Enhancements: Gerente de Topologia de Nó
Descrição de aprimoramento
- Descrição de aprimoramento de uma linha (pode ser usada como uma nota de versão): Componente Kubelet para coordenar atribuições de recursos de hardware de baixa granularidade para diferentes componentes no Kubernetes.
- Contato principal (cessionário): @klueska
- SIGs responsáveis: nó de sig
- Link da proposta de design (repositório da comunidade): https://github.com/kubernetes/community/pull/1680
- KEP PR: https://github.com/kubernetes/enhancements/pull/781
- KEP: https://github.com/kubernetes/enhancements/blob/master/keps/sig-node/0035-20190130-topology-manager.md
- Link para e2e e / ou testes de unidade: N / A ainda
- Revisor (es) - (para LGTM) recomendam que mais de 2 revisores (pelo menos um do arquivo OWNERS da área de código) concordem em revisar. Revisores de várias empresas preferidos: @ConnorDoyle @balajismaniam
- Aprovador (provavelmente do SIG / área à qual pertence o aprimoramento): @derekwaynecarr @ConnorDoyle
- Meta de melhoria (qual meta é igual a qual marco):
- Meta de lançamento alfa (xy): v1.16
- Meta de lançamento beta (xy): v1.18
- Alvo de liberação estável (xy)
 lmdaly
lmdaly
Todos 159 comentários
nó / sig
/ tipo recurso
cc @ConnorDoyle @balajismaniam @nolancon
lmdaly
em 17 jan. 2019
Posso ajudar a informar este design com base no aprendizado de Borg. Então conte comigo como um revisor / aprovador.
 vishh
em 4 fev. 2019
vishh
em 4 fev. 2019
Posso ajudar a informar este design com base no aprendizado de Borg. Então conte comigo como um revisor / aprovador.
Existe alguma documentação pública sobre como esse recurso funciona no borg?
 jeremyeder
em 11 fev. 2019
jeremyeder
em 11 fev. 2019
Não sobre NUMA AFAIK.
Na segunda-feira, 11 de fevereiro de 2019, 7h50, Jeremy Eder < [email protected] escreveu:
Posso ajudar a informar este design com base no aprendizado de Borg. Então conte comigo
como revisor / aprovador.Existe alguma documentação pública sobre como esse recurso funciona no borg?
-
Você está recebendo isto porque comentou.
Responda a este e-mail diretamente, visualize-o no GitHub
https://github.com/kubernetes/enhancements/issues/693#issuecomment-462378195 ,
ou silenciar o tópico
https://github.com/notifications/unsubscribe-auth/AGvIKPfanjb9Q5DxXAiBgv9C6Y809JX0ks5vMZFZgaJpZM4aE3uz
.
vishh
em 11 fev. 2019
FYI @claurence
Esse problema de rastreamento e o KEP (https://github.com/kubernetes/enhancements/pull/781) não chegaram a tempo para o congelamento das melhorias v1.14 nem para o prazo estendido. Agradeço que você os tenha aberto antes dos prazos, mas eles não parecem ter recebido revisão ou aprovação suficiente. Isso precisará passar pelo processo de exceção.
Até decidirmos se vale a pena a exceção, estou inclinado a suspender todos os RPs associados a esse aprimoramento.
 spiffxp
em 24 fev. 2019
spiffxp
em 24 fev. 2019
/ cc @jiayingz @ dchen1107
 jiayingz
em 25 fev. 2019
jiayingz
em 25 fev. 2019
@lmdaly Vejo que todos têm 1.14 listado na descrição como o marco alfa - uma vez que não houve um KEP implementável mesclado, este problema não está sendo rastreado para 1.14 - se houver intenções de incluí-lo nessa versão, por favor enviar um pedido de exceção.
 claurence
em 27 fev. 2019
claurence
em 27 fev. 2019
@lmdaly Vejo que todos têm 1.14 listado na descrição como o marco alfa - uma vez que não houve um KEP implementável mesclado, este problema não está sendo rastreado para 1.14 - se houver intenções de incluí-lo nessa versão, por favor enviar um pedido de exceção.
@claurence o KEP agora está mesclado (o KEP havia sido mesclado anteriormente no repo da comunidade. Isso era apenas para movê-lo para o novo repo de melhorias de acordo com as novas diretrizes), ainda precisamos enviar uma solicitação de exceção para que esse problema seja rastreado para 1,14?
lmdaly
em 5 mar. 2019
Depois de ler os PRs de design e WIP completamente, tenho preocupações de que a implementação atual não é genérica como o design de topologia original que propusemos em https://github.com/kubernetes/enhancements/pull/781. Este atualmente se parece mais com a topologia NUMA no nível do nó.
Deixei alguns comentários para uma discussão mais aprofundada aqui: https://github.com/kubernetes/kubernetes/pull/74345#discussion_r264387724
 resouer
em 11 mar. 2019
resouer
em 11 mar. 2019
a implementação atual não é genérica
Compartilhe a mesma preocupação sobre isso :) E os outros, por exemplo, links entre dispositivos (nvlinke para GPU)?
 k82cn
em 20 mar. 2019
k82cn
em 20 mar. 2019
@resouer @ k82cn A proposta inicial trata apenas de alinhar as decisões tomadas pelo gerenciador de CPU e gerenciador de dispositivos para garantir a proximidade dos dispositivos com a CPU em que o contêiner é executado. Satisfazer a afinidade entre dispositivos não era um objetivo da proposta.
Se, no entanto, a implementação atual está bloqueando a adição de afinidade entre dispositivos no futuro, terei o prazer de alterar a implementação assim que tiver uma compreensão de como está fazendo isso,
lmdaly
em 25 mar. 2019
Acho que o principal problema que vejo com a implementação atual e a capacidade de suportar afinidade entre dispositivos é o seguinte:
Para suportar a afinidade entre dispositivos, você normalmente precisa primeiro descobrir quais dispositivos você gostaria de alocar a um contêiner _antes_ de decidir que afinidade de soquete você gostaria que o contêiner tivesse.
Por exemplo, com GPUs Nvidia, para conectividade ideal, você primeiro precisa encontrar e alocar o conjunto de GPUs com os NVLINKs mais conectados _antes_ de determinar qual afinidade de soquete esse conjunto tem.
Pelo que posso dizer na proposta atual, o pressuposto é que essas operações acontecem na ordem inversa, ou seja, a afinidade do socket é decidida antes de fazer a alocação dos dispositivos.
 klueska
em 5 abr. 2019
klueska
em 5 abr. 2019
Isso não é necessariamente verdadeiro, @klueska. Se as dicas de topologia fossem estendidas para codificar a topologia de dispositivo ponto a ponto, o Gerenciador de Dispositivos poderia considerar isso ao relatar a afinidade de soquete. Em outras palavras, a topologia entre dispositivos não precisaria sair do escopo do gerenciador de dispositivos. Isso parece viável?
 ConnorDoyle
em 5 abr. 2019
ConnorDoyle
em 5 abr. 2019
Talvez eu esteja confuso sobre o fluxo de alguma forma. É assim que eu entendo:
1) Na inicialização, os plug-ins do dispositivo (não o devicemanager ) se registram com o topologymanager para que ele possa emitir callbacks posteriormente.
2) Quando um pod é enviado, o kubelet chama lifecycle.PodAdmitHandler no topologymanager .
3) O lifecycle.PodAdmitHandler chama GetTopologyHints em cada plugin de dispositivo registrado
4) Em seguida, ele mescla essas dicas para produzir um TopologyHint consolidado associado ao pod
5) Se decidiu admitir o pod, ele retorna com sucesso de lifecycle.PodAdmitHandler armazenando o consolidado TopologyHint para o pod em uma loja estadual local
6) Em algum ponto no futuro, o cpumanager e o devicemanager chamam GetAffinity(pod) no gerente de topology para recuperar o TopologyHint associado com o pod
7) O cpumanager usa esta TopologyHint` para alocar uma CPU
8) O devicemanager usa esta TopologyHint` para alocar um conjunto de dispositivos
9) A inicialização do pod continua ...
Se isso estiver correto, acho que estou lutando com o que acontece entre o momento em que o plug-in do dispositivo relata seu TopologyHints e o momento em que devicemanager faz a alocação real.
Se essas dicas têm o objetivo de codificar "preferências" para alocação, acho que o que você está dizendo é ter uma estrutura mais parecida com:
type TopologyHints struct {
hints []struct {
SocketID int
DeviceIDs []int
}
}
Onde não apenas passamos uma lista de preferências de afinidade de soquete, mas como essas preferências de afinidade de soquete se combinam com as preferências de GPU alocáveis.
