Plots2: tag visualisation de tous les tags
Ceci est une demande pour une personne ayant accès à l'édition de pages spéciales pour ajouter cette visualisation des balises du début des temps à novembre 2016 en haut de publiclab.org/tags
https://www.dropbox.com/s/s78g3ufhsav5xzo/plots_tag_graph_256_filtered.png?dl=0
CC :
@gretchengehrke
@habilement bouclé
 ebarry
ebarry
Tous les 73 commentaires
Salut, Liz - je suis un peu réticent à mettre un graphique statique comme celui-ci dans notre base de code permanente, mais peut-être qu'une suggestion pourrait être que nous affichions une "fonctionnalité" (comme nos bannières) en haut de cette page, puis les administrateurs pourraient y afficher tout ce qu'ils veulent. Cela fonctionnerait-il ?
 jywarren
le 5 juil. 2017
jywarren
le 5 juil. 2017
Il irait au-dessus ou au-dessous de cette ligne : https://github.com/publiclab/plots2/blob/master/app/views/tag/index.html.erb#L4
Et ressemble à :
<% cache('feature_tag-page-header') do %>
<%= feature('tag-page-header') %>
<% end %>
Eh bien, je ne veux pas tellement décorer cette page que je veux ajouter "un aperçu en un coup d'œil".
Un point différent, mais peut-être pertinent quant à la raison pour laquelle je suggérerais d'ajouter une visualisation graphique, c'est que cette page de balise n'a toujours pas de capacités de tri pour voir "récent" ou "populaire" et encore moins pour voir l'un ou l'autre par géographie.
ebarry
le 5 juil. 2017
Il existe en fait des liaisons python gephi que nous pourrions utiliser pour le générer dynamiquement. Je travaille actuellement sur une visualisation de réseau javascript en ce moment, alors laissez-moi voir comment cela fonctionne. Si ça se passe bien, alors je peux traduire ce que j'ai fait en un script python qui peut générer la structure de données pour ensuite être visualisée en javascript.
 skilfullycurled
le 5 juil. 2017
skilfullycurled
le 5 juil. 2017
Salut à tous - je pense qu'un graphique généré serait génial, et c'est quelque chose que nous pourrions mettre dans le code permanent.
@ebarry je ne dis pas qu'il s'agit de décoration et non de contenu, je dis plutôt que cela deviendrait rapidement obsolète, et notre objectif est également de stocker / aucun/ contenu dans notre base de code - uniquement l'infrastructure. C'est donc juste un moyen de l'implémenter - ma solution proposée semble-t-elle correcte ?
re this tag page still doesn't have any sorting capabilities to see "recent" or "popular" much less to see either of those by geography. Je serais heureux de travailler avec vous pour proposer des demandes de fonctionnalités pour que les contributeurs construisent pour résoudre ce problème si c'est une priorité pour vous. Cela pourrait être des problèmes faciles de first-timers-only si vous pouvez aider à les mettre dans la file d'attente !
jywarren
le 5 juil. 2017
Revenons à l'essentiel sur cette question :)
Quel est l'objectif de la visualisation des balises ?
Pour moi, la visualisation des balises est un moyen de représenter visuellement les balises associées, par exemple les balises qui apparaissent ensemble sur le même contenu. Pour un bon exemple, voir les clusters codés par couleur dans la visualisation de @skilfullycurled ci-dessus. Les balises de regroupement sont importantes car elles relient visuellement la présentation du site Web de l'activité communautaire _plus proche_ à ce que la communauté des laboratoires publics appelle culturellement « domaines de recherche », ou peut-être « sujets » --> c'est mon objectif réel avec tout ce problème.
Voici quelques informations générales : sur notre page de balises (https://publiclab.org/tags), nous écrivons « Nous utilisons des balises pour regrouper les recherches par sujet » et encourageons les gens à parcourir les balises (actuellement uniquement triées par activité récente). Il s'agit d'un moyen important de nommer, de créer des liens et/ou de promouvoir les personnes afin qu'elles trouvent et interagissent avec des sujets. Le tableau de bord lui-même met l'accent sur l'activité récente. Le tableau de bord comporte désormais une barre de « balises récemment utilisées » - ce qui est une étape importante mais partielle vers l'objectif de voir les « domaines de recherche » ou les « sujets ».
Pour aller de l'avant, je ne suis pas intéressé par la _navigation_ par une visualisation de balise graphique (donc 2007 !), cependant, les clusters d'activité fournissent un moyen supplémentaire important de se connecter/naviguer aux sujets. Pour atteindre l'objectif, c'est-à-dire la capacité de la page des balises à montrer quelles sont les balises les plus interconnectées, à communiquer l'étendue des sujets connectés dans un domaine de recherche, à naviguer/se connecter à un domaine de recherche et à s'abonner de manière appropriée, nous n'ont pas nécessairement besoin de flèches plongeantes codées par couleur. Réfléchissons à la façon d'atteindre ces objectifs.
Nous pourrions également envisager de mettre en miroir publiclab.org/tags sur publiclab.org/topics pour rendre le langage plus accessible.
ebarry
le 15 nov. 2017
Cool, merci Liz !
Pour essayer d'essayer une fonctionnalité plus étroite vers cet objectif, et si les pages de balises (nouveau nom flottant : pages de sujet ...!?!) avaient une liste de "sujets connexes", quelque chose comme :
Sujets connexes :
waterrunoffwetlandsturbidity
Où « lié » signifie que (en reconnaissant qu'il existe différentes façons de mesurer cela et que nous voulons un moyen « informatiquement efficace »), ce sont les balises qui apparaissent le plus souvent sur les pages qui ont déjà la balise principale. Ainsi, pour le sujet onions , nous comptons chaque page marquée avec onions et prenons le haut, disons, cinq.
Petit suivi si ce qui précède semble bon - serait-il correct de le faire uniquement pour les 20 à 30 pages les plus récentes ? Même s'il ne s'agit que d'un point de départ, cela faciliterait la mise en œuvre sans s'inquiéter de la lenteur globale du site Web. Il pourrait y avoir des moyens plus complexes de contourner ce problème, mais c'est le moyen le plus simple de commencer.
jywarren
le 16 nov. 2017
J'ai posté sur https://publiclab.org/questions/tommystyles/10-20-2017/need-your-feedback-on-tag-pages -- que pensez-vous de déplacer la discussion là-bas jusqu'à ce qu'il y ait des discrets spécifiques étapes de codage (mini projets pour les contributeurs de code) que nous pouvons faire ?
jywarren
le 16 nov. 2017
D'accord, super! revenons à cette discussion et revenons une fois que nous aurons
étapes faisables.
--
+1 336-269-1539 / @lizbarry http://twitter.com/lizbarry / lizbarry.net
Le mer. 15 novembre 2017 à 21h54, Jeffrey Warren [email protected]
a écrit:
J'ai posté sur https://publiclab.org/questions/tommystyles/10-20-
2017/besoin-de-votre-commentaire-sur-les-pages -- que pensez-vous du déménagement
discussion là-bas jusqu'à ce qu'il y ait des étapes de codage discrètes spécifiques (mini
projets pour les contributeurs de code) que nous pouvons faire ?-
Vous recevez ceci parce que vous avez été mentionné.
Répondez directement à cet e-mail, consultez-le sur GitHub
https://github.com/publiclab/plots2/issues/1502#issuecomment-344799932 ,
ou couper le fil
https://github.com/notifications/unsubscribe-auth/AAJ2n8PdvpH0GQ_wBU-Utp4xfL7XDmuJks5s26PpgaJpZM4OOvLP
.
ebarry
le 16 nov. 2017
@jywarren , @ebarry , existe-t-il une API (ou peut-être une documentation) pour connaître les «bords» du graphique ci-dessus ? Je veux dire comment les nœuds sont-ils connectés?
Merci !
 sagarpreet-chadha
le 23 janv. 2018
sagarpreet-chadha
le 23 janv. 2018
Salut @sagarpreet-chadha !
La visualisation n'est qu'une image, il n'y a donc pas d'API (encore! clin d'œil), mais je peux vous fournir la liste des arêtes de ce graphique particulier. Les formats de fichiers les plus "bruts" seraient csv et json. Les deux formats doivent fonctionner avec un graphique soit "par programmation" ( iGraph , networkx , d3.js ) soit avec une interface graphique ( Gephi , Cytoscape ).
Apparemment, vous ne pouvez pas télécharger de fichiers sur github. J'ai essayé de les télécharger dans la note de recherche du Public Lab, mais cela ne fonctionne pas. @jywarren existe-t-il un moyen de télécharger des fichiers dans une note de recherche ? Sinon, @sagarpreet-chadha, pouvez-vous publier un message dans le groupe google plots-dev (vous pouvez vous inscrire ici si vous ne l'êtes pas déjà) ? Attendons de voir ce que dit
Voici ce que vous pouvez attendre avec impatience :
plots_tag_communities_edges_w_props_9_16.csv : : liste d'arêtes uniques avec des propriétés calculées, notamment le poids de l'arête. Le poids se traduit par le nombre de fois où les balises se sont produites ensemble.
plots_tag_communities_nodes_w_props_9_16.csv : liste des nœuds avec les propriétés calculées. La plus pertinente pour l'image sur le site Web est la "classe de modularité" qui vous indique à quelle communauté appartient chaque nœud.
plots_tag_communities_9_16.json : Je ne trouve pas json aussi utile mais je sais que certaines personnes le préfèrent. Je pense que le fichier json inclut également des propriétés pour la visualisation qui se trouve sur le site Web (c'est-à-dire la couleur RVB de chaque nœud).
skilfullycurled
le 23 janv. 2018
Mise à jour : suppression de plots_tag_communities_edgelist_9_16.csv de la liste des fichiers ci-dessus. Ce fichier est d'une utilité limitée car les arêtes dupliquées avaient déjà été fusionnées en arêtes uniques avec des poids. Sans les propriétés, cette liste d'arêtes vous permettra uniquement de créer un graphique avec des poids d'arête de 1. Je chercherai le fichier d'origine avec les doublons.
skilfullycurled
le 24 janv. 2018
Merci @skillfullycurled pour ta réponse !
J'essayais en fait de créer le graphique de visualisation à l'aide de la bibliothèque javascript (d3.js ou vis.js ) afin qu'il puisse être facilement ajouté au site Web publiclab.org. Ces bibliothèques nécessitent les données sous forme de :
nodes: [
{
id: 1,
shape: 'circle',
label: 'Infrared } ] pour les nœuds .
Et pour les bords :
edges: [
{from: 1, to: 2},
{from: 1, to: 3}]
Eh bien, json serait génial, sinon je peux le créer, ou peut-être créer un objet Javascript directement (de cette façon, pas besoin d'analyser le fichier JSON).
J'ai créé un graphe factice (on peut jouer avec les nœuds et les arêtes ici 😄 ):
Qu'est-ce que tu penses ? @ebarry , @jywarren , @skillfullycurled
sagarpreet-chadha
le 24 janv. 2018
Ah. Ce serait génial! D'accord. Pour poursuivre cette conversation, nous devrons quitter "API-land" et aborder le fonctionnement de la visualisation dans Gephi et la meilleure façon de traduire ces fonctionnalités en javascript.
Puis-je vous déranger pour commencer cela comme une question ? Quelque chose comme : « Comment puis-je traduire la visualisation de balise créée dans Gephi en une version javascript ? »
Aussi, envoyez-moi un e-mail à benj. [email protected] pour que je puisse partager les fichiers. Je supprimerai mon e-mail une fois que vous l'aurez fait.
skilfullycurled
le 24 janv. 2018
En fait, je pense que nous n'avons peut-être pas besoin de quitter API-land -- l'API existante est assez robuste ces jours-ci. Je suis curieux @skillfullycurled comment vous avez généré ces bords --
pourraient-ils être générés à partir d'une liste de toutes les balises et des nœuds sur lesquels ils ont été utilisés ? C'est une requête raisonnable que nous devons générer, si elle est mise en cache.
Nous pourrions l'ajouter à l'API à https://github.com/publiclab/plots2/tree/master/app/api/srch et le documenter à https://github.com/publiclab/plots2/blob/master/doc /API.md
S'il y a suffisamment de données, la requête pourrait être quelque chose comme :
r = []
Tag.select(:name, :tid).each do |t|
nids = t.nodes.select(:nid, :status).where(status: 1).collect(&:nid)
r << [t.name, nids] if nids.length > 0
end
r # later, r.to_json
Je viens de l'exécuter en production et cela a pris environ 15 secondes. Si nous mettons cela en cache quotidiennement, je pense que c'est gérable, et nous pourrions peut-être l'améliorer davantage.
jywarren
le 25 janv. 2018
Vous pouvez également partager des fichiers sur http://gist.github.com -- cela pourrait-il fonctionner ?
jywarren
le 25 janv. 2018
Donc, en utilisant le JSON généré à partir de ma requête,
- en JavaScript, nous pouvions calculer le nombre de fois où les balises se sont produites ensemble.
- comment avez-vous regroupé/calculé les « communautés » ?
Voici un extrait :
["whitebalance", [12476, 13575]], ["wi", [12143, 13067]], ["wi-fi", [11123]], ["width-of-dvd-grating", [12838, 12875, 12895, 12899, 12902, 12926, 12990, 12991, 12995, 12999, 13006, 13014, 13019, 13037, 13046, 13057, 13062, 13069, 13077, 13088, 13089, 13094, 13103, 13117, 13125, 13131, 13133, 13136, 13152, 13154, 13157, 13159, 13169, 13178, 13181, 13183, 13188, 13226, 13248, 13283, 13302, 13305, 13308, 13315, 13316, 13340, 13349, 13355, 13366, 13401, 13402, 13409, 13414, 13423, 13429, 13432, 13434, 13437, 13439, 13440, 13443]], ["wiki", [9048, 10956]], ["wiki-gardening", [10956]], ["wild", [11707, 11711]], ["wildfires", [14803]], ["wildlife", [670]], ["wilkinson-bay", [220, 265, 280, 281, 282, 283, 284, 677]], ["wilkinsonbay", [606]], ["williamsburg", [10343, 10428, 10444]], ["willow", [9979]], ["wind", [9032, 10660, 12610, 13880, 14487, 14527, 14530, 14531, 14713, 14756]], ["wind-direction", [14527]], ["wind-sensor", [14713]], ["wind-speed-meter", [1962, 5837, 9032, 12103, 13064, 13165, 13231, 13880, 14527]], ["winder", [7717]], ["winders", [1900]], ["window", [147, 1759]], ["windows", [11434, 11677, 13037]], ["windows-7", [13037]], ["windows-7-ultimate", [13037]], ["windows-excel", [13037]], ["windspeed", [745]], ["windvane", [14527]], ["windy", [146]], ["wine", [706, 10955]], ["winter", [5161]], ["wintercamp", [5103]], ["wired", [10315]], ["wireframes", [10623]], ["wireless", [3908, 9940, 11123, 12175]], ["wisconsin", [10504, 10552, 10611, 10619, 11331, 11783, 12142, 12143, 12192, 12221, 12337, 12537, 12539, 12562, 12597, 12610, 12919, 13067, 13216, 13217, 13219, 13222, 13223, 13224, 13406, 13578, 13920, 13921, 13922, 14018, 14044, 14087, 14146, 14648]], ["with", [11772, 13742, 14728]], ["with:abdul", [13407, 13412, 13413, 13428, 13493]], ["with:adam-griffith", [11049]], ["with:amal", [12161]], ["with:amandaf", [11556]], ["with:amberwise", [12338, 13280]], ["with:ann", [12850]], ["with:basurama", [11699, 11705]], ["with:becki", [13571]], ["with:bronwen", [10952, 12480, 13493, 14587]], ["with:bsugar", [13449]], ["with:btbonval", [11789]], ["with:cfastie", [11688, 13493, 13980]], ["with:chrisjob", [10464]], ["with:cindy_excites", [11566, 11567, 14537]], ["with:damarquis", [12338]], ["with:danbeavers", [11417, 11567]],
FWIW, il peut y avoir une requête encore plus efficace comme celle-ci, mais c'est assez décent, bien qu'elle ne renvoie pas complètement ce qui est ci-dessus :
Tag.select('term_data.tid, term_data.name, community_tags.nid, community_tags.tid')
.includes(:node_tag)
.references(:node_tag)
Bien que cela ne nous dise pas si le nœud a été publié (par rapport au spam), à moins que nous y ayons également mélangé node.status . Mais c'est possible !
jywarren
le 25 janv. 2018
Salut, j'ai juste quelques questions ici,
1.) Si 2 balises appartiennent au même nœud , elles ont un bord entre elles ?
2.) Les différentes couleurs correspondent à différents types de nœuds tels que les questions, les notes, les notes de recherche, etc. ?
Merci !
sagarpreet-chadha
le 25 janv. 2018
Et je suis également d'accord pour ne pas quitter l'API -land :)
sagarpreet-chadha
le 25 janv. 2018
Arr ! D'accord. Ne nous empilons pas, s'il vous plaît. Personne ne veut plus que moi rester dans le pays des API (enfin, peut-être à l'exception de @ebarry ). D'après ce que j'ai compris, la construction d'API-land avait pratiquement été retardée indéfiniment en raison de préoccupations concernant la lenteur du site Web ( voir l'extension de la conversation ici ). Mais maintenant, @jywarren dit que ce n'est plus aussi grave, donc de bons moments de ce côté-là.
Étant donné que l'utilisation de Github peut être un obstacle à l'accès aux informations (tout le monde n'a pas accès, ne sait pas comment utiliser), je pense (euh... pensé) qu'avoir des conversations qui ne visent pas à "faire avancer les choses" dans la base de code était mieux relégué à le site Web où chacun peut apprendre d'eux. Ce ne sont pas des normes communautaires que j'ai définies (voir le propre commentaire de @jywarren ci-dessus ), mais je pense qu'elles sont bonnes.
skilfullycurled
le 25 janv. 2018
Oups, désolé @skilfullycurled, je ne me souvenais pas de votre dernier commentaire sur ce fil -- https://publiclab.org/questions/tommystyles/10-20-2017/need-your-feedback-on-tag-pages#answer - 556-comment-17709 -- où vous avez suggéré :
- ne fonctionne que sur les 250 meilleurs tags
- mise en cache hebdomadaire
Je vais revenir là-bas, mais je pense qu'avec tout le travail sur l'API, le nettoyage du code et la diffusion, nous pourrions faire une version mise en cache quotidienne ou hebdomadaire d'une telle requête, et être d'accord avec un calcul total de 10 à 15 secondes fois par semaine. Le reste serait exécuté localement dans le navigateur. Je répète ça là-bas.
jywarren
le 25 janv. 2018
@jywarren Je devrai vous répondre sur certaines de vos questions. Je posterai mon cahier jupyter plus tard. En attendant, voir ici pour une brève explication de la façon dont le graphique est créé à partir des paires de balises. Pour le code exact, voir ici .
@sagarpreet-chadha (et toute autre personne intéressée), vous pouvez voir comment un graphique d3.js a été créé à partir des données de balise en consultant le référentiel de
En ce qui concerne la détection de la communauté, si vous regardez dans le référentiel tagoverflow, vous constaterez que l'auteur a implémenté son propre algorithme. Depuis lors, d'autres ont été implémentées comme jLouvain , netClustering une implémentation CNM ( exemple d3 ). Avec une limite de 256 balises, la détection de la communauté est probablement correcte dans le navigateur.
skilfullycurled
le 25 janv. 2018
Afin de ne pas submerger la discussion sur publiclab.org avec beaucoup de données, voici un lien vers le format de données utilisé par TagOverflow :
https://api.stackexchange.com/2.1/tags/python/related/?site=stackoverflow&key=of3hmyFapahonChi8EED6g ((&pagesize=16
Il fait comme 15 appels pour récupérer les balises liées à une balise donnée (dans l'exemple ci-dessus, "python")
jywarren
le 25 janv. 2018
Donc, la différence entre cela et les données que j'ai générées ci-dessus est que ma requête répertorie les identifiants de nœud, mais ne les a pas utilisés pour établir une "relation". Mais bien sûr, le cahier Jupyter de
jywarren
le 25 janv. 2018
@sagarpreet-chadha, j'ai posté une question qui a posé et répondu à vos questions ci-dessus :
https://publiclab.org/questions/bsugar/01-25-2018/how-was-the-tag-graph-visualization-made
Je n'essaie pas d'être "passivement agressif" à propos de ma demande, mais je pense que les gens pourraient bénéficier du fait que cet aspect de la conversation soit public. Donc je suppose que cela le rend "agressif agressif". ; )
Blague à part, ravie de répondre à toutes vos questions !
skilfullycurled
le 25 janv. 2018
Salut tout le monde!
@sagarpreet-chadha, j'ai mis tous les fichiers dont vous aurez besoin ici :
https://spideroak.com/browse/share/skilfullyshared/plots-tag-graph
Le dossier est livré avec un fichier readme qui explique le contenu.
S'il vous plaît laissez-moi savoir quand vous les avez téléchargés afin que je puisse fermer le shareroom. Finalement, je les publierai sur mon compte github pour que d'autres personnes y aient accès sur le wiki.
Heureux de répondre à d'autres questions que vous pourriez avoir!
skilfullycurled
le 1 févr. 2018
Merci @skillfullycurled !
J'ai téléchargé les fichiers :-)
sagarpreet-chadha
le 2 févr. 2018
Pas de problème @sagarpreet-chadha !
PS: je vous ai laissé une réflexion de suivi dans la question wiki .
skilfullycurled
le 2 févr. 2018
Grande mise à jour sur les calculs de relation de balise basés sur ruby ici: https://publiclab.org/questions/bsugar/01-25-2018/how-was-the-tag-graph-visualization-made
plus à venir!
jywarren
le 17 janv. 2019
Quelques progrès dans https://github.com/publiclab/plots2/pull/4657 , où j'ai implémenté une instance extrêmement basique, mais en direct de Cytoscape.js (http://js.cytoscape.org/), fonctionnant à partir d'un collection hebdomadaire en cache de
Il a fallu plus de 50 secondes pour exécuter TOUTES les balises du site (qui pouvaient être mises en cache chaque semaine), mais cela a également généré plus de 8 200 balises et 31 000 bords... ce qui est beaucoup à représenter graphiquement. Voici l'ensemble complet; je pense qu'il comprend de nombreuses balises de spam : https://gist.github.com/jywarren/4b1f9a032092a8187dd802a375fcb700
Vous pouvez spécifier le nombre de balises que vous souhaitez interroger comme ceci : https://stable.publiclab.org/tag/graph.json?limit=10 (une fois entièrement publié, https://publiclab.org/tag/graph. json?limit=10)
Il est actuellement limité à 5 "bords" par nom de balise, représentant les 5 balises qui apparaissent le plus souvent à côté de la balise d'origine.
Ceci est maintenant en ligne sur le serveur de test stable (bien que cette branche se reconstruit assez souvent, donc l'URL n'est pas toujours en ligne... ironiquement) ici :
https://stable.publiclab.org/stats/graph?limit=75
Les plus grands nombres comme limit=100 ou 250 semblent montrer une sorte d'erreur et je dois chasser cela un peu. Mais c'est un très bon début.
Il y a BEAUCOUP de configurations qui peuvent être ajoutées pour affiner cela -- taille du nœud, force du lien, bien plus encore -- consultez la galerie sur http://js.cytoscape.org pour quelques possibilités. Et créer des "familles" est peut-être aussi possible, même si j'aurais besoin d'un peu plus d'informations pour cela.
jywarren
le 18 janv. 2019

jywarren
le 18 janv. 2019
Ooh, https://stable.publiclab.org/stats/graph?limit=300 semble fonctionner aussi
jywarren
le 18 janv. 2019
Détection communautaire ici ! https://github.com/upphiminn/jLouvain/blob/master/README.md
jywarren
le 19 janv. 2019
@jywarren , Super cool !!!
sagarpreet-chadha
le 19 janv. 2019
Il existe également une gamme d'algorithmes de clustering - ceux-ci peuvent être testés dans la console JavaScript :
http://js.cytoscape.org/#collection/clustering
- eles.markovClustering()
- nodes.kMeans()
- nodes.kMedoids()
- nodes.fuzzyCMeans()
- nodes.hierarchicalClustering()
- nodes.affinityPropagation()
Je ne les connais pas, mais ils semblent tous utiliser les attributs des nœuds ou des bords pour créer des clusters d'éléments similaires. Alors, que devrions-nous donner comme attributs sur lesquels fonder la similitude ?
Vous pouvez les essayer dans la console en utilisant les exemples de la documentation, par exemple :
var clusters = cy.elements().hca({
mode: 'threshold',
threshold: 5,
attributes: [
function( node ){ return node.data('count'); }
]
});
clusters; // <= then inspect what this returns to see the clusters
OK, en utilisant jlouvain j'ai pu ajouter la détection de communauté : https://github.com/upphiminn/jLouvain
Je n'ai pas assez de données de test pour voir comment cela fonctionnera, mais si #4679 réussit, je le fusionnerai et nous devrions pouvoir le voir fonctionner avec la détection de la communauté à :
https://stable.publiclab.org/stats/graph?limit=101
(une fois construit)
jywarren
le 21 janv. 2019
Salut tout le monde! Avoir l'air bien. Désolé, je n'ai pas pu répondre, je rattrape quelque chose et j'y reviendrai plus tard dans la journée.
En attendant, un autre ingrédient que je ne pense pas avoir mentionné dans aucun de mes autres articles est la mise en page. Le plus proche de ce que j'ai utilisé est probablement la disposition des forces . Techniquement, il s'agissait peut-être de quelque chose appelé force layout 2:
La disposition de la force est une sorte d'attraction/répulsion de recuit qui atteint un état stable en fonction des paramètres que vous définissez (c'est-à-dire le nombre d'itérations, la force d'attraction/répulsion). Voici une démo d3 .
En ce qui concerne la détection de communauté et les poids de bord, vous avez quelques options, mais si vous souhaitez recréer ce graphique de balise auquel il fait référence, vous avez besoin d'une co-occurrence pour que le cytoscape, comme par hasard, ait une fonction pour aider à faire Plus facile.
oe_ratio = (all_questions_count * tag_count_AB) / (tag_count_A * tag_count_B)
Où tag_count_AB = edge.parallelEdges()
En l'état, j'ai d'abord réduit l'ensemble de balises à un nombre raisonnable (disons, les 512 premiers), mais j'ai ensuite réduit les balises que j'ai utilisées pour la visualisation en n'incluant que les n premières balises (peut-être 64 ?) rapport attendu supérieur à 1.
Vous pouvez en savoir plus sur Tag Overflow . Cette méthode est un moyen de résoudre le problème où un nœud périphérique ou un nœud peut être important mais peu utilisé. Par exemple, dans un magasin, 100 personnes _pourraient_ avoir une probabilité de 85 % d'acheter du café et de la crème, mais cinq de ces personnes achètent _toujours_ du café, de la crème et des œufs. Je veux donc absolument garder 5 cartons d'œufs en stock.
Une alternative simple consiste simplement à définir le poids des arêtes entre deux nœuds comme tag_count_AB et à ne prendre que les arêtes/nœuds au-dessus d'un seuil donné. Personnellement, j'obtiens rarement de bons résultats avec cela pour la raison ci-dessus.
Concernant les autres méthodes, vous pouvez être intéressé par la page 3. (2.2) à - pg. 7 (3.1) de cet article (pas de calcul pour ces parties) qui tente de classer les différents types de méthodes de détection de communauté. Cela m'a aidé à choisir ceux qui fournissent les résultats les plus saillants compte tenu de la façon dont j'ai structuré le graphique et de ce que je veux en savoir. Par exemple, les communautés de connexions sociales communes par rapport aux communautés basées sur la fréquence à laquelle les messages sont envoyés entre deux personnes.
skilfullycurled
le 21 janv. 2019
Travailler maintenant sur un serveur stable !
jywarren
le 25 janv. 2019

Voici les 99 balises principales !
jywarren
le 25 janv. 2019
Il devrait fonctionner sur le site en direct plus tard ce soir, mais je voulais noter que la "surutilisation" des balises par certains utilisateurs a faussé le graphique d'une manière que nous avons reconnue auparavant. Je crois que l'un des utilisateurs a été modéré à partir du site, et je me suis demandé si les gens pensaient qu'il était approprié de supprimer ces balises du site ou au moins de les omettre du graphique. Les supprimer serait plus facile, mais nous pouvons également créer quelque chose pour simplement les masquer. Préférence, @ebarry @skillfullycurled ?
Pourtant, cela a l'air bien même si les paramètres d'élasticité des bords nécessitent encore quelques ajustements, et peut-être qu'un type de mise en page différent fonctionnerait mieux ...

jywarren
le 25 janv. 2019
Ouais! Nous avons certainement rencontré ce problème. Malheureusement, la seule chose à faire était de supprimer cet utilisateur particulier en tant que valeur aberrante. Quelqu'un qui utilise autant de balises peut ne pas être une valeur aberrante en soi, mais s'il crée des balises qui lui sont si spécifiques et les utilise encore et encore, alors il ne capture pas vraiment les données.
skilfullycurled
le 25 janv. 2019
Je pense que j'ai même enregistré un problème github avec une demande de fonctionnalité qui a fait apparaître un avertissement qui dirait essentiellement: "Whoaaaaaaaa, facile là-bas! On dirait que vous avez beaucoup de balises là-bas, hein?".
skilfullycurled
le 25 janv. 2019
Ah, PS. J'ai l'air génial d'ailleurs !!
skilfullycurled
le 25 janv. 2019
AAAAAAHHHHHHHHMAYZINGGGGGGGGGGG !!!!!!!!!!!!
Oui pour "supprimer manuellement cet utilisateur particulier en tant que valeur aberrante"
ebarry
le 26 janv. 2019
Je n'arrête pas de revenir sur ce fil à cause de sa qualité et de ses réflexions (espérons-le minuscules). Une autre chose que vous pourriez envisager de filtrer sont les balises de puissance (ce sont celles avec les deux points, n'est-ce pas ?). Je pense que dès que le problème de surutilisation des balises sera corrigé, nous en saurons plus sur la mise en page.
Note à moi-même : voici un lien vers un commit avec les pages importantes pour l'implémentation.
skilfullycurled
le 26 janv. 2019
Salut à tous, content pour l'enthousiasme! Je suis tombé malade mais je me rétablis maintenant et je vais travailler un peu là-dessus sur le vol de retour mardi.
Je voulais demander - ma question spécifique est de savoir si nous devrions :
- supprimer réellement les balises de cet utilisateur modéré, ou
- si nous devions essayer de les préserver mais les filtrer.
Le filtrage demanderait beaucoup plus de travail à la fois pour coder et pour les appels à la base de données, mais c'est possible.
jywarren
le 27 janv. 2019
Dans des cas comme celui-ci où un compte a été rendu "inactif" en raison de la modération, alors je pense qu'il est bon de simplement supprimer les balises de la base de données. Surtout si vous avez une sauvegarde. Pas parce que vous voudriez peut-être le restaurer, juste parce que j'ai peur de perdre des données pour toujours. Ce n'est pas sain, mais l'espace bon marché est un catalyseur malheureux. Mes sentiments seraient plus compliqués s'il s'agissait d'un compte rendu "inactif" par choix mais nous pourrons en discuter une autre fois (ou maintenant).
skilfullycurled
le 27 janv. 2019
Oui, c'est un gros sujet à méditer. Après avoir examiné s'il y a des balises que _seulement_ cet utilisateur a utilisées (exemple : aries city-point ), j'ai trouvé qu'en fait, il y a très peu de balises complètement isolées de cet utilisateur (même purelab a été utilisé à l'origine par Shan He à propos du filtrage de l'eau DIY, et research-notes a été utilisé à l'origine sur des articles discutant de la conception de notes de recherche sur le site Web).
Étant donné que cet utilisateur est modéré, notre visualisation des balises peut-elle exclure tout le contenu des utilisateurs modérés (et par extension les balises utilisées sur le contenu de cette personne) sans exclure cette balise en général, car elle peut être utilisée sur le contenu d'autres personnes ?
ebarry
le 28 janv. 2019
@ebarry , je devrais clarifier (au cas où ce ne serait pas le cas).
Quand j'ai dit:
supprimer purement et simplement les balises de la base de données
Je voulais dire avec quoi tu as terminé :
...[que] notre visualisation de balises [exclura] tout le contenu des utilisateurs modérés - et par extension les balises utilisées sur le contenu de cette personne - sans exclure cette balise en général [puisque] elle peut être utilisée sur le contenu d'autres personnes. ..
Si l'utilisateur modéré et Shan He utilisaient tous les deux le tag "purelab", "purelab" ne serait pas supprimé, juste n'importe quelle instance du tag de l'utilisateur modéré ou, de l'ITMU, si vous voulez.
La question restante (si je comprends @jywarren) est de savoir s'il faut ou non supprimer entièrement ces ITMU de la base de données, ou les conserver dans la base de données mais filtrer les ITMU lorsque toutes les balises sont demandées pour la visualisation. Les supprimer rend la vie beaucoup plus facile pour ceux qui implémentent la visualisation, mais il peut y avoir des arguments en faveur de leur conservation.
Personnellement, je pense que le premier est correct lorsque l'utilisateur a été modéré car il n'y a aucune chance que le contenu revienne un jour sur le site. Cependant, cela peut être différent si un utilisateur choisit de supprimer son compte en fonction de l'existence ou non d'une fonctionnalité permettant de le réactiver. Je pense que nous pouvons laisser cette situation pour une autre fois, mais pour le compte rendu, je voulais juste dire que mon avis judiciaire a une portée limitée.
skilfullycurled
le 28 janv. 2019
Oui pas de soucis Les NodeTags ne suppriment pas le Tag, juste le lien l'associant
balises avec nœuds et auteurs. Je l'ai déjà fait en fait mais j'ai besoin de rincer
la cache hebdomadaire (c'est ce qui a rendu tout cela possible) et il y a
quelques autres bugs urgents à résoudre qui viennent d'arriver aujourd'hui, désolé !
Le lundi 28 janvier 2019, 15 h 24 habilement bouclé < [email protected]
a écrit:
@ebarry https://github.com/ebarry , je devrais clarifier (au cas où ce ne serait pas le cas).
Quand j'ai dit:
supprimer purement et simplement les balises de la base de données
Je voulais dire avec quoi tu as terminé :
...[que] notre visualisation de balise [exclura] tout le contenu de la modération
utilisateurs -- et par extension les balises utilisées sur le contenu de cette personne -- sans
à l'exclusion de cette balise en général [car] elle peut être utilisée sur d'autres personnes
teneur...Si l'utilisateur modéré et Shan He ont tous deux utilisé le tag "purelab", "purelab"
ne serait pas supprimé, n'importe quelle instance de la balise de l'utilisateur modéré
ou, ITMU, si vous voulez.La question restante (si je comprends @jywarren
https://github.com/jywarren ) est de supprimer ou non ces ITMU
de la base de données entièrement, ou les gardons-nous dans la base de données mais filtrant
l'ITMU est sorti lorsque toutes les balises sont demandées pour la visualisation.Leur suppression rend la vie beaucoup plus facile pour ceux qui mettent en œuvre le
visualisation, mais il peut y avoir des arguments pour les préserver.-
Vous recevez ceci parce que vous avez été mentionné.
Répondez directement à cet e-mail, consultez-le sur GitHub
https://github.com/publiclab/plots2/issues/1502#issuecomment-458244753 ,
ou couper le fil
https://github.com/notifications/unsubscribe-auth/AABfJzTXlk18FzlER4PQyoomFE5VTFcrks5vH0AqgaJpZM4OOvLP
.
jywarren
le 28 janv. 2019
OK, j'ai réussi à supprimer toutes les balises créées par l'utilisateur modéré. Ils sont stockés dans des sauvegardes. C'était assez facile et n'affectera pas le code à l'avenir, contrairement à l'autre solution.
Maintenant, je veux suggérer qu'il pourrait y avoir une disposition différente que nous voulons utiliser -- nous utilisons une disposition cose , et il existe des variantes ( bilkent et autres) mais il y a aussi un cola disposition. Je ne connais vraiment pas celui qui convient à utiliser ici, mais certains semblent moins emmêler les liens. Bien que de nombreuses démos sur http://js.cytoscape.org/ aient moins d'interconnexions que notre ensemble de données. Toute contribution appréciée!
Documents sur les mises en page intégrées sur http://js.cytoscape.org/#layouts
Un autre problème que nous pouvons essayer de demander à quelqu'un de tester et d'aborder est la question de la détection de la communauté. Je n'ai pas réussi à comprendre comment cela fonctionne ou pourquoi il ne reconnaît pas les groupes ici. Les couleurs sont jolies, mais il s'agit d'un nœud par communauté. Bah.
jywarren
le 28 janv. 2019
Donc, ce problème doit maintenant être divisé en :
- itération de la mise en page (entrée bienvenue de la foule actuelle)
- détection de communauté
- filtrage de balises supplémentaire (peut-être filtrer les balises sans nœuds non approuvés pour nous débarrasser du spam ?)
Je veux également revenir sur le fait que nous affichons maintenant un nombre spécifié de balises (veuillez ne pas tester cela à ses limites, sauf si c'est sur https://stable.publiclab.org - j'ai essayé jusqu'à 1000 balises et il se charge bien mais pas plus que ça svp sur le serveur de production, même une fois)
Et nous sommes limités aux liens entre eux, chaque balise signalant un maximum de 10 balises avec lesquelles elle s'est produite. Ce n'est pas exhaustif, mais cela semblait un équilibre réalisable entre optimisation et minutie.
jywarren
le 28 janv. 2019
jywarren
le 28 janv. 2019
@jywarren , est-ce encore le dernier commit ? I parce que je voulais voir le json venant du point de terminaison /tag/graph.json et il m'a envoyé toutes les balises. Sur la base du code de ce commit, je me serais attendu à ce que 250 soit la limite stricte (ma note de lisibilité Ruby résiste).
skilfullycurled
le 31 janv. 2019
@jywarren peu importe, je n'avais pas réalisé que le graphique était maintenant dans le serveur de production, j'utilisais stable.publiclab.org.
skilfullycurled
le 31 janv. 2019
D'accord. Je viens de passer pas mal de temps à explorer cela et j'ai une meilleure idée du fonctionnement du graphique.
Maintenant, je veux suggérer qu'il pourrait y avoir une mise en page différente que nous voulons utiliser - nous utilisons un cose
Je vais regarder et réfléchir. Je pense que la question à laquelle il faut répondre ici est que voulons-nous tirer du graphique ? Par exemple, si nous sommes principalement intéressés par le fait qu'un visiteur puisse voir quelles balises sont associées à quelles balises, alors la disposition en cercle ou le cercle concentrique pourrait être la meilleure, ennuyeuse comme si elle l'était.
Si je devais deviner (informé, mais toujours une supposition) pourquoi le CoSE ne donne pas un aussi bon résultat, ce serait parce que, en examinant les données, lorsque vous atteignez un certain nombre de nœuds, les décomptes commencent être tous pareils. Ainsi, si CoSE repousse les nœuds uniquement en fonction du poids des nœuds, il est alors possible qu'il y ait une quantité égale de répulsion entre eux. Quand j'utilise la répulsion ici, je veux dire toutes les choses qui entrent dans la répulsion, par exemple, c'est aussi le réglage de la gravité. Dans ce cas, il se peut qu'il n'y ait pas assez d'itérations de l'algorithme ou que les facteurs de répulsion ne provoquent/ne permettent pas une propagation suffisante.
Un autre problème que nous pouvons essayer de demander à quelqu'un de tester et d'aborder est la question de la détection de la communauté.
Quand vous avez un moment, pouvez-vous m'indiquer le commit avec le dernier JavaScript à ce sujet ? Je peux l'obtenir via le navigateur, mais uniquement sous cette forme où il n'a aucune structure et ne contient qu'une seule ligne. Dès que je le fais, je peux en voir plus. J'ai regardé l'exemple jLouvain, et il ne semble pas avoir de paramètre pour le nombre de communautés que vous voulez, ce qui pourrait faire partie du problème. Typiquement Louvain propose un "meilleur numéro" mais parfois ce n'est pas le meilleur. L'implémentation python sur laquelle jLouvain est basé a ce paramètre mais il n'a peut-être pas été modifié.
skilfullycurled
le 31 janv. 2019
Nous y sommes:
jywarren
le 1 févr. 2019

jywarren
le 1 févr. 2019
Oh, je pensais avoir laissé un autre commentaire... où est-il passé ? attendez...
jywarren
le 1 févr. 2019
Quoi qu'il en soit, j'allais dire que je pense avoir résolu certains des problèmes de mise en page, mais jugez par vous-mêmes :
https://publiclab.org/stats/graph?limit=50
https://publiclab.org/stats/graph?limit=100
jywarren
le 1 févr. 2019
Voici le JS pour la détection de la communauté : https://github.com/publiclab/plots2/blob/master/app/views/tag/graph.html.erb#L263
Et voici la configuration de la mise en page, que nous pourrions modifier beaucoup pour essayer :
jywarren
le 1 févr. 2019
Tout d'abord, je tiens à m'excuser de ne pas pouvoir vous aider avec le gros du travail à la fin du codage. C'est facile pour quelqu'un de simplement suggérer des choses, mais je me rends compte qu'elles doivent aussi être mises en œuvre par des gens et ce n'est pas pour moi que je n'aide pas à cet égard.
Il existe un certain nombre de possibilités pour lesquelles le jLouvain ne fonctionne pas bien. @jywarren , je pense que vous
Voir ce numéro dans le référentiel jLouvain. Quelqu'un a écrit un correctif très simple qui pourrait être mis en œuvre. Je ne sais pas trop comment cela fonctionne en termes de ce qu'il renvoie : idéalement, il renvoie un résultat de détection de communauté complet pour chaque élément du tableau ? Ce serait génial et résoudrait probablement le problème de chaque nœud étant sa propre communauté.
Plus tard…
skilfullycurled
le 1 févr. 2019
Relayer une question de @shapironick qui se demandait dans une autre chaîne si, dans une future édition, il pourrait y avoir des épaisseurs et des épaisseurs variables dans les lignes de connexion pour montrer à quel point deux balises particulières sont étroitement liées ? Merci!
ebarry
le 6 févr. 2019
c'est une bonne idée. Je pense qu'à ce stade, nous devons fermer cela et ouvrir un
nouveau numéro avec une liste de contrôle des améliorations possibles à l'affichage, et
ce sera beaucoup plus facile pour les nouveaux arrivants (moins de contexte et d'historique requis pour
participer) pour venir et commencer à les mettre en œuvre. je suis presque tenté de
faites-le tourner dans un nouveau référentiel qui est /juste ce graphique/, car il
ne s'interconnecte pas autrement avec la base de code PL, mais par souci de
la cohésion communautaire gardons-la dans les parcelles2.
Liz, seriez-vous capable de lancer le nouveau numéro et de commencer avec une liste de contrôle ?
Le mercredi 6 février 2019 à 11 h 17, Liz Barry [email protected] a écrit :
Relayer une question de @shapinick https://github.com/shapinick
qui se demandait dans une autre chaîne si dans une future édition il pourrait y avoir
minceur et épaisseur variables dans les lignes de connexion pour montrer à quel point
liés deux balises particulières sont? Merci!-
Vous recevez ceci parce que vous avez été mentionné.
Répondez directement à cet e-mail, consultez-le sur GitHub
https://github.com/publiclab/plots2/issues/1502#issuecomment-461083862 ,
ou couper le fil
https://github.com/notifications/unsubscribe-auth/AABfJ9nxysbBtCAYHEW2tA8UwNH9zelFks5vKv_hgaJpZM4OOvLP
.
jywarren
le 6 févr. 2019
Yay! @shapinick ! À l'heure actuelle, la requête de base de données n'envoie que les balises top-n et le nombre de ces balises à l'échelle du site. À l'avenir, afin d'avoir des poids de bord, nous devrons apporter une modification sur le back-end pour envoyer toutes les balises au front-end afin que les comptes d'interconnexion puissent être agrégés, ou ils doivent être agrégés sur le arrière-plan. Alternativement, sur le front-end, nous calculons une certaine propriété de bord de réseau (par exemple, une certaine centralité : degré, proximité, interdépendance, etc.).
skilfullycurled
le 6 févr. 2019
Très cool! Pas de pression sur cette idée +1 pour commencer un nouveau numéro, celui-ci est épique et génial !
 shapironick
le 6 févr. 2019
shapironick
le 6 févr. 2019
À l'heure actuelle, dans les données que nous transmettons au code du graphique, je pense que nous voyons quand une balise (disons, la balise A) est liée à la balise B, et nous voyons une deuxième connexion si la balise B est liée à la balise A. Mais ça ne nous dit pas grand chose. Refactoriser pour fournir du "poids" est intéressant... je pourrais imaginer plusieurs façons de le faire aussi. Je suis d'accord, nous pouvons soit transmettre tous les node.ids chaque balise et les calculer localement, soit essayer de précalculer cela au moment où nous collectons les 5 balises les plus liées de chaque balise. (je pense que j'ai changé cela à 10 récemment, mais de toute façon).
Grand raffinement de suivi. Une fois que nous avons la liste de contrôle, nous pouvons prioriser un peu et l'améliorer progressivement. Merci!
jywarren
le 6 févr. 2019
Oh regardez, cela est entré dans le record historique ;) : https://publiclab.org/wiki/community-development#2019
ebarry
le 8 févr. 2019
En examinant cela pour un éventuel projet Summer of Code cet été, j'ai trouvé le bogue de détection de communauté, qui était subtil - les données étaient dans un objet imbriqué comme {data: { DATA }} plutôt que juste { DATA } . Corrigé dans https://github.com/publiclab/plots2/pull/9169 !
jywarren
le 9 févr. 2021

jywarren
le 9 févr. 2021
C'est juste avec nos données de test; le correctif complet sera visible dans le serveur stable une fois que nous l'aurons fusionné et qu'il sera reconstruit ; probablement 30m environ.
jywarren
le 9 févr. 2021
C'est bon, on y va :
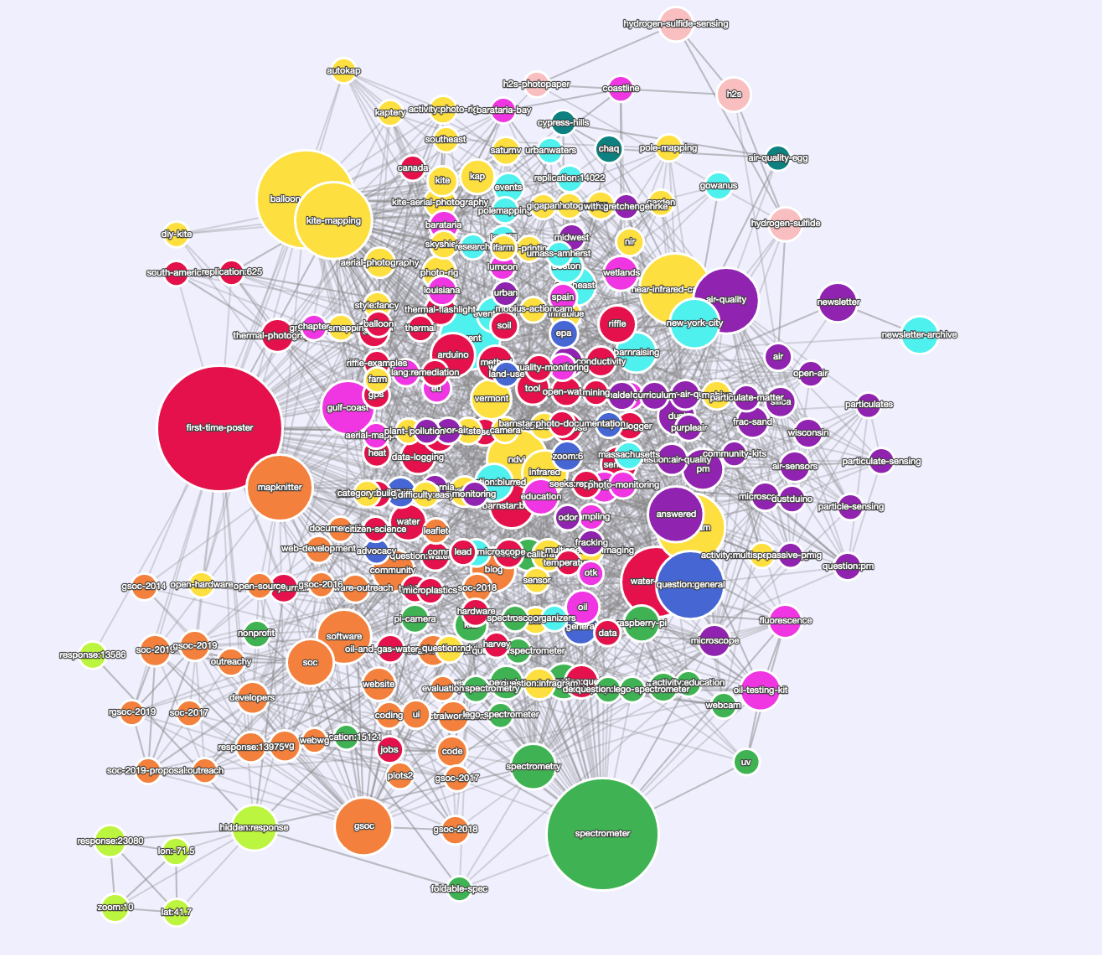
https://stable.publiclab.org/tags (rappelez-vous que cela diminuera de 10 m à chaque fois que nous fusionnerons un nouveau changement)
jywarren
le 9 févr. 2021
Questions connexes
 noi5e
·
3Commentaires
noi5e
·
3Commentaires
 milaaraujo
·
3Commentaires
milaaraujo
·
3Commentaires
 bronwen9
·
3Commentaires
bronwen9
·
3Commentaires
 grvsachdeva
·
3Commentaires
shapironick
·
3Commentaires
grvsachdeva
·
3Commentaires
shapironick
·
3Commentaires
Commentaire le plus utile
Il devrait fonctionner sur le site en direct plus tard ce soir, mais je voulais noter que la "surutilisation" des balises par certains utilisateurs a faussé le graphique d'une manière que nous avons reconnue auparavant. Je crois que l'un des utilisateurs a été modéré à partir du site, et je me suis demandé si les gens pensaient qu'il était approprié de supprimer ces balises du site ou au moins de les omettre du graphique. Les supprimer serait plus facile, mais nous pouvons également créer quelque chose pour simplement les masquer. Préférence, @ebarry @skillfullycurled ?
Pourtant, cela a l'air bien même si les paramètres d'élasticité des bords nécessitent encore quelques ajustements, et peut-être qu'un type de mise en page différent fonctionnerait mieux ...