Enhancements: Диспетчер топологии узлов
Описание улучшения
- Однострочное описание улучшения (может использоваться как примечание к выпуску): компонент Kubelet для координации детального назначения аппаратных ресурсов для различных компонентов в Kubernetes.
- Основное контактное лицо (исполнитель ):
- Ответственные SIG: sig-node
- Ссылка на проектное предложение (репозиторий сообщества): https://github.com/kubernetes/community/pull/1680
- KEP PR: https://github.com/kubernetes/enhancements/pull/781
- KEP: https://github.com/kubernetes/enhancements/blob/master/keps/sig-node/0035-20190130-topology-manager.md
- Ссылка на e2e и / или модульные тесты: пока нет
- Рецензент (ы) - (для LGTM) рекомендуют иметь 2+ рецензентов (по крайней мере, одного из файла OWNERS кодовой области), согласившихся на рецензирование. Рецензенты из нескольких компаний предпочли: @ConnorDoyle @balajismaniam
- Утверждающий (вероятно, из SIG / области, к которой относится улучшение): @derekwaynecarr @ConnorDoyle
- Цель улучшения (какая цель соответствует какой вехе):
- Целевой выпуск альфа-версии (xy): v1.16
- Целевая версия бета-версии (xy): v1.18
- Стабильная цель выпуска (xy)
 lmdaly
lmdaly
Все 159 Комментарий
/ sig узел
/ kind feature
cc @ConnorDoyle @balajismaniam @nolancon
lmdaly
17 янв. 2019
Я могу помочь в разработке этого дизайна, основываясь на опыте Борга. Так что считайте меня рецензентом / утверждающим.
 vishh
4 февр. 2019
vishh
4 февр. 2019
Я могу помочь в разработке этого дизайна, основываясь на опыте Борга. Так что считайте меня рецензентом / утверждающим.
Есть ли общедоступная документация о том, как эта функция работает в borg?
 jeremyeder
11 февр. 2019
jeremyeder
11 февр. 2019
Не про НУМА АФАИК.
В понедельник, 11 февраля 2019 г., 7:50 Джереми Эдер < [email protected] написал:
Я могу помочь в разработке этого дизайна, основываясь на опыте Борга. Так считай меня в
в качестве рецензента / утверждающего.Есть ли общедоступная документация о том, как эта функция работает в borg?
-
Вы получили это, потому что прокомментировали.
Ответьте на это письмо напрямую, просмотрите его на GitHub
https://github.com/kubernetes/enhancements/issues/693#issuecomment-462378195 ,
или отключить поток
https://github.com/notifications/unsubscribe-auth/AGvIKPfanjb9Q5DxXAiBgv9C6Y809JX0ks5vMZFZgaJpZM4aE3uz
.
vishh
11 февр. 2019
К вашему сведению @claurence
Эта проблема с отслеживанием и KEP (https://github.com/kubernetes/enhancements/pull/781) не успели вовремя заморозить улучшения v1.14 или продлить срок. Я ценю, что вы открыли их до истечения крайних сроков, но, похоже, они не получили достаточного рассмотрения или подписания. Это нужно будет пройти через процесс исключения.
Пока мы не решим, стоит ли это исключения, я склонен приостановить все PR, связанные с этим улучшением.
ссылка: https://github.com/kubernetes/kubernetes/issues/72828
 spiffxp
24 февр. 2019
spiffxp
24 февр. 2019
/ cc @jiayingz @ dchen1107
 jiayingz
25 февр. 2019
jiayingz
25 февр. 2019
@lmdaly Я вижу, что
 claurence
27 февр. 2019
claurence
27 февр. 2019
@lmdaly Я вижу, что
@claurence, KEP теперь объединен (KEP ранее был объединен в репозиторий новых улучшений в соответствии с новыми руководящими принципами), нужно ли нам по-прежнему отправлять запрос на исключение, чтобы отслеживать эту проблему для 1.14?
lmdaly
5 мар. 2019
Несмотря на то, что я внимательно прочитал проект и PR WIP, у меня возникли опасения, что текущая реализация не является универсальной, как исходный дизайн топологии, который мы предложили в https://github.com/kubernetes/enhancements/pull/781. В настоящее время эта топология больше похожа на топологию NUMA на уровне узла.
Я оставил несколько комментариев для дальнейшего обсуждения здесь: https://github.com/kubernetes/kubernetes/pull/74345#discussion_r264387724
 resouer
11 мар. 2019
resouer
11 мар. 2019
текущая реализация не является универсальной
Разделите то же беспокойство по этому поводу :) А как насчет других, например ссылок между устройствами (nvlinke для GPU)?
 k82cn
20 мар. 2019
k82cn
20 мар. 2019
@resouer @ k82cn Первоначальное предложение касается только согласования решений, принимаемых диспетчером процессора и диспетчером устройств, для обеспечения близости устройств к процессору, на котором работает контейнер. Удовлетворение сродства между устройствами не было целью предложения.
Однако если текущая реализация блокирует добавление сродства между устройствами в будущем, я буду рад изменить реализацию, как только я пойму, как это происходит,
lmdaly
25 мар. 2019
Я думаю, что основная проблема, которую я вижу с текущей реализацией и возможностью поддерживать привязку между устройствами, заключается в следующем:
Для поддержки сходства между устройствами вам обычно необходимо сначала выяснить, какие устройства вы хотите выделить для контейнера, _ перед_ принятием решения о том, какое соответствие сокета вы хотите, чтобы контейнер имел.
Например, с графическими процессорами Nvidia для оптимального подключения вам сначала нужно найти и выделить набор графических процессоров с наиболее подключенными NVLINK, _ до_ определения того, какое соответствие сокета имеет этот набор.
Исходя из того, что я могу сказать в текущем предложении, предполагается, что эти операции выполняются в обратном порядке, т. Е. Сродство сокета определяется до выделения устройств.
 klueska
5 апр. 2019
klueska
5 апр. 2019
Это не обязательно правда @klueska. Если подсказки по топологии были расширены для кодирования топологии устройства «точка-точка», диспетчер устройств мог бы учесть это при сообщении о сходстве сокетов. Другими словами, топология кросс-устройств не должна выходить за рамки диспетчера устройств. Это кажется возможным?
 ConnorDoyle
5 апр. 2019
ConnorDoyle
5 апр. 2019
Может я как-то запуталась в потоке. Вот как я это понимаю:
1) При инициализации плагины устройства (а не devicemanager ) регистрируются с помощью topologymanager чтобы он мог выполнять обратные вызовы в более позднее время.
2) При отправке пода кубелет вызывает lifecycle.PodAdmitHandler на topologymanager .
3) lifecycle.PodAdmitHandler вызывает GetTopologyHints для каждого зарегистрированного плагина устройства.
4) Затем он объединяет эти подсказки для создания консолидированного TopologyHint связанного с модулем.
5) Если он решил принять модуль, он успешно возвращается из lifecycle.PodAdmitHandler сохраняя консолидированные TopologyHint для модуля в местном государственном магазине.
6) В какой-то момент в будущем cpumanager и devicemanager вызывают GetAffinity(pod) в диспетчере topology чтобы получить TopologyHint связанный со стручком
7) cpumanager использует этот TopologyHint` для выделения ЦП
8) devicemanager использует этот TopologyHint` для выделения набора устройств
9) Инициализация модуля продолжается ...
Если это верно, я думаю, что я борюсь с тем, что происходит между моментом времени, когда плагин устройства сообщает о своем TopologyHints и временем, когда devicemanager выполняет фактическое распределение.
Если эти подсказки предназначены для кодирования «предпочтений» для распределения, то я думаю, что вы говорите о том, чтобы иметь структуру, более похожую на:
type TopologyHints struct {
hints []struct {
SocketID int
DeviceIDs []int
}
}
Где мы не только передаем список предпочтений привязки сокетов, но и как эти предпочтения привязки сокетов сочетаются с назначаемыми предпочтениями графического процессора.
Если вы думаете об этом, то я думаю, мы могли бы заставить его работать, но нам нужно как-то согласовать между cpumanager и devicemanager чтобы убедиться, что они «приняли» то же самое. намекнуть при их выделении.
Есть ли что-то, что уже позволяет это сделать, что я пропустил?
klueska
5 апр. 2019
@klueska
Я думаю, что происходит, когда вы вносите некоторые _небольшие_ исправления в ваш поток:
При инициализации плагины устройства регистрируются с помощью
devicemanagerчтобы он мог выполнять обратные вызовы для него позже.lifecycle.PodAdmitHandlerвызываетGetTopologyHintsдля каждого компонента Kubelet, учитывающего топологию, в настоящее времяdevicemanagerиcpumanager.