Se esta é a direção que você está pensando, então acho que poderíamos fazer funcionar, mas precisaríamos coordenar de alguma forma entre cpumanager e devicemanager para ter certeza de que eles "aceitaram" o mesmo dica ao fazer suas alocações.
Existe algo no lugar que já permite isso que eu perdi?
klueska
em 5 abr. 2019
@klueska
Acho que o que acontece, fazer algumas correções _pequenas_ em seu fluxo é:
Na inicialização, os plug-ins do dispositivo se registram com
devicemanagerpara que ele possa emitir callbacks posteriormente.O
lifecycle.PodAdmitHandlerchamaGetTopologyHintsem cada componente com reconhecimento de topologia no Kubelet, atualmentedevicemanagerecpumanager.
Nesse caso, o que será representado como ciente da topologia no Kubelet são cpumanager e devicemanager . O gerenciador de topologia destina-se apenas a coordenar alocações entre componentes com reconhecimento de topologia.
Por esta:
mas precisaríamos coordenar de alguma forma entre o cpumanager e o devicemanager para ter certeza de que eles "aceitaram" a mesma dica ao fazer suas alocações.
É para isso que o próprio topologymanager foi criado. De um dos rascunhos anteriores ,
Esses componentes devem ser coordenados para evitar atribuições cruzadas de NUMA. Os problemas relacionados a essa coordenação são complicados; solicitações de domínio cruzado, como “Um núcleo exclusivo no mesmo nó NUMA que o NIC atribuído” envolve tanto o CNI quanto o gerenciador de CPU. Se o gerenciador de CPU escolher primeiro, ele pode selecionar um núcleo em um nó NUMA sem um NIC disponível e vice-versa.
 eloyekunle
em 6 abr. 2019
eloyekunle
em 6 abr. 2019
Eu vejo.
Portanto, devicemanager e cpumanager implementam GetTopologyHints() e também chamam GetAffinity() , evitando a interação de direção de topologymanager com quaisquer plug-ins de dispositivos subjacentes . Olhando mais de perto o código, vejo que devicemanager simplesmente delega o controle aos plug-ins para ajudar a preencher TopologyHints , o que faz mais sentido no final das contas.
Voltando à questão / problema original que eu levantei ...
Da perspectiva da Nvidia, acho que podemos fazer tudo funcionar com este fluxo proposto, assumindo que mais informações sejam adicionadas à estrutura TopologyHints (e, consequentemente, à interface do plug-in do dispositivo) para relatar informações de link ponto a ponto no futuro .
No entanto, acho que começar com SocketMask como a estrutura de dados primária para afinidade de soquete de publicidade pode limitar nossa capacidade de expandir TopologyHints com informações ponto a ponto no futuro sem quebrar a interface existente. A principal razão é que (pelo menos no caso das GPUs Nvidia) o soquete preferido depende de quais GPUs serão realmente alocadas no final.
Por exemplo, considere a figura abaixo, ao tentar alocar 2 GPUs a um pod com conectividade ideal:
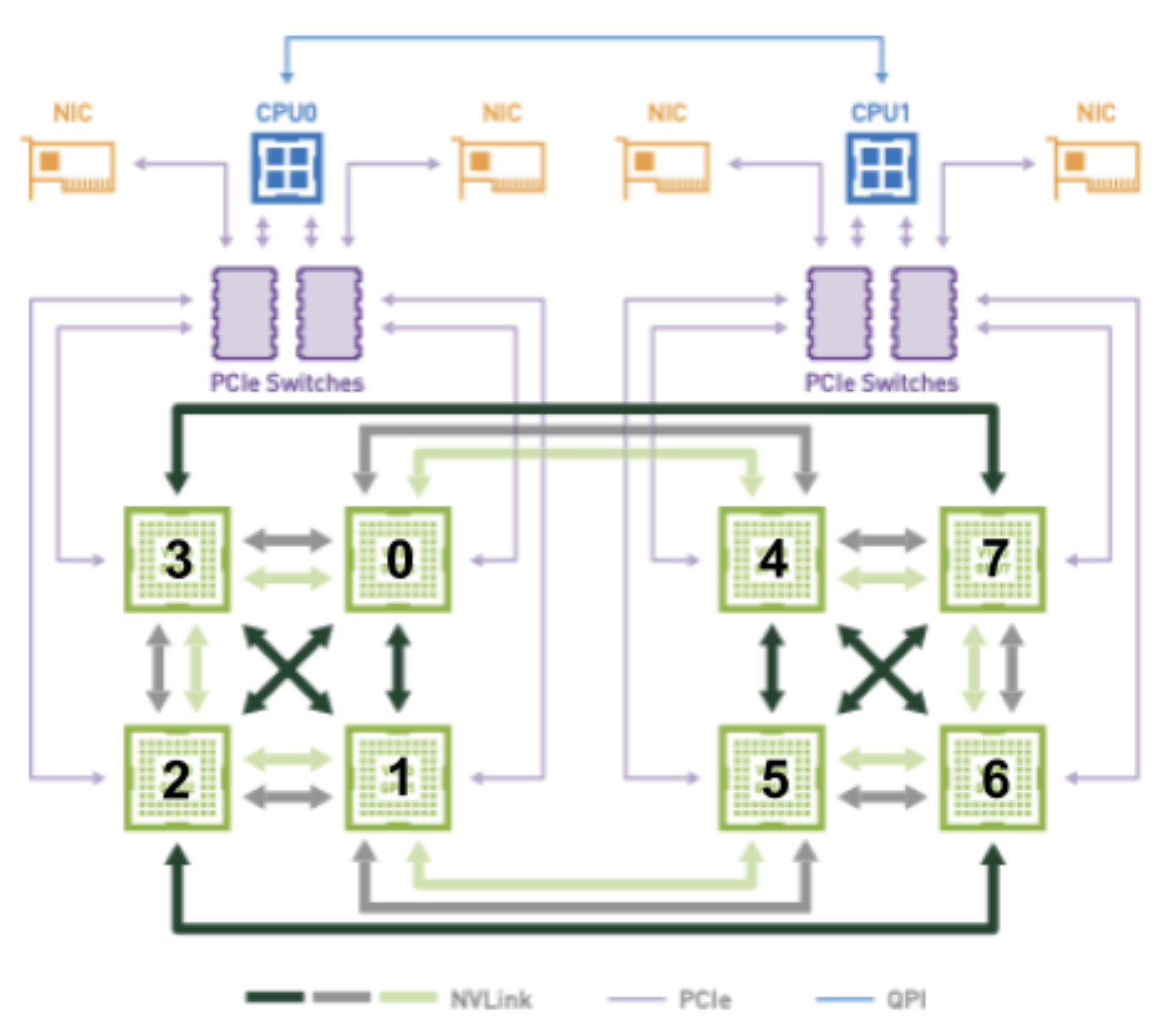
As combinações de GPU de (2, 3) e (6, 7) têm 2 NVLINKs e residem no mesmo barramento PCIe. Eles devem, portanto, ser considerados candidatos iguais ao tentar alocar 2 GPUs para um pod. Dependendo da combinação escolhida, no entanto, um soquete diferente será obviamente preferido, pois (2, 3) está conectado ao soquete 0 e (6, 7) está conectado ao soquete 1.
Esta informação precisará de alguma forma ser codificada na estrutura TopologyHints para que devicemanager possa realizar uma dessas alocações desejadas no final (ou seja, qualquer uma das topologymanager consolida as dicas até). Da mesma forma, a dependência entre as alocações de dispositivos preferenciais e o soquete preferencial precisará ser codificada em TopologyHints para que cpumanager possa alocar CPUs do soquete correto.
Uma solução potencial específica para GPUs Nvidia para este exemplo seria algo como:
type TopologyHint struct {
SocketID int
DeviceIDs []int
}
type TopologyHints []TopologyHint
devicemanagerhints := &TopologyHints{
{SocketID: 0, DeviceIDs: []int{2, 3}},
{SocketID: 1, DeviceIDs: []int{6, 7}},
}
cpumanagerhints := &TopologyHints{
{SocketID: 1},
}
Onde topologymanager consolidaria essas dicas para retornar {SocketID: 1, DeviceIDs: []int{6, 7}} como a dica preferida quando devicemanager e cpumanager posteriormente chamarem GetAffinity() .
