Enhancements: Gestionnaire de topologie de nœud
Description de l'amélioration
- Description de l'amélioration en une ligne (peut être utilisée comme note de version) : composant Kubelet pour coordonner les affectations de ressources matérielles précises pour différents composants dans Kubernetes.
- Contact principal (cessionnaire) : @klueska
- SIG responsables : sig-node
- Lien de proposition de conception (dépôt communautaire) : https://github.com/kubernetes/community/pull/1680
- RP KEP : https://github.com/kubernetes/enhancements/pull/781
- KEP : https://github.com/kubernetes/enhancements/blob/master/keps/sig-node/0035-20190130-topology-manager.md
- Lien vers e2e et/ou tests unitaires : N/A Encore
- Examinateur(s) - (pour LGTM) recommande d'avoir 2+ examinateurs (au moins un du fichier OWNERS de la zone de code) acceptés pour l'examen. Les évaluateurs de plusieurs entreprises ont préféré : @ConnorDoyle @balajismaniam
- Approbateur (probablement du SIG/de la zone à laquelle appartient l'amélioration) : @derekwaynecarr @ConnorDoyle
- Cible d'amélioration (quelle cible correspond à quel jalon) :
- Cible de la version alpha (xy) : v1.16
- Cible de la version bêta (xy) : v1.18
- Cible de version stable (xy)
 lmdaly
lmdaly
Tous les 159 commentaires
/sig nœud
/ fonction gentille
cc @ConnorDoyle @balajismaniam @nolancon
lmdaly
le 17 janv. 2019
Je peux aider à informer cette conception basée sur l'apprentissage de Borg. Alors comptez-moi comme examinateur/approbateur.
 vishh
le 4 févr. 2019
vishh
le 4 févr. 2019
Je peux aider à informer cette conception basée sur l'apprentissage de Borg. Alors comptez-moi comme examinateur/approbateur.
Existe-t-il une documentation publique sur le fonctionnement de cette fonctionnalité dans borg ?
 jeremyeder
le 11 févr. 2019
jeremyeder
le 11 févr. 2019
Pas à propos de NUMA AFAIK.
Le lundi 11 février 2019, à 7 h 50, Jeremy Eder < [email protected] a écrit :
Je peux aider à informer cette conception basée sur l'apprentissage de Borg. Alors compte-moi dans
en tant qu'examinateur/approbateur.Existe-t-il une documentation publique sur le fonctionnement de cette fonctionnalité dans borg ?
-
Vous recevez ceci parce que vous avez commenté.
Répondez directement à cet e-mail, consultez-le sur GitHub
https://github.com/kubernetes/enhancements/issues/693#issuecomment-462378195 ,
ou couper le fil
https://github.com/notifications/unsubscribe-auth/AGvIKPfanjb9Q5DxXAiBgv9C6Y809JX0ks5vMZFZgaJpZM4aE3uz
.
vishh
le 11 févr. 2019
Pour info @claurence
Ce problème de suivi et KEP (https://github.com/kubernetes/enhancements/pull/781) ne sont pas arrivés à temps pour le gel des améliorations de la v1.14 ni le délai prolongé. J'apprécie que vous les ayez ouverts avant les dates limites, mais ils ne semblaient pas avoir été suffisamment examinés ou approuvés. Cela devra passer par le processus d'exception.
Jusqu'à ce que nous décidions si cela vaut l'exception, je suis enclin à suspendre toutes les relations publiques associées à cette amélioration.
 spiffxp
le 24 févr. 2019
spiffxp
le 24 févr. 2019
/cc @jiayingz @dchen1107
 jiayingz
le 25 févr. 2019
jiayingz
le 25 févr. 2019
@lmdaly, je vois que vous avez tous 1.14 répertorié dans la description comme jalon alpha - puisqu'il n'y avait pas de KEP implémentable fusionné, ce problème n'est pas suivi pour 1.14 - s'il y a des intentions pour qu'il soit inclus dans cette version s'il vous plaît soumettre une demande d'exception.
 claurence
le 27 févr. 2019
claurence
le 27 févr. 2019
@lmdaly, je vois que vous avez tous 1.14 répertorié dans la description comme jalon alpha - puisqu'il n'y avait pas de KEP implémentable fusionné, ce problème n'est pas suivi pour 1.14 - s'il y a des intentions pour qu'il soit inclus dans cette version s'il vous plaît soumettre une demande d'exception.
@claurence le KEP est maintenant fusionné (KEP avait déjà été fusionné dans le référentiel communautaire. C'était juste pour le déplacer vers le nouveau référentiel d'améliorations conformément aux nouvelles directives), devons-nous encore soumettre une demande d'exception pour que ce problème soit suivi pour 1,14 ?
lmdaly
le 5 mars 2019
Bien qu'après avoir lu en détail la conception et les PR WIP, je crains que la mise en œuvre actuelle ne soit pas générique comme la conception de la topologie originale que nous avons proposée dans https://github.com/kubernetes/enhancements/pull/781. Celui-ci se lit actuellement davantage comme une topologie NUMA au niveau du nœud.
J'ai laissé quelques commentaires pour une discussion plus approfondie ici : https://github.com/kubernetes/kubernetes/pull/74345#discussion_r264387724
 resouer
le 11 mars 2019
resouer
le 11 mars 2019
l'implémentation actuelle n'est pas générique
Partagez la même préoccupation à ce sujet :) Qu'en est-il des autres, par exemple des liens entre les appareils (nvlinke pour GPU) ?
 k82cn
le 20 mars 2019
k82cn
le 20 mars 2019
@resouer @k82cn La proposition initiale ne traite que de l'alignement des décisions prises par le gestionnaire de processeur et le gestionnaire de périphériques pour assurer la proximité des périphériques avec le processeur sur lequel le conteneur s'exécute. Satisfaire l'affinité inter-appareils n'était pas un objectif de la proposition.
Si toutefois, l'implémentation actuelle bloque l'ajout d'affinité inter-appareils à l'avenir, je suis heureux de changer l'implémentation une fois que j'aurai compris comment elle le fait,
lmdaly
le 25 mars 2019
Je pense que le principal problème que je vois avec la mise en œuvre actuelle et la capacité à prendre en charge l'affinité inter-appareils est le suivant :
Pour prendre en charge l'affinité entre les appareils, vous devez normalement d'abord déterminer quels appareils vous souhaitez allouer à un conteneur _avant_ de décider quelle affinité de socket vous souhaitez que le conteneur ait.
Par exemple, avec les GPU Nvidia, pour une connectivité optimale, vous devez d'abord rechercher et allouer l'ensemble de GPU avec les NVLINK les plus connectés _avant_ de déterminer quelle affinité de socket cet ensemble a.
D'après ce que je peux dire dans la proposition actuelle, l'hypothèse est que ces opérations se déroulent dans l'ordre inverse, c'est-à-dire que l'affinité de socket est décidée avant de procéder à l'allocation des périphériques.
 klueska
le 5 avr. 2019
klueska
le 5 avr. 2019
Ce n'est pas nécessairement vrai @klueska. Si les conseils de topologie étaient étendus pour coder la topologie de périphérique point à point, le gestionnaire de périphériques pourrait en tenir compte lors du rapport d'affinité de socket. En d'autres termes, la topologie inter-périphériques n'aurait pas besoin de s'échapper du champ d'application du gestionnaire de périphériques. Cela semble-t-il faisable ?
 ConnorDoyle
le 5 avr. 2019
ConnorDoyle
le 5 avr. 2019
Peut-être que je suis confus au sujet du flux d'une manière ou d'une autre. Voilà comment je le comprends :
1) À l'initialisation, les plugins de périphérique (pas le devicemanager ) s'enregistrent avec le topologymanager afin qu'il puisse émettre des rappels dessus ultérieurement.
2) Lorsqu'un pod est soumis, le kubelet appelle le lifecycle.PodAdmitHandler sur le topologymanager .
3) Le lifecycle.PodAdmitHandler appelle GetTopologyHints sur chaque plugin d'appareil enregistré
4) Il fusionne ensuite ces astuces pour produire un TopologyHint consolidé associé au pod
5) S'il a décidé d'admettre le pod, il revient avec succès de lifecycle.PodAdmitHandler stockant les TopologyHint consolidés pour le pod dans un magasin d'état local
6) À un moment donné dans le futur, le cpumanager et le devicemanager appellent GetAffinity(pod) sur le gestionnaire topology pour récupérer les TopologyHint associés avec la cosse
7) Le cpumanager utilise ce TopologyHint` pour allouer un CPU
8) Le devicemanager utilise ce TopologyHint` pour allouer un ensemble de périphériques
9) L'initialisation du pod continue...
Si cela est correct, je suppose que j'ai du mal à comprendre ce qui se passe entre le moment où le plug-in de périphérique signale son TopologyHints et le moment où le devicemanager effectue l'allocation réelle.
Si ces astuces sont destinées à coder des "préférences" pour l'allocation, alors je pense que ce que vous dites est d'avoir une structure plus semblable à :
type TopologyHints struct {
hints []struct {
SocketID int
DeviceIDs []int
}
}
Où nous passons non seulement une liste de préférences d'affinité de socket, mais comment ces préférences d'affinité de socket s'associent aux préférences GPU attribuables.
Si c'est la direction que vous pensez, alors je pense que nous pourrions le faire fonctionner, mais nous aurions besoin de coordonner d'une manière ou d'une autre entre les cpumanager et les devicemanager pour nous assurer qu'ils "acceptent" la même chose indice lors de leurs attributions.
Y a-t-il quelque chose en place qui permet déjà cela que j'ai raté?
klueska
le 5 avr. 2019
@klueska
Je pense que ce qui se passe, apporter quelques corrections mineures à votre flux est :
Lors de l'initialisation, les plugins de périphérique s'enregistrent avec le
devicemanagerafin qu'il puisse émettre des rappels dessus ultérieurement.Le
lifecycle.PodAdmitHandlerappelleGetTopologyHintssur chaque composant prenant en charge la topologie dans Kubelet, actuellementdevicemanageretcpumanager.
Dans ce cas, ce qui sera représenté comme prenant en charge la topologie dans le Kubelet sont les cpumanager et les devicemanager . Le gestionnaire de topologie est uniquement destiné à coordonner les allocations entre les composants prenant en charge la topologie.
Pour ça:
mais nous aurions besoin de coordonner d'une manière ou d'une autre entre le cpumanager et le gestionnaire de périphériques pour nous assurer qu'ils "acceptent" le même indice lors de leurs allocations.
C'est pour cela que le topologymanager lui-même a été introduit. D'après l'un des premiers brouillons ,
Ces composants doivent se coordonner afin d'éviter les affectations NUMA croisées. Les problèmes liés à cette coordination sont délicats ; les requêtes inter-domaines telles que « Un cœur exclusif sur le même nœud NUMA que la carte réseau attribuée » implique à la fois CNI et le gestionnaire de CPU. Si le gestionnaire de CPU choisit en premier, il peut sélectionner un cœur sur un nœud NUMA sans NIC disponible et vice-versa.
 eloyekunle
le 6 avr. 2019
eloyekunle
le 6 avr. 2019
Je vois.
Ainsi, le devicemanager et le cpumanager implémentent tous les deux GetTopologyHints() ainsi que l'appel GetAffinity() , évitant l'interaction de direction du topologymanager avec les plug-ins de périphérique sous-jacents . En regardant de plus près le code, je vois que le devicemanager délègue simplement le contrôle aux plugins pour aider à remplir TopologyHints , ce qui est plus logique au final de toute façon.
Revenant à la question/problème d'origine que j'ai soulevé cependant...
Du point de vue de Nvidia, je pense que nous pouvons tout faire fonctionner avec ce flux proposé, en supposant que plus d'informations soient ajoutées à la structure TopologyHints (et par conséquent à l'interface du plug-in de périphérique) pour signaler les informations de lien point à point à l'avenir .
Cependant, je pense que commencer avec un SocketMask comme structure de données principale pour l'affinité de socket publicitaire peut limiter notre capacité à étendre TopologyHints avec des informations point à point à l'avenir sans casser l'interface existante. La principale raison étant que (au moins dans le cas des GPU Nvidia), le socket préféré dépend des GPU qui seront réellement alloués à la fin.
Par exemple, considérons la figure ci-dessous, lorsque vous essayez d'allouer 2 GPU à un pod avec une connectivité optimale :
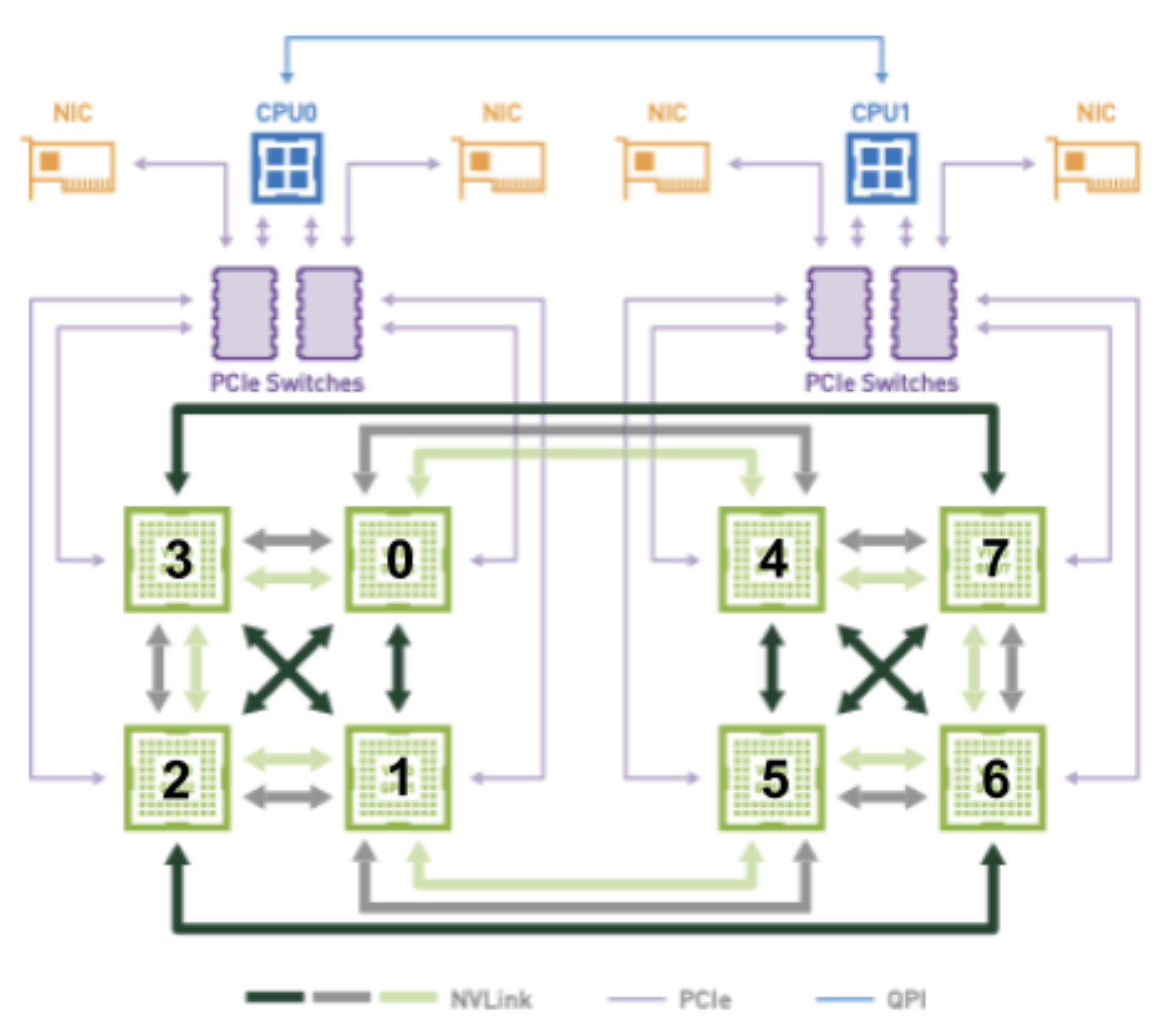
Les combinaisons GPU de (2, 3) et (6, 7) ont toutes deux 2 NVLINK et résident sur le même bus PCIe. Ils doivent donc être considérés comme des candidats égaux lorsqu'on tente d'allouer 2 GPU à un pod. Selon la combinaison choisie, cependant, une prise différente sera évidemment préférée car (2, 3) est connecté à la prise 0 et (6, 7) est connecté à la prise 1.
Cette information devra en quelque sorte être codée dans la structure TopologyHints afin que le devicemanager puisse effectuer l'une de ces allocations souhaitées à la fin (c'est-à-dire celui que le topologymanager consolide les indices jusqu'à). De même, la dépendance entre les allocations de périphériques préférées et le socket préféré devra être encodée en TopologyHints afin que le cpumanager puisse allouer des processeurs à partir du bon socket.
Une solution potentielle spécifique aux GPU Nvidia pour cet exemple ressemblerait à ceci :
type TopologyHint struct {
SocketID int
DeviceIDs []int
}
type TopologyHints []TopologyHint
devicemanagerhints := &TopologyHints{
{SocketID: 0, DeviceIDs: []int{2, 3}},
{SocketID: 1, DeviceIDs: []int{6, 7}},
}
cpumanagerhints := &TopologyHints{
{SocketID: 1},
}
Où le topologymanager consoliderait ces indices pour renvoyer {SocketID: 1, DeviceIDs: []int{6, 7}} comme indice préféré lorsque les devicemanager et cpumanager appellent plus tard GetAffinity() .
Bien que cela puisse ou non fournir une solution suffisamment générique pour tous les accélérateurs, remplacer SocketMask dans la structure TopologyHints par quelque chose de plus structuré comme ce qui suit nous permettrait d'étendre chaque indice individuel avec plus de champs dans l'avenir:
Notez que GetTopologyHints() renvoient toujours TopologyHints , tandis que GetAffinity() a été modifié pour renvoyer un seul TopologyHint plutôt que TopologyHints .
type TopologyHint struct {
SocketID int
}
type TopologyHints []TopologyHint
&TopologyHints{
{SocketID: 0},
{SocketID: 1},
}
type HintProvider interface {
GetTopologyHints(pod v1.Pod, container v1.Container) TopologyHints
}
type Store interface {
GetAffinity(podUID string, containerName string) TopologyHint
}
Les pensées?
klueska
le 9 avr. 2019
@klueska Peut-être qu'il me manque quelque chose, mais je ne vois pas la nécessité d'avoir les identifiants de périphérique pour les GPU NV Link dans le TopologyManager.
Si l'API du plug-in de périphérique était étendue pour permettre aux périphériques de renvoyer des informations sur la connectivité des périphériques point à point, comme le suggérait @ConnorDoyle , le gestionnaire de périphériques serait en mesure de renvoyer des informations de socket sur cette base.
Dans votre exemple, devicemanagerhints pourrait être les informations que les plugins de périphérique ont renvoyées au gestionnaire de périphériques. Le gestionnaire de périphériques renvoie ensuite les informations de socket à TopologyManager telles quelles et TopologyManager stocke l'indice de socket choisi.
Lors de l'allocation, le gestionnaire de périphériques appelle GetAffinity pour obtenir l'allocation de socket souhaitée (disons que le socket est 1 dans ce cas), en utilisant ces informations et les informations renvoyées par les plugins de périphérique, il peut voir que sur le socket 1, il doit attribuer des périphériques ( 6,7) car ce sont des appareils NV Link.
Est-ce que cela a du sens ou y a-t-il quelque chose qui m'échappe?
lmdaly
le 10 avr. 2019
Merci d'avoir pris le temps de clarifier cela avec moi. J'ai dû mal interpréter la suggestion originale de @ConnorDoyle :
Si les conseils de topologie étaient étendus pour coder la topologie de périphérique point à point, le gestionnaire de périphériques pourrait en tenir compte lors du rapport d'affinité de socket.
J'ai lu cela comme voulant étendre la structure TopologyHints avec des informations point à point directement.
Il semble que vous suggériez plutôt que seule l'API du plug-in de périphérique devrait être étendue pour fournir des informations point à point au devicemanager , afin qu'il puisse utiliser ces informations pour informer le SocketMask à définir dans la structure TopologyHints chaque fois que GetTopologyHints() est appelé.
Je pense que cela fonctionnera, tant que les extensions API du plug-in de périphérique sont conçues pour nous fournir des informations similaires à celles que j'ai décrites dans mon exemple ci-dessus et que le devicemanager est étendu pour stocker ces informations entre l'admission du pod et le périphérique. temps d'attribution.
À l'heure actuelle, nous avons une solution personnalisée en place chez Nvidia qui corrige notre kubelet pour faire essentiellement ce que vous suggérez (sauf que nous ne prenons aucune décision sur les plugins de périphérique - le devicemanager a été sensibilisé au GPU et prend lui-même des décisions d'allocation de GPU basées sur la topologie).
Nous voulons simplement nous assurer que la solution à long terme mise en place nous permettra de supprimer ces correctifs personnalisés à l'avenir. Et maintenant que j'ai une meilleure idée du fonctionnement du flux ici, je ne vois rien qui puisse nous bloquer.
Merci encore d'avoir pris le temps de tout clarifier.
klueska
le 10 avr. 2019
Bonjour @lmdaly , je suis le Enhancement Lead pour la 1.15. Cette fonctionnalité va-t-elle passer les étapes alpha/bêta/stable dans la version 1.15 ? S'il vous plaît laissez-moi savoir afin qu'il puisse être suivi correctement et ajouté à la feuille de calcul.
Une fois le codage commencé, veuillez répertorier tous les PR k/k pertinents dans ce numéro afin qu'ils puissent être suivis correctement.
 kacole2
le 12 avr. 2019
kacole2
le 12 avr. 2019
cette fonctionnalité aura sa propre porte de fonctionnalité et sera alpha.
/jalon 1.15
 derekwaynecarr
le 12 avr. 2019
derekwaynecarr
le 12 avr. 2019
@derekwaynecarr : Le jalon fourni n'est pas valide pour ce référentiel. Jalons dans ce référentiel : [ keps-beta , keps-ga , v1.14 , v1.15 ]
Utilisez /milestone clear pour effacer le jalon.
En réponse à ceci :
cette fonctionnalité aura sa propre porte de fonctionnalité et sera alpha.
/jalon 1.15
Les instructions pour interagir avec moi à l'aide des commentaires de relations publiques sont disponibles ici . Si vous avez des questions ou des suggestions concernant mon comportement, veuillez signaler un problème dans le
 k8s-ci-robot
le 12 avr. 2019
k8s-ci-robot
le 12 avr. 2019
/jalon v1.15
derekwaynecarr
le 12 avr. 2019
/assign @lmdaly
 justaugustus
le 28 avr. 2019
lmdaly
le 29 avr. 2019
justaugustus
le 28 avr. 2019
lmdaly
le 29 avr. 2019
@lmdaly
https://github.com/kubernetes/kubernetes/issues/72828
Mon équipe et moi envisageons de tester le gestionnaire de topologie pour une application sensible à Numa.
Alors, nous avons quelques questions.
Au-dessus des PR, ces implémentations complètes sont-elles pour le gestionnaire de topologie ?
Et est-il testé ou stable maintenant ?
 bg-chun
le 15 mai 2019
bg-chun
le 15 mai 2019
@bg-chun Nous faisons la même chose chez Nvidia. Nous avons intégré ces PR WIP dans notre pile interne et avons élaboré une stratégie d'allocation tenant compte de la topologie pour les CPU/GPU qui l'entourent. Ce faisant, nous avons découvert certains problèmes et donné des commentaires spécifiques sur ces PR.
Veuillez consulter le fil de discussion ici pour plus de détails :
https://kubernetes.slack.com/archives/C0BP8PW9G/p1556371768035800
klueska
le 15 mai 2019
Hé, @lmdaly, je suis l'ombre de la version v1.15 de la documentation.
Je vois que vous ciblez la version alpha de cette amélioration pour la version 1.15. Cela nécessite-t-il de nouveaux documents (ou modifications) ?
Juste un rappel amical, nous recherchons un PR contre k/website (branche dev-1.15) dû d'ici le jeudi 30 mai. Ce serait formidable si c'était le début de la documentation complète, mais même un PR d'espace réservé est acceptable. Faites moi savoir si vous avez des questions! ??
 daminisatya
le 18 mai 2019
daminisatya
le 18 mai 2019
@lmdaly Juste un rappel amical, nous recherchons un PR contre k/website (branche dev-1.15) dû d'ici le jeudi 30 mai. Ce serait formidable si c'était le début de la documentation complète, mais même un PR d'espace réservé est acceptable. Faites moi savoir si vous avez des questions! ??
daminisatya
le 27 mai 2019
Salut @lmdaly . Code Freeze est le jeudi 30 mai 2019 @ EOD PST . Toutes les améliorations apportées à la version doivent être complètes, y compris les tests , et les documents PR doivent être ouverts.
Je regarderai https://github.com/kubernetes/kubernetes/issues/72828 pour voir si tous sont fusionnés.
Si vous savez que cela va glisser, veuillez répondre et nous le faire savoir. Merci!
kacole2
le 28 mai 2019
@daminisatya J'ai poussé le doc PR. https://github.com/kubernetes/website/pull/14572
Faites-moi savoir si cela est fait correctement et s'il y a des éléments supplémentaires à faire. Merci pour le rappel!
lmdaly
le 28 mai 2019
Merci @lmdaly ✨
daminisatya
le 29 mai 2019
Salut @lmdaly , aujourd'hui c'est le gel du code pour le cycle de version 1.15. Il y a encore pas mal de PRs k/k qui n'ont pas encore été fusionnés à partir de votre problème de suivi https://github.com/kubernetes/kubernetes/issues/72828. Il est maintenant marqué comme À risque dans la feuille de suivi des améliorations 1.15 . Y a-t-il une grande confiance que ceux-ci seront fusionnés par EOD PST aujourd'hui ? Après ce point, seuls les problèmes de blocage de version et les PR seront autorisés dans le jalon avec une exception.
kacole2
le 30 mai 2019
/jalon clair
kacole2
le 3 juin 2019
Salut @lmdaly @derekwaynecarr , je suis le responsable de l'amélioration 1.16. Cette fonctionnalité va-t-elle passer les étapes alpha/bêta/stable dans la version 1.16 ? Veuillez me le faire savoir afin qu'il puisse être ajouté à la feuille de calcul de suivi 1.16 . Si ce n'est pas le cas, je le supprimerai du jalon et modifierai l'étiquette suivie.
Une fois le codage commencé ou s'il l'a déjà fait, veuillez répertorier tous les PR k/k pertinents dans ce numéro afin qu'ils puissent être suivis correctement.
Les dates clés sont Enhancement Freeze 7/30 et Code Freeze 8/29.
Merci.
kacole2
le 9 juil. 2019
@kacole2 merci pour le rappel. Cette fonctionnalité sera disponible en tant qu'Alpha dans la version 1.16.
La liste en cours des PR est disponible ici : https://github.com/kubernetes/kubernetes/issues/72828
Merci!
lmdaly
le 17 juil. 2019
D'accord, cela atterrira en alpha pour 1.16, nous clôturerons l'effort commencé et capturé dans le kep précédemment fusionné pour 1.15.
derekwaynecarr
le 30 juil. 2019
Salut @lmdaly , je suis l'ombre de la version v1.16 docs.
Cette amélioration nécessite-t-elle de nouveaux documents (ou modifications) ?
Juste un rappel amical, nous recherchons un PR contre k/website (branche dev-1.16) dû d'ici le vendredi 23 août. Ce serait formidable si c'était le début de la documentation complète, mais même un PR d'espace réservé est acceptable. Faites moi savoir si vous avez des questions!
Merci!
 VineethReddy02
le 1 août 2019
VineethReddy02
le 1 août 2019
Documentation PR : https://github.com/kubernetes/website/pull/15716
lmdaly
le 7 août 2019
@lmdaly Le gestionnaire de topologie fournira-t-il des informations ou une API pour indiquer aux utilisateurs la configuration NUMA pour un pod donné ?
 mJace
le 15 août 2019
mJace
le 15 août 2019
@mJace quelque chose de visible via le kubectl décrit pour le pod ?
lmdaly
le 15 août 2019
@lmdaly Ouais, kubectl describe c'est bien. ou une API pour renvoyer des informations connexes.
Étant donné que nous développons un service pour fournir des informations liées à la topologie pour les pods, comme l'état d'épinglage du processeur pour le pod et le nœud numa pour son VF transmis.
Et certains outils de surveillance tels que Weave Scope peuvent appeler l'API pour effectuer un travail de fantaisie.
L'administrateur peut dire si le VNF est sous la configuration numa appropriée, par exemple.
J'aimerais juste savoir si Topology Manager couvrira cette partie.
ou s'il y a du travail que nous pourrions faire si Topology Manager envisage de prendre en charge ce type de fonctionnalité.
mJace
le 15 août 2019
@mJace D'accord, donc actuellement, il n'y a pas d'API comme celle-ci pour Topology Manager. Je ne pense pas qu'il y ait de priorité pour cela, car avec CPU & Device Manager, il n'y a pas de visibilité sur ce qui a réellement été attribué aux pods.
Je pense donc qu'il serait bon de lancer une discussion à ce sujet et de voir quel genre de vue nous pouvons donner aux utilisateurs.
lmdaly
le 15 août 2019
Je vois, je pensais que CPU & Device Manager est capable de voir ces informations.
Peut-être que le cadvisor est un bon rôle pour fournir cette information.
Parce que cadvisor obtient des informations sur le conteneur comme le PID, etc. par ps ls .
Et c'est de la même manière que nous vérifions les informations relatives à la topologie du conteneur.
Je vais implémenter cela dans cadvisor et créer un pr pour cela.
mJace
le 15 août 2019
J'ai créé un problème connexe dans cadvisor.
https://github.com/google/cadvisor/issues/2290
mJace
le 16 août 2019
/attribuer
 khenidak
le 24 août 2019
khenidak
le 24 août 2019
+1 à la proposition de @mJace cadvisor.
Pour utiliser la lib DPDK à l'intérieur du conteneur avec CPU Manager et Topology Manager , en analysant l'affinité cpu du conteneur puis en la transmettant à dpdk lib, les deux sont requis pour l'épinglage de thread de la lib DPDK.
Pour plus de détails, si un processeur n'est pas autorisé dans le sous-système cpuset du groupe de contrôle du conteneur, les appels à sched_setaffinity pour épingler le processus sur le processeur seront filtrés.
La bibliothèque DPDK utilise pthread_setaffinity_np pour l'épinglage des threads, et pthread_setaffinity_np est un wrapper au niveau du thread de sched_setaffinity .
Et le gestionnaire de processeurs de Kubernetes définit des processeurs exclusifs sur le sous-système cpuset du groupe de contrôle du conteneur.
bg-chun
le 26 août 2019
@bg-chun J'ai compris que le changement de cadvisor avait un objectif différent : la surveillance. Pour vos besoins, il est possible de lire les processeurs attribués depuis l'intérieur du conteneur en analysant « Cpus_Allowed » ou « Cpus_Allowed_List » depuis « /proc/self/status ». Cette approche fonctionnera-t-elle pour vous ?
ConnorDoyle
le 26 août 2019
Les informations de Cpus_Allowed sont affectées par le sched_setaffinity . Donc, si l'application définit quelque chose, ce sera un sous-ensemble de ce qui est réellement autorisé par le contrôleur cpuset de Cgroup.
 kad
le 26 août 2019
kad
le 26 août 2019
@kad , je suggérais un moyen pour le lanceur dans le conteneur de découvrir les valeurs d'identification du processeur à transmettre au programme DPDK. Cela se produit donc avant que l'affinité au niveau du thread ne soit définie.
ConnorDoyle
le 26 août 2019
@ConnorDoyle
Merci pour votre suggestion, je vais y réfléchir.
Mon plan déployait le serveur tiny-rest-api pour indiquer les informations exclusives sur l'allocation des processeurs à dpdk-container.
Concernant les changements, je n'ai pas encore vu les changements de cadvisor, je ne vois que la proposition .
La proposition indique able to tell if there is any cpu affinity set for the container. dans Goal et to tell if there is any cpu affinity set for the container processes. dans Future work.
Après avoir lu la proposition, j'ai pensé que ce serait formidable si cadvisor était capable d'analyser les informations d'épinglage du processeur et de les transmettre à kubelet en tant que variable d'environnement telle que status.podIP , metadata.name et limits.cpu .
C'est la principale raison pour laquelle j'ai laissé +1.
bg-chun
le 26 août 2019
@bg-chun Vous pouvez vérifier mon premier pr sur cadvisor
https://github.com/google/cadvisor/pull/2291
J'ai terminé une fonction similaire à.
https://github.com/mJace/numacc
mais pas vraiment sûr de la bonne façon de l'implémenter dans cadvisor
C'est pourquoi je ne crée qu'un PR avec une nouvelle fonctionnalité -> afficher le PSR.
mJace
le 26 août 2019
mais pas vraiment sûr de la bonne façon de l'implémenter dans cadvisor
Peut-être pourrions-nous en discuter dans le cadre de cette proposition ? Si vous gourous pensez que cette fonctionnalité est nécessaire :)
mJace
le 26 août 2019
Le gel du code https://github.com/kubernetes/kubernetes/issues/72828 pour les PR k/k restants
kacole2
le 26 août 2019
@kacole2 tous les PR requis pour cette fonctionnalité sont fusionnés ou dans la file d'attente de fusion.
lmdaly
le 30 août 2019
Salut @lmdaly -- 1.17 Les améliorations mènent ici. Je voulais vérifier et voir si vous pensez que cette amélioration passera à alpha/beta/stable en 1.17 ?
Le calendrier de diffusion actuel est le suivant :
- Lundi 23 septembre - Début du cycle de publication
- Mardi 15 octobre, EOD PST - Gel des améliorations
- Jeudi 14 novembre, EOD PST - Gel du code
- Mardi 19 novembre - Les documents doivent être complétés et révisés
- Lundi 9 décembre - Sortie de Kubernetes 1.17.0
Si vous le faites, veuillez énumérer tous les PR k/k pertinents dans ce numéro afin qu'ils puissent être suivis correctement. ??
Merci!
/jalon clair
 mrbobbytables
le 22 sept. 2019
mrbobbytables
le 22 sept. 2019
@lmdaly existe-t-il un lien direct vers le GPU avec la discussion RDMA ?
 nickolaev
le 25 sept. 2019
nickolaev
le 25 sept. 2019
@nickolaev , Nous examinons également ce cas d'utilisation. Nous avons commencé une réflexion interne sur la façon de procéder, mais nous aimerions collaborer sur ce point.
 moshe010
le 25 sept. 2019
moshe010
le 25 sept. 2019
@moshe010 @nickolaev @lmdaly , Nous examinons également ce cas d'utilisation concernant RDMA et GPU direct. Nous aimerions collaborer à cela. Possible de démarrer un fil/discussion autour de ça ?
 Deepthidharwar
le 25 sept. 2019
Deepthidharwar
le 25 sept. 2019
Salut! J'ai une question à propos de NTM et de l'ordonnanceur. Si je comprends bien, le planificateur ne connaît pas les NUMA et peut préférer le nœud sur lequel il n'y a pas de ressources (cpu, mémoire et périphérique) sur le NUMA souhaité. Le gestionnaire de topologie refusera donc l'allocation de ressources sur ce nœud. Est-ce vrai?
 LilyaBu
le 25 sept. 2019
LilyaBu
le 25 sept. 2019
@nickolaev @Deepthidharwar , je vais lancer google doc avec des cas d'utilisation et nous pourrons y déplacer la discussion. Je posterai quelque chose la semaine prochaine. Si ça vous convient.
moshe010
le 25 sept. 2019
Je suis vraiment content de voir cette fonctionnalité. Nous avons également besoin de CPU, Hugepage, SRIOV-VF et d'autres ressources matérielles dans un seul nœud NUMA.
Mais l'énorme page n'est pas considérée comme une ressource scalaire par plug-in d'appareil, cette fonctionnalité doit-elle changer la fonctionnalité d'énorme page dans k8s ?
@iamneha
 andyzheung
le 26 sept. 2019
andyzheung
le 26 sept. 2019
@ConnorDoyle Juste pour confirmer, cette fonctionnalité a besoin d'indices de topologie à la fois du gestionnaire de processeur et du gestionnaire de périphériques ? Je l'ai testé sur 1.16 et n'a pas fonctionné, il semble qu'il n'ait reçu qu'un indice du gestionnaire de processeur mais aucun indice du côté de l'appareil.
 jianzzha
le 26 sept. 2019
jianzzha
le 26 sept. 2019
@ConnorDoyle voici un peu plus de détails :
https://gist.githubusercontent.com/jianzzha/c2a66a2514c178cca76a432029ff3387/raw/264f13dfcd06f1f80c48c113aa235fab7c33d81e/hyper%2520threading%2520enabled
jianzzha
le 26 sept. 2019
@jianzzha , Quel plugin de périphérique utilisez-vous ? Par exemple, si vous utilisez le plug-in de périphérique SR-IOV, vous devez vous assurer qu'il signale le nœud NUMA voir [1]
moshe010
le 26 sept. 2019
@andyzheung Une énorme intégration de pages est actuellement en cours de discussion et a été présentée lors de la réunion sig-node des deux dernières semaines. Voici quelques liens pertinents :
https://docs.google.com/presentation/d/1H5xhCjgCZJjdTm-mGUFwqoz8XmoVd8xTCwJ1AfVR_54/edit?usp=sharing
https://github.com/kubernetes/enhancements/pull/1245
https://github.com/kubernetes/enhancements/pull/1199
@jianzzha En ce qui concerne le plug-in de l'appareil, ne donne pas d'indices. Votre plugin a-t-il été mis à jour pour signaler les informations NUMA sur les appareils qu'il énumère ? Il doit ajouter ce champ au message de l'appareil https://github.com/kubernetes/kubernetes/blob/master/pkg/kubelet/apis/deviceplugin/v1beta1/api.proto#L100
klueska
le 26 sept. 2019
Merci les gars. Corrigé et fonctionne maintenant.
jianzzha
le 26 sept. 2019
@klueska
Concernant nvidia-gpu-device-plugin..
Je ne vois qu'un seul PR (WIP) actif pour mettre à jour nvidia-gpu-device-plugin pour Topology Manager.
Est-ce que nvidia-gpu-divice-plugin sera mis à jour pour fournir un indice de topologie avec le PR ci-dessus ? ou Y a-t-il quelque chose qui me manque ?
bg-chun
le 26 sept. 2019
@bg-chun Oui, ça devrait l'être. Je viens de contacter l'auteur. S'il ne revient pas dans les prochains jours, je mettrai à jour le plugin moi-même.
klueska
le 26 sept. 2019
@bg-chun @klueska J'ai mis à jour le correctif.
 carmark
le 27 sept. 2019
carmark
le 27 sept. 2019
@klueska @carmark
Merci pour la mise à jour et l'avis.
Je présenterai la mise à jour sr-iov-plugin et la mise à jour gpu-plugin aux utilisateurs de mon espace de travail.
bg-chun
le 27 sept. 2019
Je proposerais une amélioration pour la prochaine version.
Il s'agit essentiellement de supprimer la restriction « l'alignement de la topologie ne se produit que si le pod est en QoS garantie ».
Cette restriction rend en quelque sorte le gestionnaire de topologie inutilisable pour le moment, car je ne voudrais pas demander des processeurs exclusifs à K8, mais j'aimerais aligner les sockets de plusieurs périphériques, provenant de plusieurs pools (par exemple GPU + SR -VF IOV, etc.)
Et si ma charge de travail n'est pas sensible à la mémoire ou ne souhaite pas restreindre son utilisation de la mémoire (un autre critère de QoS garanti).
À l'avenir, lorsque, espérons-le, les pages géantes seront également alignées, cette restriction sera encore plus limitative pour l'OMI.
Existe-t-il un argument contre l'alignement individuel des ressources « alignables » ? Comme bien sûr, collectons uniquement des astuces du gestionnaire de processeur si des processeurs exclusifs sont utilisés, mais rassemblons ou du gestionnaire de mémoire lorsque l'utilisateur demande des pages énormes, etc.
Soit cela, soit si une charge de calcul supplémentaire inutile pendant le démarrage du pod est un problème, peut-être ramener l'indicateur de configuration d'origine au niveau du pod pour contrôler si l'alignement se produit ou non (ce que j'ai été surpris de voir être supprimé lors de la mise en œuvre)
 Levovar
le 30 sept. 2019
Levovar
le 30 sept. 2019
Je proposerais une amélioration pour la prochaine version.
Il s'agit essentiellement de supprimer la restriction « l'alignement de la topologie ne se produit que si le pod est en QoS garantie ».
Il s'agit de l'article numéro 8 sur notre liste TODO pour 1.17 :
https://docs.google.com/document/d/1YTUvezTLGmVtEF3KyLOX3FzfSDw9w0zB-s2Tj6PNzLA/edit#heading =h.xnehh6metosd
Existe-t-il un argument contre l'alignement individuel des ressources « alignables » ? Comme bien sûr, collectons uniquement des astuces du gestionnaire de processeur si des processeurs exclusifs sont utilisés, mais rassemblons ou du gestionnaire de mémoire lorsque l'utilisateur demande des pages énormes, etc.
Proposez-vous un mécanisme pour indiquer sélectivement au kubelet sur quelle ressource s'aligner et sur lesquelles ne pas s'aligner (c'est-à-dire que je veux aligner mes allocations CPU et GPU, mais pas mes énormes allocations de pages). Je ne pense pas que quiconque s'y opposerait carrément, mais l'interface permettant de décider sélectivement sur quelles ressources s'aligner et sur lesquelles ne pas s'aligner pourrait devenir trop lourde si nous continuons à spécifier l'alignement comme indicateur au niveau du nœud.
Soit cela, soit si une charge de calcul supplémentaire inutile pendant le démarrage du pod est un problème, peut-être ramener l'indicateur de configuration d'origine au niveau du pod pour contrôler si l'alignement se produit ou non (ce que j'ai été surpris de voir être supprimé lors de la mise en œuvre)
Il n'y avait pas assez de support pour un indicateur au niveau du pod pour justifier une proposition de mise à jour de la spécification du pod avec cela. Pour moi, il est logique de pousser cette décision au niveau des pods, car certains pods ont besoin / veulent être alignés et d'autres non, mais tout le monde n'était pas d'accord.
klueska
le 30 sept. 2019
+1 pour la suppression de la restriction de classe QoS sur l'alignement de la topologie (je l'ai ajouté à la liste :smiley:). Je n'ai pas eu le sentiment que @Levovar demande d'activer la topologie ressource par ressource, juste que nous devrions aligner toutes les ressources alignables utilisées par un conteneur donné.
Autant que je me souvienne, il n'y a jamais eu de champ au niveau du pod pour opter pour la topologie dans le KEP. La justification pour ne pas l'introduire en premier lieu était la même justification pour laisser les cœurs exclusifs implicites - Kubernetes, en tant que projet, veut être libre d'interpréter la spécification du pod de manière libérale en termes de gestion des performances au niveau des nœuds. Je sais que cette position est insatisfaisante pour certains membres de la communauté, mais nous pouvons toujours soulever à nouveau le sujet. Il existe une tension naturelle entre l'activation de fonctionnalités avancées pour quelques-uns et la modulation de la charge cognitive pour la plupart des utilisateurs.
ConnorDoyle
le 1 oct. 2019
IMO au tout début de la conception, il y avait au moins un drapeau au niveau du Pod si ma mémoire est bonne, mais c'était autour de 1,13 :D
Personnellement, je suis d'accord pour essayer d'aligner toutes les ressources tout le temps, mais "à l'époque", il y avait généralement une communauté repoussant les fonctionnalités qui induisaient des retards au démarrage ou à la décision de planification de tous les pods, peu importe si ils ont vraiment besoin de l'amélioration, ou non.
J'essayais donc simplement de « pré-répondre » à ces préoccupations avec deux options qui me venaient à l'esprit : ou introduire un indicateur de configuration.
Cependant, s'il n'y a pas de recul maintenant contre une amélioration générique, je suis totalement d'accord avec ça :)
Levovar
le 1 oct. 2019
@mrbobbytables Nous prévoyons de faire TopologyManager à beta en 1.17. Le problème de suivi est ici : https://github.com/kubernetes/kubernetes/issues/83479
klueska
le 3 oct. 2019
@bg-chun @klueska J'ai mis à jour le correctif.
Patch fusionné :
https://github.com/NVIDIA/k8s-device-plugin/commit/cc0aad87285b573127add4e487b13434a61ba0d6
Création d'une nouvelle version avec le correctif :
https://github.com/NVIDIA/k8s-device-plugin/releases/tag/1.0.0-beta2
klueska
le 3 oct. 2019
suivi de la version bêta de la v1.17
derekwaynecarr
le 4 oct. 2019
Génial, merci @derekwaynecarr . Je vais l'ajouter à la feuille :)
/étape bêta
mrbobbytables
le 6 oct. 2019
@lmdaly
Je suis l'une des ombres de la documentation v1.17.
Cette amélioration (ou le travail prévu pour la v1.17) nécessite-t-elle de nouveaux documents (ou des modifications aux documents existants) ? Sinon, pouvez-vous s'il vous plaît mettre à jour la feuille de suivi des améliorations 1.17 (ou faites-le moi savoir et je le ferai)
Si c'est le cas, juste un rappel amical, nous recherchons un PR contre k/website (branche dev-1.17) dû d'ici le vendredi 8 novembre, il peut simplement s'agir d'un PR d'espace réservé pour le moment. Faites moi savoir si vous avez des questions!
Merci!
VineethReddy02
le 21 oct. 2019
@ VineethReddy02 oui, nous avons prévu des mises à jour de la documentation pour la 1.17, si vous pouviez mettre à jour la feuille de suivi, ce serait formidable !
Nous serons sûrs d'ouvrir ce PR avant cette date, merci pour le rappel.
Le problème pour la documentation de suivi est ici : https://github.com/kubernetes/kubernetes/issues/83482
lmdaly
le 23 oct. 2019
https://github.com/kubernetes/enhancements/pull/1340
Les gars, j'ai ouvert KEP update PR pour ajouter une étiquette de nœud intégrée( beta.kubernetes.io/topology ) pour Topology Manager.
L'étiquette exposera la politique du nœud.
Je pense qu'il serait utile de planifier un pod sur un nœud particulier lorsqu'il existe des nœuds avec plusieurs politiques dans le même cluster.
Puis-je demander un avis ?
bg-chun
le 28 oct. 2019
Salut @lmdaly @derekwaynecarr
Jeremy de l'équipe d'améliorations 1.17 ici 👋. Pourriez-vous s'il vous plaît énumérer les PRs k/k qui sont en vol pour cela afin que nous puissions les suivre ? Je vois que #83492 a été fusionné, mais il semble qu'il y ait quelques autres problèmes liés à l'élément de suivi global. Nous approchons de Code Freeze le 14 novembre, nous aimerions donc avoir une idée de comment cela se passe avant cette date ! Merci beaucoup!
 jeremyrickard
le 4 nov. 2019
jeremyrickard
le 4 nov. 2019
@jeremyrickard C'est le problème de suivi pour 1.17 comme mentionné ci-dessus : https://github.com/kubernetes/enhancements/issues/693#issuecomment -538123786
klueska
le 4 nov. 2019
@lmdaly @derekwaynecarr
Un rappel amical que nous recherchons un espace réservé PR pour Docs contre k/website (branche dev-1.17) dû d'ici le vendredi 8 novembre. Il ne nous reste plus que 2 jours pour ce délai.
daminisatya
le 6 nov. 2019
Docs PR est ici d'ailleurs : https://github.com/kubernetes/website/pull/17451
lmdaly
le 8 nov. 2019
@klueska Je vois une partie du travail passer à 1,18. Envisagez-vous toujours de passer à la version bêta en 1.17, ou restera-t-il en version alpha mais changera-t-il ?
jeremyrickard
le 13 nov. 2019
Peu importe, je vois dans https://github.com/kubernetes/kubernetes/issues/85093 que vous allez passer à la version bêta dans la version 1.18 maintenant, et non dans le cadre de la version 1.17. Voulez-vous que nous suivions cela comme un changement majeur par rapport à la version alpha dans le cadre du jalon 1.17 @klueska ? Ou simplement reporter la remise des diplômes à 1,18 ?
jeremyrickard
le 13 nov. 2019
/jalon v1.18
jeremyrickard
le 15 nov. 2019
Salut @klueska
Vérification de l'équipe des améliorations 1.18 ! Prévoyez-vous toujours de passer en version bêta en 1.18 ? Enhancement Freeze sera le 28 janvier, si votre KEP nécessite des mises à jour, tandis que le Code Freeze sera le 5 mars.
Merci!
jeremyrickard
le 7 janv. 2020
Oui.
klueska
le 7 janv. 2020
@klueska merci pour la mise à jour ! Mise à jour de la fiche de suivi.
jeremyrickard
le 7 janv. 2020
@klueska alors que nous examinions les KEP pour cette version, nous avons remarqué qu'il manquait des plans de test. Afin de passer à la version bêta dans la version, il faudra ajouter des plans de test. Je vais le supprimer du jalon pour le moment, mais nous pouvons le rajouter si vous déposez une demande d'exception et ajoutez les plans de test au KEP. Toutes nos excuses pour le préavis tardif.
jeremyrickard
le 29 janv. 2020
/jalon clair
jeremyrickard
le 29 janv. 2020
@vpickard s'il vous plaît voir ci-dessus
klueska
le 29 janv. 2020
@vpickard s'il vous plaît voir ci-dessus
@klueska Merci pour l'
 vpickard
le 29 janv. 2020
vpickard
le 29 janv. 2020
@jeremyrickard Existe-t-il un modèle de plan de test vers lequel vous pouvez m'indiquer pour référence ?
vpickard
le 29 janv. 2020
@vpickard vous pouvez jeter un oeil à:
https://github.com/kubernetes/enhancements/blob/master/keps/sig-storage/20190530-pv-health-monitor.md#test -plan
et
https://github.com/kubernetes/enhancements/blob/master/keps/sig-storage/20200120-skip-permission-change.md#test -plan
Inclut un aperçu des tests unitaires et des tests e2e.
Si vous avez quelque chose qui apparaît dans la grille de test, ce serait bien de l'inclure.
jeremyrickard
le 29 janv. 2020
L'exception a été approuvée.
/jalon v1.18
jeremyrickard
le 30 janv. 2020
@jeremyrickard Plan de test fusionné : https://github.com/kubernetes/enhancements/pull/1527
klueska
le 4 févr. 2020
Salut @klueska @vpickard , juste un rappel amical que le Code Freeze entrera en vigueur le jeudi 5 mars.
Pouvez-vous s'il vous plaît lier tous les PR k/k ou tout autre PR qui devrait être suivi pour cette amélioration ?
Je vous remercie :)
 palnabarun
le 5 févr. 2020
palnabarun
le 5 févr. 2020
Salut @palnabarun
Problème de suivi ici pour la 1.18 :
https://github.com/kubernetes/kubernetes/issues/85093
PR actuellement ouverts :
https://github.com/kubernetes/kubernetes/pull/87758 (tests d'écaillage approuvés)
https://github.com/kubernetes/kubernetes/pull/87759 (WIP)
https://github.com/kubernetes/kubernetes/pull/87650 (Examiné, nécessite une approbation)
https://github.com/kubernetes/kubernetes/pull/87645 (e2e test PR, nécessite une approbation)
@vpickard pouvez-vous ajouter tous les PR e2e que j'ai manqués.
Merci
 nolancon
le 5 févr. 2020
nolancon
le 5 févr. 2020
Merci @nolancon d' avoir
palnabarun
le 5 févr. 2020
Salut @palnabarun , @nolancon ,
Quelques PR ouverts supplémentaires liés aux tests E2E :
https://github.com/kubernetes/test-infra/pull/16062 (besoin d'examen et d'approbation)
https://github.com/kubernetes/test-infra/pull/16037 (besoin d'examen et d'approbation)
vpickard
le 6 févr. 2020
Merci @vpickard pour les mises à jour supplémentaires. :)
palnabarun
le 9 févr. 2020
Bonjour @lmdaly, je suis l'une des ombres docs v1.18.
Cette amélioration pour (ou le travail prévu pour la v1.18) nécessite-t-elle de nouveaux documents (ou des modifications aux documents existants) ? Sinon, pouvez-vous s'il vous plaît mettre à jour la feuille de suivi des améliorations 1.18 (ou faites-le moi savoir et je le ferai)
Si c'est le cas, juste un rappel amical, nous recherchons un PR contre k/website (branche dev-1.18) dû d'ici le vendredi 28 février, il peut simplement s'agir d'un PR d'espace réservé pour le moment. Faites moi savoir si vous avez des questions!
 irvifa
le 9 févr. 2020
irvifa
le 9 févr. 2020
Salut @irvifa , merci pour l'
Merci.
nolancon
le 10 févr. 2020
Salut @nolancon merci pour votre réponse rapide, je change le statut en Placeholder PR maintenant .. Merci !
irvifa
le 10 févr. 2020
@palnabarun Pour info , j'ai divisé ce PR https://github.com/kubernetes/kubernetes/pull/87759 en deux PR pour faciliter le processus de révision. Le second est ici https://github.com/kubernetes/kubernetes/pull/87983 et devra également être suivi. Merci.
nolancon
le 10 févr. 2020
@nolancon Merci pour les mises à jour.
Je vois que certains des PR sont toujours en attente de fusion. Je voulais voir si vous aviez besoin de l'aide de l'équipe de publication pour amener les réviseurs et les approbateurs aux PR. Faites-nous savoir si vous avez besoin de quelque chose.
Pour info, nous sommes très proches de Code Freeze le 5 mars
palnabarun
le 27 févr. 2020
@nolancon Merci pour les mises à jour.
Je vois que certains des PR sont toujours en attente de fusion. Je voulais voir si vous aviez besoin de l'aide de l'équipe de publication pour amener les réviseurs et les approbateurs aux PR. Faites-nous savoir si vous avez besoin de quelque chose.
Pour info, nous sommes très proches de Code Freeze le 5 mars
@palnabarun Une autre mise à jour, https://github.com/kubernetes/kubernetes/pull/87983 est maintenant fermée et n'a pas besoin d'être suivie. Les modifications requises sont incluses dans le PR d'origine https://github.com/kubernetes/kubernetes/pull/87759 qui est en cours de révision.
nolancon
le 27 févr. 2020
@nolancon Cool. Je suis également en train de suivre le problème du suivi des parapluies que vous avez partagé ci-dessus. :)
palnabarun
le 27 févr. 2020
Salut @nolancon , ceci nous rappelle que nous ne sommes qu'à deux jours de Code Freeze le 5 mars .
Par le gel du code, tous les PR pertinents doivent être fusionnés, sinon vous devrez déposer une demande d'exception.
palnabarun
le 3 mars 2020
Salut @nolancon ,
Aujourd'hui EOD est Code Freeze .
Pensez-vous que https://github.com/kubernetes/kubernetes/pull/87650 serait examiné avant la date limite ?
Sinon, veuillez déposer une demande d'exception .
palnabarun
le 5 mars 2020
Salut @nolancon ,
Aujourd'hui EOD est Code Freeze .
Pensez-vous que kubernetes/kubernetes#87650 serait examiné avant la date limite ?
Sinon, veuillez déposer une demande d'exception .
Salut @palnabarun , beaucoup de progrès ont été accomplis au cours des deux derniers jours et nous sommes convaincus que tout sera approuvé et fusionné avant le gel du code. Sinon, je déposerai la demande d'exception.
Juste pour clarifier, par EOD voulez-vous dire 17 heures ou minuit PST ? Merci
nolancon
le 5 mars 2020
Juste pour clarifier, par EOD voulez-vous dire 17 heures ou minuit PST ? Merci
17 h 00 HNP.
jeremyrickard
le 5 mars 2020
Le PR est approuvé mais il manque un jalon que le nœud de signature doit ajouter pour fusionner. Je leur ai envoyé un ping, j'espère que cela se décolle et que vous n'avez pas besoin d'exception. =)
 kikisdeliveryservice
le 5 mars 2020
kikisdeliveryservice
le 5 mars 2020
Tous les PR pour ce kep semblent avoir fusionné (et approuvés dans les délais), j'ai mis à jour notre feuille de suivi des améliorations. :le sourire:
kikisdeliveryservice
le 6 mars 2020
/jalon clair
(suppression de ce problème d'amélioration du jalon v1.18 lorsque le jalon est terminé)
palnabarun
le 29 avr. 2020
Salut @nolancon @lmdaly , ombre d'améliorations pour 1.19 ici. Des plans pour cela dans la 1.19 ?
 johnbelamaric
le 4 mai 2020
johnbelamaric
le 4 mai 2020
La seule amélioration prévue pour la 1.19 est la suivante :
https://github.com/kubernetes/enhancements/pull/1121
Le reste du travail portera sur la refactorisation du code / les corrections de bogues si nécessaire.
Est-il possible de changer le propriétaire de ce problème pour moi au lieu de @lmdaly ?
klueska
le 4 mai 2020
Merci, je vais mettre à jour le contact.
/jalon v1.19
johnbelamaric
le 4 mai 2020
/assigner @klueska
/unassign @lmdaly
Voilà, Kevin https://prow.k8s.io/command-help
 pires
le 6 mai 2020
pires
le 6 mai 2020
Salut Kevin. Récemment, le format KEP a changé, et le #1620 a également fusionné la semaine dernière, ajoutant des questions d'examen de la préparation à la production au modèle KEP. Si possible, veuillez prendre le temps de reformater votre KEP et également de répondre aux questions ajoutées au modèle . Les réponses à ces questions seront utiles aux opérateurs qui utilisent et dépannent la fonctionnalité (en particulier l'élément de surveillance à ce stade). Merci!
johnbelamaric
le 13 mai 2020
@klueska ^^
johnbelamaric
le 13 mai 2020
@derekwaynecarr @klueska @johnbelamaric
Je prévois également d'ajouter une nouvelle politique de topologie sur la version 1.19 rel.
Mais il n'a pas encore été examiné par le propriétaire et le mainteneur.
(Si cela semble être difficile à faire en 1.19, faites-le moi savoir.)
- Mise à jour KEP PR : https://github.com/kubernetes/enhancements/pull/1752
- PR pour kubelet : WIP
bg-chun
le 13 mai 2020
Salut @klueska 👋 1.19 docs shadow ici ! Ce travail d'amélioration prévu pour la version 1.19 nécessite-t-il de nouveaux documents ou une modification de la documentation ?
Rappel amical que si une nouvelle/modification des documents est requise, un espace réservé PR contre k/site Web (branche dev-1.19 ) est nécessaire d'ici le vendredi 12 juin.
 annajung
le 21 mai 2020
annajung
le 21 mai 2020
Salut @klueska, j'espère que vous allez bien, vérifiez à nouveau si des documents sont requis pour cela ou non. Pourriez-vous confirmer?
annajung
le 27 mai 2020
Salut @annajung. Il y a 2 améliorations en attente qui nécessiteront toutes deux des modifications de la documentation :
1121
1752
Nous sommes toujours en train de décider si ceux-ci passeront à 1,19 ou seront poussés à 1,20. Si nous décidons de les conserver pour la 1,19, je m'assurerai de créer un PR d'espace réservé pour les documents d'ici le 12 juin.
klueska
le 29 mai 2020
Super! Merci pour la mise à jour, je mettrai à jour la feuille de suivi en conséquence ! S'il vous plaît faites le moi savoir une fois que l'espace réservé PR a été fait. Merci!
annajung
le 30 mai 2020
@lmdaly @ConnorDoyle
J'espère que c'est ici le bon endroit pour demander et donner des commentaires.
J'active les TopologyManager et CPUManager sur mon cluster k8s v1.17.
et leur police est best-effort et static
Voici les ressources de mon pod
resources:
requests:
cpu: 2
intel.com/sriov_pool_a: '1'
limits:
cpu: 2
intel.com/sriov_pool_a: '1'
Le PF du sriov_pool_a est dans le nœud NUMA 0, donc je m'attends à ce que mon pod fonctionne également sur le processeur du nœud NUMA 0.
Mais j'ai trouvé que le processus de mon pod s'exécute sur le processeur du nœud NUMA 1.
De plus, il n'y a pas de masque d'affinité cpu défini en fonction du résultat de taskset -p <pid> .
Y a-t-il quelque chose qui ne va pas? Je m'attends à ce que le conteneur ait un masque d'affinité cpu défini pour le cpu du nœud numa 0.
Y a-t-il un exemple ou un test que je puisse faire pour savoir si mon TopoloyManager fonctionne correctement ?
mJace
le 4 juin 2020
@annajung Placeholder docs PR ajouté : https://github.com/kubernetes/website/pull/21607
klueska
le 9 juin 2020
Salut @klueska ,
Pour faire suite à l'e-mail envoyé à k-dev lundi, je voulais vous informer que Code Freeze a été prolongé jusqu'au jeudi 9 juillet. Vous pouvez voir le calendrier révisé ici : https://github.com/kubernetes/sig-release/tree/master/releases/release-1.19
Nous nous attendons à ce que tous les PR soient fusionnés d'ici là. S'il vous plaît laissez-moi savoir si vous avez des questions. ??
Meilleur,
Kirsten
kikisdeliveryservice
le 18 juin 2020
Salut @klueska , un rappel amical de la prochaine échéance à venir.
N'oubliez pas de remplir votre espace réservé doc PR et de le préparer pour examen d'ici le lundi 6 juillet.
annajung
le 22 juin 2020
Merci @annajung . Étant donné que le gel du code a maintenant été déplacé au 9 juillet, est-il judicieux de repousser également la date de la documentation ? Que se passe-t-il si nous créons la documentation, mais que la fonctionnalité ne le fait pas à temps (ou le fait sous une forme légèrement différente de celle suggérée par la documentation) ?
klueska
le 23 juin 2020
Salut @klueska , c'est un bon point ! La date limite de tous les documents a également été repoussée d'une semaine avec la nouvelle date de sortie, mais je pense que vous avez un argument valable. Permettez-moi de contacter le responsable de la documentation pour la publication et de vous répondre ! Merci de l'avoir signalé !
annajung
le 24 juin 2020
Salut @klueska , merci encore d'avoir attiré notre attention sur ce point. Il y a eu un mélange avec les dates de docs pour la sortie. Comme vous l'avez mentionné, "PR ready for review" devrait arriver après le gel du code et l'a été dans les versions précédentes.
Cependant, après avoir parlé avec l'équipe de publication, nous avons décidé de conserver les dates telles quelles pour cette version 1.19 en faisant de la "PR ready for review" une date limite souple. L'équipe Docs sera flexible et travaillera avec vous/d'autres personnes qui pourraient avoir besoin de plus de temps pour s'assurer que les documents sont synchronisés avec le code. Alors que la date limite « PR prêt pour examen » ne sera pas appliquée, la « RP examinée et lue pour fusionner » le sera.
J'espère que cela vous aidera à répondre à vos préoccupations ! S'il vous plaît laissez-moi savoir si vous avez d'autres questions!
Aussi, juste un rappel amical des dates :
"Date limite des documents - PRs prêts à être examinés" est attendu pour le 6 juillet
« Docs terminés - Tous les PR examinés et prêts à être fusionnés » est attendu pour le 16 juillet
annajung
le 24 juin 2020
Salut @klueska :wave: -- 1.19 Améliorations mènent ici,
Pouvez-vous s'il vous plaît créer un lien vers tous les PR de mise en œuvre ici, afin que l'équipe de publication puisse les suivre ? :slightly_smileing_face:
Merci.
palnabarun
le 28 juin 2020
@palnabarun
Le suivi des relations publiques https://github.com/kubernetes/enhancements/pull/1121 se trouve à l'
https://github.com/kubernetes/kubernetes/pull/92665
Malheureusement, l'amélioration #1752 ne sera pas incluse dans la version, il n'y a donc pas de relations publiques à suivre.
klueska
le 30 juin 2020
Salut @klueska :wave:, je vois que les deux PR (https://github.com/kubernetes/enhancements/pull/1121 et https://github.com/kubernetes/enhancements/pull/1752) que vous avez mentionnés se référer à la même amélioration. Étant donné que https://github.com/kubernetes/enhancements/pull/1752 étend les exigences d'obtention du diplôme bêta et qu'ils ne seront pas inclus dans la version, pouvons-nous supposer qu'il n'y a pas d'autres changements attendus dans la 1.19 ?
Merci. :slightly_smileing_face:
Code Freeze commence le jeudi 9 juillet EOD PST
palnabarun
le 6 juil. 2020
@palnabarun Il s'agit d'un PR de suivi du # 92665 qui devrait atterrir aujourd'hui ou demain : https://github.com/kubernetes/kubernetes/pull/92794
Après cela, il ne devrait plus y avoir de PR pour cette version, en attendant des bogues imprévus.
klueska
le 6 juil. 2020
Impressionnant! Merci pour la mise à jour. :+1:
Nous garderons un œil sur https://github.com/kubernetes/kubernetes/pull/92794.
palnabarun
le 6 juil. 2020
@annajung https://github.com/kubernetes/website/pull/21607 est maintenant prêt à être examiné.
klueska
le 6 juil. 2020
Félicitations @klueska kubernetes/kubernetes#92794 a finalement fusionné, je mettrai à jour la feuille de suivi en conséquence 😄
kikisdeliveryservice
le 11 juil. 2020
/jalon clair
(suppression de ce problème d'amélioration du jalon v1.19 lorsque le jalon est terminé)
kikisdeliveryservice
le 12 sept. 2020
Salut @klueska
Les améliorations mènent ici. Y a-t-il des plans pour que cela soit diplômé en 1.20 ?
Merci!
Kirsten
kikisdeliveryservice
le 13 sept. 2020
Il n'est pas prévu qu'il obtienne son diplôme, mais il existe un PR qui devrait être suivi pour 1,20 lié à cette amélioration :
https://github.com/kubernetes/kubernetes/pull/92967
klueska
le 16 sept. 2020
Même s'il ne sort pas de la version 1.20, veuillez continuer à lier les PR liés à ce problème comme vous venez de le faire.
kikisdeliveryservice
le 16 sept. 2020
@kikisdeliveryservice pouvez-vous s'il vous plaît aider à comprendre le processus. La fonctionnalité Topology Manager ne sort pas de la version 1.20, mais la nouvelle fonctionnalité y sera ajoutée et en cours d'élaboration : https://github.com/kubernetes/enhancements/pull/1752 k/k : https://github. com/kubernetes/kubernetes/pull/92967. Est-ce quelque chose que nous devons suivre avec l'équipe de publication ? Cela peut simplifier le suivi de la mise à jour des documents pour la version 1.20 ou peut-être quelque chose d'autre qui est suivi.
Le changement est additif, il n'y a donc pas beaucoup de raisons de l'appeler bêta2 ou quelque chose comme ça.
Bump PR connexe qui reflète la réalité que la fonctionnalité supplémentaire n'a pas été livrée dans 1.19 : https://github.com/kubernetes/enhancements/pull/1950
 SergeyKanzhelev
le 27 oct. 2020
SergeyKanzhelev
le 27 oct. 2020
Mise à jour de la documentation Web de Topology Manager PR pour inclure la fonctionnalité de portée : https://github.com/kubernetes/website/pull/24781
 k-wiatrzyk
le 29 oct. 2020
k-wiatrzyk
le 29 oct. 2020
Je crois qu'il peut être suivi avec 1,20 et n'a pas nécessairement besoin d'être diplômé. @kikisdeliveryservice s'il vous plaît
annajung
le 29 oct. 2020
Salut @SergeyKanzhelev
En regardant l'histoire, ce n'est en fait pas le cas. On m'a dit que ce ne serait pas un diplôme supérieur, ce qui est bien et pourquoi ce KEP n'est pas suivi. Cependant, cette amélioration (à l'insu de l'équipe des améliorations) a récemment été reciblée par @k-wiatrzyk pour 1.20 en version bêta (https://github.com/kubernetes/enhancements/pull/1950).
Si vous souhaitez tirer parti du processus de publication : suivi des améliorations, faire partie du jalon de la publication et avoir l'équipe de documentation pour le suivi/avoir les documents inclus dans la version 1.20, une demande d'exception d'amélioration doit être déposée dès que possible.
kikisdeliveryservice
le 30 oct. 2020
La fonctionnalité a déjà été fusionnée dans le KEP (préexistant) (avant la date limite d'amélioration).
https://github.com/kubernetes/enhancements/pull/1752
Lors de sa mise en œuvre, les relations publiques font déjà partie du jalon.
https://github.com/kubernetes/kubernetes/pull/92967
Je ne savais pas qu'il y avait plus à faire.
A qui devons-nous déposer une exception, et pour quoi exactement ?
klueska
le 30 oct. 2020
Salut @klueska, le pr que vous faites référence a été fusionné en juin pour ajouter une version bêta dans le kep en 1.19 : https://github.com/bg-chun/enhancements/blob/f3df83cc997ff49bfbb59414545c3e4002796f19/keps/sig-node/0035-20190130-topology -manager.md#beta -v119
La date limite des améliorations pour la version 1.20 était le 6 octobre, mais le changement, déplaçant la version bêta vers la version 1.20 et supprimant la référence à la version 1.19 a été fusionné il y a 3 jours via https://github.com/kubernetes/enhancements/pull/1950
Vous pouvez trouver des instructions pour envoyer une demande d'exception ici : https://github.com/kubernetes/sig-release/blob/master/releases/EXCEPTIONS.md
kikisdeliveryservice
le 30 oct. 2020
Désolé, je ne comprends toujours pas pourquoi nous allons déposer une exception.
Je suis heureux de le faire, je ne sais pas quoi inclure dedans.
La fonctionnalité "Node Topology Manager" est déjà passée en version bêta en 1.18.
Il ne passe pas à GA en 1.20 (il reste en version bêta).
Le PR fusionné pour la 1.20 (c'est-à-dire kubernetes/kubernetes#92967) est une amélioration du code existant pour le gestionnaire de topologie, mais il n'est pas lié à une "bosse" en termes de statut alpha/beta/ga, etc.
klueska
le 30 oct. 2020
J'ai envoyé un courrier d'appel d'exception car la date limite est aujourd'hui (juste au cas où): https://groups.google.com/g/kubernetes-sig-node/c/lsy0fO6cBUY/m/_ujNkQtCCQAJ
k-wiatrzyk
le 2 nov. 2020
@kikisdeliveryservice @klueska @annajung
L'appel à exception a été approuvé, vous pouvez trouver la confirmation ici : https://groups.google.com/g/kubernetes-sig-release/c/otE2ymBKeMA/m/ML_HMQO7BwAJ
k-wiatrzyk
le 4 nov. 2020
Merci @k-wiatrzyk & @klueska Mise à jour de la feuille de suivi.
cc : @annajung
kikisdeliveryservice
le 5 nov. 2020
Salut @k-wiatrzyk @klueska
On dirait que kubernetes/kubernetes#92967 est approuvé mais nécessite une rebase.
Juste un rappel que Code Freeze arrive dans 2 jours le jeudi 12 novembre . Tous les PR doivent être fusionnés à cette date, sinon une exception est requise.
Meilleur,
Kirsten
kikisdeliveryservice
le 11 nov. 2020
Le PR a fusionné, mise à jour de la feuille - oui ! :smile_cat:
kikisdeliveryservice
le 12 nov. 2020
Questions connexes
justaugustus
·
3Commentaires
 liggitt
·
7Commentaires
liggitt
·
7Commentaires
 euank
·
13Commentaires
euank
·
13Commentaires
 msau42
·
13Commentaires
msau42
·
13Commentaires
 boynux
·
3Commentaires
boynux
·
3Commentaires
Commentaire le plus utile
Tous les PR pour ce kep semblent avoir fusionné (et approuvés dans les délais), j'ai mis à jour notre feuille de suivi des améliorations. :le sourire: