<p>xxHash в качестве контрольной суммы для обнаружения ошибок</p>
Одна из вещей, которую я постоянно не понимаю, - это то, как хеш может быть контрольной суммой (или должна ли она быть), потому что традиционно хеши оптимизированы для строк и для хеш-таблиц (DJB2 приходит на ум как давний фаворит фанатов). Однако в толпе PIC / Arduino люди все еще используют старые простые 8-битные контрольные суммы, 16-битные суммы Флетчера или 16-битную CRC. Но вы не видите много разговоров о новых контрольных суммах как о лучшем выборе с сегодняшними предположительно более быстрыми процессорами. Являются ли типы вычислений, используемых в хэшах, слишком медленными? (несмотря на то, что CRC на самом деле медленнее в программном обеспечении, чем xxHash ..) Или что-то по своей сути плохо с хэш-функциями при уменьшении до 8 или 16 бит?
Я читал, что xxHash изначально был разработан как контрольная сумма для lz4, а некоторые другие хеш-функции, такие как SeaHash, предназначены для использования в файловой системе также для контрольной суммы. Для сравнения, CRC-32 широко используется в некоторых форматах сжатия (например, ZIP / RAR). Я также читал, что CRC имеет определенные математические свойства, которые доказывают расстояния Хэмминга для обнаружения ошибок для конкретных полиномов и т.д. как мне кажется.
Это заставляет меня задуматься, не лучше ли использовать CRC-32 для целей целостности, чем быстрый и простой в реализации хэш, даже если он может иметь поражение по скорости. Есть ли у xxHash какие-либо гарантии обнаружения ошибок (допустим, 32-разрядная версия)? А если нет, то как он конкурирует с CRC-32 в качестве контрольной суммы или кода обнаружения ошибок? Какие компромиссы?
 bryc
bryc
Все 11 Комментарий
Алгоритмы CRC обычно обеспечивают гарантии обнаружения ошибок в условиях расстояний Хэмминга. Учитывая ограниченное количество переворотов битов, CRC _обязательно_ генерирует другой результат.
Это может оказаться полезным в ситуациях, когда предполагается, что ошибки изменяют только несколько бит.
Всего несколько десятилетий назад это было относительно обычным явлением, особенно в сценариях передачи, поскольку базовый сигнал все еще был очень «сырым», поэтому необнаруженные перевороты битов на физическом уровне имели место.
Однако это свойство имеет распределительную стоимость. Как только «безопасное» расстояние Хэмминга пересечено, вероятность столкновения становится хуже. Это логическое следствие принципа «голубятни». Насколько хуже? Ну, это зависит от точного CRC, но я ожидаю, что хороший CRC будет в 3-7 раз хуже. Это может показаться многословным, но это всего лишь уменьшение дисперсии на 2-3 бита, так что это не так уж и страшно. По-прежнему.
Сравните это с хешем с «идеальным» свойством распределения: любое изменение, независимо от того, является ли оно единственным битом или совершенно другим выходом, имеет вероятность ровно 1/2 ^ n вызвать коллизию. Это проще понять: риск столкновения всегда одинаков. При прямом сравнении с CRC, когда расстояние Хэмминга мало, частота столкновений хуже (поскольку оно> 0), но лучше, когда расстояние Хэмминга большое.
Перенесемся в наши дни, и ситуация в корне изменилась. У нас есть уровни за слоями логики обнаружения и исправления ошибок над физическим носителем. Мы не можем просто извлечь бит из блока флеш-памяти или прочитать бит из канала Bluetooth. Это больше не имеет смысла. Эти протоколы включают логику блоков с отслеживанием состояния, которая является более сложной, более устойчивой и постоянно компенсирует постоянный шум физического уровня. Когда они терпят неудачу, это не приведет к единственному перевороту: скорее, вся область данных будет полностью искажена, состоящая только из нулей или даже случайного шума.
В этой новой среде ставка заключается в том, что ошибки, когда они происходят, больше не относятся к категории «переворота битов». В этом случае распределительные свойства CRC становятся обязательством. Чистый хеш на самом деле имеет меньшую вероятность возникновения коллизии.
Это только при учете контрольной суммы.
Дополнительным свойством «идеального» хеша является то, что при извлечении любого сегмента битов из хеша он по-прежнему имеет вероятность столкновения 1 / 2^n , которая очень важна как источник бит для других структур, таких как хэш-таблица или фильтр Блума. Напротив, CRC не предоставляет такой гарантии. Некоторые биты оказываются очень предсказуемыми или сильно коррелированными, и при их извлечении для целей хеширования дисперсия намного хуже.
Можно сказать, что контрольная сумма и хеширование - это просто два разных домена, и их не следует путать. Действительно, это теория. Проблема в том, что при этом игнорируются удобство и практика. Удобно иметь один «миксер» для различных целей, и программисты довольствуются одним и забудут о нем. Я не могу сосчитать, сколько раз я видел, что crc32 используется для хеширования, просто потому, что он казался «достаточно случайным». Легко сказать, что этого не должно происходить, но так происходит постоянно.
В этой среде предложение решения, разработанного для обоих вариантов использования, имеет смысл, поскольку оно соответствует ожиданиям пользователей.
в толпе PIC / Arduino люди все еще используют старые простые 8-битные контрольные суммы, 16-битные суммы Флетчера или 16-битную CRC.
(...)
есть ли что-то изначально плохое с хэш-функциями при уменьшении до 8 или 16 бит?
Благодаря свойствам хорошего хеша, действительно можно извлечь из хеша 8 или 16 бит, что дает вероятность столкновения 1/256 или 1/65535. Я не вижу по этому поводу беспокойства.
Просто мы должны принять задержку _history_. Люди привыкли к определенному образу жизни, например, к использованию определенных функций контрольной суммы для вычисления контрольной суммы. Даже если есть более свежие и потенциально лучшие решения, привычки не меняются быстро.
 Cyan4973
16 июл. 2019
Cyan4973
16 июл. 2019
Алгоритмы CRC обычно обеспечивают гарантии обнаружения ошибок в условиях расстояний Хэмминга. Учитывая ограниченное количество переворотов битов, CRC _обязательно_ генерирует другой результат.
Это может оказаться полезным в ситуациях, когда предполагается, что ошибки изменяют только несколько бит.
Всего несколько десятилетий назад это было относительно обычным явлением, особенно в сценариях передачи, поскольку базовый сигнал все еще был очень «сырым», поэтому необнаруженные перевороты битов на физическом уровне имели место.Однако это свойство имеет распределительную стоимость. Как только «безопасное» расстояние Хэмминга пересечено, вероятность столкновения становится хуже. Это логическое следствие принципа «голубятни». Насколько хуже? Ну, это зависит от точного CRC, но я ожидаю, что хороший CRC будет в 3-7 раз хуже. Это может показаться многословным, но это всего лишь уменьшение дисперсии на 2-3 бита, так что это не так уж и страшно. По-прежнему.
Сравните это с хешем с «идеальным» свойством распределения: любое изменение, независимо от того, является ли оно единственным битом или совершенно другим выходом, имеет вероятность ровно 1/2 ^ n вызвать коллизию. Это проще понять: риск столкновения всегда одинаков. При прямом сравнении с CRC частота столкновений хуже (так как она> 0), когда расстояние Хэмминга мало, но лучше, когда расстояние Хэмминга велико.
Перенесемся в наши дни, и ситуация в корне изменилась. У нас есть уровни за слоями логики обнаружения и исправления ошибок над физическим носителем. Мы не можем просто извлечь бит из блока флеш-памяти или прочитать бит из канала Bluetooth. Это больше не имеет смысла. Эти протоколы включают логику блоков с отслеживанием состояния, которая является более сложной, более устойчивой и постоянно компенсирует постоянный шум физического уровня. Когда они терпят неудачу, это не приведет к единственному перевороту: скорее, вся область данных будет полностью искажена, состоящая только из нулей или даже случайного шума.
В этой новой среде ставка заключается в том, что ошибки, когда они происходят, больше не относятся к категории «переворота битов». В этом случае распределительные свойства CRC становятся обязательством. Чистый хеш на самом деле имеет меньшую вероятность возникновения коллизии.
Это только при учете контрольной суммы.
Дополнительным свойством «идеального» хеша является то, что при извлечении любого сегмента битов из хеша он по-прежнему имеет вероятность столкновения1 / 2^n, которая очень важна как источник бит для других структур, таких как хэш-таблица или фильтр Блума. Напротив, CRC не предоставляет такой гарантии. Некоторые биты оказываются очень предсказуемыми или сильно коррелированными, и при их извлечении для целей хеширования дисперсия намного хуже.Можно сказать, что контрольная сумма и хеширование - это просто два разных домена, и их не следует путать. Действительно, это теория. Проблема в том, что при этом игнорируются удобство и практика. Удобно иметь один «миксер» для различных целей, и программисты довольствуются одним и забудут о нем. Я не могу сосчитать, сколько раз я видел, что crc32 используется для хеширования, просто потому, что он казался «достаточно случайным». Легко сказать, что этого не должно происходить, но так происходит постоянно.
В этой среде предложение решения, разработанного для обоих вариантов использования, имеет смысл, поскольку оно соответствует ожиданиям пользователей.в толпе PIC / Arduino люди все еще используют старые простые 8-битные контрольные суммы, 16-битные суммы Флетчера или 16-битную CRC.
(...)
есть ли что-то изначально плохое с хэш-функциями при уменьшении до 8 или 16 бит?Благодаря свойствам хорошего хеша, действительно можно извлечь из хеша 8 или 16 бит, что дает вероятность столкновения 1/256 или 1/65535. Я не вижу по этому поводу беспокойства.
Просто мы должны принять задержку _history_. Люди привыкли к определенному образу жизни, например, к использованию определенных функций контрольной суммы для вычисления контрольной суммы. Даже если есть более свежие и потенциально лучшие решения, привычки не меняются быстро.
мы знаем, что с CRC 32 и HD = 6 он может обнаруживать любые 5-битные ошибки и может обнаруживать пакеты размером до 2 ^ 31 = около 204 МБ.
и обнаруживать все однобитовые ошибки
Сколько бит нужно изменить в xxHash, чтобы мы не могли обнаружить ошибку?
Я знаю, что в Hash даже 1-битное изменение дает совершенно другой дайджест, но как мы можем рассчитать количество битов, необходимых для создания коллизии?
другой вопрос, как вы упомянули:
Напротив, CRC не предоставляет такой гарантии. Некоторые биты оказываются очень предсказуемыми или сильно коррелированными, и при их извлечении для целей хеширования дисперсия намного хуже.
Почему это плохо? Если биты каким-то образом коррелированы, можем ли мы использовать эту корреляцию для восстановления поврежденного файла?
 arashams
6 апр. 2020
arashams
6 апр. 2020
В xxHash, сколько бит нужно изменить, чтобы мы не могли обнаружить ошибку (или коллизии)
1 бит.
xxHash - это некриптографическая хеш-функция, а не контрольная сумма. Он не дает никаких гарантий расстояния до удара или устойчивости к столкновениям.
Хотя он может неплохо с этим справиться, это не лучший выбор. Это все равно, что использовать плоскогубцы вместо гаечного ключа. Конечно, он выполнит свою работу, но он менее эффективен, чем настоящий гаечный ключ, и может вызвать повреждение.
 easyaspi314
6 апр. 2020
easyaspi314
6 апр. 2020
В xxHash, сколько бит нужно изменить, чтобы мы не могли обнаружить ошибку (или коллизии)
1 бит.
xxHash - это некриптографическая хеш-функция, а не контрольная сумма. Он не дает никаких гарантий расстояния до удара или устойчивости к столкновениям.
Хотя он может неплохо с этим справиться, это не лучший выбор. Это все равно, что использовать плоскогубцы вместо гаечного ключа. Конечно, он выполнит свою работу, но он менее эффективен, чем настоящий гаечный ключ, и может вызвать повреждение.
Вы имеете в виду, что мы можем обмануть декодер, просто изменив 1 бит данных?
это может создавать коллизии? (это страшно) и вероятность такого столкновения зависит от размера дайджеста
arashams
6 апр. 2020
Вы имеете в виду, что мы можем обмануть декодер, просто изменив 1 бит данных?
Принимая во внимание хеш-значения, полученные из двух разных типов содержимого, вероятность коллизий всегда равна 1 / 2^64 (для качественных 64-битных алгоритмов хеширования, таких как xxh64 или xxh3 ), независимо от количество изменений между этими двумя содержаниями.
Это действительно означает, что, по крайней мере теоретически, изменение одного бита может вызвать столкновение.
Теперь имейте в виду, что эта вероятность равна 1 / 2^64 , что практически бесконечно мало.
Люди относительно плохо разбираются в этой теме. Иногда они объединяют это с «маленьким», что обычно воспринимается как осязаемое количество в сознании большинства людей, например ~ 10%.
Чтобы получить более точное представление, я хотел бы обратиться к этой таблице: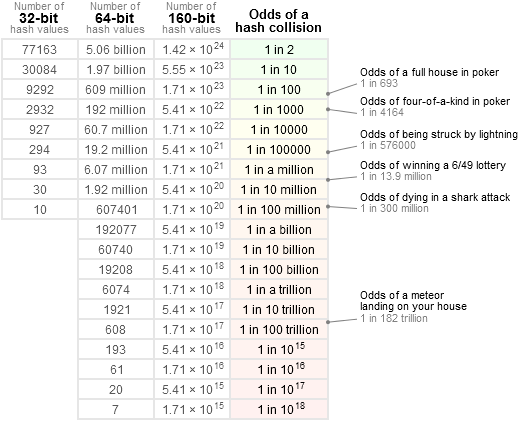
то есть: 1 / 2 ^ 64 намного ниже, чем шанс получить комету прямо на голову, и ниже, чем выигрыш в национальной лотерее _3 раза подряд_ (что было бы довольно подозрительно). На самом деле это намного ближе к "нулю". Большинство компонентов в любой системе подвержены поломке с гораздо большей вероятностью, чем это, начиная с других источников ошибок программного обеспечения.
Если кто-то хочет найти такое теоретическое 1-битное столкновение, ему потребуются довольно гигантские входные данные и довольно невероятное количество мощности для решения этой проблемы методом грубой силы. Даже в этом случае решения может не существовать: учитывая характер используемой арифметики, я не удивлюсь, если будет невозможно создать коллизию с помощью однобитовой модификации. Моя собственная ставка заключается в том, что для этого требуется как минимум 2 бита, и даже в этом случае требуется разместить их в определенных позициях ввода, чтобы иметь шанс достичь желаемой цели, делая такую модификацию больше не "случайной", следовательно, выходящей за рамки возможностей для некриптографический хеш.
Но я думаю, что процитированный текст уже все это объясняет: у настоящих crc есть гарантии на расстояние Хэмминга. Это может быть полезно, и это имело гораздо больший смысл в прошлом, когда сигналы были подвержены изменению на битовом уровне, а сама контрольная сумма была довольно маленькой (16 или 32 бит). У 16-битного хэш-алгоритма будет немалая вероятность пропустить коллизию, включающую очень небольшое количество битов, что делает его менее подходящим для задачи. Но с 64-битными или даже 128-битными хэшами сейчас на столе, я считаю, что это больше не опасный вариант просто потому, что шансы коллизии, а следовательно, и необнаруженного повреждения, непостижимо малы.
Некоторые биты оказываются очень предсказуемыми или сильно коррелированными, и при их извлечении для целей хеширования дисперсия намного хуже.
Почему это плохо?
Хэши обычно имеют больше применений, чем просто замена контрольной суммы.
На самом деле, в большинстве случаев цель хеш-алгоритмов - предоставить некоторые случайные биты для обозначения позиции в хеш-таблице. Если некоторые из этих битов становятся предсказуемыми в зависимости от содержимого, это означает, что распределение позиций в хеш-таблице больше не будет «случайным», и, как следствие, некоторые ячейки будут переполняться быстрее, чем другие, что отрицательно скажется на производительности хеш-таблицы. .
Если биты каким-то образом коррелированы, можем ли мы использовать эту корреляцию для восстановления поврежденного файла?
Это совсем другая тема.
Не удается восстановить поврежденный ввод с помощью CRC. CRC может только обнаружить ошибку, но не исправить ее.
Самовосстановление данных - это тема, в которой используются различные (и гораздо более сложные в вычислительном отношении) методы, такие как сверточные коды. Это намного сложнее.
Cyan4973
6 апр. 2020
Если кто-то хочет найти такое теоретическое 1-битное столкновение, ему потребуются довольно гигантские входные данные и довольно невероятное количество мощности для решения этой проблемы методом грубой силы. Даже в этом случае решения может не существовать: учитывая характер используемой арифметики, я не удивлюсь, если будет невозможно создать коллизию с помощью однобитовой модификации. Моя собственная ставка заключается в том, что для этого требуется как минимум 2 бита, и даже в этом случае требуется разместить их в определенных позициях ввода, чтобы иметь шанс достичь желаемой цели, делая такую модификацию больше не "случайной", следовательно, выходящей за рамки возможностей для некриптографический хеш.
261 демонстрирует одноразрядный конфликт в 64-битном варианте XXH3, хотя он зависит от начального числа и очень маловероятен при случайных входных данных.
easyaspi314
6 апр. 2020
Действительно; Чтобы быть более полным, мое предыдущее утверждение было направлено скорее на секцию большого размера для входных данных> 240 байт.
Но да, в ограниченном диапазоне размеров, когда входные данные должны точно соответствовать одному из 64-битных secret , возможна однобитная коллизия. Это казалось приемлемым, потому что коллизия, основанная на точном 64-битном вводе в определенном месте, все еще находится в пределах этой 1 / 2^64 территории, предполагая, что ввод является случайным (то есть не спроектирован для создания коллизии). Более того, secret для сопоставления может быть эффективно сделано _secret_, поэтому внешнему злоумышленнику придется переборщить, чтобы найти его.
Cyan4973
6 апр. 2020
Вы имеете в виду, что мы можем обмануть декодер, просто изменив 1 бит данных?
Принимая во внимание хеш-значения, полученные из двух разных типов содержимого, вероятность коллизий всегда равна
1 / 2^64(для качественных 64-битных алгоритмов хеширования, таких какxxh64илиxxh3), независимо от количество изменений между этими двумя содержаниями.Это действительно означает, что, по крайней мере теоретически, изменение одного бита может вызвать столкновение.
Теперь имейте в виду, что эта вероятность равна
1 / 2^64, что практически бесконечно мало.
Люди относительно плохо разбираются в этой теме. Иногда они объединяют это с «маленьким», что обычно воспринимается как осязаемое количество в сознании большинства людей, например ~ 10%.Чтобы получить более точное представление, я хотел бы обратиться к этой таблице:
то есть:
1 / 2 ^ 64намного ниже, чем шанс получить комету прямо на голову, и ниже, чем выигрыш в национальной лотерее _3 раза подряд_ (что было бы довольно подозрительно). На самом деле это намного ближе к "нулю". Большинство компонентов в любой системе подвержены поломке с гораздо большей вероятностью, чем это, начиная с других источников ошибок программного обеспечения.Если кто-то хочет найти такое теоретическое 1-битное столкновение, ему потребуются довольно гигантские входные данные и довольно невероятное количество мощности для решения этой проблемы методом грубой силы. Даже в этом случае решения может не существовать: учитывая характер используемой арифметики, я не удивлюсь, если будет невозможно создать коллизию с помощью однобитовой модификации. Моя собственная ставка заключается в том, что для этого требуется как минимум 2 бита, и даже в этом случае требуется разместить их в определенных позициях ввода, чтобы иметь шанс достичь желаемой цели, делая такую модификацию больше не "случайной", следовательно, выходящей за рамки возможностей для некриптографический хеш.
Но я думаю, что процитированный текст уже все это объясняет: у настоящих
crcесть гарантии на расстояние Хэмминга. Это может быть полезно, и это имело гораздо больший смысл в прошлом, когда сигналы были подвержены изменению на битовом уровне, а сама контрольная сумма была довольно маленькой (16 или 32 бит). У 16-битного хэш-алгоритма будет немалая вероятность пропустить коллизию, включающую очень небольшое количество битов, что делает его менее подходящим для задачи. Но с 64-битными или даже 128-битными хэшами сейчас на столе, я считаю, что это больше не опасный вариант просто потому, что шансы коллизии, а следовательно, и необнаруженного повреждения, непостижимо малы.Некоторые биты оказываются очень предсказуемыми или сильно коррелированными, и при их извлечении для целей хеширования дисперсия намного хуже.
Почему это плохо?
Хэши обычно имеют больше применений, чем просто замена контрольной суммы.
На самом деле, в большинстве случаев цель хеш-алгоритмов - предоставить некоторые случайные биты для обозначения позиции в хеш-таблице. Если некоторые из этих битов становятся предсказуемыми в зависимости от содержимого, это означает, что распределение позиций в хеш-таблице больше не будет «случайным», и, как следствие, некоторые ячейки будут переполняться быстрее, чем другие, что отрицательно скажется на производительности хеш-таблицы. .Если биты каким-то образом коррелированы, можем ли мы использовать эту корреляцию для восстановления поврежденного файла?
Это совсем другая тема.
Не удается восстановить поврежденный ввод с помощью CRC. CRC может только обнаружить ошибку, но не исправить ее.Самовосстановление данных - это тема, в которой используются различные (и гораздо более сложные в вычислительном отношении) методы, такие как сверточные коды. Это намного сложнее.
не могли бы вы подтвердить эти сценарии?
- LZ4 имеет контрольную сумму содержимого для каждого блока данных. Учтите, что у нас есть 10 ^ 6 пакетов по 1 ГБ файлов.
вероятность столкновения составляет 1/2 ^ 32 = 0,0000000002, это означает, что если мы отправим 10 ^ 10 (этот гигантский размер) пакетов, у нас может быть 2 столкновения (на основе принципа голубятни), но если мы отправим меньше этого количества, вероятность вероятность столкновения значительно снизится, так что мы сможем обнаружить все ошибки, декодер вычисляет контрольную сумму и сравнивает ее с контрольной суммой пакета, это правильно? - Контрольная сумма содержимого вычисляет контрольную сумму для сжатого файла (это необязательно, и мы можем использовать ее для обнаружения неисправности или уменьшения вероятности коллизии (до использования CC вероятность коллизии составляет 1/2 ^ 32, а затем она будет быть 1/2 ^ 64.)
arashams
8 апр. 2020
Описанный сценарий:
- Данные, сжатые LZ4, повреждены (что само по себе уже довольно редкое событие)
- Повреждение остается необнаруженным из-за хэш-коллизии.
Формат кадра LZ4 использует XXH32 , 32-битный хэш, в качестве сопутствующей контрольной суммы.
По умолчанию он применяется к содержимому всего кадра, точнее к _сжатому_ содержимому кадра (после распаковки), тем самым проверяя процесс передачи и декодирования.
Он также может дополнительно применить его к каждому блоку, и в этом случае он проверяет сумму _сжатого_ содержимого каждого блока.
Оба могут быть накоплены.
Чтобы остаться незамеченным, повреждение должно успешно пройти ___все___ контрольные суммы.
Предполагая, что контрольная сумма блока включена, и предполагая, что повреждение полностью локализовано в одном блоке, шансы прохождения и блока, и контрольной суммы кадра действительно равны 1 / 2^32 x 1 / 2^32 = 1 / 2^64 .
Теперь, если поврежденные данные находятся в нескольких блоках, либо из-за нескольких событий повреждения, либо из-за того, что один большой поврежденный раздел покрывает последовательные блоки, _это еще труднее остаться незамеченным_. Это должно было бы вызвать конфликт с каждой из задействованных контрольных сумм блока.
Например, если предположить, что повреждение распространяется на 2 блока, вероятность того, что это повреждение останется незамеченным, составляет 1 / 2^32 x 1 / 2^32 x 1 / 2^32 = 1 / 2^96 . Астрономически маленький.
Не считая того факта, что каждый поврежденный блок может быть обнаружен как не декодируемый процессом распаковки, который идет поверх этого.
Так что да, объединение контрольной суммы блока и кадра значительно увеличивает шансы обнаружения событий повреждения.
Cyan4973
8 апр. 2020
Описанный сценарий:
* LZ4-compressed data being corrupted (which is already a pretty rare event by itself) * Corruption remaining undetected due to hash collision.Формат кадра LZ4 использует
XXH32, 32-битный хэш, в качестве сопутствующей контрольной суммы.
По умолчанию он применяется к содержимому всего кадра, точнее к _сжатому_ содержимому кадра (после распаковки), тем самым проверяя процесс передачи и декодирования.
Он также может дополнительно применить его к каждому блоку, и в этом случае он проверяет сумму _сжатого_ содержимого каждого блока.
Оба могут быть накоплены.Чтобы остаться незамеченным, повреждение должно успешно пройти _ все _ применимые контрольные суммы.
Предполагая, что контрольная сумма блока включена, и предполагая, что повреждение полностью находится в пределах одного блока, шансы пройти и блок, и контрольную сумму кадра действительно равны1 / 2^32 x 1 / 2^32 = 1 / 2^64.Теперь, если поврежденные данные находятся в нескольких блоках, либо из-за нескольких событий повреждения, либо из-за того, что один большой поврежденный раздел покрывает последовательные блоки, _это еще труднее остаться незамеченным_. Это должно было бы вызвать конфликт с каждой из задействованных контрольных сумм блока.
Например, если предположить, что повреждение распространяется на 2 блока, вероятность того, что это повреждение останется незамеченным, составляет1 / 2^32 x 1 / 2^32 x 1 / 2^32 = 1 / 2^96. Астрономически маленький.Не считая того факта, что каждый поврежденный блок может быть обнаружен как не декодируемый процессом распаковки, который идет поверх этого.
Так что да, объединение контрольной суммы блока и кадра значительно увеличивает шансы обнаружения событий повреждения.
Можно ли использовать LZ4 на лету? Я имею в виду, сжимайте / распаковывайте данные, как только они у вас есть. это как-то конвейерное.
как насчет xxHash?
arashams
29 авг. 2020
Можно ли использовать LZ4 "на лету"? Я имею в виду, сжимайте / распаковывайте данные, как только они у вас есть.
Это потоковый режим. Да, это возможно.
как насчет xxHash?
Контрольная сумма кадра обновляется постоянно, но дает результат только в конце кадра. Следовательно, нет результата контрольной суммы для сравнения до конца события кадра (поток может состоять из нескольких добавленных кадров, но обычно этого не происходит).
Напротив, контрольные суммы блоков создаются в каждом блоке, поэтому они регулярно производятся и проверяются во время потоковой передачи.
Обе контрольные суммы используют XXH32 .
Cyan4973
29 авг. 2020
Смежные вопросы
 vp1981
·
7Комментарии
vp1981
·
7Комментарии
 vinniefalco
·
4Комментарии
vinniefalco
·
4Комментарии
 jtoivainen
·
4Комментарии
jtoivainen
·
4Комментарии
 xinglin
·
6Комментарии
xinglin
·
6Комментарии
 yassinm
·
5Комментарии
yassinm
·
5Комментарии
Самый полезный комментарий
Алгоритмы CRC обычно обеспечивают гарантии обнаружения ошибок в условиях расстояний Хэмминга. Учитывая ограниченное количество переворотов битов, CRC _обязательно_ генерирует другой результат.
Это может оказаться полезным в ситуациях, когда предполагается, что ошибки изменяют только несколько бит.
Всего несколько десятилетий назад это было относительно обычным явлением, особенно в сценариях передачи, поскольку базовый сигнал все еще был очень «сырым», поэтому необнаруженные перевороты битов на физическом уровне имели место.
Однако это свойство имеет распределительную стоимость. Как только «безопасное» расстояние Хэмминга пересечено, вероятность столкновения становится хуже. Это логическое следствие принципа «голубятни». Насколько хуже? Ну, это зависит от точного CRC, но я ожидаю, что хороший CRC будет в 3-7 раз хуже. Это может показаться многословным, но это всего лишь уменьшение дисперсии на 2-3 бита, так что это не так уж и страшно. По-прежнему.
Сравните это с хешем с «идеальным» свойством распределения: любое изменение, независимо от того, является ли оно единственным битом или совершенно другим выходом, имеет вероятность ровно 1/2 ^ n вызвать коллизию. Это проще понять: риск столкновения всегда одинаков. При прямом сравнении с CRC, когда расстояние Хэмминга мало, частота столкновений хуже (поскольку оно> 0), но лучше, когда расстояние Хэмминга большое.
Перенесемся в наши дни, и ситуация в корне изменилась. У нас есть уровни за слоями логики обнаружения и исправления ошибок над физическим носителем. Мы не можем просто извлечь бит из блока флеш-памяти или прочитать бит из канала Bluetooth. Это больше не имеет смысла. Эти протоколы включают логику блоков с отслеживанием состояния, которая является более сложной, более устойчивой и постоянно компенсирует постоянный шум физического уровня. Когда они терпят неудачу, это не приведет к единственному перевороту: скорее, вся область данных будет полностью искажена, состоящая только из нулей или даже случайного шума.
В этой новой среде ставка заключается в том, что ошибки, когда они происходят, больше не относятся к категории «переворота битов». В этом случае распределительные свойства CRC становятся обязательством. Чистый хеш на самом деле имеет меньшую вероятность возникновения коллизии.
Это только при учете контрольной суммы.
Дополнительным свойством «идеального» хеша является то, что при извлечении любого сегмента битов из хеша он по-прежнему имеет вероятность столкновения
1 / 2^n, которая очень важна как источник бит для других структур, таких как хэш-таблица или фильтр Блума. Напротив, CRC не предоставляет такой гарантии. Некоторые биты оказываются очень предсказуемыми или сильно коррелированными, и при их извлечении для целей хеширования дисперсия намного хуже.Можно сказать, что контрольная сумма и хеширование - это просто два разных домена, и их не следует путать. Действительно, это теория. Проблема в том, что при этом игнорируются удобство и практика. Удобно иметь один «миксер» для различных целей, и программисты довольствуются одним и забудут о нем. Я не могу сосчитать, сколько раз я видел, что crc32 используется для хеширования, просто потому, что он казался «достаточно случайным». Легко сказать, что этого не должно происходить, но так происходит постоянно.
В этой среде предложение решения, разработанного для обоих вариантов использования, имеет смысл, поскольку оно соответствует ожиданиям пользователей.
Благодаря свойствам хорошего хеша, действительно можно извлечь из хеша 8 или 16 бит, что дает вероятность столкновения 1/256 или 1/65535. Я не вижу по этому поводу беспокойства.
Просто мы должны принять задержку _history_. Люди привыкли к определенному образу жизни, например, к использованию определенных функций контрольной суммы для вычисления контрольной суммы. Даже если есть более свежие и потенциально лучшие решения, привычки не меняются быстро.