В этом случае в Kubelet с учетом топологии будут представлены символы cpumanager и devicemanager . Диспетчер топологии предназначен только для координации распределения между компонентами, поддерживающими топологию.
Для этого:
но нам нужно как-то скоординировать действия cpumanager и devicemanager, чтобы убедиться, что они «приняли» одну и ту же подсказку при выделении памяти.
Это то, для чего был введен сам topologymanager . Из одного из более ранних черновиков ,
Эти компоненты должны координироваться, чтобы избежать перекрестных назначений NUMA. Проблемы, связанные с этой координацией, сложны; Междоменные запросы, такие как «Эксклюзивное ядро на том же узле NUMA, что и назначенная сетевая карта», включают как CNI, так и диспетчер ЦП. Если диспетчер ЦП выбирает первым, он может выбрать ядро на узле NUMA без доступной сетевой карты и наоборот.
 eloyekunle
6 апр. 2019
eloyekunle
6 апр. 2019
Я понимаю.
Таким образом, devicemanager и cpumanager оба реализуют GetTopologyHints() а также вызывают GetAffinity() , избегая взаимодействия направления от topologymanager с любыми подключаемыми модулями базового устройства. . При более внимательном рассмотрении кода я вижу, что devicemanager просто делегирует управление плагинам, чтобы помочь заполнить TopologyHints , что в любом случае имеет больше смысла.
Возвращаясь к исходному вопросу / проблеме, которую я поднял ...
С точки зрения Nvidia, я думаю, что мы можем заставить все работать с этим предложенным потоком, предполагая, что дополнительная информация будет добавлена в структуру TopologyHints (и, следовательно, в интерфейс плагина устройства), чтобы сообщать информацию о двухточечных ссылках в будущем. .
Однако я думаю, что если начать с SocketMask в качестве первичной структуры данных для рекламной привязки сокетов, это может ограничить нашу способность расширять TopologyHints с помощью двухточечной информации в будущем без нарушения существующего интерфейса. Основная причина в том, что (по крайней мере, в случае графических процессоров Nvidia) предпочтительный сокет зависит от того, какие графические процессоры фактически будут выделены в конце.
Например, рассмотрите рисунок ниже при попытке выделить 2 графических процессора для модуля с оптимальным подключением:
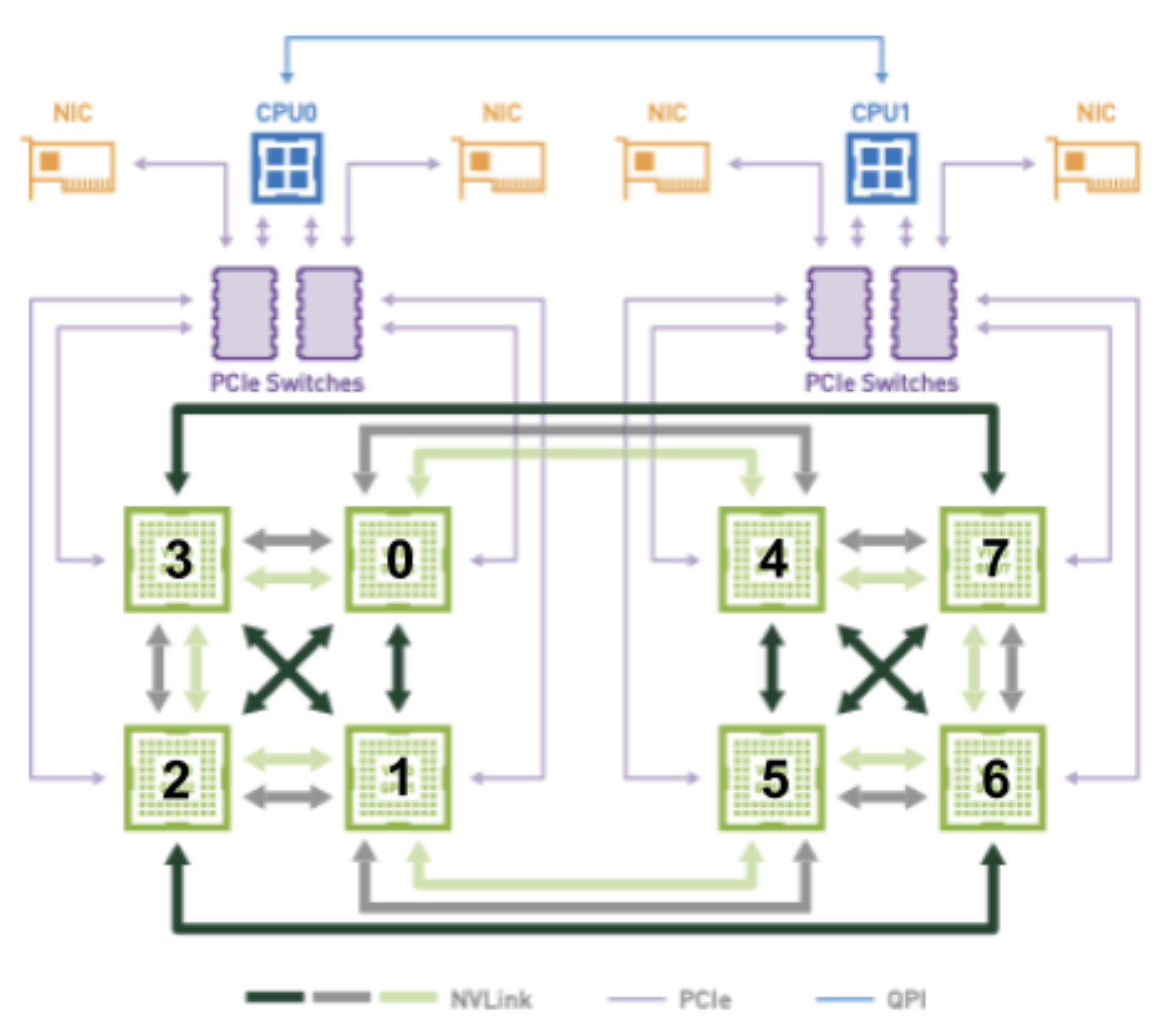
Комбинации графических процессоров (2, 3) и (6, 7) имеют по 2 NVLINK и находятся на одной шине PCIe. Поэтому их следует рассматривать как равных кандидатов при попытке выделить 2 графических процессора для модуля. Однако, в зависимости от того, какая комбинация выбрана, очевидно, что предпочтительнее будет другое гнездо, поскольку (2, 3) подключено к гнезду 0, а (6, 7) подключено к гнезду 1.
Эту информацию нужно каким-то образом закодировать в структуре TopologyHints чтобы devicemanager мог выполнить одно из этих желаемых распределений в конце (то есть в зависимости от того, какое из них topologymanager объединяет подсказки вниз до). Аналогичным образом, зависимость между выделением предпочтительных устройств и предпочтительного сокета должна быть закодирована в TopologyHints чтобы cpumanager мог выделять ЦП из правильного сокета.
Возможное решение для графических процессоров Nvidia в этом примере будет выглядеть примерно так:
type TopologyHint struct {
SocketID int
DeviceIDs []int
}
type TopologyHints []TopologyHint
devicemanagerhints := &TopologyHints{
{SocketID: 0, DeviceIDs: []int{2, 3}},
{SocketID: 1, DeviceIDs: []int{6, 7}},
}
cpumanagerhints := &TopologyHints{
{SocketID: 1},
}
Если topologymanager объединит эти подсказки, чтобы вернуть {SocketID: 1, DeviceIDs: []int{6, 7}} в качестве предпочтительной подсказки, когда devicemanager и cpumanager позже вызовут GetAffinity() .
Хотя это может обеспечить или не предоставить достаточно общее решение для всех ускорителей, замена SocketMask в структуре TopologyHints чем-то более структурированным, чем следующая, позволит нам расширить каждую отдельную подсказку дополнительными полями в будущее:
Обратите внимание, что GetTopologyHints() прежнему возвращает TopologyHints , в то время как GetAffinity() был изменен для возврата одного TopologyHint а не TopologyHints .
type TopologyHint struct {
SocketID int
}
type TopologyHints []TopologyHint
&TopologyHints{
{SocketID: 0},
{SocketID: 1},
}
type HintProvider interface {
GetTopologyHints(pod v1.Pod, container v1.Container) TopologyHints
}
type Store interface {
GetAffinity(podUID string, containerName string) TopologyHint
}
Мысли?
klueska
9 апр. 2019
@klueska Может быть, мне что-то не хватает, но я не вижу необходимости в том, чтобы идентификаторы устройств для графических процессоров NV Link попадали в TopologyManager.
Если API-интерфейс подключаемого модуля устройства был расширен, чтобы позволить устройствам отправлять обратно информацию о подключении устройств точка-точка, как предлагает
В вашем примере devicemanagerhints может быть информацией, которую плагины устройства отправляют обратно диспетчеру устройств. Затем диспетчер устройств отправляет информацию о сокете обратно в TopologyManager как есть, а TopologyManager сохраняет выбранную подсказку для сокета.
При выделении диспетчер устройств вызывает GetAffinity, чтобы получить желаемое выделение сокета (допустим, в данном случае сокет равен 1), используя эту информацию и информацию, отправленную обратно плагинами устройства, он может видеть, что на сокете 1 он должен назначить устройства ( 6,7), поскольку они являются устройствами NV Link.
Есть ли в этом смысл или что-то мне не хватает?
lmdaly
10 апр. 2019
Спасибо, что нашли время, чтобы прояснить это со мной. Я, должно быть, неправильно истолковал исходное предложение @ConnorDoyle :
Если подсказки по топологии были расширены для кодирования топологии устройства «точка-точка», диспетчер устройств мог бы учесть это при сообщении о сходстве сокетов.
Я прочитал это как желание расширить структуру TopologyHints напрямую двухточечной информацией.
Похоже, вы скорее предлагаете, чтобы нужно было расширить только API подключаемого модуля устройства, чтобы предоставить информацию точка-точка для devicemanager , чтобы он мог использовать эту информацию для информирования SocketMask для установки в структуре TopologyHints всякий раз, когда вызывается GetTopologyHints() .
Я думаю, что это будет работать, если расширения API для подключаемого модуля устройства предназначены для предоставления нам информации, аналогичной той, что я описал в моем примере выше, а devicemanager расширен для хранения этой информации между допуском модуля и устройством. время распределения.
Прямо сейчас у нас есть собственное решение в Nvidia, которое исправляет наш kubelet чтобы по существу делать то, что вы предлагаете (за исключением того, что мы не переносим никаких решений в плагины устройства - devicemanager был осведомлен о графическом процессоре и сам принимает решения о выделении графического процессора на основе топологии).
Мы просто хотим быть уверены, что какое бы долгосрочное решение ни использовалось, мы сможем удалить эти пользовательские исправления в будущем. И теперь, когда у меня есть лучшее представление о том, как здесь работает поток, я не вижу ничего, что могло бы нас заблокировать.
Еще раз спасибо, что нашли время все прояснить.
klueska
10 апр. 2019
Привет, @lmdaly , я
Как только начнется кодирование, перечислите все соответствующие PR в этом выпуске, чтобы их можно было правильно отслеживать.
 kacole2
12 апр. 2019
kacole2
12 апр. 2019
у этой функции будет собственный элемент, и она будет альфа-версией.
/ этап 1.15
 derekwaynecarr
12 апр. 2019
derekwaynecarr
12 апр. 2019
@derekwaynecarr : Указанная веха недействительна для этого репозитория. Вехи в этом репозитории: [ keps-beta , keps-ga , v1.14 , v1.15 ]
Используйте /milestone clear чтобы очистить контрольную точку.
В ответ на это :
у этой функции будет собственный элемент, и она будет альфа-версией.
/ этап 1.15
Инструкции по взаимодействию со мной с помощью PR-комментариев доступны здесь . Если у вас есть вопросы или предложения, связанные с моим поведением, сообщите о проблеме в репозиторий kubernetes / test-infra .
 k8s-ci-robot
12 апр. 2019
k8s-ci-robot
12 апр. 2019
/ milestone v1.15
derekwaynecarr
12 апр. 2019
/ назначить @lmdaly
 justaugustus
28 апр. 2019
lmdaly
29 апр. 2019
justaugustus
28 апр. 2019
lmdaly
29 апр. 2019
@lmdaly
https://github.com/kubernetes/kubernetes/issues/72828
Моя команда и я рассматриваем возможность тестирования менеджера топологии для чувствительного к numa приложения.
Итак, у нас есть несколько вопросов.
Выше PR, являются ли эти полные имплементации для менеджера топологии?
И сейчас он протестирован или стабилен?
 bg-chun
15 мая 2019
bg-chun
15 мая 2019
@ bg-chun Мы делаем то же самое в Nvidia. Мы поместили эти WIP PR в наш внутренний стек и построили вокруг него стратегию распределения с учетом топологии для процессоров / графических процессоров. При этом мы обнаружили некоторые проблемы и дали некоторые конкретные отзывы об этих PR.
Пожалуйста, просмотрите ветку обсуждения здесь, чтобы узнать больше:
https://kubernetes.slack.com/archives/C0BP8PW9G/p1556371768035800
klueska
15 мая 2019
Привет, @lmdaly Я тень выпуска документации v1.15.
Я вижу, что вы нацеливаетесь на альфа-версию этого улучшения для выпуска 1.15. Требуются ли для этого новые документы (или модификации)?
Напоминаем, что нам нужен PR-адрес k / website (ветка dev-1.15) до четверга, 30 мая. Было бы здорово, если бы это начало полной документации, но приемлем даже PR-заполнитель. Дайте знать, если у вас появятся вопросы! 😄
 daminisatya
18 мая 2019
daminisatya
18 мая 2019
@lmdaly Просто дружеское напоминание, что мы ищем PR против k / website (ветка dev-1.15) до четверга, 30 мая. Было бы здорово, если бы это начало полной документации, но приемлем даже PR-заполнитель. Дайте знать, если у вас появятся вопросы! 😄
daminisatya
27 мая 2019
Привет @lmdaly . Code Freeze - четверг, 30 мая 2019 года, EOD по тихоокеанскому стандартному времени . Все улучшения, входящие в выпуск, должны быть завершены кодом, включая тесты , и иметь открытую документацию по PR.
Посмотрим на https://github.com/kubernetes/kubernetes/issues/72828, чтобы увидеть, все ли объединены.
Если вы знаете, что это произойдет, ответьте и сообщите нам. Спасибо!
kacole2
28 мая 2019
@daminisatya Я подтолкнул документ к PR. https://github.com/kubernetes/website/pull/14572
Сообщите мне, правильно ли это сделано и нужно ли что-то сделать. Спасибо за напоминание!
lmdaly
28 мая 2019
Спасибо @lmdaly ✨
daminisatya
29 мая 2019
Привет, @lmdaly , сегодня замораживание кода для цикла выпуска 1.15. Есть еще довольно много K / K PR, которые еще не были объединены из вашей проблемы отслеживания https://github.com/kubernetes/kubernetes/issues/72828. Теперь он помечен как «Под угрозой» в листе отслеживания улучшений 1.15 . Есть ли высокая уверенность, что они будут объединены EOD PST сегодня? После этого момента в вехе будут разрешены только проблемы с блокировкой выпуска и PR, за исключением.
kacole2
30 мая 2019
/ milestone clear
kacole2
3 июн. 2019
Привет, @lmdaly @derekwaynecarr , я руководитель отдела улучшения 1.16. Будет ли эта функция переходить на стадии альфа / бета / стабильная версия 1.16? Пожалуйста, дайте мне знать, чтобы его можно было добавить в таблицу отслеживания 1.16 . Если нет, я уберу его с вехи и изменю отслеживаемый ярлык.
После начала кодирования или, если оно уже было, перечислите в этом выпуске все соответствующие K / K PR, чтобы их можно было должным образом отслеживать.
Даты вехи - замораживание улучшения 7/30 и замораживание кода 8/29.
Спасибо.
kacole2
9 июл. 2019
@ kacole2 спасибо за напоминание. Эта функция войдет в альфа-версию в 1.16.
Текущий список PR можно найти здесь: https://github.com/kubernetes/kubernetes/issues/72828
Спасибо!
lmdaly
17 июл. 2019
Согласитесь, что это появится в альфа-версии 1.16, мы завершим работу, начатую и зафиксированную в kep, ранее объединенном для 1.15.
derekwaynecarr
30 июл. 2019
Привет @lmdaly , я тень выпуска документации
Требуются ли для этого улучшения новые документы (или модификации)?
Напоминаем, что нам нужен PR-адрес k / website (ветка dev-1.16) до пятницы, 23 августа. Было бы здорово, если бы это начало полной документации, но приемлем даже PR-заполнитель. Дайте знать, если у вас появятся вопросы!
