Godot: Menggunakan struktur data paling lambat hampir setiap saat.
Saya sedang meninjau kode godot, dan saya telah menemukan pengabaian total untuk segala jenis kinerja sisi cpu, hingga ke struktur data inti. Ini menggunakan Daftar di mana-mana, ketika daftar tertaut adalah struktur data paling lambat yang dapat Anda gunakan pada PC modern. Hampir semua struktur data lain akan lebih cepat, khususnya pada struktur berukuran kecil. Ini sangat mengerikan pada hal-hal seperti daftar cahaya atau tangkapan refleksi dalam renderables, di mana Anda menyimpan 3 pointer setiap kali, alih-alih hanya memberinya susunan tumpukan 8 lampu maks (misalnya) + tambahan untuk kasus-kasus di mana itu akan terjadi lebih dari itu.
Hal yang sama dengan RID_Owner menjadi pohon yang bisa berupa peta hash, atau peta slot. Juga implementasi Octree untuk pemusnahan memiliki masalah yang sama persis.
Saya ingin bertanya tentang maksud desain di balik penggunaan daftar tertaut yang berlebihan dan absolut dan penunjuk kinerja yang mengerikan struktur data berat di mana-mana dalam kode. Apakah itu karena alasan tertentu? Dalam sebagian besar kasus, daftar tertaut "terpotong", di mana Anda melakukan daftar array yang ditautkan akan secara otomatis membawa peningkatan kinerja pada kode yang sama.
Penggunaan struktur data ini juga mencegah segala jenis paralelisme "mudah" dalam potongan kode yang baik dan benar-benar mengosongkan cache.
Saya sedang mengerjakan bukti implementasi konsep dari refactoring beberapa internal untuk menggunakan struktur data yang lebih baik. Saat ini saya sedang mengerjakan penulisan ulang kode pemusnahan yang melewati octree saat ini dan hanya menggunakan array datar dengan paralelisme opsional. Saya akan menggunakan tps-demo sebagai tolok ukur dan kembali dengan hasil, yang sebenarnya saya telah membuat tolok ukur untuk naik 25 level pada oktre...
Pada catatan lain yang lebih menyenangkan, saya sangat terkesan dengan kualitas gaya kode, semuanya mudah diikuti dan dipahami, dan dikomentari dengan cukup baik.
 vblanco20-1
vblanco20-1
Semua 61 komentar
Siapa yang butuh kinerja? :muka mengejek:
 mafiesto4
pada 27 Nov 2018
mafiesto4
pada 27 Nov 2018
Penasaran untuk melihat apa yang Anda ukur.
 avencherus
pada 27 Nov 2018
avencherus
pada 27 Nov 2018
Jadi ini bisa menjelaskan mengapa node Light2D sederhana di Godot dapat membakar komputer Anda?
 Ranoller
pada 27 Nov 2018
Ranoller
pada 27 Nov 2018
@Ranoller saya rasa tidak. Performa pencahayaan yang buruk kemungkinan besar terkait dengan bagaimana Godot melakukan pencahayaan 2D saat ini: Rendering setiap sprite n-kali (dengan n adalah jumlah lampu yang memengaruhinya).
Sunting: lihat #23593
 CptPotato
pada 27 Nov 2018
CptPotato
pada 27 Nov 2018
Untuk memperjelas, ini tentang inefisiensi sisi CPU di seluruh kode. Ini tidak ada hubungannya dengan fitur godot atau rendering GPU godot itu sendiri.
vblanco20-1
pada 27 Nov 2018
@ vblanco20-1 pada sedikit sisi singgung, Anda dan saya telah berbicara tentang node yang dimodelkan sebagai entitas ECS sebagai gantinya. Saya ingin tahu apakah triknya adalah melakukan cabang fitur godot dengan modul ent baru yang secara bertahap akan bekerja berdampingan dengan pohon. seperti get_tree() dan get_registry(). modul ent mungkin akan kehilangan seperti 80% dari fungsionalitas pohon/adegan, tetapi itu bisa berguna sebagai testbed, terutama untuk hal-hal seperti menyusun level statis besar dengan banyak objek (pemusnahan, streaming, rendering batch). Fungsionalitas dan fleksibilitas berkurang tetapi kinerja lebih baik.
 pgruenbacher
pada 27 Nov 2018
pgruenbacher
pada 27 Nov 2018
Sebelum melakukan ECS penuh (yang mungkin saya lakukan) saya ingin mengerjakan beberapa buah yang menggantung rendah sebagai percobaan. Saya mungkin mencoba untuk berorientasi pada data penuh nanti.
vblanco20-1
pada 27 Nov 2018
Jadi, pembaruan pertama:
update_dirty_instances : dari 0,2-0,25 milidetik hingga 0,1 milidetik
octree_cull (tampilan utama): dari 0,35 milidetik hingga 0,1 milidetik
Bagian yang menyenangkan? penggantian octree cull tidak menggunakan struktur akselerasi apa pun, itu hanya mengulangi array bodoh dengan semua AABB.
Bagian yang lebih lucu? Pemusnahan baru adalah 10 baris kode. Jika saya ingin memilikinya paralel, itu akan menjadi satu perubahan pada garis.
Saya akan melanjutkan penerapan pemusnahan baru saya dengan lampu, untuk melihat berapa banyak percepatan yang terakumulasi.
vblanco20-1
pada 1 Des 2018
kita mungkin harus mendapatkan direktori benchmark google juga di cabang master. Itu dapat membantu dengan memvalidasi sehingga orang tidak perlu berdebat tentang hal itu.
pgruenbacher
pada 1 Des 2018
Ada repositori godotengine/godot-tests , tetapi belum banyak orang yang menggunakannya.
 bojidar-bg
pada 2 Des 2018
bojidar-bg
pada 2 Des 2018
Pembaruan baru:

Saya telah menerapkan struktur percepatan spasial yang cukup bodoh, dengan 2 level. Saya hanya membuatnya setiap frame Perbaikan lebih lanjut bisa membuatnya lebih baik dan memperbaruinya secara dinamis daripada membuat ulang.
Pada gambar, baris yang berbeda adalah cakupan yang berbeda, dan masing-masing blok berwarna adalah tugas/potongan kode. Dalam penangkapan itu, saya melakukan pemusnahan octree dan pemusnahan saya secara berdampingan untuk mendapatkan perbandingan langsung
Ini menunjukkan bahwa menciptakan kembali seluruh struktur akselerasi lebih cepat daripada satu pemusnahan oktree lama.
Juga bahwa pemusnahan lebih lanjut cenderung sekitar setengah hingga sepertiga dari oktre saat ini.
Saya belum menemukan satu kasus di mana struktur bodoh saya lebih lambat dari oktre saat ini, selain biaya pembuatan awal.
Bonus lainnya adalah sangat ramah multithread, dan dapat diskalakan ke jumlah inti apa pun yang Anda inginkan hanya dengan paralel.
Itu juga memeriksa memori sepenuhnya secara berurutan, jadi seharusnya memungkinkan untuk membuatnya melakukan SIMD tanpa banyak kesulitan.
Detail penting lainnya adalah bahwa ini jauh lebih sederhana daripada octree saat ini, dengan baris kode yang jauh lebih sedikit.
vblanco20-1
pada 2 Des 2018
Anda menyebabkan lebih banyak hype bahwa akhir permainan takhta ....
Ranoller
pada 2 Des 2018

Memodifikasi algoritma sedikit sehingga sekarang mereka dapat menggunakan algoritma paralel C++17, yang memungkinkan programmer untuk hanya menyuruhnya melakukan paralel untuk, atau pengurutan paralel.
Speedup sekitar x2 di frustrum cull utama, tapi untuk lampu kira-kira kecepatannya sama seperti sebelumnya.
Culler saya sekarang 10 kali lebih cepat dari godot octree untuk tampilan utama.
vblanco20-1
pada 2 Des 2018
Jika Anda ingin melihat perubahannya, yang utama dan penting ada di sini:
https://github.com/vblanco20-1/godot/blob/4ab733200faa20e0dadc9306e7cc93230ebc120a/servers/visual/visual_server_scene.cpp#L387
Ini adalah fungsi pemusnahan baru. Struktur percepatan ada pada fungsi tepat di atasnya.
vblanco20-1
pada 2 Des 2018
Ini harus dikompilasi dengan VS2015? Konsol memunculkan banyak kesalahan tentang file di dalam entt\
Ranoller
pada 2 Des 2018
@Ranoller ini c++17 jadi pastikan Anda menggunakan kompiler yang lebih baru
pgruenbacher
pada 3 Des 2018
Uh, sepertinya Godot belum pindah ke c++17? Setidaknya saya ingat beberapa diskusi tentang topik ini?
 Zireael07
pada 3 Des 2018
Zireael07
pada 3 Des 2018
Godot adalah C++ 03. Langkah ini akan kontroversial. Saya merekomendasikan @vblanco20-1 untuk berbicara dengan Juan ketika dia menyelesaikan hollydays... pengoptimalan ini akan sangat bagus dan kami tidak ingin langsung "Ini Tidak Akan Pernah Terjadi TM
Ranoller
pada 3 Des 2018
@vblanco20-1
octree_cull (tampilan utama): dari 0,35 milidetik hingga 0,1 milidetik
berapa banyak objek?
 nem0
pada 3 Des 2018
nem0
pada 3 Des 2018
@nem0
@vblanco20-1
octree_cull (tampilan utama): dari 0,35 milidetik hingga 0,1 milidetik
berapa banyak objek?
Sekitar 2200. Godot octree berkinerja lebih baik jika ceknya sangat kecil, karena keluar lebih awal. Semakin besar kueri, semakin lambat godot octree dibandingkan dengan solusi saya. Jika godot octree tidak bisa keluar lebih awal dari 90% dari adegan, maka itu sangat lambat, karena pada dasarnya iterasi daftar tertaut untuk setiap objek, sementara sistem saya adalah struktur array di mana setiap baris cache menyimpan jumlah AABB yang baik, sangat mengurangi cache meleset.
Sistem saya bekerja dengan memiliki 2 level AABB, ini adalah array blok, di mana setiap blok dapat menampung 128 instance.
Tingkat atas sebagian besar merupakan array AABB + array Blok. Jika pemeriksaan AABB lolos, maka saya mengulangi blok tersebut. Blok adalah susunan struktur AABB, Mask, dan pointer ke instance. Dengan cara ini semuanya faaaaast.
Saat ini, pembuatan struktur data tingkat atas dilakukan dengan cara yang sangat bodoh. Jika dihasilkan lebih baik, kinerjanya bisa jauh lebih besar. Saya melakukan beberapa percobaan dengan ukuran blok yang berbeda selain 128.
vblanco20-1
pada 3 Des 2018
Saya telah memeriksa nomor yang berbeda, dan 128 per blok tampaknya masih menjadi sweetspot.
Dengan mengubah algoritma untuk memisahkan objek "besar" dari objek kecil, saya berhasil mendapatkan peningkatan kecepatan 30% lainnya, sebagian besar jika Anda tidak melihat ke tengah peta. Ini berfungsi karena dengan cara itu benda-benda besar tidak mengasapi blok AABB yang juga mencakup benda-benda kecil. Saya percaya bahwa 3 ukuran mungkin akan bekerja paling baik.
Pembuatan blok masih belum optimal sama sekali. Blok besar hanya menyisihkan sekitar 10 hingga 20% dari instance saat melihat ke tengah, dan hingga 50% saat melihat ke luar peta, jadi ini melakukan BANYAK pemeriksaan AABB tambahan daripada yang seharusnya dibutuhkan.
Saya pikir peningkatan mungkin adalah menggunakan kembali oktre saat ini tetapi "meratakannya".
Sekarang tidak ada satu pun kasus di mana algoritma saya sama atau lebih buruk dari oktre saat ini, bahkan tanpa eksekusi paralel.
vblanco20-1
pada 3 Des 2018
@vblanco20-1 Saya berasumsi Anda melakukan perbandingan dengan godot yang dikompilasi dalam mode release (yang menggunakan -O3 ) dan bukan editor biasa yang dibangun di debug (yang tidak memiliki optimasi dan default) benar ?
Maaf jika ini pertanyaan konyol tapi saya tidak melihat hal itu disebutkan di utas.
Kerja bagus kok :)
 Faless
pada 11 Des 2018
Faless
pada 11 Des 2018
@Faless Rilis_debugnya , yang menambahkan beberapa optimasi. Saya belum bisa menguji "rilis" penuh karena saya tidak bisa membukanya (permainan perlu dibangun juga?)
Saya punya ide tentang cara meningkatkan pemusnahan lebih banyak lagi, menghilangkan kebutuhan untuk membuat ulang setiap bingkai, dan menciptakan pengoptimalan spasial yang lebih baik. Saya akan melihat apa yang bisa saya coba. Secara teori hal seperti itu dapat menghapus regenerasi, sedikit meningkatkan kinerja pemusnahan utama, dan memiliki mode khusus untuk lampu titik yang akan meningkatkan kinerja pemusnahan mereka dengan jumlah yang sangat besar, sedemikian rupa sehingga mereka akan memiliki biaya hampir 0, karena itu akan berubah menjadi O(1) murah untuk mendapatkan "objek dalam radius".
Ini terinspirasi oleh bagaimana salah satu eksperimen saya bekerja, di mana saya melakukan 400.000 objek fisika yang saling memantul.
vblanco20-1
pada 11 Des 2018

Pemusnahan baru diterapkan sekarang. Pembuatan blok sekarang jauh lebih pintar, menghasilkan pemusnahan yang lebih cepat. Kasus khusus untuk lampu belum diterapkan.
Saya sudah berkomitmen untuk garpu saya
vblanco20-1
pada 12 Des 2018
Saya ingin tahu apakah Anda dapat menjalankan alat benchmark itu (yang dari tangkapan layar Anda) pada build dari cabang master saat ini, untuk memberi kami titik referensi tentang seberapa banyak kinerja yang diberikan implementasi Anda selama implementasi saat ini. Aku bodoh, woops.
 LikeLakers2
pada 13 Des 2018
LikeLakers2
pada 13 Des 2018
@LikeLakers2 Anda dapat melihat implementasi saat ini dan implementasinya di tangkapan layar.
 neikeq
pada 13 Des 2018
neikeq
pada 13 Des 2018
Dia menjalankan ini pada garpu utama
Pada hari Rabu, 12 Desember 2018, MichiRecRoom [email protected]
menulis:
@neikeq https://github.com/neikeq Jelaskan? Saya pikir tangkapan layar
yang telah diposting hanya implementasi nya, mengingat bagaimana posting
dengan screenshot telah worded sejauh ini.—
Anda menerima ini karena Anda berkomentar.
Balas email ini secara langsung, lihat di GitHub
https://github.com/godotengine/godot/issues/23998#issuecomment-446831151 ,
atau matikan utasnya
https://github.com/notifications/unsubscribe-auth/ADLZ9pRh9Lksse9KBfWV0z5GmHRXf5P2ks5u4crCgaJpZM4YziJp
.
pgruenbacher
pada 13 Des 2018
Apakah ada berita tentang topik ini?
CptPotato
pada 15 Jan 2019
Apakah ada berita tentang topik ini?
Saya berbicara dengan reduz. Tidak akan pernah digabungkan karena tidak sesuai dengan proyek. Saya pergi untuk melakukan eksperimen lain sebagai gantinya. Mungkin saya meningkatkan pemusnahan nanti untuk 4.0
vblanco20-1
pada 15 Jan 2019
Sayang sekali, mengingat itu terlihat sangat menjanjikan. Semoga masalah-masalah ini dapat diselesaikan tepat waktu.
CptPotato
pada 15 Jan 2019
Mungkin ini harus diberikan tonggak 4.0? Karena Reduz berencana untuk mengerjakan Vulkan untuk 4.0, dan topik ini, sementara tentang kinerja, difokuskan pada rendering, atau setidaknya OP.
 aaronfranke
pada 4 Feb 2019
aaronfranke
pada 4 Feb 2019
@ vblanco20-1 Apakah dia mengatakan bagaimana itu tidak cocok? Saya berasumsi karena pindah ke c++17?
 Two-Tone
pada 6 Feb 2019
Two-Tone
pada 6 Feb 2019
Ada masalah terkait lainnya pada tonggak sejarah: #25013
 starry-abyss
pada 6 Feb 2019
starry-abyss
pada 6 Feb 2019
Anda mungkin tertarik. Saya telah mengerjakan garpu mewah cukup lama. Hasil saat ini seperti ini:
Ditangkap di laptop gaming besar dengan cpu intel 4 inti dan GTX 1070
Godot biasa
Garpu saya di https://github.com/vblanco20-1/godot/tree/ECS_Refactor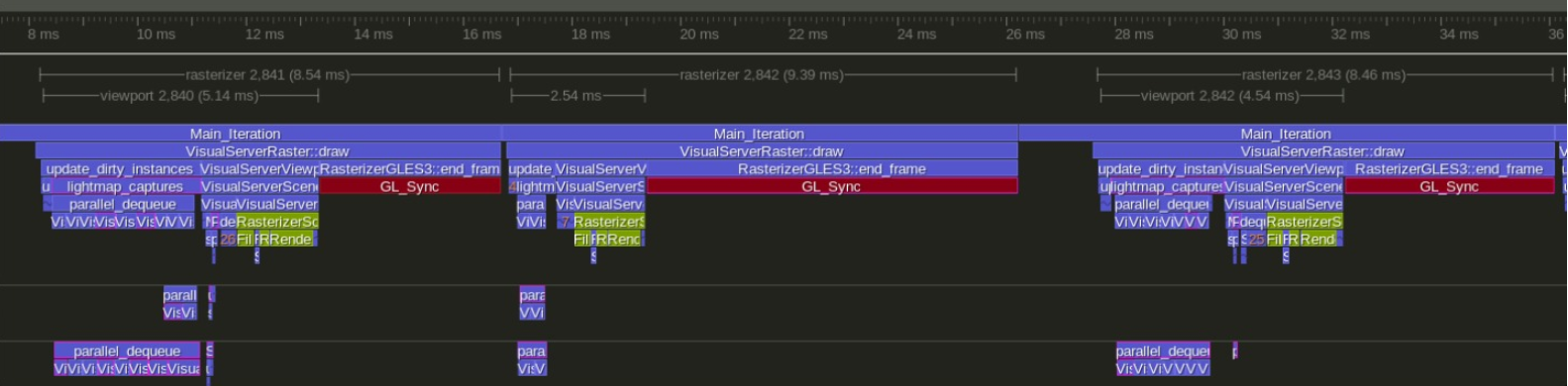
Di kedua profil, Merah pada dasarnya adalah "menunggu GPU". Saat ini macet karena terlalu banyak penarikan di opengl. Tidak dapat benar-benar diselesaikan tanpa vulkan atau menulis ulang seluruh penyaji.
Di sisi CPU, kami beralih dari frame 13 ms ke frame 5 ms. Frame "Cepat" berubah dari 5,5 md menjadi 2,5 md
Di sisi "bingkai total", kita beralih dari 13 md ke 8-9 md
~75 FPS hingga ~115 FPS
Lebih sedikit waktu CPU = lebih banyak waktu yang dapat Anda habiskan untuk bermain game. Godot saat ini terhambat pada CPU, jadi lebih banyak waktu yang dihabiskan untuk gameplay akan berarti FPS yang lebih rendah, sementara garpu saya terikat GPU, sehingga Anda dapat menambahkan lebih banyak logika gameplay dengan FPS yang tidak tersentuh karena CPU hanya "gratis" untuk cukup lama setiap frame.
BANYAK perbaikan ini dapat digabungkan menjadi godot, JIKA godot mendukung C++ modern dan memiliki sistem multithreading yang memungkinkan tugas "kecil" yang sangat murah.
Keuntungan terbesar dilakukan dengan melakukan pembacaan multithreaded shadows dan multithreaded lightmap pada objek dinamis #25013. Keduanya bekerja dengan cara yang sama. Banyak bagian lain dari penyaji juga multithread.
Keuntungan lainnya adalah Octree yang 10 hingga 20 kali lebih cepat dari godot one, dan peningkatan pada beberapa aliran rendering, seperti merekam daftar render depth-prepass dan normal-pass sekaligus, alih-alih mengulangi daftar cull 2 kali, dan perubahan signifikan pada cara kerja koneksi light->mesh (tidak ada daftar tertaut!)
Saat ini saya mencari lebih banyak peta uji selain demo TPS sehingga saya dapat memiliki lebih banyak metrik di jenis peta lainnya. Saya juga akan menulis serangkaian artikel yang menjelaskan bagaimana semua ini bekerja secara rinci.
vblanco20-1
pada 1 Jun 2019
@vblanco20-1 ini benar-benar luar biasa. Terima kasih telah berbagi!
Saya juga setuju bahwa meskipun Vulkan keren, memiliki kinerja GLES3 yang layak akan menjadi kemenangan mutlak bagi Godot. Dukungan penuh Vulkan kemungkinan tidak akan tersedia dalam waktu dekat sementara patching GLES3 adalah sesuatu yang terbukti sepenuhnya dapat dilakukan oleh orang-orang di sini saat ini.
+1 besar saya untuk membawa lebih banyak perhatian ke ini. Saya akan menjadi orang paling bahagia di Bumi jika Reduz setuju untuk mengizinkan komunitas meningkatkan GLES3. Kami sedang mengerjakan proyek 3D yang sangat serius di Godot selama 1,5 tahun sekarang, dan kami sangat mendukung Godot (termasuk donasi), tetapi kurangnya 60 FPS yang solid benar-benar menurunkan motivasi kami dan menempatkan semua upaya kami di bawah risiko besar.
Sayang sekali ini tidak mendapatkan kredit yang cukup. Jika kami tidak memiliki 60 FPS dalam beberapa bulan mendatang dengan proyek kami saat ini (cukup sederhana dalam hal 3D), kami akan gagal menghadirkan game yang dapat dimainkan dan dengan demikian semua upaya akan sia-sia. :/
@vblanco20-1 sejujurnya, saya bahkan mempertimbangkan untuk menggunakan garpu Anda sebagai basis game kami dalam produksi.
PS Beberapa pemikiran: sebagai upaya terakhir, saya pikir itu benar-benar mungkin untuk memiliki, katakanlah, 2 rasterizer GLES3 - komunitas GLES3 & GLES3.
 and3rson
pada 1 Jun 2019
and3rson
pada 1 Jun 2019
PS Beberapa pemikiran: sebagai upaya terakhir, saya pikir itu benar-benar mungkin untuk memiliki, katakanlah, 2 rasterizer GLES3 - komunitas GLES3 & GLES3.
Itu tidak masuk akal bagi saya; mungkin ide yang lebih baik untuk mendapatkan perbaikan dan peningkatan kinerja langsung ke perender GLES3 dan GLES2 (selama mereka tidak merusak rendering dengan cara utama dalam proyek yang ada).
Keuntungan lainnya adalah Octree yang 10 hingga 20 kali lebih cepat dari godot one, dan peningkatan pada beberapa aliran rendering, seperti merekam daftar render depth-prepass dan normal-pass sekaligus, alih-alih mengulangi daftar cull 2 kali, dan perubahan signifikan pada cara kerja koneksi light->mesh (tidak ada daftar tertaut!)
@vblanco20-1 Apakah mungkin untuk mengoptimalkan kedalaman prepass sambil tetap menggunakan C++03?
 Calinou
pada 1 Jun 2019
Calinou
pada 1 Jun 2019
@Calinou hal-hal prepass kedalaman adalah salah satu hal yang tidak memerlukan apa-apa dan sangat mudah digabungkan. Kelemahan utamanya adalah bahwa itu akan membutuhkan penyaji untuk menggunakan memori ekstra. Karena sekarang akan membutuhkan 2 RenderList, bukan hanya satu. Selain memori ekstra, hampir tidak ada kerugian. Biaya membangun daftar render untuk 1 pass atau 2 hampir sama berkat caching cpu, jadi itu benar-benar menghilangkan biaya prepass fill_list()
vblanco20-1
pada 1 Jun 2019
@vblanco20-1 sejujurnya, saya bahkan mempertimbangkan untuk menggunakan garpu Anda sebagai basis game kami dalam produksi.
@and3rson tolong jangan. Garpu ini murni proyek penelitian, dan bahkan tidak sepenuhnya stabil. Bahkan tidak akan dikompilasi di luar beberapa kompiler yang sangat spesifik karena penggunaan STL paralel. Garpu sebagian besar merupakan testbed ide dan praktik optimasi acak.
vblanco20-1
pada 1 Jun 2019
Alat apa yang Anda gunakan untuk membuat profil Godot? Apakah Anda perlu menambahkan flag Profiler.Begin dan Profiler.End ke sumber godot untuk menghasilkan sampel ini?
 jknightdoeswork
pada 2 Jun 2019
jknightdoeswork
pada 2 Jun 2019
Alat apa yang Anda gunakan untuk membuat profil Godot? Apakah Anda perlu menambahkan flag Profiler.Begin dan Profiler.End ke sumber godot untuk menghasilkan sampel ini?
Ini menggunakan profiler Tracy, ia memiliki berbagai jenis tanda profil lingkup, yang saya gunakan di sini. Misalnya ZoneScopedNC("Isi Daftar", 0x123abc) menambahkan tanda profil dengan nama itu dan warna hex yang Anda inginkan.
vblanco20-1
pada 2 Jun 2019
@vblanco20-1 - Apakah kita akan melihat beberapa peningkatan kinerja ini dibawa ke cabang utama godot?
 HeadClot
pada 2 Jun 2019
HeadClot
pada 2 Jun 2019
@vblanco20-1 - Apakah kita akan melihat beberapa peningkatan kinerja ini dibawa ke cabang utama godot?
Mungkin ketika C++ 11 didukung. Tapi reduz tidak benar-benar ingin lebih banyak pekerjaan pada penyaji sebelum vulkan terjadi, jadi mungkin tidak akan pernah. Beberapa temuan dari pekerjaan optimasi dapat berguna untuk penyaji 4.0.
vblanco20-1
pada 2 Jun 2019
@ vblanco20-1 keberatan berbagi kompiler dan detail lingkungan untuk cabang, saya pikir saya bisa mengetahui sebagian besar tetapi jangan buang waktu untuk mencari tahu masalah jika saya tidak perlu.
Juga tidak bisakah kita menambahkan perubahan AABB ke Godot main tanpa banyak biaya?
 swarnimarun
pada 2 Jun 2019
swarnimarun
pada 2 Jun 2019
@ vblanco20-1 keberatan berbagi kompiler dan detail lingkungan untuk cabang, saya pikir saya bisa mengetahui sebagian besar tetapi jangan buang waktu untuk mencari tahu masalah jika saya tidak perlu.
Juga tidak bisakah kita menambahkan perubahan AABB ke Godot main tanpa banyak biaya?
@swarnimarun Visual Studio 17 atau 19, salah satu pembaruan selanjutnya, berfungsi dengan baik. (jendela)
Skrip scons dimodifikasi untuk menambahkan flag cpp17. Juga, meluncurkan editor rusak sekarang. Saya sedang bekerja untuk melihat apakah saya dapat memulihkannya.
Sayangnya perubahan AABB adalah salah satu hal terbesar. Godot octree terjalin dengan BANYAK hal di server visual. Ini tidak hanya melacak objek untuk pemusnahan, tetapi juga menghubungkan objek ke probe lampu/pantulan, dengan sistemnya sendiri untuk memasangkannya. Pasangan tersebut juga bergantung pada struktur daftar tertaut dari octree, sehingga hampir tidak mungkin untuk mengadaptasi octree saat ini menjadi lebih cepat tanpa mengubah cukup banyak server visual. Sebenarnya saya masih belum bisa menyingkirkan octree godot normal di fork saya untuk beberapa jenis objek.
vblanco20-1
pada 2 Jun 2019
@vblanco20-1 Apakah Anda memiliki Patreon? Saya akan mengeluarkan sejumlah uang untuk garpu yang berfokus pada kinerja dan itu tidak membatasi diri pada C++ kuno dan saya mungkin bukan satu-satunya. Saya ingin bermain-main dengan Godot untuk proyek 3D tetapi saya kehilangan harapan bahwa itu akan menjadi layak tanpa bukti besar sebuah konsep yang membuktikan pendekatan Anda terhadap kinerja dan kegunaan untuk tim inti.
 mixedCase
pada 3 Jun 2019
mixedCase
pada 3 Jun 2019
@mixedCase Saya akan sangat ragu untuk mendukung segala jenis garpu Godot. Forking dan fragmentasi sering menjadi kematian proyek open source.
Skenario yang lebih baik, dan lebih mungkin sekarang setelah ditunjukkan bahwa C++ yang lebih baru memungkinkan pengoptimalan yang signifikan, adalah bagi Godot untuk secara resmi meningkatkan ke versi C++ yang lebih baru. Saya berharap ini terjadi di Godot 4.0, untuk meminimalkan risiko kerusakan di 3.2, dan pada waktunya agar fitur C++ baru digunakan dengan Vulkan ditambahkan ke Godot 4.0. Saya juga tidak mengharapkan perubahan signifikan akan dilakukan pada penyaji GLES 3, karena reduz ingin menghapusnya.
(Tapi saya tidak berbicara untuk para pengembang Godot, ini hanya spekulasi saya)
aaronfranke
pada 8 Jun 2019
@aaronfranke Saya setuju, saya pikir garpu permanen tidak akan ideal. Tapi dari apa yang saya kumpulkan dari apa yang dia katakan (tolong koreksi saya jika saya salah) adalah bahwa @reduz percaya bahwa fitur-fitur baru ini tidak boleh digunakan karena mereka tidak membawa sesuatu yang cukup signifikan untuk dipelajari konsepnya dan karena dia menganggap beberapa dari mereka membuat kode "tidak dapat dibaca" (setidaknya untuk pengembang yang terbiasa dengan "augmented C" bahwa C++ hampir 10 tahun yang lalu).
Saya percaya Juan adalah orang yang sangat pragmatis, jadi mungkin diperlukan bukti besar dari konsep yang menunjukkan manfaat menggunakan abstraksi modern dan struktur data yang lebih efisien untuk meyakinkannya bahwa trade off teknik mungkin sepadan. @vblanco20-1 telah melakukan pekerjaan luar biasa sejauh ini, jadi saya pribadi tidak akan ragu untuk memberikan sejumlah uang setiap bulan kepadanya jika dia ingin melakukan sesuatu seperti itu.
mixedCase
pada 10 Jun 2019
Saya terus-menerus kagum bagaimana para pengembang Godot bertindak seolah-olah mereka alergi terhadap ide, kinerja, dan kemajuan yang bagus. Sayang ini tidak ditarik.
 plabuda
pada 16 Jul 2019
plabuda
pada 16 Jul 2019
Ini adalah bagian dari serangkaian artikel yang saya kerjakan tentang pengoptimalan, tepatnya tentang penggunaan struktur data.
Godot melarang kontainer STL, dan C++03-nya. Ini berarti tidak ada operator pemindahan di kontainernya, dan kontainernya cenderung lebih buruk daripada kontainer STL itu sendiri. Di sini saya memiliki ikhtisar tentang struktur data godot, dan masalah dengannya.
Array C++ yang telah dialokasikan sebelumnya. Sangat umum di sekitar seluruh mesin. Ukurannya cenderung diatur oleh beberapa opsi konfigurasi. Ini sangat umum di perender, dan kelas array dinamis yang tepat akan bekerja dengan baik di sini.
Contoh penyalahgunaan: https://github.com/godotengine/godot/blob/master/servers/visual/visual_server_scene.h#L442
Array ini membuang-buang memori tanpa alasan yang baik, menggunakan array dinamis akan menjadi pilihan yang jauh lebih baik di sini karena akan membuat mereka hanya ukuran yang mereka butuhkan, bukan ukuran maksimum dengan konstanta kompilasi. Setiap array Instance* yang menggunakan MAX_INSTANCE_CULL menggunakan setengah megabyte memori
Vektor ( vector.h) a std::vector ekuivalen array dinamis, tetapi dengan cacat yang dalam.
Vektor secara atom dihitung ulang dengan implementasi copy-on-write. Saat kamu melakukan
Vektor a = build_vector();
Vektor b = a;
refcount akan menuju ke 2. B dan A sekarang menunjuk ke lokasi yang sama di memori, dan akan menyalin larik setelah dilakukan pengeditan. Jika Anda sekarang memodifikasi vektor A atau B, itu akan memicu salinan vektor.
Setiap kali Anda menulis ke dalam vektor, ia perlu memeriksa penghitungan atom, memperlambat setiap operasi penulisan dalam vektor. Diperkirakan godot Vector adalah 5 kali lebih lambat dari std::vector, minimal. Masalah lainnya adalah bahwa vektor akan dipindahkan secara otomatis saat Anda menghapus item darinya, menyebabkan masalah kinerja yang tidak terkendali.
PoolVector (pool_vector.h). Kurang lebih sama dengan vector, tapi sebagai pool. Ini memiliki perangkap yang sama dengan Vector, dengan copy on write tanpa alasan dan perampingan otomatis.
Daftar ( list.h) setara dengan std::list. Daftar ini memiliki 2 pointer (pertama dan terakhir) + variabel jumlah elemen. Setiap simpul dalam daftar ditautkan ganda, ditambah penunjuk tambahan ke wadah daftar itu sendiri. Overhead memori untuk setiap node dari daftar adalah 24 byte. Ini sangat berlebihan digunakan di godot karena Vector secara umum tidak terlalu bagus. Sangat disalahgunakan di seluruh mesin.
Contoh penyalahgunaan besar:
https://github.com/godotengine/godot/blob/master/servers/visual/visual_server_scene.h#L129
Tidak ada alasan apa pun untuk ini menjadi daftar, harus menjadi vektor
https://github.com/godotengine/godot/blob/master/servers/visual/visual_server_scene.h#L242
Setiap kasus ini salah. lagi, itu harus vektor atau serupa. Yang ini sebenarnya dapat menyebabkan masalah kinerja.
Kesalahan terbesar adalah menggunakan Daftar dalam oktre yang digunakan untuk pemusnahan. Saya sudah membahas detail tentang godot octree di utas ini.
SelfList(self_list.h) daftar intrusif, mirip dengan boost::intrusive_list. Yang ini selalu menyimpan 32 byte overhead per node karena juga menunjuk ke diri sendiri. Sangat disalahgunakan di seluruh mesin.
Contoh:
https://github.com/godotengine/godot/blob/master/servers/visual/visual_server_scene.h#L159
Yang ini khusus buruk. Salah satu yang terburuk di seluruh mesin. Ini menambahkan 8 petunjuk kegemukan ke setiap objek yang dapat dirender di mesin tanpa alasan apa pun. Ini tidak perlu menjadi daftar. Ini, sekali lagi, bisa berupa peta slot atau vektor, dan itulah yang saya ganti dengannya.
Peta (map.h) pohon merah-hitam. Disalahgunakan sebagai hashmap di hampir semua penggunaannya. Harus dihapus dari mesin yang mendukung OAHashmap atau Hashmap, tergantung pada penggunaan.
Setiap penggunaan Peta yang saya lihat salah. Saya tidak dapat menemukan contoh Peta yang digunakan di tempat yang masuk akal.
Hashmap ( hash_map.h) kira-kira setara dengan std::unordered_map, sebuah hashmap pengalamatan tertutup berdasarkan bucket daftar tertaut. Itu dapat diulang saat menghapus elemen.
OAHashMap( oa_hash_map.h) hashmap pengalamatan terbuka cepat yang baru ditulis. menggunakan hashing robinhood. Tidak seperti hashmap, itu tidak akan mengubah ukuran saat menghapus elemen. Struktur yang diimplementasikan dengan sangat baik, lebih baik daripada std::unordered_map.
CommandQueueMT(command_queue_mt.h) antrian perintah yang digunakan untuk berkomunikasi ke Server yang berbeda, seperti server visual. Ia bekerja dengan memiliki larik 250 kb yang di-hardcode untuk bertindak sebagai kumpulan pengalokasi, dan mengalokasikan setiap perintah sebagai objek dengan fungsi virtual call() dan post(). Ia menggunakan mutex untuk melindungi operasi push/pop. Mengunci mutex sangat mahal, saya sarankan menggunakan antrian moodycamel sebagai gantinya, yang seharusnya lebih cepat. Ini kemungkinan akan menjadi hambatan bagi game yang melakukan banyak operasi dengan server visual, seperti banyak objek bergerak.
Ini adalah kumpulan inti dari struktur data di godot. Tidak ada std::vector yang setara. Jika Anda menginginkan struktur data "array dinamis", Anda terjebak dengan Vektor, dan kekurangannya dengan salinan saat menulis dan mengurangi ukuran. Saya pikir struktur data DynamicArray adalah hal yang paling dibutuhkan godot saat ini.
Untuk garpu saya, saya menggunakan STL dan wadah lain dari perpustakaan eksternal. Saya menghindari wadah godot karena lebih buruk daripada STL untuk kinerja, dengan pengecualian 2 hashmaps.
Masalah yang saya temukan pada implementasi vulkan di 4.0. Saya tahu ini sedang dalam proses, jadi masih ada waktu untuk memperbaikinya.
Penggunaan Peta di API render. https://github.com/godotengine/godot/blob/vulkan/drivers/vulkan/rendering_device_vulkan.h#L350
Seperti yang saya komentari, tidak ada gunanya Peta dan tidak ada alasan untuk itu ada. Seharusnya hanya hashmap dalam kasus-kasus itu.
Daftar tertaut terlalu sering digunakan alih-alih hanya array atau serupa.
https://github.com/godotengine/godot/blob/vulkan/drivers/vulkan/rendering_device_vulkan.h#L680
Untungnya ini kemungkinan tidak pada loop cepat, tetapi ini masih merupakan contoh penggunaan Daftar yang seharusnya tidak digunakan
Menggunakan PoolVector dan Vector di API render. https://github.com/godotengine/godot/blob/vulkan/drivers/vulkan/rendering_device_vulkan.h#L747
Tidak ada alasan bagus untuk menggunakan 2 struktur cacat tersebut sebagai bagian dari abstraksi API render. Dengan menggunakannya, pengguna terpaksa menggunakan 2 itu, dengan kekurangannya, alih-alih dapat menggunakan struktur data lainnya. Rekomendasi adalah menggunakan pointer + ukuran pada kasus tersebut, dan masih memiliki versi fungsi yang mengambil Vektor jika diperlukan.
Contoh aktual di mana API ini akan membahayakan pengguna adalah pada fungsi pembuatan buffer vertex. Dalam format GLTF, buffer vertex akan dikemas dalam file biner. Dengan API ini, pengguna harus memuat buffer biner GLTF ke dalam memori, membuat struktur ini menyalin data untuk setiap buffer, dan kemudian menggunakan API.
Jika API mengambil pointer + size, atau struct Span<>, pengguna akan dapat langsung memuat data vertex dari buffer biner yang dimuat ke dalam API, tanpa harus melakukan konversi.
Ini sangat penting bagi orang yang berurusan dengan data simpul prosedural, seperti mesin voxel. Dengan API ini, pengembang terpaksa menggunakan Vektor untuk data simpulnya, menimbulkan biaya kinerja yang signifikan, atau harus menyalin data ke dalam Vektor, alih-alih hanya memuat data simpul langsung dari struktur internal yang digunakan pengembang.
Jika Anda tertarik untuk mengetahui lebih banyak tentang topik ini, pembicaraan terbaik yang saya tahu adalah yang satu ini dari CppCon. https://www.youtube.com/watch?v=fHNmRkzxHWs
Pembicaraan hebat lainnya adalah yang ini: https://www.youtube.com/watch?v=-8UZhDjgeZU , di mana ia menjelaskan beberapa struktur data seperti peta slot yang akan sangat berguna untuk kebutuhan godot.
vblanco20-1
pada 17 Jul 2019
Godot punya masalah performa yang bagus... kamu akan menjadi tambahan yang bagus untuk tim Godot, tolong pertimbangkan itu!
Ranoller
pada 18 Jul 2019
Saya menutup utas ini, karena menurut saya itu bukan cara yang tepat untuk berkontribusi atau membantu.
@ vblanco20-1 Sekali lagi, saya sangat menghargai bahwa Anda memiliki niat baik, tetapi Anda tidak memahami cara kerja bagian dalam mesin, atau filosofi di baliknya. Sebagian besar komentar Anda ditujukan untuk hal-hal yang tidak benar-benar Anda pahami bagaimana penggunaannya, seberapa penting mereka terhadap kinerja, atau apa prioritas mereka secara umum.
Nada bicara Anda juga terlalu agresif. Alih-alih menanyakan apa yang tidak Anda mengerti, atau mengapa sesuatu dilakukan dengan cara tertentu, Anda malah menjadi sombong. Ini bukan sikap yang tepat untuk komunitas ini.
Sebagian besar hal yang Anda sebutkan tentang pengoptimalan hanyalah permukaan yang sangat kecil dari jumlah item yang saya rencanakan untuk pengoptimalan di Godot 4.0 (ada lebih banyak hal dalam daftar saya). Saya sudah memberi tahu Anda bahwa ini akan ditulis ulang beberapa kali sejak beberapa bulan yang lalu. Jika Anda tidak percaya, tidak apa-apa, tetapi saya merasa Anda membuang-buang waktu Anda sendiri dengan ini dan membingungkan banyak orang tanpa alasan yang jelas.
Saya jelas sangat menyambut umpan balik Anda setelah saya selesai dengan pekerjaan saya, tetapi semua yang Anda lakukan sekarang adalah mengalahkan kuda mati, jadi santai saja untuk sementara waktu.
 reduz
pada 22 Jul 2019
reduz
pada 22 Jul 2019
Sekali lagi, ketika alfa Godot 4.0 diluncurkan (semoga sebelum akhir tahun ini), Anda dipersilakan untuk membuat profil semua kode baru dan memberikan umpan balik tentang cara mengoptimalkannya lebih lanjut. Saya yakin kita semua akan mendapat manfaat. Untuk saat ini, tidak ada gunanya membahas hal lain di sini karena kode yang ada akan hilang di 4.0, dan tidak ada yang akan digabungkan di cabang 3.x, di mana pada titik ini stabilitas lebih penting daripada optimasi.
Karena banyak yang mungkin penasaran dengan detail teknisnya:
- Semua kode pengindeksan spasial (apa yang ditulis ulang oleh vblanco) akan digantikan oleh algoritma linier untuk pemusnahan dengan banyak utas, dikombinasikan dengan oktre untuk pemusnahan oklusi hierarki dan SAP untuk pemeriksaan yang tumpang tindih, yang kemungkinan besar merupakan algoritme serba terbaik yang menjamin baik performa di semua jenis game. Alokasi untuk struktur ini akan berada dalam nada yang sama dengan RID_Allocator baru, yaitu O(1) ). Saya membahas ini dengan @vblanco20-1 sebelumnya dan menjelaskan bahwa pendekatannya tidak berskala baik untuk semua jenis game, karena mengharuskan pengguna untuk memiliki tingkat keahlian tertentu untuk men-tweak yang biasanya tidak diharapkan dimiliki oleh pengguna Godot biasa. Itu juga bukan pendekatan yang baik untuk menambahkan pemusnahan oklusi.
- Saya tidak akan menggunakan array ketika daftar dapat digunakan karena daftar melakukan alokasi temporal kecil dengan risiko nol perpecahan. Dalam beberapa kasus, saya lebih suka mengalokasikan array bagian (sejajar dengan halaman, sehingga menyebabkan 0 fragmentasi) yang selalu tumbuh dan tidak pernah menyusut (seperti di RID_Allocator atau CanvasItem baru di mesin 2D cabang Vulkan, yang sekarang memungkinkan Anda untuk menggambar ulang item dengan banyak perintah dengan sangat efisien), tetapi harus ada alasan kinerja untuk ini. Ketika daftar digunakan di Godot, itu karena alokasi kecil lebih disukai daripada kinerja (dan sebenarnya mereka membuat maksud kode lebih jelas untuk dibaca orang lain).
- PoolVector ditujukan untuk alokasi yang sangat besar dengan halaman memori berurutan. Sampai Godot 2.1 menggunakan kumpulan memori yang telah dialokasikan sebelumnya, tetapi ini telah dihapus di 3.x dan saat ini perilaku saat ini salah. Untuk 4.0 itu akan diganti dengan memori virtual, itu ada dalam daftar hal yang harus dilakukan.
- Membandingkan Vektor Godot<> dengan std::vector tidak ada gunanya karena mereka memiliki kasus penggunaan yang berbeda. Kami menggunakannya sebagian besar untuk meneruskan data dan kami menguncinya untuk akses cepat (melalui metode ptr() atau ptrw()). Jika kita menggunakan std::vector, Godot akan jauh lebih lambat karena penyalinan yang tidak perlu. Kami juga mengambil banyak keuntungan dari salinan pada mekanik tulis untuk berbagai kegunaan.
- Map<> hanya lebih sederhana dan ramah untuk sejumlah besar elemen dan tidak perlu khawatir tentang pertumbuhan/pengecilan yang tergesa-gesa menciptakan fragmentasi. Ketika kinerja diperlukan, HashMap digunakan sebagai gantinya (meskipun itu benar, mungkin harus menggunakan OAHashMap lebih banyak, tetapi itu terlalu baru dan tidak pernah punya waktu untuk melakukan itu). Sebagai filosofi umum, ketika kinerja bukan prioritas, alokasi kecil selalu lebih disukai daripada yang besar karena lebih mudah bagi pengalokasi memori dari sistem operasi Anda untuk menemukan lubang kecil untuk menempatkannya (yang cukup sesuai dengan apa yang dirancang untuk dilakukan) , secara efektif memakan lebih sedikit tumpukan.
Sekali lagi, Anda dapat bertanya tentang rencana dan desain kapan saja Anda inginkan daripada menjadi nakal dan mengeluh, ini bukan cara terbaik untuk membantu proyek.
Saya juga yakin bahwa banyak yang membaca utas ini bertanya-tanya mengapa pengindeks spasial lambat untuk memulai. Alasannya adalah, mungkin Anda baru mengenal Godot, tetapi hingga saat ini mesin 3D berusia lebih dari 10 tahun dan sangat ketinggalan zaman. Pekerjaan telah dilakukan untuk memodernisasinya di OpenGL ES 3.0, tetapi kami harus berhenti karena masalah yang kami temukan di OpenGL dan fakta bahwa itu tidak digunakan lagi untuk Vulkan (dan Apple meninggalkannya).
Selain itu, Godot digunakan untuk berjalan pada perangkat seperti PSP belum lama ini (yang hanya memiliki 24 MB memori yang tersedia untuk mesin dan game, jadi banyak kode inti sangat konservatif mengenai alokasi memori). Karena perangkat keras sangat berbeda sekarang, ini sedang diubah untuk kode yang lebih optimal dan menggunakan lebih banyak memori, tetapi ketika tidak diperlukan melakukan pekerjaan ini tidak ada gunanya dan tidak apa-apa Anda akan melihat daftar yang digunakan di banyak tempat di mana kinerja tidak tidak peduli.
Juga, banyak pengoptimalan yang ingin kami lakukan (memindahkan banyak kode mutex ke atom untuk kinerja yang lebih baik) harus ditunda hingga kami dapat memindahkan Godot ke C++ 11 (yang memiliki dukungan yang jauh lebih baik untuk atom sebaris dan tidak mengharuskan Anda untuk menyertakan header windows, yang mencemari seluruh namespace), yang bukan sesuatu yang dapat kami lakukan di cabang yang stabil. Perpindahan ke C++11 akan dilakukan setelah Godot 3.2 bercabang dan fitur dibekukan, jika tidak, menjaga sinkronisasi cabang Vulkan dan Master akan sangat merepotkan. Tidak perlu terburu-buru, karena saat ini fokusnya adalah pada Vulkan itu sendiri.
Maaf, semuanya membutuhkan waktu, tetapi saya lebih suka dilakukan dengan benar daripada terburu-buru. Ini terbayar lebih baik dalam jangka panjang. Saat ini semua pengoptimalan kinerja sedang dikerjakan dan akan segera siap (jika Anda menguji cabang Vulkan, mesin 2D jauh lebih cepat daripada sebelumnya).
reduz
pada 22 Jul 2019
Hai reduz,
sementara saya kebanyakan melihat bahwa poin Anda valid, saya ingin mengomentari dua yang saya tidak setuju:
- Saya tidak akan menggunakan array ketika daftar dapat digunakan karena daftar melakukan alokasi temporal kecil tanpa risiko fragmentasi. Dalam beberapa kasus, saya lebih suka mengalokasikan array bagian (sejajar dengan halaman, sehingga menyebabkan 0 fragmentasi) yang selalu tumbuh dan tidak pernah menyusut (seperti di RID_Allocator atau CanvasItem baru di mesin 2D cabang Vulkan, yang sekarang memungkinkan Anda untuk menggambar ulang item dengan banyak perintah dengan sangat efisien), tetapi harus ada alasan kinerja untuk ini. Ketika daftar digunakan di Godot, itu karena alokasi kecil lebih disukai daripada kinerja (dan sebenarnya mereka membuat maksud kode lebih jelas untuk dibaca orang lain).
Saya sangat ragu bahwa daftar tertaut akan memiliki kinerja keseluruhan yang lebih baik, baik itu kecepatan atau efisiensi memori, daripada array dinamis dengan pertumbuhan eksponensial. Yang terakhir dijamin untuk menempati paling banyak dua kali lebih banyak ruang daripada yang sebenarnya digunakan, sementara List<some pointer> menggunakan persis tiga kali lebih banyak penyimpanan (konten aktual, penunjuk berikutnya dan sebelumnya). Untuk array sectioned, semuanya terlihat lebih baik.
Ketika dibungkus dengan benar (dan sebanyak yang saya tahu dari apa yang telah saya lihat dari kode godot, mereka), mereka terlihat hampir sama untuk programmer, jadi saya tidak mengerti apa yang Anda maksud dengan "mereka [Daftar ] membuat maksud kode lebih jelas".
IMHO, Daftar valid persis dalam dua kondisi:
- Anda harus sering menghapus/menyisipkan elemen di tengah wadah
- atau Anda memerlukan penyisipan/penghapusan elemen waktu konstan (dan bukan hanya waktu konstan yang diamortisasi). Yaitu, dalam konteks waktu nyata di mana alokasi memori yang memakan waktu tidak memungkinkan, itu baik-baik saja.
- Map<> hanya lebih sederhana dan ramah untuk sejumlah besar elemen dan tidak perlu khawatir tentang pertumbuhan/pengecilan yang tergesa-gesa menciptakan fragmentasi. Ketika kinerja diperlukan, HashMap digunakan sebagai gantinya (meskipun itu benar, mungkin harus menggunakan OAHashMap lebih banyak, tetapi itu terlalu baru dan tidak pernah punya waktu untuk melakukan itu). Sebagai filosofi umum, ketika kinerja bukan prioritas, alokasi kecil selalu lebih disukai daripada yang besar karena lebih mudah bagi pengalokasi memori dari sistem operasi Anda untuk menemukan lubang kecil untuk menempatkannya (yang cukup sesuai dengan apa yang dirancang untuk dilakukan) , secara efektif memakan lebih sedikit tumpukan.
libc-allocator biasanya cukup pintar, dan karena OAHashMap (atau std::unordered_map) mengalokasikan kembali penyimpanannya dari waktu ke waktu (waktu konstan yang diamortisasi), pengalokasi biasanya berhasil menjaga blok memorinya tetap kompak. Saya sangat percaya bahwa OAHashMap tidak secara efektif mengkonsumsi lebih banyak tumpukan daripada peta pohon biner biasa seperti Peta. Sebaliknya, saya cukup yakin bahwa overhead pointer besar di setiap elemen Peta sebenarnya menghabiskan lebih banyak memori daripada fragmentasi tumpukan OAHashmap (atau std::unordered_map).
Lagi pula, saya pikir cara terbaik untuk menyelesaikan argumen semacam ini adalah dengan membandingkannya. Tentunya, ini jauh lebih berguna untuk Godot 4.0, karena -- seperti yang Anda katakan -- banyak pengoptimalan kinerja akan terjadi di sana dan tidak banyak gunanya meningkatkan jalur kode yang mungkin sepenuhnya ditulis ulang di 4.0.
Tapi @reduz , apa pendapat Anda tentang membandingkan semua perubahan ini yang disarankan @vblanco20-1 (bahkan mungkin sekarang, di 3.1). Jika @vblanco20-1 (atau siapa pun) bersedia menginvestasikan waktu untuk menulis rangkaian pembandingan seperti itu dan untuk mengevaluasi kinerja Godot3.1 (baik dalam hal kecepatan dan "konsumsi tumpukan mempertimbangkan fragmentasi") terhadap perubahan vblanco? Ini mungkin menghasilkan petunjuk berharga untuk perubahan 4.0 yang sebenarnya.
Saya pikir metodologi seperti itu cocok dengan "[hal-hal] Anda dilakukan dengan benar daripada terburu-buru" dengan baik.
@vblanco20-1: Sebenarnya, saya menghargai pekerjaan Anda. Apakah Anda akan termotivasi untuk membuat tolok ukur seperti itu, sehingga kami benar-benar dapat mengukur apakah perubahan Anda merupakan peningkatan kinerja yang sebenarnya? Saya akan sangat tertarik.
 Windfisch
pada 23 Jul 2019
Windfisch
pada 23 Jul 2019
@Windfisch Saya sarankan Anda membaca kembali posting saya di atas, karena Anda salah membaca atau salah memahami beberapa hal. Saya akan mengklarifikasi mereka untuk Anda.
- Daftar digunakan persis untuk kasus penggunaan yang Anda jelaskan, dan saya tidak pernah mengklaim bahwa mereka memiliki kinerja yang lebih baik. Mereka lebih efisien daripada array untuk menggunakan kembali tumpukan hanya karena mereka terdiri dari alokasi kecil. Pada skala (ketika Anda sering menggunakannya untuk kasus penggunaan yang dimaksudkan), ini benar-benar membuat perbedaan. Ketika kinerja diperlukan, wadah lain yang lebih cepat, lebih dikemas atau memiliki koherensi cache yang lebih baik sudah digunakan. Baik atau buruk, Victor sebagian besar fokus di salah satu area mesin yang lebih tua (jika bukan yang tertua sebenarnya) yang tidak pernah dioptimalkan sejak saat itu menjadi mesin internal yang digunakan untuk menerbitkan game untuk PSP. Ini memiliki penulisan ulang yang tertunda sejak lama, tetapi ada prioritas lain. Optimalisasi utamanya adalah pelacakan kerucut voxel berbasis CPU yang saya tambahkan baru-baru ini, yang sejujurnya, saya melakukan pekerjaan yang buruk dengan itu karena terlalu terburu-buru di dekat rilis 3.0, tetapi perbaikan yang tepat untuk ini adalah algoritma yang sama sekali berbeda, dan tidak menambahkan pemrosesan paralel seperti yang dia lakukan.
- Saya tidak pernah berdebat tentang kinerja karya @vblanco20-1 dan terus terang saya tidak peduli (jadi Anda tidak perlu membuatnya membuang waktu untuk melakukan benchmark). Alasan untuk tidak menggabungkan karyanya adalah karena 1) Algoritme yang ia gunakan memerlukan penyesuaian manual tergantung pada ukuran rata-rata objek dalam game, sesuatu yang perlu dilakukan oleh sebagian besar pengguna Godot. Saya cenderung menyukai algoritme yang mungkin sedikit lebih lambat tetapi skalanya lebih baik, tanpa perlu tweak. 2) Algoritma yang dia gunakan tidak baik untuk oklusi culling (octree sederhana lebih baik karena sifat hirarkis). 3) Algoritma yang dia gunakan tidak bagus untuk pairing (SAP seringkali lebih baik). 4) Dia menggunakan C++ 17 dan perpustakaan yang saya tidak tertarik untuk mendukung, atau lambda yang saya yakini tidak perlu 5) Saya sudah bekerja untuk mengoptimalkan ini untuk 4.0, dan cabang 3.x memiliki stabilitas sebagai prioritas dan kami berniat untuk merilis 3.2 sesegera mungkin, jadi ini tidak akan dimodifikasi atau dikerjakan di sana. Kode yang ada mungkin lebih lambat, tetapi sangat stabil dan teruji. Jika ini digabung, ada laporan bug, regresi, dll. Tidak ada yang punya waktu untuk mengerjakannya atau membantu Victor karena kami sebagian besar sudah sibuk dengan cabang 4.0. Ini semua sudah dijelaskan di atas, jadi saya sarankan Anda membaca kembali posting ini.
Bagaimanapun, saya berjanji kepada Victor bahwa kode pengindeksan dapat dicolokkan, sehingga pada akhirnya algoritma yang berbeda untuk berbagai jenis permainan juga dapat diimplementasikan.
Godot adalah open source dan begitu juga fork-nya. Kami semua terbuka dan berbagi di sini, tidak ada yang menghentikan Anda untuk menggunakan karyanya jika Anda membutuhkannya.
reduz
pada 23 Jul 2019
Karena pengoptimalan itu tampaknya tidak memengaruhi gdscript, render, atau masalah "gagap", dan ada hal-hal yang dikeluhkan orang (termasuk saya), mungkin dengan menyelesaikan pengoptimalan itu orang akan senang (termasuk saya)... tidak perlu kecepatan lua jit...
Bekerja di "salin saat menulis" adalah pengoptimalan kinerja yang sangat besar di plugin saya (dari 25 detik dalam penguraian skrip menjadi hanya 1 detik dalam skrip 7000 baris)... perlu, dalam gdscript, dalam membuat dan menyelesaikan masalah gagap... itu saja.
Ranoller
pada 23 Jul 2019
Terima kasih @reduz atas klarifikasi Anda. Itu memang membuat poin Anda lebih jelas dari posting sebelumnya.
Ada baiknya bahwa kode pengindeksan spasial akan dapat dicolokkan, karena memang yang satu itu jatuh di kaki saya sebelumnya ketika menangani banyak objek pada skala yang sangat berbeda. Menantikan 4.0.
Windfisch
pada 23 Jul 2019
Saya juga memikirkannya dan saya pikir mungkin ide yang baik untuk meletakkan beberapa dokumen bersama dengan ide-ide tentang mengoptimalkan pengindeksan spasial, sehingga lebih banyak kontributor dapat mempelajari tentang ini dan juga melemparkan ide atau melakukan implementasi. Saya memiliki ide yang sangat bagus tentang apa yang perlu dilakukan, tetapi saya yakin ada banyak ruang di sini untuk melakukan optimasi lebih lanjut dan menghasilkan algoritma yang menarik.
Kami dapat memberikan persyaratan yang sangat jelas yang kami tahu harus dipenuhi oleh algoritme (seperti, tidak memerlukan penyesuaian pengguna jika memungkinkan untuk elemen rata-rata dalam ukuran dunia, bukan hal-hal yang memaksa dengan utas jika memungkinkan -mereka tidak gratis, bagian lain dari mesin mungkin membutuhkannya juga, seperti fisika atau animasi dan mereka mengkonsumsi lebih banyak baterai di ponsel-, kompatibilitas dengan pemusnahan oklusi berbasis proyeksi ulang -jadi, beberapa bentuk hierarki mungkin diinginkan, tetapi harus diuji terhadap kekerasan juga-, jadilah pintar tentang pembaruan buffer bayangan -jangan perbarui jika tidak ada yang berubah-, jelajahi pengoptimalan seperti pemusnahan oklusi berbasis proyeksi ulang untuk bayangan terarah, dll). Kita juga bisa mendiskusikan pembuatan beberapa tes benchmark (saya tidak berpikir demo TPS adalah benchmark yang baik karena tidak memiliki banyak objek atau oklusi). @vblanco20-1 jika Anda bersedia mengikuti gaya dan filosofi pengkodean/bahasa kami, Anda tentu saja dengan senang hati membantu.
Kode rendering lainnya (render sebenarnya menggunakan RenderingDevice) kurang lebih mudah dan tidak banyak cara untuk melakukannya, tetapi pengindeksan sepertinya merupakan masalah yang lebih menarik untuk dipecahkan demi pengoptimalan.
reduz
pada 23 Jul 2019
@reduz untuk referensi tentang pengindeksan spasial. Pemusnahan berbasis ubin asli telah dihapus dan digantikan oleh Octree sekitar setengah jalan melalui utas ini. Oktre yang saya dapatkan di sana adalah WIP (kehilangan beberapa fungsionalitas re-fit), tetapi hasilnya cukup bagus untuk prototipe. Kodenya tidak begitu bagus dari sifat prototipenya, jadi hanya berguna untuk memeriksa bagaimana octree semacam ini akan tampil dalam adegan yang kompleks seperti tps-demo.
Ini terinspirasi oleh cara kerja engine octree yang tidak nyata, tetapi dengan beberapa modifikasi seperti kemungkinan iterasi yang datar.
Ide utamanya adalah bahwa hanya daun pada octree yang menahan objek, dan objek tersebut disimpan pada array ukuran 64 (ukuran waktu kompilasi, bisa berbeda). Daun octree hanya akan terbelah setelah "meluap" menjadi 65 elemen. Saat Anda menghapus objek, jika setiap daun dari simpul induk masuk ke dalam larik ukuran 64, maka kami menggabungkan daun kembali ke simpul induknya, yang menjadi daun.
Dengan melakukan itu, kita dapat meminimalkan waktu pengujian pada node, karena octree tidak akan terlalu dalam.
Hal baik lainnya yang saya lakukan adalah bahwa simpul daun juga disimpan dalam array datar, yang memungkinkan paralel-untuk dalam pemusnahan. Dengan cara ini pemusnahan hierarkis dapat digunakan saat melakukan pemusnahan untuk bayangan titik, atau operasi "kecil" lainnya, dan paralel datar untuk pemusnahan dapat digunakan untuk tampilan utama. Tentu saja bisa menggunakan hierarki untuk semuanya, tetapi bisa lebih lambat dan tidak dapat diparalelkan.
Struktur blok akan membuang sedikit memori, tetapi bahkan dalam skenario terburuk saya tidak berpikir itu akan membuang banyak memori karena node akan bergabung jika turun di bawah jumlah. Ini juga memungkinkan penggunaan pengalokasi kumpulan mengingat bahwa simpul dan daun akan memiliki ukuran yang konstan.
Saya juga memiliki beberapa oktre di garpu saya, yang digunakan untuk mengoptimalkan beberapa hal. Misalnya saya memiliki octree hanya untuk objek shadowcaster, yang memungkinkan melewatkan semua logika yang terkait dengan "dapat membuat bayangan" saat memilih untuk shadowmaps.
Tentang kekhawatiran saya terhadap Vector dan lainnya pada API render, masalah ini menjelaskan apa yang saya khawatirkan. https://github.com/godotengine/godot/issues/24731
Di perpustakaan dan C++17 hal-hal garpu .. itu tidak perlu. Garpu terlalu sering menggunakan banyak perpustakaan karena saya membutuhkan beberapa bagian dari mereka. Satu-satunya hal yang benar-benar dibutuhkan, dan yang menurut saya dibutuhkan godot, adalah antrian paralel yang kuat di industri, saya menggunakan antrian moodycamel untuk itu.
Pada lambda, penggunaannya terutama untuk pemusnahan, dan digunakan untuk menghemat sejumlah besar memori, karena Anda hanya perlu menyimpan objek yang melewati pemeriksaan Anda ke dalam larik keluaran. Alternatifnya adalah melakukan objek iterator (itulah yang dilakukan mesin tidak nyata dengan octree mereka), tetapi akhirnya menjadi kode yang lebih buruk dan jauh lebih sulit untuk ditulis.
Niat saya bukan untuk "menjadi nakal", tetapi untuk menjawab komentar yang sering muncul tentang "Anda bebas membuat garpu untuk didemonstrasikan", persis seperti yang saya lakukan. Pesan pertama di utas agak mengkhawatirkan dan tidak terlalu benar. Maaf jika saya tampak kasar kepada Anda, karena satu-satunya tujuan saya adalah membantu mesin game open source paling populer.
vblanco20-1
pada 23 Jul 2019
@vblanco20-1 Kedengarannya bagus, dan cara Anda menyebutkan octree bekerja sangat masuk akal. Sejujurnya saya tidak keberatan menerapkan antrian paralel (tampaknya cukup sederhana karena tidak memerlukan ketergantungan eksternal, dan perlu C++ 11 untuk melakukannya dengan benar, jadi tebak itu hanya akan terjadi di cabang Vulkan). Jika Anda memiliki komitmen ini, saya pasti ingin melihatnya, jadi saya dapat menggunakannya sebagai dasar untuk penulisan ulang pengindeks di cabang Vulkan (Saya hanya menulis ulang sebagian besar barang di sana, jadi tetap harus ditulis ulang ). Tentu saja jika Anda ingin membantu implementasinya (mungkin ketika ada lebih banyak hal dengan API baru), itu sangat disambut.
Penggunaan versi paralel dengan array yang diratakan memang menarik, tetapi sudut pandang saya adalah bahwa hal itu tidak akan berguna untuk pemusnahan oklusi, dan akan menarik untuk mengukur seberapa besar peningkatan dibandingkan pemusnahan octree biasa, mempertimbangkan jumlah tambahan core yang digunakan. Perlu diingat ada banyak area lain yang mungkin menggunakan banyak utas yang dapat membuat penggunaan lebih efisien (kurang kasar) (seperti fisika), jadi jika meskipun dengan pendekatan ini kita mendapatkan peningkatan yang relatif kecil, itu tidak selalu untuk kepentingan terbaik, karena mungkin membuat area lain kelaparan dari menggunakan CPU. Mungkin bisa jadi opsional.
Saya juga menemukan implementasi Bullet 3 dari dbvt cukup menarik, yang melakukan penyeimbangan diri tambahan dan alokasi linier, itu salah satu hal yang ingin saya teliti lebih lanjut (saya telah melihat pendekatan ini diimplementasikan dalam mesin berpemilik yang tidak dapat saya sebutkan :P ), dari segi algoritme, pohon biner yang seimbang secara desain jauh lebih sedikit redundan daripada oktree, dan dapat bekerja lebih baik dalam pengujian pemasangan dan oklusi, jadi pendekatan fase lebar/pemusnahan yang dapat dicolokkan mungkin sebenarnya merupakan ide yang bagus, mengingat kami membuatnya berguna adegan patokan.
Bagaimanapun, Anda sangat cerdas dan akan sangat bagus jika kita dapat bekerja sama dalam hal ini, tetapi saya hanya akan meminta Anda untuk memahami dan menghormati banyak filosofi desain yang ada yang kita miliki, meskipun mungkin tidak selalu sesuai dengan selera Anda. . Proyek ini sangat besar, dengan banyak kekuatan inersia, dan mengubah sesuatu demi selera bukanlah ide yang baik. Keramahan pengguna dan "hanya berfungsi" selalu menjadi yang pertama dalam daftar mengenai desain, dan kesederhanaan dan keterbacaan kode biasanya lebih diprioritaskan daripada efisiensi (yaitu, ketika efisiensi bukanlah tujuan karena suatu area tidak kritis). Terakhir kali kita berdiskusi, Anda ingin mengubah hampir semuanya dan tidak ingin mendengarkan alasan atau fokus pada masalah yang sebenarnya, dan bukan itu cara kami biasanya bekerja dengan komunitas dan kontributor, itulah sebabnya saran saya untuk tenang adalah dimaksudkan dengan baik.
reduz
pada 23 Jul 2019
Siapa yang butuh kinerja? :muka mengejek:
Performa dan model sumber adalah apa yang membuat saya tetap bersama Godot.
 BlueCannonBall
pada 28 Jan 2020
BlueCannonBall
pada 28 Jan 2020
Sunting: Maaf, mungkin saya beberapa di luar topik tetapi saya ingin mengklarifikasi manfaat dari open source.
@mixedCase Saya akan sangat ragu untuk mendukung segala jenis garpu Godot. Forking dan fragmentasi sering menjadi kematian proyek open source.
Saya tidak berpikir begitu. Sifat open source adalah Anda dapat menggunakan dan menggunakan kembali kode secara bebas sesuai keinginan. Jadi itu tidak akan menjadi akhir dari beberapa proyek tetapi lebih banyak opsi bagi pengguna.
Apa yang Anda katakan adalah monopoli, dan bukan itu yang mempertahankan open source. Jangan tertipu oleh perusahaan yang berpura-pura menunjukkan kepada Anda bahwa ada yang lebih baik untuk memiliki kendali penuh atas sesuatu. Itu bohong, setidaknya di dunia open source, karena jika orang lain memiliki kode, Anda juga memiliki kode tersebut. Apa yang perlu mereka lakukan adalah mengurus bagaimana menangani komunitas atau bagaimana menyetujuinya.
Bagaimanapun, pengembang asli hanya dapat menggabungkan peningkatan dari fork. Mereka bebas melakukannya selalu. Itu adalah sifat lain dari dunia open source.
Dan dalam kasus terburuk garpu akan lebih baik daripada yang asli dan banyak kontributor akan pergi ke sana. Tidak ada yang kalah, semua menang. Oh, maaf, jika sebuah perusahaan berada di belakang yang asli mungkin mereka kalah (atau mereka dapat menggabungkan perbaikan dari fork juga).
 Anyeos
pada 18 Mar 2020
Anyeos
pada 18 Mar 2020
Masalah terkait
bojidar-bg
·
3Komentar
 EdwardAngeles
·
3Komentar
EdwardAngeles
·
3Komentar
 blurymind
·
3Komentar
blurymind
·
3Komentar
 ndee85
·
3Komentar
ndee85
·
3Komentar
 mefihl
·
3Komentar
mefihl
·
3Komentar
Komentar yang paling membantu
Anda mungkin tertarik. Saya telah mengerjakan garpu mewah cukup lama. Hasil saat ini seperti ini:

Ditangkap di laptop gaming besar dengan cpu intel 4 inti dan GTX 1070
Godot biasa
Garpu saya di https://github.com/vblanco20-1/godot/tree/ECS_Refactor

Di kedua profil, Merah pada dasarnya adalah "menunggu GPU". Saat ini macet karena terlalu banyak penarikan di opengl. Tidak dapat benar-benar diselesaikan tanpa vulkan atau menulis ulang seluruh penyaji.
Di sisi CPU, kami beralih dari frame 13 ms ke frame 5 ms. Frame "Cepat" berubah dari 5,5 md menjadi 2,5 md
Di sisi "bingkai total", kita beralih dari 13 md ke 8-9 md
~75 FPS hingga ~115 FPS
Lebih sedikit waktu CPU = lebih banyak waktu yang dapat Anda habiskan untuk bermain game. Godot saat ini terhambat pada CPU, jadi lebih banyak waktu yang dihabiskan untuk gameplay akan berarti FPS yang lebih rendah, sementara garpu saya terikat GPU, sehingga Anda dapat menambahkan lebih banyak logika gameplay dengan FPS yang tidak tersentuh karena CPU hanya "gratis" untuk cukup lama setiap frame.
BANYAK perbaikan ini dapat digabungkan menjadi godot, JIKA godot mendukung C++ modern dan memiliki sistem multithreading yang memungkinkan tugas "kecil" yang sangat murah.
Keuntungan terbesar dilakukan dengan melakukan pembacaan multithreaded shadows dan multithreaded lightmap pada objek dinamis #25013. Keduanya bekerja dengan cara yang sama. Banyak bagian lain dari penyaji juga multithread.
Keuntungan lainnya adalah Octree yang 10 hingga 20 kali lebih cepat dari godot one, dan peningkatan pada beberapa aliran rendering, seperti merekam daftar render depth-prepass dan normal-pass sekaligus, alih-alih mengulangi daftar cull 2 kali, dan perubahan signifikan pada cara kerja koneksi light->mesh (tidak ada daftar tertaut!)
Saat ini saya mencari lebih banyak peta uji selain demo TPS sehingga saya dapat memiliki lebih banyak metrik di jenis peta lainnya. Saya juga akan menulis serangkaian artikel yang menjelaskan bagaimana semua ini bekerja secara rinci.