Godot: Практически каждый раз используется самая медленная структура данных.
Я просматривал код Godot и обнаружил полное игнорирование любых характеристик производительности процессора, вплоть до основных структур данных. Он использует List везде, когда связанный список является самой медленной структурой данных, которую вы можете использовать на современных ПК. Практически любая другая структура данных будет быстрее, особенно в структурах небольшого размера. Это особенно вопиюще в таких вещах, как список источников света или отражения в рендерингах, где вы каждый раз сохраняете 3 указателя, вместо того, чтобы просто давать ему стек из 8 максимальных источников света (например) + дополнительный для случаев, когда это было бы больше чем это.
То же самое с RID_Owner, являющимся деревом, где это может быть хеш-карта или карта слотов. Также реализация Octree для отбраковки имеет ту же проблему.
Я хочу спросить о намерении дизайна, стоящем за этим полным и абсолютным чрезмерным использованием связанных списков и ужасных указателей производительности тяжелых структур данных повсюду в коде. Это по особой причине? В большинстве случаев связанный список с фрагментами, в котором вы создаете связанный список массивов, автоматически увеличивает производительность того же кода.
Использование этих структур данных также предотвращает любой вид «простого» параллелизма в хорошем фрагменте кода и полностью очищает кеш.
Я работаю над доказательством реализации концепции рефакторинга некоторых внутренних компонентов для использования более совершенных структур данных. В данный момент я работаю над переписыванием кода отбраковки, который обходит текущее октодерево и просто использует плоский массив с дополнительным параллелизмом. Я буду использовать tps-demo в качестве теста и вернусь с результатами, которые на самом деле я тестировал, чтобы пройти 25 уровней в глубину этого октодерева ...
С другой стороны, я очень впечатлен качеством стиля кода, все легко понять и понять, и все довольно хорошо прокомментировано.
 vblanco20-1
vblanco20-1
Все 61 Комментарий
Кому нужна производительность? :Тролль:
 mafiesto4
27 нояб. 2018
mafiesto4
27 нояб. 2018
Любопытно посмотреть, что вы измеряете.
 avencherus
27 нояб. 2018
avencherus
27 нояб. 2018
Это может объяснить, почему простой узел Light2D в Godot может сжечь ваш компьютер?
 Ranoller
27 нояб. 2018
Ranoller
27 нояб. 2018
@Ranoller Я так не думаю. Плохая производительность освещения, скорее всего, связана с тем, как Godot выполняет 2D-освещение в данный момент: рендеринг каждого спрайта n раз (где n - количество источников света, которые на него влияют).
Изменить: см. # 23593
 CptPotato
27 нояб. 2018
CptPotato
27 нояб. 2018
Чтобы уточнить, речь идет о неэффективности ЦП по всему коду. Это не имеет ничего общего с функциями Godot или самим рендерингом Godot GPU.
vblanco20-1
27 нояб. 2018
@ vblanco20-1, немного сбоку, мы с вами говорили о том, что узлы моделируются как объекты ECS. Интересно, есть ли уловка в том, чтобы создать функциональную ветвь godot с новым модулем ent, который будет постепенно работать бок о бок с деревом. как get_tree () и get_registry (). модуль ent, вероятно, упустит около 80% функциональности дерева / сцены, но он может быть полезен в качестве испытательного стенда, особенно для таких вещей, как составление больших статических уровней с большим количеством объектов (отбраковка, потоковая передача, пакетный рендеринг). Уменьшенная функциональность и гибкость, но большая производительность.
 pgruenbacher
27 нояб. 2018
pgruenbacher
27 нояб. 2018
Перед тем, как перейти на полную ECS (что я мог бы сделать), я хочу поработать над некоторыми низко висящими фруктами в качестве эксперимента. Я мог бы попытаться полностью ориентироваться на данные позже.
vblanco20-1
27 нояб. 2018
Итак, первые обновления:
update_dirty_instances: от 0,2-0,25 миллисекунды до 0,1 миллисекунды
octree_cull (основной вид): от 0,35 миллисекунды до 0,1 миллисекунды
Самое интересное? замена для отбраковки октодерева не использует никакой структуры ускорения, она просто выполняет итерацию по немому массиву со всеми AABB.
Что еще смешнее? Новый отбор - это 10 строк кода. Если бы я хотел, чтобы это было параллельно, это было бы одно изменение линии.
Я продолжу реализацию моего нового отбраковки с помощью света, чтобы посмотреть, сколько накапливается ускорение.
vblanco20-1
1 дек. 2018
мы, вероятно, должны получить каталог тестов google, который также будет размещен в основной ветке. Это может помочь с подтверждением, чтобы людям не приходилось спорить об этом.
pgruenbacher
1 дек. 2018
Репозиторий godotengine / godot-tests есть , но пока мало кто им пользуется.
 bojidar-bg
2 дек. 2018
bojidar-bg
2 дек. 2018
Новое обновление:

Айв реализовал довольно глупую структуру пространственного ускорения с 2 уровнями. Я просто генерирую его каждый кадр. Дальнейшие улучшения могут сделать его лучше и динамически обновлять, а не переделывать.
На изображении разные строки представляют собой разные области видимости, и каждый цветной блок представляет собой задачу / фрагмент кода. В этом захвате я выполняю и отбраковку октодерева, и мою отбраковку бок о бок, чтобы иметь прямое сравнение.
Это демонстрирует, что воссоздание всей структуры ускорения происходит быстрее, чем отбраковка одного старого октодерева.
Кроме того, дальнейшие выбраковки обычно составляют от половины до одной трети текущего октодерева.
Я не нашел ни одного случая, когда моя тупая структура была медленнее, чем текущее октодерево, кроме затрат на первоначальное создание.
Еще одним преимуществом является то, что он очень дружелюбен к многопоточности и может быть увеличен до любого количества ядер, которое вы хотите, просто с помощью параллельной обработки.
Он также полностью проверяет память, поэтому должно быть возможно заставить его выполнять SIMD без особых хлопот.
Еще одна важная деталь заключается в том, что это намного проще, чем текущее октодерево, с гораздо меньшим количеством строк кода.
vblanco20-1
2 дек. 2018
Вы вызываете больше шумихи, чем конец Игры престолов ...
Ranoller
2 дек. 2018

Немного изменены алгоритмы, поэтому теперь они могут использовать параллельные алгоритмы C ++ 17, что позволяет программисту просто указать ему выполнить параллельную или параллельную сортировку.
Ускорение примерно в 2 раза в основной отсечке пирамиды, но для огней примерно такая же скорость, как и раньше.
Мой кулер теперь в 10 раз быстрее, чем годот октодерево для основного вида.
vblanco20-1
2 дек. 2018
Если вы хотите посмотреть на изменения, главное здесь:
https://github.com/vblanco20-1/godot/blob/4ab733200faa20e0dadc9306e7cc93230ebc120a/servers/visual/visual_server_scene.cpp#L387
Это новая функция отбраковки. Структура ускорения находится на функции прямо над ней.
vblanco20-1
2 дек. 2018
Это должно компилироваться с VS2015? Консоль выдает кучу ошибок о файлах внутри entt \
Ranoller
2 дек. 2018
@Ranoller это С ++ 17, поэтому убедитесь, что вы используете более новый компилятор
pgruenbacher
3 дек. 2018
Я думаю, Годо еще не перешел на С ++ 17? Хоть припомню какие-то дискуссии по теме?
 Zireael07
3 дек. 2018
Zireael07
3 дек. 2018
Годо - это C ++ 03. Этот шаг будет спорным. Я рекомендую @ vblanco20-1 поговорить с Хуаном, когда он закончит праздничные дни ... эта оптимизация будет отличной, и мы не хотим мгновенно получить сообщение «Это никогда не случится».
Ranoller
3 дек. 2018
@ vblanco20-1
octree_cull (основной вид): от 0,35 миллисекунды до 0,1 миллисекунды
сколько предметов?
 nem0
3 дек. 2018
nem0
3 дек. 2018
@ nem0
@ vblanco20-1
octree_cull (основной вид): от 0,35 миллисекунды до 0,1 миллисекунды
сколько предметов?
Около 2200. Октодерево godot работает лучше, если чек очень маленький, потому что это ранние ауты. Чем больше запрос, тем медленнее годо октодерево по сравнению с моим решением. Если годот октодерево не может преждевременно выйти из 90% сцены, тогда он будет ужасно медленным, потому что он по существу повторяет связанные списки для каждого отдельного объекта, в то время как моя система представляет собой структуру массивов, где каждая строка кэша содержит хорошее количество AABB, что значительно сокращает промахи в кэше.
Моя система работает, имея 2 уровня AABB, это массив блоков, где каждый блок может содержать 128 экземпляров.
Верхний уровень - это в основном массив AABB + массив блоков. Если проверка AABB проходит, я повторяю блок. Блок представляет собой массив структуры AABB, маски и указателя на экземпляр. Так все фаааааст.
Прямо сейчас генерация структуры данных верхнего уровня выполняется очень глупым способом. Если бы он был сгенерирован лучше, его производительность могла бы быть намного больше. Я провожу несколько экспериментов с другими размерами блоков, кроме 128.
vblanco20-1
3 дек. 2018
Я проверил разные числа, и 128 на блок, кажется, каким-то образом все еще остаются интересным местом.
Изменив алгоритм, чтобы отделить «большие» объекты от мелких, ive удалось получить еще 30% повышения скорости, в основном в том случае, если вы не смотрите в центр карты. Это работает, потому что большие объекты не раздувают блочные AABB, которые также включают в себя мелкие объекты. Я считаю, что 3 размера, вероятно, подойдут лучше всего.
Генерация блоков все еще не оптимальна. Большие блоки отбраковывают только от 10 до 20% экземпляров, если смотреть в центр, и до 50%, если смотреть за пределы карты, поэтому он выполняет МНОГО дополнительных проверок AABB, чем необходимо.
Я думаю, что улучшением, вероятно, было бы повторно использовать текущее октодерево, но «сгладить» его.
Сейчас нет ни одного случая, когда мой алгоритм был бы равен или хуже, чем текущее октодерево, даже без параллельного выполнения.
vblanco20-1
3 дек. 2018
@ vblanco20-1 Я предполагаю, что вы сравниваете Godot, скомпилированный в режиме release (который использует -O3 ), а не сборку обычного редактора в отладке (которая не имеет оптимизаций и используется по умолчанию), правильно ?
Извините, если это глупый вопрос, но я не вижу упоминания об этом в ветке.
В любом случае, хорошая работа :)
 Faless
11 дек. 2018
Faless
11 дек. 2018
@Faless Его release_debug, который добавляет некоторые оптимизации. Мне не удалось протестировать полную "версию", так как я не могу заставить ее открыть игру (игра тоже должна быть построена?)
У Айва была идея, как еще больше улучшить отбраковку, избавившись от необходимости регенерировать каждый кадр и создав лучшую пространственную оптимизацию. Я посмотрю, что я могу попробовать. Теоретически такая вещь могла бы удалить регенерацию, немного улучшить производительность основной отбраковки и иметь особый режим для точечных светильников, который значительно увеличил бы их производительность отбраковки, настолько, что они были бы почти нулевыми, потому что это превратится в дешевый O (1), чтобы получить «объекты в радиусе».
Он вдохновлен тем, как работал один из моих экспериментов, когда я делал 400 000 физических объектов, отскакивающих друг от друга.
vblanco20-1
11 дек. 2018

Реализован новый отсев. Генерация блоков теперь намного умнее, что приводит к более быстрой отбраковке. Особый случай для фонарей пока не реализован.
Я привязал это к своей вилке
vblanco20-1
12 дек. 2018
Мне любопытно, можете ли вы запустить этот тестовый инструмент (тот, который показан на ваших снимках экрана) на сборке из текущей основной ветки, чтобы дать нам ориентир того, насколько ваша реализация дает производительность по сравнению с текущей реализацией. Я болван, ухмылка.
 LikeLakers2
13 дек. 2018
LikeLakers2
13 дек. 2018
@ LikeLakers2 На скриншоте вы можете увидеть как текущую реализацию, так и его реализацию.
 neikeq
13 дек. 2018
neikeq
13 дек. 2018
Он запустил это на главной вилке
В среду, 12 декабря 2018 г., MichiRecRoom [email protected]
написал:
@neikeq https://github.com/neikeq Объясните? Думал скриншоты
которые были опубликованы, были только его реализацией, учитывая, как сообщения
со скриншотами уже написаны.-
Вы получили это, потому что прокомментировали.
Ответьте на это письмо напрямую, просмотрите его на GitHub
https://github.com/godotengine/godot/issues/23998#issuecomment-446831151 ,
или отключить поток
https://github.com/notifications/unsubscribe-auth/ADLZ9pRh9Lksse9KBfWV0z5GmHRXf5P2ks5u4crCgaJpZM4YziJp
.
pgruenbacher
13 дек. 2018
Есть какие-нибудь новости по этой теме?
CptPotato
15 янв. 2019
Есть какие-нибудь новости по этой теме?
Я разговаривал с редузом. Никогда не будет слита, потому что это не подходит для проекта. Вместо этого я пошел на другие эксперименты. Может быть, я обновлю отсечение позже до 4.0
vblanco20-1
15 янв. 2019
Жаль, учитывая, что это выглядело действительно многообещающе. Надеюсь, эти вопросы будут решены вовремя.
CptPotato
15 янв. 2019
Может быть, это стоит дать рубеж 4.0? Поскольку Reduz планирует работать над Vulkan для 4.0, и эта тема, хотя и о производительности, сосредоточена на рендеринге, или, по крайней мере, на OP.
 aaronfranke
4 февр. 2019
aaronfranke
4 февр. 2019
@ vblanco20-1 Он сказал, что не подходит? Я предполагаю из-за перехода на С ++ 17?
 Two-Tone
6 февр. 2019
Two-Tone
6 февр. 2019
Однако есть и другая проблема, связанная с этапом: # 25013
 starry-abyss
6 февр. 2019
starry-abyss
6 февр. 2019
Вам может быть интересно. Я довольно давно работал над причудливой вилкой. Текущие результаты выглядят так:
Снято на большом игровом ноутбуке с 4-ядерным процессором Intel и GTX 1070
Нормальный годот
Моя вилка на https://github.com/vblanco20-1/godot/tree/ECS_Refactor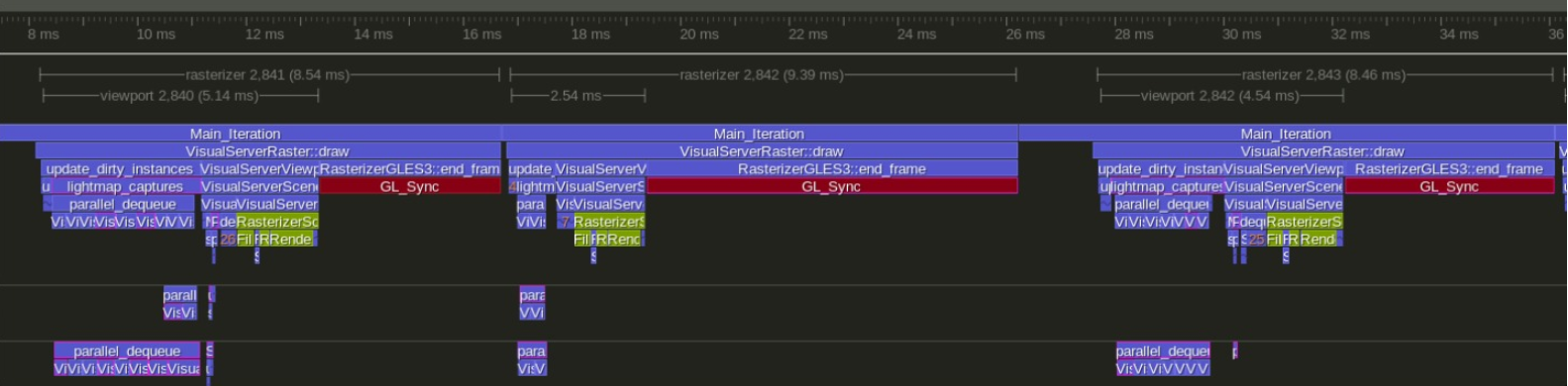
В обоих профилях красный по сути означает «ждите GPU». В настоящее время узкое место из-за слишком большого количества вызовов отрисовки в opengl. На самом деле не может быть решена без вулкана или перезаписи всего рендерера.
Что касается ЦП, мы переходим от кадров 13 мс к кадрам 5 мс. «Быстрые» кадры увеличиваются с 5,5 мс до 2,5 мс.
Что касается «всего кадра», мы переходим с 13 мс до 8–9 мс.
От ~ 75 до ~ 115 кадров в секунду
Меньше процессорного времени = больше времени, которое вы можете потратить на игровой процесс. Текущий Godot имеет узкое место в ЦП, поэтому больше времени, потраченного на игровой процесс, будет означать более низкий FPS, в то время как мой форк привязан к графическому процессору, поэтому вы можете добавить намного больше игровой логики с нетронутым FPS, поскольку ЦП просто "свободен" для довольно долго каждый кадр.
МНОЖЕСТВО этих улучшений можно объединить в godot, ЕСЛИ Godot поддерживает современный C ++ и имеет многопоточную систему, которая позволяет выполнять очень дешевые «маленькие» задачи.
Самый большой выигрыш достигается за счет многопоточного чтения теней и многопоточной карты освещения для динамических объектов # 25013. Оба они работают одинаково. Многие другие части средства визуализации также являются многопоточными.
Другими улучшениями являются Octree, которое от 10 до 20 раз быстрее, чем Godot One, и улучшения в некоторых потоках рендеринга, такие как одновременная запись списка рендеринга с предварительным проходом глубины и с обычным проходом вместо повторения списка отбраковки 2. раз, и существенное изменение того, как работает соединение свет-> сетка (нет связанного списка!)
В настоящее время я ищу больше тестовых карт, кроме демонстрации TPS, чтобы иметь больше показателей на других типах карт. Я также собираюсь написать серию статей, в которых подробно объясню, как все это работает.
vblanco20-1
1 июн. 2019
@ vblanco20-1, это просто потрясающе. Спасибо, что поделился!
Я также согласен с тем, что даже при том, что Vulkan крут, наличие достойной производительности GLES3 было бы абсолютной победой для Godot. Полная поддержка Vulkan, скорее всего, не появится в ближайшее время, а исправление GLES3 - это то, что ребята здесь оказалось полностью выполнимым прямо сейчас.
Мой огромный +1 за то, что привлекаю к этому все больше и больше внимания. Я был бы самым счастливым человеком на Земле, если бы Reduz согласился позволить сообществу улучшать GLES3. Мы делаем очень серьезный 3D-проект в Godot уже 1,5 года, и мы очень поддерживаем Godot (включая пожертвования), но отсутствие твердых 60 FPS действительно демотивирует нас и подвергает все наши усилия огромному риску.
Очень жаль, что не получает достаточно кредитов. Если у нас не будет 60 FPS в ближайшие месяцы с нашим текущим (довольно простым с точки зрения 3D) проектом, мы не сможем создать игру, в которую можно играть, и, таким образом, все усилия будут потрачены впустую. : /
@ vblanco20-1, честно говоря, я даже подумываю использовать ваш форк в качестве основы для нашей игры в продакшене.
PS Некоторые мысли: в крайнем случае, я думаю, вполне можно было бы иметь, скажем, 2 растеризатора GLES3 - GLES3 & GLES3-community.
 and3rson
1 июн. 2019
and3rson
1 июн. 2019
PS Некоторые мысли: в крайнем случае, я думаю, вполне можно было бы иметь, скажем, 2 растеризатора GLES3 - GLES3 & GLES3-community.
Для меня это не имеет смысла; Вероятно, лучше получить исправления и улучшения производительности непосредственно в средствах визуализации GLES3 и GLES2 (при условии, что они не нарушают существенные нарушения визуализации в существующих проектах).
Другими улучшениями являются Octree, которое от 10 до 20 раз быстрее, чем Godot One, и улучшения в некоторых потоках рендеринга, такие как одновременная запись списка рендеринга с предварительным проходом глубины и с обычным проходом вместо повторения списка отбраковки 2. раз, и существенное изменение того, как работает соединение свет-> сетка (нет связанного списка!)
@ vblanco20-1 Можно ли оптимизировать предварительный проход глубины, оставаясь на C ++ 03?
 Calinou
1 июн. 2019
Calinou
1 июн. 2019
@Calinou - материал для предварительного
vblanco20-1
1 июн. 2019
@ vblanco20-1, честно говоря, я даже подумываю использовать ваш форк в качестве основы для нашей игры в продакшене.
@ and3rson, пожалуйста, не
vblanco20-1
1 июн. 2019
Какие инструменты вы используете для профилирования Godot? Вам нужно было добавить флаги Profiler.Begin и Profiler.End в источник godot для создания этих образцов?
 jknightdoeswork
2 июн. 2019
jknightdoeswork
2 июн. 2019
Какие инструменты вы используете для профилирования Godot? Вам нужно было добавить флаги Profiler.Begin и Profiler.End в источник godot для создания этих образцов?
Он использует профилировщик Tracy, он имеет различные типы меток профиля прицела, которые я использую здесь. Например, ZoneScopedNC («Список заполнения», 0x123abc) добавляет метку профиля с этим именем и желаемым шестнадцатеричным цветом.
vblanco20-1
2 июн. 2019
@ vblanco20-1 - Будем ли мы видеть некоторые из этих улучшений производительности, перенесенные в основную ветку godot?
 HeadClot
2 июн. 2019
HeadClot
2 июн. 2019
@ vblanco20-1 - Будем ли мы видеть некоторые из этих улучшений производительности, перенесенные в основную ветку godot?
Может быть, когда поддерживается C ++ 11. Но на самом деле reduz не хочет дополнительной работы над рендерером до того, как произойдет vulkan, поэтому, возможно, никогда не будет. Некоторые результаты работы по оптимизации могут быть полезны для модуля рендеринга 4.0.
vblanco20-1
2 июн. 2019
@ vblanco20-1 не забывайте делиться деталями компилятора и среды для ветки, я думаю, что могу понять большую часть этого, но просто не тратьте время на выяснение проблем, если мне это не нужно.
Также нельзя ли добавить изменение AABB в основную программу Godot без особых затрат?
 swarnimarun
2 июн. 2019
swarnimarun
2 июн. 2019
@ vblanco20-1 не забывайте делиться деталями компилятора и среды для ветки, я думаю, что могу понять большую часть этого, но просто не тратьте время на выяснение проблем, если мне это не нужно.
Также нельзя ли добавить изменение AABB в основную программу Godot без особых затрат?
@swarnimarun Visual Studio 17 или 19, одно из последних обновлений, работает нормально. (окна)
В скрипт scons добавлен флаг cpp17. Также прямо сейчас нарушен запуск редактора. Я работаю, чтобы посмотреть, смогу ли я его восстановить.
К сожалению, изменение AABB - одна из самых важных вещей. Октодерево Годо связано с МНОЖЕСТВОМ визуального сервера. Он не только отслеживает объекты для отбраковки, но также соединяет объекты с датчиками освещения / отражения с помощью своей собственной системы для их объединения в пары. Эти пары также зависят от структуры связанного списка октодерева, поэтому практически невозможно адаптировать текущее октодерево, чтобы оно было быстрее, без значительного изменения визуального сервера. Фактически, я до сих пор не смог избавиться от нормального октодерева Godot в моей вилке для пары типов объектов.
vblanco20-1
2 июн. 2019
@ vblanco20-1 У вас есть Патреон? Я бы потратил немного денег на форк, ориентированный на производительность, который не ограничивается древним C ++, и я, вероятно, не единственный. Я хотел бы поиграть с Godot для 3D-проектов, но я теряю надежду, что он станет жизнеспособным без серьезного доказательства концепции, которая доказывает ваш подход к производительности и удобству использования для основной команды.
 mixedCase
3 июн. 2019
mixedCase
3 июн. 2019
@mixedCase Я бы очень не
Лучшим сценарием и более вероятным теперь, когда было продемонстрировано, что новый C ++ допускает значительную оптимизацию, является официальное обновление Godot до более новой версии C ++. Я ожидал, что это произойдет в Godot 4.0, чтобы минимизировать риск поломки в 3.2, и вовремя для использования новых функций C ++ с добавлением Vulkan в Godot 4.0. Я также не ожидаю каких-либо значительных изменений в рендерере GLES 3, так как reduz хочет его удалить.
(Но я не говорю от имени разработчиков Godot, это всего лишь мои предположения)
aaronfranke
8 июн. 2019
@aaronfranke Согласен, думаю, что постоянный форк не идеален. Но из того, что он сказал (пожалуйста, поправьте меня, если я ошибаюсь), я понял, что
Я считаю, что Хуан очень прагматичный человек, поэтому, вероятно, потребуется серьезное подтверждение концепции, демонстрирующее преимущества использования современных абстракций и более эффективных структур данных, чтобы убедить его в том, что инженерные компромиссы, вероятно, того стоят. @ vblanco20-1 проделал потрясающую работу, поэтому я лично без колебаний откладываю ему немного денег каждый месяц, если он захочет пойти на что-то подобное.
mixedCase
10 июн. 2019
Я постоянно удивляюсь тому, как разработчики Godot ведут себя так, будто у них аллергия на хорошие идеи, производительность и прогресс. Жалко, что на это не потянули.
 plabuda
16 июл. 2019
plabuda
16 июл. 2019
Это отрывок из серии статей, над которыми я работаю, об оптимизации, а именно об использовании структуры данных.
Годо запрещает контейнеры STL и его C ++ 03. Это означает, что у него нет операторов перемещения в своих контейнерах, и его контейнеры, как правило, хуже, чем сами контейнеры STL. Здесь у меня есть обзор структур данных godot и проблем с ними.
Предварительно выделенный массив C ++. Очень часто встречается во всем двигателе. Его размеры, как правило, устанавливаются некоторыми вариантами конфигурации. Это очень часто встречается в рендерере, и здесь отлично подойдет подходящий класс динамического массива.
Пример неправильного использования: https://github.com/godotengine/godot/blob/master/servers/visual/visual_server_scene.h#L442
Эти массивы тратят память без уважительной причины, использование динамического массива было бы здесь значительно лучшим вариантом, поскольку это сделало бы их только размером, который им нужен, а не максимальным размером, установленным константой компиляции. Каждый из массивов Instance *, использующих MAX_INSTANCE_CULL, использует половину мегабайта памяти.
Vector (vector.h) эквивалент динамического массива std :: vector, но с серьезным недостатком.
Пересчет вектора выполняется атомарно с реализацией копирования при записи. Когда ты делаешь
Вектор a = build_vector ();
Вектор b = a;
счетчик ссылок перейдет к 2. Теперь B и A указывают на одно и то же место в памяти и скопируют массив после того, как в нем будет произведено редактирование. Если вы сейчас измените вектор A или B, это вызовет векторную копию.
Каждый раз, когда вы пишете в вектор, вам нужно будет проверять атомарный счетчик ссылок, замедляя каждую операцию записи в векторе. По оценкам, Godot Vector как минимум в 5 раз медленнее, чем std :: vector. Другая проблема заключается в том, что вектор будет перемещаться автоматически, когда вы удаляете из него элементы, что вызывает ужасные неконтролируемые проблемы с производительностью.
PoolVector (pool_vector.h). Более или менее то же самое, что вектор, но вместо этого как пул. У него те же подводные камни, что и у Vector, с копированием при записи без причины и автоматическим уменьшением размера.
List (list.h) эквивалент std :: list. В списке есть 2 указателя (первый и последний) + переменная количества элементов. Каждый узел в списке имеет двойную связь, плюс дополнительный указатель на сам контейнер списка. Накладные расходы на память для каждого узла списка составляют 24 байта. Он ужасно часто используется в Годо из-за того, что Вектор в целом не очень хорош. Ужасно злоупотребляли всем двигателем.
Примеры большого злоупотребления:
https://github.com/godotengine/godot/blob/master/servers/visual/visual_server_scene.h#L129
Нет никаких причин для того, чтобы это был список, должен быть вектор
https://github.com/godotengine/godot/blob/master/servers/visual/visual_server_scene.h#L242
Каждый из этих случаев ошибочен. опять же, он должен быть векторным или подобным. Это действительно может вызвать проблемы с производительностью.
Самая большая ошибка - использование List в октодереве, используемом для отбраковки. Я уже подробно рассказывал о годовом октодереве в этой ветке.
SelfList (self_list.h) назойливый список, похожий на boost :: intrusive_list. Он всегда хранит 32 байта служебных данных на узел, поскольку он также указывает на себя. Ужасно злоупотребляли всем двигателем.
Примеры:
https://github.com/godotengine/godot/blob/master/servers/visual/visual_server_scene.h#L159
Этот особенно плохой. Один из худших во всем движке. Это добавляет 8 указателей жирности к каждому рендерируемому объекту в движке без какой-либо причины. Это не обязательно список. Это, опять же, может быть карта слотов или вектор, и это то, чем я его заменил.
Карта (map.h) красно-черное дерево. Неправильно используется в качестве хэш-карты практически во всех случаях. Следует удалить из движка в пользу OAHashmap или Hashmap, в зависимости от использования.
Каждое использование карты, которое я видел, было неправильным. Я не могу найти пример использования карты там, где это имеет смысл.
Hashmap (hash_map.h) примерно эквивалентен std :: unordered_map, закрытой хэш-карте адресов, основанной на сегментах связанного списка. Может перехешироваться при удалении элементов.
OAHashMap (oa_hash_map.h) недавно написанная быстрая хеш-карта с открытыми адресами. использует хеширование роботов. В отличие от hashmap, он не будет изменять размер при удалении элементов. Действительно хорошо реализованная структура, лучше, чем std :: unordered_map.
CommandQueueMT (command_queue_mt.h) очередь команд, используемая для связи с различными серверами, такими как визуальный сервер. Он работает, имея жестко запрограммированный массив 250 КБ, который действует как пул распределителя, и выделяет каждую команду как объект с функцией виртуального call () и post (). Он использует мьютексы для защиты операций push / pop. Блокирование мьютексов очень дорого, я рекомендую вместо этого использовать очередь moodycamel, которая должна быть на порядок быстрее. Это, вероятно, станет узким местом для игр, которые выполняют множество операций с визуальным сервером, например множество движущихся объектов.
Это в значительной степени основной набор структур данных в Godot. Не существует надлежащего эквивалента std :: vector. Если вам нужна структура данных «динамический массив», вы застряли с вектором и его недостатками с копией при записи и уменьшением размера. Я думаю, что сейчас Godot больше всего нуждается в структуре данных DynamicArray.
Для своей вилки я использую STL и другие контейнеры из внешних библиотек. Я избегаю контейнеров Godot, поскольку они хуже, чем STL по производительности, за исключением двух хэш-карт.
Были обнаружены проблемы с реализацией vulkan в 4.0. Я знаю, что работа ведется, так что еще есть время, чтобы это исправить.
Использование карты в API рендеринга. https://github.com/godotengine/godot/blob/vulkan/drivers/vulkan/rendering_device_vulkan.h#L350
Как я прокомментировал, нет хорошего использования Map и нет причин для ее существования. В таких случаях должно быть просто хэш-карта.
Чрезмерное использование связных списков вместо массивов или чего-то подобного.
https://github.com/godotengine/godot/blob/vulkan/drivers/vulkan/rendering_device_vulkan.h#L680
К счастью, это, скорее всего, не в быстрых циклах, но это все еще пример использования List, где его не следует использовать.
Использование PoolVector и Vector в API рендеринга. https://github.com/godotengine/godot/blob/vulkan/drivers/vulkan/rendering_device_vulkan.h#L747
Нет никаких серьезных причин использовать эти две некорректные структуры как часть абстракции API рендеринга. Используя их, пользователи вынуждены использовать эти 2 с их недостатками вместо возможности использовать любую другую структуру данных. Рекомендуется использовать указатель + размер в этих случаях и при этом иметь версию функции, которая принимает вектор, если это необходимо.
Фактический пример, когда этот API причинит вред пользователю, - это функции создания буфера вершин. В формате GLTF буферы вершин будут упакованы в двоичный файл. С помощью этого API пользователь должен будет загрузить двоичный буфер GLTF в память, создать эти структуры, копирующие данные для каждого буфера, а затем использовать API.
Если API принимает указатель + размер или структуру Span <>, пользователь сможет напрямую загрузить данные вершины из загруженного двоичного буфера в API без необходимости выполнять преобразование.
Это особенно важно для людей, которые имеют дело с процедурными данными вершин, такими как воксельный движок. С помощью этого API разработчик вынужден использовать Vector для своих данных вершин, что требует значительных затрат на производительность, или должен копировать данные в Vector вместо того, чтобы просто загружать данные вершин непосредственно из внутренних структур, которые использует разработчик.
Если вам интересно узнать больше об этой теме, лучший доклад, который я знаю, - это выступление от CppCon. https://www.youtube.com/watch?v=fHNmRkzxHWs
Другой замечательный доклад - это: https://www.youtube.com/watch?v=-8UZhDjgeZU , где объясняется несколько структур данных, таких как карта слотов, которые были бы очень полезны для нужд Годо.
vblanco20-1
17 июл. 2019
У Годо большая проблема с производительностью ... вы были бы хорошим дополнением к команде Годо, пожалуйста, примите это во внимание!
Ranoller
18 июл. 2019
Я закрываю эту цепочку, потому что не думаю, что это правильный способ внести свой вклад или помочь.
@ vblanco20-1 Опять же, я действительно ценю, что у вас хорошие намерения, но вы не понимаете ни внутренней работы движка, ни философии, стоящей за ним. Большинство ваших комментариев относятся к тому, что вы действительно не понимаете, как они используются, насколько они важны для производительности или каковы их приоритеты в целом.
Ваш тон тоже излишне агрессивен. Вместо того, чтобы спрашивать, чего вы не понимаете или почему что-то делается определенным образом, вы просто проявляете высокомерие. Это неправильное отношение к этому сообществу.
Большинство вещей, которые вы упоминаете в отношении оптимизации, - это лишь очень небольшая часть того количества элементов, которые я планировал для оптимизации в Godot 4.0 (в моем списке еще много вещей). Я уже говорил вам, что это будет переписано несколько раз, начиная с нескольких месяцев назад. Если вы мне не верите, это нормально, но я чувствую, что вы зря тратите на это свое время и сбиваете с толку множество людей без всякой очевидной причины.
Я, конечно, очень приветствую ваши отзывы, когда я закончу свою работу, но все, что вы сейчас делаете, это бьете дохлую лошадь, так что просто расслабьтесь на некоторое время.
 reduz
22 июл. 2019
reduz
22 июл. 2019
Опять же, когда будет выпущена альфа-версия Godot 4.0 (надеюсь, до конца этого года), вы можете профилировать весь новый код и давать отзывы о том, как его дальше оптимизировать. Я уверен, что все мы выиграем. На данный момент нет особого смысла обсуждать здесь что-либо еще, поскольку существующий код исчезнет в 4.0, и ничего не будет объединено в ветке 3.x, где на данный момент стабильность важнее оптимизации.
Поскольку многие могут быть заинтересованы в технических деталях:
- Весь код пространственной индексации (который переписал vblanco) будет заменен линейным алгоритмом отбраковки с несколькими потоками в сочетании с октодеревом для иерархической отсеивания окклюзии и SAP для проверки перекрытия, которые, скорее всего, являются лучшими универсальными алгоритмами, которые гарантируют хорошее производительность в любой игре. Распределение для этих структур будет происходить в том же духе, что и новый RID_Allocator, который равен O (1)). Я обсуждал это с @ vblanco20-1 раньше и объяснил, что его подход не хорошо масштабируется для всех типов игр, так как он требует от пользователя определенного уровня знаний для настройки, чего обычно не ожидают от типичного пользователя Godot. Также это был не лучший подход для добавления отбраковки окклюзии.
- Я не буду использовать массивы, когда можно использовать списки, потому что списки выполняют небольшие временные распределения с нулевым риском фрагментации. В некоторых случаях я предпочитаю выделять секционированный массив (выровненный по страницам, поэтому они вызывают 0 фрагментацию), который всегда увеличивается и никогда не сжимается (например, в RID_Allocator или новом CanvasItem в ветке Vulkan 2D-движка, которая теперь позволяет перерисовывать элементы. с большим количеством команд очень эффективно), но для этого должна быть причина производительности. Когда списки используются в Godot, это потому, что небольшие выделения предпочтительнее производительности (и на самом деле они делают код более понятным для чтения другими).
- PoolVector предназначен для очень больших распределений с последовательными страницами памяти. До Godot 2.1 он использовал предварительно выделенный пул памяти, но он был удален в 3.x, и сейчас текущее поведение неверно. В 4.0 она будет заменена виртуальной памятью, это в списке дел.
- Сравнивать Godot Vector <> с std :: vector бессмысленно, потому что у них разные варианты использования. Мы используем его в основном для передачи данных и блокируем его для быстрого доступа (с помощью методов ptr () или ptrw ()). Если бы мы использовали std :: vector, Godot был бы намного медленнее из-за ненужного копирования. Мы также пользуемся преимуществами механизма копирования при записи для различных целей.
- Map <> просто и удобнее для большого количества элементов, и вам не нужно беспокоиться о поспешном росте / перемещении, создающем фрагментацию. Когда требуется производительность, вместо этого используется HashMap (хотя это правда, вероятно, следует использовать OAHashMap больше, но он слишком новый, и у него никогда не было времени для этого). В соответствии с общей философией, когда производительность не является приоритетом, небольшие выделения всегда предпочтительнее больших, потому что распределителю памяти из вашей операционной системы легче найти крошечные дыры для их размещения (что в значительной степени то, для чего он предназначен) , эффективно потребляя меньше кучи.
Опять же, вы можете спрашивать о планах и дизайне в любое время, вместо того, чтобы жаловаться, это не лучший способ помочь проекту.
Я также уверен, что многие, читающие эту ветку, задаются вопросом, почему пространственный индексатор с самого начала работал медленно. Причина в том, что, возможно, вы новичок в Godot, но до недавнего времени 3D-движок был старше 10 лет и сильно устарел. Была проделана работа по его модернизации в OpenGL ES 3.0, но нам пришлось воздержаться из-за проблем, которые мы обнаружили в OpenGL, и того факта, что он устарел для Vulkan (и Apple отказалась от него).
Вдобавок к этому, Godot не так давно запускался на таких устройствах, как PSP (у которых было всего 24 МБ памяти, доступной как для движка, так и для игры, поэтому большая часть основного кода очень консервативна в отношении распределения памяти). Поскольку аппаратное обеспечение сейчас сильно отличается, его заменяют на более оптимальный код, использующий больше памяти, но когда в нем нет необходимости, выполнение этой работы бессмысленно, и это нормально, что вы увидите списки, используемые во многих местах, где производительность не важно.
Кроме того, многие оптимизации, которые мы хотели сделать (перенос большей части кода мьютекса для повышения производительности), пришлось отложить до тех пор, пока мы не сможем перенести Godot на C ++ 11 (который имеет гораздо лучшую поддержку встроенных атомик, и в нем нет требует, чтобы вы включали заголовки окон, которые загрязняют все пространство имен), чего мы не могли сделать в стабильной ветке. Переход на C ++ 11 произойдет после разветвления Godot 3.2 и заморозки функций, в противном случае синхронизация ветвей Vulkan и Master будет огромной проблемой. Особой спешки не стоит, так как сейчас все внимание сосредоточено на самом Вулкане.
Извините, на все нужно время, но я предпочитаю, чтобы они делались правильно, а не торопились. В долгосрочной перспективе это окупается лучше. Прямо сейчас идет работа над всеми оптимизациями производительности, и они должны быть готовы в ближайшее время (если вы тестировали ветку Vulkan, 2D-движок намного быстрее, чем раньше).
reduz
22 июл. 2019
Привет редуз,
хотя я в основном вижу, что ваши точки зрения действительны, я хотел бы прокомментировать два, с которыми я не согласен:
- Я не буду использовать массивы, когда можно использовать списки, потому что списки выполняют небольшие временные распределения с нулевым риском фрагментации. В некоторых случаях я предпочитаю выделять секционированный массив (выровненный по страницам, поэтому они вызывают 0 фрагментацию), который всегда увеличивается и никогда не сжимается (например, в RID_Allocator или новом CanvasItem в ветке Vulkan 2D-движка, которая теперь позволяет перерисовывать элементы. с большим количеством команд очень эффективно), но для этого должна быть причина производительности. Когда списки используются в Godot, это потому, что небольшие выделения предпочтительнее производительности (и на самом деле они делают код более понятным для чтения другими).
Я очень сомневаюсь, что связанный список будет иметь лучшую общую производительность, пусть это будет скорость или эффективность памяти, чем динамический массив с экспоненциальным ростом. Последний гарантированно занимает не более чем вдвое больше места, чем он фактически использует, в то время как List<some pointer> использует ровно в три раза больше памяти (фактическое содержимое, следующий и предыдущий указатели). Для секционированного массива все выглядит еще лучше.
При правильной упаковке (насколько я могу судить по тому, что я уже видел о коде godot, они и есть), они выглядят почти одинаково для программиста, поэтому я не понимаю, что вы имеете в виду, говоря «они [Списки ] сделать намерение кода более ясным ".
ИМХО, Списки действительны ровно при двух условиях:
- Вам нужно часто стирать / вставлять элементы в середине контейнера
- или вам нужна постоянная (а не только амортизированная постоянная) вставка / удаление элементов. То есть, в контекстах реального времени, где трудоемкое выделение памяти невозможно, все в порядке.
- Map <> просто и удобнее для большого количества элементов, и вам не нужно беспокоиться о поспешном росте / перемещении, создающем фрагментацию. Когда требуется производительность, вместо этого используется HashMap (хотя это правда, вероятно, следует использовать OAHashMap больше, но он слишком новый, и у него никогда не было времени для этого). В соответствии с общей философией, когда производительность не является приоритетом, небольшие выделения всегда предпочтительнее больших, потому что распределителю памяти из вашей операционной системы легче найти крошечные дыры для их размещения (что в значительной степени то, для чего он предназначен) , эффективно потребляя меньше кучи.
Распределители libc обычно довольно умны, и поскольку OAHashMap (или std :: unordered_map) время от времени перераспределяет свои хранилища (амортизируемое постоянное время), распределителю обычно удается сохранять свои блоки памяти компактными. Я твердо уверен, что OAHashMap эффективно не потребляет больше кучи, чем простая двоичная древовидная карта, такая как Map. Вместо этого я совершенно уверен, что огромные накладные расходы на указатель в каждом элементе Map на самом деле потребляют больше памяти, чем любая фрагментация кучи OAHashmap (или std :: unordered_map).
В конце концов, я думаю, что лучший способ разобраться с подобными аргументами - это сравнить их. Конечно, это гораздо более полезно для Godot 4.0, поскольку, как вы сказали, там произойдет много оптимизаций производительности, и нет особого смысла улучшать пути кода, которые в любом случае могут быть полностью переписаны в 4.0.
Но @reduz , что вы думаете о тестировании всех этих изменений, предложенных @ vblanco20-1 (возможно, даже сейчас, в версии 3.1). Если @ vblanco20-1 (или кто-то другой) готов потратить время на написание такого набора тестов и оценить производительность Godot3.1 (как с точки зрения скорости, так и «потребление кучи с учетом фрагментации») в сравнении с изменениями vblanco? Это может дать ценные подсказки для реальных изменений 4.0.
Я думаю, что такая методология хорошо подходит для ваших «[дела] делаются правильно, а не торопятся».
@ vblanco20-1: На самом деле, я ценю вашу работу. Будете ли вы заинтересованы в создании таких тестов, чтобы мы действительно могли измерить, являются ли ваши изменения фактическим улучшением производительности? Мне было бы очень интересно.
 Windfisch
23 июл. 2019
Windfisch
23 июл. 2019
@Windfisch Я предлагаю вам перечитать мой пост выше, так как вы неправильно прочитали или неправильно поняли несколько вещей. Я вам их разъясню.
- Списки используются именно для описываемого вами варианта использования, и я никогда не утверждал, что они обладают лучшей производительностью. Они более эффективны, чем массивы для повторного использования кучи, просто потому, что состоят из небольших распределений. В масштабе (когда вы используете их много по назначению) это действительно имеет значение. Когда требуется производительность, уже используются другие контейнеры, которые быстрее, более упакованы или имеют лучшую согласованность кеша. Хорошо это или плохо, но Виктор в основном сосредоточился на одной из старых областей движка (если не самой старой), которая никогда не оптимизировалась с тех пор, как это был собственный движок, используемый для публикации игр для PSP. Долгое время это ожидалось переписать, но были другие приоритеты. Его основной оптимизацией была трассировка воксельного конуса на основе ЦП, которую я недавно добавил, и, честно говоря, я плохо с ней справился, потому что она была слишком поспешна рядом с выпуском 3.0, но правильное исправление для этого - это совершенно другой алгоритм, а не добавление параллельной обработки, как он.
- Я никогда не спорил о производительности работы @ vblanco20-1, и, честно говоря, меня это не волнует (так что вам не нужно заставлять его тратить время на тесты). Причины, по которым его работа не объединяется, заключаются в том, что 1) используемые им алгоритмы требуют ручной настройки в зависимости от среднего размера объектов в игре, что необходимо будет сделать большинству пользователей Godot. Я предпочитаю алгоритмы, которые могут быть немного медленнее, но лучше масштабируемыми, без необходимости в настройке. 2) Алгоритм, который он использует, не подходит для отбраковки окклюзии (простое октодерево лучше из-за иерархической природы). 3) Алгоритм, который он использует, не подходит для спаривания (часто лучше SAP). 4) Он использует C ++ 17 и библиотеки, в поддержке которых я не заинтересован, или лямбды, которые, по моему мнению, не нужны 5) Я уже работаю над оптимизацией этого для 4.0, а в ветке 3.x приоритетом является стабильность, и мы намереваются выпустить 3.2 как можно скорее, так что это не будет там изменяться или работать. Существующий код может быть медленнее, но он очень стабилен и протестирован. Если это будет объединено, появятся отчеты об ошибках, регрессии и т. Д. Ни у кого не будет времени поработать над этим или помочь Виктору, потому что мы уже в основном заняты веткой 4.0. Все это объяснялось выше, поэтому я предлагаю вам перечитать сообщение.
В любом случае я пообещал Виктору, что код индексации может быть подключаемым, так что в конечном итоге могут быть реализованы разные алгоритмы для разных типов игр.
Годо имеет открытый исходный код, как и его форк. Мы все открыты и делимся здесь, ничто не должно мешать вам использовать его работу, если она вам нужна.
reduz
23 июл. 2019
Поскольку эта оптимизация, похоже, не влияет на gdscript, рендеринг или проблемы с "заиканием", и есть вещи, на которые люди жалуются (включая меня), возможно, с комплиментом, что люди оптимизации будут счастливы (включая меня) ... не нужно lua jit скорость ...
Работа в режиме «копирование при записи» была очень большой оптимизацией производительности в моем плагине (от 25 секунд в синтаксическом анализе скрипта до всего 1 секунды в скрипте из 7000 строк) ... я чувствую, что такого рода оптимизации заключаются в том, что мы необходимость в gdscript в рендеринге и решении проблемы заикания ... вот и все.
Ranoller
23 июл. 2019
Спасибо @reduz за разъяснения. Это действительно сделало вашу точку зрения более ясной, чем предыдущие публикации.
Хорошо, что код пространственной индексации будет подключаемым, потому что он действительно падал мне на ноги раньше, когда обрабатывал множество объектов в совершенно разных масштабах. С нетерпением жду 4.0.
Windfisch
23 июл. 2019
Я тоже думал об этом и думаю, что было бы неплохо разместить какой-нибудь общий документ с идеями по оптимизации пространственного индексирования, чтобы больше участников могли узнать об этом, а также поделиться идеями или реализовать. У меня есть очень хорошее представление о том, что нужно сделать, но я уверен, что здесь есть много возможностей для дальнейшей оптимизации и разработки интересных алгоритмов.
Мы можем поставить очень четкие требования, которым, как мы знаем, должны соответствовать алгоритмы (например, не требовать от пользователя настройки, если это возможно для средних элементов мирового размера, а не брутфорса с потоками, если это возможно - они не бесплатны, другие части движку они тоже могут понадобиться, например, физика или анимация, и они потребляют больше батареи на мобильном телефоне-, совместимость с отбраковкой окклюзии на основе повторного проецирования - так что может быть желательна какая-то форма иерархии, но ее также следует протестировать на грубую силу - будьте умны об обновлениях теневого буфера - не обновляйте, если ничего не изменилось -, изучите оптимизацию, такую как отбраковка окклюзии на основе повторной проекции для направленных теней и т. д.). Мы также можем обсудить создание некоторых тестов производительности (я не думаю, что демонстрация TPS является хорошим тестом, потому что в ней не так много объектов или перекрытия). @ vblanco20-1, если вы готовы следовать нашему стилю программирования / языку и философии, вы, конечно же, можете протянуть руку помощи.
Остальная часть кода рендеринга (фактический рендеринг с использованием RenderingDevice) более или менее проста, и способов сделать это не так много, но индексация кажется более интересной проблемой, которую нужно решить для оптимизации.
reduz
23 июл. 2019
@reduz для справки по пространственной индексации. Первоначальное отсечение на основе тайлов было удалено и заменено октодеревом примерно в середине этой цепочки. У меня есть октодерево WIP (отсутствуют некоторые функции повторной подгонки), но результаты для прототипа неплохие. Его код не так хорош по своей природе прототипа, поэтому полезно только проверить, как этот вид октодерева будет работать в сложной сцене, такой как tps-demo.
Он вдохновлен тем, как работает нереальное октодерево движка, но с некоторыми изменениями, такими как возможность плоской итерации.
Основная идея состоит в том, что только листы октодерева содержат объекты, и эти объекты хранятся в массиве размером 64 (размер времени компиляции может быть другим). Лист октодерева разделится только после того, как он «переполнится» на 65 элементов. Когда вы удаляете объекты, если каждый из листьев родительского узла помещается в массив размером 64, мы объединяем эти листья обратно в их родительский узел, который становится листом.
Делая это, мы можем минимизировать время тестирования узлов, так как октодерево не будет слишком глубоким.
Еще одна хорошая вещь, которую я делал, - это то, что листовые узлы также хранятся в плоском массиве, что позволяет выполнять параллельную отсечку. Таким образом, иерархическое отсечение можно использовать при выполнении отсечения для теней точек или других «небольших» операций, а плоское параллельное отсечение для основного вида. Конечно, можно просто использовать иерархию для всего, но это может быть медленнее и не может быть распараллелено.
Блочная структура будет тратить немного памяти, но даже в худшем случае я не думаю, что она будет тратить много памяти, поскольку узлы объединятся, если они упадут ниже суммы. Это также позволяет использовать распределитель пула, учитывая, что и узлы, и листы будут иметь постоянный размер.
У меня также есть несколько октодеревьев в моей вилке, которая используется для оптимизации некоторых вещей. Например, у меня есть октодерево только для объектов shadowcaster, что позволяет пропустить всю логику, связанную с «может отбрасывать тени» при отбраковке для карт теней.
Что касается моих проблем с Vector и другими в API рендеринга, эта проблема объясняет, о чем я беспокоился. https://github.com/godotengine/godot/issues/24731
О библиотеке и материале вилки C ++ 17 ... это не нужно. Форк использует слишком много библиотек, потому что мне нужны были некоторые их части. Единственное, что действительно нужно и что, я думаю, нужно Годоту, - это мощная в отрасли параллельная очередь, для этого я использовал очередь moodycamel.
В лямбдах они используются в основном для отбраковки и используются для экономии значительного объема памяти, так как вам нужно только сохранить объекты, которые передают ваши проверки, в выходной массив. Альтернативой является создание объектов-итераторов (это то, что нереальный движок делает с их октодеревом), но в итоге получается худший код и его намного сложнее писать.
Мое намерение состояло не в том, чтобы «стать мошенником», а в том, чтобы ответить на частые комментарии о «вы можете сделать вилку, чтобы продемонстрировать», что я и сделал. Первое сообщение в ветке немного паникерское и не очень правильное. Извините, если я показался вам грубым, так как моя единственная цель - помочь самому популярному игровому движку с открытым исходным кодом.
vblanco20-1
23 июл. 2019
@ vblanco20-1 Звучит здорово, и то, как вы упомянули октодерево, имеет большой смысл. Я, честно говоря, не возражаю против реализации параллельной очереди (кажется достаточно простой, чтобы не нуждаться во внешней зависимости, и нужен C ++ 11 для правильной работы, поэтому предполагаю, что это произойдет только в ветке Vulkan). Если вы это сделали, я определенно хочу взглянуть на это, поэтому я могу использовать его в качестве основы для перезаписи индексатора в ветке Vulkan (я просто переписываю большинство вещей там, поэтому его все равно нужно переписать ). Конечно, если вы хотите помочь с реализацией (возможно, когда появится больше вещей с новым API), это очень приветствуется.
Использование параллельной версии с уплощенными массивами интересно, но моя точка зрения на это такова, что она не будет так полезна для отбраковки окклюзии, и было бы интересно измерить, насколько лучше по сравнению с обычным отбраковкой октодерева, учитывая дополнительное количество используемых ядер. Имейте в виду, что есть много других областей, которые могут использовать несколько потоков, которые могут более эффективно (с меньшей грубой силой) использовать их (например, физика), поэтому, даже если с этим подходом мы получим относительно незначительное улучшение, это не всегда в лучших интересах, так как это может лишить другие области использования ЦП. Может быть, это необязательно.
Я также нахожу довольно интересной реализацию dbvt в Bullet 3, которая выполняет инкрементную самобалансировку и линейное распределение, это одна из вещей, которые я хотел исследовать больше (я видел этот подход, реализованный в проприетарных движках, о которых я не могу упомянуть: P), с точки зрения алгоритма, сбалансированное двоичное дерево по дизайну намного менее избыточно, чем октодерево, и может работать лучше как в тестах сопряжения, так и в тестах окклюзии, поэтому подключаемый широкофазный / отсекающий подход может быть действительно хорошей идеей, учитывая, что мы делаем правильную полезную эталонные сцены.
В любом случае, вы исключительно умны, и было бы здорово, если бы мы могли работать над этим вместе, но я просто попрошу вас понять и уважать многие из существующих философий дизайна, которые у нас есть, даже если они не всегда могут соответствовать вашему вкусу. . Проект огромный, с большой инерционной силой, и менять вещи ради вкуса - не лучшая идея. Удобство для пользователя и «просто работает» всегда на первом месте в списке, касающемся дизайна, а простота и читабельность кода обычно имеют приоритет над эффективностью (то есть, когда эффективность не является целью, потому что область не является критичной). В прошлый раз, когда мы обсуждали, вы хотели в значительной степени все изменить и не хотели слушать какие-либо аргументы или сосредоточиваться на реальных проблемах, и это не то, как мы обычно работаем с сообществом и участниками, поэтому мой совет остыть был хорошо задумано.
reduz
23 июл. 2019
Кому нужна производительность? :Тролль:
Производительность и исходная модель - вот что удерживает меня в Godot.
 BlueCannonBall
28 янв. 2020
BlueCannonBall
28 янв. 2020
Изменить: Извините, может быть, я какой-то оффтоп, но я хотел прояснить преимущества открытого исходного кода.
@mixedCase Я бы очень не
Я так не думаю. Природа открытого исходного кода заключается в том, что вы можете свободно использовать и повторно использовать код по своему усмотрению. Так что это будет не конец какого-то проекта, а больше возможностей для пользователей.
То, что вы говорите, - это монополия, и это не то, что защищает открытый исходный код. Не поддавайтесь обману со стороны компаний, которые делают вид, будто демонстрируют вам, что лучше иметь полный контроль над чем-либо. Это ложь, по крайней мере, в мире открытого кода, потому что, если у кого-то есть код, у вас тоже есть код. Что им нужно сделать, так это позаботиться о том, как вести себя с сообществом или как с этим мириться.
В любом случае оригинальные разработчики могут просто объединить улучшения из форка. Они вольны делать это всегда. Это другая природа мира открытого исходного кода.
А в худшем случае вилка будет лучше оригинала и туда пойдет много контрибьютеров. Никто не проиграл, все выиграли. Ой, извините, если компания стоит за оригиналом, возможно, они проиграли (или они также могут объединить улучшения из вилки).
 Anyeos
18 мар. 2020
Anyeos
18 мар. 2020
Смежные вопросы
 gonzo191
·
3Комментарии
gonzo191
·
3Комментарии
 rgrams
·
3Комментарии
rgrams
·
3Комментарии
 Spooner
·
3Комментарии
Spooner
·
3Комментарии
 ivanskodje
·
3Комментарии
ivanskodje
·
3Комментарии
 SleepProgger
·
3Комментарии
SleepProgger
·
3Комментарии
Самый полезный комментарий
Вам может быть интересно. Я довольно давно работал над причудливой вилкой. Текущие результаты выглядят так:

Снято на большом игровом ноутбуке с 4-ядерным процессором Intel и GTX 1070
Нормальный годот
Моя вилка на https://github.com/vblanco20-1/godot/tree/ECS_Refactor

В обоих профилях красный по сути означает «ждите GPU». В настоящее время узкое место из-за слишком большого количества вызовов отрисовки в opengl. На самом деле не может быть решена без вулкана или перезаписи всего рендерера.
Что касается ЦП, мы переходим от кадров 13 мс к кадрам 5 мс. «Быстрые» кадры увеличиваются с 5,5 мс до 2,5 мс.
Что касается «всего кадра», мы переходим с 13 мс до 8–9 мс.
От ~ 75 до ~ 115 кадров в секунду
Меньше процессорного времени = больше времени, которое вы можете потратить на игровой процесс. Текущий Godot имеет узкое место в ЦП, поэтому больше времени, потраченного на игровой процесс, будет означать более низкий FPS, в то время как мой форк привязан к графическому процессору, поэтому вы можете добавить намного больше игровой логики с нетронутым FPS, поскольку ЦП просто "свободен" для довольно долго каждый кадр.
МНОЖЕСТВО этих улучшений можно объединить в godot, ЕСЛИ Godot поддерживает современный C ++ и имеет многопоточную систему, которая позволяет выполнять очень дешевые «маленькие» задачи.
Самый большой выигрыш достигается за счет многопоточного чтения теней и многопоточной карты освещения для динамических объектов # 25013. Оба они работают одинаково. Многие другие части средства визуализации также являются многопоточными.
Другими улучшениями являются Octree, которое от 10 до 20 раз быстрее, чем Godot One, и улучшения в некоторых потоках рендеринга, такие как одновременная запись списка рендеринга с предварительным проходом глубины и с обычным проходом вместо повторения списка отбраковки 2. раз, и существенное изменение того, как работает соединение свет-> сетка (нет связанного списка!)
В настоящее время я ищу больше тестовых карт, кроме демонстрации TPS, чтобы иметь больше показателей на других типах карт. Я также собираюсь написать серию статей, в которых подробно объясню, как все это работает.