<p>xxHash كمجموع اختباري لاكتشاف الأخطاء</p>
أحد الأشياء التي أخفق في فهمها باستمرار هو كيف يمكن أن تكون التجزئة عبارة عن مجموع اختباري (أو ما إذا كان ينبغي أن تكون كذلك) ، لأن التجزئات التقليدية يتم تحسينها للسلاسل ، ولجداول التجزئة (يتبادر إلى الذهن DJB2 كمفضل قديم للمعجبين) ومع ذلك ، داخل حشد PIC / Arduino ، لا يزال الناس يستخدمون مجاميع اختبارية بسيطة قديمة 8 بت ، أو مبالغ Fletcher 16 بت أو 16 بت CRC. لكنك لا ترى الكثير من الحديث عن المجاميع الاختبارية الجديدة على أنها خيارات أفضل مع معالجات اليوم التي يفترض أنها أسرع. هل أنواع الحسابات المستخدمة في التجزئات بطيئة جدًا؟ (على الرغم من أن CRC في الواقع أبطأ في البرامج من xxHash ..) أم أن هناك شيئًا سيئًا بطبيعته مع وظائف التجزئة عند تقليله إلى 8 أو 16 بت؟
لقد قرأت أن xxHash تم تصميمه أولاً كمجموع اختباري لـ lz4 ، وبعض وظائف التجزئة الأخرى مثل SeaHash المصممة للاستخدام في نظام الملفات أيضًا للاختبار. للمقارنة ، تم استخدام CRC-32 على نطاق واسع ، أيضًا في بعض تنسيقات الضغط (مثل ZIP / RAR). لقد قرأت أيضًا أن CRC لها بعض الخصائص الرياضية التي تثبت طرق الطرق لاكتشاف الأخطاء لكثيرات حدود معينة ، وما إلى ذلك. ولكن من نواح كثيرة ، تكون التجزئة أكثر فوضوية ، وأكثر شبهًا بمولدات الأرقام الزائفة ، ومن غير المرجح أن يكون لها مثل هذه الضمانات ، على الأقل هذا هو كيف يبدو لي.
هذا يتركني أتساءل عما إذا كان من الأفضل استخدام CRC-32 لأغراض السلامة بدلاً من تجزئة سريعة وسهلة التنفيذ ، حتى لو كانت قد تعرضت لضربة في السرعة. هل لدى xxHash أي ضمانات للكشف عن الأخطاء (لنفترض إصدار 32 بت)؟ وإذا لم يكن الأمر كذلك ، فكيف يتنافس مع CRC-32 كمجموع اختباري أو رمز اكتشاف الخطأ؟ ما هي المقايضات؟
 bryc
bryc
ال 11 كومينتر
تتميز خوارزميات CRC عمومًا بضمانات اكتشاف الأخطاء في حالة مسافات الطرق. بالنظر إلى عدد محدود من تقلبات البتات ، فإن CRC _ ضروريًا_ ستولد نتيجة مختلفة.
يمكن أن يكون هذا مفيدًا في المواقف التي يُفترض فيها أن الأخطاء تقلب فقط بضع بتات.
قبل بضعة عقود فقط ، كان هذا شائعًا نسبيًا ، خاصة في سيناريوهات الإرسال ، حيث كانت الإشارة الأساسية لا تزال "خامًا" للغاية ، لذلك كانت تقلبات البت غير المكتشفة على الطبقة المادية شيئًا.
لكن هذه الخاصية لها تكلفة التوزيع. بمجرد عبور مسافة الطرق "الآمنة" ، يصبح احتمال الاصطدام أسوأ. هذه نتيجة منطقية لمبدأ حفرة الحمام. كم أسوأ؟ حسنًا ، هذا يعتمد على CRC الدقيق ، لكنني أتوقع أن تكون CRC الجيدة في نطاق أسوأ 3x - 7x. قد يبدو هذا كثيرًا ، لكنه مجرد تقليل للتشتت 2-3 بت ، لذا فهو ليس بهذا الرعب. ما يزال.
قارن ذلك مع تجزئة تتميز بخاصية توزيع "مثالية": أي تغيير ، بغض النظر عما إذا كان بت واحد أو ناتج مختلف تمامًا ، له احتمال 1/2 ^ n لتوليد تصادم. من الأسهل فهمها: خطر الاصطدام هو نفسه دائمًا. في المقارنة المباشرة مع CRC ، عندما تكون مسافة الطرق صغيرة ، يكون معدل الاصطدام أسوأ (لأنه> 0) ، ولكنه أفضل عندما تكون مسافة الطرق كبيرة.
تقدم سريعًا في الوقت الحاضر ، وقد تغير الوضع بشكل جذري. لدينا طبقات فوق طبقات من اكتشاف الأخطاء ومنطق التصحيح فوق الوسائط المادية. لا يمكننا فقط استخراج القليل من كتلة الفلاش ، ولا يمكننا القراءة قليلاً من قناة Bluetooth. لم يعد له معنى بعد الآن. تتضمن هذه البروتوكولات منطق كتلة ذي حالة ، وهو أكثر تعقيدًا ومرونة ويعوض باستمرار عن الضوضاء الدائمة للطبقة المادية. عندما يفشلون ، لن ينتج عن ذلك نقلة واحدة: بدلاً من ذلك ، ستكون منطقة البيانات الكاملة مشوشة تمامًا ، وستكون كلها أصفارًا ، أو حتى ضوضاء عشوائية.
في هذه البيئة الجديدة ، الرهان هو أن الأخطاء ، عند حدوثها ، لم تعد موجودة في فئة "bitflip". في هذه الحالة ، تصبح خصائص توزيع CRC مسؤولية. تحتوي التجزئة النقية في الواقع على احتمال أقل لتصادم.
هذا عند التفكير في الختام الاختباري فقط.
هناك خاصية إضافية للتجزئة "المثالية" وهي أنه عند استخراج أي جزء من البتات من التجزئة ، فإنه لا يزال يتميز باحتمال الاصطدام هذا 1 / 2^n ، وهو أمر مهم جدًا كمصدر للبتات للبنى الأخرى ، مثل جدول تجزئة أو مرشح بلوم. في المقابل ، لا تقدم اتفاقية حقوق الطفل مثل هذا الضمان. ينتهي الأمر ببعض البتات إلى أن تكون متوقعة جدًا أو مرتبطة بشكل كبير ، وعند استخراجها لغرض التجزئة ، يكون التشتت أسوأ بكثير.
يمكن للمرء أن يقول أن المجموع الاختباري والتجزئة هما مجرد مجالين مختلفين ، ولا ينبغي الخلط بينهما. في الواقع ، هذه هي النظرية. المشكلة هي أن هذا يتجاهل الراحة والممارسة الميدانية. إن امتلاك "خلاط" واحد متعدد الأغراض أمر ملائم ، وسيقبل المبرمجون على واحد وينسوا أمره. لا يمكنني حساب عدد المرات التي رأيت فيها crc32 مستخدمة للتجزئة ، فقط لأنها شعرت بأنها "عشوائية بما يكفي". من السهل أن نقول إنه لا ينبغي أن يحدث ذلك ، لكنه يحدث باستمرار.
في هذه البيئة ، فإن اقتراح حل مصمم للعمل بشكل جيد لكلتا حالتي الاستخدام أمر منطقي ، لأنه يطابق توقعات المستخدم.
ضمن حشد PIC / Arduino ، لا يزال الناس يستخدمون مجاميع اختبارية بسيطة قديمة 8 بت ، أو مجاميع Fletcher 16 بت أو 16 بت CRC.
(...)
هل هناك شيء سيء بطبيعته مع وظائف التجزئة عند تقليله إلى 8 أو 16 بت؟
نظرًا لخصائص التجزئة الجيدة ، فمن الممكن بالفعل استخراج 8 أو 16 بت من التجزئة ، مما ينتج عنه احتمال تصادم 1/256 أو 1/65535. لا أرى أي قلق بشأن هذا.
فقط ، علينا قبول زمن انتقال _ التاريخ_. اعتاد الناس على طريقة معينة للأشياء ، مثل استخدام وظائف المجموع الاختباري المحددة للاختبار. حتى لو كانت هناك حلول أكثر حداثة وربما أفضل ، فإن العادات لا تتغير بسرعة.
 Cyan4973
في ١٦ يوليو ٢٠١٩
Cyan4973
في ١٦ يوليو ٢٠١٩
تتميز خوارزميات CRC عمومًا بضمانات اكتشاف الأخطاء في حالة مسافات الطرق. بالنظر إلى عدد محدود من تقلبات البتات ، فإن CRC _ ضروريًا_ ستولد نتيجة مختلفة.
يمكن أن يكون هذا مفيدًا في المواقف التي يُفترض فيها أن الأخطاء تقلب فقط بضع بتات.
قبل بضعة عقود فقط ، كان هذا شائعًا نسبيًا ، خاصة في سيناريوهات الإرسال ، حيث كانت الإشارة الأساسية لا تزال "خامًا" للغاية ، لذلك كانت تقلبات البت غير المكتشفة على الطبقة المادية شيئًا.لكن هذه الخاصية لها تكلفة التوزيع. بمجرد عبور مسافة الطرق "الآمنة" ، يصبح احتمال الاصطدام أسوأ. هذه نتيجة منطقية لمبدأ حفرة الحمام. كم أسوأ؟ حسنًا ، هذا يعتمد على CRC الدقيق ، لكنني أتوقع أن تكون CRC الجيدة في نطاق أسوأ 3x - 7x. قد يبدو هذا كثيرًا ، لكنه مجرد تقليل للتشتت 2-3 بت ، لذا فهو ليس بهذا الرعب. ما يزال.
قارن ذلك مع تجزئة تتميز بخاصية توزيع "مثالية": أي تغيير ، بغض النظر عما إذا كان بت واحد أو ناتج مختلف تمامًا ، له احتمال 1/2 ^ n لتوليد تصادم. من الأسهل فهمها: خطر الاصطدام هو نفسه دائمًا. في مقارنة مباشرة مع CRC ، يكون معدل الاصطدام أسوأ (لأنه> 0) عندما تكون مسافة الطرق صغيرة ، ولكنه أفضل عندما تكون مسافة الطرق كبيرة.
تقدم سريعًا في الوقت الحاضر ، وقد تغير الوضع بشكل جذري. لدينا طبقات فوق طبقات من اكتشاف الأخطاء ومنطق التصحيح فوق الوسائط المادية. لا يمكننا فقط استخراج القليل من كتلة الفلاش ، ولا يمكننا القراءة قليلاً من قناة Bluetooth. لم يعد له معنى بعد الآن. تتضمن هذه البروتوكولات منطق كتلة ذي حالة ، وهو أكثر تعقيدًا ومرونة ويعوض باستمرار عن الضوضاء الدائمة للطبقة المادية. عندما يفشلون ، لن ينتج عن ذلك نقلة واحدة: بدلاً من ذلك ، ستكون منطقة البيانات الكاملة مشوشة تمامًا ، وستكون كلها أصفارًا ، أو حتى ضوضاء عشوائية.
في هذه البيئة الجديدة ، الرهان هو أن الأخطاء ، عند حدوثها ، لم تعد موجودة في فئة "bitflip". في هذه الحالة ، تصبح خصائص توزيع CRC مسؤولية. تحتوي التجزئة النقية في الواقع على احتمال أقل لتصادم.
هذا عند التفكير في الختام الاختباري فقط.
هناك خاصية إضافية للتجزئة "المثالية" وهي أنه عند استخراج أي جزء من البتات من التجزئة ، فإنه لا يزال يتميز باحتمال الاصطدام هذا1 / 2^n، وهو أمر مهم جدًا كمصدر للبتات للبنى الأخرى ، مثل جدول تجزئة أو مرشح بلوم. في المقابل ، لا تقدم اتفاقية حقوق الطفل مثل هذا الضمان. ينتهي الأمر ببعض البتات إلى أن تكون متوقعة جدًا أو مرتبطة بشكل كبير ، وعند استخراجها لغرض التجزئة ، يكون التشتت أسوأ بكثير.يمكن للمرء أن يقول أن المجموع الاختباري والتجزئة هما مجرد مجالين مختلفين ، ولا ينبغي الخلط بينهما. في الواقع ، هذه هي النظرية. المشكلة هي أن هذا يتجاهل الراحة والممارسة الميدانية. إن امتلاك "خلاط" واحد متعدد الأغراض أمر ملائم ، وسيقبل المبرمجون على واحد وينسوا أمره. لا يمكنني حساب عدد المرات التي رأيت فيها crc32 مستخدمة للتجزئة ، فقط لأنها شعرت بأنها "عشوائية بما يكفي". من السهل أن نقول إنه لا ينبغي أن يحدث ذلك ، لكنه يحدث باستمرار.
في هذه البيئة ، فإن اقتراح حل مصمم للعمل بشكل جيد لكلتا حالتي الاستخدام أمر منطقي ، لأنه يطابق توقعات المستخدم.ضمن حشد PIC / Arduino ، لا يزال الناس يستخدمون مجاميع اختبارية بسيطة قديمة 8 بت ، أو مجاميع Fletcher 16 بت أو 16 بت CRC.
(...)
هل هناك شيء سيء بطبيعته مع وظائف التجزئة عند تقليله إلى 8 أو 16 بت؟نظرًا لخصائص التجزئة الجيدة ، فمن الممكن بالفعل استخراج 8 أو 16 بت من التجزئة ، مما ينتج عنه احتمال تصادم 1/256 أو 1/65535. لا أرى أي قلق بشأن هذا.
فقط ، علينا قبول زمن انتقال _ التاريخ_. اعتاد الناس على طريقة معينة للأشياء ، مثل استخدام وظائف المجموع الاختباري المحددة للاختبار. حتى لو كانت هناك حلول أكثر حداثة وربما أفضل ، فإن العادات لا تتغير بسرعة.
نعلم أنه باستخدام CRC 32 واستخدام HD = 6 ، يمكنه اكتشاف أي أخطاء 5 بت ويمكنه اكتشاف رشقات تصل إلى 2 ^ 31 = حوالي 204 ميجابايت
واكتشاف جميع الأخطاء أحادية البت
في xxHash ، كم عدد وحدات البت التي يجب تغييرها حتى لا نكتشف خطأ ما؟
أعلم في Hash أن التغيير حتى 1 بت يجعل ملخصًا مختلفًا تمامًا ولكن كيف يمكننا حساب عدد البتات اللازمة لإنشاء الاصطدام؟
سؤال آخر كما ذكرت:
في المقابل ، لا تقدم اتفاقية حقوق الطفل مثل هذا الضمان. ينتهي الأمر ببعض البتات إلى أن تكون متوقعة جدًا أو مرتبطة بشكل كبير ، وعند استخراجها لغرض التجزئة ، يكون التشتت أسوأ بكثير.
لماذا هذا سيء؟ إذا كانت البتات مترابطة بطريقة ما ، فهل يمكننا استخدام هذا الارتباط لإصلاح الملف التالف؟
 arashams
في ٦ أبريل ٢٠٢٠
arashams
في ٦ أبريل ٢٠٢٠
في xxHash ، كم عدد البتات التي يجب تغييرها حتى لا نكتشف خطأ (أو تصادمات)
1 بت.
xxHash هي دالة تجزئة غير مشفرة ، وليست مجموع اختباري. لا يوفر أي مسافة طرق أو ضمانات مقاومة التصادم.
في حين أنه يمكن أن يقوم بعمل لائق في ذلك ، إلا أنه ليس الخيار الأفضل. إنه مثل استخدام الزردية كمفتاح ربط. بالتأكيد ، ستنجز المهمة ، لكنها أقل فاعلية من مفتاح الربط الحقيقي وقد تسبب ضررًا.
 easyaspi314
في ٦ أبريل ٢٠٢٠
easyaspi314
في ٦ أبريل ٢٠٢٠
في xxHash ، كم عدد البتات التي يجب تغييرها حتى لا نكتشف خطأ (أو تصادمات)
1 بت.
xxHash هي دالة تجزئة غير مشفرة ، وليست مجموع اختباري. لا يوفر أي مسافة طرق أو ضمانات مقاومة التصادم.
في حين أنه يمكن أن يقوم بعمل لائق في ذلك ، إلا أنه ليس الخيار الأفضل. إنه مثل استخدام الزردية كمفتاح ربط. بالتأكيد ، ستنجز المهمة ، لكنها أقل فاعلية من مفتاح الربط الحقيقي وقد تسبب ضررًا.
هل تقصد أنه يمكننا خداع وحدة فك التشفير بتغيير بت واحد فقط من البيانات؟
يمكن أن تخلق تصادمات؟ (هذا مخيف) ويعتمد احتمال حدوث مثل هذا التصادم على حجم الهضم
arashams
في ٦ أبريل ٢٠٢٠
هل تقصد أنه يمكننا خداع وحدة فك التشفير بتغيير بت واحد فقط من البيانات؟
بالنظر إلى قيم التجزئة الناتجة من محتويين مختلفين ، يكون احتمال التضاربات دائمًا 1 / 2^64 (للحصول على خوارزميات تجزئة 64 بت عالية الجودة ، مثل xxh64 أو xxh3 ) ، مهما كان مقدار التعديلات بين هذين المحتوىين.
إنه يعني بالفعل ، على الأقل من الناحية النظرية ، أن تغيير بت واحد قد يكون قادرًا على إحداث تصادم.
الآن ، ضع في اعتبارك أن هذا الاحتمال هو 1 / 2^64 ، وهو متناهي الصغر إلى حد كبير.
الناس سيئون نسبيًا في فهم هذا الموضوع. أحيانًا يخلطون بينه وبين "صغير" ، والذي يميل إلى أن يُنظر إليه على أنه مبلغ ملموس في أذهان معظم الناس ، مثل ~ 10٪.
من أجل الحصول على فكرة أكثر دقة ، أود أن أشير إلى هذا الجدول: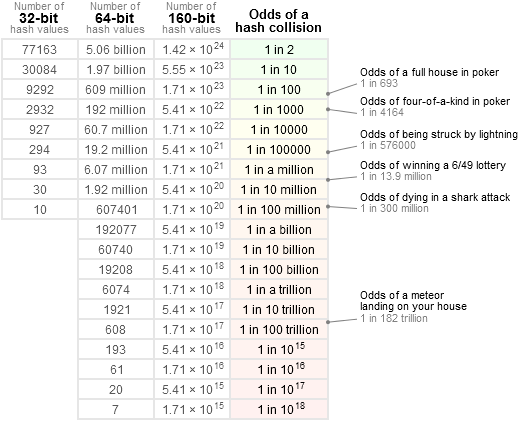
على سبيل المثال: 1 / 2 ^ 64 أقل بكثير من فرصة تلقي مذنب مباشرة على رأس المرء ، وأقل من ربح اليانصيب الوطني _3 مرات متتالية _ (وهو ما يفضل أن يكون مريبًا). هذا هو في الواقع أقرب بكثير إلى "خالية". معظم المكونات في أي نظام معرضة للانقطاع باحتمالية أكبر بكثير من ذلك ، بدءًا من المصادر الأخرى لأخطاء البرامج.
إذا أراد المرء أن يجد مثل هذا التصادم النظري 1 بت ، سيحتاج المرء إلى مدخلات عملاقة ومقدارًا لا يُصدق من القوة لفرض حل لهذه المشكلة. حتى مع ذلك ، قد لا يوجد حل: بالنظر إلى طبيعة الحساب المستخدم ، لن أتفاجأ إذا كان من المستحيل إحداث تصادم بتعديل بت واحد. أراهن أن الأمر يتطلب 2 بت على الأقل ، وحتى ذلك الحين ، فإنه يتطلب وضعها في مواضع إدخال محددة للحصول على فرصة لتحقيق الهدف المنشود ، مما يجعل مثل هذا التعديل لم يعد "عشوائيًا" ، وبالتالي خارج نطاق تجزئة غير مشفرة.
لكنني أعتقد أن النص المقتبس يشرح بالفعل كل هذا: crc الحقيقي له ضمانات على مسافة الطرق. يمكن أن يكون هذا مفيدًا ، وقد كان أكثر منطقية في الماضي ، عندما كانت الإشارات عرضة للتعديل على مستوى البت ، وعندما كان المجموع الاختباري نفسه صغيرًا نوعًا ما (16 أو 32 بت). سيكون لخوارزمية التجزئة ذات 16 بت فرصة ضئيلة لتفويت تصادم يتضمن القليل جدًا من التقلبات ، مما يجعلها أقل ملاءمة للمهمة. ولكن مع وجود تجزئات 64 بت أو حتى 128 بت على الطاولة الآن ، أعتقد أن هذا لم يعد خيارًا خطيرًا ، ببساطة لأن فرص الاصطدام ، ومن ثم الفساد غير المكتشف ، ضئيلة بشكل لا يمكن فهمه.
ينتهي الأمر ببعض البتات إلى أن تكون متوقعة جدًا أو مرتبطة بشكل كبير ، وعند استخراجها لغرض التجزئة ، يكون التشتت أسوأ بكثير.
لماذا هذا سيء؟
تستخدم التجزئة بشكل عام أكثر من مجرد استبدال المجموع الاختباري.
في الواقع ، في معظم الحالات ، يكون الغرض من خوارزميات التجزئة هو توفير بعض البتات العشوائية لتعيين موضع في جدول التجزئة. إذا أصبحت بعض هذه البتات قابلة للتنبؤ اعتمادًا على المحتوى ، فهذا يعني أن توزيع المواضع في جدول التجزئة لن يكون "عشوائيًا" ، ونتيجة لذلك ، ستتدفق بعض الخلايا بشكل أسرع من الأخرى ، مما يؤثر سلبًا على أداء جدول التجزئة .
إذا كانت البتات مترابطة بطريقة ما ، فهل يمكننا استخدام هذا الارتباط لإصلاح الملف التالف؟
هذا موضوع مختلف تماما
لا يصلح أحد المدخلات التالفة باستخدام CRC. يمكن لـ CRC اكتشاف الخطأ فقط ، وليس إصلاحه.
تعد بيانات الإصلاح الذاتي موضوعًا ، وتستخدم تقنيات مختلفة (وأكثر ارتباطًا بالحسابات) ، مثل الأكواد التلافيفية. هذا أكثر تعقيدًا بكثير.
Cyan4973
في ٦ أبريل ٢٠٢٠
إذا أراد المرء أن يجد مثل هذا التصادم النظري 1 بت ، سيحتاج المرء إلى مدخلات عملاقة ومقدارًا لا يُصدق من القوة لفرض حل لهذه المشكلة. حتى مع ذلك ، قد لا يوجد حل: بالنظر إلى طبيعة الحساب المستخدم ، لن أتفاجأ إذا كان من المستحيل إحداث تصادم بتعديل بت واحد. أراهن أن الأمر يتطلب 2 بت على الأقل ، وحتى ذلك الحين ، فإنه يتطلب وضعها في مواضع إدخال محددة للحصول على فرصة لتحقيق الهدف المنشود ، مما يجعل مثل هذا التعديل لم يعد "عشوائيًا" ، وبالتالي خارج نطاق تجزئة غير مشفرة.
يوضح الشكل 261 تصادمًا فرديًا في متغير 64 بت من XXH3 ، على الرغم من أنه يعتمد على البذور ومن غير المحتمل جدًا حدوثه في المدخلات العشوائية
easyaspi314
في ٦ أبريل ٢٠٢٠
في الواقع؛ لكي تكون أكثر اكتمالًا ، كان بياني السابق موجهًا إلى قسم الحجم الكبير ، للمدخلات> 240 بايت.
لكن نعم ، في النطاق المحدود للأحجام حيث يجب أن يتطابق الإدخال تمامًا مع واحد من 64 بت secret ، يصبح تضارب بت واحد ممكنًا. لقد شعرت بقبول لأن التصادم المستند إلى إدخال دقيق لـ 64 بت في موقع محدد لا يزال ضمن هذه المنطقة 1 / 2^64 ، بافتراض أن الإدخال عشوائي (أي غير مصمم هندسيًا لإنتاج تصادم). علاوة على ذلك ، فإن secret للمطابقة يمكن أن يتم بشكل فعال _ سري _ ، لذلك سيتعين على المهاجم الخارجي أن يجبر طريقه للعثور عليه.
Cyan4973
في ٦ أبريل ٢٠٢٠
هل تقصد أنه يمكننا خداع وحدة فك التشفير بتغيير بت واحد فقط من البيانات؟
بالنظر إلى قيم التجزئة الناتجة من محتويين مختلفين ، يكون احتمال التضاربات دائمًا
1 / 2^64(للحصول على خوارزميات تجزئة 64 بت عالية الجودة ، مثلxxh64أوxxh3) ، مهما كان مقدار التعديلات بين هذين المحتوىين.إنه يعني بالفعل ، على الأقل من الناحية النظرية ، أن تغيير بت واحد قد يكون قادرًا على إحداث تصادم.
الآن ، ضع في اعتبارك أن هذا الاحتمال هو
1 / 2^64، وهو متناهي الصغر إلى حد كبير.
الناس سيئون نسبيًا في فهم هذا الموضوع. أحيانًا يخلطون بينه وبين "صغير" ، والذي يميل إلى أن يُنظر إليه على أنه مبلغ ملموس في أذهان معظم الناس ، مثل ~ 10٪.من أجل الحصول على فكرة أكثر دقة ، أود أن أشير إلى هذا الجدول:
على سبيل المثال:
1 / 2 ^ 64أقل بكثير من فرصة تلقي مذنب مباشرة على رأس المرء ، وأقل من ربح اليانصيب الوطني _3 مرات متتالية _ (وهو ما يفضل أن يكون مريبًا). هذا هو في الواقع أقرب بكثير إلى "خالية". معظم المكونات في أي نظام معرضة للانقطاع باحتمالية أكبر بكثير من ذلك ، بدءًا من المصادر الأخرى لأخطاء البرامج.إذا أراد المرء أن يجد مثل هذا التصادم النظري 1 بت ، سيحتاج المرء إلى مدخلات عملاقة ومقدارًا لا يُصدق من القوة لفرض حل لهذه المشكلة. حتى مع ذلك ، قد لا يوجد حل: بالنظر إلى طبيعة الحساب المستخدم ، لن أتفاجأ إذا كان من المستحيل إحداث تصادم بتعديل بت واحد. أراهن أن الأمر يتطلب 2 بت على الأقل ، وحتى ذلك الحين ، فإنه يتطلب وضعها في مواضع إدخال محددة للحصول على فرصة لتحقيق الهدف المنشود ، مما يجعل مثل هذا التعديل لم يعد "عشوائيًا" ، وبالتالي خارج نطاق تجزئة غير مشفرة.
لكنني أعتقد أن النص المقتبس يشرح بالفعل كل هذا:
crcالحقيقي له ضمانات على مسافة الطرق. يمكن أن يكون هذا مفيدًا ، وقد كان أكثر منطقية في الماضي ، عندما كانت الإشارات عرضة للتعديل على مستوى البت ، وعندما كان المجموع الاختباري نفسه صغيرًا نوعًا ما (16 أو 32 بت). سيكون لخوارزمية التجزئة ذات 16 بت فرصة ضئيلة لتفويت تصادم يتضمن القليل جدًا من التقلبات ، مما يجعلها أقل ملاءمة للمهمة. ولكن مع وجود تجزئات 64 بت أو حتى 128 بت على الطاولة الآن ، أعتقد أن هذا لم يعد خيارًا خطيرًا ، ببساطة لأن فرص الاصطدام ، ومن ثم الفساد غير المكتشف ، ضئيلة بشكل لا يمكن فهمه.ينتهي الأمر ببعض البتات إلى أن تكون متوقعة جدًا أو مرتبطة بشكل كبير ، وعند استخراجها لغرض التجزئة ، يكون التشتت أسوأ بكثير.
لماذا هذا سيء؟
تستخدم التجزئة بشكل عام أكثر من مجرد استبدال المجموع الاختباري.
في الواقع ، في معظم الحالات ، يكون الغرض من خوارزميات التجزئة هو توفير بعض البتات العشوائية لتعيين موضع في جدول التجزئة. إذا أصبحت بعض هذه البتات قابلة للتنبؤ اعتمادًا على المحتوى ، فهذا يعني أن توزيع المواضع في جدول التجزئة لن يكون "عشوائيًا" ، ونتيجة لذلك ، ستتدفق بعض الخلايا بشكل أسرع من الأخرى ، مما يؤثر سلبًا على أداء جدول التجزئة .إذا كانت البتات مترابطة بطريقة ما ، فهل يمكننا استخدام هذا الارتباط لإصلاح الملف التالف؟
هذا موضوع مختلف تماما
لا يصلح أحد المدخلات التالفة باستخدام CRC. يمكن لـ CRC اكتشاف الخطأ فقط ، وليس إصلاحه.تعد بيانات الإصلاح الذاتي موضوعًا ، وتستخدم تقنيات مختلفة (وأكثر ارتباطًا بالحسابات) ، مثل الأكواد التلافيفية. هذا أكثر تعقيدًا بكثير.
هل يمكنك تأكيد هذه السيناريوهات؟
- يحتوي LZ4 على مجموع اختباري للمحتوى لكل كتلة بيانات ، ضع في اعتبارك أن لدينا 10 ^ 6 حزم من ملفات 1 جيجابايت
احتمال الاصطدام هو 1/2 ^ 32 = 0.0000000002 ، فهذا يعني أنه إذا أرسلنا 10 ^ 10 (هذا الحجم العملاق) قد يكون لدينا تصادمان (بناءً على مبدأ Pigeonhole) ولكن إذا أرسلنا أقل من هذا المبلغ ، فإن الاحتمال من رؤية التصادم سينخفض بشكل كبير حتى نتمكن من اكتشاف جميع الأخطاء ، يقوم مفكك الشفرة بحساب المجموع الاختباري ومقارنته بالمجموع الاختباري للحزمة ، هل هذا صحيح؟ - يحسب المجموع الاختباري للمحتوى المجموع الاختباري على الملف المضغوط (إنه اختياري ويمكننا استخدامه لاكتشاف الخروج عن الترتيب أو لتقليل احتمالية الاصطدام (قبل استخدام CC ، يكون احتمال حدوث تضارب 1/2 ^ 32 ثم يكون 1/2 ^ 64.)
arashams
في ٨ أبريل ٢٠٢٠
السيناريو الموصوف هو:
- تلف بيانات LZ4 المضغوطة (وهو بالفعل حدث نادر جدًا بحد ذاته)
- يبقى الفساد غير مكتشف بسبب تضارب التجزئة.
يستخدم تنسيق الإطار LZ4 XXH32 ، تجزئة 32 بت ، كمجموع اختباري مصاحب.
يتم تطبيقه افتراضيًا على محتوى الإطار الكامل ، وبشكل أكثر دقة محتوى الإطار _غير مضغوط (بعد فك الضغط) ، وبالتالي التحقق من صحة كل من عملية الإرسال وفك التشفير.
ويمكنه أيضًا تطبيقه اختياريًا على كل كتلة ، وفي هذه الحالة يقوم بفحص المحتوى _ المضغوط_ لكل كتلة.
كلاهما يمكن أن يتراكم.
للبقاء غير مكتشفة ، يجب أن يجتاز الفساد بنجاح ___جميع___المجموعات الاختبارية القابلة للتطبيق.
بافتراض أن المجموع الاختباري للكتلة ممكّن ، وبافتراض أن الفساد يقع بالكامل داخل كتلة واحدة ، فإن فرص اجتياز كل من الكتلة ومجموع الإطار الاختباري هي بالفعل 1 / 2^32 x 1 / 2^32 = 1 / 2^64 .
الآن ، إذا كانت البيانات التالفة موجودة في كتل متعددة ، إما بسبب وجود أحداث فساد متعددة ، أو لأن قسمًا واحدًا تالفًا كبيرًا يغطي الكتل المتتالية ، فمن الأصعب أن يظل الفساد غير مكتشف. سيتعين عليه إنشاء تصادم مع كل مجموعة من مجموعات اختبارية للكتل المعنية.
على سبيل المثال ، بافتراض انتشار الفساد في كتلتين ، فإن فرص بقاء هذا الفساد غير مكتشفة هي 1 / 2^32 x 1 / 2^32 x 1 / 2^32 = 1 / 2^96 . صغير فلكيًا.
دون احتساب حقيقة أن كل كتلة تالفة قد يتم اكتشافها على أنها غير قابلة للتشفير من خلال عملية فك الضغط ، والتي تأتي على رأس ذلك.
لذا ، نعم ، الجمع بين المجموع الاختباري للكتلة والإطار يزيد بشكل كبير من فرص اكتشاف أحداث الفساد.
Cyan4973
في ٨ أبريل ٢٠٢٠
السيناريو الموصوف هو:
* LZ4-compressed data being corrupted (which is already a pretty rare event by itself) * Corruption remaining undetected due to hash collision.يستخدم تنسيق الإطار LZ4
XXH32، تجزئة 32 بت ، كمجموع اختباري مصاحب.
يتم تطبيقه افتراضيًا على محتوى الإطار الكامل ، وبشكل أكثر دقة محتوى الإطار _غير مضغوط (بعد فك الضغط) ، وبالتالي التحقق من صحة كل من عملية الإرسال وفك التشفير.
ويمكنه أيضًا تطبيقه اختياريًا على كل كتلة ، وفي هذه الحالة يقوم بفحص المحتوى _ المضغوط_ لكل كتلة.
كلاهما يمكن أن يتراكم.للبقاء غير مكتشفة ، يجب أن يجتاز الفساد بنجاح _ جميع _ المجاميع الاختبارية القابلة للتطبيق.
بافتراض أن المجموع الاختباري للكتلة ممكّن ، وبافتراض أن الفساد يقع بالكامل داخل كتلة واحدة ، فإن فرص اجتياز كل من الكتلة ومجموع الإطار الاختباري هي بالفعل1 / 2^32 x 1 / 2^32 = 1 / 2^64.الآن ، إذا كانت البيانات التالفة موجودة في كتل متعددة ، إما بسبب وجود أحداث فساد متعددة ، أو لأن قسمًا واحدًا تالفًا كبيرًا يغطي الكتل المتتالية ، فمن الأصعب أن يظل الفساد غير مكتشف. سيتعين عليه إنشاء تصادم مع كل مجموعة من مجموعات اختبارية للكتل المعنية.
على سبيل المثال ، بافتراض انتشار الفساد في كتلتين ، فإن فرص بقاء هذا الفساد غير مكتشفة هي1 / 2^32 x 1 / 2^32 x 1 / 2^32 = 1 / 2^96. صغير فلكيًا.دون احتساب حقيقة أن كل كتلة تالفة قد يتم اكتشافها على أنها غير قابلة للتشفير من خلال عملية فك الضغط ، والتي تأتي على رأس ذلك.
لذا ، نعم ، الجمع بين المجموع الاختباري للكتلة والإطار يزيد بشكل كبير من فرص اكتشاف أحداث الفساد.
هل من الممكن استخدام LZ4 أثناء التنقل؟ أعني ، قم بضغط / فك ضغط البيانات بمجرد حصولك على جزء منها. هو بطريقة أو بأخرى خطوط الأنابيب.
ماذا عن xxHash؟
arashams
في ٢٩ أغسطس ٢٠٢٠
ق من الممكن استخدام LZ4 على الطاير؟ أعني ، قم بضغط / فك ضغط البيانات بمجرد حصولك على جزء منها.
هذا هو وضع التدفق. نعم هذا ممكن.
ماذا عن xxHash؟
يتم تحديث المجموع الاختباري للإطار بشكل مستمر ، ولكنه ينتج فقط نتيجة في نهاية الإطار. لذلك ، لا توجد نتيجة مجموع اختباري للمقارنة حتى نهاية حدث الإطار (قد يتكون التدفق من إطارات ملحقة متعددة ، ولكن بشكل عام لا يتكون).
في المقابل ، يتم إنشاء مجاميع اختبارية للكتل في كل كتلة ، بحيث يتم إنتاجها وفحصها بانتظام أثناء البث.
يستخدم كلا المجموع الاختباري XXH32 .
Cyan4973
في ٢٩ أغسطس ٢٠٢٠
القضايا ذات الصلة
 devnoname120
·
8تعليقات
devnoname120
·
8تعليقات
 vp1981
·
7تعليقات
vp1981
·
7تعليقات
 yassinm
·
5تعليقات
yassinm
·
5تعليقات
 vinniefalco
·
4تعليقات
vinniefalco
·
4تعليقات
 carstenskyboxlabs
·
6تعليقات
carstenskyboxlabs
·
6تعليقات
التعليق الأكثر فائدة
تتميز خوارزميات CRC عمومًا بضمانات اكتشاف الأخطاء في حالة مسافات الطرق. بالنظر إلى عدد محدود من تقلبات البتات ، فإن CRC _ ضروريًا_ ستولد نتيجة مختلفة.
يمكن أن يكون هذا مفيدًا في المواقف التي يُفترض فيها أن الأخطاء تقلب فقط بضع بتات.
قبل بضعة عقود فقط ، كان هذا شائعًا نسبيًا ، خاصة في سيناريوهات الإرسال ، حيث كانت الإشارة الأساسية لا تزال "خامًا" للغاية ، لذلك كانت تقلبات البت غير المكتشفة على الطبقة المادية شيئًا.
لكن هذه الخاصية لها تكلفة التوزيع. بمجرد عبور مسافة الطرق "الآمنة" ، يصبح احتمال الاصطدام أسوأ. هذه نتيجة منطقية لمبدأ حفرة الحمام. كم أسوأ؟ حسنًا ، هذا يعتمد على CRC الدقيق ، لكنني أتوقع أن تكون CRC الجيدة في نطاق أسوأ 3x - 7x. قد يبدو هذا كثيرًا ، لكنه مجرد تقليل للتشتت 2-3 بت ، لذا فهو ليس بهذا الرعب. ما يزال.
قارن ذلك مع تجزئة تتميز بخاصية توزيع "مثالية": أي تغيير ، بغض النظر عما إذا كان بت واحد أو ناتج مختلف تمامًا ، له احتمال 1/2 ^ n لتوليد تصادم. من الأسهل فهمها: خطر الاصطدام هو نفسه دائمًا. في المقارنة المباشرة مع CRC ، عندما تكون مسافة الطرق صغيرة ، يكون معدل الاصطدام أسوأ (لأنه> 0) ، ولكنه أفضل عندما تكون مسافة الطرق كبيرة.
تقدم سريعًا في الوقت الحاضر ، وقد تغير الوضع بشكل جذري. لدينا طبقات فوق طبقات من اكتشاف الأخطاء ومنطق التصحيح فوق الوسائط المادية. لا يمكننا فقط استخراج القليل من كتلة الفلاش ، ولا يمكننا القراءة قليلاً من قناة Bluetooth. لم يعد له معنى بعد الآن. تتضمن هذه البروتوكولات منطق كتلة ذي حالة ، وهو أكثر تعقيدًا ومرونة ويعوض باستمرار عن الضوضاء الدائمة للطبقة المادية. عندما يفشلون ، لن ينتج عن ذلك نقلة واحدة: بدلاً من ذلك ، ستكون منطقة البيانات الكاملة مشوشة تمامًا ، وستكون كلها أصفارًا ، أو حتى ضوضاء عشوائية.
في هذه البيئة الجديدة ، الرهان هو أن الأخطاء ، عند حدوثها ، لم تعد موجودة في فئة "bitflip". في هذه الحالة ، تصبح خصائص توزيع CRC مسؤولية. تحتوي التجزئة النقية في الواقع على احتمال أقل لتصادم.
هذا عند التفكير في الختام الاختباري فقط.
هناك خاصية إضافية للتجزئة "المثالية" وهي أنه عند استخراج أي جزء من البتات من التجزئة ، فإنه لا يزال يتميز باحتمال الاصطدام هذا
1 / 2^n، وهو أمر مهم جدًا كمصدر للبتات للبنى الأخرى ، مثل جدول تجزئة أو مرشح بلوم. في المقابل ، لا تقدم اتفاقية حقوق الطفل مثل هذا الضمان. ينتهي الأمر ببعض البتات إلى أن تكون متوقعة جدًا أو مرتبطة بشكل كبير ، وعند استخراجها لغرض التجزئة ، يكون التشتت أسوأ بكثير.يمكن للمرء أن يقول أن المجموع الاختباري والتجزئة هما مجرد مجالين مختلفين ، ولا ينبغي الخلط بينهما. في الواقع ، هذه هي النظرية. المشكلة هي أن هذا يتجاهل الراحة والممارسة الميدانية. إن امتلاك "خلاط" واحد متعدد الأغراض أمر ملائم ، وسيقبل المبرمجون على واحد وينسوا أمره. لا يمكنني حساب عدد المرات التي رأيت فيها crc32 مستخدمة للتجزئة ، فقط لأنها شعرت بأنها "عشوائية بما يكفي". من السهل أن نقول إنه لا ينبغي أن يحدث ذلك ، لكنه يحدث باستمرار.
في هذه البيئة ، فإن اقتراح حل مصمم للعمل بشكل جيد لكلتا حالتي الاستخدام أمر منطقي ، لأنه يطابق توقعات المستخدم.
نظرًا لخصائص التجزئة الجيدة ، فمن الممكن بالفعل استخراج 8 أو 16 بت من التجزئة ، مما ينتج عنه احتمال تصادم 1/256 أو 1/65535. لا أرى أي قلق بشأن هذا.
فقط ، علينا قبول زمن انتقال _ التاريخ_. اعتاد الناس على طريقة معينة للأشياء ، مثل استخدام وظائف المجموع الاختباري المحددة للاختبار. حتى لو كانت هناك حلول أكثر حداثة وربما أفضل ، فإن العادات لا تتغير بسرعة.