<p>xxHash als Prüfsumme zur Fehlererkennung</p>
Eines der Dinge, die ich immer wieder nicht verstehe, ist, wie ein Hash eine Prüfsumme sein kann (oder ob sie es sein sollte), da Hashes traditionell für Strings und für Hash-Tabellen optimiert sind (DJB2 kommt mir als alter Fanfavorit in den Sinn). Innerhalb der PIC/Arduino-Menge verwenden die Leute jedoch immer noch alte einfache 8-Bit-Prüfsummen, 16-Bit-Fletcher-Summen oder 16-Bit-CRC. Aber Sie sehen nicht viel über neue Prüfsummen als bessere Wahl mit den vermeintlich schnelleren Prozessoren von heute. Sind die in Hashes verwendeten Berechnungsarten zu langsam? (obwohl CRC in Software tatsächlich langsamer ist als xxHash..) Oder ist etwas von Natur aus schlecht mit Hash-Funktionen, wenn es auf 8 oder 16 Bit reduziert wird?
Ich habe gelesen, dass xxHash zuerst als Prüfsumme für lz4 entwickelt wurde und einige andere Hash-Funktionen wie SeaHash für die Verwendung in einem Dateisystem auch für Prüfsummen entwickelt wurden. Zum Vergleich ist CRC-32 weit verbreitet, auch in einigen Komprimierungsformaten (wie ZIP/RAR). Ich habe auch gelesen, dass CRC bestimmte mathematische Eigenschaften hat, die Hamming-Distanzen zur Fehlererkennung für bestimmte Polynome usw. beweisen. Aber in vielerlei Hinsicht sind Hashes chaotischer, ähneln eher Pseudozahlengeneratoren und haben solche Garantien zumindest unwahrscheinlich wie es mir scheint.
Dies lässt mich fragen, ob es besser ist, CRC-32 für Integritätszwecke zu verwenden, als einen schnellen, einfach zu implementierenden Hash, auch wenn er möglicherweise einen Geschwindigkeitsverlust hat. Hat xxHash irgendwelche Fehlererkennungsgarantien (nehmen wir eine 32-Bit-Version an)? Und wenn nicht, wie konkurriert es mit CRC-32 als Prüfsumme oder Fehlererkennungscode? Was sind die Kompromisse?
 bryc
bryc
Alle 11 Kommentare
CRC-Algorithmen bieten im Allgemeinen Garantien der Fehlererkennung unter der Bedingung von Hamming-Abständen. Bei einer begrenzten Anzahl von Bit-Flips erzeugt der CRC _notwendigerweise_ ein anderes Ergebnis.
Dies kann sich in Situationen als nützlich erweisen, in denen angenommen wird, dass Fehler nur einige Bits umkehren.
Noch vor wenigen Jahrzehnten war dies vor allem in Übertragungsszenarien relativ üblich, da das zugrunde liegende Signal noch sehr "roh" war, also unentdeckte Bit-Flips auf der physikalischen Schicht an der Tagesordnung waren.
Für diese Eigenschaft fallen jedoch Vertriebskosten an. Sobald die „sichere“ Hamming-Distanz überschritten ist, wird die Kollisionswahrscheinlichkeit größer. Dies ist eine logische Konsequenz des Schubladenprinzips. Wie viel schlimmer? Nun, es hängt vom genauen CRC ab, aber ich erwarte, dass ein guter CRC im 3x-7x schlechteren Bereich liegt. Das mag viel klingen, aber es ist nur eine 2-3-Bit-Dispersionsreduzierung, also ist es nicht so schlimm. Immer noch.
Vergleichen Sie das mit einem Hash mit "idealer" Verteilungseigenschaft: Jede Änderung, egal ob es sich um ein einzelnes Bit oder eine völlig andere Ausgabe handelt, hat eine Wahrscheinlichkeit von genau 1/2^n, eine Kollision zu erzeugen. Es ist einfacher zu begreifen: Die Kollisionsgefahr ist immer gleich. Im direkten Vergleich mit CRC ist die Kollisionsrate bei kleiner Hamming-Distanz schlechter (da sie > 0 ist), aber besser, wenn die Hamming-Distanz groß ist.
Schneller Vorlauf heutzutage, und die Situation hat sich radikal geändert. Wir haben Schichten über Schichten von Fehlererkennungs- und Korrekturlogik über den physischen Medien. Wir können nicht nur ein bisschen aus einem Flash-Block extrahieren, noch können wir ein bisschen aus einem Bluetooth-Kanal lesen. Es macht keinen Sinn mehr. Diese Protokolle betten eine zustandsbehaftete Blocklogik ein, die komplexer und widerstandsfähiger ist und ständig das permanente Rauschen der physikalischen Schicht kompensiert. Wenn sie fehlschlagen, führt dies nicht zu einem einzigen Flip: Stattdessen wird ein vollständiger Datenbereich vollständig durcheinander gebracht, der nur Nullen oder sogar zufälliges Rauschen enthält.
In dieser neuen Umgebung besteht die Wette darin, dass Fehler, wenn sie auftreten, nicht mehr in der Kategorie "Bitflip" sind. In diesem Fall werden die Vertriebseigenschaften von CRC zu einer Haftung. Ein reiner Hash hat tatsächlich eine geringere Wahrscheinlichkeit, eine Kollision zu erzeugen.
Dies ist, wenn nur die Prüfsumme in Betracht gezogen wird.
Eine zusätzliche Eigenschaft eines "idealen" Hashs ist, dass er beim Extrahieren eines Bitsegments aus dem Hash immer noch diese 1 / 2^n Kollisionswahrscheinlichkeit aufweist, die als Bitquelle für andere Strukturen sehr wichtig ist, wie Hash-Tabelle oder Bloom-Filter. Im Gegensatz dazu bietet CRC keine solche Garantie. Einige der Bits sind am Ende sehr vorhersehbar oder stark korreliert, und wenn sie für Hash-Zwecke extrahiert werden, ist die Streuung viel schlimmer.
Man könnte sagen, dass Prüfsumme und Hashing einfach 2 verschiedene Domänen sind und nicht verwechselt werden sollten. Tatsächlich ist das die Theorie. Das Problem ist, dass dies die Bequemlichkeit und die praktische Praxis missachtet. Es ist praktisch, einen "Mixer" für mehrere Zwecke zu haben, und Programmierer werden sich mit einem zufriedengeben und ihn vergessen. Ich kann nicht zählen, wie oft ich gesehen habe, wie crc32 für Hashing verwendet wurde, nur weil es sich "zufällig genug" anfühlte. Es ist leicht zu sagen, dass es nicht passieren sollte, aber es passiert ständig.
In dieser Umgebung ist es sinnvoll, eine Lösung vorzuschlagen, die für beide Anwendungsfälle gut geeignet ist, da sie den Erwartungen der Benutzer entspricht.
innerhalb der PIC/Arduino-Menge verwenden die Leute immer noch alte einfache 8-Bit-Prüfsummen, 16-Bit-Fletcher-Summen oder 16-Bit-CRC.
(...)
ist etwas von Natur aus schlecht mit Hash-Funktionen, wenn sie auf 8 oder 16 Bit reduziert werden?
Aufgrund der Eigenschaften eines guten Hashs ist es tatsächlich möglich, 8 oder 16 Bit aus einem Hash zu extrahieren, was zu einer Kollisionswahrscheinlichkeit von 1/256 oder 1/65535 führt. Ich sehe diesbezüglich keine Bedenken.
Wir müssen nur die Latenz von _history_ akzeptieren. Menschen sind an bestimmte Dinge gewöhnt, beispielsweise an die Verwendung bestimmter Prüfsummenfunktionen für die Prüfsummenbildung. Auch wenn es neuere und potenziell bessere Lösungen gibt, ändern sich Gewohnheiten nicht schnell.
 Cyan4973
am 16. Juli 2019
Cyan4973
am 16. Juli 2019
CRC-Algorithmen bieten im Allgemeinen Garantien der Fehlererkennung unter der Bedingung von Hamming-Abständen. Bei einer begrenzten Anzahl von Bit-Flips erzeugt der CRC _notwendigerweise_ ein anderes Ergebnis.
Dies kann sich in Situationen als nützlich erweisen, in denen angenommen wird, dass Fehler nur einige Bits umkehren.
Noch vor wenigen Jahrzehnten war dies vor allem in Übertragungsszenarien relativ üblich, da das zugrunde liegende Signal noch sehr "roh" war, also unentdeckte Bit-Flips auf der physikalischen Schicht an der Tagesordnung waren.Für diese Eigenschaft fallen jedoch Vertriebskosten an. Sobald die „sichere“ Hamming-Distanz überschritten ist, wird die Kollisionswahrscheinlichkeit größer. Dies ist eine logische Konsequenz des Schubladenprinzips. Wie viel schlimmer? Nun, es hängt vom genauen CRC ab, aber ich erwarte, dass ein guter CRC im 3x-7x schlechteren Bereich liegt. Das mag viel klingen, aber es ist nur eine 2-3-Bit-Dispersionsreduzierung, also ist es nicht so schlimm. Immer noch.
Vergleichen Sie das mit einem Hash mit "idealer" Verteilungseigenschaft: Jede Änderung, egal ob es sich um ein einzelnes Bit oder eine völlig andere Ausgabe handelt, hat eine Wahrscheinlichkeit von genau 1/2^n, eine Kollision zu erzeugen. Es ist einfacher zu begreifen: Die Kollisionsgefahr ist immer gleich. Im direkten Vergleich mit CRC ist die Kollisionsrate bei kleiner Hamming-Distanz schlechter (da >0), aber bei großer Hamming-Distanz besser.
Schneller Vorlauf heutzutage, und die Situation hat sich radikal geändert. Wir haben Schichten über Schichten von Fehlererkennungs- und Korrekturlogik über den physischen Medien. Wir können nicht nur ein bisschen aus einem Flash-Block extrahieren, noch können wir ein bisschen aus einem Bluetooth-Kanal lesen. Es macht keinen Sinn mehr. Diese Protokolle betten eine zustandsbehaftete Blocklogik ein, die komplexer und widerstandsfähiger ist und ständig das permanente Rauschen der physikalischen Schicht kompensiert. Wenn sie fehlschlagen, führt dies nicht zu einem einzigen Flip: Stattdessen wird ein vollständiger Datenbereich vollständig durcheinander gebracht, der nur Nullen oder sogar zufälliges Rauschen enthält.
In dieser neuen Umgebung besteht die Wette darin, dass Fehler, wenn sie auftreten, nicht mehr in der Kategorie "Bitflip" sind. In diesem Fall werden die Vertriebseigenschaften von CRC zu einer Haftung. Ein reiner Hash hat tatsächlich eine geringere Wahrscheinlichkeit, eine Kollision zu erzeugen.
Dies ist, wenn nur die Prüfsumme in Betracht gezogen wird.
Eine zusätzliche Eigenschaft eines "idealen" Hashs ist, dass er beim Extrahieren eines Bitsegments aus dem Hash immer noch diese1 / 2^nKollisionswahrscheinlichkeit aufweist, die als Bitquelle für andere Strukturen sehr wichtig ist, wie Hash-Tabelle oder Bloom-Filter. Im Gegensatz dazu bietet CRC keine solche Garantie. Einige der Bits sind am Ende sehr vorhersehbar oder stark korreliert, und wenn sie für Hash-Zwecke extrahiert werden, ist die Streuung viel schlimmer.Man könnte sagen, dass Prüfsumme und Hashing einfach 2 verschiedene Domänen sind und nicht verwechselt werden sollten. Tatsächlich ist das die Theorie. Das Problem ist, dass dies die Bequemlichkeit und die praktische Praxis missachtet. Es ist praktisch, einen "Mixer" für mehrere Zwecke zu haben, und Programmierer werden sich mit einem zufriedengeben und ihn vergessen. Ich kann nicht zählen, wie oft ich gesehen habe, wie crc32 für Hashing verwendet wurde, nur weil es sich "zufällig genug" anfühlte. Es ist leicht zu sagen, dass es nicht passieren sollte, aber es passiert ständig.
In dieser Umgebung ist es sinnvoll, eine Lösung vorzuschlagen, die für beide Anwendungsfälle gut geeignet ist, da sie den Erwartungen der Benutzer entspricht.innerhalb der PIC/Arduino-Menge verwenden die Leute immer noch alte einfache 8-Bit-Prüfsummen, 16-Bit-Fletcher-Summen oder 16-Bit-CRC.
(...)
ist etwas von Natur aus schlecht mit Hash-Funktionen, wenn sie auf 8 oder 16 Bit reduziert werden?Aufgrund der Eigenschaften eines guten Hashs ist es tatsächlich möglich, 8 oder 16 Bit aus einem Hash zu extrahieren, was zu einer Kollisionswahrscheinlichkeit von 1/256 oder 1/65535 führt. Ich sehe diesbezüglich keine Bedenken.
Wir müssen nur die Latenz von _history_ akzeptieren. Menschen sind an bestimmte Dinge gewöhnt, beispielsweise an die Verwendung bestimmter Prüfsummenfunktionen für die Prüfsummenbildung. Auch wenn es neuere und potenziell bessere Lösungen gibt, ändern sich Gewohnheiten nicht schnell.
wir wissen, dass mit CRC 32 und HD = 6 alle 5-Bit-Fehler erkannt werden können und Bursts bis zu 2 ^ 31 = ca. 204 MB . erkannt werden können
und alle Einzelbitfehler erkennen
Wie viele Bits müssen in xxHash geändert werden, damit wir keinen Fehler erkennen können?
Ich weiß, dass in Hash selbst 1-Bit-Änderungen einen völlig anderen Digest ergeben, aber wie können wir die Anzahl der Bits berechnen, die zum Erzeugen einer Kollision erforderlich sind?
eine andere frage ist wie du erwähnt hast:
Im Gegensatz dazu bietet CRC keine solche Garantie. Einige der Bits sind am Ende sehr vorhersehbar oder stark korreliert, und wenn sie für Hash-Zwecke extrahiert werden, ist die Streuung viel schlimmer.
Warum ist das schlimm? Wenn Bits irgendwie korreliert sind, können wir diese Korrelation verwenden, um die beschädigte Datei zu reparieren?
 arashams
am 6. Apr. 2020
arashams
am 6. Apr. 2020
Wie viele Bits müssen in xxHash geändert werden, damit wir keinen Fehler (oder keine Kollisionen) erkennen können
1 Bit.
xxHash ist eine nicht-kryptografische Hash-Funktion, keine Prüfsumme. Es bietet keine Garantien für Hamming-Distanz oder Kollisionssicherheit.
Obwohl es einen anständigen Job machen kann, ist es nicht die beste Wahl. Es ist, als würde man eine Zange als Schraubenschlüssel verwenden. Sicher, es wird die Arbeit erledigen, aber es ist weniger effektiv als ein echter Schraubenschlüssel und kann Schäden verursachen.
 easyaspi314
am 6. Apr. 2020
easyaspi314
am 6. Apr. 2020
Wie viele Bits müssen in xxHash geändert werden, damit wir keinen Fehler (oder keine Kollisionen) erkennen können
1 Bit.
xxHash ist eine nicht-kryptografische Hash-Funktion, keine Prüfsumme. Es bietet keine Garantien für Hamming-Distanz oder Kollisionssicherheit.
Obwohl es einen anständigen Job machen kann, ist es nicht die beste Wahl. Es ist, als würde man eine Zange als Schraubenschlüssel verwenden. Sicher, es wird die Arbeit erledigen, aber es ist weniger effektiv als ein echter Schraubenschlüssel und kann Schäden verursachen.
Meinst du, wir können den Decoder täuschen, indem wir nur 1 Bit Daten ändern?
es kann Kollisionen verursachen? (das ist beängstigend) und die Wahrscheinlichkeit einer solchen Kollision hängt von der Größe des Digests ab
arashams
am 6. Apr. 2020
Meinst du, wir können den Decoder täuschen, indem wir nur 1 Bit Daten ändern?
Betrachtet man Hash-Werte, die aus zwei verschiedenen Inhalten erzeugt wurden, beträgt die Kollisionswahrscheinlichkeit immer 1 / 2^64 (für 64-Bit-Hash-Algorithmen guter Qualität, wie xxh64 oder xxh3 ), was auch immer Menge der Änderungen zwischen diesen 2 Inhalten.
Es bedeutet in der Tat, dass zumindest theoretisch eine Änderung eines einzelnen Bits in der Lage sein könnte, eine Kollision zu erzeugen.
Denken Sie daran, dass diese Wahrscheinlichkeit 1 / 2^64 beträgt, was ziemlich verschwindend klein ist.
Die Leute verstehen dieses Thema relativ schlecht. Sie verwechseln es manchmal mit "klein", was in den Köpfen der meisten Menschen als greifbarer Betrag wahrgenommen wird, etwa 10 %.
Um eine genauere Vorstellung zu bekommen, verweise ich gerne auf diese Tabelle: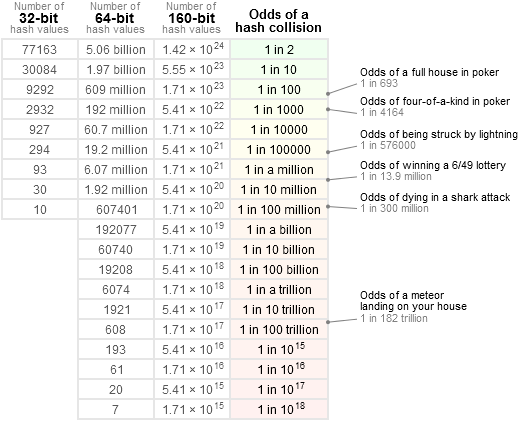
dh : 1 / 2 ^ 64 ist viel geringer als die Chance, einen Kometen direkt auf den Kopf zu bekommen, und niedriger als die nationale Lotterie _3 Mal hintereinander_ zu gewinnen (was eher verdächtig wäre). Dies ist eigentlich viel näher an "null". Die meisten Komponenten in jedem System können mit einer _viel_ höheren Wahrscheinlichkeit brechen, beginnend mit anderen Quellen von Softwarefehlern.
Wenn man eine solche theoretische 1-Bit-Kollision finden will, bräuchte man einen ziemlich gigantischen Input und eine ziemlich unglaubliche Menge an Kraft, um eine Brute-Force-Lösung für dieses Problem zu finden. Selbst dann könnte es keine Lösung geben: Angesichts der Natur der verwendeten Arithmetik wäre ich nicht überrascht, wenn es unmöglich wäre, eine Kollision mit einer einzigen Bit-Modifikation zu erzeugen. Meine eigene Wette ist, dass es mindestens 2 Bits braucht, und selbst dann müssen sie an bestimmten Eingabepositionen platziert werden, um eine Chance zu haben, das gewünschte Ziel zu erreichen, so dass eine solche Änderung nicht mehr "zufällig" ist und daher nicht mehr möglich ist ein nicht-kryptografischer Hash.
Aber ich denke, der zitierte Text erklärt all dies bereits: echte crc haben Garantien auf die Hamming-Distanz. Dies kann nützlich sein und war in der Vergangenheit viel sinnvoller, wenn Signale auf Bitebene modifiziert werden konnten und die Prüfsumme selbst eher klein war (16 oder 32 Bit). Ein 16-Bit-Hash-Algorithmus hätte eine nicht zu vernachlässigende Chance, eine Kollision mit sehr wenigen Bit-Flips zu verpassen, was ihn für die Aufgabe weniger geeignet macht. Aber mit 64-Bit- oder sogar 128-Bit-Hashes, die jetzt auf dem Tisch liegen, glaube ich, dass dies keine gefährliche Option mehr ist, einfach weil die Wahrscheinlichkeit einer Kollision, also einer unentdeckten Korruption, unermesslich gering ist.
Einige der Bits sind am Ende sehr vorhersehbar oder stark korreliert, und wenn sie für Hash-Zwecke extrahiert werden, ist die Streuung viel schlimmer.
Warum ist das schlimm?
Hashes haben im Allgemeinen mehr Verwendungsmöglichkeiten als nur das Ersetzen von Prüfsummen.
Tatsächlich besteht der Zweck von Hash-Algorithmen in den meisten Fällen darin, einige zufällige Bits bereitzustellen, um eine Position in einer Hash-Tabelle zu bestimmen. Wenn einige dieser Bits je nach Inhalt vorhersagbar werden, bedeutet dies, dass die Verteilung der Positionen in der Hash-Tabelle nicht mehr "zufällig" ist und als Folge davon einige Zellen schneller überlaufen als andere, was sich negativ auf die Leistung der Hash-Tabelle auswirkt .
Wenn Bits irgendwie korreliert sind, können wir diese Korrelation verwenden, um die beschädigte Datei zu reparieren?
Das ist ein ganz anderes Thema.
Einen beschädigten Eingang repariert man nicht mit einem CRC. Ein CRC kann einen Fehler nur erkennen, nicht reparieren.
Selbstreparierende Daten sind ein Thema und verwenden verschiedene (und viel mehr rechenintensive) Techniken, wie z. B. Faltungscodes. Dies ist viel komplexer.
Cyan4973
am 6. Apr. 2020
Wenn man eine solche theoretische 1-Bit-Kollision finden will, bräuchte man einen ziemlich gigantischen Input und eine ziemlich unglaubliche Menge an Kraft, um eine Brute-Force-Lösung für dieses Problem zu finden. Selbst dann könnte es keine Lösung geben: Angesichts der Natur der verwendeten Arithmetik wäre ich nicht überrascht, wenn es unmöglich wäre, eine Kollision mit einer einzigen Bit-Modifikation zu erzeugen. Meine eigene Wette ist, dass es mindestens 2 Bits braucht, und selbst dann müssen sie an bestimmten Eingabepositionen platziert werden, um eine Chance zu haben, das gewünschte Ziel zu erreichen, so dass eine solche Änderung nicht mehr "zufällig" ist und daher nicht mehr möglich ist ein nicht-kryptografischer Hash.
261 zeigt eine Single-Bit-Kollision in der 64-Bit-Variante von XXH3, obwohl sie Seed-abhängig ist und bei zufälligen Eingaben sehr unwahrscheinlich ist
easyaspi314
am 6. Apr. 2020
Tatsächlich; Um vollständiger zu sein, war meine vorherige Aussage eher auf den großen Abschnitt für Eingaben > 240 Byte gerichtet.
Aber ja, in dem begrenzten Größenbereich, in dem die Eingabe genau einem der 64-Bit- secret , wird eine Einzel-Bit-Kollision möglich. Es fühlte sich akzeptabel an, weil eine Kollision, die auf einer präzisen 64-Bit-Eingabe an einer genauen Position basiert, immer noch innerhalb dieses 1 / 2^64 Gebiets liegt, vorausgesetzt, die Eingabe ist zufällig (dh nicht darauf ausgelegt, eine Kollision zu erzeugen). Darüber hinaus kann das zu vergleichende secret effektiv _geheim_ gemacht werden, sodass ein externer Angreifer es mit Brute-Force finden muss, um es zu finden.
Cyan4973
am 6. Apr. 2020
Meinst du, wir können den Decoder täuschen, indem wir nur 1 Bit Daten ändern?
Betrachtet man Hash-Werte, die aus zwei verschiedenen Inhalten erzeugt wurden, beträgt die Kollisionswahrscheinlichkeit immer
1 / 2^64(für 64-Bit-Hash-Algorithmen guter Qualität, wiexxh64oderxxh3), was auch immer Menge der Änderungen zwischen diesen 2 Inhalten.Es bedeutet in der Tat, dass zumindest theoretisch eine Änderung eines einzelnen Bits in der Lage sein könnte, eine Kollision zu erzeugen.
Denken Sie daran, dass diese Wahrscheinlichkeit
1 / 2^64beträgt, was ziemlich verschwindend klein ist.
Die Leute verstehen dieses Thema relativ schlecht. Sie verwechseln es manchmal mit "klein", was in den Köpfen der meisten Menschen als greifbarer Betrag wahrgenommen wird, etwa 10 %.Um eine genauere Vorstellung zu bekommen, verweise ich gerne auf diese Tabelle:
dh :
1 / 2 ^ 64ist viel geringer als die Chance, einen Kometen direkt auf den Kopf zu bekommen, und niedriger als die nationale Lotterie _3 Mal hintereinander_ zu gewinnen (was eher verdächtig wäre). Dies ist eigentlich viel näher an "null". Die meisten Komponenten in jedem System können mit einer _viel_ höheren Wahrscheinlichkeit brechen, beginnend mit anderen Quellen von Softwarefehlern.Wenn man eine solche theoretische 1-Bit-Kollision finden will, bräuchte man einen ziemlich gigantischen Input und eine ziemlich unglaubliche Menge an Kraft, um eine Brute-Force-Lösung für dieses Problem zu finden. Selbst dann könnte es keine Lösung geben: Angesichts der Natur der verwendeten Arithmetik wäre ich nicht überrascht, wenn es unmöglich wäre, eine Kollision mit einer einzigen Bit-Modifikation zu erzeugen. Meine eigene Wette ist, dass es mindestens 2 Bits braucht, und selbst dann müssen sie an bestimmten Eingabepositionen platziert werden, um eine Chance zu haben, das gewünschte Ziel zu erreichen, so dass eine solche Änderung nicht mehr "zufällig" ist und daher nicht mehr möglich ist ein nicht-kryptografischer Hash.
Aber ich denke, der zitierte Text erklärt all dies bereits: echte
crchaben Garantien auf die Hamming-Distanz. Dies kann nützlich sein und war in der Vergangenheit viel sinnvoller, wenn Signale auf Bitebene modifiziert werden konnten und die Prüfsumme selbst eher klein war (16 oder 32 Bit). Ein 16-Bit-Hash-Algorithmus hätte eine nicht zu vernachlässigende Chance, eine Kollision mit sehr wenigen Bit-Flips zu verpassen, was ihn für die Aufgabe weniger geeignet macht. Aber mit 64-Bit- oder sogar 128-Bit-Hashes, die jetzt auf dem Tisch liegen, glaube ich, dass dies keine gefährliche Option mehr ist, einfach weil die Wahrscheinlichkeit einer Kollision, also einer unentdeckten Korruption, unermesslich gering ist.Einige der Bits sind am Ende sehr vorhersehbar oder stark korreliert, und wenn sie für Hash-Zwecke extrahiert werden, ist die Streuung viel schlimmer.
Warum ist das schlimm?
Hashes haben im Allgemeinen mehr Verwendungsmöglichkeiten als nur das Ersetzen von Prüfsummen.
Tatsächlich besteht der Zweck von Hash-Algorithmen in den meisten Fällen darin, einige zufällige Bits bereitzustellen, um eine Position in einer Hash-Tabelle zu bestimmen. Wenn einige dieser Bits je nach Inhalt vorhersagbar werden, bedeutet dies, dass die Verteilung der Positionen in der Hash-Tabelle nicht mehr "zufällig" ist und als Folge davon einige Zellen schneller überlaufen als andere, was sich negativ auf die Leistung der Hash-Tabelle auswirkt .Wenn Bits irgendwie korreliert sind, können wir diese Korrelation verwenden, um die beschädigte Datei zu reparieren?
Das ist ein ganz anderes Thema.
Einen beschädigten Eingang repariert man nicht mit einem CRC. Ein CRC kann einen Fehler nur erkennen, nicht reparieren.Selbstreparierende Daten sind ein Thema und verwenden verschiedene (und viel mehr rechenintensive) Techniken, wie z. B. Faltungscodes. Dies ist viel komplexer.
Könnten Sie diese Szenarien bestätigen?
- LZ4 hat eine Inhaltsprüfsumme für jeden Datenblock. Bedenken Sie, dass wir 10^6 Pakete mit 1-GB-Dateien haben
die Kollisionswahrscheinlichkeit ist 1/2^32 = 0.0000000002 Dies bedeutet, dass wir beim Senden von 10^10 (dieser riesigen) Paketen möglicherweise 2 Kollisionen haben (basierend auf dem Pigeonhole-Prinzip), aber wenn wir weniger als diese Menge senden, ist die Wahrscheinlichkeit eine Kollision zu sehen, wird deutlich sinken, damit wir alle Fehler erkennen können, der Decoder berechnet die Prüfsumme und vergleicht sie mit der Paketprüfsumme, ist das richtig? - Die Inhaltsprüfsumme berechnet die Prüfsumme über die komprimierte Datei (sie ist optional und wir können sie verwenden, um eine fehlerhafte Reihenfolge zu erkennen oder die Kollisionswahrscheinlichkeit zu reduzieren (Vor der Verwendung von CC beträgt die Kollisionswahrscheinlichkeit 1/2 ^ 32 und dann würde es) 1/2 ^ 64 sein.)
arashams
am 8. Apr. 2020
Das beschriebene Szenario ist:
- LZ4-komprimierte Daten werden beschädigt (was an sich schon ein ziemlich seltenes Ereignis ist)
- Korruption bleibt aufgrund von Hash-Kollision unentdeckt.
Das LZ4-Frame-Format verwendet XXH32 , einen 32-Bit-Hash, als begleitende Prüfsumme.
Es wird standardmäßig auf den Inhalt des gesamten Frames angewendet, genauer gesagt auf den _unkomprimierten_ Inhalt des Frames (nach der Dekomprimierung), wodurch sowohl der Übertragungs- als auch der Decodierprozess validiert werden.
Es kann es auch optional auf jeden Block anwenden, in welchem Fall es den _komprimierten_ Inhalt jedes Blocks überprüft.
Beides kann kumuliert werden.
Um unentdeckt zu bleiben, muss eine Beschädigung ___alle___ zutreffende Prüfsummen erfolgreich bestehen.
Unter der Annahme, dass die Blockprüfsumme aktiviert ist und die Beschädigung vollständig innerhalb eines einzelnen Blocks lokalisiert ist, beträgt die Wahrscheinlichkeit, sowohl die Block- als auch die Rahmenprüfsumme zu passieren, tatsächlich 1 / 2^32 x 1 / 2^32 = 1 / 2^64 .
Wenn sich nun beschädigte Daten in mehreren Blöcken befinden, entweder weil es mehrere Korruptionsereignisse gibt oder weil ein einzelner großer beschädigter Abschnitt aufeinanderfolgende Blöcke abdeckt, ist es _noch schwieriger für die Beschädigung, unentdeckt zu bleiben_. Es müsste eine Kollision mit jeder der beteiligten Blockprüfsummen erzeugen.
Unter der Annahme, dass die Korruption auf 2 Blöcke verteilt ist, beträgt die Wahrscheinlichkeit, dass diese Korruption unentdeckt bleibt, 1 / 2^32 x 1 / 2^32 x 1 / 2^32 = 1 / 2^96 . Astronomisch klein.
Abgesehen davon, dass jeder beschädigte Block durch den Dekompressionsprozess, der noch dazu kommt, als nicht dekodierbar erkannt werden kann.
Ja, die Kombination von Block- und Frame-Prüfsumme erhöht die Wahrscheinlichkeit, Korruptionsereignisse zu erkennen, dramatisch.
Cyan4973
am 8. Apr. 2020
Das beschriebene Szenario ist:
* LZ4-compressed data being corrupted (which is already a pretty rare event by itself) * Corruption remaining undetected due to hash collision.Das LZ4-Frame-Format verwendet
XXH32, einen 32-Bit-Hash, als begleitende Prüfsumme.
Es wird standardmäßig auf den Inhalt des gesamten Frames angewendet, genauer gesagt auf den _unkomprimierten_ Inhalt des Frames (nach der Dekomprimierung), wodurch sowohl der Übertragungs- als auch der Decodierprozess validiert werden.
Es kann es auch optional auf jeden Block anwenden, in welchem Fall es den _komprimierten_ Inhalt jedes Blocks überprüft.
Beides kann kumuliert werden.Um unentdeckt zu bleiben, muss eine Korruption _ alle _ zutreffenden Prüfsummen erfolgreich bestehen.
Unter der Annahme, dass die Blockprüfsumme aktiviert ist und die Beschädigung vollständig innerhalb eines einzelnen Blocks lokalisiert ist, beträgt die Wahrscheinlichkeit, sowohl die Block- als auch die Rahmenprüfsumme zu passieren, tatsächlich1 / 2^32 x 1 / 2^32 = 1 / 2^64.Wenn sich nun beschädigte Daten in mehreren Blöcken befinden, entweder weil es mehrere Korruptionsereignisse gibt oder weil ein einzelner großer beschädigter Abschnitt aufeinanderfolgende Blöcke abdeckt, ist es _noch schwieriger für die Beschädigung, unentdeckt zu bleiben_. Es müsste eine Kollision mit jeder der beteiligten Blockprüfsummen erzeugen.
Unter der Annahme, dass die Korruption auf 2 Blöcke verteilt ist, beträgt die Wahrscheinlichkeit, dass diese Korruption unentdeckt bleibt,1 / 2^32 x 1 / 2^32 x 1 / 2^32 = 1 / 2^96. Astronomisch klein.Abgesehen davon, dass jeder beschädigte Block durch den Dekompressionsprozess, der noch dazu kommt, als nicht dekodierbar erkannt werden kann.
Ja, die Kombination von Block- und Frame-Prüfsumme erhöht die Wahrscheinlichkeit, Korruptionsereignisse zu erkennen, dramatisch.
Ist es möglich, LZ4 im laufenden Betrieb zu verwenden? Ich meine, komprimieren/dekomprimieren Sie die Daten, sobald Sie etwas davon haben. es ist irgendwie Pipelining.
Was ist mit dem xxHash?
arashams
am 29. Aug. 2020
Ist es möglich, LZ4 im laufenden Betrieb zu verwenden? Ich meine, komprimieren/dekomprimieren Sie die Daten, sobald Sie etwas davon haben.
Dies ist der Streaming-Modus. Ja, es ist möglich.
Was ist mit dem xxHash?
Die Rahmenprüfsumme wird ständig aktualisiert, liefert aber erst am Ende des Rahmens ein Ergebnis. Daher gibt es kein Prüfsummenergebnis zum Vergleichen bis zu einem Frame-Ende-Ereignis (ein Stream kann aus mehreren angehängten Frames bestehen, ist dies jedoch im Allgemeinen nicht).
Dagegen werden an jedem Block Blockprüfsummen erstellt, die also regelmäßig beim Streaming erzeugt und überprüft werden.
Beide Prüfsummen verwenden XXH32 .
Cyan4973
am 29. Aug. 2020
Verwandte Themen
easyaspi314
·
6Kommentare
 jvriezen
·
6Kommentare
jvriezen
·
6Kommentare
 vinniefalco
·
4Kommentare
easyaspi314
·
7Kommentare
vinniefalco
·
4Kommentare
easyaspi314
·
7Kommentare
 boazsegev
·
6Kommentare
boazsegev
·
6Kommentare
Hilfreichster Kommentar
CRC-Algorithmen bieten im Allgemeinen Garantien der Fehlererkennung unter der Bedingung von Hamming-Abständen. Bei einer begrenzten Anzahl von Bit-Flips erzeugt der CRC _notwendigerweise_ ein anderes Ergebnis.
Dies kann sich in Situationen als nützlich erweisen, in denen angenommen wird, dass Fehler nur einige Bits umkehren.
Noch vor wenigen Jahrzehnten war dies vor allem in Übertragungsszenarien relativ üblich, da das zugrunde liegende Signal noch sehr "roh" war, also unentdeckte Bit-Flips auf der physikalischen Schicht an der Tagesordnung waren.
Für diese Eigenschaft fallen jedoch Vertriebskosten an. Sobald die „sichere“ Hamming-Distanz überschritten ist, wird die Kollisionswahrscheinlichkeit größer. Dies ist eine logische Konsequenz des Schubladenprinzips. Wie viel schlimmer? Nun, es hängt vom genauen CRC ab, aber ich erwarte, dass ein guter CRC im 3x-7x schlechteren Bereich liegt. Das mag viel klingen, aber es ist nur eine 2-3-Bit-Dispersionsreduzierung, also ist es nicht so schlimm. Immer noch.
Vergleichen Sie das mit einem Hash mit "idealer" Verteilungseigenschaft: Jede Änderung, egal ob es sich um ein einzelnes Bit oder eine völlig andere Ausgabe handelt, hat eine Wahrscheinlichkeit von genau 1/2^n, eine Kollision zu erzeugen. Es ist einfacher zu begreifen: Die Kollisionsgefahr ist immer gleich. Im direkten Vergleich mit CRC ist die Kollisionsrate bei kleiner Hamming-Distanz schlechter (da sie > 0 ist), aber besser, wenn die Hamming-Distanz groß ist.
Schneller Vorlauf heutzutage, und die Situation hat sich radikal geändert. Wir haben Schichten über Schichten von Fehlererkennungs- und Korrekturlogik über den physischen Medien. Wir können nicht nur ein bisschen aus einem Flash-Block extrahieren, noch können wir ein bisschen aus einem Bluetooth-Kanal lesen. Es macht keinen Sinn mehr. Diese Protokolle betten eine zustandsbehaftete Blocklogik ein, die komplexer und widerstandsfähiger ist und ständig das permanente Rauschen der physikalischen Schicht kompensiert. Wenn sie fehlschlagen, führt dies nicht zu einem einzigen Flip: Stattdessen wird ein vollständiger Datenbereich vollständig durcheinander gebracht, der nur Nullen oder sogar zufälliges Rauschen enthält.
In dieser neuen Umgebung besteht die Wette darin, dass Fehler, wenn sie auftreten, nicht mehr in der Kategorie "Bitflip" sind. In diesem Fall werden die Vertriebseigenschaften von CRC zu einer Haftung. Ein reiner Hash hat tatsächlich eine geringere Wahrscheinlichkeit, eine Kollision zu erzeugen.
Dies ist, wenn nur die Prüfsumme in Betracht gezogen wird.
Eine zusätzliche Eigenschaft eines "idealen" Hashs ist, dass er beim Extrahieren eines Bitsegments aus dem Hash immer noch diese
1 / 2^nKollisionswahrscheinlichkeit aufweist, die als Bitquelle für andere Strukturen sehr wichtig ist, wie Hash-Tabelle oder Bloom-Filter. Im Gegensatz dazu bietet CRC keine solche Garantie. Einige der Bits sind am Ende sehr vorhersehbar oder stark korreliert, und wenn sie für Hash-Zwecke extrahiert werden, ist die Streuung viel schlimmer.Man könnte sagen, dass Prüfsumme und Hashing einfach 2 verschiedene Domänen sind und nicht verwechselt werden sollten. Tatsächlich ist das die Theorie. Das Problem ist, dass dies die Bequemlichkeit und die praktische Praxis missachtet. Es ist praktisch, einen "Mixer" für mehrere Zwecke zu haben, und Programmierer werden sich mit einem zufriedengeben und ihn vergessen. Ich kann nicht zählen, wie oft ich gesehen habe, wie crc32 für Hashing verwendet wurde, nur weil es sich "zufällig genug" anfühlte. Es ist leicht zu sagen, dass es nicht passieren sollte, aber es passiert ständig.
In dieser Umgebung ist es sinnvoll, eine Lösung vorzuschlagen, die für beide Anwendungsfälle gut geeignet ist, da sie den Erwartungen der Benutzer entspricht.
Aufgrund der Eigenschaften eines guten Hashs ist es tatsächlich möglich, 8 oder 16 Bit aus einem Hash zu extrahieren, was zu einer Kollisionswahrscheinlichkeit von 1/256 oder 1/65535 führt. Ich sehe diesbezüglich keine Bedenken.
Wir müssen nur die Latenz von _history_ akzeptieren. Menschen sind an bestimmte Dinge gewöhnt, beispielsweise an die Verwendung bestimmter Prüfsummenfunktionen für die Prüfsummenbildung. Auch wenn es neuere und potenziell bessere Lösungen gibt, ändern sich Gewohnheiten nicht schnell.