Plots2: визуализация всех тегов
Это просьба к тем, кто имеет доступ к редактированию специальных страниц, чтобы добавить эту визуализацию тегов с начала времен до ноября 2016 года в начало publiclab.org/tags.
https://www.dropbox.com/s/s78g3ufhsav5xzo/plots_tag_graph_256_filtered.png?dl=0
CC:
@gretchengehrke
@skilfullycurled
 ebarry
ebarry
Все 73 Комментарий
Привет, Лиз, я немного не хочу помещать такую статическую графику в нашу постоянную базу кода, но, возможно, есть предложение, чтобы мы отображали «функцию» (например, наши баннеры) в верхней части этой страницы, а затем администраторы могут отображать там все, что хотят. Это сработает?
 jywarren
5 июл. 2017
jywarren
5 июл. 2017
Он будет располагаться выше или ниже этой строки: https://github.com/publiclab/plots2/blob/master/app/views/tag/index.html.erb#L4
И выглядят так:
<% cache('feature_tag-page-header') do %>
<%= feature('tag-page-header') %>
<% end %>
Что ж, я не столько хочу украшать эту страницу, сколько хочу добавить «понимание с первого взгляда».
Другой момент, но, возможно, актуальный в отношении того, почему я предлагаю добавить графическую визуализацию, заключается в том, что на этой странице тегов по-прежнему нет никаких возможностей сортировки, чтобы увидеть «недавние» или «популярные», не говоря уже о том, чтобы увидеть их по географическому признаку.
ebarry
5 июл. 2017
На самом деле существуют привязки python gephi, которые мы могли бы использовать для его динамической генерации. Я на самом деле сейчас работаю над визуализацией сети с помощью javascript, поэтому позвольте мне посмотреть, как это работает. Если все пойдет хорошо, я могу перевести то, что я сделал, в скрипт python, который может сгенерировать структуру данных, которая затем будет визуализирована в javascript.
 skilfullycurled
5 июл. 2017
skilfullycurled
5 июл. 2017
Привет всем - я думаю, что сгенерированный график был бы отличным, и это то, что мы могли бы вставить в постоянный код.
@ebarry я не говорю, что это украшение, а не контент, я скорее говорю, что это быстро
re this tag page still doesn't have any sorting capabilities to see "recent" or "popular" much less to see either of those by geography. Я был бы рад поработать с вами, чтобы составить несколько запросов о функциях, чтобы побудить участников создавать для решения этой проблемы, если это является для вас приоритетом. Могут возникнуть простые first-timers-only проблемы, если вы поможете поставить их в очередь!
jywarren
5 июл. 2017
Вернемся к основам этого вопроса :)
Какова цель визуализации тегов?
Для меня визуализация тегов - это способ визуального изображения связанных тегов, например тегов, которые появляются вместе в одном и том же контенте. В качестве отличного примера см. Цветные кластеры в визуализации @skilfullycurled выше. Теги кластеризации важны, потому что они визуально связывают представление на веб-сайте деятельности сообщества _closer_ с тем, что сообщество Public Lab в культуре называет «областями исследований» или, возможно, «темами» -> это моя настоящая цель в этой проблеме.
Вот некоторая справочная информация: на нашей странице тегов (https://publiclab.org/tags) мы пишем «Мы используем теги для группировки исследований по темам» и призываем людей просматривать теги (в настоящее время отсортированные только по недавним действиям). Это важный способ, которым мы называем, ссылаемся и / или продвигаем людей, чтобы они находили темы и занимались ими. Сама панель инструментов подчеркивает недавнюю активность. На панели инструментов теперь есть панель «недавно использованные теги», которая является важным, но частичным шагом к цели просмотра «областей исследования» или «тем».
Двигаясь вперед, меня не интересует _навигация_ с помощью визуализации графических тегов (так что в 2007 году!), Однако кластеры действий предоставляют важный дополнительный способ подключения / перехода к темам. Для достижения цели, под которой я подразумеваю возможность для страницы тегов показывать, какие теги наиболее взаимосвязаны, сообщать о широте связанных тем в области исследования, перемещаться / подключаться к области исследования и соответствующим образом подписываться, мы не обязательно нужны летающие стрелки с цветовой кодировкой. Давайте подумаем, как достичь этих целей.
Мы могли бы также рассмотреть возможность зеркалирования publiclab.org/tags на publiclab.org/topics, чтобы сделать язык более доступным.
ebarry
15 нояб. 2017
Круто, спасибо Лиз!
Чтобы попытаться сделать один удар по более узкой функции для достижения этой цели, что, если бы страницы тегов (плавающее новое имя: страницы тем ...!?!) Имели список "Связанных тем", например:
Связанные темы:
waterrunoffwetlandsturbidity
Где «связанный» означает, что (подтверждая, что существуют разные способы измерения этого и что нам нужен какой-то «вычислительно эффективный» способ), это теги, которые чаще всего появляются на страницах, которые уже имеют основной тег. Итак, для темы onions мы подсчитываем каждую страницу с тегами onions и берем верхние, скажем, пять.
Небольшое продолжение, если все вышесказанное звучит хорошо - можно ли сделать это только для последних 20-30 страниц? Даже если это всего лишь отправная точка, это упростит реализацию, не беспокоясь о том, что это приведет к общей медлительности веб-сайта. Могут быть более сложные способы обойти это, но это самый простой способ начать.
jywarren
16 нояб. 2017
Я написал кросс-пост на https://publiclab.org/questions/tommystyles/10-20-2017/need-your-feedback-on-tag-pages - что вы думаете о переносе обсуждения туда, пока не появятся конкретные дискретные шаги кодирования (мини-проекты для разработчиков кода), которые мы можем сделать?
jywarren
16 нояб. 2017
Ок, отлично! давай перейдем к этому обсуждению и вернемся, когда у нас будет
выполнимые шаги.
