<p>xxHash como suma de comprobación para la detección de errores</p>
Una de las cosas que continuamente no entiendo es cómo un hash puede ser una suma de comprobación (o si debería serlo), porque tradicionalmente los hash están optimizados para cadenas y para tablas hash (DJB2 me viene a la mente como un viejo favorito de los fanáticos). Sin embargo, dentro de la multitud de PIC / Arduino, la gente todavía usa viejas sumas de comprobación simples de 8 bits, sumas Fletcher de 16 bits o CRC de 16 bits. Pero no cree que se hable mucho de las nuevas sumas de comprobación como mejores opciones con los procesadores supuestamente más rápidos de hoy. ¿Son demasiado lentos los tipos de cálculos utilizados en hashes? (a pesar de que CRC es más lento en software que xxHash ..) ¿O hay algo intrínsecamente malo con las funciones hash cuando se reducen a 8 o 16 bits?
He leído que xxHash fue diseñado primero como una suma de comprobación para lz4, y algunas otras funciones hash como SeaHash diseñadas para su uso en un sistema de archivos también para la suma de comprobación. A modo de comparación, CRC-32 se ha utilizado ampliamente, también en algunos formatos de compresión (como ZIP / RAR). También he leído que CRC tiene ciertas propiedades matemáticas que prueban las distancias de Hamming para la detección de errores para polinomios específicos, etc. Pero en muchos sentidos los hashes son más caóticos, más parecidos a pseudo-generadores de números, es poco probable que tengan tales garantías, al menos eso como me parece.
Esto me deja preguntándome si es mejor usar CRC-32 para propósitos de integridad en lugar de un hash rápido y fácil de implementar, incluso si puede tener un golpe de velocidad. ¿Tiene xxHash alguna garantía de detección de errores (supongamos una versión de 32 bits)? Y si no es así, ¿cómo compite con CRC-32 como suma de comprobación o código de detección de errores? ¿Cuáles son las compensaciones?
 bryc
bryc
Todos 11 comentarios
Los algoritmos CRC generalmente ofrecen garantías de detección de errores en condiciones de distancias de martillo. Dado un número limitado de cambios de bits, el CRC _necesariamente_ generará un resultado diferente.
Esto puede resultar útil en situaciones en las que se presume que los errores solo cambian unos pocos bits.
Hace solo unas décadas, esto era relativamente común, especialmente en escenarios de transmisión, ya que la señal subyacente todavía estaba muy "cruda", por lo que los cambios de bits no detectados en la capa física eran una cosa.
Sin embargo, esta propiedad tiene un costo de distribución. Una vez que se cruza la distancia de martilleo "segura", la probabilidad de colisión empeora. Esta es una consecuencia lógica del principio de casillero. ¿Cuánto peor? Bueno, depende del CRC exacto, pero espero que un buen CRC esté en el rango 3x - 7x peor. Eso puede parecer mucho, pero es solo una reducción de la dispersión de 2-3 bits, por lo que no es tan terrible. Todavía.
Compare eso con un hash con propiedad de distribución "ideal": cualquier cambio, no importa si es un solo bit o una salida completamente diferente, tiene exactamente 1/2 ^ n de probabilidad de generar una colisión. Es más fácil de entender: el riesgo de colisión es siempre el mismo. En una comparación directa con CRC, cuando la distancia de martilleo es pequeña, la tasa de colisión es peor (ya que es> 0), pero es mejor cuando la distancia de martilleo es grande.
Un avance rápido hoy en día, y la situación ha cambiado radicalmente. Tenemos capas sobre capas de lógica de detección y corrección de errores por encima de los medios físicos. No podemos simplemente extraer un poco de un bloque de flash, ni podemos leer un poco de un canal Bluetooth. Ya no tiene sentido. Estos protocolos incorporan una lógica de bloques con estado, que es más compleja, más resistente y compensa constantemente el ruido permanente de la capa física. Cuando fallan, eso no va a producir un solo cambio: más bien, una región de datos completa estará completamente desordenada, siendo todo ceros o incluso ruido aleatorio.
En este nuevo entorno, la apuesta es que los errores, cuando ocurren, ya no están en la categoría "bitflip". En cuyo caso, las propiedades de distribución de CRC se convierten en un pasivo. Un hash puro en realidad tiene una probabilidad menor de producir una colisión.
Esto es solo cuando se considera la suma de verificación.
Una propiedad adicional de un hash "ideal" es que, al extraer cualquier segmento de bits del hash, todavía presenta esta probabilidad de colisión 1 / 2^n , que es muy importante como fuente de bits para otras estructuras, como tabla hash o filtro de floración. Por el contrario, CRC no ofrece dicha garantía. Algunos de los bits terminan siendo muy predecibles o altamente correlacionados, y al extraerlos con el propósito de hash, la dispersión es mucho peor.
Se podría decir que la suma de comprobación y el hash son simplemente 2 dominios diferentes y no deben confundirse. De hecho, esa es la teoría. El problema es que esto ignora la conveniencia y la práctica de campo. Tener un "mezclador" para múltiples propósitos es conveniente, y los programadores se conformarán con uno y se olvidarán de él. No puedo contar cuántas veces he visto usar crc32 para hash, solo porque se sintió "lo suficientemente aleatorio". Es fácil decir que no debería suceder, pero sucede constantemente.
En este entorno, tiene sentido proponer una solución diseñada para funcionar bien para ambos casos de uso, ya que se ajusta a las expectativas del usuario.
Dentro de la multitud de PIC / Arduino, la gente todavía usa viejas sumas de comprobación simples de 8 bits, sumas Fletcher de 16 bits o CRC de 16 bits.
(...)
¿Hay algo intrínsecamente malo con las funciones hash cuando se reducen a 8 o 16 bits?
Debido a las propiedades de un buen hash, es posible extraer 8 o 16 bits de un hash, lo que da como resultado una probabilidad de colisión de 1/256 o 1/65535. No veo ninguna preocupación en esto.
Simplemente, tenemos que aceptar la latencia de _history_. Las personas están acostumbradas a ciertas cosas, como el uso de funciones de suma de verificación específicas para la suma de verificación. Incluso si existen soluciones más recientes y potencialmente mejores, los hábitos no cambian rápidamente.
 Cyan4973
en 16 jul. 2019
Cyan4973
en 16 jul. 2019
Los algoritmos CRC generalmente ofrecen garantías de detección de errores en condiciones de distancias de martillo. Dado un número limitado de cambios de bits, el CRC _necesariamente_ generará un resultado diferente.
Esto puede resultar útil en situaciones en las que se presume que los errores solo cambian unos pocos bits.
Hace solo unas décadas, esto era relativamente común, especialmente en escenarios de transmisión, ya que la señal subyacente todavía estaba muy "cruda", por lo que los cambios de bits no detectados en la capa física eran una cosa.Sin embargo, esta propiedad tiene un costo de distribución. Una vez que se cruza la distancia de martilleo "segura", la probabilidad de colisión empeora. Esta es una consecuencia lógica del principio de casillero. ¿Cuánto peor? Bueno, depende del CRC exacto, pero espero que un buen CRC esté en el rango 3x - 7x peor. Eso puede parecer mucho, pero es solo una reducción de la dispersión de 2-3 bits, por lo que no es tan terrible. Todavía.
Compare eso con un hash con propiedad de distribución "ideal": cualquier cambio, no importa si es un solo bit o una salida completamente diferente, tiene exactamente 1/2 ^ n de probabilidad de generar una colisión. Es más fácil de entender: el riesgo de colisión es siempre el mismo. En una comparación directa con CRC, la tasa de colisión es peor (ya que es> 0) cuando la distancia de martilleo es pequeña, pero es mejor cuando la distancia de martilleo es grande.
Un avance rápido hoy en día, y la situación ha cambiado radicalmente. Tenemos capas sobre capas de lógica de detección y corrección de errores por encima de los medios físicos. No podemos simplemente extraer un poco de un bloque de flash, ni podemos leer un poco de un canal Bluetooth. Ya no tiene sentido. Estos protocolos incorporan una lógica de bloques con estado, que es más compleja, más resistente y compensa constantemente el ruido permanente de la capa física. Cuando fallan, eso no va a producir un solo cambio: más bien, una región de datos completa estará completamente desordenada, siendo todo ceros o incluso ruido aleatorio.
En este nuevo entorno, la apuesta es que los errores, cuando ocurren, ya no están en la categoría "bitflip". En cuyo caso, las propiedades de distribución de CRC se convierten en un pasivo. Un hash puro en realidad tiene una probabilidad menor de producir una colisión.
Esto es solo cuando se considera la suma de verificación.
Una propiedad adicional de un hash "ideal" es que, al extraer cualquier segmento de bits del hash, todavía presenta esta probabilidad de colisión1 / 2^n, que es muy importante como fuente de bits para otras estructuras, como tabla hash o filtro de floración. Por el contrario, CRC no ofrece dicha garantía. Algunos de los bits terminan siendo muy predecibles o altamente correlacionados, y al extraerlos con el propósito de hash, la dispersión es mucho peor.Se podría decir que la suma de comprobación y el hash son simplemente 2 dominios diferentes y no deben confundirse. De hecho, esa es la teoría. El problema es que esto ignora la conveniencia y la práctica de campo. Tener un "mezclador" para múltiples propósitos es conveniente, y los programadores se conformarán con uno y se olvidarán de él. No puedo contar cuántas veces he visto usar crc32 para hash, solo porque se sintió "lo suficientemente aleatorio". Es fácil decir que no debería suceder, pero sucede constantemente.
En este entorno, tiene sentido proponer una solución diseñada para funcionar bien para ambos casos de uso, ya que se ajusta a las expectativas del usuario.Dentro de la multitud de PIC / Arduino, la gente todavía usa viejas sumas de comprobación simples de 8 bits, sumas Fletcher de 16 bits o CRC de 16 bits.
(...)
¿Hay algo intrínsecamente malo con las funciones hash cuando se reducen a 8 o 16 bits?Debido a las propiedades de un buen hash, es posible extraer 8 o 16 bits de un hash, lo que da como resultado una probabilidad de colisión de 1/256 o 1/65535. No veo ninguna preocupación en esto.
Simplemente, tenemos que aceptar la latencia de _history_. Las personas están acostumbradas a ciertas cosas, como el uso de funciones de suma de verificación específicas para la suma de verificación. Incluso si existen soluciones más recientes y potencialmente mejores, los hábitos no cambian rápidamente.
sabemos que con CRC 32 y usando HD = 6 puede detectar cualquier error de 5 bits y puede detectar ráfagas de hasta 2 ^ 31 = aproximadamente 204 MB
y detectar todos los errores de un solo bit
En xxHash, ¿cuántos bits deben cambiarse para que no podamos detectar un error?
Sé que en Hash incluso un cambio de 1 bit genera un resumen totalmente diferente, pero ¿cómo podemos calcular la cantidad de bits necesarios para crear una colisión?
otra pregunta es como mencionaste:
Por el contrario, CRC no ofrece dicha garantía. Algunos de los bits terminan siendo muy predecibles o altamente correlacionados, y al extraerlos con el propósito de hash, la dispersión es mucho peor.
¿Por qué es tan malo? Si los bits están correlacionados de alguna manera, ¿podemos usar esta correlación para reparar el archivo dañado?
 arashams
en 6 abr. 2020
arashams
en 6 abr. 2020
En xxHash, cuántos bits deben cambiarse para que no podamos detectar un error (o colisiones)
1 bit.
xxHash es una función hash no criptográfica, no una suma de comprobación. No proporciona ninguna distancia de martilleo ni garantías de resistencia a colisiones.
Si bien puede hacer un trabajo decente, no es la mejor opción. Es como usar unos alicates a modo de llave inglesa. Seguro, hará el trabajo, pero es menos efectivo que una llave real y puede causar daños.
 easyaspi314
en 6 abr. 2020
easyaspi314
en 6 abr. 2020
En xxHash, cuántos bits deben cambiarse para que no podamos detectar un error (o colisiones)
1 bit.
xxHash es una función hash no criptográfica, no una suma de comprobación. No proporciona ninguna distancia de martilleo ni garantías de resistencia a colisiones.
Si bien puede hacer un trabajo decente, no es la mejor opción. Es como usar unos alicates a modo de llave inglesa. Seguro, hará el trabajo, pero es menos efectivo que una llave real y puede causar daños.
¿Quiere decir que podemos engañar al decodificador con solo cambiar 1 bit de datos?
puede crear colisiones? (eso da miedo) y la probabilidad de tal colisión depende del tamaño del resumen
arashams
en 6 abr. 2020
¿Quiere decir que podemos engañar al decodificador con solo cambiar 1 bit de datos?
Teniendo en cuenta los valores hash producidos a partir de 2 contenidos diferentes, la probabilidad de colisiones es siempre 1 / 2^64 (para algoritmos hash de 64 bits de buena calidad, como xxh64 o xxh3 ), cualquiera que sea la cantidad de modificaciones entre esos 2 contenidos.
De hecho, significa que, al menos en teoría, un cambio de un solo bit podría generar una colisión.
Ahora, tenga en cuenta que esta probabilidad es 1 / 2^64 , que es prácticamente infinitesimal.
La gente es relativamente mala para entender este tema. A veces lo combinan con "pequeño", que tiende a percibirse como una cantidad tangible en la mente de la mayoría de las personas, como ~ 10%.
Para tener una idea más precisa, me gusta referirme a esta tabla: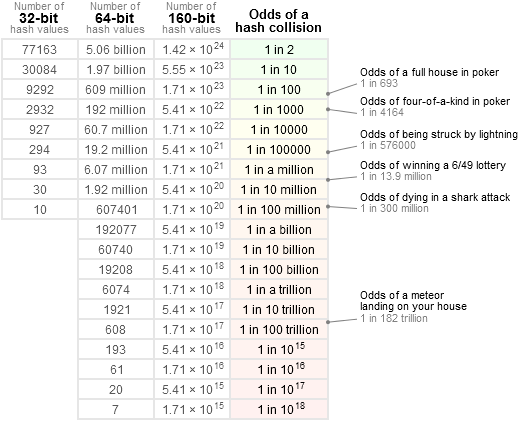
es decir: 1 / 2 ^ 64 es mucho menor que la posibilidad de recibir un cometa directamente en la cabeza, y menor que ganar la lotería nacional _3 veces seguidas_ (lo cual sería sospechoso). En realidad, esto está mucho más cerca de "nulo". La mayoría de los componentes de cualquier sistema son susceptibles de romperse con una probabilidad _mucho_ mayor que esa, comenzando con otras fuentes de errores de software.
Si uno quiere encontrar una colisión de 1 bit tan teórica, necesitaría una entrada bastante gigantesca y una cantidad de potencia bastante increíble para forzar una solución a este problema. Incluso entonces, es posible que no exista una solución: considerando la naturaleza de la aritmética empleada, no me sorprendería que fuera imposible generar una colisión con una modificación de un solo bit. Mi propia apuesta es que se necesitan al menos 2 bits, e incluso entonces, es necesario colocarlos en posiciones de entrada específicas para tener la oportunidad de lograr el objetivo deseado, lo que hace que dicha modificación ya no sea "aleatoria", por lo tanto, fuera del alcance de un hash no criptográfico.
Pero creo que el texto citado ya explica todo esto: los crc reales tienen garantías sobre la distancia de martillo. Esto puede ser útil, y tenía mucho más sentido en el pasado, cuando las señales eran susceptibles de ser modificadas a nivel de bits y cuando las sumas de comprobación eran bastante pequeñas (16 o 32 bits). Un algoritmo hash de 16 bits tendría una posibilidad no despreciable de perder una colisión que involucre muy pocos cambios de bits, lo que lo haría menos adecuado para la tarea. Pero con hashes de 64 bits o incluso de 128 bits ahora sobre la mesa, creo que esta ya no es una opción peligrosa, simplemente porque las posibilidades de colisión, por lo tanto de corrupción no detectada, son increíblemente pequeñas.
Algunos de los bits terminan siendo muy predecibles o altamente correlacionados, y al extraerlos con el propósito de hash, la dispersión es mucho peor.
¿Por qué es tan malo?
Los hash tienen generalmente más usos que el simple reemplazo de suma de comprobación.
En realidad, en la mayoría de los casos, el propósito de los algoritmos hash es proporcionar algunos bits aleatorios para designar una posición en una tabla hash. Si algunos de estos bits se vuelven predecibles según el contenido, significa que la distribución de posiciones en la tabla hash ya no será "aleatoria" y, como consecuencia, algunas celdas se desbordarán más rápido que otras, lo que afectará negativamente el rendimiento de la tabla hash. .
Si los bits están correlacionados de alguna manera, ¿podemos usar esta correlación para reparar el archivo dañado?
Este es un tema completamente diferente.
No se repara una entrada dañada con un CRC. Un CRC solo puede detectar un error, no repararlo.
Los datos de autorreparación son un tema y utilizan técnicas diferentes (y mucho más involucradas computacionalmente), como los códigos convolucionales. Esto es mucho más complejo.
Cyan4973
en 6 abr. 2020
Si uno quiere encontrar una colisión de 1 bit tan teórica, necesitaría una entrada bastante gigantesca y una cantidad de potencia bastante increíble para forzar una solución a este problema. Incluso entonces, es posible que no exista una solución: considerando la naturaleza de la aritmética empleada, no me sorprendería que fuera imposible generar una colisión con una modificación de un solo bit. Mi propia apuesta es que se necesitan al menos 2 bits, e incluso entonces, es necesario colocarlos en posiciones de entrada específicas para tener la oportunidad de lograr el objetivo deseado, lo que hace que dicha modificación ya no sea "aleatoria", por lo tanto, fuera del alcance de un hash no criptográfico.
261 demuestra una colisión de un solo bit en la variante de 64 bits de XXH3, aunque depende de la semilla y es muy poco probable que ocurra en entradas aleatorias
easyaspi314
en 6 abr. 2020
En efecto; para ser más completo, mi declaración anterior se dirigió más bien a la sección de gran tamaño, para entradas> 240 bytes.
Pero sí, en el rango limitado de tamaños donde la entrada tiene que coincidir exactamente con uno de los secret de 64 bits, es posible una colisión de un solo bit. Se sintió aceptable porque una colisión basada en una entrada precisa de 64 bits en una ubicación precisa todavía está dentro de este territorio 1 / 2^64 , asumiendo que la entrada es aleatoria (es decir, no está diseñada para producir una colisión). Además, el secret para igualar se puede hacer efectivamente _secret_, por lo que un atacante externo tendrá que usar la fuerza bruta para encontrarlo.
Cyan4973
en 6 abr. 2020
¿Quiere decir que podemos engañar al decodificador con solo cambiar 1 bit de datos?
Teniendo en cuenta los valores hash producidos a partir de 2 contenidos diferentes, la probabilidad de colisiones es siempre
1 / 2^64(para algoritmos hash de 64 bits de buena calidad, comoxxh64oxxh3), cualquiera que sea la cantidad de modificaciones entre esos 2 contenidos.De hecho, significa que, al menos en teoría, un cambio de un solo bit podría generar una colisión.
Ahora, tenga en cuenta que esta probabilidad es
1 / 2^64, que es prácticamente infinitesimal.
La gente es relativamente mala para entender este tema. A veces lo combinan con "pequeño", que tiende a percibirse como una cantidad tangible en la mente de la mayoría de las personas, como ~ 10%.Para tener una idea más precisa, me gusta referirme a esta tabla:
es decir:
1 / 2 ^ 64es mucho menor que la posibilidad de recibir un cometa directamente en la cabeza, y menor que ganar la lotería nacional _3 veces seguidas_ (lo cual sería sospechoso). En realidad, esto está mucho más cerca de "nulo". La mayoría de los componentes de cualquier sistema son susceptibles de romperse con una probabilidad _mucho_ mayor que esa, comenzando con otras fuentes de errores de software.Si uno quiere encontrar una colisión de 1 bit tan teórica, necesitaría una entrada bastante gigantesca y una cantidad de potencia bastante increíble para forzar una solución a este problema. Incluso entonces, es posible que no exista una solución: considerando la naturaleza de la aritmética empleada, no me sorprendería que fuera imposible generar una colisión con una modificación de un solo bit. Mi propia apuesta es que se necesitan al menos 2 bits, e incluso entonces, es necesario colocarlos en posiciones de entrada específicas para tener la oportunidad de lograr el objetivo deseado, lo que hace que dicha modificación ya no sea "aleatoria", por lo tanto, fuera del alcance de un hash no criptográfico.
Pero creo que el texto citado ya explica todo esto: los
crcreales tienen garantías sobre la distancia de martillo. Esto puede ser útil, y tenía mucho más sentido en el pasado, cuando las señales eran susceptibles de ser modificadas a nivel de bits y cuando las sumas de comprobación eran bastante pequeñas (16 o 32 bits). Un algoritmo hash de 16 bits tendría una posibilidad no despreciable de perder una colisión que involucre muy pocos cambios de bits, lo que lo haría menos adecuado para la tarea. Pero con hashes de 64 bits o incluso de 128 bits ahora sobre la mesa, creo que esta ya no es una opción peligrosa, simplemente porque las posibilidades de colisión, por lo tanto de corrupción no detectada, son increíblemente pequeñas.Algunos de los bits terminan siendo muy predecibles o altamente correlacionados, y al extraerlos con el propósito de hash, la dispersión es mucho peor.
¿Por qué es tan malo?
Los hash tienen generalmente más usos que el simple reemplazo de suma de comprobación.
En realidad, en la mayoría de los casos, el propósito de los algoritmos hash es proporcionar algunos bits aleatorios para designar una posición en una tabla hash. Si algunos de estos bits se vuelven predecibles según el contenido, significa que la distribución de posiciones en la tabla hash ya no será "aleatoria" y, como consecuencia, algunas celdas se desbordarán más rápido que otras, lo que afectará negativamente el rendimiento de la tabla hash. .Si los bits están correlacionados de alguna manera, ¿podemos usar esta correlación para reparar el archivo dañado?
Este es un tema completamente diferente.
No se repara una entrada dañada con un CRC. Un CRC solo puede detectar un error, no repararlo.Los datos de autorreparación son un tema y utilizan técnicas diferentes (y mucho más involucradas computacionalmente), como los códigos convolucionales. Esto es mucho más complejo.
¿Podrías confirmar estos escenarios?
- LZ4 tiene suma de comprobación de contenido para cada bloque de datos. Considere que tenemos 10 ^ 6 paquetes de archivos de 1 GB.
la probabilidad de colisión es 1/2 ^ 32 = 0.0000000002 significa que si enviamos 10 ^ 10 (este tamaño gigante) paquetes podemos tener 2 colisiones (según el principio Pigeonhole) pero si enviamos menos de esta cantidad, la probabilidad de ver una colisión se reducirá significativamente para que podamos detectar todos los errores, el decodificador calcula la suma de comprobación y la compara con la suma de comprobación del paquete, ¿es correcto? - La suma de verificación de contenido calcula la suma de verificación sobre el archivo comprimido (es opcional y podemos usarlo para detectar fuera de servicio o para reducir la probabilidad de colisión (antes de usar CC, la probabilidad de una colisión es 1/2 ^ 32 y luego sería sea 1/2 ^ 64.)
arashams
en 8 abr. 2020
El escenario descrito es:
- Los datos comprimidos con LZ4 se corrompen (que ya es un evento bastante raro en sí mismo)
- La corrupción permanece sin ser detectada debido a la colisión de hash.
El formato de trama LZ4 usa XXH32 , un hash de 32 bits, como suma de comprobación complementaria.
Se aplica de forma predeterminada al contenido del cuadro completo, más precisamente al contenido _descomprimido_ del cuadro (después de la descompresión), validando así tanto el proceso de transmisión como el de decodificación.
Opcionalmente también puede aplicarlo a cada bloque, en cuyo caso comprueba el contenido _comprimido_ de cada bloque.
Ambos se pueden acumular.
Para permanecer sin ser detectado, una corrupción debe pasar con éxito ___todas las sumas de comprobación aplicables.
Suponiendo que la suma de comprobación del bloque esté habilitada, y suponiendo que la corrupción esté completamente ubicada dentro de un solo bloque, las posibilidades de pasar tanto el bloque como la suma de comprobación del marco son de hecho 1 / 2^32 x 1 / 2^32 = 1 / 2^64 .
Ahora, si los datos corruptos residen en varios bloques, ya sea porque hay varios eventos de corrupción o porque una sola sección corrupta grande cubre bloques consecutivos, es _incluso más difícil que la corrupción no se detecte_. Tendría que generar una colisión con cada una de las sumas de comprobación de bloques involucradas.
Por ejemplo, suponiendo que la corrupción se distribuya en 2 bloques, las posibilidades de que esta corrupción no se detecte son 1 / 2^32 x 1 / 2^32 x 1 / 2^32 = 1 / 2^96 . Astronómicamente pequeño.
Sin contar el hecho de que cada bloque dañado puede ser detectado como no codificable por el proceso de descompresión, que se suma a eso.
Entonces, sí, la combinación de suma de verificación de bloque y marco aumenta drásticamente las posibilidades de detectar eventos de corrupción.
Cyan4973
en 8 abr. 2020
El escenario descrito es:
* LZ4-compressed data being corrupted (which is already a pretty rare event by itself) * Corruption remaining undetected due to hash collision.El formato de trama LZ4 usa
XXH32, un hash de 32 bits, como suma de comprobación complementaria.
Se aplica de forma predeterminada al contenido del cuadro completo, más precisamente al contenido _descomprimido_ del cuadro (después de la descompresión), validando así tanto el proceso de transmisión como el de decodificación.
Opcionalmente también puede aplicarlo a cada bloque, en cuyo caso comprueba el contenido _comprimido_ de cada bloque.
Ambos se pueden acumular.Para permanecer sin ser detectado, una corrupción debe pasar con éxito _ todas _ las sumas de comprobación aplicables.
Suponiendo que la suma de comprobación del bloque esté habilitada, y suponiendo que la corrupción esté completamente ubicada dentro de un solo bloque, las posibilidades de pasar tanto el bloque como la suma de comprobación del marco son de hecho1 / 2^32 x 1 / 2^32 = 1 / 2^64.Ahora, si los datos corruptos residen en varios bloques, ya sea porque hay varios eventos de corrupción o porque una sola sección corrupta grande cubre bloques consecutivos, es _incluso más difícil que la corrupción no se detecte_. Tendría que generar una colisión con cada una de las sumas de comprobación de bloques involucradas.
Por ejemplo, suponiendo que la corrupción se distribuya en 2 bloques, las posibilidades de que esta corrupción no se detecte son1 / 2^32 x 1 / 2^32 x 1 / 2^32 = 1 / 2^96. Astronómicamente pequeño.Sin contar el hecho de que cada bloque dañado puede ser detectado como no codificable por el proceso de descompresión, que se suma a eso.
Entonces, sí, la combinación de suma de verificación de bloque y marco aumenta drásticamente las posibilidades de detectar eventos de corrupción.
¿Es posible utilizar LZ4 sobre la marcha? Quiero decir, comprima / descomprima los datos tan pronto como tenga algunos de ellos. de alguna manera está canalizando.
¿qué pasa con el xxHash?
arashams
en 29 ago. 2020
¿Es posible utilizar LZ4 sobre la marcha? Quiero decir, comprima / descomprima los datos tan pronto como tenga algunos de ellos.
Este es el modo de transmisión. Sí, es posible.
¿qué pasa con el xxHash?
La suma de comprobación del fotograma se actualiza continuamente, pero solo produce un resultado al final del fotograma. Por lo tanto, no hay un resultado de suma de comprobación con el que comparar hasta un evento de fin de cuadro (un flujo puede constar de varios cuadros adjuntos, pero generalmente no).
Por el contrario, las sumas de comprobación de bloque se crean en cada bloque, por lo que se producen y verifican regularmente durante la transmisión.
Ambas sumas de comprobación emplean XXH32 .
Cyan4973
en 29 ago. 2020
Temas relacionados
 eloff
·
6Comentarios
eloff
·
6Comentarios
 jtoivainen
·
4Comentarios
jtoivainen
·
4Comentarios
 jvriezen
·
6Comentarios
jvriezen
·
6Comentarios
 xinglin
·
6Comentarios
xinglin
·
6Comentarios
 carstenskyboxlabs
·
6Comentarios
carstenskyboxlabs
·
6Comentarios
Comentario más útil
Los algoritmos CRC generalmente ofrecen garantías de detección de errores en condiciones de distancias de martillo. Dado un número limitado de cambios de bits, el CRC _necesariamente_ generará un resultado diferente.
Esto puede resultar útil en situaciones en las que se presume que los errores solo cambian unos pocos bits.
Hace solo unas décadas, esto era relativamente común, especialmente en escenarios de transmisión, ya que la señal subyacente todavía estaba muy "cruda", por lo que los cambios de bits no detectados en la capa física eran una cosa.
Sin embargo, esta propiedad tiene un costo de distribución. Una vez que se cruza la distancia de martilleo "segura", la probabilidad de colisión empeora. Esta es una consecuencia lógica del principio de casillero. ¿Cuánto peor? Bueno, depende del CRC exacto, pero espero que un buen CRC esté en el rango 3x - 7x peor. Eso puede parecer mucho, pero es solo una reducción de la dispersión de 2-3 bits, por lo que no es tan terrible. Todavía.
Compare eso con un hash con propiedad de distribución "ideal": cualquier cambio, no importa si es un solo bit o una salida completamente diferente, tiene exactamente 1/2 ^ n de probabilidad de generar una colisión. Es más fácil de entender: el riesgo de colisión es siempre el mismo. En una comparación directa con CRC, cuando la distancia de martilleo es pequeña, la tasa de colisión es peor (ya que es> 0), pero es mejor cuando la distancia de martilleo es grande.
Un avance rápido hoy en día, y la situación ha cambiado radicalmente. Tenemos capas sobre capas de lógica de detección y corrección de errores por encima de los medios físicos. No podemos simplemente extraer un poco de un bloque de flash, ni podemos leer un poco de un canal Bluetooth. Ya no tiene sentido. Estos protocolos incorporan una lógica de bloques con estado, que es más compleja, más resistente y compensa constantemente el ruido permanente de la capa física. Cuando fallan, eso no va a producir un solo cambio: más bien, una región de datos completa estará completamente desordenada, siendo todo ceros o incluso ruido aleatorio.
En este nuevo entorno, la apuesta es que los errores, cuando ocurren, ya no están en la categoría "bitflip". En cuyo caso, las propiedades de distribución de CRC se convierten en un pasivo. Un hash puro en realidad tiene una probabilidad menor de producir una colisión.
Esto es solo cuando se considera la suma de verificación.
Una propiedad adicional de un hash "ideal" es que, al extraer cualquier segmento de bits del hash, todavía presenta esta probabilidad de colisión
1 / 2^n, que es muy importante como fuente de bits para otras estructuras, como tabla hash o filtro de floración. Por el contrario, CRC no ofrece dicha garantía. Algunos de los bits terminan siendo muy predecibles o altamente correlacionados, y al extraerlos con el propósito de hash, la dispersión es mucho peor.Se podría decir que la suma de comprobación y el hash son simplemente 2 dominios diferentes y no deben confundirse. De hecho, esa es la teoría. El problema es que esto ignora la conveniencia y la práctica de campo. Tener un "mezclador" para múltiples propósitos es conveniente, y los programadores se conformarán con uno y se olvidarán de él. No puedo contar cuántas veces he visto usar crc32 para hash, solo porque se sintió "lo suficientemente aleatorio". Es fácil decir que no debería suceder, pero sucede constantemente.
En este entorno, tiene sentido proponer una solución diseñada para funcionar bien para ambos casos de uso, ya que se ajusta a las expectativas del usuario.
Debido a las propiedades de un buen hash, es posible extraer 8 o 16 bits de un hash, lo que da como resultado una probabilidad de colisión de 1/256 o 1/65535. No veo ninguna preocupación en esto.
Simplemente, tenemos que aceptar la latencia de _history_. Las personas están acostumbradas a ciertas cosas, como el uso de funciones de suma de verificación específicas para la suma de verificación. Incluso si existen soluciones más recientes y potencialmente mejores, los hábitos no cambian rápidamente.