Спасибо!
 VineethReddy02
1 авг. 2019
VineethReddy02
1 авг. 2019
Документация по связям с общественностью: https://github.com/kubernetes/website/pull/15716
lmdaly
7 авг. 2019
@lmdaly Будет ли менеджер топологии предоставлять какую-либо информацию или API, чтобы сообщить пользователям конфигурацию NUMA для данного модуля?
 mJace
15 авг. 2019
mJace
15 авг. 2019
@mJace что-то видимое в описании модуля kubectl?
lmdaly
15 авг. 2019
@lmdaly Да, kubectl describe - это хорошо. или какой-нибудь API для возврата связанной информации.
Поскольку мы разрабатываем сервис для предоставления некоторой информации, связанной с топологией для модулей, такой как статус закрепления ЦП для модуля и узел numa для проходящего через него VF.
И какой-нибудь инструмент мониторинга, такой как Weave Scope, может вызывать api для выполнения какой-то причудливой работы.
Например, администратор может определить, находится ли VNF в правильной конфигурации numa.
Просто хотелось бы узнать, покроет ли Менеджер топологии эту часть.
или если есть какая-то работа, которую мы могли бы сделать, если Topology Manager планирует поддерживать такую функциональность.
mJace
15 авг. 2019
@mJace Хорошо, в настоящее время нет такого API для Topology Manager. Я не думаю, что для этого есть приоритет, так как в случае с CPU и диспетчером устройств не видно, что на самом деле было назначено модулям.
Так что я думаю, что было бы хорошо начать обсуждение этого и посмотреть, какое мнение мы можем дать пользователям.
lmdaly
15 авг. 2019
Понятно, я думал, что ЦП и диспетчер устройств могут видеть эту информацию.
Может быть, советник может предоставить эту информацию.
Потому что в основном cadvisor получает информацию о контейнере, такую как PID и т. Д., С помощью ps ls .
Таким же образом мы проверяем информацию о топологии контейнера.
Я буду реализовывать это в cadvisor и создавать PR для этого.
mJace
15 авг. 2019
Я создал связанную проблему в cadvisor.
https://github.com/google/cadvisor/issues/2290
mJace
16 авг. 2019
/назначать
 khenidak
24 авг. 2019
khenidak
24 авг. 2019
+1 к предложению @mJace cadvisor.
Чтобы использовать DPDK lib внутри контейнера с CPU Manager и Topology Manager , анализируя сходство процессора с контейнером, а затем передавая его в dpdk lib, оба требуются для закрепления потоков библиотеки DPDK.
Для получения дополнительной информации, если процессор не разрешен в подсистеме cgroup cpuset контейнера, вызовы sched_setaffinity для закрепления процесса на процессоре будут отфильтрованы.
Библиотека DPDK использует pthread_setaffinity_np для закрепления потоков, а pthread_setaffinity_np - это оболочка уровня потока sched_setaffinity .
А CPU Manager Kubernetes устанавливает эксклюзивный процессор для подсистемы cgroup cpuset контейнера.
bg-chun
26 авг. 2019
@ bg-chun Я понял, что изменение cadvisor служит другой цели: мониторингу. Для вашего требования можно прочитать назначенные ЦП изнутри контейнера, проанализировав Cpus_Allowed или Cpus_Allowed_List из / proc / self / status. Подойдет ли вам такой подход?
ConnorDoyle
26 авг. 2019
На информацию Cpus_Allowed , влияет sched_setaffinity . Итак, если приложение что-то устанавливает, это будет подмножество того, что действительно разрешено контроллером cpuset Cgroup.
 kad
26 авг. 2019
kad
26 авг. 2019
@kad , я предлагал средство запуска в контейнере узнать значения идентификатора процессора для передачи программе DPDK. Таким образом, это происходит до того, как будет установлена привязка уровня потока.
ConnorDoyle
26 авг. 2019
@ConnorDoyle
Спасибо за ваше предложение, я учту его.
Мой план заключался в развертывании сервера tiny-rest-api, чтобы передавать dpdk-контейнеру информацию о выделении эксклюзивных процессоров.
Что касается изменений, то изменений cadvisor пока не видел, вижу только предложение .
В предложении указано able to tell if there is any cpu affinity set for the container. в поле "Цель" и to tell if there is any cpu affinity set for the container processes. в поле "Будущие работы".
Прочитав предложение, я подумал, что было бы здорово, если бы cadvisor мог анализировать информацию о закреплении процессора, а kubelet передавал ее в контейнер в качестве переменной среды, такой как status.podIP , metadata.name и limits.cpu .
Это основная причина, по которой я ушел из +1.
bg-chun
26 авг. 2019
@ bg-chun Вы можете проверить мою первую PR на cadvisor
https://github.com/google/cadvisor/pull/2291
Я закончил подобную функцию на.
https://github.com/mJace/numacc
но не совсем уверен, как правильно реализовать его в cadvisor
Вот почему я создаю PR только с одной новой функцией -> показать PSR.
mJace
26 авг. 2019
но не совсем уверен, как правильно реализовать его в cadvisor
Может быть, мы могли бы обсудить это в рамках этого предложения? Если вы, гуру, считаете, что эта функция нужна :)
mJace
26 авг. 2019
Заморозка кода версии 1.16 https://github.com/kubernetes/kubernetes/issues/72828 для оставшихся PR k / k
kacole2
26 авг. 2019
@ kacole2 все требуемые PR для этой функции объединены или помещены в очередь объединения.
lmdaly
30 авг. 2019
Привет, @lmdaly - 1.17 Здесь
Текущий график выпуска:
- Понедельник, 23 сентября - начинается цикл выпуска.
- Вторник, 15 октября, EOD (тихоокеанское стандартное время) - замораживание улучшений
- Четверг, 14 ноября, EOD (тихоокеанское стандартное время) - Code Freeze
- Вторник, 19 ноября - документы должны быть заполнены и проверены.
- 9 декабря, понедельник - релиз Kubernetes 1.17.0
Если да, перечислите все соответствующие PR в этом выпуске, чтобы их можно было отслеживать должным образом. 👍
Спасибо!
/ milestone clear
 mrbobbytables
22 сент. 2019
mrbobbytables
22 сент. 2019
@lmdaly есть ли прямая ссылка на GPU с обсуждением RDMA?
 nickolaev
25 сент. 2019
nickolaev
25 сент. 2019
@nickolaev , Мы тоже рассматриваем этот вариант использования. Мы начали некоторое внутреннее размышление о том, как это сделать, но мы хотели бы сотрудничать в этом.
 moshe010
25 сент. 2019
moshe010
25 сент. 2019
@ moshe010 @nickolaev @lmdaly , Мы тоже изучаем этот вариант использования, относящийся непосредственно к RDMA и GPU. Мы хотели бы сотрудничать в этом. Можно ли начать обсуждение этого вопроса?
 Deepthidharwar
25 сент. 2019
Deepthidharwar
25 сент. 2019
Привет! У меня вопрос по NTM и планировщику. Насколько я понимаю, планировщик не знает о NUMA и может предпочесть узел, на котором нет ресурсов (процессор, память и устройство) на желаемом NUMA. Таким образом, менеджер топологии откажется от выделения ресурсов на этом узле. Это правда?
 LilyaBu
25 сент. 2019
LilyaBu
25 сент. 2019
@nickolaev @Deepthidharwar , я начну google doc с вариантами использования, и мы можем перенести обсуждение на него. Я опубликую кое-что на следующей неделе. Если что с тобой все в порядке.
moshe010
25 сент. 2019
Я действительно рад видеть эту функцию. Нам также требуется восстановление ЦП, Hugepage, SRIOV-VF и другого оборудования в одном узле NUMA.
Но огромная страница не реализуется как скалярный ресурс плагином устройства, нужна ли эта функция для изменения функции огромной страницы в k8s?