-
+1 336-269-1539 / @lizbarry http://twitter.com/lizbarry / lizbarry.net
В среду, 15 ноября 2017 г., в 21:54, Джеффри Уоррен [email protected]
написал:
Я разместил кросс-пост на https://publiclab.org/questions/tommystyles/10-20-
2017 / need-your-feedback-on-tag-pages - что вы думаете о перемещении
обсуждение там, пока не появятся конкретные шаги дискретного кодирования (мини
проекты для разработчиков кода) мы можем сделать?-
Вы получаете это, потому что вас упомянули.
Ответьте на это письмо напрямую, просмотрите его на GitHub
https://github.com/publiclab/plots2/issues/1502#issuecomment-344799932 ,
или отключить поток
https://github.com/notifications/unsubscribe-auth/AAJ2n8PdvpH0GQ_wBU-Utp4xfL7XDmuJks5s26PpgaJpZM4OOvLP
.
ebarry
16 нояб. 2017
@jywarren , @ebarry , есть ли какой-нибудь API (или, возможно, документация), чтобы узнать «ребра» в приведенном выше графике? Я имею в виду, как связаны узлы?
Спасибо 😄!
 sagarpreet-chadha
23 янв. 2018
sagarpreet-chadha
23 янв. 2018
Привет @ sagarpreet-chadha!
Визуализация - это просто изображение, поэтому API (пока!) Нет, но я могу предоставить вам список ребер из этого конкретного графа. Наиболее "сырые" форматы файлов - это csv и json. Оба формата должны работать с графом либо «программно» ( iGraph , networkx , d3.js ), либо с графическим интерфейсом ( Gephi , Cytoscape ).
Видимо нельзя загружать файлы на github. Я попытался загрузить их в заметку об исследовании Public Lab, но ничего не вышло. @jywarren есть ли способ загрузить файлы в заметку об исследовании? Если нет, @ sagarpreet-chadha, можете ли вы сделать сообщение в googlegroup plots-dev (вы можете зарегистрироваться здесь, если вы еще этого не сделали)? Давайте подождем, чтобы увидеть, что говорит @jywarren, потому что было бы здорово, если бы они были прямо в заметке об исследовании.
Вот что вы можете ожидать:
plots_tag_communities_edges_w_props_9_16.csv:: список уникальных ребер с вычисленными свойствами, в частности, весом ребра. Вес означает, сколько раз теги встречались вместе.
plots_tag_communities_nodes_w_props_9_16.csv: список узлов с вычисленными свойствами. Наиболее актуален для изображения на веб-сайте «класс модульности», который сообщает вам, к какому сообществу принадлежит каждый узел.
plots_tag_communities_9_16.json: я не считаю json таким полезным, но знаю, что некоторым он нравится. Я думаю, что файл json также включает свойства для визуализации на веб-сайте (т.е. цвет RGB каждого узла).
skilfullycurled
23 янв. 2018
Обновление: удален plots_tag_communities_edgelist_9_16.csv из списка файлов выше. Этот файл имеет ограниченное использование, потому что повторяющиеся ребра уже были объединены в уникальные ребра с весами. Без свойств этот список ребер позволит вам построить граф только с весом ребер 1. Я буду искать исходный файл с дубликатами.
skilfullycurled
24 янв. 2018
Спасибо @skilfullycurled за ответ!
На самом деле я пытался построить граф визуализации с использованием библиотеки javascript (d3.js или vis.js ), чтобы его можно было легко добавить на сайт publiclab.org. Этим библиотекам требуются данные в виде:
nodes: [
{
id: 1,
shape: 'circle',
label: 'Infrared } ] для узлов .
И для кромок :
edges: [
{from: 1, to: 2},
{from: 1, to: 3}]
Ну, json был бы отличным, иначе я мог бы его создать или, возможно, создать объект Javascript напрямую (таким образом, нет необходимости анализировать файл JSON).
Я создал фиктивный граф (здесь мы можем поиграть с узлами и ребрами 😄):
Что вы думаете ? @ebarry , @jywarren , @skilfullycurled
sagarpreet-chadha
24 янв. 2018
Ах. Это было бы круто! Хорошо. Для продолжения этого разговора нам нужно оставить «территорию API» и перейти к тому, как работает визуализация в Gephi и как лучше всего перевести эти функции в javascript.
Могу я попросить вас начать с вопроса ? Что-то вроде: «Как я могу перевести визуализацию тегов, созданную в Gephi, в версию javascript?»
Кроме того, напиши мне электронное письмо на Бенджа. [email protected], чтобы я мог поделиться файлами. Я удалю свой адрес электронной почты, как только вы это сделаете.
skilfullycurled
24 янв. 2018
На самом деле я думаю, что нам, возможно, не нужно покидать территорию API - существующий API в наши дни довольно надежен. Мне любопытно, @skilfullycurled, как вы создали эти края -
могут ли они быть сгенерированы только что из списка всех тегов и узлов, на которых они использовались? Это разумный запрос для нас, если он кэширован.
Мы могли бы добавить его в API по адресу https://github.com/publiclab/plots2/tree/master/app/api/srch и задокументировать его по адресу https://github.com/publiclab/plots2/blob/master/doc. /API.md
Если данных достаточно, запрос может быть примерно таким:
r = []
Tag.select(:name, :tid).each do |t|
nids = t.nodes.select(:nid, :status).where(status: 1).collect(&:nid)
r << [t.name, nids] if nids.length > 0
end
r # later, r.to_json
Я только что запустил это в продакшене, и это заняло около 15 секунд. Если мы будем кэшировать это ежедневно, я думаю, что это выполнимо, и мы сможем улучшить его дальше.
jywarren
25 янв. 2018
Также вы можете делиться файлами на http://gist.github.com - может ли это сработать?
jywarren
25 янв. 2018
Итак, используя JSON, сгенерированный из моего запроса,
- в JavaScript мы могли подсчитать, сколько раз теги встречались вместе.
- как вы группировали / рассчитывали «сообщества»?
Вот отрывок:
["whitebalance", [12476, 13575]], ["wi", [12143, 13067]], ["wi-fi", [11123]], ["width-of-dvd-grating", [12838, 12875, 12895, 12899, 12902, 12926, 12990, 12991, 12995, 12999, 13006, 13014, 13019, 13037, 13046, 13057, 13062, 13069, 13077, 13088, 13089, 13094, 13103, 13117, 13125, 13131, 13133, 13136, 13152, 13154, 13157, 13159, 13169, 13178, 13181, 13183, 13188, 13226, 13248, 13283, 13302, 13305, 13308, 13315, 13316, 13340, 13349, 13355, 13366, 13401, 13402, 13409, 13414, 13423, 13429, 13432, 13434, 13437, 13439, 13440, 13443]], ["wiki", [9048, 10956]], ["wiki-gardening", [10956]], ["wild", [11707, 11711]], ["wildfires", [14803]], ["wildlife", [670]], ["wilkinson-bay", [220, 265, 280, 281, 282, 283, 284, 677]], ["wilkinsonbay", [606]], ["williamsburg", [10343, 10428, 10444]], ["willow", [9979]], ["wind", [9032, 10660, 12610, 13880, 14487, 14527, 14530, 14531, 14713, 14756]], ["wind-direction", [14527]], ["wind-sensor", [14713]], ["wind-speed-meter", [1962, 5837, 9032, 12103, 13064, 13165, 13231, 13880, 14527]], ["winder", [7717]], ["winders", [1900]], ["window", [147, 1759]], ["windows", [11434, 11677, 13037]], ["windows-7", [13037]], ["windows-7-ultimate", [13037]], ["windows-excel", [13037]], ["windspeed", [745]], ["windvane", [14527]], ["windy", [146]], ["wine", [706, 10955]], ["winter", [5161]], ["wintercamp", [5103]], ["wired", [10315]], ["wireframes", [10623]], ["wireless", [3908, 9940, 11123, 12175]], ["wisconsin", [10504, 10552, 10611, 10619, 11331, 11783, 12142, 12143, 12192, 12221, 12337, 12537, 12539, 12562, 12597, 12610, 12919, 13067, 13216, 13217, 13219, 13222, 13223, 13224, 13406, 13578, 13920, 13921, 13922, 14018, 14044, 14087, 14146, 14648]], ["with", [11772, 13742, 14728]], ["with:abdul", [13407, 13412, 13413, 13428, 13493]], ["with:adam-griffith", [11049]], ["with:amal", [12161]], ["with:amandaf", [11556]], ["with:amberwise", [12338, 13280]], ["with:ann", [12850]], ["with:basurama", [11699, 11705]], ["with:becki", [13571]], ["with:bronwen", [10952, 12480, 13493, 14587]], ["with:bsugar", [13449]], ["with:btbonval", [11789]], ["with:cfastie", [11688, 13493, 13980]], ["with:chrisjob", [10464]], ["with:cindy_excites", [11566, 11567, 14537]], ["with:damarquis", [12338]], ["with:danbeavers", [11417, 11567]],
FWIW может быть еще более эффективный запрос, подобный этому, но он довольно приличный, хотя и не возвращает полностью то, что указано выше:
Tag.select('term_data.tid, term_data.name, community_tags.nid, community_tags.tid')
.includes(:node_tag)
.references(:node_tag)
Хотя это не скажет нам, был ли узел опубликован (по сравнению со спамом), если мы не добавим туда node.status . Но это возможно!
jywarren
25 янв. 2018
Привет, у меня здесь всего несколько вопросов,
1.) Если 2 тега принадлежат одному узлу, между ними есть ребро?
2.) Разные цвета предназначены для разных типов узлов, таких как вопросы, заметки, исследовательские заметки и т. Д. ?
Спасибо 😄!
sagarpreet-chadha
25 янв. 2018
И еще я согласен не покидать API-страну :)
sagarpreet-chadha
25 янв. 2018
Арг! Хорошо. Не будем наваливаться, пожалуйста. Никто не хочет оставаться в API- лэнде больше, чем я (ну, может быть, за исключением см. Продолжение разговора здесь ). Но теперь @jywarren говорит, что это больше не так важно, так что хорошие времена для этого конца.
Поскольку использование Github может быть препятствием для доступа к информации (не каждый имеет доступ, знает, как ее использовать), я думаю (э-э ... подумал), что разговоры, которые не о "выполнении задач" в кодовой базе, лучше отнести к веб-сайт, на котором каждый может учиться у них. Это не нормы сообщества, которые я установил (см. Собственный комментарий @jywarren выше ), но я думаю, что они хорошие.
skilfullycurled
25 янв. 2018
К сожалению, @skilfullycurled, я не вспомнил ваш последний комментарий к этой теме - https://publiclab.org/questions/tommystyles/10-20-2017/need-your-feedback-on-tag-pages#answer - 556-comment-17709 - где вы предложили:
- работает только с 250 верхними тегами
- кеширование еженедельно
Я пингуюсь туда, но я думаю, что со всей работой над API, очисткой кода и расширением доступа мы могли бы делать ежедневную или еженедельную кешированную версию такого запроса, и все будет в порядке с 10-15-секундными общими вычислениями. раз в неделю. Остальное будет выполняться локально в браузере. Повторяя это там.
jywarren
25 янв. 2018
@jywarren Мне нужно Здесь краткое объяснение того, как граф создается из пар тегов. Точный код см. Здесь .
@ sagarpreet-chadha (и всем, кому интересно), вы можете увидеть, как граф d3.js был создан из данных тега, проверив репозиторий для
Что касается обнаружения сообщества, если вы посмотрите в репозиторий tagoverflow, вы обнаружите, что автор реализовал свой собственный алгоритм. С тех пор были реализованы другие, такие как jLouvain , netClustering реализация CNM ( пример d3 ). С ограничением в 256 тегов их обнаружение сообщества, вероятно, нормально в браузере.
skilfullycurled
25 янв. 2018
Чтобы не перегружать обсуждение publiclab.org большим количеством данных, вот ссылка на формат данных, который использует TagOverflow:
https://api.stackexchange.com/2.1/tags/python/related/?site=stackoverflow&key=of3hmyFapahonChi8EED6g ((& pagesize = 16
Он делает около 15 вызовов, чтобы получить, какие теги относятся к данному тегу (в приведенном выше примере "python").
jywarren
25 янв. 2018
Таким образом, разница между этим и данными, которые я сгенерировал выше, заключается в том, что в моем запросе перечислены идентификаторы узлов, но они не использовались для установления «взаимосвязанности». Но, конечно же, блокнот Jupyter от @skilfullycurled делает это! Круто, спасибо, что поделились!
jywarren
25 янв. 2018
@ sagarpreet-chadha, я разместил вопрос, который задал и ответил на ваши вопросы выше:
https://publiclab.org/questions/bsugar/01-25-2018/how-was-the-tag-graph-visualization-made
Я не пытаюсь быть «пассивно-агрессивным» в отношении своей просьбы, но я думаю, что людям было бы полезно, если бы этот аспект беседы был публичным. Думаю, это делает его «агрессивным агрессивным». ; )
Шутки в сторону, с удовольствием отвечу на любые вопросы!
skilfullycurled
25 янв. 2018
Привет всем!
@ sagarpreet-chadha, я положил сюда все нужные файлы:
https://spideroak.com/browse/share/skilfullyshared/plots-tag-graph
В папке есть файл readme, в котором объясняется ее содержимое.
Пожалуйста, дайте мне знать, когда вы их загрузите, чтобы я мог закрыть общую комнату. В конце концов, я отправлю их в свою учетную запись github, чтобы другие люди имели доступ к вики.
Будем рады ответить на любые ваши вопросы!
skilfullycurled
1 февр. 2018
Спасибо, @skilfullycurled !
Я скачал файлы :-)
sagarpreet-chadha
2 февр. 2018
Нет проблем @ sagarpreet-chadha!
PS: Я оставил вам дополнительную мысль в вопросе вики .
skilfullycurled
2 февр. 2018
Отличное обновление расчетов связности тегов на основе рубинов здесь: https://publiclab.org/questions/bsugar/01-25-2018/how-was-the-tag-graph-visualization-made
скоро еще!
jywarren
17 янв. 2019
Некоторый прогресс в https://github.com/publiclab/plots2/pull/4657 , где я реализовал чрезвычайно простой, но живой экземпляр Cytoscape.js (http://js.cytoscape.org/), работающий с еженедельная кэшированная коллекция
Запуск для ВСЕХ тегов на сайте занял более 50 секунд (которые можно кэшировать еженедельно), но это также сгенерировало 8200+ тегов и 31k ребер ... что очень много для графического отображения. Вот полный комплект; я думаю, что в нем много спам-тегов: https://gist.github.com/jywarren/4b1f9a032092a8187dd802a375fcb700
Вы можете указать количество тегов, которые хотите запросить, следующим образом: https://stable.publiclab.org/tag/graph.json?limit=10 (после полной публикации https://publiclab.org/tag/graph. json? limit = 10)
В настоящее время он ограничен 5 «краями» для каждого тега, представляющими 5 тегов, которые чаще всего встречаются рядом с исходным тегом.
Теперь это работает на стабильном тестовом сервере (хотя эта ветка довольно часто перестраивается, поэтому URL-адрес не всегда в сети ... по иронии судьбы) здесь:
https://stable.publiclab.org/stats/graph?limit=75
Большие числа, такие как limit = 100 или 250, похоже, показывают какую-то ошибку, и мне нужно немного разобраться с этим. Но это неплохое начало.
Есть МНОГО конфигураций, которые можно добавить, чтобы уточнить это - размер узла, сила ссылок и многое другое - посмотрите галерею на http://js.cytoscape.org, чтобы узнать о некоторых возможностях. И создание «семей» тоже возможно, хотя для этого мне понадобится немного больше информации.
jywarren
18 янв. 2019

jywarren
18 янв. 2019
Ох, https://stable.publiclab.org/stats/graph?limit=300, похоже, тоже работает
jywarren
18 янв. 2019
Обнаружение сообщества здесь! https://github.com/upphiminn/jLouvain/blob/master/README.md
jywarren
19 янв. 2019
@jywarren , супер круто !!!
sagarpreet-chadha
19 янв. 2019
Также существует ряд алгоритмов кластеризации - их можно протестировать в консоли JavaScript:
http://js.cytoscape.org/#collection/clustering
- eles.markovКластеризация ()
- node.kMeans ()
- node.kMedoids ()
- node.fuzzyCMeans ()
- node.hierarchicalClustering ()
- node.affinityPropagation ()
Я не знаком с ними, но все они, похоже, используют атрибуты узлов или ребер для создания кластеров похожих элементов. Итак, что мы должны дать в качестве атрибутов, на которых основывается сходство?
Вы можете попробовать это в консоли, используя примеры в документации, например:
var clusters = cy.elements().hca({
mode: 'threshold',
threshold: 5,
attributes: [
function( node ){ return node.data('count'); }
]
});
clusters; // <= then inspect what this returns to see the clusters
Хорошо, используя jlouvain я смог добавить обнаружение сообщества: https://github.com/upphiminn/jLouvain
У меня недостаточно тестовых данных, чтобы увидеть, как это будет работать, но если # 4679 пройдет, я объединю его, и мы сможем увидеть, как он работает с обнаружением сообщества по адресу:
https://stable.publiclab.org/stats/graph?limit=101
(как только он построится)
jywarren
21 янв. 2019
Привет всем! Выглядящий клево. Извините, я не смог ответить, но кое-что хочу сказать, вернусь к этому позже сегодня.
Между тем, еще один ингредиент, о котором я не думаю, что упоминал ни в одном из своих постов, - это макет. Наиболее близким к тому, что я использовал, вероятно, является силовая раскладка . Технически это могло быть что-то под названием Force Layout 2:
Схема силы - это своего рода отжигающее притяжение / отталкивание, которое достигает устойчивого состояния в зависимости от установленных вами параметров (то есть количества итераций, силы притяжения / отталкивания). Вот демо d3 .
Что касается обнаружения сообщества и весов ребер, у вас есть несколько вариантов, но если вы хотите воссоздать этот граф тегов, на который он ссылается, тогда вам понадобится совместное появление, которое, как подсказывает удача, имеет функцию, помогающую сделать Полегче.
oe_ratio = (all_questions_count * tag_count_AB) / (tag_count_A * tag_count_B)
Где tag_count_AB = Edge.parallelEdges ()
Как бы то ни было, я сначала сузил набор тегов до некоторого разумного числа (скажем, верхних 512), но затем я сузил теги, которые я использовал для визуализации, включив только верхние n тегов (может быть, 64?) С наблюдаемым к ожидаемому коэффициенту выше 1.
Вы можете прочитать больше из Tag Overflow . Этот метод - один из способов решить проблему, когда граничный или узловой узел может быть важным, но малоиспользуемым. Например, в магазине 100 человек с вероятностью 85% купят кофе и сливки, но пятеро из них всегда будут покупать кофе, сливки и яйца. Поэтому я определенно хочу иметь на складе 5 коробок яиц.
Простая альтернатива - просто сделать вес ребра между двумя узлами tag_count_AB и брать только ребра / узлы выше заданного порога. Лично я редко получаю от этого хорошие результаты по вышеуказанной причине.
Что касается других методов, вас могут заинтересовать стр. 3. (2.2) - стр. 7 (3.1) этой статьи (без математики для этих частей), в которой делается попытка классифицировать различные типы методов обнаружения сообществ. Это помогло мне выбрать те, которые обеспечивают наиболее заметные результаты с учетом того, как я структурировал график, и того, что я хочу узнать из него. Например, сообщества с общими социальными связями и сообщества в зависимости от того, как часто сообщения отправляются между двумя людьми.
skilfullycurled
21 янв. 2019
Работаем на стабильном сервере!
jywarren
25 янв. 2019

Здесь 99 лучших тегов!
jywarren
25 янв. 2019
Он должен быть запущен на действующем сайте сегодня вечером, но я хотел отметить, что «чрезмерное использование» тегов некоторыми пользователями привело к искажению графика так, как мы распознали раньше. Я считаю, что один из пользователей был модерирован с сайта, и мне было интересно, считают ли люди целесообразным удалить эти теги с сайта или, по крайней мере, исключить их из диаграммы. Удалить их было бы проще, но мы также можем создать что-нибудь, чтобы просто скрыть их. Предпочтение, @ebarry @skilfullycurled ?
Тем не менее, это выглядит красиво, хотя настройки эластичности краев все еще нуждаются в некоторой настройке, и, возможно, другой тип макета будет работать лучше ...

jywarren
25 янв. 2019
Ага! Мы определенно столкнулись с этой проблемой. К сожалению, единственное, что оставалось сделать, - это удалить этого конкретного пользователя как выброса. Кто-то, использующий такое количество тегов, может не быть исключением сам по себе, но если он создает теги, которые настолько специфичны для себя, и использует их снова и снова, то на самом деле он не собирает данные.
skilfullycurled
25 янв. 2019
Думаю, я даже зарегистрировал проблему на github с запросом функции, в котором появилось предупреждение, в котором, по сути, говорилось: «Да ладно, парень! Похоже, у вас там много тегов, а?».
skilfullycurled
25 янв. 2019
Ой, PS. Выглядит, кстати, потрясающе !!
skilfullycurled
25 янв. 2019
AAAAAAHHHHHHHHMAYZINGGGGGGGGGG !!!!!!!!!!!!
Да, чтобы вручную "удалить [ing] этого конкретного пользователя как выброса"
ebarry
26 янв. 2019
Я просто продолжаю возвращаться к этой теме, потому что она потрясающая, и думаю о вещах (надеюсь, крошечных). Еще одна вещь, которую вы можете рассмотреть для фильтрации, - это теги питания (это те, которые имеют двоеточие, верно?). Думаю, как только проблема чрезмерного использования тегов будет исправлена, мы узнаем больше о макете.
Примечание для себя: вот ссылка на коммит со страницами, которые важны для реализации.
skilfullycurled
26 янв. 2019
Всем привет, рад за энтузиазм! Я заболел, но сейчас выздоравливаю и буду немного поработать над этим во вторник рейсом домой.
Я действительно хотел спросить - мой конкретный вопрос в том, должны ли мы:
- на самом деле удалить теги от этого модерируемого пользователя, или
- если мы должны попытаться сохранить их, но отфильтровать их.
Фильтрация потребовала бы значительно больших усилий как для кода, так и для вызовов базы данных, но это возможно.
jywarren
27 янв. 2019
В таких случаях, как этот, когда учетная запись была сделана «неактивной» из-за модерации, я думаю, что можно сразу удалить теги из базы данных. Особенно если у вас есть бэкап. Не потому, что вы, возможно, захотите восстановить его, просто потому, что я боюсь потерять данные навсегда. Это вредно, но дешевое пространство - неудачный помощник. Мои чувства были бы более сложными, если бы эта учетная запись была сделана «неактивной» по своему выбору, но мы можем обсудить это в другой раз (или сейчас).
skilfullycurled
27 янв. 2019
Да, это большая тема для размышлений. Проверив, есть ли теги, которые _только__ использовал этот пользователь (пример: aries city-point ), я обнаружил, что на самом деле очень мало тегов, полностью изолированных для этого пользователя (даже purelab изначально использовался Шан Хэ для фильтрации воды своими руками, а research-notes изначально использовался в сообщениях, обсуждающих дизайн исследовательских заметок на веб-сайте).
Поскольку этот пользователь является модерируемым, может ли наша визуализация тегов исключить весь контент от модерируемых пользователей - и, соответственно, теги, используемые в контенте этого человека, - без исключения этого тега в целом, поскольку он может использоваться в контенте других людей?
ebarry
28 янв. 2019
@ebarry , я должен уточнить (на случай, если это не так).
Когда я сказал:
полностью удалить теги из базы данных
Я имел в виду то, чем вы закончили:
... [что] наша визуализация тегов [будет] исключать весь контент от модерируемых пользователей - и, соответственно, теги, используемые в контенте этого человека - без исключения этого тега в целом, [поскольку] он может использоваться в контенте других людей. ..
Если модерируемый пользователь и Шан Хе оба использовали тег «purelab», «purelab» не был бы удален, просто любой экземпляр тега от модерируемого пользователя или, если хотите, ITMU.
Остающийся вопрос (если я понимаю @jywarren) заключается в том, следует ли полностью удалять эти ITMU из базы данных, или мы сохраняем их в базе данных, но отфильтровываем ITMU, когда все теги запрашиваются для визуализации. Их удаление значительно облегчает жизнь тем, кто реализует визуализацию, но могут быть аргументы в пользу их сохранения.
Лично я считаю, что первое нормально, когда пользователь прошел модерацию, потому что нет никаких шансов, что контент когда-либо вернется на сайт. Однако все может быть иначе, если пользователь решит удалить свою учетную запись в зависимости от того, есть ли какие-либо функции, с помощью которых он может повторно активировать ее. Я думаю, что мы можем оставить эту ситуацию на другой раз, но для протокола я просто хотел сказать, что мое судебное мнение ограничено по объему.
skilfullycurled
28 янв. 2019
Да, не беспокойтесь, NodeTags не удаляет тег, а только ссылку, связывающую
теги с узлами и авторами. Я уже сделал это на самом деле, но нужно смыть
еженедельный кеш (вот что сделало все это возможным) и есть
Еще пара срочных ошибок, которые нужно исправить в первую очередь, которые возникли сегодня, извините!
В понедельник, 28 января 2019 г., 15:24 skilfullycurled < [email protected]
написал:
@ebarry https://github.com/ebarry , я должен уточнить (на случай, если это не так).
Когда я сказал:
полностью удалить теги из базы данных
Я имел в виду то, чем вы закончили:
... [что] наша визуализация тега [будет] исключать весь контент из модерируемых
пользователей - и, соответственно, тегов, используемых в контенте этого человека - без
за исключением этого тега в целом [поскольку] он может использоваться на других людях
содержание...Если модерируемый пользователь и Шан Хэ оба использовали тег «purelab», «purelab»
не будет удален, просто любой экземпляр тега от модерируемого пользователя
или ITMU, если хотите.Остающийся вопрос (понимаю ли я @jywarren
https://github.com/jywarren ), следует ли удалять эти ITMU
из базы данных полностью, или мы сохраняем их в базе данных, но фильтруем
ITMU отключается, когда все теги запрашиваются для визуализации.Их удаление значительно упрощает жизнь тем, кто внедряет
визуализации, но могут быть аргументы в пользу их сохранения.-
Вы получаете это, потому что вас упомянули.
Ответьте на это письмо напрямую, просмотрите его на GitHub
https://github.com/publiclab/plots2/issues/1502#issuecomment-458244753 ,
или отключить поток
https://github.com/notifications/unsubscribe-auth/AABfJzTXlk18FzlER4PQyoomFE5VTFcrks5vH0AqgaJpZM4OOvLP
.
jywarren
28 янв. 2019
ОК, удалось удалить все теги, созданные модерируемым пользователем. Они хранятся в резервных копиях. Это было довольно просто и не повлияет на дальнейшее продвижение кода, в отличие от другого решения.
Теперь я хочу предположить, что может быть другой макет, который мы хотим использовать - мы используем макет cose , и есть варианты ( bilkent и другие), но есть также cola layout. Я действительно не знаю, какой из них использовать здесь, но некоторые, кажется, меньше запутывают ссылки. Хотя во многих демонстрациях на http://js.cytoscape.org/ меньше ссылок, чем в нашем наборе данных. Любой вклад приветствуется!
Документы по встроенным макетам на http://js.cytoscape.org/#layouts.
Еще одна проблема, которую мы можем попросить кого-нибудь протестировать и заняться, - это вопрос об обнаружении сообщества. Я не смог понять, как это работает или почему здесь не распознаются группы. Цвета хорошие, но по одному узлу на сообщество. Ба.
jywarren
28 янв. 2019
Итак, теперь эту проблему нужно разбить на:
- итерация макета (приветствие от текущей толпы)
- обнаружение сообщества
- дополнительная фильтрация тегов (может быть, отфильтровать теги без неутвержденных узлов, чтобы избавиться от спама?)
также хочу еще раз напомнить, что сейчас мы просматриваем указанное количество тегов (пожалуйста, не проверяйте это до пределов, если только он не находится на https://stable.publiclab.org - я пробовал до 1000 тегов, и он загружается хорошо, но не более того, пожалуйста, на производственном сервере хоть раз)
И мы ограничены связями между ними, причем каждый тег сообщает максимум о 10 тегах, которые он встретил рядом. Это не является исчерпывающим, но кажется возможным балансом оптимизации и тщательности.
jywarren
28 янв. 2019
jywarren
28 янв. 2019
@jywarren , это все еще последний коммит ? Я, потому что я хотел увидеть json, исходящий из конечной точки /tag/graph.json, и он отправил мне все теги. Основываясь на коде этого коммита, я ожидал, что 250 будет жестким пределом (мое примечание о читабельности Ruby выдерживает).
skilfullycurled
31 янв. 2019
@jywarren, неважно, я не понимал, что график теперь находится на рабочем сервере, я использовал stable.publiclab.org.
skilfullycurled
31 янв. 2019
Хорошо. Я просто потратил немало времени на изучение этого и лучше чувствую, как работает график.
Теперь я хочу предположить, что мы могли бы использовать другой макет - мы используем cose
Я посмотрю и подумаю. Я думаю, что здесь необходимо ответить на вопрос, что мы хотим извлечь из графика? Например, если мы в первую очередь заинтересованы в том, чтобы посетитель мог видеть, какие теги связаны с какими из них, то лучше всего подойдет макет круга или концентрический круг , как если бы они были скучными.
Если бы мне пришлось предположить (информированное, но все же предположение) относительно того, почему CoSE не дает такого большого результата, это было бы потому, что, глядя на данные, когда вы достигаете определенного количества узлов, счет начинается чтобы все были похожи. Итак, если CoSE отталкивает узлы только на основе веса узла, то, возможно, между ними существует равное количество отталкиваний. Когда я использую здесь отталкивание, я имею в виду все, что входит в отталкивание, например, гравитацию. В этом случае может случиться так, что не хватает итераций алгоритма или факторы отталкивания не вызывают / не допускают достаточного распространения.
Еще одна проблема, которую мы можем попросить кого-нибудь протестировать и заняться, - это вопрос об обнаружении сообщества.
Когда у вас будет время, не могли бы вы указать мне на коммит с последней версией JavaScript? Я могу получить его через браузер, но только в том виде, в котором он не имеет никакой структуры и представляет собой всего одну строку. Как только я это сделаю, я увижу больше. Я посмотрел на пример jLouvain, и, похоже, у него нет настройки того, сколько сообществ вы хотите, что могло бы быть частью проблемы. Обычно Лувен предлагает «лучший номер», но иногда и не лучший. Реализация python, на которой основан jLouvain, имеет этот параметр, но, возможно, он не изменился.
skilfullycurled
31 янв. 2019
Вот и мы:
jywarren
1 февр. 2019

jywarren
1 февр. 2019
О, я думал, что оставил еще один комментарий ... Куда он делся? Подожди...
jywarren
1 февр. 2019
В любом случае, я собирался сказать, что, кажется, разобрался с некоторыми проблемами компоновки, но судите сами:
https://publiclab.org/stats/graph?limit=50
https://publiclab.org/stats/graph?limit=100
jywarren
1 февр. 2019
Вот JS для обнаружения сообщества: https://github.com/publiclab/plots2/blob/master/app/views/tag/graph.html.erb#L263
А вот конфигурация макета, которую мы могли бы многое настроить, чтобы опробовать:
jywarren
1 февр. 2019
Во-первых, я хочу извиниться за то, что не могу помочь с тяжелой работой по кодированию. Легко просто предлагать что-то, но я понимаю, что они также должны быть реализованы людьми, и я не теряю уверенности в том, что я не помогаю в этом отношении.
Есть несколько вариантов того, почему jLouvain не работает хорошо. @jywarren , я думаю, вы уже
См. Эту проблему в репозитории jLouvain. Кто-то написал очень простое исправление, которое можно было реализовать. Я не совсем уверен, как это работает с точки зрения того, что он возвращает: в идеале он возвращает результат обнаружения всего сообщества для каждого элемента в массиве? Это было бы здорово и, вероятно, решило бы проблему того, что каждый узел является собственным сообществом.
Подробнее позже…
skilfullycurled
1 февр. 2019
Передавая вопрос от
ebarry
6 февр. 2019
это отличная идея. Я думаю, что на этом этапе нам нужно закрыть это и открыть
новый выпуск с контрольным списком возможных доработок дисплея, и
для новичков будет намного проще (меньше контекста и истории требуется для
участвовать), чтобы войти и начать их реализацию. Я почти соблазняюсь
разверните его в новый репозиторий, которым является / просто этот график /, поскольку он
иначе не соединяется с базой кода PL, но ради
сплоченность сообщества давайте сохраним это в сюжетах2.
Лиз, не могли бы вы начать новый выпуск и начать с контрольного списка?
В среду, 6 февраля 2019 г., в 11:17 Лиз Барри [email protected] написала:
Передача вопроса от https://github.com/shapironick
кто задавался вопросом на другом канале, может ли в будущем выпуске быть
различной толщины и толщины соединительных линий, чтобы показать, насколько близко
связаны какие-то два конкретных тега? Спасибо!-
Вы получаете это, потому что вас упомянули.
Ответьте на это письмо напрямую, просмотрите его на GitHub
https://github.com/publiclab/plots2/issues/1502#issuecomment-461083862 ,
или отключить поток
https://github.com/notifications/unsubscribe-auth/AABfJ9nxysbBtCAYHEW2tA8UwNH9zelFks5vKv_hgaJpZM4OOvLP
.
jywarren
6 февр. 2019
Ура! @shapironick! Прямо сейчас запрос к базе данных отправляет только первые n тегов и количество этих тегов по всему сайту. В будущем, чтобы иметь веса ребер, нам нужно будет внести изменения в серверную часть, чтобы либо отправлять все теги во внешний интерфейс, чтобы можно было агрегировать счетчики соединений, либо их нужно объединить на задний конец. В качестве альтернативы, во внешнем интерфейсе мы вычисляем некоторые свойства границы сети (например, некоторую центральность: степень, близость, промежуточность и т. Д.).
skilfullycurled
6 февр. 2019
Очень круто! Никаких предрассудков на эту идею +1 к запуску нового выпуска, но это эпично и круто!
 shapironick
6 февр. 2019
shapironick
6 февр. 2019
Прямо сейчас в данных, которые мы передаем коду графа, я думаю, мы видим, когда один тег (скажем, тег A) связан с тегом B, и мы видим второе соединение, если тег B ссылается на тег A. Но это мало что нам говорит. Рефакторинг для придания «веса» интересен ... Я тоже могу представить несколько способов сделать это. Я согласен, мы могли бы либо передать все node.ids которые есть у каждого тега, и вычислить это локально, либо мы могли бы попытаться предварительно вычислить это в момент, когда мы собираем 5 самых популярных тегов каждого тега. (я думаю, что недавно изменил это на 10, но все равно).
Отличная доработка. Как только у нас будет контрольный список, мы можем немного расставить приоритеты и постепенно улучшать его. Спасибо!
jywarren
6 февр. 2019
Ой, смотрите, это вошло в историю;): https://publiclab.org/wiki/community-development#2019
ebarry
8 февр. 2019
Исследуя это для возможного проекта Summer of Code этим предстоящим летом, я обнаружил ошибку обнаружения сообщества, которая была незаметной - данные находились во вложенном объекте, таком как {data: { DATA }} а не просто в { DATA } . Исправлено в https://github.com/publiclab/plots2/pull/9169 !
jywarren
9 февр. 2021

jywarren
9 февр. 2021
Это только с нашими тестовыми данными; полное исправление будет видно на стабильном сервере, как только мы его объединим и он перестроится; вероятно 30м или около того.
jywarren
9 февр. 2021
Хорошо, мы идем:
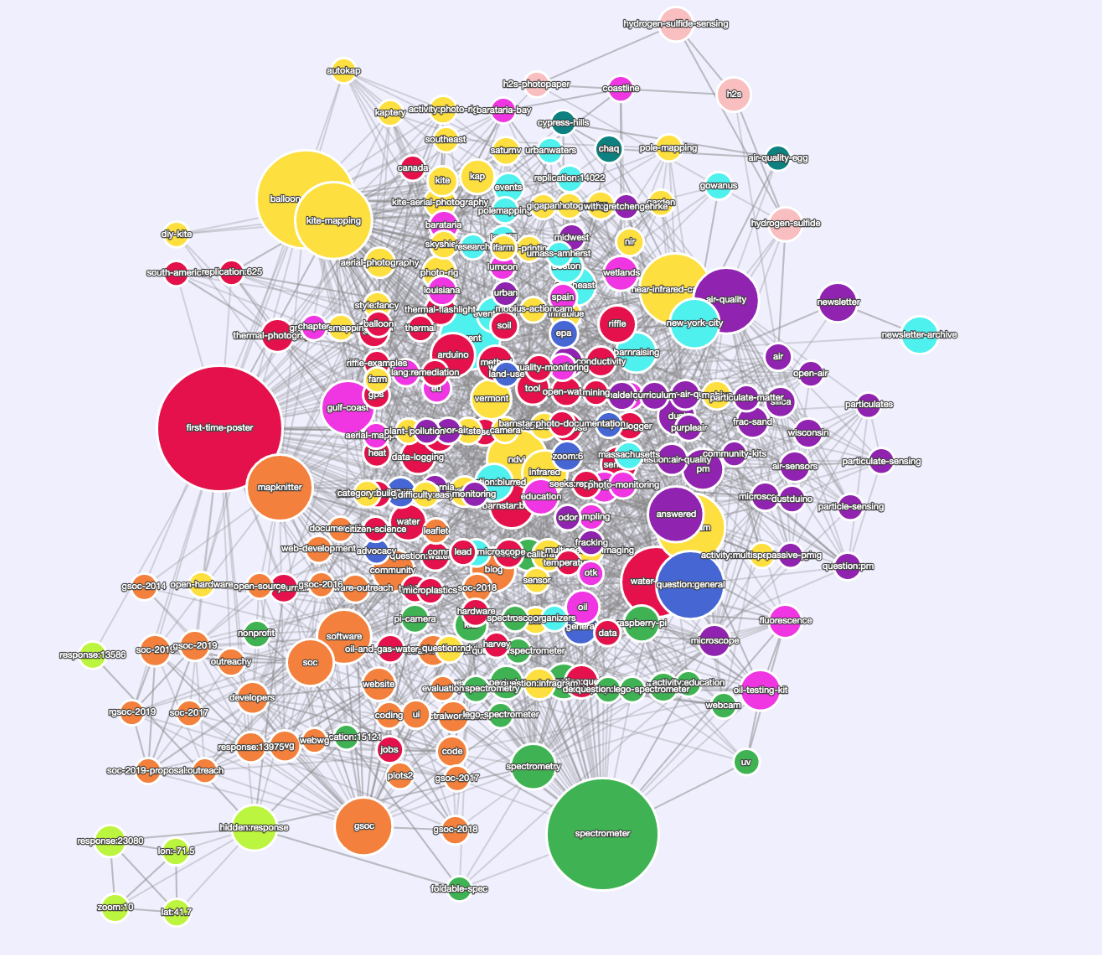
https://stable.publiclab.org/tags (помните, что это значение будет уменьшаться на 10 м каждый раз, когда мы объединяем новое изменение)
jywarren
9 февр. 2021
Смежные вопросы
![first-timers[bot] picture](https://avatars.githubusercontent.com/in/4832?v=4&s=40) first-timers[bot]
·
3Комментарии
first-timers[bot]
·
3Комментарии
first-timers[bot]
·
3Комментарии
first-timers[bot]
·
3Комментарии
 milaaraujo
·
3Комментарии
milaaraujo
·
3Комментарии
milaaraujo
·
3Комментарии
milaaraujo
·
3Комментарии
 noi5e
·
3Комментарии
noi5e
·
3Комментарии
Самый полезный комментарий
Он должен быть запущен на действующем сайте сегодня вечером, но я хотел отметить, что «чрезмерное использование» тегов некоторыми пользователями привело к искажению графика так, как мы распознали раньше. Я считаю, что один из пользователей был модерирован с сайта, и мне было интересно, считают ли люди целесообразным удалить эти теги с сайта или, по крайней мере, исключить их из диаграммы. Удалить их было бы проще, но мы также можем создать что-нибудь, чтобы просто скрыть их. Предпочтение, @ebarry @skilfullycurled ?
Тем не менее, это выглядит красиво, хотя настройки эластичности краев все еще нуждаются в некоторой настройке, и, возможно, другой тип макета будет работать лучше ...