Embora isso possa ou não fornecer uma solução genérica o suficiente para todos os aceleradores, substituir SocketMask na estrutura TopologyHints por algo estruturado mais como o seguinte nos permitiria expandir cada dica individual com mais campos em o futuro:
Observe que GetTopologyHints() ainda retorna TopologyHints , enquanto GetAffinity() foi modificado para retornar um único TopologyHint vez de TopologyHints .
type TopologyHint struct {
SocketID int
}
type TopologyHints []TopologyHint
&TopologyHints{
{SocketID: 0},
{SocketID: 1},
}
type HintProvider interface {
GetTopologyHints(pod v1.Pod, container v1.Container) TopologyHints
}
type Store interface {
GetAffinity(podUID string, containerName string) TopologyHint
}
Pensamentos?
klueska
em 9 abr. 2019
@klueska Talvez eu esteja faltando alguma coisa, mas não vejo a necessidade de que os IDs de dispositivo para GPUs NV Link sejam preenchidos no TopologyManager.
Se a API do Plug-in do Dispositivo fosse estendida para permitir que os dispositivos enviem de volta informações sobre a conectividade ponto a ponto do dispositivo, conforme sugerido por @ConnorDoyle , o gerenciador de dispositivos seria capaz de enviar informações de soquete de volta com base nisso.
Em seu exemplo, devicemanagerhints pode ser a informação que os plug-ins do dispositivo enviaram de volta ao gerenciador do dispositivo. O gerenciador de dispositivos então envia de volta as informações do soquete para o TopologyManager como estão agora e o TopologyManager armazena a dica do soquete escolhido.
Na alocação, o devicemanager chama GetAffinity para obter a alocação de soquete desejada (digamos que o soquete é 1 neste caso), usando essas informações e as informações enviadas de volta pelos plug-ins do dispositivo, ele pode ver que no soquete 1 ele deve atribuir dispositivos ( 6,7) por serem dispositivos NV Link.
Isso faz sentido ou há algo que estou perdendo?
lmdaly
em 10 abr. 2019
Obrigado por reservar um tempo para esclarecer isso comigo. Devo ter interpretado mal a sugestão original de @ConnorDoyle :
Se as dicas de topologia fossem estendidas para codificar a topologia de dispositivo ponto a ponto, o Gerenciador de Dispositivos poderia considerar isso ao relatar a afinidade de soquete.
Eu li isso como um desejo de estender a estrutura TopologyHints com informações ponto a ponto diretamente.
Parece que você está sugerindo que apenas a API do plug-in do dispositivo precise ser estendida para fornecer informações ponto a ponto para devicemanager , para que ele possa usar essas informações para informar SocketMask para definir na estrutura TopologyHints sempre que GetTopologyHints() é chamado.
Acho que isso funcionará, contanto que as extensões de API para o plug-in do dispositivo sejam projetadas para nos fornecer informações semelhantes às que descrevi no meu exemplo acima e o devicemanager seja estendido para armazenar essas informações entre a admissão do pod e o dispositivo tempo de alocação.
No momento, temos uma solução personalizada em vigor na Nvidia que corrige nosso kubelet para essencialmente fazer o que você está sugerindo (exceto que não entregamos nenhuma decisão aos plug-ins de dispositivo - o devicemanager tornou-se ciente da GPU e toma decisões de alocação de GPU com base na topologia por conta própria).
Queremos apenas ter certeza de que qualquer solução de longo prazo implementada nos permitirá remover esses patches personalizados no futuro. E agora que tenho uma imagem melhor de como funciona o fluxo aqui, não vejo nada que nos bloqueie.
Obrigado novamente por esclarecer tudo.
klueska
em 10 abr. 2019
Olá @lmdaly , sou o líder de aprimoramento do 1.15. Este recurso estará graduando os estágios alfa / beta / estável no 1.15? Informe-me para que possa ser rastreado corretamente e adicionado à planilha.
Assim que a codificação começar, liste todos os PRs k / k relevantes nesta edição para que possam ser rastreados corretamente.
 kacole2
em 12 abr. 2019
kacole2
em 12 abr. 2019
este recurso terá seu próprio portal de recursos e será alfa.
/ marco 1,15
 derekwaynecarr
em 12 abr. 2019
derekwaynecarr
em 12 abr. 2019
@derekwaynecarr : O marco fornecido não é válido para este repositório. Marcos neste repositório: [ keps-beta , keps-ga , v1.14 , v1.15 ]
Use /milestone clear para limpar o marco.
Em resposta a isso :
este recurso terá seu próprio portal de recursos e será alfa.
/ marco 1,15
Instruções para interagir comigo usando comentários de RP estão disponíveis aqui . Se você tiver dúvidas ou sugestões relacionadas ao meu comportamento, registre um problema no repositório kubernetes / test-infra .
 k8s-ci-robot
em 12 abr. 2019
k8s-ci-robot
em 12 abr. 2019
/ milestone v1.15
derekwaynecarr
em 12 abr. 2019
/ assign @lmdaly
 justaugustus
em 28 abr. 2019
lmdaly
em 29 abr. 2019
justaugustus
em 28 abr. 2019
lmdaly
em 29 abr. 2019
@lmdaly
https://github.com/kubernetes/kubernetes/issues/72828
Minha equipe e eu consideramos testar o gerenciador de topologia para um aplicativo sensível.
Portanto, temos algumas perguntas.
Acima dos PRs, essas são implementações completas para o gerenciador de topologia?
E é testado ou estável agora?
 bg-chun
em 15 mai. 2019
bg-chun
em 15 mai. 2019
@ bg-chun Estamos fazendo o mesmo na Nvidia. Colocamos esses WIP PRs em nossa pilha interna e criamos uma estratégia de alocação com reconhecimento de topologia para CPUs / GPUs em torno deles. Ao fazer isso, descobrimos alguns problemas e demos alguns comentários específicos sobre esses PRs.
Consulte o tópico de discussão aqui para obter mais detalhes:
https://kubernetes.slack.com/archives/C0BP8PW9G/p1556371768035800
klueska
em 15 mai. 2019
Ei, @lmdaly , sou a sombra de lançamento de documentos v1.15.
Vejo que você está almejando a versão alfa desse aprimoramento para a versão 1.15. Isso requer novos documentos (ou modificações)?
Apenas um lembrete amigável de que estamos procurando um PR contra k / website (branch dev-1.15) com vencimento na quinta-feira, 30 de maio. Seria ótimo se fosse o início da documentação completa, mas até mesmo um PR de espaço reservado é aceitável. Deixe-me saber se você tiver alguma dúvida! 😄
 daminisatya
em 18 mai. 2019
daminisatya
em 18 mai. 2019
@lmdaly Apenas um lembrete amigável de que estamos procurando um PR contra k / website (branch dev-1.15) para quinta-feira, 30 de maio. Seria ótimo se fosse o início da documentação completa, mas até mesmo um PR de espaço reservado é aceitável. Deixe-me saber se você tiver alguma dúvida! 😄
daminisatya
em 27 mai. 2019
Olá @lmdaly . Code Freeze é quinta-feira, 30 de maio de 2019 @ EOD PST . Todas as melhorias que vão para o lançamento devem ter o código completo, incluindo testes , e ter documentos PRs abertos.
Estarei olhando em https://github.com/kubernetes/kubernetes/issues/72828 para ver se todos estão mesclados.
Se você sabe que isso vai escorregar, responda e nos informe. Obrigado!
kacole2
em 28 mai. 2019
@daminisatya Eu empurrei o doc PR. https://github.com/kubernetes/website/pull/14572
Deixe-me saber se isso foi feito corretamente e se houver algo adicional a ser feito. Obrigado pela lembrança!
lmdaly
em 28 mai. 2019
Obrigado @lmdaly ✨
daminisatya
em 29 mai. 2019
Olá @lmdaly , hoje é o congelamento de código para o ciclo de lançamento 1.15. Ainda existem alguns PRs k / k que ainda não foram combinados de seu problema de rastreamento https://github.com/kubernetes/kubernetes/issues/72828. Agora está sendo marcado como Em risco na planilha de rastreamento de aprimoramento 1.15 . Há uma grande confiança de que eles serão mesclados pela EOD PST hoje? Após este ponto, apenas problemas de bloqueio de liberação e PRs serão permitidos no marco, com uma exceção.
kacole2
em 30 mai. 2019
/ marco claro
kacole2
em 3 jun. 2019
Olá @lmdaly @derekwaynecarr , sou o líder de aprimoramento do 1.16. Este recurso estará graduando os estágios alfa / beta / estável no 1.16? Informe-me para que possa ser adicionado à planilha de rastreamento 1.16 . Se não estiver se formando, vou removê-lo do marco e mudar o rótulo rastreado.
Assim que a codificação começar ou se já tiver começado, liste todos os PRs k / k relevantes nesta edição para que possam ser rastreados corretamente.
As datas dos marcos são Enhancement Freeze 7/30 e Code Freeze 29/8.