@iamneha
 andyzheung
26 сент. 2019
andyzheung
26 сент. 2019
@ConnorDoyle Просто чтобы подтвердить, эта функция требует подсказок топологии как от диспетчера процессора, так и от диспетчера устройств? Я тестировал его на 1.16 и не работал, кажется, он получил только подсказку от менеджера процессора, но не подсказку со стороны устройства.
 jianzzha
26 сент. 2019
jianzzha
26 сент. 2019
@ConnorDoyle, вот еще немного подробностей:
https://gist.githubusercontent.com/jianzzha/c2a66a2514c178cca76a432029ff3387/raw/264f13dfcd06f1f80c48c113aa235fab7c33d81e/hyper%2520threading%2520enabled
jianzzha
26 сент. 2019
@jianzzha , какой плагин устройства вы используете? Например, если вы используете подключаемый модуль устройства SR-IOV, вам необходимо убедиться, что он сообщает об узле NUMA, см. [1]
moshe010
26 сент. 2019
@andyzheung Огромная интеграция страниц в настоящее время обсуждается и была представлена на собрании sig-узла за последние две недели. Вот несколько соответствующих ссылок:
https://docs.google.com/presentation/d/1H5xhCjgCZJjdTm-mGUFwqoz8XmoVd8xTCwJ1AfVR_54/edit?usp=sharing
https://github.com/kubernetes/enhancements/pull/1245
https://github.com/kubernetes/enhancements/pull/1199
@jianzzha По поводу плагина устройства подсказок не даю. Обновлен ли ваш плагин для передачи информации NUMA о перечисленных устройствах? Это поле необходимо добавить в сообщение устройства https://github.com/kubernetes/kubernetes/blob/master/pkg/kubelet/apis/deviceplugin/v1beta1/api.proto#L100.
klueska
26 сент. 2019
Спасибо, парни. Исправлено и работает сейчас.
jianzzha
26 сент. 2019
@klueska
По поводу nvidia-gpu-device-plugin ..
Я вижу только один активный PR (WIP) для обновления nvidia-gpu-device-plugin для Topology Manger.
Будет ли обновлен плагин nvidia-gpu-divice-plugin, чтобы предоставлять подсказку по топологии с указанным выше PR? или я что-то скучаю?
bg-chun
26 сент. 2019
@ bg-chun Да, так и должно быть. Только что пингулировал автора. Если он не вернется через день или около того, я обновлю плагин сам.
klueska
26 сент. 2019
@ bg-chun @klueska Я обновил патч.
 carmark
27 сент. 2019
carmark
27 сент. 2019
@klueska @carmark
Спасибо за обновление и уведомление.
Я представлю обновление sr-iov-plugin и обновление gpu-plugin пользователям в моей рабочей области.
bg-chun
27 сент. 2019
Я бы предложил улучшение для следующего выпуска.
Речь идет об удалении «выравнивания топологии, только если для модуля установлено ограничение гарантированного QoS».
Это ограничение делает меня непригодным для использования Topology Manager в настоящий момент, потому что я не хотел бы запрашивать эксклюзивные процессоры от K8s, однако я хотел бы выровнять сокеты нескольких устройств, поступающих из нескольких пулов (например, GPU + SR -ИОВ В.Ф. и др.)
Также что, если моя рабочая нагрузка не чувствительна к памяти или не хочу ограничивать ее использование памяти (еще один критерий гарантированного QoS).
В будущем, когда мы будем надеяться, что огромные страницы также будут выровнены, это ограничение будет ощущаться еще более ограничивающим ИМО.
Есть ли аргумент против индивидуального выравнивания «регулируемых» ресурсов? Конечно, давайте собираем подсказки из диспетчера ЦП только в том случае, если используются эксклюзивные ЦП, но независимо давайте собираем подсказки из диспетчера устройств, если пользователю требуются устройства, имеющие информацию о сокетах, или из диспетчера памяти, когда пользователь запрашивает огромные страницы и т. Д.
Либо это, либо если ненужная дополнительная вычислительная нагрузка во время запуска Pod вызывает беспокойство, возможно, вернуть исходный флаг конфигурации уровня Pod, чтобы контролировать, происходит ли выравнивание или нет (что я был удивлен, увидев, что он был отменен во время реализации)
 Levovar
30 сент. 2019
Levovar
30 сент. 2019
Я бы предложил улучшение для следующего выпуска.
Речь идет об удалении «выравнивания топологии, только если для модуля установлено ограничение гарантированного QoS».
Это пункт номер 8 в нашем списке TODO для 1.17:
https://docs.google.com/document/d/1YTUvezTLGmVtEF3KyLOX3FzfSDw9w0zB-s2Tj6PNzLA/edit#heading = h.xnehh6metosd
Есть ли аргумент против индивидуального выравнивания «регулируемых» ресурсов? Конечно, давайте собираем подсказки из диспетчера ЦП только в том случае, если используются эксклюзивные ЦП, но независимо давайте собираем подсказки из диспетчера устройств, если пользователю требуются устройства, имеющие информацию о сокетах, или из диспетчера памяти, когда пользователь запрашивает огромные страницы и т. Д.
Вы предлагаете механизм, позволяющий выборочно сообщать kubelet, какие ресурсы выравнивать, а какие не выравнивать (т.е. я хочу выровнять выделение ресурсов ЦП и ГП, но не выделения огромных страниц). Я не думаю, что кто-то будет категорически против этого, но интерфейс для выборочного решения, какие ресурсы выравнивать, а какие не выравнивать, может стать слишком громоздким, если мы продолжим указывать выравнивание как флаг на уровне узла.
Либо это, либо если ненужная дополнительная вычислительная нагрузка во время запуска Pod вызывает беспокойство, возможно, вернуть исходный флаг конфигурации уровня Pod, чтобы контролировать, происходит ли выравнивание или нет (что я был удивлен, увидев, что он был отменен во время реализации)
Не было достаточной поддержки для флага уровня модуля, чтобы оправдать предложение обновить спецификацию модуля этим. Для меня имеет смысл довести это решение до уровня модуля, поскольку некоторые модули нуждаются / хотят выравнивания, а некоторые нет, но не все были согласны.
klueska
30 сент. 2019
+1 за снятие ограничения класса QoS на выравнивание топологии (добавил в список: смайлик :). Я не понял, что @Levovar просит включить топологию для каждого ресурса, просто мы должны согласовать все настраиваемые ресурсы, используемые данным контейнером.
Насколько я помню, в KEP никогда не было поля на уровне пода для выбора топологии. Основанием для отказа от его внедрения было то же, что и для оставления неявных исключительных ядер - Kubernetes как проект хочет иметь возможность свободно интерпретировать спецификацию подов с точки зрения управления производительностью на уровне узлов. Я знаю, что такая позиция не удовлетворяет некоторых членов сообщества, но мы всегда можем поднять эту тему снова. Существует естественное противоречие между включением расширенных функций для немногих и регулированием когнитивной нагрузки для большинства пользователей.
ConnorDoyle
1 окт. 2019
ИМО на самых ранних этапах дизайна, по крайней мере, был флаг уровня Pod, если мне не изменяет память, но он был около 1.13: D
Лично я согласен с попыткой постоянно согласовывать все ресурсы, но «в те времена» сообщество обычно выступало против функций, которые приводили к задержкам запуска или решения по планированию всех модулей, независимо от того, они действительно нуждаются в улучшении, или нет.
Итак, я просто пытался «заранее решить» эти проблемы, имея в виду два варианта: предварительное согласование групп ресурсов на основе некоторых критериев (легко определить для ЦП, сложнее для других); или введите какой-нибудь флаг конфигурации.
Однако, если сейчас нет возражений против общего улучшения, меня это полностью устраивает :)
Levovar
1 окт. 2019
@mrbobbytables Мы планируем перейти от TopologyManager к beta в 1.17. Проблема с отслеживанием здесь: https://github.com/kubernetes/kubernetes/issues/83479
klueska
3 окт. 2019
@ bg-chun @klueska Я обновил патч.
Патч объединен:
https://github.com/NVIDIA/k8s-device-plugin/commit/cc0aad87285b573127add4e487b13434a61ba0d6
Создан новый релиз с патчем:
https://github.com/NVIDIA/k8s-device-plugin/releases/tag/1.0.0-beta2
klueska
3 окт. 2019
бета-версия отслеживания для v1.17
derekwaynecarr
4 окт. 2019
Отлично, спасибо @derekwaynecarr . Добавлю на лист :)
/ этап бета
mrbobbytables
6 окт. 2019
@lmdaly
Я один из тени документации v1.17.
Требуются ли для этого улучшения (или работы, запланированной на v1.17) какие-либо новые документы (или модификации существующих документов)? Если нет, не могли бы вы обновить лист отслеживания улучшений 1.17 (или дайте мне знать, и я сделаю это)
Если это так, просто дружеское напоминание, что мы ищем PR против k / website (ветка dev-1.17) к пятнице, 8 ноября, в настоящее время это может быть просто PR-агент. Дайте знать, если у вас появятся вопросы!
Спасибо!
VineethReddy02
21 окт. 2019
@ VineethReddy02 да, мы запланировали обновления документации для 1.17, если бы вы могли обновить трекер, было бы здорово!
Мы обязательно откроем этот PR до этого, спасибо за напоминание.
Проблема с отслеживанием документации для этого находится здесь: https://github.com/kubernetes/kubernetes/issues/83482
lmdaly
23 окт. 2019
https://github.com/kubernetes/enhancements/pull/1340
Ребята, я открыл KEP update PR, чтобы добавить встроенную метку узла ( beta.kubernetes.io/topology ) для Topology Manager.
Этикетка будет раскрывать политику узла.
Я думаю, это было бы полезно для планирования пода для конкретного узла, когда в одном кластере есть узлы с несколькими политиками.
Могу я попросить обзор?
bg-chun
28 окт. 2019
Привет, @lmdaly @derekwaynecarr
Джереми из команды улучшений 1.17 здесь 👋. Не могли бы вы перечислить K / K PR, которые находятся в полете для этого, чтобы мы могли их отслеживать? Я вижу, что # 83492 был объединен, но, похоже, есть еще несколько связанных проблем, связанных с общим элементом отслеживания. Мы приближаемся к Code Freeze 14 ноября, поэтому мы хотели бы получить представление о том, как это происходит до этого! Большое спасибо!
 jeremyrickard
4 нояб. 2019
jeremyrickard
4 нояб. 2019
@jeremyrickard Это проблема отслеживания для версии 1.17, как упоминалось выше: https://github.com/kubernetes/enhancements/issues/693#issuecomment -538123786
klueska
4 нояб. 2019
@lmdaly @derekwaynecarr
Напоминаем, что нам нужен PR-заполнитель для Документов против k / website (ветка dev-1.17), который должен быть опубликован к пятнице, 8 ноября. У нас есть еще 2 дня до этого срока.
daminisatya
6 нояб. 2019
Документы PR здесь, кстати: https://github.com/kubernetes/website/pull/17451
lmdaly
8 нояб. 2019
@klueska Я вижу, что часть работы улучшена до версии 1.18. Вы все еще планируете перейти на бета-версию в 1.17, или она останется альфа-версией, но изменится?
jeremyrickard
13 нояб. 2019
Неважно, я вижу в https://github.com/kubernetes/kubernetes/issues/85093, что вы собираетесь перейти на бета-версию 1.18, а не как часть 1.17. Вы хотите, чтобы мы отслеживали это как серьезное изменение альфа-версии в рамках этапа 1.17 @klueska? Или просто отложить градуировку до 1.18?
jeremyrickard
13 нояб. 2019
/ milestone v1.18
jeremyrickard
15 нояб. 2019
Привет @klueska
1.18 проверка команды улучшений! Вы все еще планируете перейти на бета-версию в 1.18? Заморозка улучшений произойдет 28 января, если ваш KEP потребует каких-либо обновлений, а заморозка кода - 5 марта.
Спасибо!
jeremyrickard
7 янв. 2020
да.
klueska
7 янв. 2020
@klueska спасибо за обновление! Обновление листа отслеживания.
jeremyrickard
7 янв. 2020
@klueska, когда мы просматривали KEP для этого выпуска, мы заметили, что в нем отсутствуют планы тестирования. Чтобы перейти к бета-версии в выпуске, необходимо добавить планы тестирования. На данный момент я собираюсь удалить его из вехи, но мы можем добавить его обратно, если вы отправите запрос на
jeremyrickard
29 янв. 2020
/ milestone clear
jeremyrickard
29 янв. 2020
@vpickard см. выше
klueska
29 янв. 2020
@vpickard см. выше
@klueska Спасибо за внимание. Будет работать над добавлением плана тестирования в KEP и подавать запрос на исключение. Мы активно разрабатываем тестовые примеры и уже подготовили некоторые PR тестирования, а некоторые еще выполняются, в том числе этот:
 vpickard
29 янв. 2020
vpickard
29 янв. 2020
@jeremyrickard Есть ли шаблон плана тестирования, на который вы можете указать мне для справки?
vpickard
29 янв. 2020
@vpickard вы можете посмотреть:
https://github.com/kubernetes/enhancements/blob/master/keps/sig-storage/20190530-pv-health-monitor.md#test -plan
и
https://github.com/kubernetes/enhancements/blob/master/keps/sig-storage/20200120-skip-permission-change.md#test -plan
Включите обзор модульных тестов и тестов e2e.
Если у вас есть что-то, что отображается в тестовой сетке, было бы здорово включить ее.
jeremyrickard
29 янв. 2020
Исключение было одобрено.
/ milestone v1.18
jeremyrickard
30 янв. 2020
@jeremyrickard План тестирования объединен: https://github.com/kubernetes/enhancements/pull/1527
klueska
4 февр. 2020
Привет, @klueska @vpickard , просто дружеское напоминание о том, что замораживание кода вступит в силу в четверг, 5 марта.
Не могли бы вы связать все PR k / k или любые другие PR, которые следует отслеживать для этого улучшения?
Спасибо :)
 palnabarun
5 февр. 2020
palnabarun
5 февр. 2020
Привет @palnabarun
Проблема с отслеживанием здесь для 1.18:
https://github.com/kubernetes/kubernetes/issues/85093
Текущие открытые PR:
https://github.com/kubernetes/kubernetes/pull/87758 (одобрено, испытания на отслаивание)
https://github.com/kubernetes/kubernetes/pull/87759 (WIP)
https://github.com/kubernetes/kubernetes/pull/87650 (проверено, требуется одобрение)
https://github.com/kubernetes/kubernetes/pull/87645 (PR теста e2e, требуется одобрение)
@vpickard, можешь ли ты добавить какие-нибудь пиарщики e2e, которые я пропустил?
Спасибо
 nolancon
5 февр. 2020
nolancon
5 февр. 2020
Спасибо @nolancon за то, что
palnabarun
5 февр. 2020
Привет @palnabarun , @nolancon!
Несколько дополнительных открытых PR, связанных с тестами E2E:
https://github.com/kubernetes/test-infra/pull/16062 (требуется проверка и одобрение)
https://github.com/kubernetes/test-infra/pull/16037 (требуется проверка и одобрение)
vpickard
6 февр. 2020
Спасибо @vpickard за дополнительные обновления. :)
palnabarun
9 февр. 2020
Привет @lmdaly Я один из теней в документации v1.18.
Требуются ли для этого улучшения (или работы, запланированной для v1.18) какие-либо новые документы (или модификации существующих документов)? Если нет, не могли бы вы обновить лист отслеживания улучшений 1.18 (или дайте мне знать, и я сделаю это)
Если это так, просто дружеское напоминание, что мы ищем PR против k / website (ветка dev-1.18) к пятнице, 28 февраля. В настоящее время это может быть просто PR-агент. Дайте знать, если у вас появятся вопросы!
 irvifa
9 февр. 2020
irvifa
9 февр. 2020
Привет, @irvifa , спасибо за внимание. Я открыл PR здесь kubernetes / сайт №19050 с парочкой незначительных изменений. На данный момент этот PR является WIP, я удалю его из WIP, как только будут выполнены критерии для перехода на бета-версию (PR выше все еще находится на рассмотрении).
Спасибо.
nolancon
10 февр. 2020
Привет, @nolancon, спасибо за быстрый ответ, сейчас я меняю статус на Placeholder PR .. Спасибо!
irvifa
10 февр. 2020
@palnabarun К вашему сведению, я разделил этот PR https://github.com/kubernetes/kubernetes/pull/87759 на два PR, чтобы облегчить процесс проверки. Второй находится здесь https://github.com/kubernetes/kubernetes/pull/87983, и его также нужно будет отслеживать. Спасибо.
nolancon
10 февр. 2020
@nolancon Спасибо за обновления.
Я вижу, что некоторые из PR все еще ожидают объединения. Я хотел узнать, не нужна ли вам помощь команды разработчиков в привлечении рецензентов и утверждающих к PR. Сообщите нам, если вам что-нибудь понадобится.
К вашему сведению, мы очень близки к Code Freeze 5 марта
palnabarun
27 февр. 2020
@nolancon Спасибо за обновления.
Я вижу, что некоторые из PR все еще ожидают объединения. Я хотел узнать, не нужна ли вам помощь команды разработчиков в привлечении рецензентов и утверждающих к PR. Сообщите нам, если вам что-нибудь понадобится.
К вашему сведению, мы очень близки к Code Freeze 5 марта
@palnabarun Еще одно обновление https://github.com/kubernetes/kubernetes/pull/87983 теперь закрыто, и его не нужно отслеживать. Необходимые изменения включены в исходный PR https://github.com/kubernetes/kubernetes/pull/87759, который находится на рассмотрении.
nolancon
27 февр. 2020
@nolancon Круто. Я также отслеживаю проблему с зонтичным трекером, о которой вы рассказали выше. :)
palnabarun
27 февр. 2020
Привет, @nolancon , это напоминание о том, что 5 марта до Code Freeze осталось всего два дня.
По замораживанию кода все соответствующие PR должны быть объединены, иначе вам нужно будет подать запрос на исключение.
palnabarun
3 мар. 2020
Привет @nolancon!
Сегодня EOD - это Code Freeze .
Как вы думаете, https://github.com/kubernetes/kubernetes/pull/87650 будет рассмотрен в срок?
Если нет, отправьте запрос об
palnabarun
5 мар. 2020
Привет @nolancon!
Сегодня EOD - это Code Freeze .
Как вы думаете, kubernetes / kubernetes # 87650 будут рассмотрены в срок?
Если нет, отправьте запрос об
Привет, @palnabarun , за последние пару дней был достигнут большой прогресс, и мы уверены, что все будет одобрено и объединено до замораживания кода. Если нет, я подам запрос об исключении.
Чтобы уточнить, под EOD вы имеете в виду 17:00 или полночь по тихоокеанскому стандартному времени? Спасибо
nolancon
5 мар. 2020
Чтобы уточнить, под EOD вы имеете в виду 17:00 или полночь по тихоокеанскому стандартному времени? Спасибо
17:00 по тихоокеанскому стандартному времени.
jeremyrickard
5 мар. 2020
PR утвержден, но отсутствует веха, которую необходимо добавить sig-узлу для слияния. Я пинговал их в слабину, надеюсь, он отключается, и вам не нужно исключение. знак равно
 kikisdeliveryservice
5 мар. 2020
kikisdeliveryservice
5 мар. 2020
Все PR для этого кепа, кажется, объединены (и утверждены к крайнему сроку), я обновил наш лист отслеживания улучшений. :улыбка:
kikisdeliveryservice
6 мар. 2020
/ milestone clear
(устранение этой проблемы улучшения из этапа v1.18 по завершении этапа)
palnabarun
29 апр. 2020
Привет, @nolancon @lmdaly , улучшения
 johnbelamaric
4 мая 2020
johnbelamaric
4 мая 2020
Единственное запланированное улучшение для 1.19:
https://github.com/kubernetes/enhancements/pull/1121
Остальная работа будет связана с рефакторингом кода / исправлением ошибок по мере необходимости.
Можно ли как-нибудь изменить владельца этого выпуска на меня вместо @lmdaly?
klueska
4 мая 2020
Спасибо, обновлю контакт.
/ веха v1.19
johnbelamaric
4 мая 2020
/ назначить @klueska
/ отменить назначение @lmdaly
Вот и все, Кевин https://prow.k8s.io/command-help
 pires
6 мая 2020
pires
6 мая 2020
Привет, Кевин. Недавно формат KEP был изменен, а также на прошлой неделе был объединен # 1620, добавив в шаблон KEP вопросы проверки готовности производства. Если возможно, найдите время, чтобы переформатировать KEP, а также ответьте на вопросы, добавленные в шаблон . Ответы на эти вопросы будут полезны операторам, использующим эту функцию и устраняющей ее неисправности (особенно на данном этапе, в части мониторинга). Спасибо!
johnbelamaric
13 мая 2020
@klueska ^^
johnbelamaric
13 мая 2020
@derekwaynecarr @klueska @johnbelamaric
Я также планирую добавить новую политику топологии на 1.19 rel.
Но он еще не получил рецензию со стороны владельца и обслуживающего персонала.
(Если в 1.19 это будет сложно сделать, дайте мне знать.)
- PR обновления KEP: https://github.com/kubernetes/enhancements/pull/1752
- PR для кубелет: WIP
bg-chun
13 мая 2020
Привет @klueska 👋 1.19 docs shadow здесь! Требует ли эта работа по усовершенствованию, запланированная для версии 1.19, новой или измененной документации?
Напоминаем, что если требуются новые / модификация документов, к пятнице, 12 июня, потребуется PR-заполнитель для k / website (ветка dev-1.19 ).
 annajung
21 мая 2020
annajung
21 мая 2020
Привет, @klueska, надеюсь, у тебя все хорошо, проверяюсь еще раз, чтобы узнать, нужны ли для этого документы или нет. Не могли бы вы подтвердить?
annajung
27 мая 2020
Привет @annajung. Есть 2 незавершенных улучшения, оба из которых потребуют изменений в документации:
1121
1752
Мы все еще решаем, дойдут ли они до версии 1.19 или до 1.20. Если мы решим сохранить их для версии 1.19, я обязательно создам PR для документов до 12 июня.
klueska
29 мая 2020
Здорово! Спасибо за обновление, я обновлю лист отслеживания соответственно! Пожалуйста, дайте мне знать, когда будет сделан PR-заполнитель. Спасибо!
annajung
30 мая 2020
@lmdaly @ConnorDoyle
Я надеюсь, что это подходящее место, чтобы задать вопрос и оставить отзыв.
Я включаю TopologyManager и CPUManager на моем кластере k8s v1.17.
и их политика: best-effort и static
Вот ресурсы моего модуля
resources:
requests:
cpu: 2
intel.com/sriov_pool_a: '1'
limits:
cpu: 2
intel.com/sriov_pool_a: '1'
PF sriov_pool_a находится в узле NUMA 0, поэтому я ожидаю, что мой модуль также должен работать на процессоре узла NUMA 0.
Но я обнаружил, что процесс моего модуля выполняется на ЦП узла NUMA 1.
Кроме того, нет маски сродства процессора, установленной в соответствии с результатом taskset -p <pid> .
Здесь что-то не так? Я ожидаю, что в контейнере должна быть установлена маска сродства ЦП для ЦП узла numa 0.
Есть ли какой-нибудь пример или тест, который я могу сделать, чтобы узнать, правильно ли работает мой TopoloyManager ?
mJace
4 июн. 2020
Добавлен PR для документов- https://github.com/kubernetes/website/pull/21607
klueska
9 июн. 2020
Привет @klueska ,
В ответ на электронное письмо, отправленное k-dev в понедельник, я хотел сообщить вам, что Code Freeze продлен до четверга, 9 июля. Вы можете увидеть обновленное расписание здесь: https://github.com/kubernetes/sig-release/tree/master/releases/release-1.19
Мы ожидаем, что к тому времени все PR будут объединены. Пожалуйста, дай мне знать, если возникнут какие-либо вопросы. 😄
Лучший,
Кирстен
kikisdeliveryservice
18 июн. 2020
Привет, @klueska , дружеское напоминание о приближении следующего дедлайна.
Не забудьте заполнить PR своего документа-заполнителя и подготовить его к рассмотрению до понедельника, 6 июля.
annajung
22 июн. 2020
Спасибо @annajung . Поскольку замораживание кода теперь перенесено на 9 июля, имеет ли смысл переносить дату выпуска документации? Что произойдет, если мы создадим документацию, но функция не успеет вовремя (или внесет ее в несколько иную форму, чем предлагается в документации)?
klueska
23 июн. 2020
Привет @klueska , это отличный момент! Крайний срок для всех документов также был перенесен на неделю с новой датой выпуска, но я думаю, что у вас есть веская точка зрения. Позвольте мне связаться с руководителем отдела документации и свяжемся с вами! Спасибо, что указали на это!
annajung
24 июн. 2020
Привет, @klueska , еще раз спасибо за то, что обратили на это наше внимание. Были перепутаны даты выпуска документации. Как вы упомянули, «PR, готовый к проверке» должен появиться после замораживания кода и был в прошлых выпусках.
Однако, поговорив с командой по выпуску, мы решили оставить даты, как есть для этого выпуска 1.19, сделав «PR готов к рассмотрению» мягким крайним сроком. Команда Документов будет гибкой и будет работать с вами / другими людьми, которым может потребоваться дополнительное время, чтобы убедиться, что документы синхронизированы с кодом. В то время как крайний срок «PR готов к рассмотрению» не будет соблюдаться, будет соблюден срок «PR просмотрен и прочитан для слияния».
Надеюсь, это поможет ответить на ваши вопросы! Пожалуйста, дайте мне знать, если у вас возникнут еще вопросы!
Также просто дружеское напоминание о свиданиях:
Срок подачи документов - PR готовы к рассмотрению до 6 июля.
«Документы завершены - все PR рассмотрены и готовы к объединению» - до 16 июля.
annajung
24 июн. 2020
Привет @klueska : wave: - Улучшения 1.19. Ведите сюда,
Не могли бы вы дать ссылку на все PR реализации здесь, чтобы команда разработчиков могла их отслеживать? : Little_smiling_face:
Спасибо.
palnabarun
28 июн. 2020
@palnabarun
Отслеживание PR https://github.com/kubernetes/enhancements/pull/1121 можно найти по адресу:
https://github.com/kubernetes/kubernetes/pull/92665
К сожалению, усовершенствование № 1752 не войдет в релиз, поэтому нет PR, чтобы отслеживать его.
klueska
30 июн. 2020
Привет, @klueska : wave :, я вижу, что оба PR (https://github.com/kubernetes/enhancements/pull/1121 и https://github.com/kubernetes/enhancements/pull/1752), которые вы упомянули относятся к тому же усовершенствованию. Поскольку https://github.com/kubernetes/enhancements/pull/1752 расширяет требования к выпуску бета-версии, и они не будут включены в выпуск, можем ли мы предположить, что в 1.19 не ожидается дальнейших изменений?
Спасибо. : Little_smiling_face:
Замораживание кода начнется в четверг, 9 июля, EOD по тихоокеанскому стандартному времени.
palnabarun
6 июл. 2020
@palnabarun Это продолжение PR # 92665, которое должно появиться сегодня или завтра: https://github.com/kubernetes/kubernetes/pull/92794
После этого не должно быть больше PR для этого выпуска, ожидающих непредвиденных ошибок.
klueska
6 июл. 2020
Потрясающий! Спасибо за обновление. : +1:
Мы будем следить за https://github.com/kubernetes/kubernetes/pull/92794.
palnabarun
6 июл. 2020
@annajung https://github.com/kubernetes/website/pull/21607 теперь готов к рассмотрению.
klueska
6 июл. 2020
Поздравляю, @klueska kubernetes / kubernetes # 92794 наконец-то объединились, я соответствующим образом обновлю лист отслеживания 😄
kikisdeliveryservice
11 июл. 2020
/ milestone clear
(устранение этой проблемы улучшения из этапа v1.19 по завершении этапа)
kikisdeliveryservice
12 сент. 2020
Привет @klueska
Улучшения ведут сюда. Есть ли какие-то планы на выпуск в 1.20?
Спасибо!
Кирстен
kikisdeliveryservice
13 сент. 2020
Планов по его выпуску нет, но есть PR, который следует отслеживать на предмет 1.20, связанный с этим улучшением:
https://github.com/kubernetes/kubernetes/pull/92967
klueska
16 сент. 2020
Несмотря на то, что в 1.20 он не выходит, продолжайте связывать связанные PR с этой проблемой, как вы только что сделали.
kikisdeliveryservice
16 сент. 2020
@kikisdeliveryservice, не могли бы вы помочь разобраться в этом процессе. Функция диспетчера топологии не выпускается в версии 1.20, но новая функция будет добавлена к ней и сейчас разрабатывается: https://github.com/kubernetes/enhancements/pull/1752 k / k: https: // github. com / kubernetes / kubernetes / pull / 92967. Это то, что нам нужно отслеживать вместе с командой разработчиков? Это может упростить отслеживание обновления документации для версии 1.20 или, может быть, еще чего-то, что отслеживается.
Изменение носит аддитивный характер, поэтому нет особых причин называть его бета2 или что-то в этом роде.
Связанный PR, который отражает реальность того, что дополнительная функция не была добавлена в 1.19: https://github.com/kubernetes/enhancements/pull/1950
 SergeyKanzhelev
27 окт. 2020
SergeyKanzhelev
27 окт. 2020
PR обновления веб-документации Topology Manager, чтобы включить функцию области: https://github.com/kubernetes/website/pull/24781
 k-wiatrzyk
29 окт. 2020
k-wiatrzyk
29 окт. 2020
Я считаю, что это можно отследить с помощью 1.20, и не обязательно переходить на следующий уровень. @kikisdeliveryservice, пожалуйста, свяжитесь с нами, если это неверно. Я буду отслеживать общий k / website как часть релиза 1.20, пока не услышу иное.
annajung
29 окт. 2020
Привет @SergeyKanzhelev
Если посмотреть на историю, то на самом деле это не так. Мне сказали, что это не будет градацией выше, что нормально и почему этот KEP не отслеживается. Однако это улучшение (без ведома команды разработчиков) было недавно перенаправлено @ k-wiatrzyk для 1.20 в качестве бета-версии (https://github.com/kubernetes/enhancements/pull/1950).
Если вы хотите использовать процесс выпуска: отслеживание улучшений, участие в этапах выпуска и наличие команды документации, отслеживающей это / наличие документов, включенных в выпуск 1.20, запрос исключения улучшения должен быть подан как можно скорее.
kikisdeliveryservice
30 окт. 2020
Эта функция уже была включена в (ранее существовавший) KEP (до истечения крайнего срока доработки).
https://github.com/kubernetes/enhancements/pull/1752
В его реализации PR уже является важной вехой.
https://github.com/kubernetes/kubernetes/pull/92967
Я не знал, что мне нужно больше делать.
Кому нужно подавать исключение и для чего именно?
klueska
30 окт. 2020
Привет, @klueska, PR, на который вы ссылаетесь, был объединен в июне для добавления бета-версии в kep в 1.19: https://github.com/bg-chun/enhancements/blob/f3df83cc997ff49bfbb59414545c3e4002796f19/keps/sig-node/0035-20190130-topology -manager.md # beta -v119
Крайний срок для улучшений для 1.20 - 6 октября, но изменение, перемещение бета-версии до 1.20 и удаление ссылки на 1.19, было объединено 3 дня назад через https://github.com/kubernetes/enhancements/pull/1950.
Вы можете найти инструкции по отправке запроса на исключение здесь: https://github.com/kubernetes/sig-release/blob/master/releases/EXCEPTIONS.md
kikisdeliveryservice
30 окт. 2020
Извините, я все еще не понимаю, для чего мы будем подавать исключение.
Я счастлив этим заниматься, просто не знаю, что в него включить.
Функция «Диспетчер топологии узлов» уже переведена на бета-версию в 1.18.
Это не переход на GA в 1.20 (он остается в стадии бета-тестирования).
Объединяемый PR для версии 1.20 (т.е. kubernetes / kubernetes # 92967) является улучшением существующего кода для менеджера топологии, но не связан с «ударом» с точки зрения его статуса как альфа / бета / га и т. Д.
klueska
30 окт. 2020
Я отправил сообщение об исключении, так как крайний срок сегодня (на всякий случай): https://groups.google.com/g/kubernetes-sig-node/c/lsy0fO6cBUY/m/_ujNkQtCCQAJ
k-wiatrzyk
2 нояб. 2020
@kikisdeliveryservice @klueska @annajung
Запрос на исключение был одобрен, вы можете найти подтверждение здесь: https://groups.google.com/g/kubernetes-sig-release/c/otE2ymBKeMA/m/ML_HMQO7BwAJ
k-wiatrzyk
4 нояб. 2020
Спасибо @ k-wiatrzyk & @klueska Обновил лист отслеживания.
Копия: @annajung
kikisdeliveryservice
5 нояб. 2020
Привет, @ k-wiatrzyk @klueska
Похоже, kubernetes / kubernetes # 92967 одобрен, но требует перебазирования.
Напоминаем, что Code Freeze появится через 2 дня в четверг, 12 ноября . Все PR должны быть объединены к этой дате, в противном случае требуется исключение .
Лучший,
Кирстен
kikisdeliveryservice
11 нояб. 2020
ПР слитный, обновляющий лист - ура! : smile_cat:
kikisdeliveryservice
12 нояб. 2020
Смежные вопросы
 dekkagaijin
·
9Комментарии
dekkagaijin
·
9Комментарии
 saschagrunert
·
6Комментарии
saschagrunert
·
6Комментарии
 prameshj
·
9Комментарии
prameshj
·
9Комментарии
 robscott
·
11Комментарии
robscott
·
11Комментарии
 xing-yang
·
13Комментарии
xing-yang
·
13Комментарии
Самый полезный комментарий
Все PR для этого кепа, кажется, объединены (и утверждены к крайнему сроку), я обновил наш лист отслеживания улучшений. :улыбка: