Restic: As restaurações podem ser ainda mais rápidas
Graças à fusão do PR1719, as restaurações em repouso são _muito_ mais rápidas.
Eles poderiam ser ainda mais rápidos, no entanto.
Para fins de teste, restaurei de um bucket AWS S3 restic na mesma região (us-west-1) como uma instância i3.8xlarge EC2 dedicada. A restauração foi contra o nvme de 4x1,9 TB na instância, RAID-0 distribuído via LVM com um sistema de arquivos xfs por baixo. A instância tem uma largura de banda teórica de 10 gbit / s para S3.
Com o workerCount em filerestorer.go aumentado para 32 (do limite compilado de 8), o restic restaura uma mistura de 228k arquivos com um tamanho médio de arquivo de 8 KB e um tamanho máximo de arquivo de 364 GB a uma média de 160mbit / s.
Em comparação, rclone com --transfers = 32 move os dados do mesmo balde a 5.636 mbit / s, mais de 30x mais rápido.
Não é uma comparação de maçãs com maçãs. Os blobs de dados Restic têm um tamanho semelhante a 4096 KB, não 8 KB, e abrir / fechar arquivos certamente tem _algumas_ sobrecargas. Mas ainda é uma diferença grande o suficiente para apontar para um gargalo no repouso.
Fico feliz em testar coisas, fornecer instrumentação ou ajudar de qualquer outra forma!
 pmkane
pmkane
Todos 71 comentários
160mbit / seg realmente parece lento. Eu estava chegando perto de 200 Mbps em um macbook pro insignificante baixando de onedrive por meio da conexão de 1 Gbps (rápido). Eu realmente não posso dizer nada específico sem acesso aos seus sistemas e repositório, mas aqui estão algumas coisas que eu faria para restringir o problema, sem uma ordem específica:
- Estimar o tempo que leva para baixar o arquivo de pacote único em thread único. Você pode calcular isso a partir do seu teste de download rclone 32x, mas também estou curioso para saber a hora de baixar pacotes individuais com curl para que possamos estimar a sobrecarga de solicitação de http também.
- Eu verificaria as estatísticas do sistema operacional quanto restic realmente baixa do S3 durante a restauração. Isso nos dirá se a restauração baixa arquivos de pacotes individuais várias vezes (o que é possível, mas não deve acontecer com muita frequência, a menos que eu tenha esquecido alguma coisa).
- O nível de simultaneidade S3 parece estar limitado a apenas 5 conexões . Isso pode explicar a velocidade de restauração que você vê dada a estimativa de velocidade de thread único acima? O que acontece se você aumentar o limite de conexão de back-end S3 para corresponder ao do restaurador?
- Faça um gráfico da utilização da rede durante a restauração para ver se há lacunas ou lentidão.
- Exclua esse arquivo de 364 GB da restauração e veja o que acontece. Arquivos individuais são restaurados sequencialmente, portanto, este arquivo pode desviar significativamente a velocidade média de download.
 ifedorenko
em 7 nov. 2018
ifedorenko
em 7 nov. 2018
Olá!
Obrigado pela resposta. Isso foi interessante para cavar
tl; dr: aumentar as conexões s3 é a chave, mas os aumentos de desempenho que ela fornece são temporários, estranhamente.
- A transferência de pacotes de um único diretório (3062 arquivos totalizando 13 GB) / com rclone --transfers 1 é executada a 233mbit / s. Confirmado com lsof que está sendo executado apenas com um único encadeamento e uma única conexão https nesse modo. A velocidade de pico é alcançada com --transfers 32 (8,5 gbit / seg, essencialmente velocidade de linha para esta instância i3.8xlarge ec2). Em ambos os casos, estamos gravando na matriz nvme listrada.
- Fico feliz em coletar algumas estatísticas, mas o que você gostaria de ver, especificamente? (mas pode não ser necessário, por favor veja abaixo)
- Vou matar dois coelhos com uma cajadada só aqui! Aqui está um gráfico de utilização da rede durante restaurações com:
- um estoque restic com este PR mesclado (commit c0572ca15f946c622d9c4009347dc4d6c31cba4c)
- restic com workerCount saltou para 32 e filesWriterCount saltou para 128
- restic com as alterações anteriores + conexões s3 aumentadas para 32.
- resitc com as mudanças anteriores + conexões s3 aumentadas para 64.
- rclone com --transfers 32 movendo os dados / diretório
O número da largura de banda está em kbps e foi medido em intervalos de 3 segundos ao longo de 10 minutos. Para as execuções do restic, começamos a coletar dados _após_ o restic já havia começado a restaurar os arquivos (ou seja, exclui o tempo de inicialização e o tempo que o Restic gasta no início da execução recriando a hierarquia de diretórios. Durante todas as execuções, a utilização da CPU no instância não ultrapassou 25%.
Obtemos um ligeiro solavanco ao aumentar o workerCount, mas a simultaneidade S3 parece onde está o ganho real. Mas, embora comece forte (chegando perto da velocidade do rclone, às vezes!), As taxas caem abruptamente e permanecem baixas pelo resto da execução. O restic também gera erros que se parecem com "erro de ignorar para [caminho redigido]: capacidade de cache insuficiente: solicitado 2148380, disponível 872640" que não ocorre com simultaneidade s3 inferior.
Como você pode ver, o desempenho de rclone começa alto e permanece alto, portanto, não é uma situação em que as gravações vão para o cache de buffer da instância e param quando são descarregadas no disco. A matriz nvme é mais rápida do que o canal de rede, em termos de taxa de transferência.
- Não acho que o único arquivo grande seja um fator, já que estou medindo IO de disco / rede durante a restauração, então o fato de que pode demorar um pouco para que aquele único arquivo seja completamente restaurado não afetará os números que nós está olhando aqui.
Diante do exposto, parece que aumentar a simultaneidade do S3 é o que será necessário para obter taxas razoáveis aqui, mas é preciso descobrir por que o desempenho está caindo (e se está relacionado a erros de cache ou não).
Se tornar uma instância i3 rápida e algum espaço s3 e largura de banda disponível para seu teste for útil, me avise, feliz em patrocinar isso.
pmkane
em 7 nov. 2018
233mbit / seg vezes 32 é 7456 e um pouco menos que 8,5 gbit / seg. O que é estranho. Eu esperava que o download de thread único fosse mais rápido do que a taxa de transferência por stream de download de multi-thread. Não tenho certeza do que isso significa, no entanto, se alguma coisa.
Eu estava tentando confirmar que o restic não baixa novamente os mesmos pacotes repetidamente. Acho que o gráfico mostra que baixar novamente não é um problema, então não há necessidade de mais estatísticas, pelo menos não agora.
Você pode confirmar a escala do gráfico? rclone paira em torno da linha rotulada como "1000000", se for "1.000.000 kbps", o que eu acho que significa "1 gbps" e não se alinha com o número "8,5 gbit / s" que você mencionou anteriormente.
Como eu disse, os arquivos individuais são restaurados sequencialmente. O download de 364 GB a 233mbit / s levará cerca de 3,5 horas, e provavelmente mais devido à sobrecarga por pacote e à descriptografia, tudo ocorrendo sequencialmente. Não é possível dizer se 3,5 horas é algo que você pode descartar como insignificante sem saber quanto o resto da restauração leva.
Quanto ao erro not enough cache capacity , aumente averagePackSize para o tamanho do maior arquivo de pacote em seu repositório (quão grande é, aliás?) E eu preciso pensar em como dimensionar melhor o cache, não tenho um responda ainda.
ifedorenko
em 7 nov. 2018
Olá!
Opa, desculpe. A escala no gráfico é KB / s, não kbit / s. Portanto, 1.012.995 na primeira linha equivale a 8,1 gbit / s.
Eu entendi que os arquivos foram restaurados sequencialmente, mas não entendi que não há paralelismo para a recuperação do pacote para um único arquivo. Isso é definitivamente um obstáculo para backups com arquivos grandes, já que esse se torna seu fator limitante. Seria fantástico ter algum paralelismo aqui por esse motivo.
Com uma amostra de 10 baldes aleatórios, nosso tamanho máximo de pacote é um pouco abaixo de 12 MB e nosso tamanho médio de pacote é 4,3 MB.
Talvez com mais workers e conexões S3, estejamos excedendo packCacheCapacity de (workerCount + 5) * averagePackSize. Vou tentar aumentar isso e ver se os erros desaparecem.
pmkane
em 7 nov. 2018
Talvez com mais workers e conexões S3, estejamos excedendo packCacheCapacity de (workerCount + 5) * averagePackSize. Vou tentar aumentar isso e ver se os erros desaparecem.
O tamanho do cache é calculado com base no tamanho do arquivo do pacote de 5 MB e workerCount . Aumentar workerCount aumenta o tamanho do cache. Portanto, há um vazamento de memória ou a restauração precisa armazenar em cache muitos arquivos 12MB por puro acaso. Aumentar averagePackSize para 12MB deve nos dizer qual.
ifedorenko
em 7 nov. 2018
Sem erros de cache com averagePackSize definido como 12.
Se houver alguma outra informação que possamos fornecer que seja útil, entre em contato. Obrigado novamente.
pmkane
em 8 nov. 2018
Parece que estamos perdendo o paralelismo à medida que a restauração avança e não parece estar relacionado a arquivos grandes. Vou montar um caso de teste e apresentar um relatório.
pmkane
em 8 nov. 2018
Olá!
Eu tentei reproduzir as quedas de desempenho que eu estava vendo com minha mixagem de arquivos de produção com três combinações de arquivos artificiais diferentes.
Para todos os testes, usei c0572ca15f946c622d9c4009347dc4d6c31cba4c com conexões S3 aumentadas para 128, workerCount aumentado para 128, filesWriterCount aumentado para 128 e averagePackSize aumentado para 12 * 1024 * 1024.
Todos os testes usaram arquivos com dados aleatórios, para evitar quaisquer impactos da desduplicação.
Para o primeiro teste, criei e fiz backup de 4.000 arquivos de 100 MB, divididos igualmente em 100 diretórios (cerca de 400 GB no total). Backups e restaurações foram executados a partir de volumes nvme distribuídos em uma instância i3.8xlarge. O depósito de backup estava localizado na mesma região da instância (us-west-1).
Com essa combinação de arquivos, vi velocidades médias de 9,7 gbit / s (!) Sem perda de paralelismo ou velocidade em toda a restauração. Esses números estão no mesmo nível ou acima dos números do rclone e são essencialmente a velocidade da linha, o que é fantástico.
Em seguida, criei e fiz backup de 400.000 arquivos de 1 MB, divididos igualmente em 100 diretórios (novamente, cerca de 400 GB no total).
Os mesmos (excelentes) resultados acima.
Finalmente, criei 40 diretórios com 1 arquivo de 10 GB por diretório. Aqui, as coisas ficaram interessantes.
Eu esperava que essa restauração fosse um pouco mais lenta, já que o restic só seria capaz de fazer 40 restaurações simultâneas com 40 conexões para S3.
Em vez disso, entretanto, enquanto o Restic abre todos os 40 arquivos para gravações e gravações em todos os 40 arquivos simultaneamente, ele mantém apenas uma única conexão TCP para S3 aberta por vez, não 40.
Deixe-me saber quais estatísticas ou instrumentação você gostaria de ver.
pmkane
em 8 nov. 2018
Você pode confirmar que havia 128 conexões S3 durante os testes "rápidos"?
ifedorenko
em 8 nov. 2018
Sim foram.
pmkane
em 8 nov. 2018
Curioso ... O suporte a arquivos grandes não está no topo da minha lista de prioridades, para ser honesto, mas posso encontrar algum tempo para examinar isso nas próximas semanas. Se alguém quiser se aprofundar nisso antes de mim, por favor, me avise.
ifedorenko
em 8 nov. 2018
Fiz mais alguns testes e realmente parece que o tamanho do arquivo é uma pista falsa, são as contagens de arquivos que estão conduzindo a contagem de conexões da AWS.
Com 128 arquivos de 10 MB em 4 diretórios, o restic abre apenas 6 conexões para AWS, embora esteja gravando em todos os 128 arquivos.
Com 512 arquivos de 10 MB em 4 diretórios, o restic abre 18 conexões ao longo de sua vida útil, embora tenha 128 arquivos abertos ao mesmo tempo.
Com 5.120 arquivos de 10 MB em 4 diretórios, o restic abre apenas 75 conexões para a AWS ao longo de sua vida útil, novamente mantendo 128 arquivos abertos por vez.
Ímpar!
pmkane
em 8 nov. 2018
Eu ficaria realmente surpreso se o cliente Go S3 não agrupasse e reutilizasse conexões http. Provavelmente, não há correlação direta entre o número de workers simultâneos e soquetes TCP abertos. Portanto, por exemplo, se a restauração for um processamento lento de pacotes baixados por qualquer motivo, a mesma conexão S3 será compartilhada por vários funcionários.
ifedorenko
em 8 nov. 2018
Existem duas propriedades do restaurador simultâneo atual que são responsáveis pela maior parte da complexidade da implementação e muito provavelmente causam a lentidão relatada aqui:
- arquivos individuais são restaurados do início ao fim
- o número de arquivos em andamento é mínimo
A implementação será muito mais simples, usará menos memória e muito provavelmente será mais rápida em muitos casos se concordarmos em gravar blobs de arquivo em qualquer ordem e permitir qualquer número de arquivos em andamento.
A desvantagem é que não será possível dizer quantos dados já foram restaurados em um determinado arquivo até o final da restauração. O que pode ser confuso, especialmente se a restauração falhar ou for encerrada. Portanto, você pode ver um arquivo de 10 GB no sistema de arquivos, que na realidade possui apenas alguns bytes gravados no final do arquivo.
@ fd0 você acha que vale a pena melhorar a restauração atual do início ao fim? Pessoalmente, estou pronto para admitir que foi além da engenharia da minha parte e posso fornecer uma implementação fora de ordem mais simples, se você concordar.
ifedorenko
em 16 nov. 2018
Não me lembro se o Restic oferece suporte à restauração para a saída padrão. Se isso acontecer, você obviamente precisará manter a restauração do início ao fim para ele (possivelmente como um caso especial).
 pvgoran
em 16 nov. 2018
pvgoran
em 16 nov. 2018
@ifedorenko Pessoalmente, sou a favor da simplificação, em geral, especialmente se vier com aumentos de desempenho. Estou tentando entender as vantagens e desvantagens:
A desvantagem é que não será possível dizer quantos dados já foram restaurados em um determinado arquivo até o final da restauração.
Se não estamos falando de milhares de arquivos gravados simultaneamente, talvez um mapa do nome do arquivo para bytes gravados pudesse ser usado? Obviamente, isso não tornará as informações disponíveis para o sistema de arquivos, mas, para relatórios de progresso, ainda pode ser feito, não? (E para retomar uma restauração que foi interrompida, talvez apenas verificando os blobs e deslocamentos do arquivo em busca de bytes não nulos, talvez? Não sei.)
Não me lembro se o Restic oferece suporte à restauração para a saída padrão. Se isso acontecer, você obviamente precisará manter a restauração do início ao fim para ele (possivelmente como um caso especial).
Acho que não - não tenho certeza de como isso funcionaria de qualquer maneira, uma vez que as restaurações são vários arquivos, você precisaria codificá-los de alguma forma e separá-los de alguma forma, eu acho.
 mholt
em 16 nov. 2018
mholt
em 16 nov. 2018
Se não estamos falando de milhares de arquivos gravados simultaneamente, talvez um mapa do nome do arquivo para bytes gravados pudesse ser usado?
A implementação mais simples é abrir e fechar arquivos para gravar blobs individuais. Se for muito lento, teremos que encontrar uma maneira de manter os arquivos abertos para várias gravações de blob, por exemplo, armazenando em cache os identificadores de arquivos abertos e ordenando os downloads de pacotes para favorecer os arquivos já abertos.
O Restore já rastreia quais blobs foram gravados em quais arquivos e quais ainda estão pendentes. Não espero que essa parte mude muito. O progresso é monitorado em uma estrutura de dados separada e não espero que isso mude também.
E para retomar uma restauração que foi interrompida, talvez apenas verificando os blobs e deslocamentos do arquivo em busca de bytes não nulos?
O currículo precisa verificar as somas de verificação dos arquivos no disco para decidir quais blobs ainda precisam ser restaurados. Acredito que isso seja verdade, independentemente de a restauração ser sequencial ou fora de ordem. Por exemplo, se o currículo se recupera de uma queda de energia, não acho que ele possa assumir que todos os blocos de arquivos foram enviados para os discos antes do corte de energia, ou seja, os arquivos podem ter lacunas ou blocos parcialmente escritos.
ifedorenko
em 16 nov. 2018
@pmkane gostaria de saber se você pode tentar # 2101? ele implementa a restauração fora de ordem, embora as gravações em arquivos individuais ainda sejam serializadas e o desempenho da restauração de arquivos grandes ainda possa ser inferior ao ideal. e você precisa ajustar o número de trabalhadores como antes.
ifedorenko
em 27 nov. 2018
Absolutamente. Estou viajando esta semana, mas farei o teste assim que puder e apresentarei um relatório.
pmkane
em 27 nov. 2018
@ifedorenko Eu tentei este PR e ele cria com sucesso a estrutura do diretório, mas todas as restaurações de arquivo falham com erros como:
Carga(, 3172070, 0) erro retornado, tentando novamente após 12.182749645s: EOF
mestre restaura bem.
Meu comando de restauração é:
/usr/local/bin/restic.outoforder -r s3: s3.amazonaws.com/ [redigido] -p /root/.restic_pass restore [snapshotid] -t.
Deixe-me saber quais informações adicionais posso fornecer para ajudar a depurar.
pmkane
em 1 dez. 2018
Quantas solicitações simultâneas de download S3 você permite? Se for 128, você pode limitar a 32 (que sabemos que funciona)?
Semi-relacionado ... você sabe quantos arquivos de índice seu repositório real tem? Tentando estimar quanta memória o restaurador precisa.
ifedorenko
em 1 dez. 2018
Não especifiquei um limite de conexão, então presumo que o padrão seja 5.
Recebo os mesmos erros com -o s3.connections = 2 e -o s3.connections = 1.
Atualmente, tenho 85 blobs de índice no índice / pasta. Eles têm 745 MB de tamanho total.
pmkane
em 1 dez. 2018
Hmm. Vou dar uma olhada quando chegar ao meu computador mais tarde hoje. A propósito, "erro retornado, nova tentativa" é um aviso, não um erro, então pode estar relacionado à falha de restauração ou pode ser apenas uma pista falsa.
ifedorenko
em 1 dez. 2018
Não tenho certeza de como eu perdi ... o restaurador não leu totalmente todos os arquivos do pacote do back-end na maioria dos casos. Deve ser consertado agora. @pmkane você pode tentar seu teste novamente?
ifedorenko
em 2 dez. 2018
Vou dar uma volta!
pmkane
em 2 dez. 2018
Confirmado que os arquivos foram restaurados com sucesso com esta correção. Testando o desempenho agora.
pmkane
em 2 dez. 2018
Infelizmente, parece que é mais lento que o mestre. Todos os testes são executados na instância i3.8xlarge descrita acima.
Com um workerCount de 8 (o padrão), a ramificação fora de serviço foi restaurada a 86mbit / s.
Com um workerCount aumentado para 32, ele se saiu um pouco melhor - com média de 160mbit / s.
A utilização da CPU com este branch é significativamente maior do que no master, mas não está maximizando a CPU da instância em nenhum dos casos.
Curiosamente, a UI de restauração faz com que pareça que algo está "travando", quase como se estivesse competindo consigo mesmo por um bloqueio em algum lugar.
Fico feliz em fornecer mais detalhes, criação de perfil ou uma instância de teste para replicar.
pmkane
em 2 dez. 2018
Só para confirmar, você tinha o restaurador e a contagem de trabalhadores de back-end s3 configurados para 32, certo?
Algumas idéias que podem explicar o comportamento que você observou:
- As gravações em arquivos individuais ainda são serializadas. _Adivinhei_ que não seria um problema com sistemas de arquivos de destino rápido, mas nunca medi isso.
- Abrir / fechar o arquivo ao redor de cada blob certamente contribui para a sobrecarga do restaurador. Quando eu medi isso em macos, fui capaz de "abrir o arquivo; gravar um byte; fechar o arquivo" 100 mil vezes em aproximadamente 70 segundos, o que se aproxima da sobrecarga de gravação de blobs de 100 mil. O teste foi realmente simples e a sobrecarga na vida real pode ser significativamente maior.
- No momento, não tenho uma explicação plausível para a alta utilização da CPU. A implementação fora de ordem descriptografa cada blob apenas uma vez (o mestre descriptografa os blobs para cada arquivo de destino) e há muito menos contabilidade em comparação com o mestre. Talvez as gravações "esparsas" de arquivos não sejam realmente esparsas e exijam que Go ou OS façam algo pesado na CPU. Realmente não sei.
ifedorenko
em 2 dez. 2018
Ei!
Isso mesmo. workerCount foi definido como 8 ou 32 em internal / restorer / filerestorer.go e -o s3.connections = 32 foi passado por meio do restic cli em ambos os casos.
pmkane
em 3 dez. 2018
Aqui está uma visão de nível superior dos dados de rastreamento enquanto a ramificação fora de serviço está restaurando arquivos com 8 trabalhadores.
Parece que há pausas significativas (> 500-1000ms) que os trabalhadores realizam com frequência.
pmkane
em 3 dez. 2018
Decidi gastar mais tempo nisso e comecei escrevendo um teste autônomo simples que gera bytes aleatórios de 10 GiB em blocos de 4 KB. Meu objetivo era avaliar a rapidez com que meu sistema pode mover bytes. Para minha surpresa, este teste levou 18,64 segundos para ser executado no meu macbook pro (2018, 2.6 GHz Intel Core i7). O que se traduz em cerca de 4,29 Gigabits / s ou cerca de metade do que a Ethernet 10G pode fazer. E isso sem qualquer criptografia ou rede ou E / S de disco. E eu estava usando o Xoshiro256 ** prng, math/rand era cerca de 2x mais lento, o que obviamente não vem ao caso. A questão é que o restaurador precisa processar blobs em vários threads para saturar a rede 10G, e / S de rede multithread por si só não é suficiente.
E, apenas por diversão, o rust impl comparável gera 10GiB de bytes aleatórios em 3,1 segundos e java em 10,77s. Vai saber :-)
ifedorenko
em 6 fev. 2019
Teste interessante!
Eu entendo que o restic terá sua taxa limitada pelo tempo que leva para restaurar o maior arquivo, atualmente.
No momento, no entanto, esse não é o nosso bloqueador, pois sei que o restic pode restaurar um único arquivo muito mais rápido do que os 160mbit / s que vemos aqui.
Vou montar um repositório de teste de 100 GB consistindo em arquivos de 10 MB no SSD rápido e no S3 e rodar alguns números, para obter o melhor cenário atual no master e neste branch.
pmkane
em 6 fev. 2019
Oi pessoal existe alguma maneira de alterar o número de trabalhadores usando um parâmetro ou tem que ser feito diretamente no código? Também estamos tendo o problema de restaurações lentas e gostaria de melhorar o que temos de alguma forma ... Por favor, me diga se posso contribuir com testes para ajudar a melhorar essa parte!
Obrigado!
 robvalca
em 19 fev. 2019
robvalca
em 19 fev. 2019
@robvalca qual backend você usa? com que rapidez rclone copia seu repo para o sistema de destino? o que é a velocidade de restauração do Restic?
No momento, não tenho certeza do que está acontecendo, então seria muito útil se você pudesse fornecer um repositório de teste e etapas que eu possa usar para reproduzir o problema localmente (e por "repositório de teste" quero dizer lixo / dados aleatórios, não privado dados, por favor).
ifedorenko
em 22 fev. 2019
@ifedorenko estamos usando S3 (ceph + radosgw) como backend (gerenciado por nós). Tentei copiar o repo usando rclone e estes são os resultados:
rclone copy -P remote: cboxback-aabbcc / / var / tmp / restic / aabbcc /
Transferido: 127.309G / 127.309 GBytes, 100%, 45,419 MBytes / s, ETA 0s
Erros: 0
Verificações: 0/0, -
Transferido: 25435/25435, 100%
Tempo decorrido: 47m50.2s
A restauração do repo usando o restic "stock" 0.9.4 levou cerca de 8 horas. Em ambos os casos, estou usando conexões S3 32 e o mesmo host de destino. Coloquei um pouco mais de informações neste tópico do fórum.
Prepararei um repositório para você testar e avisarei quando estiver pronto,
Muito obrigado pela ajuda!
robvalca
em 25 fev. 2019
@robvalca você pode tentar restaurar usando meu branch out-order-restore ? o branch deve melhorar o desempenho de restauração de arquivos muito grandes, o que parece ser o problema que você enfrenta.
se o branch não melhorar o desempenho de restauração para você, carregue o repositório de teste para um depósito s3 público e poste o nome do depósito e a senha do repositório aqui.
ifedorenko
em 26 fev. 2019
@pmkane é possível restaurar um grande número de arquivos idênticos ou quase idênticos? isso explicaria a contenda entre os trabalhadores, eu acho.
Editar: na verdade, você pode repetir o teste de desempenho de restauração usando o # 2101 mais recente? Ele deve lidar melhor com gravações simultâneas no mesmo arquivo e mesmo blob em vários arquivos.
ifedorenko
em 26 fev. 2019
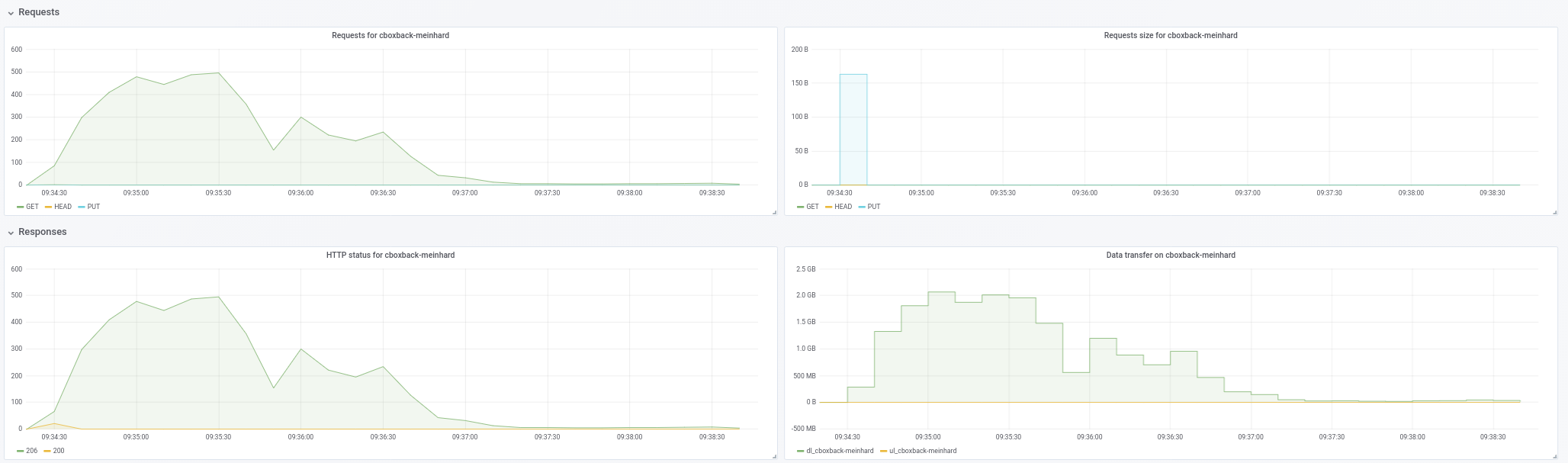
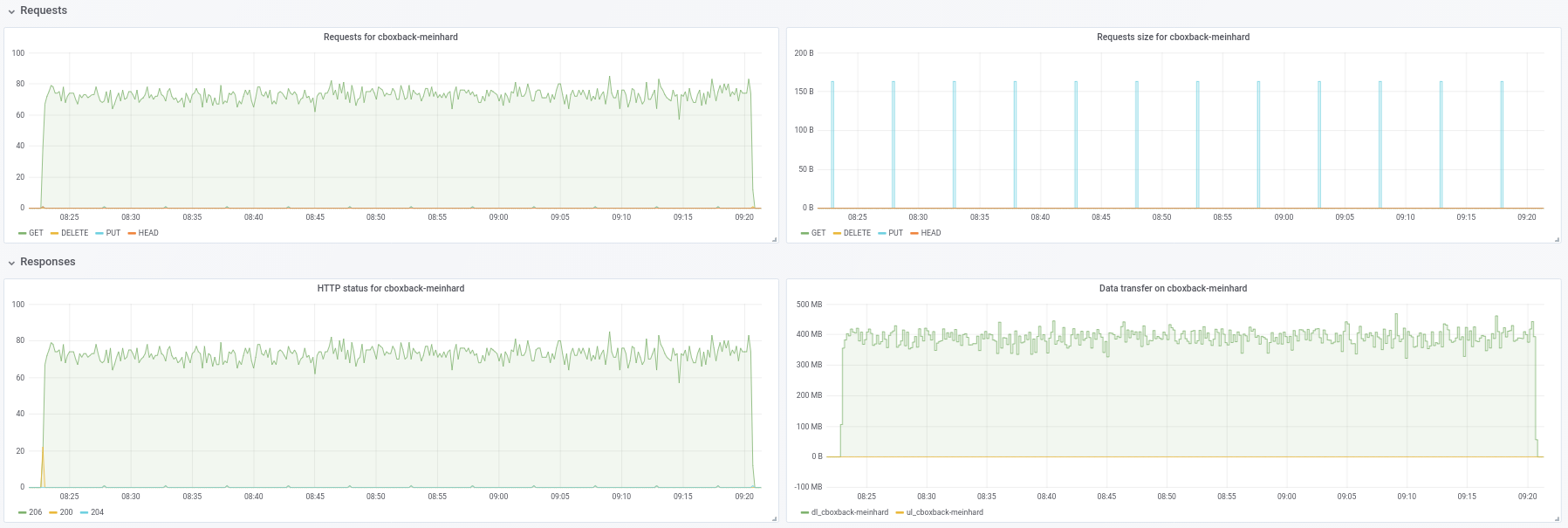
@ifedorenko de fato, com a versão out-order agora é muito melhor! Demorou menos de uma hora, o que é mais próximo do que consegui com rclone. Alguns comentários que eu poderia extrair de meus testes para que talvez você possa considerá-los úteis (veja os gráficos em anexo!):
- No restic normal
0.9.4o processo começa mais rápido, com picos de200MB/sece estamos recebendo quase50 requestspor segundo no lado S3. Depois de apenas alguns minutos, a degradação acontece e as solicitações caem para 1 ou mais e a velocidade ~5MB/secdurante o resto do processo. - Com a versão "ooo", a velocidade de transferência é algo como
40MB/sece ~8S3 solicitações constantes durante todo o processo. - Outra coisa que notei é que quase não vejo melhora no aumento das conexões S3, isso é esperado?
32 conexões:
Created 2197 directories, listed 171.141 GiB in 20930 files
Restored 171.136 GiB in 170258 files
real 57m54.588s
user 229m25.229s
sys 6m51.763s
64 conexões
real 53m13.876s
user 242m57.081s
sys 7m12.455s
- Finalmente fiz um teste com outro repositório diferente (51G, 1.3M de arquivos pequenos, muitas duplicatas) e ainda é mais rápido do que 0.9.4 por uma boa margem:
0.9.4
real 16m6.966s
user 25m4.116s
sys 4m19.424s
0.9.4-ooo:
real 8m14.375s
user 14m30.107s
sys 3m41.538s
Portanto, não está melhorando apenas com arquivos grandes, melhora todos os casos !!
E aliás, a nova visualização de progresso da restauração é ótima !! 8)
Avise-me se quiser que eu faça outros testes.
Obrigado!
robvalca
em 26 fev. 2019
Obrigado pelo feedback, @robvalca , é muito útil.
- Outra coisa que notei é que quase não vejo melhora no aumento das conexões S3, isso é esperado?
Desculpe, esqueci de mencionar que você precisa alterar o código para aumentar o número de trabalhos de restauração simultâneos. Está codificado para 8 no momento:
https://github.com/ifedorenko/restic/blob/099f51c01c189a84b96be86ce6be61a45e3705fc/internal/restorer/filerestorer.go#L22
Avise-me se quiser que eu faça outros testes.
Ainda não sabemos o que está causando a aparente contenção do trabalhador durante a restauração fora de ordem mencionada anteriormente nesta edição https://github.com/restic/restic/issues/2074#issuecomment -443759511. Você pode testar este commit específico
https://github.com/ifedorenko/restic/commit/d410668ce3a8c7284d86a2b06bf42a0e654d43bc? Se você observar a contenção com seus repositórios, isso significaria que não é específico para os dados do pmkane e que minhas mudanças recentes corrigem a contenção.
Obrigado novamente por sua ajuda.
ifedorenko
em 26 fev. 2019
Olá a todos - ainda monitorando isso, mas foram absolutamente atolados. Vou colocar o papo em dia neste fim de semana e ver se ainda podemos reproduzir com
pmkane
em 26 fev. 2019
@ifedorenko Obrigado, com 32 trabalhadores o processo é muito mais rápido indo para 30min o que é um ótimo resultado. Eu tentei também aumentar workers / s3.connections para 64/64, 128/128, mas não vejo melhorias, obtendo quase os mesmos resultados. De qualquer forma, estou feliz com os resultados atuais.
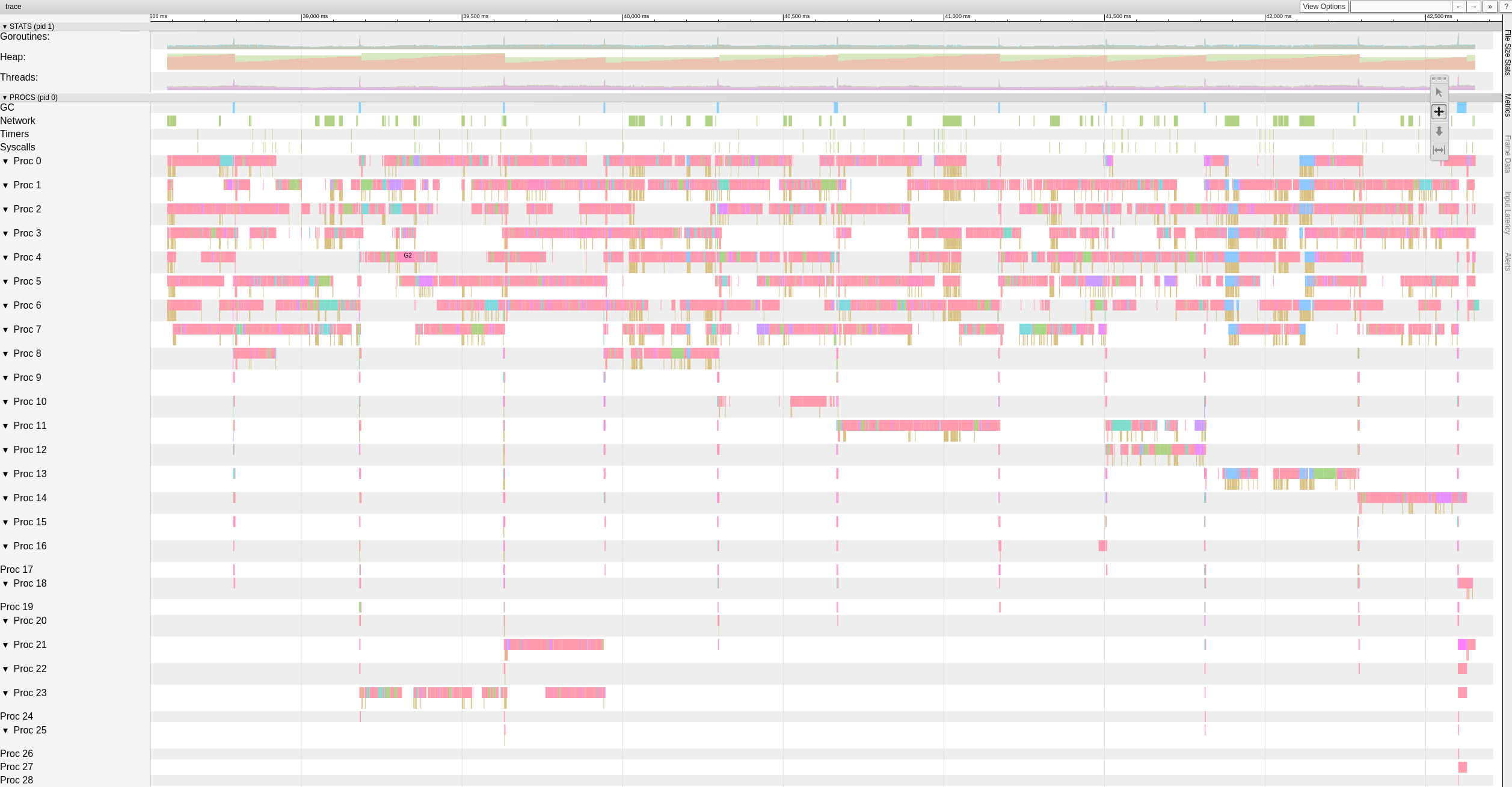
Experimentei também a versão com https://github.com/ifedorenko/restic/commit/d410668 que você me apontou e aqui está uma captura de tela do trace. Não tenho muita experiência com este tipo de ferramenta, mas parece semelhante aos resultados do @pmkane . Eu o executei com 8 trabalhadores e com -o s3.connections=32
robvalca
em 27 fev. 2019
@robvalca então ifedorenko @ d410668 foi significativamente mais lento em comparação com o chefe do ramo, certo? esta é uma boa notícia, significa que provavelmente tratamos de todos os problemas conhecidos. obrigado pela atualização.
ifedorenko
em 27 fev. 2019
@ifedorenko não, esqueci de mencionar, o desempenho é mais ou menos igual ao do chefe da filial (fora de serviço) com o mesmo número de trabalhadores (8) e S3.conexões (32). Ambos levaram ~ 55m, o que está de acordo com o tempo de transferência do repo com rclone (~ 47m)
Deixe-me saber se você quiser que eu teste com outros parâmetros;)
robvalca
em 27 fev. 2019
Encontrei o gatilho para problemas de desempenho em meu caso de uso. O desempenho da restauração de arquivos grandes não é linear além de um determinado tamanho de arquivo.
Para testar, criei um novo repo no S3 e depois fiz backup de 6 arquivos contendo dados aleatórios para o repo. Os arquivos tinham 1, 5, 10, 20, 40 e 80 GB de tamanho.
Como nos testes anteriores, os testes foram executados em instâncias i3.8xlarge com os backups e restaurações ocorrendo em SSD rápido e distribuído.
Os tempos de backup foram lineares, conforme esperado (8, 25, 46, 92, 177 e 345 segundos).
Os tempos de restauração, no entanto, não eram:
1gb, 5s
5gb, 17s
10gb, 33s
20gb, 85s
40gb, 256s
80gb, 807s
Portanto, há algo estranho acontecendo com arquivos grandes e desempenho de restauração.
O intervalo é denominado pmk-large-restic-test e o intervalo e seu conteúdo são públicos. Está em us-west-1 e a senha do repo do restic é a senha
Os IDs de instantâneo para os arquivos são:
1gb: 0154ae25
5gb: 3013e883
10gb: 7463efa8
20gb: 292650c6
40gb: 5acb4bee
80gb: d1b7e323
Avise-me se houver mais dados que eu possa fornecer!
pmkane
em 27 fev. 2019
@pmkane, você pode confirmar que usou o mais recente chefe da https://github.com/ifedorenko/restic/tree/out-order-restore branch (https://github.com/ifedorenko/restic/commit/ead78b375f2efed6de57c99b6766edbe9322e009 para ser específico) ?
ifedorenko
em 27 fev. 2019
Sim eu fiz. Desculpe por não mencionar isso.
pmkane
em 27 fev. 2019
(usou 32 workers e conexões 32 s3 em todas as execuções com ead78b3)
pmkane
em 27 fev. 2019
Você sabe se preciso fazer algo especial para acessar esse intervalo? Nunca usei baldes públicos antes, então não tenho certeza se estou fazendo algo errado ou se o usuário não tem acesso. (Posso acessar os baldes da minha equipe muito bem, então sei que meu sistema pode acessar o s3 em geral)
ifedorenko
em 27 fev. 2019
Ei @ifedorenko ,
pmkane
em 27 fev. 2019
Desculpe por isso, eu apliquei uma política de intervalo público, mas não atualizei os objetos no próprio intervalo. Você deve conseguir acessá-lo agora. Observe que você precisará usar --no-lock, já que concedi apenas permissões de leitura.
pmkane
em 27 fev. 2019
Sim. Posso acessar o repo agora. Vou brincar com ele mais tarde esta noite.
ifedorenko
em 27 fev. 2019
E caso seja útil / mais fácil de testar, vemos características de desempenho semelhantes ao fazer restaurações dos mesmos arquivos de / para um repositório em SSD rápido, tirando S3 da equação.
pmkane
em 28 fev. 2019
@pmkane posso reproduzir o problema localmente e não preciso mais acessar aquele balde. isso foi muito útil, obrigado.
ifedorenko
em 28 fev. 2019
@ifedorenko , fantástico. Vou deletar o balde.
pmkane
em 28 fev. 2019
@pmkane, por favor, out-order-restore branch quando tiver tempo. Não tive tempo para testar isso no ec2, mas no meu macbook a restauração parece estar limitada pela velocidade de gravação do disco e corresponde a rclone agora.
ifedorenko
em 1 mar. 2019
@ifedorenko , isso parece muito promissor. Estou iniciando um teste agora.
pmkane
em 1 mar. 2019
@ifedorenko , bingo.
Foram restaurados 133 GB de blobs que representam uma mistura de tamanhos de arquivo, o maior sendo 78 GB, em pouco menos de 16 minutos. Anteriormente, essa restauração demorava quase um dia. Suspeito que podemos obter isso ainda mais rápido brincando com o número de restoreWorkers, mas é muito rápido do jeito que está.
Obrigado pelo seu trabalho árduo nisso!
pmkane
em 1 mar. 2019
E para a posteridade: nosso desempenho de restauração dobra de 8-> 16 e novamente de 16-> 32 trabalhadores de restauração. 32-> 64 só é bom para um aumento de ~ 50% no topo de 32, ponto no qual estamos restaurando em cerca de 3 gbit / s. Quase no mesmo nível do rclone.
Eu sei que há um desejo de minimizar a quantidade de configuração necessária para extrair o melhor desempenho do restic, mas este é um salto grande o suficiente, especialmente para usuários com grandes conjuntos de arquivos, que seria bom ser capaz de especificar o número de trabalhadores em tempo de execução.
pmkane
em 1 mar. 2019
Não sei por que a restauração ainda não consegue obter a velocidade total do fio. Há verificação de hash de blob redundante que você pode comentar para ver se é o responsável.
ifedorenko
em 2 mar. 2019
Vou dar uma chance.
pmkane
em 2 mar. 2019
Olá a todos, Executei alguns testes usando a última solicitação de pull # 2195 e o desempenho continua melhorando!
(20k arquivos pequenos, arquivos 2x70G, 170G no total)
8w_32c
real 27m46.185s
user 24m31.290s
sys 3m55.153s
32w_32c
real 15m30.904s
user 24m1.982s
sys 4m55.128s
64w_32c
real 18m37.566s
user 23m33.684s
sys 5m3.024s
64w_64c
real 17m12.314s
user 23m44.318s
sys 4m43.090s
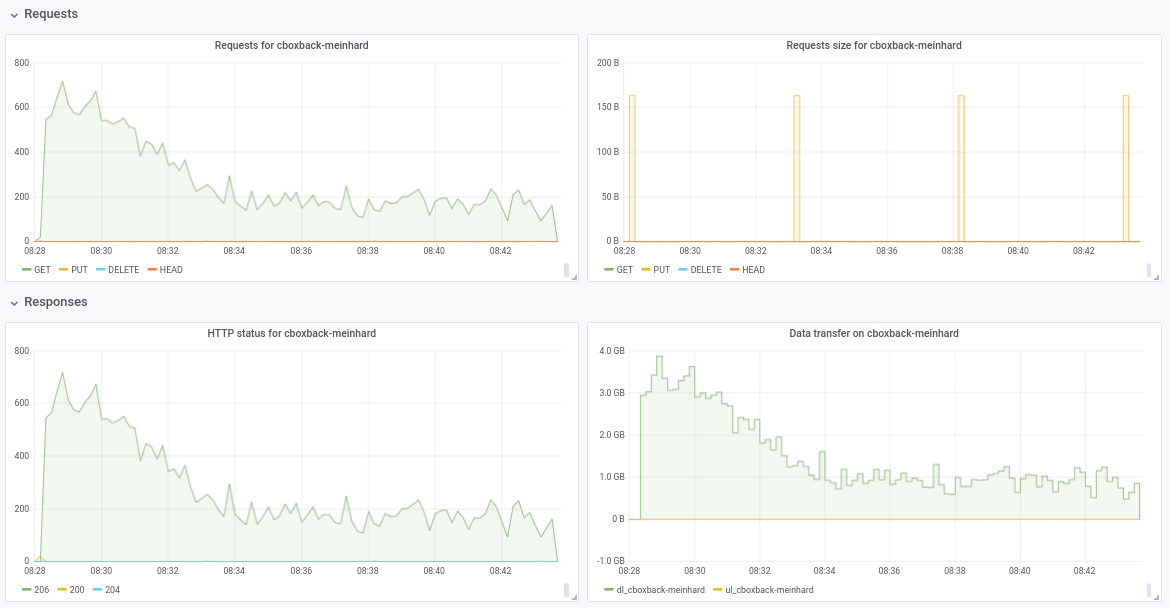
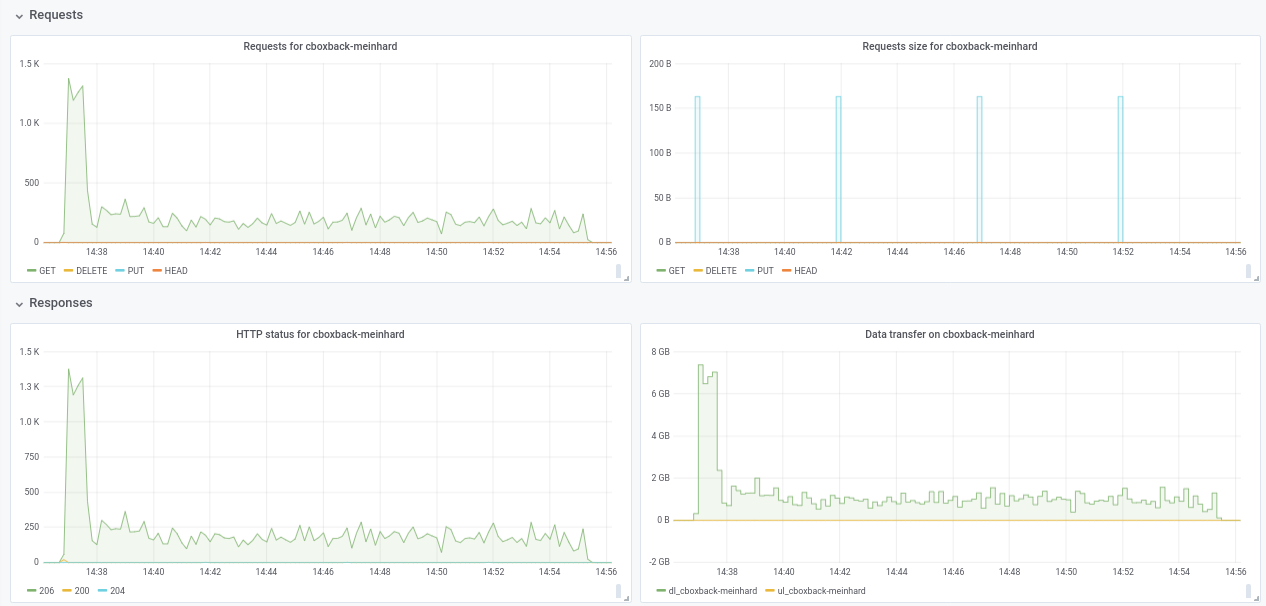
Não tenho certeza sobre a queda de desempenho de 32w para 64w (testado várias vezes e parece legítimo). Anexo alguns gráficos durante o processo, parece que existe alguma degradação ou limite, deveria ser assim? Por exemplo, com 64 trabalhadores, o processo começa em 6 gbit / s, mas depois cai para menos de 1 gbit / s até o final do processo (o que eu acho que corresponde ao tempo para processar esses arquivos grandes). A primeira captura de tela está com 32w, 32c e a segunda com 64w, 32c.
Também concordo com @pmkane , seria útil alterar o número do trabalhador na linha de comando. Seria muito útil para cenários de recuperação de desastres, quando você deseja restaurar seus dados o mais rápido possível. Há uma solicitação de pull sobre isso feita por meu colega de trabalho # 2178
De qualquer forma, estou realmente impressionado com as melhorias realizadas! muito obrigado @ifedorenko
robvalca
em 4 mar. 2019
++. Obrigado @ifedorenko , isso é uma mudança no jogo para o restic.
pmkane
em 4 mar. 2019
Obrigado pelo relatório detalhado @robvalca. Alguma chance de você fornecer um repositório de teste que eu possa no AWS (ou GCP ou Azure) ou localmente? Não vi queda na velocidade de restauração de arquivos grandes em meus testes e gostaria de entender o que está acontecendo lá.
ifedorenko
em 4 mar. 2019
@pmkane Eu também gostaria de configurar essas coisas em tempo de execução . Minha sugestão foi torná-los --option opções para que eles não atrapalhem os sinalizadores ou comandos regulares, mas estão lá para usuários 'avançados' que desejam experimentar ou ajustar sua situação incomum. Eles nem precisam ser documentados e podem receber nomes que deixam claro que você não pode contar com eles, como --option experimental.fooCount=32 .
 whereisaaron
em 4 mar. 2019
whereisaaron
em 4 mar. 2019
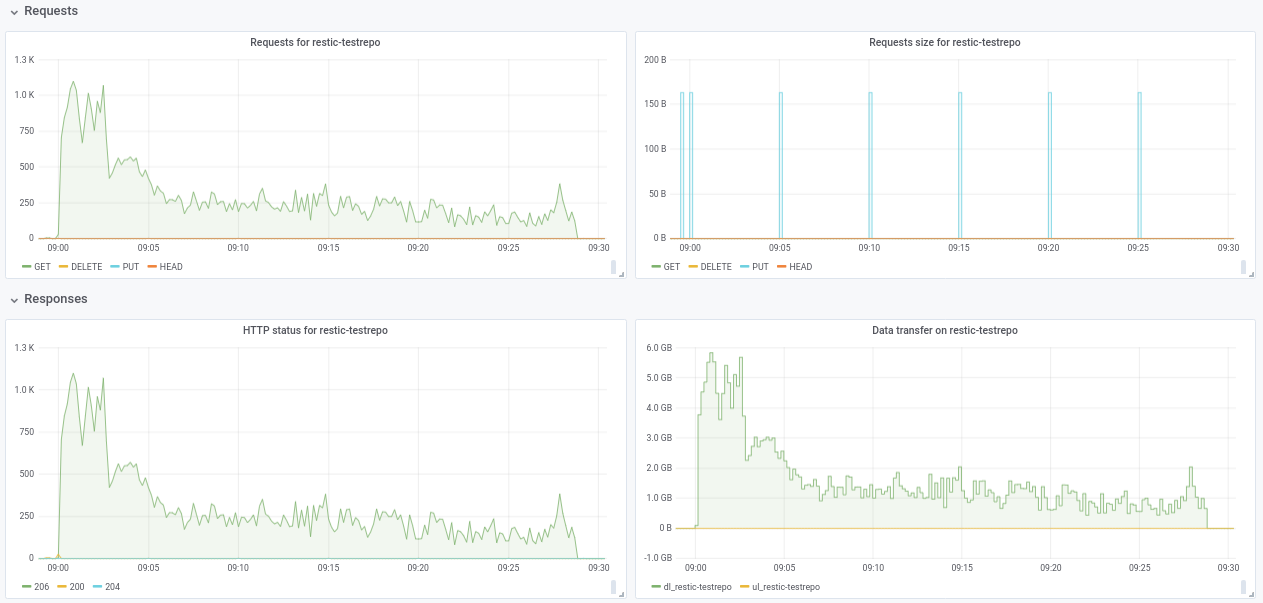
oi @ifedorenko , criei um inúteis em s3.cern.ch/restic-testrepo . É mais ou menos o mesmo formato que eu estava tentando (muitos arquivos pequenos e alguns muito grandes) e também consegui reproduzir o mesmo comportamento neste (plotagem em anexo). A senha do repo é restic . Avise-me se tiver problemas para acessá-lo.
robvalca
em 5 mar. 2019
@robvalca Não consigo reproduzir o problema usando seu repositório de teste. No AWS (us-east-2, s3 repo, i3.4xlarge 2x nvme raid0 target), vejo velocidade de restauração estável de 0,68 GB / s ao usar 32 workers e 32 conexões (tempo total de restauração de 6m20s). Seu sistema de destino não consegue sustentar 10 GB / s por muito tempo, se eu fosse adivinhar, pelo menos é o que eu verificaria primeiro se fosse resolver o problema mais adiante.
@pmkane curiosamente, também não posso confirmar suas observações. Como mencionei acima, vejo velocidade de restauração de 0,68 GB / s usando o último branch out-of-order-restore-no-progress (a restauração parecia vinculada à CPU) e 0,81 GB / s se eu desabilitar a verificação de hash de blob redundante (a restauração não parecia CPU- vinculado). Não sei o quão mais rápido uma rede de "até 10 Gbps" pode ir, mas acho que já estamos no território de "retornos decrescentes".
ifedorenko
em 6 mar. 2019
@ifedorenko Concordo plenamente com relação a: retornos decrescentes. É bastante rápido para nós do jeito que está.
pmkane
em 6 mar. 2019
@ifedorenko interessante, vou investigar isso ao nosso lado. De qualquer forma, é rápido o suficiente para nós também, muito obrigado pelo seu esforço.
robvalca
em 7 mar. 2019
Curioso sobre o status de obter isso mesclado. Este branch, combinado com o trabalho de @cbane na velocidade de poda, torna o restic utilizável para backups extremamente grandes.
pmkane
em 22 ago. 2019
Em breve ... 👀
 rawtaz
em 26 fev. 2020
rawtaz
em 26 fev. 2020
Fechando isso agora que o # 2195 foi mesclado. Sinta-se à vontade para reabri-lo se os detalhes desse problema não tiverem sido resolvidos. Se ainda houver melhorias a serem feitas que não sejam do tipo discutido nesta edição, abra uma nova edição. Obrigado!
rawtaz
em 26 fev. 2020
Questões relacionadas
 rakor
·
5Comentários
rakor
·
5Comentários
 christian-vent
·
3Comentários
christian-vent
·
3Comentários
 fd0
·
4Comentários
fd0
·
4Comentários
 TheLastProject
·
3Comentários
TheLastProject
·
3Comentários
 fbartels
·
3Comentários
fbartels
·
3Comentários
Comentários muito úteis
Curioso sobre o status de obter isso mesclado. Este branch, combinado com o trabalho de @cbane na velocidade de poda, torna o restic utilizável para backups extremamente grandes.