Plots2: Tag-Visualisierung aller Tags
Dies ist eine Bitte an jemanden, der Zugriff auf die Bearbeitung spezieller Seiten hat, diese Visualisierung von Tags von Anfang bis November 2016 oben auf publiclab.org/tags . hinzuzufügen
https://www.dropbox.com/s/s78g3ufhsav5xzo/plots_tag_graph_256_filtered.png?dl=0
CC:
@gretchengehrke
@gekonnt gelockt
 ebarry
ebarry
Alle 73 Kommentare
Hi, Liz - ich zögere ein bisschen, eine statische Grafik wie diese in unsere permanente Codebasis aufzunehmen, aber vielleicht könnte ein Vorschlag sein, dass wir ein "Feature" (wie unsere Banner) oben auf dieser Seite anzeigen und dann Admins können dort alles anzeigen, was sie wollen. Funktioniert das?
 jywarren
am 5. Juli 2017
jywarren
am 5. Juli 2017
Es würde über oder unter diese Zeile gehen: https://github.com/publiclab/plots2/blob/master/app/views/tag/index.html.erb#L4
Und sehen aus wie:
<% cache('feature_tag-page-header') do %>
<%= feature('tag-page-header') %>
<% end %>
Nun, ich möchte diese Seite nicht so sehr dekorieren, sondern "Einblick auf einen Blick" hinzufügen.
Ein anderer Punkt, aber möglicherweise relevant, warum ich das Hinzufügen einer grafischen Visualisierung vorschlagen würde, ist, dass diese Tag-Seite immer noch keine Sortierfunktionen hat, um "neueste" oder "beliebte" zu sehen, geschweige denn, um beides nach Geografie zu sehen.
ebarry
am 5. Juli 2017
Es gibt tatsächlich Python-Gephi-Bindungen, die wir verwenden könnten, um sie dynamisch zu generieren. Ich arbeite gerade an einer Javascript-Netzwerkvisualisierung, also lassen Sie mich sehen, wie das funktioniert. Wenn es gut läuft, kann ich das, was ich getan habe, in ein Python-Skript übersetzen, das die Datenstruktur generieren kann, die dann in Javascript visualisiert werden kann.
 skilfullycurled
am 5. Juli 2017
skilfullycurled
am 5. Juli 2017
Hallo zusammen - ich denke, ein generierter Graph wäre großartig und ist etwas, das wir in den permanenten Code einfügen könnten.
@ebarry Ich sage nicht, dass dies Dekoration und kein Inhalt ist, ich sage eher, dass dies schnell veraltet wäre, und unser Ziel ist es auch, /kein/ Inhalt in unserer Codebasis zu speichern - nur Infrastruktur. Dies ist also nur eine Möglichkeit, es zu implementieren - klingt meine vorgeschlagene Lösung in Ordnung?
zu this tag page still doesn't have any sorting capabilities to see "recent" or "popular" much less to see either of those by geography. Ich würde mich freuen, mit Ihnen zusammenzuarbeiten, um einige Funktionsanfragen zu entwickeln, damit Mitwirkende bauen können, um dieses Problem zu lösen, wenn dies für Sie eine Priorität ist. Könnte ein paar einfache first-timers-only Probleme sein, wenn Sie helfen können, sie in die Warteschlange zu bekommen!
jywarren
am 5. Juli 2017
Kommen wir zu diesem Thema zurück zu den Grundlagen :)
Was ist das Ziel der Visualisierung von Tags?
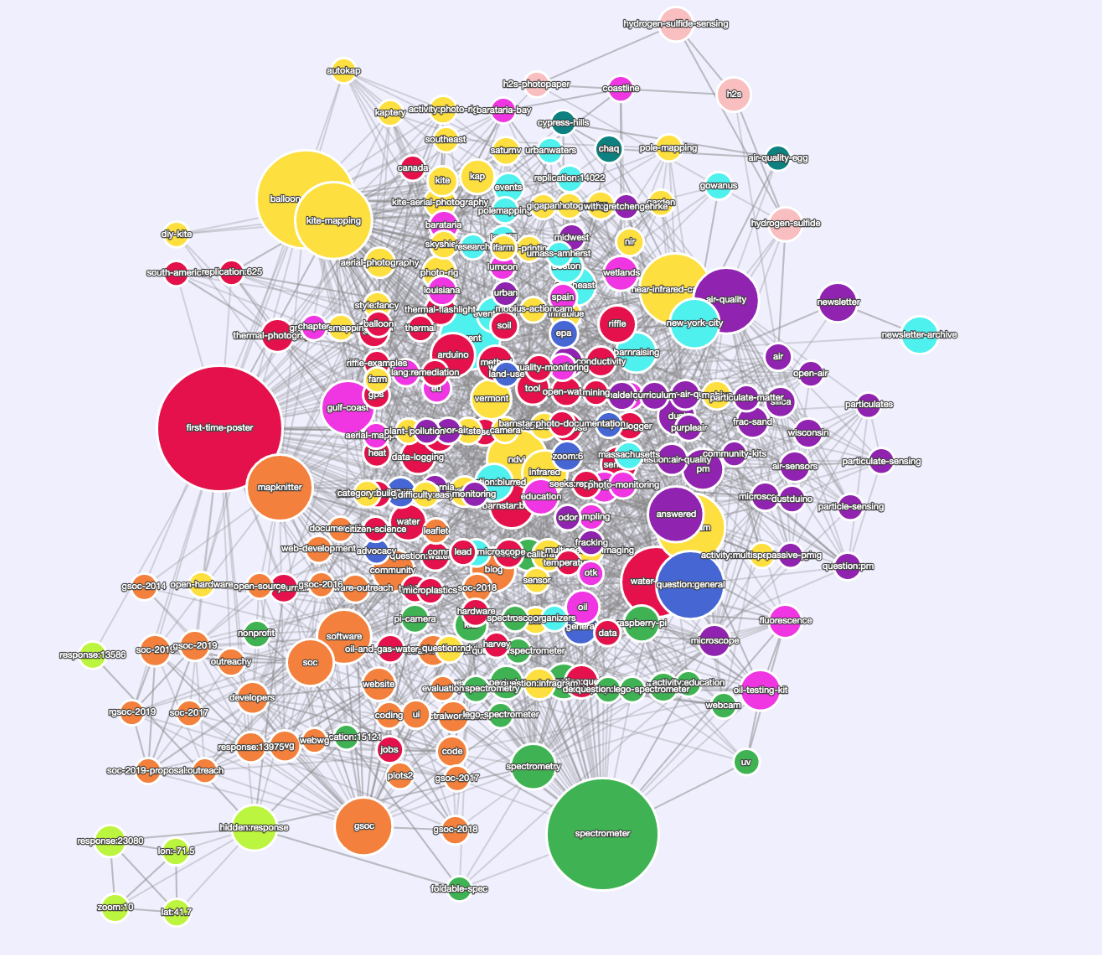
Für mich ist die Visualisierung von Tags eine Möglichkeit, zusammengehörige Tags visuell darzustellen, zB Tags, die zusammen auf demselben Inhalt erscheinen. Ein großartiges Beispiel finden Sie in den farbcodierten Clustern in der obigen Visualisierung von _näher_ mit dem das ist mein eigentliches Ziel mit dieser ganzen Ausgabe.
Hier einige Hintergrundinformationen: Auf unserer Tags-Seite (https://publiclab.org/tags) schreiben wir "Wir verwenden Tags, um Recherchen nach Themen zu gruppieren" und ermutigen die Leute, Tags zu durchsuchen (derzeit nur nach letzten Aktivitäten sortiert). Dies ist ein wichtiger Weg, um Menschen zu benennen, zu verlinken und/oder zu fördern, um Themen zu finden und sich mit ihnen zu beschäftigen. Das Dashboard selbst hebt die jüngsten Aktivitäten hervor. Das Dashboard verfügt jetzt über eine Leiste „Zuletzt verwendete Tags“ – ein wichtiger, aber nur ein kleiner Schritt zum Ziel, „Forschungsbereiche“ oder „Themen“ zu sehen.
Um fortzufahren, bin ich nicht daran interessiert, durch eine grafische Tag-Visualisierung zu _navigieren_ (also 2007!), jedoch bieten die Aktivitätscluster eine wichtige zusätzliche Möglichkeit, sich mit Themen zu verbinden/zu navigieren. Um das Ziel zu erreichen, d. h. die Fähigkeit der Tags-Seite zu zeigen, welche Tags am stärksten miteinander verbunden sind, die Breite der verbundenen Themen in einem Forschungsgebiet zu kommunizieren, zu einem Forschungsgebiet zu navigieren/eine Verbindung herzustellen und angemessen zu abonnieren, haben wir benötigen nicht unbedingt farbcodierte Swooping-Pfeile. Lassen Sie uns darüber nachdenken, wie wir diese Ziele erreichen können.
Wir könnten auch erwägen, publiclab.org/tags unter publiclab.org/topics zu spiegeln, um die Sprache zugänglicher zu machen.
ebarry
am 15. Nov. 2017
Cool, danke Liz!
Was wäre, wenn Tag-Seiten (ein schwebender neuer Name: Themenseiten ...!?!)
Verwandte Themen:
waterrunoffwetlandsturbidity
Wobei "verwandt" bedeutet, dass dies die Tags sind, die am häufigsten auf Seiten erscheinen, die bereits das primäre Tag haben. Für das Thema onions wir also jede Seite, die mit onions getaggt ist, und nehmen die oberste, sagen wir, fünf.
Kleines Follow-up, wenn das oben Gesagte gut klingt – wäre es in Ordnung, dies nur für die letzten 20-30 Seiten zu tun? Auch wenn dies nur ein Ausgangspunkt ist, würde dies die Implementierung erleichtern, ohne sich Sorgen machen zu müssen, dass die Website insgesamt langsam wird. Es könnte komplexere Wege geben, aber dies ist der einfachste Weg, um zu beginnen.
jywarren
am 16. Nov. 2017
Ich habe Cross-Posting unter https://publiclab.org/questions/tommystyles/10-20-2017/need-your-feedback-on-tag-pages gemacht – was hältst du davon, Diskussionen dorthin zu verschieben, bis es bestimmte diskrete gibt? Codierungsschritte (Miniprojekte für Code-Mitwirkende) die wir machen können?
jywarren
am 16. Nov. 2017
okay super! lass uns zu dieser Diskussion rübergehen und zurückkommen, sobald wir es getan haben
machbare Schritte.
--
+1 336-269-1539 / @lizbarry http://twitter.com/lizbarry / lizbarry.net
Am Mittwoch, 15. November 2017 um 21:54 Uhr, Jeffrey Warren [email protected]
schrieb:
Ich habe Cross-Posting unter https://publiclab.org/questions/tommystyles/10-20- gemacht.
2017/need-your-feedback-on-tag-pages -- was halten Sie von einem Umzug
Diskussion dort drüben, bis es spezifische diskrete Codierungsschritte gibt (mini
Projekte für Code-Mitwirkende) können wir machen?—
Sie erhalten dies, weil Sie erwähnt wurden.
Antworten Sie direkt auf diese E-Mail und zeigen Sie sie auf GitHub an
https://github.com/publiclab/plots2/issues/1502#issuecomment-344799932 ,
oder den Thread stumm schalten
https://github.com/notifications/unsubscribe-auth/AAJ2n8PdvpH0GQ_wBU-Utp4xfL7XDmuJks5s26PpgaJpZM4OOvLP
.
ebarry
am 16. Nov. 2017
@jywarren , @ebarry , gibt es eine API (oder vielleicht eine Dokumentation), um die "Kanten" in der obigen Grafik zu kennen? Ich meine, wie sind Knoten verbunden?
Danke 😄 !
 sagarpreet-chadha
am 23. Jan. 2018
sagarpreet-chadha
am 23. Jan. 2018
Hey @sagarpreet-chadha!
Die Visualisierung ist nur ein Bild, daher gibt es keine API (noch! zwinker), aber ich kann Ihnen die Liste der Kanten aus diesem bestimmten Diagramm zur Verfügung stellen. Die "rohesten" Dateiformate wären csv und json. Beide Formate sollten mit einem Graphen entweder "programmatisch" ( iGraph , networkx , d3.js ) oder mit einer GUI ( Gephi , Cytoscape ) arbeiten.
Anscheinend können Sie keine Dateien auf Github hochladen. Ich habe versucht, sie in die Forschungsnotiz des öffentlichen Labors hochzuladen, aber es funktioniert nicht. @jywarren gibt es eine Möglichkeit, Dateien in eine Forschungsnotiz hochzuladen? Wenn nicht, @sagarpreet-chadha, kannst du einen Beitrag in der plots-dev googlegroup verfassen (du kannst dich hier anmelden, falls du es noch nicht bist)? Warten wir ab, was @jywarren sagt, denn es wäre großartig, sie direkt in der Forschungsnotiz zu haben.
Darauf können Sie sich jedoch freuen:
plots_tag_communities_edges_w_props_9_16.csv: : Liste eindeutiger Kanten mit berechneten Eigenschaften, insbesondere das Gewicht der Kante. Die Gewichtung entspricht der Häufigkeit, mit der die Tags zusammen aufgetreten sind.
plots_tag_communities_nodes_w_props_9_16.csv: Liste der Knoten mit berechneten Eigenschaften. Am relevantesten für das Bild auf der Website ist die "Modularitätsklasse", die Ihnen sagt, zu welcher Community jeder Knoten gehört.
plots_tag_communities_9_16.json: Ich finde json nicht so nützlich, aber ich weiß, dass einige Leute es bevorzugen. Ich denke, die JSON-Datei enthält auch Eigenschaften für die Visualisierung auf der Website (dh RGB-Farbe jedes Knotens).
skilfullycurled
am 23. Jan. 2018
Update: plots_tag_communities_edgelist_9_16.csv aus der obigen Dateiliste entfernt. Diese Datei ist von begrenztem Nutzen, da die doppelten Kanten bereits zu eindeutigen Kanten mit Gewichtungen zusammengeführt wurden. Ohne die Eigenschaften können Sie mit dieser Kantenliste nur einen Graphen mit Kantengewichten von 1 erstellen. Ich suche nach der Originaldatei mit den Duplikaten.
skilfullycurled
am 24. Jan. 2018
Danke @skillcurled für deine Antwort!
Ich habe tatsächlich versucht, das Visualisierungsdiagramm mit der Javascript-Bibliothek (d3.js oder vis.js ) zu
nodes: [
{
id: 1,
shape: 'circle',
label: 'Infrared } ] für Knoten .
Und für Kanten :
edges: [
{from: 1, to: 2},
{from: 1, to: 3}]
Nun, json wäre großartig, sonst kann ich es erstellen oder vielleicht direkt ein Javascript-Objekt erstellen (auf diese Weise muss die JSON-Datei nicht geparst werden).
Ich habe einen Dummy-Graphen erstellt (wir können hier mit den Knoten und den Kanten spielen 😄 ):
Was denken Sie ? @ebarry , @jywarren , @skillfullycurled
sagarpreet-chadha
am 24. Jan. 2018
Ah. Das wäre super! Okay. Um dieses Gespräch weiterzuführen, müssen wir "API-Land" verlassen und uns mit der Funktionsweise der Visualisierung in Gephi und der besten Methode zur Übersetzung dieser Funktionen in Javascript befassen.
Darf ich Ihnen die Mühe machen, dies als Frage zu beginnen ? Etwa: "Wie kann ich die in Gephi erstellte Tag-Visualisierung in eine Javascript-Version übersetzen?"
Schicke mir auch eine E-Mail an benj. [email protected], damit ich die Dateien teilen kann. Ich werde meine E-Mail entfernen, sobald Sie dies tun.
skilfullycurled
am 24. Jan. 2018
Eigentlich denke ich, dass wir das API-Land vielleicht nicht verlassen müssen – die bestehende API ist heutzutage ziemlich robust. Ich bin gespannt, @skillcurled, wie Sie diese Kanten erzeugt haben --
Könnten sie frisch aus einer Liste aller Tags und der Knoten generiert werden, auf denen sie verwendet wurden? Das ist eine vernünftige Abfrage für uns, wenn sie zwischengespeichert wird.
Wir könnten es bei der API hinzufügen https://github.com/publiclab/plots2/tree/master/app/api/srch und dokumentieren sie in https://github.com/publiclab/plots2/blob/master/doc /API.md
Wenn es genügend Daten gibt, könnte die Abfrage etwa so aussehen:
r = []
Tag.select(:name, :tid).each do |t|
nids = t.nodes.select(:nid, :status).where(status: 1).collect(&:nid)
r << [t.name, nids] if nids.length > 0
end
r # later, r.to_json
Ich habe das gerade in der Produktion ausgeführt und es dauerte ungefähr 15 Sekunden. Wenn wir das täglich zwischenspeichern, denke ich, dass es überschaubar ist und wir es möglicherweise weiter verbessern können.
jywarren
am 25. Jan. 2018
Sie können auch Dateien unter http://gist.github.com freigeben - könnte das funktionieren?
jywarren
am 25. Jan. 2018
Verwenden Sie also den aus meiner Abfrage generierten JSON,
- in JavaScript könnten wir berechnen, wie oft die Tags zusammen aufgetreten sind.
- Wie hast du "Communities" gruppiert/berechnet?
Hier ein Auszug:
["whitebalance", [12476, 13575]], ["wi", [12143, 13067]], ["wi-fi", [11123]], ["width-of-dvd-grating", [12838, 12875, 12895, 12899, 12902, 12926, 12990, 12991, 12995, 12999, 13006, 13014, 13019, 13037, 13046, 13057, 13062, 13069, 13077, 13088, 13089, 13094, 13103, 13117, 13125, 13131, 13133, 13136, 13152, 13154, 13157, 13159, 13169, 13178, 13181, 13183, 13188, 13226, 13248, 13283, 13302, 13305, 13308, 13315, 13316, 13340, 13349, 13355, 13366, 13401, 13402, 13409, 13414, 13423, 13429, 13432, 13434, 13437, 13439, 13440, 13443]], ["wiki", [9048, 10956]], ["wiki-gardening", [10956]], ["wild", [11707, 11711]], ["wildfires", [14803]], ["wildlife", [670]], ["wilkinson-bay", [220, 265, 280, 281, 282, 283, 284, 677]], ["wilkinsonbay", [606]], ["williamsburg", [10343, 10428, 10444]], ["willow", [9979]], ["wind", [9032, 10660, 12610, 13880, 14487, 14527, 14530, 14531, 14713, 14756]], ["wind-direction", [14527]], ["wind-sensor", [14713]], ["wind-speed-meter", [1962, 5837, 9032, 12103, 13064, 13165, 13231, 13880, 14527]], ["winder", [7717]], ["winders", [1900]], ["window", [147, 1759]], ["windows", [11434, 11677, 13037]], ["windows-7", [13037]], ["windows-7-ultimate", [13037]], ["windows-excel", [13037]], ["windspeed", [745]], ["windvane", [14527]], ["windy", [146]], ["wine", [706, 10955]], ["winter", [5161]], ["wintercamp", [5103]], ["wired", [10315]], ["wireframes", [10623]], ["wireless", [3908, 9940, 11123, 12175]], ["wisconsin", [10504, 10552, 10611, 10619, 11331, 11783, 12142, 12143, 12192, 12221, 12337, 12537, 12539, 12562, 12597, 12610, 12919, 13067, 13216, 13217, 13219, 13222, 13223, 13224, 13406, 13578, 13920, 13921, 13922, 14018, 14044, 14087, 14146, 14648]], ["with", [11772, 13742, 14728]], ["with:abdul", [13407, 13412, 13413, 13428, 13493]], ["with:adam-griffith", [11049]], ["with:amal", [12161]], ["with:amandaf", [11556]], ["with:amberwise", [12338, 13280]], ["with:ann", [12850]], ["with:basurama", [11699, 11705]], ["with:becki", [13571]], ["with:bronwen", [10952, 12480, 13493, 14587]], ["with:bsugar", [13449]], ["with:btbonval", [11789]], ["with:cfastie", [11688, 13493, 13980]], ["with:chrisjob", [10464]], ["with:cindy_excites", [11566, 11567, 14537]], ["with:damarquis", [12338]], ["with:danbeavers", [11417, 11567]],
FWIW kann es eine noch effizientere Abfrage wie diese geben, aber diese ist ziemlich anständig, obwohl sie nicht vollständig zurückgibt, was oben steht:
Tag.select('term_data.tid, term_data.name, community_tags.nid, community_tags.tid')
.includes(:node_tag)
.references(:node_tag)
Obwohl dies uns nicht sagen würde, ob der Knoten veröffentlicht wurde (im Vergleich zu Spam), es sei denn, wir haben dort auch node.status gemischt. Aber das ist möglich!
jywarren
am 25. Jan. 2018
Hallo, ich habe hier nur ein paar Fragen,
1.) Wenn 2 Tags zum selben Knoten gehören, haben sie eine Kante dazwischen?
2.) Die verschiedenen Farben stehen für verschiedene Arten von Knoten wie Fragen, Notizen, Forschungsnotizen usw. ?
Danke 😄 !
sagarpreet-chadha
am 25. Jan. 2018
Und ich bin auch damit einverstanden, das API-Land nicht zu verlassen :)
sagarpreet-chadha
am 25. Jan. 2018
Arg! Okay. Lass uns nicht weitermachen, bitte. Niemand möchte mehr im API-Land bleiben als ich ( naja , vielleicht mit Ausnahme von siehe Erweiterung der Konversation hier ). Aber jetzt sagt @jywarren, dass es keine so große Sache mehr ist, also gute Zeiten in diesem
Da die Verwendung von Github eine Barriere für zugängliche Informationen darstellen kann (nicht jeder hat Zugriff, weiß wie man sie verwendet), denke ich (äh ... dachte), Gespräche zu führen, bei denen es nicht darum geht, in der Codebasis "Dinge zu erledigen" die Website, auf der jeder von ihnen lernen kann. Dies sind keine Gemeinschaftsnormen, die ich festgelegt habe (siehe @jywarrens eigenen Kommentar oben ), aber ich denke, sie sind gut.
skilfullycurled
am 25. Jan. 2018
Ups , sorry https://publiclab.org/questions/tommystyles/10-20-2017/need-your-feedback-on-tag-pages#answer - 556-comment-17709 – wo Sie vorgeschlagen haben:
- läuft nur auf den Top 250 Tags
- wöchentlich zwischenspeichern
Ich werde dort drüben wieder anpingen, aber ich denke, dass wir mit all der Arbeit an der API, der Codebereinigung und der Reichweite eine tägliche oder wöchentliche Cache-Version einer solchen Abfrage durchführen könnten und mit 10-15 Sekunden Gesamtberechnung in Ordnung sein könnten Zeit pro Woche. Der Rest wird lokal im Browser ausgeführt. Wiederhole das dort drüben.
jywarren
am 25. Jan. 2018
@jywarren Ich muss mich bei einigen deiner Fragen an dich hier eine kurze Erklärung, wie der Graph aus den Tag-Paaren erstellt wird. Den genauen Code finden Sie hier .
@sagarpreet-chadha (und alle anderen Interessierten) können Sie sehen, wie ein d3.js-Diagramm aus den Tag-Daten erstellt wurde, indem Sie sich das Repository für
Was die Community-Erkennung anbelangt, wenn Sie im Tagoverflow-Repository nachsehen, werden Sie feststellen, dass der Autor einen eigenen Algorithmus implementiert hat. Seitdem wurden andere wie jLouvain implementiert, netClustering eine CNM-Implementierung ( d3-Beispiel ). Mit einem Limit von 256 Tags ist die Community-Erkennung im Browser wahrscheinlich in Ordnung.
skilfullycurled
am 25. Jan. 2018
Um die publiclab.org-Diskussion nicht mit vielen Daten zu überfrachten, hier ein Link zum Datenformat, das TagOverflow verwendet:
https://api.stackexchange.com/2.1/tags/python/related/?site=stackoverflow&key=of3hmyFapahonChi8EED6g ((&pagesize=16
Es macht etwa 15 Aufrufe, um abzurufen, welche Tags sich auf ein bestimmtes Tag beziehen (im obigen Beispiel "Python")
jywarren
am 25. Jan. 2018
Der Unterschied zu den oben generierten Daten besteht also darin, dass meine Abfrage die Knoten-IDs auflistet, sie jedoch nicht verwendet hat, um "Beziehungen" herzustellen. Aber natürlich macht das Jupyter-Notebook von
jywarren
am 25. Jan. 2018
@sagarpreet-chadha, ich habe eine Frage gestellt, in der Ihre Fragen oben gestellt und beantwortet wurden:
https://publiclab.org/questions/bsugar/01-25-2018/how-was-the-tag-graph-visualization-made
Ich versuche nicht, in Bezug auf meine Bitte "passiv aggressiv" zu sein, aber ich denke, die Leute könnten davon profitieren, dass dieser Aspekt des Gesprächs öffentlich ist. Ich denke, das macht es "aggressiv aggressiv". ; )
Spaß beiseite, beantworte gerne alle Fragen!
skilfullycurled
am 25. Jan. 2018
Hallo allerseits!
@sagarpreet-chadha, ich habe alle Dateien, die Sie brauchen, hier abgelegt:
https://spideroak.com/browse/share/skillfullyshared/plots-tag-graph
Dem Ordner liegt eine Readme-Datei bei, die den Inhalt erklärt.
Bitte lassen Sie mich wissen, wenn Sie sie heruntergeladen haben, damit ich den Shareroom schließen kann. Irgendwann poste ich sie auf meinem Github-Konto, damit andere Leute im Wiki darauf zugreifen können.
Beantworte gerne weitere Fragen!
skilfullycurled
am 1. Feb. 2018
Danke @skillfullycurled !
Ich habe die Dateien heruntergeladen :-)
sagarpreet-chadha
am 2. Feb. 2018
Kein Problem @sagarpreet-chadha!
PS: Ich habe dir in der Wiki-Frage einen Nachdenken hinterlassen.
skilfullycurled
am 2. Feb. 2018
Tolles Update zu Ruby-basierten Tag-Relationness-Berechnungen hier: https://publiclab.org/questions/bsugar/01-25-2018/how-was-the-tag-graph-visualization-made
mehr in Kürze!
jywarren
am 17. Jan. 2019
Einige Fortschritte in https://github.com/publiclab/plots2/pull/4657 , wo ich eine extrem einfache, aber Live-Instanz von Cytoscape.js (http://js.cytoscape.org/) implementiert habe, die von a . läuft wöchentliche zwischengespeicherte Sammlung von
Es dauerte über 50 Sekunden, um für ALLE Tags auf der Site zu laufen (die wöchentlich zwischengespeichert werden konnten), aber das generierte auch mehr als 8200 Tags und 31k Kanten ... was viel zu grafisch darstellen ist. Hier ist das komplette Set; Ich denke, es enthält viele Spam-Tags: https://gist.github.com/jywarren/4b1f9a032092a8187dd802a375fcb700
Sie können die Anzahl der Tags, die Sie abfragen möchten, wie folgt angeben:
Es ist derzeit auf 5 "Kanten" pro Tag-Name beschränkt, was die 5 Tags darstellt, die neben dem ursprünglichen Tag am häufigsten vorkommen.
Dies ist jetzt auf dem stabilen Testserver live (obwohl dieser Zweig ziemlich oft neu aufgebaut wird, sodass die URL nicht immer online ist ... ironischerweise) hier:
https://stable.publiclab.org/stats/graph?limit=75
Die größeren Werte wie limit=100 oder 250 scheinen einen Fehler zu zeigen und ich muss das ein bisschen nach unten jagen. Aber das ist ein ziemlich guter Anfang.
Es gibt viele Konfigurationen, die hinzugefügt werden können, um dies zu verfeinern – Knotengröße, Linkstärke, vieles mehr – in der Galerie unter http://js.cytoscape.org finden Sie einige Möglichkeiten. Und "Familien" zu machen ist vielleicht auch möglich, obwohl ich dafür etwas mehr Input bräuchte.
jywarren
am 18. Jan. 2019

jywarren
am 18. Jan. 2019
Ooh, https://stable.publiclab.org/stats/graph?limit=300 scheint auch zu funktionieren
jywarren
am 18. Jan. 2019
Community-Erkennung hier! https://github.com/upphiminn/jLouvain/blob/master/README.md
jywarren
am 19. Jan. 2019
@jywarren , super cool !!!
sagarpreet-chadha
am 19. Jan. 2019
Außerdem gibt es eine Reihe von Clustering-Algorithmen – diese können in der JavaScript-Konsole getestet werden:
http://js.cytoscape.org/#collection/clustering
- eles.markovClustering()
- Knoten.kMeans()
- Knoten.kMedoids()
- node.fuzzyCMeans()
- node.hierarchicalClustering()
- node.affinityPropagation()
Ich kenne diese nicht, aber sie scheinen alle Attribute der Knoten oder Kanten zu verwenden, um Cluster ähnlicher Elemente zu erstellen. Also, was sollten wir als Attribute angeben, auf denen Ähnlichkeit basiert?
Sie können diese in der Konsole anhand der Beispiele in den Dokumenten ausprobieren, z. B.:
var clusters = cy.elements().hca({
mode: 'threshold',
threshold: 5,
attributes: [
function( node ){ return node.data('count'); }
]
});
clusters; // <= then inspect what this returns to see the clusters
OK, mit jlouvain ich die Community-Erkennung hinzufügen: https://github.com/upphiminn/jLouvain
Ich habe nicht genügend Testdaten, um zu sehen, wie das funktioniert, aber wenn #4679 erfolgreich ist, werde ich es zusammenführen und wir sollten es mit Community-Erkennung sehen können unter:
https://stable.publiclab.org/stats/graph?limit=101
(sobald es aufgebaut ist)
jywarren
am 21. Jan. 2019
Hallo allerseits! Sieht toll aus. Tut mir leid, dass ich nicht antworten konnte, habe etwas nachgeholt und werde später darauf zurückkommen.
In der Zwischenzeit ist eine weitere Zutat, die ich in keinem meiner anderen Beiträge erwähnt habe, das Layout. Diejenige, die dem, was ich verwendet habe, am nächsten kommt, ist wahrscheinlich das Force-Layout . Technisch könnte es sich um etwas namens Force Layout 2 gehandelt haben:
Das Kraft-Layout ist eine Art glühende Anziehung/Abstoßung, die basierend auf den von Ihnen eingestellten Parametern (dh der Anzahl der Iterationen, Stärke der Anziehung/Abstoßung) einen stationären Zustand erreicht. Hier ist eine d3-Demo .
Was die Community-Erkennung und die Kantengewichte angeht, haben Sie einige Optionen, aber wenn Sie das Tag-Diagramm, auf das sich dies bezieht, neu erstellen möchten, benötigen Sie ein gemeinsames Auftreten, welches Cytoscape, wie es der Zufall so will, eine Funktion hat, die dabei hilft Einfacher.
oe_ratio = (all_questions_count * tag_count_AB) / (tag_count_A * tag_count_B)
Wobei tag_count_AB = edge.parallelEdges()
So wie es war, habe ich zuerst den Satz von Tags auf eine vernünftige Anzahl eingegrenzt (z zu erwartetem Verhältnis über 1.
Weitere Informationen finden Sie unter
Eine einfache Alternative besteht darin, das Kantengewicht zwischen zwei Knoten auf tag_count_AB zu setzen und nur Kanten/Knoten über einem bestimmten Schwellenwert zu verwenden. Persönlich erziele ich damit aus den oben genannten Gründen selten gute Ergebnisse.
Bezüglich der anderen Methoden interessiert Sie vielleicht S. 3. (2.2) bis - S. . 7 (3.1) dieses Papiers (keine Mathematik für diese Teile), das versucht, die verschiedenen Arten von Methoden zur Erkennung von Gemeinschaften zu klassifizieren. Dies hat mir geholfen, diejenigen auszuwählen, die die herausragendsten Ergebnisse liefern, wenn man bedenkt, wie ich das Diagramm strukturiert habe und was ich daraus wissen möchte. Zum Beispiel Gemeinschaften mit gemeinsamen sozialen Verbindungen im Vergleich zu Gemeinschaften, die darauf basieren, wie häufig Nachrichten zwischen zwei Personen gesendet werden.
skilfullycurled
am 21. Jan. 2019
Arbeiten jetzt auf stabilem Server!
jywarren
am 25. Jan. 2019

Hier w 99 Top-Tags!
jywarren
am 25. Jan. 2019
Es sollte heute Abend auf der Live-Site laufen, aber ich wollte darauf hinweisen, dass die "übermäßige Verwendung" von Tags durch einige Benutzer das Diagramm in einer Weise verzerrt hat, die wir zuvor erkannt haben. Ich glaube, einer der Benutzer wurde von der Site moderiert, und ich fragte mich, ob die Leute es für angebracht hielten, diese Tags entweder von der Site zu löschen oder sie zumindest aus der Grafik wegzulassen. Sie zu löschen wäre einfacher, aber wir können auch etwas herstellen, um sie nur zu verschleiern. Präferenz, @ebarry @skillfullycurled ?
Trotzdem sieht das gut aus, auch wenn die Einstellungen für die Kantenelastizität noch etwas optimiert werden müssen und vielleicht ein anderer Layouttyp besser funktionieren würde ...

jywarren
am 25. Jan. 2019
Jep! Wir sind definitiv auf dieses Problem gestoßen. Leider musste nur der betreffende Benutzer als Ausreißer entfernt werden. Jemand, der so viele Tags verwendet, mag an sich kein Ausreißer sein, aber wenn er Tags erstellt, die so spezifisch für sich selbst sind und sie immer wieder verwendet, dann erfasst er die Daten nicht wirklich.
skilfullycurled
am 25. Jan. 2019
Ich glaube, ich habe sogar ein Github-Problem mit einer Funktionsanfrage protokolliert, bei der eine Warnung angezeigt wurde, die im Wesentlichen lautete: "Whoaaaaaaaa, einfach da, Kerl! Sieht aus, als hättest du viele Tags dort, eh?".
skilfullycurled
am 25. Jan. 2019
Ach, PS. Sieht übrigens super aus!!
skilfullycurled
am 25. Jan. 2019
AAAAAAHHHHHHHHMAYZINGGGGGGGGGGG!!!!!!!!!!!!
Ja, um diesen bestimmten Benutzer manuell als Ausreißer zu entfernen
ebarry
am 26. Jan. 2019
Ich kehre immer wieder zu diesem Thread zurück, weil er so großartig ist und an Dinge denke (hoffentlich winzig). Eine andere Sache, die Sie zum Filtern in Betracht ziehen könnten, sind die Power-Tags (das sind die mit den Doppelpunkten, oder?). Ich denke, sobald das Problem der Tag-Übernutzung behoben ist, werden wir mehr über das Layout wissen.
Hinweis an mich selbst: Hier ist ein Link zu einem Commit mit den Seiten, die für die Implementierung wichtig sind.
skilfullycurled
am 26. Jan. 2019
Hallo zusammen, freut mich über die Begeisterung! Ich bin krank geworden, erhole mich aber jetzt und werde auf dem Heimflug am Dienstag ein bisschen daran arbeiten.
Ich wollte fragen - meine konkrete Frage ist, ob wir:
- Tags von diesem moderierten Benutzer tatsächlich löschen, oder
- wenn wir versuchen sollten, sie zu bewahren, aber herauszufiltern.
Das Filtern würde sowohl beim Code als auch bei den Datenbankaufrufen erheblich mehr Aufwand bedeuten, ist aber möglich.
jywarren
am 27. Jan. 2019
In Fällen wie diesem, in denen ein Konto aufgrund von Moderation "inaktiv" wurde, denke ich, dass es in Ordnung ist, die Tags einfach aus der Datenbank zu löschen. Vor allem, wenn Sie ein Backup haben. Nicht, weil Sie es vielleicht wiederherstellen möchten, sondern nur, weil ich Angst habe, Daten für immer zu verlieren. Es ist nicht gesund, aber billiger Platz ist ein unglücklicher Wegbereiter. Meine Gefühle wären komplizierter, wenn dies ein Konto wäre, das freiwillig "inaktiv" gemacht wurde, aber wir können das ein anderes Mal (oder jetzt) besprechen.
skilfullycurled
am 27. Jan. 2019
Ja, das ist ein großes Thema zum Nachdenken. Nachdem ich überprüft habe, ob es Tags gibt, die _nur_ dieser Benutzer verwendet hat (Beispiel: aries city-point ), stellte ich fest, dass es tatsächlich nur sehr wenige Tags gibt, die für diesen Benutzer vollständig isoliert sind (sogar purelab wurde ursprünglich von Shan He für DIY-Wasserfilter verwendet, und research-notes wurde ursprünglich für Beiträge verwendet, in denen das Design von Forschungsnotizen auf der Website diskutiert wurde).
Da dieser Benutzer moderiert ist, kann unsere Tag-Visualisierung alle Inhalte von moderierten Benutzern ausschließen – und damit auch die Tags, die für die Inhalte dieser Person verwendet werden –, ohne dieses Tag im Allgemeinen auszuschließen, da es für die Inhalte anderer Personen verwendet werden könnte?
ebarry
am 28. Jan. 2019
@ebarry , ich sollte klarstellen (falls nicht).
Als ich sagte:
lösche die Tags direkt aus der Datenbank
Ich meinte das, womit du geschlossen hast:
...[dass] unsere Tag-Visualisierung alle Inhalte von moderierten Benutzern ausschließt – und damit auch die Tags, die für die Inhalte dieser Person verwendet werden –, ohne diese Tags im Allgemeinen auszuschließen, [da] sie für die Inhalte anderer Personen verwendet werden können. ..
Wenn der moderierte Benutzer und Shan He beide das Tag "purelab" verwenden würden, würde "purelab" nicht gelöscht, sondern nur jede Instanz des Tags des moderierten Benutzers oder ITMUs, wenn Sie so wollen.
Die verbleibende Frage (wenn ich @jywarren verstehe) ist, ob diese ITMUs vollständig aus der Datenbank gelöscht werden sollen oder nicht, oder ob wir sie in der Datenbank behalten, aber die ITMUs herausfiltern, wenn alle Tags für die Visualisierung angefordert werden. Sie zu löschen erleichtert denjenigen, die die Visualisierung implementieren, das Leben erheblich, aber es kann Argumente geben, sie beizubehalten.
Ich persönlich denke, ersteres ist in Ordnung, wenn der Benutzer moderiert wurde, da es keine Chance gibt, dass der Inhalt jemals auf die Site zurückkehrt. Dies kann jedoch anders sein, wenn ein Benutzer sein Konto löschen möchte, je nachdem, ob es Funktionen gibt, mit denen er es reaktivieren kann. Ich denke, wir können diese Situation für ein anderes Mal belassen, aber für das Protokoll wollte ich nur sagen, dass meine gerichtliche Meinung begrenzt ist.
skilfullycurled
am 28. Jan. 2019
Ja, keine Sorge NodeTags löschen das Tag nicht, nur den Link, der verknüpft ist
Tags mit Knoten und Autoren. Ich habe es tatsächlich schon getan, muss aber spülen
der wöchentliche Cache (das hat das Ganze erst möglich gemacht) und es gibt
ein paar dringendere Fehler, die erst heute behoben werden müssen, Entschuldigung!
Am Mo, 28.01.2019, 15:24 Uhr gekonnt gelockt < [email protected]
schrieb:
@ebarry https://github.com/ebarry , sollte ich klarstellen (falls nicht).
Als ich sagte:
lösche die Tags direkt aus der Datenbank
Ich meinte das, womit du geschlossen hast:
...[dass] unsere Tag-Visualisierung alle Inhalte von der Moderation ausschließt
Benutzer -- und damit auch die Tags, die auf den Inhalten dieser Person verwendet werden -- ohne
Ausschließen dieses Tags im Allgemeinen, [da] es für andere Personen verwendet werden kann
Inhalt...Wenn der moderierte Benutzer und Shan He beide das Tag "purelab", "purelab"
würde nicht gelöscht, nur jede Instanz des Tags des moderierten Benutzers
oder ITMUs, wenn Sie so wollen.Die verbleibende Frage (wenn ich @jywarren verstehe
https://github.com/jywarren ) ist, ob diese ITMUs gelöscht werden sollen oder nicht
vollständig aus der Datenbank, oder behalten wir sie in der Datenbank, aber filtern?
die ITMU ist aus, wenn alle Tags für die Visualisierung angefordert werden.Sie zu löschen macht das Leben für diejenigen viel einfacher, die die
Visualisierung, aber es kann Argumente für deren Erhaltung geben.—
Sie erhalten dies, weil Sie erwähnt wurden.
Antworten Sie direkt auf diese E-Mail und zeigen Sie sie auf GitHub an
https://github.com/publiclab/plots2/issues/1502#issuecomment-458244753 ,
oder den Thread stumm schalten
https://github.com/notifications/unsubscribe-auth/AABfJzTXlk18FzlER4PQyoomFE5VTFcrks5vH0AqgaJpZM4OOvLP
.
jywarren
am 28. Jan. 2019
OK, es ist gelungen, alle vom moderierten Benutzer erstellten Tags zu löschen. Sie werden in Backups gespeichert. Dies war ziemlich einfach und wirkt sich im Gegensatz zur anderen Lösung nicht auf den Code aus.
Jetzt möchte ich vorschlagen, dass wir möglicherweise ein anderes Layout verwenden möchten - wir verwenden ein cose Layout, und es gibt Variationen ( bilkent und andere), aber es gibt auch eine cola Layout. Ich kenne wirklich nicht den richtigen, um ihn hier zu verwenden, aber einige scheinen die Links weniger zu verwickeln. Obwohl viele der Demos auf http://js.cytoscape.org/ weniger
Dokumente zu integrierten Layouts unter http://js.cytoscape.org/#layouts
Ein weiteres Thema, bei dem wir versuchen können, jemanden zu bitten, ihn auszuprobieren und aufzugreifen, ist die Frage der Community-Erkennung. Ich konnte nicht herausfinden, wie es funktioniert oder warum es hier keine Gruppen erkennt. Die Farben sind nett, aber sie sind ein Knoten pro Community. Bah.
jywarren
am 28. Jan. 2019
Dieses Problem muss jetzt also aufgeteilt werden in:
- Layout-Iteration (Eingabe von der aktuellen Menge willkommen)
- Community-Erkennung
- zusätzliche Tag-Filterung (vielleicht Tags ohne nicht genehmigte Knoten herausfiltern, um uns von Spam zu befreien?)
Ich möchte auch noch einmal darauf hinweisen, dass wir jetzt eine bestimmte Anzahl von Tags anzeigen (bitte testen Sie dies nicht bis zu seinen Grenzen, es sei denn, es ist auf https://stable.publiclab.org - ich habe bis zu 1000 Tags ausprobiert und es wird geladen gut, aber nicht mehr bitte auf dem Produktionsserver, auch nur einmal)
Und wir sind auf Links zwischen ihnen beschränkt, wobei jedes Tag maximal 10 Tags meldet, neben denen es aufgetreten ist. Dies ist nicht umfassend, schien aber ein machbares Gleichgewicht zwischen Optimierung und Gründlichkeit zu sein.
jywarren
am 28. Jan. 2019
jywarren
am 28. Jan. 2019
skilfullycurled
am 31. Jan. 2019
@jywarren egal , ich wusste nicht, dass sich der Graph jetzt auf dem Produktionsserver befindet, ich habe stable.publiclab.org verwendet.
skilfullycurled
am 31. Jan. 2019
Okay. Ich habe gerade ziemlich viel Zeit damit verbracht, dies zu untersuchen, und bekomme ein besseres Gefühl dafür, wie das Diagramm funktioniert.
Jetzt möchte ich vorschlagen, dass wir möglicherweise ein anderes Layout verwenden möchten – wir verwenden eine Kose
Ich werde es mir anschauen und überlegen. Ich denke, die Frage, die hier beantwortet werden muss, ist, was wollen wir aus der Grafik herauslesen? Wenn wir beispielsweise in erster Linie daran interessiert sind, dass ein Besucher sehen kann, welche Tags mit welchen verknüpft sind, ist das Kreislayout oder der konzentrische Kreis möglicherweise das Beste, wenn es langweilig wäre.
Wenn ich eine Vermutung (informiert, aber immer noch eine Vermutung) anstellen müsste, warum die CoSE kein so gutes Ergebnis liefert, würde dies daran liegen, dass beim Betrachten der Daten, wenn Sie eine bestimmte Knotenzahl erreichen, die Zählungen beginnen allen gleich sein. Wenn CoSE die Knoten also nur basierend auf der Knotengewichtung abstößt, ist es möglich, dass zwischen ihnen eine gleiche Abstoßung besteht. Wenn ich hier Abstoßung verwende, meine ich all die Dinge, die in Abstoßung einfließen, zum Beispiel auch die Schwerkrafteinstellung. In diesem Fall kann es sein, dass nicht genügend Iterationen des Algorithmus vorhanden sind oder die Abstoßungsfaktoren nicht genügend Streuung verursachen/ermöglichen.
Ein weiteres Thema, bei dem wir versuchen können, jemanden zu bitten, ihn auszuprobieren und aufzugreifen, ist die Frage der Community-Erkennung.
Wenn Sie einen Moment Zeit haben, können Sie mich auf den Commit mit dem neuesten JavaScript dazu hinweisen? Ich kann es über den Browser abrufen, aber nur in dieser Form, in der es keine Struktur hat und nur eine einzige Zeile ist. Sobald ich das tue, kann ich mehr sehen. Ich habe mir das jLouvain-Beispiel angesehen, und es scheint keine Einstellung dafür zu geben, wie viele Communities Sie möchten, was ein Teil des Problems sein könnte. Typischerweise bietet Louvain eine "beste Zahl", aber manchmal ist es nicht die beste. Die Python-Implementierung, auf der jLouvain basiert, hat diesen Parameter, hat es aber möglicherweise nicht geschafft.
skilfullycurled
am 31. Jan. 2019
Da sind wir:
jywarren
am 1. Feb. 2019

jywarren
am 1. Feb. 2019
Oh, ich dachte, ich hätte noch einen Kommentar hinterlassen... wo ist er hin? abwarten...
jywarren
am 1. Feb. 2019
Wie auch immer, ich wollte sagen, dass ich denke, dass ich einige der Layoutprobleme herausgefunden habe, aber urteilt selbst:
https://publiclab.org/stats/graph?limit=50
https://publiclab.org/stats/graph?limit=100
jywarren
am 1. Feb. 2019
Hier ist das JS für die Community-Erkennung: https://github.com/publiclab/plots2/blob/master/app/views/tag/graph.html.erb#L263
Und hier ist die Layout-Konfiguration, an der wir viel optimieren könnten, um sie auszuprobieren:
jywarren
am 1. Feb. 2019
Zuerst möchte ich mich entschuldigen, dass ich bei der schweren Arbeit am Coding-Ende nicht helfen kann. Es ist einfach für einen, Dinge nur vorzuschlagen, aber mir ist klar, dass sie auch von Menschen umgesetzt werden müssen und es ist mir nicht entgangen, dass ich in dieser Hinsicht nicht helfe.
Es gibt eine Reihe von Möglichkeiten, warum der jLouvain nicht gut funktioniert. @jywarren , ich denke, Sie lösen bereits eine davon, nämlich dass nicht genug Farben vorhanden waren. Trotzdem habe ich in der Konsole nach den Communities gesucht und jeder Knoten ist eine andere Community, was für mich bedeutet, dass der Algorithmus keinen guten Ort zum Aufhören findet. Normalerweise gibt es einen Parameter dafür, wie viele Communities/Sensibilität/Auflösung Sie haben möchten, und dann spielen Sie damit, bis Sie etwas bekommen, das ungefähr richtig aussieht.
Sehen Sie sich dieses Problem im jLouvain-Repository an. Jemand hat einen sehr einfachen Fix geschrieben, der implementiert werden könnte. Ich bin mir nicht ganz sicher, wie es in Bezug auf die Rückgabe funktioniert: Idealerweise gibt es für jedes Element im Array ein gesamtes Community-Erkennungsergebnis zurück? Das wäre großartig und würde wahrscheinlich das Problem lösen, dass jeder Knoten eine eigene Community ist.
Später mehr…
skilfullycurled
am 1. Feb. 2019
Weiterleiten einer Frage von @shapironick, der sich in einem anderen Kanal gefragt hat, ob in einer zukünftigen Ausgabe die Verbindungslinien unterschiedlich dünn und dick sein könnten, um zu zeigen, wie eng zwei bestimmte Tags miteinander verwandt sind? Vielen Dank!
ebarry
am 6. Feb. 2019
das ist eine tolle Idee. Ich denke, an dieser Stelle müssen wir das schließen und ein öffnen
neue Ausgabe mit Checkliste möglicher Verfeinerungen der Anzeige, und
für Neuankömmlinge wird es viel einfacher sein (weniger Kontext und Geschichte erforderlich, um
teilnehmen), um einzusteigen und mit deren Umsetzung zu beginnen. Ich bin fast versucht,
spinnen Sie es in ein neues Repository aus, das /nur dieser Graph/ ist, da es
verbindet sich sonst nicht mit der PL-Codebasis, aber aus Gründen der
gemeinschaftszusammenhalt lasst es uns in plots2 halten.
Liz, könnten Sie die neue Ausgabe beginnen und mit einer Checkliste beginnen?
Am Mittwoch, den 6. Februar 2019 um 11:17 Uhr schrieb Liz Barry [email protected] :
Weiterleiten einer Frage von @shapironick https://github.com/shapironick
der sich in einem anderen Kanal gefragt hat, ob es in einer zukünftigen Ausgabe so sein könnte
unterschiedliche Dünne und Dicke in den Verbindungslinien, um zu zeigen, wie eng
verwandt sind zwei bestimmte Tags? Vielen Dank!—
Sie erhalten dies, weil Sie erwähnt wurden.
Antworten Sie direkt auf diese E-Mail und zeigen Sie sie auf GitHub an
https://github.com/publiclab/plots2/issues/1502#issuecomment-461083862 ,
oder den Thread stumm schalten
https://github.com/notifications/unsubscribe-auth/AABfJ9nxysbBtCAYHEW2tA8UwNH9zelFks5vKv_hgaJpZM4OOvLP
.
jywarren
am 6. Feb. 2019
Yay! @shapironick! Im Moment sendet die Datenbankabfrage nur die Top-n-Tags und die Anzahl dieser Tags auf der gesamten Site. In Zukunft müssten wir, um Kantengewichte zu haben, eine Änderung am Back-End vornehmen, um entweder alle Tags an das Front-End zu senden, damit die Verbindungszahlen aggregiert werden können, oder sie müssen auf dem aggregiert werden hinteres Ende. Alternativ berechnen wir am Front-End eine Netzwerkkanteneigenschaft (z. B. eine Zentralität: Grad, Nähe, Zwischenheit usw.).
skilfullycurled
am 6. Feb. 2019
Sehr cool! Keine Vorfreude auf diese Idee +1 zum Starten einer neuen Ausgabe, diese ist jedoch episch und großartig!
 shapironick
am 6. Feb. 2019
shapironick
am 6. Feb. 2019
Im Moment sehen wir in den Daten, die wir an den Diagrammcode übergeben, glaube ich, wenn ein Tag (z. B. Tag A) mit Tag B verknüpft ist, und wir sehen eine zweite Verbindung, wenn Tag B mit Tag A verknüpft ist das sagt uns nicht wirklich viel. Refactoring zur Bereitstellung von "Gewicht" ist interessant ... ich könnte mir auch ein paar Möglichkeiten vorstellen, dies zu tun. Ich stimme zu, wir könnten entweder alle node.ids die jedes Tag hat, und diese lokal berechnen, oder wir könnten versuchen, dies in dem Moment vorzuberechnen, in dem wir die fünf am meisten verwandten Tags jedes Tags sammeln. (Ich glaube, ich habe dies vor kurzem auf 10 geändert, aber trotzdem).
Tolle Nachbearbeitung. Sobald wir die Checkliste haben, können wir ein wenig Prioritäten setzen und diese schrittweise verbessern. Vielen Dank!
jywarren
am 6. Feb. 2019
Oh schau, das hat es in die historische Aufzeichnung geschafft ;) : https://publiclab.org/wiki/community-development#2019
ebarry
am 8. Feb. 2019
Als ich dies für ein mögliches Summer of Code-Projekt im kommenden Sommer untersuchte, fand ich den Community-Erkennungsfehler, der subtil war – die Daten befanden sich in einem verschachtelten Objekt wie {data: { DATA }} und nicht nur in { DATA } . Behoben in https://github.com/publiclab/plots2/pull/9169 !
jywarren
am 9. Feb. 2021

jywarren
am 9. Feb. 2021
Das ist nur mit unseren Testdaten; Der vollständige Fix wird auf dem Stable-Server sichtbar sein, sobald wir ihn zusammenführen und neu erstellt haben; wahrscheinlich 30m oder so.
jywarren
am 9. Feb. 2021
Schön los gehts:
https://stable.publiclab.org/tags (denken Sie daran, dass dies jedes Mal, wenn wir eine neue Änderung zusammenführen, um 10 m ausfällt)
jywarren
am 9. Feb. 2021
Verwandte Themen
 bronwen9
·
3Kommentare
shapironick
·
3Kommentare
bronwen9
·
3Kommentare
shapironick
·
3Kommentare
 keshavsethi
·
3Kommentare
jywarren
·
3Kommentare
ebarry
·
3Kommentare
keshavsethi
·
3Kommentare
jywarren
·
3Kommentare
ebarry
·
3Kommentare
Hilfreichster Kommentar
Es sollte heute Abend auf der Live-Site laufen, aber ich wollte darauf hinweisen, dass die "übermäßige Verwendung" von Tags durch einige Benutzer das Diagramm in einer Weise verzerrt hat, die wir zuvor erkannt haben. Ich glaube, einer der Benutzer wurde von der Site moderiert, und ich fragte mich, ob die Leute es für angebracht hielten, diese Tags entweder von der Site zu löschen oder sie zumindest aus der Grafik wegzulassen. Sie zu löschen wäre einfacher, aber wir können auch etwas herstellen, um sie nur zu verschleiern. Präferenz, @ebarry @skillfullycurled ?
Trotzdem sieht das gut aus, auch wenn die Einstellungen für die Kantenelastizität noch etwas optimiert werden müssen und vielleicht ein anderer Layouttyp besser funktionieren würde ...