Berkat penggabungan PR1719, pemulihan di restic _way_ lebih cepat.
Namun, mereka bisa lebih cepat lagi.
Untuk tujuan pengujian, saya memulihkan dari bucket AWS S3 restic di wilayah yang sama (us-barat-1) sebagai instans i3.8xlarge EC2 khusus. Pemulihan bertentangan dengan nvme 4x1.9TB dalam instance, bergaris RAID-0 melalui LVM dengan sistem file xfs di bawahnya. Instance memiliki bandwidth teoritis 10gbit/dtk ke S3.
Dengan workerCount di filerestorer.go mencapai 32 (dari batas kompilasi 8), restic mengembalikan campuran 228k file dengan ukuran file rata-rata 8KB dan ukuran file maksimum 364GB dengan rata-rata 160mbit/dtk.
Sebagai perbandingan, rclone dengan --transfers=32 memindahkan data dari bucket yang sama pada 5636 mbit/dtk, lebih dari 30x lebih cepat.
Ini bukan perbandingan apel dengan apel. Gumpalan data restic berukuran 4096KB, bukan 8KB, dan membuka/menutup file pasti memiliki _some_ overhea. Tapi itu masih merupakan perbedaan yang cukup besar sehingga kemungkinan mengarah pada hambatan dalam restic.
Saya senang menguji berbagai hal, menyediakan instrumentasi, atau membantu dengan cara lain apa pun!
 pmkane
pmkane
Semua 71 komentar
160mbit/sec memang terlihat lambat. Saya mendekati 200Mbps pada unduhan macbook pro kecil dari onedrive melalui (diberikan cepat) koneksi ke 1Gbps. Saya tidak dapat mengatakan sesuatu yang spesifik tanpa akses ke sistem dan repositori Anda, tetapi berikut adalah beberapa hal yang akan saya lakukan untuk mempersempit masalah, tanpa urutan tertentu:
- Perkirakan waktu yang diperlukan untuk mengunduh file paket tunggal pada satu utas. Anda dapat menghitung ini dari tes unduhan rclone 32x Anda, tetapi saya juga ingin tahu waktu untuk mengunduh paket individual dengan curl sehingga kami dapat memperkirakan overhead permintaan http juga.
- Saya akan memeriksa statistik OS berapa banyak sebenarnya unduhan restic dari S3 selama pemulihan. Ini akan memberi tahu kami jika pemulihan mengunduh file paket individual beberapa kali (yang mungkin, tetapi tidak boleh terlalu sering terjadi, kecuali saya mengabaikan sesuatu).
- Tingkat konkurensi S3 tampaknya terbatas hanya pada 5 koneksi . Bisakah ini menjelaskan kecepatan pemulihan yang Anda lihat dengan perkiraan kecepatan utas tunggal dari atas? Apa yang terjadi jika Anda meningkatkan batas koneksi backend S3 agar sesuai dengan restorer?
- Grafik pemanfaatan jaringan selama pemulihan untuk melihat apakah ada celah atau penurunan.
- Kecualikan file 364GB itu dari pemulihan dan lihat apa yang terjadi. File individual saat ini dipulihkan secara berurutan, sehingga file yang satu ini dapat secara signifikan mengubah kecepatan unduhan rata-rata.
 ifedorenko
pada 7 Nov 2018
ifedorenko
pada 7 Nov 2018
Hai, yang di sana!
Terima kasih balasannya. Ini menarik untuk digali
tl; dr: meningkatkan koneksi s3 adalah kuncinya, tetapi peningkatan kinerja yang diberikannya bersifat sementara, anehnya.
- Mentransfer paket senilai satu direktori (3062 file dengan total 13GB) / dengan rclone --transfers 1 berjalan pada 233mbit/dtk. Dikonfirmasi dengan lsof bahwa itu hanya berjalan dengan satu utas dan satu koneksi https dalam mode itu. Kecepatan puncak dicapai dengan --transfers 32 (8,5 gbit/dtk, pada dasarnya kecepatan jalur untuk instans i3.8xlarge ec2 ini). Dalam kedua kasus kami menulis ke array nvme bergaris.
- Senang mengumpulkan beberapa statistik, tetapi apa yang ingin Anda lihat, khususnya? (tetapi mungkin tidak diperlukan, silakan lihat di bawah)
- Akan membunuh dua burung dengan satu batu di sini! Berikut grafik pemanfaatan jaringan selama pemulihan dengan:
- sisa stok dengan PR ini digabungkan (komit c0572ca15f946c622d9c4009347dc4d6c31cba4c)
- restic dengan workerCount menabrak 32 dan filesWriterCount menabrak 128
- restic dengan perubahan sebelumnya + koneksi s3 meningkat menjadi 32.
- resitc dengan perubahan sebelumnya + koneksi s3 meningkat menjadi 64.
- rclone dengan --transfers 32 memindahkan data/ direktori
Jumlah bandwidth dalam kbps dan diambil pada interval 3 detik selama 10 menit. Untuk proses restic, kami mulai mengumpulkan data _after_ restic sudah mulai benar-benar memulihkan file (yaitu, tidak termasuk waktu startup dan waktu yang dihabiskan restic di awal proses menciptakan kembali hierarki direktori. Selama semua proses, penggunaan CPU pada contoh tidak melebihi 25%.
Kami mendapatkan sedikit perbedaan dari peningkatan workerCount, tetapi konkurensi S3 terlihat seperti di mana kemenangan sebenarnya. Tapi sementara itu mulai kuat (mendekati kecepatan rclone, kadang-kadang!), Harga turun tiba-tiba dan tetap turun selama sisa perjalanan. restic juga memunculkan kesalahan yang terlihat seperti "mengabaikan kesalahan untuk [path disunting]: kapasitas cache tidak cukup: diminta 2148380, tersedia 872640" yang tidak dibuang dengan konkurensi s3 yang lebih rendah.
Seperti yang Anda lihat, kinerja rclone mulai tinggi dan tetap tinggi, jadi ini bukan situasi di mana penulisan akan ke cache buffer instance dan kemudian terhenti ketika mereka dipindahkan ke disk. Array nvme lebih cepat daripada pipa jaringan, dari segi throughput.
- Saya tidak berpikir satu file besar adalah faktor, karena saya mengukur IO disk/jaringan selama pemulihan, jadi fakta bahwa mungkin perlu beberapa saat agar file tunggal itu dipulihkan sepenuhnya tidak akan memengaruhi jumlah yang kami sedang melihat ke sini.
Mengingat hal di atas, sepertinya meningkatkan konkurensi S3 adalah apa yang diperlukan untuk mendapatkan harga yang wajar di sini, tetapi perlu mencari tahu mengapa kinerjanya menurun (dan apakah itu terkait dengan kesalahan cache atau tidak).
Jika membuat instans i3 cepat dan beberapa ruang dan bandwidth s3 tersedia untuk pengujian Anda akan membantu, beri tahu saya, dengan senang hati mensponsori itu.
pmkane
pada 7 Nov 2018
233mbit/dtk kali 32 adalah 7456 dan sedikit kurang dari 8,5 gbit/dtk. Yang aneh. Saya berharap unduhan utas tunggal lebih cepat daripada throughput per aliran unduhan multi-utas. Tidak yakin apa artinya ini, jika ada.
Saya ingin memastikan restic tidak mengunduh ulang paket yang sama berulang kali. Saya pikir grafik menunjukkan unduhan ulang tidak menjadi masalah, jadi tidak perlu lebih banyak statistik, setidaknya tidak sekarang.
Bisakah Anda mengkonfirmasi skala grafik? rclone melayang di sekitar garis berlabel "1000000", jika itu adalah "1.000.000 kbps", yang menurut saya berarti "1gbps" dan tidak sesuai dengan angka "8.5 gbit/sec" yang Anda sebutkan sebelumnya.
Seperti yang saya katakan, file individual dipulihkan secara berurutan. Pengunduhan 364 GB pada 233mbit/s akan memakan waktu sekitar 3,5 jam, dan mungkin lebih lama karena overhead per paket dan dekripsi, yang semuanya terjadi secara berurutan. Tidak tahu apakah 3,5 jam adalah sesuatu yang dapat Anda buang sebagai tidak signifikan tanpa mengetahui berapa banyak sisa pemulihan yang diperlukan.
Untuk kesalahan not enough cache capacity , naikkan averagePackSize ke ukuran file paket terbesar di repositori Anda (berapa besar, btw?) Dan saya perlu memikirkan bagaimana ukuran cache yang lebih baik, belum siap menjawab belum.
ifedorenko
pada 7 Nov 2018
Hai, yang di sana!
Ups, maaf. Skala dalam grafik adalah KB/detik bukan kbit/detik. Jadi 1.012.995 di baris pertama adalah 8.1gbit/detik.
Saya mengerti bahwa file dipulihkan secara berurutan, tetapi tidak mengerti bahwa tidak ada paralelisme untuk pengambilan paket untuk satu file. Itu pasti sedikit batu sandungan untuk backup dengan file besar, karena itu menjadi faktor pembatas Anda. Akan luar biasa untuk memiliki beberapa paralelisme di sini karena alasan itu.
Mengambil sampel 10 ember acak, ukuran paket maksimum kami hanya di bawah 12MB dan ukuran paket rata-rata kami adalah 4,3MB.
Mungkin dengan lebih banyak pekerja dan koneksi S3, kami melebihi kapasitas packCache dari (workerCount + 5) * rata-rataPackSize. Saya akan mencoba meningkatkannya dan melihat apakah kesalahannya hilang.
pmkane
pada 7 Nov 2018
Mungkin dengan lebih banyak pekerja dan koneksi S3, kami melebihi kapasitas packCache dari (workerCount + 5) * rata-rataPackSize. Saya akan mencoba meningkatkannya dan melihat apakah kesalahannya hilang.
Ukuran cache dihitung berdasarkan ukuran file paket 5MB dan workerCount . Meningkatkan workerCount meningkatkan ukuran cache. Jadi apakah ada kebocoran memori atau pemulihan, perlu untuk men-cache banyak file 12MB secara kebetulan. Menaikkan averagePackSize ke 12MB akan memberi tahu kami yang mana.
ifedorenko
pada 7 Nov 2018
Tidak ada kesalahan cache dengan averagePackSize diatur ke 12.
Jika ada info lain yang dapat kami berikan yang dapat membantu, beri tahu saya! Terima kasih lagi.
pmkane
pada 8 Nov 2018
Sepertinya kita kehilangan paralelisme saat pemulihan berlangsung dan sepertinya tidak terkait dengan file besar. Saya akan mengumpulkan kasus uji dan melaporkan kembali.
pmkane
pada 8 Nov 2018
Hai, yang di sana!
Saya mencoba mereproduksi penurunan kinerja yang saya lihat dengan campuran file produksi saya dengan tiga campuran file buatan yang berbeda.
Untuk semua tes, saya menggunakan c0572ca15f946c622d9c4009347dc4d6c31cba4c dengan koneksi S3 meningkat menjadi 128, workerCount meningkat menjadi 128, filesWriterCount meningkat menjadi 128 dan rata-rataPackSize meningkat menjadi 12 * 1024 * 1024.
Semua pengujian menggunakan file dengan data acak, untuk menghindari dampak dari deduplikasi.
Untuk pengujian pertama, saya membuat dan mencadangkan 4.000 file 100MB, dibagi secara merata di 100 direktori (total ~400GB). Pencadangan dan pemulihan dijalankan dari volume nvme bergaris pada instans i3.8xlarge. Bucket cadangan adalah lokasi di region yang sama dengan instance (us-west-1).
Dengan campuran file ini, saya melihat kecepatan rata-rata 9,7gbit/dtk (!) tanpa kehilangan paralelisme atau kecepatan di seluruh pemulihan penuh. Angka-angka ini setara atau di atas angka rclone dan pada dasarnya kecepatan garis, yang fantastis.
Saya kemudian membuat dan mencadangkan 400.000 file 1MB, dibagi secara merata di 100 direktori (sekali lagi, ~ total 400GB).
Hasil yang sama (sangat baik) seperti di atas.
Akhirnya, saya membuat 40 direktori dengan 1 file 10GB per direktori. Di sini, hal-hal menjadi menarik.
Saya berharap pemulihan ini akan sedikit lebih lambat, karena restic hanya dapat melakukan 40 pemulihan simultan dengan 40 koneksi ke S3.
Namun, sebaliknya, sementara Restic membuka semua 40 file untuk menulis dan menulis ke semua 40 file secara bersamaan, itu hanya membuat satu koneksi TCP ke S3 terbuka pada satu waktu, bukan 40.
Beri tahu saya statistik atau instrumentasi apa yang ingin Anda lihat.
pmkane
pada 8 Nov 2018
Bisakah Anda mengonfirmasi ada 128 koneksi S3 selama pengujian "cepat"?
ifedorenko
pada 8 Nov 2018
Ya ada.
pmkane
pada 8 Nov 2018
Penasaran... Dukungan file besar tidak terlalu tinggi dalam daftar prioritas saya, tapi saya mungkin menemukan beberapa waktu untuk melihat ini dalam beberapa minggu ke depan. Jika ada yang ingin menggali ini sebelum saya melakukannya, beri tahu saya.
ifedorenko
pada 8 Nov 2018
Melakukan beberapa pengujian lagi dan sepertinya ukuran file adalah ikan haring merah, jumlah file yang mendorong jumlah koneksi AWS.
Dengan 128 file 10 MB di 4 direktori, restic hanya membuka 6 koneksi ke AWS, meskipun menulis ke semua 128 file.
Dengan 512 file 10 MB dalam 4 direktori, restic membuka 18 koneksi selama masa pakainya, meskipun memiliki 128 file yang dibuka sekaligus.
Dengan 5.120 file 10 MB dalam 4 direktori, restic hanya membuka 75 koneksi ke AWS selama masa pakainya, sekali lagi menahan 128 file terbuka sekaligus.
Aneh!
pmkane
pada 8 Nov 2018
Saya akan sangat terkejut jika klien Go S3 tidak mengumpulkan & menggunakan kembali koneksi http. Kemungkinan besar tidak ada korelasi satu-ke-satu antara jumlah pekerja bersamaan dan soket TCP terbuka. Jadi, misalnya, jika pemulihan lambat memproses paket yang diunduh karena alasan apa pun, koneksi S3 yang sama akan digunakan bersama oleh banyak pekerja.
ifedorenko
pada 8 Nov 2018
Ada dua properti dari pemulih bersamaan saat ini yang bertanggung jawab atas sebagian besar kompleksitas implementasi dan kemungkinan besar menyebabkan pelambatan yang dilaporkan di sini:
- file individual dipulihkan dari awal hingga akhir
- jumlah file yang sedang diproses dijaga agar tetap minimum
Implementasi akan jauh lebih sederhana, menggunakan lebih sedikit memori dan sangat mungkin lebih cepat dalam banyak kasus jika kita setuju untuk menulis gumpalan file dalam urutan apa pun dan mengizinkan sejumlah file yang sedang diproses.
Kelemahannya, tidak mungkin untuk mengetahui berapa banyak data yang telah dipulihkan dalam file apa pun hingga akhir pemulihan. Yang mungkin membingungkan, terutama jika pemulihan macet atau terbunuh. Jadi Anda mungkin melihat file 10GB pada sistem file, yang pada kenyataannya hanya memiliki beberapa byte yang ditulis di akhir file.
@ fd0 menurut Anda apakah perlu meningkatkan pemulihan awal hingga akhir saat ini? Secara pribadi, saya siap untuk mengakui bahwa itu adalah rekayasa di pihak saya dan dapat memberikan implementasi yang lebih sederhana jika Anda setuju.
ifedorenko
pada 16 Nov 2018
Saya tidak ingat apakah Restic mendukung pemulihan ke output standar. Jika ya, Anda jelas harus menyimpan pemulihan awal hingga akhir untuk itu (mungkin sebagai kasus khusus).
 pvgoran
pada 16 Nov 2018
pvgoran
pada 16 Nov 2018
@ifedorenko Saya pribadi mendukung penyederhanaan, secara umum, terutama jika itu disertai dengan peningkatan kinerja. Saya mencoba memahami pengorbanannya:
Kelemahannya, tidak mungkin untuk mengetahui berapa banyak data yang telah dipulihkan dalam file apa pun hingga akhir pemulihan.
Jika kita tidak membicarakan ribuan file yang ditulis secara bersamaan di sini, mungkin peta nama file ke byte yang ditulis dapat digunakan? Jelas tidak akan membuat info tersedia ke sistem file, tetapi, untuk pelaporan kemajuan, masih bisa dilakukan, bukan? (Dan untuk melanjutkan pemulihan yang terganggu, mungkin hanya memeriksa gumpalan dan offset file untuk byte non-null, mungkin? Saya tidak tahu.)
Saya tidak ingat apakah Restic mendukung pemulihan ke output standar. Jika ya, Anda jelas harus menyimpan pemulihan awal hingga akhir untuk itu (mungkin sebagai kasus khusus).
Saya rasa tidak - toh tidak yakin bagaimana cara kerjanya, karena pemulihan adalah banyak file, Anda harus menyandikannya entah bagaimana dan memisahkannya entah bagaimana menurut saya.
 mholt
pada 16 Nov 2018
mholt
pada 16 Nov 2018
Jika kita tidak membicarakan ribuan file yang ditulis secara bersamaan di sini, mungkin peta nama file ke byte yang ditulis dapat digunakan?
Implementasi paling sederhana adalah membuka dan menutup file untuk menulis gumpalan individu. Jika ini terbukti terlalu lambat, maka kita harus menemukan cara untuk menjaga file tetap terbuka untuk beberapa penulisan blob, misalnya dengan menyimpan file yang terbuka di cache dan memesan unduhan paket untuk mendukung file yang sudah terbuka.
Pulihkan sudah melacak gumpalan apa yang ditulis ke file apa dan apa yang masih tertunda. Saya tidak berharap bagian ini banyak berubah. Kemajuan dilacak dalam struktur data terpisah dan saya juga tidak berharap itu berubah.
Dan untuk melanjutkan pemulihan yang terganggu, mungkin hanya memeriksa gumpalan dan offset file untuk byte non-null, mungkin?
Resume perlu memverifikasi checksum file pada disk untuk memutuskan gumpalan apa yang masih perlu dipulihkan. Saya percaya ini benar terlepas dari apakah pemulihan berurutan atau rusak. Sebagai contoh, jika resume pulih dari kegagalan daya, saya tidak berpikir itu dapat mengasumsikan semua blok file di-flush ke disk sebelum pemadaman listrik, yaitu file dapat memiliki celah atau blok yang ditulis sebagian.
ifedorenko
pada 16 Nov 2018
@pmkane bertanya-tanya apakah Anda dapat mencoba #2101? itu mengimplementasikan pemulihan yang tidak berurutan, meskipun penulisan ke file individual masih bersambung dan kinerja pemulihan file besar mungkin masih kurang optimal. dan Anda perlu mengubah jumlah pekerja seperti sebelumnya.
ifedorenko
pada 27 Nov 2018
Sangat. Saya bepergian minggu ini tetapi akan menguji sesegera mungkin dan melaporkan kembali.
pmkane
pada 27 Nov 2018
@ifedorenko Saya mencoba PR ini dan berhasil membuat struktur direktori, tetapi kemudian semua
Memuat(, 3172070, 0) mengembalikan kesalahan, mencoba lagi setelah 12.182749645s: EOF
master memulihkan baik-baik saja.
Perintah pemulihan saya adalah:
/usr/local/bin/restic.outoforder -r s3:s3.amazonaws.com/[redacted] -p /root/.restic_pass restore [snapshotid] -t .
Beri tahu saya info tambahan apa yang bisa saya berikan untuk membantu debug.
pmkane
pada 1 Des 2018
Berapa banyak permintaan unduhan S3 bersamaan yang Anda izinkan? Jika 128, dapatkah Anda membatasinya menjadi 32 (yang kami tahu berfungsi)?
Semi-terkait... apakah Anda tahu berapa banyak file indeks yang dimiliki repositori Anda yang sebenarnya? Mencoba memperkirakan berapa banyak kebutuhan pemulih memori.
ifedorenko
pada 1 Des 2018
Saya tidak menentukan batas koneksi, jadi saya menganggapnya default ke 5.
Saya mendapatkan kesalahan yang sama dengan -o s3.connections=2 dan -o s3.connections=1.
Saat ini saya memiliki 85 gumpalan indeks di folder index/. Ukuran totalnya 745MB.
pmkane
pada 1 Des 2018
Hmm. Saya akan melihat lagi ketika saya sampai di komputer saya nanti hari ini. Btw, "error yang dikembalikan, coba lagi" adalah peringatan, bukan kesalahan, jadi mungkin terkait dengan kegagalan pemulihan atau mungkin hanya ikan haring merah.
ifedorenko
pada 1 Des 2018
Tidak yakin bagaimana saya melewatkannya ... pemulih tidak sepenuhnya membaca semua file paket dari backend dalam banyak kasus. Harus diperbaiki sekarang. @pmkane dapatkah Anda mencoba tes Anda lagi?
ifedorenko
pada 2 Des 2018
Aku akan memberikannya pusaran!
pmkane
pada 2 Des 2018
Dikonfirmasi bahwa file berhasil dipulihkan dengan perbaikan ini. Menguji kinerja sekarang.
pmkane
pada 2 Des 2018
Sayangnya sepertinya lebih lambat dari master. Semua pengujian dijalankan pada instans i3.8xlarge yang dijelaskan di atas.
Dengan workerCount 8 (default), cabang yang rusak dipulihkan pada 86mbit/dtk.
Dengan workerCount mencapai 32, hasilnya sedikit lebih baik -- rata-rata pada 160mbit/dtk.
Pemanfaatan CPU dengan cabang ini secara signifikan lebih tinggi daripada di master, tetapi tidak memaksimalkan CPU instans dalam kedua kasus tersebut.
Secara anekdot, UI pemulihan membuatnya tampak seperti ada sesuatu yang "menempel", hampir seperti bersaing dengan dirinya sendiri untuk mengunci di suatu tempat.
Dengan senang hati memberikan lebih banyak detail, pembuatan profil, atau contoh uji untuk direplikasi.
pmkane
pada 2 Des 2018
Hanya untuk mengonfirmasi, Anda memiliki jumlah pekerja pemulih dan backend s3 yang disetel ke 32, bukan?
Beberapa pemikiran yang mungkin menjelaskan perilaku yang Anda amati:
- Menulis ke file individu masih serial. Saya _menebak_ ini tidak akan menjadi masalah dengan sistem file target cepat, tetapi tidak pernah mengukurnya.
- File buka/tutup di sekitar setiap gumpalan pasti berkontribusi pada overhead pemulih. Ketika saya mengukur ini di macos, saya dapat "membuka file; menulis satu byte; menutup file" 100 ribu kali dalam ~ 70 detik, yang mendekati overhead menulis 100 ribu gumpalan. Tesnya sangat sederhana dan overhead kehidupan nyata mungkin jauh lebih tinggi.
- Saat ini saya tidak memiliki penjelasan yang masuk akal untuk penggunaan CPU yang tinggi. Implementasi yang tidak berurutan mendekripsi setiap gumpalan hanya sekali (master mendekripsi gumpalan untuk setiap file target), dan pembukuan jauh lebih sedikit dibandingkan dengan master. Mungkin penulisan file "jarang" tidak terlalu jarang dan mengharuskan Go atau OS melakukan sesuatu yang membutuhkan banyak CPU. Tidak benar-benar tahu.
ifedorenko
pada 2 Des 2018
Hei!
Betul sekali. workerCount disetel ke 8 atau 32 di internal/restorer/filerestorer.go dan -o s3.connections=32 diteruskan melalui restic cli dalam kedua kasus.
pmkane
pada 3 Des 2018
Berikut adalah tampilan tingkat atas dari data pelacakan saat cabang yang rusak sedang memulihkan file dengan 8 pekerja.
Sepertinya ada jeda signifikan (>500-1000 md) yang sering dialami pekerja.
pmkane
pada 3 Des 2018
Saya memutuskan untuk meluangkan lebih banyak waktu untuk ini dan mulai dengan menulis tes mandiri sederhana yang menghasilkan byte acak 10GiB dalam blok 4KiB. Tujuan saya adalah untuk menilai seberapa cepat sistem saya dapat memindahkan byte. Sangat mengejutkan saya, tes ini membutuhkan waktu 18,64 detik untuk dijalankan pada macbook pro saya (2018, Intel Core i7) 2,6 GHz. Yang diterjemahkan menjadi ~ 4,29 Gigabits/s atau sekitar setengah dari apa yang dapat dilakukan ethernet 10G. Dan ini tanpa crypto atau net atau disk i/o. Dan saya menggunakan Xoshiro256** prng, math/rand sekitar 2x lebih lambat, yang tentu saja benar-benar tidak penting. Intinya adalah, restorer harus memproses gumpalan pada beberapa utas untuk menjenuhkan jaringan 10G, net i/o multithreaded dengan sendirinya tidak cukup.
Dan hanya untuk bersenang-senang, impl karat yang sebanding menghasilkan 10GiB byte acak dalam 3,1 detik, dan java dalam 10,77 detik. Pergi gambar :-)
ifedorenko
pada 6 Feb 2019
Tes yang menarik!
Saya mengerti bahwa restic akan dibatasi oleh jumlah waktu yang diperlukan untuk memulihkan file terbesar, saat ini.
Saat ini, bagaimanapun, itu bukan pemblokir kami, karena saya tahu bahwa restic dapat memulihkan satu file jauh lebih cepat daripada 160mbit/detik yang kita lihat di sini.
Saya akan menyusun repo uji 100GB yang terdiri dari file 10MB pada SSD cepat dan di S3 dan menjalankan beberapa angka, untuk mendapatkan skenario kasus terbaik saat ini di master dan di cabang ini.
pmkane
pada 6 Feb 2019
Hai semua, apakah ada cara untuk mengubah jumlah pekerja menggunakan parameter atau harus dilakukan langsung pada kode? Kami juga mengalami masalah pemulihan yang lambat dan saya ingin meningkatkan apa yang kami miliki... Tolong beri tahu saya jika saya dapat berkontribusi dengan tes untuk membantu meningkatkan bagian ini!
Terima kasih!
 robvalca
pada 19 Feb 2019
robvalca
pada 19 Feb 2019
@robvalca backend apa yang Anda gunakan? seberapa cepat rclone menyalin repo Anda ke sistem target? apa itu kecepatan restic restore?
Saat ini saya tidak yakin apa yang terjadi, jadi akan sangat berguna jika Anda dapat memberikan repo pengujian dan langkah-langkah yang dapat saya gunakan untuk mereproduksi masalah secara lokal (dan dengan "test repo" maksud saya data sampah/acak, tidak ada data pribadi mohon datanya).
ifedorenko
pada 22 Feb 2019
@ifedorenko kami menggunakan S3 (ceph+radosgw) sebagai backend (dikelola oleh kami). Saya sudah mencoba menyalin repo menggunakan rclone dan ini adalah hasilnya:
rclone copy -P remote:cboxback-aabbcc/ /var/tmp/restic/aabbcc/
Ditransfer: 127.309G / 127.309 GByte, 100%, 45.419 MBytes/s, ETA 0s
Kesalahan: 0
Cek : 0/ 0, -
Ditransfer: 25435 / 25435, 100%
Waktu yang berlalu: 47m50.2s
Pemulihan repo menggunakan restic "stok" 0.9.4 membutuhkan waktu ~8 jam. Dalam kedua kasus saya menggunakan 32 koneksi S3 dan host target yang sama. Saya telah menempatkan sedikit informasi lebih lanjut di utas forum ini.
Saya akan menyiapkan repo untuk Anda uji dan memberi tahu Anda jika sudah siap,
Terima kasih banyak atas bantuan Anda!
robvalca
pada 25 Feb 2019
@robvalca dapatkah Anda mencoba memulihkan menggunakan cabang out-order-restore saya ? cabang seharusnya meningkatkan kinerja pemulihan file yang sangat besar, yang tampaknya menjadi masalah yang Anda hadapi.
jika cabang tidak meningkatkan kinerja pemulihan untuk Anda, harap unggah repo uji ke ember s3 publik dan posting nama ember dan kata sandi repo di sini.
ifedorenko
pada 26 Feb 2019
@pmkane apakah mungkin Anda mengembalikan sejumlah besar file yang identik atau hampir identik? itu akan menjelaskan perselisihan di antara para pekerja, saya pikir.
Sunting: sebenarnya, dapatkah Anda mencoba kembali uji kinerja pemulihan Anda menggunakan #2101 terbaru? Itu harus menangani penulisan bersamaan ke file yang sama dan gumpalan yang sama ke banyak file dengan lebih baik sekarang.
ifedorenko
pada 26 Feb 2019
@ifedorenko memang, dengan versi out-order sekarang jauh lebih baik! Butuh waktu kurang dari satu jam yang lebih dekat dari apa yang saya dapatkan dengan rclone. Beberapa komentar yang dapat saya ekstrak dari pengujian saya jadi mungkin Anda dapat menemukannya berguna (lihat plot terlampir juga!):
- Pada restic normal
0.9.4proses dimulai lebih cepat, dengan puncak200MB/secdan kami mendapatkan hampir50 requestsper detik di sisi S3. Setelah hanya beberapa menit, degradasi terjadi dan permintaan turun menjadi 1 atau lebih dan kecepatan ~5MB/secselama sisa proses. - Dengan versi "ooo", kecepatan transfer adalah seperti
40MB/secdan ~8Permintaan S3 stabil selama semua proses. - Hal lain yang saya perhatikan adalah saya hampir tidak melihat peningkatan pada peningkatan koneksi S3, apakah ini yang diharapkan?
32 koneksi:
Created 2197 directories, listed 171.141 GiB in 20930 files
Restored 171.136 GiB in 170258 files
real 57m54.588s
user 229m25.229s
sys 6m51.763s
64 koneksi
real 53m13.876s
user 242m57.081s
sys 7m12.455s
- Akhirnya melakukan tes dengan repositori lain yang berbeda (51G, 1.3M file kecil, banyak duplikat) dan masih lebih cepat dari 0.9.4 dengan margin yang baik:
0.9.4
real 16m6.966s
user 25m4.116s
sys 4m19.424s
0.9.4-oo:
real 8m14.375s
user 14m30.107s
sys 3m41.538s
Jadi tidak hanya meningkatkan dengan file besar, itu meningkatkan semua kasus!!
Dan btw, tampilan kemajuan baru dari pemulihan bagus!! 8)
Beri tahu saya jika Anda ingin saya melakukan beberapa tes lain.
Terima kasih!
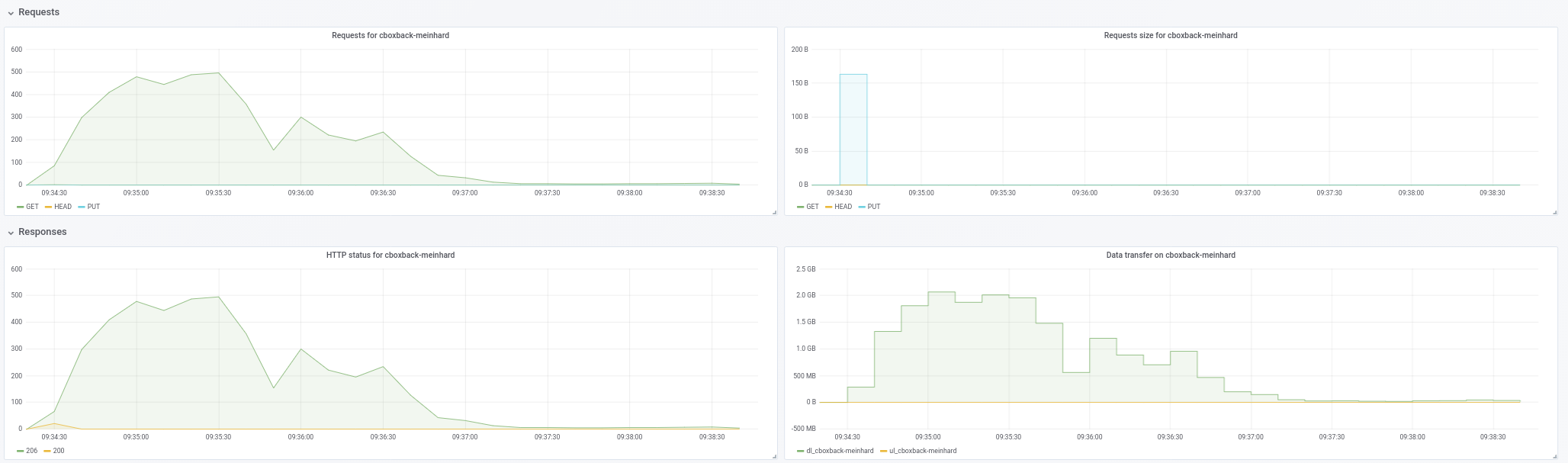
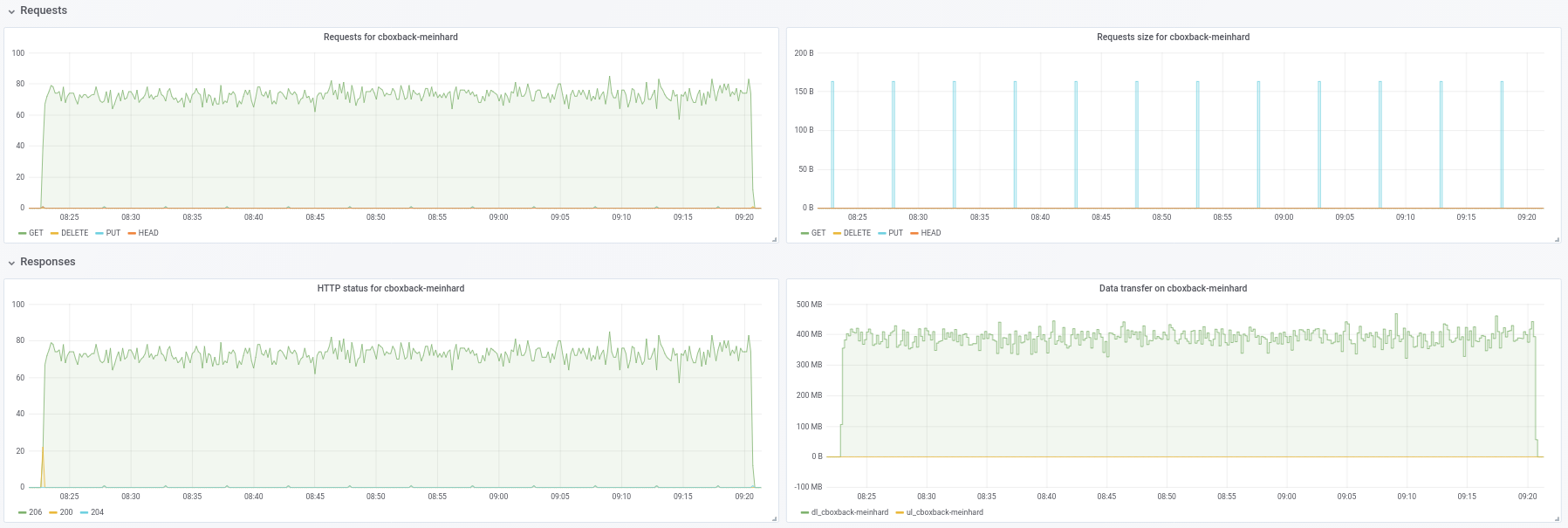
robvalca
pada 26 Feb 2019
Terima kasih atas feedbacknya, @robvalca , sangat bermanfaat.
- Hal lain yang saya perhatikan adalah saya hampir tidak melihat peningkatan pada peningkatan koneksi S3, apakah ini yang diharapkan?
Maaf, lupa menyebutkan bahwa Anda perlu mengubah kode untuk menambah jumlah pekerja pemulihan bersamaan. Ini di-hardcode ke 8 saat ini:
https://github.com/ifedorenko/restic/blob/099f51c01c189a84b96be86ce6be61a45e3705fc/internal/restorer/filerestorer.go#L22
Beri tahu saya jika Anda ingin saya melakukan beberapa tes lain.
Kami masih tidak tahu apa yang menyebabkan pertikaian pekerja selama pemulihan rusak yang disebutkan sebelumnya dalam masalah ini https://github.com/restic/restic/issues/2074#issuecomment -443759511. Bisakah Anda menguji komit khusus ini?
https://github.com/ifedorenko/restic/commit/d410668ce3a8c7284d86a2b06bf42a0e654d43bc? Jika Anda mengamati perselisihan dengan repositori Anda, itu berarti itu tidak spesifik untuk data pmkane dan bahwa perubahan terbaru saya memperbaiki perselisihan tersebut.
Terima kasih sekali lagi atas bantuan Anda.
ifedorenko
pada 26 Feb 2019
Hi semua -- masih memantau ini, tapi sudah benar-benar kebanjiran. Saya akan menyusul akhir pekan ini dan melihat apakah kami masih dapat mereproduksi dengan ifedorenko@d410668. Data kami tidak identik/hampir identik, tetapi jika itu penting, sebagian besar dikompresi.
pmkane
pada 26 Feb 2019
@ifedorenko Terima kasih, dengan 32 pekerja prosesnya jauh lebih cepat hingga 30 menit yang merupakan hasil yang bagus. Saya sudah mencoba juga meningkatkan pekerja/s3.koneksi ke 64/64, 128/128 tetapi saya tidak melihat peningkatan, mendapatkan hasil yang hampir sama. Bagaimanapun, saya senang dengan hasil saat ini.
Saya mencoba juga versi dengan https://github.com/ifedorenko/restic/commit/d410668 Anda menunjuk saya dan ini adalah tangkapan layar dari jejaknya. Saya tidak punya banyak pengalaman dengan alat semacam ini tetapi tampaknya mirip dengan hasil @pmkane . Saya telah menjalankannya dengan 8 pekerja dan dengan -o s3.connections=32
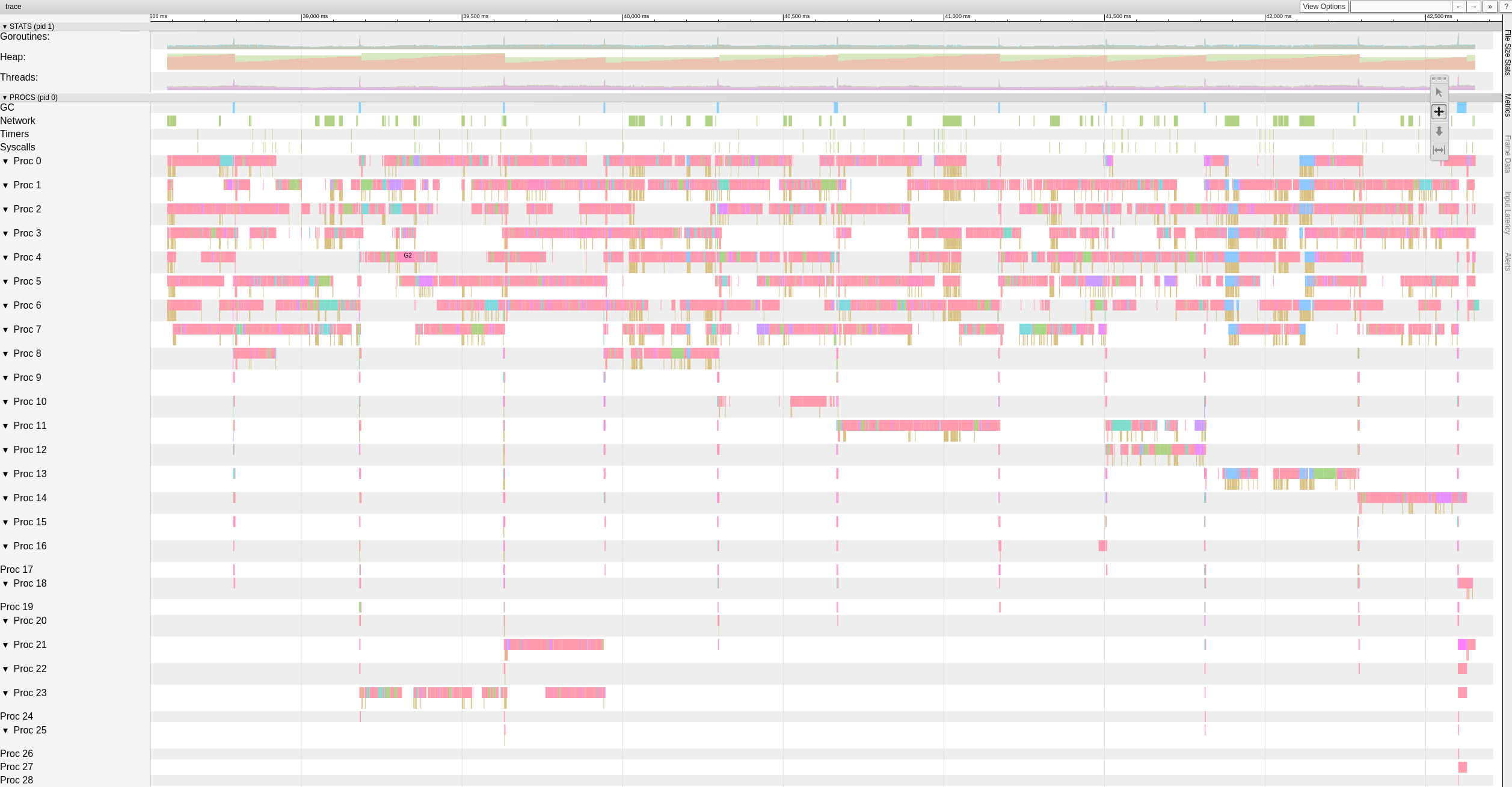
robvalca
pada 27 Feb 2019
@robvalca jadi ifedorenko@d410668 secara signifikan lebih lambat dibandingkan dengan kepala cabang, kan? ini adalah kabar baik, artinya kita mungkin telah mengatasi semua masalah yang diketahui. terima kasih atas pembaruannya.
ifedorenko
pada 27 Feb 2019
@ifedorenko tidak, saya lupa menyebutkan, kinerjanya kurang lebih sama dengan kepala cabang (out-of-order) dengan jumlah pekerja yang sama (8) dan S3.koneksi (32). Keduanya membutuhkan waktu ~55m, yang sejalan dengan waktu untuk mentransfer repo dengan rclone (~47m)
Beri tahu saya jika Anda ingin saya menguji dengan parameter lain;)
robvalca
pada 27 Feb 2019
Saya menemukan pemicu masalah kinerja dalam kasus penggunaan saya. Mengembalikan kinerja untuk file besar adalah non-linear di luar ukuran file tertentu.
Untuk menguji, saya membuat repo baru di S3 dan kemudian mencadangkan 6 file yang berisi data acak ke repo. File berukuran 1, 5, 10, 20, 40 dan 80GB.
Seperti pengujian sebelumnya, pengujian dijalankan pada instans i3.8xlarge dengan pencadangan dan pemulihan terjadi pada SSD bergaris yang cepat.
Waktu pencadangan linier, seperti yang diharapkan (8, 25, 46, 92, 177, dan 345 detik).
Namun, waktu pemulihan bukanlah:
1gb, 5s
5gb, 17s
10gb, 33s
20gb, 85s
40gb, 256s
80gb, 807s
Jadi ada sesuatu yang aneh terjadi dengan file besar dan memulihkan kinerja.
Ember tersebut diberi nama pmk-large-restic-test dan ember beserta isinya bersifat publik. Ada di us-west-1 dan kata sandi repo restic adalah kata sandi
Id snapshot untuk file adalah:
1gb: 0154ae25
5gb: 3013e883
10gb: 7463efa8
20gb: 292650c6
40gb: 5acb4bee
80gb: d1b7e323
Beri tahu saya jika ada lebih banyak data yang bisa saya berikan!
pmkane
pada 27 Feb 2019
@pmkane dapatkah Anda mengonfirmasi bahwa Anda menggunakan kepala terbaru https://github.com/ifedorenko/restic/tree/out-order-restore cabang (https://github.com/ifedorenko/restic/commit/ead78b375f2efed6de57c99b6766edbe9322e009 untuk lebih spesifik) ?
ifedorenko
pada 27 Feb 2019
Ya saya lakukan. Maaf untuk tidak menyebutkan itu.
pmkane
pada 27 Feb 2019
(menggunakan 32 pekerja dan 32 koneksi s3 di semua proses dengan ead78b3)
pmkane
pada 27 Feb 2019
Apakah Anda tahu jika saya perlu melakukan sesuatu yang istimewa untuk mengakses ember itu? Saya tidak pernah menggunakan ember publik sebelumnya, jadi tidak yakin apakah saya melakukan kesalahan atau pengguna tidak memiliki akses. (Saya dapat mengakses bucket tim saya dengan baik, jadi saya tahu sistem saya dapat mengakses s3 secara umum)
ifedorenko
pada 27 Feb 2019
Hei @ifedorenko , tunggu
pmkane
pada 27 Feb 2019
Maaf tentang itu, saya telah menerapkan kebijakan ember publik, tetapi belum memperbarui objek di ember itu sendiri. Anda harus dapat mengaksesnya sekarang. Perhatikan bahwa Anda harus menggunakan --no-lock, karena saya hanya memberikan izin baca.
pmkane
pada 27 Feb 2019
Ya. Saya dapat mengakses repo sekarang. Akan bermain dengannya nanti malam.
ifedorenko
pada 27 Feb 2019
Dan jika itu membantu/lebih mudah untuk diuji, kami melihat karakteristik kinerja yang serupa saat melakukan pemulihan file yang sama ke/dari repo pada SSD cepat, mengeluarkan S3 dari persamaan.
pmkane
pada 28 Feb 2019
@pmkane Saya dapat mereproduksi masalah secara lokal dan tidak memerlukan akses ke ember itu lagi. ini sangat bermanfaat, terima kasih.
ifedorenko
pada 28 Feb 2019
@ifedorenko , fantastis. Saya akan menghapus ember.
pmkane
pada 28 Feb 2019
@pmkane tolong coba lagi cabang out-order-restore terbaru ketika Anda punya waktu. Saya tidak punya waktu untuk menguji ini di EC2, tetapi pada pemulihan macbook saya tampaknya dibatasi oleh kecepatan tulis disk dan cocok dengan rclone sekarang.
ifedorenko
pada 1 Mar 2019
@ifedorenko , kedengarannya sangat menjanjikan. Aku sedang melakukan tes sekarang.
pmkane
pada 1 Mar 2019
@ifedorenko , bingo.
Memulihkan gumpalan senilai 133GB yang mewakili campuran ukuran file, yang terbesar adalah 78GB, hanya dalam waktu kurang dari 16 menit. Sebelumnya, pemulihan ini akan memakan waktu lebih lama. Saya kira kita masih bisa mendapatkan ini lebih cepat dengan bermain dengan jumlah restoreWorkers, tapi itu jauh lebih cepat seperti sekarang.
Terima kasih atas kerja keras Anda dalam hal ini!
pmkane
pada 1 Mar 2019
Dan untuk anak cucu: kinerja pemulihan kami berlipat ganda dari 8->16 dan lagi dari 16->32 pekerja pemulihan. 32->64 hanya bagus untuk ~50% benjolan di atas 32, di mana kami memulihkan sekitar 3gbit/dtk. Hampir setara dengan rclone.
Saya tahu bahwa ada keinginan untuk meminimalkan jumlah konfigurasi yang diperlukan untuk mengekstrak kinerja terbaik dari restic, tetapi yang ini adalah lompatan yang cukup besar, terutama untuk pengguna dengan kumpulan file besar, yang akan menyenangkan untuk dapat menentukan jumlah pekerja pada saat runtime.
pmkane
pada 1 Mar 2019
Tidak yakin mengapa pemulihan masih tidak bisa mendapatkan kecepatan kabel penuh. Ada pemeriksaan hash gumpalan yang berlebihan, Anda dapat berkomentar untuk melihat apakah itu bertanggung jawab.
ifedorenko
pada 2 Mar 2019
Saya akan mencobanya.
pmkane
pada 2 Mar 2019
Hai semua, saya menjalankan beberapa tes menggunakan permintaan tarik terbaru #2195 dan kinerjanya terus meningkat!
(20k file kecil, file 2x70G, total 170G)
8w_32c
real 27m46.185s
user 24m31.290s
sys 3m55.153s
32w_32c
real 15m30.904s
user 24m1.982s
sys 4m55.128s
64w_32c
real 18m37.566s
user 23m33.684s
sys 5m3.024s
64w_64c
real 17m12.314s
user 23m44.318s
sys 4m43.090s
Tidak yakin tentang penurunan kinerja dari 32w ke 64w (diuji beberapa kali dan tampaknya sah). Saya lampirkan beberapa grafik selama proses, tampaknya ada beberapa penurunan atau batas, harus seperti ini? Misalnya, dengan 64 pekerja, proses dimulai pada 6gbit/dtk tetapi setelah itu turun menjadi kurang dari 1gbit/dtk hingga akhir proses (yang menurut saya sesuai dengan waktu untuk memproses file-file besar itu). Tangkapan layar pertama dengan 32w, 32c dan yang kedua dengan 64w, 32c.
Saya juga setuju dengan @pmkane , akan berguna untuk mengubah nomor pekerja dari baris perintah. Ini akan sangat berguna untuk skenario pemulihan bencana ketika Anda ingin memulihkan data Anda secepat mungkin. Ada permintaan tarik tentang ini oleh rekan kerja saya #2178
Bagaimanapun saya sangat terkesan dengan peningkatan yang dilakukan! terima kasih banyak @ifedorenko
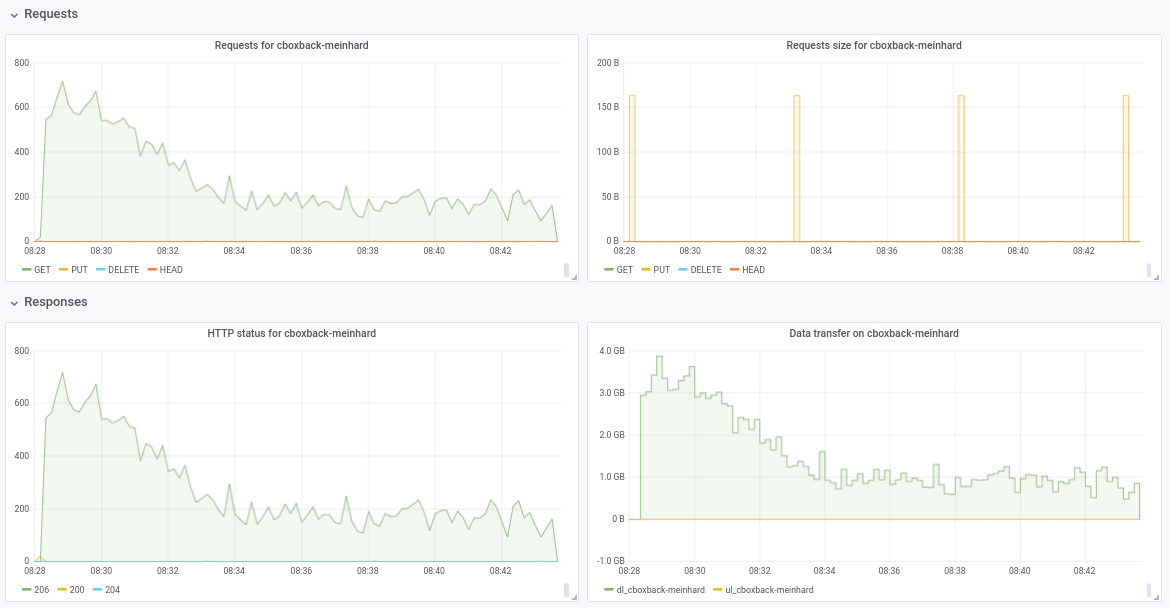
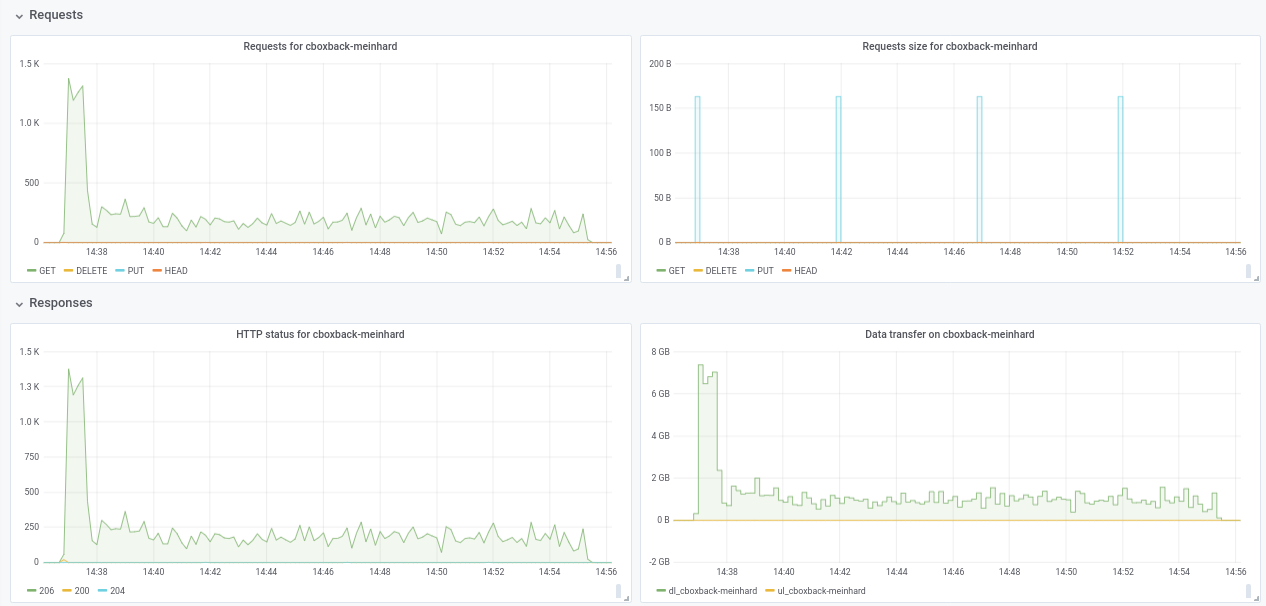
robvalca
pada 4 Mar 2019
++. Terima kasih @ifedorenko , ini adalah hal yang mengubah permainan untuk istirahat.
pmkane
pada 4 Mar 2019
Terima kasih atas laporan detailnya @robvalca. Adakah kemungkinan Anda dapat memberikan repositori pengujian yang saya bisa di AWS (atau GCP atau Azure) atau secara lokal? Saya tidak melihat penurunan kecepatan pemulihan file besar dalam pengujian saya dan ingin memahami apa yang terjadi di sana.
ifedorenko
pada 4 Mar 2019
@pmkane Saya juga ingin mengonfigurasi hal-hal ini saat dijalankan . Saran saya adalah menjadikannya opsi --option sehingga mereka tidak mengacaukan flag atau perintah biasa, tetapi ada untuk pengguna 'lanjutan' yang ingin bereksperimen atau menyesuaikan situasi mereka yang tidak biasa. Mereka bahkan tidak perlu didokumentasikan dan dapat diberi nama yang memperjelas bahwa Anda tidak dapat mengandalkannya, seperti --option experimental.fooCount=32 .
 whereisaaron
pada 4 Mar 2019
whereisaaron
pada 4 Mar 2019
hai @ifedorenko , saya telah membuat repo publik dengan data sampah di s3.cern.ch/restic-testrepo . Ini kurang lebih bentuknya sama dengan yang saya coba (banyak file kecil dan beberapa yang sangat besar) dan saya juga dapat mereproduksi perilaku yang sama pada ini (plot terlampir). Kata sandi untuk repo adalah restic . Beri tahu saya jika Anda kesulitan mengaksesnya.
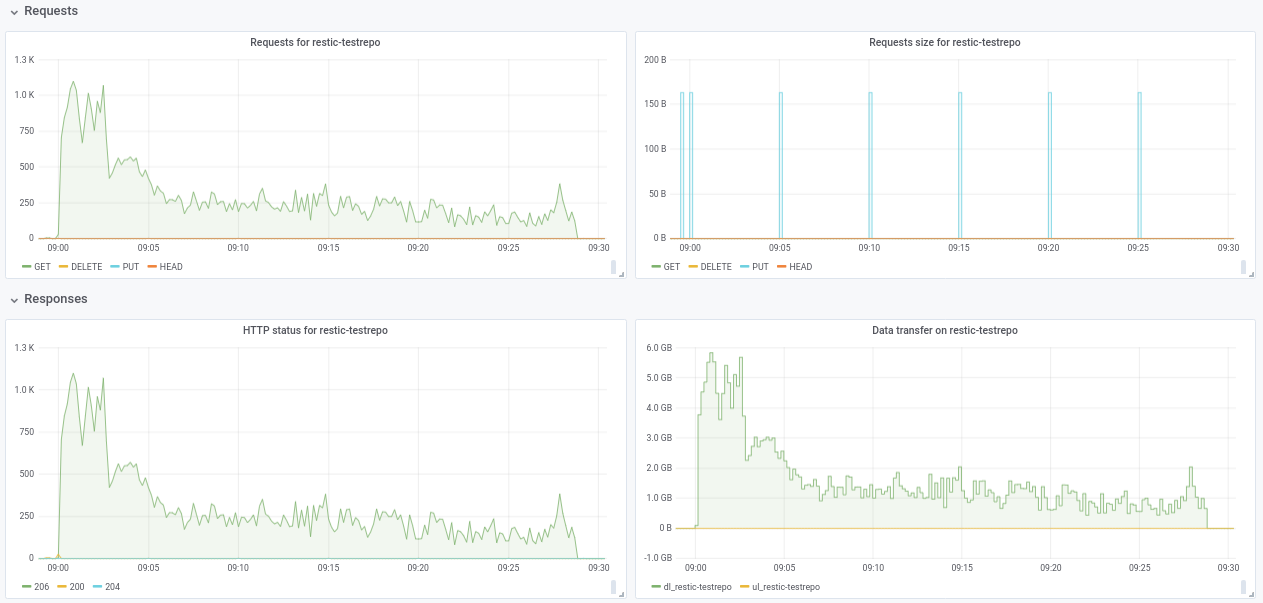
robvalca
pada 5 Mar 2019
@robvalca Saya tidak dapat mereproduksi masalah menggunakan repositori pengujian Anda. Di AWS (us-east-2, s3 repo, i3.4xlarge 2x nvme raid0 target) saya melihat kecepatan pemulihan 0,68 GB/s yang stabil saat menggunakan 32 pekerja dan 32 koneksi (total waktu pemulihan 6m20s). Sistem target Anda tidak dapat mempertahankan 10GB/s untuk waktu yang lama, jika saya harus menebak, setidaknya itulah yang akan saya periksa terlebih dahulu jika saya ingin memecahkan masalah ini lebih lanjut.
@pmkane menariknya, saya juga tidak bisa mengonfirmasi pengamatan Anda. Seperti yang saya sebutkan di atas, saya melihat kecepatan pemulihan 0,68 GB/s menggunakan cabang out-of-order-restore-no-progress (pemulihan tampak terikat CPU), dan 0,81 GB/s jika saya menonaktifkan pemeriksaan hash blob yang berlebihan (pemulihan tidak terlihat CPU- melompat). Saya tidak tahu seberapa cepat jaringan "hingga 10 Gbps" dapat berjalan, tetapi saya pikir kami sudah berada di wilayah "pengembalian yang berkurang".
ifedorenko
pada 6 Mar 2019
@ifedorenko Saya setuju dengan sepenuh hati tentang: pengembalian yang semakin berkurang. Ini cukup cepat bagi kita.
pmkane
pada 6 Mar 2019
@ifedorenko menarik, saya akan menyelidiki ini di pihak kami. Ngomong-ngomong Ini cukup cepat untuk kami juga, terima kasih banyak atas usahamu.
robvalca
pada 7 Mar 2019
Ingin tahu tentang status penggabungan ini. Cabang ini, dikombinasikan dengan pekerjaan @cbane untuk mempercepat pemangkasan, membuat restic dapat digunakan untuk pencadangan yang sangat besar.
pmkane
pada 22 Agu 2019
Segera...
 rawtaz
pada 26 Feb 2020
rawtaz
pada 26 Feb 2020
Menutup ini sekarang karena #2195 telah digabungkan. Jangan ragu untuk membukanya kembali jika hal-hal spesifik tentang masalah ini belum terselesaikan. Jika masih ada perbaikan yang harus dilakukan yang bukan dari jenis yang dibahas dalam edisi ini, silakan buka edisi baru. Terima kasih!
rawtaz
pada 26 Feb 2020
Masalah terkait
 axllent
·
4Komentar
axllent
·
4Komentar
 viric
·
5Komentar
viric
·
5Komentar
 McKael
·
4Komentar
whereisaaron
·
3Komentar
McKael
·
4Komentar
whereisaaron
·
3Komentar
 shibumi
·
3Komentar
shibumi
·
3Komentar
Komentar yang paling membantu
Ingin tahu tentang status penggabungan ini. Cabang ini, dikombinasikan dengan pekerjaan @cbane untuk mempercepat pemangkasan, membuat restic dapat digunakan untuk pencadangan yang sangat besar.