Plots2: visualisasi tag dari semua tag
Ini adalah permintaan bagi seseorang yang memiliki akses untuk mengedit halaman khusus untuk menambahkan visualisasi tag ini dari awal waktu hingga November 2016 ke bagian atas publiclab.org/tags
https://www.dropbox.com/s/s78g3ufhsav5xzo/plots_tag_graph_256_filtered.png?dl=0
CC:
@gretchengehrke
@skillfullycurled
 ebarry
ebarry
Semua 73 komentar
Hai, Liz - saya agak enggan untuk menempatkan grafik statis seperti ini di basis kode permanen kami, tetapi mungkin sarannya adalah kami menampilkan "fitur" (seperti spanduk kami) di bagian atas halaman itu, dan kemudian admin bisa menampilkan apa pun yang mereka inginkan di sana. Apakah itu akan berhasil?
 jywarren
pada 5 Jul 2017
jywarren
pada 5 Jul 2017
Itu akan berada di atas atau di bawah baris ini: https://github.com/publiclab/plots2/blob/master/app/views/tag/index.html.erb#L4
Dan terlihat seperti:
<% cache('feature_tag-page-header') do %>
<%= feature('tag-page-header') %>
<% end %>
Yah, saya tidak begitu ingin menghias halaman itu karena saya ingin menambahkan "wawasan sekilas" .
Poin yang berbeda, tetapi mungkin relevan mengapa saya menyarankan menambahkan visualisasi grafis adalah bahwa halaman tag ini masih tidak memiliki kemampuan penyortiran untuk melihat "terbaru" atau "populer" apalagi untuk melihat salah satu dari mereka berdasarkan geografi.
ebarry
pada 5 Jul 2017
Sebenarnya ada python gephi binding yang bisa kita gunakan untuk membuatnya secara dinamis. Saya sebenarnya sedang mengerjakan visualisasi jaringan javascript sekarang, jadi biarkan saya melihat bagaimana hasilnya. Jika berjalan dengan baik, maka saya dapat menerjemahkan apa yang saya lakukan menjadi skrip python yang dapat menghasilkan struktur data untuk kemudian divisualisasikan dalam javascript.
 skilfullycurled
pada 5 Jul 2017
skilfullycurled
pada 5 Jul 2017
Hai, semuanya - saya pikir grafik yang dihasilkan akan bagus, dan merupakan sesuatu yang bisa kita masukkan ke dalam kode permanen.
@ebarry saya tidak mengatakan ini adalah dekorasi dan bukan konten, saya lebih mengatakan ini akan cepat ketinggalan zaman, dan juga tujuan kami adalah untuk menyimpan /no/ konten di basis kode kami -- hanya infrastruktur. Jadi ini hanya cara untuk mengimplementasikannya -- apakah solusi yang saya usulkan terdengar OK?
re this tag page still doesn't have any sorting capabilities to see "recent" or "popular" much less to see either of those by geography. Saya akan senang bekerja sama dengan Anda untuk mengajukan beberapa permintaan fitur agar kontributor membangun untuk menyelesaikan ini jika itu adalah prioritas bagi Anda. Bisa jadi masalah first-timers-only jika Anda bisa membantu memasukkannya ke dalam antrian!
jywarren
pada 5 Jul 2017
Mari kita kembali ke dasar tentang masalah ini :)
Apa tujuan memvisualisasikan tag?
Bagi saya, memvisualisasikan tag adalah cara untuk menggambarkan tag terkait secara visual, misalnya tag yang muncul bersamaan pada konten yang sama. Untuk contoh yang bagus, lihat kluster berkode warna dalam visualisasi @skillfullycurled di atas. Tag pengelompokan penting karena secara visual menghubungkan presentasi situs web tentang aktivitas komunitas ini adalah tujuan saya yang sebenarnya dengan seluruh masalah ini.
Berikut beberapa informasi latar belakang: pada halaman tag kami (https://publiclab.org/tags) kami menulis "Kami menggunakan tag untuk mengelompokkan penelitian berdasarkan topik" dan mendorong orang untuk menelusuri tag (saat ini hanya diurutkan berdasarkan aktivitas terbaru). Ini adalah cara penting yang kami beri nama, tautkan, dan/atau promosikan orang untuk menemukan dan terlibat dengan topik. Dasbor itu sendiri menekankan aktivitas terbaru. Dasbor sekarang menampilkan bilah "tag yang baru-baru ini digunakan" -- yang merupakan langkah penting namun sebagian untuk tujuan melihat "area penelitian" atau "topik".
Untuk bergerak maju, saya tidak tertarik _navigasi_ dengan visualisasi tag grafis (jadi 2007!), namun, kelompok aktivitas menyediakan cara tambahan yang penting untuk menghubungkan/menavigasi ke topik. Untuk mencapai tujuan, yang saya maksud adalah kemampuan halaman tag untuk menunjukkan tag mana yang paling saling berhubungan, untuk mengomunikasikan luasnya topik yang terhubung di area penelitian, untuk menavigasi/menghubungkan ke area penelitian, dan berlangganan dengan tepat, kami tidak perlu panah menukik berkode warna. Mari kita pikirkan bagaimana mencapai tujuan-tujuan ini.
Kami mungkin juga mempertimbangkan mirroring publiclab.org/tags di publiclab.org/topics untuk membuat bahasa lebih mudah diakses.
ebarry
pada 15 Nov 2017
Keren, terima kasih Liz!
Untuk mencoba satu tikaman pada fitur yang lebih sempit menuju tujuan ini, bagaimana jika halaman tag (nama baru mengambang: halaman topik ...!?!) memiliki daftar "Topik terkait", seperti:
Topik terkait:
waterrunoffwetlandsturbidity
Di mana "terkait" berarti bahwa (mengakui bahwa ada berbagai cara untuk mengukur ini, dan bahwa kami menginginkan cara yang "efisien secara komputasi") ini adalah tag yang paling sering muncul di halaman yang sudah memiliki tag utama. Jadi untuk topik onions , kami menghitung setiap halaman yang ditandai dengan onions dan mengambil yang teratas, katakanlah, lima.
Tindak lanjut kecil jika hal di atas terdengar bagus -- apakah boleh melakukan ini hanya untuk 20-30 halaman terbaru? Bahkan jika ini hanya titik awal, itu akan membuatnya lebih mudah untuk diterapkan tanpa khawatir akan menyebabkan kelambatan situs web secara keseluruhan. Mungkin ada cara yang lebih rumit untuk mengatasi hal ini, tetapi ini adalah cara termudah untuk memulai.
jywarren
pada 16 Nov 2017
Saya memposting silang di https://publiclab.org/questions/tommystyles/10-20-2017/need-your-feedback-on-tag-pages -- apa pendapat Anda tentang memindahkan diskusi ke sana sampai ada diskrit tertentu langkah-langkah pengkodean (proyek mini untuk kontributor kode) yang bisa kita buat?
jywarren
pada 16 Nov 2017
OK bagus! mari kita pergi ke diskusi itu dan kembali setelah kita melakukannya
langkah-langkah yang bisa dilakukan.
--
+1 336-269-1539 / @lizbarry http://twitter.com/lizbarry / lizbarry.net
Pada hari Rabu, 15 Nov 2017 jam 21:54, Jeffrey Warren [email protected]
menulis:
Saya memposting silang di https://publiclab.org/questions/tommystyles/10-20-
2017/need-your-feedback-on-tag-pages -- apa pendapat Anda tentang pindah?
diskusi di sana sampai ada langkah-langkah pengkodean diskrit tertentu (mini
proyek untuk kontributor kode) yang bisa kita buat?—
Anda menerima ini karena Anda disebutkan.
Balas email ini secara langsung, lihat di GitHub
https://github.com/publiclab/plots2/issues/1502#issuecomment-344799932 ,
atau matikan utasnya
https://github.com/notifications/unsubscribe-auth/AAJ2n8PdvpH0GQ_wBU-Utp4xfL7XDmuJks5s26PpgaJpZM4OOvLP
.
ebarry
pada 16 Nov 2017
@jywarren , @ebarry , apakah ada API (atau mungkin dokumentasi) untuk mengetahui 'tepi' pada grafik di atas? Maksud saya bagaimana node terhubung?
Terima kasih !
 sagarpreet-chadha
pada 23 Jan 2018
sagarpreet-chadha
pada 23 Jan 2018
Hai @sagarpreet-chadha!
Visualisasinya hanyalah sebuah gambar sehingga tidak ada API (belum! mengedipkan mata) namun saya dapat memberi Anda daftar tepi dari grafik tersebut. Format file yang paling "mentah" adalah csv dan json. Kedua format harus bekerja dengan grafik baik "secara terprogram" ( iGraph , networkx , d3.js ) atau dengan GUI ( Gephi , Cytoscape ).
Rupanya Anda tidak dapat mengunggah file di github. Saya mencoba mengunggahnya ke catatan penelitian Lab Umum tetapi tidak berhasil. @jywarren apakah ada cara untuk mengunggah file ke catatan penelitian? Jika tidak, @sagarpreet-chadha, dapatkah Anda membuat posting di googlegroup plots-dev (Anda dapat mendaftar di sini jika belum)? Mari kita tunggu apa yang dikatakan @jywarren karena akan sangat bagus untuk memilikinya langsung di catatan penelitian.
Inilah yang dapat Anda nantikan:
plots_tag_communities_edges_w_props_9_16.csv: : daftar tepi unik dengan properti yang dihitung, khususnya bobot tepi. Bobot diterjemahkan ke berapa kali tag muncul bersamaan.
plots_tag_communities_nodes_w_props_9_16.csv: daftar node dengan properti terhitung. Yang paling relevan dengan gambar di situs web adalah "kelas modularitas" yang memberi tahu Anda komunitas mana yang dimiliki setiap node.
plots_tag_communities_9_16.json: Saya tidak menemukan json berguna tetapi saya tahu beberapa orang lebih menyukainya. Saya pikir file json juga menyertakan properti untuk visualisasi yang ada di situs web (yaitu warna RGB dari setiap node).
skilfullycurled
pada 23 Jan 2018
Pembaruan: menghapus plots_tag_communities_edgelist_9_16.csv dari daftar file di atas. File ini terbatas penggunaannya karena tepi duplikat telah digabungkan menjadi tepi unik dengan bobot. Tanpa properti, daftar tepi ini hanya akan memungkinkan Anda untuk membuat grafik dengan bobot tepi 1. Saya akan mencari file asli dengan duplikat.
skilfullycurled
pada 24 Jan 2018
Terima kasih @skillfullycurled atas balasan Anda!
Saya sebenarnya mencoba membuat grafik visualisasi menggunakan pustaka javascript (d3.js atau vis.js ) sehingga dapat dengan mudah ditambahkan ke situs web publiclab.org. Pustaka ini membutuhkan data berupa :
nodes: [
{
id: 1,
shape: 'circle',
label: 'Infrared } ] untuk node .
Dan untuk tepi :
edges: [
{from: 1, to: 2},
{from: 1, to: 3}]
Yah json akan lebih bagus jika tidak saya dapat membuatnya, atau mungkin membuat objek Javascript secara langsung (dengan cara ini tidak perlu menguraikan file JSON).
Saya telah membuat grafik dummy (kita bisa bermain dengan node dan edge di sini ):
Bagaimana menurutmu ? @ebarry , @jywarren , @skillfullycurled
sagarpreet-chadha
pada 24 Jan 2018
Ah. Itu akan luar biasa! Oke. Untuk melanjutkan percakapan ini, kita harus meninggalkan "API-land" dan beralih ke cara kerja visualisasi di Gephi dan cara terbaik untuk menerjemahkan fitur tersebut ke dalam javascript.
Bisakah saya menyusahkan Anda untuk memulai ini sebagai pertanyaan ? Sesuatu seperti, "Bagaimana saya bisa menerjemahkan visualisasi tag yang dibuat di Gephi ke dalam versi javascript?"
Juga, kirimi saya email di benj. [email protected] jadi saya bisa berbagi file. Saya akan menghapus email saya setelah Anda melakukannya.
skilfullycurled
pada 24 Jan 2018
Sebenarnya saya pikir kita mungkin tidak perlu meninggalkan API-land -- API yang ada saat ini cukup kuat. Saya ingin tahu @skillfullycurled bagaimana Anda menghasilkan tepi itu --
dapatkah mereka dibuat baru dari daftar semua tag dan node tempat mereka digunakan? Itu adalah kueri yang masuk akal untuk kami buat, jika di-cache.
Kami dapat menambahkannya ke API di https://github.com/publiclab/plots2/tree/master/app/api/srch dan mendokumentasikannya di https://github.com/publiclab/plots2/blob/master/doc /API.md
Jika datanya cukup, kuerinya bisa seperti:
r = []
Tag.select(:name, :tid).each do |t|
nids = t.nodes.select(:nid, :status).where(status: 1).collect(&:nid)
r << [t.name, nids] if nids.length > 0
end
r # later, r.to_json
Saya baru saja menjalankannya di produksi dan butuh sekitar 15 detik. Jika kami menyimpannya setiap hari, saya pikir itu dapat dikelola, dan kami mungkin dapat meningkatkannya lebih lanjut.
jywarren
pada 25 Jan 2018
Anda juga dapat berbagi file di http://Gist.github.com -- dapatkah itu berfungsi?
jywarren
pada 25 Jan 2018
Jadi, menggunakan JSON yang dihasilkan dari kueri saya,
- di JavaScript, kita bisa menghitung berapa kali tag muncul bersamaan.
- bagaimana Anda mengelompokkan/menghitung "komunitas"?
Berikut kutipannya:
["whitebalance", [12476, 13575]], ["wi", [12143, 13067]], ["wi-fi", [11123]], ["width-of-dvd-grating", [12838, 12875, 12895, 12899, 12902, 12926, 12990, 12991, 12995, 12999, 13006, 13014, 13019, 13037, 13046, 13057, 13062, 13069, 13077, 13088, 13089, 13094, 13103, 13117, 13125, 13131, 13133, 13136, 13152, 13154, 13157, 13159, 13169, 13178, 13181, 13183, 13188, 13226, 13248, 13283, 13302, 13305, 13308, 13315, 13316, 13340, 13349, 13355, 13366, 13401, 13402, 13409, 13414, 13423, 13429, 13432, 13434, 13437, 13439, 13440, 13443]], ["wiki", [9048, 10956]], ["wiki-gardening", [10956]], ["wild", [11707, 11711]], ["wildfires", [14803]], ["wildlife", [670]], ["wilkinson-bay", [220, 265, 280, 281, 282, 283, 284, 677]], ["wilkinsonbay", [606]], ["williamsburg", [10343, 10428, 10444]], ["willow", [9979]], ["wind", [9032, 10660, 12610, 13880, 14487, 14527, 14530, 14531, 14713, 14756]], ["wind-direction", [14527]], ["wind-sensor", [14713]], ["wind-speed-meter", [1962, 5837, 9032, 12103, 13064, 13165, 13231, 13880, 14527]], ["winder", [7717]], ["winders", [1900]], ["window", [147, 1759]], ["windows", [11434, 11677, 13037]], ["windows-7", [13037]], ["windows-7-ultimate", [13037]], ["windows-excel", [13037]], ["windspeed", [745]], ["windvane", [14527]], ["windy", [146]], ["wine", [706, 10955]], ["winter", [5161]], ["wintercamp", [5103]], ["wired", [10315]], ["wireframes", [10623]], ["wireless", [3908, 9940, 11123, 12175]], ["wisconsin", [10504, 10552, 10611, 10619, 11331, 11783, 12142, 12143, 12192, 12221, 12337, 12537, 12539, 12562, 12597, 12610, 12919, 13067, 13216, 13217, 13219, 13222, 13223, 13224, 13406, 13578, 13920, 13921, 13922, 14018, 14044, 14087, 14146, 14648]], ["with", [11772, 13742, 14728]], ["with:abdul", [13407, 13412, 13413, 13428, 13493]], ["with:adam-griffith", [11049]], ["with:amal", [12161]], ["with:amandaf", [11556]], ["with:amberwise", [12338, 13280]], ["with:ann", [12850]], ["with:basurama", [11699, 11705]], ["with:becki", [13571]], ["with:bronwen", [10952, 12480, 13493, 14587]], ["with:bsugar", [13449]], ["with:btbonval", [11789]], ["with:cfastie", [11688, 13493, 13980]], ["with:chrisjob", [10464]], ["with:cindy_excites", [11566, 11567, 14537]], ["with:damarquis", [12338]], ["with:danbeavers", [11417, 11567]],
FWIW mungkin ada beberapa permintaan yang lebih efisien seperti ini tetapi ini cukup baik, meskipun tidak mengembalikan sepenuhnya apa yang ada di atas:
Tag.select('term_data.tid, term_data.name, community_tags.nid, community_tags.tid')
.includes(:node_tag)
.references(:node_tag)
Meskipun ini tidak akan memberi tahu kami apakah simpul itu diterbitkan (vs. spam) kecuali kami juga mencampur node.status di sana. Tapi itu mungkin!
jywarren
pada 25 Jan 2018
Hai, saya hanya punya beberapa pertanyaan di sini,
1.) Jika 2 tag milik simpul yang sama, mereka memiliki tepi di antara mereka?
2.) Warna yang berbeda untuk berbagai jenis simpul seperti pertanyaan , catatan , catatan penelitian , dll. ?
Terima kasih !
sagarpreet-chadha
pada 25 Jan 2018
Dan saya juga setuju untuk tidak meninggalkan API -land :)
sagarpreet-chadha
pada 25 Jan 2018
Arg! Oke. Jangan menumpuk, tolong. Tidak ada yang ingin tinggal di API-land lebih dari saya (well, mungkin dengan pengecualian @ebarry ). Dalam pemahaman saya, pembangunan API-land telah ditunda tanpa batas waktu karena kekhawatiran atas kelambanan situs web ( lihat ekstensi percakapan di sini ). Tapi sekarang @jywarren mengatakan itu bukan masalah besar lagi, jadi saat yang tepat untuk itu.
Karena menggunakan Github dapat menjadi penghalang untuk informasi yang dapat diakses (tidak semua orang memiliki akses, tahu cara menggunakannya), saya pikir (er...pikir) melakukan percakapan yang bukan tentang "menyelesaikan sesuatu" dalam basis kode lebih baik diturunkan ke situs web tempat semua orang dapat belajar dari mereka. Ini bukan norma komunitas yang saya tetapkan (lihat komentar @jywarren sendiri di
skilfullycurled
pada 25 Jan 2018
Ups, maaf @skilfullycurled Saya tidak ingat komentar terakhir Anda di utas itu -- https://publiclab.org/questions/tommystyles/10-20-2017/need-your-feedback-on-tag-pages#answer - 556-comment-17709 -- tempat Anda menyarankan:
- hanya berjalan di atas 250 tag
- caching mingguan
Saya akan melakukan ping kembali ke sana, tetapi saya pikir dengan semua pekerjaan pada API, pembersihan kode, dan penjangkauan, kami dapat melakukan versi cache harian atau mingguan dari kueri semacam itu, dan baik-baik saja dengan total komputasi 10-15 detik waktu per minggu. Sisanya akan dijalankan secara lokal di browser. Mengulangi ini di sana.
jywarren
pada 25 Jan 2018
@jywarren Saya perlu menjawab beberapa pertanyaan Anda. Saya akan memposting buku catatan jupyter saya nanti. Sementara itu, lihat di sini untuk penjelasan singkat tentang bagaimana grafik dibuat dari pasangan tag. Untuk kode yang tepat, lihat di sini .
@sagarpreet-chadha (dan siapa pun yang tertarik) Anda dapat melihat bagaimana grafik d3.js dibuat dari data tag dengan memeriksa repo untuk tagoverflow yang merupakan inspirasi untuk proyek ini.
Mengenai deteksi komunitas, jika Anda melihat di repositori tagoverflow, Anda akan menemukan bahwa penulis menerapkan algoritme mereka sendiri. Sejak saat itu, yang lain telah diimplementasikan seperti jLouvain , netClustering dan implementasi CNM ( contoh d3 ). Dengan batas 256 tag, deteksi komunitas mereka mungkin baik-baik saja di browser.
skilfullycurled
pada 25 Jan 2018
Agar tidak membanjiri diskusi publiclab.org dengan banyak data, berikut ini tautan ke format data yang digunakan TagOverflow:
https://api.stackexchange.com/2.1/tags/python/related/?site=stackoverflow&key=of3hmyFapahonChi8EED6g ((&pagesize=16
Itu membuat seperti 15 panggilan untuk mengambil tag apa yang berhubungan dengan tag yang diberikan (dalam contoh di atas, "python")
jywarren
pada 25 Jan 2018
Jadi perbedaan antara itu dan data yang saya hasilkan di atas adalah bahwa kueri saya mencantumkan id simpul, tetapi belum menggunakannya untuk membangun "keterkaitan". Tapi tentu saja @skilfullycurled 's notebook Jupyter melakukan hal ini! Keren, terima kasih sudah berbagi!
jywarren
pada 25 Jan 2018
@sagarpreet-chadha, saya memposting pertanyaan yang menanyakan dan menjawab pertanyaan Anda di atas:
https://publiclab.org/questions/bsugar/01-25-2018/how-was-the-tag-graph-visualization-made
Saya tidak mencoba untuk menjadi "pasif agresif" tentang permintaan saya, tetapi saya pikir orang-orang dapat mengambil manfaat dari aspek percakapan ini menjadi publik. Jadi saya kira itu membuatnya "agresif agresif". ; )
Semua bercanda, senang menjawab pertanyaan apa pun!
skilfullycurled
pada 25 Jan 2018
Hai semuanya!
@sagarpreet-chadha, saya meletakkan semua file yang Anda perlukan di sini:
https://spideroak.com/browse/share/skilfullyshared/plots-tag-graph
Folder tersebut dilengkapi dengan file readme yang menjelaskan isinya.
Tolong beri tahu saya jika Anda telah mengunduhnya sehingga saya dapat menutup ruang berbagi. Akhirnya, saya akan mempostingnya ke akun github saya agar orang lain dapat mengaksesnya di wiki.
Dengan senang hati menjawab pertanyaan lebih lanjut yang mungkin Anda miliki!
skilfullycurled
pada 1 Feb 2018
Terima kasih @skillfullycurled !
Saya telah mengunduh file :-)
sagarpreet-chadha
pada 2 Feb 2018
Tidak masalah @sagarpreet-chadha!
PS: Saya meninggalkan Anda pemikiran tindak lanjut di pertanyaan wiki .
skilfullycurled
pada 2 Feb 2018
Pembaruan hebat pada perhitungan keterkaitan tag berbasis ruby di sini: https://publiclab.org/questions/bsugar/01-25-2018/how-was-the-tag-graph-visualization-made
lebih segera!
jywarren
pada 17 Jan 2019
Beberapa kemajuan di https://github.com/publiclab/plots2/pull/4657 , di mana saya menerapkan contoh Cytoscape.js yang sangat mendasar, tetapi langsung (http://js.cytoscape.org/), kehabisan koleksi cache mingguan dari
Butuh waktu lebih dari 50 detik untuk menjalankan SEMUA tag di situs (yang dapat di-cache setiap minggu) tetapi itu juga menghasilkan 8200+ tag dan 31k tepi... yang sangat banyak untuk digambarkan. Berikut set lengkapnya; saya pikir itu termasuk banyak tag spam: https://Gist.github.com/jywarren/4b1f9a032092a8187dd802a375fcb700
Anda dapat menentukan # tag yang ingin Anda kueri seperti ini: https://stable.publiclab.org/tag/graph.json?limit=10 (setelah dipublikasikan sepenuhnya, https://publiclab.org/tag/graph. json?batas=10)
Saat ini dibatasi hingga 5 "tepi" per nama tag, mewakili 5 tag yang paling sering muncul di samping tag asli.
Ini sekarang aktif di server uji stabil (walaupun cabang ini cukup sering membangun kembali sehingga URL tidak selalu online... ironisnya) di sini:
https://stable.publiclab.org/stats/graph?limit=75
Jumlah yang lebih besar seperti limit=100 atau 250 tampaknya menunjukkan semacam kesalahan dan saya harus sedikit mengejarnya. Tapi ini awal yang cukup bagus.
Ada BANYAK konfigurasi yang dapat ditambahkan untuk menyempurnakan ini -- ukuran simpul, kekuatan tautan, lebih banyak lagi -- lihat galeri di http://js.cytoscape.org untuk beberapa kemungkinan. Dan membuat "keluarga" mungkin juga, meskipun saya perlu sedikit lebih banyak masukan untuk itu.
jywarren
pada 18 Jan 2019

jywarren
pada 18 Jan 2019
Ooh, https://stable.publiclab.org/stats/graph?limit=300 sepertinya berfungsi juga
jywarren
pada 18 Jan 2019
Deteksi komunitas di sini! https://github.com/upphiminn/jLouvain/blob/master/README.md
jywarren
pada 19 Jan 2019
@jywarren , Keren banget!!!
sagarpreet-chadha
pada 19 Jan 2019
Juga ada berbagai algoritme pengelompokan - ini dapat diuji di konsol JavaScript:
http://js.cytoscape.org/#collection/clustering
- eles.markovClustering()
- node.kMeans()
- node.kMedioids()
- node.fuzzyCMeans()
- node.hierarchicalClustering()
- node.afinitasPropagasi()
Saya tidak terbiasa dengan ini tetapi mereka semua tampaknya menggunakan atribut node atau edge untuk membuat cluster elemen serupa. Jadi, apa yang harus kita berikan sebagai atribut yang menjadi dasar kesamaan?
Anda dapat mencoba ini di konsol menggunakan contoh di dokumen, hal-hal seperti:
var clusters = cy.elements().hca({
mode: 'threshold',
threshold: 5,
attributes: [
function( node ){ return node.data('count'); }
]
});
clusters; // <= then inspect what this returns to see the clusters
Oke, menggunakan jlouvain Saya dapat menambahkan deteksi komunitas: https://github.com/upphiminn/jLouvain
Saya tidak memiliki cukup data pengujian untuk melihat cara kerjanya, tetapi jika #4679 lolos, saya akan menggabungkannya dan kita akan dapat melihatnya berjalan dengan deteksi komunitas di:
https://stable.publiclab.org/stats/graph?limit=101
(setelah dibangun)
jywarren
pada 21 Jan 2019
Hai semuanya! Terlihat mengagumkan. Maaf saya belum bisa membalas, mengejar sesuatu dan akan kembali lagi nanti hari ini.
Sementara itu, bahan lain yang menurut saya tidak saya sebutkan di posting saya yang lain adalah tata letak. Yang paling dekat dengan yang saya gunakan mungkin adalah force layout . Secara teknis itu mungkin sesuatu yang disebut tata letak gaya 2:
Tata letak gaya adalah semacam daya tarik/penolakan anil yang mencapai kondisi mapan berdasarkan parameter yang Anda tetapkan (yaitu jumlah iterasi, kekuatan tarik/tolak). Berikut demo d3 .
Adapun deteksi komunitas dan bobot tepi, Anda memiliki beberapa opsi tetapi jika Anda ingin membuat ulang grafik tag yang mengacu pada ini, maka Anda memerlukan co-kejadian yang cytoscape, seperti yang diharapkan, memiliki fungsi untuk membantu membuat lebih mudah.
oe_ratio = (all_questions_count * tag_count_AB) / (tag_count_A * tag_count_B)
Di mana tag_count_AB = edge.parallelEdges()
Seperti itu, pertama-tama saya mempersempit kumpulan tag ke beberapa nomor yang masuk akal (katakanlah, 512 teratas), tetapi kemudian saya mempersempit tag yang saya gunakan untuk visualisasi dengan hanya menyertakan tag n teratas (mungkin 64?) dengan rasio yang diharapkan di atas 1.
Anda dapat membaca lebih lanjut dari Tag Overflow . Metode ini adalah salah satu cara untuk mengatasi masalah di mana tepi atau simpul simpul mungkin penting tetapi penggunaannya rendah. Misalnya, di sebuah toko, 100 orang _mungkin_ memiliki kemungkinan 85% untuk membeli kopi dan krim, tetapi lima dari orang tersebut _selalu_ membeli kopi, krim, dan telur. Jadi saya pasti ingin menyimpan 5 karton telur dalam stok.
Alternatif yang mudah adalah dengan membuat bobot tepi antara dua simpul menjadi tag_count_AB dan hanya mengambil tepi/simpul di atas ambang yang diberikan. Secara pribadi, saya jarang mendapatkan hasil yang baik dengan ini karena alasan di atas.
Mengenai metode lain, Anda mungkin tertarik pada hal 3. (2.2) hingga - hal. 7 (3.1) dari makalah ini (tidak ada matematika untuk bagian ini) yang mencoba untuk mengklasifikasikan berbagai jenis metode deteksi komunitas. Ini telah membantu saya memilih yang memberikan hasil paling menonjol mengingat bagaimana saya menyusun grafik dan apa yang ingin saya ketahui darinya. Misalnya, komunitas koneksi sosial umum vs komunitas berdasarkan seberapa sering pesan dikirim antara dua orang.
skilfullycurled
pada 21 Jan 2019
Bekerja sekarang di server yang stabil!
jywarren
pada 25 Jan 2019

Di sini w 99 tag teratas!
jywarren
pada 25 Jan 2019
Seharusnya sudah berjalan di situs langsung nanti malam, tetapi saya ingin mencatat bahwa "penggunaan tag yang berlebihan" oleh beberapa pengguna telah mengubah grafik dengan cara yang telah kami kenali sebelumnya. Saya yakin salah satu pengguna telah dimoderasi dari situs tersebut, dan saya bertanya-tanya apakah orang-orang berpikir pantas untuk menghapus tag tersebut dari situs atau setidaknya menghilangkannya dari grafik. Menghapusnya akan lebih mudah tetapi kita juga bisa membuat sesuatu untuk mengaburkannya. Preferensi, @ebarry @skillfullycurled ?
Tetap saja, ini terlihat bagus meskipun pengaturan pada elastisitas tepi masih memerlukan beberapa penyesuaian, dan mungkin jenis tata letak yang berbeda akan bekerja lebih baik...

jywarren
pada 25 Jan 2019
Ya! Kami pasti pernah mengalami masalah ini. Sayangnya, satu-satunya hal yang harus dilakukan adalah menghapus pengguna tersebut sebagai outlier. Seseorang yang menggunakan tag sebanyak itu mungkin bukan outlier dalam dirinya sendiri, tetapi jika mereka membuat tag yang sangat spesifik untuk diri mereka sendiri dan menggunakannya berulang kali, maka itu tidak benar-benar menangkap data.
skilfullycurled
pada 25 Jan 2019
Saya pikir saya bahkan mencatat masalah github dengan permintaan fitur yang memunculkan peringatan yang pada dasarnya akan mengatakan, "Whoaaaaaaaa, mudah kawan! Sepertinya Anda punya banyak tag di sana, eh?".
skilfullycurled
pada 25 Jan 2019
Oh, PS. Omong-omong, terlihat luar biasa!!
skilfullycurled
pada 25 Jan 2019
AAAAAAHHHHHHHMAYZINGGGGGGGGG!!!!!!!!!!!!
Ya untuk secara manual "menghapus [ing] pengguna tertentu sebagai outlier"
ebarry
pada 26 Jan 2019
Saya terus kembali ke utas ini karena betapa hebatnya dan memikirkan banyak hal (semoga kecil). Hal lain yang mungkin Anda pertimbangkan untuk difilter adalah tag daya (yang memiliki titik dua, kan?). Saya pikir segera setelah masalah penggunaan tag yang berlebihan diperbaiki, maka kita akan tahu lebih banyak tentang tata letak.
Catatan untuk diri sendiri: inilah tautan ke komit dengan halaman yang penting untuk implementasi.
skilfullycurled
pada 26 Jan 2019
Hai semua, senang atas antusiasmenya! Saya jatuh sakit tetapi sekarang sudah pulih dan akan bekerja sedikit dalam penerbangan pulang pada hari Selasa.
Saya memang ingin bertanya - pertanyaan spesifik saya adalah apakah kita harus:
- benar-benar menghapus tag dari pengguna yang dimoderasi ini, atau
- jika kita harus mencoba melestarikannya tetapi menyaringnya.
Pemfilteran akan jauh lebih berhasil baik untuk kode maupun untuk panggilan basis data, tetapi dimungkinkan.
jywarren
pada 27 Jan 2019
Dalam kasus seperti ini di mana akun telah dibuat "tidak aktif" karena moderasi, maka saya pikir tidak apa-apa untuk menghapus tag dari database secara langsung. Apalagi jika Anda memiliki cadangan. Bukan karena Anda mungkin ingin memulihkannya, hanya karena saya khawatir kehilangan data selamanya. Ini tidak sehat, tetapi ruang yang murah adalah pemicu yang tidak menguntungkan. Perasaan saya akan lebih rumit jika ini adalah akun yang dibuat "tidak aktif" karena pilihan tetapi kita dapat mendiskusikannya lain kali (atau sekarang).
skilfullycurled
pada 27 Jan 2019
Ya, ini adalah topik besar untuk direnungkan. Setelah meninjau apakah ada tag yang _only_ telah digunakan oleh pengguna ini (contoh: aries city-point ), saya menemukan bahwa sebenarnya ada sangat sedikit tag yang sepenuhnya terisolasi untuk pengguna ini (bahkan purelab awalnya digunakan oleh Shan He tentang penyaringan air DIY, dan research-notes awalnya digunakan pada posting yang membahas desain catatan penelitian di situs web).
Karena pengguna ini dimoderasi, dapatkah visualisasi tag kami mengecualikan semua konten dari pengguna yang dimoderasi -- dan dengan ekstensi tag yang digunakan pada konten orang itu -- tanpa mengecualikan tag itu secara umum karena dapat digunakan pada konten orang lain?
ebarry
pada 28 Jan 2019
@ebarry , saya harus mengklarifikasi (kalau tidak).
Ketika saya berkata:
hapus tag dari database langsung
Maksud saya apa yang Anda tutup dengan:
...[bahwa] visualisasi tag kami [akan] mengecualikan semua konten dari pengguna yang dimoderasi -- dan dengan ekstensi tag yang digunakan pada konten orang tersebut -- tanpa mengecualikan tag itu secara umum [karena] tag tersebut dapat digunakan pada konten orang lain. ..
Jika pengguna yang dimoderasi dan Shan He sama-sama menggunakan tag "purelab", "purelab" tidak akan dihapus, sembarang tag dari pengguna yang dimoderasi atau, ITMU, jika Anda mau.
Pertanyaan yang tersisa (jika saya mengerti @jywarren) adalah apakah akan menghapus ITMU ini dari database seluruhnya atau tidak, atau apakah kita menyimpannya di database tetapi memfilter ITMU ketika semua tag diminta untuk visualisasi. Menghapusnya membuat hidup lebih mudah bagi mereka yang menerapkan visualisasi, tetapi mungkin ada argumen untuk melestarikannya.
Secara pribadi, saya pikir yang pertama tidak apa-apa ketika pengguna telah dimoderasi karena tidak ada kemungkinan konten akan kembali ke situs. Namun, ini mungkin berbeda jika pengguna memilih untuk menghapus akun mereka berdasarkan ada atau tidaknya fungsi di mana mereka dapat mengaktifkannya kembali. Saya pikir kita dapat meninggalkan situasi itu untuk lain waktu, tetapi sebagai catatan saya hanya ingin mengatakan bahwa opini yudisial saya terbatas dalam ruang lingkup.
skilfullycurled
pada 28 Jan 2019
Ya jangan khawatir NodeTags tidak menghapus Tag, hanya tautan yang terkait
tag dengan node dan penulis. Saya sudah melakukannya sebenarnya tetapi perlu menyiram
cache mingguan (itulah yang membuat semua ini menjadi mungkin) dan ada
beberapa bug yang lebih mendesak untuk diatasi terlebih dahulu yang baru saja muncul hari ini, maaf!
Pada Sen, Jan 28, 2019, 15:24 terampil meringkuk < [email protected]
menulis:
@ebarry https://github.com/ebarry , saya harus mengklarifikasi (kalau-kalau tidak).
Ketika saya berkata:
hapus tag dari database langsung
Maksud saya apa yang Anda tutup dengan:
...[bahwa] visualisasi tag kami [akan] mengecualikan semua konten dari moderasi
pengguna -- dan dengan ekstensi tag yang digunakan pada konten orang itu -- tanpa
mengecualikan tag itu secara umum [karena] tag tersebut dapat digunakan pada milik orang lain
isi...Jika pengguna yang dimoderasi dan Shan He sama-sama menggunakan tag "purelab", "purelab"
tidak akan dihapus, sembarang tag dari pengguna yang dimoderasi
atau, ITMU, jika Anda mau.Pertanyaan yang tersisa (jika saya mengerti @jywarren
https://github.com/jywarren ) adalah apakah akan menghapus ITMU ini atau tidak
dari database sepenuhnya, atau apakah kita menyimpannya di database tetapi menyaring
ITMU keluar ketika semua tag diminta untuk visualisasi.Menghapusnya membuat hidup lebih mudah bagi mereka yang menerapkan
visualisasi, tetapi mungkin ada argumen untuk melestarikannya.—
Anda menerima ini karena Anda disebutkan.
Balas email ini secara langsung, lihat di GitHub
https://github.com/publiclab/plots2/issues/1502#issuecomment-458244753 ,
atau matikan utasnya
https://github.com/notifications/unsubscribe-auth/AABfJzTXlk18FzlER4PQyoomFE5VTFcrks5vH0AqgaJpZM4OOvLP
.
jywarren
pada 28 Jan 2019
Oke, berhasil menghapus semua tag yang dibuat oleh pengguna yang dimoderasi. Mereka disimpan dalam cadangan. Ini cukup mudah dan tidak akan mempengaruhi kode untuk bergerak maju, tidak seperti solusi lainnya.
Sekarang saya ingin menyarankan bahwa mungkin ada tata letak berbeda yang ingin kita gunakan -- kita menggunakan tata letak cose , dan ada variasi ( bilkent dan lainnya) tetapi ada juga cola tata letak. Saya benar-benar tidak tahu yang tepat untuk digunakan di sini, tetapi beberapa tampaknya lebih sedikit mengaitkan tautan. Meskipun banyak demo di http://js.cytoscape.org/ memiliki lebih sedikit interlink daripada kumpulan data kami. Setiap masukan dihargai!
Dokumen tentang tata letak bawaan di
Masalah lain yang dapat kami coba untuk meminta seseorang untuk menguji dan mengambil adalah pertanyaan tentang deteksi komunitas. Saya belum dapat mengetahui cara kerjanya atau mengapa tidak mengenali grup di sini. Warnanya bagus, tapi satu simpul per komunitas. Bah.
jywarren
pada 28 Jan 2019
Jadi masalah ini sekarang perlu dipecah menjadi:
- iterasi tata letak (masukan sambutan dari kerumunan saat ini)
- deteksi komunitas
- pemfilteran tag tambahan (mungkin memfilter tag tanpa node yang tidak disetujui untuk membersihkan diri dari spam?)
juga ingin meninjau kembali bahwa kami sekarang melihat # tag tertentu (jangan uji ini hingga batasnya kecuali di https://stable.publiclab.org -- saya telah mencoba hingga 1000 tag dan memuat baiklah tetapi tidak lebih dari itu tolong di server produksi, bahkan sekali)
Dan kami terbatas pada tautan di antara mereka dengan setiap tag melaporkan maksimal 10 tag yang telah terjadi bersamaan. Ini tidak komprehensif, tetapi tampaknya merupakan keseimbangan yang layak antara pengoptimalan vs. ketelitian.
jywarren
pada 28 Jan 2019
jywarren
pada 28 Jan 2019
@jywarren , apakah ini masih komit terbaru ? Saya karena saya ingin melihat json datang dari titik akhir /tag/graph.json dan itu mengirimi saya semua tag. Berdasarkan kode dalam komit itu, saya mengharapkan 250 menjadi batas keras (catatan keterbacaan Ruby saya bertahan).
skilfullycurled
pada 31 Jan 2019
@jywarren sudahlah, saya tidak menyadari grafik sekarang ada di server produksi, saya menggunakan stable.publiclab.org.
skilfullycurled
pada 31 Jan 2019
Oke. Saya baru saja menghabiskan cukup banyak waktu untuk menjelajahi ini, dan saya mendapatkan perasaan yang lebih baik tentang cara kerja grafik.
Sekarang saya ingin menyarankan bahwa mungkin ada tata letak berbeda yang ingin kita gunakan -- kita menggunakan cose
Saya akan melihat dan memikirkannya. Saya pikir pertanyaan yang perlu dijawab di sini adalah apa yang ingin kita peroleh dari grafik? Misalnya, jika kami terutama ingin pengunjung dapat melihat tag mana yang terkait dengan tag mana, maka tata letak lingkaran atau lingkaran konsentris mungkin yang terbaik, seolah membosankan.
Jika saya harus menebak (diinformasikan, tetapi masih menebak) mengapa CoSE tidak memberikan hasil yang bagus, itu karena, dalam melihat data, saat Anda mencapai jumlah node tertentu, penghitungan dimulai untuk semua menjadi serupa. Jadi, jika CoSE menolak node hanya berdasarkan berat node, maka mungkin ada jumlah tolakan yang sama di antara mereka. Ketika saya menggunakan tolakan di sini, maksud saya semua hal yang menjadi tolakan, misalnya, pengaturan gravitasi juga. Dalam hal ini, bisa jadi tidak ada iterasi yang cukup dari algoritme atau faktor tolakan tidak menyebabkan/memungkinkan penyebaran yang cukup.
Masalah lain yang dapat kami coba untuk meminta seseorang untuk menguji dan mengambil adalah pertanyaan tentang deteksi komunitas.
Jika Anda punya waktu, bisakah Anda mengarahkan saya ke komit dengan JavaScript terbaru tentang ini? Saya bisa mendapatkannya melalui browser tetapi hanya dalam bentuk yang tidak memiliki struktur apa pun dan hanya satu baris. Segera setelah saya melakukannya, saya dapat melihat lebih banyak. Saya melihat contoh jLouvain, dan tampaknya tidak memiliki pengaturan untuk berapa banyak komunitas yang Anda inginkan yang mungkin menjadi bagian dari masalah. Biasanya Louvain menawarkan "nomor terbaik" tetapi terkadang itu bukan yang terbaik. Implementasi python yang menjadi dasar jLouvain memang memiliki parameter ini tetapi mungkin tidak berhasil.
skilfullycurled
pada 31 Jan 2019
Di sana kami:
jywarren
pada 1 Feb 2019

jywarren
pada 1 Feb 2019
Oh saya pikir saya akan meninggalkan komentar lain ... kemana perginya? tunggu sebentar...
jywarren
pada 1 Feb 2019
Bagaimanapun saya akan mengatakan bahwa saya pikir saya telah menemukan beberapa masalah tata letak tetapi nilai sendiri:
https://publiclab.org/stats/graph?limit=50
https://publiclab.org/stats/graph?limit=100
jywarren
pada 1 Feb 2019
Inilah JS untuk deteksi komunitas: https://github.com/publiclab/plots2/blob/master/app/views/tag/graph.html.erb#L263
Dan inilah konfigurasi tata letak, yang dapat kami ubah banyak untuk dicoba:
jywarren
pada 1 Feb 2019
Pertama, saya ingin meminta maaf bahwa saya tidak dapat membantu dengan beban berat di akhir pengkodean. Sangat mudah bagi seseorang hanya untuk menyarankan hal-hal tetapi saya menyadari bahwa mereka juga harus dilaksanakan oleh orang-orang dan tidak hilang pada saya bahwa saya tidak membantu dalam hal itu.
Ada beberapa kemungkinan mengapa jLouvain tidak bekerja dengan baik. @jywarren , saya pikir Anda sudah menyelesaikan salah satunya yaitu tidak ada cukup warna. Namun, saya memeriksa di konsol untuk komunitas dan setiap node adalah komunitas yang berbeda yang bagi saya menyiratkan bahwa algoritme tidak menemukan tempat yang baik untuk berhenti. Biasanya, ada parameter untuk berapa banyak komunitas/sensitivitas/resolusi yang ingin Anda miliki dan kemudian Anda bermain dengannya sampai Anda mendapatkan sesuatu yang tampak benar.
Lihat ini masalah ini di repositori jLouvain. Seseorang menulis perbaikan yang sangat sederhana yang dapat diterapkan. Saya tidak yakin bagaimana cara kerjanya dalam hal apa yang dikembalikannya: idealnya mengembalikan seluruh hasil deteksi komunitas untuk setiap elemen dalam array? Itu akan luar biasa, dan mungkin memecahkan masalah setiap simpul menjadi komunitasnya sendiri.
Nanti lagi…
skilfullycurled
pada 1 Feb 2019
Menyampaikan pertanyaan dari
ebarry
pada 6 Feb 2019
itu ide bagus. Saya pikir pada titik ini kita perlu menutup ini dan membuka
masalah baru dengan daftar periksa kemungkinan penyempurnaan tampilan, dan
akan lebih mudah bagi pendatang baru (lebih sedikit konteks dan sejarah yang diperlukan untuk
berpartisipasi) untuk masuk dan mulai menerapkannya. Saya hampir tergoda untuk
putar ke dalam repositori baru yaitu /hanya grafik ini/, karena itu
sebaliknya tidak interkoneksi dengan basis kode PL, tetapi demi
kohesi komunitas mari kita simpan di kavling2.
Liz, bisakah kamu memulai edisi baru dan memulai dengan daftar periksa?
Pada Rabu, 6 Februari 2019 pukul 11:17 Liz Barry [email protected] menulis:
Menyampaikan pertanyaan dari https://github.com/shapironick
siapa yang bertanya-tanya di saluran lain apakah di edisi mendatang mungkin ada
memvariasikan ketipisan dan ketebalan di jalur sambungan untuk menunjukkan seberapa dekat
terkait dua tag tertentu? Terima kasih!—
Anda menerima ini karena Anda disebutkan.
Balas email ini secara langsung, lihat di GitHub
https://github.com/publiclab/plots2/issues/1502#issuecomment-461083862 ,
atau matikan utasnya
https://github.com/notifications/unsubscribe-auth/AABfJ9nxysbBtCAYHEW2tA8UwNH9zelFks5vKv_hgaJpZM4OOvLP
.
jywarren
pada 6 Feb 2019
Ya! @shapironick! Saat ini, kueri basis data hanya mengirimkan tag-n teratas dan jumlah tag tersebut di seluruh situs. Di masa mendatang, untuk memiliki bobot tepi, kami perlu membuat perubahan di bagian belakang untuk mengirim semua tag ke ujung depan sehingga jumlah interkoneksi dapat digabungkan, atau mereka perlu digabungkan pada ujung belakang. Atau, di ujung depan kami menghitung beberapa properti tepi jaringan (misalnya, beberapa sentralitas: derajat, kedekatan, keantaraan, dll.).
skilfullycurled
pada 6 Feb 2019
Sangat keren! Tidak ada presh pada ide itu +1 untuk memulai masalah baru yang satu ini epik dan mengagumkan!
 shapironick
pada 6 Feb 2019
shapironick
pada 6 Feb 2019
Saat ini dalam data yang kami berikan ke kode grafik, saya pikir kami melihat ketika satu tag (katakanlah, tag A) ditautkan ke tag B, dan kami melihat koneksi kedua jika tag B menautkan kembali ke tag A. Tapi yang tidak benar-benar memberitahu kita banyak. Refactoring untuk memberikan "bobot" itu menarik ... saya bisa membayangkan beberapa cara untuk melakukan ini juga. Saya setuju, kita dapat memasukkan semua node.ids yang dimiliki setiap tag, dan menghitungnya secara lokal, atau kita dapat mencoba menghitungnya terlebih dahulu saat kita mengumpulkan 5 tag teratas dari masing-masing tag yang paling terkait. (saya pikir saya mengubah ini menjadi 10 baru-baru ini, tetapi bagaimanapun juga).
Penyempurnaan tindak lanjut yang bagus. Setelah kami memiliki daftar periksa, kami dapat memprioritaskan sedikit dan secara bertahap meningkatkan ini. Terima kasih!
jywarren
pada 6 Feb 2019
Oh lihat, ini berhasil menjadi catatan sejarah ;) : https://publiclab.org/wiki/community-development#2019
ebarry
pada 8 Feb 2019
Saat melihat ini untuk kemungkinan proyek Summer of Code musim panas mendatang, saya menemukan bug deteksi komunitas, yang halus -- data ada di objek bersarang seperti {data: { DATA }} daripada hanya { DATA } . Diperbaiki di https://github.com/publiclab/plots2/pull/9169 !
jywarren
pada 9 Feb 2021

jywarren
pada 9 Feb 2021
Itu hanya dengan data pengujian kami; perbaikan penuh akan terlihat di server stabil setelah kami menggabungkannya dan membangunnya kembali; mungkin 30m atau lebih.
jywarren
pada 9 Feb 2021
Bagus kita pergi:
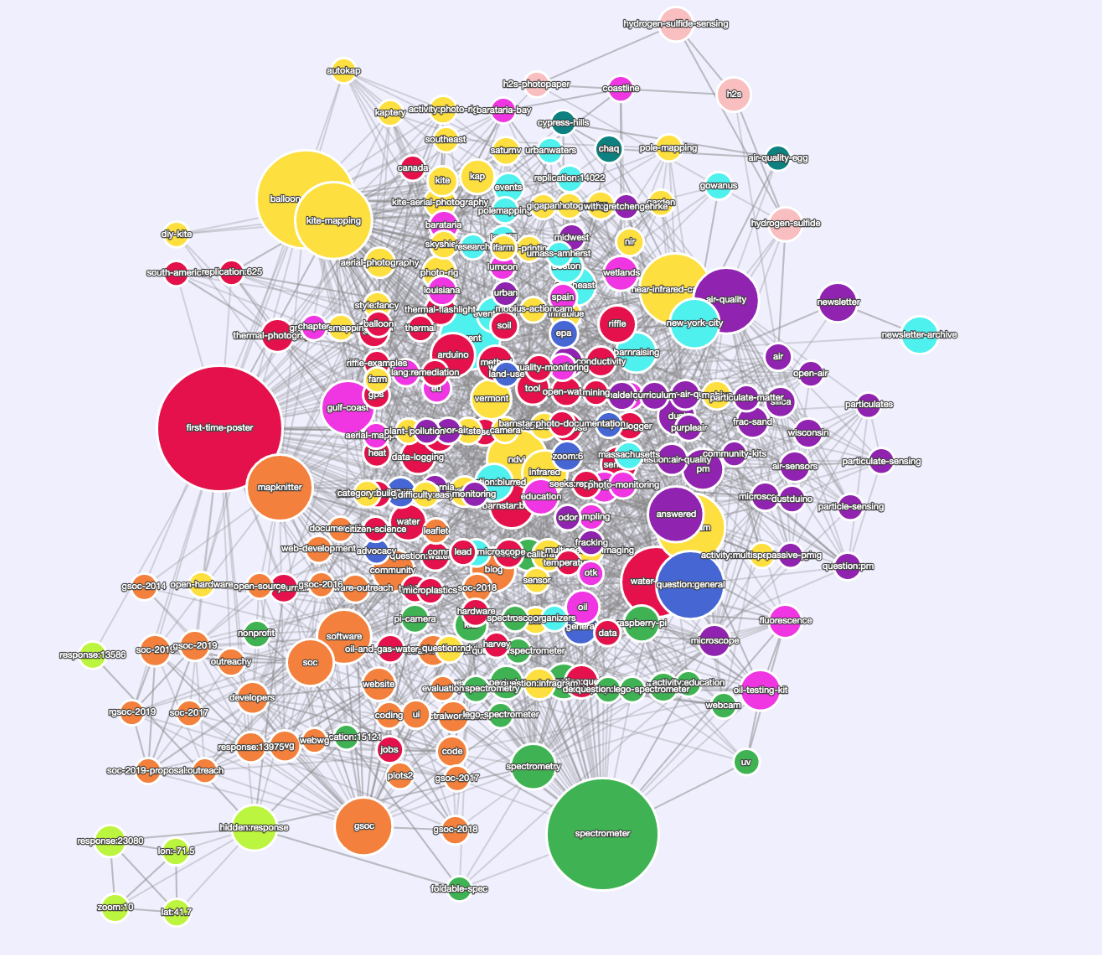
https://stable.publiclab.org/tags (ingat ini akan turun selama 10m setiap kali kami menggabungkan perubahan baru)
jywarren
pada 9 Feb 2021
Masalah terkait
 grvsachdeva
·
3Komentar
ebarry
·
3Komentar
grvsachdeva
·
3Komentar
ebarry
·
3Komentar
 keshavsethi
·
3Komentar
keshavsethi
·
3Komentar
![first-timers[bot] picture](https://avatars.githubusercontent.com/in/4832?v=4&s=40) first-timers[bot]
·
3Komentar
grvsachdeva
·
3Komentar
first-timers[bot]
·
3Komentar
grvsachdeva
·
3Komentar
Komentar yang paling membantu
Seharusnya sudah berjalan di situs langsung nanti malam, tetapi saya ingin mencatat bahwa "penggunaan tag yang berlebihan" oleh beberapa pengguna telah mengubah grafik dengan cara yang telah kami kenali sebelumnya. Saya yakin salah satu pengguna telah dimoderasi dari situs tersebut, dan saya bertanya-tanya apakah orang-orang berpikir pantas untuk menghapus tag tersebut dari situs atau setidaknya menghilangkannya dari grafik. Menghapusnya akan lebih mudah tetapi kita juga bisa membuat sesuatu untuk mengaburkannya. Preferensi, @ebarry @skillfullycurled ?
Tetap saja, ini terlihat bagus meskipun pengaturan pada elastisitas tepi masih memerlukan beberapa penyesuaian, dan mungkin jenis tata letak yang berbeda akan bekerja lebih baik...