我一直无法理解的一件事是散列如何成为校验和(或者它们是否应该是),因为传统上散列是针对字符串和散列表进行优化的(DJB2 是老粉丝的最爱)。 然而,在 PIC/Arduino 人群中,人们仍然使用旧的简单 8 位校验和、16 位 Fletcher 和或 16 位 CRC。 但是您并没有看到很多关于新校验和是当今据称更快的处理器的更好选择的讨论。 哈希中使用的计算类型是否太慢? (尽管 CRC 在软件中实际上比 xxHash 慢。)或者当减少到 8 位或 16 位时,散列函数本身就不好?
我读过 xxHash 最初被设计为 lz4 的校验和,还有一些其他哈希函数,例如 SeaHash,设计用于文件系统也用于校验和。 相比之下,CRC-32 已被广泛使用,也在某些压缩格式(如 ZIP/RAR)中使用。 我还读到 CRC 具有某些数学特性,它证明了特定多项式等的错误检测的汉明距离。在我看来如何。
这让我想知道是否最好使用 CRC-32 来实现完整性目的,而不是快速、简单地实现散列,即使它可能会降低速度。 xxHash 是否有任何错误检测保证(假设是 32 位版本)? 如果不是,它如何与 CRC-32 作为校验和或错误检测代码竞争? 有哪些权衡?
 bryc
bryc
所有11条评论
CRC 算法通常具有在汉明距离条件下的错误检测保证。 给定有限数量的位翻转,CRC 将_必然_生成不同的结果。
在假定错误仅翻转几位的情况下,这可以证明很方便。
就在几十年前,这还比较普遍,尤其是在传输场景中,因为底层信号仍然非常“原始”,因此物理层上未被检测到的位翻转是一件很常见的事情。
但是,此属性具有分配成本。 一旦越过“安全”汉明距离,碰撞的概率就会变差。 这是鸽巢原理的逻辑结果。 差多少? 嗯,这取决于确切的 CRC,但我预计好的 CRC 会在 3 到 7 倍的差范围内。 这听起来可能很多,但它只是减少了 2-3 位色散,所以并没有那么可怕。 仍然。
与具有“理想”分布特性的散列形成对比:任何更改,无论是单个位还是完全不同的输出,都有恰好 1 / 2^n 的概率产生碰撞。 更容易掌握:碰撞的风险总是相同的。 与CRC直接比较,当汉明距离较小时碰撞率更差(因为它>0),但当汉明距离较大时更好。
如今快进了,情况已经发生了根本性的变化。 我们在物理媒体之上有一层又一层的错误检测和纠正逻辑。 我们不能只从闪存块中提取一点,也不能从蓝牙通道中读取一点。 已经没有意义了。 这些协议嵌入了一个有状态的块逻辑,它更复杂,更有弹性,不断补偿物理层的永久噪声。 当它们失败时,不会产生一次翻转:相反,一个完整的数据区域将完全混乱,全部为零,甚至是随机噪声。
在这个新环境中,可以肯定的是,当错误发生时,它们不再属于“bitflip”类别。 在这种情况下,CRC 的分销属性成为负债。 纯散列实际上产生冲突的可能性较低。
这是仅在考虑校验和时。
“理想”散列的另一个属性是,当从散列中提取任何位段时,它仍然具有这种1 / 2^n碰撞概率,这对于其他结构的位源非常重要,例如哈希表或布隆过滤器。 相比之下,CRC 不提供此类保证。 一些位最终非常可预测或高度相关,当为了散列目的提取它们时,分散性要差得多。
可以说校验和和散列只是 2 个不同的域,不应混淆。 确实,这就是理论。 问题是,这无视方便和现场实践。 拥有一个用于多种用途的“混合器”很方便,程序员会满足于一个而忘记它。 我数不清有多少次看到 crc32 用于散列,只是因为它感觉“足够随机”。 说它不应该发生很容易,但它确实不断发生。
在这种环境下,提出一个设计用于两种用例的解决方案是有意义的,因为它符合用户的期望。
在 PIC/Arduino 人群中,人们仍然使用旧的简单 8 位校验和、16 位 Fletcher 和或 16 位 CRC。
(……)
当减少到 8 位或 16 位时,散列函数本质上是不是不好?
由于良好散列的特性,确实可以从散列中提取 8 位或 16 位,从而产生 1/256 或 1/65535 的碰撞概率。 我看不出对此有任何顾虑。
只是,我们必须接受_history_的延迟。 人们习惯于某种方式的事物,例如使用特定的校验和函数进行校验和。 即使有更新的、可能更好的解决方案,习惯也不会很快改变。
 Cyan4973
于 2019-07-16
Cyan4973
于 2019-07-16
CRC 算法通常具有在汉明距离条件下的错误检测保证。 给定有限数量的位翻转,CRC 将_必然_生成不同的结果。
在假定错误仅翻转几位的情况下,这可以证明很方便。
就在几十年前,这还比较普遍,尤其是在传输场景中,因为底层信号仍然非常“原始”,因此物理层上未被检测到的位翻转是一件很常见的事情。但是,此属性具有分配成本。 一旦越过“安全”汉明距离,碰撞的概率就会变差。 这是鸽巢原理的逻辑结果。 差多少? 嗯,这取决于确切的 CRC,但我预计好的 CRC 会在 3 到 7 倍的差范围内。 这听起来可能很多,但它只是减少了 2-3 位色散,所以并没有那么可怕。 仍然。
与具有“理想”分布特性的散列形成对比:任何更改,无论是单个位还是完全不同的输出,都有恰好 1 / 2^n 的概率产生碰撞。 更容易掌握:碰撞的风险总是相同的。 与CRC直接比较,当汉明距离较小时碰撞率更差(因为它>0),但当汉明距离较大时更好。
如今快进了,情况已经发生了根本性的变化。 我们在物理媒体之上有一层又一层的错误检测和纠正逻辑。 我们不能只从闪存块中提取一点,也不能从蓝牙通道中读取一点。 已经没有意义了。 这些协议嵌入了一个有状态的块逻辑,它更复杂,更有弹性,不断补偿物理层的永久噪声。 当它们失败时,不会产生一次翻转:相反,一个完整的数据区域将完全混乱,全部为零,甚至是随机噪声。
在这个新环境中,可以肯定的是,当错误发生时,它们不再属于“bitflip”类别。 在这种情况下,CRC 的分销属性成为负债。 纯散列实际上产生冲突的可能性较低。
这是仅在考虑校验和时。
“理想”散列的另一个属性是,当从散列中提取任何位段时,它仍然具有这种1 / 2^n碰撞概率,这对于其他结构的位源非常重要,例如哈希表或布隆过滤器。 相比之下,CRC 不提供此类保证。 一些位最终非常可预测或高度相关,当为了散列目的提取它们时,分散性要差得多。可以说校验和和散列只是 2 个不同的域,不应混淆。 确实,这就是理论。 问题是,这无视方便和现场实践。 拥有一个用于多种用途的“混合器”很方便,程序员会满足于一个而忘记它。 我数不清有多少次看到 crc32 用于散列,只是因为它感觉“足够随机”。 说它不应该发生很容易,但它确实不断发生。
在这种环境下,提出一个设计用于两种用例的解决方案是有意义的,因为它符合用户的期望。在 PIC/Arduino 人群中,人们仍然使用旧的简单 8 位校验和、16 位 Fletcher 和或 16 位 CRC。
(……)
当减少到 8 位或 16 位时,散列函数本质上是不是不好?由于良好散列的特性,确实可以从散列中提取 8 位或 16 位,从而产生 1/256 或 1/65535 的碰撞概率。 我看不出对此有任何顾虑。
只是,我们必须接受_history_的延迟。 人们习惯于某种方式的事物,例如使用特定的校验和函数进行校验和。 即使有更新的、可能更好的解决方案,习惯也不会很快改变。
我们知道,使用 CRC 32 并使用 HD=6,它可以检测任何 5 位错误,并且可以检测高达 2^31=约 204MB 的突发
并检测所有单位错误
在 xxHash 中,需要更改多少位才能检测不到错误?
我知道在 Hash 中,即使是 1 位更改也会产生完全不同的摘要,但是我们如何计算创建冲突所需的位数?
另一个问题是你提到的:
相比之下,CRC 不提供此类保证。 一些位最终非常可预测或高度相关,当为了散列目的提取它们时,分散性要差得多。
为什么那么糟糕? 如果位以某种方式相关,我们可以使用这种相关性来修复损坏的文件吗?
 arashams
于 2020-04-06
arashams
于 2020-04-06
在 xxHash 中,需要更改多少位,以便我们无法检测到错误(或冲突)
1 位。
xxHash 是非加密哈希函数,不是校验和。 它不提供任何汉明距离或抗碰撞保证。
虽然它可以做得不错,但它不是最佳选择。 这就像使用钳子作为扳手。 当然,它可以完成工作,但它不如真正的扳手有效,并且可能会造成损坏。
 easyaspi314
于 2020-04-06
easyaspi314
于 2020-04-06
在 xxHash 中,需要更改多少位,以便我们无法检测到错误(或冲突)
1 位。
xxHash 是非加密哈希函数,不是校验和。 它不提供任何汉明距离或抗碰撞保证。
虽然它可以做得不错,但它不是最佳选择。 这就像使用钳子作为扳手。 当然,它可以完成工作,但它不如真正的扳手有效,并且可能会造成损坏。
你的意思是我们只需改变 1 位数据就可以欺骗解码器?
它会产生碰撞吗? (这很可怕)并且这种碰撞的概率取决于摘要大小
arashams
于 2020-04-06
你的意思是我们只需改变 1 位数据就可以欺骗解码器?
考虑到由 2 个不同内容产生的哈希值,冲突的概率总是1 / 2^64 (对于高质量的 64 位哈希算法,例如xxh64或xxh3 ),无论这两个内容之间的修改量。
这确实意味着,至少在理论上,单个位的更改可能会产生冲突。
现在,请记住,这个概率是1 / 2^64 ,几乎是无穷小的。
人们对这个话题的理解相对较差。 他们有时将其与“小”混为一谈,后者在大多数人的脑海中往往被视为一个有形的数量,例如约 10%。
为了得到更准确的想法,我喜欢参考这张表: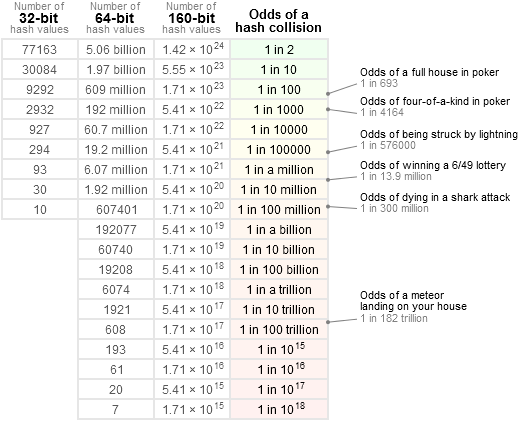
即: 1 / 2 ^ 64比直接收到彗星的几率要低得多,比连续_3次_中国家彩票的几率要低得多(这倒是值得怀疑)。 这实际上更接近于“null”。 从其他软件错误来源开始,任何系统中的大多数组件都容易以比这高得多的概率被破坏。
如果想要找到这样一个理论上的 1 位碰撞,就需要非常庞大的输入和非常令人难以置信的力量来强力解决这个问题。 即便如此,可能也不存在解决方案:考虑到所采用算术的性质,如果不可能通过单个位修改产生冲突,我也不会感到惊讶。 我自己打赌它至少需要 2 位,即使这样,它也需要将它们放在特定输入的位置以有机会实现预期目标,使这种修改不再“随机”,因此超出了范围非加密哈希。
但我认为引用的文字已经解释了这一切:真正的crc对汉明距离有保证。 这可能很有用,并且在过去更有意义,当信号容易在位级别修改时,并且校验和本身相当小(16 或 32 位)。 一个 16 位的散列算法有一个不可忽略的机会错过涉及很少位翻转的碰撞,使其不太适合该任务。 但是现在有了 64 位甚至 128 位哈希,我相信这不再是一个危险的选择,仅仅因为冲突的机会,因此未被发现的损坏,是不可思议的小。
一些位最终非常可预测或高度相关,当为了散列目的提取它们时,分散性要差得多。
为什么那么糟糕?
哈希通常比校验和替换有更多的用途。
实际上,在大多数情况下,哈希算法的目的是提供一些随机位以指定哈希表中的位置。 如果其中一些位根据内容变得可预测,则意味着哈希表中的位置分布将不再是“随机的”,因此,某些单元格会比其他单元格溢出得更快,从而对哈希表的性能产生负面影响.
如果位以某种方式相关,我们可以使用这种相关性来修复损坏的文件吗?
这是一个完全不同的话题。
不能用 CRC 修复损坏的输入。 CRC 只能检测错误,不能修复错误。
自修复数据是一个主题,它使用不同的(并且涉及更多计算)技术,例如卷积码。 这要复杂得多。
Cyan4973
于 2020-04-06
如果想要找到这样一个理论上的 1 位碰撞,就需要非常庞大的输入和非常令人难以置信的力量来强力解决这个问题。 即便如此,可能也不存在解决方案:考虑到所采用算术的性质,如果不可能通过单个位修改产生冲突,我也不会感到惊讶。 我自己打赌它至少需要 2 位,即使这样,它也需要将它们放在特定输入的位置以有机会实现预期目标,使这种修改不再“随机”,因此超出了范围非加密哈希。
261 演示了 XXH3 的 64 位变体中的单个位冲突,尽管它依赖于种子并且在随机输入上不太可能发生
easyaspi314
于 2020-04-06
确实; 更完整地说,我之前的陈述是针对大尺寸部分的,输入 > 240 字节。
但是,是的,在输入必须与 64 位secret中的一个完全匹配的有限大小范围内,单比特冲突成为可能。 感觉是可以接受的,因为基于精确位置的精确 64 位输入的碰撞仍然在这个1 / 2^64区域内,假设输入是随机的(即不是为了产生碰撞而设计的)。 此外,要匹配的secret可以有效地_secret_,因此外部攻击者将不得不通过暴力来找到它。
Cyan4973
于 2020-04-06
你的意思是我们只需改变 1 位数据就可以欺骗解码器?
考虑到由 2 个不同内容产生的哈希值,冲突的概率总是
1 / 2^64(对于高质量的 64 位哈希算法,例如xxh64或xxh3),无论这两个内容之间的修改量。这确实意味着,至少在理论上,单个位的更改可能会产生冲突。
现在,请记住,这个概率是
1 / 2^64,几乎是无穷小的。
人们对这个话题的理解相对较差。 他们有时将其与“小”混为一谈,后者在大多数人的脑海中往往被视为一个有形的数量,例如约 10%。为了得到更准确的想法,我喜欢参考这张表:
即:
1 / 2 ^ 64比直接收到彗星的几率要低得多,比连续_3次_中国家彩票的几率要低得多(这倒是值得怀疑)。 这实际上更接近于“null”。 从其他软件错误来源开始,任何系统中的大多数组件都容易以比这高得多的概率被破坏。如果想要找到这样一个理论上的 1 位碰撞,就需要非常庞大的输入和非常令人难以置信的力量来强力解决这个问题。 即便如此,可能也不存在解决方案:考虑到所采用算术的性质,如果不可能通过单个位修改产生冲突,我也不会感到惊讶。 我自己打赌它至少需要 2 位,即使这样,它也需要将它们放在特定输入的位置以有机会实现预期目标,使这种修改不再“随机”,因此超出了范围非加密哈希。
但我认为引用的文字已经解释了这一切:真正的
crc对汉明距离有保证。 这可能很有用,并且在过去更有意义,当信号容易在位级别修改时,并且校验和本身相当小(16 或 32 位)。 一个 16 位的散列算法有一个不可忽略的机会错过涉及很少位翻转的碰撞,使其不太适合该任务。 但是现在有了 64 位甚至 128 位哈希,我相信这不再是一个危险的选择,仅仅因为冲突的机会,因此未被发现的损坏,是不可思议的小。一些位最终非常可预测或高度相关,当为了散列目的提取它们时,分散性要差得多。
为什么那么糟糕?
哈希通常比校验和替换有更多的用途。
实际上,在大多数情况下,哈希算法的目的是提供一些随机位以指定哈希表中的位置。 如果其中一些位根据内容变得可预测,则意味着哈希表中的位置分布将不再是“随机的”,因此,某些单元格会比其他单元格溢出得更快,从而对哈希表的性能产生负面影响.如果位以某种方式相关,我们可以使用这种相关性来修复损坏的文件吗?
这是一个完全不同的话题。
不能用 CRC 修复损坏的输入。 CRC 只能检测错误,不能修复错误。自修复数据是一个主题,它使用不同的(并且涉及更多计算)技术,例如卷积码。 这要复杂得多。
你能确认这些场景吗?
- LZ4 对每个数据块都有内容校验和,假设我们有 10^6 个数据包的 1GB 文件
碰撞的概率是 1/2^32 = 0.0000000002 这意味着如果我们发送 10^10(这个巨大的大小)数据包,我们可能会有 2 个碰撞(基于鸽子洞原理)但是如果我们发送的数量少于这个数量,概率看到碰撞会显着下降,以便我们可以检测到所有错误,解码器计算校验和并将其与数据包校验和进行比较,这是正确的吗? - 内容校验和计算压缩文件的校验和(它是可选的,我们可以用它来检测乱序或减少冲突的概率(在使用 CC 之前,冲突的概率是 1/2 ^ 32,然后它会为 1/2 ^ 64。)
arashams
于 2020-04-08
描述的场景是:
- LZ4 压缩数据被损坏(这本身已经是一个非常罕见的事件)
- 由于散列冲突,损坏仍未被检测到。
LZ4 帧格式使用XXH32 (一个 32 位哈希)作为伴随校验和。
它默认应用于完整帧的内容,更准确地说是帧的 _uncompressed_ 内容(解压缩后),从而验证传输和解码过程。
它还可以选择将其应用于每个块,在这种情况下,它会对每个块的 _compressed_ 内容进行校验和。
两者都可以累积。
为了不被发现,损坏必须成功通过___all___适用的校验和。
假设启用了块校验和,并假设损坏完全位于单个块内,则通过块和帧校验和的机会确实是1 / 2^32 x 1 / 2^32 = 1 / 2^64 。
现在,如果损坏的数据驻留在多个块中,无论是因为有多个损坏事件,还是因为单个大的损坏部分覆盖了连续的块,损坏保持不被检测到_甚至更难_。 它必须与所涉及的每个块校验和产生冲突。
例如,假设损坏分布在 2 个块上,这种损坏未被检测到的可能性是1 / 2^32 x 1 / 2^32 x 1 / 2^32 = 1 / 2^96 。 天文数字小。
不计算每个损坏的块可能被解压缩过程检测为不可解码的事实,这是最重要的。
所以是的,结合块和帧校验和极大地增加了检测损坏事件的机会。
Cyan4973
于 2020-04-08
描述的场景是:
* LZ4-compressed data being corrupted (which is already a pretty rare event by itself) * Corruption remaining undetected due to hash collision.LZ4 帧格式使用
XXH32(一个 32 位哈希)作为伴随校验和。
它默认应用于完整帧的内容,更准确地说是帧的 _uncompressed_ 内容(解压缩后),从而验证传输和解码过程。
它还可以选择将其应用于每个块,在这种情况下,它会对每个块的 _compressed_ 内容进行校验和。
两者都可以累积。要保持不被发现,损坏必须成功通过_所有_适用的校验和。
假设启用了块校验和,并假设损坏完全位于单个块内,则通过块和帧校验和的机会确实是1 / 2^32 x 1 / 2^32 = 1 / 2^64。现在,如果损坏的数据驻留在多个块中,无论是因为有多个损坏事件,还是因为单个大的损坏部分覆盖了连续的块,损坏保持不被检测到_甚至更难_。 它必须与所涉及的每个块校验和产生冲突。
例如,假设损坏分布在 2 个块上,这种损坏未被检测到的可能性是1 / 2^32 x 1 / 2^32 x 1 / 2^32 = 1 / 2^96。 天文数字小。不计算每个损坏的块可能被解压缩过程检测为不可解码的事实,这是最重要的。
所以是的,结合块和帧校验和极大地增加了检测损坏事件的机会。
是否可以即时使用 LZ4? 我的意思是,一旦获得数据,就立即压缩/解压缩数据。 它以某种方式流水线化。
xxHash 呢?
arashams
于 2020-08-29
可以即时使用 LZ4 吗? 我的意思是,一旦获得数据,就立即压缩/解压缩数据。
这是流媒体模式。 是的,有可能。
xxHash 呢?
帧校验和不断更新,但仅在帧结束时产生结果。 因此,直到帧结束事件(一个流可能包含多个附加帧,但通常不包含)之前,都没有要比较的校验和结果。
相比之下,块校验和是在每个块中创建的,因此在流式传输时会定期生成和检查它们。
两个校验和都使用XXH32 。
Cyan4973
于 2020-08-29
相关问题
 tonda-kriz
·
33评论
tonda-kriz
·
33评论
 aras-p
·
38评论
Cyan4973
·
35评论
easyaspi314
·
21评论
easyaspi314
·
20评论
aras-p
·
38评论
Cyan4973
·
35评论
easyaspi314
·
21评论
easyaspi314
·
20评论
最有用的评论
CRC 算法通常具有在汉明距离条件下的错误检测保证。 给定有限数量的位翻转,CRC 将_必然_生成不同的结果。
在假定错误仅翻转几位的情况下,这可以证明很方便。
就在几十年前,这还比较普遍,尤其是在传输场景中,因为底层信号仍然非常“原始”,因此物理层上未被检测到的位翻转是一件很常见的事情。
但是,此属性具有分配成本。 一旦越过“安全”汉明距离,碰撞的概率就会变差。 这是鸽巢原理的逻辑结果。 差多少? 嗯,这取决于确切的 CRC,但我预计好的 CRC 会在 3 到 7 倍的差范围内。 这听起来可能很多,但它只是减少了 2-3 位色散,所以并没有那么可怕。 仍然。
与具有“理想”分布特性的散列形成对比:任何更改,无论是单个位还是完全不同的输出,都有恰好 1 / 2^n 的概率产生碰撞。 更容易掌握:碰撞的风险总是相同的。 与CRC直接比较,当汉明距离较小时碰撞率更差(因为它>0),但当汉明距离较大时更好。
如今快进了,情况已经发生了根本性的变化。 我们在物理媒体之上有一层又一层的错误检测和纠正逻辑。 我们不能只从闪存块中提取一点,也不能从蓝牙通道中读取一点。 已经没有意义了。 这些协议嵌入了一个有状态的块逻辑,它更复杂,更有弹性,不断补偿物理层的永久噪声。 当它们失败时,不会产生一次翻转:相反,一个完整的数据区域将完全混乱,全部为零,甚至是随机噪声。
在这个新环境中,可以肯定的是,当错误发生时,它们不再属于“bitflip”类别。 在这种情况下,CRC 的分销属性成为负债。 纯散列实际上产生冲突的可能性较低。
这是仅在考虑校验和时。
“理想”散列的另一个属性是,当从散列中提取任何位段时,它仍然具有这种
1 / 2^n碰撞概率,这对于其他结构的位源非常重要,例如哈希表或布隆过滤器。 相比之下,CRC 不提供此类保证。 一些位最终非常可预测或高度相关,当为了散列目的提取它们时,分散性要差得多。可以说校验和和散列只是 2 个不同的域,不应混淆。 确实,这就是理论。 问题是,这无视方便和现场实践。 拥有一个用于多种用途的“混合器”很方便,程序员会满足于一个而忘记它。 我数不清有多少次看到 crc32 用于散列,只是因为它感觉“足够随机”。 说它不应该发生很容易,但它确实不断发生。
在这种环境下,提出一个设计用于两种用例的解决方案是有意义的,因为它符合用户的期望。
由于良好散列的特性,确实可以从散列中提取 8 位或 16 位,从而产生 1/256 或 1/65535 的碰撞概率。 我看不出对此有任何顾虑。
只是,我们必须接受_history_的延迟。 人们习惯于某种方式的事物,例如使用特定的校验和函数进行校验和。 即使有更新的、可能更好的解决方案,习惯也不会很快改变。