Enhancements: Administrador de topología de nodo
Descripción de la mejora
- Descripción de la mejora de una línea (se puede usar como nota de la versión): componente de Kubelet para coordinar asignaciones de recursos de hardware detalladas para diferentes componentes en Kubernetes.
- Contacto principal (cesionario): @klueska
- Responsables SIG: sig-node
- Enlace de propuesta de diseño (repositorio de la comunidad): https://github.com/kubernetes/community/pull/1680
- KEP PR: https://github.com/kubernetes/enhancements/pull/781
- KEP: https://github.com/kubernetes/enhancements/blob/master/keps/sig-node/0035-20190130-topology-manager.md
- Enlace a e2e y / o pruebas unitarias: N / A todavía
- Revisores: (para LGTM) recomiendan tener más de 2 revisores (al menos uno del archivo de PROPIETARIOS de área de código) que estén de acuerdo para revisar. Revisores de varias empresas preferidos: @ConnorDoyle @balajismaniam
- Aprobador (probablemente de SIG / área a la que pertenece la mejora): @derekwaynecarr @ConnorDoyle
- Objetivo de mejora (qué objetivo es igual a qué hito):
- Objetivo de lanzamiento alfa (xy): v1.16
- Objetivo de lanzamiento beta (xy): v1.18
- Objetivo de liberación estable (xy)
 lmdaly
lmdaly
Todos 159 comentarios
/ sig nodo
/ tipo de característica
cc @ConnorDoyle @balajismaniam @nolancon
lmdaly
en 17 ene. 2019
Puedo ayudar a informar este diseño basándome en el aprendizaje de Borg. Así que cuenten conmigo como revisor / aprobador.
 vishh
en 4 feb. 2019
vishh
en 4 feb. 2019
Puedo ayudar a informar este diseño basándome en el aprendizaje de Borg. Así que cuenten conmigo como revisor / aprobador.
¿Existe alguna documentación pública sobre cómo funciona esta característica en borg?
 jeremyeder
en 11 feb. 2019
jeremyeder
en 11 feb. 2019
No se trata de NUMA AFAIK.
El lunes 11 de febrero de 2019 a las 7:50 a.m. Jeremy Eder < [email protected] escribió:
Puedo ayudar a informar este diseño basándome en el aprendizaje de Borg. Así que cuenta conmigo
como revisor / aprobador.¿Existe alguna documentación pública sobre cómo funciona esta característica en borg?
-
Estás recibiendo esto porque comentaste.
Responda a este correo electrónico directamente, véalo en GitHub
https://github.com/kubernetes/enhancements/issues/693#issuecomment-462378195 ,
o silenciar el hilo
https://github.com/notifications/unsubscribe-auth/AGvIKPfanjb9Q5DxXAiBgv9C6Y809JX0ks5vMZFZgaJpZM4aE3uz
.
vishh
en 11 feb. 2019
FYI @claurence
Este problema de seguimiento y KEP (https://github.com/kubernetes/enhancements/pull/781) no llegaron a tiempo para la congelación de las mejoras v1.14 ni para la fecha límite extendida. Aprecio que los haya abierto antes de las fechas límite, pero no parece que hayan recibido una revisión o aprobación suficientes. Esto deberá pasar por el proceso de excepción.
Hasta que decidamos si vale la pena la excepción, me inclino a suspender todas las relaciones públicas asociadas con esta mejora.
 spiffxp
en 24 feb. 2019
spiffxp
en 24 feb. 2019
/ cc @jiayingz @ dchen1107
 jiayingz
en 25 feb. 2019
jiayingz
en 25 feb. 2019
@lmdaly Veo que todos ustedes tienen 1.14 en la descripción como el hito alfa, ya que no hubo un KEP implementable combinado, este problema no se está rastreando para 1.14, si hay intenciones de que se incluya en esa versión, por favor enviar una solicitud de excepción.
 claurence
en 27 feb. 2019
claurence
en 27 feb. 2019
@lmdaly Veo que todos ustedes tienen 1.14 en la descripción como el hito alfa, ya que no hubo un KEP implementable combinado, este problema no se está rastreando para 1.14, si hay intenciones de que se incluya en esa versión, por favor enviar una solicitud de excepción.
@claurence el KEP ahora está fusionado (KEP se había fusionado previamente en el repositorio de la comunidad. Esto fue solo para moverlo al repositorio de nuevas mejoras según las nuevas pautas), ¿aún necesitamos enviar una solicitud de excepción para rastrear este problema? por 1,14?
lmdaly
en 5 mar. 2019
Si bien después de leer detenidamente el diseño y los WIP PR, me preocupa que la implementación actual no sea genérica como el diseño de topología original que propusimos en https://github.com/kubernetes/enhancements/pull/781. Este actualmente se lee más como topología NUMA en el nivel de nodo.
Dejé algunos comentarios para una mayor discusión aquí: https://github.com/kubernetes/kubernetes/pull/74345#discussion_r264387724
 resouer
en 11 mar. 2019
resouer
en 11 mar. 2019
la implementación actual no es genérica
Comparta la misma preocupación sobre eso :) ¿Qué hay de otros, por ejemplo, enlaces entre dispositivos (nvlinke para GPU)?
 k82cn
en 20 mar. 2019
k82cn
en 20 mar. 2019
@resouer @ k82cn La propuesta inicial solo trata de alinear las decisiones tomadas por el administrador de la CPU y el administrador de dispositivos para garantizar la proximidad de los dispositivos con la CPU en la que se ejecuta el contenedor. Satisfacer la afinidad entre dispositivos no era un objetivo de la propuesta.
Sin embargo, si la implementación actual está bloqueando la adición de afinidad entre dispositivos en el futuro, me complace cambiar la implementación una vez que entienda cómo lo está haciendo.
lmdaly
en 25 mar. 2019
Creo que el problema principal que veo con la implementación actual y la capacidad de admitir la afinidad entre dispositivos es el siguiente:
Para admitir la afinidad entre dispositivos, normalmente primero debe averiguar qué dispositivos le gustaría asignar a un contenedor _antes_ de decidir qué afinidad de socket le gustaría que tuviera el contenedor.
Por ejemplo, con las GPU de Nvidia, para una conectividad óptima, primero debe buscar y asignar el conjunto de GPU con los NVLINK más conectados _antes_ de determinar qué afinidad de socket tiene ese conjunto.
Por lo que puedo decir en la propuesta actual, la suposición es que estas operaciones ocurren en orden inverso, es decir, la afinidad del socket se decide antes de realizar la asignación de dispositivos.
 klueska
en 5 abr. 2019
klueska
en 5 abr. 2019
Eso no es necesariamente cierto @klueska. Si las sugerencias de topología se extendieran para codificar la topología de dispositivos punto a punto, el Administrador de dispositivos podría considerar eso al informar la afinidad de socket. En otras palabras, la topología entre dispositivos no tendría que escaparse del alcance del administrador de dispositivos. ¿Eso parece factible?
 ConnorDoyle
en 5 abr. 2019
ConnorDoyle
en 5 abr. 2019
Quizás estoy confundido acerca del flujo de alguna manera. Así es como lo entiendo:
1) En la inicialización, los complementos del dispositivo (no devicemanager ) se registran con topologymanager para que puedan emitir devoluciones de llamada en un momento posterior.
2) Cuando se envía un pod, el kubelet llama al lifecycle.PodAdmitHandler en el topologymanager .
3) El lifecycle.PodAdmitHandler llama a GetTopologyHints en cada complemento de dispositivo registrado
4) Luego fusiona estas sugerencias para producir un TopologyHint consolidado asociado con el pod
5) Si decidió admitir la cápsula, regresa con éxito desde lifecycle.PodAdmitHandler almacenando el TopologyHint consolidado para la cápsula en una tienda estatal local
6) En algún momento en el futuro, el cpumanager y el devicemanager llaman a GetAffinity(pod) en el administrador topology para recuperar el TopologyHint asociado con la vaina
7) El cpumanager usa este TopologyHint` para asignar una CPU
8) El devicemanager usa este TopologyHint` para asignar un conjunto de dispositivos
9) Continúa la inicialización del pod ...
Si esto es correcto, supongo que estoy luchando con lo que sucede entre el momento en que el complemento del dispositivo informa su TopologyHints y el momento en que devicemanager hace la asignación real.
Si estas sugerencias están destinadas a codificar "preferencias" para la asignación, creo que lo que está diciendo es tener una estructura más parecida a:
type TopologyHints struct {
hints []struct {
SocketID int
DeviceIDs []int
}
}
Donde no solo pasamos una lista de preferencias de afinidad de socket, sino cómo esas preferencias de afinidad de socket se emparejan con las preferencias de GPU asignables.
