Plots2: visualización de etiquetas de todas las etiquetas
Esta es una solicitud para que alguien con acceso a la edición de páginas especiales agregue esta visualización de etiquetas desde el comienzo del tiempo hasta noviembre de 2016 en la parte superior de publiclab.org/tags
https://www.dropbox.com/s/s78g3ufhsav5xzo/plots_tag_graph_256_filtered.png?dl=0
CC:
@gretchengehrke
@hillycurled
 ebarry
ebarry
Todos 73 comentarios
Hola, Liz. Soy un poco reacia a poner un gráfico estático como este en nuestra base de código permanente, pero tal vez una sugerencia podría ser que mostramos una "característica" (como nuestros banners) en la parte superior de esa página, y luego los administradores. podría mostrar lo que quieran allí. Funcionaría eso?
 jywarren
en 5 jul. 2017
jywarren
en 5 jul. 2017
Iría por encima o por debajo de esta línea: https://github.com/publiclab/plots2/blob/master/app/views/tag/index.html.erb#L4
Y lucir como:
<% cache('feature_tag-page-header') do %>
<%= feature('tag-page-header') %>
<% end %>
Bueno, no quiero tanto decorar esa página como agregar "información de un vistazo".
Un punto diferente, pero quizás relevante en cuanto a por qué sugeriría agregar una visualización gráfica es que esta página de etiquetas aún no tiene ninguna capacidad de clasificación para ver "recientes" o "populares" y mucho menos para ver cualquiera de esos por geografía.
ebarry
en 5 jul. 2017
En realidad, existen enlaces de python gephi que podríamos usar para generarlo dinámicamente. De hecho, estoy trabajando en una visualización de red de JavaScript en este momento, así que déjame ver cómo funciona. Si va bien, puedo traducir lo que hice en un script de Python que pueda generar la estructura de datos para luego visualizarla en javascript.
 skilfullycurled
en 5 jul. 2017
skilfullycurled
en 5 jul. 2017
Hola a todos, creo que un gráfico generado sería genial, y es algo que podríamos poner en el código permanente.
@ebarry No estoy diciendo que esto sea decoración y no contenido, más bien digo que esto quedaría desactualizado rápidamente, y también nuestro objetivo es almacenar / no / contenido en nuestra base de código, solo infraestructura. Entonces, esta es solo una forma de implementarlo: ¿mi solución propuesta suena bien?
re this tag page still doesn't have any sorting capabilities to see "recent" or "popular" much less to see either of those by geography. Me complacerá trabajar con usted para presentar algunas solicitudes de funciones para que los contribuyentes creen para resolver esto si es una prioridad para usted. ¡Podrían ser algunos problemas fáciles first-timers-only si puedes ayudar a ponerlos en la cola!
jywarren
en 5 jul. 2017
Volvamos a lo básico sobre este tema :)
¿Cuál es el objetivo de visualizar etiquetas?
Para mí, visualizar etiquetas es una forma de representar visualmente etiquetas asociadas, por ejemplo, etiquetas que aparecen juntas en el mismo contenido. Para ver un gran ejemplo, vea los grupos codificados por colores en la visualización de @skilfullycurled anterior. Las etiquetas de agrupación en clústeres son importantes porque conectan visualmente la presentación del sitio web de la actividad de la comunidad _ más cercana_ a lo que la comunidad de Public Lab denomina culturalmente "áreas de investigación", o quizás "temas" -> este es mi objetivo real con todo este problema.
Aquí hay algunos antecedentes: en nuestra página de etiquetas (https://publiclab.org/tags) escribimos "Usamos etiquetas para agrupar la investigación por tema" y alentamos a las personas a buscar etiquetas (actualmente solo ordenadas por actividad reciente). Esta es una forma importante en la que nombramos, vinculamos y / o promovemos a las personas para que encuentren temas e interactúen con ellos. El Tablero en sí enfatiza la actividad reciente. El panel ahora presenta una barra de "etiquetas usadas recientemente", que es un paso importante pero parcial hacia el objetivo de ver "áreas de investigación" o "temas".
Para seguir adelante, no estoy interesado en _navegar_ mediante una visualización de etiqueta gráfica (¡2007!), Sin embargo, los grupos de actividad proporcionan una forma adicional importante de conectarse / navegar a temas. Para lograr el objetivo, me refiero a la capacidad de la página de etiquetas para mostrar cuáles son las etiquetas más interconectadas, comunicar la amplitud de temas conectados en un área de investigación, navegar / conectarse a un área de investigación y suscribirse adecuadamente no necesariamente necesitan flechas en picada codificadas por colores. Pensemos en cómo lograr estos objetivos.
También podríamos considerar la posibilidad de duplicar publiclab.org/tags en publiclab.org/topics para que el idioma sea más accesible.
ebarry
en 15 nov. 2017
¡Genial, gracias Liz!
Para intentar una puñalada en una función más limitada hacia este objetivo, ¿qué pasaría si las páginas de etiquetas (nuevo nombre flotante: páginas de temas ...!?!) Tuvieran una lista de "Temas relacionados", algo como:
Temas relacionados:
waterrunoffwetlandsturbidity
Donde "relacionado" significa que (reconociendo que hay diferentes formas de medir esto, y que queremos alguna forma "computacionalmente eficiente") estas son las etiquetas que aparecen con mayor frecuencia en las páginas que ya tienen la etiqueta principal. Entonces, para el tema onions , contamos cada página etiquetada con onions y tomamos la parte superior, digamos, cinco.
Un pequeño seguimiento si lo anterior suena bien: ¿estaría bien hacer esto únicamente para las 20 a 30 páginas más recientes? Incluso si esto es solo un punto de partida, eso facilitaría la implementación sin preocuparse de que cause una lentitud general del sitio web. Podría haber formas más complejas de evitar esto, pero esta es la forma más fácil de comenzar.
jywarren
en 16 nov. 2017
Hice una publicación cruzada en https://publiclab.org/questions/tommystyles/10-20-2017/need-your-feedback-on-tag-pages : ¿qué piensas acerca de mover la discusión allí hasta que haya discretos específicos? pasos de codificación (mini proyectos para contribuyentes de código) que podemos hacer?
jywarren
en 16 nov. 2017
¡vale genial! vayamos a esa discusión y regresemos una vez que tengamos
Pasos factibles.
-
+ 1336-269-1539 / @lizbarry http://twitter.com/lizbarry / lizbarry.net
El miércoles 15 de noviembre de 2017 a las 9:54 p.m., Jeffrey Warren [email protected]
escribió:
Hice publicaciones cruzadas en https://publiclab.org/questions/tommystyles/10-20-
2017 / need-your-feedback-on-tag-pages: ¿qué opinas sobre la mudanza?
discusión allí hasta que haya pasos específicos de codificación discreta (mini
proyectos para contribuyentes de código) que podemos hacer?-
Recibes esto porque te mencionaron.
Responda a este correo electrónico directamente, véalo en GitHub
https://github.com/publiclab/plots2/issues/1502#issuecomment-344799932 ,
o silenciar el hilo
https://github.com/notifications/unsubscribe-auth/AAJ2n8PdvpH0GQ_wBU-Utp4xfL7XDmuJks5s26PpgaJpZM4OOvLP
.
ebarry
en 16 nov. 2017
@jywarren , @ebarry , ¿hay alguna API (o quizás documentación) para conocer los 'bordes' en el gráfico anterior? Quiero decir, ¿cómo están conectados los nodos?
¡Gracias 😄!
 sagarpreet-chadha
en 23 ene. 2018
sagarpreet-chadha
en 23 ene. 2018
¡Hola @ sagarpreet-chadha!
La visualización es solo una imagen, por lo que no hay API (¡todavía! Guiño), sin embargo, puedo proporcionarle la lista de bordes de ese gráfico en particular. Los formatos de archivo más "crudos" serían csv y json. Ambos formatos deberían funcionar con un gráfico, ya sea "mediante programación" ( iGraph , networkx , d3.js ) o con una GUI ( Gephi , Cytoscape ).
Aparentemente, no puede cargar archivos en github. Intenté subirlos a la nota de investigación del laboratorio público, pero no funciona. @jywarren, ¿hay alguna forma de cargar archivos en una nota de investigación? Si no es así, @ sagarpreet-chadha, ¿puedes hacer una publicación en el grupo de google plots-dev (puedes registrarte aquí si aún no lo estás)? Esperemos a ver qué dice @jywarren porque sería genial tenerlos directamente en la nota de investigación.
Sin embargo, esto es lo que puede esperar:
plots_tag_communities_edges_w_props_9_16.csv:: lista de bordes únicos con propiedades calculadas, en particular el peso del borde. El peso se traduce en la cantidad de veces que las etiquetas aparecieron juntas.
plots_tag_communities_nodes_w_props_9_16.csv: lista de nodos con propiedades calculadas. Lo más relevante para la imagen del sitio web es la "clase de modularidad" que le indica a qué comunidad pertenece cada nodo.
plots_tag_communities_9_16.json: No encuentro que json sea tan útil, pero sé que algunas personas lo prefieren. Creo que el archivo json también incluye propiedades para la visualización que está en el sitio web (es decir, el color RGB de cada nodo).
skilfullycurled
en 23 ene. 2018
Actualización: se eliminó plots_tag_communities_edgelist_9_16.csv de la lista de archivos anterior. Este archivo es de uso limitado porque los bordes duplicados ya se habían fusionado en bordes únicos con pesos. Sin las propiedades, esta lista de bordes solo le permitirá construir un gráfico con pesos de borde de 1. Buscaré el archivo original con los duplicados.
skilfullycurled
en 24 ene. 2018
¡Gracias @skilfullycurled por tu respuesta!
En realidad, estaba tratando de construir el gráfico de visualización usando la biblioteca javascript (d3.js o vis.js ) para que pudiera agregarse fácilmente al sitio web publiclab.org. Estas bibliotecas requieren los datos en forma de:
nodes: [
{
id: 1,
shape: 'circle',
label: 'Infrared } ] para nodos .
Y para los bordes :
edges: [
{from: 1, to: 2},
{from: 1, to: 3}]
Bueno, json sería genial, de lo contrario, puedo crearlo, o tal vez crear un objeto Javascript directamente (de esta manera, no es necesario analizar el archivo JSON).
He creado un gráfico ficticio (podemos jugar con los nodos y los bordes aquí 😄):
Qué piensas ? @ebarry , @jywarren , @skilfullycurled
sagarpreet-chadha
en 24 ene. 2018
¡Ah! ¡Que sería increíble! Bueno. Para promover esta conversación, tendremos que dejar "API-land" y pasar a cómo funciona la visualización en Gephi y la mejor manera de traducir esas características en javascript.
¿Puedo molestarte para que comiences esto como una pregunta ? Algo como, "¿Cómo puedo traducir la visualización de etiquetas creada en Gephi a una versión de JavaScript?"
Además, envíame un correo electrónico a benj. [email protected] para poder compartir los archivos. Eliminaré mi correo electrónico una vez que lo haga.
skilfullycurled
en 24 ene. 2018
En realidad, creo que es posible que no necesitemos dejar API-land; la API existente es bastante sólida en estos días. Tengo curiosidad @skilfullycurled cómo
¿Podrían generarse nuevos a partir de una lista de todas las etiquetas y los nodos en los que se han utilizado? Esa es una consulta razonable para que la generemos, si se almacena en caché.
Podríamos agregarlo a la API en https://github.com/publiclab/plots2/tree/master/app/api/srch y documentarlo en https://github.com/publiclab/plots2/blob/master/doc /API.md
Si son suficientes datos, la consulta podría ser algo como:
r = []
Tag.select(:name, :tid).each do |t|
nids = t.nodes.select(:nid, :status).where(status: 1).collect(&:nid)
r << [t.name, nids] if nids.length > 0
end
r # later, r.to_json
Lo ejecuté en producción y me llevó unos 15 segundos. Si lo almacenamos en caché a diario, creo que es manejable y podríamos mejorarlo aún más.
jywarren
en 25 ene. 2018
También puede compartir archivos en http://gist.github.com , ¿podría funcionar?
jywarren
en 25 ene. 2018
Entonces, usando el JSON generado a partir de mi consulta,
- en JavaScript, podríamos calcular la cantidad de veces que las etiquetas aparecieron juntas.
- ¿Cómo agruparon / calcularon las "comunidades"?
He aquí un extracto:
["whitebalance", [12476, 13575]], ["wi", [12143, 13067]], ["wi-fi", [11123]], ["width-of-dvd-grating", [12838, 12875, 12895, 12899, 12902, 12926, 12990, 12991, 12995, 12999, 13006, 13014, 13019, 13037, 13046, 13057, 13062, 13069, 13077, 13088, 13089, 13094, 13103, 13117, 13125, 13131, 13133, 13136, 13152, 13154, 13157, 13159, 13169, 13178, 13181, 13183, 13188, 13226, 13248, 13283, 13302, 13305, 13308, 13315, 13316, 13340, 13349, 13355, 13366, 13401, 13402, 13409, 13414, 13423, 13429, 13432, 13434, 13437, 13439, 13440, 13443]], ["wiki", [9048, 10956]], ["wiki-gardening", [10956]], ["wild", [11707, 11711]], ["wildfires", [14803]], ["wildlife", [670]], ["wilkinson-bay", [220, 265, 280, 281, 282, 283, 284, 677]], ["wilkinsonbay", [606]], ["williamsburg", [10343, 10428, 10444]], ["willow", [9979]], ["wind", [9032, 10660, 12610, 13880, 14487, 14527, 14530, 14531, 14713, 14756]], ["wind-direction", [14527]], ["wind-sensor", [14713]], ["wind-speed-meter", [1962, 5837, 9032, 12103, 13064, 13165, 13231, 13880, 14527]], ["winder", [7717]], ["winders", [1900]], ["window", [147, 1759]], ["windows", [11434, 11677, 13037]], ["windows-7", [13037]], ["windows-7-ultimate", [13037]], ["windows-excel", [13037]], ["windspeed", [745]], ["windvane", [14527]], ["windy", [146]], ["wine", [706, 10955]], ["winter", [5161]], ["wintercamp", [5103]], ["wired", [10315]], ["wireframes", [10623]], ["wireless", [3908, 9940, 11123, 12175]], ["wisconsin", [10504, 10552, 10611, 10619, 11331, 11783, 12142, 12143, 12192, 12221, 12337, 12537, 12539, 12562, 12597, 12610, 12919, 13067, 13216, 13217, 13219, 13222, 13223, 13224, 13406, 13578, 13920, 13921, 13922, 14018, 14044, 14087, 14146, 14648]], ["with", [11772, 13742, 14728]], ["with:abdul", [13407, 13412, 13413, 13428, 13493]], ["with:adam-griffith", [11049]], ["with:amal", [12161]], ["with:amandaf", [11556]], ["with:amberwise", [12338, 13280]], ["with:ann", [12850]], ["with:basurama", [11699, 11705]], ["with:becki", [13571]], ["with:bronwen", [10952, 12480, 13493, 14587]], ["with:bsugar", [13449]], ["with:btbonval", [11789]], ["with:cfastie", [11688, 13493, 13980]], ["with:chrisjob", [10464]], ["with:cindy_excites", [11566, 11567, 14537]], ["with:damarquis", [12338]], ["with:danbeavers", [11417, 11567]],
FWIW, puede haber una consulta aún más eficiente como esta, pero esta es bastante decente, aunque no devuelve completamente lo que se muestra arriba:
Tag.select('term_data.tid, term_data.name, community_tags.nid, community_tags.tid')
.includes(:node_tag)
.references(:node_tag)
Aunque esto no nos diría si el nodo se publicó (frente a spam) a menos que también mezclemos node.status allí. ¡Pero eso es posible!
jywarren
en 25 ene. 2018
Hola, tengo unas pocas preguntas aquí.
1.) Si 2 etiquetas pertenecen al mismo nodo, ¿tienen una ventaja entre ellas?
2.) Los diferentes colores son para diferentes tipos de nodos como preguntas, notas, notas de investigación, etc. ?
¡Gracias 😄!
sagarpreet-chadha
en 25 ene. 2018
Y también estoy de acuerdo con no dejar la API -land :)
sagarpreet-chadha
en 25 ene. 2018
Arg! Bueno. No apilemos, por favor. Nadie quiere quedarse en API-land más que yo (bueno, quizás con la excepción de @ebarry ). Según tengo entendido, la construcción de API-land casi se había retrasado indefinidamente debido a preocupaciones sobre la lentitud del sitio web ( consulte la extensión de la conversación aquí ). Pero ahora @jywarren dice que ya no es tan importante, que son buenos momentos en ese sentido.
Dado que el uso de Github puede ser una barrera para la información accesible (no todos tienen acceso, no saben cómo usar), creo (er ... pensé) tener conversaciones que no sean sobre "hacer las cosas" en el código base se relegaron mejor a el sitio web donde todos pueden aprender de ellos. Estas no son las normas de la comunidad que establecí (ver el propio comentario de @jywarren más arriba ) pero creo que son buenas.
skilfullycurled
en 25 ene. 2018
Vaya, lo siento @skilfullycurled No había recordado su último comentario en ese hilo - https://publiclab.org/questions/tommystyles/10-20-2017/need-your-feedback-on-tag-pages#answer - 556-comment-17709 - donde sugirió:
- solo se ejecuta en las 250 etiquetas principales
- almacenamiento en caché semanalmente
Haré ping en la parte de atrás, pero creo que con todo el trabajo en la API, la limpieza del código y el alcance, podríamos hacer una versión en caché diaria o semanal de dicha consulta, y estar bien con un cálculo total de 10-15 segundos. tiempo por semana. El resto se ejecutará localmente en el navegador. Repitiendo esto por ahí.
jywarren
en 25 ene. 2018
@jywarren Necesitaré comunicarme con usted sobre algunas de sus preguntas. Publicaré mi cuaderno de jupyter más tarde. Mientras tanto, consulte aquí para obtener una breve explicación de cómo se crea el gráfico a partir de los pares de etiquetas. Para obtener el código exacto, consulte aquí .
@ sagarpreet-chadha (y cualquier otra persona que esté interesada) puede ver cómo se creó un gráfico d3.js a partir de los datos de la etiqueta consultando el repositorio de tagoverflow, que fue la inspiración para este proyecto.
Con respecto a la detección de la comunidad, si miras en el repositorio de tagoverflow encontrarás que el autor implementó su propio algoritmo. Desde entonces, se han implementado otros como jLouvain , netClustering una implementación CNM ( ejemplo d3 ). Con un límite de 256 etiquetas, la detección de comunidades probablemente esté bien en el navegador.
skilfullycurled
en 25 ene. 2018
Para no abrumar la discusión de publiclab.org con una gran cantidad de datos, aquí hay un enlace al formato de datos que usa TagOverflow:
https://api.stackexchange.com/2.1/tags/python/related/?site=stackoverflow&key=of3hmyFapahonChi8EED6g ((& pagesize = 16
Hace como 15 llamadas para buscar qué etiquetas se relacionan con una etiqueta determinada (en el ejemplo anterior, "python")
jywarren
en 25 ene. 2018
Entonces, la diferencia entre eso y los datos que generé anteriormente es que mi consulta enumera los identificadores de nodo, pero no los ha usado para establecer la "relación". ¡Pero, por supuesto, el cuaderno Jupyter de @skilfullycurled hace esto! Genial, ¡gracias por compartir!
jywarren
en 25 ene. 2018
@ sagarpreet-chadha, publiqué una pregunta que preguntaba y respondía sus preguntas arriba:
https://publiclab.org/questions/bsugar/01-25-2018/how-was-the-tag-graph-visualization-made
No estoy tratando de ser "pasivo-agresivo" con mi solicitud, pero creo que la gente podría beneficiarse de que este aspecto de la conversación sea pública. Así que supongo que eso lo convierte en "agresivo agresivo". ; )
Dejando a un lado las bromas, ¡feliz de responder cualquier pregunta!
skilfullycurled
en 25 ene. 2018
¡Hola a todos!
@ sagarpreet-chadha, puse todos los archivos que necesitará aquí:
https://spideroak.com/browse/share/skilfullyshared/plots-tag-graph
La carpeta viene con un archivo Léame que explica el contenido.
Por favor, avíseme cuando los haya descargado para que pueda cerrar la habitación compartida. Eventualmente, los publicaré en mi cuenta de github para que otras personas tengan acceso a la wiki.
¡Encantado de responder cualquier otra pregunta que pueda tener!
skilfullycurled
en 1 feb. 2018
¡Gracias @skilfullycurled !
He descargado los archivos :-)
sagarpreet-chadha
en 2 feb. 2018
¡No hay problema @ sagarpreet-chadha!
PD: Te dejé un pensamiento de seguimiento en la pregunta wiki .
skilfullycurled
en 2 feb. 2018
Gran actualización sobre los cálculos de relación de etiquetas basados en rubí aquí: https://publiclab.org/questions/bsugar/01-25-2018/how-was-the-tag-graph-visualization-made
¡más pronto!
jywarren
en 17 ene. 2019
Algún progreso en https://github.com/publiclab/plots2/pull/4657 , donde implementé una instancia extremadamente básica, pero en vivo de Cytoscape.js (http://js.cytoscape.org/), que se ejecuta desde un colección en caché semanal de
Se necesitaron más de 50 segundos para ejecutar TODAS las etiquetas en el sitio (que podrían almacenarse en caché semanalmente) pero eso también generó más de 8200 etiquetas y 31k bordes ... que es mucho para graficar. Aquí está el juego completo; Creo que incluye muchas etiquetas de spam: https://gist.github.com/jywarren/4b1f9a032092a8187dd802a375fcb700
Puede especificar el número de etiquetas que desea consultar de esta manera: https://stable.publiclab.org/tag/graph.json?limit=10 (una vez publicado por completo, https://publiclab.org/tag/graph. json? límite = 10)
Actualmente está limitado a 5 "bordes" por nombre de etiqueta, lo que representa las 5 etiquetas que aparecen con mayor frecuencia junto a la etiqueta original.
Esto ahora está en vivo en el servidor de prueba estable (aunque esta rama se reconstruye con bastante frecuencia, por lo que la URL no siempre está en línea ... irónicamente) aquí:
https://stable.publiclab.org/stats/graph?limit=75
Los recuentos más grandes, como límite = 100 o 250, parecen mostrar algún tipo de error y tengo que perseguirlo un poco. Pero este es un buen comienzo.
Hay MUCHAS configuraciones que se pueden agregar para refinar esto (tamaño del nodo, fuerza del enlace, mucho más), consulte la galería en http://js.cytoscape.org para ver algunas posibilidades. Y hacer "familias" también puede ser posible, aunque necesitaría un poco más de información para eso.
jywarren
en 18 ene. 2019

jywarren
en 18 ene. 2019
Oh, https://stable.publiclab.org/stats/graph?limit=300 parece funcionar también
jywarren
en 18 ene. 2019
¡Detección de comunidad aquí! https://github.com/upphiminn/jLouvain/blob/master/README.md
jywarren
en 19 ene. 2019
@jywarren , ¡¡¡super guay !!!
sagarpreet-chadha
en 19 ene. 2019
También hay una variedad de algoritmos de agrupación en clústeres, que se pueden probar en la consola de JavaScript:
http://js.cytoscape.org/#collection/clustering
- eles.markovClustering ()
- nodos.kMeans ()
- nodos.kMedoids ()
- nodes.fuzzyCMeans ()
- nodes.hierarchicalClustering ()
- nodes.affinityPropagation ()
No estoy familiarizado con estos, pero todos parecen usar atributos de los nodos o bordes para crear grupos de elementos similares. Entonces, ¿qué debemos dar como atributos en los que basar la similitud?
Puede probar estos en la consola usando los ejemplos en los documentos, cosas como:
var clusters = cy.elements().hca({
mode: 'threshold',
threshold: 5,
attributes: [
function( node ){ return node.data('count'); }
]
});
clusters; // <= then inspect what this returns to see the clusters
De acuerdo, usando jlouvain pude agregar detección de comunidad: https://github.com/upphiminn/jLouvain
No tengo suficientes datos de prueba para ver cómo funcionará esto, pero si se aprueba el # 4679, lo fusionaré y deberíamos poder verlo ejecutándose con la detección de la comunidad en:
https://stable.publiclab.org/stats/graph?limit=101
(una vez que se construye)
jywarren
en 21 ene. 2019
¡Hola a todos! Viéndose genial. Lo siento, no he podido responder, me estoy poniendo al día con algunas cosas y volveré a esto más tarde hoy.
Mientras tanto, otro ingrediente que no creo haber mencionado en ninguna de mis otras publicaciones es el diseño. El más cercano a lo que usé es probablemente el diseño de fuerza . Técnicamente, puede haber sido algo llamado diseño de fuerza 2:
El diseño de la fuerza es una especie de atracción / repulsión de recocido que alcanza un estado estable según los parámetros que establezca (es decir, el número de iteraciones, la fuerza de atracción / repulsión). Aquí hay una demostración de d3 .
En cuanto a la detección de la comunidad y los pesos de los bordes, tiene algunas opciones, pero si desea recrear ese gráfico de etiquetas al que se hace referencia, entonces necesita una co-ocurrencia en la que cytoscape, como la fortuna lo tiene, tiene una función para ayudar a hacer más fácil.
oe_ratio = (all_questions_count * tag_count_AB) / (tag_count_A * tag_count_B)
Donde tag_count_AB = bordes.parallelEdges ()
Tal como estaban las cosas, primero reduje el conjunto de etiquetas a un número razonable (por ejemplo, los primeros 512), pero luego reduje las etiquetas que usé para la visualización al incluir solo las n etiquetas principales (¿tal vez 64?) Con un observado a la relación esperada por encima de 1.
Puede leer más en Tag Overflow . Este método es una forma de solucionar el problema en el que un nodo de borde o nodo puede ser importante pero de poco uso. Por ejemplo, en una tienda 100 personas _podría_ tener un 85% de probabilidad de comprar café y crema, pero cinco de esas personas _siempre_ compran café, crema y huevos. Así que definitivamente quiero tener 5 cartones de huevos en stock.
Una alternativa fácil es simplemente hacer que el peso del borde entre dos nodos sea tag_count_AB y solo tomar los bordes / nodos por encima de un umbral determinado. Personalmente, rara vez obtengo buenos resultados con esto debido a la razón anterior.
Con respecto a los otros métodos, puede que le interese la pág. 3. (2.2) a - pág. 7 (3.1) de este documento (sin matemáticas para estas partes) que intenta clasificar los diferentes tipos de métodos de detección comunitaria. Esto me ha ayudado a elegir los que brindan los resultados más destacados dada la forma en que he estructurado el gráfico y lo que quiero saber de él. Por ejemplo, comunidades de conexiones sociales comunes frente a comunidades basadas en la frecuencia con la que se envían mensajes entre dos personas.
skilfullycurled
en 21 ene. 2019
¡Trabajando ahora en un servidor estable!
jywarren
en 25 ene. 2019

¡Aquí con 99 etiquetas superiores!
jywarren
en 25 ene. 2019
Debería estar ejecutándose en el sitio en vivo esta noche, pero quería señalar que el "uso excesivo" de las etiquetas por parte de algunos usuarios ha sesgado el gráfico de una manera que hemos reconocido antes. Creo que uno de los usuarios ha sido moderado del sitio, y me preguntaba si la gente pensaba que era apropiado eliminar esas etiquetas del sitio o al menos omitirlas del gráfico. Eliminarlos sería más fácil, pero también podemos crear algo para ocultarlos. ¿Preferencia, @ebarry @skilfullycurled ?
Aún así, esto se ve bien a pesar de que la configuración de la elasticidad del borde todavía necesita algunos ajustes, y tal vez un tipo de diseño diferente funcionaría mejor ...

jywarren
en 25 ene. 2019
¡Sí! Definitivamente nos hemos encontrado con este problema. Desafortunadamente, lo único que se podía hacer era eliminar a ese usuario en particular como un valor atípico. Alguien que usa tantas etiquetas puede no ser un valor atípico en sí mismo, pero si está creando etiquetas que son tan específicas para sí mismo y las usa una y otra vez, entonces realmente no está capturando los datos.
skilfullycurled
en 25 ene. 2019
Creo que incluso registré un problema de github con una solicitud de función que apareció una advertencia que, en esencia, diría: "¡Guau, tranquilo amigo! Parece que tienes muchas etiquetas allí, ¿eh?".
skilfullycurled
en 25 ene. 2019
Oh, PD. ¡¡Luciendo increíble por cierto !!
skilfullycurled
en 25 ene. 2019
AAAAAAHHHHHHHHMAYZINGGGGGGGGGG !!!!!!!!!!!!
Sí para "eliminar manualmente ese usuario en particular como un valor atípico"
ebarry
en 26 ene. 2019
Sigo volviendo a este hilo por lo increíble que es y por pensar en las cosas (con suerte, pequeñas). Otra cosa que podría considerar filtrar son las etiquetas de poder (esas son las que tienen dos puntos, ¿no?). Creo que tan pronto como se solucione el problema del uso excesivo de etiquetas, sabremos más sobre el diseño.
Nota personal: aquí hay un enlace a un compromiso con las páginas que son importantes para la implementación.
skilfullycurled
en 26 ene. 2019
Hola a todos, ¡me alegro del entusiasmo! Me enfermé, pero ahora me estoy recuperando y trabajaré un poco en esto en el vuelo a casa el martes.
Quería preguntar, mi pregunta específica es si deberíamos:
- eliminar etiquetas de este usuario moderado, o
- si deberíamos intentar preservarlos pero filtrarlos.
El filtrado supondría mucho más trabajo tanto para el código como para las llamadas a la base de datos, pero es posible.
jywarren
en 27 ene. 2019
En casos como este, en el que una cuenta se ha vuelto "inactiva" debido a la moderación, creo que está bien eliminar las etiquetas de la base de datos directamente. Especialmente si tienes una copia de seguridad. No porque desee restaurarlo, solo porque tengo ansiedad por perder datos para siempre. No es saludable, pero el espacio barato es un facilitador desafortunado. Mis sentimientos serían más complicados si este fuera un relato que se hizo "inactivo" por elección, pero podemos discutirlo en otro momento (o ahora).
skilfullycurled
en 27 ene. 2019
Sí, este es un gran tema para contemplar. Después de revisar si hay etiquetas que _sólo_ este usuario ha usado (ejemplo: aries city-point ), descubrí que en realidad hay muy pocas etiquetas completamente aisladas para este usuario (incluso purelab fue usado originalmente por Shan He para el filtrado de agua de bricolaje, y research-notes se usó originalmente en publicaciones sobre el diseño de notas de investigación en el sitio web).
Dado que este usuario está moderado, ¿nuestra visualización de etiquetas puede excluir todo el contenido de los usuarios moderados y, por extensión, las etiquetas utilizadas en el contenido de esa persona, sin excluir esa etiqueta en general, ya que puede usarse en el contenido de otras personas?
ebarry
en 28 ene. 2019
@ebarry , debo aclarar (en caso de que no fuera así).
Cuando dije:
eliminar las etiquetas de la base de datos directamente
Quise decir con lo que cerraste:
... [que] nuestra visualización de etiquetas [excluirá] todo el contenido de los usuarios moderados - y por extensión las etiquetas utilizadas en el contenido de esa persona - sin excluir esa etiqueta en general [ya que] puede usarse en el contenido de otras personas. ..
Si el usuario moderado y Shan He usaron la etiqueta "purelab", "purelab" no se eliminaría, solo cualquier instancia de la etiqueta del usuario moderado o de ITMU, por así decirlo.
La pregunta restante (si entiendo a @jywarren) es si eliminar o no estas ITMU de la base de datos por completo, o las mantenemos en la base de datos pero filtramos las ITMU cuando se solicitan todas las etiquetas para la visualización. Eliminarlos hace la vida mucho más fácil para quienes implementan la visualización, pero puede haber argumentos para preservarlos.
Personalmente, creo que lo primero está bien cuando el usuario ha sido moderado porque no hay posibilidad de que el contenido vuelva al sitio. Sin embargo, esto podría ser diferente si un usuario elige eliminar su cuenta en función de si existe o no alguna funcionalidad en la que pueda reactivarla. Creo que podemos dejar esa situación para otro momento, pero para que conste, solo quería decir que mi opinión judicial tiene un alcance limitado.
skilfullycurled
en 28 ene. 2019
Sí, no te preocupes, NodeTags no borra la etiqueta, solo el enlace asociado
etiquetas con nodos y autores. En realidad ya lo hice pero necesito enjuagar
el caché semanal (eso es lo que hizo posible todo esto) y hay
un par de errores más urgentes para abordar primero que surgieron hoy, ¡lo siento!
El lunes 28 de enero de 2019 a las 3:24 p. M. Rizado hábilmente < [email protected]
escribió:
@ebarry https://github.com/ebarry , debo aclarar (en caso de que no fuera así).
Cuando dije:
eliminar las etiquetas de la base de datos directamente
Quise decir con lo que cerraste:
... [que] nuestra visualización de etiquetas [excluirá] todo el contenido de moderado
usuarios y, por extensión, las etiquetas utilizadas en el contenido de esa persona, sin
excluyendo esa etiqueta en general [ya que] se puede usar en otras personas
contenido...Si el usuario moderado y Shan He utilizaron la etiqueta "purelab", "purelab"
no se eliminaría, solo cualquier instancia de la etiqueta del usuario moderado
o ITMU, si lo desea.La pregunta restante (si entiendo a @jywarren
https://github.com/jywarren ) es si eliminar o no estos ITMU
de la base de datos por completo, o los mantenemos en la base de datos pero filtramos
la ITMU sale cuando se solicitan todas las etiquetas para la visualización.Eliminarlos hace la vida mucho más fácil para quienes implementan el
visualización, pero puede haber argumentos para preservarlos.-
Recibes esto porque te mencionaron.
Responda a este correo electrónico directamente, véalo en GitHub
https://github.com/publiclab/plots2/issues/1502#issuecomment-458244753 ,
o silenciar el hilo
https://github.com/notifications/unsubscribe-auth/AABfJzTXlk18FzlER4PQyoomFE5VTFcrks5vH0AqgaJpZM4OOvLP
.
jywarren
en 28 ene. 2019
OK, logré eliminar todas las etiquetas creadas por el usuario moderado. Se almacenan en copias de seguridad. Esto fue bastante fácil y no afectará al código en el futuro, a diferencia de la otra solución.
Ahora quiero sugerir que podría haber un diseño diferente que queramos usar: estamos usando un diseño cose , y hay variaciones ( bilkent y otros) pero también hay un cola diseño. Realmente no sé cuál es el apropiado para usar aquí, pero algunos parecen enredar menos los enlaces. Aunque muchas de las demostraciones en http://js.cytoscape.org/ tienen menos enlaces que nuestro conjunto de datos. ¡Cualquier aportación apreciada!
Documentos sobre diseños integrados en http://js.cytoscape.org/#layouts
Otro tema que podemos intentar pedirle a alguien que pruebe y aborde es la cuestión de la detección de la comunidad. No he podido averiguar cómo funciona o por qué no reconoce grupos aquí. Los colores son agradables, pero son un nodo por comunidad. Bah.
jywarren
en 28 ene. 2019
Entonces, este problema ahora debe dividirse en:
- iteración de diseño (entrada de bienvenida de la multitud actual)
- detección de comunidad
- filtrado de etiquetas adicional (¿tal vez filtrar etiquetas sin nodos no aprobados para deshacernos del spam?)
También quiero volver a visitar que ahora estamos viendo un número específico de etiquetas (no pruebe esto hasta sus límites a menos que esté en https://stable.publiclab.org; probé hasta 1000 etiquetas y se carga bien, pero no más que eso, por favor en el servidor de producción, aunque sea una vez)
Y estamos limitados a los enlaces entre ellos con cada etiqueta que informa un máximo de 10 etiquetas que se han producido al mismo tiempo. Esto no es exhaustivo, pero parecía un equilibrio factible de optimización frente a minuciosidad.
jywarren
en 28 ene. 2019
jywarren
en 28 ene. 2019
@jywarren , ¿sigue siendo este el último compromiso ? Yo porque quería ver el json viniendo del punto final /tag/graph.json y me envió todas las etiquetas. Según el código de esa confirmación, habría esperado que 250 fuera el límite estricto (se resiste mi nota de legibilidad de Ruby).
skilfullycurled
en 31 ene. 2019
@jywarren no importa, no me di cuenta de que el gráfico estaba ahora en el servidor de producción, estaba usando stable.publiclab.org.
skilfullycurled
en 31 ene. 2019
Bueno. Pasé bastante tiempo explorando esto y estoy teniendo una mejor idea de cómo está funcionando el gráfico.
Ahora quiero sugerir que podría haber un diseño diferente que queramos usar: estamos usando un cose
Lo echaré un vistazo y lo pensaré. Creo que la pregunta que debe responderse aquí es ¿qué queremos que se extraiga del gráfico? Por ejemplo, si estamos interesados principalmente en que un visitante pueda ver qué etiquetas están asociadas con cuáles, entonces el diseño del círculo concéntrico podrían ser los mejores, por aburridos que sean.
Si tuviera que adivinar (informado, pero aún adivinar) sobre por qué CoSE no está dando un resultado tan bueno, sería porque, al mirar los datos, a medida que alcanza un cierto recuento de nodos, comienzan los recuentos. que todos sean similares. Entonces, si CoSE repele los nodos basándose solo en el peso del nodo, entonces es posible que haya una cantidad igual de repulsión entre ellos. Cuando utilizo la repulsión aquí, me refiero a todas las cosas que entran en repulsión, por ejemplo, su configuración de gravedad también. En ese caso, podría ser que no haya suficientes iteraciones del algoritmo o que los factores de repulsión no causen / permitan una propagación suficiente.
Otro tema que podemos intentar pedirle a alguien que pruebe y aborde es la cuestión de la detección de la comunidad.
Cuando tenga un momento, ¿puede indicarme el compromiso con el último JavaScript sobre esto? Puedo obtenerlo a través del navegador, pero solo en esa forma donde no tiene ninguna estructura y es solo una línea. Tan pronto como lo hago, puedo ver más. Miré el ejemplo de jLouvain y no parece tener una configuración para cuántas comunidades desea, lo que podría ser parte del problema. Normalmente, Louvain ofrece un "mejor número", pero a veces no es el mejor. La implementación de Python en la que se basa jLouvain tiene este parámetro, pero es posible que no lo haya superado.
skilfullycurled
en 31 ene. 2019
Alli estamos nosotros:
jywarren
en 1 feb. 2019

jywarren
en 1 feb. 2019
Oh, pensé que había dejado otro comentario ... ¿a dónde fue? Aférrate...
jywarren
en 1 feb. 2019
De todos modos, iba a decir que creo que he descubierto algunos de los problemas de diseño, pero juzguen ustedes mismos:
https://publiclab.org/stats/graph?limit=50
https://publiclab.org/stats/graph?limit=100
jywarren
en 1 feb. 2019
Aquí está el JS para la detección de la comunidad: https://github.com/publiclab/plots2/blob/master/app/views/tag/graph.html.erb#L263
Y aquí está la configuración del diseño, que podríamos modificar mucho para probar:
jywarren
en 1 feb. 2019
Primero, quiero disculparme por no poder ayudar con el trabajo pesado en el extremo de la codificación. Es fácil para uno solo sugerir cosas, pero me doy cuenta de que también deben ser implementadas por personas y no se me escapa que no estoy ayudando en ese sentido.
Hay varias posibilidades de por qué jLouvain no está funcionando bien. @jywarren , creo que ya estás resolviendo uno de ellos que es que no había suficientes colores. Aún así, verifiqué las comunidades en la consola y cada nodo es una comunidad diferente, lo que para mí implica que el algoritmo no encuentra un buen lugar para detenerse. Por lo general, hay un parámetro para la cantidad de comunidades / sensibilidad / resolución que le gustaría tener y luego juega con él hasta que obtiene algo que se ve bien.
Vea este problema en el repositorio de jLouvain. Alguien escribió una solución muy simple que podría implementarse. No estoy seguro de cómo funciona en términos de lo que devuelve: lo ideal es que devuelva un resultado de detección de la comunidad completa para cada elemento de la matriz. Eso sería increíble y probablemente resolvería el problema de que cada nodo sea su propia comunidad.
Más tarde…
skilfullycurled
en 1 feb. 2019
Transmitiendo una pregunta de @shapironick que se preguntaba en otro canal si en una edición futura podría haber diferentes delgadez y grosor en las líneas de conexión para mostrar qué tan estrechamente relacionadas están dos etiquetas en particular. ¡Gracias!
ebarry
en 6 feb. 2019
es una gran idea. Creo que en este punto debemos cerrar esto y abrir una
nuevo número con una lista de verificación de posibles mejoras en la pantalla, y
será mucho más fácil para los recién llegados (se requiere menos contexto e historia para
participar) para entrar y comenzar a implementarlos. Casi estoy tentado a
gírelo en un nuevo repositorio que es / solo este gráfico /, ya que
no se interconecta de otra manera con la base de código PL, pero por el bien de
cohesión de la comunidad vamos a mantenerlo en parcelas2.
Liz, ¿podrías comenzar el nuevo número y comenzar con una lista de verificación?
El miércoles 6 de febrero de 2019 a las 11:17 a.m., Liz Barry [email protected] escribió:
Transmitiendo una pregunta de @shapironick https://github.com/shapironick
quién se preguntaba en otro canal si en una próxima edición podría haber
variando la delgadez y el grosor en las líneas de conexión para mostrar qué tan cerca
¿Qué dos etiquetas en particular están relacionadas? ¡Gracias!-
Recibes esto porque te mencionaron.
Responda a este correo electrónico directamente, véalo en GitHub
https://github.com/publiclab/plots2/issues/1502#issuecomment-461083862 ,
o silenciar el hilo
https://github.com/notifications/unsubscribe-auth/AABfJ9nxysbBtCAYHEW2tA8UwNH9zelFks5vKv_hgaJpZM4OOvLP
.
jywarren
en 6 feb. 2019
¡Hurra! @shapironick! En este momento, la consulta de la base de datos solo envía las etiquetas top-n y el recuento de esas etiquetas en todo el sitio. En el futuro, para tener pesos de borde, tendríamos que hacer un cambio en el back-end para enviar todas las etiquetas al front-end para que se puedan agregar los recuentos de interconexión, o deben agregarse en el back end. Alternativamente, en el extremo frontal calculamos alguna propiedad del borde de la red (por ejemplo, cierta centralidad: grado, cercanía, intermediación, etc.).
skilfullycurled
en 6 feb. 2019
¡Muy genial! No hay que adelantarse a esa idea +1 para comenzar un nuevo número, ¡aunque este es épico e increíble!
 shapironick
en 6 feb. 2019
shapironick
en 6 feb. 2019
En este momento, en los datos que estamos pasando al código del gráfico, creo que vemos cuando una etiqueta (digamos, la etiqueta A) está vinculada a la etiqueta B, y vemos una segunda conexión si la etiqueta B se vincula a la etiqueta A. Pero eso realmente no nos dice mucho. Refactorizar para proporcionar "peso" es interesante ... podría imaginar algunas formas de hacer esto también. Estoy de acuerdo, podríamos pasar todos los node.ids que tiene cada etiqueta y calcularlo localmente, o podríamos intentar calcularlo previamente en el momento en que recopilemos las 5 etiquetas más relacionadas con cada etiqueta. (Creo que cambié esto a 10 recientemente, pero de todos modos).
Gran refinamiento de seguimiento. Una vez que tengamos la lista de verificación, podemos priorizar un poco y mejorar esto gradualmente. ¡Gracias!
jywarren
en 6 feb. 2019
Oh, mira, esto se convirtió en el registro histórico;): https://publiclab.org/wiki/community-development#2019
ebarry
en 8 feb. 2019
Mientras investigaba esto para un posible proyecto Summer of Code este próximo verano, encontré el error de detección de la comunidad, que era sutil: los datos estaban en un objeto anidado como {data: { DATA }} lugar de solo { DATA } . ¡Corregido en https://github.com/publiclab/plots2/pull/9169 !
jywarren
en 9 feb. 2021

jywarren
en 9 feb. 2021
Eso es solo con nuestros datos de prueba; el arreglo completo será visible en el servidor estable una vez que lo fusionemos y se reconstruya; probablemente unos 30 m.
jywarren
en 9 feb. 2021
Bien ahí vamos:
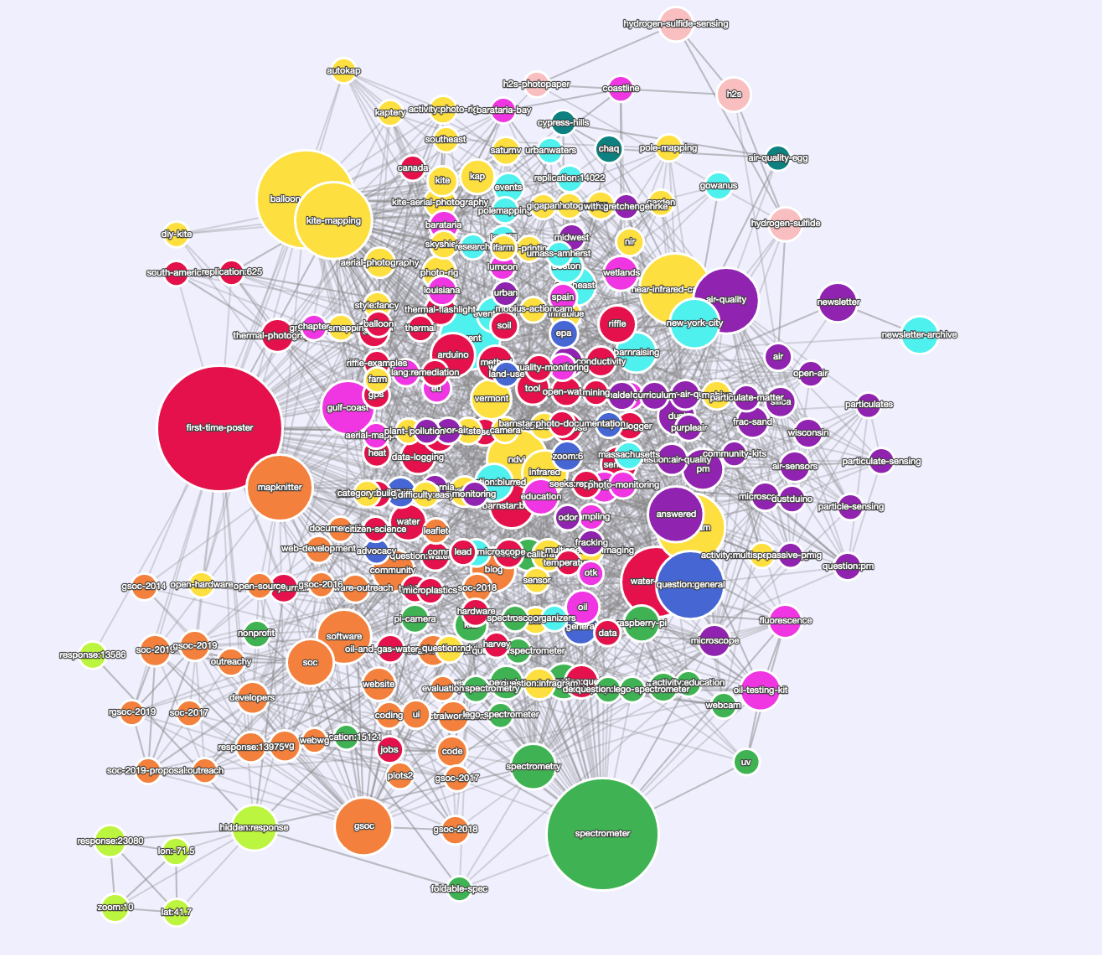
https://stable.publiclab.org/tags (recuerde que esto bajará durante 10 m cada vez que combinemos un nuevo cambio)
jywarren
en 9 feb. 2021
Temas relacionados
 grvsachdeva
·
3Comentarios
grvsachdeva
·
3Comentarios
![first-timers[bot] picture](https://avatars.githubusercontent.com/in/4832?v=4&s=40) first-timers[bot]
·
3Comentarios
first-timers[bot]
·
3Comentarios
 RuthNjeri
·
3Comentarios
RuthNjeri
·
3Comentarios
 divyabaid16
·
3Comentarios
first-timers[bot]
·
3Comentarios
divyabaid16
·
3Comentarios
first-timers[bot]
·
3Comentarios
Comentario más útil
Debería estar ejecutándose en el sitio en vivo esta noche, pero quería señalar que el "uso excesivo" de las etiquetas por parte de algunos usuarios ha sesgado el gráfico de una manera que hemos reconocido antes. Creo que uno de los usuarios ha sido moderado del sitio, y me preguntaba si la gente pensaba que era apropiado eliminar esas etiquetas del sitio o al menos omitirlas del gráfico. Eliminarlos sería más fácil, pero también podemos crear algo para ocultarlos. ¿Preferencia, @ebarry @skilfullycurled ?
Aún así, esto se ve bien a pesar de que la configuración de la elasticidad del borde todavía necesita algunos ajustes, y tal vez un tipo de diseño diferente funcionaría mejor ...