Godot: Fast jedes Mal die langsamste Datenstruktur verwenden.
Ich habe den Code von Godot überprüft und festgestellt, dass jede Art von CPU-seitiger Leistung bis hin zu den Kerndatenstrukturen völlig ignoriert wird. Es wird überall List verwendet, wenn eine verknüpfte Liste die langsamste Datenstruktur ist, die Sie auf modernen PCs verwenden können. Fast jede andere Datenstruktur wäre schneller, insbesondere bei kleinen Strukturen. Es ist besonders ungeheuerlich bei Dingen wie der Lichtliste oder Reflexionsaufnahmen in Renderables, bei denen Sie jedes Mal 3 Zeiger speichern, anstatt nur ein Stapelarray von 8 maximalen Lichtern (zum Beispiel) + ein Extra für die Fälle zu geben, in denen dies der Fall wäre mehr als das.
Das Gleiche gilt für RID_Owner, der ein Baum ist, bei dem es sich um eine Hash-Map oder eine Slotmap handeln könnte. Auch die Octree-Implementierung für das Culling hat genau das gleiche Problem.
Ich möchte nach der Designabsicht hinter dieser totalen und absoluten Übernutzung von Linked Lists und schrecklichen Leistungszeiger-lastigen Datenstrukturen überall im Code fragen. Hat das einen bestimmten Grund? In den meisten Fällen würde eine "aufgeteilte" verknüpfte Liste, bei der Sie eine verknüpfte Liste von Arrays erstellen, automatisch Leistungssteigerungen für denselben Code bringen.
Die Verwendung dieser Datenstrukturen verhindert auch jede Art von "einfacher" Parallelität in einem guten Teil des Codes und zerstört den Cache vollständig.
Ich arbeite daran, eine Proof-of-Concept-Implementierung zu erstellen, bei der einige der Interna umgestaltet werden, um bessere Datenstrukturen zu verwenden. Im Moment arbeite ich an einer Neufassung des Culling-Codes, der den aktuellen Octree umgeht und nur ein flaches Array mit optionaler Parallelität verwendet. Ich werde die tps-Demo als Benchmark verwenden und mit Ergebnissen zurückkommen, die ich tatsächlich so bewertet habe, dass sie 25 Level tief in diesem Octree gehen ...
Außerdem bin ich sehr beeindruckt von der Qualität des Codestils, alles ist leicht zu verstehen und zu verstehen und ziemlich gut kommentiert.
 vblanco20-1
vblanco20-1
Alle 61 Kommentare
Wer braucht Leistung? :Troll Gesicht:
 mafiesto4
am 27. Nov. 2018
mafiesto4
am 27. Nov. 2018
Seien Sie gespannt, was Sie messen.
 avencherus
am 27. Nov. 2018
avencherus
am 27. Nov. 2018
Dies kann also erklären, warum ein einfacher Light2D-Knoten in Godot Ihren Computer brennen kann?
 Ranoller
am 27. Nov. 2018
Ranoller
am 27. Nov. 2018
@Ranoller Ich glaube nicht. Die schlechte Beleuchtungsleistung hängt höchstwahrscheinlich damit zusammen, wie Godot derzeit 2D-Beleuchtung durchführt: Jedes Sprite n-mal rendern (wobei n die Anzahl der Lichter ist, die es beeinflussen).
Bearbeiten: siehe #23593
 CptPotato
am 27. Nov. 2018
CptPotato
am 27. Nov. 2018
Zur Verdeutlichung geht es hier um CPU-seitige Ineffizienzen im gesamten Code. Dies hat nichts mit den Godot-Funktionen oder dem Godot-GPU-Rendering selbst zu tun.
vblanco20-1
am 27. Nov. 2018
@vblanco20-1 Auf einem kleinen Seitentangens hatten Sie und ich darüber gesprochen, dass die Knoten stattdessen als ECS-Entitäten modelliert werden. Ich frage mich, ob der Trick darin besteht, einen Feature-Zweig von Godot mit einem neuen ent-Modul zu erstellen, das nach und nach Seite an Seite mit dem Baum arbeiten würde. wie ein get_tree() und get_registry(). Das ent-Modul würde wahrscheinlich 80% der Funktionalität des Baums/der Szene vermissen, aber es könnte als Testumgebung nützlich sein, insbesondere für Dinge wie das Erstellen großer statischer Ebenen mit vielen Objekten (Culling, Streaming, Batch-Rendering). Reduzierte Funktionalität und Flexibilität, aber höhere Leistung.
 pgruenbacher
am 27. Nov. 2018
pgruenbacher
am 27. Nov. 2018
Bevor ich volles ECS mache (was ich tun könnte) möchte ich als Experiment an einigen niedrig hängenden Früchten arbeiten. Ich könnte später versuchen, vollständig datenorientiert zu arbeiten.
vblanco20-1
am 27. Nov. 2018
Also erste Updates:
update_dirty_instances : von 0,2-0,25 Millisekunden bis 0,1 Millisekunden
octree_cull (die Hauptansicht): von 0,35 Millisekunden bis 0,1 Millisekunden
Der lustige Teil? Der Ersatz für Octree Cull verwendet keine Beschleunigungsstruktur, sondern iteriert nur über ein dummes Array mit allen AABBs.
Der noch lustigere Teil? Das neue Culling besteht aus 10 Zeilen Code. Wenn ich es parallel haben wollte, wäre es eine einzige Änderung an der Linie.
Ich werde mit der Implementierung meines neuen Culling mit den Lichtern fortfahren, um zu sehen, wie viel die Beschleunigung ansammelt.
vblanco20-1
am 1. Dez. 2018
Wir sollten wahrscheinlich auch ein Google-Benchmark-Verzeichnis im Master-Zweig erstellen. Das kann bei der Validierung helfen, damit die Leute nicht darüber streiten müssen.
pgruenbacher
am 1. Dez. 2018
Es gibt das Godotengine/godot-tests Repository, aber noch nicht viele Leute benutzen es.
 bojidar-bg
am 2. Dez. 2018
bojidar-bg
am 2. Dez. 2018
Neues Update:

Ich habe eine ziemlich dumme räumliche Beschleunigungsstruktur mit 2 Ebenen implementiert. Ich erzeuge es nur jeden Frame. Weitere Verbesserungen könnten es verbessern und dynamisch aktualisieren, anstatt es neu zu erstellen.
Im Bild sind die verschiedenen Zeilen verschiedene Bereiche, und jeder der farbigen Blöcke ist eine Aufgabe/ein Codeblock. In dieser Aufnahme mache ich sowohl den Octree Cull als auch meinen Cull Seite an Seite, um einen direkten Vergleich zu haben
Es zeigt, dass die Wiederherstellung der gesamten Beschleunigungsstruktur schneller ist als eine einzelne alte Octree-Kürzung.
Auch, dass weitere Keulungen in der Regel etwa die Hälfte bis ein Drittel des aktuellen Octrees ausmachen.
Ich habe keinen einzigen Fall gefunden, in dem meine dumme Struktur langsamer ist als der aktuelle Octree, abgesehen von den Kosten für die anfängliche Erstellung.
Ein weiterer Bonus ist, dass es sehr Multithread-freundlich ist und auf jede gewünschte Kernanzahl skaliert werden kann, nur mit einer Parallele für.
Es überprüft auch den Speicher vollständig fortlaufend, so dass es möglich sein sollte, SIMD ohne großen Aufwand durchzuführen.
Ein weiteres wichtiges Detail ist, dass es viel einfacher ist als der aktuelle Octree, mit viel weniger Codezeilen.
vblanco20-1
am 2. Dez. 2018
Sie verursachen mehr Hype als das Ende von Game of Thrones ....
Ranoller
am 2. Dez. 2018

Die Algorithmen wurden ein wenig modifiziert, sodass sie jetzt C++17-Parallelalgorithmen verwenden können, was es dem Programmierer ermöglicht, ihm einfach zu sagen, dass er eine Parallele für oder eine parallele Sortierung durchführen soll.
Beschleunigung von etwa x2 im Hauptfrustrum-Auslöschung, aber für die Lichter ist die Geschwindigkeit ungefähr gleich wie zuvor.
Mein Culler ist jetzt 10 mal schneller als Godot Octree für die Hauptansicht.
vblanco20-1
am 2. Dez. 2018
Wenn Sie sich die Änderungen ansehen möchten, ist das Wichtigste hier:
https://github.com/vblanco20-1/godot/blob/4ab733200faa20e0dadc9306e7cc93230ebc120a/servers/visual/visual_server_scene.cpp#L387
Dies ist die neue Culling-Funktion. Die Beschleunigungsstruktur befindet sich auf der Funktion direkt darüber.
vblanco20-1
am 2. Dez. 2018
Dies sollte mit VS2015 kompilieren? Die Konsole gibt eine Reihe von Fehlern zu den Dateien in entt\ aus
Ranoller
am 2. Dez. 2018
@Ranoller es ist c++17, also stellen Sie sicher, dass Sie einen neueren Compiler verwenden
pgruenbacher
am 3. Dez. 2018
Äh, ich glaube Godot ist noch nicht auf c++17 umgestiegen? Zumindest erinnere ich mich an einige Diskussionen zu dem Thema?
 Zireael07
am 3. Dez. 2018
Zireael07
am 3. Dez. 2018
Godot ist C++ 03. Dieser Schritt wird umstritten sein. Ich empfehle @vblanco20-1, mit Juan zu sprechen, wenn er die Feiertage beendet hat ... diese Optimierung wird großartig sein und wir wollen nicht sofort ein "This Will Never Happend TM"
Ranoller
am 3. Dez. 2018
@vblanco20-1
octree_cull (die Hauptansicht): von 0,35 Millisekunden bis 0,1 Millisekunden
wie viele objekte?
 nem0
am 3. Dez. 2018
nem0
am 3. Dez. 2018
@nem0
@vblanco20-1
octree_cull (die Hauptansicht): von 0,35 Millisekunden bis 0,1 Millisekunden
wie viele objekte?
Um 2200. Der Godot Octree schneidet besser ab, wenn der Check sehr klein ist, da er früh ausfällt. Je größer die Abfrage, desto langsamer wird Godot Octree im Vergleich zu meiner Lösung. Wenn der Godot-Octree 90 % der Szene nicht vorzeitig beenden kann, dann ist er schrecklich langsam, da er im Wesentlichen verknüpfte Listen für jedes einzelne Objekt iteriert, während mein System aus Arrays besteht, bei denen jede Cache-Zeile eine gute Menge an AABBs enthält, was stark reduziert wird Cache verfehlt.
Mein System funktioniert mit 2 Ebenen von AABBs, einem Array von Blöcken, wobei jeder Block 128 Instanzen enthalten kann.
Die oberste Ebene besteht hauptsächlich aus einem Array von AABBs + einem Array von Blöcken. Wenn die AABB-Prüfung erfolgreich ist, dann iteriere ich den Block. Der Block ist ein Array der Struktur von AABBs, Maske und einem Zeiger auf die Instanz. So ist alles faaaaast.
Im Moment erfolgt die Generierung der Datenstruktur der obersten Ebene auf sehr dumme Weise. Wenn es besser generiert wäre, könnte seine Leistung viel größer sein. Ich führe einige Experimente mit anderen Blockgrößen als 128 durch.
vblanco20-1
am 3. Dez. 2018
Ich habe verschiedene Nummern überprüft, und 128 pro Block scheint immer noch der Sweetspot zu sein.
Durch die Änderung des Algorithmus, um "große" Objekte von kleinen Objekten zu trennen, habe ich es geschafft, ein weiteres Geschwindigkeits-Upgrade von 30% zu erzielen, hauptsächlich dann, wenn Sie nicht in die Mitte der Karte schauen. Es funktioniert, weil die großen Objekte die Block-AABBs, die auch kleine Objekte enthalten, nicht aufblähen. Ich glaube, dass 3 Größen wahrscheinlich am besten funktionieren würden.
Die Blockgenerierung ist immer noch nicht optimal. Die großen Blöcke selektieren nur etwa 10 bis 20 % der Instanzen, wenn Sie in die Mitte schauen, und bis zu 50 %, wenn Sie außerhalb der Karte schauen.
Ich denke, eine Verbesserung wäre wahrscheinlich, den aktuellen Octree wiederzuverwenden, aber "flacher" zu machen.
Es gibt jetzt keinen einzigen Fall, in dem mein Algorithmus gleich oder schlechter als der aktuelle Octree ist, auch ohne parallele Ausführung.
vblanco20-1
am 3. Dez. 2018
@vblanco20-1 Ich gehe davon aus, dass Sie Ihren Vergleich mit Godot durchführen, der im release Modus kompiliert wurde (der -O3 ) und nicht mit dem regulären Editor-Build in Debug (der keine Optimierungen hat und Standard ist) richtig ?
Tut mir leid, wenn die Frage dumm ist, aber ich sehe keine Erwähnung in dem Thread.
Schöne Arbeit trotzdem :)
 Faless
am 11. Dez. 2018
Faless
am 11. Dez. 2018
@Faless Sein release_debug, der einige Optimierungen hinzufügt. Ich konnte die vollständige "Version" nicht testen, da ich das Spiel nicht öffnen kann (das Spiel muss auch erstellt werden?)
Ich hatte eine Idee, wie man das Culling noch viel weiter verbessern kann, indem man die Notwendigkeit beseitigt, jeden Frame zu regenerieren und eine bessere räumliche Optimierung zu erzielen. Mal sehen was ich versuchen kann. Theoretisch könnte so etwas das Regenerieren entfernen, die Leistung des Hauptabschusses etwas verbessern und einen speziellen Modus für Punktlichter haben, der ihre Abschussleistung um einen großen Betrag erhöhen würde, so dass sie fast 0 Kosten hätten, weil es wird zu einem billigen O(1), um die "Objekte in einem Radius" zu erhalten.
Es ist inspiriert von der Funktionsweise eines meiner Experimente, bei dem ich 400.000 physikalische Objekte mache, die voneinander abprallen.
vblanco20-1
am 11. Dez. 2018

Neues Culling ist jetzt implementiert. Die Blockgenerierung ist jetzt viel intelligenter, was zu einer schnelleren Aussonderung führt. Der Sonderfall für Leuchten ist noch nicht implementiert.
Ich habe es meiner Gabel übergeben
vblanco20-1
am 12. Dez. 2018
Ich bin gespannt, ob Sie dieses Benchmark-Tool (das aus Ihren Screenshots) auf einem Build aus dem aktuellen Master-Zweig ausführen können, um uns einen Anhaltspunkt dafür zu geben, wie viel Leistung Ihre Implementierung gegenüber der aktuellen Implementierung bietet. Ich bin ein Dummkopf, woops.
 LikeLakers2
am 13. Dez. 2018
LikeLakers2
am 13. Dez. 2018
@LikeLakers2 Sie können sowohl die aktuelle Implementierung als auch seine Implementierung im Screenshot sehen.
 neikeq
am 13. Dez. 2018
neikeq
am 13. Dez. 2018
Er hat das auf einer Meistergabel laufen lassen
Am Mittwoch, 12. Dezember 2018, MichiRecRoom [email protected]
schrieb:
@neikeq https://github.com/neikeq Erklären? Ich dachte die Screenshots
die gepostet wurden, waren nur von seiner Umsetzung, wenn man bedenkt, wie die Beiträge
mit Screenshots wurden bisher formuliert.—
Sie erhalten dies, weil Sie einen Kommentar abgegeben haben.
Antworten Sie direkt auf diese E-Mail und zeigen Sie sie auf GitHub an
https://github.com/godotengine/godot/issues/23998#issuecomment-446831151 ,
oder den Thread stumm schalten
https://github.com/notifications/unsubscribe-auth/ADLZ9pRh9Lksse9KBfWV0z5GmHRXf5P2ks5u4crCgaJpZM4YziJp
.
pgruenbacher
am 13. Dez. 2018
Gibt es Neuigkeiten zu diesem Thema?
CptPotato
am 15. Jan. 2019
Gibt es Neuigkeiten zu diesem Thema?
Ich habe mit reduz gesprochen. Wird nie zusammengeführt, weil es nicht zum Projekt passt. Stattdessen habe ich andere Experimente gemacht. Vielleicht aktualisiere ich das Culling später für 4.0
vblanco20-1
am 15. Jan. 2019
Das ist schade, wenn man bedenkt, dass es wirklich vielversprechend aussah. Hoffentlich werden diese Probleme rechtzeitig bearbeitet.
CptPotato
am 15. Jan. 2019
Vielleicht sollte dies der 4.0-Meilenstein gegeben werden? Da Reduz plant, an Vulkan für 4.0 zu arbeiten, und dieses Thema, während es um Leistung geht, konzentriert sich auf Rendering, oder zumindest auf OP.
 aaronfranke
am 4. Feb. 2019
aaronfranke
am 4. Feb. 2019
@vblanco20-1 Hat er gesagt, dass es nicht passt? Ich gehe davon aus wegen der Umstellung auf c++17?
 Two-Tone
am 6. Feb. 2019
Two-Tone
am 6. Feb. 2019
Es gibt jedoch ein anderes verwandtes Problem mit dem Meilenstein: #25013
 starry-abyss
am 6. Feb. 2019
starry-abyss
am 6. Feb. 2019
Du könntest interessiert sein. Ich arbeite schon eine ganze Weile an der schicken Gabel. Die aktuellen Ergebnisse sehen so aus:
Aufgenommen auf einem großen Gaming-Laptop mit einer 4-Kern-Intel-CPU und GTX 1070
Normaler Godot
Mein Fork unter https://github.com/vblanco20-1/godot/tree/ECS_Refactor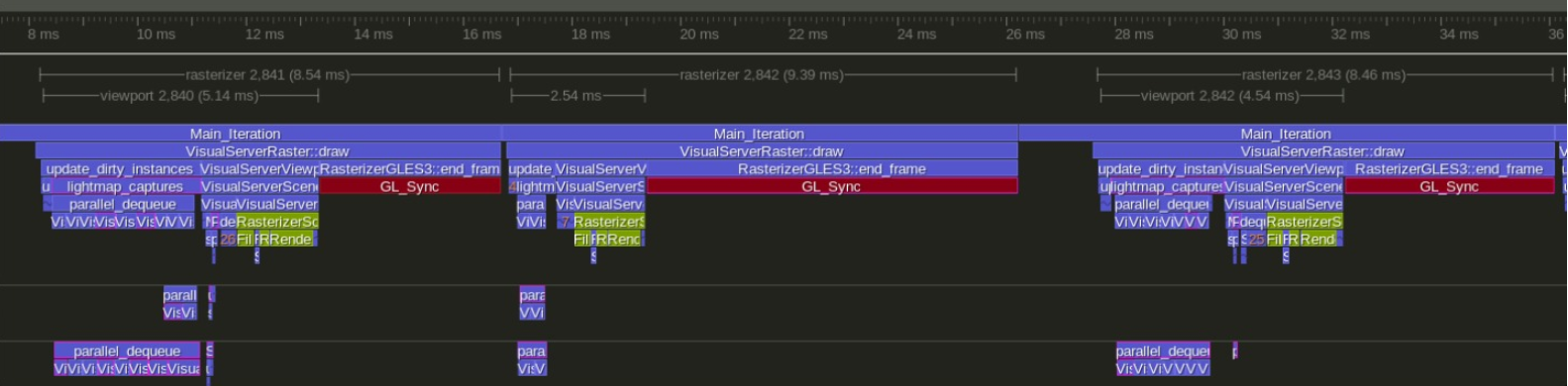
In beiden Profilen ist das Rot im Wesentlichen "auf GPU warten". Derzeit Engpass aufgrund zu vieler Drawcalls auf opengl. Kann nicht wirklich gelöst werden ohne vulkan oder den gesamten Renderer neu zu schreiben.
Auf der CPU-Seite gehen wir von 13 ms Frames auf 5 ms Frames. "Schnelle" Frames reichen von 5,5 ms auf 2,5 ms
Auf der "Gesamtrahmen"-Seite gehen wir von 13 ms auf 8-9 ms
~75 FPS bis ~115 FPS
Weniger CPU-Zeit = mehr Zeit, die Sie für das Gameplay aufwenden können. Der aktuelle Godot hat einen Engpass bei der CPU, so dass mehr Zeit für das Gameplay weniger FPS bedeutet, während mein Fork GPU-gebunden ist eine ganze Weile jeder Frame.
Viele dieser Verbesserungen sind in Godot einfügbar, WENN Godot modernes C++ unterstützt und ein Multithreading-System hat, das sehr billige "kleine" Aufgaben ermöglicht.
Der größte Gewinn wird durch Multithreaded-Schatten und Multithread-Lightmap-Lesen auf dynamischen Objekten #25013 erzielt. Beides funktioniert auf die gleiche Weise. Viele andere Teile des Renderers sind ebenfalls multithreaded.
Andere Vorteile sind ein Octree, das 10 bis 20 Mal schneller ist als Godot One, und Verbesserungen bei einigen Rendering-Fluss, wie z Mal, und eine signifikante Änderung der Funktionsweise der Licht->Mesh-Verbindung (keine verlinkte Liste!)
Ich suche derzeit nach weiteren Testkarten als der TPS-Demo, damit ich mehr Metriken in anderen Kartentypen haben kann. Ich werde auch eine Reihe von Artikeln schreiben, die erklären, wie das alles im Detail funktioniert.
vblanco20-1
am 1. Juni 2019
@vblanco20-1 das ist total genial. Danke für das Teilen!
Ich stimme auch zu, dass, obwohl Vulkan cool ist, eine anständige GLES3-Leistung ein absoluter Gewinn für Godot wäre. Die volle Vulkan-Unterstützung wird wahrscheinlich in absehbarer Zeit nicht landen, während das Patchen von GLES3 etwas ist, das sich die Leute hier im Moment als vollständig machbar erwiesen haben.
Mein großes +1 dafür, dass ich immer mehr darauf aufmerksam gemacht habe. Ich wäre der glücklichste Mensch auf Erden, wenn Reduz zustimmen würde, der Community zu erlauben, GLES3 zu verbessern. Wir führen jetzt seit 1,5 Jahren ein sehr ernsthaftes 3D-Projekt in Godot durch und unterstützen Godot sehr (einschließlich Spenden), aber der Mangel an soliden 60 FPS demotiviert uns wirklich und setzt alle unsere Bemühungen einem großen Risiko aus.
Es ist wirklich eine Schande, dass dies nicht genug Credits bekommt. Wenn wir in den nächsten Monaten mit unserem aktuellen (in Bezug auf 3D ziemlich einfachen) Projekt nicht 60 FPS haben, werden wir kein spielbares Spiel liefern und somit ist der ganze Aufwand vergeblich. :/
@vblanco20-1 Ehrlich gesagt überlege ich sogar, deine Gabel als Basis für unser Spiel in der Produktion zu verwenden.
PS Einige Gedanken: Als letzten Ausweg denke ich, dass es durchaus möglich wäre, sagen wir, 2 GLES3-Rasterizer zu haben - GLES3 & GLES3-Community.
 and3rson
am 1. Juni 2019
and3rson
am 1. Juni 2019
PS Einige Gedanken: Als letzten Ausweg denke ich, dass es durchaus möglich wäre, sagen wir, 2 GLES3-Rasterizer zu haben - GLES3 & GLES3-Community.
Das macht für mich keinen Sinn; Es ist wahrscheinlich eine bessere Idee, Korrekturen und Leistungsverbesserungen direkt in die GLES3- und GLES2-Renderer zu integrieren (sofern sie das Rendering in bestehenden Projekten nicht in erheblichem Maße unterbrechen).
Andere Vorteile sind ein Octree, das 10 bis 20 Mal schneller ist als Godot One, und Verbesserungen bei einigen Rendering-Fluss, wie z Mal, und eine signifikante Änderung der Funktionsweise der Licht->Mesh-Verbindung (keine verlinkte Liste!)
@vblanco20-1 Wäre es möglich, den Tiefenvorlauf zu optimieren, während man bei C++03 bleibt?
 Calinou
am 1. Juni 2019
Calinou
am 1. Juni 2019
@Calinou das Tiefen-Prepass-Zeug ist eines der Dinge, die nichts brauchen und sehr leicht zusammengeführt werden können. Der größte Nachteil besteht darin, dass der Renderer zusätzlichen Speicher verwenden muss. Da es jetzt 2 RenderList anstelle von nur einer benötigt. Abgesehen vom zusätzlichen Speicher gibt es so gut wie keine Nachteile. Die Kosten für die Erstellung der Renderliste für 1 oder 2 Durchläufe sind dank des CPU-Caching fast gleich, sodass die Kosten für die Prepass-Füllliste () fast vollständig beseitigt werden.
vblanco20-1
am 1. Juni 2019
@vblanco20-1 Ehrlich gesagt überlege ich sogar, deine Gabel als Basis für unser Spiel in der Produktion zu verwenden.
@and3rson bitte nicht. Diese Gabel ist ein reines Forschungsprojekt und nicht einmal ganz stabil. Tatsächlich wird es aufgrund der Verwendung von paralleler STL nicht einmal außerhalb einiger sehr spezifischer Compiler kompiliert. Der Fork ist meistens ein Testbed für zufällige Optimierungsideen und -praktiken.
vblanco20-1
am 1. Juni 2019
Welche Tools verwenden Sie, um Godot zu profilieren? Mussten Sie die Flags Profiler.Begin und Profiler.End zur Godot-Quelle hinzufügen, um diese Beispiele zu generieren?
 jknightdoeswork
am 2. Juni 2019
jknightdoeswork
am 2. Juni 2019
Welche Tools verwenden Sie, um Godot zu profilieren? Mussten Sie die Flags Profiler.Begin und Profiler.End zur Godot-Quelle hinzufügen, um diese Beispiele zu generieren?
Es verwendet den Tracy Profiler und hat verschiedene Arten von Zielfernrohrprofilmarkierungen, die ich hier verwende. Zum Beispiel fügt ZoneScopedNC("Fill List", 0x123abc) eine Profilmarkierung mit diesem Namen und der gewünschten Hexadezimalfarbe hinzu.
vblanco20-1
am 2. Juni 2019
@vblanco20-1 - Werden einige dieser Leistungsverbesserungen in den Godot-Hauptzweig übernommen?
 HeadClot
am 2. Juni 2019
HeadClot
am 2. Juni 2019
@vblanco20-1 - Werden einige dieser Leistungsverbesserungen in den Godot-Hauptzweig übernommen?
Vielleicht, wenn C++11 unterstützt wird. Aber reduz will nicht wirklich mehr Arbeit am Renderer, bevor vulkan passiert, also vielleicht nie. Einige der Erkenntnisse aus der Optimierungsarbeit könnten für den 4.0-Renderer nützlich sein.
vblanco20-1
am 2. Juni 2019
@ vblanco20-1 macht es mir nichts aus, die Compiler- und Umgebungsdetails für den Zweig zu teilen, ich denke, ich kann das meiste davon herausfinden, aber verschwende einfach keine Zeit damit, Probleme herauszufinden, wenn ich nicht muss.
Können wir die AABB-Änderung nicht auch ohne große Kosten zu Godot hinzufügen?
 swarnimarun
am 2. Juni 2019
swarnimarun
am 2. Juni 2019
@ vblanco20-1 macht es mir nichts aus, die Compiler- und Umgebungsdetails für den Zweig zu teilen, ich denke, ich kann das meiste davon herausfinden, aber verschwende einfach keine Zeit damit, Probleme herauszufinden, wenn ich nicht muss.
Können wir die AABB-Änderung nicht auch ohne große Kosten zu Godot hinzufügen?
@swarnimarun Visual Studio 17 oder 19, eines der späteren Updates, funktioniert
Das scons-Skript wurde geändert, um das Flag cpp17 hinzuzufügen. Außerdem ist das Starten des Editors im Moment defekt. Ich arbeite daran, ob ich es wiederherstellen kann.
Leider ist die AABB-Änderung eines der größten Dinge. Godot Octree ist mit vielen Dingen im visuellen Server verflochten. Es verfolgt nicht nur Objekte zum Aussortieren, sondern verbindet Objekte auch mit Lichtern/Reflexionssonden mit einem eigenen System zum Koppeln. Diese Paare hängen auch von der verknüpften Listenstruktur des Octrees ab, daher ist es fast unmöglich, den aktuellen Octree schneller anzupassen, ohne viel am visuellen Server zu ändern. Tatsächlich war ich immer noch nicht in der Lage, den normalen Godot-Octree in meiner Gabel für ein paar Objekttypen loszuwerden.
vblanco20-1
am 2. Juni 2019
@vblanco20-1 Hast du einen Patreon? Ich würde etwas Geld für einen auf Leistung ausgerichteten Fork ausgeben, der sich nicht auf altes C++ beschränkt, und ich bin wahrscheinlich nicht der einzige. Ich würde gerne mit Godot für 3D-Projekte herumspielen, aber ich verliere die Hoffnung, dass es ohne einen großen Beweis realisierbar wird, ein Konzept, das Ihrem Kernteam Ihre Herangehensweise an Leistung und Benutzerfreundlichkeit beweist.
 mixedCase
am 3. Juni 2019
mixedCase
am 3. Juni 2019
@mixedCase Ich würde sehr zögern, jede Art von Fork von Godot zu unterstützen. Forking und Fragmentierung sind oft der Tod von Open-Source-Projekten.
Das bessere Szenario und wahrscheinlicher jetzt, da gezeigt wurde, dass neueres C++ erhebliche Optimierungen ermöglicht, besteht darin, dass Godot offiziell auf eine neuere Version von C++ aktualisiert. Ich würde erwarten, dass dies in Godot 4.0 geschieht, um das Risiko von Brüchen in 3.2 zu minimieren und rechtzeitig für die Nutzung der neuen C++-Funktionen mit Vulkan, der zu Godot 4.0 hinzugefügt wird. Ich erwarte auch keine wesentlichen Änderungen am GLES 3-Renderer, da reduz ihn löschen möchte.
(Aber ich spreche nicht für die Godot-Entwickler, das ist nur meine Spekulation)
aaronfranke
am 8. Juni 2019
@aaronfranke Ich stimme zu, ich denke, dass eine permanente Gabel nicht ideal wäre. Aber nach dem, was ich aus seinen Aussagen entnommen habe (bitte korrigieren Sie mich, wenn ich falsch @reduz der Meinung, dass diese neueren Funktionen nicht verwendet werden sollten, weil sie nichts Bedeutendes bringen, um die Konzepte zu lernen, und weil er empfindet einige von ihnen als "unlesbar" (zumindest für Entwickler, die an das "erweiterte C" gewöhnt sind, das C++ vor fast 10 Jahren war).
Ich glaube, dass Juan eine sehr pragmatische Person ist, daher würde es wahrscheinlich einen großen Proof of Concept erfordern, der die Vorteile der Verwendung moderner Abstraktionen und effizienterer Datenstrukturen demonstriert, um ihn davon zu überzeugen, dass sich die technischen Kompromisse wahrscheinlich lohnen. @vblanco20-1 hat bisher erstaunliche Arbeit geleistet, daher würde ich persönlich nicht zögern, ihm jeden Monat etwas Geld zur Verfügung zu stellen, wenn er so etwas machen möchte.
mixedCase
am 10. Juni 2019
Ich bin immer wieder erstaunt, wie Godot-Entwickler so tun, als wären sie allergisch gegen gute Ideen, Leistung und Fortschritt. Schade, dass das nicht eingezogen wurde.
 plabuda
am 16. Juli 2019
plabuda
am 16. Juli 2019
Dies ist ein Stück aus einer Reihe von Artikeln, an denen ich arbeite, über die Optimierungen, insbesondere über die Verwendung der Datenstruktur.
Godot verbietet die STL-Container und sein C++03. Dies bedeutet, dass es keine Umzugsoperatoren in seinen Containern gibt und seine Container in der Regel schlechter sind als die STL-Container selbst. Hier habe ich einen Überblick über die Godot-Datenstrukturen und die damit verbundenen Probleme.
Vorab zugewiesenes C++-Array. Sehr häufig um den gesamten Motor herum. Seine Größen werden in der Regel durch eine Konfigurationsoption festgelegt. Dies ist im Renderer sehr üblich, und eine richtige dynamische Array-Klasse würde hier hervorragend funktionieren.
Missbrauchsbeispiel: https://github.com/godotengine/godot/blob/master/servers/visual/visual_server_scene.h#L442
Diese Arrays verschwenden ohne triftigen Grund Speicher, die Verwendung eines dynamischen Arrays wäre hier eine wesentlich bessere Option, da sie nur die erforderliche Größe haben würden, anstatt die maximale Größe durch eine Kompilierungskonstante. Jedes der Instanz*-Arrays, die MAX_INSTANCE_CULL verwenden, verwendet ein halbes Megabyte Arbeitsspeicher
Vector ( vector.h) ein std::vector dynamisches Array-Äquivalent, aber mit einem großen Fehler.
Der Vektor wird mit einer Copy-on-Write-Implementierung atomar refcounted. Wenn Sie das tun
Vektor a = build_vector();
Vektor b = a;
der Refcount geht auf 2. B und A zeigen jetzt auf dieselbe Stelle im Speicher und kopieren das Array, sobald eine Bearbeitung daran vorgenommen wurde. Wenn Sie nun Vektor A oder B ändern, wird eine Vektorkopie ausgelöst.
Jedes Mal, wenn Sie in einen Vektor schreiben, muss der atomare Refcount überprüft werden, wodurch jeder einzelne Schreibvorgang im Vektor verlangsamt wird. Es wird geschätzt, dass Godot Vector mindestens 5-mal langsamer ist als std::vector. Ein weiteres Problem ist, dass der Vektor automatisch verschoben wird, wenn Sie Elemente daraus entfernen, was zu schrecklichen unkontrollierbaren Leistungsproblemen führt.
PoolVektor (pool_vector.h). Mehr oder weniger wie ein Vektor, aber stattdessen als Pool. Es hat die gleichen Fallstricke wie Vector, mit grundlosem Kopieren beim Schreiben und automatischer Verkleinerung.
Liste ( list.h) ein std::list-Äquivalent. Die Liste hat 2 Zeiger (erster und letzter) + eine Elementanzahlvariable. Jeder Knoten in der Liste ist doppelt verknüpft, plus ein zusätzlicher Zeiger auf den Listencontainer selbst. Der Speicher-Overhead für jeden Knoten der Liste beträgt 24 Byte. Es wird in Godot schrecklich überstrapaziert, da Vector im Allgemeinen nicht sehr gut ist. Entsetzlich missbraucht über den gesamten Motor.
Beispiele für großen Missbrauch:
https://github.com/godotengine/godot/blob/master/servers/visual/visual_server_scene.h#L129
Kein Grund dafür, dass dies eine Liste sein sollte, sollte ein Vektor sein
https://github.com/godotengine/godot/blob/master/servers/visual/visual_server_scene.h#L242
Jeder einzelne dieser Fälle ist falsch. wieder sollte es ein Vektor oder ähnlich sein. Dieser kann tatsächlich Leistungsprobleme verursachen.
Der größte Fehler ist die Verwendung von List im Octree, der für das Culling verwendet wird. Ich bin in diesem Thread bereits ausführlich auf den Godot-Octree eingegangen.
SelfList(self_list.h) eine aufdringliche Liste, ähnlich wie boost::intrusive_list. Dieser speichert immer 32 Byte Overhead pro Knoten, da er auch auf sich selbst zeigt. Entsetzlich missbraucht über den gesamten Motor.
Beispiele:
https://github.com/godotengine/godot/blob/master/servers/visual/visual_server_scene.h#L159
Dieser ist besonders schlimm. Einer der schlechtesten im gesamten Motor. Dies fügt jedem einzelnen renderbaren Objekt in der Engine ohne jeden Grund 8 Points of Fatness hinzu. Es muss keine Liste sein. Es kann wieder eine Slotmap oder ein Vektor sein, und damit habe ich es ersetzt.
Map(map.h) einen rot-schwarzen Baum. Wird in fast allen Anwendungen als Hashmap missbraucht. Sollte je nach Nutzung zugunsten von OAHashmap oder Hashmap aus der Engine gelöscht werden.
Jede Verwendung von Map, die ich gesehen habe, war falsch. Ich kann kein Beispiel für eine Map finden, die dort verwendet wird, wo es Sinn macht.
Hashmap ( hash_map.h) entspricht in etwa std::unordered_map, einer geschlossenen Adressierungs-Hashmap basierend auf Linked-List-Buckets. Es kann sich beim Entfernen von Elementen aufwärmen.
OAHashMap( oa_hash_map.h) neu geschriebene Hashmap mit schneller offener Adressierung. verwendet Robinhood-Hashing. Im Gegensatz zu Hashmap wird die Größe beim Entfernen von Elementen nicht geändert. Wirklich gut implementierte Struktur, besser als std::unordered_map.
CommandQueueMT(command_queue_mt.h) Die Befehlswarteschlange, die für die Kommunikation mit den verschiedenen Servern verwendet wird, z. B. dem visuellen Server. Es funktioniert, indem es ein fest codiertes 250-KB-Array hat, das als Allocator-Pool fungiert, und weist jeden Befehl als Objekt mit einer virtuellen call()- und post()-Funktion zu. Es verwendet Mutexe, um die Push/Pop-Operationen zu schützen. Das Sperren von Mutexes ist sehr teuer, ich empfehle stattdessen die Moodycamel-Warteschlange zu verwenden, die eine Größenordnung schneller sein sollte. Dies wird wahrscheinlich zu einem Engpass für Spiele, die viele Operationen mit dem visuellen Server ausführen, wie z. B. viele sich bewegende Objekte.
Dies ist so ziemlich der Kernsatz von Datenstrukturen in Godot. Es gibt kein richtiges std::vector-Äquivalent. Wenn Sie die Datenstruktur "dynamisches Array" wünschen, bleiben Sie bei Vector und seinen Nachteilen beim Kopieren beim Schreiben und Verkleinern hängen. Ich denke, eine DynamicArray-Datenstruktur ist das, was Godot derzeit am meisten braucht.
Für meinen Fork verwende ich STL und andere Container aus externen Bibliotheken. Ich vermeide Godot-Container, da sie in Bezug auf die Leistung schlechter sind als die STL, mit Ausnahme der 2 Hashmaps.
Bei der vulkan-Implementierung in 4.0 wurden Probleme gefunden. Ich weiß, dass es in Arbeit ist, also ist noch Zeit, es zu reparieren.
Verwendung von Map in der Render-API. https://github.com/godotengine/godot/blob/vulkan/drivers/vulkan/rendering_device_vulkan.h#L350
Wie ich bemerkt habe, gibt es keinen guten Nutzen von Map und keinen Grund für ihre Existenz. Sollte in diesen Fällen nur Hashmap sein.
Überbeanspruchung von verknüpften Listen anstelle von nur Arrays oder ähnlichem.
https://github.com/godotengine/godot/blob/vulkan/drivers/vulkan/rendering_device_vulkan.h#L680
Glücklicherweise ist dies wahrscheinlich nicht in den schnellen Schleifen, aber es ist immer noch ein Beispiel für die Verwendung von List, wo es nicht verwendet werden sollte
Verwenden von PoolVector und Vector in der Render-API. https://github.com/godotengine/godot/blob/vulkan/drivers/vulkan/rendering_device_vulkan.h#L747
Es gibt keinen wirklich guten Grund, diese beiden fehlerhaften Strukturen als Teil der Render-API-Abstraktion zu verwenden. Durch ihre Verwendung sind Benutzer gezwungen, diese 2 mit ihren Nachteilen zu verwenden, anstatt in der Lage zu sein, andere Datenstrukturen zu verwenden. Es wird empfohlen, in diesen Fällen Zeiger + Größe zu verwenden und trotzdem eine Version der Funktion zu haben, die bei Bedarf einen Vektor annimmt.
Ein tatsächliches Beispiel, bei dem diese API einem Benutzer schadet, sind die Funktionen zum Erstellen von Scheitelpunktpuffern. Im GLTF-Format werden die Vertex-Puffer in eine Binärdatei gepackt. Mit dieser API muss der Benutzer den GLTF-Binärpuffer in den Speicher laden, diese Strukturen erstellen, die Daten für jeden Puffer kopieren und dann die API verwenden.
Wenn die API Zeiger + Größe oder eine Span<>-Struktur annehmen würde, könnte der Benutzer die Scheitelpunktdaten direkt aus dem geladenen Binärpuffer in die API laden, ohne eine Konvertierung durchführen zu müssen.
Dies ist besonders wichtig für Personen, die mit prozeduralen Vertexdaten arbeiten, wie z. B. einer Voxel-Engine. Mit dieser API ist der Entwickler gezwungen, Vector für seine Vertex-Daten zu verwenden, was zu erheblichen Performance-Kosten führt oder die Daten in einen Vector kopieren muss, anstatt die Vertex-Daten direkt aus den internen Strukturen zu laden, die der Entwickler verwendet.
Wenn Sie mehr über dieses Thema erfahren möchten, ist der beste Vortrag, den ich kenne, dieser von der CppCon. https://www.youtube.com/watch?v=fHNmRkzxHWs
Andere großartige Vorträge sind diese: https://www.youtube.com/watch?v=-8UZhDjgeZU , wo einige Datenstrukturen wie die Slotmap erklärt werden, die für Godot-Anforderungen sehr nützlich wären.
vblanco20-1
am 17. Juli 2019
Godot hat ein großes Leistungsproblem... du wärst eine gute Ergänzung für das Godot-Team, bitte bedenke das!
Ranoller
am 18. Juli 2019
Ich schließe diesen Thread, weil ich nicht denke, dass es der richtige Weg ist, einen Beitrag zu leisten oder zu helfen.
@vblanco20-1 Auch hier schätze ich es sehr, dass Sie gute Absichten haben, aber Sie verstehen weder das Innenleben des Motors noch die Philosophie dahinter. Die meisten Ihrer Kommentare beziehen sich auf Dinge, von denen Sie nicht wirklich verstehen, wie sie verwendet werden, wie wichtig sie für die Leistung sind oder was ihre Prioritäten im Allgemeinen sind.
Ihr Ton ist auch unnötig aggressiv. Anstatt zu fragen, was du nicht verstehst oder warum etwas auf eine bestimmte Art und Weise gemacht wird, gehst du einfach arrogant raus. Das ist nicht die richtige Einstellung für diese Community.
Die meisten der Dinge, die Sie bezüglich der Optimierung erwähnen, sind nur eine sehr kleine Oberfläche der Menge an Elementen, die ich für die Optimierung in Godot 4.0 geplant habe (es gibt noch viele weitere Dinge in meiner Liste). Ich habe Ihnen bereits gesagt, dass dies seit einigen Monaten mehrmals umgeschrieben werden würde. Wenn Sie mir nicht glauben, ist es in Ordnung, aber ich habe das Gefühl, dass Sie damit Ihre eigene Zeit verschwenden und viele Leute ohne ersichtlichen Grund verwirren.
Ich freue mich natürlich sehr über Ihr Feedback, wenn ich mit meiner Arbeit fertig bin, aber alles, was Sie jetzt tun, ist, ein totes Pferd zu schlagen, also entspannen Sie sich eine Weile.
 reduz
am 22. Juli 2019
reduz
am 22. Juli 2019
Auch hier, wenn eine Alpha von Godot 4.0 ausgerollt wird (hoffentlich noch vor Ende dieses Jahres), sind Sie herzlich eingeladen, den gesamten neuen Code zu profilieren und Feedback zu geben, wie er weiter optimiert werden kann. Ich bin sicher, dass wir alle davon profitieren werden. Im Moment macht es nicht viel Sinn, hier etwas anderes zu diskutieren, da bestehender Code in 4.0 verschwinden wird und nichts im 3.x-Zweig zusammengeführt wird, wo Stabilität zu diesem Zeitpunkt wichtiger ist als Optimierungen.
Da viele auf die technischen Details neugierig sein dürften:
- Der gesamte Spatial-Indexing-Code (was von Vblanco neu geschrieben wurde) wird durch einen linearen Algorithmus für das Culling mit mehreren Threads ersetzt, kombiniert mit einem Octree für das hierarchische Occlusion-Culling und einem SAP für überlappende Prüfungen, die höchstwahrscheinlich die besten Allrounder-Algorithmen sind, die gut sind Leistung bei jeder Art von Spiel. Die Zuweisung für diese Strukturen erfolgt in der gleichen Weise wie der neue RID_Allocator, der O(1) ist. Ich habe dies zuvor mit @vblanco20-1 besprochen und erklärt, dass sein Ansatz nicht für alle Arten von Spielen geeignet ist, da der Benutzer ein gewisses Maß an Fachwissen erfordert, um zu optimieren, was normalerweise vom typischen Godot-Benutzer nicht erwartet wird. Es war auch kein guter Ansatz, um Okklusions-Kulling hinzuzufügen.
- Ich werde keine Arrays verwenden, wenn Listen verwendet werden können, da Listen kleine zeitliche Zuordnungen ohne das Risiko einer Abfrage durchführen. In einigen Fällen ziehe ich es vor, ein unterteiltes Array zuzuweisen (an Seiten ausgerichtet, sodass sie eine 0-Fragmentierung verursachen), das immer wächst und nie schrumpft (wie in RID_Allocator oder dem neuen CanvasItem im 2D-Engine-Vulkan-Zweig, mit dem Sie jetzt Elemente neu zeichnen können mit vielen Befehlen sehr effizient), aber dafür muss es einen Performance-Grund geben. Wenn Listen in Godot verwendet werden, liegt dies daran, dass kleine Zuweisungen gegenüber der Leistung bevorzugt werden (und tatsächlich machen sie die Codeabsicht für andere klarer lesbar).
- PoolVector ist für sehr große Zuweisungen mit aufeinanderfolgenden Speicherseiten gedacht. Bis Godot 2.1 wurde ein vorab zugewiesener Speicherpool verwendet, aber dieser wurde in 3.x entfernt und im Moment ist das aktuelle Verhalten falsch. Für 4.0 wird es durch virtuellen Speicher ersetzt, es steht auf der Liste der Dinge, die zu tun sind.
- Ein Vergleich von Godots Vector<> mit std::vector ist sinnlos, da sie unterschiedliche Anwendungsfälle haben. Wir verwenden es hauptsächlich zum Weitergeben von Daten und sperren es für den schnellen Zugriff (über die Methoden ptr() oder ptrw()). Wenn wir std::vector verwenden, wäre Godot aufgrund des unnötigen Kopierens viel langsamer. Wir nutzen auch die Copy-on-Write-Mechanik für viele verschiedene Anwendungen.
- Map<> ist einfach einfacher und freundlicher für eine große Anzahl von Elementen und Sie müssen sich keine Sorgen über hastiges Wachsen/Schrumpfen machen, das zu Fragmentierung führt. Wenn Leistung erforderlich ist, wird stattdessen HashMap verwendet (obwohl es wahr ist, sollte wahrscheinlich mehr OAHashMap verwenden, aber es ist zu neu und hatte nie Zeit dafür). Als allgemeine Philosophie gilt: Wenn Leistung keine Priorität hat, werden kleine Zuweisungen immer großen gegenüber großen bevorzugt, da es für den Speicherzuordner Ihres Betriebssystems einfacher ist, kleine Lücken zu finden, um sie einzufügen (was so ziemlich das ist, was es tun soll). , effektiv weniger Haufen verbrauchen.
Auch hier können Sie jederzeit nach Plänen und Design fragen, anstatt sich zu beschweren und sich zu beschweren. Dies ist nicht der beste Weg, um dem Projekt zu helfen.
Ich bin mir auch sicher, dass sich viele, die diesen Thread lesen, fragen, warum der Spatial Indexer anfangs langsam war. Der Grund ist, dass Sie vielleicht neu bei Godot sind, aber bis vor kurzem war die 3D-Engine mehr als 10 Jahre alt und extrem veraltet. Es wurde daran gearbeitet, es in OpenGL ES 3.0 zu modernisieren, aber wir mussten aufhören aufgrund von Problemen, die wir in OpenGL fanden und der Tatsache, dass es für Vulkan veraltet war (und Apple es aufgab).
Darüber hinaus lief Godot vor nicht allzu langer Zeit auf Geräten wie der PSP (die nur 24 MB Speicher für Engine und Spiel zur Verfügung hatte, so dass ein Großteil des Kerncodes in Bezug auf die Speicherzuweisung sehr konservativ ist). Da die Hardware jetzt sehr unterschiedlich ist, wird dies für Code geändert, der optimaler ist und mehr Speicher benötigt nicht wichtig.
Außerdem mussten viele Optimierungen, die wir vornehmen wollten (viele des Mutex-Codes in Atomics für eine bessere Leistung verschieben), auf Eis gelegt werden, bis wir Godot auf C++11 verschieben konnten (was eine viel bessere Unterstützung für Inline-Atomics bietet und dies nicht tut). Sie müssen Windows-Header einfügen, die den gesamten Namespace verschmutzen), was in einem stabilen Zweig nicht möglich war. Der Wechsel zu C++11 wird erfolgen, nachdem Godot 3.2 verzweigt ist und die Funktionen eingefroren sind. Andernfalls wäre es ein großer Schmerz, Vulkan als Master-Zweig zu synchronisieren. Es eilt nicht viel, denn aktuell liegt der Fokus nun auf Vulkan selbst.
Tut mir leid, die Dinge brauchen Zeit, aber ich bevorzuge es, dass sie richtig gemacht werden, anstatt sie zu überstürzen. Das zahlt sich langfristig besser aus. Momentan wird an allen Leistungsoptimierungen gearbeitet und sie sollten bald fertig sein (wenn man den Vulkan-Zweig getestet hat, ist die 2D-Engine viel schneller als früher).
reduz
am 22. Juli 2019
Hallo reduz,
Während ich meistens sehe, dass Ihre Punkte gültig sind, möchte ich zwei kommentieren, denen ich nicht zustimme:
- Ich werde keine Arrays verwenden, wenn Listen verwendet werden können, da Listen kleine zeitliche Zuordnungen ohne Fragmentierungsrisiko durchführen. In einigen Fällen ziehe ich es vor, ein unterteiltes Array zuzuweisen (an Seiten ausgerichtet, sodass sie eine 0-Fragmentierung verursachen), das immer wächst und nie schrumpft (wie in RID_Allocator oder dem neuen CanvasItem im 2D-Engine-Vulkan-Zweig, mit dem Sie jetzt Elemente neu zeichnen können mit vielen Befehlen sehr effizient), aber dafür muss es einen Performance-Grund geben. Wenn Listen in Godot verwendet werden, liegt dies daran, dass kleine Zuweisungen gegenüber der Leistung bevorzugt werden (und tatsächlich machen sie die Codeabsicht für andere klarer lesbar).
Ich bezweifle stark, dass eine verknüpfte Liste eine bessere Gesamtleistung haben wird, sei es Geschwindigkeit oder Speichereffizienz, als ein dynamisches Array mit exponentiellem Wachstum. Letzteres belegt garantiert höchstens doppelt so viel Speicherplatz, wie es tatsächlich benötigt, während ein List<some pointer> genau dreimal so viel Speicherplatz belegt (der eigentliche Inhalt, der next- und der prev-Zeiger). Für ein unterteiltes Array sieht es noch besser aus.
Wenn sie richtig verpackt sind (und soweit ich dem, was ich bereits vom Godot-Code gesehen habe, sagen kann, sind sie es) sehen sie für den Programmierer ziemlich gleich aus, daher verstehe ich nicht, was Sie mit "sie [Listen ] machen die Absicht des Codes klarer".
IMHO, Listen sind genau unter zwei Bedingungen gültig:
- Sie müssen häufig Elemente in der Mitte des Containers löschen/einfügen
- oder Sie benötigen ein zeitkonstantes (und nicht nur amortisiertes zeitkonstantes) Einfügen/Löschen von Elementen. Dh in Echtzeitkontexten, in denen eine zeitaufwendige Speicherzuweisung nicht möglich ist, sind sie in Ordnung.
- Map<> ist einfach einfacher und freundlicher für eine große Anzahl von Elementen und Sie müssen sich keine Sorgen über hastiges Wachsen/Schrumpfen machen, das zu Fragmentierung führt. Wenn Leistung erforderlich ist, wird stattdessen HashMap verwendet (obwohl es wahr ist, sollte wahrscheinlich mehr OAHashMap verwenden, aber es ist zu neu und hatte nie Zeit dafür). Als allgemeine Philosophie gilt: Wenn Leistung keine Priorität hat, werden kleine Zuweisungen immer großen gegenüber großen bevorzugt, da es für den Speicherzuordner Ihres Betriebssystems einfacher ist, kleine Lücken zu finden, um sie einzufügen (was so ziemlich das ist, was es tun soll). , effektiv weniger Haufen verbrauchen.
libc-allocators sind normalerweise ziemlich schlau, und da eine OAHashMap (oder eine std::unordered_map) ihre Speicher von Zeit zu Zeit neu zuweist (amortized constant-time), schafft es der Allocator normalerweise, seine Speicherblöcke kompakt zu halten. Ich bin fest davon überzeugt, dass eine OAHashMap nicht effektiv mehr Heap verbraucht als eine einfache binäre Baumkarte wie Map. Stattdessen bin ich mir ziemlich sicher, dass der enorme Zeiger-Overhead in jedem Element von Map tatsächlich mehr Speicher verbraucht als jede Heap-Fragmentierung von OAHashmap (oder std::unordered_map).
Schließlich denke ich, dass der beste Weg, diese Art von Argumenten zu klären, darin besteht, sie zu vergleichen. Dies ist sicherlich für Godot 4.0 von viel größerem Nutzen, da - wie Sie sagten - dort viele Leistungsoptimierungen stattfinden und es nicht viel Sinn macht, Codepfade zu verbessern, die in 4.0 sowieso komplett neu geschrieben werden können.
Aber @reduz , was halten Sie von einem Benchmarking all dieser Änderungen, die @vblanco20-1 vorgeschlagen hat (vielleicht sogar jetzt, in 3.1). Wenn @vblanco20-1 (oder jemand anderes) bereit ist, die Zeit zu investieren, um eine solche Benchmarking-Suite zu schreiben und die Leistung von Godot3.1 (sowohl in Bezug auf Geschwindigkeit als auch "Heap-Verbrauch unter Berücksichtigung der Fragmentierung") im Vergleich zu den Änderungen von vblanco zu bewerten? Es könnte wertvolle Hinweise für die aktuellen 4.0-Änderungen liefern.
Ich denke, dass eine solche Methodik gut zu Ihrem "[Dinge] werden richtig gemacht, anstatt sie zu überstürzen" passt.
@vblanco20-1: Tatsächlich schätze ich Ihre Arbeit. Wären Sie motiviert, solche Benchmarks zu erstellen, damit wir tatsächlich messen können, ob Ihre Änderungen tatsächliche Leistungsverbesserungen sind? Ich wäre sehr interessiert.
 Windfisch
am 23. Juli 2019
Windfisch
am 23. Juli 2019
@Windfisch Ich schlage vor, Sie lesen meinen obigen Beitrag noch einmal, da Sie einige Dinge falsch gelesen oder falsch verstanden haben. Ich erkläre sie dir.
- Listen werden genau für den von Ihnen beschriebenen Anwendungsfall verwendet, und ich habe nie behauptet, dass sie eine bessere Leistung haben. Sie sind effizienter als Arrays für die Wiederverwendung von Heap, einfach weil sie aus kleinen Zuweisungen bestehen. Auf einer Skala (wenn Sie sie für ihren beabsichtigten Anwendungsfall häufig verwenden) macht dies wirklich einen Unterschied. Wenn Leistung erforderlich ist, werden bereits andere Container verwendet, die schneller, gepackter sind oder eine bessere Cache-Kohärenz aufweisen. Im Guten wie im Schlechten konzentrierte sich Victor hauptsächlich auf einen der älteren Engine-Bereiche (wenn nicht sogar den ältesten), der nie optimiert wurde, da er eine hauseigene Engine war, die zum Veröffentlichen von Spielen für PSP verwendet wurde. Hier stand schon lange eine Überarbeitung an, aber es gab andere Prioritäten. Seine Hauptoptimierung war das CPU-basierte Voxel-Cone-Tracing, das ich kürzlich hinzugefügt habe, was ich ehrlich gesagt schlecht gemacht habe, weil es in der Nähe der 3.0-Version zu schnell war, aber die richtige Lösung dafür ist ein völlig anderer Algorithmus und nicht parallele Verarbeitung hinzufügen, wie er es tat.
- Ich habe nie über die Leistung der Arbeit von @vblanco20-1 gestritten und ist mir ehrlich gesagt egal (Sie müssen ihn also nicht dazu bringen, Zeit mit Benchmarks zu verschwenden). Die Gründe dafür, seine Arbeit nicht zusammenzuführen, sind, dass 1) die Algorithmen, die er verwendet, manuelle Anpassungen erfordern, abhängig von der durchschnittlichen Größe der Objekte im Spiel, was die meisten Godot-Benutzer tun müssen. Ich bevorzuge Algorithmen, die vielleicht etwas langsamer sind, aber besser skalieren, ohne dass Anpassungen erforderlich sind. 2) Der von ihm verwendete Algorithmus ist nicht gut für das Okklusions-Culling (einfacher Octree ist aufgrund der hierarchischen Natur besser). 3) Der von ihm verwendete Algorithmus ist nicht gut für das Pairing (SAP ist oft besser). 4) Er verwendet C++17 und Bibliotheken, die ich nicht unterstützen möchte, oder Lambdas, die ich für unnötig halte 5) Ich arbeite bereits daran, dies für 4.0 zu optimieren, und der 3.x-Zweig hat Stabilität als Priorität und wir beabsichtigen, 3.2 so schnell wie möglich zu veröffentlichen, daher wird dies dort nicht geändert oder bearbeitet. Vorhandener Code ist möglicherweise langsamer, aber er ist sehr stabil und getestet. Wenn dies zusammengeführt wird, gibt es Fehlerberichte, Regressionen usw. Niemand wird Zeit haben, daran zu arbeiten oder Victor zu helfen, da wir bereits hauptsächlich mit dem 4.0-Zweig beschäftigt sind. Dies ist alles oben erklärt, daher empfehle ich Ihnen, den Beitrag noch einmal zu lesen.
Auf jeden Fall habe ich Victor versprochen, dass Indexierungscode steckbar sein kann, sodass schließlich auch verschiedene Algorithmen für verschiedene Arten von Spielen implementiert werden können.
Godot ist Open Source und sein Fork auch. Wir sind alle offen und teilen hier, nichts sollte Sie davon abhalten, seine Arbeit zu nutzen, wenn Sie sie brauchen.
reduz
am 23. Juli 2019
Da sich diese Optimierungen nicht auf gdscript, rendern oder die "stotternden" Probleme auswirken, und es gibt Dinge, über die sich die Leute beschweren (ich schließe ein), vielleicht mit dem Ziel, dass die Leute glücklich sein werden (ich schließe ein) ... braucht es nicht Lua-Jit-Geschwindigkeit...
Funktioniert in "Copy on Write" war eine sehr große Leistungsoptimierung in einem meiner Plugins (von 25 Sekunden in einem Skriptparse auf nur 1 Sekunde in einem Skript mit 7000 Zeilen)... brauchen, in gdscript, in rendern und das Stotterproblem lösen... das ist alles.
Ranoller
am 23. Juli 2019
Danke @reduz für deine Klarstellung. Es hat Ihre Punkte in der Tat klarer gemacht als die vorherigen Postings.
Es ist gut, dass der Spatial-Indexing-Code steckbar ist, denn tatsächlich fiel mir dieser Code schon früher auf die Füße, als ich viele Objekte in sehr unterschiedlichen Maßstäben handhabte. Freue mich auf 4.0.
Windfisch
am 23. Juli 2019
Ich habe auch darüber nachgedacht und denke, dass es eine gute Idee sein könnte, ein gemeinsames Dokument mit Ideen zur Optimierung der räumlichen Indexierung zu veröffentlichen, damit mehr Mitwirkende darüber erfahren und auch Ideen einbringen oder Implementierungen durchführen können. Ich habe eine sehr gute Vorstellung davon, was zu tun ist, aber ich bin mir sicher, dass hier viel Raum für weitere Optimierungen und interessante Algorithmen vorhanden ist.
Wir können sehr klare Anforderungen stellen, von denen wir wissen, dass sie Algorithmen erfüllen müssen (z. B. keine Benutzeranpassung für durchschnittliche Elemente in der Weltgröße, wenn möglich, keine Brute-Force-Zeug mit Threads, wenn möglich - sie sind nicht kostenlos, andere Teile der Engine benötigt sie möglicherweise auch, z über Schattenpufferaktualisierungen -nicht aktualisieren, wenn sich nichts geändert hat-, Optimierungen untersuchen, wie z. Wir können auch die Erstellung einiger Benchmarktests besprechen (ich glaube nicht, dass die TPS-Demo ein guter Benchmark ist, da sie nicht so viele Objekte oder Okklusion hat). @vblanco20-1 Wenn Sie bereit sind, unserem Programmier- / Sprachstil und unserer Philosophie zu folgen, können Sie natürlich gerne mithelfen.
Der Rest des Rendering-Codes (das eigentliche Rendering mit RenderingDevice) ist mehr oder weniger einfach und es gibt nicht viele Möglichkeiten, dies zu tun, aber die Indizierung scheint ein interessanteres Problem zu sein, das zur Optimierung gelöst werden muss.
reduz
am 23. Juli 2019
@reduz als Referenz zur räumlichen Indizierung. Das ursprüngliche, auf Kacheln basierende Culling wurde entfernt und etwa nach der Hälfte dieses Threads durch ein Octree ersetzt. Der Octree, den ich dort bekommen habe, ist WIP (es fehlen einige Refit-Funktionen), aber die Ergebnisse sind für den Prototyp ziemlich gut. Sein Code ist aufgrund seiner Prototypnatur nicht so gut, daher ist er nur nützlich, um zu überprüfen, wie diese Art von Octree in einer komplexen Szene wie tps-demo funktionieren würde.
Es ist inspiriert von der Funktionsweise des irrealen Engine-Octree, jedoch mit einigen Modifikationen wie der Möglichkeit einer flachen Iteration.
Die Hauptidee ist, dass nur die Blätter auf dem Octree Objekte enthalten und diese Objekte in einem Array der Größe 64 gehalten werden (Größe der Kompilierungszeit kann unterschiedlich sein). Ein Octree-Blatt teilt sich erst auf, wenn es in 65 Elemente "überläuft". Wenn Sie Objekte entfernen und jedes der Blätter des Elternknotens in das 64-Größen-Array passt, führen wir die Blätter wieder in ihren Elternknoten zusammen, der zu einem Blatt wird.
Dadurch können wir den Zeitaufwand für das Testen der Knoten minimieren, da der Octree am Ende nicht zu tief wird.
Eine weitere gute Sache, die ich gemacht habe, ist, dass die Blattknoten auch in einem flachen Array gespeichert werden, was eine Parallelität beim Culling ermöglicht. Auf diese Weise kann der hierarchische Cull beim Cull für Punktschatten oder andere "kleine" Operationen verwendet werden, und der flache parallele Cull kann für die Hauptansicht verwendet werden. Natürlich könnte man hierarchisch für alles verwenden, könnte aber langsamer sein und nicht parallelisiert werden.
Die Blockstruktur wird ein wenig Speicher verschwenden, aber selbst im schlimmsten Fall denke ich nicht, dass sie viel Speicher verschwendet, da die Knoten zusammengeführt werden, wenn sie unter eine bestimmte Menge fallen. Es ermöglicht auch die Verwendung eines Poolzuordners, da sowohl die Knoten als auch die Blätter eine konstante Größe haben.
Ich habe auch mehrere Octrees in meiner Gabel, die verwendet werden, um einige Dinge zu optimieren. Zum Beispiel habe ich einen Octree nur für Shadowcaster-Objekte, der es ermöglicht, die gesamte Logik im Zusammenhang mit "kann Schatten werfen" beim Culling für Shadowmaps zu überspringen.
In Bezug auf meine Bedenken bezüglich Vector und anderen bezüglich der Render-API erklärt dieses Problem, worüber ich mir Sorgen machte. https://github.com/godotengine/godot/issues/24731
Auf der Bibliothek und dem C++17-Zeug des Forks.. das ist unnötig. Der Fork überlastet viele Bibliotheken, weil ich einige Teile davon benötigt habe. Das einzige, was wirklich gebraucht wird und was Godot meiner Meinung nach braucht, ist eine branchenführende parallele Warteschlange, ich habe dafür moodycamel Queue verwendet.
Auf den Lambdas wird ihre Verwendung hauptsächlich zum Culling verwendet, und sie wird verwendet, um eine erhebliche Menge an Speicher zu sparen, da Sie nur die Objekte speichern müssen, die Ihre Prüfungen an das Ausgabearray übergeben. Die Alternative besteht darin, Iterator-Objekte zu erstellen (das macht die irreale Engine mit ihrem Octree), aber am Ende ist es schlechterer Code und viel schwieriger zu schreiben.
Meine Absicht war nicht, "schurkenhaft zu werden", sondern häufige Kommentare zu "Sie sind frei, eine Gabel zu machen, um zu demonstrieren" zu beantworten, was genau das ist, was ich getan habe. Die erste Nachricht im Thread ist etwas alarmierend und nicht sehr korrekt. Tut mir leid, wenn ich Ihnen gegenüber unhöflich erschienen bin, denn mein einziges Ziel ist es, der beliebtesten Open-Source-Spiele-Engine zu helfen.
vblanco20-1
am 23. Juli 2019
@ vblanco20-1 Das klingt großartig, und die Art und Weise, wie Sie die Octree-Funktion erwähnen, ist sehr sinnvoll. Es macht mir ehrlich gesagt nichts aus, eine parallele Warteschlange zu implementieren (scheint einfach genug, um keine externe Abhängigkeit zu benötigen, und benötigt C++11, um dies richtig zu tun, also schätze, das wird nur im Vulkan-Zweig passieren). Wenn du das zugesagt hast, werde ich es mir auf jeden Fall ansehen wollen, damit ich es als Grundlage für das Indexer-Rewrite im Vulkan-Zweig verwenden kann (ich schreibe gerade das meiste dort um, also muss es sowieso neu geschrieben werden ). Wenn Sie bei der Implementierung helfen möchten (wahrscheinlich, wenn mit der neuen API noch mehr vorhanden ist), ist dies natürlich sehr willkommen.
Die Verwendung einer parallelen Version mit abgeflachten Arrays ist interessant, aber mein Standpunkt dazu ist, dass sie für das Okklusions-Culling nicht so nützlich ist, und es wäre interessant zu messen, wie viel Verbesserung gegenüber dem regulären Octree-Culling ist. unter Berücksichtigung der zusätzlichen Menge an verwendeten Kernen. Denken Sie daran, dass es viele andere Bereiche gibt, die möglicherweise mehrere Threads verwenden, die sie effizienter (weniger rohe Gewalt) verwenden (wie die Physik). Wenn wir also mit diesem Ansatz eine relativ geringfügige Verbesserung erzielen, ist dies nicht immer der Fall im besten Interesse, da es andere Bereiche davon abhalten kann, CPU zu verwenden. Vielleicht könnte es optional sein.
Ich finde auch die Implementierung von dbvt in Bullet 3 ziemlich interessant, die einen inkrementellen Selbstausgleich und eine lineare Zuweisung durchführt. Was den Algorithmus angeht, ist ein ausgewogener Binärbaum vom Design her viel weniger redundant als ein Octree und kann sowohl bei Pairing- als auch bei Okklusionstests besser funktionieren Benchmark-Szenen.
Auf jeden Fall sind Sie außergewöhnlich schlau und es wäre toll, wenn wir daran zusammenarbeiten könnten, aber ich bitte Sie nur, viele unserer bestehenden Designphilosophien zu verstehen und zu respektieren, auch wenn sie möglicherweise nicht immer Ihrem Geschmack entsprechen . Das Projekt ist riesig, mit viel Trägheitskraft, und Dinge aus Geschmacksgründen zu ändern, ist einfach keine gute Idee. Benutzerfreundlichkeit und "einfach funktioniert" stehen beim Design immer an erster Stelle, und Einfachheit und Lesbarkeit des Codes haben in der Regel Vorrang vor Effizienz (dh wenn Effizienz kein Ziel ist, weil ein Bereich nicht kritisch ist). Als wir das letzte Mal diskutiert haben, wolltest du so ziemlich das Ganze ändern und wolltest dir keine Argumente anhören oder dich auf tatsächliche Probleme konzentrieren, und so arbeiten wir normalerweise nicht mit der Community und den Mitwirkenden, weshalb mein Rat zum Chillen war gut gemeint.
reduz
am 23. Juli 2019
Wer braucht Leistung? :Troll Gesicht:
Performance und Quellmodell halten mich bei Godot.
 BlueCannonBall
am 28. Jan. 2020
BlueCannonBall
am 28. Jan. 2020
Bearbeiten: Entschuldigung, vielleicht bin ich ein Offtopic, aber ich wollte die Vorteile von Open Source klarstellen.
@mixedCase Ich würde sehr zögern, jede Art von Fork von Godot zu unterstützen. Forking und Fragmentierung sind oft der Tod von Open-Source-Projekten.
Ich glaube nicht. Die Natur von Open Source besteht darin, dass Sie den Code nach Belieben frei verwenden und wiederverwenden können. Das wird also nicht das Ende einiger Projekte sein, sondern mehr Optionen für die Benutzer.
Was Sie sagen, ist ein Monopol, und das ist nicht das, was Open Source verteidigt. Lassen Sie sich nicht von Unternehmen betrügen, die vorgeben, Ihnen zu zeigen, dass es besser ist, die volle Kontrolle über etwas zu haben. Das ist zumindest in der Open-Source-Welt eine Lüge, denn wenn jemand anderer den Code hat, hast du auch den Code. Was sie tun müssen, ist, sich darum zu kümmern, wie man mit einer Gemeinschaft umgeht oder wie man damit einverstanden ist.
Wie auch immer, die ursprünglichen Entwickler können Verbesserungen aus dem Fork einfach zusammenführen. Es steht ihnen immer frei, dies zu tun. Das ist eine andere Natur der Open-Source-Welt.
Und im schlimmsten Fall wird die Gabel besser als das Original sein und viele Mitwirkende werden dorthin gehen. Niemand hat verloren, alle gewinnen. Oh, sorry, wenn ein Unternehmen hinter dem Original steckt, hat es vielleicht verloren (oder es kann auch die Verbesserungen aus dem Fork zusammenführen).
 Anyeos
am 18. März 2020
Anyeos
am 18. März 2020
Verwandte Themen
 kirilledelman
·
3Kommentare
kirilledelman
·
3Kommentare
 EdwardAngeles
·
3Kommentare
EdwardAngeles
·
3Kommentare
 ndee85
·
3Kommentare
ndee85
·
3Kommentare
 ivanskodje
·
3Kommentare
ivanskodje
·
3Kommentare
 testman42
·
3Kommentare
testman42
·
3Kommentare
Hilfreichster Kommentar
Du könntest interessiert sein. Ich arbeite schon eine ganze Weile an der schicken Gabel. Die aktuellen Ergebnisse sehen so aus:

Aufgenommen auf einem großen Gaming-Laptop mit einer 4-Kern-Intel-CPU und GTX 1070
Normaler Godot
Mein Fork unter https://github.com/vblanco20-1/godot/tree/ECS_Refactor

In beiden Profilen ist das Rot im Wesentlichen "auf GPU warten". Derzeit Engpass aufgrund zu vieler Drawcalls auf opengl. Kann nicht wirklich gelöst werden ohne vulkan oder den gesamten Renderer neu zu schreiben.
Auf der CPU-Seite gehen wir von 13 ms Frames auf 5 ms Frames. "Schnelle" Frames reichen von 5,5 ms auf 2,5 ms
Auf der "Gesamtrahmen"-Seite gehen wir von 13 ms auf 8-9 ms
~75 FPS bis ~115 FPS
Weniger CPU-Zeit = mehr Zeit, die Sie für das Gameplay aufwenden können. Der aktuelle Godot hat einen Engpass bei der CPU, so dass mehr Zeit für das Gameplay weniger FPS bedeutet, während mein Fork GPU-gebunden ist eine ganze Weile jeder Frame.
Viele dieser Verbesserungen sind in Godot einfügbar, WENN Godot modernes C++ unterstützt und ein Multithreading-System hat, das sehr billige "kleine" Aufgaben ermöglicht.
Der größte Gewinn wird durch Multithreaded-Schatten und Multithread-Lightmap-Lesen auf dynamischen Objekten #25013 erzielt. Beides funktioniert auf die gleiche Weise. Viele andere Teile des Renderers sind ebenfalls multithreaded.
Andere Vorteile sind ein Octree, das 10 bis 20 Mal schneller ist als Godot One, und Verbesserungen bei einigen Rendering-Fluss, wie z Mal, und eine signifikante Änderung der Funktionsweise der Licht->Mesh-Verbindung (keine verlinkte Liste!)
Ich suche derzeit nach weiteren Testkarten als der TPS-Demo, damit ich mehr Metriken in anderen Kartentypen haben kann. Ich werde auch eine Reihe von Artikeln schreiben, die erklären, wie das alles im Detail funktioniert.