopologyHints{
{SocketID: 0},
{SocketID: 1},
}
type HintProvider interface {
GetTopologyHints(pod v1.Pod, container v1.Container) TopologyHints
}
type Store interface {
GetAffinity(podUID string, containerName string) TopologyHint
}
Thoughts?
klueska
on 9 Apr 2019
@klueska Maybe I am missing something, but I don't see the need to have the device IDs for NV Link GPUs populate up to the TopologyManager.
If the Device Plugin API was extended to allow devices to send back information on point to point device connectivity as @ConnorDoyle suggested, then the device manager would be able to send back socket information based on this.
In your example devicemanagerhints could be the information the device plugins sent back to the devicemanager. The device manager then sends back the socket information back to TopologyManager as is now and TopologyManager stores the chosen socket hint.
On allocation, the devicemanager calls GetAffinity to get the desired socket allocation(lets say the socket is 1 in this case), using this information and the information sent back by the device plugins, it can see that on socket 1 it should assign devices (6,7) as they are NV Link devices.
Does that make sense or is there something I am missing?
lmdaly
on 10 Apr 2019
Thanks for taking the time to clarify this with me. I must have misinterpreted @ConnorDoyle's original suggestion:
If the topology hints were extended to encode point-to-point device topology, the Device Manager could consider that when reporting socket affinity.
I read this as wanting to extend the TopologyHints struct with point-to-point information directly.
It sounds like you are rather suggesting that only the device plugin API should need to be extended to provide point-to-point information to the devicemanager, so that it can use this information to inform the SocketMask to set in the TopologyHints struct whenever GetTopologyHints() is called.
I think this will work, so long as the API extensions to the device plugin are designed to give us information similar to what I outlined in my example above and the devicemanager is extended to store this information between pod admission and device allocation time.
Right now we have a custom solution in place at Nvidia that patches our kubelet to essentially do what you are suggesting (except that we don't shell any decisions out to device plugins -- the devicemanager has been made GPU aware and makes topology-based GPU allocation decisions itself).
We just want to make sure that whatever long term solution is put in place will allow us to remove these custom patches in the future. And now that I have a better picture of how the flow here works, I don't see anything that would block us.
Thanks again for taking the time to clarify everything.
klueska
on 10 Apr 2019
Hello @lmdaly , I'm the Enhancement Lead for 1.15. Is this feature going to be graduating alpha/beta/stable stages in 1.15? Please let me know so it can be tracked properly and added to the spreadsheet.
Once coding begins, please list all relevant k/k PRs in this issue so they can be tracked properly.
 kacole2
on 12 Apr 2019
kacole2
on 12 Apr 2019
this feature will its own feature gate, and will be alpha.
/milestone 1.15
 derekwaynecarr
on 12 Apr 2019
derekwaynecarr
on 12 Apr 2019
@derekwaynecarr: The provided milestone is not valid for this repository. Milestones in this repository: [keps-beta, keps-ga, v1.14, v1.15]
Use /milestone clear to clear the milestone.
In response to this:
this feature will its own feature gate, and will be alpha.
/milestone 1.15
Instructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes/test-infra repository.
 k8s-ci-robot
on 12 Apr 2019
k8s-ci-robot
on 12 Apr 2019
/milestone v1.15
derekwaynecarr
on 12 Apr 2019
/assign @lmdaly
 justaugustus
on 28 Apr 2019
lmdaly
on 29 Apr 2019
justaugustus
on 28 Apr 2019
lmdaly
on 29 Apr 2019
@lmdaly
https://github.com/kubernetes/kubernetes/issues/72828
My team and i consider testing topology manager for numa sensitive application.
So, we have some questions.
Above PRs, are these full implimentaions for topology manager?
And Does it tested or stable now?
 bg-chun
on 15 May 2019
bg-chun
on 15 May 2019
@bg-chun We are doing the same at Nvidia. We have pulled these WIP PRs into our internal stack and have built a topology-aware allocation strategy for CPUs/GPUs around it. In doing so, we uncovered some issues and gave some specific feedback on these PRs.
Please see the discussion thread here for more details:
https://kubernetes.slack.com/archives/C0BP8PW9G/p1556371768035800
klueska
on 15 May 2019
Hey, @lmdaly I'm the v1.15 docs release shadow.
I see that you are targeting the alpha version of this enhancement for the 1.15 release. Does this require any new docs (or modifications)?
Just a friendly reminder we're looking for a PR against k/website (branch dev-1.15) due by Thursday, May 30th. It would be great if it's the start of the full documentation, but even a placeholder PR is acceptable. Let me know if you have any questions! 😄
 daminisatya
on 18 May 2019
daminisatya
on 18 May 2019
@lmdaly Just a friendly reminder we're looking for a PR against k/website (branch dev-1.15) due by Thursday, May 30th. It would be great if it's the start of the full documentation, but even a placeholder PR is acceptable. Let me know if you have any questions! 😄
daminisatya
on 27 May 2019
Hi @lmdaly . Code Freeze is Thursday, May 30th 2019 @ EOD PST. All enhancements going into the release must be code-complete, including tests, and have docs PRs open.
Will be looking at https://github.com/kubernetes/kubernetes/issues/72828 to see if all are merged.
If you know this will slip, please reply back and let us know. Thanks!
kacole2
on 28 May 2019
@daminisatya I have pushed the doc PR. https://github.com/kubernetes/website/pull/14572
Let me know if it is done correctly and if there is anything additional items need to be done. Thanks for the reminder!
lmdaly
on 28 May 2019
Thank you @lmdaly ✨
daminisatya
on 29 May 2019
Hi @lmdaly, today is code freeze for the 1.15 release cycle. There are still quite a few k/k PRs that have not yet been merged from your tracking issue https://github.com/kubernetes/kubernetes/issues/72828. It's now being marked as At Risk in the 1.15 Enhancement Tracking Sheet. Is there a high confidence these will be merged by EOD PST today? After this point, only release-blocking issues and PRs will be allowed in the milestone with an exception.
kacole2
on 30 May 2019
/milestone clear
kacole2
on 3 Jun 2019
Hi @lmdaly @derekwaynecarr , I'm the 1.16 Enhancement Lead. Is this feature going to be graduating alpha/beta/stable stages in 1.16? Please let me know so it can be added to the 1.16 Tracking Spreadsheet. If not's graduating, I will remove it from the milestone and change the tracked label.
Once coding begins or if it already has, please list all relevant k/k PRs in this issue so they can be tracked properly.
Milestone dates are Enhancement Freeze 7/30 and Code Freeze 8/29.
Thank you.
kacole2
on 9 Jul 2019
@kacole2 thanks for the reminder. This feature will be going in as Alpha in 1.16.
The ongoing list of PRs can be found here: https://github.com/kubernetes/kubernetes/issues/72828
Thanks!
lmdaly
on 17 Jul 2019
Agree this will land in alpha for 1.16, we will close out the effort started and captured in the kep previously merged for 1.15.
derekwaynecarr
on 30 Jul 2019
Hi @lmdaly , I'm the v1.16 docs release shadow.
Does this enhancement require any new docs (or modifications)?
Just a friendly reminder we're looking for a PR against k/website (branch dev-1.16) due by Friday,August 23rd. It would be great if it's the start of the full documentation, but even a placeholder PR is acceptable. Let me know if you have any questions!
Thanks!
 VineethReddy02
on 1 Aug 2019
VineethReddy02
on 1 Aug 2019
Documentation PR: https://github.com/kubernetes/website/pull/15716
lmdaly
on 7 Aug 2019
@lmdaly Will topology manager provide any information or API to tell users the NUMA configuration for given pod?
 mJace
on 15 Aug 2019
mJace
on 15 Aug 2019
@mJace something visible via the kubectl describe for the pod?
lmdaly
on 15 Aug 2019
@lmdaly Yeah, kubectl describe is good. or some api to return related information.
Since we are developing a service to provide some topology related information for pods, like cpu pinning status for pod, and numa node for it's pass-throughed VF.
And some monitor tool like weave scope can call the api to do some fancy work.
Admin can tell if the VNF is under proper numa configuration, for example.
Just Like to know if Topology Manager will cover this part.
or if there's any work we could do if Topology Manager plan to support this kind of functionality.
mJace
on 15 Aug 2019
@mJace Okay, so currently there is no API like that for Topology Manager. I don't think there is precedence for this, as with CPU & Device Manager there isn't visibility into what has actually been assigned to the pods.
So I think it would be good to start a discussion on this and see what kind of view we can give the users.
lmdaly
on 15 Aug 2019
I see, I thought CPU & Device Manager is able to see this information.
Maybe the cadvisor is a good role to provide this information.
Because basically cadvisor gets container information like PID, etc. by ps ls.
And it's the same way that we check container's topology related information.
I will implement this in cadvisor and create a pr for it.
mJace
on 15 Aug 2019
I've created a related issue in cadvisor.
https://github.com/google/cadvisor/issues/2290
mJace
on 16 Aug 2019
/assign
 khenidak
on 24 Aug 2019
khenidak
on 24 Aug 2019
+1 to @mJace cadvisor proposal.
To use DPDK lib inside container with CPU Manager and Topology Manager, parsing cpu affinity of container then passing it to dpdk lib, both are required for thread pinning of DPDK lib.
For more details, If a cpus are not allowed in container's cgroup cpuset subsystem, calls to sched_setaffinity to pin process on the cpus will be filtered out.
DPDK lib utilizes pthread_setaffinity_np for thread pinning, and pthread_setaffinity_np is a thread-level wrapper of sched_setaffinity.
And CPU Manager of Kubernetes sets exclusive cpus on container's cgroup cpuset subsystem.
bg-chun
on 26 Aug 2019
@bg-chun I understood the cadvisor change as serving a different purpose: monitoring. For your requirement it’s possible to read the assigned CPUs from inside the container by parsing ‘Cpus_Allowed’ or ‘Cpus_Allowed_List’ from ‘/proc/self/status’. Will that approach work for you?
ConnorDoyle
on 26 Aug 2019
@ConnorDoyle information in /proc/*/status like Cpus_Allowed is affected by the sched_setaffinity. So, if application sets something, it will be subset of what is really allowed by Cgroup's cpuset controller.
 kad
on 26 Aug 2019
kad
on 26 Aug 2019
@kad, I was suggesting a way for the launcher within the container to find out cpu id values to pass down to the DPDK program. So this happens before the thread level affinity is set.
ConnorDoyle
on 26 Aug 2019
@ConnorDoyle
Thankyou for your suggestion, I will consider it.
My plan was deploying tiny-rest-api server to tell exclusive CPUs allocation info to dpdk-container.
Regarding changes, I didn't see the cadvisor changes yet, I see only the proposal.
The proposal says able to tell if there is any cpu affinity set for the container. in Goal and to tell if there is any cpu affinity set for the container processes. in Future work.
After reading the proposal, I just thought it would be great if cadvisor is able to parse cpu pinning info and kubelet pass it into the container as an environment variable such as status.podIP, metadata.name, and limits.cpu.
That is the main reason why I left +1.
bg-chun
on 26 Aug 2019
@bg-chun You can check my first pr at cadvisor
https://github.com/google/cadvisor/pull/2291
I've finish some similar function at.
https://github.com/mJace/numacc
but not really sure what's the proper way to implement it in cadvisor
That's why I only create a PR with one new feature -> show PSR.
mJace
on 26 Aug 2019
but not really sure what's the proper way to implement it in cadvisor
Maybe we could discuss this under that proposal? If you gurus think this feature is needed :)
mJace
on 26 Aug 2019
@lmdaly code freeze for 1.16 is on Thursday 8/29. We will be tracking https://github.com/kubernetes/kubernetes/issues/72828 for remaining k/k PRs
kacole2
on 26 Aug 2019
@kacole2 all the required PRs for this feature are merged or in the merge queue.
lmdaly
on 30 Aug 2019
Hey there @lmdaly -- 1.17 Enhancements lead here. I wanted to check in and see if you think this Enhancement will be graduating to alpha/beta/stable in 1.17?
The current release schedule is:
- Monday, September 23 - Release Cycle Begins
- Tuesday, October 15, EOD PST - Enhancements Freeze
- Thursday, November 14, EOD PST - Code Freeze
- Tuesday, November 19 - Docs must be completed and reviewed
- Monday, December 9 - Kubernetes 1.17.0 Released
If you do, please list all relevant k/k PRs in this issue so they can be tracked properly. 👍
Thanks!
/milestone clear
 mrbobbytables
on 22 Sep 2019
mrbobbytables
on 22 Sep 2019
@lmdaly is there a link to the GPU direct with RDMA discussion?
 nickolaev
on 25 Sep 2019
nickolaev
on 25 Sep 2019
@nickolaev, We also looking on this use case. We did start some internal thinking on how to do this, but we would love to collaborate on this.
 moshe010
on 25 Sep 2019
moshe010
on 25 Sep 2019
@moshe010 @nickolaev @lmdaly , We too looking into this use case pertaining to RDMA and GPU direct. We would like to collaborate on this. Possible to start a thread/discussion around this ?
 Deepthidharwar
on 25 Sep 2019
Deepthidharwar
on 25 Sep 2019
Hello! I have a question about NTM and scheduler. As i understand, scheduler does not know about NUMAs and can prefer node on that there is no resources (cpu, memory and device) on desired NUMA. So topology manager will refuse resource allocation on that node. Is it true?
 LilyaBu
on 25 Sep 2019
LilyaBu
on 25 Sep 2019
@nickolaev @Deepthidharwar, I will start google doc with use-cases and we can move the discussion to it. I will post something next week. If that ok with you.
moshe010
on 25 Sep 2019
I am really happy to see this feature. We also need CPU, Hugepage, SRIOV-VFs and other hardware resorce in single NUMA node.
But hugepage is not realize as a scalar resource by device plugin, is this feature need to change the hugepage feature in k8s?
@iamneha
 andyzheung
on 26 Sep 2019
andyzheung
on 26 Sep 2019
@ConnorDoyle Just to confirm, this feature needs topology hints from both cpu manager and device manager? I tested it on 1.16 and didn't work, it seems it only got hint from cpu manager but no hint from device side.
 jianzzha
on 26 Sep 2019
jianzzha
on 26 Sep 2019
@ConnorDoyle here is a a bit of more details:
https://gist.githubusercontent.com/jianzzha/c2a66a2514c178cca76a432029ff3387/raw/264f13dfcd06f1f80c48c113aa235fab7c33d81e/hyper%2520threading%2520enabled
jianzzha
on 26 Sep 2019
@jianzzha , What Device plugin are you using? For example if you use SR-IOV device plugin you need to make sure it reports NUMA node see [1]
moshe010
on 26 Sep 2019
@andyzheung Huge page integration is currently being discussed and has been presented in the sig-node meeting the past two weeks. Here are some relevant links:
https://docs.google.com/presentation/d/1H5xhCjgCZJjdTm-mGUFwqoz8XmoVd8xTCwJ1AfVR_54/edit?usp=sharing
https://github.com/kubernetes/enhancements/pull/1245
https://github.com/kubernetes/enhancements/pull/1199
@jianzzha Regarding the device plugin not giving hints. Has your plugin been updated to report NUMA information about the devices that it enumerates? It needs to add this field to the Device message https://github.com/kubernetes/kubernetes/blob/master/pkg/kubelet/apis/deviceplugin/v1beta1/api.proto#L100
klueska
on 26 Sep 2019
thanks guys. Fixed and works now.
jianzzha
on 26 Sep 2019
@klueska
Regarding nvidia-gpu-device-plugin..
I can see only one active PR(WIP) to update nvidia-gpu-device-plugin for Topology Manger.
Will nvidia-gpu-divice-plugin be updated to provide topology hint with above PR? or Is there something I miss?
bg-chun
on 26 Sep 2019
@bg-chun Yes it should be. Just pinged the author. If he doesn't get back in the next day or so, I will update the plugin myself.
klueska
on 26 Sep 2019
@bg-chun @klueska I have updated the patch.
 carmark
on 27 Sep 2019
carmark
on 27 Sep 2019
@klueska @carmark
Thank you for updating and the notice.
I will introduce sr-iov-plugin update and gpu-plugin update to users in my workspace.
bg-chun
on 27 Sep 2019
I would propose an enhancement for the next release.
It is about basically removing the "topology alignment only happens if the Pod is in Guaranteed QoS" restriction.
This restriction kind of makes the Topology Manager unusable for me at the moment, because I wouldn't like to ask for exclusive CPUs from K8s, however I would like to align the sockets of multiple devices, coming from multiple pools (e.g. GPU + SR-IOV VFs etc.)
Also what if my workload is not sensitive to memory, or would not like to restrict its mem usage (another criteria of Guaranteed QoS).
In the future when hopefully hugepages will be also aligned this restriction will feel even more limiting IMO.
Is there any argument against individually aligning the "alignable" resources? Like sure, let's only gather hints from CPU Manager if exclusive CPUs are used, but independently let's gather hints from Device Manager if user requires Devices having socket information, or from the memory manager when user asks for hugepages etc.
Either this, or if unnecessary extra computation load during Pod startup is a concern maybe bring back the original Pod-level config flag to control whether alignment happens, or not (which I was surprised to see getting scrapped during implementation)
 Levovar
on 30 Sep 2019
Levovar
on 30 Sep 2019
I would propose an enhancement for the next release.
It is about basically removing the "topology alignment only happens if the Pod is in Guaranteed QoS" restriction.
This is item number 8 on our TODO list for 1.17:
https://docs.google.com/document/d/1YTUvezTLGmVtEF3KyLOX3FzfSDw9w0zB-s2Tj6PNzLA/edit#heading=h.xnehh6metosd
Is there any argument against individually aligning the "alignable" resources? Like sure, let's only gather hints from CPU Manager if exclusive CPUs are used, but independently let's gather hints from Device Manager if user requires Devices having socket information, or from the memory manager when user asks for hugepages etc.
Are you proposing there be a mechanism to selectively tell the kubelet which resource to align on and which ones not to align on (i.e. I want to align my CPU and GPU allocations, but not my huge page allocations). I don't think anyone would be outright opposed to this, but the interface for selectively deciding which resources to align on and which not to align on could get overly cumbersome if we continue to specify alignment as a flag at the node level.
Either this, or if unnecessary extra computation load during Pod startup is a concern maybe bring back the original Pod-level config flag to control whether alignment happens, or not (which I was surprised to see getting scrapped during implementation)
There wasn't enough support for a pod-level flag to warrant a proposal to update the pod spec with this. To me it makes sense to push this decision to the pod level since some pods need / want alignment and some don't, but not everyone was in agreement.
klueska
on 30 Sep 2019
+1 for removing the QoS class restriction on topology alignment (I added it to the list :smiley:). I didn't get the sense @Levovar is asking for enabling topology on a per-resource basis, just that we should align all of the alignable resources used by a given container.
As far as I can remember, there was never a pod-level field for opting-in to topology in the KEP. The rationale for not introducing it in the first place was the same rationale for leaving exclusive cores implicit -- Kubernetes as a project wants to be free to interpret the pod spec liberally in terms of node-level performance management. I know that stance is unsatisfying to some members of the community, but we can always raise the topic again. There's a natural tension between enabling advanced features for the few vs. modulating cognitive load for most users.
ConnorDoyle
on 1 Oct 2019
IMO in the very early stages of the design at least there was a Pod-level flag if my memory serves me well, but it was around 1.13 :D
I'm personally okay with trying to align all resources all the time, but "back in the days" there was usually a community push back against features which would introduce delays to the startup, or to the scheduling decision of all Pods, regardless whether they really need the enhancement, or not.
So I was just trying to "pre-address" those concerns with two options coming to my mind: pre-gate the alignment of resource groups based on some criteria (easy to define for CPU, harder for others); or introduce some config flag.
However, if there is no push back now against a generic enhancement I'm totally cool with that :)
Levovar
on 1 Oct 2019
@mrbobbytables We are planning to graduate the TopologyManager to beta in 1.17. The tracking issue is here: https://github.com/kubernetes/kubernetes/issues/83479
klueska
on 3 Oct 2019
@bg-chun @klueska I have updated the patch.
Patch merged:
https://github.com/NVIDIA/k8s-device-plugin/commit/cc0aad87285b573127add4e487b13434a61ba0d6
Created new release with the patch:
https://github.com/NVIDIA/k8s-device-plugin/releases/tag/1.0.0-beta2
klueska
on 3 Oct 2019
tracking beta for v1.17
derekwaynecarr
on 4 Oct 2019
Awesome, thank you @derekwaynecarr . I'll add it to the sheet :)
/stage beta
mrbobbytables
on 6 Oct 2019
@lmdaly
I'm one of the v1.17 docs shadows.
Does this enhancement (or the work planned for v1.17) require any new docs (or modifications to existing docs)? If not, can you please update the 1.17 Enhancement Tracker Sheet (or let me know and I’ll do so)
If so, just a friendly reminder we're looking for a PR against k/website (branch dev-1.17) due by Friday, Nov 8th, it can just be a placeholder PR at this time. Let me know if you have any questions!
Thanks!
VineethReddy02
on 21 Oct 2019
@VineethReddy02 yep we have planned documentation updates for 1.17, if you could update the tracker sheet that would be great!
We will be sure to open that PR before then, thanks for the reminder.
Issue for tracking documentation for this is here: https://github.com/kubernetes/kubernetes/issues/83482
lmdaly
on 23 Oct 2019
https://github.com/kubernetes/enhancements/pull/1340
Guys, I opened KEP update PR to add a built-in node label(beta.kubernetes.io/topology) for Topology Manager.
The label will expose the policy of the node.
I think it would be helpful for scheduling a pod to the particular node when there are nodes with multiple policies in the same cluster.
May I ask for a review?
bg-chun
on 28 Oct 2019
Hi @lmdaly @derekwaynecarr
Jeremy from the 1.17 enhancements team here 👋. Could you please list out the k/k PRs that are in flight for this so we can track them? I see #83492 was merged, but there look to be a few more related issues hanging off the overall tracking item. We're closing in on Code Freeze on Nov 14th, so we'd like to get a idea of how this is going before then! Thanks so much!
 jeremyrickard
on 4 Nov 2019
jeremyrickard
on 4 Nov 2019
@jeremyrickard This is the tracking issue for 1.17 as mentioned above: https://github.com/kubernetes/enhancements/issues/693#issuecomment-538123786
klueska
on 4 Nov 2019
@lmdaly @derekwaynecarr
A friendly reminder we are looking for a placeholder PR for Docs against k/website (branch dev-1.17) due by Friday, Nov 8th. We just have 2 days more for this deadline.
daminisatya
on 6 Nov 2019
Docs PR is here btw: https://github.com/kubernetes/website/pull/17451
lmdaly
on 8 Nov 2019
@klueska I see some of the work bumped to 1.18. Are you still planning to graduate this to beta in 1.17, or will it be staying as alpha but changing?
jeremyrickard
on 13 Nov 2019
Nevermind, I see in https://github.com/kubernetes/kubernetes/issues/85093 that you're going to jump to beta in 1.18 now, not as part of 1.17. Do you want us to track this as a major change to the alpha version as part of the 1.17 milestone @klueska? Or just defer the graduation to 1.18?
jeremyrickard
on 13 Nov 2019
/milestone v1.18
jeremyrickard
on 15 Nov 2019
Hey @klueska
1.18 enhancements team checking in! Do you still plan on graduating this to beta in 1.18? Enhancement Freeze will be Jan 28th, if your KEP requires any updates, while Code Freeze will be March 5th.
Thank you!
jeremyrickard
on 7 Jan 2020
Yes.
klueska
on 7 Jan 2020
@klueska thanks for the update! Updating the tracking sheet.
jeremyrickard
on 7 Jan 2020
@klueska as we were reviewing the KEPs for this release, we noticed that this is missing test plans. In order to graduate to beta in the release, it's going to need to have test plans added. I'm going to remove it from the milestone for now, but we can add it back in if you file an Exception Request and add the test plans tot he KEP. Apologies for the late notice.
jeremyrickard
on 29 Jan 2020
/milestone clear
jeremyrickard
on 29 Jan 2020
@vpickard please see above
klueska
on 29 Jan 2020
@vpickard please see above
@klueska Thanks for the heads up. Will work on adding the test plan to the KEP and file an Exception Request. We are actively developing test cases and have some testing PRs done, and some in progress, including this one:
 vpickard
on 29 Jan 2020
vpickard
on 29 Jan 2020
@jeremyrickard Is there a test plan template that you can point me to for reference?
vpickard
on 29 Jan 2020
@vpickard you can take a look at:
https://github.com/kubernetes/enhancements/blob/master/keps/sig-storage/20190530-pv-health-monitor.md#test-plan
and
https://github.com/kubernetes/enhancements/blob/master/keps/sig-storage/20200120-skip-permission-change.md#test-plan
Include overview of the unit tests and e2e tests.
If you have anything that shows up in test grid, it would be great to include.
jeremyrickard
on 29 Jan 2020
Exception was approved.
/milestone v1.18
jeremyrickard
on 30 Jan 2020
@jeremyrickard Test plan merged: https://github.com/kubernetes/enhancements/pull/1527
klueska
on 4 Feb 2020
Hi @klueska @vpickard, just a friendly reminder that the Code Freeze will go into effect on Thursday 5th March.
Can you please link all the k/k PRs or any other PRs which should be tracked for this enhancement?
Thank You :)
 palnabarun
on 5 Feb 2020
palnabarun
on 5 Feb 2020
Hi @palnabarun
Tracking issue here for 1.18:
https://github.com/kubernetes/kubernetes/issues/85093
Current open PRs:
https://github.com/kubernetes/kubernetes/pull/87758 (Approved, flaking tests)
https://github.com/kubernetes/kubernetes/pull/87759 (WIP)
https://github.com/kubernetes/kubernetes/pull/87650 (Reviewed, needs approval)
https://github.com/kubernetes/kubernetes/pull/87645 (e2e test PR, needs approval)
@vpickard can you add any e2e PRs I've missed.
Thanks
 nolancon
on 5 Feb 2020
nolancon
on 5 Feb 2020
Thanks @nolancon for linking the PR's and the umbrella issue here. I have added the PRs to the tracking sheet.
palnabarun
on 5 Feb 2020
Hi @palnabarun, @nolancon,
A few additional open PRs related to E2E tests:
https://github.com/kubernetes/test-infra/pull/16062 (needs review and approval)
https://github.com/kubernetes/test-infra/pull/16037 (needs review and approval)
vpickard
on 6 Feb 2020
Thanks @vpickard for the additional updates. :)
palnabarun
on 9 Feb 2020
Hello @lmdaly I'm one of the v1.18 docs shadows.
Does this enhancement for (or the work planned for v1.18) require any new docs (or modifications to existing docs)? If not, can you please update the 1.18 Enhancement Tracker Sheet (or let me know and I'll do so)
If so, just a friendly reminder we're looking for a PR against k/website (branch dev-1.18) due by Friday, Feb 28th., it can just be a placeholder PR at this time. Let me know if you have any questions!
 irvifa
on 9 Feb 2020
irvifa
on 9 Feb 2020
Hi @irvifa, thanks for the heads up. I've opened a PR here kubernetes/website#19050 with a couple of minor changes. This PR is WIP for now, I will remove it from WIP once criteria for moving to Beta is met (PRs above still under review).
Thanks.
nolancon
on 10 Feb 2020
Hi @nolancon thanks for your swift response, I change the status to Placeholder PR now.. Thanks!
irvifa
on 10 Feb 2020
@palnabarun FYI, I've split this PR https://github.com/kubernetes/kubernetes/pull/87759 into two PRs to ease the review process. The second one is here https://github.com/kubernetes/kubernetes/pull/87983 and will also need to be tracked. Thanks.
nolancon
on 10 Feb 2020
@nolancon Thank you for the updates.
I see that some of the PR's are still pending to be merged. I wanted to see if you need help from the release team in getting Reviewers and Approvers to the PR's. Let us know if you need anything.
FYI, we are very near to Code Freeze on 5th March
palnabarun
on 27 Feb 2020
@nolancon Thank you for the updates.
I see that some of the PR's are still pending to be merged. I wanted to see if you need help from the release team in getting Reviewers and Approvers to the PR's. Let us know if you need anything.
FYI, we are very near to Code Freeze on 5th March
@palnabarun One more update, https://github.com/kubernetes/kubernetes/pull/87983 is now closed and does not need to be tracked. Required changes are included in original PR https://github.com/kubernetes/kubernetes/pull/87759 which is under review.
nolancon
on 27 Feb 2020
@nolancon Cool. I am also tracking the umbrella tracker issue that you shared above. :)
palnabarun
on 27 Feb 2020
Hi @nolancon, this a reminder that we are just two days away from Code Freeze on 5th March.
By the Code Freeze, all the relevant PR's should be merged else you would need to file an exception request.
palnabarun
on 3 Mar 2020
Hi @nolancon,
Today EOD is Code Freeze.
Do you think https://github.com/kubernetes/kubernetes/pull/87650 would get reviewed by the deadline?
If not, please file an exception request.
palnabarun
on 5 Mar 2020
Hi @nolancon,
Today EOD is Code Freeze.
Do you think kubernetes/kubernetes#87650 would get reviewed by the deadline?
If not, please file an exception request.
Hi @palnabarun, a lot of progress has been made in the last couple of days and we are confident of getting everything approved and merged before code freeze. If not, I will file the exception request.
Just to clarify, by EOD do you mean 5pm or midnight PST? Thanks
nolancon
on 5 Mar 2020
Just to clarify, by EOD do you mean 5pm or midnight PST? Thanks
5 PM PST.
jeremyrickard
on 5 Mar 2020
The PR is approved but is missing a milestone which sig-node needs to add to merge. I've pinged them in slack, hopefully it gets unstuck and you dont need exception. =)
 kikisdeliveryservice
on 5 Mar 2020
kikisdeliveryservice
on 5 Mar 2020
All PRs for this kep seem to have merged (and approved by the deadline), I've updated our enhancements tracking sheet. :smile:
kikisdeliveryservice
on 6 Mar 2020
/milestone clear
(removing this enhancement issue from the v1.18 milestone as the milestone is complete)
palnabarun
on 29 Apr 2020
Hi @nolancon @lmdaly, enhancements shadow for 1.19 here. Any plans for this in 1.19?
 johnbelamaric
on 4 May 2020
johnbelamaric
on 4 May 2020
The only planned enhancement for 1.19 is this:
https://github.com/kubernetes/enhancements/pull/1121
The rest of the work will be on code refactoring / bug fixes as necessary.
Is there anyway to change the owner of this issue to me instead of @lmdaly?
klueska
on 4 May 2020
Thanks, I'll update the contact.
/milestone v1.19
johnbelamaric
on 4 May 2020
/assign @klueska
/unassign @lmdaly
Here you have it, Kevin https://prow.k8s.io/command-help
 pires
on 6 May 2020
pires
on 6 May 2020
Hi Kevin. Recently the KEP format has changed, and also #1620 merged last week, adding production readiness review questions to the KEP template. If possible, please take the time to reformat your KEP and also answer the questions add to the template. The answers to those questions will be helpful to operators using and troubleshooting the feature (particularly the monitoring piece at this stage). Thanks!
johnbelamaric
on 13 May 2020
@klueska ^^
johnbelamaric
on 13 May 2020
@derekwaynecarr @klueska @johnbelamaric
I also plan to add new topology policy on 1.19 rel.
But it didnt get review by owner and maintainer yet.
(If it seems to be hard to make in 1.19, please let me know.)
- KEP Update PR: https://github.com/kubernetes/enhancements/pull/1752
- PR for kubelet: WIP
bg-chun
on 13 May 2020
Hi @klueska 👋 1.19 docs shadow here! Does this enhancement work planned for 1.19 require new or modification to docs?
Friendly reminder that if new/modification to docs are required, a placeholder PR against k/website (branch dev-1.19) are needed by Friday, June 12.
 annajung
on 21 May 2020
annajung
on 21 May 2020
Hi @klueska hope you're doing well, checking in again to see if docs are required for this or not. Could you confirm?
annajung
on 27 May 2020
Hi @annajung. There are 2 pending enhancements that will both require docs changes:
1121
1752
We are still deciding if these will make it into 1.19 or be pushed to 1.20. If we decide to keep them for 1.19, I will be sure to create a placeholder PR for the docs by June 12th.
klueska
on 29 May 2020
Great! Thank you for the update, I'll update the tracking sheet accordingly! Please do let me know once placeholder PR have been made. Thank you!
annajung
on 30 May 2020
@lmdaly @ConnorDoyle
I hope here is the right place to ask and give some feedback.
I turn on the TopologyManager and CPUManager on my k8s cluster v1.17.
and their policy is best-effort and static
Here is my pod's resources
resources:
requests:
cpu: 2
intel.com/sriov_pool_a: '1'
limits:
cpu: 2
intel.com/sriov_pool_a: '1'
The PF of the sriov_pool_a is in NUMA node 0, so I expect my pod should runs on NUMA node 0's cpu too.
But I found the process of my pod is running on NUMA node 1's cpu.
Also, there's no cpu affinity mask set according the the result of taskset -p <pid>.
Is there something wrong? I expect the container should have cpu affinity mask set for the numa node 0's cpu.
Is there any example or test that I can do to know if my TopoloyManager is working correctly?
mJace
on 4 Jun 2020
@annajung Placeholder docs PR added: https://github.com/kubernetes/website/pull/21607
klueska
on 9 Jun 2020
Hi @klueska ,
To follow-up on the email sent to k-dev on Monday, I wanted to let you know that Code Freeze has been extended to Thursday, July 9th. You can see the revised schedule here: https://github.com/kubernetes/sig-release/tree/master/releases/release-1.19
We expect all PRs to be merged by that time. Please let me know if you have any questions. 😄
Best,
Kirsten
kikisdeliveryservice
on 18 Jun 2020
Hi @klueska, a friendly reminder of the next deadline coming up.
Please remember to populate your placeholder doc PR and get it ready for review by Monday, July 6th.
annajung
on 22 Jun 2020
Thanks @annajung . Since the code freeze has now ben moved to July 9th, does it make sense to push the docs date forward as well? What happens if we create the documentation, but the the feature doesn't make it in in time (or makes it in in a slightly different form than what the documentation suggests)?
klueska
on 23 Jun 2020
Hi @klueska, that's a great point! All docs deadline also has been pushed a week with the new release date, but I think you have a valid point. Let me reach out to the docs lead for the release and get back to you! Thank you for pointing this out!
annajung
on 24 Jun 2020
Hi @klueska, thank you again for bringing this up to our attention. There has been a mix up with the docs dates for the release. As you mentioned, "PR ready for review" should come after code freeze and have been in the past releases.
However, after speaking with the release team, we have decided to keep the dates as is for this 1.19 release by making the "PR ready for review" a soft deadline. Docs team will be flexible and work with you/others who might need extra time to make sure docs are sync with the code. While "PR ready for review" deadline will not be enforced, the "PR reviewed and read to merge" will be.
Hope this helps answer your concerns! Please let me know if you have any more questions!
Also, just a friendly reminder of dates:
"Docs deadline - PRs ready for review" is due by July 6th
"Docs complete - All PRs reviewed and ready to merge" is due by July 16th
annajung
on 24 Jun 2020
Hi @klueska :wave: -- 1.19 Enhancements Lead here,
Can you please link to all the implementation PRs here, so that the release team can track them? :slightly_smiling_face:
Thank you.
palnabarun
on 28 Jun 2020
@palnabarun
The PR tracking https://github.com/kubernetes/enhancements/pull/1121 can be found at:
https://github.com/kubernetes/kubernetes/pull/92665
Unfortunately enhancement #1752 will not be making it into the release, so there is no PR to track for it.
klueska
on 30 Jun 2020
Hi @klueska :wave:, I see that both of the PRs (https://github.com/kubernetes/enhancements/pull/1121 and https://github.com/kubernetes/enhancements/pull/1752) that you mentioned refer to the same enhancement. Since https://github.com/kubernetes/enhancements/pull/1752 extends the Beta graduation requirements and they won't be making it into the release, can we assume that there are no further changes expected in 1.19?
Thank you. :slightly_smiling_face:
Code Freeze begins on Thursday, July 9th EOD PST
palnabarun
on 6 Jul 2020
@palnabarun This is a follow-on PR to #92665 that should land today or tomorrow: https://github.com/kubernetes/kubernetes/pull/92794
After that there should be no more PRs for this release, pending unforeseen bugs.
klueska
on 6 Jul 2020
Awesome! Thank you for the update. :+1:
We will keep an eye on https://github.com/kubernetes/kubernetes/pull/92794.
palnabarun
on 6 Jul 2020
@annajung https://github.com/kubernetes/website/pull/21607 is now ready for review.
klueska
on 6 Jul 2020
Congrats @klueska kubernetes/kubernetes#92794 has finally merged, I will update the tracking sheet accordingly 😄
kikisdeliveryservice
on 11 Jul 2020
/milestone clear
(removing this enhancement issue from the v1.19 milestone as the milestone is complete)
kikisdeliveryservice
on 12 Sep 2020
Hi @klueska
Enhancements Lead here. Are there any plans for this to graduate in 1.20?
Thanks!
Kirsten
kikisdeliveryservice
on 13 Sep 2020
There are no plans for it to graduate, but there is a PR that should be tracked for 1.20 related to this enhancement:
https://github.com/kubernetes/kubernetes/pull/92967
klueska
on 16 Sep 2020
Even though it's not graduating in 1.20, please do continue to link related PRs to this issue as you've just done.
kikisdeliveryservice
on 16 Sep 2020
@kikisdeliveryservice can you please help understand the process. The Topology Manager feature is not graduating in 1.20, but the new feature will be added to it and being worked on now: https://github.com/kubernetes/enhancements/pull/1752 k/k: https://github.com/kubernetes/kubernetes/pull/92967. Is this something we need to track with the release team? It may simplify tracking the docs update for 1.20 or maybe something else that is being tracked.
The change is additive so there is not much reason to call it beta2 or something.
Related bump PR that reflects the reality that the extra feature wasn't shipped in 1.19: https://github.com/kubernetes/enhancements/pull/1950
 SergeyKanzhelev
on 27 Oct 2020
SergeyKanzhelev
on 27 Oct 2020
Topology Manager web documentation update PR to include the scope feature: https://github.com/kubernetes/website/pull/24781
 k-wiatrzyk
on 29 Oct 2020
k-wiatrzyk
on 29 Oct 2020
I believe it can be tracked with 1.20 and does not necessarily need to graduate. @kikisdeliveryservice please chime in if that's not correct. I will track the shared k/website as part of the 1.20 release until I hear otherwise.
annajung
on 29 Oct 2020
Hi @SergeyKanzhelev
Looking at the history this actually isn't the case. I was told that this would not be graduating above, which is fine and why this KEP is untracked. However, this enhancement (unbeknownst to the enhancements team) was recently retargetted by @k-wiatrzyk for 1.20 as beta (https://github.com/kubernetes/enhancements/pull/1950).
If you want to leverage the release process: enhancements tracking, being a part of the release milestone and having docs team tracking this/having docs included in the 1.20 release, an enhancement exception request should be filed ASAP.
kikisdeliveryservice
on 30 Oct 2020
The feature was already merged into the (pre-existing) KEP (before the enhancement deadline).
https://github.com/kubernetes/enhancements/pull/1752
At it's implementation PR is already part of the milestone.
https://github.com/kubernetes/kubernetes/pull/92967
I wasn't aware there was any more to do.
With whom do we need to file an exception, and for what exactly?
klueska
on 30 Oct 2020
Hi @klueska the pr you are referencing was merged in June for adding beta into the kep in 1.19: https://github.com/bg-chun/enhancements/blob/f3df83cc997ff49bfbb59414545c3e4002796f19/keps/sig-node/0035-20190130-topology-manager.md#beta-v119
The enhancements deadline for 1.20 was October 6th but the change, moving beta to 1.20 and removing the reference to 1.19 was merged 3 days ago via https://github.com/kubernetes/enhancements/pull/1950
You can find instructions for sending an exception request here: https://github.com/kubernetes/sig-release/blob/master/releases/EXCEPTIONS.md
kikisdeliveryservice
on 30 Oct 2020
Sorry, I'm still confused as to what we will be filing an exception for.
I'm happy to do it, I'm just not sure what to include in it.
The "Node Topology Manager" feature already graduated to beta in 1.18.
It is not graduting to GA in 1.20 (it is staying in beta).
The PR being merged for 1.20 (i.e. kubernetes/kubernetes#92967) is an improvement to the existing code for the Topology Manager, but it is not related to a "bump" in terms of its status as alpha/beta/ga, etc.
klueska
on 30 Oct 2020
I have sent a Call of Exception mail as the deadline is today (just in case): https://groups.google.com/g/kubernetes-sig-node/c/lsy0fO6cBUY/m/_ujNkQtCCQAJ
k-wiatrzyk
on 2 Nov 2020
@kikisdeliveryservice @klueska @annajung
The Call for Exception was approved, you can find the confirmation here: https://groups.google.com/g/kubernetes-sig-release/c/otE2ymBKeMA/m/ML_HMQO7BwAJ
k-wiatrzyk
on 4 Nov 2020
Thanks @k-wiatrzyk & @klueska Updated the tracking sheet.
cc: @annajung
kikisdeliveryservice
on 5 Nov 2020
Hey @k-wiatrzyk @klueska
Looks like kubernetes/kubernetes#92967 is approved but needs a rebase.
Just a reminder that Code Freeze is coming up in 2 days on Thursday, November 12th. All PRs must be merged by that date, otherwise an Exception is required.
Best,
Kirsten
kikisdeliveryservice
on 11 Nov 2020
The PR merged, updating sheet - yay! :smile_cat:
kikisdeliveryservice
on 12 Nov 2020
Related issues
 mitar
·
8Comments
mitar
·
8Comments
 robscott
·
11Comments
robscott
·
11Comments
 dekkagaijin
·
9Comments
dekkagaijin
·
9Comments
 wlan0
·
9Comments
wlan0
·
9Comments
 prameshj
·
9Comments
prameshj
·
9Comments
Most helpful comment
All PRs for this kep seem to have merged (and approved by the deadline), I've updated our enhancements tracking sheet. :smile: