这是对有权编辑特殊页面的人的请求,以便将这个从时间开始到 2016 年 11 月的标签可视化添加到 publiclab.org/tags 的顶部
https://www.dropbox.com/s/s78g3ufhsav5xzo/plots_tag_graph_256_filtered.png?dl=0
抄送:
@gretchengehrke
@巧妙地卷曲
 ebarry
ebarry
所有73条评论
嗨,Liz - 我有点不愿意在我们的永久代码库中放置这样的静态图形,但也许建议我们在该页面的顶部显示一个“功能”(如我们的横幅),然后是管理员可以在那里展示他们想要的任何东西。 那行得通吗?
 jywarren
于 2017-07-05
jywarren
于 2017-07-05
它会高于或低于这一行: https :
看起来像:
<% cache('feature_tag-page-header') do %>
<%= feature('tag-page-header') %>
<% end %>
嗯,我不想装饰那个页面,因为我想添加“一目了然的洞察力”。
一个不同的观点,但可能与我为什么建议添加图形可视化有关的是,这个标签页仍然没有任何排序功能来查看“最近”或“流行”,更不用说按地理位置查看其中任何一个。
ebarry
于 2017-07-05
实际上,我们可以使用 python gephi 绑定来动态生成它。 我现在实际上正在研究 javascript 网络可视化,所以让我看看它是如何工作的。 如果一切顺利,那么我可以将我所做的翻译成一个 python 脚本,该脚本可以生成数据结构,然后在 javascript 中进行可视化。
 skilfullycurled
于 2017-07-05
skilfullycurled
于 2017-07-05
大家好 - 我认为生成的图形会很棒,并且我们可以将其放入永久代码中。
@ebarry我不是说这是装饰而不是内容,我更多的是说这会很快过时,而且我们的目标是将 /no/ 内容存储在我们的代码库中——只有基础设施。 所以这只是实现它的一种方式——我提出的解决方案听起来好吗?
重新this tag page still doesn't have any sorting capabilities to see "recent" or "popular" much less to see either of those by geography.如果这是您的优先事项,我很乐意与您合作提出一些功能请求,让贡献者构建来解决这个问题。 如果您能帮助将它们加入队列,那么可能是一些简单的first-timers-only问题!
jywarren
于 2017-07-05
让我们回到这个问题的基础:)
可视化标签的目标是什么?
对我来说,可视化标签是一种可视化描述相关标签的方式,例如在同一内容上一起出现的标签。 例如,请参阅上面@skillfullycurled可视化中的颜色编码集群。 聚类标签很重要,因为它们在视觉上将网站对社区活动的呈现_这是我在整个问题中的实际目标。
以下是一些背景信息:在我们的标签页面 (https://publiclab.org/tags) 上,我们写了“我们使用标签按主题对研究进行分组”并鼓励人们浏览标签(目前仅按最近的活动排序)。 这是我们命名、链接和/或促进人们查找和参与主题的重要方式。 仪表板本身强调最近的活动。 仪表板现在具有“最近使用的标签”栏——这是实现“研究领域”或“主题”目标的重要但部分步骤。
继续前进,我对通过图形标签可视化进行 _navigating_ 不感兴趣(所以 2007 年!),但是,活动集群提供了连接/导航到主题的重要附加方式。 为了实现这个目标,我的意思是标签页面能够显示哪些是最相互关联的标签,传达研究领域中相关主题的广度,导航/连接到研究领域,以及适当地订阅我们不一定需要颜色编码的俯冲箭头。 让我们想想如何实现这些目标。
我们也可能考虑在 publiclab.org/topics 上镜像 publiclab.org/tags 以使该语言更易于访问。
ebarry
于 2017-11-15
酷,谢谢lz!
为了尝试针对此目标尝试更窄的功能,如果标记页面(浮动新名称:主题页面......!?!)有一个“相关主题”列表,例如:
相关主题:
waterrunoffwetlandsturbidity
其中“相关”意味着(承认有不同的方法来衡量这一点,并且我们想要一些“计算高效”的方法)这些是最常出现在已经具有主标签的页面上的标签。 因此,对于主题onions ,我们对标有onions每个页面进行计数,并取顶部,例如,五个。
如果上述内容听起来不错,请进行小的跟进——是否可以仅针对最近的 20-30 页执行此操作? 即使这只是一个起点,这也会使这更容易实施,而不必担心它会导致整体网站变慢。 可能有更复杂的方法来解决这个问题,但这是最简单的入门方法。
jywarren
于 2017-11-16
我在https://publiclab.org/questions/tommystyles/10-20-2017/need-your-feedback-on-tag-pages 上交叉发布——你如何看待将讨论转移到那里直到有特定的离散我们可以制作编码步骤(代码贡献者的迷你项目)?
jywarren
于 2017-11-16
太好了! 让我们继续讨论,然后再回来
可行的步骤。
——
+1 336-269-1539 / @lizbarry http://twitter.com/lizbarry / lizbarry.net
2017 年 11 月 15 日星期三晚上 9:54,Jeffrey Warren通知@github.com
写道:
我在https://publiclab.org/questions/tommystyles/10-20-交叉发布
2017/need-your-feedback-on-tag-pages -- 你怎么看搬家
在那里讨论直到有特定的离散编码步骤(迷你
代码贡献者的项目)我们可以做?—
你收到这个是因为你被提到了。
直接回复本邮件,在GitHub上查看
https://github.com/publiclab/plots2/issues/1502#issuecomment-344799932 ,
或静音线程
https://github.com/notifications/unsubscribe-auth/AAJ2n8PdvpH0GQ_wBU-Utp4xfL7XDmuJks5s26PpgaJpZM4OOvLP
.
ebarry
于 2017-11-16
@jywarren , @ebarry ,是否有任何 API(或文档)可以了解上图中的“边缘”? 我的意思是节点是如何连接的?
谢谢😄!
 sagarpreet-chadha
于 2018-01-23
sagarpreet-chadha
于 2018-01-23
嘿@sagarpreet-chadha!
可视化只是一个图像,所以没有 API(还没有!眨眼)但是我可以为您提供来自该特定图形的边列表。 最“原始”的文件格式是 csv 和 json。 两种格式都应该“以编程方式”( iGraph 、 networkx 、 d3.js )或 GUI( Gephi 、 Cytoscape )使用图形。
显然你不能在github上上传文件。 我试图将它们上传到公共实验室研究笔记,但它不起作用。 @jywarren有没有办法将文件上传到研究笔记? 如果没有,@sagarpreet-chadha,你能在plots-dev googlegroup 发帖吗(如果你还没有注册,可以在这里注册)? 让我们拭目以待,看看@jywarren 怎么说,因为将它们直接放在研究笔记中会很棒。
不过,您可以期待以下内容:
plots_tag_communities_edges_w_props_9_16.csv::具有计算属性的唯一边列表,特别是边的权重。 权重转化为标签一起出现的次数。
plots_tag_communities_nodes_w_props_9_16.csv:具有计算属性的节点列表。 与网站上的图像最相关的是“模块化类”,它告诉您每个节点属于哪个社区。
plots_tag_communities_9_16.json:我不认为 json 有用,但我知道有些人更喜欢它。 我认为 json 文件还包括网站上可视化的属性(即每个节点的 RGB 颜色)。
skilfullycurled
于 2018-01-23
更新:从上面的文件列表中删除了 plots_tag_communities_edgelist_9_16.csv。 此文件的用途有限,因为重复的边已合并为具有权重的唯一边。 如果没有这些属性,此边列表将只允许您构建边权重为 1 的图形。我将查找包含重复项的原始文件。
skilfullycurled
于 2018-01-24
谢谢@skillfullycurled的回复!
我实际上是在尝试使用 javascript 库(d3.js 或vis.js )构建可视化图,以便可以轻松地将其添加到 publiclab.org 网站。 这些库需要以下形式的数据:
nodes: [
{
id: 1,
shape: 'circle',
label: 'Infrared } ]用于节点。
对于边缘:
edges: [
{from: 1, to: 2},
{from: 1, to: 3}]
那么 json 会很棒,否则我可以创建它,或者直接创建一个 Javascript 对象(这样就不需要解析 JSON 文件)。
我创建了一个虚拟图(我们可以在这里玩节点和边😄):
你怎么认为 ? @ebarry 、 @jywarren 、 @skillfullycurled
sagarpreet-chadha
于 2018-01-24
啊。 那将是真棒! 好的。 为了进一步讨论这个话题,我们需要离开“API 领域”,进入 Gephi 中的可视化如何工作以及将这些功能转换为 javascript 的最佳方式。
我能麻烦你开始这个问题吗? 类似于,“如何将 Gephi 中创建的标签可视化转换为 javascript 版本?”
另外,请在 benj 给我发一封电子邮件。 [email protected]以便我可以共享文件。 一旦你这样做,我会删除我的电子邮件。
skilfullycurled
于 2018-01-24
实际上,我认为我们可能不需要离开 API 领域——这些天现有的 API 非常强大。 我很好奇@skillfullycurled你是如何生成这些边缘的——
它们可以从所有标签和它们使用过的节点的列表中重新生成吗? 如果缓存,这是我们生成的合理查询。
我们可以将它添加到https://github.com/publiclab/plots2/tree/master/app/api/srch的 API 中,并将其记录在https://github.com/publiclab/plots2/blob/master/doc /API.md
如果有足够的数据,查询可能是这样的:
r = []
Tag.select(:name, :tid).each do |t|
nids = t.nodes.select(:nid, :status).where(status: 1).collect(&:nid)
r << [t.name, nids] if nids.length > 0
end
r # later, r.to_json
我只是在生产中运行它,大约花了 15 秒。 如果我们每天缓存它,我认为它是可以管理的,我们可能能够进一步改进它。
jywarren
于 2018-01-25
您也可以在http://gist.github.com 上共享文件——这可行吗?
jywarren
于 2018-01-25
因此,使用从我的查询生成的 JSON,
- 在 JavaScript 中,我们可以计算标签一起出现的次数。
- 你是如何分组/计算“社区”的?
这是摘录:
["whitebalance", [12476, 13575]], ["wi", [12143, 13067]], ["wi-fi", [11123]], ["width-of-dvd-grating", [12838, 12875, 12895, 12899, 12902, 12926, 12990, 12991, 12995, 12999, 13006, 13014, 13019, 13037, 13046, 13057, 13062, 13069, 13077, 13088, 13089, 13094, 13103, 13117, 13125, 13131, 13133, 13136, 13152, 13154, 13157, 13159, 13169, 13178, 13181, 13183, 13188, 13226, 13248, 13283, 13302, 13305, 13308, 13315, 13316, 13340, 13349, 13355, 13366, 13401, 13402, 13409, 13414, 13423, 13429, 13432, 13434, 13437, 13439, 13440, 13443]], ["wiki", [9048, 10956]], ["wiki-gardening", [10956]], ["wild", [11707, 11711]], ["wildfires", [14803]], ["wildlife", [670]], ["wilkinson-bay", [220, 265, 280, 281, 282, 283, 284, 677]], ["wilkinsonbay", [606]], ["williamsburg", [10343, 10428, 10444]], ["willow", [9979]], ["wind", [9032, 10660, 12610, 13880, 14487, 14527, 14530, 14531, 14713, 14756]], ["wind-direction", [14527]], ["wind-sensor", [14713]], ["wind-speed-meter", [1962, 5837, 9032, 12103, 13064, 13165, 13231, 13880, 14527]], ["winder", [7717]], ["winders", [1900]], ["window", [147, 1759]], ["windows", [11434, 11677, 13037]], ["windows-7", [13037]], ["windows-7-ultimate", [13037]], ["windows-excel", [13037]], ["windspeed", [745]], ["windvane", [14527]], ["windy", [146]], ["wine", [706, 10955]], ["winter", [5161]], ["wintercamp", [5103]], ["wired", [10315]], ["wireframes", [10623]], ["wireless", [3908, 9940, 11123, 12175]], ["wisconsin", [10504, 10552, 10611, 10619, 11331, 11783, 12142, 12143, 12192, 12221, 12337, 12537, 12539, 12562, 12597, 12610, 12919, 13067, 13216, 13217, 13219, 13222, 13223, 13224, 13406, 13578, 13920, 13921, 13922, 14018, 14044, 14087, 14146, 14648]], ["with", [11772, 13742, 14728]], ["with:abdul", [13407, 13412, 13413, 13428, 13493]], ["with:adam-griffith", [11049]], ["with:amal", [12161]], ["with:amandaf", [11556]], ["with:amberwise", [12338, 13280]], ["with:ann", [12850]], ["with:basurama", [11699, 11705]], ["with:becki", [13571]], ["with:bronwen", [10952, 12480, 13493, 14587]], ["with:bsugar", [13449]], ["with:btbonval", [11789]], ["with:cfastie", [11688, 13493, 13980]], ["with:chrisjob", [10464]], ["with:cindy_excites", [11566, 11567, 14537]], ["with:damarquis", [12338]], ["with:danbeavers", [11417, 11567]],
FWIW 可能有一些更有效的查询,但这是相当不错的,虽然没有完全返回上面的内容:
Tag.select('term_data.tid, term_data.name, community_tags.nid, community_tags.tid')
.includes(:node_tag)
.references(:node_tag)
尽管这不会告诉我们节点是否已发布(与垃圾邮件相比),除非我们还在其中混合了node.status 。 但这是可能的!
jywarren
于 2018-01-25
嗨,我在这里只有几个问题,
1.) 如果 2 个标签属于同一个节点,它们之间有一条边吗?
2.) 不同的颜色代表不同类型的节点,如问题、笔记、研究笔记等。 ?
谢谢😄!
sagarpreet-chadha
于 2018-01-25
而且我也同意不离开 API -land :)
sagarpreet-chadha
于 2018-01-25
啊! 好的。 我们不要堆积,拜托。 没有人比我更想留在 API 领域(好吧,也许@ebarry 除外)。 据我了解,由于担心网站缓慢,API-land 的构建几乎被无限期推迟(请参阅此处的对话扩展)。 但现在@jywarren说这不再是什么大不了的事了,所以这方面的美好时光。
由于使用 Github 可能成为获取信息的障碍(不是每个人都可以访问,知道如何使用),我认为(呃……思想)在代码库中进行与“完成工作”无关的对话更好地降级为每个人都可以向他们学习的网站。 这些不是我设定的社区规范(请参阅上面@jywarren自己的评论),但我确实认为它们是好的。
skilfullycurled
于 2018-01-25
哎呀,对不起@skilfullycurled我没有记住该线程的最后一个注释- https://publiclab.org/questions/tommystyles/10-20-2017/need-your-feedback-on-tag-pages#answer - 556-comment-17709 - 您建议的地方:
- 只在前 250 个标签上运行
- 每周缓存
我会回到那里,但我认为通过 API、代码清理和外展的所有工作,我们可以每天或每周执行一次此类查询的缓存版本,并且总计算时间为 10-15 秒每周一次。 其余的将在浏览器中本地运行。 在那边重复这个。
jywarren
于 2018-01-25
@jywarren我需要就您的一些问题回复您。 稍后我会发布我的 jupyter notebook。 同时,请参阅此处简要说明如何从标签对创建图形。 有关确切代码,请参见此处。
@sagarpreet-chadha(以及其他任何感兴趣的人)您可以通过查看tagoverflow的 repo 来了解如何从标记数据创建 d3.js 图,这是该项目的灵感来源。
关于社区检测,如果您查看 tagoverflow 存储库,您会发现作者实现了他们自己的算法。 从那时起,其他人已经实现,例如jLouvain , netClustering一个 CNM 实现( d3 示例)。 由于 256 个标签的限制,他们的社区检测在浏览器中可能很好。
skilfullycurled
于 2018-01-25
为了不让大量数据淹没 publiclab.org 的讨论,这里有一个指向 TagOverflow 使用的数据格式的链接:
https://api.stackexchange.com/2.1/tags/python/related/?site=stackoverflow&key=of3hmyFapahonChi8EED6g ((&pagesize=16
它进行了 15 次调用以获取与给定标签相关的标签(在上面的示例中,“python”)
jywarren
于 2018-01-25
所以它与我上面生成的数据之间的区别在于我的查询列出了节点 ID,但没有使用它们来建立“相关性”。 但当然@skillfullycurled的 Jupyter 笔记本可以做到这一点! 酷,谢谢分享!
jywarren
于 2018-01-25
@sagarpreet-chadha,我发布了一个问题,在上面提出并回答了您的问题:
https://publiclab.org/questions/bsugar/01-25-2018/how-was-the-tag-graph-visualization-made
我并不是要对我的请求采取“被动攻击”的态度,但我认为人们可以从公开对话的这一方面中受益。 所以我想这使它成为“积极进取”。 ; )
开个玩笑,很高兴回答任何问题!
skilfullycurled
于 2018-01-25
嘿大家!
@sagarpreet-chadha,我把你需要的所有文件都放在这里:
https://spideroak.com/browse/share/skillfullyshared/plots-tag-graph
该文件夹附带一个解释内容的自述文件。
当您下载它们时请告诉我,以便我可以关闭共享室。 最后,我会将它们发布到我的 github 帐户,供其他人在 wiki 上访问。
很高兴回答您可能有的任何其他问题!
skilfullycurled
于 2018-02-01
谢谢@skillfullycurled !
我已经下载了文件:-)
sagarpreet-chadha
于 2018-02-02
没问题@sagarpreet-chadha!
PS:我在维基问题中给你留下了一个后续的想法。
skilfullycurled
于 2018-02-02
关于基于 ruby 的标签相关性计算的重大更新: https :
很快!
jywarren
于 2019-01-17
https://github.com/publiclab/plots2/pull/4657 中的一些进展,在那里我实现了一个非常基本但实时的 Cytoscape.js (http://js.cytoscape.org/) 实例,运行了每周缓存的集合
为站点上的所有标签运行花费了 50 多秒(可以每周缓存一次),但这也生成了 8200 多个标签和 31k 条边......这是很多图表。 这是全套; 我认为它包含大量垃圾邮件标签: https :
您可以指定要查询的标签数量,如下所示: https :
目前每个标记名限制为 5 个“边”,代表最常出现在原始标记旁边的 5 个标记。
这现在在稳定的测试服务器上运行(尽管这个分支经常重建,所以 URL 并不总是在线......具有讽刺意味的是)在这里:
https://stable.publiclab.org/stats/graph?limit=75
较大的计数,如 limit=100 或 250 似乎显示出某种错误,我必须稍微追一下。 但这是一个很好的开始。
有很多配置可以添加来优化它——节点大小、链接强度等等——查看http://js.cytoscape.org 上的画廊了解一些可能性。 制作“家庭”也可能是可能的,尽管我需要更多的投入。
jywarren
于 2019-01-18

jywarren
于 2019-01-18
jywarren
于 2019-01-19
@jywarren ,超级酷!!!
sagarpreet-chadha
于 2019-01-19
还有一系列聚类算法 - 这些可以在 JavaScript 控制台中测试:
http://js.cytoscape.org/#collection/clustering
- eles.markovClustering()
- 节点.kMeans()
- 节点.kMedoids()
- node.fuzzyCMeans()
- nodes.hierarchicalClustering()
- node.affinityPropagation()
我不熟悉这些,但它们似乎都使用节点或边的属性来创建相似元素的集群。 那么,我们应该给出什么作为相似性基础的属性?
您可以使用文档中的示例在控制台中尝试这些,例如:
var clusters = cy.elements().hca({
mode: 'threshold',
threshold: 5,
attributes: [
function( node ){ return node.data('count'); }
]
});
clusters; // <= then inspect what this returns to see the clusters
好的,使用jlouvain我能够添加社区检测: https :
我没有足够的测试数据来查看这将如何工作,但如果 #4679 通过,我将合并它,我们应该能够在以下位置看到它与社区检测一起运行:
https://stable.publiclab.org/stats/graph?limit=101
(一旦建立)
jywarren
于 2019-01-21
嘿大家! 看起来很赞。 抱歉,我一直无法回复,赶上一些事情,今天晚些时候再回来。
与此同时,我认为我在其他任何帖子中都没有提到的另一个要素是布局。 最接近我使用的可能是force layout 。 从技术上讲,它可能是一种叫做力布局 2 的东西:
力布局是一种退火吸引/排斥,它根据您设置的参数(即迭代次数、吸引/排斥强度)达到稳定状态。 这是一个d3 演示。
至于社区检测和边缘权重,您有几个选择,但是如果您想重新创建参考的标签图,那么您需要共现哪个 cytoscape,正如财富所拥有的那样,具有帮助制作的功能更轻松。
oe_ratio = (all_questions_count * tag_count_AB) / (tag_count_A * tag_count_B)
其中 tag_count_AB = edge.parallelEdges()
照原样,我首先将标签集缩小到某个合理的数字(例如,前 512 个),但随后我通过仅包含前 n 个标签(可能是 64 个?)预期比率高于 1。
您可以从标签溢出中阅读更多内容。 此方法是解决边缘或节点节点可能很重要但使用率低的问题的一种方法。 例如,在一家商店,100 人_可能_有 85% 的概率购买咖啡和奶油,但其中 5 人_总是_购买咖啡、奶油和鸡蛋。 所以我绝对想保留 5 箱鸡蛋的库存。
一个简单的替代方法是将两个节点之间的边权重设为 tag_count_AB,并且只取给定阈值以上的边/节点。 就我个人而言,由于上述原因,我很少得到好的结果。
关于其他方法,您可能对 pg 3. (2.2) to - pg 感兴趣。 7此的(3.1)纸(无数学对这些部件),其尝试不同类型的社区检测方法分类。 考虑到我如何构建图表以及我想从中了解什么,这帮助我选择了能够提供最显着结果的结果。 例如,具有共同社会关系的社区与基于两个人之间发送消息的频率的社区。
skilfullycurled
于 2019-01-21
现在在稳定的服务器上工作!
jywarren
于 2019-01-25

这里有 99 个顶级标签!
jywarren
于 2019-01-25
它应该会在今晚晚些时候在实时网站上运行,但我想指出,一些用户“过度使用”标签已经以我们之前认识到的方式扭曲了图表。 我相信其中一位用户已经从该站点中进行了审核,我想知道人们是否认为从站点中删除这些标签或至少从图表中省略它们是否合适。 删除它们会更容易,但我们也可以制作一些东西来掩盖它们。 偏好, @ ebarry @skillfullycurled ?
尽管如此,即使边缘弹性的设置仍然需要一些调整,这看起来还是不错的,也许不同的布局类型会更好......

jywarren
于 2019-01-25
是的! 我们肯定遇到过这个问题。 不幸的是,唯一要做的就是删除该特定用户作为异常值。 使用这么多标签的人本身可能并不是一个异常值,但如果他们正在创建对自己如此特定的标签并一遍又一遍地使用它们,那么它并没有真正捕获数据。
skilfullycurled
于 2019-01-25
我想我什至记录了一个带有功能请求的 github 问题,该问题弹出一个警告,本质上说,“哇,好家伙!看起来你自己有很多标签,嗯?”。
skilfullycurled
于 2019-01-25
哦,PS。 顺便说一句看起来棒极了!!
skilfullycurled
于 2019-01-25
AAAAAAHHHHHHHMAYZINGGGGGGGGGG!!!!!!!!!!!!
是手动“删除[ing]该特定用户作为异常值”
ebarry
于 2019-01-26
我只是不断地回到这个线程,因为它是多么棒,并且思考事情(希望很小)。 您可能会考虑过滤的另一件事是电源标签(那些是带有冒号的标签,对吗?)。 我认为一旦标签过度使用问题得到纠正,我们就会对布局有更多的了解。
自我注意:这是一个提交的链接,其中包含对实现很重要的页面。
skilfullycurled
于 2019-01-26
大家好,很高兴有这样的热情! 我生病了,但现在正在康复,将在周二回家的航班上解决这个问题。
我确实想问 - 我的具体问题是我们是否应该:
- 实际删除此受监管用户的标签,或
- 如果我们应该尝试保留它们但将它们过滤掉。
过滤对于编码和数据库调用来说都将是相当多的工作,但这是可能的。
jywarren
于 2019-01-27
在这种情况下,由于节制而使帐户“处于非活动状态”,那么我认为直接从数据库中删除标签就可以了。 特别是如果你有备份。 不是因为您可能想要恢复它,只是因为我担心永远丢失数据。 这并不健康,但廉价的空间是一个不幸的推动因素。 如果这是一个被选择“不活动”的帐户,我的感觉会更复杂,但我们可以在下次(或现在)讨论这个问题。
skilfullycurled
于 2019-01-27
是的,这是一个值得思考的大话题。 在查看是否有 _only_ 该用户使用过的标签(例如: aries city-point )后,我发现实际上很少有标签完全独立于该用户(甚至purelab最初是山河关于DIY滤水用的, research-notes最初是用在网站上讨论研究笔记设计的帖子上)。
既然这个用户是经过审核的,我们的标签可视化是否可以排除所有来自经过审核的用户的内容——以及扩展用于该人内容的标签——而不排除该标签,因为它可能会用于其他人的内容?
ebarry
于 2019-01-28
@ebarry ,我应该澄清一下(如果不是的话)。
当我说:
彻底从数据库中删除标签
我的意思是你关闭的内容:
...[那] 我们的标签可视化 [将] 排除来自受审核用户的所有内容——以及扩展用于该人内容的标签——通常不排除该标签[因为]它可能会用于其他人的内容。 ..
如果审核用户和何单都使用了标签“purelab”,则不会删除“purelab”,只会删除来自审核用户或 ITMU 的标签的任何实例,如果您愿意的话。
剩下的问题(如果我理解 @jywarren)是是否要从数据库中完全删除这些 ITMU,或者我们是否将它们保留在数据库中但在可视化请求所有标签时过滤掉 ITMU。 删除它们使那些实施可视化的人的生活变得更加轻松,但可能存在保留它们的论据。
就个人而言,我认为当用户经过审核后,前者是可以的,因为内容永远不会返回到网站。 但是,如果用户根据是否有任何可以重新激活帐户的功能选择删除其帐户,则情况可能会有所不同。 我认为我们可以将这种情况再搁置一段时间,但为了记录起见,我只想说我的司法意见范围有限。
skilfullycurled
于 2019-01-28
是的不用担心NodeTags不删除标签,只是链接关联
带有节点和作者的标签。 我实际上已经做到了,但需要冲洗
每周缓存(这就是让这一切成为可能的原因),还有
今天刚出现的几个更紧急的错误需要首先解决,抱歉!
2019 年 1 月 28 日星期一下午 3:24 巧妙卷曲 < [email protected]
写道:
@ebarry https://github.com/ebarry ,我应该澄清一下(如果不是)。
当我说:
彻底从数据库中删除标签
我的意思是你关闭的内容:
...[那] 我们的标签可视化 [将] 从审核中排除所有内容
用户 - 以及扩展用于该人内容的标签 - 没有
一般排除该标签[因为]它可能会用于其他人的
内容...如果审核用户和单和都使用了标签“purelab”,“purelab”
不会被删除,只会删除来自受监管用户的标签的任何实例
或者,ITMU,如果你愿意的话。剩下的问题(如果我理解@jywarren
https://github.com/jywarren ) 是要不要删除这些 ITMU
完全来自数据库,还是我们将它们保留在数据库中但过滤
当所有标签都被请求用于可视化时,ITMU 将退出。删除它们使那些实施
可视化,但可能有理由保留它们。—
你收到这个是因为你被提到了。
直接回复本邮件,在GitHub上查看
https://github.com/publiclab/plots2/issues/1502#issuecomment-458244753 ,
或静音线程
https://github.com/notifications/unsubscribe-auth/AABfJzTXlk18FzlER4PQyoomFE5VTFcrks5vH0AqgaJpZM4OOvLP
.
jywarren
于 2019-01-28
好的,已成功删除由受监管用户创建的所有标签。 它们存储在备份中。 与其他解决方案不同,这非常容易并且不会影响代码的前进。
现在我想建议我们可能想要使用不同的布局——我们使用的是cose布局,并且有变化( bilkent和其他),但也有一个cola布局。 我真的不知道在这里使用哪个合适,但有些似乎更少纠缠链接。 尽管http://js.cytoscape.org/ 上的许多演示比我们的数据集具有更少的互连。 任何输入表示赞赏!
有关内置布局的文档,请访问http://js.cytoscape.org/#layouts
我们可以尝试请人测试和处理的另一个问题是社区检测问题。 我一直无法弄清楚它是如何工作的,或者为什么它不能在这里识别组。 颜色很好,但它们是每个社区的一个节点。 呸。
jywarren
于 2019-01-28
所以这个问题现在需要分解为:
- 布局迭代(欢迎来自当前人群的输入)
- 社区检测
- 额外的标签过滤(也许过滤掉没有未经批准的节点的标签来摆脱垃圾邮件?)
还想回顾一下我们现在正在查看指定数量的标签(请不要测试它的限制,除非它在 https://stable.publiclab.org 上——我已经尝试了多达 1000 个标签并且它加载了很好,但仅此而已,请在生产服务器上,甚至一次)
我们仅限于它们之间的链接,每个标签最多报告 10 个与它一起出现的标签。 这并不全面,但似乎是优化与彻底性的可行平衡。
jywarren
于 2019-01-28
jywarren
于 2019-01-28
@jywarren ,这还是最新的提交吗? 我因为我想看到来自端点/tag/graph.json的 json 并且它向我发送了所有标签。 根据该提交中的代码,我预计 250 将是硬限制(我的 Ruby 可读性说明)。
skilfullycurled
于 2019-01-31
@jywarren没关系,我没有意识到图表现在在生产服务器中,我使用的是 stable.publiclab.org。
skilfullycurled
于 2019-01-31
好的。 我只是花了相当多的时间来探索这一点,并且对图表的工作方式有了更好的了解。
现在我想建议我们可能想要使用不同的布局——我们正在使用一个 cos
我会看看并考虑一下。 我认为这里需要回答的问题是我们想从图中收集什么? 例如,如果我们主要对访问者能够看到哪些标签与哪些标签相关联感兴趣,那么圆形布局或同心圆可能是最好的,尽管它们可能很无聊。
如果我不得不猜测(知情,但仍然是猜测)为什么 CoSE 没有产生那么好的结果,那将是因为在查看数据时,当您达到某个节点数时,计数开始都是相似的。 因此,如果 CoSE 仅根据节点权重排斥节点,那么它们之间可能存在等量的排斥。 当我在这里使用排斥时,我指的是所有进入排斥的事物,例如,它也是重力设置。 在这种情况下,可能是算法的迭代次数不足,或者排斥因子不会导致/允许足够的传播。
我们可以尝试请人测试和处理的另一个问题是社区检测问题。
当你有时间时,你能指点我用最新的 JavaScript 提交吗? 我可以通过浏览器获取它,但只能以没有任何结构且只有一行的形式获取。 只要我这样做,我就能看到更多。 我查看了 jLouvain 示例,它似乎没有设置您想要的社区数量,这可能是问题的一部分。 通常,Louvain 会提供“最佳数字”,但有时也不是最佳数字。 jLouvain 基于的python 实现确实有这个参数,但它可能没有完成。
skilfullycurled
于 2019-01-31
我们在那里:
jywarren
于 2019-02-01

jywarren
于 2019-02-01
哦,我还以为我留下了另一条评论……它去哪儿了? 不挂断...
jywarren
于 2019-02-01
无论如何,我想说我想我已经弄清楚了一些布局问题,但请自行判断:
https://publiclab.org/stats/graph?limit=50
https://publiclab.org/stats/graph?limit=100
jywarren
于 2019-02-01
这是社区检测的JS: https :
这是布局配置,我们可以对其进行大量调整以进行尝试:
jywarren
于 2019-02-01
首先,我想道歉,我无法帮助解决编码端的繁重工作。 仅仅提出建议很容易,但我意识到它们也必须由人们实施,我并没有忘记我在这方面没有提供帮助。
jLouvain 表现不佳的原因有多种可能。 @jywarren ,我认为您已经在解决其中一个问题,那就是颜色不够。 尽管如此,我还是在控制台中查看了社区,每个节点都是一个不同的社区,这对我来说意味着算法没有找到一个好的停下来的地方。 通常,有一个参数来说明您想要拥有多少社区/敏感度/分辨率,然后您可以使用它,直到获得看起来正确的东西。
在 jLouvain 存储库中查看此问题。 有人写了一个可以实现的非常简单的修复程序。 我不太确定它在返回什么方面是如何工作的:理想情况下,它为数组中的每个元素返回整个社区检测结果? 那太棒了,可能会解决每个节点都是自己社区的问题。
稍后更多…
skilfullycurled
于 2019-02-01
转达@shapironick 的一个问题,他在另一个频道中想知道在未来的版本中,连接线是否可能会有不同的细度和
ebarry
于 2019-02-06
好主意啊。 我认为此时我们需要关闭它并打开一个
新问题,包括可能对显示进行改进的清单,以及
对于新人来说会容易得多(需要更少的背景和历史
参与)进来并开始实施它们。 我几乎想
将它分拆到一个新的存储库中,该存储库就是/只是这个图/,因为它
不以其他方式与 PL 代码库互连,但为了
社区凝聚力让我们将其保留在 plots2 中。
丽兹,你能开始新的问题并从清单开始吗?
2019 年 2 月 6 日星期三上午 11:17,Liz Barry [email protected]写道:
转达@shapironick https://github.com/shapironick的问题
谁在另一个频道想知道在未来的版本中是否可能有
连接线的不同细度和粗细以显示连接线的紧密程度
相关的任何两个特定标签是? 谢谢!—
你收到这个是因为你被提到了。
直接回复本邮件,在GitHub上查看
https://github.com/publiclab/plots2/issues/1502#issuecomment-461083862 ,
或静音线程
https://github.com/notifications/unsubscribe-auth/AABfJ9nxysbBtCAYHEW2tA8UwNH9zelFks5vKv_hgaJpZM4OOvLP
.
jywarren
于 2019-02-06
好极了! @夏皮罗尼克! 现在,数据库查询仅发送前 n 个标签和站点范围内这些标签的计数。 将来,为了获得边权重,我们需要在后端进行更改,将所有标签发送到前端以便可以聚合互连计数,或者需要在后端。 或者,在前端,我们计算一些网络边缘属性(例如,一些中心性:度、接近度、介数等)。
skilfullycurled
于 2019-02-06
很酷! 不喜欢这个想法+1开始新一期这个是史诗般的,真棒!
 shapironick
于 2019-02-06
shapironick
于 2019-02-06
现在在我们传递给图形代码的数据中,我想我们确实看到了一个标签(比如标签 A)何时链接到标签 B,如果标签 B 链接回标签 A,我们会看到第二个连接。但是这并没有真正告诉我们多少。 重构以提供“权重”很有趣……我也可以想象一些方法来做到这一点。 我同意,我们可以传入每个标签具有的所有node.ids ,并在本地计算它,或者我们可以尝试在我们收集每个标签的前 5 个最相关标签时预先计算它。 (我想我最近将其更改为 10,但无论如何)。
很好的后续细化。 一旦我们有了清单,我们就可以确定优先级并逐步改进它。 谢谢!
jywarren
于 2019-02-06
哦,看,这已成为历史记录;): https :
ebarry
于 2019-02-08
在为即将到来的夏天的一个可能的 Summer of Code 项目研究这个问题时,我发现了社区检测错误,这是一个微妙的问题——数据位于像{data: { DATA }}这样的嵌套对象中,而不仅仅是{ DATA } 。 在https://github.com/publiclab/plots2/pull/9169 中修复!
jywarren
于 2021-02-09

jywarren
于 2021-02-09
这只是我们的测试数据; 一旦我们合并它并重建它,完整的修复将在稳定的服务器中可见; 大概30m左右。
jywarren
于 2021-02-09
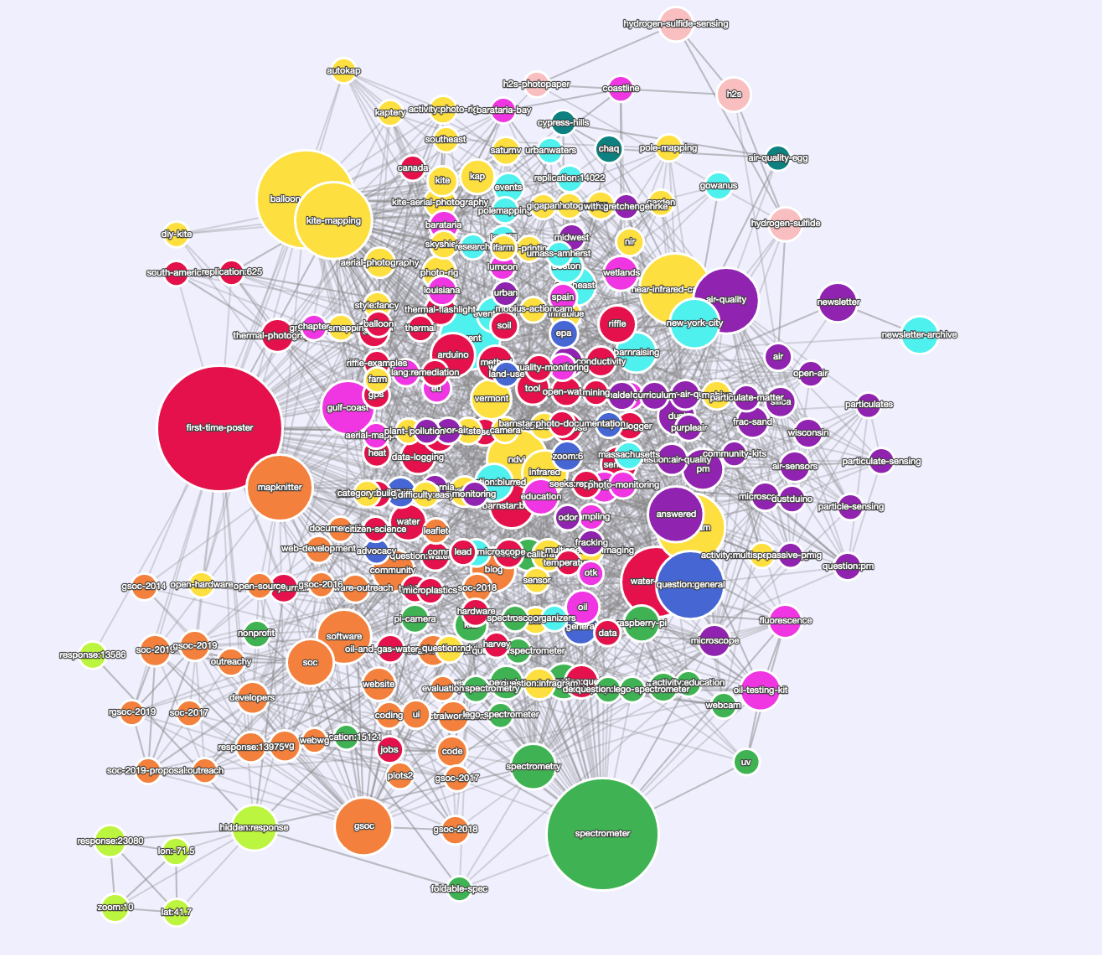 jywarren
于 2021-02-09
jywarren
于 2021-02-09
相关问题
 milaaraujo
·
3评论
milaaraujo
·
3评论
milaaraujo
·
3评论
milaaraujo
·
3评论
 bronwen9
·
3评论
jywarren
·
3评论
bronwen9
·
3评论
jywarren
·
3评论
 keshavsethi
·
3评论
keshavsethi
·
3评论
最有用的评论
它应该会在今晚晚些时候在实时网站上运行,但我想指出,一些用户“过度使用”标签已经以我们之前认识到的方式扭曲了图表。 我相信其中一位用户已经从该站点中进行了审核,我想知道人们是否认为从站点中删除这些标签或至少从图表中省略它们是否合适。 删除它们会更容易,但我们也可以制作一些东西来掩盖它们。 偏好, @ ebarry @skillfullycurled ?
尽管如此,即使边缘弹性的设置仍然需要一些调整,这看起来还是不错的,也许不同的布局类型会更好......