Si esta es la dirección en la que está pensando, entonces creo que podríamos hacerlo funcionar, pero de alguna manera tendríamos que coordinar entre cpumanager y devicemanager para asegurarnos de que "aceptaron" lo mismo. pista al hacer sus asignaciones.
¿Hay algo en su lugar que permita esto ya que me perdí?
klueska
en 5 abr. 2019
@klueska
Creo que lo que sucede al hacer algunas correcciones _ menores_ en tu flujo es:
En la inicialización, los complementos del dispositivo se registran con
devicemanagerpara que puedan emitir devoluciones de llamada en un momento posterior.El
lifecycle.PodAdmitHandlerllama aGetTopologyHintsen cada componente con reconocimiento de topología en Kubelet, actualmentedevicemanagerycpumanager.
En este caso, lo que se representará como con reconocimiento de topología en Kubelet son cpumanager y devicemanager . El administrador de topología solo está diseñado para coordinar asignaciones entre componentes que reconocen la topología.
Para esto:
pero necesitaríamos coordinar de alguna manera entre el cpumanager y el devicemanager para asegurarnos de que "aceptaron" la misma pista al hacer sus asignaciones.
Esto es para lo que se introdujo el topologymanager sí. De uno de los borradores anteriores ,
Estos componentes deben coordinarse para evitar asignaciones NUMA cruzadas. Los problemas relacionados con esta coordinación son delicados; Las solicitudes entre dominios, como "Un núcleo exclusivo en el mismo nodo NUMA que la NIC asignada", involucran tanto a CNI como al administrador de CPU. Si el administrador de CPU elige primero, puede seleccionar un núcleo en un nodo NUMA sin una NIC disponible y viceversa.
 eloyekunle
en 6 abr. 2019
eloyekunle
en 6 abr. 2019
Veo.
Entonces, devicemanager y cpumanager implementan GetTopologyHints() y llaman GetAffinity() , evitando la interacción de dirección desde topologymanager con cualquier complemento de dispositivo subyacente . Mirando más de cerca el código, veo que el devicemanager simplemente delega el control a los complementos para ayudar a completar TopologyHints , lo que tiene más sentido al final de todos modos.
Sin embargo, volviendo a la pregunta / problema original que planteé ...
Desde la perspectiva de Nvidia, creo que podemos hacer que todo funcione con este flujo propuesto, asumiendo que se agrega más información a la estructura TopologyHints (y, en consecuencia, a la interfaz del complemento del dispositivo) para reportar información de enlace punto a punto en el futuro. .
Sin embargo, creo que comenzar con SocketMask como la estructura de datos principal para la afinidad de socket de publicidad puede limitar nuestra capacidad para expandir TopologyHints con información punto a punto en el futuro sin romper la interfaz existente. La razón principal es que (al menos en el caso de las GPU de Nvidia) el socket preferido depende de qué GPU realmente se asignarán al final.
Por ejemplo, considere la figura siguiente, cuando intente asignar 2 GPU a un pod con conectividad óptima:
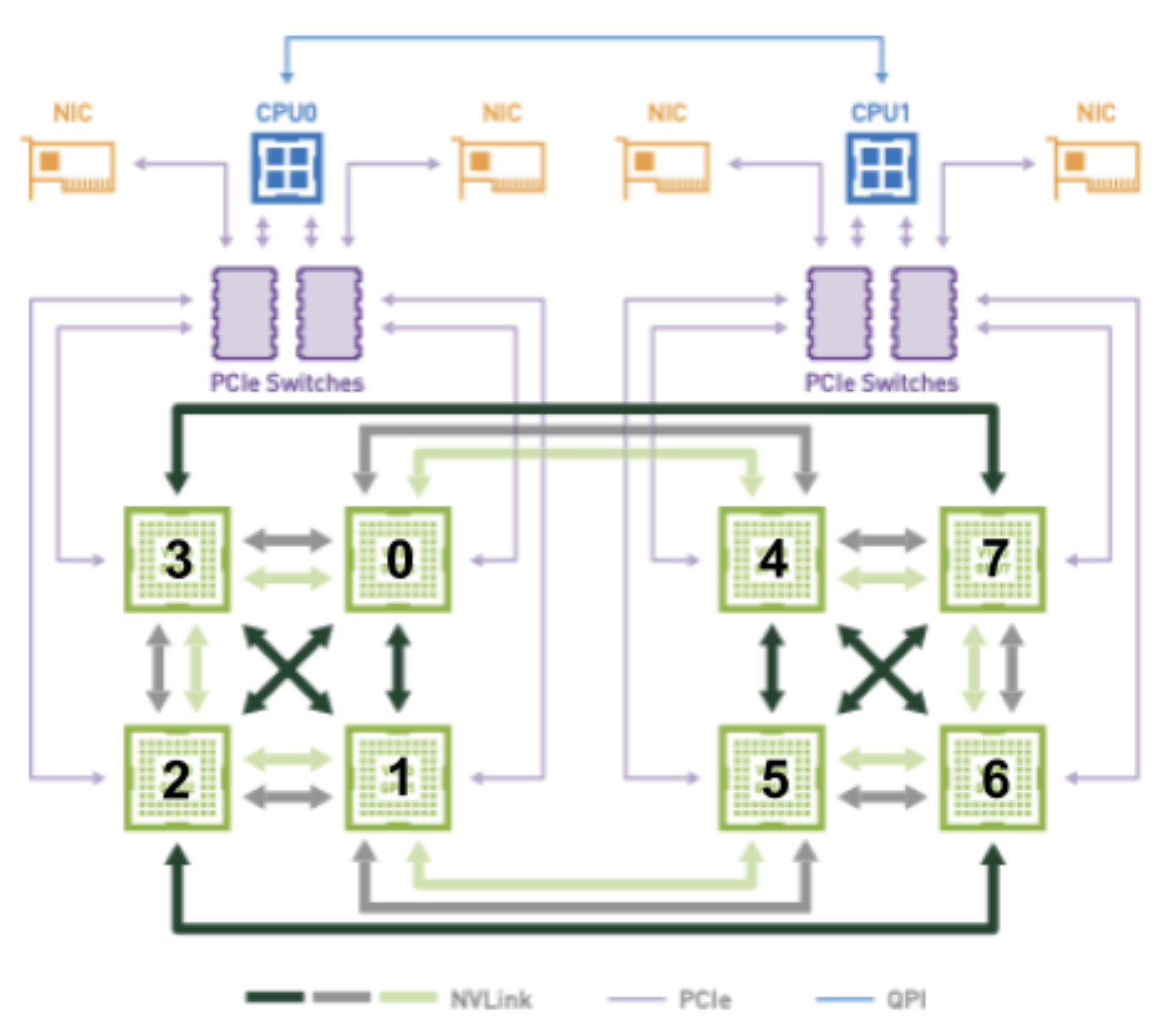
Las combinaciones de GPU de (2, 3) y (6, 7) tienen 2 NVLINK y residen en el mismo bus PCIe. Por lo tanto, deben considerarse candidatos iguales al intentar asignar 2 GPU a un pod. Sin embargo, dependiendo de la combinación elegida, obviamente se preferirá un enchufe diferente, ya que (2, 3) está conectado al enchufe 0 y (6, 7) está conectado al enchufe 1.
De alguna manera, esta información deberá codificarse en la estructura TopologyHints para que devicemanager pueda realizar una de estas asignaciones deseadas al final (es decir, cualquiera que topologymanager consolide las sugerencias Abajo a). Del mismo modo, la dependencia entre las asignaciones de dispositivos preferidas y el socket preferido deberá codificarse en TopologyHints para que cpumanager pueda asignar CPU desde el socket correcto.
Una posible solución específica para las GPU de Nvidia para este ejemplo se vería así:
type TopologyHint struct {
SocketID int
DeviceIDs []int
}
type TopologyHints []TopologyHint
devicemanagerhints := &TopologyHints{
{SocketID: 0, DeviceIDs: []int{2, 3}},
{SocketID: 1, DeviceIDs: []int{6, 7}},
}
cpumanagerhints := &TopologyHints{
{SocketID: 1},
}
Donde topologymanager consolidaría estas sugerencias para devolver {SocketID: 1, DeviceIDs: []int{6, 7}} como la sugerencia preferida cuando devicemanager y cpumanager luego llamen GetAffinity() .
