Enhancements: Knotentopologie-Manager
Beschreibung der Verbesserung
- Einzeilige Beschreibung der Erweiterung (kann als Versionshinweis verwendet werden): Kubelet-Komponente zum Koordinieren feinkörniger Hardware-Ressourcenzuweisungen für verschiedene Komponenten in Kubernetes.
- Hauptkontakt (Bevollmächtigter):
- Verantwortliche SIGs: sign-node
- Link zum Designvorschlag (Community-Repo): https://github.com/kubernetes/community/pull/1680
- KEP-PR: https://github.com/kubernetes/enhancements/pull/781
- KEP: https://github.com/kubernetes/enhancements/blob/master/keps/sig-node/0035-20190130-topology-manager.md
- Link zu e2e- und/oder Unit-Tests: N/A Noch
- Rezensenten - (für LGTM) empfehlen, dass 2+ Rezensenten (mindestens einer aus der Datei OWNERS des Codebereichs) der Überprüfung zugestimmt haben. Rezensenten von mehreren Unternehmen bevorzugt: @ConnorDoyle @balajismaniam
- Genehmiger (wahrscheinlich von SIG/Bereich, zu dem die Erweiterung gehört): @derekwaynecarr @ConnorDoyle
- Verbesserungsziel (welches Ziel entspricht welchem Meilenstein):
- Alpha-Release-Ziel (xy): v1.16
- Beta-Release-Ziel (xy): v1.18
- Stabiles Freigabeziel (xy)
 lmdaly
lmdaly
Alle 159 Kommentare
/sig-Knoten
/freundliches Feature
cc @ConnorDoyle @balajismaniam @nolancon
lmdaly
am 17. Jan. 2019
Ich kann dazu beitragen, dieses Design basierend auf dem Lernen von Borg zu informieren. Zählen Sie mich also als Gutachter/Genehmiger.
 vishh
am 4. Feb. 2019
vishh
am 4. Feb. 2019
Ich kann dazu beitragen, dieses Design basierend auf dem Lernen von Borg zu informieren. Zählen Sie mich also als Gutachter/Genehmiger.
Gibt es eine öffentliche Dokumentation zur Funktionsweise dieser Funktion in Borg?
 jeremyeder
am 11. Feb. 2019
jeremyeder
am 11. Feb. 2019
Nicht über NUMA AFAIK.
Am Mo, 11. Feb 2019, 7:50 AM schrieb Jeremy Eder < [email protected] :
Ich kann dazu beitragen, dieses Design basierend auf dem Lernen von Borg zu informieren. Also zähl mich dazu
als Gutachter/Genehmiger.Gibt es eine öffentliche Dokumentation zur Funktionsweise dieser Funktion in Borg?
—
Sie erhalten dies, weil Sie einen Kommentar abgegeben haben.
Antworten Sie direkt auf diese E-Mail und zeigen Sie sie auf GitHub an
https://github.com/kubernetes/enhancements/issues/693#issuecomment-462378195 ,
oder den Thread stumm schalten
https://github.com/notifications/unsubscribe-auth/AGvIKPfanjb9Q5DxXAiBgv9C6Y809JX0ks5vMZFZgaJpZM4aE3uz
.
vishh
am 11. Feb. 2019
Zur Info @claurence
Dieses Tracking-Problem und KEP (https://github.com/kubernetes/enhancements/pull/781) haben es nicht rechtzeitig zum Einfrieren der v1.14-Erweiterungen oder zur verlängerten Frist geschafft. Ich weiß es zu schätzen, dass Sie diese vor Ablauf der Fristen geöffnet haben, aber sie schienen keine ausreichende Überprüfung oder Unterschrift zu erhalten. Dies muss den Ausnahmeprozess durchlaufen.
Bis wir entscheiden, ob dies die Ausnahme wert ist, neige ich dazu, alle PRs im Zusammenhang mit dieser Verbesserung zurückzuhalten.
Referenz: https://github.com/kubernetes/kubernetes/issues/72828
 spiffxp
am 24. Feb. 2019
spiffxp
am 24. Feb. 2019
/cc @jiayingz @dchen1107
 jiayingz
am 25. Feb. 2019
jiayingz
am 25. Feb. 2019
@lmdaly Ich sehe, Sie haben 1.14 in der Beschreibung als Alpha-Meilenstein aufgeführt - da es keinen zusammengeführten implementierbaren KEP gab, wird dieses Problem nicht für 1.14 verfolgt - wenn beabsichtigt ist, es in diese Version aufzunehmen, bitte einen Ausnahmeantrag stellen.
 claurence
am 27. Feb. 2019
claurence
am 27. Feb. 2019
@lmdaly Ich sehe, Sie haben 1.14 in der Beschreibung als Alpha-Meilenstein aufgeführt - da es keinen zusammengeführten implementierbaren KEP gab, wird dieses Problem nicht für 1.14 verfolgt - wenn beabsichtigt ist, es in diese Version aufzunehmen, bitte einen Ausnahmeantrag stellen.
@claurence das KEP ist jetzt zusammengeführt (KEP war zuvor im Community-Repository zusammengeführt worden. Dies war nur, um es gemäß den neuen Richtlinien in das neue Erweiterungs-Repository zu verschieben), müssen wir noch eine Ausnahmeanforderung einreichen, um dieses Problem zu verfolgen? für 1,14?
lmdaly
am 5. März 2019
Nachdem ich die Design- und WIP-PRs gründlich gelesen habe, habe ich jedoch Bedenken, dass die aktuelle Implementierung nicht so allgemein ist wie das ursprüngliche Topologiedesign, das wir in https://github.com/kubernetes/enhancements/pull/781 vorgeschlagen haben
Ich habe hier einige Kommentare zur weiteren Diskussion hinterlassen: https://github.com/kubernetes/kubernetes/pull/74345#discussion_r264387724
 resouer
am 11. März 2019
resouer
am 11. März 2019
die aktuelle Implementierung ist nicht generisch
Teilen Sie die gleichen Bedenken darüber :) Wie sieht es mit anderen aus, zB Verbindungen zwischen Geräten (nvlinke für GPU)?
 k82cn
am 20. März 2019
k82cn
am 20. März 2019
@resouer @k82cn Der ursprüngliche Vorschlag befasst sich nur mit der
Wenn die aktuelle Implementierung jedoch das Hinzufügen von Affinität zwischen Geräten in Zukunft blockiert, kann ich die Implementierung gerne ändern, sobald ich ein Verständnis dafür habe, wie dies funktioniert.
lmdaly
am 25. März 2019
Ich denke, das Hauptproblem, das ich bei der aktuellen Implementierung und der Fähigkeit, die Affinität zwischen Geräten zu unterstützen, sehe, ist Folgendes:
Um die Affinität zwischen Geräten zu unterstützen, müssen Sie normalerweise zuerst herausfinden, welche Geräte Sie einem Container zuordnen möchten, _bevor_ Sie entscheiden, welche Socket-Affinität der Container haben soll.
Bei Nvidia-GPUs müssen Sie beispielsweise für eine optimale Konnektivität zuerst den Satz von GPUs mit den am häufigsten verbundenen NVLINKs finden und zuweisen, _bevor_ Sie feststellen, welche Socket-Affinität dieser Satz hat.
Soweit ich dem aktuellen Vorschlag entnehmen kann, wird davon ausgegangen, dass diese Vorgänge in umgekehrter Reihenfolge ablaufen, dh die Socket-Affinität wird vor der Zuweisung von Geräten festgelegt.
 klueska
am 5. Apr. 2019
klueska
am 5. Apr. 2019
Das stimmt nicht unbedingt @klueska. Wenn die Topologiehinweise erweitert würden, um eine Punkt-zu-Punkt-Gerätetopologie zu codieren, könnte der Geräte-Manager dies berücksichtigen, wenn er die Socket-Affinität meldet. Mit anderen Worten, die geräteübergreifende Topologie müsste nicht aus dem Bereich des Geräte-Managers herausfallen. Scheint das machbar?
 ConnorDoyle
am 5. Apr. 2019
ConnorDoyle
am 5. Apr. 2019
Vielleicht bin ich irgendwie verwirrt über den Flow. So verstehe ich es:
1) Bei der Initialisierung registrieren sich Geräte-Plugins (nicht devicemanager ) bei topologymanager damit sie zu einem späteren Zeitpunkt Rückrufe ausführen können.
2) Wenn ein Pod gesendet wird, ruft das Kubelet das lifecycle.PodAdmitHandler auf dem topologymanager .
3) Die lifecycle.PodAdmitHandler ruft GetTopologyHints auf jedem registrierten Geräte-Plugin auf
4) Es führt dann diese Hinweise zusammen, um ein konsolidiertes TopologyHint zu erstellen, das mit dem Pod verknüpft ist
5) Wenn es sich entschieden hat, den Pod zuzulassen, kehrt es erfolgreich von lifecycle.PodAdmitHandler speichert die konsolidierten TopologyHint für den Pod in einem lokalen staatlichen Speicher
6) Irgendwann in der Zukunft rufen cpumanager und devicemanager GetAffinity(pod) auf dem topology Manager auf, um die zugehörigen TopologyHint abzurufen mit der hülse
7) Das cpumanager verwendet diesen TopologyHint` um eine CPU zuzuordnen
8) devicemanager verwendet diesen TopologyHint`, um eine Reihe von Geräten zuzuordnen
9) Initialisierung des Pods wird fortgesetzt...
Wenn dies richtig ist, kämpfe ich wahrscheinlich damit, was zwischen dem Zeitpunkt passiert, an dem das Geräte-Plugin seine TopologyHints meldet und dem Zeitpunkt, an dem devicemanager die tatsächliche Zuweisung vornimmt.
Wenn diese Hinweise dazu dienen sollen, "Präferenzen" für die Zuweisung zu codieren, dann denke ich, dass Sie eine Struktur wie folgt haben:
type TopologyHints struct {
hints []struct {
SocketID int
DeviceIDs []int
}
}
Dabei übergeben wir nicht nur eine Liste von Socket-Affinitätspräferenzen, sondern auch, wie diese Socket-Affinitätspräferenzen mit zuweisbaren GPU-Präferenzen gepaart werden.
Wenn Sie in diese Richtung denken, könnten wir es schaffen, aber wir müssten uns irgendwie zwischen den cpumanager und den devicemanager , um sicherzustellen, dass sie dasselbe "akzeptiert" haben Hinweis bei der Zuweisung.
Gibt es etwas, das dies bereits ermöglicht, was ich übersehen habe?
klueska
am 5. Apr. 2019
@klueska
Ich denke, was passiert, wenn Sie einige _kleinere_ Korrekturen an Ihrem Flow vornehmen, ist:
Bei der Initialisierung registrieren sich Geräte-Plugins bei
devicemanagerdamit sie zu einem späteren Zeitpunkt Rückrufe ausführen können.lifecycle.PodAdmitHandlerruftGetTopologyHintsfür jede topologiefähige Komponente im Kubelet auf, derzeitdevicemanagerundcpumanager.
In diesem Fall werden im Kubelet das cpumanager und das devicemanager als topologiebewusst dargestellt. Der Topologiemanager ist nur dazu gedacht, Zuweisungen zwischen topologiebewussten Komponenten zu koordinieren.
Dafür:
aber wir müssten uns irgendwie zwischen dem cpumanager und dem devicemanager abstimmen, um sicherzustellen, dass sie den gleichen Hinweis bei der Zuweisung "akzeptiert" haben.
Dafür wurde das topologymanager selbst eingeführt. Aus einem der früheren Entwürfe ,
Diese Komponenten sollten aufeinander abgestimmt sein, um Kreuz-NUMA-Zuweisungen zu vermeiden. Die Probleme im Zusammenhang mit dieser Koordination sind knifflig; domänenübergreifende Anfragen wie „Ein exklusiver Kern auf demselben NUMA-Knoten wie die zugewiesene NIC“ betreffen sowohl CNI als auch den CPU-Manager. Wenn der CPU-Manager zuerst wählt, kann er einen Kern auf einem NUMA-Knoten ohne verfügbare NIC auswählen und umgekehrt.
 eloyekunle
am 6. Apr. 2019
eloyekunle
am 6. Apr. 2019
Ich verstehe.
Also implementieren devicemanager und cpumanager beide GetTopologyHints() und rufen GetAffinity() , um eine Richtungsinteraktion von topologymanager mit allen zugrunde liegenden Geräte-Plugins zu vermeiden . Wenn ich mir den Code genauer ansehe, sehe ich, dass devicemanager einfach die Kontrolle an die Plugins delegiert, um beim Ausfüllen von TopologyHints zu helfen, was am Ende sowieso mehr Sinn macht.
Um auf die ursprüngliche Frage / das ursprüngliche Problem zurückzukommen, das ich aufgeworfen habe ....
Aus Sicht von Nvidia denke ich, dass wir mit diesem vorgeschlagenen Ablauf alles zum Laufen bringen können, vorausgesetzt, dass mehr Informationen zur TopologyHints Struktur (und folglich zur Geräte-Plugin-Schnittstelle) hinzugefügt werden, um in Zukunft Punkt-zu-Punkt-Link-Informationen zu melden .
Ich denke jedoch, dass das Beginnen mit einem SocketMask als primäre Datenstruktur für die Werbung für Socket-Affinität unsere Fähigkeit einschränken könnte, TopologyHints in Zukunft mit Punkt-zu-Punkt-Informationen zu erweitern, ohne die vorhandene Schnittstelle zu beschädigen. Der Hauptgrund ist, dass (zumindest bei Nvidia-GPUs) der bevorzugte Sockel davon abhängt, welche GPUs am Ende tatsächlich zugewiesen werden.
Betrachten Sie beispielsweise die folgende Abbildung, wenn Sie versuchen, einem Pod mit optimaler Konnektivität 2 GPUs zuzuweisen:
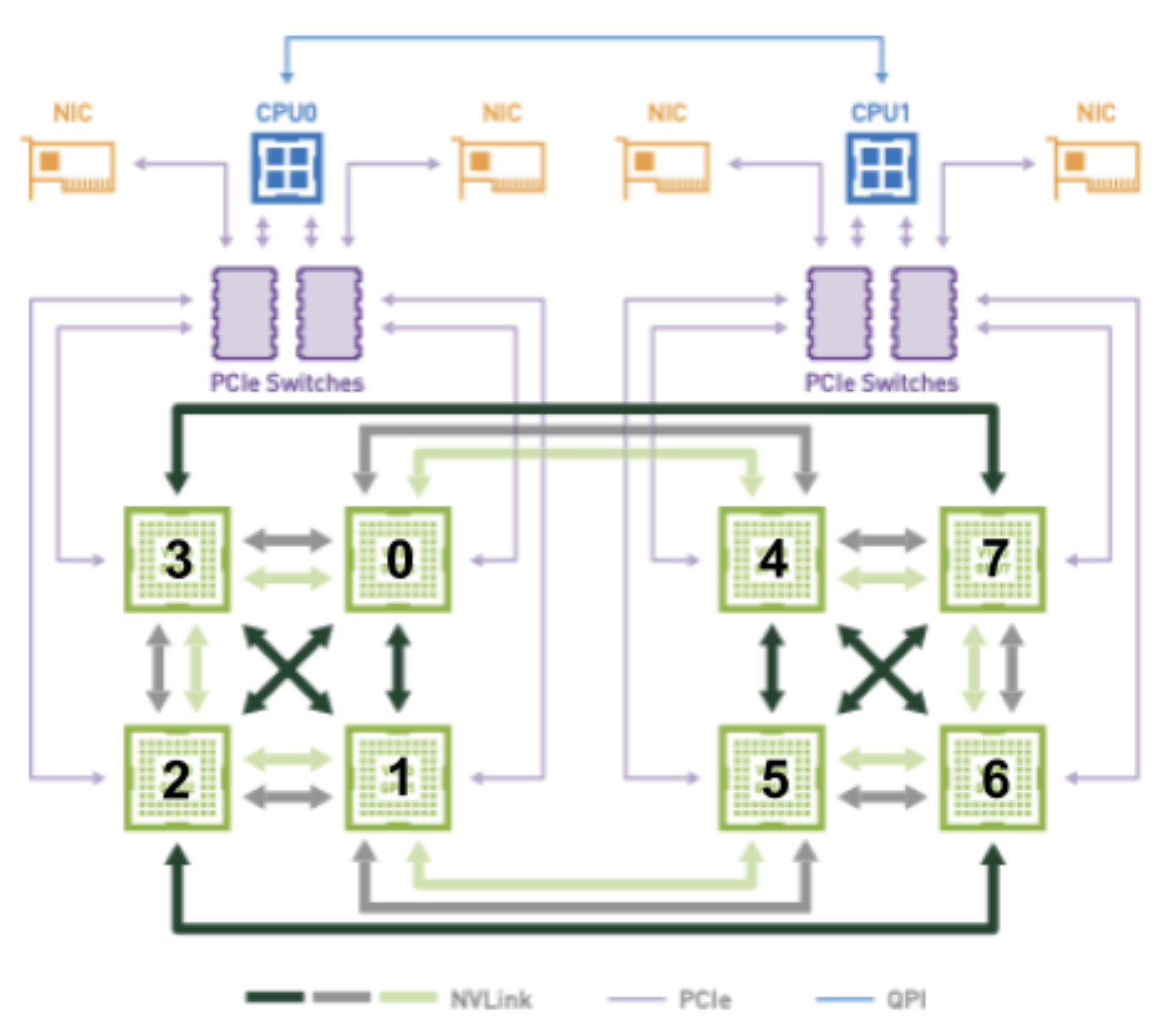
Die GPU-Kombinationen von (2, 3) und (6, 7) haben beide 2 NVLINKs und befinden sich auf demselben PCIe-Bus. Sie sollten daher als gleichwertige Kandidaten betrachtet werden, wenn Sie versuchen, einem Pod 2 GPUs zuzuweisen. Abhängig von der gewählten Kombination wird jedoch natürlich eine andere Buchse bevorzugt, da (2, 3) an Buchse 0 angeschlossen ist und (6, 7) an Buchse 1 angeschlossen ist.
Diese Informationen müssen irgendwie in das TopologyHints Struct codiert werden, damit devicemanager am Ende eine dieser gewünschten Zuordnungen durchführen kann (dh je nachdem, welche der topologymanager die Hinweise konsolidiert bis zu). Ebenso muss die Abhängigkeit zwischen den bevorzugten Gerätezuweisungen und dem bevorzugten Sockel in TopologyHints kodiert werden, damit cpumanager CPUs vom richtigen Sockel zuweisen kann.
Eine mögliche Lösung speziell für Nvidia-GPUs für dieses Beispiel würde in etwa so aussehen:
type TopologyHint struct {
SocketID int
DeviceIDs []int
}
type TopologyHints []TopologyHint
devicemanagerhints := &TopologyHints{
{SocketID: 0, DeviceIDs: []int{2, 3}},
{SocketID: 1, DeviceIDs: []int{6, 7}},
}
cpumanagerhints := &TopologyHints{
{SocketID: 1},
}
Wobei topologymanager diese Hinweise konsolidieren würde, um {SocketID: 1, DeviceIDs: []int{6, 7}} als den bevorzugten Hinweis zurückzugeben, wenn devicemanager und cpumanager später GetAffinity() aufrufen.
Während dies kann oder auch eine generische genug Lösung für alle Beschleuniger nicht bieten, ersetzen SocketMask in TopologyHints Struktur mit etwas strukturiert mehr wie die folgenden würde uns erlauben , jeden einzelnen Hinweis mit mehr Feldern zu erweitern in die Zukunft:
Beachten Sie, dass GetTopologyHints() immer noch TopologyHints , während GetAffinity() geändert wurde, um ein einzelnes TopologyHint anstelle von TopologyHints .
type TopologyHint struct {
SocketID int
}
type TopologyHints []TopologyHint
&TopologyHints{
{SocketID: 0},
{SocketID: 1},
}
type HintProvider interface {
GetTopologyHints(pod v1.Pod, container v1.Container) TopologyHints
}
type Store interface {
GetAffinity(podUID string, containerName string) TopologyHint
}
Die Gedanken?
klueska
am 9. Apr. 2019
@klueska Vielleicht fehlt mir etwas, aber ich sehe nicht die Notwendigkeit, die Geräte-IDs für NV-Link-GPUs im TopologyManager auffüllen zu lassen.