Obrigada.
kacole2
em 9 jul. 2019
@ kacole2 obrigado pelo lembrete. Este recurso será lançado como Alpha em 1.16.
A lista contínua de PRs pode ser encontrada aqui: https://github.com/kubernetes/kubernetes/issues/72828
Obrigado!
lmdaly
em 17 jul. 2019
Concordar que isso vai pousar em alfa para 1.16, fecharemos o esforço iniciado e capturado no kep previamente mesclado para 1.15.
derekwaynecarr
em 30 jul. 2019
Olá @lmdaly , sou a sombra de lançamento de documentos
Este aprimoramento requer novos documentos (ou modificações)?
Apenas um lembrete amigável de que estamos procurando um PR contra k / website (branch dev-1.16) que deve ser feito na sexta-feira, 23 de agosto. Seria ótimo se fosse o início da documentação completa, mas até mesmo um PR de espaço reservado é aceitável. Deixe-me saber se você tiver alguma dúvida!
Obrigado!
 VineethReddy02
em 1 ago. 2019
VineethReddy02
em 1 ago. 2019
Documentação PR: https://github.com/kubernetes/website/pull/15716
lmdaly
em 7 ago. 2019
@lmdaly O gerenciador de topologia fornecerá alguma informação ou API para informar aos usuários a configuração NUMA para determinado pod?
 mJace
em 15 ago. 2019
mJace
em 15 ago. 2019
@mJace algo visível por meio do kubectl describe para o pod?
lmdaly
em 15 ago. 2019
@lmdaly Sim, kubectl describe é bom. ou alguma API para retornar informações relacionadas.
Já que estamos desenvolvendo um serviço para fornecer algumas informações relacionadas à topologia para pods, como o status de fixação da CPU para o pod e o nó de numa para seu VF passado.
E alguma ferramenta de monitor, como o weave scope, pode chamar a API para fazer um trabalho sofisticado.
Admin pode dizer se o VNF está sob a configuração adequada de numa, por exemplo.
Apenas gostaria de saber se o Topology Manager irá cobrir esta parte.
ou se houver algum trabalho que possamos fazer se o Topology Manager planeja oferecer suporte a esse tipo de funcionalidade.
mJace
em 15 ago. 2019
@mJace Ok, então atualmente não existe uma API como essa para o Topology Manager. Não acho que haja precedência para isso, já que com o CPU & Device Manager não há visibilidade do que foi realmente atribuído aos pods.
Portanto, acho que seria bom começar uma discussão sobre isso e ver que tipo de visão podemos oferecer aos usuários.
lmdaly
em 15 ago. 2019
Entendo, pensei que o CPU & Device Manager é capaz de ver essas informações.
Talvez o cadvisor seja uma boa função para fornecer essas informações.
Porque basicamente o cadvisor obtém informações do contêiner como PID, etc. por ps ls .
E é da mesma forma que verificamos as informações relacionadas à topologia do contêiner.
Vou implementar isso no cadvisor e criar um pr para ele.
mJace
em 15 ago. 2019
Eu criei um problema relacionado no cadvisor.
https://github.com/google/cadvisor/issues/2290
mJace
em 16 ago. 2019
/atribuir
 khenidak
em 24 ago. 2019
khenidak
em 24 ago. 2019
+1 para a proposta cadvisor @mJace.
Para usar DPDK lib dentro do contêiner com CPU Manager e Topology Manager , analisando a afinidade de cpu do contêiner e depois passando para dpdk lib, ambos são necessários para a fixação de thread de DPDK lib.
Para obter mais detalhes, se um cpus não for permitido no subsistema cpuset do contêiner, as chamadas para sched_setaffinity para fixar o processo no cpus serão filtradas.
DPDK lib utiliza pthread_setaffinity_np para fixação de thread, e pthread_setaffinity_np é um wrapper de nível de thread de sched_setaffinity .
E o CPU Manager do Kubernetes define cpus exclusivo no subsistema cpuset do contêiner.
bg-chun
em 26 ago. 2019
@ bg-chun Eu entendi que a mudança do cadvisor servia a um propósito diferente: monitorar. Para sua necessidade, é possível ler as CPUs atribuídas de dentro do contêiner analisando 'Cpus_Allowed' ou 'Cpus_Allowed_List' em '/ proc / self / status'. Essa abordagem funcionará para você?
ConnorDoyle
em 26 ago. 2019
As informações do Cpus_Allowed são afetadas pelo sched_setaffinity . Portanto, se a aplicação definir algo, será um subconjunto do que é realmente permitido pelo controlador cpuset do Cgroup.
 kad
em 26 ago. 2019
kad
em 26 ago. 2019
@kad , eu estava sugerindo uma maneira para o inicializador dentro do contêiner descobrir os valores de cpu id para passar para o programa DPDK. Portanto, isso acontece antes que a afinidade de nível de encadeamento seja definida.
ConnorDoyle
em 26 ago. 2019
@ConnorDoyle
Obrigado por sua sugestão, irei considerá-la.
Meu plano era implantar o servidor tiny-rest-api para informar informações de alocação de CPUs exclusivas ao dpdk-container.
Em relação às mudanças, ainda não vi as mudanças do cadvisor, vejo apenas a proposta .
A proposta diz able to tell if there is any cpu affinity set for the container. em Meta e to tell if there is any cpu affinity set for the container processes. em Trabalho futuro.
Depois de ler a proposta, achei que seria ótimo se o cadvisor pudesse analisar as informações de fixação da CPU e o kubelet passá-las para o contêiner como uma variável de ambiente , como status.podIP , metadata.name e limits.cpu .
Esse é o principal motivo pelo qual saí do +1.
bg-chun
em 26 ago. 2019
@ bg-chun Você pode verificar meu primeiro pr no cadvisor
https://github.com/google/cadvisor/pull/2291
Terminei alguma função semelhante em.
https://github.com/mJace/numacc
mas não tenho certeza de qual é a maneira correta de implementá-lo no cadvisor
É por isso que eu só crio um PR com um novo recurso -> show PSR.
mJace
em 26 ago. 2019
mas não tenho certeza de qual é a maneira correta de implementá-lo no cadvisor
Talvez pudéssemos discutir isso sob essa proposta? Se seus gurus acham que esse recurso é necessário :)
mJace
em 26 ago. 2019
O congelamento do código https://github.com/kubernetes/kubernetes/issues/72828 para k / k PRs restantes
kacole2
em 26 ago. 2019
@ kacole2 todos os PRs necessários para este recurso estão mesclados ou na fila de mesclagem.
lmdaly
em 30 ago. 2019
Olá @lmdaly - 1.17 As melhorias
A programação de lançamento atual é:
- Segunda-feira, 23 de setembro - Começa o ciclo de lançamento
- Terça-feira, 15 de outubro, EOD PST - Congelamento de melhorias
- Quinta-feira, 14 de novembro, EOD PST - Código Congelado
- Terça-feira, 19 de novembro - os documentos devem ser preenchidos e revisados
- Segunda-feira, 9 de dezembro - Kubernetes 1.17.0 lançado
Em caso afirmativo, liste todos os PRs k / k relevantes nesta edição para que possam ser rastreados corretamente. 👍
Obrigado!
/ marco claro
 mrbobbytables
em 22 set. 2019
mrbobbytables
em 22 set. 2019
@lmdaly há um link direto para a GPU com a discussão de RDMA?
 nickolaev
em 25 set. 2019
nickolaev
em 25 set. 2019
@nickolaev , também
 moshe010
em 25 set. 2019
moshe010
em 25 set. 2019
@ moshe010 @nickolaev @lmdaly , Nós também
 Deepthidharwar
em 25 set. 2019
Deepthidharwar
em 25 set. 2019
Olá! Tenho uma pergunta sobre o NTM e o planejador. Pelo que entendi, o planejador não sabe sobre NUMAs e pode preferir um nó em que não haja recursos (cpu, memória e dispositivo) no NUMA desejado. Portanto, o gerenciador de topologia recusará a alocação de recursos nesse nó. É verdade?
 LilyaBu
em 25 set. 2019
LilyaBu
em 25 set. 2019
@nickolaev @Deepthidharwar , vou iniciar o google doc com casos de uso e podemos mover a discussão para ele. Vou postar algo na próxima semana. Se estiver tudo bem com você.
moshe010
em 25 set. 2019
Estou muito feliz em ver esse recurso. Também precisamos de CPU, Hugepage, SRIOV-VFs e outros resorce de hardware em um único nó NUMA.
Mas o largepage não é percebido como um recurso escalar por plug-in de dispositivo. Esse recurso precisa alterar o recurso largepage no k8s?
@iamneha
 andyzheung
em 26 set. 2019
andyzheung
em 26 set. 2019
@ConnorDoyle Apenas para confirmar, esse recurso precisa de dicas de topologia do gerenciador de CPU e do gerenciador de dispositivos? Eu testei no 1.16 e não funcionou, parece que só recebeu uma dica do gerenciador de CPU, mas nenhuma dica do lado do dispositivo.
 jianzzha
em 26 set. 2019
jianzzha
em 26 set. 2019
@ConnorDoyle aqui está um pouco mais de detalhes:
https://gist.githubusercontent.com/jianzzha/c2a66a2514c178cca76a432029ff3387/raw/264f13dfcd06f1f80c48c113aa235fab7c33d81e/hyper%2520threading%2520ativado
jianzzha
em 26 set. 2019
@jianzzha , Qual plugin de dispositivo você está usando? Por exemplo, se você usar o plugin de dispositivo SR-IOV, você precisa se certificar de que ele relata o nó NUMA, consulte [1]
moshe010
em 26 set. 2019
@andyzheung A grande integração da página está sendo discutida e foi apresentada na reunião do nó sig nas últimas duas semanas. Aqui estão alguns links relevantes:
https://docs.google.com/presentation/d/1H5xhCjgCZJjdTm-mGUFwqoz8XmoVd8xTCwJ1AfVR_54/edit?usp=sharing
https://github.com/kubernetes/enhancements/pull/1245
https://github.com/kubernetes/enhancements/pull/1199
@jianzzha Em relação ao plugin do dispositivo não dá dicas. Seu plug-in foi atualizado para relatar informações NUMA sobre os dispositivos que ele enumera? É necessário adicionar este campo à mensagem do dispositivo https://github.com/kubernetes/kubernetes/blob/master/pkg/kubelet/apis/deviceplugin/v1beta1/api.proto#L100
klueska
em 26 set. 2019
obrigado rapazes. Corrigido e funciona agora.
jianzzha
em 26 set. 2019
@klueska
Sobre nvidia-gpu-device-plugin ..
Eu posso ver apenas um PR (WIP) ativo para atualizar nvidia-gpu-device-plugin para Topology Manager.
O nvidia-gpu-divice-plugin será atualizado para fornecer dicas de topologia com o PR acima? ou há algo que eu sinto falta?
bg-chun
em 26 set. 2019
@ bg-chun Sim, deveria ser. Apenas pinguei o autor. Se ele não voltar no dia seguinte ou depois, eu mesmo atualizarei o plugin.
klueska
em 26 set. 2019
@ bg-chun @klueska Eu atualizei o patch.
 carmark
em 27 set. 2019
carmark
em 27 set. 2019
@klueska @carmark
Obrigado pela atualização e pelo aviso.
Apresentarei a atualização do plugin sr-iov e a atualização do plugin gpu aos usuários em meu espaço de trabalho.
bg-chun
em 27 set. 2019
Eu proporia um aprimoramento para o próximo lançamento.
Trata-se basicamente de remover o "alinhamento de topologia só acontece se o pod estiver em restrição de QoS garantida".
Essa restrição meio que torna o Topology Manager inutilizável para mim no momento, porque eu não gostaria de pedir CPUs exclusivas de K8s, no entanto, gostaria de alinhar os sockets de vários dispositivos, vindos de vários pools (por exemplo, GPU + SR -IOV VFs etc.)
E se minha carga de trabalho não for sensível à memória ou não quiser restringir seu uso de mem (outro critério de QoS garantido).
No futuro, quando espero que as páginas enormes também sejam alinhadas, essa restrição parecerá ainda mais limitadora da IMO.
Existe algum argumento contra o alinhamento individual dos recursos "alinhaveis"? Com certeza, vamos apenas reunir dicas do Gerenciador de CPU se CPUs exclusivas forem usadas, mas , ou do gerenciador de memória quando o usuário solicitar páginas enormes, etc.
Ou isso, ou se a carga de computação extra desnecessária durante a inicialização do pod for uma preocupação, talvez traga de volta a sinalização de configuração no nível do pod original para controlar se o alinhamento acontece ou não (que fiquei surpreso ao ver sendo descartado durante a implementação)
 Levovar
em 30 set. 2019
Levovar
em 30 set. 2019
Eu proporia um aprimoramento para o próximo lançamento.
Trata-se basicamente de remover o "alinhamento de topologia só acontece se o pod estiver em restrição de QoS garantida".
Este é o item número 8 em nossa lista TODO para 1.17:
https://docs.google.com/document/d/1YTUvezTLGmVtEF3KyLOX3FzfSDw9w0zB-s2Tj6PNzLA/edit#heading = h.xnehh6metosd
Existe algum argumento contra o alinhamento individual dos recursos "alinhaveis"? Com certeza, vamos apenas reunir dicas do Gerenciador de CPU se CPUs exclusivas forem usadas, mas , ou do gerenciador de memória quando o usuário solicitar páginas enormes, etc.
Você está propondo que haja um mecanismo para informar seletivamente ao kubelet qual recurso alinhar e quais não alinhar (ou seja, quero alinhar minhas alocações de CPU e GPU, mas não minhas grandes alocações de página). Não acho que alguém se oporia a isso, mas a interface para decidir seletivamente quais recursos alinhar e quais não alinhar pode se tornar excessivamente complicada se continuarmos a especificar o alinhamento como um sinalizador no nível do nó.
Ou isso, ou se a carga de computação extra desnecessária durante a inicialização do pod for uma preocupação, talvez traga de volta a sinalização de configuração no nível do pod original para controlar se o alinhamento acontece ou não (que fiquei surpreso ao ver sendo descartado durante a implementação)
Não havia suporte suficiente para um sinalizador no nível do pod para justificar uma proposta de atualização das especificações do pod com isso. Para mim, faz sentido levar essa decisão ao nível do pod, já que alguns pods precisam / querem alinhamento e outros não, mas nem todos estavam de acordo.
klueska
em 30 set. 2019
+1 para remover a restrição da classe QoS no alinhamento da topologia (eu adicionei à lista: smiley :). Não entendi que o @Levovar está pedindo a habilitação da topologia por recurso, apenas que devemos alinhar todos os recursos alinhaveis usados por um determinado contêiner.
Pelo que me lembro, nunca houve um campo de nível de pod para ativar a topologia no KEP. A justificativa para não introduzi-lo em primeiro lugar foi a mesma justificativa para deixar núcleos exclusivos implícitos - o Kubernetes, como um projeto, deseja ser livre para interpretar a especificação do pod liberalmente em termos de gerenciamento de desempenho no nível do nó. Sei que essa postura não é satisfatória para alguns membros da comunidade, mas sempre podemos levantar o assunto novamente. Há uma tensão natural entre habilitar recursos avançados para poucos e modular a carga cognitiva para a maioria dos usuários.
ConnorDoyle
em 1 out. 2019
IMO, nos estágios iniciais do projeto, pelo menos, havia um sinalizador no nível do pod, se minha memória não me falha, mas foi em torno de 1.13: D
Pessoalmente, estou bem em tentar alinhar todos os recursos o tempo todo, mas "no passado" geralmente havia uma resistência da comunidade contra recursos que introduziriam atrasos na inicialização ou na decisão de agendamento de todos os pods, independentemente de eles realmente precisam do aprimoramento, ou não.
Então, eu estava apenas tentando "pré-endereçar" essas preocupações com duas opções vindo à minha mente: pré-bloquear o alinhamento de grupos de recursos com base em alguns critérios (fácil de definir para CPU, mais difícil para outros); ou introduzir algum sinalizador de configuração.
No entanto, se não houver resistência agora contra um aprimoramento genérico, estou totalmente bem com isso :)
Levovar
em 1 out. 2019
@mrbobbytables Estamos planejando graduar TopologyManager para beta em 1.17. O problema de rastreamento está aqui: https://github.com/kubernetes/kubernetes/issues/83479
klueska
em 3 out. 2019
@ bg-chun @klueska Eu atualizei o patch.
Patch mesclado:
https://github.com/NVIDIA/k8s-device-plugin/commit/cc0aad87285b573127add4e487b13434a61ba0d6
Nova versão criada com o patch:
https://github.com/NVIDIA/k8s-device-plugin/releases/tag/1.0.0-beta2
klueska
em 3 out. 2019
rastreamento beta para v1.17
derekwaynecarr
em 4 out. 2019
Incrível, obrigado @derekwaynecarr . Vou adicioná-lo à planilha :)
/ stage beta
mrbobbytables
em 6 out. 2019
@lmdaly
Eu sou uma das sombras de docs v1.17.