Si bien esto puede proporcionar o no una solución suficientemente genérica para todos los aceleradores, reemplazar SocketMask en la estructura TopologyHints con algo estructurado más como lo siguiente nos permitiría expandir cada sugerencia individual con más campos en el futuro:
Tenga en cuenta que GetTopologyHints() todavía devuelve TopologyHints , mientras que GetAffinity() se ha modificado para devolver un solo TopologyHint lugar de TopologyHints .
type TopologyHint struct {
SocketID int
}
type TopologyHints []TopologyHint
&TopologyHints{
{SocketID: 0},
{SocketID: 1},
}
type HintProvider interface {
GetTopologyHints(pod v1.Pod, container v1.Container) TopologyHints
}
type Store interface {
GetAffinity(podUID string, containerName string) TopologyHint
}
¿Pensamientos?
klueska
en 9 abr. 2019
@klueska Tal vez me esté perdiendo algo, pero no veo la necesidad de que los ID de dispositivo para las GPU NV Link se completen en TopologyManager.
Si la API del complemento de dispositivo se extendió para permitir que los dispositivos devuelvan información sobre la conectividad de dispositivo punto a punto como sugirió @ConnorDoyle , entonces el administrador de dispositivos podría enviar información de sockets de regreso en función de esto.
En su ejemplo, devicemanagerhints podría ser la información que los complementos del dispositivo enviaron al administrador del dispositivo. Luego, el administrador de dispositivos devuelve la información de socket a TopologyManager como está ahora y TopologyManager almacena la sugerencia de socket elegida.
En la asignación, el administrador de dispositivos llama a GetAffinity para obtener la asignación de socket deseada (digamos que el socket es 1 en este caso), utilizando esta información y la información enviada por los complementos del dispositivo, puede ver que en el socket 1 debe asignar dispositivos ( 6,7) ya que son dispositivos NV Link.
¿Tiene sentido o hay algo que me falta?
lmdaly
en 10 abr. 2019
Gracias por tomarse el tiempo para aclarar esto conmigo. Debo haber malinterpretado la sugerencia original de @ConnorDoyle :
Si las sugerencias de topología se extendieran para codificar la topología de dispositivos punto a punto, el Administrador de dispositivos podría considerar eso al informar la afinidad de socket.
Leí esto como si quisiera extender la estructura TopologyHints con información punto a punto directamente.
Parece que está sugiriendo que solo la API del complemento del dispositivo debería ampliarse para proporcionar información punto a punto al devicemanager , de modo que pueda usar esta información para informar al SocketMask a en el conjunto TopologyHints struct siempre GetTopologyHints() se llama.
Creo que esto funcionará, siempre y cuando las extensiones de API para el complemento del dispositivo estén diseñadas para brindarnos información similar a la que describí en mi ejemplo anterior y el devicemanager se extienda para almacenar esta información entre la admisión al pod y el dispositivo. tiempo de asignación.
En este momento, tenemos una solución personalizada en Nvidia que parchea nuestro kubelet para hacer esencialmente lo que está sugiriendo (excepto que no descartamos ninguna decisión en los complementos del dispositivo: el devicemanager se ha hecho consciente de la GPU y toma decisiones de asignación de GPU basadas en topología).
Solo queremos asegurarnos de que cualquier solución a largo plazo que se implemente nos permitirá eliminar estos parches personalizados en el futuro. Y ahora que tengo una mejor idea de cómo funciona el flujo aquí, no veo nada que nos bloquee.
Gracias nuevamente por tomarse el tiempo para aclarar todo.
klueska
en 10 abr. 2019
Hola @lmdaly , soy el líder de mejora de 1.15. ¿Esta característica va a graduar las etapas alfa / beta / estable en 1.15? Házmelo saber para poder realizar un seguimiento adecuado y agregarlo a la hoja de cálculo.
Una vez que comience la codificación, enumere todos los RP k / k relevantes en este número para que se puedan rastrear correctamente.
 kacole2
en 12 abr. 2019
kacole2
en 12 abr. 2019
esta función tendrá su propia puerta de función y será alfa.
/ hito 1,15
 derekwaynecarr
en 12 abr. 2019
derekwaynecarr
en 12 abr. 2019
@derekwaynecarr : el hito proporcionado no es válido para este repositorio. Hitos en este repositorio: [ keps-beta , keps-ga , v1.14 , v1.15 ]
Utilice /milestone clear para borrar el hito.
En respuesta a esto :
esta función tendrá su propia puerta de función y será alfa.
/ hito 1,15
Las instrucciones para interactuar conmigo usando comentarios de relaciones públicas están disponibles aquí . Si tiene preguntas o sugerencias relacionadas con mi comportamiento, presente un problema en el repositorio de kubernetes / test-infra .
 k8s-ci-robot
en 12 abr. 2019
k8s-ci-robot
en 12 abr. 2019
/ hito v1.15
derekwaynecarr
en 12 abr. 2019
/ asignar @lmdaly
 justaugustus
en 28 abr. 2019
lmdaly
en 29 abr. 2019
justaugustus
en 28 abr. 2019
lmdaly
en 29 abr. 2019
@lmdaly
https://github.com/kubernetes/kubernetes/issues/72828
Mi equipo y yo consideramos probar el administrador de topología para aplicaciones sensibles a numa.
Entonces, tenemos algunas preguntas.
Por encima de los PR, ¿son estas implicaciones completas para el administrador de topología?
¿Y es probado o estable ahora?
 bg-chun
en 15 may. 2019
bg-chun
en 15 may. 2019
@ bg-chun Estamos haciendo lo mismo en Nvidia. Hemos incorporado estos WIP PR a nuestra pila interna y hemos creado una estrategia de asignación con reconocimiento de topología para CPU / GPU a su alrededor. Al hacerlo, descubrimos algunos problemas y brindamos comentarios específicos sobre estos RP.
Consulte el hilo de discusión aquí para obtener más detalles:
https://kubernetes.slack.com/archives/C0BP8PW9G/p1556371768035800
klueska
en 15 may. 2019
Hola, @lmdaly , soy la versión 1.15 de la versión de documentos.
Veo que está apuntando a la versión alfa de esta mejora para la versión 1.15. ¿Requiere esto algún documento nuevo (o modificaciones)?
Solo un recordatorio amistoso de que estamos buscando un PR contra k / website (branch dev-1.15) que vence el jueves 30 de mayo. Sería genial si es el comienzo de la documentación completa, pero incluso un PR de marcador de posición es aceptable. ¡Hazme saber si tienes alguna pregunta! 😄
 daminisatya
en 18 may. 2019
daminisatya
en 18 may. 2019
@lmdaly Solo un recordatorio amistoso de que estamos buscando un PR contra k / sitio web (sucursal dev-1.15) que
daminisatya
en 27 may. 2019
Hola @lmdaly . Code Freeze es el jueves 30 de mayo de 2019 @ EOD PST . Todas las mejoras que se introduzcan en la versión deben ser de código completo, incluidas las pruebas , y tener documentos PR abiertos.
Miraré https://github.com/kubernetes/kubernetes/issues/72828 para ver si todos están fusionados.
Si sabe que esto se deslizará, responda y háganoslo saber. ¡Gracias!
kacole2
en 28 may. 2019
@daminisatya He empujado el doc PR. https://github.com/kubernetes/website/pull/14572
Avíseme si se hizo correctamente y si hay algo adicional que deba hacerse. ¡Gracias por el recordatorio!
lmdaly
en 28 may. 2019
Gracias @lmdaly ✨
daminisatya
en 29 may. 2019
Hola @lmdaly , hoy se congela el código para el ciclo de lanzamiento 1.15. Todavía hay bastantes k / k PR que aún no se han fusionado de su problema de seguimiento https://github.com/kubernetes/kubernetes/issues/72828. Ahora está marcado como En riesgo en la hoja de seguimiento de mejoras 1.15 . ¿Existe una alta confianza en que se fusionarán con EOD PST hoy? Después de este punto, solo se permitirán problemas de bloqueo de versiones y RP en el hito con una excepción.
kacole2
en 30 may. 2019
/ hito claro
kacole2
en 3 jun. 2019
Hola @lmdaly @derekwaynecarr , soy el líder de mejora 1.16. ¿Esta característica va a graduar las etapas alfa / beta / estable en 1.16? Por favor, avíseme para que se pueda agregar a la hoja de cálculo de seguimiento 1.16 . Si no se está graduando, lo eliminaré del hito y cambiaré la etiqueta de seguimiento.
Una vez que comience la codificación o si ya lo ha hecho, enumere todos los RP k / k relevantes en este número para que se puedan rastrear correctamente.
Las fechas de hitos son Enhancement Freeze el 30 de julio y Code Freeze el 29 de agosto.
Gracias.
kacole2
en 9 jul. 2019
@ kacole2 gracias por el recordatorio. Esta característica entrará como Alfa en 1.16.
La lista actual de RP se puede encontrar aquí: https://github.com/kubernetes/kubernetes/issues/72828
¡Gracias!
lmdaly
en 17 jul. 2019
De acuerdo, esto aterrizará en alfa por 1,16, cerraremos el esfuerzo iniciado y capturado en el kep previamente fusionado por 1,15.
derekwaynecarr
en 30 jul. 2019
Hola @lmdaly , soy la versión de los documentos v1.16.
¿Esta mejora requiere nuevos documentos (o modificaciones)?
Solo un recordatorio amistoso que estamos buscando un PR contra k / website (branch dev-1.16) para el viernes 23 de agosto. Sería genial si es el comienzo de la documentación completa, pero incluso un PR de marcador de posición es aceptable. ¡Hazme saber si tienes alguna pregunta!
¡Gracias!
 VineethReddy02
en 1 ago. 2019
VineethReddy02
en 1 ago. 2019
Documentación PR: https://github.com/kubernetes/website/pull/15716
lmdaly
en 7 ago. 2019
@lmdaly ¿El administrador de topología proporcionará alguna información o API para decirles a los usuarios la configuración de NUMA para un pod determinado?
 mJace
en 15 ago. 2019
mJace
en 15 ago. 2019
@mJace ¿ algo visible a través de la descripción de kubectl para el pod?
lmdaly
en 15 ago. 2019
@lmdaly Sí, kubectl describe es bueno. o alguna api para devolver información relacionada.
Dado que estamos desarrollando un servicio para proporcionar información relacionada con la topología para los pods, como el estado de fijación de la CPU para el pod y el nodo numa para su VF de paso a través.
Y alguna herramienta de monitoreo como el alcance de tejido puede llamar a la API para hacer un trabajo elegante.
El administrador puede saber si el VNF está bajo la configuración de numa adecuada, por ejemplo.
Solo quisiera saber si Topology Manager cubrirá esta parte.
o si hay algún trabajo que podamos hacer si Topology Manager planea admitir este tipo de funcionalidad.
mJace
en 15 ago. 2019
@mJace De acuerdo, actualmente no hay una API como esa para Topology Manager. No creo que haya precedencia para esto, ya que con CPU & Device Manager no hay visibilidad de lo que realmente se ha asignado a los pods.
Así que creo que sería bueno iniciar una discusión sobre esto y ver qué tipo de vista podemos ofrecer a los usuarios.
lmdaly
en 15 ago. 2019
Ya veo, pensé que CPU & Device Manager puede ver esta información.
Tal vez el caraton sea un buen papel para proporcionar esta información.
Porque, básicamente, ca 0000- obtiene información del contenedor como PID, etc.por ps ls .
Y es de la misma manera que verificamos la información relacionada con la topología del contenedor.
Implementaré esto en ca went y crearé un pr para ello.
mJace
en 15 ago. 2019
Creé un problema relacionado en ca went.
https://github.com/google/ca went/issues/2290
mJace
en 16 ago. 2019
/asignar
 khenidak
en 24 ago. 2019
khenidak
en 24 ago. 2019
+1 a la propuesta de @mJace ca went.
Para usar DPDK lib dentro del contenedor con CPU Manager y Topology Manager , analizando la afinidad de CPU del contenedor y luego pasándolo a dpdk lib, ambos son necesarios para la fijación de subprocesos de DPDK lib.
Para obtener más detalles, si no se permite un cpus en el subsistema cgroup cpuset del contenedor, se filtrarán las llamadas a sched_setaffinity para fijar el proceso en el cpus.
DPDK lib utiliza pthread_setaffinity_np para la fijación de subprocesos, y pthread_setaffinity_np es un contenedor a nivel de subproceso de sched_setaffinity .
Y CPU Manager of Kubernetes establece cpus exclusivo en el subsistema cgroup cpuset del contenedor.
bg-chun
en 26 ago. 2019
@ bg-chun Entendí que el cambio de ca went tiene un propósito diferente: monitorear. Para su requerimiento, es posible leer las CPU asignadas desde el interior del contenedor analizando 'Cpus_Allowed' o 'Cpus_Allowed_List' de '/ proc / self / status'. ¿Ese enfoque funcionará para usted?
ConnorDoyle
en 26 ago. 2019
La información de Cpus_Allowed se ve afectada por sched_setaffinity . Entonces, si la aplicación establece algo, será un subconjunto de lo que realmente está permitido por el controlador cpuset de Cgroup.
 kad
en 26 ago. 2019
kad
en 26 ago. 2019
@kad , estaba sugiriendo una forma para que el lanzador dentro del contenedor averigüe los valores de identificación de la CPU para transmitirlos al programa DPDK. Entonces esto sucede antes de que se establezca la afinidad de nivel de subproceso.
ConnorDoyle
en 26 ago. 2019
@ConnorDoyle
Gracias por tu sugerencia, la consideraré.
Mi plan era implementar el servidor tiny-rest-api para decirle información exclusiva de asignación de CPU a dpdk-container.
Con respecto a los cambios, todavía no vi los cambios de ca went, solo veo la propuesta .
La propuesta dice able to tell if there is any cpu affinity set for the container. en Meta y to tell if there is any cpu affinity set for the container processes. en Trabajo futuro.
Después de leer la propuesta, pensé que sería genial si ca went puede analizar la información de fijación de la CPU y kubelet la pasa al contenedor como una variable de entorno como status.podIP , metadata.name y limits.cpu .
Esa es la razón principal por la que dejé +1.
bg-chun
en 26 ago. 2019
@ bg-chun Puedes consultar mi primer informe de relaciones públicas en ca went
https://github.com/google/ca went/pull/2291
Terminé una función similar en.
https://github.com/mJace/numacc
pero no estoy realmente seguro de cuál es la forma correcta de implementarlo en ca went
Es por eso que solo creo un PR con una nueva característica -> mostrar PSR.
mJace
en 26 ago. 2019
pero no estoy realmente seguro de cuál es la forma correcta de implementarlo en ca went
¿Quizás podríamos discutir esto bajo esa propuesta? Si los gurús creen que esta función es necesaria :)
mJace
en 26 ago. 2019
La congelación del código de https://github.com/kubernetes/kubernetes/issues/72828 para los k / k PR restantes
kacole2
en 26 ago. 2019
@ kacole2 todos los RP requeridos para esta función están fusionados o en la cola de fusión.
lmdaly
en 30 ago. 2019
Hola @lmdaly - 1.17 Las mejoras conducen aquí. Quería registrarme y ver si crees que esta Mejora se graduará en alfa / beta / estable en 1.17.
El calendario de lanzamiento actual es:
- Lunes 23 de septiembre: comienza el ciclo de lanzamiento
- Martes, 15 de octubre, EOD PST - Congelación de mejoras
- Jueves, 14 de noviembre, EOD PST - Code Freeze
- Martes 19 de noviembre: los documentos deben completarse y revisarse
- Lunes 9 de diciembre: lanzamiento de Kubernetes 1.17.0
Si lo hace, enumere todos los RP k / k relevantes en este número para que se puedan rastrear correctamente. 👍
¡Gracias!
/ hito claro
 mrbobbytables
en 22 sept. 2019
mrbobbytables
en 22 sept. 2019
@lmdaly, ¿hay un enlace directo a la GPU con la discusión de RDMA?
 nickolaev
en 25 sept. 2019
nickolaev
en 25 sept. 2019
@nickolaev , también estamos analizando este caso de uso. Empezamos a pensar internamente sobre cómo hacer esto, pero nos encantaría colaborar en esto.
 moshe010
en 25 sept. 2019
moshe010
en 25 sept. 2019
@ moshe010 @nickolaev @lmdaly , Nosotros también estamos investigando este caso de uso relacionado con RDMA y GPU directo. Nos gustaría colaborar en esto. ¿Es posible iniciar un hilo / discusión sobre esto?
 Deepthidharwar
en 25 sept. 2019
Deepthidharwar
en 25 sept. 2019
¡Hola! Tengo una pregunta sobre NTM y el programador. Según tengo entendido, el programador no conoce las NUMA y puede preferir el nodo en el que no hay recursos (CPU, memoria y dispositivo) en la NUMA deseada. Entonces, el administrador de topología rechazará la asignación de recursos en ese nodo. ¿Es verdad?
 LilyaBu
en 25 sept. 2019
LilyaBu
en 25 sept. 2019
@nickolaev @Deepthidharwar , comenzaré google doc con casos de uso y podemos mover la discusión hacia él. Publicaré algo la semana que viene. Si te parece bien.
moshe010
en 25 sept. 2019
Estoy muy feliz de ver esta función. También necesitamos CPU, Hugepage, SRIOV-VF y otros recursos de hardware en un solo nodo NUMA.
Pero la página enorme no se reconoce como un recurso escalar por el complemento del dispositivo, ¿es esta función necesaria para cambiar la función de página enorme en k8s?
@iamneha
 andyzheung
en 26 sept. 2019
andyzheung
en 26 sept. 2019
@ConnorDoyle Solo para confirmar, ¿esta función necesita sugerencias de topología tanto del administrador de la CPU como del administrador de dispositivos? Lo probé en 1.16 y no funcionó, parece que solo recibió una pista del administrador de la CPU, pero ninguna pista del lado del dispositivo.
 jianzzha
en 26 sept. 2019
jianzzha
en 26 sept. 2019
@ConnorDoyle aquí hay un poco más de detalles:
https://gist.githubusercontent.com/jianzzha/c2a66a2514c178cca76a432029ff3387/raw/264f13dfcd06f1f80c48c113aa235fab7c33d81e/hyper%2520threading%2520enabled
jianzzha
en 26 sept. 2019
@jianzzha , ¿Qué complemento de dispositivo estás usando? Por ejemplo, si usa el complemento de dispositivo SR-IOV, debe asegurarse de que informe del nodo NUMA, consulte [1]
moshe010
en 26 sept. 2019
@andyzheung Actualmente se está discutiendo la integración de una página enorme y se ha presentado en la reunión de sig-node las últimas dos semanas. A continuación, se muestran algunos enlaces relevantes:
https://docs.google.com/presentation/d/1H5xhCjgCZJjdTm-mGUFwqoz8XmoVd8xTCwJ1AfVR_54/edit?usp=sharing
https://github.com/kubernetes/enhancements/pull/1245
https://github.com/kubernetes/enhancements/pull/1199
@jianzzha Respecto al complemento del dispositivo, no da pistas. ¿Se actualizó su complemento para proporcionar información NUMA sobre los dispositivos que enumera? Debe agregar este campo al mensaje del dispositivo https://github.com/kubernetes/kubernetes/blob/master/pkg/kubelet/apis/deviceplugin/v1beta1/api.proto#L100
klueska
en 26 sept. 2019
gracias chicos. Fijo y funciona ahora.
jianzzha
en 26 sept. 2019
@klueska
Respecto a nvidia-gpu-device-plugin ..
Solo puedo ver un PR activo
¿Se actualizará nvidia-gpu-divice-plugin para proporcionar una pista de topología con el PR anterior? o hay algo que extraño?
bg-chun
en 26 sept. 2019
@ bg-chun Sí, debería serlo. Acabo de hacer ping al autor. Si no vuelve al día siguiente, actualizaré el complemento yo mismo.
klueska
en 26 sept. 2019
@ bg-chun @klueska He actualizado el parche.
 carmark
en 27 sept. 2019
carmark
en 27 sept. 2019
@klueska @carmark
Gracias por la actualización y el aviso.
Presentaré la actualización sr-iov-plugin y la actualización gpu-plugin a los usuarios de mi espacio de trabajo.
bg-chun
en 27 sept. 2019
Propondría una mejora para el próximo lanzamiento.
Básicamente, se trata de eliminar la "alineación de topología solo ocurre si el Pod está en la restricción de QoS garantizada".
Esta restricción hace que el Administrador de topología sea inutilizable para mí en este momento, porque no me gustaría pedir CPU exclusivas de K8, sin embargo, me gustaría alinear los sockets de múltiples dispositivos, provenientes de múltiples grupos (por ejemplo, GPU + SR -VF VF, etc.)
Además, ¿qué sucede si mi carga de trabajo no es sensible a la memoria, o no quisiera restringir su uso de mem (otro criterio de QoS garantizada)?
En el futuro, cuando es de esperar que las páginas gigantes también se alineen, esta restricción se sentirá aún más limitante, en mi opinión.
¿Existe algún argumento en contra de alinear individualmente los recursos "alineables"? Por supuesto, solo recopilemos sugerencias del Administrador de CPU si se utilizan CPU exclusivas, pero recopilemos de forma o del administrador de memoria cuando el usuario solicita páginas enormes, etc.
O esto, o si la carga de cálculo adicional innecesaria durante el inicio del Pod es una preocupación, tal vez recupere el indicador de configuración de nivel de Pod original para controlar si ocurre la alineación o no (lo cual me sorprendió ver que se descarta durante la implementación)
 Levovar
en 30 sept. 2019
Levovar
en 30 sept. 2019
Propondría una mejora para el próximo lanzamiento.
Básicamente, se trata de eliminar la "alineación de topología solo ocurre si el Pod está en la restricción de QoS garantizada".
Este es el artículo número 8 en nuestra lista TODO para 1.17:
https://docs.google.com/document/d/1YTUvezTLGmVtEF3KyLOX3FzfSDw9w0zB-s2Tj6PNzLA/edit#heading = h.xnehh6metosd
¿Existe algún argumento en contra de alinear individualmente los recursos "alineables"? Por supuesto, solo recopilemos sugerencias del Administrador de CPU si se utilizan CPU exclusivas, pero recopilemos de forma o del administrador de memoria cuando el usuario solicita páginas enormes, etc.
¿Está proponiendo que haya un mecanismo para decirle selectivamente al kubelet qué recurso alinear y cuáles no alinear (es decir, quiero alinear mis asignaciones de CPU y GPU, pero no mis asignaciones de páginas enormes). No creo que nadie se oponga rotundamente a esto, pero la interfaz para decidir de forma selectiva qué recursos alinear y cuáles no alinear podría volverse demasiado engorrosa si continuamos especificando la alineación como una bandera a nivel de nodo.
O esto, o si la carga de cálculo adicional innecesaria durante el inicio del Pod es una preocupación, tal vez recupere el indicador de configuración de nivel de Pod original para controlar si ocurre la alineación o no (lo cual me sorprendió ver que se descarta durante la implementación)
No hubo suficiente soporte para una bandera a nivel de pod para justificar una propuesta para actualizar la especificación del pod con esto. Para mí, tiene sentido llevar esta decisión al nivel de los grupos, ya que algunos grupos necesitan / quieren alineación y otros no, pero no todos estaban de acuerdo.
klueska
en 30 sept. 2019
+1 para eliminar la restricción de clase de QoS en la alineación de la topología (lo agregué a la lista: smiley :). No tuve la sensación de que @Levovar está pidiendo habilitar la topología por recurso, solo que deberíamos alinear todos los recursos alineables utilizados por un contenedor determinado.
Por lo que puedo recordar, nunca hubo un campo de nivel de pod para optar por la topología en el KEP. El motivo para no introducirlo en primer lugar fue el mismo motivo para dejar implícitos núcleos exclusivos: Kubernetes, como proyecto, quiere tener la libertad de interpretar la especificación del pod de forma liberal en términos de gestión del rendimiento a nivel de nodo. Sé que esa postura no satisface a algunos miembros de la comunidad, pero siempre podemos volver a plantear el tema. Existe una tensión natural entre habilitar funciones avanzadas para unos pocos versus modular la carga cognitiva para la mayoría de los usuarios.
ConnorDoyle
en 1 oct. 2019
En mi opinión, en las primeras etapas del diseño, al menos había una bandera de nivel de cápsula si mi memoria no me falla, pero estaba alrededor de 1.13: D
Personalmente, estoy de acuerdo con tratar de alinear todos los recursos todo el tiempo, pero "en el pasado", por lo general, la comunidad rechazaba las funciones que presentaban retrasos en el inicio o en la decisión de programación de todos los pods, independientemente de si realmente necesitan la mejora, o no.
Así que solo estaba tratando de "pre-abordar" esas preocupaciones con dos opciones que me vienen a la mente: pre-gatear la alineación de los grupos de recursos en base a algunos criterios (fácil de definir para la CPU, más difícil para otros); o introducir alguna bandera de configuración.
Sin embargo, si no hay ningún rechazo ahora contra una mejora genérica, estoy totalmente de acuerdo con eso :)
Levovar
en 1 oct. 2019
@mrbobbytables Estamos planeando graduar el TopologyManager a beta en 1.17. El problema de seguimiento está aquí: https://github.com/kubernetes/kubernetes/issues/83479
klueska
en 3 oct. 2019
@ bg-chun @klueska He actualizado el parche.
Parche fusionado:
https://github.com/NVIDIA/k8s-device-plugin/commit/cc0aad87285b573127add4e487b13434a61ba0d6
Nueva versión creada con el parche:
https://github.com/NVIDIA/k8s-device-plugin/releases/tag/1.0.0-beta2
klueska
en 3 oct. 2019
beta de seguimiento para v1.17
derekwaynecarr
en 4 oct. 2019
Genial, gracias @derekwaynecarr . Lo agregaré a la hoja :)
/ etapa beta
mrbobbytables
en 6 oct. 2019
@lmdaly
Soy una de las sombras de documentos v1.17.
¿Esta mejora (o el trabajo planificado para la v1.17) requiere algún documento nuevo (o modificaciones a los documentos existentes)? Si no es así, ¿puede actualizar la hoja de seguimiento de mejoras 1.17 (o avíseme y lo haré)?
Si es así, solo un recordatorio amistoso de que estamos buscando un PR contra k / website (branch dev-1.17) que vence el viernes 8 de noviembre, puede ser un PR de marcador de posición en este momento. ¡Hazme saber si tienes alguna pregunta!
¡Gracias!
VineethReddy02
en 21 oct. 2019
@ VineethReddy02 Sí , hemos planeado actualizaciones de documentación para la
Nos aseguraremos de abrir ese PR antes de esa fecha, gracias por el recordatorio.
El problema para el seguimiento de la documentación para esto está aquí: https://github.com/kubernetes/kubernetes/issues/83482
lmdaly
en 23 oct. 2019
https://github.com/kubernetes/enhancements/pull/1340
Chicos, abrí KEP update PR para agregar una etiqueta de nodo incorporada ( beta.kubernetes.io/topology ) para Topology Manager.
La etiqueta expondrá la política del nodo.
Creo que sería útil programar un pod para el nodo en particular cuando hay nodos con múltiples políticas en el mismo clúster.
¿Puedo pedir una revisión?
bg-chun
en 28 oct. 2019
Hola @lmdaly @derekwaynecarr
Jeremy del equipo de mejoras 1.17 aquí 👋. ¿Podría enumerar los k / k PR que están en vuelo para esto para que podamos rastrearlos? Veo que el número 83492 se fusionó, pero parece que hay algunos problemas más relacionados que cuelgan del elemento de seguimiento general. Nos acercaremos a Code Freeze el 14 de noviembre, ¡así que nos gustaría tener una idea de cómo va esto antes de esa fecha! ¡Muchas gracias!
 jeremyrickard
en 4 nov. 2019
jeremyrickard
en 4 nov. 2019
@jeremyrickard Este es el problema de seguimiento para 1.17 como se mencionó anteriormente: https://github.com/kubernetes/enhancements/issues/693#issuecomment -538123786
klueska
en 4 nov. 2019
@lmdaly @derekwaynecarr
Un recordatorio amistoso de que estamos buscando un PR de marcador de posición para Docs contra k / website (branch dev-1.17) para el viernes 8 de noviembre. Solo tenemos 2 días más para este plazo.
daminisatya
en 6 nov. 2019
Docs PR está aquí por cierto: https://github.com/kubernetes/website/pull/17451
lmdaly
en 8 nov. 2019
@klueska Veo que parte del trabajo aumentó a 1,18. ¿Todavía planeas graduar esto a beta en 1.17, o permanecerá como alfa pero cambiará?
jeremyrickard
en 13 nov. 2019
No importa, veo en https://github.com/kubernetes/kubernetes/issues/85093 que ahora saltarás a la versión beta en 1.18, no como parte de 1.17. ¿Quieres que hagamos un seguimiento de esto como un cambio importante en la versión alfa como parte del hito 1.17 @klueska? ¿O simplemente aplazar la graduación a 1,18?
jeremyrickard
en 13 nov. 2019
/ hito v1.18
jeremyrickard
en 15 nov. 2019
Hola @klueska
1.18 mejoras en el registro del equipo. ¿Todavía planeas graduar esto a beta en 1.18? Enhancement Freeze será el 28 de enero, si su KEP requiere alguna actualización, mientras que Code Freeze será el 5 de marzo.
¡Gracias!
jeremyrickard
en 7 ene. 2020
Si.
klueska
en 7 ene. 2020
@klueska ¡ gracias por la actualización! Actualización de la hoja de seguimiento.
jeremyrickard
en 7 ene. 2020
@klueska mientras Solicitud de excepción y agrega los planes de prueba al KEP. Disculpas por el retraso.
jeremyrickard
en 29 ene. 2020
/ hito claro
jeremyrickard
en 29 ene. 2020
@vpickard por favor vea arriba
klueska
en 29 ene. 2020
@vpickard por favor vea arriba
@klueska Gracias por el
 vpickard
en 29 ene. 2020
vpickard
en 29 ene. 2020
@jeremyrickard ¿Existe una plantilla de plan de prueba a la que pueda señalarme como referencia?
vpickard
en 29 ene. 2020
@vpickard puedes echarle un vistazo a:
https://github.com/kubernetes/enhancements/blob/master/keps/sig-storage/20190530-pv-health-monitor.md#test -plan
y
https://github.com/kubernetes/enhancements/blob/master/keps/sig-storage/20200120-skip-permission-change.md#test -plan
Incluya una descripción general de las pruebas unitarias y las pruebas e2e.
Si tiene algo que aparezca en la cuadrícula de prueba, sería genial incluirlo.
jeremyrickard
en 29 ene. 2020
Se aprobó la excepción.
/ hito v1.18
jeremyrickard
en 30 ene. 2020
@jeremyrickard Plan de prueba combinado: https://github.com/kubernetes/enhancements/pull/1527
klueska
en 4 feb. 2020
Hola @klueska @vpickard , solo un recordatorio amistoso de que Code Freeze entrará en vigencia el jueves 5 de marzo.
¿Puede vincular todos los RP de k / k o cualquier otro RP que deba ser rastreado para esta mejora?
Gracias :)
 palnabarun
en 5 feb. 2020
palnabarun
en 5 feb. 2020
Hola @palnabarun
Problema de seguimiento aquí para 1.18:
https://github.com/kubernetes/kubernetes/issues/85093
RP abiertos actuales:
https://github.com/kubernetes/kubernetes/pull/87758 (Aprobado, pruebas de descamación)
https://github.com/kubernetes/kubernetes/pull/87759 (WIP)
https://github.com/kubernetes/kubernetes/pull/87650 (Revisado, necesita aprobación)
https://github.com/kubernetes/kubernetes/pull/87645 (PR de prueba e2e, necesita aprobación)
@vpickard, ¿puedes agregar cualquier PR de e2e que me haya perdido?
Gracias
 nolancon
en 5 feb. 2020
nolancon
en 5 feb. 2020
Gracias @nolancon por vincular las relaciones públicas y el tema general aquí. He añadido los RP a la hoja de seguimiento.
palnabarun
en 5 feb. 2020
Hola @palnabarun , @nolancon ,
Algunas PR abiertas adicionales relacionadas con las pruebas E2E:
https://github.com/kubernetes/test-infra/pull/16062 (necesita revisión y aprobación)
https://github.com/kubernetes/test-infra/pull/16037 (necesita revisión y aprobación)
vpickard
en 6 feb. 2020
Gracias @vpickard por las actualizaciones adicionales. :)
palnabarun
en 9 feb. 2020
Hola @lmdaly , soy una de las sombras de documentos v1.18.
¿Esta mejora para (o el trabajo planeado para v1.18) requiere algún documento nuevo (o modificaciones a los documentos existentes)? Si no es así, ¿puede actualizar la hoja de seguimiento de mejoras 1.18 (o avíseme y lo haré)?
Si es así, solo un recordatorio amistoso de que estamos buscando un PR contra k / website (branch dev-1.18) que vence el viernes 28 de febrero. Puede ser un PR de marcador de posición en este momento. ¡Hazme saber si tienes alguna pregunta!
 irvifa
en 9 feb. 2020
irvifa
en 9 feb. 2020
Hola @irvifa , gracias por el
Gracias.
nolancon
en 10 feb. 2020
Hola @nolancon, gracias por tu rápida respuesta, cambio el estado a Placeholder PR ahora ... ¡Gracias!
irvifa
en 10 feb. 2020
@palnabarun FYI, he dividido este PR https://github.com/kubernetes/kubernetes/pull/87759 en dos PR para facilitar el proceso de revisión. El segundo está aquí https://github.com/kubernetes/kubernetes/pull/87983 y también deberá ser rastreado. Gracias.
nolancon
en 10 feb. 2020
@nolancon Gracias por las actualizaciones.
Veo que algunos de los RP aún están pendientes de fusionarse. Quería ver si necesita ayuda del equipo de lanzamiento para que los Revisores y Aprobadores lleguen a los RP. Dejanos saber si necesitas algo.
Para su información, estamos muy cerca de Code Freeze el 5 de marzo
palnabarun
en 27 feb. 2020
@nolancon Gracias por las actualizaciones.
Veo que algunos de los RP aún están pendientes de fusionarse. Quería ver si necesita ayuda del equipo de lanzamiento para que los Revisores y Aprobadores lleguen a los RP. Dejanos saber si necesitas algo.
Para su información, estamos muy cerca de Code Freeze el 5 de marzo
@palnabarun Una actualización más, https://github.com/kubernetes/kubernetes/pull/87983 ahora está cerrado y no necesita ser rastreado. Los cambios necesarios se incluyen en el PR original https://github.com/kubernetes/kubernetes/pull/87759, que se encuentra en revisión.
nolancon
en 27 feb. 2020
@nolancon Genial. También estoy rastreando el problema del rastreador de paraguas que compartiste anteriormente. :)
palnabarun
en 27 feb. 2020
Hola @nolancon , este es un recordatorio de que estamos a solo dos días de Code Freeze el 5 de marzo .
Por Code Freeze, todos los RP relevantes deben fusionarse; de lo contrario, deberá presentar una solicitud de excepción.
palnabarun
en 3 mar. 2020
Hola @nolancon ,
Hoy EOD es Code Freeze .
¿Crees que https://github.com/kubernetes/kubernetes/pull/87650 se revisaría antes de la fecha límite?
De lo contrario, presente una solicitud de excepción .
palnabarun
en 5 mar. 2020
Hola @nolancon ,
Hoy EOD es Code Freeze .
¿Crees que kubernetes / kubernetes # 87650 sería revisado antes de la fecha límite?
De lo contrario, presente una solicitud de excepción .
Hola @palnabarun , se ha avanzado mucho en los últimos días y estamos seguros de que todo
Solo para aclarar, por EOD, ¿te refieres a las 5 p.m. o a la medianoche (hora estándar del Pacífico)? Gracias
nolancon
en 5 mar. 2020
Solo para aclarar, por EOD, ¿te refieres a las 5 p.m. o a la medianoche (hora estándar del Pacífico)? Gracias
5 p.m. PST.
jeremyrickard
en 5 mar. 2020
El RP está aprobado pero le falta un hito que sig-node debe agregar para fusionarse. Les hice ping en holgura, espero que se despegue y no necesite una excepción. =)
 kikisdeliveryservice
en 5 mar. 2020
kikisdeliveryservice
en 5 mar. 2020
Todos los RP de este kep parecen haberse fusionado (y aprobado antes de la fecha límite). Actualicé nuestra hoja de seguimiento de mejoras. :sonrisa:
kikisdeliveryservice
en 6 mar. 2020
/ hito claro
(eliminando este problema de mejora del hito v1.18 cuando se complete el hito)
palnabarun
en 29 abr. 2020
Hola @nolancon @lmdaly , mejoras en la sombra para 1.19 aquí. ¿Algún plan para esto en 1.19?
 johnbelamaric
en 4 may. 2020
johnbelamaric
en 4 may. 2020
La única mejora planificada para 1.19 es la siguiente:
https://github.com/kubernetes/enhancements/pull/1121
El resto del trabajo estará en la refactorización de código / corrección de errores según sea necesario.
¿Hay alguna forma de cambiarme el propietario de este problema en lugar de @lmdaly?
klueska
en 4 may. 2020
Gracias, actualizaré el contacto.
/ hito v1.19
johnbelamaric
en 4 may. 2020
/ asignar @klueska
/ anular la asignación de @lmdaly
Aquí lo tienes, Kevin https://prow.k8s.io/command-help
 pires
en 6 may. 2020
pires
en 6 may. 2020
Hola Kevin. Recientemente, el formato KEP ha cambiado y también el # 1620 se fusionó la semana pasada, agregando preguntas de revisión de preparación de producción a la plantilla KEP. Si es posible, tómese el tiempo para reformatear su KEP y también responda las preguntas agregadas a la plantilla . Las respuestas a esas preguntas serán útiles para los operadores que utilicen y solucionen problemas de la función (en particular, la pieza de monitoreo en esta etapa). ¡Gracias!
johnbelamaric
en 13 may. 2020
@klueska ^^
johnbelamaric
en 13 may. 2020
@derekwaynecarr @klueska @johnbelamaric
También planeo agregar una nueva política de topología en 1.19 rel.
Pero aún no ha sido revisado por el propietario ni el encargado del mantenimiento.
(Si parece difícil de hacer en 1.19, hágamelo saber).
- Actualización de KEP PR: https://github.com/kubernetes/enhancements/pull/1752
- Relaciones públicas para kubelet: WIP
bg-chun
en 13 may. 2020
Hola @klueska 👋 1.19 docs shadow here! ¿Este trabajo de mejora planificado para 1.19 requiere nuevos documentos o modificaciones?
Recordatorio amistoso de que si se requieren nuevos / modificaciones en los documentos, se necesita un marcador de posición PR contra k / sitio web (sucursal dev-1.19 ) antes del viernes 12 de junio.
 annajung
en 21 may. 2020
annajung
en 21 may. 2020
Hola @klueska, espero que lo estés haciendo bien. Vuelve a consultar para ver si se requieren documentos para esto o no. ¿Podrias confirmar?
annajung
en 27 may. 2020
Hola @annajung. Hay 2 mejoras pendientes que requerirán cambios en los documentos:
1121
1752
Todavía estamos decidiendo si estos llegarán a 1,19 o si se llevarán a 1,20. Si decidimos mantenerlos por 1.19, me aseguraré de crear un marcador de posición para los documentos antes del 12 de junio.
klueska
en 29 may. 2020
¡Estupendo! Gracias por la actualización, actualizaré la hoja de seguimiento en consecuencia. Por favor, avíseme una vez que se hayan realizado las relaciones públicas del marcador de posición. ¡Gracias!
annajung
en 30 may. 2020
@lmdaly @ConnorDoyle
Espero que este sea el lugar adecuado para preguntar y dar algunos comentarios.
Enciendo TopologyManager y CPUManager en mi clúster k8s v1.17.
y su política es best-effort y static
Aquí están los recursos de mi pod
resources:
requests:
cpu: 2
intel.com/sriov_pool_a: '1'
limits:
cpu: 2
intel.com/sriov_pool_a: '1'
El PF de sriov_pool_a está en el nodo 0 de NUMA, por lo que espero que mi pod también se ejecute en la CPU del nodo 0 de NUMA.
Pero encontré que el proceso de mi pod se está ejecutando en la CPU del nodo 1 de NUMA.
Además, no hay una máscara de afinidad de CPU establecida según el resultado de taskset -p <pid> .
¿Hay algo mal? Supongo que el contenedor debería tener una máscara de afinidad de CPU configurada para la CPU del nodo 0 de numa.
¿Hay algún ejemplo o prueba que pueda hacer para saber si mi TopoloyManager está funcionando correctamente?
mJace
en 4 jun. 2020
@annajung Placeholder docs PR agregado: https://github.com/kubernetes/website/pull/21607
klueska
en 9 jun. 2020
Hola @klueska ,
Para dar seguimiento al correo electrónico enviado a k-dev el lunes, quería informarles que Code Freeze se ha extendido hasta el jueves 9 de julio. Puede ver el calendario revisado aquí: https://github.com/kubernetes/sig-release/tree/master/releases/release-1.19
Esperamos que todos los RP se fusionen en ese momento. Por favor hazme saber si tienes preguntas. 😄
Mejor,
Kirsten
kikisdeliveryservice
en 18 jun. 2020
Hola @klueska , un recordatorio amistoso de la próxima fecha límite.
Recuerde rellenar su documento PR de marcador de posición y prepárelo para su revisión antes del lunes 6 de julio.
annajung
en 22 jun. 2020
Gracias @annajung . Dado que la congelación del código se ha trasladado al 9 de julio, ¿tiene sentido adelantar también la fecha de los documentos? ¿Qué sucede si creamos la documentación, pero la función no llega a tiempo (o lo hace de una forma ligeramente diferente a la que sugiere la documentación)?
klueska
en 23 jun. 2020
Hola @klueska , ¡ese es un gran punto! La fecha límite de todos los documentos también se ha retrasado una semana con la nueva fecha de lanzamiento, pero creo que tiene un punto válido. ¡Permítame comunicarme con el líder de documentos para obtener el lanzamiento y comunicarme con usted! ¡Gracias por señalar esto!
annajung
en 24 jun. 2020
Hola @klueska , gracias de nuevo por informarnos sobre esto. Ha habido una confusión con las fechas de los documentos para el lanzamiento. Como mencionaste, "PR listo para revisión" debería aparecer después de la congelación del código y ha estado en versiones anteriores.
Sin embargo, después de hablar con el equipo de lanzamiento, hemos decidido mantener las fechas como están para este lanzamiento 1.19 haciendo que el "PR listo para revisión" sea una fecha límite flexible. El equipo de Documentos será flexible y trabajará contigo o con otras personas que puedan necesitar más tiempo para asegurarse de que los documentos estén sincronizados con el código. Si bien no se aplicará la fecha límite de "RP listo para revisión", sí se aplicará el "RP revisado y leído para fusionar".