Wenn die Geräte-Plugin-API erweitert wurde, um es Geräten zu ermöglichen, Informationen über die Punkt-zu-Punkt-Gerätekonnektivität zurückzusenden, wie von @ConnorDoyle vorgeschlagen, dann könnte der Geräte-Manager basierend darauf Socket-Informationen
In Ihrem Beispiel könnten devicemanagerhints die Informationen sein, die die Geräte-Plugins an den Gerätemanager zurückgesendet haben. Der Gerätemanager sendet dann die Socket-Informationen wie jetzt an TopologyManager zurück und TopologyManager speichert den ausgewählten Socket-Hinweis.
Bei der Zuweisung ruft der Gerätemanager GetAffinity auf, um die gewünschte Socket-Zuweisung zu erhalten (sagen wir, der Socket ist in diesem Fall 1 6,7), da es sich um NV Link-Geräte handelt.
Macht das Sinn oder fehlt mir etwas?
lmdaly
am 10. Apr. 2019
Danke, dass Sie sich die Zeit genommen haben, dies mit mir zu klären. Ich muss den ursprünglichen Vorschlag von @ConnorDoyle falsch
Wenn die Topologiehinweise erweitert würden, um eine Punkt-zu-Punkt-Gerätetopologie zu codieren, könnte der Geräte-Manager dies berücksichtigen, wenn er die Socket-Affinität meldet.
Ich habe dies so gelesen, dass ich die TopologyHints Struktur direkt um Punkt-zu-Punkt-Informationen erweitern möchte.
Es hört sich so an, als ob Sie eher vorschlagen, dass nur die Geräte-Plugin-API erweitert werden muss, um Punkt-zu-Punkt-Informationen an devicemanager bereitzustellen, damit diese Informationen verwendet werden können, um SocketMask zu informieren. TopologyHints Struktur zu setzen, wenn GetTopologyHints() aufgerufen wird.
Ich denke, das wird funktionieren, solange die API-Erweiterungen des Geräte-Plugins so konzipiert sind, dass sie uns ähnliche Informationen liefern, wie ich sie in meinem obigen Beispiel beschrieben habe, und das devicemanager erweitert wird, um diese Informationen zwischen Pod-Zulassung und Gerät zu speichern Zuteilungszeit.
Im Moment haben wir bei Nvidia eine benutzerdefinierte Lösung, die unsere kubelet um im Wesentlichen das zu tun, was Sie vorschlagen (außer dass wir keine Entscheidungen für Geräte-Plugins treffen – die devicemanager wurde GPU-sensibel gemacht und trifft selbst topologiebasierte Entscheidungen zur GPU-Zuweisung).
Wir möchten nur sicherstellen, dass jede langfristige Lösung es uns ermöglicht, diese benutzerdefinierten Patches in Zukunft zu entfernen. Und jetzt, wo ich ein besseres Bild davon habe, wie der Fluss hier funktioniert, sehe ich nichts, was uns blockieren würde.
Nochmals vielen Dank, dass Sie sich die Zeit genommen haben, alles zu klären.
klueska
am 10. Apr. 2019
Hallo @lmdaly , ich bin der Enhancement Lead für 1.15. Wird diese Funktion in 1.15 die Alpha-/Beta-/Stable-Phasen abschließen? Bitte lassen Sie es mich wissen, damit es richtig verfolgt und der Tabelle hinzugefügt werden kann.
Sobald die Codierung beginnt, listen Sie bitte alle relevanten k/k-PRs in dieser Ausgabe auf, damit sie ordnungsgemäß nachverfolgt werden können.
 kacole2
am 12. Apr. 2019
kacole2
am 12. Apr. 2019
Dieses Feature wird sein eigenes Feature-Gate haben und ist Alpha.
/Meilenstein 1,15
 derekwaynecarr
am 12. Apr. 2019
derekwaynecarr
am 12. Apr. 2019
@derekwaynecarr : Der angegebene Meilenstein ist für dieses Repository nicht gültig. Meilensteine in diesem Repository: [ keps-beta , keps-ga , v1.14 , v1.15 ]
Verwenden Sie /milestone clear , um den Meilenstein zu löschen.
Als Antwort darauf :
Dieses Feature wird sein eigenes Feature-Gate haben und ist Alpha.
/Meilenstein 1,15
Anleitungen zur Interaktion mit mir über PR-Kommentare finden Sie hier . Wenn Sie Fragen oder Vorschläge zu meinem Verhalten haben, reichen Sie bitte ein Problem gegen das
 k8s-ci-robot
am 12. Apr. 2019
k8s-ci-robot
am 12. Apr. 2019
/Meilenstein v1.15
derekwaynecarr
am 12. Apr. 2019
/ @lmdaly zuweisen
 justaugustus
am 28. Apr. 2019
lmdaly
am 29. Apr. 2019
justaugustus
am 28. Apr. 2019
lmdaly
am 29. Apr. 2019
@lmdaly
https://github.com/kubernetes/kubernetes/issues/72828
Mein Team und ich erwägen, den Topology Manager für numa-sensitive Anwendungen zu testen.
Wir haben also einige Fragen.
Sind diese über den PRs hinausgehenden Implementierungen für den Topologie-Manager vollständig?
Und ist es jetzt getestet oder stabil?
 bg-chun
am 15. Mai 2019
bg-chun
am 15. Mai 2019
@bg-chun Wir machen das gleiche bei Nvidia. Wir haben diese WIP-PRs in unseren internen Stack aufgenommen und eine topologiebewusste Zuweisungsstrategie für CPUs/GPUs entwickelt. Dabei haben wir einige Probleme aufgedeckt und konkretes Feedback zu diesen PRs gegeben.
Weitere Informationen finden Sie hier im Diskussionsthread:
https://kubernetes.slack.com/archives/C0BP8PW9G/p1556371768035800
klueska
am 15. Mai 2019
Hey, @lmdaly, ich bin der Versionsschatten der Dokumente von v1.15.
Wie ich sehe, streben Sie die Alpha-Version dieser Erweiterung für die Version 1.15 an. Erfordert dies neue Dokumente (oder Änderungen)?
Nur eine freundliche Erinnerung, wir suchen eine PR gegen k/website (Zweig dev-1.15) bis Donnerstag, den 30. Mai. Es wäre toll, wenn dies der Anfang der vollständigen Dokumentation wäre, aber selbst ein Platzhalter-PR ist akzeptabel. Lassen Sie es mich wissen, wenn Sie Fragen haben! 😄
 daminisatya
am 18. Mai 2019
daminisatya
am 18. Mai 2019
@lmdaly Nur eine freundliche Erinnerung, wir suchen eine PR gegen k/website (Zweig dev-1.15) bis Donnerstag, den 30. Mai. Es wäre toll, wenn dies der Anfang der vollständigen Dokumentation wäre, aber selbst ein Platzhalter-PR ist akzeptabel. Lassen Sie es mich wissen, wenn Sie Fragen haben! 😄
daminisatya
am 27. Mai 2019
Hallo @lmdaly . Code Freeze ist Donnerstag, der 30. Mai 2019 @ EOD PST . Alle Erweiterungen, die in die Veröffentlichung eingehen, müssen vollständig im Code enthalten sein, einschließlich Tests , und die Dokumentations-PRs müssen geöffnet sein.
Werde unter https://github.com/kubernetes/kubernetes/issues/72828 nachsehen , ob alle zusammengeführt sind.
Wenn Sie wissen, dass dies verrutscht, antworten Sie bitte zurück und teilen Sie uns dies mit. Danke!
kacole2
am 28. Mai 2019
@daminisatya Ich habe die Doc-PR gepusht. https://github.com/kubernetes/website/pull/14572
Lassen Sie mich wissen, ob es richtig gemacht wurde und ob noch etwas getan werden muss. Danke für die Erinnerung!
lmdaly
am 28. Mai 2019
Danke @lmdaly ✨
daminisatya
am 29. Mai 2019
Hallo @lmdaly , heute ist Code Freeze für den Release-Zyklus 1.15. Es gibt noch einige k/k-PRs, die noch nicht aus Ihrem Tracking-Problem https://github.com/kubernetes/kubernetes/issues/72828 zusammengeführt wurden. Es wird jetzt im Verbesserungs-Tracking-Blatt 1.15 als gefährdet gekennzeichnet . Besteht ein hohes Vertrauen, dass diese heute von EOD PST zusammengeführt werden? Ab diesem Zeitpunkt sind mit Ausnahme nur noch Release-Blocking Issues und PRs im Meilenstein erlaubt.
kacole2
am 30. Mai 2019
/Meilenstein klar
kacole2
am 3. Juni 2019
Hallo @lmdaly @derekwaynecarr , ich bin der 1.16 Enhancement Lead. Wird diese Funktion in 1.16 die Alpha-/Beta-/Stable-Phasen abschließen? Bitte lassen Sie es mich wissen, damit es der 1.16-Tracking-Tabelle hinzugefügt werden kann. Wenn dies nicht der Fall ist, werde ich es aus dem Meilenstein entfernen und das nachverfolgte Label ändern.
Wenn die Codierung beginnt oder bereits erfolgt ist, listen Sie bitte alle relevanten k/k-PRs in dieser Ausgabe auf, damit sie ordnungsgemäß nachverfolgt werden können.
Meilensteintermine sind Enhancement Freeze 30.07. und Code Freeze 29.08.
Danke schön.
kacole2
am 9. Juli 2019
@kacole2 danke für die Erinnerung. Diese Funktion wird in 1.16 als Alpha eingeführt.
Die laufende Liste der PRs finden Sie hier: https://github.com/kubernetes/kubernetes/issues/72828
Danke!
lmdaly
am 17. Juli 2019
Stimmen Sie zu, dass dies für 1.16 in Alpha landen wird.
derekwaynecarr
am 30. Juli 2019
Hallo @lmdaly , ich bin der Versionsschatten von v1.16 docs.
Erfordert diese Verbesserung neue Dokumente (oder Änderungen)?
Nur eine freundliche Erinnerung, wir suchen eine PR gegen k/website (Zweig dev-1.16), die bis Freitag, den 23. August fällig ist. Es wäre toll, wenn dies der Anfang der vollständigen Dokumentation wäre, aber selbst ein Platzhalter-PR ist akzeptabel. Lassen Sie es mich wissen, wenn Sie Fragen haben!
Danke!
 VineethReddy02
am 1. Aug. 2019
VineethReddy02
am 1. Aug. 2019
Dokumentations-PR: https://github.com/kubernetes/website/pull/15716
lmdaly
am 7. Aug. 2019
@lmdaly Wird der Topologie-Manager Informationen oder API bereitstellen, um Benutzern die NUMA-Konfiguration für einen bestimmten Pod mitzuteilen?
 mJace
am 15. Aug. 2019
mJace
am 15. Aug. 2019
@mJace etwas sichtbar über die kubectl-Beschreibung für den Pod?
lmdaly
am 15. Aug. 2019
@lmdaly Ja, kubectl describe ist gut. oder eine API, um zugehörige Informationen zurückzugeben.
Da wir einen Dienst entwickeln, der einige topologiebezogene Informationen für Pods bereitstellt, z.
Und einige Monitor-Tools wie das Weave-Scope können die API aufrufen, um ein paar ausgefallene Arbeiten zu erledigen.
Der Administrator kann beispielsweise feststellen, ob sich der VNF in der richtigen numa-Konfiguration befindet.
Ich möchte nur wissen, ob Topology Manager diesen Teil abdeckt.
oder ob wir etwas tun könnten, wenn Topology Manager plant, diese Art von Funktionalität zu unterstützen.
mJace
am 15. Aug. 2019
@mJace Okay, derzeit gibt es keine
Daher denke ich, dass es gut wäre, eine Diskussion darüber zu beginnen und zu sehen, welche Sichtweise wir den Benutzern geben können.
lmdaly
am 15. Aug. 2019
Wie ich sehe, dachte ich, dass der CPU- und Geräte-Manager diese Informationen sehen kann.
Vielleicht ist der Cadvisor eine gute Rolle, um diese Informationen bereitzustellen.
Denn grundsätzlich erhält cadvisor Container-Informationen wie PID usw. von ps ls .
Auf dieselbe Weise überprüfen wir die topologiebezogenen Informationen des Containers.
Ich werde dies in cadvisor implementieren und eine PR dafür erstellen.
mJace
am 15. Aug. 2019
Ich habe ein ähnliches Problem in cadvisor erstellt.
https://github.com/google/cadvisor/issues/2290
mJace
am 16. Aug. 2019
/zuordnen
 khenidak
am 24. Aug. 2019
khenidak
am 24. Aug. 2019
+1 an @mJace Cadvisor-Vorschlag.
Um die DPDK-Lib innerhalb eines Containers mit CPU Manager und Topology Manager , die CPU-Affinität des Containers zu analysieren und sie dann an die dpdk-Lib zu übergeben, sind beide für das Thread-Pinning der DPDK-Lib erforderlich.
Für weitere Details: Wenn eine CPU im cgroup-cpuset-Subsystem des Containers nicht zulässig ist, werden Aufrufe von sched_setaffinity zum Anheften des Prozesses an die CPU herausgefiltert.
Die DPDK-Bibliothek verwendet pthread_setaffinity_np zum Anheften pthread_setaffinity_np ist ein Wrapper auf Thread-Ebene von sched_setaffinity .
Und der CPU-Manager von Kubernetes legt die exklusive CPU auf dem cgroup-cpuset-Subsystem des Containers fest.
bg-chun
am 26. Aug. 2019
@bg-chun Ich habe den Cadvisor-Wechsel als einen anderen Zweck verstanden: die Überwachung. Für Ihre Anforderung ist es möglich, die zugewiesenen CPUs aus dem Container heraus zu lesen, indem Sie 'Cpus_Allowed' oder 'Cpus_Allowed_List' aus '/proc/self/status' parsen. Wird dieser Ansatz für Sie funktionieren?
ConnorDoyle
am 26. Aug. 2019
@ConnorDoyle- Informationen in /proc/*/status wie Cpus_Allowed von sched_setaffinity . Wenn die Anwendung also etwas festlegt, ist dies eine Teilmenge dessen, was der cpuset Controller von Cgroup wirklich erlaubt.
 kad
am 26. Aug. 2019
kad
am 26. Aug. 2019
@kad , ich habe dem Launcher im Container eine Möglichkeit vorgeschlagen, die CPU-ID-Werte herauszufinden, die an das DPDK-Programm weitergegeben werden sollen. Dies geschieht also, bevor die Affinität auf Thread-Ebene festgelegt wird.
ConnorDoyle
am 26. Aug. 2019
@ConnorDoyle
Danke für deinen Vorschlag, ich werde ihn berücksichtigen.
Mein Plan war die Bereitstellung eines Tiny-Rest-Api-Servers, um dem dpdk-container exklusive CPUs-Zuweisungsinformationen mitzuteilen.
Was die Änderungen betrifft, so habe ich die Cadvisor-Änderungen noch nicht gesehen, ich sehe nur den Vorschlag .
Der Vorschlag sagt able to tell if there is any cpu affinity set for the container. in Ziel und to tell if there is any cpu affinity set for the container processes. in Zukünftige Arbeit.
Nachdem ich den Vorschlag gelesen hatte, dachte ich, es wäre großartig, wenn cadvisor die CPU-Pinning-Informationen analysieren und kubelet als Umgebungsvariable wie status.podIP , metadata.name und limits.cpu den Container übergeben könnte
Das ist der Hauptgrund, warum ich +1 gelassen habe.
bg-chun
am 26. Aug. 2019
@bg-chun Meinen ersten PR könnt ihr bei cadvisor checken
https://github.com/google/cadvisor/pull/2291
Ich habe eine ähnliche Funktion beendet.
https://github.com/mJace/numacc
bin mir aber nicht sicher, wie man es in cadvisor richtig umsetzt
Deshalb erstelle ich nur eine PR mit einem neuen Feature -> PSR anzeigen.
mJace
am 26. Aug. 2019
bin mir aber nicht sicher, wie man es in cadvisor richtig umsetzt
Vielleicht könnten wir dies im Rahmen dieses Vorschlags diskutieren? Wenn Sie Gurus denken, dass diese Funktion benötigt wird :)
mJace
am 26. Aug. 2019
@lmdaly Code Freeze für 1.16 ist am Donnerstag, den 29.08. Wir werden https://github.com/kubernetes/kubernetes/issues/72828 für verbleibende k/k PRs verfolgen
kacole2
am 26. Aug. 2019
@kacole2 alle erforderlichen PRs für diese Funktion werden zusammengeführt oder befinden sich in der Zusammenführungswarteschlange.
lmdaly
am 30. Aug. 2019
Hallo @lmdaly -- 1.17 Verbesserungen führen hierher. Ich wollte einchecken und sehen, ob Sie denken, dass diese Verbesserung in 1.17 zu Alpha/Beta/Stable wird?
Der aktuelle Veröffentlichungsplan ist:
- Montag, 23. September – Beginn des Veröffentlichungszyklus
- Dienstag, 15. Oktober, EOD PST - Verbesserungen einfrieren
- Donnerstag, 14. November EOD PST - Code Freeze
- Dienstag, 19. November – Dokumente müssen ausgefüllt und überprüft werden
- Montag, 9. Dezember – Kubernetes 1.17.0 veröffentlicht
Wenn Sie dies tun, listen Sie bitte alle relevanten k/k-PRs in dieser Ausgabe auf, damit sie ordnungsgemäß nachverfolgt werden können. 👍
Danke!
/Meilenstein klar
 mrbobbytables
am 22. Sept. 2019
mrbobbytables
am 22. Sept. 2019
@lmdaly gibt es einen direkten Link zur GPU mit RDMA-Diskussion?
 nickolaev
am 25. Sept. 2019
nickolaev
am 25. Sept. 2019
@nickolaev , Wir schauen uns auch diesen Anwendungsfall an. Wir haben intern darüber nachgedacht, wie das geht, aber wir würden gerne daran zusammenarbeiten.
 moshe010
am 25. Sept. 2019
moshe010
am 25. Sept. 2019
@moshe010 @nickolaev @lmdaly , Auch wir untersuchen diesen Anwendungsfall in Bezug auf RDMA und GPU direkt. Daran möchten wir gerne mitwirken. Kann man dazu einen Thread/Diskussion eröffnen?
 Deepthidharwar
am 25. Sept. 2019
Deepthidharwar
am 25. Sept. 2019
Hallo! Ich habe eine Frage zu NTM und Scheduler. Wie ich verstehe, kennt der Scheduler keine NUMAs und kann einen Knoten bevorzugen, auf dem keine Ressourcen (CPU, Speicher und Gerät) auf dem gewünschten NUMA vorhanden sind. Daher wird der Topologie-Manager die Ressourcenzuweisung auf diesem Knoten verweigern. Ist es wahr?
 LilyaBu
am 25. Sept. 2019
LilyaBu
am 25. Sept. 2019
@nickolaev @Deepthidharwar , ich werde Google Doc mit Anwendungsfällen starten und wir können die Diskussion darauf verschieben. Nächste Woche poste ich was. Wenn das für dich in Ordnung ist.
moshe010
am 25. Sept. 2019
Ich freue mich sehr, diese Funktion zu sehen. Wir benötigen auch CPU, Hugepage, SRIOV-VFs und andere Hardwareressourcen in einem einzelnen NUMA-Knoten.
Aber Hugepage wird nicht als skalare Ressource durch das Geräte-Plugin realisiert. Muss diese Funktion die Hugepage-Funktion in k8s ändern?
@iamneha
 andyzheung
am 26. Sept. 2019
andyzheung
am 26. Sept. 2019
@ConnorDoyle Nur um zu bestätigen, benötigt diese Funktion Topologiehinweise sowohl vom CPU-Manager als auch vom Geräte-Manager? Ich habe es auf 1.16 getestet und hat nicht funktioniert, es scheint, dass es nur einen Hinweis vom CPU-Manager, aber keinen Hinweis von der Geräteseite erhalten hat.
 jianzzha
am 26. Sept. 2019
jianzzha
am 26. Sept. 2019
@ConnorDoyle hier ist ein bisschen mehr Details:
https://gist.githubusercontent.com/jianzzha/c2a66a2514c178cca76a432029ff3387/raw/264f13dfcd06f1f80c48c113aa235fab7c33d81e/hyper%2520threading%2520enabled
jianzzha
am 26. Sept. 2019
@jianzzha , Welches Geräte-Plugin verwenden Sie? Wenn Sie beispielsweise das SR-IOV-Geräte-Plugin verwenden, müssen Sie sicherstellen, dass es den NUMA-Knoten meldet, siehe [1]
moshe010
am 26. Sept. 2019
@andyzheung Eine riesige Seitenintegration wird derzeit diskutiert und wurde in den letzten zwei Wochen im Sign-Node-Meeting vorgestellt. Hier einige relevante Links:
https://docs.google.com/presentation/d/1H5xhCjgCZJjdTm-mGUFwqoz8XmoVd8xTCwJ1AfVR_54/edit?usp=sharing
https://github.com/kubernetes/enhancements/pull/1245
https://github.com/kubernetes/enhancements/pull/1199
@jianzzha Bezüglich des Geräte-Plugins gibt es keine Hinweise. Wurde Ihr Plugin aktualisiert, um NUMA-Informationen zu den Geräten zu melden, die es aufzählt? Dieses Feld muss der Gerätenachricht https://github.com/kubernetes/kubernetes/blob/master/pkg/kubelet/apis/deviceplugin/v1beta1/api.proto#L100 . hinzugefügt werden
klueska
am 26. Sept. 2019
danke Leute. Behoben und funktioniert jetzt.
jianzzha
am 26. Sept. 2019
@klueska
Bezüglich nvidia-gpu-device-plugin..
Ich kann nur einen aktiven PR (WIP) sehen , um nvidia-gpu-device-plugin für Topology Manger zu aktualisieren.
Wird nvidia-gpu-divice-plugin aktualisiert, um einen Topologiehinweis mit obigem PR bereitzustellen? oder vermisse ich etwas?
bg-chun
am 26. Sept. 2019
@bg-chun Ja, so sollte es sein. Habe gerade den Autor angepingt. Wenn er am nächsten Tag oder so nicht zurückkommt, werde ich das Plugin selbst aktualisieren.
klueska
am 26. Sept. 2019
@bg-chun @klueska Ich habe den Patch aktualisiert.
 carmark
am 27. Sept. 2019
carmark
am 27. Sept. 2019
@klueska @carmark
Vielen Dank für die Aktualisierung und den Hinweis.
Ich werde den Benutzern in meinem Arbeitsbereich sr-iov-plugin update und gpu-plugin update vorstellen.
bg-chun
am 27. Sept. 2019
Ich würde eine Verbesserung für die nächste Version vorschlagen.
Es geht im Grunde darum, die Einschränkung "Topologieausrichtung erfolgt nur, wenn der Pod sich in garantierter QoS befindet" zu entfernen.
Diese Einschränkung macht den Topology Manager für mich im Moment irgendwie unbrauchbar, da ich nicht nach exklusiven CPUs von K8s fragen möchte, aber die Sockel mehrerer Geräte, die aus mehreren Pools kommen (zB GPU + SR -IOV VFs usw.)
Was auch, wenn meine Arbeitslast nicht speicherempfindlich ist oder die Speichernutzung nicht einschränken möchte (ein weiteres Kriterium für garantierte QoS).
In Zukunft, wenn hoffentlich auch riesige Seiten ausgerichtet werden, wird sich diese Einschränkung IMO noch einschränkender anfühlen.
Gibt es Argumente gegen eine individuelle Ausrichtung der "ausrichtbaren" Ressourcen? Lassen Sie uns natürlich nur Hinweise vom CPU-Manager sammeln, wenn exklusive CPUs verwendet werden, aber unabhängig davon sammeln wir Hinweise vom Geräte-Manager, wenn der Benutzer Geräte mit Socket-Informationen benötigt, oder vom Speichermanager, wenn der Benutzer nach Hugepages usw. fragt.
Entweder dies, oder wenn unnötige zusätzliche Rechenlast während des Pod-Starts ein Problem darstellt, bringen Sie möglicherweise das ursprüngliche Konfigurationsflag auf Pod-Ebene zurück, um zu steuern, ob die Ausrichtung erfolgt oder nicht (was ich überrascht war, dass es während der Implementierung verschrottet wurde).
 Levovar
am 30. Sept. 2019
Levovar
am 30. Sept. 2019
Ich würde eine Verbesserung für die nächste Version vorschlagen.
Es geht im Grunde darum, die Einschränkung "Topologieausrichtung erfolgt nur, wenn der Pod sich in garantierter QoS befindet" zu entfernen.
Dies ist die Nummer 8 auf unserer TODO-Liste für 1.17:
https://docs.google.com/document/d/1YTUvezTLGmVtEF3KyLOX3FzfSDw9w0zB-s2Tj6PNzLA/edit#heading =h.xnehh6metosd
Gibt es Argumente gegen eine individuelle Ausrichtung der "ausrichtbaren" Ressourcen? Lassen Sie uns natürlich nur Hinweise vom CPU-Manager sammeln, wenn exklusive CPUs verwendet werden, aber unabhängig davon sammeln wir Hinweise vom Geräte-Manager, wenn der Benutzer Geräte mit Socket-Informationen benötigt, oder vom Speichermanager, wenn der Benutzer nach Hugepages usw. fragt.
Schlagen Sie vor, dass es einen Mechanismus gibt, der dem Kubelet selektiv mitteilt, an welchen Ressourcen es ausgerichtet werden soll und an welchen nicht (dh ich möchte meine CPU- und GPU-Zuweisungen ausrichten, aber nicht meine riesigen Seitenzuweisungen). Ich glaube nicht, dass irgendjemand dem direkt widersprechen würde, aber die Schnittstelle, um selektiv zu entscheiden, an welchen Ressourcen ausgerichtet werden soll und an welchen nicht, könnte zu umständlich werden, wenn wir die Ausrichtung weiterhin als Flag auf Knotenebene angeben.
Entweder dies, oder wenn unnötige zusätzliche Rechenlast während des Pod-Starts ein Problem darstellt, bringen Sie möglicherweise das ursprüngliche Konfigurationsflag auf Pod-Ebene zurück, um zu steuern, ob die Ausrichtung erfolgt oder nicht (was ich überrascht war, dass es während der Implementierung verschrottet wurde).
Es gab nicht genügend Unterstützung für ein Flag auf Pod-Ebene, um einen Vorschlag zur Aktualisierung der Pod-Spezifikation zu rechtfertigen. Für mich ist es sinnvoll, diese Entscheidung auf Pod-Ebene zu verschieben, da einige Pods Ausrichtung brauchen / wollen und andere nicht, aber nicht alle waren sich einig.
klueska
am 30. Sept. 2019
+1 zum Entfernen der QoS-Klassenbeschränkung für die Topologieausrichtung (ich habe sie der Liste hinzugefügt :smiley:). Ich habe nicht das Gefühl, dass @Levovar nach der Aktivierung der Topologie pro Ressource fragt, nur dass wir alle ausrichtbaren Ressourcen ausrichten sollten, die von einem bestimmten Container verwendet werden.
Soweit ich mich erinnern kann, gab es im KEP nie ein Feld auf Pod-Ebene, um sich für die Topologie zu entscheiden. Der Grund dafür, sie gar nicht erst einzuführen, war der gleiche Grund, exklusive Kerne implizit zu belassen – Kubernetes als Projekt möchte die Pod-Spezifikation in Bezug auf das Leistungsmanagement auf Knotenebene frei interpretieren können. Ich weiß, dass diese Haltung für einige Mitglieder der Community unbefriedigend ist, aber wir können das Thema immer wieder ansprechen. Es besteht eine natürliche Spannung zwischen der Aktivierung erweiterter Funktionen für die wenigen und der Modulation der kognitiven Belastung für die meisten Benutzer.
ConnorDoyle
am 1. Okt. 2019
IMO in der sehr frühen Phase des Designs gab es zumindest eine Flagge auf Pod-Ebene, wenn ich mich gut erinnere, aber es war ungefähr 1,13 :D
Ich persönlich bin damit einverstanden, ständig alle Ressourcen aufeinander abzustimmen, aber "früher" gab es normalerweise einen Widerstand der Community gegen Funktionen, die Verzögerungen beim Start oder bei der Planungsentscheidung aller Pods mit sich bringen würden, unabhängig davon, ob sie brauchen wirklich die Verbesserung, oder nicht.
Ich habe also nur versucht, diese Bedenken mit zwei Optionen "voranzugehen", die mir in den Sinn kamen: die Ausrichtung von Ressourcengruppen basierend auf einigen Kriterien (einfach zu definieren für die CPU, schwieriger für andere); oder führen Sie ein Konfigurations-Flag ein.
Wenn es jetzt jedoch keinen Pushback gegen eine generische Erweiterung gibt, bin ich damit total cool :)
Levovar
am 1. Okt. 2019
@mrbobbytables Wir planen, die TopologyManager beta in 1.17 auf https://github.com/kubernetes/kubernetes/issues/83479
klueska
am 3. Okt. 2019
@bg-chun @klueska Ich habe den Patch aktualisiert.
Patch zusammengeführt:
https://github.com/NVIDIA/k8s-device-plugin/commit/cc0aad87285b573127add4e487b13434a61ba0d6
Neue Version mit dem Patch erstellt:
https://github.com/NVIDIA/k8s-device-plugin/releases/tag/1.0.0-beta2
klueska
am 3. Okt. 2019
Tracking-Beta für v1.17
derekwaynecarr
am 4. Okt. 2019
Super , danke
/Bühne Beta
mrbobbytables
am 6. Okt. 2019
@lmdaly
Ich bin einer der v1.17 Docs Shadows.
Erfordert diese Verbesserung (oder die für v1.17) geplante Arbeit neue Dokumente (oder Änderungen an bestehenden Dokumenten)? Wenn nicht, können Sie bitte das 1.17 Enhancement Tracker Sheet aktualisieren (oder lassen Sie es mich wissen und ich werde dies tun)
Wenn ja, nur eine freundliche Erinnerung, wir suchen eine PR gegen k/website (Zweig dev-1.17), die bis Freitag, den 8. November fällig ist, es kann zu diesem Zeitpunkt nur eine Platzhalter-PR sein. Lassen Sie es mich wissen, wenn Sie Fragen haben!
Danke!
VineethReddy02
am 21. Okt. 2019
@VineethReddy02 ja, wir haben Dokumentations-Updates für 1.17 geplant, wenn du das Tracker-Blatt aktualisieren könntest, wäre das großartig!
Wir werden diese PR sicher vorher öffnen, danke für die Erinnerung.
Das Problem für die Nachverfolgungsdokumentation dafür ist hier: https://github.com/kubernetes/kubernetes/issues/83482
lmdaly
am 23. Okt. 2019
https://github.com/kubernetes/enhancements/pull/1340
Leute, ich habe KEP Update PR geöffnet, um eine integrierte Knotenbezeichnung ( beta.kubernetes.io/topology ) für den Topologie-Manager hinzuzufügen.
Das Label macht die Richtlinie des Knotens verfügbar.
Ich denke, es wäre hilfreich, einen Pod für den bestimmten Knoten zu planen, wenn Knoten mit mehreren Richtlinien im selben Cluster vorhanden sind.
Darf ich um eine Bewertung bitten?
bg-chun
am 28. Okt. 2019
Hallo @lmdaly @derekwaynecarr
Jeremy vom 1.17-Erweiterungen-Team hier 👋. Könnten Sie bitte die k/k-PRs auflisten, die dafür im Umlauf sind, damit wir sie verfolgen können? Ich sehe, dass #83492 zusammengeführt wurde, aber es scheint noch ein paar weitere Probleme zu geben, die mit dem gesamten Tracking-Element hängen. Wir schließen Code Freeze am 14. November ab, also möchten wir uns vorher ein Bild davon machen, wie es läuft! Vielen Dank!
 jeremyrickard
am 4. Nov. 2019
jeremyrickard
am 4. Nov. 2019
@jeremyrickard Dies ist das oben erwähnte Tracking-Problem für 1.17: https://github.com/kubernetes/enhancements/issues/693#issuecomment -538123786
klueska
am 4. Nov. 2019
@lmdaly @derekwaynecarr
Eine freundliche Erinnerung, wir suchen nach einem Platzhalter-PR für Docs gegen k/website (Zweig dev-1.17), der bis Freitag, den 8. November fällig ist. Wir haben nur noch 2 Tage für diese Frist.
daminisatya
am 6. Nov. 2019
Docs PR ist übrigens hier: https://github.com/kubernetes/website/pull/17451
lmdaly
am 8. Nov. 2019
@klueska Ich sehe, dass einige der Arbeiten auf 1.18
jeremyrickard
am 13. Nov. 2019
Egal, ich sehe in https://github.com/kubernetes/kubernetes/issues/85093, dass Sie jetzt in 1.18 zur Beta wechseln werden, nicht als Teil von 1.17. Möchten Sie, dass wir dies als wichtige Änderung der Alpha-Version im Rahmen des 1.17-Meilensteins @klueska verfolgen? Oder einfach den Abschluss auf 1,18 verschieben?
jeremyrickard
am 13. Nov. 2019
/Meilenstein v1.18
jeremyrickard
am 15. Nov. 2019
Hey @klueska
1.18 Erweiterungsteam checkt ein! Planen Sie immer noch, die Betaversion in 1.18 zu erweitern? Enhancement Freeze wird am 28. Januar sein, wenn Ihr KEP Updates benötigt, während Code Freeze am 5. März ist.
Danke schön!
jeremyrickard
am 7. Jan. 2020
Ja.
klueska
am 7. Jan. 2020
@klueska danke für das Update! Aktualisieren des Tracking-Blatts.
jeremyrickard
am 7. Jan. 2020
@klueska Als wir die KEPs für diese Version überprüft haben, haben wir festgestellt, dass hier Testpläne fehlen. Um in der Veröffentlichung zur Beta zu gelangen, müssen Testpläne hinzugefügt werden. Ich werde es vorerst aus dem Meilenstein entfernen, aber wir können es wieder hinzufügen, wenn Sie einen Ausnahmeantrag stellen und die Testpläne dem KEP hinzufügen. Entschuldigung für die späte Benachrichtigung.
jeremyrickard
am 29. Jan. 2020
/Meilenstein klar
jeremyrickard
am 29. Jan. 2020
@vpickard siehe oben
klueska
am 29. Jan. 2020
 vpickard
am 29. Jan. 2020
vpickard
am 29. Jan. 2020
@jeremyrickard Gibt es eine
vpickard
am 29. Jan. 2020
@vpickard können Sie sich ansehen:
https://github.com/kubernetes/enhancements/blob/master/keps/sig-storage/20190530-pv-health-monitor.md#test -plan
und
https://github.com/kubernetes/enhancements/blob/master/keps/sig-storage/20200120-skip-permission-change.md#test -plan
Fügen Sie eine Übersicht über die Unit-Tests und e2e-Tests hinzu.
Wenn Sie etwas haben, das im Testraster angezeigt wird, wäre es großartig, es aufzunehmen.
jeremyrickard
am 29. Jan. 2020
Ausnahme wurde genehmigt.
/Meilenstein v1.18
jeremyrickard
am 30. Jan. 2020
@jeremyrickard Testplan zusammengeführt: https://github.com/kubernetes/enhancements/pull/1527
klueska
am 4. Feb. 2020
Hallo @klueska @vpickard , nur eine freundliche Erinnerung daran, dass das Code Freeze am Donnerstag, den 5. März in Kraft tritt.
Können Sie bitte alle k/k-PRs oder andere PRs verlinken, die für diese Verbesserung verfolgt werden sollten?
Danke schön :)
 palnabarun
am 5. Feb. 2020
palnabarun
am 5. Feb. 2020
Hallo @palnabarun
Tracking-Problem hier für 1.18:
https://github.com/kubernetes/kubernetes/issues/85093
Aktuelle offene PRs:
https://github.com/kubernetes/kubernetes/pull/87758 (Genehmigt, Abplatztests)
https://github.com/kubernetes/kubernetes/pull/87759 (WIP)
https://github.com/kubernetes/kubernetes/pull/87650 (Überprüft, muss genehmigt werden)
https://github.com/kubernetes/kubernetes/pull/87645 (e2e Test PR, genehmigungspflichtig)
@vpickard können Sie alle e2e-PRs hinzufügen, die ich verpasst habe.
Danke
 nolancon
am 5. Feb. 2020
nolancon
am 5. Feb. 2020
Danke @nolancon für die Verlinkung der PR's und des
palnabarun
am 5. Feb. 2020
Hallo @palnabarun , @nolancon ,
Einige zusätzliche offene PRs zu E2E-Tests:
https://github.com/kubernetes/test-infra/pull/16062 (erfordert Überprüfung und Genehmigung)
https://github.com/kubernetes/test-infra/pull/16037 (erfordert Überprüfung und Genehmigung)
vpickard
am 6. Feb. 2020
Danke @vpickard für die zusätzlichen Updates. :)
palnabarun
am 9. Feb. 2020
Hallo @lmdaly, ich bin einer der v1.18 Docs Shadows.
Erfordert diese Verbesserung für (oder die für v1.18) geplante Arbeit neue Dokumente (oder Änderungen an bestehenden Dokumenten)? Wenn nicht, können Sie bitte das 1.18 Enhancement Tracker Sheet aktualisieren (oder lassen Sie es mich wissen und ich werde dies tun)
Wenn ja, nur eine freundliche Erinnerung, wir suchen eine PR gegen k/website (Zweig dev-1.18), die bis Freitag, den 28. Februar fällig ist. Es kann derzeit nur eine Platzhalter-PR sein. Lassen Sie es mich wissen, wenn Sie Fragen haben!
 irvifa
am 9. Feb. 2020
irvifa
am 9. Feb. 2020
Hallo @irvifa , danke für die
Danke.
nolancon
am 10. Feb. 2020
Hallo @nolancon, danke für deine schnelle Antwort, ich ändere den Status jetzt auf Platzhalter-PR.. Danke!
irvifa
am 10. Feb. 2020
@palnabarun Zur Info , ich habe diese PR https://github.com/kubernetes/kubernetes/pull/87759 in zwei PRs aufgeteilt, um den Überprüfungsprozess zu vereinfachen. Der zweite ist hier https://github.com/kubernetes/kubernetes/pull/87983 und muss ebenfalls verfolgt werden. Danke.
nolancon
am 10. Feb. 2020
@nolancon Vielen Dank für die Updates.
Ich sehe, dass einige der PRs noch nicht zusammengeführt werden müssen. Ich wollte sehen, ob Sie Hilfe vom Release-Team brauchen, um Reviewer und Genehmiger zu den PRs zu bringen. Lassen Sie es uns wissen, wenn Sie etwas brauchen.
Zu Ihrer Information, wir stehen kurz vor Code Freeze am 5. März
palnabarun
am 27. Feb. 2020
@nolancon Vielen Dank für die Updates.
Ich sehe, dass einige der PRs noch nicht zusammengeführt werden müssen. Ich wollte sehen, ob Sie Hilfe vom Release-Team brauchen, um Reviewer und Genehmiger zu den PRs zu bringen. Lassen Sie es uns wissen, wenn Sie etwas brauchen.
Zu Ihrer Information, wir stehen kurz vor Code Freeze am 5. März
@palnabarun Ein weiteres Update, https://github.com/kubernetes/kubernetes/pull/87983 ist jetzt geschlossen und muss nicht nachverfolgt werden. Erforderliche Änderungen sind in der ursprünglichen PR https://github.com/kubernetes/kubernetes/pull/87759 enthalten, die derzeit überprüft wird.
nolancon
am 27. Feb. 2020
@nolancon Cool. Ich verfolge auch das Problem mit dem Regenschirm-Tracker, das Sie oben geteilt haben. :)
palnabarun
am 27. Feb. 2020
Hallo @nolancon , das ist eine Erinnerung daran , dass wir am 5. März nur noch zwei Tage vom
Beim Code Freeze sollten alle relevanten PRs zusammengeführt werden, sonst müssten Sie einen Ausnahmeantrag stellen.
palnabarun
am 3. März 2020
Hallo @nolancon ,
Heute ist EOD Code Freeze .
Glauben Sie, dass https://github.com/kubernetes/kubernetes/pull/87650 innerhalb der Frist überprüft wird?
Falls nicht, stellen Sie bitte einen Ausnahmeantrag .
palnabarun
am 5. März 2020
Hallo @nolancon ,
Heute ist EOD Code Freeze .
Glauben Sie, dass kubernetes/kubernetes#87650 fristgerecht überprüft wird?
Falls nicht, stellen Sie bitte einen Ausnahmeantrag .
Hallo @palnabarun , in den letzten Tagen wurden viele Fortschritte gemacht und wir sind zuversichtlich, dass alles genehmigt und zusammengeführt wird, bevor der Code einfriert. Wenn nicht, werde ich den Ausnahmeantrag stellen.
Nur zur Klarstellung, meinst du mit EOD 17:00 Uhr oder Mitternacht PST? Danke
nolancon
am 5. März 2020
Nur zur Klarstellung, meinst du mit EOD 17:00 Uhr oder Mitternacht PST? Danke
17:00 Uhr PST.
jeremyrickard
am 5. März 2020
Der PR ist genehmigt, aber es fehlt ein Meilenstein, den Sign-Node für die Zusammenführung hinzufügen muss. Ich habe sie in Slack gepingt, hoffentlich löst es sich und Sie brauchen keine Ausnahme. =)
 kikisdeliveryservice
am 5. März 2020
kikisdeliveryservice
am 5. März 2020
Alle PRs für diesen Bestand scheinen zusammengeführt (und bis zum Stichtag genehmigt) zu sein. Ich habe unser Tracking-Sheet für Verbesserungen aktualisiert. :Lächeln:
kikisdeliveryservice
am 6. März 2020
/Meilenstein klar
(Entfernen dieses Verbesserungsproblems aus dem Meilenstein v1.18, wenn der Meilenstein abgeschlossen ist)
palnabarun
am 29. Apr. 2020
Hallo @nolancon @lmdaly , Schattenverbesserungen für 1.19 hier. Gibt es Pläne dafür in 1.19?
 johnbelamaric
am 4. Mai 2020
johnbelamaric
am 4. Mai 2020
Die einzige geplante Erweiterung für 1.19 ist diese:
https://github.com/kubernetes/enhancements/pull/1121
Der Rest der Arbeit wird sich bei Bedarf auf Code-Refactoring/Bugfixes beziehen.
Gibt es irgendwie den Besitzer dieses Problems in mich anstelle von @lmdaly zu ändern?
klueska
am 4. Mai 2020
Danke, ich werde den Kontakt aktualisieren.
/Meilenstein v1.19
johnbelamaric
am 4. Mai 2020
/assign @klueska
/unassign @lmdaly
Hier hast du es, Kevin https://prow.k8s.io/command-help
 pires
am 6. Mai 2020
pires
am 6. Mai 2020
Hallo Kevin. Vor kurzem hat sich das KEP-Format geändert, und auch #1620 wurde letzte Woche zusammengeführt, wodurch der KEP-Vorlage Fragen zur Überprüfung der Produktionsbereitschaft hinzugefügt wurden. Bitte nehmen Sie sich nach Möglichkeit die Zeit, Ihre KEP neu zu formatieren und beantworten Sie auch die Fragen, die Sie der Vorlage hinzufügen. Die Antworten auf diese Fragen werden für Bediener hilfreich sein, die die Funktion verwenden und Fehler beheben (insbesondere das Überwachungselement in dieser Phase). Danke!
johnbelamaric
am 13. Mai 2020
@klueska ^^
johnbelamaric
am 13. Mai 2020
@derekwaynecarr @klueska @johnbelamaric
Ich plane auch, eine neue Topologierichtlinie auf 1.19 rel hinzuzufügen.
Aber es wurde noch nicht von Besitzer und Betreuer überprüft.
(Wenn es in 1.19 schwierig zu sein scheint, lassen Sie es mich wissen.)
- KEP-Update-PR: https://github.com/kubernetes/enhancements/pull/1752
- PR für Kubelet: WIP
bg-chun
am 13. Mai 2020
Hi @klueska 👋 1.19 docs shadow hier! Erfordert diese für 1.19 geplante Erweiterungsarbeit neue oder geänderte Dokumente?
Freundliche Erinnerung daran, dass, wenn neue/Änderungen an Dokumenten erforderlich sind, bis Freitag, 12. Juni, ein Platzhalter-PR gegen k/Website (Zweig dev-1.19 ) erforderlich ist.
 annajung
am 21. Mai 2020
annajung
am 21. Mai 2020
Hallo @klueska , ich hoffe, es geht Ihnen gut.
annajung
am 27. Mai 2020
Hallo @annajung. Es gibt 2 ausstehende Verbesserungen, die beide Änderungen an der Dokumentation erfordern:
1121
1752
Wir entscheiden noch, ob diese es in 1.19 schaffen oder auf 1.20 geschoben werden. Wenn wir uns entscheiden, sie für 1.19 zu behalten, werde ich bis zum 12. Juni einen Platzhalter-PR für die Dokumente erstellen.
klueska
am 29. Mai 2020
Toll! Vielen Dank für das Update, ich werde das Tracking-Sheet entsprechend aktualisieren! Bitte lassen Sie es mich wissen, sobald Platzhalter-PR erstellt wurde. Danke schön!
annajung
am 30. Mai 2020
@lmdaly @ConnorDoyle
Ich hoffe, hier ist der richtige Ort, um nachzufragen und Feedback zu geben.
Ich schalte TopologyManager und CPUManager auf meinem k8s-Cluster v1.17 ein.
und ihre Richtlinien sind best-effort und static
Hier sind die Ressourcen meines Pods
resources:
requests:
cpu: 2
intel.com/sriov_pool_a: '1'
limits:
cpu: 2
intel.com/sriov_pool_a: '1'
Der PF von sriov_pool_a befindet sich in NUMA-Knoten 0, daher gehe ich davon aus, dass mein Pod auch auf der CPU von NUMA-Knoten 0 laufen sollte.
Aber ich habe festgestellt, dass der Prozess meines Pods auf der CPU von NUMA-Knoten 1 ausgeführt wird.
Außerdem gibt es keine CPU-Affinitätsmaske, die dem Ergebnis von taskset -p <pid> .
Stimmt irgendetwas nicht? Ich gehe davon aus, dass der Container eine CPU-Affinitätsmaske für die CPU des Numa-Knotens 0 haben sollte.
Gibt es ein Beispiel oder einen Test, mit dem ich feststellen kann, ob mein TopoloyManager richtig funktioniert?
mJace
am 4. Juni 2020
@annajung Platzhalter-Dokumente PR hinzugefügt: https://github.com/kubernetes/website/pull/21607
klueska
am 9. Juni 2020
Hallo @klueska ,
Zur Nachbearbeitung der E-Mail, die am Montag an k-dev gesendet wurde, möchte ich Sie wissen lassen, dass Code Freeze bis Donnerstag, den 9. Juli, verlängert wurde. Den überarbeiteten Zeitplan können Sie hier einsehen: https://github.com/kubernetes/sig-release/tree/master/releases/release-1.19
Wir erwarten, dass bis zu diesem Zeitpunkt alle PRs zusammengeführt werden. Bitte lassen Sie es mich wissen, wenn Sie Fragen haben. 😄
Am besten,
Kirsten
kikisdeliveryservice
am 18. Juni 2020
Hallo @klueska , eine freundliche Erinnerung an die nächste Deadline.
Bitte denken Sie daran, Ihren Platzhalter-Dokument-PR auszufüllen und bis Montag, den 6. Juli, zur Überprüfung vorzubereiten.
annajung
am 22. Juni 2020
Danke @annajung . Da der Code-Freeze jetzt auf den 9. Juli verschoben wurde, ist es dann sinnvoll, auch das Docs-Datum vorzuziehen? Was passiert, wenn wir die Dokumentation erstellen, die Funktion jedoch nicht rechtzeitig (oder in einer etwas anderen Form als in der Dokumentation vorgeschlagen) erstellt wird?
klueska
am 23. Juni 2020
Hallo @klueska , das ist ein toller Punkt! Die Frist für alle Dokumente wurde mit dem neuen Veröffentlichungsdatum auch um eine Woche verschoben, aber ich denke, Sie haben einen gültigen Punkt. Lassen Sie mich die Docs-Leitung für die Veröffentlichung erreichen und mich bei Ihnen zurückmelden! Vielen Dank für den Hinweis!
annajung
am 24. Juni 2020
Hallo @klueska , nochmals
Nach Rücksprache mit dem Veröffentlichungsteam haben wir uns jedoch entschieden, die Daten für diese Version 1.19 unverändert zu lassen, indem wir die "PR zur Überprüfung" zu einer weichen Frist machen. Das Docs-Team ist flexibel und arbeitet mit Ihnen/anderen zusammen, die möglicherweise zusätzliche Zeit benötigen, um sicherzustellen, dass die Dokumente mit dem Code synchronisiert werden. Während die Frist "PR zur Überprüfung bereit" nicht eingehalten wird, wird die Frist "PR überprüft und zur Zusammenführung gelesen" eingehalten.
Ich hoffe, dies hilft, Ihre Bedenken zu beantworten! Bitte lassen Sie es mich wissen, wenn Sie weitere Fragen haben!
Außerdem nur eine freundliche Erinnerung an die Termine:
"Docs-Deadline - PRs bereit zur Überprüfung" ist bis zum 6. Juli fällig
"Dokumente abgeschlossen - Alle PRs überprüft und bereit zum Zusammenführen" ist bis zum 16. Juli fällig
annajung
am 24. Juni 2020
Hallo @klueska :wave: -- 1.19 Erweiterungen führen hierher,
Können Sie hier bitte alle Implementierungs-PRs verlinken, damit das Release-Team sie verfolgen kann? :leicht_smiling_face:
Danke schön.
palnabarun
am 28. Juni 2020
@palnabarun
Das PR-Tracking https://github.com/kubernetes/enhancements/pull/1121 finden Sie unter:
https://github.com/kubernetes/kubernetes/pull/92665
Leider wird die Erweiterung #1752 es nicht in die Veröffentlichung schaffen, daher gibt es keine PR dafür.
klueska
am 30. Juni 2020
Hallo @klueska :wave:, Ich sehe, dass beide PRs (https://github.com/kubernetes/enhancements/pull/1121 und https://github.com/kubernetes/enhancements/pull/1752) die du erwähnt hast beziehen sich auf die gleiche Verbesserung. Da https://github.com/kubernetes/enhancements/pull/1752 die Beta-Abschlussanforderungen erweitert und sie es nicht in die Veröffentlichung schaffen, können wir davon ausgehen, dass in 1.19 keine weiteren Änderungen erwartet werden?
Danke schön. :leicht_smiling_face:
Code Freeze beginnt am Donnerstag, den 9. Juli EOD PST
palnabarun
am 6. Juli 2020
@palnabarun Dies ist eine Folge-PR zu #92665, die heute oder morgen landen sollte: https://github.com/kubernetes/kubernetes/pull/92794
Danach sollte es keine PRs mehr für diese Version geben, bis auf unvorhergesehene Fehler.
klueska
am 6. Juli 2020
Genial! Danke für das Update. :+1:
Wir werden https://github.com/kubernetes/kubernetes/pull/92794 im Auge behalten
palnabarun
am 6. Juli 2020
@annajung https://github.com/kubernetes/website/pull/21607 ist jetzt zur Überprüfung bereit.
klueska
am 6. Juli 2020
Herzlichen Glückwunsch @klueska kubernetes/kubernetes#92794 ist endlich fusioniert, ich werde das Tracking-Sheet entsprechend aktualisieren 😄
kikisdeliveryservice
am 11. Juli 2020
/Meilenstein klar
(Entfernen dieses Verbesserungsproblems aus dem Meilenstein v1.19, wenn der Meilenstein abgeschlossen ist)
kikisdeliveryservice
am 12. Sept. 2020
Hallo @klueska
Verbesserungen führen hierher. Gibt es Pläne für diesen Abschluss in 1.20?
Danke!
Kirsten
kikisdeliveryservice
am 13. Sept. 2020
Es gibt keine Pläne für einen Abschluss, aber es gibt eine PR, die für 1.20 im Zusammenhang mit dieser Verbesserung verfolgt werden sollte:
https://github.com/kubernetes/kubernetes/pull/92967
klueska
am 16. Sept. 2020
Auch wenn die Version 1.20 noch nicht abgeschlossen ist, verlinken Sie bitte weiterhin verwandte PRs zu dieser Ausgabe, wie Sie es gerade getan haben.
kikisdeliveryservice
am 16. Sept. 2020
@kikisdeliveryservice können Sie bitte helfen, den Prozess zu verstehen. Die Funktion Topology Manager wird in 1.20 nicht abgeschlossen, aber die neue Funktion wird hinzugefügt und wird jetzt bearbeitet: https://github.com/kubernetes/enhancements/pull/1752 k/k: https://github. com/kubernetes/kubernetes/pull/92967. Müssen wir das mit dem Release-Team verfolgen? Es kann das Nachverfolgen des Docs-Updates für 1.20 oder vielleicht etwas anderes, das nachverfolgt wird, vereinfachen.
Die Änderung ist additiv, daher gibt es nicht viel Grund, sie Beta2 oder so zu nennen.
Zugehörige Bump-PR, die die Realität widerspiegelt, dass die zusätzliche Funktion in 1.19 nicht ausgeliefert wurde: https://github.com/kubernetes/enhancements/pull/1950
 SergeyKanzhelev
am 27. Okt. 2020
SergeyKanzhelev
am 27. Okt. 2020
Topology Manager-Webdokumentation aktualisiert PR, um die Scope-Funktion aufzunehmen: https://github.com/kubernetes/website/pull/24781
 k-wiatrzyk
am 29. Okt. 2020
k-wiatrzyk
am 29. Okt. 2020
Ich glaube, es kann mit 1,20 nachverfolgt werden und muss nicht unbedingt abgeschlossen werden. @kikisdeliveryservice bitte
annajung
am 29. Okt. 2020
Hallo @SergeyKanzhelev
Wenn man sich die Historie ansieht, ist dies tatsächlich nicht der Fall. Mir wurde gesagt, dass dies kein Abschluss wäre, was in Ordnung ist und warum dieser KEP nicht verfolgt wird. Diese Erweiterung (ohne Wissen des Erweiterungsteams) wurde jedoch kürzlich von @k-wiatrzyk für 1.20 als Beta (https://github.com/kubernetes/enhancements/pull/1950) neu aufgelegt.
Wenn Sie den Release-Prozess nutzen möchten: Verbesserungsverfolgung, Teil des Release-Meilensteins und Dokumentationsteam, das dies verfolgt / Dokumente in der Version 1.20 enthalten, sollte so schnell wie möglich eine Ausnahmeanforderung für eine Verbesserung eingereicht werden.
kikisdeliveryservice
am 30. Okt. 2020
Das Feature wurde bereits in das (vorhandene) KEP (vor Ablauf der Erweiterungsfrist) eingebunden.
https://github.com/kubernetes/enhancements/pull/1752
Bei der Umsetzung ist PR bereits Teil des Meilensteins.
https://github.com/kubernetes/kubernetes/pull/92967
Mir war nicht bewusst, dass es noch mehr zu tun gibt.
Bei wem müssen wir eine Ausnahme beantragen und wofür genau?
klueska
am 30. Okt. 2020
Hallo @klueska, die Pr, auf die Sie verweisen, wurde im Juni zusammengeführt, um Beta in das Kep in 1.19 hinzuzufügen: https://github.com/bg-chun/enhancements/blob/f3df83cc997ff49bfbb59414545c3e4002796f19/keps/sig-node/0035-20190130-topology -manager.md#beta -v119
Die Frist für die Erweiterungen für 1.20 war der 6. Oktober, aber die Änderung, das Verschieben der Beta auf 1.20 und das Entfernen des Verweises auf 1.19 wurde vor 3 Tagen über https://github.com/kubernetes/enhancements/pull/1950 zusammengeführt
Anweisungen zum Senden einer Ausnahmeanforderung finden Sie hier: https://github.com/kubernetes/sig-release/blob/master/releases/EXCEPTIONS.md
kikisdeliveryservice
am 30. Okt. 2020
Tut mir leid, ich bin immer noch verwirrt, wofür wir eine Ausnahme beantragen werden.
Ich mache das gerne, ich bin mir nur nicht sicher, was ich darin aufnehmen soll.
Das Feature "Node Topology Manager" wurde bereits in 1.18 auf Beta abgestuft.
Es graduiert nicht auf GA in 1.20 (es bleibt in der Beta).
Der für 1.20 zusammengeführte PR (dh kubernetes/kubernetes#92967) ist eine Verbesserung des bestehenden Codes für den Topologie-Manager, hat jedoch keinen Bezug zu einem "Bump" in Bezug auf seinen Status als Alpha/Beta/ga usw.
klueska
am 30. Okt. 2020
Ich habe eine Call of Exception-Mail gesendet, da die Frist heute ist (nur für den Fall): https://groups.google.com/g/kubernetes-sig-node/c/lsy0fO6cBUY/m/_ujNkQtCCQAJ
k-wiatrzyk
am 2. Nov. 2020
@kikisdeliveryservice @klueska @annajung
Der Call for Exception wurde genehmigt, die Bestätigung finden Sie hier: https://groups.google.com/g/kubernetes-sig-release/c/otE2ymBKeMA/m/ML_HMQO7BwAJ
k-wiatrzyk
am 4. Nov. 2020
Danke @k-wiatrzyk & @klueska Das Tracking-Sheet wurde aktualisiert.
cc: @annajung
kikisdeliveryservice
am 5. Nov. 2020
Hey @k-wiatrzyk @klueska
Anscheinend ist kubernetes/kubernetes#92967 genehmigt, benötigt aber ein Rebase.
Nur zur Erinnerung, dass Code Freeze in 2 Tagen am Donnerstag, den 12. November erscheint . Alle PRs müssen bis zu diesem Datum zusammengeführt werden, andernfalls ist eine Ausnahme erforderlich.
Am besten,
Kirsten
kikisdeliveryservice
am 11. Nov. 2020
Die PR zusammengeführt, Aktualisierungsblatt - yay! :smile_cat:
kikisdeliveryservice
am 12. Nov. 2020
Verwandte Themen
 saschagrunert
·
6Kommentare
saschagrunert
·
6Kommentare
 liggitt
·
7Kommentare
liggitt
·
7Kommentare
 majgis
·
5Kommentare
majgis
·
5Kommentare
 euank
·
13Kommentare
euank
·
13Kommentare
 wojtek-t
·
12Kommentare
wojtek-t
·
12Kommentare
Hilfreichster Kommentar
Alle PRs für diesen Bestand scheinen zusammengeführt (und bis zum Stichtag genehmigt) zu sein. Ich habe unser Tracking-Sheet für Verbesserungen aktualisiert. :Lächeln: