由于 PR1719 的合并,restic 中的恢复_way_ 更快。
然而,它们还可以更快。
出于测试目的,我从与专用 i3.8xlarge EC2 实例相同的区域 (us-west-1) 中的静态 AWS S3 存储桶中恢复。 恢复与实例中的 4x1.9TB nvme 背道而驰,通过 LVM 将 RAID-0 条带化,并在下面使用 xfs 文件系统。 该实例具有到 S3 的理论上 10gbit/秒的带宽。
随着 filerestorer.go 中的 workerCount 增加到 32(从编译限制为 8),restic 以平均 160mbit/sec 的速度恢复 228k 文件的混合,文件大小中位数为 8KB,最大文件大小为 364GB。
相比之下,带有 --transfers=32 的 rclone 以 5636 mbit/sec 的速度从同一个存储桶移动数据,快了 30 多倍。
这不是苹果与苹果的比较。 Restic 数据 blob 的大小为 4096KB,而不是 8KB,打开/关闭文件肯定有_一些_开销。 但这仍然是一个足够大的差异,它可能指向 restic 的瓶颈。
我很乐意测试事物、提供仪器或以任何其他方式提供帮助!
 pmkane
pmkane
所有71条评论
160mbit/sec 确实看起来很慢。 我在一台微不足道的 macbook pro 上通过(快速授予)1Gbps ftth 连接从 onedrive 下载时接近 200Mbps。 如果无法访问您的系统和存储库,我真的无法说出任何具体内容,但是我可以通过以下几件事来缩小问题的范围,没有特定的顺序:
- 估计在单线程上下载单个包文件所需的时间。 您可以从 rclone 32x 下载测试中计算出这一点,但我也很想知道使用 curl 下载单个包的时间,以便我们也可以估计 http 请求开销。
- 我会检查操作系统统计信息在恢复期间从 S3 实际下载了多少 restic。 这将告诉我们恢复是否多次下载单个包文件(这是可能的,但不应该经常发生,除非我忽略了一些东西)。
- S3 并发级别似乎仅限于5 个连接。 这能解释您在上面给出的单线程速度估计中看到的恢复速度吗? 如果您增加 S3 后端连接限制以匹配恢复者的连接限制,会发生什么?
- 在恢复期间绘制网络利用率图表,以查看是否存在任何差距或减速。
- 从还原中排除该 364GB 文件,看看会发生什么。 单个文件目前是按顺序恢复的,因此这个文件会显着影响平均下载速度。
 ifedorenko
于 2018-11-07
ifedorenko
于 2018-11-07
你好呀!
谢谢回复。 这很有趣
tl;dr:增加 s3 连接是关键,但奇怪的是它提供的性能提升是暂时的。
- 使用 rclone --transfers 1 以 233mbit/sec 的速度传输单个目录的数据包(3062 个文件,总计 13GB)。 与 lsof 确认它仅在该模式下使用单个线程和单个 https 连接运行。 峰值速度是通过 --transfers 32 实现的(8.5 gbit/sec,对于这个 i3.8xlarge ec2 实例来说基本上是线速度)。 在这两种情况下,我们都在写入条带化 nvme 数组。
- 很高兴收集一些统计数据,但您具体想看到什么? (但可能不是必需的,请参见下文)
- 这里要一石二鸟! 这是恢复期间网络利用率
- 与此 PR 合并的股票股票 (commit c0572ca15f946c622d9c4009347dc4d6c31cba4c)
- 休息时 workerCount 增加到 32,filesWriterCount 增加到 128
- 与之前的更改保持一致 + s3 连接增加到 32。
- resitc 与之前的更改 + s3 连接增加到 64。
- rclone 与 --transfers 32 移动数据/目录
带宽数以 kbps 为单位,在 10 分钟内以 3 秒的间隔获取。 对于 restic 运行,我们开始收集数据 _after_restic 已经开始实际恢复文件(即,它不包括启动时间和 restic 在运行开始重新创建目录层次结构所花费的时间。在所有运行期间,CPU 利用率在实例不超过 25%。
我们通过增加 workerCount 得到了轻微的提升,但 S3 并发看起来才是真正的胜利所在。 但是,虽然它开始时很强劲(有时接近 rclone 速度!),但速率突然下降,并在接下来的运行中保持下降。 restic 还会抛出看起来像“忽略 [路径编辑] 的错误:缓存容量不足:请求 2148380,可用 872640”的错误,它不会在较低的 s3 并发性下抛出。
如您所见,rclone 性能从高开始并保持高水平,因此不会出现写入将进入实例的缓冲区缓存然后在刷新到磁盘时停止的情况。 在吞吐量方面,nvme 阵列比网络管道快。
- 我不认为单个大文件是一个因素,因为我在恢复过程中测量磁盘/网络 IO,因此该单个文件可能需要一段时间才能完全恢复这一事实不会影响我们的数字正在看这里。
鉴于上述情况,看起来提高 S3 并发性是在这里获得合理速率所需要的,但需要弄清楚性能下降的原因(以及它是否与缓存错误有关)。
如果为您的测试提供快速的 i3 实例和一些 s3 空间和带宽会有所帮助,请告诉我,很高兴赞助。
pmkane
于 2018-11-07
233mbit/sec 乘以 32 是 7456,比 8.5 gbit/sec 少很多。 这很奇怪。 我期望单线程下载比多线程下载的每流吞吐量更快。 但是,不确定这意味着什么,如果有的话。
我想确认 restic 不会一遍又一遍地重新下载相同的包。 我认为图表显示重新下载不是问题,所以不需要更多的统计数据,至少现在不需要。
你能确认图表比例吗? rclone 在标记为“1000000”的线周围盘旋,如果那是“1,000,000 kbps”,我认为这意味着“1gbps”并且与您之前提到的“8.5 gbit/sec”数字不一致。
就像我说的,单个文件是按顺序恢复的。 以 233mbit/s 的速度下载 364 GB 大约需要 3.5 小时,由于每个包的开销和解密,所有这些都是按顺序发生的,可能会更长。 无法判断 3.5 小时是否是您可以将其视为微不足道的东西,而无需知道其余的恢复需要多少时间。
至于not enough cache capacity错误,将averagePackSize增加到存储库中最大包文件的大小(它有多大,顺便说一句?)我需要考虑如何更好地调整缓存大小,不要准备好还没有回答。
ifedorenko
于 2018-11-07
你好呀!
哎呀,对不起。 图中的标度是 KB/sec 而不是 kbit/sec。 所以第一行的 1,012,995 是 8.1gbit/sec。
我知道文件是按顺序恢复的,但不明白单个文件的包检索没有并行性。 对于大文件备份来说,这绝对是一个绊脚石,因为这成为您的限制因素。 出于这个原因,在这里有一些并行性会很棒。
抽样 10 个随机桶,我们的最大包大小略低于 12MB,我们的平均包大小为 4.3MB。
也许随着更多的工人和 S3 连接,我们超过了 (workerCount + 5) * averagePackSize 的 packCacheCapacity。 我会尝试提高它,看看错误是否消失。
pmkane
于 2018-11-07
也许随着更多的工人和 S3 连接,我们超过了 (workerCount + 5) * averagePackSize 的 packCacheCapacity。 我会尝试提高它,看看错误是否消失。
缓存大小根据 5MB 包文件大小和workerCount 。 增加workerCount增加缓存大小。 因此,无论是内存泄漏还是恢复都需要缓存许多 12MB 文件,这纯粹是偶然的。 将averagePackSize增加到 12MB 应该告诉我们哪个。
ifedorenko
于 2018-11-07
averagePackSize 设置为 12 时没有缓存错误。
如果我们可以提供任何其他有用的信息,请告诉我! 再次感谢。
pmkane
于 2018-11-08
随着恢复的进行,看起来我们正在失去并行性,并且看起来与大文件无关。 我会整理一个测试用例并报告回来。
pmkane
于 2018-11-08
你好呀!
我试图用三种不同的人工文件混合重现我在生产文件混合中看到的性能下降。
对于所有测试,我使用了 c0572ca15f946c622d9c4009347dc4d6c31cba4c,其中 S3 连接数增加到 128,workerCount 增加到 128,filesWriterCount 增加到 128,averagePackSize 增加到 12 * 1024 * 1024。
所有测试都使用带有随机数据的文件,以避免重复数据删除的任何影响。
对于第一个测试,我创建并备份了 4,000 个 100MB 的文件,平均分配到 100 个目录(总共约 400GB)。 备份和恢复是从 i3.8xlarge 实例上的条带化 nvme 卷运行的。 备份存储桶与实例位于同一区域 (us-west-1)。
使用此文件组合,我看到平均速度为 9.7gbit/sec (!),并且在整个恢复过程中没有损失并行性或速度。 这些数字与 rclone 数字相当或更高,并且基本上是线速度,这太棒了。
随后,我创建并备份了 400,000 个 1MB 文件,均匀分布在 100 个目录中(同样,总共约 400GB)。
与上述相同(优秀)的结果。
最后,我创建了 40 个目录,每个目录有 1 个 10GB 的文件。 在这里,事情变得有趣了。
我预计这个恢复会稍微慢一点,因为 restic 只能在 40 个连接到 S3 的情况下进行 40 个同时恢复。
相反,虽然 Restic 打开所有 40 个文件进行写入并同时写入所有 40 个文件,但它一次只打开一个到 S3 的 TCP 连接,而不是 40 个。
让我知道你想看到什么统计数据或仪器。
pmkane
于 2018-11-08
您能否确认在“快速”测试期间有 128 个 S3 连接?
ifedorenko
于 2018-11-08
是有。
pmkane
于 2018-11-08
好奇……老实说,大文件支持在我的优先级列表中并不高,但我可能会在接下来的几周内找时间研究一下。 如果有人想在我之前深入研究这个问题,请告诉我。
ifedorenko
于 2018-11-08
做了一些更多的测试,它实际上看起来像文件大小是一个红鲱鱼,它是驱动 AWS 连接数的文件数。
4 个目录中有 128 个 10 MB 文件,restic 只打开了 6 个到 AWS 的连接,即使它正在写入所有 128 个文件。
4 个目录中有 512 个 10 MB 文件,restic 在其生命周期内打开 18 个连接,即使它一次打开 128 个文件。
在 4 个目录中拥有 5,120 个 10 MB 文件,restic 在其生命周期内仅打开了 75 个到 AWS 的连接,同样一次打开了 128 个文件。
奇怪的!
pmkane
于 2018-11-08
如果 Go S3 客户端没有池和重用 http 连接,我真的很惊讶。 并发工作线程的数量和打开的 TCP 套接字之间很可能没有一一对应的关系。 因此,例如,如果无论出于何种原因,恢复处理下载包的速度很慢,则多个工作人员将共享相同的 S3 连接。
ifedorenko
于 2018-11-08
当前并发恢复器的两个属性导致了大部分实现复杂性,并且很可能导致此处报告的速度变慢:
- 单个文件从头到尾恢复
- 进行中文件的数量保持在最低限度
如果我们同意以任何顺序写入文件 blob 并允许任意数量的正在进行的文件,则实现将简单得多,使用更少的内存,并且在许多情况下很可能会更快。
不利的一面是,在恢复结束之前,无法知道任何给定文件中已经恢复了多少数据。 这可能会令人困惑,尤其是在恢复崩溃或被杀死的情况下。 因此,您可能会在文件系统上看到 10GB 的文件,实际上在文件末尾写入的字节很少。
@fd0您认为改进当前的从头到尾的还原是否值得? 就我个人而言,我准备承认它在我的部分已经过度设计,如果您同意,可以提供更简单的乱序实现。
ifedorenko
于 2018-11-16
我不记得 Restic 是否支持恢复到标准输出。 如果是这样,您显然需要为它保留从头到尾的恢复(可能作为特例)。
 pvgoran
于 2018-11-16
pvgoran
于 2018-11-16
@ifedorenko我个人一般赞成简化,尤其是在性能提升的情况下。 不过,我试图了解权衡:
不利的一面是,在恢复结束之前,无法知道任何给定文件中已经恢复了多少数据。
如果我们不是在这里讨论数千个并发写入的文件,也许可以使用文件名到写入字节的映射? 显然不会将信息提供给文件系统,但是,对于进度报告,仍然可以完成,不是吗? (并恢复被中断的恢复,也许只是检查文件的 blob 和偏移量是否有非空字节,也许?我不知道。)
我不记得 Restic 是否支持恢复到标准输出。 如果是这样,您显然需要为它保留从头到尾的恢复(可能作为特例)。
我不认为它会 - 不确定这将如何工作,因为恢复是多个文件,你需要以某种方式对它们进行编码,并以某种方式将它们分开,我认为。
 mholt
于 2018-11-16
mholt
于 2018-11-16
如果我们不是在这里讨论数千个并发写入的文件,也许可以使用文件名到写入字节的映射?
最简单的实现是打开和关闭文件以写入单个 blob。 如果这被证明太慢,那么我们将不得不找到一种方法来保持文件为多个 blob 写入打开,例如通过缓存打开的文件句柄和排序包下载以支持已打开的文件。
恢复已经跟踪了哪些 blob 写入了哪些文件以及哪些尚未处理。 我不希望这部分有太大变化。 进度在单独的数据结构中进行跟踪,我也不希望这种情况发生变化。
并恢复被中断的恢复,也许只是检查文件的 blob 和偏移量是否有非空字节?
Resume 需要验证磁盘上文件的校验和,以确定哪些 blob 仍需要恢复。 我相信无论恢复是顺序的还是乱序的,这都是正确的。 例如,如果恢复从断电中恢复,我认为它不能假设所有文件块在断电前都被刷新到磁盘,即文件可能有间隙或部分写入的块。
ifedorenko
于 2018-11-16
@pmkane想知道您是否可以尝试 #2101? 它实现了无序恢复,尽管对单个文件的写入仍然是序列化的,并且大文件的恢复性能可能仍然不是最佳的。 并且您需要像以前一样调整工人数量。
ifedorenko
于 2018-11-27
绝对地。 我这周要去旅行,但我会尽快测试并报告。
pmkane
于 2018-11-27
@ifedorenko我试过这个 PR 并且它成功地创建了目录结构,但随后所有文件恢复都失败并出现如下错误:
加载(, 3172070, 0) 返回错误,12.182749645s 后重试:EOF
大师恢复正常。
我的恢复命令是:
/usr/local/bin/restic.outoforder -r s3:s3.amazonaws.com/[redacted] -p /root/.restic_pass restore [snapshotid] -t 。
让我知道我可以提供哪些附加信息来帮助调试。
pmkane
于 2018-12-01
您允许多少个并发 S3 下载请求? 如果是 128,您能否将其限制为 32(我们知道有效)?
半相关……你知道你真正的仓库有多少个索引文件吗? 试图估计内存恢复器需要多少。
ifedorenko
于 2018-12-01
我没有指定连接限制,所以我假设它默认为 5。
我用 -o s3.connections=2 和 -o s3.connections=1 得到同样的错误。
我目前在 index/ 文件夹中有 85 个索引 blob。 它们的总大小为 745MB。
pmkane
于 2018-12-01
唔。 当我今天晚些时候拿到我的电脑时,我再看看。 顺便说一句,“返回错误,重试”是一个警告,而不是一个错误,所以它可能与恢复失败有关,也可能只是一个红鲱鱼。
ifedorenko
于 2018-12-01
不知道我是怎么错过的……在大多数情况下,恢复程序并没有完全读取后端的所有包文件。 现在应该修好了。 @pmkane你能再试一次吗?
ifedorenko
于 2018-12-02
我来试一试!
pmkane
于 2018-12-02
确认使用此修复程序成功恢复文件。 现在测试性能。
pmkane
于 2018-12-02
不幸的是,它看起来比 master 慢。 所有测试都在上述 i3.8xlarge 实例上运行。
workerCount 为 8(默认值)时,乱序分支以 86mbit/sec 的速度恢复。
当 workerCount 增加到 32 时,它的表现要好一些——平均为 160 兆位/秒。
此分支的 CPU 利用率明显高于 master,但在任何一种情况下都不会使实例 CPU 达到最大值。
有趣的是,恢复 UI 看起来好像有什么东西在“粘住”,几乎就像它在与自己竞争某个地方的锁。
很高兴提供更多详细信息、分析或要复制的测试实例。
pmkane
于 2018-12-02
确认一下,您将恢复程序和 s3 后端工作人员的数量都设置为 32,对吗?
一些想法可以解释您观察到的行为:
- 对单个文件的写入仍然是序列化的。 我_猜测_这对于快速目标文件系统来说不是问题,但从未测量过。
- 每个 blob 周围的文件打开/关闭肯定会增加恢复器的开销。 当我在 macos 上进行测量时,我能够在大约 70 秒内“打开文件;写入一个字节;关闭文件”100K 次,这近似于写入 100K blob 的开销。 测试非常简单,现实生活中的开销可能要高得多。
- 我目前对高 CPU 利用率没有合理的解释。 乱序实现只对每个 blob 解密一次(master 为每个目标文件解密 blob),与 master 相比,簿记要少得多。 也许“稀疏”文件写入并不是真的稀疏,需要 Go 或 OS 做一些 CPU 密集型的事情。 真不知道。
ifedorenko
于 2018-12-02
嘿!
这是正确的。 在 internal/restorer/filerestorer.go 中,workerCount 被设置为 8 或 32,并且 -o s3.connections=32 在两种情况下都通过 restic cli 传递。
pmkane
于 2018-12-03
这是跟踪数据的顶级视图,而 out of order 分支正在使用 8 个工作人员恢复文件。
看起来工作人员经常遇到明显的(> 500-1000ms)暂停。
pmkane
于 2018-12-03
我决定在这上面多花点时间,开始编写简单的独立测试,在 4KiB 块中生成 10GiB 随机字节。 我的目标是评估我的系统移动字节的速度。 令我惊讶的是,在我的 macbook pro(2018 年,2.6 GHz Intel Core i7)上执行此测试需要 18.64 秒。 这相当于 ~4.29 Gigabits/s 或大约 10G 以太网可以做的一半。 这没有任何加密或网络或磁盘 i/o。 而且我使用的是 Xoshiro256** prng, math/rand慢了大约 2 倍,这当然完全无关紧要。 关键是,恢复程序必须在多个线程上处理 blob 才能使 10G 网络饱和,多线程网络 i/o 本身是不够的。
只是为了好玩,类似的 rust impl 在 3.1 秒内生成 10GiB 的随机字节,在 10.77 秒内生成 java。 去搞清楚 :-)
ifedorenko
于 2019-02-06
有趣的测试!
我知道 restic 将受到当前恢复最大文件所需的时间量的限制。
然而,现在这不是我们的拦截器,因为我知道 restic 可以比我们在这里看到的 160mbit/sec 更快地恢复单个文件。
我将在快速 SSD 和 S3 中组合一个 100GB 的测试存储库,其中包含 10MB 文件并运行一些数字,以获得当前在 master 和此分支中的最佳情况。
pmkane
于 2019-02-06
大家好,有什么方法可以使用参数更改worker的数量还是必须直接在代码上完成? 我们也遇到了恢复缓慢的问题,我想以某种方式改进我们所拥有的......请让我知道我是否可以通过测试来帮助改进这部分!
谢谢!
 robvalca
于 2019-02-19
robvalca
于 2019-02-19
@robvalca你使用什么后端? rclone将您的存储库复制到目标系统的速度有多快? 什么是restic恢复速度?
现在我不确定发生了什么,所以如果你能提供一个测试仓库和我可以用来在本地重现问题的步骤会非常有用(“测试仓库”我的意思是垃圾/随机数据,没有私人请提供数据)。
ifedorenko
于 2019-02-22
@ifedorenko我们使用 S3 (ceph+radosgw) 作为后端(由我们管理)。 我尝试使用 rclone 复制 repo,结果如下:
rclone copy -P remote:cboxback-aabbcc/ /var/tmp/restic/aabbcc/
传输:127.309G / 127.309 GBytes, 100%, 45.419 MBytes/s, ETA 0s
错误:0
检查:0 / 0,-
转出:25435 / 25435,100%
经过时间:47分50.2秒
使用 "stock" restic 0.9.4 恢复 repo 需要大约 8 小时。 在这两种情况下,我都使用 32 个 S3 连接和相同的目标主机。 我在这个论坛帖子中提供了更多信息。
我会准备一个 repo 供您测试,并在准备好后通知您,
非常感谢您的帮助!
robvalca
于 2019-02-25
@robvalca您可以尝试使用我的out-order-restore分支
如果分支没有为您提高恢复性能,请将测试存储库上传到公共 s3 存储桶并在此处发布存储桶名称和存储库密码。
ifedorenko
于 2019-02-26
@pmkane是否有可能恢复大量相同或几乎相同的文件? 我认为这可以解释工人之间的争论。
编辑:实际上,您可以使用最新的 #2101 重试恢复性能测试吗? 它现在应该更好地处理对同一文件的并发写入和对多个文件的同一 blob 的并发写入。
ifedorenko
于 2019-02-26
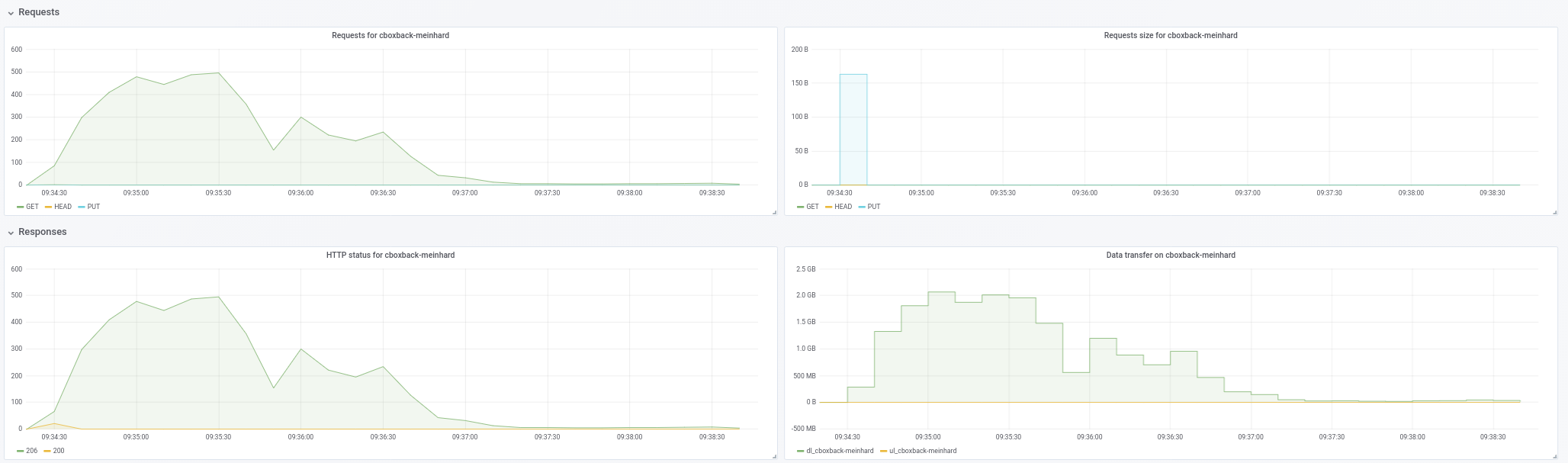
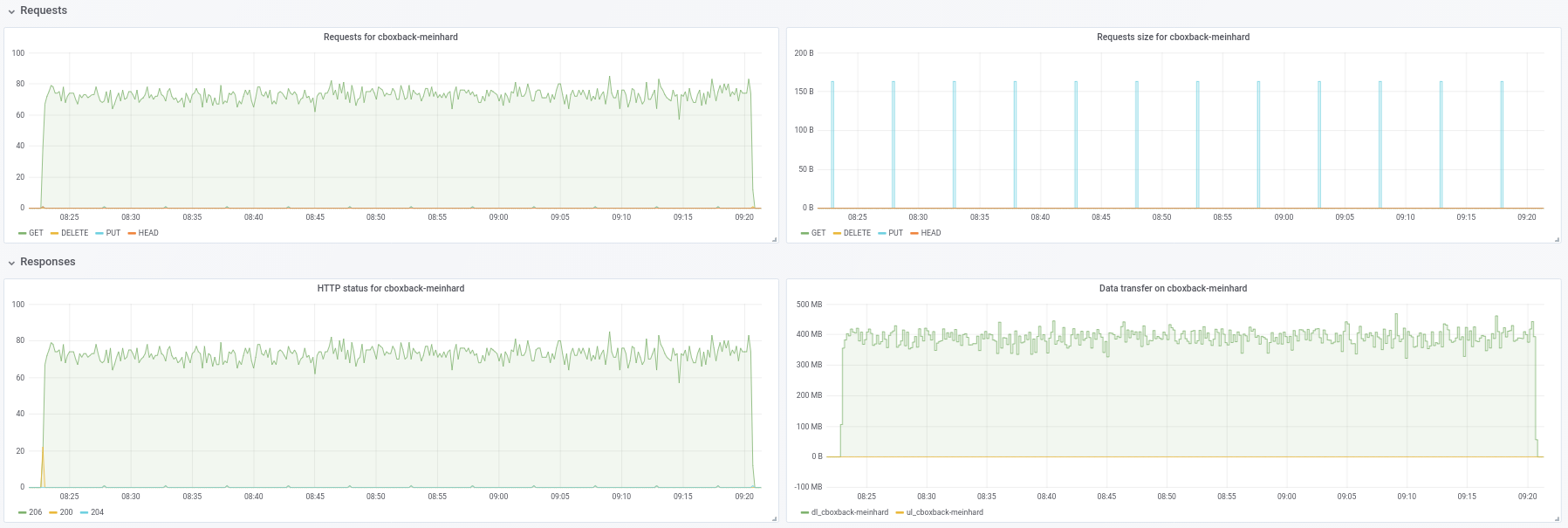
@ifedorenko确实,现在使用乱序版本要好得多! 花了不到一小时的时间,这与我使用 rclone 所获得的时间更接近。 我可以从我的测试中提取一些评论,所以也许你会发现它们很有用(也请参见附图!):
- 在正常的
0.9.4该过程开始得更快,峰值为200MB/sec,我们在 S3 端每秒获得几乎50 requests。 几分钟后,降级发生了,请求下降到 1 左右,在剩下的过程中速度 ~5MB/sec。 - 使用“ooo”版本,传输速度类似于
40MB/sec和 ~8S3 请求在整个过程中稳定。 - 我注意到的另一件事是,我发现增加 S3 连接几乎没有任何改进,这是预期的吗?
32个连接:
Created 2197 directories, listed 171.141 GiB in 20930 files
Restored 171.136 GiB in 170258 files
real 57m54.588s
user 229m25.229s
sys 6m51.763s
64 个连接
real 53m13.876s
user 242m57.081s
sys 7m12.455s
- 最后用另一个不同的存储库(51G,1.3M 小文件,大量重复)做了一个测试,仍然比 0.9.4 快很多:
0.9.4
real 16m6.966s
user 25m4.116s
sys 4m19.424s
0.9.4-ooo:
real 8m14.375s
user 14m30.107s
sys 3m41.538s
因此,不仅可以改善大文件,还可以改善所有情况!!
顺便说一句,恢复的新进度视图很好! 8)
如果你想让我做一些其他的测试,请告诉我。
谢谢!
robvalca
于 2019-02-26
感谢您的反馈, @robvalca ,它非常有用。
- 我注意到的另一件事是,我发现增加 S3 连接几乎没有任何改进,这是预期的吗?
抱歉,忘了提及您需要更改代码以增加并发恢复工作者的数量。 目前它被硬编码为 8:
https://github.com/ifedorenko/restic/blob/099f51c01c189a84b96be86ce6be61a45e3705fc/internal/restorer/filerestorer.go#L22
如果你想让我做一些其他的测试,请告诉我。
我们仍然不知道是什么导致了本期前面提到的无序恢复期间明显的工作器争用https://github.com/restic/restic/issues/2074#issuecomment -443759511。 你能测试这个特定的提交吗
https://github.com/ifedorenko/restic/commit/d410668ce3a8c7284d86a2b06bf42a0e654d43bc? 如果您观察到与您的存储库的争用,那将意味着它不是特定于 pmkane 的数据,并且我最近的更改修复了争用。
再次感谢你的帮助。
ifedorenko
于 2019-02-26
大家好 - 仍在监视这个,但已经完全被淹没了。 这个周末我会赶上,看看我们是否还可以通过ifedorenko@d410668 重现。 我们的数据并不相同/几乎相同,但如果重要的话,其中大部分都被压缩了。
pmkane
于 2019-02-26
@ifedorenko谢谢,有 32 个工人,这个过程要快得多,缩短到 30 分钟,这是一个很好的结果。 我也尝试将 workers/s3.connections 增加到 64/64、128/128,但我没有看到任何改进,得到了几乎相同的结果。 无论如何,我对目前的结果感到满意。
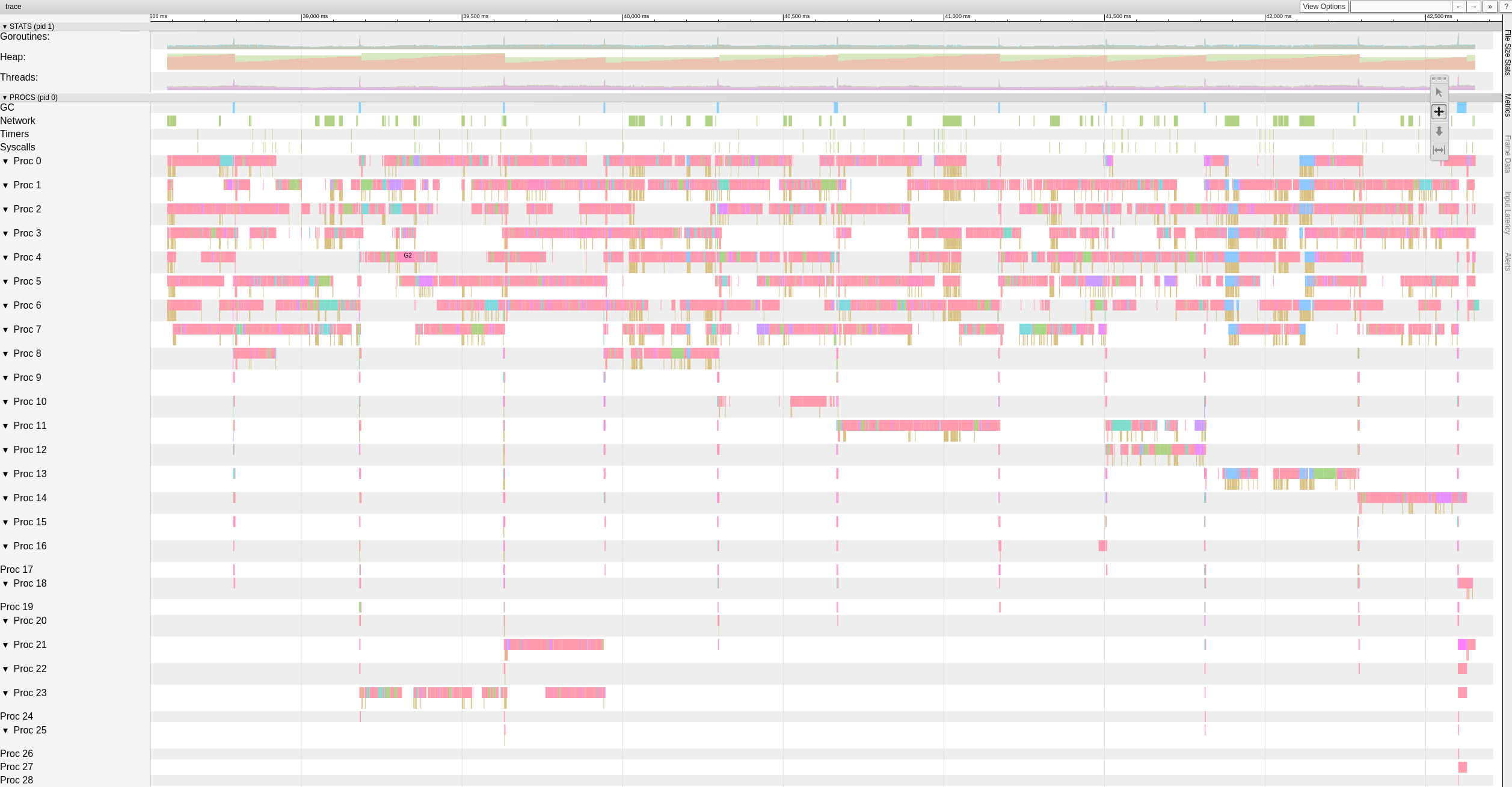
我也尝试了https://github.com/ifedorenko/restic/commit/d410668你指给我的版本,这里是跟踪的截图。 我对这种工具没有太多经验,但似乎与@pmkane结果相似。 我用 8 个工人和-o s3.connections=32运行它
robvalca
于 2019-02-27
@robvalca所以ifedorenko@d410668与分支负责人相比要慢得多,对吗? 这是个好消息,意味着我们可能已经解决了所有已知问题。 谢谢你的更新。
ifedorenko
于 2019-02-27
@ifedorenko不,我忘了提,性能或多或少与具有相同工人数 (8) 和 S3.connections(32) 的分支负责人(乱序)相同。 两者都花了 ~55m,这与使用 rclone 传输 repo 的时间一致(~47m)
如果您希望我使用其他参数进行测试,请告诉我;)
robvalca
于 2019-02-27
我在我的用例中找到了性能问题的触发器。 大文件的恢复性能在超过特定文件大小时是非线性的。
为了进行测试,我在 S3 中创建了一个新的存储库,然后将包含随机数据的 6 个文件备份到该存储库。 这些文件的大小分别为 1、5、10、20、40 和 80GB。
与之前的测试一样,测试在 i3.8xlarge 实例上运行,备份和恢复发生在快速、条带化的 SSD 上。
正如预期的那样,备份时间是线性的(8、25、46、92、177 和 345 秒)。
然而,恢复时间不是:
1GB,5s
5GB,17s
10GB,33s
20GB,85s
40GB,256s
80GB, 807s
因此,大文件和恢复性能会发生一些奇怪的事情。
存储桶名为 pmk-large-restic-test,存储桶及其内容是公开的。 它在 us-west-1 中,restic repo 密码是 password
文件的快照 ID 为:
1GB:0154ae25
5GB:3013e883
10GB:7463efa8
20GB:292650c6
40GB:5acb4bee
80GB:d1b7e323
如果我可以提供更多数据,请告诉我!
pmkane
于 2019-02-27
@pmkane您能否确认您使用了https://github.com/ifedorenko/restic/tree/out-order-restore分支的最新负责人(具体来说是
ifedorenko
于 2019-02-27
是的,我做到了。 很抱歉没有提到这一点。
pmkane
于 2019-02-27
(使用 ead78b3 在所有运行中使用 32 个工作线程和 32 个 s3 连接)
pmkane
于 2019-02-27
你知道我是否需要做任何特别的事情来访问那个存储桶吗? 我以前从未使用过公共存储桶,所以不确定是我做错了什么还是用户无权访问。 (我可以很好地访问我团队的存储桶,所以我知道我的系统通常可以访问 s3)
ifedorenko
于 2019-02-27
嘿@ifedorenko ,找个没有特权的地方试试。
pmkane
于 2019-02-27
抱歉,我已经应用了公共存储桶策略,但没有更新存储桶本身中的对象。 您现在应该可以访问它了。 请注意,您需要使用 --no-lock,因为我只授予了读取权限。
pmkane
于 2019-02-27
是的。 我现在可以访问 repo。 今晚晚些时候会和它一起玩。
ifedorenko
于 2019-02-27
如果它有帮助/更容易测试,我们会在快速 SSD 上将相同文件恢复到/从存储库恢复时看到类似的性能特征,将 S3 排除在外。
pmkane
于 2019-02-28
@pmkane我可以在本地重现该问题,并且不再需要访问该存储桶。 这非常有用,谢谢。
ifedorenko
于 2019-02-28
@ifedorenko ,太棒了。 我将删除存储桶。
pmkane
于 2019-02-28
@pmkane请在有时间的时候再试一次最新的out-order-restore分支。 我没有时间在 ec2 中对此进行测试,但是在我的 macbook 上恢复似乎受到磁盘写入速度的限制并且现在匹配 rclone。
ifedorenko
于 2019-03-01
@ifedorenko ,这听起来很有希望。 我现在正在做一个测试。
pmkane
于 2019-03-01
@ifedorenko ,宾果游戏。
在不到 16 分钟的时间内恢复了 133GB 的 blob,这些 blob 代表文件大小的混合,最大的是 78GB。 以前,此还原将花费一天中的大部分时间。 我怀疑我们仍然可以通过使用 restoreWorkers 的数量来加快速度,但它现在已经足够快了。
感谢您为此付出的辛勤工作!
pmkane
于 2019-03-01
对于后代:我们的恢复性能从 8->16 和从 16->32 恢复工作者翻倍。 32->64 仅适用于 32 之上约 50% 的颠簸,此时我们正在以大约 3gbit/sec 的速度恢复。 几乎与 rclone 相当。
我知道人们希望最大限度地减少从 restic 中提取最佳性能所需的配置量,但这是一个足够大的跳跃,特别是对于拥有大文件集的用户来说,能够指定运行时的工作线程数。
pmkane
于 2019-03-01
不知道为什么恢复仍然无法获得全线速。 有多余的blob 哈希检查,您可以注释掉它是否负责。
ifedorenko
于 2019-03-02
我试试看。
pmkane
于 2019-03-02
大家好,我使用最新的 pull request #2195 进行了一些测试,性能不断提高!
(20k 小文件,2x70G 文件,共 170G)
8w_32c
real 27m46.185s
user 24m31.290s
sys 3m55.153s
32w_32c
real 15m30.904s
user 24m1.982s
sys 4m55.128s
64w_32c
real 18m37.566s
user 23m33.684s
sys 5m3.024s
64w_64c
real 17m12.314s
user 23m44.318s
sys 4m43.090s
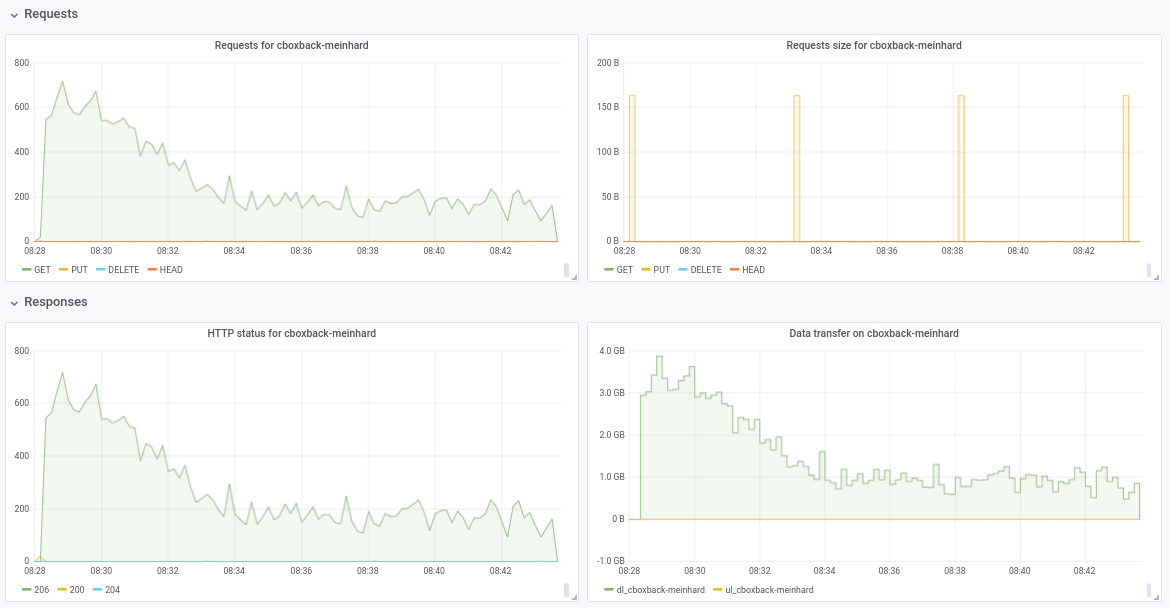
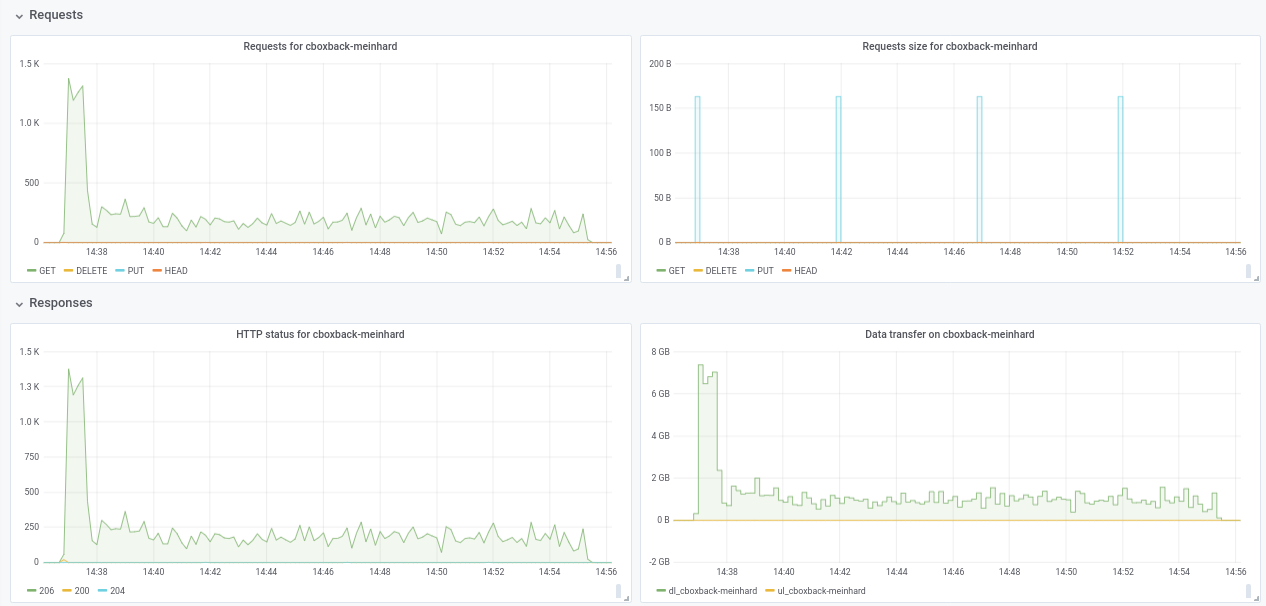
不确定性能从 32w 下降到 64w(经过多次测试,似乎是合法的)。 我在过程中附上一些图表,似乎有一些退化或限制,应该是这样的? 例如,对于 64 个工作人员,该过程以 6gbit/sec 开始,但之后下降到小于 1gbit/sec 直到过程结束(我认为这对应于处理这些大文件的时间)。 第一个截图是 32w、32c,第二个截图是 64w、32c。
我也同意@pmkane ,
无论如何,我对所做的改进印象深刻! 非常感谢@ifedorenko
robvalca
于 2019-03-04
++。 谢谢@ifedorenko ,这是restic 改变游戏规则的东西。
pmkane
于 2019-03-04
感谢@robvalca 的详细报告。 您是否有机会在 AWS(或 GCP 或 Azure)或本地提供我可以使用的测试存储库? 我在测试中没有看到大文件恢复速度下降,我想了解那里发生了什么。
ifedorenko
于 2019-03-04
@pmkane我也想在运行时配置这些东西。 我的建议是为它们设置--option选项,这样它们就不会使常规标志或命令变得混乱,但对于想要试验或调整以适应其异常情况的“高级”用户而言,它们是可用的。 它们甚至不需要被记录下来,并且可以给它们命名,以明确你不能指望它们,比如--option experimental.fooCount=32 。
 whereisaaron
于 2019-03-04
whereisaaron
于 2019-03-04
嗨@ifedorenko ,我在s3.cern.ch/restic-testrepo创建了一个包含垃圾数据的公共回购。 它或多或少与我尝试的形状相同(很多小文件和一些非常大的文件),而且我可以在此(附图)上重现相同的行为。 回购的密码是restic 。 如果您在访问它时遇到任何问题,请告诉我。
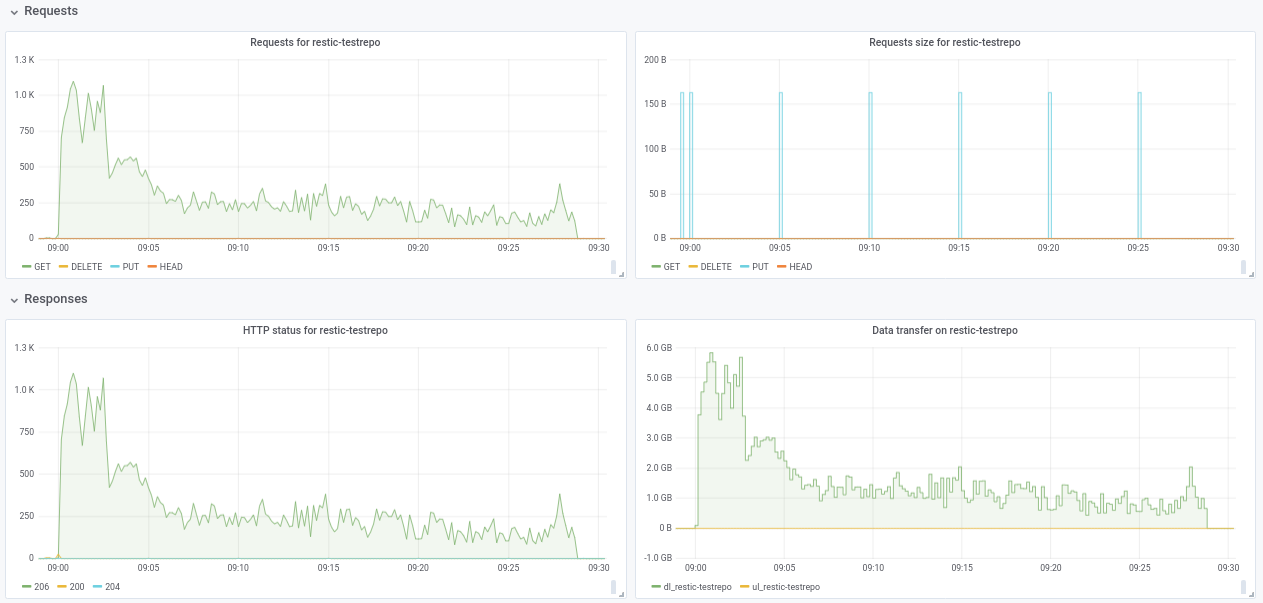
robvalca
于 2019-03-05
@robvalca我无法使用您的测试存储库重现该问题。 在 AWS(us-east-2、s3 repo、 i3.4xlarge 2x nvme raid0 目标)中,当使用 32 个工作线程和 32 个连接(总恢复时间 6 分 20 秒)时,我看到稳定的 0.68 GB/s 恢复速度。 你的目标系统不能长时间维持 10GB/s,如果我猜的话,至少这是我首先检查的,如果我要进一步解决这个问题。
@pmkane有趣的是,我也无法确认您的观察结果。 正如我上面提到的,我看到使用最新的out-of-order-restore-no-progress分支(恢复看起来受 CPU 限制)的恢复速度为 0.68 GB/s,如果禁用冗余 blob 哈希检查(恢复看起来不是 CPU-),则恢复速度
ifedorenko
于 2019-03-06
@ifedorenko我完全同意:收益递减。 对我们来说,它已经足够快了。
pmkane
于 2019-03-06
@ifedorenko很有趣,我会在我们这边进行调查。 无论如何,它对我们来说也足够快,非常感谢您的努力。
robvalca
于 2019-03-07
对合并后的状态感到好奇。这个分支,结合@cbane在 prune 加速方面的工作,使 restic 可用于极大的备份。
pmkane
于 2019-08-22
很快……👀
 rawtaz
于 2020-02-26
rawtaz
于 2020-02-26
现在关闭 #2195 已合并。 如果此问题的具体细节尚未解决,请随时重新打开它。 如果还有待改进的问题不是本期讨论的类型,请开一个新问题。 谢谢!
rawtaz
于 2020-02-26
相关问题
 stevesbrain
·
3评论
stevesbrain
·
3评论
 viric
·
5评论
viric
·
5评论
 fd0
·
4评论
mholt
·
4评论
fd0
·
4评论
mholt
·
4评论
 McKael
·
4评论
McKael
·
4评论
最有用的评论
对合并后的状态感到好奇。这个分支,结合@cbane在 prune 加速方面的工作,使 restic 可用于极大的备份。