<p>xxHash como soma de verificação para detecção de erros</p>
Uma das coisas que continuamente não consigo entender é como um hash pode ser uma soma de verificação (ou se deveria ser), porque tradicionalmente os hashes são otimizados para strings e para tabelas de hash (DJB2 vem à mente como um antigo favorito dos fãs). No entanto, no meio do PIC / Arduino, as pessoas ainda usam somas de verificação simples e antigas de 8 bits, somas Fletcher de 16 bits ou CRC de 16 bits. Mas você não vê muita conversa sobre novas somas de verificação como sendo as melhores escolhas com os processadores supostamente mais rápidos de hoje. Os tipos de cálculos usados em hashes são muito lentos? (apesar de CRC ser realmente mais lento no software do que xxHash ..) Ou algo é inerentemente ruim com funções de hash quando reduzido para 8 ou 16 bits?
Eu li que xxHash foi projetado primeiro como uma soma de verificação para lz4 e algumas outras funções de hash, como SeaHash, projetadas para uso em um sistema de arquivos também para soma de verificação. Para efeito de comparação, o CRC-32 tem sido amplamente utilizado, também em alguns formatos de compactação (como ZIP / RAR). Eu também li que o CRC tem certas propriedades matemáticas que prova distâncias de hamming para detecção de erros para polinômios específicos, etc. Mas em muitos aspectos os hashes são mais caóticos, mais parecidos com geradores de pseudo-números, improváveis de ter tais garantias, pelo menos como me parece.
Isso me deixa pensando se é melhor usar o CRC-32 para fins de integridade em vez de um hash rápido e simples de implementar, mesmo que tenha um acerto de velocidade. O xxHash tem alguma garantia de detecção de erro (vamos supor a versão de 32 bits)? E, se não, como ele compete com o CRC-32 como soma de verificação ou código de detecção de erro? Quais são as vantagens e desvantagens?
 bryc
bryc
Todos 11 comentários
Os algoritmos CRC geralmente oferecem garantias de detecção de erros sob a condição de distâncias intermediárias. Dado um número limitado de bit flips, o CRC irá _necessariamente_ gerar um resultado diferente.
Isso pode ser útil em situações em que se presume que os erros mudam apenas alguns bits.
Apenas algumas décadas atrás, isso era relativamente comum, especialmente em cenários de transmissão, já que o sinal subjacente ainda era muito "bruto", então as viradas de bits não detectadas na camada física eram uma coisa.
No entanto, esta propriedade tem um custo de distribuição. Uma vez que a distância "segura" de Hamming é cruzada, a probabilidade de colisão piora. Esta é uma consequência lógica do princípio da classificação. Muito pior? Bem, depende do CRC exato, mas espero que um bom CRC esteja na faixa 3x - 7x pior. Isso pode parecer muito, mas é apenas uma redução de dispersão de 2-3 bits, então não é tão terrível. Ainda.
Compare isso com um hash apresentando propriedade de distribuição "ideal": qualquer mudança, não importa se é um único bit ou uma saída completamente diferente, tem exatamente 1/2 ^ n probabilidade de gerar uma colisão. É mais simples de entender: o risco de colisão é sempre o mesmo. Em uma comparação direta com o CRC, quando a distância de Hamming é pequena, a taxa de colisão é pior (já que é> 0), mas é melhor quando a distância de Hamming é grande.
Avance rapidamente e a situação mudou radicalmente. Temos camadas sobre camadas de detecção de erros e lógica de correção acima da mídia física. Não podemos simplesmente extrair um pouco de um bloco de flash, nem podemos ler um pouco de um canal Bluetooth. Não faz mais sentido. Esses protocolos incorporam uma lógica de bloco com estado, que é mais complexa, mais resiliente, compensando constantemente o ruído permanente da camada física. Quando eles falham, isso não vai produzir uma única inversão: em vez disso, uma região de dados completa será completamente alterada, sendo toda zeros ou até mesmo ruído aleatório.
Nesse novo ambiente, a aposta é que os erros, quando acontecem, não estão mais na categoria "bitflip". Nesse caso, as propriedades de distribuição da CRC tornam-se um passivo. Na verdade, um hash puro tem uma probabilidade menor de produzir uma colisão.
Isso ocorre quando se considera apenas a soma de verificação.
Uma propriedade adicional de um hash "ideal" é que, ao extrair qualquer segmento de bits do hash, ele ainda apresenta esta 1 / 2^n probabilidade de colisão, que é muito importante como fonte de bits para outras estruturas, como tabela hash ou filtro bloom. Em contraste, a CRC não oferece tal garantia. Alguns dos bits acabam sendo muito previsíveis ou altamente correlacionados e, ao extraí-los para fins de hash, a dispersão é muito pior.
Pode-se dizer que a soma de verificação e o hashing são simplesmente 2 domínios diferentes e não devem ser confundidos. Na verdade, essa é a teoria. O problema é que isso desconsidera a conveniência e a prática de campo. Ter um "mixer" para múltiplas finalidades é conveniente, e os programadores irão se contentar com um e esquecê-lo. Eu não posso contar quantas vezes eu vi crc32 usado para hash, só porque parecia "aleatório o suficiente". É fácil dizer que não deveria acontecer, mas acontece, constantemente.
Nesse ambiente, propor uma solução projetada para funcionar bem para os dois casos de uso faz sentido, pois atende às expectativas do usuário.
no meio do PIC / Arduino, as pessoas ainda usam somas de verificação simples e antigas de 8 bits, somas Fletcher de 16 bits ou CRC de 16 bits.
(...)
há algo inerentemente ruim com funções hash quando reduzidas para 8 ou 16 bits?
Devido às propriedades de um bom hash, é realmente possível extrair 8 ou 16 bits de um hash, resultando em uma probabilidade de colisão de 1/256 ou 1/65535. Não vejo nenhuma preocupação com isso.
Apenas, temos que aceitar a latência de _history_. As pessoas estão acostumadas a uma certa maneira de fazer as coisas, como usar funções de soma de verificação específicas para soma de verificação. Mesmo que existam soluções mais recentes e potencialmente melhores, os hábitos não mudam rapidamente.
 Cyan4973
em 16 jul. 2019
Cyan4973
em 16 jul. 2019
Os algoritmos CRC geralmente oferecem garantias de detecção de erros sob a condição de distâncias intermediárias. Dado um número limitado de bit flips, o CRC irá _necessariamente_ gerar um resultado diferente.
Isso pode ser útil em situações em que se presume que os erros mudam apenas alguns bits.
Apenas algumas décadas atrás, isso era relativamente comum, especialmente em cenários de transmissão, já que o sinal subjacente ainda era muito "bruto", então as viradas de bits não detectadas na camada física eram uma coisa.No entanto, esta propriedade tem um custo de distribuição. Uma vez que a distância "segura" de Hamming é cruzada, a probabilidade de colisão piora. Esta é uma consequência lógica do princípio da classificação. Muito pior? Bem, depende do CRC exato, mas espero que um bom CRC esteja na faixa 3x - 7x pior. Isso pode parecer muito, mas é apenas uma redução de dispersão de 2-3 bits, então não é tão terrível. Ainda.
Compare isso com um hash apresentando propriedade de distribuição "ideal": qualquer mudança, não importa se é um único bit ou uma saída completamente diferente, tem exatamente 1/2 ^ n probabilidade de gerar uma colisão. É mais simples de entender: o risco de colisão é sempre o mesmo. Em uma comparação direta com o CRC, a taxa de colisão é pior (já que é> 0) quando a distância de hamming é pequena, mas é melhor quando a distância de hamming é grande.
Avance rapidamente e a situação mudou radicalmente. Temos camadas sobre camadas de detecção de erros e lógica de correção acima da mídia física. Não podemos simplesmente extrair um pouco de um bloco de flash, nem podemos ler um pouco de um canal Bluetooth. Não faz mais sentido. Esses protocolos incorporam uma lógica de bloco com estado, que é mais complexa, mais resiliente, compensando constantemente o ruído permanente da camada física. Quando eles falham, isso não vai produzir uma única inversão: em vez disso, uma região de dados completa será completamente alterada, sendo toda zeros ou até mesmo ruído aleatório.
Nesse novo ambiente, a aposta é que os erros, quando acontecem, não estão mais na categoria "bitflip". Nesse caso, as propriedades de distribuição da CRC tornam-se um passivo. Na verdade, um hash puro tem uma probabilidade menor de produzir uma colisão.
Isso ocorre quando se considera apenas a soma de verificação.
Uma propriedade adicional de um hash "ideal" é que, ao extrair qualquer segmento de bits do hash, ele ainda apresenta esta1 / 2^nprobabilidade de colisão, que é muito importante como fonte de bits para outras estruturas, como tabela hash ou filtro bloom. Em contraste, a CRC não oferece tal garantia. Alguns dos bits acabam sendo muito previsíveis ou altamente correlacionados e, ao extraí-los para fins de hash, a dispersão é muito pior.Pode-se dizer que a soma de verificação e o hashing são simplesmente 2 domínios diferentes e não devem ser confundidos. Na verdade, essa é a teoria. O problema é que isso desconsidera a conveniência e a prática de campo. Ter um "mixer" para múltiplas finalidades é conveniente, e os programadores irão se contentar com um e esquecê-lo. Eu não posso contar quantas vezes eu vi crc32 usado para hash, só porque parecia "aleatório o suficiente". É fácil dizer que não deveria acontecer, mas acontece, constantemente.
Nesse ambiente, propor uma solução projetada para funcionar bem para os dois casos de uso faz sentido, pois atende às expectativas do usuário.no meio do PIC / Arduino, as pessoas ainda usam somas de verificação simples e antigas de 8 bits, somas Fletcher de 16 bits ou CRC de 16 bits.
(...)
há algo inerentemente ruim com funções hash quando reduzidas para 8 ou 16 bits?Devido às propriedades de um bom hash, é realmente possível extrair 8 ou 16 bits de um hash, resultando em uma probabilidade de colisão de 1/256 ou 1/65535. Não vejo nenhuma preocupação com isso.
Apenas, temos que aceitar a latência de _history_. As pessoas estão acostumadas a uma certa maneira de fazer as coisas, como usar funções de soma de verificação específicas para soma de verificação. Mesmo que existam soluções mais recentes e potencialmente melhores, os hábitos não mudam rapidamente.
sabemos que com CRC 32 e usando HD = 6 ele pode detectar qualquer erro de 5 bits e pode detectar rajadas de até 2 ^ 31 = cerca de 204 MB
e detectar todos os erros de bit único
Em xxHash, quantos bits precisam ser alterados para que não possamos detectar um erro?
Eu sei que no Hash até mesmo a mudança de 1 bit faz um resumo totalmente diferente, mas como podemos calcular o número de bits necessários para criar a colisão?
outra pergunta é como você mencionou:
Em contraste, a CRC não oferece tal garantia. Alguns dos bits acabam sendo muito previsíveis ou altamente correlacionados e, ao extraí-los para fins de hash, a dispersão é muito pior.
Por que isso é ruim? Se os bits estiverem de alguma forma correlacionados, podemos usar essa correlação para reparar o arquivo danificado?
 arashams
em 6 abr. 2020
arashams
em 6 abr. 2020
Em xxHash, quantos bits precisam ser alterados para que não possamos detectar um erro (ou colisões)
1 bit.
xxHash é uma função hash não criptográfica, não uma soma de verificação. Ele não oferece nenhuma garantia de distância ou resistência à colisão.
Embora possa fazer um trabalho decente, não é a melhor escolha. É como usar um alicate como uma chave inglesa. Claro, ela fará o trabalho, mas é menos eficaz do que uma chave de boca real e pode causar danos.
 easyaspi314
em 6 abr. 2020
easyaspi314
em 6 abr. 2020
Em xxHash, quantos bits precisam ser alterados para que não possamos detectar um erro (ou colisões)
1 bit.
xxHash é uma função hash não criptográfica, não uma soma de verificação. Ele não oferece nenhuma garantia de distância ou resistência à colisão.
Embora possa fazer um trabalho decente, não é a melhor escolha. É como usar um alicate como uma chave inglesa. Claro, ela fará o trabalho, mas é menos eficaz do que uma chave de boca real e pode causar danos.
você quer dizer que podemos enganar o decodificador apenas alterando 1 bit de dados?
pode criar colisões? (isso é assustador) e a probabilidade de tal colisão depende do tamanho do resumo
arashams
em 6 abr. 2020
você quer dizer que podemos enganar o decodificador apenas alterando 1 bit de dados?
Considerando os valores de hash produzidos a partir de 2 conteúdos diferentes, a probabilidade de colisões é sempre 1 / 2^64 (para algoritmos de hash de 64 bits de boa qualidade, como xxh64 ou xxh3 ), qualquer que seja o quantidade de modificações entre esses 2 conteúdos.
Na verdade, significa que, pelo menos em teoria, uma mudança de um único bit pode ser capaz de gerar uma colisão.
Agora, lembre-se de que essa probabilidade é 1 / 2^64 , que é praticamente infinitesimal.
As pessoas são relativamente ruins em entender este tópico. Eles às vezes o confundem com "pequeno", que tende a ser percebido como uma quantidade tangível na mente da maioria das pessoas, como ~ 10%.
Para ter uma ideia mais precisa, gosto de consultar esta tabela: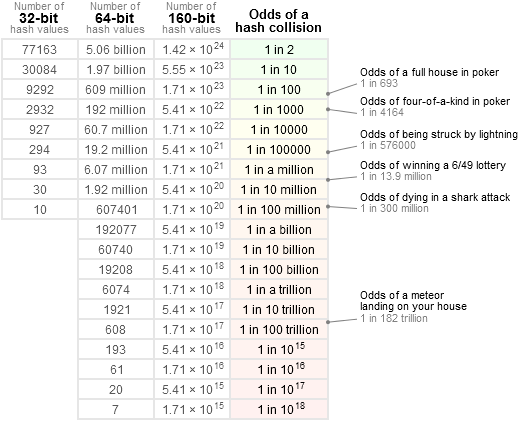
ou seja: 1 / 2 ^ 64 é muito menor do que a chance de receber um cometa diretamente na cabeça e menor do que ganhar na loteria nacional _3 vezes consecutivas_ (o que seria bastante suspeito). Na verdade, isso é muito mais próximo de "nulo". A maioria dos componentes em qualquer sistema é suscetível a quebrar com uma probabilidade _muito_ maior do que isso, começando com outras fontes de bugs de software.
Se alguém quiser encontrar tal colisão teórica de 1 bit, será necessário uma entrada bem gigantesca e uma quantidade inacreditável de potência para obter uma solução de força bruta para este problema. Mesmo assim, pode não existir uma solução: considerando a natureza da aritmética empregada, eu não ficaria surpreso se fosse impossível gerar uma colisão com uma modificação de um único bit. Minha aposta é que são necessários pelo menos 2 bits e, mesmo assim, é necessário colocá-los em posições de entrada específicas para ter uma chance de atingir o objetivo desejado, fazendo com que tal modificação não seja mais "aleatória", portanto, fora do escopo para um hash não criptográfico.
Mas acho que o texto citado já explica tudo isso: crc reais têm garantias na distância de hamming. Isso pode ser útil, e fazia muito mais sentido no passado, quando os sinais eram suscetíveis de serem modificados no nível de bit e quando a própria soma de verificação era bastante pequena (16 ou 32 bits). Um algoritmo de hash de 16 bits teria uma chance não desprezível de perder uma colisão envolvendo muito poucas inversões de bits, tornando-o menos adequado para a tarefa. Mas, com hashes de 64 ou mesmo 128 bits agora em jogo, acredito que essa não seja mais uma opção perigosa, simplesmente porque as chances de colisão, portanto de corrupção não detectada, são incomensuravelmente pequenas.
Alguns dos bits acabam sendo muito previsíveis ou altamente correlacionados e, ao extraí-los para fins de hash, a dispersão é muito pior.
Por que isso é ruim?
Hashes geralmente têm mais usos do que apenas substituição de soma de verificação.
Na verdade, na maioria dos casos, o objetivo dos algoritmos de hash é fornecer alguns bits aleatórios para designar uma posição em uma tabela de hash. Se alguns desses bits se tornarem previsíveis dependendo do conteúdo, isso significa que a distribuição de posições na tabela hash não será mais "aleatória" e, como consequência, algumas células irão transbordar mais rápido do que outras, impactando negativamente o desempenho da tabela hash .
Se os bits estiverem de alguma forma correlacionados, podemos usar essa correlação para reparar o arquivo danificado?
Este é um tópico completamente diferente.
Não se repara uma entrada danificada com um CRC. Um CRC pode apenas detectar um erro, não repará-lo.
Dados de autorreparação são um tópico e usam técnicas diferentes (e muito mais envolvidas computacionalmente), como códigos convolucionais. Isso é muito mais complexo.
Cyan4973
em 6 abr. 2020
Se alguém quiser encontrar tal colisão teórica de 1 bit, será necessário uma entrada bem gigantesca e uma quantidade inacreditável de potência para obter uma solução de força bruta para este problema. Mesmo assim, pode não existir uma solução: considerando a natureza da aritmética empregada, eu não ficaria surpreso se fosse impossível gerar uma colisão com uma modificação de um único bit. Minha aposta é que são necessários pelo menos 2 bits e, mesmo assim, é necessário colocá-los em posições de entrada específicas para ter uma chance de atingir o objetivo desejado, fazendo com que tal modificação não seja mais "aleatória", portanto, fora do escopo para um hash não criptográfico.
261 demonstra uma colisão de bit único na variante de 64 bits de XXH3, embora seja dependente da semente e muito improvável de acontecer em entradas aleatórias
easyaspi314
em 6 abr. 2020
De fato; para ser mais completo, minha declaração anterior foi direcionada para a seção de tamanho grande, para entradas> 240 bytes.
Mas sim, no intervalo limitado de tamanhos em que a entrada deve corresponder exatamente a um dos secret de 64 bits, uma colisão de um único bit se torna possível. Pareceu aceitável porque uma colisão baseada em uma entrada precisa de 64 bits em um local preciso ainda está dentro desse território 1 / 2^64 , presumindo que a entrada seja aleatória (ou seja, não projetada para produzir uma colisão). Além disso, o secret para combinar pode ser feito efetivamente _secreto_, então um invasor externo terá que usar força bruta para encontrá-lo.
Cyan4973
em 6 abr. 2020
você quer dizer que podemos enganar o decodificador apenas alterando 1 bit de dados?
Considerando os valores de hash produzidos a partir de 2 conteúdos diferentes, a probabilidade de colisões é sempre
1 / 2^64(para algoritmos de hash de 64 bits de boa qualidade, comoxxh64ouxxh3), qualquer que seja o quantidade de modificações entre esses 2 conteúdos.Na verdade, significa que, pelo menos em teoria, uma mudança de um único bit pode ser capaz de gerar uma colisão.
Agora, lembre-se de que essa probabilidade é
1 / 2^64, que é praticamente infinitesimal.
As pessoas são relativamente ruins em entender este tópico. Eles às vezes o confundem com "pequeno", que tende a ser percebido como uma quantidade tangível na mente da maioria das pessoas, como ~ 10%.Para ter uma ideia mais precisa, gosto de consultar esta tabela:
ou seja:
1 / 2 ^ 64é muito menor do que a chance de receber um cometa diretamente na cabeça e menor do que ganhar na loteria nacional _3 vezes consecutivas_ (o que seria bastante suspeito). Na verdade, isso é muito mais próximo de "nulo". A maioria dos componentes em qualquer sistema é suscetível a quebrar com uma probabilidade _muito_ maior do que isso, começando com outras fontes de bugs de software.Se alguém quiser encontrar tal colisão teórica de 1 bit, será necessário uma entrada bem gigantesca e uma quantidade inacreditável de potência para obter uma solução de força bruta para este problema. Mesmo assim, pode não existir uma solução: considerando a natureza da aritmética empregada, eu não ficaria surpreso se fosse impossível gerar uma colisão com uma modificação de um único bit. Minha aposta é que são necessários pelo menos 2 bits e, mesmo assim, é necessário colocá-los em posições de entrada específicas para ter uma chance de atingir o objetivo desejado, fazendo com que tal modificação não seja mais "aleatória", portanto, fora do escopo para um hash não criptográfico.
Mas acho que o texto citado já explica tudo isso:
crcreais têm garantias na distância de hamming. Isso pode ser útil, e fazia muito mais sentido no passado, quando os sinais eram suscetíveis de serem modificados no nível de bit e quando a própria soma de verificação era bastante pequena (16 ou 32 bits). Um algoritmo de hash de 16 bits teria uma chance não desprezível de perder uma colisão envolvendo muito poucas inversões de bits, tornando-o menos adequado para a tarefa. Mas, com hashes de 64 ou mesmo 128 bits agora em jogo, acredito que essa não seja mais uma opção perigosa, simplesmente porque as chances de colisão, portanto de corrupção não detectada, são incomensuravelmente pequenas.Alguns dos bits acabam sendo muito previsíveis ou altamente correlacionados e, ao extraí-los para fins de hash, a dispersão é muito pior.
Por que isso é ruim?
Hashes geralmente têm mais usos do que apenas substituição de soma de verificação.
Na verdade, na maioria dos casos, o objetivo dos algoritmos de hash é fornecer alguns bits aleatórios para designar uma posição em uma tabela de hash. Se alguns desses bits se tornarem previsíveis dependendo do conteúdo, isso significa que a distribuição de posições na tabela hash não será mais "aleatória" e, como consequência, algumas células irão transbordar mais rápido do que outras, impactando negativamente o desempenho da tabela hash .Se os bits estiverem de alguma forma correlacionados, podemos usar essa correlação para reparar o arquivo danificado?
Este é um tópico completamente diferente.
Não se repara uma entrada danificada com um CRC. Um CRC pode apenas detectar um erro, não repará-lo.Dados de autorreparação são um tópico e usam técnicas diferentes (e muito mais envolvidas computacionalmente), como códigos convolucionais. Isso é muito mais complexo.
você poderia confirmar esses cenários?
- LZ4 tem checksum de conteúdo para cada bloco de dados, considere que temos 10 ^ 6 pacotes de arquivos de 1 GB
a probabilidade de colisão é 1/2 ^ 32 = 0,0000000002, isso significa que se enviarmos 10 ^ 10 (este tamanho gigante) pacotes, podemos ter 2 colisões (com base no princípio Pigeonhole), mas se enviarmos menos do que este valor, a probabilidade de ver uma colisão cairá significativamente para que possamos detectar todos os erros, o decodificador calcula a soma de verificação e compara com a soma de verificação do pacote, correto? - A soma de verificação de conteúdo calcula a soma de verificação sobre o arquivo compactado (é opcional e podemos usá-lo para detectar desordem ou para reduzir a probabilidade de colisão (antes de usar CC, a probabilidade de uma colisão é 1/2 ^ 32 e então seria ser 1/2 ^ 64.)
arashams
em 8 abr. 2020
O cenário descrito é:
- Dados compactados LZ4 corrompidos (o que já é um evento bastante raro por si só)
- Corrupção não detectada devido à colisão de hash.
O formato de quadro LZ4 usa XXH32 , um hash de 32 bits, como soma de verificação complementar.
É aplicado por padrão ao conteúdo do quadro completo, mais precisamente ao conteúdo _não compactado_ do quadro (após a descompressão), validando assim o processo de transmissão e decodificação.
Ele também pode opcionalmente aplicá-lo a cada bloco, nesse caso, ele faz a soma de verificação do conteúdo _comprimido_ de cada bloco.
Ambos podem ser acumulados.
Para permanecer não detectado, uma corrupção deve passar com êxito em ___todas___ as somas de verificação aplicáveis.
Presumindo que a soma de verificação do bloco esteja habilitada, e supondo que a corrupção esteja inteiramente localizada em um único bloco, as chances de passar pelo bloco e pela soma de verificação do quadro são de fato 1 / 2^32 x 1 / 2^32 = 1 / 2^64 .
Agora, se os dados corrompidos residirem em vários blocos, seja porque há vários eventos de corrupção, ou porque uma única grande seção corrompida cobre blocos consecutivos, é _ainda mais difícil para a corrupção permanecer não detectada_. Teria que gerar uma colisão com cada uma das somas de verificação de bloco envolvidas.
Por exemplo, presumindo que a corrupção está espalhada em 2 blocos, as chances dessa corrupção permanecer não detectada são 1 / 2^32 x 1 / 2^32 x 1 / 2^32 = 1 / 2^96 . Astronomicamente pequeno.
Sem contar o fato de que cada bloco corrompido pode ser detectado como não decodificável pelo processo de descompressão, que vem em cima disso.
Então, sim, combinar a soma de verificação de bloco e quadro aumenta drasticamente as chances de detectar eventos de corrupção.
Cyan4973
em 8 abr. 2020
O cenário descrito é:
* LZ4-compressed data being corrupted (which is already a pretty rare event by itself) * Corruption remaining undetected due to hash collision.O formato de quadro LZ4 usa
XXH32, um hash de 32 bits, como soma de verificação complementar.
É aplicado por padrão ao conteúdo do quadro completo, mais precisamente ao conteúdo _não compactado_ do quadro (após a descompressão), validando assim o processo de transmissão e decodificação.
Ele também pode opcionalmente aplicá-lo a cada bloco, nesse caso, ele faz a soma de verificação do conteúdo _comprimido_ de cada bloco.
Ambos podem ser acumulados.Para permanecer não detectado, uma corrupção deve passar em _ todas as _ somas de verificação aplicáveis.
Presumindo que a soma de verificação do bloco esteja habilitada, e presumindo que a corrupção esteja inteiramente localizada em um único bloco, as chances de passar pelo bloco e pela soma de verificação do quadro são de fato1 / 2^32 x 1 / 2^32 = 1 / 2^64.Agora, se os dados corrompidos residirem em vários blocos, seja porque há vários eventos de corrupção, ou porque uma única grande seção corrompida cobre blocos consecutivos, é _ainda mais difícil para a corrupção permanecer não detectada_. Teria que gerar uma colisão com cada uma das somas de verificação de bloco envolvidas.
Por exemplo, presumindo que a corrupção está espalhada em 2 blocos, as chances dessa corrupção permanecer não detectada são1 / 2^32 x 1 / 2^32 x 1 / 2^32 = 1 / 2^96. Astronomicamente pequeno.Sem contar o fato de que cada bloco corrompido pode ser detectado como não decodificável pelo processo de descompressão, que vem em cima disso.
Então, sim, combinar a soma de verificação de bloco e quadro aumenta drasticamente as chances de detectar eventos de corrupção.
É possível usar o LZ4 em tempo real? Quer dizer, comprima / descompacte os dados assim que tiver alguns deles. é de alguma forma pipelining.
o que acontece com o xxHash?
arashams
em 29 ago. 2020
É possível usar o LZ4 em tempo real? Quer dizer, comprima / descompacte os dados assim que tiver alguns deles.
Este é o modo de streaming. Sim, é possível.
o que acontece com o xxHash?
A soma de verificação do quadro é atualizada continuamente, mas só produz um resultado no final do quadro. Portanto, não há resultado de soma de verificação para comparar até o final do evento de quadro (um fluxo pode consistir em vários quadros anexados, mas geralmente não).
Em contraste, as somas de verificação de bloco são criadas em cada bloco, portanto, são produzidas e verificadas regularmente durante o streaming.
Ambas as somas de verificação empregam XXH32 .
Cyan4973
em 29 ago. 2020
Questões relacionadas
 jvriezen
·
6Comentários
jvriezen
·
6Comentários
 t-mat
·
3Comentários
t-mat
·
3Comentários
 yassinm
·
5Comentários
yassinm
·
5Comentários
 xinglin
·
6Comentários
xinglin
·
6Comentários
 vp1981
·
7Comentários
vp1981
·
7Comentários
Comentários muito úteis
Os algoritmos CRC geralmente oferecem garantias de detecção de erros sob a condição de distâncias intermediárias. Dado um número limitado de bit flips, o CRC irá _necessariamente_ gerar um resultado diferente.
Isso pode ser útil em situações em que se presume que os erros mudam apenas alguns bits.
Apenas algumas décadas atrás, isso era relativamente comum, especialmente em cenários de transmissão, já que o sinal subjacente ainda era muito "bruto", então as viradas de bits não detectadas na camada física eram uma coisa.
No entanto, esta propriedade tem um custo de distribuição. Uma vez que a distância "segura" de Hamming é cruzada, a probabilidade de colisão piora. Esta é uma consequência lógica do princípio da classificação. Muito pior? Bem, depende do CRC exato, mas espero que um bom CRC esteja na faixa 3x - 7x pior. Isso pode parecer muito, mas é apenas uma redução de dispersão de 2-3 bits, então não é tão terrível. Ainda.
Compare isso com um hash apresentando propriedade de distribuição "ideal": qualquer mudança, não importa se é um único bit ou uma saída completamente diferente, tem exatamente 1/2 ^ n probabilidade de gerar uma colisão. É mais simples de entender: o risco de colisão é sempre o mesmo. Em uma comparação direta com o CRC, quando a distância de Hamming é pequena, a taxa de colisão é pior (já que é> 0), mas é melhor quando a distância de Hamming é grande.
Avance rapidamente e a situação mudou radicalmente. Temos camadas sobre camadas de detecção de erros e lógica de correção acima da mídia física. Não podemos simplesmente extrair um pouco de um bloco de flash, nem podemos ler um pouco de um canal Bluetooth. Não faz mais sentido. Esses protocolos incorporam uma lógica de bloco com estado, que é mais complexa, mais resiliente, compensando constantemente o ruído permanente da camada física. Quando eles falham, isso não vai produzir uma única inversão: em vez disso, uma região de dados completa será completamente alterada, sendo toda zeros ou até mesmo ruído aleatório.
Nesse novo ambiente, a aposta é que os erros, quando acontecem, não estão mais na categoria "bitflip". Nesse caso, as propriedades de distribuição da CRC tornam-se um passivo. Na verdade, um hash puro tem uma probabilidade menor de produzir uma colisão.
Isso ocorre quando se considera apenas a soma de verificação.
Uma propriedade adicional de um hash "ideal" é que, ao extrair qualquer segmento de bits do hash, ele ainda apresenta esta
1 / 2^nprobabilidade de colisão, que é muito importante como fonte de bits para outras estruturas, como tabela hash ou filtro bloom. Em contraste, a CRC não oferece tal garantia. Alguns dos bits acabam sendo muito previsíveis ou altamente correlacionados e, ao extraí-los para fins de hash, a dispersão é muito pior.Pode-se dizer que a soma de verificação e o hashing são simplesmente 2 domínios diferentes e não devem ser confundidos. Na verdade, essa é a teoria. O problema é que isso desconsidera a conveniência e a prática de campo. Ter um "mixer" para múltiplas finalidades é conveniente, e os programadores irão se contentar com um e esquecê-lo. Eu não posso contar quantas vezes eu vi crc32 usado para hash, só porque parecia "aleatório o suficiente". É fácil dizer que não deveria acontecer, mas acontece, constantemente.
Nesse ambiente, propor uma solução projetada para funcionar bem para os dois casos de uso faz sentido, pois atende às expectativas do usuário.
Devido às propriedades de um bom hash, é realmente possível extrair 8 ou 16 bits de um hash, resultando em uma probabilidade de colisão de 1/256 ou 1/65535. Não vejo nenhuma preocupação com isso.
Apenas, temos que aceitar a latência de _history_. As pessoas estão acostumadas a uma certa maneira de fazer as coisas, como usar funções de soma de verificação específicas para soma de verificação. Mesmo que existam soluções mais recentes e potencialmente melhores, os hábitos não mudam rapidamente.