Godot: Usando a estrutura de dados mais lenta quase sempre.
Eu estava revisando o código de godot e descobri que desconsidera completamente qualquer tipo de desempenho do lado da CPU, até as principais estruturas de dados. É usar Listar em todos os lugares, quando uma lista vinculada é a estrutura de dados mais lenta que você pode usar em PCs modernos. Quase qualquer outra estrutura de dados seria mais rápida, especialmente em estruturas de pequeno porte. É especialmente notório em coisas como a lista de luz ou capturas de reflexão em renderizáveis, onde você armazena 3 ponteiros de cada vez, em vez de apenas fornecer uma matriz de pilha de 8 luzes máximas (por exemplo) + um extra para os casos em que seria mais que isso.
A mesma coisa com RID_Owner sendo uma árvore onde poderia ser um mapa hash ou um mapa de slots. Além disso, a implementação do Octree para abate tem exatamente o mesmo problema.
Eu quero perguntar sobre a intenção de design por trás desse uso excessivo total e absoluto de listas vinculadas e estruturas de dados pesadas de ponteiro de desempenho terrível em todo o código. Isso é por um motivo específico? Na maioria dos casos, uma lista vinculada "fragmentada", onde você faz uma lista vinculada de matrizes, traria automaticamente ganhos de desempenho no mesmo código.
O uso dessas estruturas de dados também evita qualquer tipo de paralelismo "fácil" em uma boa parte do código e destrói completamente o cache.
Estou trabalhando para fazer uma implementação de prova de conceito de refatoração de alguns dos componentes internos para usar melhores estruturas de dados. No momento, estou trabalhando na reescrita do código de seleção que ignora a octree atual e usa apenas uma matriz plana com paralelismo opcional. Usarei o tps-demo como referência e voltarei com os resultados, que na verdade eu comparei para chegar a 25 níveis de profundidade naquela octree ...
Em outra nota mais feliz, estou muito impressionado com a qualidade do estilo do código, tudo é fácil de seguir e entender, e muito bem comentado.
 vblanco20-1
vblanco20-1
Todos 61 comentários
Quem precisa de desempenho? :cara de gozo:
 mafiesto4
em 27 nov. 2018
mafiesto4
em 27 nov. 2018
Curioso para ver o que você mede.
 avencherus
em 27 nov. 2018
avencherus
em 27 nov. 2018
Então, isso pode explicar por que um simples nó Light2D em Godot pode queimar seu computador?
 Ranoller
em 27 nov. 2018
Ranoller
em 27 nov. 2018
@Ranoller acho que não. O desempenho de iluminação ruim está provavelmente relacionado a como Godot executa a iluminação 2D no momento: Renderizar cada sprite n vezes (com n sendo o número de luzes que o estão afetando).
Editar: ver # 23593
 CptPotato
em 27 nov. 2018
CptPotato
em 27 nov. 2018
Para esclarecer, trata-se de ineficiências do lado da CPU em todo o código. Isso não tem nada a ver com os recursos do godot ou a própria renderização da GPU do godot.
vblanco20-1
em 27 nov. 2018
@ vblanco20-1 em uma tangente lateral, você e eu conversamos sobre os nós sendo modelados como entidades ECS. Eu me pergunto se o truque é fazer um branch de recursos de godot com um novo módulo ent que funcionaria gradualmente lado a lado com a árvore. como get_tree () e get_registry (). o módulo ent provavelmente perderia cerca de 80% da funcionalidade da árvore / cena, mas poderia ser útil como um ambiente de teste, especialmente para coisas como compor grandes níveis estáticos com muitos objetos (seleção, streaming, renderização em lote). Funcionalidade e flexibilidade reduzidas, mas maior desempenho.
 pgruenbacher
em 27 nov. 2018
pgruenbacher
em 27 nov. 2018
Antes de usar o ECS completo (o que eu devo fazer), quero trabalhar em algumas frutas ao alcance como um experimento. Posso tentar orientar totalmente os dados mais tarde.
vblanco20-1
em 27 nov. 2018
Então, primeiras atualizações:
update_dirty_instances: de 0,2-0,25 milissegundos a 0,1 milissegundo
octree_cull (a visualização principal): de 0,35 milissegundos a 0,1 milissegundo
A parte divertida? a substituição de octree cull não usa nenhuma estrutura de aceleração, apenas itera sobre uma matriz burra com todos os AABBs.
A parte ainda mais engraçada? A nova seleção é de 10 linhas de código. Se eu quisesse ter um paralelo, seria uma única mudança na linha.
Continuarei com a implementação de meu novo abate com as luzes, para ver o quanto a aceleração se acumula.
vblanco20-1
em 1 dez. 2018
provavelmente devemos ter um diretório de benchmark do Google indo também para o branch master. Isso pode ajudar na validação, para que as pessoas não tenham que discutir sobre isso.
pgruenbacher
em 1 dez. 2018
Existe o repositório godotengine / godot-tests , mas
 bojidar-bg
em 2 dez. 2018
bojidar-bg
em 2 dez. 2018
Nova atualização:

Ive implementou uma estrutura de aceleração espacial bastante burra, com 2 níveis. Estou apenas gerando a cada frame. Melhorias adicionais poderiam torná-lo melhor e atualizá-lo dinamicamente em vez de refazê-lo.
Na imagem, as diferentes linhas são escopos diferentes e cada bloco colorido é uma tarefa / pedaço de código. Nessa captura, estou fazendo o abate de octree e meu abate lado a lado para ter uma comparação direta
Isso demonstra que recriar toda a estrutura de aceleração é mais rápido do que um único corte de octree antigo.
Além disso, os demais abates tendem a ser cerca de metade a um terço da octree atual.
Não encontrei um único caso em que minha estrutura burra seja mais lenta do que a octree atual, além do custo da criação inicial.
Outro bônus é que é muito compatível com multithread e pode ser escalado para qualquer contagem de núcleo que você quiser, apenas com um paralelo para.
Ele também verifica a memória de forma completamente contígua, portanto, deve ser possível fazê-lo executar o SIMD sem muitos problemas.
Outro detalhe importante é que é muito mais simples do que a octree atual, com muito menos linhas de código.
vblanco20-1
em 2 dez. 2018
Você está causando mais hype que o fim do jogo dos tronos ....
Ranoller
em 2 dez. 2018

Modifiquei um pouco os algos para que agora possam usar os algoritmos paralelos do C ++ 17, que permite ao programador apenas dizer para fazer um paralelo para, ou uma classificação paralela.
Aceleração de cerca de x2 no abate do frustrum principal, mas para as luzes é quase a mesma velocidade de antes.
Meu coletor é agora 10 vezes mais rápido do que godot octree para a visualização principal.
vblanco20-1
em 2 dez. 2018
Se você quiser ver as mudanças, o mais importante é aqui:
https://github.com/vblanco20-1/godot/blob/4ab733200faa20e0dadc9306e7cc93230ebc120a/servers/visual/visual_server_scene.cpp#L387
Esta é a nova função de abate. A estrutura de aceleração está na função logo acima dela.
vblanco20-1
em 2 dez. 2018
Isso deve compilar com VS2015? O console lança um monte de erros sobre os arquivos dentro de entt \
Ranoller
em 2 dez. 2018
@Ranoller é c ++ 17, então certifique-se de usar um compilador mais recente
pgruenbacher
em 3 dez. 2018
Uh, eu acho que Godot ainda não mudou para c ++ 17? Pelo menos me lembro de algumas discussões sobre o assunto?
 Zireael07
em 3 dez. 2018
Zireael07
em 3 dez. 2018
Godot é C ++ 03. Este movimento será controverso. Recomendo @ vblanco20-1 para falar com o Juan quando terminar as férias ... esta optimização vai ser óptima e não queremos um instantâneo "This Will Never Happend TM
Ranoller
em 3 dez. 2018
@ vblanco20-1
octree_cull (a visualização principal): de 0,35 milissegundos a 0,1 milissegundo
quantos objetos?
 nem0
em 3 dez. 2018
nem0
em 3 dez. 2018
@ nem0
@ vblanco20-1
octree_cull (a visualização principal): de 0,35 milissegundos a 0,1 milissegundo
quantos objetos?
Por volta de 2200. O godot octree tem melhor desempenho se o cheque for muito pequeno, porque sai cedo. Quanto maior a consulta, mais lento o godot octree é comparado à minha solução. Se o godot octree não consegue remover 90% da cena antes do tempo, então é terrivelmente lento, porque é essencialmente uma iteração de listas vinculadas para cada objeto, enquanto meu sistema é uma estrutura de arrays onde cada linha de cache contém uma boa quantidade de AABBs, reduzindo muito falhas de cache.
Meu sistema funciona com 2 níveis de AABBs, é uma matriz de blocos, onde cada bloco pode conter 128 instâncias.
O nível superior é principalmente uma matriz de AABBs + uma matriz de blocos. Se a verificação AABB for aprovada, eu itero o bloco. O bloco é uma matriz de estrutura de AABBs, máscara e um ponteiro para a instância. Assim tudo é faaaaast.
No momento, a geração da estrutura de dados de nível superior é feita de uma maneira muito burra. Se fosse melhor gerado, seu desempenho poderia ser muito maior. Estou realizando alguns experimentos com blocos de tamanhos diferentes, além de 128.
vblanco20-1
em 3 dez. 2018
Eu verifiquei diferentes números e 128 por bloco parece ainda ser o sweetspot de alguma forma.
Ao alterar o algoritmo para separar objetos "grandes" de objetos pequenos, ive conseguiu obter outra atualização de 30% na velocidade, principalmente no caso em que você não está olhando para o centro do mapa. Funciona porque dessa forma os objetos grandes não incham os AABBs do bloco que também incluem objetos pequenos. Eu acredito que 3 tamanhos provavelmente funcionariam melhor.
A geração de blocos ainda não é ideal. Os blocos grandes selecionam apenas cerca de 10 a 20% das instâncias ao olhar para o centro, e até 50% ao olhar para fora do mapa, então ele realiza MUITAS verificações de AABB extras do que deveria.
Acho que uma melhoria provavelmente seria reutilizar a octree atual, mas "achatá-la".
Agora não há um único caso em que meu algoritmo seja igual ou pior do que a octree atual, mesmo sem execução paralela.
vblanco20-1
em 3 dez. 2018
@ vblanco20-1 Presumo que você esteja fazendo sua comparação com godot compilado no modo release (que usa -O3 ) e não o editor regular compilado em depuração (que não tem otimizações e é o padrão) certo ?
Desculpe se é uma pergunta boba, mas não vejo nenhuma menção a isso no tópico.
Bom trabalho de qualquer maneira :)
 Faless
em 11 dez. 2018
Faless
em 11 dez. 2018
@Faless É release_debug, que adiciona algumas otimizações. Não consegui testar o "lançamento" completo porque não consigo fazer com que ele abra o jogo (o jogo também precisa ser construído?)
Eu tive uma ideia de como melhorar muito mais a seleção, eliminando a necessidade de regenerar cada quadro e criando uma melhor otimização espacial. Vou ver o que posso tentar. Em teoria, tal coisa poderia remover o regenerado, melhorar um pouco o desempenho do abate principal e ter um modo específico para luzes pontuais que aumentariam o desempenho do abate em uma quantidade enorme, tanto que teriam um custo quase zero, porque vai se transformar em um O (1) barato para obter os "objetos em um raio".
É inspirado em como um dos meus experimentos funcionou, onde estou fazendo 400.000 objetos físicos quicando uns nos outros.
vblanco20-1
em 11 dez. 2018

Novo abate está implementado agora. A geração de blocos agora é muito mais inteligente, resultando em um abate mais rápido. O caso especial para luzes ainda não foi implementado.
Eu cometi no meu garfo
vblanco20-1
em 12 dez. 2018
Estou curioso para saber se você pode executar essa ferramenta de benchmark (aquela das suas capturas de tela) em uma compilação do branch master atual, para nos dar um ponto de referência de quanto desempenho sua implementação está proporcionando em relação à implementação atual. Eu sou um idiota, woops.
 LikeLakers2
em 13 dez. 2018
LikeLakers2
em 13 dez. 2018
@ LikeLakers2 Você pode ver a implementação atual e sua implementação na captura de tela.
 neikeq
em 13 dez. 2018
neikeq
em 13 dez. 2018
Ele executou isso em um garfo mestre
Na quarta-feira, 12 de dezembro de 2018, MichiRecRoom [email protected]
escreveu:
@neikeq https://github.com/neikeq Explique? Eu pensei que as imagens
que foram postadas eram apenas de sua implementação, visto como as postagens
com screenshots foram redigidos até agora.-
Você está recebendo isso porque comentou.
Responda a este e-mail diretamente, visualize-o no GitHub
https://github.com/godotengine/godot/issues/23998#issuecomment-446831151 ,
ou silenciar o tópico
https://github.com/notifications/unsubscribe-auth/ADLZ9pRh9Lksse9KBfWV0z5GmHRXf5P2ks5u4crCgaJpZM4YziJp
.
pgruenbacher
em 13 dez. 2018
Há alguma notícia sobre esse assunto?
CptPotato
em 15 jan. 2019
Há alguma notícia sobre esse assunto?
Falei com reduz. Nunca será mesclado porque não se encaixa no projeto. Em vez disso, fui fazer outros experimentos. Talvez eu atualize o abate mais tarde para 4.0
vblanco20-1
em 15 jan. 2019
É uma pena, considerando que parecia realmente promissor. Esperançosamente, essas questões serão resolvidas a tempo.
CptPotato
em 15 jan. 2019
Talvez deva ser dado o marco 4.0? Já que Reduz está planejando trabalhar no Vulkan para 4.0, e este tópico, embora seja sobre desempenho, é focado em renderização, ou pelo menos OP é.
 aaronfranke
em 4 fev. 2019
aaronfranke
em 4 fev. 2019
@ vblanco20-1 Ele disse como não cabe? Estou assumindo por causa da mudança para c ++ 17?
 Two-Tone
em 6 fev. 2019
Two-Tone
em 6 fev. 2019
No entanto, há um outro problema relacionado no marco: # 25013
 starry-abyss
em 6 fev. 2019
starry-abyss
em 6 fev. 2019
Você pode estar interessado. Já faz um bom tempo que estou trabalhando no garfo sofisticado. Os resultados atuais são assim:
Capturado em um grande laptop para jogos com uma CPU Intel de 4 núcleos e GTX 1070
Godot normal
Meu fork em https://github.com/vblanco20-1/godot/tree/ECS_Refactor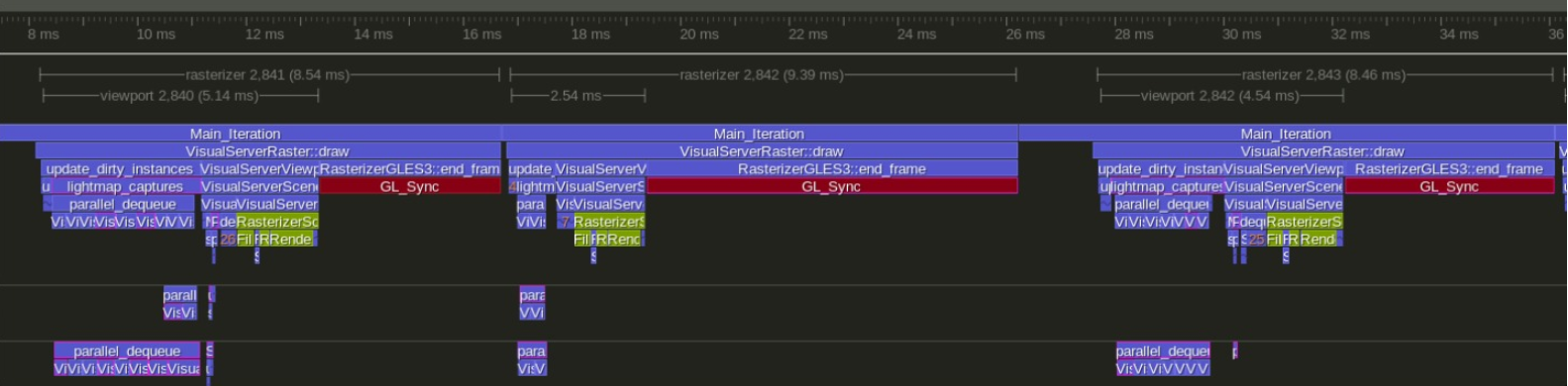
Em ambos os perfis, o Vermelho é essencialmente "esperar pela GPU". Atualmente com gargalo devido a muitos drawcalls no opengl. Realmente não pode ser resolvido sem vulkan ou reescrever todo o renderizador.
No lado da CPU, vamos de quadros de 13 ms para quadros de 5 ms. Os frames "rápidos" vão de 5,5 ms a 2,5 ms
No lado do "quadro total", vamos de 13 ms a 8-9 ms
~ 75 FPS a ~ 115 FPS
Menos tempo de CPU = mais tempo que você pode gastar no jogo. O godot atual é afunilado na CPU, então mais tempo gasto no jogo significará FPS mais baixo, enquanto meu fork está vinculado à GPU, então você pode adicionar muito mais lógica de jogo com o FPS intocado, já que a CPU é apenas "livre" para um bom tempo a cada quadro.
MUITAS dessas melhorias podem ser mescladas em godot, se godot suportasse C ++ moderno e tivesse um sistema multithreading que permite tarefas "pequenas" muito baratas.
O maior ganho é obtido ao fazer sombras multithread e mapa de luz multithread nos objetos dinâmicos # 25013. Ambos funcionam da mesma maneira. Muitas outras partes do renderizador também são multithread.
Outros ganhos são um Octree que é de 10 a 20 vezes mais rápido do que godot um, e melhorias em alguns dos fluxos de renderização, como gravar a lista de renderização de passagem normal e pré-passagem de uma vez, em vez de iterar a lista de seleção 2 vezes, e uma mudança significativa em como a conexão luz-> malha funciona (sem lista vinculada!)
No momento, estou procurando mais mapas de teste além da demonstração TPS para que eu possa ter mais métricas em outros tipos de mapas. Também vou escrever uma série de artigos explicando como tudo isso funciona em detalhes.
vblanco20-1
em 1 jun. 2019
@ vblanco20-1 isso é totalmente incrível. Obrigado por compartilhar!
Eu também concordo que, embora Vulkan seja legal, ter um desempenho decente no GLES3 seria uma vitória absoluta para Godot. O suporte total ao Vulkan provavelmente não chegará tão cedo, enquanto a correção do GLES3 é algo que os caras aqui provaram ser totalmente viáveis agora.
Meu grande +1 por trazer mais e mais atenção para isso. Eu seria a pessoa mais feliz do planeta se Reduz concordasse em permitir que a comunidade melhorasse o GLES3. Estamos fazendo um projeto 3D muito sério em Godot há 1,5 anos e apoiamos Godot (incluindo doações), mas a falta de 60 FPS sólidos realmente nos desmotiva e coloca todos os nossos esforços em um grande risco.
É realmente uma pena que não esteja recebendo créditos suficientes. Se não tivermos 60 FPS nos próximos meses com nosso projeto atual (muito simples em termos de 3D), não conseguiremos entregar um jogo jogável e, portanto, todo o esforço será perdido. : /
@ vblanco20-1 honestamente, estou até pensando em usar seu garfo como base do nosso jogo em produção.
PS Algumas reflexões: como último recurso, acho que seria totalmente possível ter, digamos, 2 rasterizadores GLES3 - comunidade GLES3 e GLES3.
 and3rson
em 1 jun. 2019
and3rson
em 1 jun. 2019
PS Algumas reflexões: como último recurso, acho que seria totalmente possível ter, digamos, 2 rasterizadores GLES3 - comunidade GLES3 e GLES3.
Isso não faz sentido para mim; provavelmente é uma ideia melhor obter correções e melhorias de desempenho diretamente nos renderizadores GLES3 e GLES2 (contanto que eles não quebrem a renderização nas principais formas em projetos existentes).
Outros ganhos são um Octree que é de 10 a 20 vezes mais rápido do que godot um, e melhorias em alguns dos fluxos de renderização, como gravar a lista de renderização de passagem normal e pré-passagem de uma vez, em vez de iterar a lista de seleção 2 vezes, e uma mudança significativa em como a conexão luz-> malha funciona (sem lista vinculada!)
@ vblanco20-1 Seria possível otimizar o pré-passo de profundidade ao permanecer no C ++ 03?
 Calinou
em 1 jun. 2019
Calinou
em 1 jun. 2019
@Calinou o material de pré-passo de profundidade é uma das coisas que não precisa de nada e é facilmente mesclável. Sua principal desvantagem é que exigirá que o renderizador use memória extra. Como agora precisará de 2 RenderList em vez de apenas um. Além da memória extra, não há praticamente nenhuma desvantagem. O custo de construção da lista de renderização para 1 passagem ou 2 é quase o mesmo graças ao cache da CPU, então ele remove quase completamente o custo da pré-passagem fill_list ()
vblanco20-1
em 1 jun. 2019
@ vblanco20-1 honestamente, estou até pensando em usar seu garfo como base do nosso jogo em produção.
@ and3rson, por favor, não. Este garfo é puramente um projeto de pesquisa e nem mesmo é totalmente estável. Na verdade, ele nem mesmo compila fora de alguns compiladores muito específicos devido ao uso de STL paralelo. A bifurcação é principalmente um teste de ideias e práticas de otimização aleatória.
vblanco20-1
em 1 jun. 2019
Quais ferramentas você está usando para criar o perfil de Godot? Você precisou adicionar os sinalizadores Profiler.Begin e Profiler.End à origem do godot para gerar essas amostras?
 jknightdoeswork
em 2 jun. 2019
jknightdoeswork
em 2 jun. 2019
Quais ferramentas você está usando para criar o perfil de Godot? Você precisou adicionar os sinalizadores Profiler.Begin e Profiler.End à origem do godot para gerar essas amostras?
Está usando o perfilador Tracy, tem diferentes tipos de marca de perfil de escopo, que uso aqui. Por exemplo, ZoneScopedNC ("Fill List", 0x123abc) adiciona uma marca de perfil com esse nome e a cor hexadecimal desejada.
vblanco20-1
em 2 jun. 2019
@ vblanco20-1 - Veremos algumas dessas melhorias de desempenho trazidas para o branch principal do godot?
 HeadClot
em 2 jun. 2019
HeadClot
em 2 jun. 2019
@ vblanco20-1 - Veremos algumas dessas melhorias de desempenho trazidas para o branch principal do godot?
Talvez quando o C ++ 11 for compatível. Mas reduz realmente não quer mais trabalho no renderizador antes que o vulkan aconteça, então pode ser nunca. Algumas das descobertas do trabalho de otimização podem ser úteis para o renderizador 4.0.
vblanco20-1
em 2 jun. 2019
@ vblanco20-1 me importa em compartilhar os detalhes do compilador e do ambiente para o branch, acho que posso descobrir a maior parte, mas simplesmente não perca tempo tentando descobrir os problemas se não for necessário.
Também não podemos adicionar a alteração AABB ao Godot principal sem muito custo?
 swarnimarun
em 2 jun. 2019
swarnimarun
em 2 jun. 2019
@ vblanco20-1 me importa em compartilhar os detalhes do compilador e do ambiente para o branch, acho que posso descobrir a maior parte, mas simplesmente não perca tempo tentando descobrir os problemas se não for necessário.
Também não podemos adicionar a alteração AABB ao Godot principal sem muito custo?
@swarnimarun Visual Studio 17 ou 19, uma das atualizações posteriores, funciona bem. (janelas)
O script scons foi modificado para adicionar o sinalizador cpp17. Além disso, o editor de inicialização está quebrado agora. Estou trabalhando para ver se consigo restaurá-lo.
Infelizmente, a mudança do AABB é uma das maiores coisas. Godot octree está entrelaçado com MUITAS coisas no servidor visual. Ele não apenas rastreia objetos para seleção, mas também conecta objetos a sondas de luz / reflexão, com seu próprio sistema para emparelhá-los. Esses pares também dependem da estrutura de lista vinculada da octree, então é quase impossível adaptar a octree atual para ser mais rápida sem alterar muito o servidor visual. Na verdade, ainda não fui capaz de me livrar do godot octree normal em meu garfo para alguns tipos de objetos.
vblanco20-1
em 2 jun. 2019
@ vblanco20-1 Você tem um Patreon? Eu colocaria algum dinheiro em uma bifurcação focada em desempenho e que não se restringe ao C ++ antigo e provavelmente não sou o único. Eu gostaria de brincar com Godot para projetos 3D, mas estou perdendo a esperança de que se torne viável sem uma grande prova de um conceito que prova sua abordagem de desempenho e usabilidade para a equipe principal.
 mixedCase
em 3 jun. 2019
mixedCase
em 3 jun. 2019
@mixedCase Eu ficaria extremamente hesitante em apoiar qualquer tipo de fork de Godot. A bifurcação e a fragmentação costumam ser a morte de projetos de código aberto.
O melhor cenário, e mais provável agora que foi demonstrado que o C ++ mais recente permite otimizações significativas, é Godot atualizar oficialmente para uma versão mais recente do C ++. Eu esperaria que isso acontecesse no Godot 4.0, para minimizar o risco de quebras no 3.2, e a tempo para os novos recursos C ++ a serem utilizados com o Vulkan sendo adicionado ao Godot 4.0. Também não espero que sejam feitas alterações significativas no renderizador GLES 3, pois reduz deseja excluí-lo.
(Mas eu não falo pelos devs de Godot, isso é apenas minha especulação)
aaronfranke
em 8 jun. 2019
@aaronfranke Eu concordo, acho que um fork permanente não seria o ideal. Mas pelo que deduzi do que ele disse (corrija-me se estiver errado) é que
Acredito que Juan seja uma pessoa muito pragmática, então provavelmente seria necessária uma grande prova de conceito que demonstrasse os benefícios de usar abstrações modernas e estruturas de dados mais eficientes para convencê-lo de que as compensações de engenharia provavelmente valem a pena. @ vblanco20-1 tem feito um trabalho incrível até agora, então eu, pessoalmente, não hesitaria em colocar algum dinheiro todo mês para ele se ele quiser fazer algo assim.
mixedCase
em 10 jun. 2019
Estou perpetuamente surpreso como os devs de Godot agem como se fossem alérgicos a boas ideias, desempenho e progresso. É uma pena que isso não tenha sido puxado.
 plabuda
em 16 jul. 2019
plabuda
em 16 jul. 2019
Este é um pedaço de uma série de artigos em que estou trabalhando sobre as otimizações, justamente sobre o uso da estrutura de dados.
Godot bane os contêineres STL e seu C ++ 03. Isso significa que não há operadores de movimentação em seus contêineres, e seus contêineres tendem a ser piores do que os próprios contêineres STL. Aqui, tenho uma visão geral das estruturas de dados de Godot e os problemas com elas.
Matriz C ++ pré-alocada. Muito comum em todo o motor. Seus tamanhos tendem a ser definidos por alguma opção de configuração. Isso é muito comum no renderizador, e uma classe de array dinâmica adequada funcionaria muito bem aqui.
Exemplo de uso indevido: https://github.com/godotengine/godot/blob/master/servers/visual/visual_server_scene.h#L442
Esses arrays estão desperdiçando memória sem um bom motivo, usar um array dinâmico seria uma opção significativamente melhor aqui, pois faria com que eles tivessem apenas o tamanho que precisam ter, em vez do tamanho máximo por uma constante de compilação. Cada uma das matrizes Instance * usando MAX_INSTANCE_CULL está usando meio megabyte de memória
Vector (vector.h) um equivalente de array dinâmico std :: vector, mas com uma falha profunda.
O vetor é atomicamente recontado com uma implementação de cópia na gravação. Quando você faz
Vetor a = build_vector ();
Vetor b = a;
o refcount irá para 2. B e A agora apontam para o mesmo local na memória e copiarão o array assim que uma edição for feita nele. Se agora você modificar o vetor A ou B, uma cópia do vetor será acionada.
Cada vez que você escreve em um vetor, será necessário verificar o refcount atômico, diminuindo a velocidade de cada operação de gravação no vetor. Estima-se que godot Vector seja 5 vezes mais lento que std :: vector, no mínimo. Outro problema é que o vetor será realocado automaticamente quando você remover itens dele, causando problemas de desempenho incontroláveis terríveis.
PoolVector (pool_vector.h). Mais ou menos o mesmo que um vetor, mas como um pool. Ele tem as mesmas armadilhas do Vector, com cópia na gravação sem motivo e redução automática.
Listar (list.h) um equivalente a std :: list. A lista tem 2 ponteiros (primeiro e último) + uma variável de contagem de elemento. Cada nó na lista é duplamente vinculado, mais um ponteiro extra para o próprio contêiner da lista. A sobrecarga de memória para cada nó da lista é de 24 bytes. É terrivelmente usado em excesso em godot devido ao Vector não ser muito bom em geral. Terrivelmente mal utilizado em todo o motor.
Exemplos de grande uso indevido:
https://github.com/godotengine/godot/blob/master/servers/visual/visual_server_scene.h#L129
Nenhuma razão para que seja uma lista, deve ser um vetor
https://github.com/godotengine/godot/blob/master/servers/visual/visual_server_scene.h#L242
Cada um desses casos está errado. novamente, deve ser vetorial ou similar. Este pode realmente causar problemas de desempenho.
O maior erro é usar List na octree usada para abate. Já entrei em detalhes sobre o godot octree neste tópico.
SelfList (self_list.h) uma lista intrusiva, semelhante a boost :: intrusive_list. Este sempre armazena 32 bytes de sobrecarga por nó, pois também aponta para si mesmo. Terrivelmente mal utilizado em todo o motor.
Exemplos:
https://github.com/godotengine/godot/blob/master/servers/visual/visual_server_scene.h#L159
Este é especialmente ruim. Um dos piores de todo o motor. Isso está adicionando 8 indicadores de gordura a cada objeto renderizável no mecanismo sem nenhum motivo. Não há necessidade de que seja uma lista. Ele, novamente, pode ser um slotmap ou um vetor, e foi por isso que o substituí.
Mapeie (map.h) uma árvore vermelho-preta. Usado indevidamente como hashmap em quase todos os seus usos. Deve ser excluído do mecanismo em favor de OAHashmap ou Hashmap, dependendo do uso.
Cada uso do mapa que vi estava errado. Não consigo encontrar um exemplo de mapa sendo usado onde faz sentido.
Hashmap (hash_map.h) aproximadamente equivalente a std :: unordered_map, um hashmap de endereço fechado baseado em depósitos de listas vinculadas. Ele pode refazer o hash ao remover elementos.
OAHashMap (oa_hash_map.h) hashmap de endereço aberto rápido recém-escrito. usa hashing robinhood. Ao contrário do hashmap, ele não será redimensionado ao remover elementos. Estrutura muito bem implementada, melhor do que std :: unordered_map.
CommandQueueMT (command_queue_mt.h) a fila de comandos usada para se comunicar com os diferentes servidores, como o servidor visual. Ele funciona tendo um array de 250 kb codificado para atuar como pool de alocadores e aloca cada comando como um objeto com uma função virtual call () e post (). Ele usa mutexes para proteger as operações push / pop. Bloquear mutexes é muito caro, eu recomendo usar a fila moodycamel, que deve ser uma ordem de magnitude mais rápida. É provável que isso se torne um gargalo para jogos que realizam muitas operações com o servidor visual, como muitos objetos em movimento.
Esses são basicamente o conjunto principal de estruturas de dados em godot. Não há equivalente std :: vector adequado. Se você deseja a estrutura de dados de “array dinâmico”, está preso ao Vector e suas desvantagens com a cópia na gravação e redução do tamanho. Acho que uma estrutura de dados DynamicArray é o que Godot mais precisa agora.
Para minha bifurcação, eu uso STL e outros contêineres de bibliotecas externas. Eu evito contêineres de godot, pois eles são piores do que o STL para desempenho, com exceção dos 2 hashmaps.
Problemas encontrados na implementação do Vulkan em 4.0. Eu sei que seu trabalho está em andamento, então ainda há tempo para consertá-lo.
Uso do mapa na API de renderização. https://github.com/godotengine/godot/blob/vulkan/drivers/vulkan/rendering_device_vulkan.h#L350
Como comentei, não existe um bom uso do Map e nenhuma razão para ele existir. Deve ser apenas hashmap nesses casos.
Uso excessivo de listas vinculadas em vez de apenas matrizes ou similares.
https://github.com/godotengine/godot/blob/vulkan/drivers/vulkan/rendering_device_vulkan.h#L680
Felizmente, isso provavelmente não está nos loops rápidos, mas ainda é um exemplo de uso de List onde não deveria ser usado
Usando PoolVector e Vector na API de renderização. https://github.com/godotengine/godot/blob/vulkan/drivers/vulkan/rendering_device_vulkan.h#L747
Não há nenhum bom motivo para usar essas 2 estruturas com falhas como parte da abstração da API de renderização. Ao usá-los, os usuários são forçados a usar esses 2, com suas desvantagens, em vez de poder usar qualquer outra estrutura de dados. Uma recomendação é usar ponteiro + tamanho nesses casos, e ainda ter uma versão da função que leva um Vector se necessário.
Um exemplo real em que esta API prejudicará um usuário é nas funções de criação do buffer de vértice. No formato GLTF, os buffers de vértice virão compactados em um arquivo binário. Com essa API, o usuário terá que carregar o buffer binário GLTF na memória, criar essas estruturas copiando os dados de cada buffer e, em seguida, usar a API.
Se a API tiver um ponteiro + tamanho ou uma estrutura Span <>, o usuário poderá carregar diretamente os dados de vértice do buffer binário carregado na API, sem ter que realizar uma conversão.
Isso é especialmente importante para pessoas que lidam com dados procedurais de vértices, como um motor de voxel. Com esta API, o desenvolvedor é forçado a usar Vector para seus dados de vértice, incorrendo em um custo de desempenho significativo, ou tem que copiar os dados em um Vector, ao invés de apenas carregar os dados de vértice diretamente das estruturas internas que o desenvolvedor usa.
Se você tem interesse em saber mais sobre esse assunto, a melhor palestra que conheço é essa da CppCon. https://www.youtube.com/watch?v=fHNmRkzxHWs
Outra ótima palestra é esta: https://www.youtube.com/watch?v=-8UZhDjgeZU , onde explica algumas estruturas de dados, como o slotmap, que seriam muito úteis para as necessidades de Godot.
vblanco20-1
em 17 jul. 2019
Godot tem um grande problema de performance ... você seria uma boa adição ao time de godot, por favor, considere isso!
Ranoller
em 18 jul. 2019
Estou encerrando este tópico, porque não acho que seja a maneira certa de contribuir ou ajudar.
@ vblanco20-1 Novamente, eu realmente aprecio que você tenha boas intenções, mas você não entende nada do funcionamento interno do motor, ou a filosofia por trás dele. A maioria dos seus comentários é sobre coisas que você realmente não entende como são usadas, como são críticas para o desempenho ou quais são suas prioridades em geral.
Seu tom também é desnecessariamente agressivo. Em vez de perguntar o que você não entende, ou por que algo é feito de certa maneira, você simplesmente sai com toda a arrogância. Esta não é a atitude certa para esta comunidade.
A maioria das coisas que você está mencionando sobre a otimização são apenas uma pequena superfície da quantidade de itens que planejei para otimização no Godot 4.0 (há muito mais coisas na minha lista). Eu já disse que isso seria reescrito várias vezes há vários meses. Se você não acredita em mim, tudo bem, mas sinto que você está perdendo seu próprio tempo com isso e confundindo muitas pessoas sem motivo aparente.
Obviamente, recebo muito bem o seu feedback assim que terminar meu trabalho, mas tudo o que você está fazendo agora é bater em um cavalo morto, então relaxe um pouco.
 reduz
em 22 jul. 2019
reduz
em 22 jul. 2019
Novamente, quando um alfa do Godot 4.0 for lançado (com sorte antes do final deste ano), você será bem-vindo para criar um perfil de todo o novo código e fornecer feedback sobre como otimizá-lo ainda mais. Tenho certeza de que todos nos beneficiaremos. Por enquanto, não há muito sentido em discutir qualquer outra coisa aqui, já que o código existente desaparecerá no 4.0, e nada será mesclado no branch 3.x, onde neste ponto a estabilidade é mais importante do que otimizações.
Uma vez que muitos podem estar curiosos sobre os detalhes técnicos:
- Todo o código de indexação espacial (o que vblanco reescreveu) será substituído por um algoritmo linear para abate com vários threads, combinado com uma octree para abate de oclusão hierárquica e um SAP para verificações sobrepostas, que são provavelmente os melhores algoritmos completos que garantem o bem desempenho em qualquer tipo de jogo. A alocação para essas estruturas será na mesma linha do novo RID_Allocator, que é O (1)). Discuti isso com @ vblanco20-1 antes e expliquei que sua abordagem não se adapta bem a todos os tipos de jogos, pois exige que o usuário tenha um certo grau de especialização para ajustar o que normalmente não se espera de um usuário típico de Godot. Também não era uma boa abordagem para adicionar seleção de oclusão.
- Não vou usar arrays quando as listas puderem ser usadas porque as listas fazem pequenas alocações temporais com risco zero de fragmentação. Em alguns casos, prefiro alocar uma matriz seccionada (alinhada às páginas, para que causem 0 fragmentação) que sempre aumenta e nunca diminui (como em RID_Allocator ou o novo CanvasItem no branch Vulkan do mecanismo 2D, que agora permite redesenhar itens com muitos comandos de forma muito eficiente), mas deve haver um motivo de desempenho para isso. Quando listas são usadas em Godot, é porque pequenas alocações são preferidas ao desempenho (e na verdade elas tornam a intenção do código mais clara para outros lerem).
- PoolVector se destina a alocações muito grandes com páginas de memória consecutivas. Até Godot 2.1 ele usava um pool de memória pré-alocado, mas isso foi removido na 3.xe agora o comportamento atual está errado. No 4.0 será substituído pela memória virtual, está na lista de coisas a fazer.
- Comparar Godot's Vector <> com std :: vector é inútil porque eles têm diferentes casos de uso. Usamo-lo principalmente para passar dados e bloqueá-lo para acesso rápido (via métodos ptr () ou ptrw ()). Se usássemos std :: vector, Godot seria muito mais lento devido a cópias desnecessárias. Também aproveitamos muito a mecânica de cópia na escrita para muitos usos diferentes.
- Map <> é apenas mais simples e amigável para uma grande quantidade de elementos e não há necessidade de se preocupar com o crescimento acelerado / rápido criando fragmentação. Quando o desempenho é necessário, o HashMap é usado (embora seja verdade, provavelmente deve usar mais o OAHashMap, mas é muito novo e nunca teve tempo para fazer isso). Como filosofia geral, quando o desempenho não é prioridade, pequenas alocações são sempre preferidas em vez de grandes porque é mais fácil para o alocador de memória de seu sistema operacional encontrar pequenos orifícios para colocá-los (que é basicamente o que ele foi projetado para fazer) , efetivamente consumindo menos heap.
Novamente, você pode perguntar sobre planos e designs a qualquer hora que quiser, em vez de se queixar e desonrar, essa não é a melhor maneira de ajudar o projeto.
Também tenho certeza de que muitos lendo este tópico estão se perguntando por que o indexador espacial era lento para começar. A razão é que, talvez você seja novo em Godot, mas até muito recentemente o motor 3D tinha mais de 10 anos e estava extremamente desatualizado. Trabalhou-se para modernizá-lo no OpenGL ES 3.0, mas tivemos que desistir devido a problemas que encontramos no OpenGL e ao fato de estar obsoleto para o Vulkan (e a Apple o abandonou).
Somado a isso, Godot costumava rodar em dispositivos como o PSP não muito tempo atrás (que tinha apenas 24 MB de memória disponível tanto para o motor quanto para o jogo, então muito do código do núcleo é muito conservador em relação à alocação de memória). Como o hardware é muito diferente agora, isso está sendo alterado para o código que é mais ideal e usa mais memória, mas quando não é necessário, fazer este trabalho é inútil e é bom que você veja listas usadas em muitos lugares onde o desempenho sim não importa.
Além disso, muitas otimizações que queríamos fazer (mover muitos do código mutex para atômicas para melhor desempenho) tiveram que ser colocadas em espera até que pudéssemos mover Godot para C ++ 11 (que tem um suporte muito melhor para atômicas embutidas e não exigimos que você inclua cabeçalhos de janelas, que poluem todo o namespace), o que não era algo que poderíamos fazer em um branch estável. A mudança para o C ++ 11 ocorrerá depois que Godot 3.2 for ramificado e o recurso travado, caso contrário, manter Vulkan an Master branches em sincronia seria uma grande dor. Não há muita pressa, já que atualmente o foco está agora no próprio Vulkan.
Desculpe, as coisas levam tempo, mas eu prefiro que sejam feitas corretamente em vez de apressá-las. A longo prazo, compensa melhor. No momento, todas as otimizações de desempenho estão sendo trabalhadas e devem estar prontas em breve (se você testou o branch Vulkan, o mecanismo 2D é muito mais rápido do que costumava ser).
reduz
em 22 jul. 2019
Hi reduz,
embora eu veja principalmente que seus pontos são válidos, gostaria de comentar dois dos quais discordo:
- Não vou usar arrays quando as listas puderem ser usadas porque as listas fazem pequenas alocações temporais com risco zero de fragmentação. Em alguns casos, prefiro alocar uma matriz seccionada (alinhada às páginas, para que causem 0 fragmentação) que sempre aumenta e nunca diminui (como em RID_Allocator ou o novo CanvasItem no branch Vulkan do mecanismo 2D, que agora permite redesenhar itens com muitos comandos de forma muito eficiente), mas deve haver um motivo de desempenho para isso. Quando listas são usadas em Godot, é porque pequenas alocações são preferidas ao desempenho (e na verdade elas tornam a intenção do código mais clara para outros lerem).
Duvido muito que uma lista vinculada tenha um desempenho geral melhor, seja velocidade ou eficiência de memória, do que uma matriz dinâmica com crescimento exponencial. Este último tem a garantia de ocupar no máximo duas vezes mais espaço do que realmente usa, enquanto um List<some pointer> usa exatamente três vezes mais armazenamento (o conteúdo real, o próximo e o ponteiro anterior). Para uma matriz seccionada, as coisas parecem ainda melhores.
Quando devidamente embalados (e pelo que posso dizer pelo que já vi do código de godot, eles são), eles parecem praticamente iguais para o programador, então não entendo o que você quer dizer com "eles [Listas ] tornar a intenção do código mais clara ".
IMHO, as listas são válidas exatamente em duas condições:
- Você precisa apagar / inserir elementos freqüentemente no meio do contêiner
- ou você precisa de inserção / exclusão de elementos em tempo constante (e não apenas tempo constante amortizado). Ou seja, em contextos de tempo real onde uma alocação de memória demorada não é possível, eles estão bem.
- Map <> é apenas mais simples e amigável para uma grande quantidade de elementos e não há necessidade de se preocupar com o crescimento acelerado / rápido criando fragmentação. Quando o desempenho é necessário, o HashMap é usado (embora seja verdade, provavelmente deve usar mais o OAHashMap, mas é muito novo e nunca teve tempo para fazer isso). Como filosofia geral, quando o desempenho não é prioridade, pequenas alocações são sempre preferidas em vez de grandes porque é mais fácil para o alocador de memória de seu sistema operacional encontrar pequenos orifícios para colocá-los (que é basicamente o que ele foi projetado para fazer) , efetivamente consumindo menos heap.
Os alocadores libc são geralmente bastante inteligentes, e como um OAHashMap (ou um std :: unordered_map) realoca seus armazenamentos de tempos em tempos (tempo constante amortizado), o alocador geralmente consegue manter seus blocos de memória compactos. Acredito firmemente que um OAHashMap não consome efetivamente mais heap do que um mapa de árvore binária simples como o Map. Em vez disso, tenho certeza de que a enorme sobrecarga do ponteiro em cada elemento de Map, na verdade, consome mais memória do que qualquer fragmentação de heap de OAHashmap (ou std :: unordered_map).
Afinal, acho que a melhor maneira de resolver esses tipos de argumentos é compará-los. Certamente, isso é muito mais útil para Godot 4.0, uma vez que - como você disse - muitas otimizações de desempenho acontecerão lá e não há muito uso para melhorar os caminhos de código que podem ser completamente reescritos no 4.0 de qualquer maneira.
Mas @reduz , o que você acha do benchmarking de todas essas mudanças que @ vblanco20-1 sugeriu (talvez até agora, em 3.1). Se @ vblanco20-1 (ou qualquer outra pessoa) está disposto a investir tempo para escrever tal suíte de benchmarking e para avaliar o desempenho de Godot3.1 (tanto em termos de velocidade quanto em "consumo de heap considerando a fragmentação") em relação às mudanças do vblanco? Pode render dicas valiosas para as mudanças reais do 4.0.
Acho que essa metodologia se ajusta bem às suas "[as coisas] são feitas corretamente, em vez de apressá-las".
@ vblanco20-1: Na verdade, agradeço seu trabalho. Você ficaria motivado para criar tais benchmarks, para que possamos realmente medir se suas alterações são melhorias reais de desempenho? Eu estaria muito interessado.
 Windfisch
em 23 jul. 2019
Windfisch
em 23 jul. 2019
@Windfisch Eu sugiro que você releia meu post acima, pois você leu ou entendeu mal algumas coisas. Vou esclarecê-los para você.
- As listas são usadas exatamente para o caso de uso que você descreve, e nunca afirmei que elas têm melhor desempenho. Eles são mais eficientes do que os arrays para reutilizar o heap simplesmente porque são compostos de pequenas alocações. Em uma escala (quando você os usa muito para o caso de uso pretendido), isso realmente faz a diferença. Quando o desempenho é necessário, outros contêineres que são mais rápidos, mais compactados ou têm melhor coerência de cache já são usados. Para o bem ou para o mal, Victor se concentrou principalmente em uma das áreas de motor mais antigas (se não a mais antiga, na verdade) que nunca foi otimizada desde o tempo em que era um motor interno usado para publicar jogos para PSP. Isso tinha uma reescrita pendente há muito tempo, mas havia outras prioridades. Sua principal otimização foi o rastreamento de cone de voxel baseado em CPU que adicionei recentemente, que para ser honesto, fiz um péssimo trabalho com isso porque estava muito apressado perto do lançamento 3.0, mas a correção adequada para isso é um algoritmo totalmente diferente, e não adicionando processamento paralelo como ele fez.
- Eu nunca discuti sobre o desempenho do trabalho de @ vblanco20-1 e francamente não me importo com isso (então você não precisa fazer com que ele perca tempo fazendo benchmarks). Os motivos para não mesclar seu trabalho são: 1) Os algoritmos que ele usa precisam de ajustes manuais, dependendo do tamanho médio dos objetos no jogo, algo que a maioria dos usuários de Godot precisará fazer. Eu tendo a preferir algoritmos que podem ser um pouco mais lentos, mas têm melhor escalabilidade, sem a necessidade de ajustes. 2) O algoritmo que ele usa não é bom para seleção de oclusão (octree simples é melhor devido à natureza hierárquica). 3) O algoritmo que ele usa não é bom para emparelhamento (SAP geralmente é melhor). 4) Ele usa C ++ 17 e bibliotecas que não tenho interesse em suportar, ou lambdas que acredito serem desnecessários 5) Já estou trabalhando na otimização para 4.0, e o branch 3.x tem a estabilidade como prioridade e nós pretendo lançar o 3.2 o mais rápido possível, então isso não será modificado ou trabalhado lá. O código existente pode ser mais lento, mas é muito estável e testado. Se isso for mesclado e houver relatórios de bugs, regressões, etc. Ninguém terá tempo para trabalhar nisso ou ajudar Victor porque já estamos ocupados principalmente com o branch 4.0. Tudo isso foi explicado acima, então sugiro que você releia a postagem.
Em qualquer caso, prometi a Victor que o código de indexação pode ser plugável, então, eventualmente, algoritmos diferentes para diferentes tipos de jogos também podem ser implementados.
Godot é open source, assim como seu fork. Estamos todos abertos e compartilhando aqui, nada deve impedi-lo de usar o trabalho dele se precisar.
reduz
em 23 jul. 2019
Já que essas otimizações parecem não afetar o gdscript, render ou os problemas de "gagueira", e há coisas que as pessoas reclamam (eu inclui), talvez com a realização de otimizações as pessoas ficarão felizes (eu inclui) ... não precisa velocidade lua jit ...
Trabalhar em "cópia na gravação" foi uma grande otimização de desempenho em um plugin meu (de 25 segundos em uma análise de script a apenas 1 segundo em um script de 7.000 linhas) ... sinto que esse tipo de otimizações são que nós precisa, em gdscript, em render e realizar o problema de gagueira ... isso é tudo.
Ranoller
em 23 jul. 2019
Obrigado @reduz pelo seu esclarecimento. De fato, deixou seus pontos mais claros do que as postagens anteriores.
É bom que o código de indexação espacial seja plugável, porque de fato aquele caiu no meu pé antes ao manusear muitos objetos em escalas muito diferentes. Ansioso para 4.0.
Windfisch
em 23 jul. 2019
Eu também estava pensando sobre isso e acho que pode ser uma boa ideia colocar algum documento compartilhado com ideias sobre como otimizar a indexação espacial, para que mais colaboradores possam aprender sobre isso e também lançar ideias ou fazer implementações. Tenho uma ideia muito boa sobre o que precisa ser feito, mas tenho certeza de que há muito espaço aqui para fazer mais otimizações e criar algoritmos interessantes.
Podemos colocar requisitos muito claros que sabemos que os algoritmos devem atender (como em, não exigir ajustes do usuário, se possível, para elementos médios no tamanho do mundo, não material de força bruta com threads se possível - eles não são gratuitos, outras partes do o motor também pode precisar deles, como física ou animação, e eles consomem mais bateria no celular- compatibilidade com seleção de oclusão baseada em reprojeção -então, alguma forma de hierarquia pode ser desejada, mas deve ser testada contra força bruta também-, seja inteligente sobre atualizações de buffer de sombra - não atualize se nada mudou -, explore otimizações, como re-projeção com base na seleção de oclusão para sombras direcionais, etc). Também podemos discutir a criação de alguns testes de benchmark (não acho que o demo TPS seja um bom benchmark porque não tem tantos objetos ou oclusão). @ vblanco20-1 se você deseja seguir nosso estilo e filosofia de codificação / linguagem, é claro que é mais do que bem-vindo para ajudar.
O resto do código de renderização (renderização real usando RenderingDevice) é mais ou menos direto e não há muitas maneiras de fazer isso, mas a indexação parece um problema mais interessante de resolver para otimização.
reduz
em 23 jul. 2019
@reduz para referência na indexação espacial. O abate original baseado em ladrilhos foi removido e substituído por um Octree na metade deste tópico. O octree que recebi lá é WIP (faltando algumas funcionalidades de re-ajuste), mas os resultados são muito bons para o protótipo. Seu código não é tão bom por causa de sua natureza de protótipo, então só é útil verificar como esse tipo de octree funcionaria em uma cena complexa como tps-demo.
É inspirado em como funciona o motor irreal octree, mas com algumas modificações, como a possibilidade de uma iteração plana.
A ideia principal é que apenas as folhas na octree contêm objetos, e esses objetos são mantidos em um array de tamanho 64 (o tamanho do tempo de compilação pode ser diferente). Uma folha de octree só se dividirá quando "estourar" em 65 elementos. Quando você remove objetos, se cada uma das folhas do nó pai caber no array de tamanho 64, então mesclamos as folhas de volta em seu nó pai, que se torna uma folha.
Fazendo isso, podemos minimizar o tempo de teste nos nós, pois a octree não ficará muito profunda.
Outra coisa boa que eu estava fazendo é que os nós folha também são armazenados em uma matriz plana, o que permite um for paralelo na seleção. Desta forma, a seleção hierárquica pode ser usada ao fazer a seleção para sombras de pontos ou outras operações "pequenas", e o plano paralelo para seleção pode ser usado para a visualização principal. Claro, poderia usar apenas hierárquico para tudo, mas poderia ser mais lento e não pode ser paralelizado.
A estrutura do bloco vai desperdiçar um pouco de memória, mas mesmo nos piores cenários, não acho que vai desperdiçar muita memória, pois os nós irão se fundir se ficarem abaixo de uma quantidade. Também permite o uso de um alocador de pool, uma vez que tanto os nós quanto as folhas terão um tamanho constante.
Eu também tenho vários octrees em meu fork, que são usados para otimizar algumas coisas. Por exemplo, eu tenho uma octree apenas para objetos shadowcaster, o que permite pular toda a lógica relacionada a "pode lançar sombras" ao selecionar mapas de sombras.
Sobre minhas preocupações com o Vector e outros na API de renderização, esse problema explica com o que eu estava preocupado. https://github.com/godotengine/godot/issues/24731
Na biblioteca e em C ++ 17 coisas da bifurcação .. isso é desnecessário. A bifurcação usa muitas bibliotecas porque eu precisava de algumas partes delas. A única coisa que é realmente necessária, e que eu acho que Godot precisa, é uma fila paralela de força da indústria, usei a fila moodycamel para ela.
Nos lambdas, seu uso é principalmente para seleção e é usado para economizar uma quantidade significativa de memória, já que você só precisa salvar os objetos que passam por suas verificações no array de saída. A alternativa é fazer objetos iteradores (isso é o que o motor irreal faz com sua octree), mas acaba sendo um código pior e muito mais difícil de escrever.
Minha intenção não era "pirar", mas responder a comentários frequentes sobre "você está livre para fazer um garfo para demonstrar", que é exatamente o que eu fiz. A primeira mensagem do tópico é um pouco alarmista e não muito correta. Desculpe se pareci rude com você, pois meu único objetivo é ajudar o mecanismo de jogo de código aberto mais popular.
vblanco20-1
em 23 jul. 2019
@ vblanco20-1 Parece ótimo, e a maneira como você menciona o funcionamento do octree faz muito sentido. Sinceramente, não me importo de implementar uma fila paralela (parece simples o suficiente para não precisar de uma dependência externa e preciso do C ++ 11 para fazer isso corretamente, então acho que isso acontecerá apenas no branch Vulkan). Se você tiver confirmado isso, com certeza vou querer dar uma olhada, para que possa usá-lo como base para a reescrita do indexador no branch Vulkan (estou apenas reescrevendo a maioria das coisas lá, então precisa ser reescrito de qualquer maneira ) Claro, se você quiser ajudar na implementação (provavelmente quando houver mais coisas no lugar com a nova API), é muito bem-vindo.
O uso de uma versão paralela com matrizes achatadas é interessante, mas meu ponto de vista sobre isso é que não será tão útil para a seleção de oclusão, e seria interessante medir o quanto de uma melhoria em relação à seleção de octree regular é, considerando a quantidade extra de núcleos usados. Tenha em mente que existem muitas outras áreas que podem estar usando vários threads que podem fazer um uso mais eficiente (menos força bruta) (como a física), então, mesmo que com esta abordagem obtivemos uma melhoria relativamente marginal, nem sempre é no melhor interesse, pois pode impedir que outras áreas usem a CPU. Talvez possa ser opcional.
Também acho a implementação de dbvt do Bullet 3 muito interessante, que faz aut balanceamento incremental e alocação linear, é uma das coisas que eu queria pesquisar mais (eu vi essa abordagem implementada em motores proprietários, não posso mencionar: P), no que diz respeito ao algoritmo, uma árvore binária balanceada é projetada apenas muito menos redundante do que uma octree e pode funcionar melhor em testes de emparelhamento e de oclusão, portanto, uma abordagem plugável de fase ampla / seleção pode ser uma boa ideia, desde que seja útil cenas de referência.
Em qualquer caso, você é excepcionalmente inteligente e seria ótimo se pudéssemos trabalhar juntos nisso, mas peço apenas que entenda e respeite muitas das filosofias de design existentes que temos, mesmo que nem sempre sejam adequadas ao seu gosto . O projeto é enorme, com muita força de inércia, e mudar as coisas pelo gosto do gosto não é uma boa ideia. A facilidade de uso e "simplesmente funciona" estão sempre em primeiro lugar na lista em relação ao design, e a simplicidade e a legibilidade do código geralmente têm prioridade sobre a eficiência (ou seja, quando a eficiência não é uma meta porque uma área não é crítica). Da última vez que discutimos, você queria mudar praticamente tudo e não queria ouvir nenhum raciocínio ou se concentrar em problemas reais, e não é assim que costumamos trabalhar com a comunidade e os colaboradores, por isso meu conselho para relaxar foi bem intencionado.
reduz
em 23 jul. 2019
Quem precisa de desempenho? :cara de gozo:
Desempenho e modelo de fonte é o que me mantém com Godot.
 BlueCannonBall
em 28 jan. 2020
BlueCannonBall
em 28 jan. 2020
Edit: Desculpe, talvez eu seja um offtopic, mas eu queria esclarecer os benefícios do código aberto.
@mixedCase Eu ficaria extremamente hesitante em apoiar qualquer tipo de fork de Godot. A bifurcação e a fragmentação costumam ser a morte de projetos de código aberto.
Acho que não. A natureza do código aberto é apenas que você pode usar e reutilizar o código livremente como quiser. Então isso não será o fim de algum projeto, mas sim mais opções para os usuários.
O que você diz é um monopólio, e não é isso que defende o código aberto. Não seja enganado por empresas que pretendem mostrar a você que é melhor ter controle total sobre alguma coisa. Isso é mentira, pelo menos no mundo do código aberto, porque se outra pessoa tem o código, você também tem o código. O que eles precisam fazer é cuidar de como lidar com uma comunidade ou como aceitar isso.
De qualquer forma, os desenvolvedores originais podem apenas mesclar melhorias do fork. Eles são livres para fazer isso sempre. Essa é outra natureza do mundo do código aberto.
E no pior dos casos, o fork será melhor do que o original e muitos contribuidores irão para lá. Ninguém perdeu, todos ganham. Oh, desculpe, se uma empresa está por trás do original, talvez eles tenham perdido (ou eles podem mesclar as melhorias do fork também).
 Anyeos
em 18 mar. 2020
Anyeos
em 18 mar. 2020
Questões relacionadas
 mefihl
·
3Comentários
mefihl
·
3Comentários
 nunodonato
·
3Comentários
nunodonato
·
3Comentários
 EdwardAngeles
·
3Comentários
bojidar-bg
·
3Comentários
EdwardAngeles
·
3Comentários
bojidar-bg
·
3Comentários
 timoschwarzer
·
3Comentários
timoschwarzer
·
3Comentários
Comentários muito úteis
Você pode estar interessado. Já faz um bom tempo que estou trabalhando no garfo sofisticado. Os resultados atuais são assim:

Capturado em um grande laptop para jogos com uma CPU Intel de 4 núcleos e GTX 1070
Godot normal
Meu fork em https://github.com/vblanco20-1/godot/tree/ECS_Refactor

Em ambos os perfis, o Vermelho é essencialmente "esperar pela GPU". Atualmente com gargalo devido a muitos drawcalls no opengl. Realmente não pode ser resolvido sem vulkan ou reescrever todo o renderizador.
No lado da CPU, vamos de quadros de 13 ms para quadros de 5 ms. Os frames "rápidos" vão de 5,5 ms a 2,5 ms
No lado do "quadro total", vamos de 13 ms a 8-9 ms
~ 75 FPS a ~ 115 FPS
Menos tempo de CPU = mais tempo que você pode gastar no jogo. O godot atual é afunilado na CPU, então mais tempo gasto no jogo significará FPS mais baixo, enquanto meu fork está vinculado à GPU, então você pode adicionar muito mais lógica de jogo com o FPS intocado, já que a CPU é apenas "livre" para um bom tempo a cada quadro.
MUITAS dessas melhorias podem ser mescladas em godot, se godot suportasse C ++ moderno e tivesse um sistema multithreading que permite tarefas "pequenas" muito baratas.
O maior ganho é obtido ao fazer sombras multithread e mapa de luz multithread nos objetos dinâmicos # 25013. Ambos funcionam da mesma maneira. Muitas outras partes do renderizador também são multithread.
Outros ganhos são um Octree que é de 10 a 20 vezes mais rápido do que godot um, e melhorias em alguns dos fluxos de renderização, como gravar a lista de renderização de passagem normal e pré-passagem de uma vez, em vez de iterar a lista de seleção 2 vezes, e uma mudança significativa em como a conexão luz-> malha funciona (sem lista vinculada!)
No momento, estou procurando mais mapas de teste além da demonstração TPS para que eu possa ter mais métricas em outros tipos de mapas. Também vou escrever uma série de artigos explicando como tudo isso funciona em detalhes.