<p>xxHash comme somme de contrôle pour la détection d'erreurs</p>
L'une des choses que je ne parviens toujours pas à comprendre, c'est comment un hachage peut être une somme de contrôle (ou s'il devrait l'être), car traditionnellement, les hachages sont optimisés pour les chaînes et pour les tables de hachage (DJB2 me vient à l'esprit comme un vieux favori des fans). Cependant, au sein de la foule PIC/Arduino, les gens utilisent encore d'anciennes sommes de contrôle simples à 8 bits, des sommes de Fletcher à 16 bits ou un CRC à 16 bits. Mais vous ne voyez pas beaucoup de discussions sur les nouvelles sommes de contrôle comme étant de meilleurs choix avec les processeurs censés être plus rapides d'aujourd'hui. Les types de calculs utilisés dans les hachages sont-ils trop lents ? (bien que le CRC soit en fait plus lent dans le logiciel que xxHash ..) Ou est-ce que quelque chose est intrinsèquement mauvais avec les fonctions de hachage lorsqu'il est réduit à 8 ou 16 bits ?
J'ai lu que xxHash a d'abord été conçu comme une somme de contrôle pour lz4, et d'autres fonctions de hachage telles que SeaHash conçues pour être utilisées dans un système de fichiers également pour la somme de contrôle. A titre de comparaison, CRC-32 a été largement utilisé, également dans certains formats de compression (comme ZIP/RAR). J'ai également lu que le CRC a certaines propriétés mathématiques qui prouvent les distances de blocage pour la détection d'erreurs pour des polynômes spécifiques, etc. Mais à bien des égards, les hachages sont plus chaotiques, ressemblant davantage à des générateurs de pseudo-nombres, peu susceptibles d'avoir de telles garanties, du moins c'est comment il me semble.
Cela me laisse me demander s'il vaut mieux utiliser CRC-32 à des fins d'intégrité plutôt qu'un hachage rapide et simple à mettre en œuvre, même s'il peut avoir un impact sur la vitesse. xxHash a-t-il des garanties de détection d'erreurs (supposons une version 32 bits) ? Et sinon, comment rivalise-t-il avec le CRC-32 en tant que somme de contrôle ou code de détection d'erreurs ? Quels sont les compromis ?
 bryc
bryc
Tous les 11 commentaires
Les algorithmes CRC présentent généralement des garanties de détection d'erreur sous condition de distances de Hamming. Étant donné un nombre limité de basculements de bits, le CRC générera _nécessairement_ un résultat différent.
Cela peut s'avérer utile dans les situations où les erreurs sont supposées ne renverser que quelques bits.
Il y a quelques décennies à peine, cela était relativement courant, en particulier dans les scénarios de transmission, car le signal sous-jacent était encore très "brut", donc les retournements de bits non détectés sur la couche physique étaient une chose.
Cette propriété a cependant un coût de distribution. Une fois la distance de « sécurité » franchie, la probabilité de collision s'aggrave. C'est une conséquence logique du principe du pigeonnier. Combien pire ? Eh bien, cela dépend du CRC exact, mais je m'attends à ce que le bon CRC soit dans la plage 3x - 7x pire. Cela peut sembler beaucoup, mais c'est juste une réduction de dispersion de 2-3 bits, donc ce n'est pas si terrible. Encore.
Comparez cela avec un hachage présentant une propriété de distribution "idéale": tout changement, qu'il s'agisse d'un seul bit ou d'une sortie complètement différente, a exactement 1 / 2^n probabilité de générer une collision. C'est plus simple à appréhender : le risque de collision est toujours le même. En comparaison directe avec le CRC, lorsque la distance de Hamming est faible, le taux de collision est pire (puisqu'il est > 0), mais il est meilleur lorsque la distance de Hamming est grande.
Avance rapide de nos jours, et la situation a radicalement changé. Nous avons des couches sur des couches de logique de détection et de correction d'erreur au-dessus du support physique. Nous ne pouvons pas simplement extraire un peu d'un bloc flash, ni lire un peu d'un canal Bluetooth. Cela n'a plus de sens. Ces protocoles embarquent une logique de bloc avec état, plus complexe, plus résiliente, compensant en permanence le bruit permanent de la couche physique. Lorsqu'ils échouent, cela ne produira pas un seul retournement : au contraire, une région de données complète sera complètement brouillée, n'étant constituée que de zéros ou même de bruit aléatoire.
Dans ce nouvel environnement, le pari est que les erreurs, lorsqu'elles se produisent, ne sont plus dans la catégorie "bitflip". Dans ce cas, les propriétés de distribution du CRC deviennent un passif. Un hachage pur a en fait une probabilité plus faible de produire une collision.
C'est uniquement lorsque l'on considère la somme de contrôle.
Une propriété supplémentaire d'un hachage "idéal" est que, lors de l'extraction d'un segment de bits du hachage, il présente toujours cette probabilité de collision 1 / 2^n , qui est très importante en tant que source de bits pour d'autres structures, telles que table de hachage ou filtre bloom. En revanche, CRC ne fournit pas une telle garantie. Certains bits finissent par être très prévisibles ou fortement corrélés, et lors de leur extraction à des fins de hachage, la dispersion est bien pire.
On pourrait dire que la somme de contrôle et le hachage sont simplement 2 domaines différents, et ne doivent pas être confondus. En effet, c'est la théorie. Le problème est que cela ne tient pas compte de la commodité et de la pratique sur le terrain. Avoir un "mixer" à usage multiple est pratique, et les programmeurs se contenteront d'un seul et l'oublieront. Je ne peux pas compter combien de fois j'ai vu crc32 utilisé pour le hachage, simplement parce qu'il semblait "assez aléatoire". Il est facile de dire que cela ne devrait pas arriver, mais c'est le cas, constamment.
Dans cet environnement, proposer une solution conçue pour bien fonctionner pour les deux cas d'utilisation a du sens, car elle correspond aux attentes des utilisateurs.
au sein de la foule PIC/Arduino, les gens utilisent encore d'anciennes sommes de contrôle simples à 8 bits, des sommes de Fletcher à 16 bits ou un CRC à 16 bits.
(...)
est-ce que quelque chose est intrinsèquement mauvais avec les fonctions de hachage lorsqu'elles sont réduites à 8 ou 16 bits ?
En raison des propriétés d'un bon hachage, il est en effet possible d'extraire 8 ou 16 bits d'un hachage, ce qui entraîne une probabilité de collision de 1/256 ou 1/65535. Je ne vois aucune inquiétude à ce sujet.
Juste, nous devons accepter la latence de _history_. Les gens sont habitués à une certaine manière de faire, comme l'utilisation de fonctions de somme de contrôle spécifiques pour la somme de contrôle. Même s'il existe des solutions plus récentes et potentiellement meilleures, les habitudes ne changent pas rapidement.
 Cyan4973
le 16 juil. 2019
Cyan4973
le 16 juil. 2019
Les algorithmes CRC présentent généralement des garanties de détection d'erreur sous condition de distances de Hamming. Étant donné un nombre limité de basculements de bits, le CRC générera _nécessairement_ un résultat différent.
Cela peut s'avérer utile dans les situations où les erreurs sont supposées ne renverser que quelques bits.
Il y a quelques décennies à peine, cela était relativement courant, en particulier dans les scénarios de transmission, car le signal sous-jacent était encore très "brut", donc les retournements de bits non détectés sur la couche physique étaient une chose.Cette propriété a cependant un coût de distribution. Une fois la distance de « sécurité » franchie, la probabilité de collision s'aggrave. C'est une conséquence logique du principe du pigeonnier. Combien pire ? Eh bien, cela dépend du CRC exact, mais je m'attends à ce que le bon CRC soit dans la plage 3x - 7x pire. Cela peut sembler beaucoup, mais c'est juste une réduction de dispersion de 2-3 bits, donc ce n'est pas si terrible. Encore.
Comparez cela avec un hachage présentant une propriété de distribution "idéale": tout changement, qu'il s'agisse d'un seul bit ou d'une sortie complètement différente, a exactement 1 / 2^n probabilité de générer une collision. C'est plus simple à appréhender : le risque de collision est toujours le même. En comparaison directe avec le CRC, le taux de collision est pire (puisqu'il est > 0) lorsque la distance de Hamming est petite, mais il est meilleur lorsque la distance de Hamming est grande.
Avance rapide de nos jours, et la situation a radicalement changé. Nous avons des couches sur des couches de logique de détection et de correction d'erreur au-dessus du support physique. Nous ne pouvons pas simplement extraire un peu d'un bloc flash, ni lire un peu d'un canal Bluetooth. Cela n'a plus de sens. Ces protocoles embarquent une logique de bloc avec état, plus complexe, plus résiliente, compensant en permanence le bruit permanent de la couche physique. Lorsqu'ils échouent, cela ne produira pas un seul retournement : au contraire, une région de données complète sera complètement brouillée, n'étant constituée que de zéros ou même de bruit aléatoire.
Dans ce nouvel environnement, le pari est que les erreurs, lorsqu'elles se produisent, ne sont plus dans la catégorie "bitflip". Dans ce cas, les propriétés de distribution du CRC deviennent un passif. Un hachage pur a en fait une probabilité plus faible de produire une collision.
C'est uniquement lorsque l'on considère la somme de contrôle.
Une propriété supplémentaire d'un hachage "idéal" est que, lors de l'extraction d'un segment de bits du hachage, il présente toujours cette probabilité de collision1 / 2^n, qui est très importante en tant que source de bits pour d'autres structures, telles que table de hachage ou filtre bloom. En revanche, CRC ne fournit pas une telle garantie. Certains bits finissent par être très prévisibles ou fortement corrélés, et lors de leur extraction à des fins de hachage, la dispersion est bien pire.On pourrait dire que la somme de contrôle et le hachage sont simplement 2 domaines différents, et ne doivent pas être confondus. En effet, c'est la théorie. Le problème est que cela ne tient pas compte de la commodité et de la pratique sur le terrain. Avoir un "mixer" à usage multiple est pratique, et les programmeurs se contenteront d'un seul et l'oublieront. Je ne peux pas compter combien de fois j'ai vu crc32 utilisé pour le hachage, simplement parce qu'il semblait "assez aléatoire". Il est facile de dire que cela ne devrait pas arriver, mais c'est le cas, constamment.
Dans cet environnement, proposer une solution conçue pour bien fonctionner pour les deux cas d'utilisation a du sens, car elle correspond aux attentes des utilisateurs.au sein de la foule PIC/Arduino, les gens utilisent encore d'anciennes sommes de contrôle simples à 8 bits, des sommes de Fletcher à 16 bits ou un CRC à 16 bits.
(...)
est-ce que quelque chose est intrinsèquement mauvais avec les fonctions de hachage lorsqu'elles sont réduites à 8 ou 16 bits ?En raison des propriétés d'un bon hachage, il est en effet possible d'extraire 8 ou 16 bits d'un hachage, ce qui entraîne une probabilité de collision de 1/256 ou 1/65535. Je ne vois aucune inquiétude à ce sujet.
Juste, nous devons accepter la latence de _history_. Les gens sont habitués à une certaine manière de faire, comme l'utilisation de fonctions de somme de contrôle spécifiques pour la somme de contrôle. Même s'il existe des solutions plus récentes et potentiellement meilleures, les habitudes ne changent pas rapidement.
nous savons qu'avec CRC 32 et en utilisant HD=6, il peut détecter toutes les erreurs de 5 bits et il peut détecter des rafales jusqu'à 2^31 = environ 204 Mo
et détecter toutes les erreurs sur un seul bit
Dans xxHash, combien de bits faut-il changer pour qu'on ne puisse pas détecter une erreur ?
Je sais que dans Hash, même un changement d'un bit fait un résumé totalement différent, mais comment pouvons-nous calculer le nombre de bits nécessaires pour créer une collision ?
une autre question est comme vous l'avez mentionné:
En revanche, CRC ne fournit pas une telle garantie. Certains bits finissent par être très prévisibles ou fortement corrélés, et lors de leur extraction à des fins de hachage, la dispersion est bien pire.
Pourquoi est-ce mauvais ? Si les bits sont en quelque sorte corrélés, pouvons-nous utiliser cette corrélation pour réparer le fichier endommagé ?
 arashams
le 6 avr. 2020
arashams
le 6 avr. 2020
Dans xxHash, combien de bits doivent être modifiés pour que nous ne puissions pas détecter une erreur (ou des collisions)
1 peu.
xxHash est une fonction de hachage non cryptographique, pas une somme de contrôle. Il ne fournit aucune garantie de distance de Hamming ou de résistance aux collisions.
Bien qu'il puisse y faire un travail décent, ce n'est pas le meilleur choix. C'est comme utiliser une pince comme clé. Bien sûr, il fera le travail, mais il est moins efficace qu'une vraie clé et peut causer des dommages.
 easyaspi314
le 6 avr. 2020
easyaspi314
le 6 avr. 2020
Dans xxHash, combien de bits doivent être modifiés pour que nous ne puissions pas détecter une erreur (ou des collisions)
1 peu.
xxHash est une fonction de hachage non cryptographique, pas une somme de contrôle. Il ne fournit aucune garantie de distance de Hamming ou de résistance aux collisions.
Bien qu'il puisse y faire un travail décent, ce n'est pas le meilleur choix. C'est comme utiliser une pince comme clé. Bien sûr, il fera le travail, mais il est moins efficace qu'une vraie clé et peut causer des dommages.
voulez-vous dire que nous pouvons tromper le décodeur en changeant juste 1 bit de données ?
cela peut créer des collisions ? (ça fait peur) et la probabilité d'une telle collision dépend de la taille du condensé
arashams
le 6 avr. 2020
voulez-vous dire que nous pouvons tromper le décodeur en changeant juste 1 bit de données ?
Compte tenu des valeurs de hachage produites à partir de 2 contenus différents, la probabilité de collision est toujours de 1 / 2^64 (pour des algorithmes de hachage 64 bits de bonne qualité, tels que xxh64 ou xxh3 ), quel que soit le quantité de modifications entre ces 2 contenus.
Cela signifie en effet que, au moins en théorie, un changement d'un seul bit pourrait être capable de générer une collision.
Maintenant, gardez à l'esprit que cette probabilité est de 1 / 2^64 , ce qui est à peu près infinitésimal.
Les gens sont relativement mal à comprendre ce sujet. Ils le confondent parfois avec « petit », qui a tendance à être perçu comme un montant tangible dans l'esprit de la plupart des gens, comme environ 10 %.
Afin d'avoir une idée plus précise, j'aime me référer à ce tableau :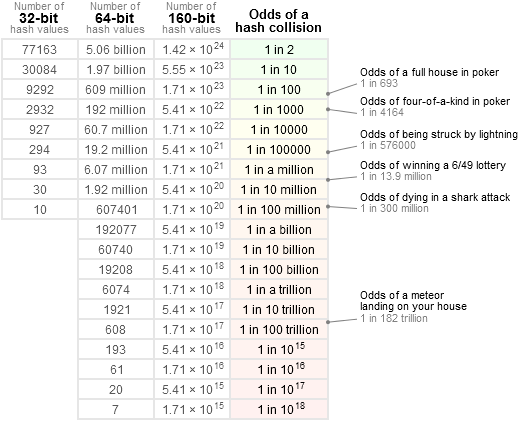
c'est-à-dire : 1 / 2 ^ 64 est bien inférieur à la chance de recevoir une comète directement sur la tête, et inférieur à gagner à la loterie nationale _3 fois de suite_ (ce qui serait plutôt suspect). C'est en fait beaucoup plus proche de "null". La plupart des composants de n'importe quel système sont susceptibles de casser avec une probabilité _beaucoup_ plus élevée que cela, à commencer par d'autres sources de bogues logiciels.
Si l'on veut trouver une telle collision théorique à 1 bit, il faudrait une entrée assez gigantesque et une quantité de puissance assez incroyable pour forcer brutalement une solution à ce problème. Même alors, une solution pourrait ne pas exister : compte tenu de la nature de l'arithmétique employée, je ne serais pas surpris qu'il soit impossible de générer une collision avec une seule modification de bit. Mon propre pari est qu'il faut au moins 2 bits, et même dans ce cas, il faut les placer dans des positions d'entrée spécifiques pour avoir une chance d'atteindre l'objectif souhaité, en faisant une telle modification n'est plus "aléatoire", donc hors de portée pour un hachage non cryptographique.
Mais je pense que le texte cité explique déjà tout cela : les vrais crc ont des garanties sur la distance de Hamming. Cela peut être utile, et cela avait beaucoup plus de sens dans le passé, lorsque les signaux étaient susceptibles d'être modifiés au niveau du bit, et lorsque les sommes de contrôle elles-mêmes étaient plutôt petites (16 ou 32 bits). Un algorithme de hachage 16 bits aurait une chance non négligeable de rater une collision impliquant très peu de retournements de bits, ce qui le rendrait moins adapté à la tâche. Mais avec des hachages 64 bits ou même 128 bits maintenant sur la table, je pense que ce n'est plus une option dangereuse, simplement parce que les risques de collision, donc de corruption non détectée, sont incroyablement faibles.
Certains bits finissent par être très prévisibles ou fortement corrélés, et lors de leur extraction à des fins de hachage, la dispersion est bien pire.
Pourquoi est-ce mauvais ?
Les hachages ont généralement plus d'utilisations que le simple remplacement de la somme de contrôle.
En fait, dans la plupart des cas, le but des algorithmes de hachage est de fournir des bits aléatoires afin de désigner une position dans une table de hachage. Si certains de ces bits deviennent prévisibles en fonction du contenu, cela signifie que la distribution des positions dans la table de hachage ne sera plus "aléatoire", et par conséquent, certaines cellules déborderont plus rapidement que d'autres, ce qui aura un impact négatif sur les performances de la table de hachage. .
Si les bits sont en quelque sorte corrélés, pouvons-nous utiliser cette corrélation pour réparer le fichier endommagé ?
C'est un sujet complètement différent.
On ne répare pas une entrée endommagée avec un CRC. Un CRC peut uniquement détecter une erreur, pas la réparer.
Les données d'auto-réparation sont un sujet et utilisent des techniques différentes (et beaucoup plus complexes en termes de calcul), telles que les codes convolutifs. C'est beaucoup plus complexe.
Cyan4973
le 6 avr. 2020
Si l'on veut trouver une telle collision théorique à 1 bit, il faudrait une entrée assez gigantesque et une quantité de puissance assez incroyable pour forcer brutalement une solution à ce problème. Même alors, une solution pourrait ne pas exister : compte tenu de la nature de l'arithmétique employée, je ne serais pas surpris qu'il soit impossible de générer une collision avec une seule modification de bit. Mon propre pari est qu'il faut au moins 2 bits, et même dans ce cas, il faut les placer dans des positions d'entrée spécifiques pour avoir une chance d'atteindre l'objectif souhaité, en faisant une telle modification n'est plus "aléatoire", donc hors de portée pour un hachage non cryptographique.
261 démontre une collision sur un seul bit dans la variante 64 bits de XXH3, bien qu'elle dépende de la graine et qu'il soit très peu probable qu'elle se produise sur des entrées aléatoires
easyaspi314
le 6 avr. 2020
En effet; pour être plus complet, ma déclaration précédente était plutôt dirigée vers la section de grande taille, pour les entrées > 240 octets.
Mais oui, dans la gamme limitée de tailles où l'entrée doit correspondre exactement à l'un des 64 bits secret , une collision sur un seul bit devient possible. Cela semblait acceptable car une collision basée sur une entrée 64 bits précise à un emplacement précis se situe toujours dans ce territoire 1 / 2^64 , en supposant que l'entrée est aléatoire (c'est-à-dire non conçue pour produire une collision). De plus, le secret à rechercher peut être rendu _secret_, donc un attaquant externe devra forcer pour le trouver.
Cyan4973
le 6 avr. 2020
voulez-vous dire que nous pouvons tromper le décodeur en changeant juste 1 bit de données ?
Compte tenu des valeurs de hachage produites à partir de 2 contenus différents, la probabilité de collision est toujours de
1 / 2^64(pour des algorithmes de hachage 64 bits de bonne qualité, tels quexxh64ouxxh3), quel que soit le quantité de modifications entre ces 2 contenus.Cela signifie en effet que, au moins en théorie, un changement d'un seul bit pourrait être capable de générer une collision.
Maintenant, gardez à l'esprit que cette probabilité est de
1 / 2^64, ce qui est à peu près infinitésimal.
Les gens sont relativement mal à comprendre ce sujet. Ils le confondent parfois avec « petit », qui a tendance à être perçu comme un montant tangible dans l'esprit de la plupart des gens, comme environ 10 %.Afin d'avoir une idée plus précise, j'aime me référer à ce tableau :
c'est-à-dire :
1 / 2 ^ 64est bien inférieur à la chance de recevoir une comète directement sur la tête, et inférieur à gagner à la loterie nationale _3 fois de suite_ (ce qui serait plutôt suspect). C'est en fait beaucoup plus proche de "null". La plupart des composants de n'importe quel système sont susceptibles de casser avec une probabilité _beaucoup_ plus élevée que cela, à commencer par d'autres sources de bogues logiciels.Si l'on veut trouver une telle collision théorique à 1 bit, il faudrait une entrée assez gigantesque et une quantité de puissance assez incroyable pour forcer brutalement une solution à ce problème. Même alors, une solution pourrait ne pas exister : compte tenu de la nature de l'arithmétique employée, je ne serais pas surpris qu'il soit impossible de générer une collision avec une seule modification de bit. Mon propre pari est qu'il faut au moins 2 bits, et même dans ce cas, il faut les placer dans des positions d'entrée spécifiques pour avoir une chance d'atteindre l'objectif souhaité, en faisant une telle modification n'est plus "aléatoire", donc hors de portée pour un hachage non cryptographique.
Mais je pense que le texte cité explique déjà tout cela : les vrais
crcont des garanties sur la distance de Hamming. Cela peut être utile, et cela avait beaucoup plus de sens dans le passé, lorsque les signaux étaient susceptibles d'être modifiés au niveau du bit, et lorsque les sommes de contrôle elles-mêmes étaient plutôt petites (16 ou 32 bits). Un algorithme de hachage 16 bits aurait une chance non négligeable de rater une collision impliquant très peu de retournements de bits, ce qui le rendrait moins adapté à la tâche. Mais avec des hachages 64 bits ou même 128 bits maintenant sur la table, je pense que ce n'est plus une option dangereuse, simplement parce que les risques de collision, donc de corruption non détectée, sont incroyablement faibles.Certains bits finissent par être très prévisibles ou fortement corrélés, et lors de leur extraction à des fins de hachage, la dispersion est bien pire.
Pourquoi est-ce mauvais ?
Les hachages ont généralement plus d'utilisations que le simple remplacement de la somme de contrôle.
En fait, dans la plupart des cas, le but des algorithmes de hachage est de fournir des bits aléatoires afin de désigner une position dans une table de hachage. Si certains de ces bits deviennent prévisibles en fonction du contenu, cela signifie que la distribution des positions dans la table de hachage ne sera plus "aléatoire", et par conséquent, certaines cellules déborderont plus rapidement que d'autres, ce qui aura un impact négatif sur les performances de la table de hachage. .Si les bits sont en quelque sorte corrélés, pouvons-nous utiliser cette corrélation pour réparer le fichier endommagé ?
C'est un sujet complètement différent.
On ne répare pas une entrée endommagée avec un CRC. Un CRC peut uniquement détecter une erreur, pas la réparer.Les données d'auto-réparation sont un sujet et utilisent des techniques différentes (et beaucoup plus complexes en termes de calcul), telles que les codes convolutifs. C'est beaucoup plus complexe.
pourriez-vous confirmer ces scénarios?
- LZ4 a une somme de contrôle de contenu pour chaque bloc de données, considérez que nous avons 10^6 paquets de fichiers de 1 Go
la probabilité de collision est de 1/2^32 = 0,0000000002 cela signifie que si nous envoyons 10^10 (cette taille géante) paquets nous pouvons avoir 2 collisions (basées sur le principe Pigeonhole) mais si nous envoyons moins que ce montant, la probabilité de voir une collision diminuera de manière significative afin que nous puissions détecter toutes les erreurs, le décodeur calcule la somme de contrôle et la compare avec la somme de contrôle du paquet, est-ce correct ? - La somme de contrôle du contenu calcule la somme de contrôle sur le fichier compressé (elle est facultative et nous pouvons l'utiliser pour détecter le désordre ou pour réduire la probabilité de collision (Avant d'utiliser CC, la probabilité d'une collision est de 1/2 ^ 32 et être 1/2 ^ 64.)
arashams
le 8 avr. 2020
Le scénario décrit est :
- Les données compressées LZ4 sont corrompues (ce qui est déjà un événement assez rare en soi)
- La corruption n'a pas été détectée en raison d'une collision de hachage.
Le format de trame LZ4 utilise XXH32 , un hachage 32 bits, comme somme de contrôle associée.
Il est appliqué par défaut au contenu complet de la trame, plus précisément au contenu _non compressé_ de la trame (après décompression), validant ainsi à la fois le processus de transmission et de décodage.
Il peut également éventuellement l'appliquer à chaque bloc, auquel cas il effectue la somme de contrôle du contenu _compressé_ de chaque bloc.
Les deux peuvent être cumulés.
Pour ne pas être détectée, une corruption doit réussir ___toutes___ les sommes de contrôle applicables.
En supposant que la somme de contrôle de bloc soit activée et que la corruption soit entièrement localisée dans un seul bloc, les chances de passer à la fois la somme de contrôle du bloc et de la trame sont en effet de 1 / 2^32 x 1 / 2^32 = 1 / 2^64 .
Désormais, si des données corrompues résident dans plusieurs blocs, soit parce qu'il y a plusieurs événements de corruption, soit parce qu'une seule grande section corrompue couvre des blocs consécutifs, il est encore plus difficile pour la corruption de ne pas être détectée_. Il devrait générer une collision avec chacune des sommes de contrôle de bloc impliquées.
Par exemple, en supposant que la corruption est répartie sur 2 blocs, les chances que cette corruption ne soit pas détectée sont de 1 / 2^32 x 1 / 2^32 x 1 / 2^32 = 1 / 2^96 . Astronomiquement petit.
Sans compter le fait que chaque bloc corrompu peut être détecté comme non décodable par le processus de décompression, qui vient s'ajouter à cela.
Alors oui, combiner la somme de contrôle des blocs et des trames augmente considérablement les chances de détecter des événements de corruption.
Cyan4973
le 8 avr. 2020
Le scénario décrit est :
* LZ4-compressed data being corrupted (which is already a pretty rare event by itself) * Corruption remaining undetected due to hash collision.Le format de trame LZ4 utilise
XXH32, un hachage 32 bits, comme somme de contrôle associée.
Il est appliqué par défaut au contenu complet de la trame, plus précisément au contenu _non compressé_ de la trame (après décompression), validant ainsi à la fois le processus de transmission et de décodage.
Il peut également éventuellement l'appliquer à chaque bloc, auquel cas il effectue la somme de contrôle du contenu _compressé_ de chaque bloc.
Les deux peuvent être cumulés.Pour ne pas être détectée, une corruption doit réussir _ toutes les _ sommes de contrôle applicables.
En supposant que la somme de contrôle de bloc soit activée et que la corruption soit entièrement localisée dans un seul bloc, les chances de passer à la fois la somme de contrôle du bloc et de la trame sont en effet de1 / 2^32 x 1 / 2^32 = 1 / 2^64.Désormais, si des données corrompues résident dans plusieurs blocs, soit parce qu'il y a plusieurs événements de corruption, soit parce qu'une seule grande section corrompue couvre des blocs consécutifs, il est encore plus difficile pour la corruption de ne pas être détectée_. Il devrait générer une collision avec chacune des sommes de contrôle de bloc impliquées.
Par exemple, en supposant que la corruption soit répartie sur 2 blocs, les chances que cette corruption ne soit pas détectée sont de1 / 2^32 x 1 / 2^32 x 1 / 2^32 = 1 / 2^96. Astronomiquement petit.Sans compter le fait que chaque bloc corrompu peut être détecté comme non décodable par le processus de décompression, qui vient s'ajouter à cela.
Alors oui, combiner la somme de contrôle des blocs et des trames augmente considérablement les chances de détecter des événements de corruption.
Est-il possible d'utiliser LZ4 à la volée ? Je veux dire, compressez/décompressez les données dès que vous en avez une partie. c'est en quelque sorte du pipeline.
qu'en est-il du xxHash ?
arashams
le 29 août 2020
est-il possible d'utiliser le LZ4 à la volée ? Je veux dire, compressez/décompressez les données dès que vous en avez une partie.
C'est le mode de diffusion. Oui c'est possible.
qu'en est-il du xxHash ?
La somme de contrôle de la trame est mise à jour en continu, mais ne produit un résultat qu'à la fin de la trame. Par conséquent, il n'y a pas de résultat de somme de contrôle à comparer jusqu'à un événement de fin de trame (un flux peut être constitué de plusieurs trames ajoutées, mais ce n'est généralement pas le cas).
En revanche, des sommes de contrôle de bloc sont créées à chaque bloc, elles sont donc régulièrement produites et vérifiées lors du streaming.
Les deux sommes de contrôle utilisent XXH32 .
Cyan4973
le 29 août 2020
Questions connexes
 vinniefalco
·
4Commentaires
vinniefalco
·
4Commentaires
 jvriezen
·
6Commentaires
jvriezen
·
6Commentaires
 WayneD
·
7Commentaires
WayneD
·
7Commentaires
 gitmko0
·
7Commentaires
gitmko0
·
7Commentaires
 witedragen
·
3Commentaires
witedragen
·
3Commentaires
Commentaire le plus utile
Les algorithmes CRC présentent généralement des garanties de détection d'erreur sous condition de distances de Hamming. Étant donné un nombre limité de basculements de bits, le CRC générera _nécessairement_ un résultat différent.
Cela peut s'avérer utile dans les situations où les erreurs sont supposées ne renverser que quelques bits.
Il y a quelques décennies à peine, cela était relativement courant, en particulier dans les scénarios de transmission, car le signal sous-jacent était encore très "brut", donc les retournements de bits non détectés sur la couche physique étaient une chose.
Cette propriété a cependant un coût de distribution. Une fois la distance de « sécurité » franchie, la probabilité de collision s'aggrave. C'est une conséquence logique du principe du pigeonnier. Combien pire ? Eh bien, cela dépend du CRC exact, mais je m'attends à ce que le bon CRC soit dans la plage 3x - 7x pire. Cela peut sembler beaucoup, mais c'est juste une réduction de dispersion de 2-3 bits, donc ce n'est pas si terrible. Encore.
Comparez cela avec un hachage présentant une propriété de distribution "idéale": tout changement, qu'il s'agisse d'un seul bit ou d'une sortie complètement différente, a exactement 1 / 2^n probabilité de générer une collision. C'est plus simple à appréhender : le risque de collision est toujours le même. En comparaison directe avec le CRC, lorsque la distance de Hamming est faible, le taux de collision est pire (puisqu'il est > 0), mais il est meilleur lorsque la distance de Hamming est grande.
Avance rapide de nos jours, et la situation a radicalement changé. Nous avons des couches sur des couches de logique de détection et de correction d'erreur au-dessus du support physique. Nous ne pouvons pas simplement extraire un peu d'un bloc flash, ni lire un peu d'un canal Bluetooth. Cela n'a plus de sens. Ces protocoles embarquent une logique de bloc avec état, plus complexe, plus résiliente, compensant en permanence le bruit permanent de la couche physique. Lorsqu'ils échouent, cela ne produira pas un seul retournement : au contraire, une région de données complète sera complètement brouillée, n'étant constituée que de zéros ou même de bruit aléatoire.
Dans ce nouvel environnement, le pari est que les erreurs, lorsqu'elles se produisent, ne sont plus dans la catégorie "bitflip". Dans ce cas, les propriétés de distribution du CRC deviennent un passif. Un hachage pur a en fait une probabilité plus faible de produire une collision.
C'est uniquement lorsque l'on considère la somme de contrôle.
Une propriété supplémentaire d'un hachage "idéal" est que, lors de l'extraction d'un segment de bits du hachage, il présente toujours cette probabilité de collision
1 / 2^n, qui est très importante en tant que source de bits pour d'autres structures, telles que table de hachage ou filtre bloom. En revanche, CRC ne fournit pas une telle garantie. Certains bits finissent par être très prévisibles ou fortement corrélés, et lors de leur extraction à des fins de hachage, la dispersion est bien pire.On pourrait dire que la somme de contrôle et le hachage sont simplement 2 domaines différents, et ne doivent pas être confondus. En effet, c'est la théorie. Le problème est que cela ne tient pas compte de la commodité et de la pratique sur le terrain. Avoir un "mixer" à usage multiple est pratique, et les programmeurs se contenteront d'un seul et l'oublieront. Je ne peux pas compter combien de fois j'ai vu crc32 utilisé pour le hachage, simplement parce qu'il semblait "assez aléatoire". Il est facile de dire que cela ne devrait pas arriver, mais c'est le cas, constamment.
Dans cet environnement, proposer une solution conçue pour bien fonctionner pour les deux cas d'utilisation a du sens, car elle correspond aux attentes des utilisateurs.
En raison des propriétés d'un bon hachage, il est en effet possible d'extraire 8 ou 16 bits d'un hachage, ce qui entraîne une probabilité de collision de 1/256 ou 1/65535. Je ne vois aucune inquiétude à ce sujet.
Juste, nous devons accepter la latence de _history_. Les gens sont habitués à une certaine manière de faire, comme l'utilisation de fonctions de somme de contrôle spécifiques pour la somme de contrôle. Même s'il existe des solutions plus récentes et potentiellement meilleures, les habitudes ne changent pas rapidement.