Restic: Wiederherstellungen könnten noch schneller sein
Dank der Zusammenführung von PR1719 sind Wiederherstellungen in Restic _viel_ schneller.
Sie könnten jedoch noch schneller sein.
Zu Testzwecken habe ich aus einem restic AWS S3-Bucket in derselben Region (us-west-1) wie eine dedizierte i3.8xlarge EC2-Instance wiederhergestellt. Die Wiederherstellung erfolgte gegen die 4x1,9 TB nvme in der Instanz, gestreiftes RAID-0 über LVM mit einem xfs-Dateisystem darunter. Die Instanz hat eine theoretische Bandbreite von 10 Gbit/s zu S3.
Da workerCount in filerestorer.go auf 32 angehoben wurde (vom einkompilierten Limit von 8), stellt restic eine Mischung aus 228k-Dateien mit einer mittleren Dateigröße von 8 KB und einer maximalen Dateigröße von 364 GB bei durchschnittlich 160 Mbit/s wieder her.
Im Vergleich dazu verschiebt rclone mit --transfers=32 Daten aus demselben Bucket mit 5636 Mbit/s, mehr als 30x schneller.
Es ist kein Vergleich von Äpfeln zu Äpfeln. Restische Datenblobs sind 4096 KB groß, nicht 8 KB, und das Öffnen/Schließen von Dateien hat sicherlich _etwas_ Overhea. Aber es ist immer noch ein Unterschied, der groß genug ist, dass er wahrscheinlich auf einen Engpass bei Restik hindeutet.
Ich teste gerne, stelle Instrumente zur Verfügung oder helfe in sonstiger Weise!
 pmkane
pmkane
Alle 71 Kommentare
160 mbit/s sehen in der Tat langsam aus. Ich war fast 200Mbps auf einem mickrigen MacBook Pro, das von Onedrive über eine (zugegebene schnelle) 1Gbps ftth-Verbindung heruntergeladen wurde. Ich kann ohne Zugriff auf Ihre Systeme und Ihr Repository nichts Spezifisches sagen, aber hier sind ein paar Dinge, die ich tun würde, um das Problem in keiner bestimmten Reihenfolge einzugrenzen:
- Schätzen Sie die Zeit ein, die benötigt wird, um eine einzelne Pack-Datei in einem einzelnen Thread herunterzuladen. Sie können dies aus Ihrem rclone 32x-Download-Test berechnen, aber ich wäre auch neugierig, wie lange es dauert, einzelne Pakete mit curl herunterzuladen, damit wir auch den HTTP-Request-Overhead abschätzen können.
- Ich würde die OS-Statistiken überprüfen, wie viel Restic während der Wiederherstellung tatsächlich von S3 herunterlädt. Dies wird uns sagen, ob Restore einzelne Pack-Dateien mehrmals herunterlädt (was möglich ist, aber nicht sehr oft passieren sollte, es sei denn, ich habe etwas übersehen).
- Die Parallelitätsebene S3 scheint auf nur 5 Verbindungen beschränkt zu sein. Kann dies die Wiederherstellungsgeschwindigkeit erklären, die Sie bei der oben angegebenen Single-Thread-Geschwindigkeitsschätzung sehen? Was passiert, wenn Sie das S3-Back-End-Verbindungslimit erhöhen, um dem des Wiederherstellers zu entsprechen?
- Stellen Sie die Netzwerkauslastung während der Wiederherstellung grafisch dar, um zu sehen, ob Lücken oder Verlangsamungen vorhanden sind.
- Schließen Sie diese 364-GB-Datei von der Wiederherstellung aus und sehen Sie, was passiert. Einzelne Dateien werden derzeit sequentiell wiederhergestellt, sodass diese eine Datei die durchschnittliche Download-Geschwindigkeit erheblich verzerren kann.
 ifedorenko
am 7. Nov. 2018
ifedorenko
am 7. Nov. 2018
Hi!
Danke für die Antwort. Das war interessant zu vertiefen
tl;dr: Das Aufstocken von s3-Verbindungen ist der Schlüssel, aber die Leistungssteigerungen, die es bietet, sind seltsamerweise vorübergehend.
- Die Übertragung der Pakete eines einzelnen Verzeichnisses (3062 Dateien mit insgesamt 13 GB) / mit rclone --transfers 1 läuft mit 233 Mbit/s. Bestätigt mit lsof, dass es in diesem Modus nur mit einem einzelnen Thread und einer einzelnen https-Verbindung läuft. Die Spitzengeschwindigkeit wird mit --transfers 32 (8,5 Gbit/s, im Wesentlichen Leitungsgeschwindigkeit für diese i3.8xlarge ec2-Instanz) erreicht. In beiden Fällen schreiben wir in das gestreifte nvme-Array.
- Ich freue mich, ein paar Statistiken zu sammeln, aber was möchten Sie konkret sehen? (ist aber möglicherweise nicht erforderlich, siehe unten)
- Hier schlagen wir zwei Fliegen mit einer Klappe! Hier ist ein Diagramm der Netzwerkauslastung während Wiederherstellungen mit:
- ein Aktienrestrikt mit diesem PR zusammengeführt (commit c0572ca15f946c622d9c4009347dc4d6c31cba4c)
- restic mit workerCount auf 32 und filesWriterCount auf 128 erhöht
- Restic mit den vorherigen Änderungen + s3-Verbindungen auf 32 erhöht.
- resitc mit den vorherigen Änderungen + s3-Verbindungen auf 64 erhöht.
- rclone mit --transfers 32 Verschieben des data/-Verzeichnisses
Die Bandbreitenzahlen sind in kbps und wurden in 3-Sekunden-Intervallen über 10 Minuten gemessen. Für die Restic-Läufe haben wir mit dem Sammeln von Daten begonnen, _nach_ restic bereits damit begonnen hatte, Dateien tatsächlich wiederherzustellen (dh es schließt die Startzeit und die Zeit aus, die restic zu Beginn des Laufs für die Wiederherstellung der Verzeichnishierarchie aufwendet Instanz 25 % nicht überschritten.
Wir bekommen einen leichten Schub durch die Erhöhung des workerCount, aber die S3-Parallelität scheint der wahre Gewinn zu sein. Aber während es am Anfang stark ist (manchmal nähert sich die Rclone-Geschwindigkeit!), fallen die Raten abrupt ab und bleiben für den Rest des Laufs niedrig. restic wirft auch Fehler aus, die wie "Ignorieren von Fehler für [Pfad redigiert]: nicht genügend Cache-Kapazität: angefordert 2148380, verfügbar 872640" aussehen, die bei niedrigerer s3-Parallelität nicht ausgegeben werden.
Wie Sie sehen können, beginnt die Leistung von rclone hoch und bleibt hoch. Es ist also keine Situation, in der Schreibvorgänge in den Puffercache der Instanz gehen und dann anhalten, wenn sie auf die Festplatte gespült werden. Das nvme-Array ist vom Durchsatz her schneller als die Netzwerkpipe.
- Ich glaube nicht, dass die einzelne große Datei ein Faktor ist, da ich während der Wiederherstellung die Festplatten-/Netzwerk-E/A messe. Die Tatsache, dass es eine Weile dauern kann, bis diese einzelne Datei vollständig wiederhergestellt ist, hat keinen Einfluss auf die Zahlen, die wir schaue mir hier an.
Angesichts der obigen Ausführungen sieht es so aus, als ob die S3-Parallelität erhöht werden muss, um hier vernünftige Preise zu erzielen, aber Sie müssen herausfinden, warum die Leistung sinkt (und ob dies mit den Cache-Fehlern zusammenhängt oder nicht).
Wenn es hilfreich wäre, eine schnelle i3-Instanz und etwas s3-Speicherplatz und -Bandbreite für Ihre Tests zur Verfügung zu stellen, lassen Sie es mich wissen, damit ich das gerne sponsere.
pmkane
am 7. Nov. 2018
233 Mbit/s mal 32 sind 7456 und etwas weniger als 8,5 Gbit/s. Was seltsam ist. Ich habe erwartet, dass der Singlethread-Download schneller ist als der Durchsatz pro Stream beim Multithread-Download. Nicht sicher, was dies bedeutet, wenn überhaupt.
Ich wollte bestätigen, dass restic nicht immer wieder dieselben Pakete herunterlädt. Ich denke, die Grafik zeigt, dass erneute Downloads kein Problem darstellen, daher sind keine weiteren Statistiken erforderlich, zumindest nicht jetzt.
Können Sie die Grafikskalierung bestätigen? rclone schwebt um die mit "1000000" beschriftete Zeile, wenn dies "1.000.000 kbps" ist, was meiner Meinung nach "1gbps" bedeutet und nicht mit der zuvor erwähnten "8,5 gbit/sec"-Zahl übereinstimmt.
Wie gesagt, einzelne Dateien werden sequentiell wiederhergestellt. Der Download von 364 GB bei 233 Mbit/s dauert etwa 3,5 Stunden und wahrscheinlich länger aufgrund des Over-Pack-Overheads und der Entschlüsselung, die alle nacheinander erfolgen. Ich kann nicht sagen, ob 3,5 Stunden etwas sind, das Sie als unbedeutend verwerfen können, ohne zu wissen, wie lange die restliche Wiederherstellung dauert.
Was den not enough cache capacity Fehler angeht , erhöhen Sie
ifedorenko
am 7. Nov. 2018
Hi!
Hoppla, es tut mir leid. Die Skala in der Grafik ist KB/sek, nicht kbit/sek. 1.012.995 in der ersten Reihe sind also 8,1 Gbit/s.
Ich habe verstanden, dass Dateien sequentiell wiederhergestellt wurden, aber nicht, dass es keine Parallelität für das Abrufen von Paketen für eine einzelne Datei gibt. Das ist definitiv ein Stolperstein für Backups mit großen Dateien, da dies zu Ihrem limitierenden Faktor wird. Aus diesem Grund wäre es fantastisch, hier eine gewisse Parallelität zu haben.
Bei einer Stichprobe von 10 zufälligen Buckets liegt unsere maximale Packgröße knapp unter 12 MB und unsere durchschnittliche Packgröße beträgt 4,3 MB.
Vielleicht überschreiten wir mit mehr Workern und S3-Verbindungen die packCacheCapacity von (workerCount + 5) * AveragePackSize. Ich werde versuchen, das zu erhöhen und zu sehen, ob die Fehler verschwinden.
pmkane
am 7. Nov. 2018
Vielleicht überschreiten wir mit mehr Workern und S3-Verbindungen die packCacheCapacity von (workerCount + 5) * AveragePackSize. Ich werde versuchen, das zu erhöhen und zu sehen, ob die Fehler verschwinden.
Die Cachegröße wird basierend auf 5 MB Packdateigröße und workerCount berechnet. Durch Erhöhen von workerCount die Cachegröße erhöht. Entweder liegt also ein Speicherleck vor oder die Wiederherstellung muss viele 12-MB-Dateien zufällig zwischenspeichern. Eine Erhöhung von averagePackSize auf 12 MB sollte uns sagen, was.
ifedorenko
am 7. Nov. 2018
Keine Cache-Fehler, wenn AveragePackSize auf 12 gesetzt ist.
Wenn es noch andere hilfreiche Informationen gibt, die wir zur Verfügung stellen können, lassen Sie es mich wissen! Danke noch einmal.
pmkane
am 8. Nov. 2018
Es sieht so aus, als würden wir im Laufe der Wiederherstellung die Parallelität verlieren und es scheint nicht mit großen Dateien zusammenzuhängen. Ich werde einen Testfall zusammenstellen und berichten.
pmkane
am 8. Nov. 2018
Hi!
Ich habe versucht, die Leistungseinbußen, die ich bei meiner Produktionsdateimischung sah, mit drei verschiedenen künstlichen Dateimischungen zu reproduzieren.
Für alle Tests habe ich c0572ca15f946c622d9c4009347dc4d6c31cba4c mit S3-Verbindungen auf 128, workerCount auf 128, filesWriterCount auf 128 und AveragePackSize auf 12 * 1024 * 1024 verwendet.
Alle Tests verwendeten Dateien mit Zufallsdaten, um Auswirkungen der Deduplizierung zu vermeiden.
Für den ersten Test habe ich 4.000 100-MB-Dateien erstellt und gesichert, die gleichmäßig auf 100 Verzeichnisse verteilt sind (insgesamt ~400 GB). Sicherungen und Wiederherstellungen wurden von gestreiften nvme-Volumes auf einer i3.8xlarge-Instanz ausgeführt. Der Backup-Bucket befand sich in derselben Region wie die Instanz (us-west-1).
Bei diesem Dateimix habe ich durchschnittliche Geschwindigkeiten von 9,7 Gbit/s (!) ohne Parallelitäts- oder Geschwindigkeitsverlust über die gesamte Wiederherstellung gesehen. Diese Zahlen sind gleichauf oder über den Rclone-Zahlen und sind im Wesentlichen die Leitungsgeschwindigkeit, was fantastisch ist.
Anschließend habe ich 400.000 1-MB-Dateien erstellt und gesichert, die gleichmäßig auf 100 Verzeichnisse aufgeteilt wurden (wiederum insgesamt ~ 400 GB).
Gleiche (ausgezeichnete) Ergebnisse wie oben.
Schließlich habe ich 40 Verzeichnisse mit 1 10-GB-Datei pro Verzeichnis erstellt. Hier wurde es interessant.
Ich hatte erwartet, dass diese Wiederherstellung etwas langsamer sein würde, da restic nur 40 gleichzeitige Wiederherstellungen mit 40 Verbindungen zu S3 durchführen könnte.
Während Restic jedoch alle 40 Dateien für Schreibvorgänge öffnet und gleichzeitig in alle 40 Dateien schreibt, hält es nur eine einzige TCP-Verbindung zu S3 gleichzeitig geöffnet, nicht 40.
Teilen Sie mir mit, welche Statistiken oder Instrumente Sie sehen möchten.
pmkane
am 8. Nov. 2018
Können Sie bestätigen, dass es bei "schnellen" Tests 128 S3-Verbindungen gab?
ifedorenko
am 8. Nov. 2018
Ja, die gab es.
pmkane
am 8. Nov. 2018
Neugierig... Um ehrlich zu sein, steht die Unterstützung großer Dateien nicht ganz oben auf meiner Prioritätenliste, aber ich werde vielleicht in den nächsten Wochen etwas Zeit finden, mir das anzuschauen. Wenn sich jemand vor mir damit befassen möchte, lass es mich bitte wissen.
ifedorenko
am 8. Nov. 2018
Habe noch einige Tests durchgeführt und es sieht tatsächlich so aus, als ob die Dateigröße ein roter Hering ist, es sind die Dateizahlen, die die Anzahl der AWS-Verbindungen antreiben.
Mit 128 10 MB-Dateien in 4 Verzeichnissen öffnet restic nur 6 Verbindungen zu AWS, obwohl es in alle 128 Dateien schreibt.
Mit 512 10 MB Dateien in 4 Verzeichnissen öffnet restic während seiner Lebensdauer 18 Verbindungen, obwohl es 128 Dateien gleichzeitig geöffnet hat.
Mit 5.120 10-MB-Dateien in 4 Verzeichnissen öffnet restic im Laufe seiner Lebensdauer nur 75 Verbindungen zu AWS, wobei wiederum 128 Dateien gleichzeitig geöffnet bleiben.
Seltsam!
pmkane
am 8. Nov. 2018
Ich wäre wirklich überrascht, wenn der Go S3-Client HTTP-Verbindungen nicht zusammenfassen und wiederverwenden würde. Höchstwahrscheinlich gibt es keine Eins-zu-Eins-Korrelation zwischen der Anzahl gleichzeitiger Worker und offenen TCP-Sockets. Wenn beispielsweise die Wiederherstellung heruntergeladene Pakete aus irgendeinem Grund langsam verarbeitet, wird dieselbe S3-Verbindung von mehreren Mitarbeitern gemeinsam genutzt.
ifedorenko
am 8. Nov. 2018
Es gibt zwei Eigenschaften des aktuellen Concurrent Restorer, die für den Großteil der Implementierungskomplexität verantwortlich sind und sehr wahrscheinlich die hier gemeldete Verlangsamung verursachen:
- einzelne Dateien werden von Anfang bis Ende wiederhergestellt
- Anzahl der laufenden Dateien wird auf ein Minimum beschränkt
Die Implementierung wird viel einfacher sein, weniger Speicher verbrauchen und in vielen Fällen sehr wahrscheinlich schneller sein, wenn wir zustimmen, Datei-Blobs in beliebiger Reihenfolge zu schreiben und eine beliebige Anzahl von Dateien in Bearbeitung zuzulassen.
Der Nachteil ist, dass es bis zum Ende der Wiederherstellung nicht möglich ist, festzustellen, wie viele Daten bereits in einer bestimmten Datei wiederhergestellt wurden. Dies kann verwirrend sein, insbesondere wenn die Wiederherstellung abstürzt oder abgebrochen wird. Sie sehen also möglicherweise eine 10-GB-Datei auf dem Dateisystem, das in Wirklichkeit nur wenige Bytes am Ende der Datei geschrieben hat.
@fd0 ist es Ihrer Meinung nach
ifedorenko
am 16. Nov. 2018
Ich erinnere mich nicht, ob Restic die Wiederherstellung der Standardausgabe unterstützt. Wenn dies der Fall ist, müssen Sie natürlich die Wiederherstellung von Anfang bis Ende beibehalten (möglicherweise als Sonderfall).
 pvgoran
am 16. Nov. 2018
pvgoran
am 16. Nov. 2018
@ifedorenko Ich persönlich bin im Allgemeinen für Vereinfachung, insbesondere wenn es um Leistungssteigerungen geht. Ich versuche jedoch, die Kompromisse zu verstehen:
Der Nachteil ist, dass es bis zum Ende der Wiederherstellung nicht möglich ist, festzustellen, wie viele Daten bereits in einer bestimmten Datei wiederhergestellt wurden.
Wenn wir hier nicht von Tausenden von gleichzeitig geschriebenen Dateien sprechen, könnte vielleicht eine Zuordnung von Dateinamen zu geschriebenen Bytes verwendet werden? Offensichtlich werden die Informationen dem Dateisystem nicht zur Verfügung gestellt, aber für die Fortschrittsberichterstattung könnte es trotzdem gemacht werden, oder? (Und um eine unterbrochene Wiederherstellung fortzusetzen, vielleicht nur die Blobs und Offsets der Datei auf Nicht-Null-Bytes zu überprüfen, vielleicht? Keine Ahnung.)
Ich erinnere mich nicht, ob Restic die Wiederherstellung der Standardausgabe unterstützt. Wenn dies der Fall ist, müssen Sie natürlich die Wiederherstellung von Anfang bis Ende beibehalten (möglicherweise als Sonderfall).
Ich glaube nicht, dass dies der Fall ist - ich bin mir sowieso nicht sicher, wie das funktionieren würde, da Wiederherstellungen mehrere Dateien sind, müssten Sie sie irgendwie codieren und sie irgendwie trennen, denke ich.
 mholt
am 16. Nov. 2018
mholt
am 16. Nov. 2018
Wenn wir hier nicht von Tausenden von gleichzeitig geschriebenen Dateien sprechen, könnte vielleicht eine Zuordnung von Dateinamen zu geschriebenen Bytes verwendet werden?
Die einfachste Implementierung besteht darin, Dateien zu öffnen und zu schließen, um einzelne Blobs zu schreiben. Wenn sich dies als zu langsam erweist, müssen wir einen Weg finden, Dateien für mehrere Blob-Schreibvorgänge offen zu halten, zum Beispiel durch Zwischenspeichern von geöffneten Dateihandles und Anordnen von Paket-Downloads, um bereits geöffnete Dateien zu bevorzugen.
Restore verfolgt bereits, welche Blobs in welche Dateien geschrieben wurden und welche noch ausstehend sind. Ich erwarte nicht, dass sich an diesem Teil viel ändern wird. Der Fortschritt wird in einer separaten Datenstruktur verfolgt und ich erwarte auch nicht, dass sich das ändert.
Und um eine unterbrochene Wiederherstellung fortzusetzen, vielleicht nur die Blobs und Offsets der Datei auf Nicht-Null-Bytes zu überprüfen?
Resume muss die Prüfsummen der Dateien auf dem Datenträger überprüfen, um zu entscheiden, welche Blobs noch wiederhergestellt werden müssen. Ich glaube, dies gilt unabhängig davon, ob die Wiederherstellung sequenziell oder nicht in der Reihenfolge erfolgt. Wenn sich Resume zum Beispiel nach einem Stromausfall erholt, kann nicht davon ausgegangen werden, dass alle Dateiblöcke vor dem Stromausfall auf die Platten geleert wurden, dh Dateien können Lücken oder teilweise geschriebene Blöcke aufweisen.
ifedorenko
am 16. Nov. 2018
@pmkane frage mich, ob du #2101 versuchen kannst? Es implementiert eine Wiederherstellung außerhalb der Reihenfolge, obwohl Schreibvorgänge in einzelne Dateien immer noch serialisiert werden und die Wiederherstellungsleistung großer Dateien möglicherweise immer noch nicht optimal ist. und Sie müssen die Anzahl der Arbeiter wie zuvor optimieren.
ifedorenko
am 27. Nov. 2018
Absolut. Ich bin diese Woche unterwegs, werde aber so schnell wie möglich testen und berichten.
pmkane
am 27. Nov. 2018
@ifedorenko Ich habe diesen PR ausprobiert und er erstellt erfolgreich die Verzeichnisstruktur, aber dann schlagen alle Dateiwiederherstellungen mit Fehlern wie:
Belastung(, 3172070, 0) Fehler zurückgegeben, erneuter Versuch nach 12.182749645s: EOF
Meister stellt gut wieder her.
Mein Wiederherstellungsbefehl lautet:
/usr/local/bin/restic.outoforder -r s3:s3.amazonaws.com/[redacted] -p /root/.restic_pass restore [snapshotid] -t .
Lassen Sie mich wissen, welche zusätzlichen Informationen ich zum Debuggen bereitstellen kann.
pmkane
am 1. Dez. 2018
Wie viele gleichzeitige S3-Download-Anforderungen sind zulässig? Wenn es 128 sind, können Sie es auf 32 begrenzen (von denen wir wissen, dass es funktioniert)?
Semi-bezogen... wissen Sie, wie viele Indexdateien Ihr echtes Repository hat? Versuchen zu schätzen, wie viel Speicherwiederhersteller benötigt.
ifedorenko
am 1. Dez. 2018
Ich habe kein Verbindungslimit angegeben, daher gehe ich davon aus, dass es standardmäßig auf 5 eingestellt ist.
Ich erhalte die gleichen Fehler mit -o s3.connections=2 und -o s3.connections=1.
Ich habe derzeit 85 Index-Blobs im Ordner index/. Sie haben eine Gesamtgröße von 745 MB.
pmkane
am 1. Dez. 2018
Hmm. Ich schaue heute noch einmal nach, wenn ich an meinem Computer ankomme. Übrigens, "Returned Error, Retrying" ist eine Warnung, kein Fehler, daher kann es mit dem Wiederherstellungsfehler zusammenhängen oder nur ein Ablenkungsmanöver sein.
ifedorenko
am 1. Dez. 2018
Ich bin mir nicht sicher, wie ich es verpasst habe ... der Wiederhersteller hat in den meisten Fällen nicht alle Packdateien aus dem Backend gelesen. Sollte jetzt behoben sein. @pmkane kannst du deinen Test noch einmal versuchen?
ifedorenko
am 2. Dez. 2018
Ich werde es krachen lassen!
pmkane
am 2. Dez. 2018
Bestätigt, dass Dateien mit diesem Fix erfolgreich wiederhergestellt wurden. Jetzt Leistung testen.
pmkane
am 2. Dez. 2018
Leider sieht es so aus, als wäre es langsamer als Master. Alle Tests laufen auf der oben beschriebenen i3.8xlarge-Instanz.
Bei einem workerCount von 8 (Standard) wird der außer Betrieb befindliche Zweig mit 86 Mbit/s wiederhergestellt.
Mit einem auf 32 gestiegenen workerCount lief es etwas besser – im Durchschnitt bei 160 Mbit/s.
Die CPU-Auslastung mit diesem Zweig ist deutlich höher als beim Master, aber in beiden Fällen wird die Instanz-CPU nicht ausgeschöpft.
Anekdotisch lässt die Wiederherstellungs-Benutzeroberfläche es so aussehen, als ob etwas "kleben bleibt", fast so, als ob es irgendwo um eine Sperre mit sich selbst konkurriert.
Gerne stellen wir Ihnen weitere Details, Profilerstellung oder eine Testinstanz zum Replizieren zur Verfügung.
pmkane
am 2. Dez. 2018
Nur zur Bestätigung, Sie hatten die Anzahl der Wiederhersteller- und s3-Back-End-Worker auf 32 gesetzt, oder?
Einige Gedanken, die das von Ihnen beobachtete Verhalten erklären könnten:
- Schreibvorgänge in einzelne Dateien werden weiterhin serialisiert. Ich _schätze_, dass dies bei schnellen Zieldateisystemen kein Problem sein würde, habe es aber nie gemessen.
- Das Öffnen/Schließen von Dateien um jedes Blob trägt sicherlich zum Overhead des Wiederherstellers bei. Als ich dies auf Macos gemessen habe, konnte ich in ~ 70 Sekunden 100K-mal "Datei öffnen; ein Byte schreiben; Datei schließen", was ungefähr dem Aufwand für das Schreiben von 100K-Blobs entspricht. Der Test war wirklich einfach und der reale Overhead kann deutlich höher sein.
- Ich habe derzeit keine plausible Erklärung für die hohe CPU-Auslastung. Eine Implementierung außerhalb der Reihenfolge entschlüsselt jedes Blob nur einmal (der Master entschlüsselt die Blobs für jede Zieldatei), und im Vergleich zum Master ist viel weniger Buchhaltung erforderlich. Vielleicht sind "sparse" Dateischreibvorgänge nicht wirklich spärlich und erfordern, dass Go oder OS etwas CPU-lastiges tun. Weiß nicht wirklich.
ifedorenko
am 2. Dez. 2018
Sie da!
Korrekt. workerCount wurde in internal/restorer/filerestorer.go auf 8 oder 32 gesetzt und -o s3.connections=32 wurde in beiden Fällen über das restic cli übergeben.
pmkane
am 3. Dez. 2018
Hier sehen Sie eine Ansicht der Ablaufverfolgungsdaten auf oberster Ebene, während der Zweig "Außer Betrieb" Dateien mit 8 Mitarbeitern wiederherstellt.
Es sieht so aus, als ob es signifikante (>500-1000ms) Pausen gibt, die die Arbeiter häufig treffen.
pmkane
am 3. Dez. 2018
Ich beschloss, mehr Zeit damit zu verbringen und begann mit dem Schreiben eines einfachen Standalone-Tests, der 10 GiB zufällige Bytes in 4KiB-Blöcken generiert. Mein Ziel war es zu beurteilen, wie schnell mein System Bytes verschieben kann. Zu meiner großen Überraschung dauerte dieser Test auf meinem MacBook Pro (2018, 2,6 GHz Intel Core i7) 18,64 Sekunden. Das entspricht etwa 4,29 Gigabit/s oder etwa der Hälfte dessen, was 10G-Ethernet leisten kann. Und das ohne Krypto oder Net oder Disk I/O. Und ich habe Xoshiro256** prng verwendet, math/rand war ungefähr 2x langsamer, was natürlich völlig nebensächlich ist. Der Punkt ist, dass der Wiederhersteller Blobs auf mehreren Threads verarbeiten muss, um das 10G-Netzwerk zu sättigen, Multithread-Netto-E/A allein reicht nicht aus.
Und nur zum Spaß generiert vergleichbares Rust Impl 10 GiB zufälliger Bytes in 3,1 Sekunden und Java in 10,77 Sekunden. Stelle dir das vor :-)
ifedorenko
am 6. Feb. 2019
Interessanter Test!
Ich verstehe, dass die Rate von Restic durch die Zeit begrenzt wird, die zum Wiederherstellen der derzeit größten Datei benötigt wird.
Im Moment ist das jedoch nicht unser Blocker, da ich weiß, dass Restic eine einzelne Datei viel schneller wiederherstellen kann als die 160 Mbit/s, die wir hier sehen.
Ich werde ein 100GB Test-Repo bestehend aus 10MB Dateien auf schneller SSD und in S3 zusammenstellen und einige Zahlen laufen lassen, um das aktuelle Best-Case-Szenario in Master und in diesem Zweig zu erhalten.
pmkane
am 6. Feb. 2019
Hallo zusammen, gibt es eine Möglichkeit, die Anzahl der Arbeiter mit einem Parameter zu ändern oder muss dies direkt am Code erfolgen? Wir haben auch das Problem der langsamen Wiederherstellungen und ich möchte das, was wir haben, irgendwie verbessern... Bitte lassen Sie es mich wissen, wenn ich mit Tests dazu beitragen kann, diesen Teil zu verbessern!
Vielen Dank!
 robvalca
am 19. Feb. 2019
robvalca
am 19. Feb. 2019
@robvalca welches Backend verwendest du? Wie schnell kopiert rclone Ihr Repo auf das Zielsystem? Was ist Restic-Restore-Geschwindigkeit?
Im Moment bin ich mir nicht sicher, was los ist, daher wäre es wirklich nützlich, wenn Sie ein Test-Repository und Schritte bereitstellen könnten, mit denen ich das Problem lokal reproduzieren kann (und mit "Test-Repository" meine ich Junk- / Zufallsdaten, keine privaten) Daten bitte).
ifedorenko
am 22. Feb. 2019
@ifedorenko wir verwenden S3 (ceph+radosgw) als Backend (von uns verwaltet). Ich habe versucht, das Repo mit rclone zu kopieren und dies sind die Ergebnisse:
rclone copy -P remote:cboxback-aabbcc/ /var/tmp/restic/aabbcc/
Übertragen: 127,309G / 127,309 GByte, 100%, 45,419 MByte/s, ETA 0s
Fehler: 0
Prüfungen: 0 / 0, -
Übertragen: 25435 / 25435, 100%
Verstrichene Zeit: 47m50,2s
Die Wiederherstellung des Repos mit "stock" restic 0.9.4 dauerte ~8 Stunden. In beiden Fällen verwende ich 32 S3-Verbindungen und denselben Zielhost. Ich habe ein wenig mehr Informationen in diesen Forenthread gepackt .
Ich werde ein Repo für Sie zum Testen vorbereiten und Sie wissen lassen, wenn es fertig ist.
Vielen Dank für Ihre Hilfe!
robvalca
am 25. Feb. 2019
@robvalca können Sie versuchen, mit meinem out-order-restore- Zweig eine
Wenn der Branch die Wiederherstellungsleistung für Sie nicht verbessert, laden Sie das Test-Repository in einen öffentlichen s3-Bucket hoch und geben Sie hier den Bucket-Namen und das Repository-Passwort ein.
ifedorenko
am 26. Feb. 2019
@pmkane ist es möglich, dass Sie eine große Anzahl identischer oder fast identischer Dateien wiederherstellen? das würde den Streit unter den Arbeitern erklären, denke ich.
Bearbeiten: Können Sie Ihren Wiederherstellungs-Perf-Test mit dem neuesten # 2101 wiederholen? Es sollte jetzt besser gleichzeitige Schreibvorgänge in dieselbe Datei und dasselbe Blob in mehrere Dateien verarbeiten.
ifedorenko
am 26. Feb. 2019
@ifedorenko in der Tat, mit der Out-Order-Version ist es jetzt viel besser! Es dauerte weniger als eine Stunde, was näher an dem ist, was ich mit rclone habe. Einige Kommentare, die ich aus meinen Tests extrahieren konnte, damit Sie sie vielleicht nützlich finden (siehe auch angehängte Plots!):
- Bei normalen
0.9.4beginnt der Prozess schneller, mit Spitzen von200MB/secund wir erhalten fast50 requestspro Sekunde auf S3-Seite. Nach nur ein paar Minuten tritt die Verschlechterung ein und die Anforderungen sinken auf 1 oder so und die Geschwindigkeit während des restlichen Prozesses ~5MB/sec. - Bei der "ooo"-Version beträgt die Übertragungsgeschwindigkeit ungefähr
40MB/secund ~8S3-Anfragen sind während des gesamten Prozesses konstant. - Eine andere Sache, die mir aufgefallen ist, ist, dass ich fast keine Verbesserung bei der Erhöhung der S3-Verbindungen sehe. Ist dies zu erwarten?
32 Anschlüsse:
Created 2197 directories, listed 171.141 GiB in 20930 files
Restored 171.136 GiB in 170258 files
real 57m54.588s
user 229m25.229s
sys 6m51.763s
64 Verbindungen
real 53m13.876s
user 242m57.081s
sys 7m12.455s
- Habe schließlich einen Test mit einem anderen anderen Repository durchgeführt (51G, 1,3M kleine Dateien, viele Duplikate) und ist immer noch mit einem guten Abstand schneller als 0.9.4:
0.9.4
real 16m6.966s
user 25m4.116s
sys 4m19.424s
0.9.4-ooo:
real 8m14.375s
user 14m30.107s
sys 3m41.538s
Verbessert sich also nicht nur bei großen Dateien, sondern in allen Fällen!
Und übrigens, die neue Fortschrittsansicht der Wiederherstellung ist schön!! 8)
Lassen Sie es mich wissen, wenn Sie möchten, dass ich weitere Tests mache.
Vielen Dank!
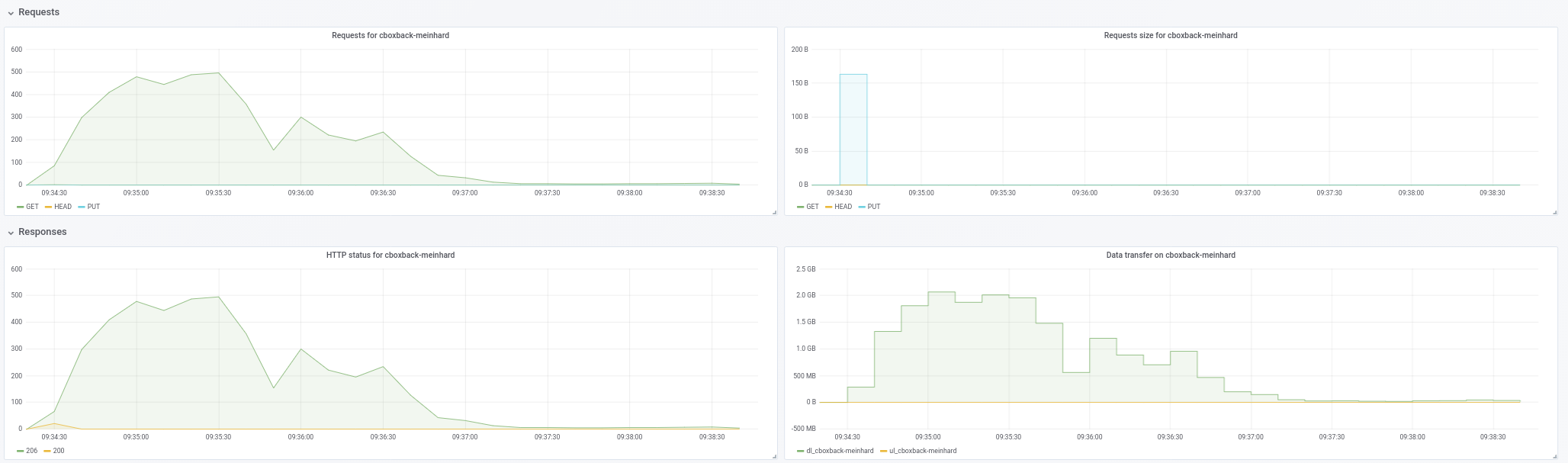
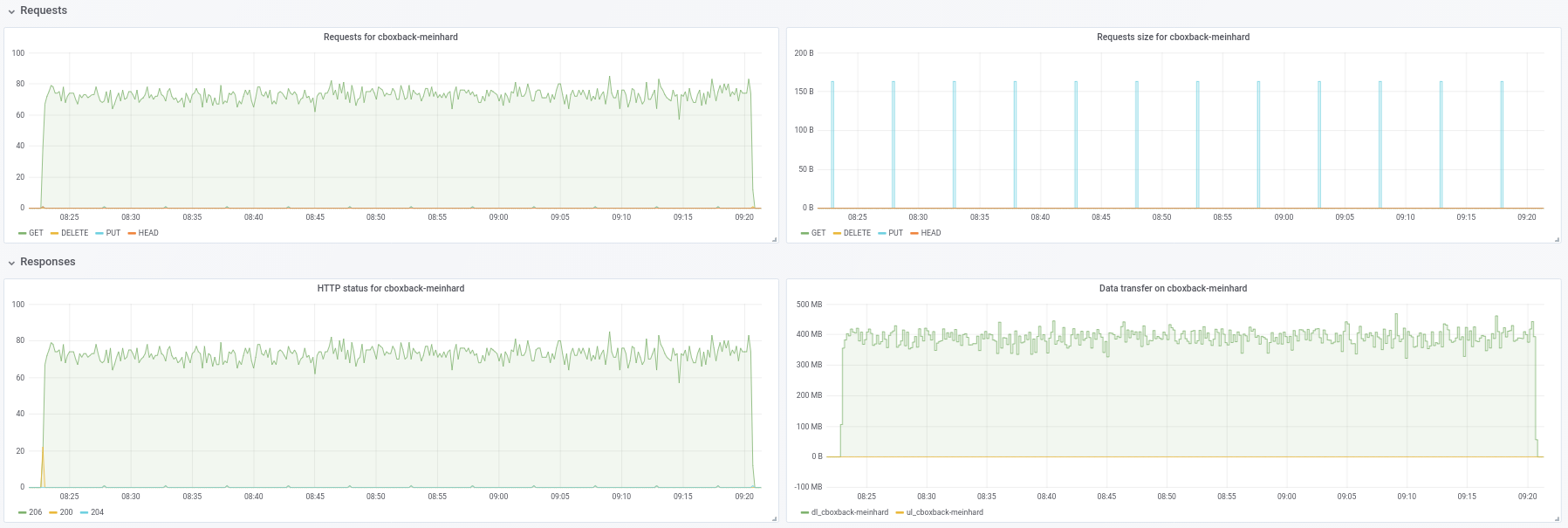
robvalca
am 26. Feb. 2019
Vielen Dank für das Feedback, @robvalca , es ist sehr nützlich.
- Eine andere Sache, die mir aufgefallen ist, ist, dass ich fast keine Verbesserung bei der Erhöhung der S3-Verbindungen sehe. Ist dies zu erwarten?
Entschuldigung, ich habe vergessen zu erwähnen, dass Sie den Code ändern müssen, um die Anzahl der gleichzeitigen Wiederherstellungsarbeiter zu erhöhen. Es ist im Moment auf 8 hartcodiert:
https://github.com/ifedorenko/restic/blob/099f51c01c189a84b96be86ce6be61a45e3705fc/internal/restorer/filerestorer.go#L22
Lassen Sie es mich wissen, wenn Sie möchten, dass ich weitere Tests mache.
Wir wissen immer noch nicht, was offensichtliche Arbeitskonflikte während der Wiederherstellung außerhalb der Reihenfolge verursacht, die zuvor in dieser Ausgabe https://github.com/restic/restic/issues/2074#issuecomment -443759511 erwähnt wurde. Können Sie diesen speziellen Commit testen?
https://github.com/ifedorenko/restic/commit/d410668ce3a8c7284d86a2b06bf42a0e654d43bc? Wenn Sie den Konflikt mit Ihren Repositorys beobachten, bedeutet dies, dass er nicht spezifisch für die Daten von pmkane ist und dass meine jüngsten Änderungen den Konflikt beheben.
Nochmals vielen Dank für Ihre Hilfe.
ifedorenko
am 26. Feb. 2019
Hallo zusammen - ich überwache das immer noch, bin aber absolut überfordert. Ich werde dieses Wochenende nachholen und sehen, ob wir noch mit ifedorenko@d410668 reproduzieren
pmkane
am 26. Feb. 2019
@ifedorenko Danke, mit 32 Mitarbeitern geht der Prozess viel schneller auf 30 Minuten, was ein großartiges Ergebnis ist. Ich habe auch versucht, works/s3.connections auf 64/64, 128/128 zu erhöhen, aber ich sehe keine Verbesserungen und bekomme fast die gleichen Ergebnisse. Mit den aktuellen Ergebnissen bin ich jedenfalls zufrieden.
Ich habe auch die Version mit https://github.com/ifedorenko/restic/commit/d410668 ausprobiert, auf die Sie mich hingewiesen haben und hier ist ein Screenshot des Trace. Ich habe nicht allzu viel Erfahrung mit dieser Art von Tools, scheint aber den @pmkane- Ergebnissen ähnlich zu -o s3.connections=32
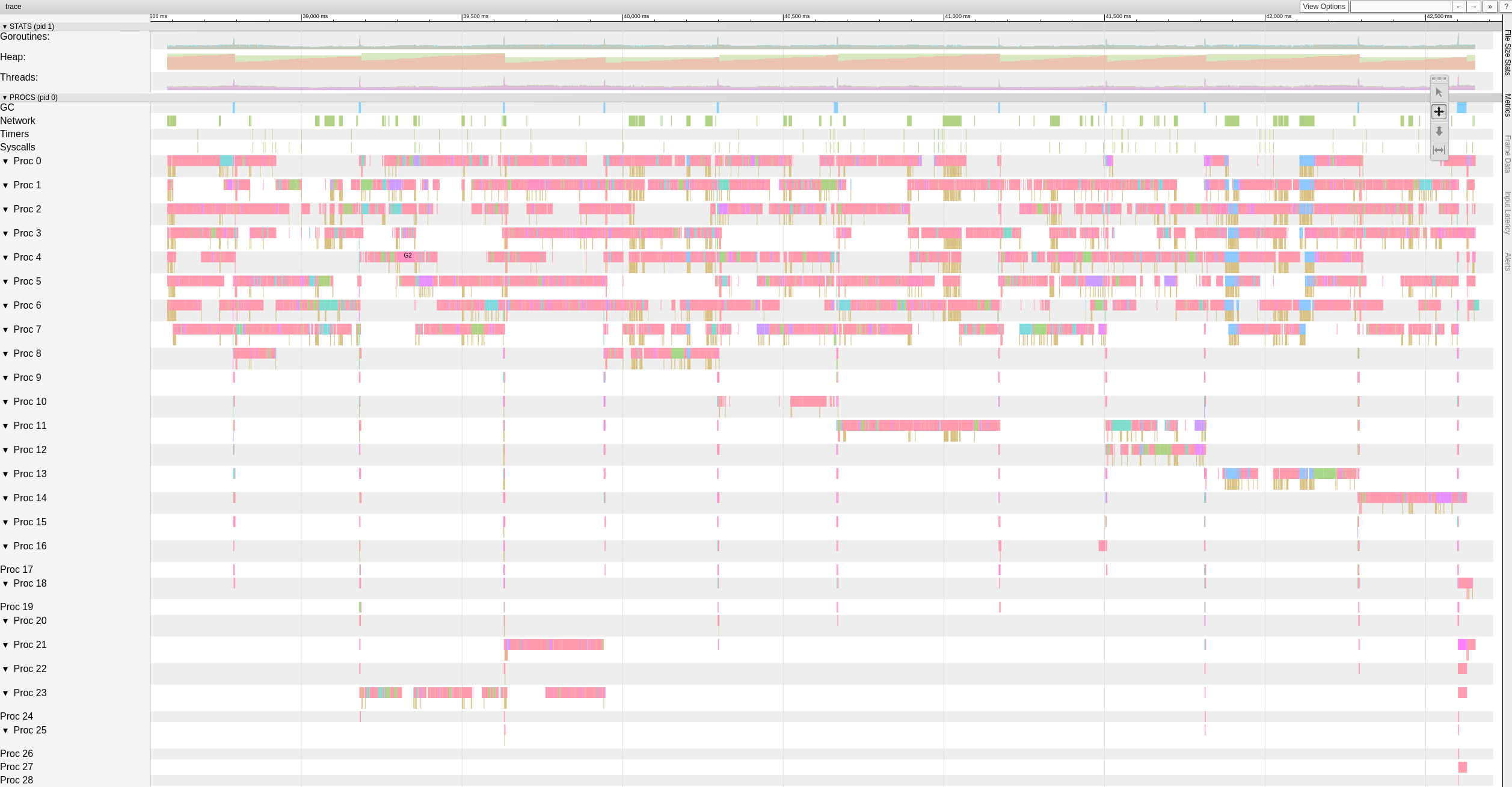
robvalca
am 27. Feb. 2019
@robvalca also ifedorenko@d410668 war im Vergleich zum
ifedorenko
am 27. Feb. 2019
@ifedorenko nein, ich habe vergessen zu erwähnen, die Leistung ist mehr oder weniger die gleiche wie die des Filialleiters (außer Betrieb) mit der gleichen Anzahl von Arbeitern(8) und S3.Verbindungen(32). Beide brauchten ~55m, was der Zeit für die Übertragung des Repo mit rclone entspricht (~47m).
Lass es mich wissen, wenn ich mit anderen Parametern testen soll ;)
robvalca
am 27. Feb. 2019
Ich habe den Auslöser für Leistungsprobleme in meinem Anwendungsfall gefunden. Die Wiederherstellungsleistung für große Dateien ist ab einer bestimmten Dateigröße nichtlinear.
Zum Testen habe ich in S3 ein neues Repository erstellt und dann 6 Dateien mit zufälligen Daten im Repository gesichert. Die Dateien waren 1, 5, 10, 20, 40 und 80 GB groß.
Wie bei früheren Tests wurden die Tests auf i3.8xlarge-Instanzen durchgeführt, wobei die Backups und Wiederherstellungen auf schnellen SSDs mit Stripes durchgeführt wurden.
Die Backup-Zeiten waren erwartungsgemäß linear (8, 25, 46, 92, 177 und 345 Sekunden).
Die Wiederherstellungszeiten waren jedoch nicht:
1 GB, 5 Sekunden
5 GB, 17 Sekunden
10 GB, 33 s
20 GB, 85 s
40 GB, 256 s
80 GB, 807 s
Es passiert also etwas Seltsames mit großen Dateien und der Wiederherstellung der Leistung.
Der Bucket heißt pmk-large-restic-test und der Bucket und sein Inhalt sind öffentlich. Es ist in us-west-1 und das restliche Repo-Passwort ist password
Die Snapshot-IDs für die Dateien sind:
1 GB: 0154ae25
5 GB: 3013e883
10 GB: 7463efa8
20 GB: 292650c6
40 GB: 5acb4bee
80 GB: d1b7e323
Lassen Sie mich wissen, wenn ich weitere Daten zur Verfügung stellen kann!
pmkane
am 27. Feb. 2019
@pmkane können Sie bestätigen , dass Sie letzten Leiter verwenden https://github.com/ifedorenko/restic/tree/out-order-restore Zweig (https://github.com/ifedorenko/restic/commit/ead78b375f2efed6de57c99b6766edbe9322e009 um genau zu sein) ?
ifedorenko
am 27. Feb. 2019
Ja, habe ich. Entschuldigung, dass ich das nicht erwähnt habe.
pmkane
am 27. Feb. 2019
(verwendet 32 Worker und 32 s3-Verbindungen über alle Läufe mit ead78b3)
pmkane
am 27. Feb. 2019
Wissen Sie, ob ich etwas Besonderes tun muss, um auf diesen Eimer zuzugreifen? Ich habe noch nie öffentliche Buckets verwendet, bin mir also nicht sicher, ob ich etwas falsch mache oder der Benutzer keinen Zugriff hat. (Ich kann problemlos auf die Buckets meines Teams zugreifen, daher weiß ich, dass mein System im Allgemeinen auf s3 zugreifen kann)
ifedorenko
am 27. Feb. 2019
Hey @ifedorenko ,
pmkane
am 27. Feb. 2019
Entschuldigung, ich hatte eine öffentliche Bucket-Richtlinie angewendet, aber die Objekte im Bucket selbst nicht aktualisiert. Sie sollten jetzt darauf zugreifen können. Beachten Sie, dass Sie --no-lock verwenden müssen, da ich nur Leseberechtigungen erteilt habe.
pmkane
am 27. Feb. 2019
Jep. Ich kann jetzt auf das Repo zugreifen. Werde heute Abend damit spielen.
ifedorenko
am 27. Feb. 2019
Und falls es hilfreich/einfacher zu testen ist, sehen wir ähnliche Leistungsmerkmale bei der Wiederherstellung derselben Dateien in/aus einem Repo auf einer schnellen SSD, wodurch S3 aus der Gleichung herausgenommen wird.
pmkane
am 28. Feb. 2019
@pmkane Ich kann das Problem lokal reproduzieren und benötige keinen Zugriff mehr auf diesen Bucket. das war sehr nützlich, danke.
ifedorenko
am 28. Feb. 2019
@ifedorenko , fantastisch. Ich werde den Eimer löschen.
pmkane
am 28. Feb. 2019
@pmkane Bitte Out-Order-Restore- Filiale noch einmal, wenn Sie Zeit haben. Ich hatte keine Zeit, dies in ec2 zu testen, aber auf meinem MacBook scheint die Wiederherstellung durch die Schreibgeschwindigkeit der Festplatte begrenzt zu sein und stimmt jetzt mit rclone überein.
ifedorenko
am 1. März 2019
@ifedorenko , das klingt sehr vielversprechend. Ich starte jetzt einen Test.
pmkane
am 1. März 2019
@ifedorenko , Bingo.
Wiederherstellung von 133 GB Blobs, die eine Mischung aus Dateigrößen darstellen, wobei die größte 78 GB beträgt, in knapp 16 Minuten. Zuvor hätte diese Wiederherstellung den größten Teil eines Tages gedauert. Ich vermute, dass wir dies noch schneller erreichen können, indem wir mit der Anzahl der restoreWorker spielen, aber es ist so wie es aussieht sehr schnell.
Danke für deine Mühe dabei!
pmkane
am 1. März 2019
Und für die Nachwelt: Unsere Wiederherstellungsleistung verdoppelt sich von 8->16 und erneut von 16->32 Wiederherstellungsarbeitern. 32->64 ist nur gut für einen ~50% Anstieg auf 32, an welchem Punkt wir mit etwa 3 Gbit/s wiederherstellen. Fast auf Augenhöhe mit rclone.
Ich weiß, dass der Wunsch besteht, den Konfigurationsaufwand zu minimieren, der erforderlich ist, um die beste Leistung aus Restic herauszuholen, aber dieser Sprung ist ein großer Sprung, insbesondere für Benutzer mit großen Dateisätzen, dass es schön wäre, dies angeben zu können Anzahl der Arbeiter zur Laufzeit.
pmkane
am 1. März 2019
Ich bin mir nicht sicher, warum die Wiederherstellung immer noch nicht die volle Geschwindigkeit erreichen kann. Es gibt einen redundanten Blob-Hash-Check, den Sie
ifedorenko
am 2. März 2019
Ich werde es versuchen.
pmkane
am 2. März 2019
Hallo zusammen, ich habe einige Tests mit dem neuesten Pull-Request #2195 durchgeführt und die Leistung verbessert sich weiter!
(20.000 kleine Dateien, 2x70G Dateien, 170G insgesamt)
8w_32c
real 27m46.185s
user 24m31.290s
sys 3m55.153s
32w_32c
real 15m30.904s
user 24m1.982s
sys 4m55.128s
64w_32c
real 18m37.566s
user 23m33.684s
sys 5m3.024s
64w_64c
real 17m12.314s
user 23m44.318s
sys 4m43.090s
Nicht sicher über den Leistungsabfall von 32 W auf 64 W (mehrmals getestet und scheint legitim). Ich füge während des Prozesses einige Diagramme an, scheint es eine Verschlechterung oder ein Limit zu geben, sollte das so sein? Bei 64 Workern beginnt der Prozess beispielsweise mit 6 Gbit/s, fällt dann aber bis zum Ende des Prozesses auf weniger als 1 Gbit/s ab (was meiner Meinung nach der Zeit für die Verarbeitung dieser großen Dateien entspricht). Der erste Screenshot ist mit 32w, 32c und der zweite mit 64w, 32c.
Ich stimme auch @pmkane zu , es wäre nützlich, die Arbeiternummer über die Befehlszeile zu ändern. Es wäre sehr nützlich für Disaster Recovery-Szenarien, wenn Sie Ihre Daten so schnell wie möglich wiederherstellen möchten. Dazu gibt es eine Pull-Anfrage von meinem Kollegen #2178
Wie auch immer, ich bin wirklich beeindruckt von den durchgeführten Verbesserungen! vielen Dank @ifedorenko
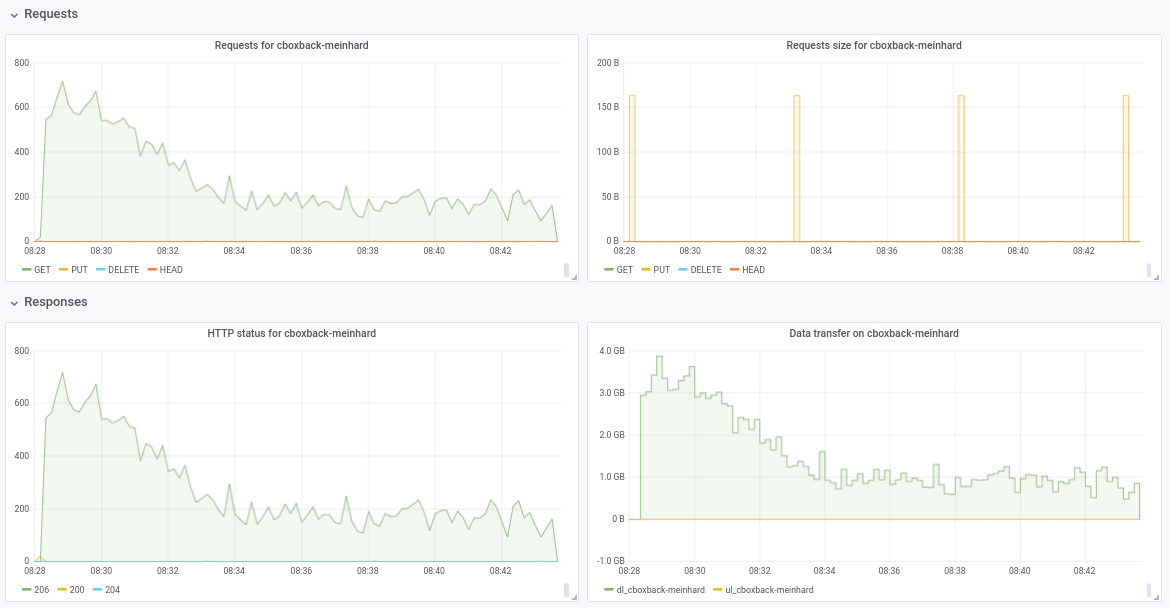
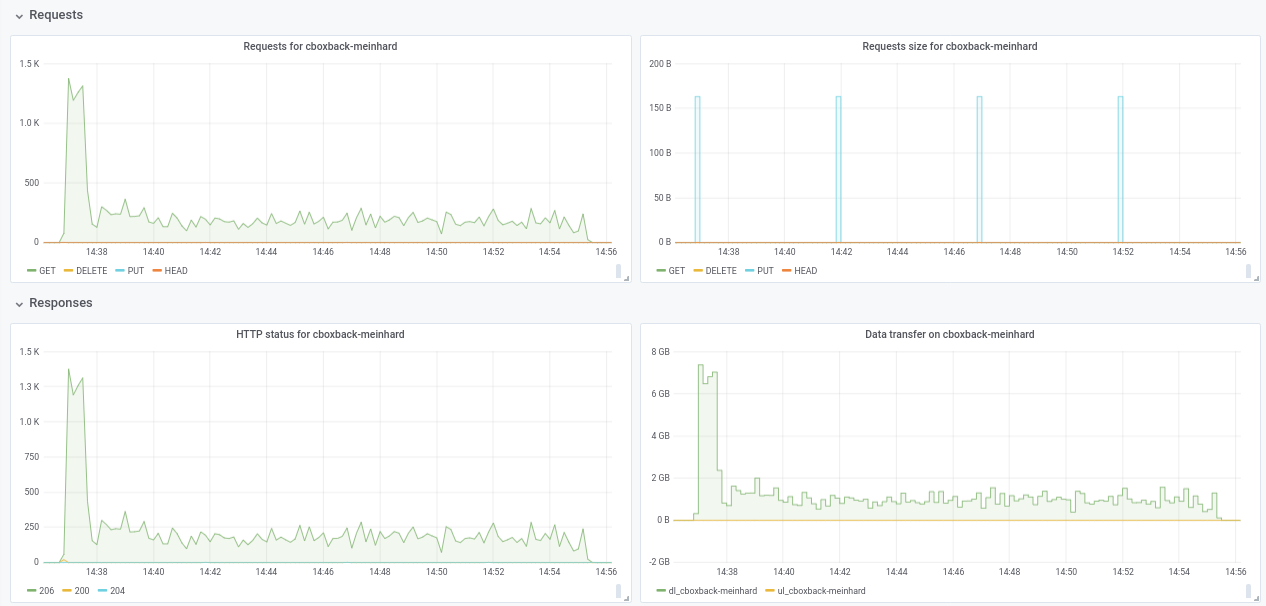
robvalca
am 4. März 2019
++. Danke @ifedorenko , das ist bahnbrechendes Zeug für Restic.
pmkane
am 4. März 2019
Danke für den ausführlichen Bericht @robvalca. Besteht die Möglichkeit, ein Test-Repository bereitzustellen, das ich entweder in AWS (oder GCP oder Azure) oder lokal bereitstellen kann? Ich habe in meinen Tests keinen Rückgang der Wiederherstellungsgeschwindigkeit für große Dateien festgestellt und würde gerne verstehen, was dort vor sich geht.
ifedorenko
am 4. März 2019
@pmkane Ich möchte diese Dinge auch zur Laufzeit konfigurieren . Mein Vorschlag war, ihnen --option Optionen zu geben, damit sie die regulären Flags oder Befehle nicht überladen, sondern für 'fortgeschrittene' Benutzer da sind, die experimentieren oder sich auf ihre ungewöhnliche Situation einstellen möchten. Sie müssen nicht einmal dokumentiert werden und können mit Namen versehen werden, die deutlich machen, dass man sich nicht auf sie verlassen kann, wie --option experimental.fooCount=32 .
 whereisaaron
am 4. März 2019
whereisaaron
am 4. März 2019
Hallo @ifedorenko , ich habe ein öffentliches Repo mit Junk-Daten unter s3.cern.ch/restic-testrepo . Es hat mehr oder weniger die gleiche Form wie die, die ich ausprobiert habe (viele kleine Dateien und ein paar sehr große) und auch ich konnte das gleiche Verhalten auf diesem reproduzieren (angehängter Plot). Das Passwort für das Repository lautet restic . Lassen Sie es mich wissen, wenn Sie Probleme beim Zugriff darauf haben.
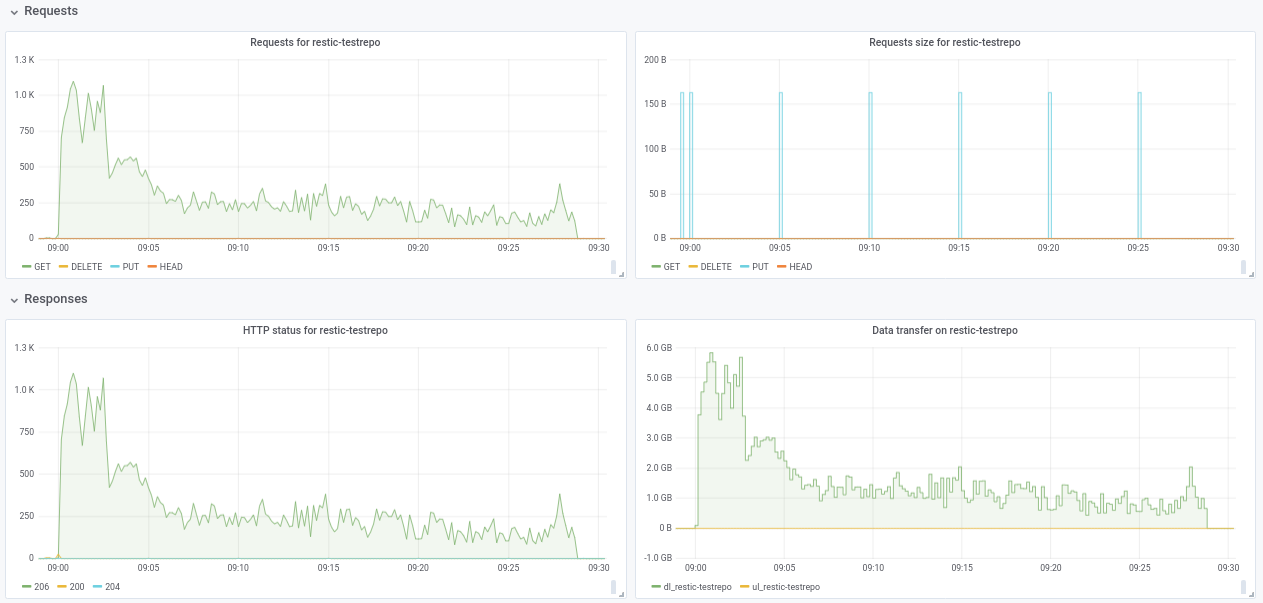
robvalca
am 5. März 2019
@robvalca Ich kann das Problem mit Ihrem Test-Repository nicht reproduzieren. In AWS (us-east-2, s3 repo, i3.4xlarge 2x nvme raid0 target) sehe ich eine konstante Wiederherstellungsgeschwindigkeit von 0,68 GB/s bei Verwendung von 32 Arbeitern und 32 Verbindungen (Gesamtwiederherstellungszeit 6m20s). Ihr Zielsystem kann 10 GB / s nicht lange halten, wenn ich raten würde, zumindest würde ich das zuerst überprüfen, wenn ich das Problem weiter beheben würde.
@pmkane interessanterweise kann ich deine Beobachtungen auch nicht bestätigen. Wie ich oben erwähnt habe, sehe ich eine Wiederherstellungsgeschwindigkeit von 0,68 GB/s mit dem neuesten out-of-order-restore-no-progress Zweig (Wiederherstellung sah CPU-gebunden aus) und 0,81 GB/s, wenn ich die redundante Blob-Hash-Prüfung deaktiviere (Wiederherstellung sah nicht nach CPU- gebunden). Ich weiß nicht, wie viel schneller "bis zu 10 Gbps"-Netzwerke gehen können, aber ich denke, wir befinden uns bereits sehr im Bereich "Rückgänge mit abnehmender Rendite".
ifedorenko
am 6. März 2019
@ifedorenko Ich stimme voll und ganz zu: abnehmende Renditen. So wie es ist, ist es für uns schnell genug.
pmkane
am 6. März 2019
@ifedorenko interessant, ich werde das an unserer Seite untersuchen. Jedenfalls ist es auch für uns schnell genug, vielen Dank für Ihre Mühe.
robvalca
am 7. März 2019
Neugierig auf den Status der Integration . Dieser Zweig, kombiniert mit
pmkane
am 22. Aug. 2019
Bald... 👀
 rawtaz
am 26. Feb. 2020
rawtaz
am 26. Feb. 2020
Dies wird nun geschlossen, da #2195 zusammengeführt wurde. Sie können es jederzeit wieder öffnen, wenn die Einzelheiten dieses Problems nicht behoben wurden. Wenn noch Verbesserungen vorgenommen werden müssen, die nicht der in dieser Ausgabe behandelten Art entsprechen, öffnen Sie bitte eine neue Ausgabe. Vielen Dank!
rawtaz
am 26. Feb. 2020
Verwandte Themen
 jpic
·
3Kommentare
jpic
·
3Kommentare
 stevesbrain
·
3Kommentare
whereisaaron
·
3Kommentare
stevesbrain
·
3Kommentare
whereisaaron
·
3Kommentare
 fd0
·
4Kommentare
fd0
·
4Kommentare
 viric
·
5Kommentare
viric
·
5Kommentare
Hilfreichster Kommentar
Neugierig auf den Status der Integration . Dieser Zweig, kombiniert mit