Este aprimoramento (ou o trabalho planejado para v1.17) requer novos documentos (ou modificações nos documentos existentes)? Se não, você pode atualizar a Folha de Rastreador de Aprimoramento 1.17 (ou me avise e eu o farei)
Em caso afirmativo, apenas um lembrete amigável de que estamos procurando um PR para o site k / (branch dev-1.17) com vencimento até sexta-feira, 8 de novembro, pode ser apenas um PR no momento. Deixe-me saber se você tiver alguma dúvida!
Obrigado!
VineethReddy02
em 21 out. 2019
@ VineethReddy02 sim, planejamos atualizações de documentação para 1.17, se você pudesse atualizar a folha de acompanhamento, seria ótimo!
Teremos certeza de abrir esse PR antes disso, obrigado pelo lembrete.
O problema para rastreamento de documentação para isso está aqui: https://github.com/kubernetes/kubernetes/issues/83482
lmdaly
em 23 out. 2019
https://github.com/kubernetes/enhancements/pull/1340
Pessoal, abri o PR de atualização do KEP para adicionar um rótulo de nó embutido ( beta.kubernetes.io/topology ) para o Gerenciador de Topologia.
O rótulo irá expor a política do nó.
Acho que seria útil para agendar um pod para um nó específico quando houver nós com várias políticas no mesmo cluster.
Posso pedir uma revisão?
bg-chun
em 28 out. 2019
Olá @lmdaly @derekwaynecarr
Jeremy da equipe de melhorias 1.17 aqui 👋. Você poderia listar os k / k PRs que estão em andamento para que possamos rastreá-los? Vejo que o # 83492 foi mesclado, mas parece que há mais alguns problemas relacionados pendurados no item de rastreamento geral. Estamos fechando o Code Freeze em 14 de novembro, então gostaríamos de ter uma ideia de como isso está indo antes disso! Muito obrigado!
 jeremyrickard
em 4 nov. 2019
jeremyrickard
em 4 nov. 2019
@jeremyrickard Este é o problema de rastreamento para 1.17, conforme mencionado acima: https://github.com/kubernetes/enhancements/issues/693#issuecomment -538123786
klueska
em 4 nov. 2019
@lmdaly @derekwaynecarr
Um lembrete amigável de que estamos procurando um espaço reservado para RP do Docs em relação ao site k / (branch dev-1.17), que deve ser entregue na sexta-feira, 8 de novembro. Só temos mais 2 dias para este prazo.
daminisatya
em 6 nov. 2019
O Docs PR está aqui entre: https://github.com/kubernetes/website/pull/17451
lmdaly
em 8 nov. 2019
@klueska , vejo que parte do trabalho aumentou para 1,18. Você ainda está planejando mudar para beta no 1.17, ou permanecerá como alfa, mas mudará?
jeremyrickard
em 13 nov. 2019
Esqueça, vejo em https://github.com/kubernetes/kubernetes/issues/85093 que você vai pular para a versão beta no 1.18 agora, não como parte do 1.17. Você quer que rastreemos isso como uma mudança importante para a versão alfa como parte do marco 1.17 @klueska? Ou apenas adiar a graduação para 1,18?
jeremyrickard
em 13 nov. 2019
/ milestone v1.18
jeremyrickard
em 15 nov. 2019
Ei @klueska
1.18 equipe de melhorias verificando! Você ainda planeja graduar isso para beta no 1.18? O Congelamento de Aprimoramento será em 28 de janeiro, se o seu KEP exigir alguma atualização, enquanto o Congelamento de Código será em 5 de março.
Obrigada!
jeremyrickard
em 7 jan. 2020
sim.
klueska
em 7 jan. 2020
@klueska obrigado pela atualização! Atualizando a folha de acompanhamento.
jeremyrickard
em 7 jan. 2020
@klueska como estávamos revisando os KEPs para este lançamento, percebemos que faltam planos de teste. Para passar para a versão beta no lançamento, será necessário adicionar planos de teste. Vou removê-lo do marco por agora, mas podemos adicioná-lo novamente se você preencher uma Solicitação de Exceção e adicionar os planos de teste ao KEP. Desculpas pelo aviso tardio.
jeremyrickard
em 29 jan. 2020
/ marco claro
jeremyrickard
em 29 jan. 2020
@vpickard veja acima
klueska
em 29 jan. 2020
 vpickard
em 29 jan. 2020
vpickard
em 29 jan. 2020
@jeremyrickard Existe um modelo de plano de teste que você pode apontar como referência?
vpickard
em 29 jan. 2020
@vpickard você pode dar uma olhada em:
https://github.com/kubernetes/enhancements/blob/master/keps/sig-storage/20190530-pv-health-monitor.md#test -plan
e
https://github.com/kubernetes/enhancements/blob/master/keps/sig-storage/20200120-skip-permission-change.md#test -plan
Inclui uma visão geral dos testes de unidade e testes e2e.
Se você tiver algo que apareça na grade de teste, seria ótimo incluir.
jeremyrickard
em 29 jan. 2020
A exceção foi aprovada.
/ milestone v1.18
jeremyrickard
em 30 jan. 2020
@jeremyrickard Plano de teste mesclado: https://github.com/kubernetes/enhancements/pull/1527
klueska
em 4 fev. 2020
Olá @klueska @vpickard , apenas um lembrete amigável de que o Code Freeze entrará em vigor na quinta-feira, 5 de março.
Você pode vincular todos os PRs k / k ou quaisquer outros PRs que devam ser rastreados para este aprimoramento?
Obrigada :)
 palnabarun
em 5 fev. 2020
palnabarun
em 5 fev. 2020
Olá @palnabarun
Rastreando o problema aqui para 1.18:
https://github.com/kubernetes/kubernetes/issues/85093
PRs abertos atuais:
https://github.com/kubernetes/kubernetes/pull/87758 (aprovado, testes de descamação)
https://github.com/kubernetes/kubernetes/pull/87759 (WIP)
https://github.com/kubernetes/kubernetes/pull/87650 (Revisado, precisa de aprovação)
https://github.com/kubernetes/kubernetes/pull/87645 (teste e2e PR, aprovação necessária)
@vpickard você pode adicionar qualquer PRs da e2e que eu perdi.
Obrigado
 nolancon
em 5 fev. 2020
nolancon
em 5 fev. 2020
Obrigado @nolancon por vincular as relações públicas e a questão guarda-chuva aqui. Eu adicionei os PRs à folha de acompanhamento.
palnabarun
em 5 fev. 2020
Olá @palnabarun , @nolancon ,
Alguns PRs abertos adicionais relacionados aos testes E2E:
https://github.com/kubernetes/test-infra/pull/16062 (precisa de revisão e aprovação)
https://github.com/kubernetes/test-infra/pull/16037 (precisa de revisão e aprovação)
vpickard
em 6 fev. 2020
Obrigado @vpickard pelas atualizações adicionais. :)
palnabarun
em 9 fev. 2020
Olá @lmdaly , sou uma das sombras do docs v1.18.
Este aprimoramento para (ou o trabalho planejado para v1.18) requer novos documentos (ou modificações nos documentos existentes)? Se não, você pode atualizar a Folha de Rastreador de Aprimoramento 1.18 (ou me avise e eu o farei)
Em caso afirmativo, apenas um lembrete amigável de que estamos procurando um PR contra k / website (branch dev-1.18) com vencimento até sexta-feira, 28 de fevereiro., Pode ser apenas um PR no momento. Deixe-me saber se você tiver alguma dúvida!
 irvifa
em 9 fev. 2020
irvifa
em 9 fev. 2020
Olá @irvifa , obrigado pelo
Obrigado.
nolancon
em 10 fev. 2020
Olá @nolancon, obrigado pela sua resposta rápida, mudo o status para Placeholder PR agora. Obrigado!
irvifa
em 10 fev. 2020
@palnabarun Para https://github.com/kubernetes/kubernetes/pull/87759 em dois PRs para facilitar o processo de revisão. O segundo está aqui https://github.com/kubernetes/kubernetes/pull/87983 e também precisa ser rastreado. Obrigado.
nolancon
em 10 fev. 2020
@nolancon Obrigado pelas atualizações.
Vejo que alguns dos PR ainda estão pendentes de fusão. Eu queria ver se você precisa da ajuda da equipe de lançamento para levar Revisores e Aprovadores aos PR. Deixe-nos saber se você precisar de alguma coisa.
Para sua informação, estamos muito perto do Code Freeze em 5 de março
palnabarun
em 27 fev. 2020
@nolancon Obrigado pelas atualizações.
Vejo que alguns dos PR ainda estão pendentes de fusão. Eu queria ver se você precisa da ajuda da equipe de lançamento para levar Revisores e Aprovadores aos PR. Deixe-nos saber se você precisar de alguma coisa.
Para sua informação, estamos muito perto do Code Freeze em 5 de março
@palnabarun Mais uma atualização, https://github.com/kubernetes/kubernetes/pull/87983 agora está fechado e não precisa ser rastreado. As mudanças necessárias estão incluídas no PR original https://github.com/kubernetes/kubernetes/pull/87759, que está sob revisão.
nolancon
em 27 fev. 2020
@nolancon Cool. Também estou rastreando o problema do rastreador de guarda-chuva que você compartilhou acima. :)
palnabarun
em 27 fev. 2020
Olá @nolancon , Code Freeze em 5 de março .
Pelo Code Freeze, todos os PRs relevantes devem ser mesclados, caso contrário, você precisaria registrar uma solicitação de exceção.
palnabarun
em 3 mar. 2020
Olá @nolancon ,
Hoje EOD é Code Freeze .
Você acha que https://github.com/kubernetes/kubernetes/pull/87650 seria revisado dentro do prazo?
Caso contrário, registre uma solicitação de exceção .
palnabarun
em 5 mar. 2020
Olá @nolancon ,
Hoje EOD é Code Freeze .
Você acha que o kubernetes / kubernetes # 87650 seria revisado dentro do prazo?
Caso contrário, registre uma solicitação de exceção .
Olá @palnabarun , muito progresso foi feito nos últimos dias e estamos confiantes de que tudo será aprovado e mesclado antes do congelamento do código. Caso contrário, apresentarei a solicitação de exceção.
Só para esclarecer, por EOD você quer dizer 17h ou meia-noite PST? Obrigado
nolancon
em 5 mar. 2020
Só para esclarecer, por EOD você quer dizer 17h ou meia-noite PST? Obrigado
17h PST.
jeremyrickard
em 5 mar. 2020
O PR foi aprovado, mas está faltando um marco que o nó de assinatura precisa adicionar para mesclar. Eu executei o ping deles na folga, espero que ele se solte e você não precise de exceção. =)
 kikisdeliveryservice
em 5 mar. 2020
kikisdeliveryservice
em 5 mar. 2020
Todos os PRs para este kep parecem ter sido mesclados (e aprovados dentro do prazo), eu atualizei nossa folha de acompanhamento de melhorias. :sorriso:
kikisdeliveryservice
em 6 mar. 2020
/ marco claro
(removendo este problema de aprimoramento do marco v1.18 quando o marco é concluído)
palnabarun
em 29 abr. 2020
Olá @nolancon @lmdaly , aprimoramentos de sombra para 1.19 aqui. Algum plano para isso em 1.19?
 johnbelamaric
em 4 mai. 2020
johnbelamaric
em 4 mai. 2020
A única melhoria planejada para 1.19 é esta:
https://github.com/kubernetes/enhancements/pull/1121
O resto do trabalho será na refatoração de código / correção de bugs conforme necessário.
Existe alguma maneira de mudar o proprietário deste problema para mim em vez de @lmdaly?
klueska
em 4 mai. 2020
Obrigado, vou atualizar o contato.
/ milestone v1.19
johnbelamaric
em 4 mai. 2020
/ assign @klueska
/ unassign @lmdaly
Aqui está, Kevin https://prow.k8s.io/command-help
 pires
em 6 mai. 2020
pires
em 6 mai. 2020
Olá, Kevin. Recentemente, o formato KEP foi alterado e também o # 1620 foi mesclado na semana passada, adicionando questões de revisão de prontidão de produção ao modelo KEP. Se possível, reserve um tempo para reformatar seu KEP e também responda às perguntas adicionadas ao modelo . As respostas a essas perguntas serão úteis para os operadores que usam e solucionam o problema do recurso (principalmente a parte de monitoramento neste estágio). Obrigado!
johnbelamaric
em 13 mai. 2020
@klueska ^^
johnbelamaric
em 13 mai. 2020
@derekwaynecarr @klueska @johnbelamaric
Também pretendo adicionar uma nova política de topologia em 1.19 rel.
Mas ainda não foi revisado pelo proprietário e pelo mantenedor.
(Se parecer difícil de fazer no 1.19, por favor, me avise.)
- PR de atualização do KEP: https://github.com/kubernetes/enhancements/pull/1752
- PR para kubelet: WIP
bg-chun
em 13 mai. 2020
Olá, @klueska 👋 1.19 docs shadow here! Este trabalho de aprimoramento planejado para 1.19 requer novo ou modificação nos documentos?
Lembrete amigável de que se uma nova / modificação nos documentos for necessária, um marcador de posição PR contra k / website (branch dev-1.19 ) será necessário até sexta-feira, 12 de junho.
 annajung
em 21 mai. 2020
annajung
em 21 mai. 2020
Olá, @klueska, espero que você esteja bem.
annajung
em 27 mai. 2020
Olá @annajung. Existem 2 melhorias pendentes que exigirão alterações de documentos:
1121
1752
Ainda estamos decidindo se isso chegará a 1,19 ou será empurrado para 1,20. Se decidirmos mantê-los por 1.19, com certeza vou criar um PR para os documentos até 12 de junho.
klueska
em 29 mai. 2020
Excelente! Obrigado pela atualização, atualizarei a folha de acompanhamento de acordo! Por favor, deixe-me saber uma vez que o espaço reservado PR tiver sido feito. Obrigada!
annajung
em 30 mai. 2020
@lmdaly @ConnorDoyle
Espero que este seja o lugar certo para perguntar e dar alguns comentários.
Eu ligo TopologyManager e CPUManager no meu cluster k8s v1.17.
e sua política é best-effort e static
Aqui estão os recursos do meu pod
resources:
requests:
cpu: 2
intel.com/sriov_pool_a: '1'
limits:
cpu: 2
intel.com/sriov_pool_a: '1'
O PF do sriov_pool_a está no nó 0 do NUMA, então espero que meu pod deva ser executado na CPU do nó 0 do NUMA também.
Mas descobri que o processo do meu pod está sendo executado na CPU do nó 1 do NUMA.
Além disso, não há máscara de afinidade de CPU definida de acordo com o resultado de taskset -p <pid> .
Há algo de errado? Espero que o contêiner tenha uma máscara de afinidade de CPU definida para a CPU do nó 0 numa.
Existe algum exemplo ou teste que eu possa fazer para saber se meu TopoloyManager está funcionando corretamente?
mJace
em 4 jun. 2020
@annajung Placeholder docs PR adicionado: https://github.com/kubernetes/website/pull/21607
klueska
em 9 jun. 2020
Olá @klueska ,
Para acompanhar o e-mail enviado para k-dev na segunda-feira, gostaria de informar que o Code Freeze foi estendido para quinta-feira, 9 de julho. Você pode ver a programação revisada aqui: https://github.com/kubernetes/sig-release/tree/master/releases/release-1.19
Esperamos que todos os RPs sejam mesclados nessa época. Por favor, deixe-me saber se você tem alguma dúvida. 😄
melhor,
Kirsten
kikisdeliveryservice
em 18 jun. 2020
Olá @klueska , um lembrete amigável do próximo prazo final.
Lembre-se de preencher o seu documento de RP de espaço reservado e deixá-lo pronto para revisão na segunda-feira, 6 de julho.
annajung
em 22 jun. 2020
Obrigado @annajung . Uma vez que o congelamento de código foi movido para 9 de julho, faz sentido adiantar a data dos documentos também? O que acontece se criarmos a documentação, mas o recurso não chegar a tempo (ou o fizer de uma forma ligeiramente diferente da que a documentação sugere)?
klueska
em 23 jun. 2020
Olá @klueska , é um ótimo ponto! O prazo de todos os documentos também foi adiado em uma semana com a nova data de lançamento, mas acho que você tem um ponto válido. Deixe-me entrar em contato com o líder de documentos para o lançamento e entrar em contato com você! Obrigado por apontar isto!
annajung
em 24 jun. 2020
Olá, @klueska , obrigado novamente por nos chamar a atenção para isso. Houve uma confusão com as datas dos documentos para o lançamento. Como você mencionou, "PR pronto para revisão" deve vir após o congelamento do código e esteve nas versões anteriores.
No entanto, depois de falar com a equipe de lançamento, decidimos manter as datas como estão para este lançamento 1.19 tornando o "PR pronto para revisão" um prazo flexível. A equipe do Documentos será flexível e trabalhará com você / outras pessoas que precisem de mais tempo para garantir que os documentos estejam sincronizados com o código. Embora o prazo "PR pronto para revisão" não seja cumprido, o "PR revisado e lido para mesclar" o será.
Espero que isso ajude a responder às suas preocupações! Entre em contato se tiver mais perguntas.
Além disso, apenas um lembrete amigável de datas:
"Prazo do Docs - PRs prontos para revisão" é devido até 6 de julho
"Documentos concluídos - Todos os PRs revisados e prontos para mesclar" deve ser entregue em 16 de julho
annajung
em 24 jun. 2020
Olá @klueska : wave: - 1.19, líder de melhorias aqui,
Você pode criar um link para todos os PRs de implementação aqui, para que a equipe de lançamento possa rastreá-los? : ligeiramente_smiling_face:
Obrigada.
palnabarun
em 28 jun. 2020
@palnabarun
O acompanhamento de PR https://github.com/kubernetes/enhancements/pull/1121 pode ser encontrado em:
https://github.com/kubernetes/kubernetes/pull/92665
Infelizmente, o aprimoramento nº 1752 não chegará ao lançamento, portanto, não há PR para rastreá-lo.
klueska
em 30 jun. 2020
Olá @klueska : wave :, vejo que ambos os PRs (https://github.com/kubernetes/enhancements/pull/1121 e https://github.com/kubernetes/enhancements/pull/1752) que você mencionou referem-se ao mesmo aprimoramento. Visto que https://github.com/kubernetes/enhancements/pull/1752 estende os requisitos de graduação do Beta e eles não farão isso no lançamento, podemos assumir que não há mais mudanças esperadas no 1.19?
Obrigada. : ligeiramente_smiling_face:
O Code Freeze começa na quinta-feira, 9 de julho EOD PST
palnabarun
em 6 jul. 2020
@palnabarun Esta é uma continuação de PR para # 92665 que deve chegar hoje ou amanhã: https://github.com/kubernetes/kubernetes/pull/92794
Depois disso, não deve haver mais PRs para este lançamento, com bugs imprevistos pendentes.
klueska
em 6 jul. 2020
Impressionante! Obrigado pela atualização. : +1:
Estaremos de olho em https://github.com/kubernetes/kubernetes/pull/92794.
palnabarun
em 6 jul. 2020
@annajung https://github.com/kubernetes/website/pull/21607 está pronto para revisão.
klueska
em 6 jul. 2020
Parabéns, @klueska kubernetes / kubernetes # 92794 finalmente foi mesclado. Vou atualizar a planilha de acompanhamento de acordo 😄
kikisdeliveryservice
em 11 jul. 2020
/ marco claro
(removendo este problema de aprimoramento do marco v1.19 quando o marco é concluído)
kikisdeliveryservice
em 12 set. 2020
Oi @klueska
Melhorias liderar aqui. Há planos para que isso se gradue em 1.20?
Obrigado!
Kirsten
kikisdeliveryservice
em 13 set. 2020
Não há planos para a graduação, mas há um PR que deve ser rastreado para 1.20 relacionado a esta melhoria:
https://github.com/kubernetes/kubernetes/pull/92967
klueska
em 16 set. 2020
Mesmo que não esteja se formando em 1.20, continue a vincular PRs relacionados a este problema como você acabou de fazer.
kikisdeliveryservice
em 16 set. 2020
@kikisdeliveryservice pode, por favor, ajudar a compreender o processo. O recurso Topology Manager não está graduando em 1.20, mas o novo recurso será adicionado a ele e será trabalhado agora: https://github.com/kubernetes/enhancements/pull/1752 k / k: https: // github. com / kubernetes / kubernetes / pull / 92967. É algo que precisamos rastrear com a equipe de lançamento? Isso pode simplificar o rastreamento da atualização de documentos para 1.20 ou talvez alguma outra coisa que esteja sendo monitorada.
A mudança é aditiva, então não há muita razão para chamá-la de beta2 ou algo assim.
PR de aumento relacionado que reflete a realidade de que o recurso extra não foi enviado no 1.19: https://github.com/kubernetes/enhancements/pull/1950
 SergeyKanzhelev
em 27 out. 2020
SergeyKanzhelev
em 27 out. 2020
PR de atualização da documentação da web do Topology Manager para incluir o recurso de escopo: https://github.com/kubernetes/website/pull/24781
 k-wiatrzyk
em 29 out. 2020
k-wiatrzyk
em 29 out. 2020
Acredito que pode ser rastreado com 1.20 e não necessariamente precisa se formar. @kikisdeliveryservice entre em
annajung
em 29 out. 2020
Olá @SergeyKanzhelev
Olhando para a história, esse não é o caso. Disseram-me que isso não seria uma graduação acima, o que é bom e porque esse KEP não foi rastreado. No entanto, esse aprimoramento (sem o conhecimento da equipe de aprimoramentos) foi recentemente redirecionado por @ k-wiatrzyk para 1.20 como beta (https://github.com/kubernetes/enhancements/pull/1950).
Se você deseja alavancar o processo de lançamento: rastreamento de melhorias, sendo uma parte do marco de lançamento e tendo a equipe de documentos acompanhando isso / tendo documentos incluídos no lançamento 1.20, uma solicitação de exceção de melhoria deve ser preenchida o mais rápido possível.
kikisdeliveryservice
em 30 out. 2020
O recurso já foi incorporado ao KEP (pré-existente) (antes do prazo de aprimoramento).
https://github.com/kubernetes/enhancements/pull/1752
Na sua implementação, a RP já faz parte do marco.
https://github.com/kubernetes/kubernetes/pull/92967
Eu não sabia que havia mais o que fazer.
Com quem precisamos registrar uma exceção, e para que exatamente?
klueska
em 30 out. 2020
Olá @klueska, o pr que você está se referindo foi mesclado em junho para adicionar beta ao kep em 1.19: https://github.com/bg-chun/enhancements/blob/f3df83cc997ff49bfbb59414545c3e4002796f19/keps/sig-node/0035-20190130-topology -manager.md # beta -v119
O prazo de aprimoramentos para 1.20 era 6 de outubro, mas a mudança, movendo o beta para 1.20 e removendo a referência para 1.19 foi mesclada três dias atrás via https://github.com/kubernetes/enhancements/pull/1950
Você pode encontrar instruções para enviar uma solicitação de exceção aqui: https://github.com/kubernetes/sig-release/blob/master/releases/EXCEPTIONS.md
kikisdeliveryservice
em 30 out. 2020
Ainda estou confuso sobre o motivo pelo qual abriremos uma exceção.
Estou feliz em fazer isso, só não tenho certeza do que incluir nele.
O recurso "Node Topology Manager" já se tornou beta em 1.18.
Não está graduando para GA em 1.20 (está permanecendo em beta).
O PR que está sendo mesclado para 1.20 (ou seja, kubernetes / kubernetes # 92967) é uma melhoria do código existente para o Gerenciador de Topologia, mas não está relacionado a um "aumento" em termos de seu status como alfa / beta / ga, etc.
klueska
em 30 out. 2020
Enviei um e-mail de Call of Exception porque o prazo é hoje (apenas para garantir): https://groups.google.com/g/kubernetes-sig-node/c/lsy0fO6cBUY/m/_ujNkQtCCQAJ
k-wiatrzyk
em 2 nov. 2020
@kikisdeliveryservice @klueska @annajung
A chamada de exceção foi aprovada, você pode encontrar a confirmação aqui: https://groups.google.com/g/kubernetes-sig-release/c/otE2ymBKeMA/m/ML_HMQO7BwAJ
k-wiatrzyk
em 4 nov. 2020
Obrigado @ k-wiatrzyk & @klueska Atualizou a folha de acompanhamento.
cc: @annajung
kikisdeliveryservice
em 5 nov. 2020
Ei @ k-wiatrzyk @klueska
Parece que o kubernetes / kubernetes # 92967 foi aprovado, mas precisa de um rebase.
Apenas um lembrete de que o Code Freeze está chegando em 2 dias na quinta - exceção é necessária.
melhor,
Kirsten
kikisdeliveryservice
em 11 nov. 2020
O PR se fundiu, atualizando a planilha - yay! : smile_cat:
kikisdeliveryservice
em 12 nov. 2020
Questões relacionadas
 sparciii
·
13Comentários
sparciii
·
13Comentários
 msau42
·
13Comentários
msau42
·
13Comentários
 euank
·
13Comentários
justaugustus
·
7Comentários
euank
·
13Comentários
justaugustus
·
7Comentários
 wlan0
·
9Comentários
wlan0
·
9Comentários
Comentários muito úteis
Todos os PRs para este kep parecem ter sido mesclados (e aprovados dentro do prazo), eu atualizei nossa folha de acompanhamento de melhorias. :sorriso: