Godot: Utilizando la estructura de datos más lenta casi siempre.
Estaba revisando el código de godot y encontré una total indiferencia por cualquier tipo de rendimiento del lado de la CPU, hasta las estructuras de datos centrales. Está usando List en todas partes, cuando una lista vinculada es la estructura de datos más lenta que puede usar en las PC modernas. Casi cualquier otra estructura de datos sería más rápida, especialmente en estructuras de pequeño tamaño. Es especialmente atroz en cosas como la lista de luz o las capturas de reflexión en renderizables, donde está almacenando 3 punteros cada vez, en lugar de simplemente darle una matriz de pila de 8 luces máximas (por ejemplo) + un extra para los casos en los que estaría más que eso.
Lo mismo ocurre con RID_Owner como un árbol donde podría ser un mapa hash o un mapa de ranuras. Además, la implementación de Octree para el sacrificio selectivo tiene exactamente el mismo problema.
Quiero preguntar sobre la intención de diseño detrás de ese uso excesivo total y absoluto de listas enlazadas y estructuras de datos pesadas de puntero de rendimiento terrible en todas partes del código. ¿Es eso por una razón específica? En la mayoría de los casos, una lista enlazada "fragmentada", donde se hace una lista enlazada de matrices, traerá automáticamente ganancias de rendimiento en el mismo código.
El uso de estas estructuras de datos también evita cualquier tipo de paralelismo "fácil" en una buena parte del código y destruye completamente la caché.
Estoy trabajando en hacer una implementación de prueba de concepto para refactorizar algunos de los componentes internos para usar mejores estructuras de datos. En este momento estoy trabajando en una reescritura del código de selección que omite el octárbol actual y solo usa una matriz plana con paralelismo opcional. Usaré el tps-demo como punto de referencia y volveré con resultados, que de hecho he comparado para llegar a 25 niveles de profundidad en ese octárbol ...
En otra nota más feliz, estoy muy impresionado con la calidad del estilo del código, todo es fácil de seguir y entender, y está bastante bien comentado.
 vblanco20-1
vblanco20-1
Todos 61 comentarios
¿Quién necesita desempeño? :Cara de burla:
 mafiesto4
en 27 nov. 2018
mafiesto4
en 27 nov. 2018
Curioso por ver lo que mide.
 avencherus
en 27 nov. 2018
avencherus
en 27 nov. 2018
Entonces, ¿esto puede explicar por qué un simple nodo Light2D en Godot puede quemar su computadora?
 Ranoller
en 27 nov. 2018
Ranoller
en 27 nov. 2018
@Ranoller No lo creo. Lo más probable es que el mal rendimiento de la iluminación esté relacionado con la forma en que Godot realiza la iluminación 2D en este momento: renderizando cada sprite n veces (siendo n el número de luces que lo están afectando).
Editar: ver # 23593
 CptPotato
en 27 nov. 2018
CptPotato
en 27 nov. 2018
Para aclarar, se trata de ineficiencias del lado de la CPU en todo el código. Esto no tiene nada que ver con las características de godot o el renderizado de la GPU de godot en sí.
vblanco20-1
en 27 nov. 2018
@ vblanco20-1 en un poco de tangente lateral, usted y yo habíamos hablado sobre los nodos que se modelaban como entidades ECS en su lugar. Me pregunto si el truco consiste en hacer una rama característica de godot con un nuevo módulo ent que trabajaría gradualmente en paralelo con el árbol. como get_tree () y get_registry (). el módulo ent probablemente perdería como el 80% de la funcionalidad del árbol / escena, pero podría ser útil como banco de pruebas, especialmente para cosas como componer grandes niveles estáticos con muchos objetos (selección, transmisión, renderizado por lotes). Funcionalidad y flexibilidad reducidas pero mayor rendimiento.
 pgruenbacher
en 27 nov. 2018
pgruenbacher
en 27 nov. 2018
Antes de pasar a ECS completo (lo que podría hacer), quiero trabajar en algunas frutas bajas como experimento. Podría intentar orientarme completamente a los datos más adelante.
vblanco20-1
en 27 nov. 2018
Entonces, primeras actualizaciones:
update_dirty_instances: de 0.2-0.25 milisegundos a 0.1 milisegundos
octree_cull (la vista principal): de 0,35 milisegundos a 0,1 milisegundos
¿La parte divertida? el reemplazo de octree cull no usa ninguna estructura de aceleración, solo itera sobre una matriz tonta con todos los AABB.
¿La parte aún más divertida? La nueva selección es de 10 líneas de código. Si quisiera tenerlo en paralelo, sería un solo cambio en la línea.
Continuaré implementando mi nueva selección con las luces, para ver cuánto se acumula la aceleración.
vblanco20-1
en 1 dic. 2018
probablemente deberíamos tener un directorio de referencia de Google en la rama maestra. Eso puede ayudar con la validación para que la gente no tenga que discutir al respecto.
pgruenbacher
en 1 dic. 2018
Existe el repositorio godotengine / godot-tests , pero todavía no mucha gente lo está usando.
 bojidar-bg
en 2 dic. 2018
bojidar-bg
en 2 dic. 2018
Nueva actualización:

He implementado una estructura de aceleración espacial bastante tonta, con 2 niveles. Solo lo estoy generando en cada cuadro Una mejora adicional podría mejorarlo y actualizarlo dinámicamente en lugar de rehacerlo.
En la imagen, las diferentes filas son ámbitos diferentes, y cada uno de los bloques coloreados es una tarea / fragmento de código. En esa captura, estoy haciendo tanto el sacrificio de octárbol como el mío uno al lado del otro para tener una comparación directa
Demuestra que recrear toda la estructura de aceleración es más rápido que un solo sacrificio de octárbol antiguo.
Además, los sacrificios adicionales tienden a ser aproximadamente de la mitad a un tercio del octárbol actual.
No he encontrado un solo caso en el que mi estructura tonta sea más lenta que el octárbol actual, aparte del costo de la creación inicial.
Otra ventaja es que es muy compatible con múltiples subprocesos y se puede escalar a cualquier recuento de núcleos que desee solo con un paralelo.
También verifica la memoria completamente contigously, por lo que debería ser posible hacer SIMD sin mucha molestia.
Otro detalle importante es que es mucho más simple que el octárbol actual, con muchas menos líneas de código.
vblanco20-1
en 2 dic. 2018
Estás causando más revuelo que el final de juego de tronos ...
Ranoller
en 2 dic. 2018

Modificamos un poco los algoritmos para que ahora puedan usar algoritmos paralelos de C ++ 17, lo que le permite al programador simplemente decirle que haga un orden en paralelo o en paralelo.
Aceleración de aproximadamente x2 en el frustrum principal sacrificado, pero para las luces es aproximadamente la misma velocidad que antes.
Mi culler es ahora 10 veces más rápido que godot octree para la vista principal.
vblanco20-1
en 2 dic. 2018
Si desea ver los cambios, lo más importante está aquí:
https://github.com/vblanco20-1/godot/blob/4ab733200faa20e0dadc9306e7cc93230ebc120a/servers/visual/visual_server_scene.cpp#L387
Esta es la nueva función de selección. La estructura de aceleración está en la función justo encima de ella.
vblanco20-1
en 2 dic. 2018
¿Esto debería compilarse con VS2015? La consola arroja un montón de errores sobre los archivos dentro de entt \
Ranoller
en 2 dic. 2018
@Ranoller es c ++ 17, así que asegúrese de usar un compilador más nuevo
pgruenbacher
en 3 dic. 2018
Uh, creo que Godot aún no se ha mudado a c ++ 17. ¿Al menos recuerdo algunas discusiones sobre el tema?
 Zireael07
en 3 dic. 2018
Zireael07
en 3 dic. 2018
Godot es C ++ 03. Este movimiento será controvertido. Recomiendo a @ vblanco20-1 que hable con Juan cuando termine las vacaciones ... esta optimización será genial y no queremos un mensaje instantáneo "This Will Never Happend TM
Ranoller
en 3 dic. 2018
@ vblanco20-1
octree_cull (la vista principal): de 0,35 milisegundos a 0,1 milisegundos
cuantos objetos?
 nem0
en 3 dic. 2018
nem0
en 3 dic. 2018
@ nem0
@ vblanco20-1
octree_cull (la vista principal): de 0,35 milisegundos a 0,1 milisegundos
cuantos objetos?
Alrededor de las 2200. El godot octree funciona mejor si el cheque es muy pequeño, porque sale temprano. Cuanto más grande es la consulta, más lento es el octárbol de godot en comparación con mi solución. Si el godot octree no puede sacar temprano el 90% de la escena, entonces es terriblemente lento, porque esencialmente itera listas vinculadas para cada objeto, mientras que mi sistema es una estructura de matrices donde cada línea de caché contiene una buena cantidad de AABB, lo que reduce en gran medida fallas de caché.
Mi sistema funciona al tener 2 niveles de AABB, es una matriz de bloques, donde cada bloque puede contener 128 instancias.
El nivel superior es principalmente una matriz de AABB + una matriz de Bloques. Si pasa la verificación AABB, iteraré el bloque. El bloque es una matriz de estructura de AABB, máscara y un puntero a la instancia. De esta manera todo es faaaaast.
En este momento, la generación de la estructura de datos de nivel superior se realiza de una manera muy tonta. Si se generara mejor, su rendimiento podría ser mucho mayor. Estoy realizando algunos experimentos con diferentes tamaños de bloques distintos de 128.
vblanco20-1
en 3 dic. 2018
He comprobado números diferentes, y 128 por bloque parece seguir siendo el punto dulce de alguna manera.
Al cambiar el algoritmo para separar los objetos "grandes" de los pequeños, me las arreglé para obtener otra mejora de velocidad del 30%, principalmente en el caso de que no esté mirando hacia el centro del mapa. Funciona porque de esa manera los objetos grandes no hinchan los AABB del bloque que también incluyen objetos pequeños. Creo que probablemente 3 tamaños funcionarían mejor.
La generación de bloques todavía no es óptima en absoluto. Los bloques grandes solo eliminan entre el 10 y el 20% de las instancias cuando se mira en el centro, y hasta el 50% cuando se mira fuera del mapa, por lo que está realizando MUCHAS comprobaciones AABB adicionales de las que debería necesitar.
Creo que una mejora probablemente sería reutilizar el octárbol actual pero "aplanarlo".
Ahora no hay un solo caso en el que mi algoritmo sea igual o peor que el octárbol actual, incluso sin una ejecución paralela.
vblanco20-1
en 3 dic. 2018
@ vblanco20-1 Supongo que está haciendo su comparación con godot compilado en el modo release (que usa -O3 ) y no el editor normal construido en debug (que no tiene optimizaciones y es predeterminado) correcto ?
Lo siento si es una pregunta tonta, pero no veo ninguna mención de eso en el hilo.
Buen trabajo de todos modos :)
 Faless
en 11 dic. 2018
Faless
en 11 dic. 2018
@Faless Su release_debug, que agrega algunas optimizaciones. No he podido probar el "lanzamiento" completo porque no puedo conseguir que abra el juego (¿también es necesario crear el juego?)
Tuve una idea sobre cómo mejorar mucho más la selección, eliminando la necesidad de regenerar cada fotograma y creando una mejor optimización espacial. Veré lo que puedo intentar. En teoría, tal cosa podría eliminar la regeneración, mejorar un poco el rendimiento de la eliminación principal y tener un modo específico para las luces puntuales que aumentaría su rendimiento de eliminación en una gran cantidad, tanto que tendrían un costo cercano a 0, porque se convertirá en un O (1) barato para obtener los "objetos en un radio".
Está inspirado en cómo funcionó uno de mis experimentos, donde estoy haciendo 400.000 objetos físicos que rebotan entre sí.
vblanco20-1
en 11 dic. 2018

Ahora se implementa un nuevo sacrificio. La generación de bloques ahora es mucho más inteligente, lo que resulta en una eliminación más rápida. El caso especial de las luces aún no se ha implementado.
Lo he comprometido con mi tenedor
vblanco20-1
en 12 dic. 2018
Tengo curiosidad por saber si puede ejecutar esa herramienta de referencia (la de sus capturas de pantalla) en una compilación de la rama maestra actual, para darnos un punto de referencia de cuánto rendimiento está dando su implementación sobre la implementación actual. Soy un tonto, vaya.
 LikeLakers2
en 13 dic. 2018
LikeLakers2
en 13 dic. 2018
@ LikeLakers2 Puede ver tanto la implementación actual como su implementación en la captura de pantalla.
 neikeq
en 13 dic. 2018
neikeq
en 13 dic. 2018
Corrió esto en una bifurcación maestra
El miércoles 12 de diciembre de 2018, MichiRecRoom [email protected]
escribió:
@neikeq https://github.com/neikeq ¿Explicar? Pensé en las capturas de pantalla
que se han publicado fueron solo de su implementación, dado que las publicaciones
con capturas de pantalla se han redactado hasta ahora.-
Estás recibiendo esto porque hiciste un comentario.
Responda a este correo electrónico directamente, véalo en GitHub
https://github.com/godotengine/godot/issues/23998#issuecomment-446831151 ,
o silenciar el hilo
https://github.com/notifications/unsubscribe-auth/ADLZ9pRh9Lksse9KBfWV0z5GmHRXf5P2ks5u4crCgaJpZM4YziJp
.
pgruenbacher
en 13 dic. 2018
¿Hay novedades sobre este tema?
CptPotato
en 15 ene. 2019
¿Hay novedades sobre este tema?
Hablé con Reduz. Nunca se fusionará porque no encaja con el proyecto. En su lugar, fui a hacer otros experimentos. Tal vez actualice la selección más tarde para 4.0
vblanco20-1
en 15 ene. 2019
Es una pena, considerando que parecía realmente prometedor. Es de esperar que estos problemas se solucionen a tiempo.
CptPotato
en 15 ene. 2019
¿Quizás a esto se le debería dar el hito 4.0? Dado que Reduz está planeando trabajar en Vulkan para 4.0, y este tema, aunque se refiere al rendimiento, se centra en el renderizado, o al menos en OP.
 aaronfranke
en 4 feb. 2019
aaronfranke
en 4 feb. 2019
@ vblanco20-1 ¿Dijo que no encaja? ¿Supongo que debido al cambio a c ++ 17?
 Two-Tone
en 6 feb. 2019
Two-Tone
en 6 feb. 2019
Sin embargo, hay otro problema relacionado con el hito: # 25013
 starry-abyss
en 6 feb. 2019
starry-abyss
en 6 feb. 2019
Tú podrías estar interesado. He estado trabajando en el elegante tenedor durante bastante tiempo. Los resultados actuales son así:
Capturado en una gran computadora portátil para juegos con una CPU Intel de 4 núcleos y GTX 1070
Godot normal
Mi bifurcación en https://github.com/vblanco20-1/godot/tree/ECS_Refactor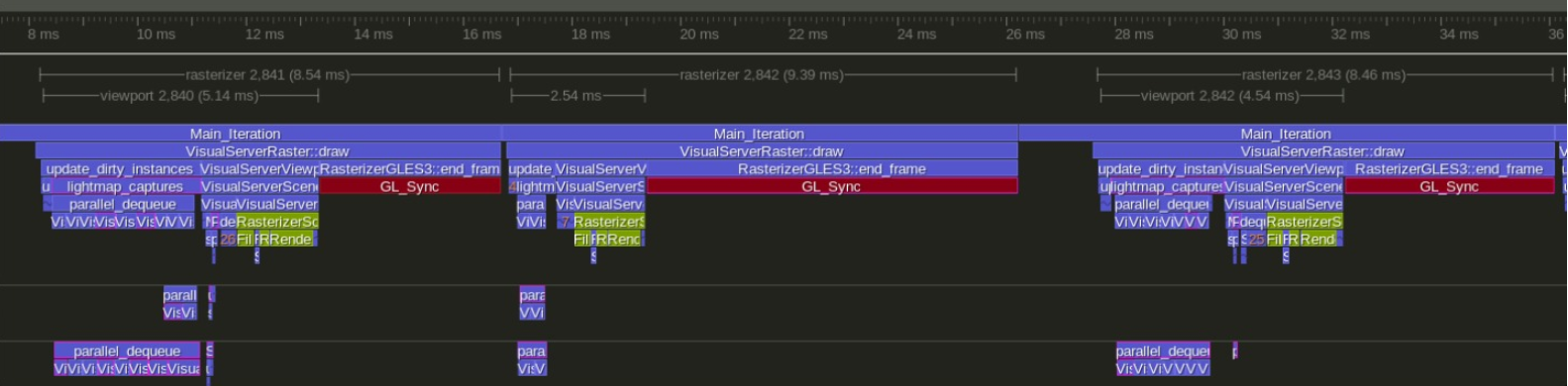
En ambos perfiles, el rojo es esencialmente "esperar a la GPU". Actualmente con cuello de botella debido a demasiados inconvenientes en opengl. Realmente no se puede resolver sin vulkan o sin volver a escribir todo el renderizador.
En el lado de la CPU, pasamos de cuadros de 13 ms a cuadros de 5 ms. Los fotogramas "rápidos" van de 5,5 ms a 2,5 ms
En el lado del "cuadro total", pasamos de 13 ms a 8-9 ms
~ 75 FPS a ~ 115 FPS
Menos tiempo de CPU = más tiempo que puedes dedicar al juego. El godot actual tiene un cuello de botella en la CPU, por lo que más tiempo dedicado al juego significará FPS más bajos, mientras que mi bifurcación está vinculada a la GPU, por lo que puede agregar mucha más lógica de juego con el FPS intacto, ya que la CPU es simplemente "gratuita" para bastante tiempo cada fotograma.
MUCHAS de estas mejoras se pueden fusionar en godot, SI godot es compatible con C ++ moderno y tiene un sistema de subprocesos múltiples que permite tareas "pequeñas" muy baratas.
La mayor ganancia se obtiene haciendo sombras multiproceso y lectura de mapas de luz multiproceso en objetos dinámicos # 25013. Ambos funcionan de la misma manera. Muchas otras partes del renderizador también son multiproceso.
Otras ganancias son un Octree que es de 10 a 20 veces más rápido que Godot One, y mejoras en parte del flujo de renderizado, como grabar tanto la lista de renderizado de preparación de profundidad como de paso normal a la vez, en lugar de iterar la lista de selección 2 veces, y un cambio significativo en cómo funciona la conexión de luz-> malla (¡sin lista enlazada!)
Actualmente estoy buscando más mapas de prueba además de la demostración de TPS para poder tener más métricas en otros tipos de mapas. También voy a escribir una serie de artículos que expliquen en detalle cómo funciona todo esto.
vblanco20-1
en 1 jun. 2019
@ vblanco20-1 esto es totalmente asombroso. ¡Gracias por compartir!
También estoy de acuerdo en que, aunque Vulkan es genial, tener un rendimiento decente en GLES3 sería una victoria absoluta para Godot. Es probable que el soporte completo de Vulkan no llegue pronto, mientras que parchear GLES3 es algo que los muchachos aquí demostraron ser completamente factibles en este momento.
Mi gran +1 por atraer más y más atención a esto. Sería la persona más feliz del mundo si Reduz aceptara permitir que la comunidad mejorara GLES3. Estamos haciendo un proyecto 3D muy serio en Godot desde hace 1,5 años, y apoyamos mucho a Godot (incluidas las donaciones), pero la falta de 60 FPS sólidos realmente nos desmotiva y pone todos nuestros esfuerzos bajo un gran riesgo.
Es una lástima que no se obtengan suficientes créditos. Si no tendremos 60 FPS en los próximos meses con nuestro proyecto actual (bastante simple en términos de 3D), no lograremos entregar un juego jugable y, por lo tanto, se desperdiciará todo el esfuerzo. : /
@ vblanco20-1 Honestamente, incluso estoy considerando usar tu fork como base de nuestro juego en producción.
PD: Algunas reflexiones: como último recurso, creo que sería totalmente posible incluso tener, digamos, 2 rasterizadores GLES3: comunidad GLES3 y GLES3.
 and3rson
en 1 jun. 2019
and3rson
en 1 jun. 2019
PD: Algunas reflexiones: como último recurso, creo que sería totalmente posible incluso tener, digamos, 2 rasterizadores GLES3: comunidad GLES3 y GLES3.
Eso no tiene sentido para mí; Probablemente sea una mejor idea obtener correcciones y mejoras de rendimiento directamente en los renderizadores GLES3 y GLES2 (siempre que no interrumpan el renderizado de manera importante en proyectos existentes).
Otras ganancias son un Octree que es de 10 a 20 veces más rápido que Godot One, y mejoras en parte del flujo de renderizado, como grabar tanto la lista de renderizado de preparación de profundidad como de paso normal a la vez, en lugar de iterar la lista de selección 2 veces, y un cambio significativo en cómo funciona la conexión de luz-> malla (¡sin lista enlazada!)
@ vblanco20-1 ¿Sería posible optimizar la preparación de profundidad mientras permanece en C ++ 03?
 Calinou
en 1 jun. 2019
Calinou
en 1 jun. 2019
@Calinou, el material de preparación en profundidad es una de las cosas que no necesita nada y es muy fácil de fusionar. Su principal desventaja es que requerirá que el renderizador use memoria extra. Como ahora necesitará 2 RenderList en lugar de solo uno. Aparte de la memoria adicional, prácticamente no hay inconvenientes. El costo de construir la lista de renderizado para 1 paso o 2 es casi el mismo gracias al almacenamiento en caché de la CPU, por lo que elimina prácticamente por completo el costo de prepass fill_list ()
vblanco20-1
en 1 jun. 2019
@ vblanco20-1 Honestamente, incluso estoy considerando usar tu fork como base de nuestro juego en producción.
@ and3rson por favor no lo
vblanco20-1
en 1 jun. 2019
¿Qué herramientas usas para perfilar a Godot? ¿Necesitaba agregar los indicadores Profiler.Begin y Profiler.End a la fuente godot para generar estas muestras?
 jknightdoeswork
en 2 jun. 2019
jknightdoeswork
en 2 jun. 2019
¿Qué herramientas usas para perfilar a Godot? ¿Necesitaba agregar los indicadores Profiler.Begin y Profiler.End a la fuente godot para generar estas muestras?
Está usando el generador de perfiles de Tracy, tiene diferentes tipos de marca de perfil de alcance, que utilizo aquí. Por ejemplo, ZoneScopedNC ("Lista de relleno", 0x123abc) agrega una marca de perfil con ese nombre y el color hexadecimal que desee.
vblanco20-1
en 2 jun. 2019
@ vblanco20-1 - ¿Veremos algunas de estas mejoras de rendimiento en la rama principal de godot?
 HeadClot
en 2 jun. 2019
HeadClot
en 2 jun. 2019
@ vblanco20-1 - ¿Veremos algunas de estas mejoras de rendimiento en la rama principal de godot?
Quizás cuando se admita C ++ 11. Pero reduz realmente no quiere más trabajo en el renderizador antes de que ocurra vulkan, por lo que es posible que nunca. Algunos de los hallazgos del trabajo de optimización podrían ser útiles para el renderizador 4.0.
vblanco20-1
en 2 jun. 2019
@ vblanco20-1 le importa compartir el compilador y los detalles del entorno para la rama, creo que puedo resolver la mayor parte, pero no pierda el tiempo resolviendo problemas si no es necesario.
Además, ¿no podemos agregar el cambio AABB a Godot main sin mucho costo?
 swarnimarun
en 2 jun. 2019
swarnimarun
en 2 jun. 2019
@ vblanco20-1 le importa compartir el compilador y los detalles del entorno para la rama, creo que puedo resolver la mayor parte, pero no pierda el tiempo resolviendo problemas si no es necesario.
Además, ¿no podemos agregar el cambio AABB a Godot main sin mucho costo?
@swarnimarun Visual Studio 17 o 19, una de las actualizaciones posteriores, funciona bien. (ventanas)
El script scons se modificó para agregar el indicador cpp17. Además, el editor de inicio no funciona en este momento. Estoy trabajando para ver si puedo restaurarlo.
Lamentablemente, el cambio de AABB es una de las cosas más importantes. Godot octree está entrelazado con MUCHAS cosas en el servidor visual. No solo realiza un seguimiento de los objetos para su selección, sino que también los conecta a luces / sondas de reflexión, con su propio sistema para emparejarlos. Esos pares también dependen de la estructura de la lista enlazada del octárbol, por lo que es casi imposible adaptar el octárbol actual para que sea más rápido sin cambiar mucho el servidor visual. De hecho, todavía no he podido deshacerme del octárbol de godot normal en mi tenedor para un par de tipos de objetos.
vblanco20-1
en 2 jun. 2019
@ vblanco20-1 ¿Tienes un Patreon? Apostaría algo de dinero a una bifurcación centrada en el rendimiento y que no se limita a la antigua C ++ y probablemente no sea el único. Me gustaría jugar con Godot para proyectos en 3D, pero estoy perdiendo la esperanza de que sea viable sin una gran prueba de un concepto que demuestre su enfoque del rendimiento y la usabilidad para el equipo central.
 mixedCase
en 3 jun. 2019
mixedCase
en 3 jun. 2019
@mixedCase Sería extremadamente reacio a apoyar cualquier tipo de bifurcación de Godot. La bifurcación y la fragmentación suelen ser la muerte de los proyectos de código abierto.
El mejor escenario, y más probable ahora que se ha demostrado que el C ++ más nuevo permite optimizaciones significativas, es que Godot se actualice oficialmente a una versión más nueva de C ++. Esperaría que esto sucediera en Godot 4.0, para minimizar el riesgo de roturas en 3.2, y a tiempo para que las nuevas características de C ++ se utilicen con Vulkan agregado a Godot 4.0. Tampoco espero que se realicen cambios significativos en el renderizador GLES 3, ya que reduz quiere eliminarlo.
(Pero no hablo por los desarrolladores de Godot, esto es solo mi especulación)
aaronfranke
en 8 jun. 2019
@aaronfranke Estoy de acuerdo, creo que una bifurcación permanente no sería lo ideal. Pero de lo que he recopilado de lo que dijo ( corríjame si me equivoco) es que
Creo que Juan es una persona muy pragmática, por lo que probablemente se necesitaría una gran prueba de concepto que demuestre los beneficios de usar abstracciones modernas y estructuras de datos más eficientes para convencerlo de que las compensaciones de ingeniería probablemente valgan la pena. @ vblanco20-1 ha hecho un trabajo increíble hasta ahora, así que personalmente no dudaría en depositar algo de dinero cada mes para él si quisiera hacer algo así.
mixedCase
en 10 jun. 2019
Estoy siempre asombrado de cómo los desarrolladores de Godot actúan como si fueran alérgicos a las buenas ideas, el desempeño y el progreso. Es una pena que no se haya recuperado.
 plabuda
en 16 jul. 2019
plabuda
en 16 jul. 2019
Este es un fragmento de una serie de artículos en los que estoy trabajando sobre las optimizaciones, precisamente sobre el uso de la estructura de datos.
Godot prohíbe los contenedores STL y su C ++ 03. Esto significa que no tiene operadores de movimiento en sus contenedores, y sus contenedores tienden a ser peores que los propios contenedores STL. Aquí tengo una descripción general de las estructuras de datos de godot y los problemas con ellas.
Matriz de C ++ preasignada. Muy común en todo el motor. Sus tamaños tienden a establecerse mediante alguna opción de configuración. Esto es muy común en el renderizador, y una clase de matriz dinámica adecuada funcionaría muy bien aquí.
Ejemplo de mal uso: https://github.com/godotengine/godot/blob/master/servers/visual/visual_server_scene.h#L442
Estas matrices están desperdiciando memoria sin una buena razón, usar una matriz dinámica sería una opción significativamente mejor aquí, ya que las haría solo del tamaño que necesitan, en lugar del tamaño máximo por una constante de compilación. Cada uno de los arreglos de Instancia * que usan MAX_INSTANCE_CULL está usando medio megabyte de memoria
Vector (vector.h) un equivalente de matriz dinámica std :: vector, pero con un defecto profundo.
El vector se vuelve a contar atómicamente con una implementación de copia en escritura. Cuando tu lo hagas
Vector a = build_vector ();
Vector b = a;
el recuento de referencias irá a 2. B y A ahora apuntan a la misma ubicación en la memoria, y copiarán la matriz una vez que se realice una edición. Si ahora modifica el vector A o B, activará una copia del vector.
Cada vez que escriba en un vector, deberá verificar el recuento de ref. Atómico, lo que ralentizará cada operación de escritura en el vector. Se estima que godot Vector es 5 veces más lento que std :: vector, como mínimo. Otro problema es que el vector se reubicará automáticamente cuando elimine elementos de él, causando terribles problemas de rendimiento incontrolables.
PoolVector (pool_vector.h). Más o menos lo mismo que un vector, pero como un conjunto. Tiene las mismas dificultades que Vector, con copia en escritura sin motivo y reducción automática de tamaño.
List (list.h) un equivalente de std :: list. La lista tiene 2 punteros (primero y último) + una variable de recuento de elementos. Cada nodo de la lista tiene un enlace doble, más un puntero adicional al contenedor de la lista. La sobrecarga de memoria para cada nodo de la lista es de 24 bytes. Se usa horriblemente en exceso en godot debido a que Vector no es muy bueno en general. Horriblemente mal usado en todo el motor.
Ejemplos de gran mal uso:
https://github.com/godotengine/godot/blob/master/servers/visual/visual_server_scene.h#L129
No hay motivo alguno para que esto sea una lista, debería ser un vector
https://github.com/godotengine/godot/blob/master/servers/visual/visual_server_scene.h#L242
Cada uno de estos casos está mal. de nuevo, debería ser vectorial o similar. Este en realidad puede causar problemas de rendimiento.
El mayor error es usar List en el octárbol usado para sacrificar. Ya he entrado en detalles sobre el octárbol de godot en este hilo.
SelfList (self_list.h) una lista intrusiva, similar a boost :: intrusive_list. Este siempre almacena 32 bytes de sobrecarga por nodo, ya que también apunta a sí mismo. Horriblemente mal usado en todo el motor.
Ejemplos:
https://github.com/godotengine/godot/blob/master/servers/visual/visual_server_scene.h#L159
Este es especialmente malo. Uno de los peores de todo el motor. Esto está agregando 8 punteros de grosor a cada objeto renderizable en el motor sin ningún motivo. No es necesario que sea una lista. De nuevo, puede ser un mapa de tragamonedas o un vector, y eso es con lo que lo reemplacé.
Mapa (map.h) de un árbol rojo-negro. Usado incorrectamente como mapa hash en casi todos sus usos. Debe eliminarse del motor a favor de OAHashmap o Hashmap, según el uso.
Cada uso de Map que vi fue incorrecto. No puedo encontrar un ejemplo de un mapa que se utilice donde tenga sentido.
Hashmap (hash_map.h) aproximadamente equivalente a std :: unordered_map, un hashmap de direcciones cerrado basado en grupos de listas vinculadas. Puede refrito al eliminar elementos.
OAHashMap (oa_hash_map.h) hashmap de direccionamiento abierto rápido recién escrito. utiliza hash de robinhood. A diferencia de hashmap, no cambiará de tamaño al eliminar elementos. Estructura realmente bien implementada, mejor que std :: unordered_map.
CommandQueueMT (command_queue_mt.h) la cola de comandos utilizada para comunicarse con los diferentes servidores, como el servidor visual. Funciona al tener una matriz codificada de 250 kb para actuar como grupo de asignadores, y asigna cada comando como un objeto con una función virtual call () y post (). Utiliza mutex para proteger las operaciones push / pop. Bloquear mutexes es muy caro, recomiendo usar la cola de moodycamel en su lugar, que debería ser un orden de magnitud más rápido. Es probable que esto se convierta en un cuello de botella para los juegos que realizan muchas operaciones con el servidor visual, como muchos objetos en movimiento.
Estos son prácticamente el conjunto básico de estructuras de datos en godot. No hay un equivalente de std :: vector adecuado. Si desea la estructura de datos de "matriz dinámica", está atascado con Vector y sus inconvenientes con la copia en escritura y reducción de tamaño. Creo que una estructura de datos DynamicArray es lo que más necesita Godot en este momento.
Para mi bifurcación, uso STL y otros contenedores de bibliotecas externas. Evito los contenedores godot ya que son peores que el STL para el rendimiento, con la excepción de los 2 hashmaps.
He encontrado problemas en la implementación de vulkan en 4.0. Sé que está trabajando, así que todavía hay tiempo para arreglarlo.
Uso de Map en la API de renderizado. https://github.com/godotengine/godot/blob/vulkan/drivers/vulkan/rendering_device_vulkan.h#L350
Como comenté, no hay un buen uso de Map y no hay razón para que exista. Debería ser solo hashmap en esos casos.
Uso excesivo de listas vinculadas en lugar de solo matrices o similar.
https://github.com/godotengine/godot/blob/vulkan/drivers/vulkan/rendering_device_vulkan.h#L680
Afortunadamente, esto probablemente no esté en los bucles rápidos, pero sigue siendo un ejemplo del uso de List donde no debería usarse
Usando PoolVector y Vector en la API de renderizado. https://github.com/godotengine/godot/blob/vulkan/drivers/vulkan/rendering_device_vulkan.h#L747
No hay una buena razón para usar esas 2 estructuras defectuosas como parte de la abstracción de la API de renderizado. Al usarlos, los usuarios se ven obligados a usar esos 2, con sus inconvenientes, en lugar de poder usar cualquier otra estructura de datos. Una recomendación es usar pointer + size en esos casos, y aún tener una versión de la función que tome un Vector si es necesario.
Un ejemplo real en el que esta API dañará a un usuario es en las funciones de creación de búfer de vértice. En el formato GLTF, los búferes de vértice vendrán empaquetados en un archivo binario. Con esta API, el usuario tendrá que cargar el búfer binario GLTF en la memoria, crear estas estructuras copiando los datos para cada búfer y luego usar la API.
Si la API tomara pointer + size, o una estructura Span <>, el usuario podría cargar directamente los datos de vértice desde el búfer binario cargado en la API, sin tener que realizar una conversión.
Esto es especialmente importante para las personas que tratan con datos de vértices de procedimiento, como un motor de voxel. Con esta API, el desarrollador se ve obligado a usar Vector para sus datos de vértice, incurriendo en un costo de rendimiento significativo, o tiene que copiar los datos en un Vector, en lugar de simplemente cargar los datos de vértice directamente desde las estructuras internas que utiliza el desarrollador.
Si está interesado en saber más sobre este tema, la mejor charla que conozco es esta de CppCon. https://www.youtube.com/watch?v=fHNmRkzxHWs
Otra gran charla es esta: https://www.youtube.com/watch?v=-8UZhDjgeZU , donde explica algunas estructuras de datos como el mapa de tragamonedas que sería muy útil para las necesidades de Godot.
vblanco20-1
en 17 jul. 2019
Godot tiene un gran problema de rendimiento ... usted sería una buena adición al equipo de godot, ¡por favor considere eso!
Ranoller
en 18 jul. 2019
Estoy cerrando este hilo porque no creo que sea la forma correcta de contribuir o ayudar.
@ vblanco20-1 Una vez más, realmente aprecio que tengas buenas intenciones, pero no entiendes el funcionamiento interno del motor o la filosofía detrás de él. La mayoría de sus comentarios se refieren a cosas que realmente no comprende cómo se usan, qué tan importantes son para el desempeño o cuáles son sus prioridades en general.
Tu tono también es innecesariamente agresivo. En lugar de preguntar qué es lo que no entiendes, o por qué se hace algo de cierta manera, simplemente te vuelves arrogante. Esta no es la actitud correcta para esta comunidad.
La mayoría de las cosas que está mencionando con respecto a la optimización son solo una superficie muy pequeña de la cantidad de elementos que planeé optimizar en Godot 4.0 (hay muchas más cosas en mi lista). Ya les dije que esto sería reescrito varias veces desde hace varios meses. Si no me cree, está bien, pero siento que está perdiendo su tiempo con esto y confundiendo a mucha gente sin una razón obvia.
Obviamente, agradezco mucho tus comentarios una vez que haya terminado con mi trabajo, pero todo lo que estás haciendo ahora es vencer a un caballo muerto, así que relájate un rato.
 reduz
en 22 jul. 2019
reduz
en 22 jul. 2019
Una vez más, cuando se lance un alpha de Godot 4.0 (con suerte antes de finales de este año), puede perfilar todo el nuevo código y dar su opinión sobre cómo optimizarlo aún más. Estoy seguro de que todos nos beneficiaremos. Por ahora, no tiene mucho sentido discutir nada más aquí, ya que el código existente desaparecerá en 4.0 y nada se fusionará en la rama 3.x, donde en este punto la estabilidad es más importante que las optimizaciones.
Dado que muchos pueden sentir curiosidad por los detalles técnicos:
- Todo el código de indexación espacial (lo que reescribió vblanco) será reemplazado por un algoritmo lineal para la selección con múltiples subprocesos, combinado con un octárbol para la selección de oclusión jerárquica y un SAP para comprobaciones superpuestas, que probablemente sean los mejores algoritmos más completos que garantizan una buena rendimiento en cualquier tipo de juego. La asignación para estas estructuras será en la misma línea que el nuevo RID_Allocator, que es O (1)). Hablé de esto con @ vblanco20-1 antes y expliqué que su enfoque no se adapta bien a todos los tipos de juegos, ya que requiere que el usuario tenga un cierto grado de experiencia para modificar, lo que comúnmente no se espera que tenga el usuario típico de Godot. Tampoco fue un buen enfoque para agregar eliminación de oclusión.
- No usaré matrices cuando se puedan usar listas porque las listas hacen pequeñas asignaciones temporales con cero riesgo de fracturación. En algunos casos, prefiero asignar una matriz seccionada (alineada a las páginas, por lo que causan 0 fragmentación) que siempre crecen y nunca se encogen (como en RID_Allocator o el nuevo CanvasItem en la rama Vulkan del motor 2D, que ahora le permite volver a dibujar elementos con muchos comandos de manera muy eficiente), pero tiene que haber una razón de rendimiento para esto. Cuando se usan listas en Godot es porque se prefieren las asignaciones pequeñas sobre el rendimiento (y en realidad hacen que la intención del código sea más clara para que otros la lean).
- PoolVector está diseñado para asignaciones muy grandes con páginas de memoria consecutivas. Hasta Godot 2.1, usaba un grupo de memoria preasignado, pero esto se eliminó en 3.xy ahora mismo el comportamiento actual es incorrecto. Para 4.0 será reemplazado por memoria virtual, está en la lista de cosas por hacer.
- Comparar Vector <> de Godot con std :: vector no tiene sentido porque tienen diferentes casos de uso. Lo usamos principalmente para pasar datos y lo bloqueamos para un acceso rápido (a través de los métodos ptr () o ptrw ()). Si usáramos std :: vector, Godot sería mucho más lento debido a la copia innecesaria. También aprovechamos mucho la mecánica de copiar sobre escritura para muchos usos diferentes.
- Map <> es simplemente más simple y amigable para una gran cantidad de elementos y no hay necesidad de preocuparse por el crecimiento / encogimiento hasta que se pueda crear fragmentación. Cuando se requiere rendimiento, se usa HashMap en su lugar (aunque es cierto, probablemente debería usar OAHashMap más, pero es demasiado nuevo y nunca tuve tiempo para hacer eso). Como filosofía general, cuando el rendimiento no es una prioridad, siempre se prefieren las asignaciones pequeñas a las grandes porque es más fácil para el asignador de memoria de su sistema operativo encontrar pequeños agujeros para colocarlos (que es más o menos para lo que está diseñado) , consumiendo menos montón.
Una vez más, puede preguntar sobre los planes y el diseño en cualquier momento que desee en lugar de volverse deshonesto y quejarse, esta no es la mejor manera de ayudar al proyecto.
También estoy seguro de que muchos de los que leen este hilo se preguntan por qué el indexador espacial fue lento para empezar. La razón es que, tal vez eres nuevo en Godot, pero hasta hace muy poco el motor 3D tenía más de 10 años y estaba extremadamente desactualizado. Se trabajó para modernizarlo en OpenGL ES 3.0, pero tuvimos que desistir debido a problemas que encontramos en OpenGL y al hecho de que estaba obsoleto para Vulkan (y Apple lo abandonó).
Sumado a esto, Godot solía ejecutarse en dispositivos como la PSP no hace mucho tiempo (que solo tenía 24 MB de memoria disponible tanto para el motor como para el juego, por lo que gran parte del código central es muy conservador con respecto a la asignación de memoria). Como el hardware es muy diferente ahora, esto se está cambiando por un código que es más óptimo y usa más memoria, pero cuando no es necesario, hacer este trabajo no tiene sentido y está bien que vea listas utilizadas en muchos lugares donde el rendimiento sí lo hace. no importa.
Además, muchas optimizaciones que queríamos hacer (mover muchos de los códigos mutex a atómicos para un mejor rendimiento) tuvieron que dejarse en espera hasta que pudiéramos mover Godot a C ++ 11 (que tiene mucho mejor soporte para atómicos en línea y no lo hace). requiere que incluyas encabezados de Windows, que contaminan todo el espacio de nombres), lo cual no era algo que pudiéramos hacer en una rama estable. El cambio a C ++ 11 tendrá lugar después de que Godot 3.2 se ramifique y se congelen las funciones; de lo contrario, mantener sincronizadas las ramas de Vulkan y Master sería un gran dolor. No hay mucha prisa, ya que actualmente la atención se centra en Vulkan.
Lo siento, las cosas llevan tiempo, pero prefiero que se hagan correctamente en lugar de apresurarlas. Se amortiza mejor a largo plazo. En este momento, se están trabajando en todas las optimizaciones de rendimiento y deberían estar listas pronto (si probó la rama Vulkan, el motor 2D es mucho más rápido de lo que solía ser).
reduz
en 22 jul. 2019
Hola reduz,
Si bien principalmente veo que sus puntos son válidos, me gustaría comentar dos en los que no estoy de acuerdo:
- No usaré matrices cuando se puedan usar listas porque las listas hacen pequeñas asignaciones temporales con cero riesgo de fragmentación. En algunos casos, prefiero asignar una matriz seccionada (alineada a las páginas, por lo que causan 0 fragmentación) que siempre crecen y nunca se encogen (como en RID_Allocator o el nuevo CanvasItem en la rama Vulkan del motor 2D, que ahora le permite volver a dibujar elementos con muchos comandos de manera muy eficiente), pero tiene que haber una razón de rendimiento para esto. Cuando se usan listas en Godot es porque se prefieren las asignaciones pequeñas sobre el rendimiento (y en realidad hacen que la intención del código sea más clara para que otros la lean).
Dudo mucho que una lista vinculada tenga un mejor rendimiento general, ya sea en velocidad o eficiencia de la memoria, que una matriz dinámica con crecimiento exponencial. Se garantiza que este último ocupará como máximo el doble de espacio del que realmente usa, mientras que un List<some pointer> usa exactamente tres veces más almacenamiento (el contenido real, el puntero next y prev). Para una matriz seccionada, las cosas se ven aún mejor.
Cuando se envuelven correctamente (y por lo que puedo decir por lo que ya he visto del código de godot, lo son), se ven más o menos iguales para el programador, por lo que no entiendo a qué te refieres con "ellos [Listas ] hacen que la intención del código sea más clara ".
En mi humilde opinión, las listas son válidas exactamente en dos condiciones:
- Necesita borrar / insertar elementos con frecuencia en el medio del contenedor
- o necesita la inserción / eliminación de elementos en tiempo constante (y no solo en tiempo constante amortizado). Es decir, en contextos en tiempo real donde no es posible una asignación de memoria que requiera mucho tiempo, están bien.
- Map <> es simplemente más simple y amigable para una gran cantidad de elementos y no hay necesidad de preocuparse por el crecimiento / encogimiento hasta que se pueda crear fragmentación. Cuando se requiere rendimiento, se usa HashMap en su lugar (aunque es cierto, probablemente debería usar OAHashMap más, pero es demasiado nuevo y nunca tuve tiempo para hacer eso). Como filosofía general, cuando el rendimiento no es una prioridad, siempre se prefieren las asignaciones pequeñas a las grandes porque es más fácil para el asignador de memoria de su sistema operativo encontrar pequeños agujeros para colocarlos (que es más o menos para lo que está diseñado) , consumiendo menos montón.
Los asignadores de libc suelen ser bastante inteligentes, y dado que un OAHashMap (o un std :: unordered_map) reasigna sus almacenamientos de vez en cuando (tiempo constante amortizado), el asignador generalmente se las arregla para mantener sus bloques de memoria compactos. Creo firmemente que un OAHashMap no consume más montón que un mapa de árbol binario simple como Map. En cambio, estoy bastante seguro de que la enorme sobrecarga del puntero en cada elemento de Map realmente consume más memoria que cualquier fragmentación de montón de OAHashmap (o std :: unordered_map).
Después de todo, creo que la mejor manera de resolver este tipo de argumentos es compararlos. Seguramente, esto es mucho más útil para Godot 4.0, ya que, como dijiste, se producirán muchas optimizaciones de rendimiento allí y no hay mucho uso de mejorar las rutas de código que de todos modos pueden reescribirse por completo en 4.0.
Pero @reduz , ¿qué piensas de la evaluación comparativa de todos estos cambios que sugirió @ vblanco20-1 (tal vez incluso ahora, en 3.1)? ¿Si @ vblanco20-1 (o cualquier otra persona) está dispuesto a invertir el tiempo en escribir una suite de evaluación comparativa y evaluar el desempeño de Godot3.1 (tanto en términos de velocidad y "consumo de pila considerando la fragmentación") contra los cambios de vblanco? Podría dar pistas valiosas para los cambios reales de 4.0.
Creo que esa metodología se adapta bien a sus "[las cosas] se hacen correctamente en lugar de apresurarlas".
@ vblanco20-1: De hecho, agradezco su trabajo. ¿Estaría motivado para crear tales puntos de referencia, para que podamos medir realmente si sus cambios son mejoras reales en el rendimiento? Me interesaría mucho.
 Windfisch
en 23 jul. 2019
Windfisch
en 23 jul. 2019
@Windfisch Te sugiero que vuelvas a leer mi publicación anterior, ya que has leído o entendido mal algunas cosas. Te las aclararé.
- Las listas se utilizan exactamente para el caso de uso que describe, y nunca dije que tuvieran un mejor rendimiento. Son más eficientes que las matrices para reutilizar el montón simplemente porque están formadas por pequeñas asignaciones. A escala (cuando los usa mucho para su caso de uso previsto), esto realmente marca la diferencia. Cuando se requiere rendimiento, ya se utilizan otros contenedores que son más rápidos, más empaquetados o tienen una mejor coherencia de caché. Para bien o para mal, Victor se centró principalmente en una de las áreas de motor más antiguas (si no la más antigua en realidad) que nunca se optimizó desde que era un motor interno utilizado para publicar juegos para PSP. Esto tenía una reescritura pendiente desde hace mucho tiempo, pero había otras prioridades. Su principal optimización fue el rastreo de cono de vóxel basado en CPU que agregué recientemente, que para ser honesto, hice un mal trabajo con eso porque fue demasiado apresurado cerca de la versión 3.0, pero la solución adecuada para esto es un algoritmo completamente diferente, y no agregando procesamiento paralelo como lo hizo él.
- Nunca discutí sobre el desempeño del trabajo de @ vblanco20-1 y, francamente, no me importa (por lo que no es necesario que pierda el tiempo haciendo evaluaciones comparativas). Las razones para no fusionar su trabajo es porque 1) Los algoritmos que usa necesitan ajustes manuales dependiendo del tamaño promedio de los objetos en el juego, algo que la mayoría de los usuarios de Godot necesitarán hacer. Tiendo a favorecer algoritmos que pueden ser un poco más lentos pero escalan mejor, sin la necesidad de ajustes. 2) El algoritmo que usa no es bueno para la eliminación de oclusiones (el octárbol simple es mejor debido a la naturaleza jerárquica). 3) El algoritmo que usa no es bueno para el emparejamiento (SAP suele ser mejor). 4) Él usa C ++ 17 y bibliotecas que no estoy interesado en admitir, o lambdas que creo que son innecesarias 5) Ya estoy trabajando para optimizar esto para 4.0, y la rama 3.x tiene la estabilidad como prioridad y nosotros tiene la intención de lanzar 3.2 lo antes posible, por lo que no se modificará ni se trabajará en él allí. El código existente puede ser más lento, pero es muy estable y probado. Si esto se fusiona y hay informes de errores, regresiones, etc. Nadie tendrá tiempo para trabajar en ello o ayudar a Víctor porque ya estamos casi ocupados con la rama 4.0. Todo esto se explica anteriormente, por lo que le sugiero que vuelva a leer la publicación.
En cualquier caso, le prometí a Victor que el código de indexación se puede conectar, por lo que eventualmente también se pueden implementar diferentes algoritmos para diferentes tipos de juegos.
Godot es de código abierto y también lo es su bifurcación. Todos estamos abiertos y compartiendo aquí, nada debería impedirte usar su trabajo si lo necesitas.
reduz
en 23 jul. 2019
Dado que las optimizaciones parecen no afectar gdscript, render o los problemas de "tartamudeo", y hay cosas de las que la gente se queja (yo incluyo), tal vez con las optimizaciones la gente estará feliz (yo incluyo) ... no es necesario velocidad lua jit ...
Trabajos en "copiar al escribir" fue una optimización de rendimiento muy grande en un complemento mío (de 25 segundos en un análisis de script a solo 1 segundo en un script de 7000 líneas) ... siento que este tipo de optimizaciones son las que necesita, en gdscript, en render y lograr el problema de tartamudeo ... eso es todo.
Ranoller
en 23 jul. 2019
Gracias @reduz por tu aclaración. De hecho, dejó sus puntos más claros que las publicaciones anteriores.
Es bueno que el código de indexación espacial sea enchufable, porque de hecho se me cayó de pie antes cuando manejaba muchos objetos a escalas muy diferentes. Esperando la 4.0.
Windfisch
en 23 jul. 2019
También estaba pensando en ello y creo que puede ser una buena idea poner algún documento compartido con ideas sobre cómo optimizar la indexación espacial, para que más contribuyentes puedan aprender sobre esto y también lanzar ideas o realizar implementaciones. Tengo una muy buena idea de lo que hay que hacer, pero estoy seguro de que hay mucho espacio aquí para hacer más optimizaciones y crear algoritmos interesantes.
Podemos poner requisitos muy claros que sabemos que los algoritmos tienen que cumplir (por ejemplo, que no requieran ajustes por parte del usuario si es posible para elementos promedio en el tamaño mundial, no cosas de fuerza bruta con subprocesos si es posible, no son libres, otras partes del el motor también puede necesitarlos, como la física o la animación y consumen más batería en el móvil-, compatibilidad con la eliminación de oclusión basada en la reproyección -por lo tanto, se puede desear alguna forma de jerarquía, pero también debe probarse contra la fuerza bruta-, sea inteligente acerca de las actualizaciones del búfer de sombra -no actualice si no ha cambiado nada-, explore optimizaciones como la eliminación selectiva de oclusión basada en reproyección para sombras direccionales, etc.). También podemos discutir la creación de algunas pruebas de referencia (no creo que la demostración de TPS sea una buena referencia porque no tiene tantos objetos u oclusión). @ vblanco20-1 si está dispuesto a seguir nuestro estilo y filosofía de codificación / lenguaje, por supuesto, es más que bienvenido a echar una mano.
El resto del código de renderizado (renderizado real usando RenderingDevice) es más o menos sencillo y no hay muchas formas de hacerlo, pero la indexación parece un problema más interesante de resolver para la optimización.
reduz
en 23 jul. 2019
@reduz como referencia sobre la indexación espacial. La selección original basada en mosaicos se eliminó y se reemplazó por un Octree aproximadamente a la mitad de este hilo. El octárbol que obtuve es WIP (falta alguna funcionalidad de reajuste), pero los resultados son bastante buenos para el prototipo. Su código no es tan bueno por su naturaleza de prototipo, por lo que solo es útil verificar cómo se comportaría este tipo de octárbol en una escena compleja como tps-demo.
Está inspirado en cómo funciona el motor irreal octree, pero con algunas modificaciones como la posibilidad de una iteración plana.
La idea principal es que solo las hojas del octárbol contienen objetos, y esos objetos se mantienen en una matriz de tamaño 64 (el tamaño del tiempo de compilación puede ser diferente). Una hoja de octárbol solo se dividirá una vez que se "desborde" en 65 elementos. Cuando elimina objetos, si cada una de las hojas del nodo principal encaja en la matriz de 64 tamaños, fusionamos las hojas de nuevo en su nodo principal, que se convierte en una hoja.
Al hacer eso, podemos minimizar el tiempo de prueba en los nodos, ya que el octárbol no terminará siendo demasiado profundo.
Otra cosa buena que estaba haciendo es que los nodos hoja también se almacenan en una matriz plana, lo que permite un paralelo en el sacrificio. De esta forma, el sacrificio jerárquico se puede utilizar al realizar el sacrificio de sombras puntuales u otras operaciones "pequeñas", y el paralelo plano para el sacrificio selectivo se puede utilizar para la vista principal. Por supuesto, podría usar jerárquico para todo, pero podría ser más lento y no se puede paralelizar.
La estructura de bloques desperdiciará un poco de memoria, pero incluso en el peor de los casos, no creo que desperdicie mucha memoria ya que los nodos se fusionarán si caen por debajo de una cantidad. También permite utilizar un asignador de pool dado que tanto los nodos como las hojas tendrán un tamaño constante.
También tengo varios octrees en mi fork, que se utilizan para optimizar algunas cosas. Por ejemplo, tengo un octárbol solo para objetos shadowcaster, que permite omitir toda la lógica relacionada con "puede proyectar sombras" cuando se seleccionan los mapas de sombras.
En mi preocupación por Vector y otros sobre la API de renderizado, este problema explica lo que me preocupaba. https://github.com/godotengine/godot/issues/24731
En la biblioteca y C ++ 17 cosas de la bifurcación ... eso es innecesario. La bifurcación usa en exceso muchas bibliotecas porque necesitaba algunas partes de ellas. Lo único que realmente se necesita, y que creo que Godot necesita, es una cola paralela de fuerza de la industria, utilicé la cola de Moodycamel para ello.
En las lambdas, su uso es principalmente para selección y se usa para ahorrar una cantidad significativa de memoria, ya que solo necesita guardar los objetos que pasan sus comprobaciones en la matriz de salida. La alternativa es hacer objetos iteradores (eso es lo que hace el motor irreal con su octárbol), pero termina siendo un código peor y mucho más difícil de escribir.
Mi intención no era "volverse pícaro", sino responder comentarios frecuentes sobre "eres libre de hacer una bifurcación para demostrar", que es exactamente lo que he hecho. El primer mensaje del hilo es un poco alarmista y no muy correcto. Lo siento si me mostré grosero contigo, ya que mi único objetivo es ayudar al motor de juegos de código abierto más popular.
vblanco20-1
en 23 jul. 2019
@ vblanco20-1 Eso suena muy bien, y la forma en que mencionas que el octárbol funciona tiene mucho sentido. Honestamente, no me importa implementar una cola paralela (parece lo suficientemente simple como para no necesitar una dependencia externa y necesito C ++ 11 para hacerlo correctamente, así que supongo que eso sucederá solo en la rama Vulkan). Si ha confirmado esto, definitivamente querré echarle un vistazo, para poder usarlo como base para la reescritura del indexador en la rama Vulkan (solo estoy reescribiendo la mayoría de las cosas allí, por lo que debe reescribirse de todos modos ). Por supuesto, si desea ayudar con la implementación (probablemente cuando haya más cosas implementadas con la nueva API), es muy bienvenido.
El uso de una versión paralela con matrices aplanadas es interesante, pero mi punto de vista es que no será tan útil para la eliminación de oclusiones, y sería interesante medir qué tan grande es una mejora con respecto a la eliminación de octárboles regular, considerando la cantidad extra de núcleos utilizados. Tenga en cuenta que hay muchas otras áreas que pueden estar usando múltiples subprocesos que pueden hacer un uso más eficiente (menos fuerza bruta) (como la física), por lo que incluso si con este enfoque obtenemos una mejora relativamente marginal, no siempre es así. en el mejor de los intereses, ya que puede privar a otras áreas del uso de CPU. Quizás podría ser opcional.
También encuentro bastante interesante la implementación de Bullet 3 de dbvt, que hace un autoequilibrio incremental y una asignación lineal, es una de las cosas que quería investigar más (he visto este enfoque implementado en motores propietarios que no puedo mencionar: P), como algoritmo, un árbol binario balanceado es por diseño mucho menos redundante que un octárbol, y puede funcionar mejor tanto en pruebas de emparejamiento como de oclusión, por lo que un enfoque de fase ancha / eliminación enchufable puede ser en realidad una buena idea, dado que hacemos lo adecuado escenas de referencia.
En cualquier caso, eres excepcionalmente inteligente y sería genial si pudiéramos trabajar juntos en esto, pero solo te pediré que comprendas y respetes muchas de las filosofías de diseño existentes que tenemos, incluso si no siempre se adaptan a tus gustos. . El proyecto es enorme, con mucha fuerza inercial, y cambiar las cosas por los gustos no es una buena idea. La facilidad de uso y "simplemente funciona" es siempre lo primero en la lista con respecto al diseño, y la simplicidad y la legibilidad del código generalmente tienen prioridad sobre la eficiencia (es decir, cuando la eficiencia no es un objetivo porque un área no es crítica). La última vez que hablamos, querías cambiar casi todo el asunto y no querías escuchar ningún razonamiento o enfocarte en problemas reales, y no es así como solemos trabajar con la comunidad y los colaboradores, por lo que mi consejo para relajarte fue bien intencionado.
reduz
en 23 jul. 2019
¿Quién necesita desempeño? :Cara de burla:
El modelo de rendimiento y fuente es lo que me mantiene con Godot.
 BlueCannonBall
en 28 ene. 2020
BlueCannonBall
en 28 ene. 2020
Editar: Lo siento, tal vez soy algo fuera de tema, pero quería aclarar los beneficios del código abierto.
@mixedCase Sería extremadamente reacio a apoyar cualquier tipo de bifurcación de Godot. La bifurcación y la fragmentación suelen ser la muerte de los proyectos de código abierto.
No lo creo. La naturaleza del código abierto es solo que puede usar y reutilizar el código libremente como lo desee. Entonces eso no será el final de algún proyecto sino más opciones para los usuarios.
Lo que dices es un monopolio, y eso no es lo que defiende el código abierto. No se deje engañar por empresas que pretenden mostrarle que es mejor tener el control total de algo. Eso es mentira, al menos en el mundo del código abierto, porque si alguien más tiene el código, tú también tienes el código. Lo que tienen que hacer es ocuparse de cómo manejar una comunidad o cómo estar de acuerdo con eso.
De todos modos, los desarrolladores originales pueden combinar las mejoras de la bifurcación. Son libres de hacerlo siempre. Esa es otra naturaleza del mundo del código abierto.
Y en el peor de los casos, la bifurcación será mejor que la original y una gran cantidad de contribuyentes irán allí. Nadie pierde, todos ganan. Oh, lo siento, si una empresa está detrás del original, tal vez perdieron (o también pueden fusionar las mejoras de la bifurcación).
 Anyeos
en 18 mar. 2020
Anyeos
en 18 mar. 2020
Temas relacionados
 RebelliousX
·
3Comentarios
RebelliousX
·
3Comentarios
 EdwardAngeles
·
3Comentarios
EdwardAngeles
·
3Comentarios
 SleepProgger
·
3Comentarios
SleepProgger
·
3Comentarios
 blurymind
·
3Comentarios
blurymind
·
3Comentarios
 rgrams
·
3Comentarios
rgrams
·
3Comentarios
Comentario más útil
Tú podrías estar interesado. He estado trabajando en el elegante tenedor durante bastante tiempo. Los resultados actuales son así:

Capturado en una gran computadora portátil para juegos con una CPU Intel de 4 núcleos y GTX 1070
Godot normal
Mi bifurcación en https://github.com/vblanco20-1/godot/tree/ECS_Refactor

En ambos perfiles, el rojo es esencialmente "esperar a la GPU". Actualmente con cuello de botella debido a demasiados inconvenientes en opengl. Realmente no se puede resolver sin vulkan o sin volver a escribir todo el renderizador.
En el lado de la CPU, pasamos de cuadros de 13 ms a cuadros de 5 ms. Los fotogramas "rápidos" van de 5,5 ms a 2,5 ms
En el lado del "cuadro total", pasamos de 13 ms a 8-9 ms
~ 75 FPS a ~ 115 FPS
Menos tiempo de CPU = más tiempo que puedes dedicar al juego. El godot actual tiene un cuello de botella en la CPU, por lo que más tiempo dedicado al juego significará FPS más bajos, mientras que mi bifurcación está vinculada a la GPU, por lo que puede agregar mucha más lógica de juego con el FPS intacto, ya que la CPU es simplemente "gratuita" para bastante tiempo cada fotograma.
MUCHAS de estas mejoras se pueden fusionar en godot, SI godot es compatible con C ++ moderno y tiene un sistema de subprocesos múltiples que permite tareas "pequeñas" muy baratas.
La mayor ganancia se obtiene haciendo sombras multiproceso y lectura de mapas de luz multiproceso en objetos dinámicos # 25013. Ambos funcionan de la misma manera. Muchas otras partes del renderizador también son multiproceso.
Otras ganancias son un Octree que es de 10 a 20 veces más rápido que Godot One, y mejoras en parte del flujo de renderizado, como grabar tanto la lista de renderizado de preparación de profundidad como de paso normal a la vez, en lugar de iterar la lista de selección 2 veces, y un cambio significativo en cómo funciona la conexión de luz-> malla (¡sin lista enlazada!)
Actualmente estoy buscando más mapas de prueba además de la demostración de TPS para poder tener más métricas en otros tipos de mapas. También voy a escribir una serie de artículos que expliquen en detalle cómo funciona todo esto.