¡Espero que esto ayude a responder a sus inquietudes! Por favor, avíseme si tiene más preguntas.
Además, solo un recordatorio amistoso de las fechas:
"Fecha límite de documentos: RRPP listos para revisión" vence el 6 de julio.
"Documentos completados: todos los RP revisados y listos para combinar" vence el 16 de julio
annajung
en 24 jun. 2020
Hola @klueska : ola: - 1.19 Mejoras
¿Puede vincular a todos los RP de implementación aquí, para que el equipo de lanzamiento pueda rastrearlos? : leve_sonriente_cara:
Gracias.
palnabarun
en 28 jun. 2020
@palnabarun
El seguimiento de relaciones públicas https://github.com/kubernetes/enhancements/pull/1121 se puede encontrar en:
https://github.com/kubernetes/kubernetes/pull/92665
Desafortunadamente, la mejora # 1752 no se incluirá en el lanzamiento, por lo que no hay un PR para rastrearla.
klueska
en 30 jun. 2020
Hola @klueska : wave :, Veo que los dos RP (https://github.com/kubernetes/enhancements/pull/1121 y https://github.com/kubernetes/enhancements/pull/1752) que mencionaste se refieren a la misma mejora. Dado que https://github.com/kubernetes/enhancements/pull/1752 amplía los requisitos de graduación Beta y no se incluirán en la versión, ¿podemos asumir que no se esperan más cambios en la versión 1.19?
Gracias. : leve_sonriente_cara:
Code Freeze comienza el jueves 9 de julio EOD PST
palnabarun
en 6 jul. 2020
@palnabarun Este es un PR de seguimiento al # 92665 que debería aterrizar hoy o mañana: https://github.com/kubernetes/kubernetes/pull/92794
Después de eso, no debería haber más RP para esta versión, a la espera de errores imprevistos.
klueska
en 6 jul. 2020
¡Impresionante! Gracias por la actualizacion. : +1:
Estaremos atentos a https://github.com/kubernetes/kubernetes/pull/92794.
palnabarun
en 6 jul. 2020
@annajung https://github.com/kubernetes/website/pull/21607 ya está listo para su revisión.
klueska
en 6 jul. 2020
Felicidades @klueska kubernetes / kubernetes # 92794 finalmente se ha fusionado, actualizaré la hoja de seguimiento en consecuencia 😄
kikisdeliveryservice
en 11 jul. 2020
/ hito claro
(eliminando este problema de mejora del hito v1.19 cuando se complete el hito)
kikisdeliveryservice
en 12 sept. 2020
Hola @klueska
Las mejoras conducen aquí. ¿Hay planes para que esto se gradúe en 1.20?
¡Gracias!
Kirsten
kikisdeliveryservice
en 13 sept. 2020
No hay planes para que se gradúe, pero hay un PR que se debe rastrear para 1.20 relacionado con esta mejora:
https://github.com/kubernetes/kubernetes/pull/92967
klueska
en 16 sept. 2020
A pesar de que no se graduará en 1.20, continúe vinculando los RP relacionados con este problema como acaba de hacerlo.
kikisdeliveryservice
en 16 sept. 2020
@kikisdeliveryservice , ¿puede ayudarnos a comprender el proceso? La función del Administrador de topología no se graduará en 1.20, pero la nueva función se agregará y se trabajará en ella ahora: https://github.com/kubernetes/enhancements/pull/1752 k / k: https: // github. com / kubernetes / kubernetes / pull / 92967. ¿Es esto algo que debemos rastrear con el equipo de lanzamiento? Puede simplificar el seguimiento de la actualización de documentos para 1.20 o tal vez algo más que se está rastreando.
El cambio es aditivo, por lo que no hay muchas razones para llamarlo beta2 o algo así.
RP relacionado que refleja la realidad de que la función adicional no se envió en 1.19: https://github.com/kubernetes/enhancements/pull/1950
 SergeyKanzhelev
en 27 oct. 2020
SergeyKanzhelev
en 27 oct. 2020
Actualización de la documentación web de Topology Manager PR para incluir la función de alcance: https://github.com/kubernetes/website/pull/24781
 k-wiatrzyk
en 29 oct. 2020
k-wiatrzyk
en 29 oct. 2020
Creo que se puede rastrear con 1.20 y no necesariamente necesita graduarse. @kikisdeliveryservice por favor
annajung
en 29 oct. 2020
Hola @SergeyKanzhelev
Mirando la historia, este no es el caso. Me dijeron que esto no sería graduarse arriba, lo cual está bien y por qué no se realiza un seguimiento de este KEP. Sin embargo, esta mejora (sin el conocimiento del equipo de mejoras) fue recientemente reorientada por @ k-wiatrzyk para 1.20 como beta (https://github.com/kubernetes/enhancements/pull/1950).
Si desea aprovechar el proceso de publicación: seguimiento de mejoras, ser parte del hito de la publicación y hacer que el equipo de documentación realice un seguimiento de esto / que los documentos se incluyan en la versión 1.20, se debe presentar una solicitud de excepción de mejora lo antes posible.
kikisdeliveryservice
en 30 oct. 2020
La función ya se fusionó con el KEP (preexistente) (antes de la fecha límite de mejora).
https://github.com/kubernetes/enhancements/pull/1752
En su implementación, las relaciones públicas ya son parte del hito.
https://github.com/kubernetes/kubernetes/pull/92967
No sabía que había nada más que hacer.
¿Con quién debemos presentar una excepción y para qué exactamente?
klueska
en 30 oct. 2020
Hola @klueska, el PR al que hace referencia se fusionó en junio para agregar beta al kep en 1.19: https://github.com/bg-chun/enhancements/blob/f3df83cc997ff49bfbb59414545c3e4002796f19/keps/sig-node/0035-20190130-topology -manager.md # beta -v119
La fecha límite de mejoras para 1.20 fue el 6 de octubre, pero el cambio, moviendo beta a 1.20 y eliminando la referencia a 1.19, se fusionó hace 3 días a través de https://github.com/kubernetes/enhancements/pull/1950
Puede encontrar instrucciones para enviar una solicitud de excepción aquí: https://github.com/kubernetes/sig-release/blob/master/releases/EXCEPTIONS.md
kikisdeliveryservice
en 30 oct. 2020
Lo siento, todavía estoy confundido en cuanto a por qué presentaremos una excepción.
Estoy feliz de hacerlo, pero no estoy seguro de qué incluir.
La función "Administrador de topología de nodo" ya pasó a la versión beta en 1.18.
No se está graduando a GA en 1.20 (se queda en beta).
El PR que se fusiona para 1.20 (es decir, kubernetes / kubernetes # 92967) es una mejora del código existente para el Administrador de topología, pero no está relacionado con un "aumento" en términos de su estado como alfa / beta / ga, etc.
klueska
en 30 oct. 2020
He enviado un correo de Llamada de excepción ya que la fecha límite es hoy (por si acaso): https://groups.google.com/g/kubernetes-sig-node/c/lsy0fO6cBUY/m/_ujNkQtCCQAJ
k-wiatrzyk
en 2 nov. 2020
@kikisdeliveryservice @klueska @annajung
Se aprobó la convocatoria de excepción, puede encontrar la confirmación aquí: https://groups.google.com/g/kubernetes-sig-release/c/otE2ymBKeMA/m/ML_HMQO7BwAJ
k-wiatrzyk
en 4 nov. 2020
Gracias @ k-wiatrzyk y @klueska Actualizó la hoja de seguimiento.
cc: @annajung
kikisdeliveryservice
en 5 nov. 2020
Hola @ k-wiatrzyk @klueska
Parece que kubernetes / kubernetes # 92967 está aprobado pero necesita una nueva base.
Solo un recordatorio de que Code Freeze llegará en 2 días el jueves 12 de noviembre . Todos los RP deben fusionarse antes de esa fecha; de lo contrario, se requiere una excepción .
Mejor,
Kirsten
kikisdeliveryservice
en 11 nov. 2020
El PR se fusionó, actualizando la hoja - ¡yay! : smile_cat:
kikisdeliveryservice
en 12 nov. 2020
Temas relacionados
 wlan0
·
9Comentarios
wlan0
·
9Comentarios
 justinsb
·
11Comentarios
justinsb
·
11Comentarios
 dekkagaijin
·
9Comentarios
dekkagaijin
·
9Comentarios
 robscott
·
11Comentarios
robscott
·
11Comentarios
 saschagrunert
·
6Comentarios
saschagrunert
·
6Comentarios
Comentario más útil
Todos los RP de este kep parecen haberse fusionado (y aprobado antes de la fecha límite). Actualicé nuestra hoja de seguimiento de mejoras. :sonrisa: