Restic: يمكن أن تكون عمليات الاستعادة أسرع
بفضل دمج PR1719 ، تكون عمليات الاستعادة في restic _way_ أسرع.
يمكن أن تكون أسرع.
لأغراض الاختبار ، استعدت من حاوية AWS S3 الثابتة في نفس المنطقة (us-west-1) كمثال مخصص لـ i3.8xlarge EC2. ذهبت الاستعادة مقابل 4x1.9TB nvme في المثال ، مخطط RAID-0 عبر LVM مع نظام ملفات xfs تحته. يحتوي المثيل على عرض نطاق نظري يبلغ 10 جيجابت / ثانية إلى S3.
مع workerCount في filerestorer.go ارتفع إلى 32 (من الحد المجمع البالغ 8) ، يستعيد restic مزيجًا من 228 ألف ملف بحجم ملف متوسط يبلغ 8 كيلوبايت وحجم ملف أقصى يبلغ 364 جيجابايت بمتوسط 160 ميجابت / ثانية.
وبالمقارنة ، فإن rclone مع - التحويلات = 32 ينقل البيانات من نفس المجموعة بسرعة 5636 ميجابت / ثانية ، أي أسرع بأكثر من 30 مرة.
إنها ليست مقارنة بين التفاح والتفاح. يبلغ حجم كتل البيانات Restic 4096KB ، وليس 8KB ، ومن المؤكد أن فتح / إغلاق الملفات به بعض الإجهاد. لكنه لا يزال فرقًا كبيرًا بما يكفي لأنه يشير على الأرجح إلى عنق الزجاجة في حالة الراحة.
يسعدني اختبار الأشياء أو توفير الأجهزة أو المساعدة بأي طريقة أخرى!
 pmkane
pmkane
ال 71 كومينتر
160 ميجابت / ثانية تبدو بطيئة بالفعل. كنت أقترب من 200 ميجابت في الثانية على جهاز macbook pro الصغير الذي يتم تنزيله من onedrive over (يمنح سريعًا) اتصال 1Gbps ftth. لا يمكنني حقًا قول أي شيء محدد دون الوصول إلى أنظمتك ومستودعك ، ولكن فيما يلي بعض الأشياء التي يجب أن أقوم بها لتضييق نطاق المشكلة ، بدون ترتيب معين:
- تقدير الوقت المستغرق لتنزيل ملف حزمة واحدة على مؤشر ترابط واحد. يمكنك حساب ذلك من اختبار تنزيل rclone 32x الخاص بك ، لكنني سأكون فضوليًا أيضًا لمعرفة الوقت اللازم لتنزيل الحزم الفردية باستخدام curl حتى نتمكن من تقدير عبء طلب http أيضًا.
- كنت أتحقق من إحصائيات نظام التشغيل عن مقدار التنزيل الفعلي من S3 أثناء الاستعادة. سيخبرنا هذا ما إذا كانت استعادة ملفات الحزم الفردية التي تم تنزيلها عدة مرات (وهو أمر ممكن ، ولكن لا ينبغي أن يحدث كثيرًا ، إلا إذا أغفلت شيئًا ما).
- يبدو أن مستوى التزامن S3 يقتصر على 5 اتصالات فقط. هل يمكن أن يفسر هذا سرعة الاستعادة التي تراها معطى تقدير السرعة أحادي الخيط من الأعلى؟ ماذا يحدث إذا قمت بزيادة حد اتصال الواجهة الخلفية بخدمة S3 لمطابقة المرمم؟
- استخدم الرسم البياني لشبكة الرسم البياني أثناء الاستعادة لمعرفة ما إذا كان هناك أي فجوات أو تباطؤ.
- استبعد هذا الملف بحجم 364 جيجابايت من الاستعادة وشاهد ما سيحدث. تتم حاليًا استعادة الملفات الفردية بالتتابع ، لذلك يمكن لهذا الملف الواحد أن يؤدي إلى انحراف متوسط سرعة التنزيل بشكل كبير.
 ifedorenko
في ٧ نوفمبر ٢٠١٨
ifedorenko
في ٧ نوفمبر ٢٠١٨
أهلا!
شكرا على الرد. كان هذا مثيرًا للتنقيب فيه
tl ؛ dr: إن زيادة اتصالات s3 هو المفتاح ، لكن تعزيزات الأداء التي توفرها مؤقتة ، بشكل غريب.
- نقل حزم بقيمة دليل واحد (3062 ملفًا بإجمالي 13 جيجابايت) / مع rclone - عمليات النقل 1 تعمل بسرعة 233 ميجابت / ثانية. تم التأكيد مع lsof أنه يعمل فقط مع سلسلة محادثات واحدة واتصال https واحد في هذا الوضع. يتم تحقيق سرعة الذروة من خلال - التحويلات 32 (8.5 جيجابت / ثانية ، سرعة الخط بشكل أساسي لمثيل i3.8xlarge ec2). في كلتا الحالتين نكتب إلى مصفوفة nvme المخططة.
- يسعدني جمع بعض الإحصائيات ، ولكن ما الذي ترغب في رؤيته على وجه التحديد؟ (ولكن قد لا تكون مطلوبة ، يرجى الاطلاع أدناه)
- ذاهب لقتل عصفورين بحجر واحد هنا! فيما يلي رسم بياني لاستخدام الشبكة أثناء عمليات الاستعادة باستخدام:
- تم دمج بقية الأسهم مع هذا العلاقات العامة (الالتزام c0572ca15f946c622d9c4009347dc4d6c31cba4c)
- restic مع workerCount ارتفع إلى 32 وارتفع filesWriterCount إلى 128
- restic مع التغييرات السابقة + زادت اتصالات s3 إلى 32.
- resitc مع التغييرات السابقة + زادت اتصالات s3 إلى 64.
- rclone مع نقل 32 - نقل البيانات / الدليل
رقم النطاق الترددي بالكيلوبت في الثانية وتم التقاطه على فترات 3 ثوانٍ على مدى 10 دقائق. بالنسبة لعمليات التشغيل الباقية ، بدأنا في جمع البيانات _ بعد_ بدأ restic بالفعل في استعادة الملفات بالفعل (على سبيل المثال ، يستبعد وقت بدء التشغيل والوقت الذي يقضيه restic في بداية التشغيل لإعادة إنشاء التسلسل الهرمي للدليل. وأثناء جميع عمليات التشغيل ، كان استخدام وحدة المعالجة المركزية على لم يتجاوز مثيل 25٪.
نحصل على عثرة طفيفة من زيادة العامل ، ولكن يبدو أن التزامن S3 هو المكان الذي يكون فيه الفوز الحقيقي. ولكن بينما تبدأ قوية (تقترب من سرعة النسخ ، في بعض الأحيان!) ، تنخفض المعدلات بشكل مفاجئ وتظل منخفضة لبقية المدى. يطرح restic أيضًا أخطاءً تبدو مثل "تجاهل الخطأ لـ [تم تنقيح المسار]: سعة ذاكرة التخزين المؤقت غير كافية: المطلوبة 2148380 ، 872640 المتوفر" التي لا تتسبب في انخفاض تزامن s3.
كما ترى ، يبدأ أداء rclone عالياً ويظل مرتفعًا ، لذا فهو ليس موقفًا تنتقل فيه عمليات الكتابة إلى ذاكرة التخزين المؤقت للمثيل ثم تتوقف عند نقلها إلى القرص. تعد صفيف nvme أسرع من أنبوب الشبكة ، من حيث الإنتاجية.
- لا أعتقد أن الملف الكبير المنفرد يعد عاملاً ، لأنني أقوم بقياس إدخال / إخراج الشبكة على القرص أثناء الاستعادة ، لذا فإن حقيقة أن استعادة هذا الملف الفردي بالكامل قد تستغرق بعض الوقت لن تؤثر على الأرقام التي تبحث هنا.
بالنظر إلى ما سبق ، يبدو أن رفع مستوى التزامن S3 هو ما يتطلبه الأمر للحصول على أسعار معقولة هنا ، ولكن عليك معرفة سبب انخفاض الأداء (وما إذا كان مرتبطًا بأخطاء ذاكرة التخزين المؤقت أم لا).
إذا كان إنشاء مثيل i3 سريعًا وبعض مساحة s3 وعرض النطاق الترددي المتاح للاختبار سيكون مفيدًا ، فيرجى إبلاغي بذلك ، ويسعدني رعاية ذلك.
pmkane
في ٧ نوفمبر ٢٠١٨
233 ميجابت / ثانية 32 مرة هو 7456 وأقل قليلاً من 8.5 جيجابت / ثانية. وهو أمر غريب. كنت أتوقع أن يكون التنزيل أحادي الخيوط أسرع من معدل النقل لكل دفق للتنزيل متعدد الخيوط. لست متأكدًا مما يعنيه هذا ، ومع ذلك ، إذا كان هناك أي شيء.
كنت أتطلع لتأكيد أن restic لا يعيد تنزيل الحزم نفسها مرارًا وتكرارًا. أعتقد أن الرسم البياني يوضح أن عمليات إعادة التنزيل ليست مشكلة ، لذلك لا داعي لمزيد من الإحصائيات ، على الأقل ليس الآن.
هل يمكنك تأكيد مقياس الرسم البياني؟ يحوم rclone حول الخط المسمى "1000000" ، إذا كان هذا هو "1000000 كيلو بت في الثانية" ، والذي أعتقد أنه يعني "1 جيجابت في الثانية" ولا يتوافق مع الرقم "8.5 جيجابت / ثانية" الذي ذكرته سابقًا.
كما قلت ، تتم استعادة الملفات الفردية بالتتابع. سيستغرق تنزيل 364 جيجابايت بسرعة 233 ميجابت / ثانية حوالي 3.5 ساعة ، وربما أطول بسبب الحمل الزائد لكل حزمة وفك التشفير ، وكل ذلك يحدث بالتتابع. لا يمكنك معرفة ما إذا كانت 3.5 ساعات هي شيء يمكنك تجاهله على أنه غير مهم دون معرفة مقدار ما تستغرقه عملية الاستعادة المتبقية.
بالنسبة لخطأ not enough cache capacity ، قم بزيادة حجم متوسط الحزمة إلى حجم أكبر ملف حزمة في المستودع الخاص بك (ما هو حجمه ، راجع للشغل؟)
ifedorenko
في ٧ نوفمبر ٢٠١٨
أهلا!
عفوًا ، أنا آسف. المقياس في الرسم البياني هو كيلوبايت / ثانية وليس كيلوبت / ثانية. إذن 1012995 في الصف الأول تساوي 8.1 جيجابت / ثانية.
لقد فهمت أنه تمت استعادة الملفات بالتتابع ، لكنني لم أفهم أنه لا يوجد توازي لاسترداد الحزمة لملف واحد. هذا بالتأكيد يمثل حجر عثرة بالنسبة للنسخ الاحتياطية ذات الملفات الكبيرة ، حيث يصبح ذلك عاملاً مقيدًا لك. سيكون من الرائع وجود بعض التوازي هنا لهذا السبب.
أخذ عينات من 10 مجموعات عشوائية ، يكون الحد الأقصى لحجم الحزمة أقل بقليل من 12 ميجا بايت ومتوسط حجم الحزمة لدينا هو 4.3 ميجا بايت.
ربما مع وجود عدد أكبر من العاملين واتصالات S3 ، فقد تجاوزنا حزمة packCacheCapacity البالغة (workerCount + 5) * averagePackSize. سأحاول زيادة ذلك ومعرفة ما إذا كانت الأخطاء ستختفي.
pmkane
في ٧ نوفمبر ٢٠١٨
ربما مع وجود عدد أكبر من العاملين واتصالات S3 ، فقد تجاوزنا حزمة packCacheCapacity البالغة (workerCount + 5) * averagePackSize. سأحاول زيادة ذلك ومعرفة ما إذا كانت الأخطاء ستختفي.
يتم حساب حجم ذاكرة التخزين المؤقت بناءً على حجم ملف الحزمة 5 ميجابايت و workerCount . تؤدي زيادة workerCount زيادة حجم ذاكرة التخزين المؤقت. لذلك إما أن يكون هناك تسرب للذاكرة أو تحتاج الاستعادة إلى تخزين العديد من الملفات بحجم 12 ميغا بايت عن طريق الصدفة البحتة. يجب أن يخبرنا رفع قيمة averagePackSize إلى 12 ميجابايت.
ifedorenko
في ٧ نوفمبر ٢٠١٨
لا توجد أخطاء في ذاكرة التخزين المؤقت مع ضبط averagePackSize على 12.
إذا كانت هناك أي معلومات أخرى يمكننا تقديمها والتي ستكون مفيدة ، فيرجى إبلاغي بذلك! شكرا لك مرة أخرى.
pmkane
في ٨ نوفمبر ٢٠١٨
يبدو أننا نفقد التوازي مع تقدم عملية الاستعادة ولا يبدو أنها مرتبطة بالملفات الكبيرة. سأضع حالة اختبار وأبلغ مرة أخرى.
pmkane
في ٨ نوفمبر ٢٠١٨
أهلا!
لقد حاولت إعادة إنتاج انخفاضات الأداء التي كنت أراها مع مزيج ملف الإنتاج الخاص بي مع ثلاثة مزج ملفات اصطناعية مختلفة.
بالنسبة لجميع الاختبارات ، استخدمت c0572ca15f946c622d9c4009347dc4d6c31cba4c مع زيادة اتصالات S3 إلى 128 ، وزاد عدد العمال إلى 128 ، وزاد عدد filesWriterCount إلى 128 وزاد متوسط PackSize إلى 12 * 1024 * 1024.
استخدمت جميع الاختبارات ملفات تحتوي على بيانات عشوائية ، لتجنب أي تأثيرات ناتجة عن إلغاء البيانات المكررة.
بالنسبة للاختبار الأول ، قمت بإنشاء 4000 ملف 100 ميجابايت وعمل نسخة احتياطية منها ، مقسمة بالتساوي على 100 دليل (حوالي 400 جيجابايت إجمالاً). تم تشغيل النسخ الاحتياطية والاستعادة من وحدات تخزين nvme المخططة على مثيل i3.8xlarge. كانت حاوية النسخ الاحتياطي موجودة في نفس المنطقة مثل المثيل (us-west-1).
باستخدام مزيج الملفات هذا ، رأيت سرعات متوسطة تبلغ 9.7 جيجابت / ثانية (!) مع عدم فقدان التوازي أو السرعة عبر الاستعادة الكاملة. هذه الأرقام متساوية أو أعلى من أرقام rclone وهي أساسًا سرعة الخط ، وهو أمر رائع.
ثم قمت بعد ذلك بإنشاء ونسخ 400000 ملف 1 ميجابايت احتياطيًا ، مقسمة بالتساوي على 100 دليل (مرة أخرى ، 400 جيجابايت إجمالاً).
نفس النتائج (ممتازة) على النحو الوارد أعلاه.
أخيرًا ، قمت بإنشاء 40 دليلًا بملف 1 10 جيجابايت لكل دليل. هنا ، أصبحت الأمور ممتعة.
كنت أتوقع أن تكون هذه الاستعادة أبطأ قليلاً ، لأن restic لن يكون قادرًا إلا على إجراء 40 عملية استعادة متزامنة مع 40 اتصالاً بـ S3.
بدلاً من ذلك ، بينما يفتح Restic جميع الملفات الأربعين للكتابة والكتابة إلى جميع الملفات الأربعين في وقت واحد ، فإنه يحافظ فقط على اتصال TCP واحد بـ S3 مفتوحًا في المرة الواحدة ، وليس 40.
اسمحوا لي أن أعرف ما هي الإحصائيات أو الأجهزة التي ترغب في رؤيتها.
pmkane
في ٨ نوفمبر ٢٠١٨
هل يمكنك تأكيد وجود 128 اتصالاً بمعيار S3 أثناء الاختبارات "السريعة"؟
ifedorenko
في ٨ نوفمبر ٢٠١٨
نعم ، كان هناك.
pmkane
في ٨ نوفمبر ٢٠١٨
فضولي ... دعم الملفات الكبيرة ليس على رأس قائمة أولوياتي لأكون صادقًا ، ولكن قد أجد بعض الوقت للنظر في هذا الأمر في الأسابيع القليلة المقبلة. إذا أراد أي شخص البحث في هذا قبل أن أفعل ، فيرجى إبلاغي بذلك.
ifedorenko
في ٨ نوفمبر ٢٠١٨
تم إجراء المزيد من الاختبارات ويبدو في الواقع أن حجم الملف هو رنجة حمراء ، وأعداد الملفات هي التي تدفع عدد اتصالات AWS.
مع 128 ملفًا بحجم 10 ميغابايت في 4 أدلة ، يفتح restic 6 اتصالات فقط بـ AWS ، على الرغم من أنه يكتب إلى جميع الملفات البالغ عددها 128.
مع 512 ملفًا بحجم 10 ميجا بايت في 4 أدلة ، يفتح restic 18 اتصالًا طوال حياته ، على الرغم من أنه يحتوي على 128 ملفًا مفتوحًا في كل مرة.
مع 5120 ملفًا بحجم 10 ميجابايت في 4 أدلة ، يفتح restic 75 اتصالاً فقط بـ AWS على مدار حياته ، ويحتفظ مرة أخرى بـ 128 ملفًا مفتوحًا في كل مرة.
الفردية!
pmkane
في ٨ نوفمبر ٢٠١٨
سأكون مندهشًا حقًا إذا لم يقم عميل Go S3 بتجميع وإعادة استخدام اتصالات http. على الأرجح لا توجد علاقة فردية بين عدد العمال المتزامنين ومآخذ TCP المفتوحة. لذلك ، على سبيل المثال ، إذا كانت الاستعادة بطيئة في معالجة الحزم التي تم تنزيلها لأي سبب من الأسباب ، فسيتم مشاركة نفس اتصال S3 بواسطة عدة عمال.
ifedorenko
في ٨ نوفمبر ٢٠١٨
هناك خاصيتان لبرنامج الاستعادة المتزامن الحالي المسؤولان عن الجزء الأكبر من تعقيد التنفيذ ومن المحتمل جدًا أنهما يتسببان في التباطؤ الذي تم الإبلاغ عنه هنا:
- تتم استعادة الملفات الفردية من البداية إلى النهاية
- يتم الاحتفاظ بعدد الملفات قيد التقدم إلى الحد الأدنى
سيكون التنفيذ أبسط بكثير ، وسيستخدم ذاكرة أقل ومن المحتمل جدًا أن يكون أسرع في كثير من الحالات إذا وافقنا على كتابة ملفات كبيرة بأي ترتيب والسماح بأي عدد من الملفات قيد التقدم.
الجانب السلبي ، لن يكون من الممكن معرفة مقدار البيانات التي تمت استعادتها بالفعل في أي ملف معين حتى نهاية الاستعادة. الأمر الذي قد يكون محيرًا ، خاصةً في حالة استعادة الأعطال أو الوفاة. لذلك قد ترى ملفًا بحجم 10 جيجا بايت على نظام الملفات ، والذي يحتوي في الواقع على عدد قليل من البايتات المكتوبة في نهاية الملف.
@ fd0 هل تعتقد أن الأمر يستحق تحسين الاستعادة الحالية من البداية إلى النهاية؟ أنا شخصياً على استعداد للاعتراف بأن الأمر كان يتعلق بالهندسة من جانبي ويمكنني تقديم تنفيذ أبسط خارج الطلب إذا وافقت.
ifedorenko
في ١٦ نوفمبر ٢٠١٨
لا أتذكر ما إذا كان Restic يدعم الاستعادة إلى الإخراج القياسي. إذا حدث ذلك ، فمن الواضح أنك ستحتاج إلى الاحتفاظ بالاستعادة من البداية إلى النهاية (ربما كحالة خاصة).
 pvgoran
في ١٦ نوفمبر ٢٠١٨
pvgoran
في ١٦ نوفمبر ٢٠١٨
ifedorenko أنا شخصياً أؤيد التبسيط ، بشكل عام ، خاصة إذا كان يأتي مع
الجانب السلبي ، لن يكون من الممكن معرفة مقدار البيانات التي تمت استعادتها بالفعل في أي ملف معين حتى نهاية الاستعادة.
إذا لم نتحدث هنا عن آلاف الملفات المكتوبة بشكل متزامن ، فربما يمكن استخدام خريطة اسم الملف للبايت المكتوب؟ من الواضح أنه لن يجعل المعلومات متاحة لنظام الملفات ، ولكن ، للإبلاغ عن التقدم ، لا يزال من الممكن القيام بذلك ، أليس كذلك؟ (ولاستئناف الاستعادة التي تمت مقاطعتها ، ربما مجرد التحقق من النقط والإزاحات في الملف بحثًا عن وحدات بايت غير فارغة ، ربما؟ لا أعرف.)
لا أتذكر ما إذا كان Restic يدعم الاستعادة إلى الإخراج القياسي. إذا حدث ذلك ، فمن الواضح أنك ستحتاج إلى الاحتفاظ بالاستعادة من البداية إلى النهاية (ربما كحالة خاصة).
لا أعتقد أنه كذلك - لست متأكدًا من كيفية عمل ذلك على أي حال ، نظرًا لأن عمليات الاستعادة عبارة عن ملفات متعددة ، فستحتاج إلى ترميزها بطريقة ما وفصلها بطريقة ما على ما أعتقد.
 mholt
في ١٦ نوفمبر ٢٠١٨
mholt
في ١٦ نوفمبر ٢٠١٨
إذا لم نتحدث هنا عن آلاف الملفات المكتوبة بشكل متزامن ، فربما يمكن استخدام خريطة اسم الملف للبايت المكتوب؟
أبسط طريقة هي فتح الملفات وإغلاقها لكتابة نقاط فردية. إذا ثبت أن هذا بطيء جدًا ، فسنضطر إلى إيجاد طريقة لإبقاء الملفات مفتوحة لكتابة blob متعددة ، على سبيل المثال عن طريق التخزين المؤقت لمقابض الملفات المفتوحة وطلب تنزيلات الحزم لتفضيل الملفات المفتوحة بالفعل.
تقوم ميزة الاستعادة بالفعل بتتبع النقاط التي تمت كتابتها على الملفات وما لا يزال معلقًا. لا أتوقع أن يتغير هذا الجزء كثيرًا. يتم تتبع التقدم في بنية بيانات منفصلة ولا أتوقع أن يتغير ذلك أيضًا.
ولاستئناف الاستعادة التي تمت مقاطعتها ، ربما مجرد التحقق من النقط والإزاحات للملف بحثًا عن وحدات بايت غير فارغة ، ربما؟
يحتاج السيرة الذاتية إلى التحقق من المجموع الاختباري للملفات الموجودة على القرص لتحديد النقاط التي لا تزال بحاجة إلى استعادتها. أعتقد أن هذا صحيح بغض النظر عما إذا كانت الاستعادة متسلسلة أو خارج الترتيب. على سبيل المثال ، إذا تم استرداد استئناف من انقطاع التيار الكهربائي ، لا أعتقد أنه يمكن أن تفترض أن جميع كتل الملفات قد تم مسحها على الأقراص قبل انقطاع التيار الكهربائي ، أي يمكن أن تحتوي الملفات على فجوات أو كتل مكتوبة جزئيًا.
ifedorenko
في ١٦ نوفمبر ٢٠١٨
pmkane أتساءل عما إذا كان يمكنك تجربة # 2101؟ يقوم بتنفيذ الاستعادة خارج الترتيب ، على الرغم من أن عمليات الكتابة إلى الملفات الفردية لا تزال متسلسلة وقد تظل استعادة أداء الملفات الكبيرة دون المستوى الأمثل. وتحتاج إلى تعديل عدد العمال كما كان من قبل.
ifedorenko
في ٢٧ نوفمبر ٢٠١٨
على الاطلاق. أنا أسافر هذا الأسبوع لكنني سأختبر بأسرع ما يمكنني وأعيد التقرير.
pmkane
في ٢٧ نوفمبر ٢٠١٨
ifedorenko لقد جربت هذا العلاقات العامة وقام بإنشاء بنية الدليل بنجاح ، ولكن بعد ذلك تفشل جميع عمليات استعادة الملفات مع وجود أخطاء مثل:
حمل(، 3172070، 0) إرجاع خطأ ، إعادة المحاولة بعد 12.182749645s: EOF
سيد يعيد غرامة.
أمر الاستعادة الخاص بي هو:
/usr/local/bin/restic.outoforder -r s3: s3.amazonaws.com/ [منقح] -p /root/.restic_pass Restore [snapshotid] -t.
اسمحوا لي أن أعرف ما هي المعلومات الإضافية التي يمكنني تقديمها للمساعدة في التصحيح.
pmkane
في ١ ديسمبر ٢٠١٨
كم عدد طلبات تنزيل S3 المتزامنة التي تسمح بها؟ إذا كان العدد 128 ، فهل يمكنك قصره على 32 (وهو ما نعرف أنه يعمل)؟
شبه مرتبطة ... هل تعرف عدد ملفات الفهرس الموجودة في مستودعك الحقيقي؟ محاولة تقدير مقدار ما يحتاجه برنامج استعادة الذاكرة.
ifedorenko
في ١ ديسمبر ٢٠١٨
لم أحدد حدًا للاتصال ، لذلك أفترض أنه كان افتراضيًا إلى 5.
أحصل على نفس الأخطاء مع -o s3.connections = 2 و -o s3.connections = 1.
لدي حاليًا 85 نقطة فهرس في الفهرس / المجلد. يبلغ حجمها الإجمالي 745 ميغا بايت.
pmkane
في ١ ديسمبر ٢٠١٨
همم. سألقي نظرة أخرى عندما أصل إلى جهاز الكمبيوتر الخاص بي في وقت لاحق اليوم. راجع للشغل ، "الخطأ المُعاد ، إعادة المحاولة" هو تحذير وليس خطأ ، لذلك قد يكون مرتبطًا بفشل الاستعادة أو قد يكون مجرد رنجة حمراء.
ifedorenko
في ١ ديسمبر ٢٠١٨
لست متأكدًا من كيف فاتني ذلك ... لم يقرأ المرمم جميع ملفات الحزمة بالكامل من الواجهة الخلفية في معظم الحالات. يجب إصلاحه الآن. pmkane هل يمكنك تجربة الاختبار مرة أخرى؟
ifedorenko
في ٢ ديسمبر ٢٠١٨
سأعطيها دوامة!
pmkane
في ٢ ديسمبر ٢٠١٨
تم التأكيد على استعادة الملفات بنجاح مع هذا الإصلاح. أداء الاختبار الآن.
pmkane
في ٢ ديسمبر ٢٠١٨
لسوء الحظ يبدو أنه أبطأ من السيد. يتم تشغيل جميع الاختبارات على مثيل i3.8xlarge الموضح أعلاه.
مع workerCount من 8 (الافتراضي) ، تمت استعادة فرع خارج الترتيب بمعدل 86 ميجابت / ثانية.
مع صدم عامل عامل إلى 32 ، كان يعمل بشكل أفضل قليلاً - بمتوسط 160 ميجابت / ثانية.
يعد استخدام وحدة المعالجة المركزية مع هذا الفرع أعلى بكثير مما هو عليه في الرئيسي ، ولكنه لا يصل إلى الحد الأقصى لوحدة المعالجة المركزية للمثيل في كلتا الحالتين.
من خلال القصص المتناقلة ، تجعل واجهة المستخدم الخاصة بالاستعادة الأمر يبدو كما لو أن شيئًا ما "يلتصق" ، تقريبًا كما لو كان يتنافس مع نفسه للحصول على قفل في مكان ما.
يسعدنا تقديم المزيد من التفاصيل أو التنميط أو نسخة اختبار لتكرارها.
pmkane
في ٢ ديسمبر ٢٠١٨
فقط للتأكيد ، تم تعيين كل من المرمم وعامل الواجهة الخلفية s3 على 32 ، أليس كذلك؟
زوجان من الأفكار التي قد تفسر السلوك الذي لاحظته:
- لا تزال عمليات الكتابة إلى الملفات الفردية متسلسلة. اعتقدت أن هذه لن تكون مشكلة في أنظمة الملفات سريعة الهدف ، ولكن لم يتم قياسها مطلقًا.
- من المؤكد أن فتح / إغلاق الملف حول كل نقطة يساهم في زيادة الحمل على المرمم. عندما قمت بقياس هذا على نظام التشغيل macos ، تمكنت من "فتح ملف ؛ كتابة بايت واحد ؛ إغلاق الملف" 100 ألف مرة في 70 ثانية تقريبًا ، وهو ما يقرب من 100 ألف نقطة. كان الاختبار بسيطًا حقًا وقد تكون النفقات العامة الواقعية أعلى بكثير.
- ليس لدي حاليًا تفسير معقول للاستخدام العالي لوحدة المعالجة المركزية. يقوم التنفيذ خارج الطلب بفك تشفير كل نقطة واحدة فقط (يقوم البرنامج بفك تشفير النقاط لكل ملف هدف) ، وهناك الكثير من إمساك الدفاتر مقارنة بالسيد. ربما لا تكون عمليات كتابة الملفات "المتفرقة" قليلة جدًا وتتطلب Go أو OS القيام بشيء ثقيل في وحدة المعالجة المركزية. لا أعرف حقًا.
ifedorenko
في ٢ ديسمبر ٢٠١٨
مرحبا يا من هناك!
هذا صحيح. تم تعيين عامل عامل إلى 8 أو 32 في داخلي / مرمم / filerestorer.go و -o s3.connections = 32 تم تمريره عبر cli الثابت في كلتا الحالتين.
pmkane
في ٣ ديسمبر ٢٠١٨
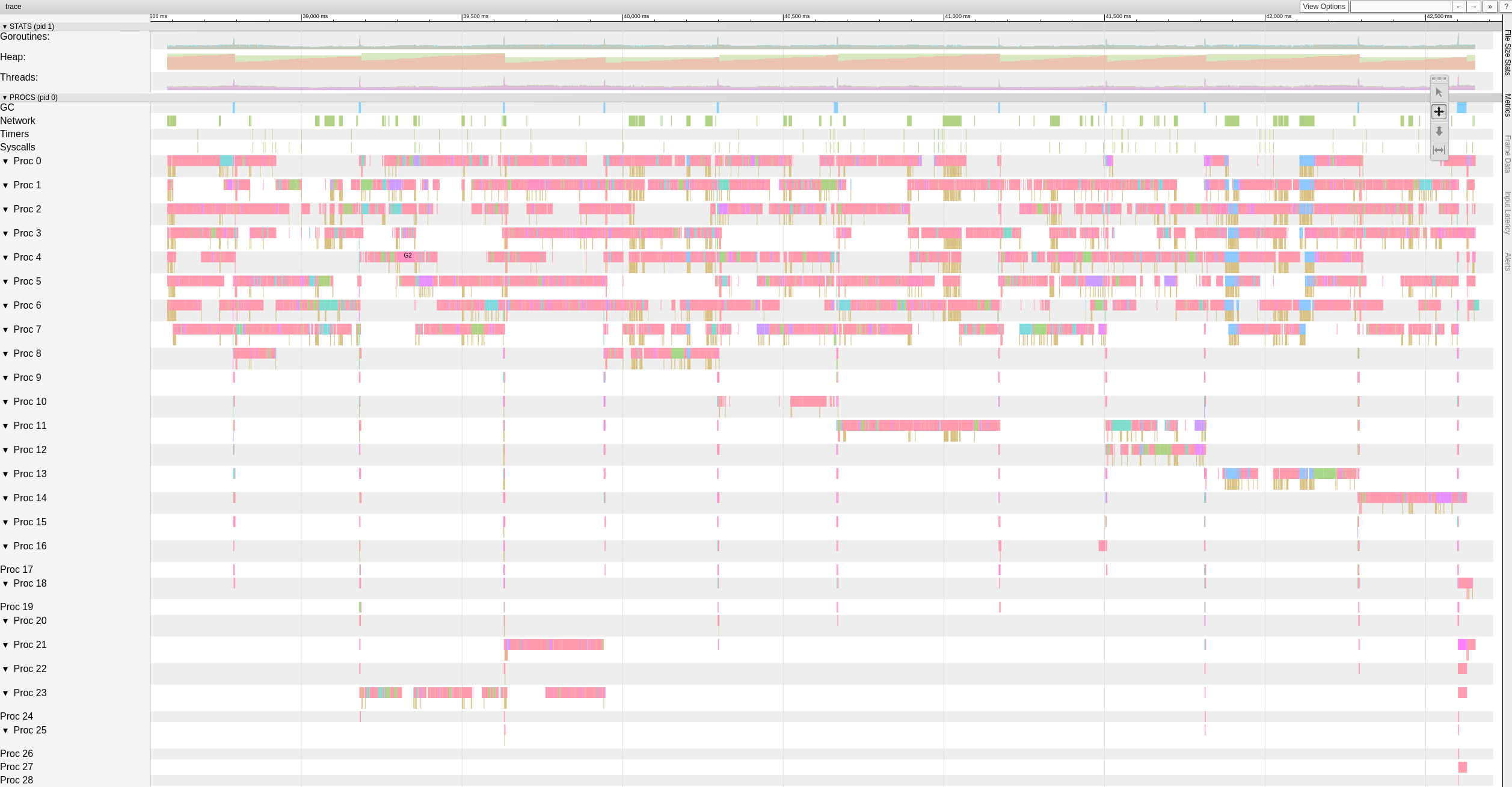
فيما يلي عرض المستوى الأعلى لبيانات التتبع بينما يقوم فرع خارج الترتيب باستعادة الملفات مع 8 عمال.
يبدو أن هناك فترات توقف كبيرة (> 500-1000 مللي ثانية) يضربها العمال بشكل متكرر.
pmkane
في ٣ ديسمبر ٢٠١٨
قررت قضاء المزيد من الوقت في هذا الأمر وبدأت بكتابة اختبار بسيط قائم بذاته يولد 10 جيجا بايت بايت عشوائي في كتل 4KiB. كان هدفي هو تقييم السرعة التي يمكن أن يتحرك بها نظامي بالبايت. لدهشتي ، استغرق هذا الاختبار 18.64 ثانية لتنفيذه على جهاز macbook pro الخاص بي (2018 ، معالج Intel Core i7 بسرعة 2.6 جيجاهرتز). وهو ما يُترجم إلى حوالي 4.29 جيجابت / ثانية أو حوالي نصف ما يمكن أن تفعله شبكة إيثرنت بسرعة 10 جيجابت. وهذا بدون أي تشفير أو شبكة أو قرص i / o. وكنت أستخدم Xoshiro256 ** prng ، كان math/rand أبطأ بنحو 2x ، وهو بالطبع بجانب النقطة تمامًا. النقطة المهمة هي أن المرمم يجب أن يعالج النقط على خيوط متعددة من أجل تشبع شبكة 10G ، فإن صافي الإدخال / الإخراج متعدد الخيوط بحد ذاته ليس كافيًا.
وللمتعة فقط ، يولد الصدأ المماثل 10 جيجا بايت من البايت العشوائي في 3.1 ثانية ، والجافا في 10.77 ثانية. إذهب واستنتج :-)
ifedorenko
في ٦ فبراير ٢٠١٩
اختبار مثير للاهتمام!
أتفهم أن restic سيكون محدودًا بمعدل الوقت المستغرق لاستعادة أكبر ملف حاليًا.
في الوقت الحالي ، هذا ليس مانعنا ، حيث أعلم أن restic يمكنه استعادة ملف واحد أسرع بكثير من 160 ميجابت / ثانية التي نراها هنا.
سأقوم بتجميع مستودع اختبار سعة 100 جيجابايت يتكون من ملفات 10 ميجابايت على SSD سريع وفي S3 وتشغيل بعض الأرقام ، للحصول على أفضل سيناريو حالي في الحالة الرئيسية وفي هذا الفرع.
pmkane
في ٦ فبراير ٢٠١٩
مرحبًا بالجميع ، هل هناك أي طريقة لتغيير عدد العمال الذين يستخدمون معلمة أو يجب إجراؤها مباشرة على الكود؟ نواجه أيضًا مشكلة الاستعادة البطيئة وأود تحسين ما لدينا بطريقة ما ... يرجى إعلامي إذا كان بإمكاني المساهمة في الاختبارات للمساعدة في تحسين هذا الجزء!
شكرا!
 robvalca
في ١٩ فبراير ٢٠١٩
robvalca
في ١٩ فبراير ٢٠١٩
robvalca ما الخلفية التي تستخدمها؟ ما مدى سرعة نسخ rclone الريبو الخاص بك إلى النظام المستهدف؟ ما هو restic استعادة السرعة؟
لست متأكدًا الآن مما يحدث ، لذا سيكون من المفيد حقًا إذا كان بإمكانك تقديم اختبار إعادة الشراء والخطوات التي يمكنني استخدامها لإعادة إنتاج المشكلة محليًا (ومن خلال "اختبار إعادة الشراء" أعني البيانات غير المرغوب فيها / العشوائية ، ولا توجد بيانات خاصة البيانات من فضلك).
ifedorenko
في ٢٢ فبراير ٢٠١٩
ifedorenko نحن نستخدم S3 (ceph + radosgw) كخلفية (نديرها من قبلنا). لقد حاولت نسخ الريبو باستخدام rclone وهذه هي النتائج:
rclone copy -P remote: cboxback-aabbcc / / var / tmp / restic / aabbcc /
المنقولة: 127.309G / 127.309 GBytes ، 100٪ ، 45.419 ميجابايت / ثانية ، الوقت المتوقع 0 ثانية
الأخطاء: 0
الشيكات: 0/0، -
المنقولة: 25435/25435 ، 100٪
الوقت المنقضي: 47 دقيقة و 50.2 ثانية
استغرقت استعادة الريبو باستخدام "المخزون" 0.9.4 حوالي 8 ساعات. في كلتا الحالتين ، أستخدم 32 اتصالاً من نوع S3 والمضيف المستهدف نفسه. لقد وضعت المزيد من المعلومات في موضوع المنتدى هذا.
سأقوم بإعداد الريبو لك لاختباره وإعلامك عندما تكون جاهزًا ،
شكرا جزيلا لمساعدتك!
robvalca
في ٢٥ فبراير ٢٠١٩
robvalca هل يمكنك محاولة الاستعادة باستخدام فرع الاستعادة خارج الطلب الخاص بي ؟ من المفترض أن يقوم الفرع بتحسين أداء استعادة الملفات الكبيرة جدًا ، والتي يبدو أنها المشكلة التي تواجهها.
إذا لم يحسن الفرع أداء الاستعادة بالنسبة لك ، فيرجى تحميل الريبو التجريبي إلى حاوية s3 العامة ونشر اسم المستودع وكلمة مرور الريبو هنا.
ifedorenko
في ٢٦ فبراير ٢٠١٩
pmkane هل من الممكن أن تقوم باستعادة عدد كبير من الملفات المتطابقة أو المتطابقة تقريبًا؟ هذا من شأنه أن يفسر الخلاف بين العمال ، على ما أعتقد.
تحرير: في الواقع ، هل يمكنك إعادة محاولة استعادة الأداء باستخدام أحدث # 2101؟ يجب أن يتعامل مع عمليات الكتابة المتزامنة لنفس الملف ونفس النقطة إلى ملفات متعددة بشكل أفضل الآن.
ifedorenko
في ٢٦ فبراير ٢٠١٩
ifedorenko في الواقع ، مع إصدار الطلب الآن أفضل بكثير! لقد استغرق الأمر أقل من ساعة وهو أقرب مما لدي مع rclone. بعض التعليقات التي يمكنني استخلاصها من اختباراتي ، لذا ربما يمكنك العثور عليها مفيدة (انظر المؤامرات المرفقة أيضًا!):
- على العادية restic
0.9.4بدء العملية أسرع، مع قمم200MB/secونحن الحصول على ما يقرب50 requestsفي الثانية على الجانب S3. بعد دقيقتين فقط ، يحدث التدهور وتنخفض الطلبات إلى 1 أو نحو ذلك والسرعة ~5MB/secخلال بقية العملية. - مع إصدار "ooo" ، تكون سرعة النقل شيئًا مثل
40MB/secو ~8S3 طلبات ثابتة أثناء كل العملية. - شيء آخر لاحظته هو أنني لا أرى أي تحسن تقريبًا في زيادة اتصالات S3 ، هل هذا متوقع؟
32 زملاء:
Created 2197 directories, listed 171.141 GiB in 20930 files
Restored 171.136 GiB in 170258 files
real 57m54.588s
user 229m25.229s
sys 6m51.763s
64 اتصالات
real 53m13.876s
user 242m57.081s
sys 7m12.455s
- أخيرًا ، أجرى اختبارًا مع مستودع تخزين مختلف آخر (51G ، 1.3 مليون ملف صغير ، الكثير من التكرارات) ولا يزال أسرع من 0.9.4 بهامش جيد:
0.9.4
real 16m6.966s
user 25m4.116s
sys 4m19.424s
0.9.4-ooo:
real 8m14.375s
user 14m30.107s
sys 3m41.538s
فليس فقط التحسن بالملفات الكبيرة بل يحسن كل الحالات !!
وبالمناسبة ، فإن عرض التقدم الجديد للاستعادة جميل !! 8)
اسمحوا لي أن أعرف إذا كنت تريد مني إجراء بعض الاختبارات الأخرى.
شكرا!
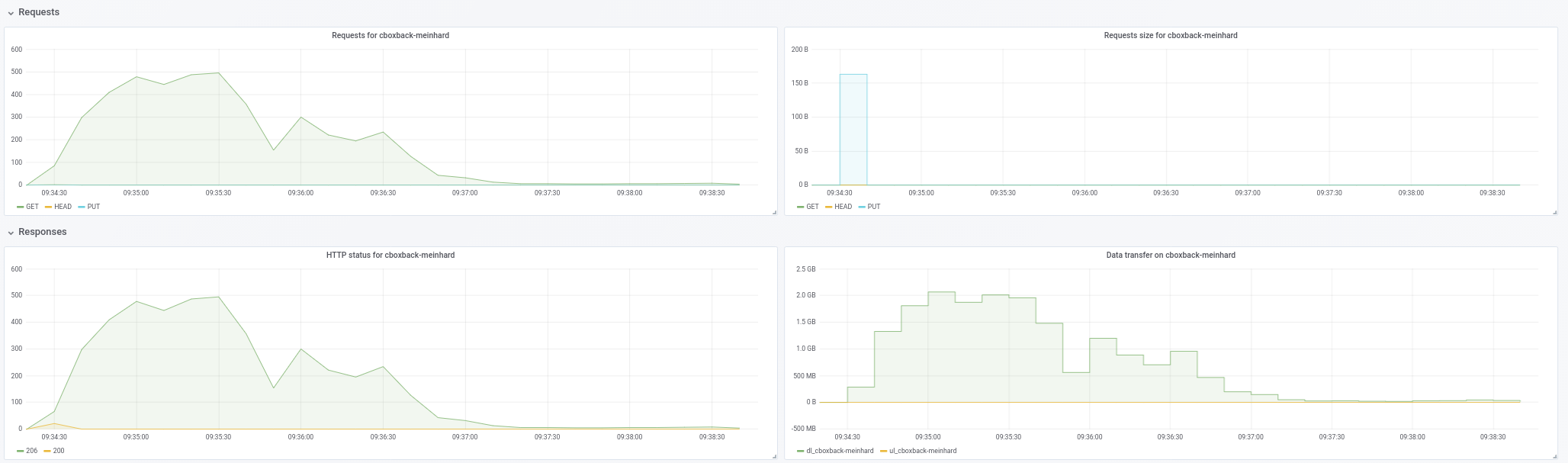
robvalca
في ٢٦ فبراير ٢٠١٩
شكرا لك على ردود الفعل ، robvalca ، إنها مفيدة جدا.
- شيء آخر لاحظته هو أنني لا أرى أي تحسن تقريبًا في زيادة اتصالات S3 ، هل هذا متوقع؟
عذرًا ، نسيت أن تذكر أنك بحاجة إلى تغيير الرمز لزيادة عدد عمال الاستعادة المتزامنة. تم ترميزه الثابت إلى 8 في الوقت الحالي:
https://github.com/ifedorenko/restic/blob/099f51c01c189a84b96be86ce6be61a45e3705fc/internal/restorer/filerestorer.go#L22
اسمحوا لي أن أعرف إذا كنت تريد مني إجراء بعض الاختبارات الأخرى.
ما زلنا لا نعرف سبب الخلاف الواضح بين العمال أثناء الاستعادة خارج الطلب المذكور سابقًا في هذه المشكلة https://github.com/restic/restic/issues/2074#issuecomment -443759511. هل يمكنك اختبار هذا الالتزام المحدد
https://github.com/ifedorenko/restic/commit/d410668ce3a8c7284d86a2b06bf42a0e654d43bc؟ إذا لاحظت الخلاف مع مستودعاتك ، فهذا يعني أنه ليس خاصًا ببيانات pmkane وأن التغييرات الأخيرة التي أجريتها تعمل على إصلاح الخلاف.
أشكركم مرة أخرى على مساعدتكم.
ifedorenko
في ٢٦ فبراير ٢٠١٩
مرحبًا بالجميع - ما زلت أراقب هذا ، لكن تم إغراقه تمامًا. سوف ألحق بالركب في نهاية هذا الأسبوع وأرى ما إذا كان لا يزال بإمكاننا التكاثر باستخدام
pmkane
في ٢٦ فبراير ٢٠١٩
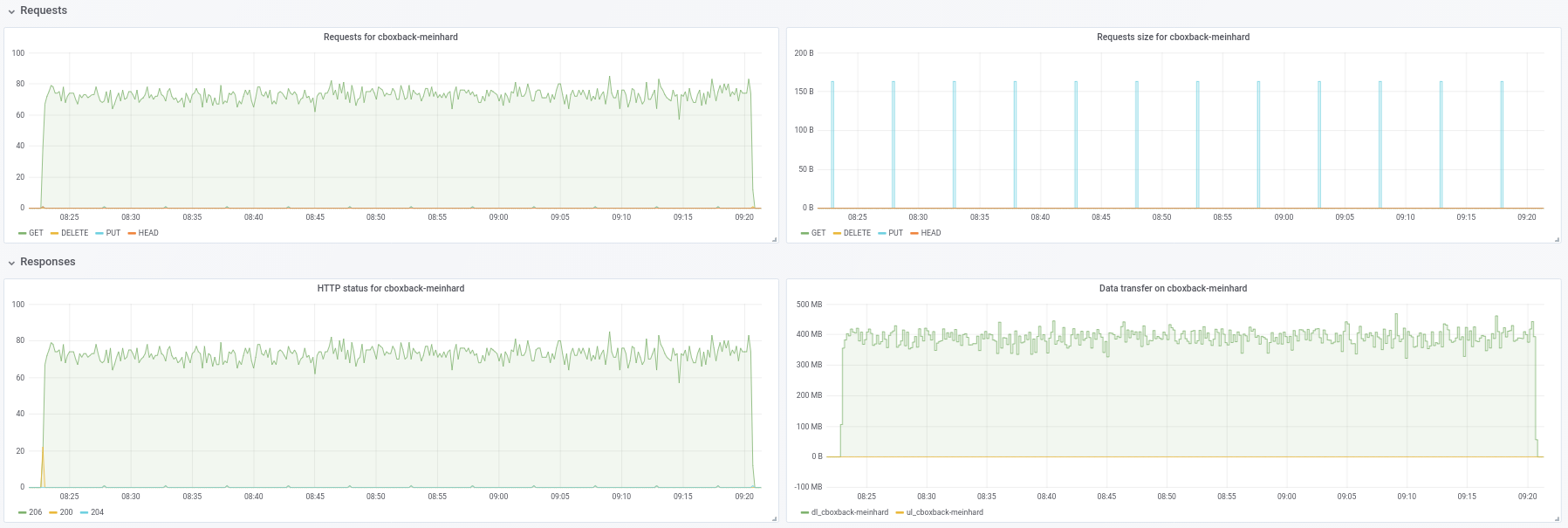
ifedorenko شكرًا ، مع 32 عاملاً ، كانت العملية أسرع بكثير حيث تصل إلى 30 دقيقة وهي نتيجة رائعة. لقد حاولت أيضًا زيادة عدد العاملين / s3.connections إلى 64/64 ، 128/128 ولكني لا أرى أي تحسينات ، وأحصل على نفس النتائج تقريبًا. على أي حال ، أنا سعيد بالنتائج الحالية.
لقد جربت أيضًا الإصدار باستخدام https://github.com/ifedorenko/restic/commit/d410668 الذي pmkane . لقد قمت بتشغيله مع 8 عمال -o s3.connections=32
robvalca
في ٢٧ فبراير ٢٠١٩
robvalca لذلك إذا كان
ifedorenko
في ٢٧ فبراير ٢٠١٩
ifedorenko لا ، نسيت أن أذكر ، الأداء هو نفسه إلى حد ما من رئيس الفرع (خارج الترتيب) مع نفس عدد العمال (8) و S3 اتصالات (32). استغرق كلاهما حوالي 55 مترًا ، وهو ما يتماشى مع الوقت اللازم لنقل الريبو باستخدام rclone (حوالي 47 مترًا)
اسمحوا لي أن أعرف إذا كنت تريد مني الاختبار باستخدام معلمات أخرى ؛)
robvalca
في ٢٧ فبراير ٢٠١٩
لقد وجدت مشغل مشكلات الأداء في حالة الاستخدام الخاصة بي. أداء استعادة الملفات الكبيرة غير خطي يتجاوز حجم ملف معين.
للاختبار ، قمت بإنشاء ريبو جديد في S3 ثم قمت بعمل نسخة احتياطية من 6 ملفات تحتوي على بيانات عشوائية إلى الريبو. كانت الملفات بحجم 1 و 5 و 10 و 20 و 40 و 80 جيجابايت.
كما هو الحال مع الاختبارات السابقة ، تم إجراء الاختبارات على مثيلات i3.8xlarge مع حدوث النسخ الاحتياطية والاستعادة على محرك أقراص ذي حالة صلبة سريع ومخطط.
كانت أوقات النسخ الاحتياطي خطية ، كما هو متوقع (8 ، 25 ، 46 ، 92 ، 177 و 345 ثانية).
ومع ذلك ، فإن أوقات الاستعادة لم تكن:
1 جيجابايت ، 5 ثوانٍ
5 جيجابايت ، 17 ثانية
10 جيجابايت ، 33 ثانية
20 جيجابايت ، 85 ثانية
40 جيجابايت ، 256 ثانية
80 جيجابايت ، 807 ثانية
لذلك هناك شيء غريب يحدث مع الملفات الكبيرة واستعادة الأداء.
يُطلق على الدلو اسم pmk-large-restic-test ، وتكون الجرافة ومحتوياتها عامة. إنه في us-west-1 وكلمة مرور الريبو الباقية هي كلمة المرور
معرفات اللقطة للملفات هي:
1 غيغابايت: 0154ae25
5 غيغابايت: 3013 e883
10 غيغابايت: 7463efa8
20 غيغابايت: 292650c6
40 جيجابايت: 5acb4bee
80 جيجابايت: d1b7e323
يُرجى إعلامي إذا كان هناك المزيد من البيانات التي يمكنني تقديمها!
pmkane
في ٢٧ فبراير ٢٠١٩
pmkane ، هل يمكنك تأكيد أنك استخدمت أحدث رأس من https://github.com/ifedorenko/restic/tree/out-order-restore Branch (https://github.com/ifedorenko/restic/commit/ead78b375f2efed6de57c99b6766edbe9322e009 لتكون محددًا) ؟
ifedorenko
في ٢٧ فبراير ٢٠١٩
نعم فعلت. آسف لعدم ذكر ذلك.
pmkane
في ٢٧ فبراير ٢٠١٩
(تم استخدام 32 عاملاً و 32 اتصالاً s3 عبر جميع المسارات مع / ead78b3)
pmkane
في ٢٧ فبراير ٢٠١٩
هل تعلم ما إذا كنت بحاجة إلى القيام بأي شيء خاص للوصول إلى هذه المجموعة؟ لم أستخدم الحاويات العامة من قبل ، لذا لست متأكدًا مما إذا كنت أفعل شيئًا خاطئًا أو أن المستخدم لا يمكنه الوصول. (يمكنني الوصول إلى حاويات فريقي على ما يرام ، لذلك أعرف أن نظامي يمكنه الوصول إلى s3 بشكل عام)
ifedorenko
في ٢٧ فبراير ٢٠١٩
مرحبًا ifedorenko ، انتظر ، دعني أحصل على مكان ما بدون امتياز وحاول.
pmkane
في ٢٧ فبراير ٢٠١٩
نأسف لذلك ، لقد طبقت سياسة الحاوية العامة ، لكني لم أقم بتحديث الكائنات الموجودة في الحاوية نفسها. يجب أن تكون قادرًا على الوصول إليه الآن. لاحظ أنك ستحتاج إلى استخدام - no-lock ، لأنني منحت أذونات القراءة فقط.
pmkane
في ٢٧ فبراير ٢٠١٩
نعم. يمكنني الوصول إلى الريبو الآن. سيلعب معها لاحقا الليلة.
ifedorenko
في ٢٧ فبراير ٢٠١٩
وفي حالة ما إذا كان الاختبار مفيدًا / أسهل ، فإننا نرى خصائص أداء مماثلة عند إجراء عمليات استعادة لنفس الملفات من / إلى الريبو على SSD السريع ، مما يؤدي إلى إخراج S3 من المعادلة.
pmkane
في ٢٨ فبراير ٢٠١٩
pmkane يمكنني إعادة إنتاج المشكلة محليًا ولست بحاجة إلى الوصول إلى هذه المجموعة بعد الآن. كان هذا مفيدًا جدًا ، شكرًا لك.
ifedorenko
في ٢٨ فبراير ٢٠١٩
ifedorenko ، رائع. سأحذف الدلو.
pmkane
في ٢٨ فبراير ٢٠١٩
pmkane ، يرجى إعطاء أحدث فرع لاستعادة الطلبات الخارجية محاولة أخرى عندما يكون لديك الوقت. لم يكن لدي الوقت لاختبار ذلك في ec2 ، ولكن يبدو أن استعادة جهاز macbook الخاص بي محدودة بسبب سرعة كتابة القرص والمطابقات rclone الآن.
ifedorenko
في ١ مارس ٢٠١٩
ifedorenko ، هذا يبدو واعدًا جدًا. أنا أقوم بإجراء اختبار الآن.
pmkane
في ١ مارس ٢٠١٩
ifedorenko ، بنغو.
تمت استعادة ما قيمته 133 جيجا بايت من النقاط التي تمثل مزيجًا من أحجام الملفات ، أكبرها 78 جيجا بايت ، في أقل من 16 دقيقة. في السابق ، كان من الممكن أن تستغرق عملية الاستعادة هذه الجزء الأفضل من اليوم. أظن أنه يمكننا الحصول على هذا بشكل أسرع من خلال اللعب مع عدد عمال الاستعادة ، لكنه سريع جدًا كما هو.
شكرا لعملكم الشاق في هذا!
pmkane
في ١ مارس ٢٠١٩
وللأجيال القادمة: يتضاعف أداء الاستعادة لدينا من 8> 16 ومرة أخرى من 16 إلى> 32 عاملاً. 32-> 64 جيد فقط لنتوء بنسبة 50٪ أعلى من 32 ، وعند هذه النقطة نستعيد حوالي 3 جيجابت / ثانية. تقريبا على قدم المساواة مع rclone.
أعلم أن هناك رغبة في تقليل مقدار التكوين المطلوب لاستخراج أفضل أداء من restic ، لكن هذا يمثل قفزة كبيرة بما يكفي ، خاصة للمستخدمين الذين لديهم مجموعات ملفات كبيرة ، وسيكون من الجيد أن تكون قادرًا على تحديد عدد العمال في وقت التشغيل.
pmkane
في ١ مارس ٢٠١٩
لست متأكدًا من سبب استمرار عدم القدرة على استعادة السرعة الكاملة للسلك. هناك علامة تجزئة blob زائدة عن الحاجة يمكنك التعليق عليها لمعرفة ما إذا كانت مسؤولة.
ifedorenko
في ٢ مارس ٢٠١٩
سأجربه.
pmkane
في ٢ مارس ٢٠١٩
مرحبًا بالجميع ، لقد أجريت بعض الاختبارات باستخدام أحدث طلب سحب # 2195 ويستمر الأداء في التحسن!
(20 ألف ملف صغير ، 2x70 جرام ، إجمالي 170 جرام)
8w_32c
real 27m46.185s
user 24m31.290s
sys 3m55.153s
32w_32c
real 15m30.904s
user 24m1.982s
sys 4m55.128s
64w_32c
real 18m37.566s
user 23m33.684s
sys 5m3.024s
64w_64c
real 17m12.314s
user 23m44.318s
sys 4m43.090s
لست متأكدًا من انخفاض الأداء من 32 واط إلى 64 واط (تم اختباره عدة مرات ويبدو أنه شرعي). أرفق بعض الرسوم البيانية أثناء العملية ، يبدو أن هناك بعض التدهور أو الحد ، هل يجب أن يكون مثل هذا؟ على سبيل المثال ، مع 64 عاملاً ، تبدأ العملية بسرعة 6 جيجابت / ثانية ولكن بعد ذلك تنخفض إلى أقل من 1 جيجابت / ثانية حتى نهاية العملية (والتي أعتقد أن هذا يتوافق مع وقت معالجة تلك الملفات الكبيرة). لقطة الشاشة الأولى 32 واط ، 32 درجة مئوية والثانية 64 واط ، 32 درجة مئوية.
أتفق أيضًا مع pmkane ، سيكون من المفيد تغيير رقم العامل من سطر الأوامر. سيكون مفيدًا جدًا لسيناريوهات التعافي من الكوارث عندما تريد استعادة بياناتك في أسرع وقت ممكن. هناك طلب سحب بخصوص هذا من قبل زميلي في العمل رقم 2178
على أي حال ، أنا معجب حقًا بالتحسينات التي تم إجراؤها! شكرا جزيلا ifedorenko
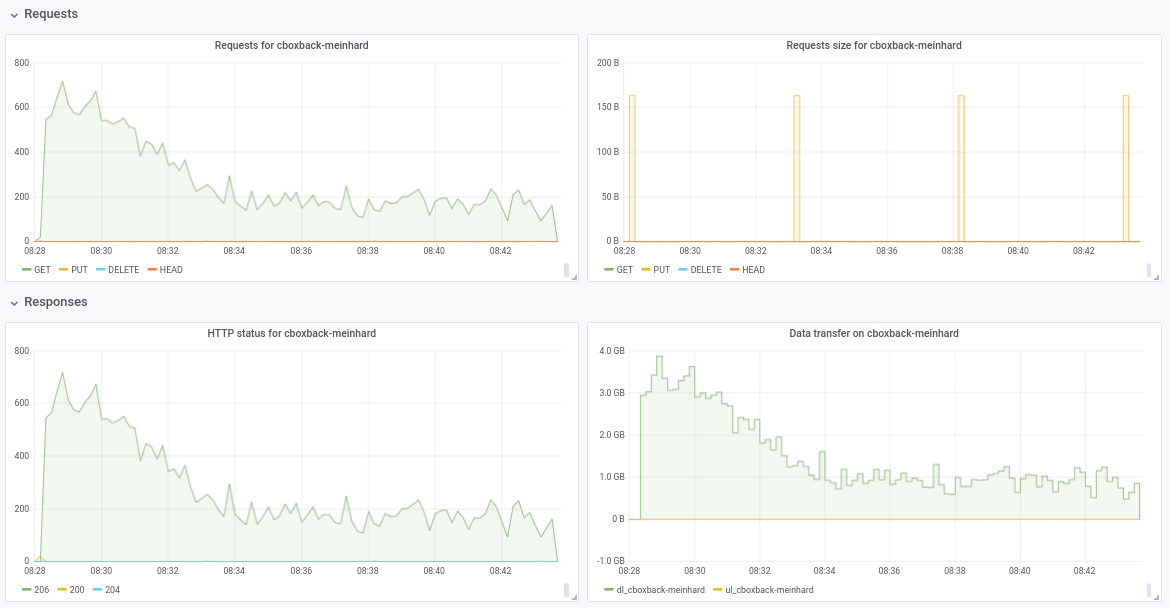
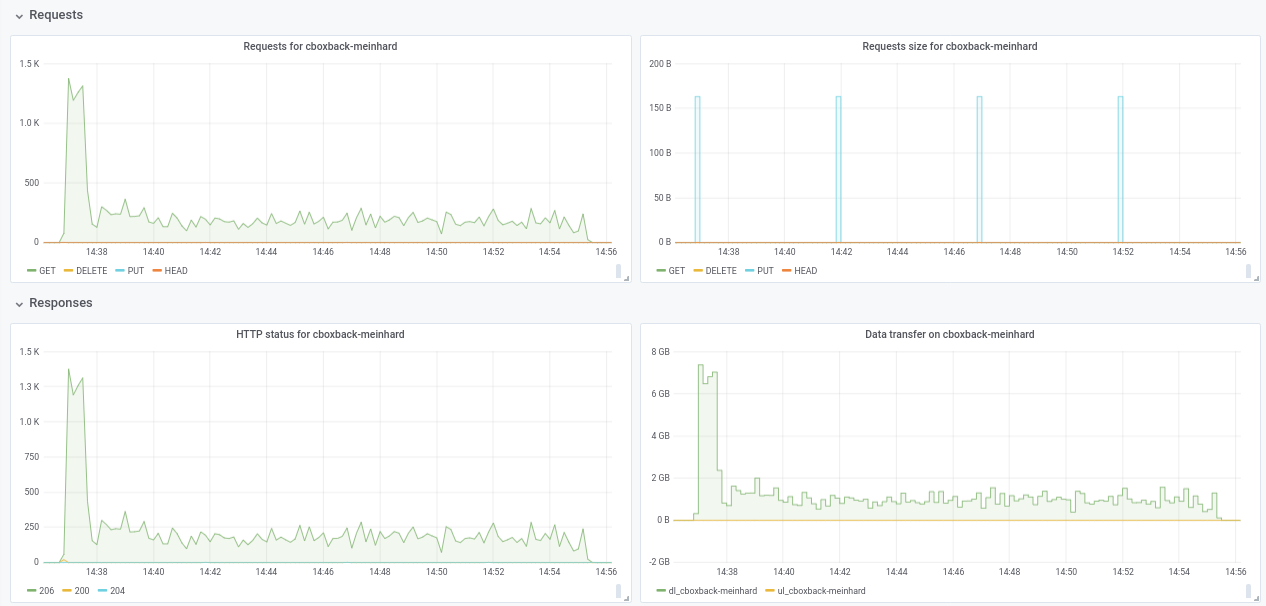
robvalca
في ٤ مارس ٢٠١٩
++. شكرًا لك ifedorenko ، هذه أشياء متغيرة للعبة لريستيك.
pmkane
في ٤ مارس ٢٠١٩
شكرا لك على التقرير المفصلrobvalca. هل هناك أي فرصة لتزويدك بمستودع اختبار يمكنني استخدامه إما في AWS (أو GCP أو Azure) أو محليًا؟ لم أرَ انخفاضًا في سرعة استعادة الملفات الكبيرة في اختباراتي وأود أن أفهم ما يجري هناك.
ifedorenko
في ٤ مارس ٢٠١٩
pmkane أود أيضًا تكوين هذه الأشياء في وقت التشغيل . كان اقتراحي هو جعلها خيارات --option حتى لا تشوش العلامات أو الأوامر العادية ، ولكنها موجودة للمستخدمين "المتقدمين" الذين يرغبون في تجربة أو ضبط وضعهم غير المعتاد. لا يحتاجون حتى إلى التوثيق ويمكن إعطاؤهم أسماء توضح أنه لا يمكنك الاعتماد عليهم ، مثل --option experimental.fooCount=32 .
 whereisaaron
في ٤ مارس ٢٠١٩
whereisaaron
في ٤ مارس ٢٠١٩
مرحبًا ifedorenko ، لقد قمت بإنشاء ريبو عام ببيانات غير مهمة بسعر s3.cern.ch/restic-testrepo . إنه إلى حد ما نفس الشكل الذي كنت أحاوله (الكثير من الملفات الصغيرة وعدد قليل من الملفات الكبيرة جدًا) ويمكنني أيضًا إعادة إنتاج نفس السلوك في هذه (المؤامرة المرفقة). كلمة مرور الريبو هي restic . اسمحوا لي أن أعرف إذا كان لديك أي مشكلة في الوصول إليه.
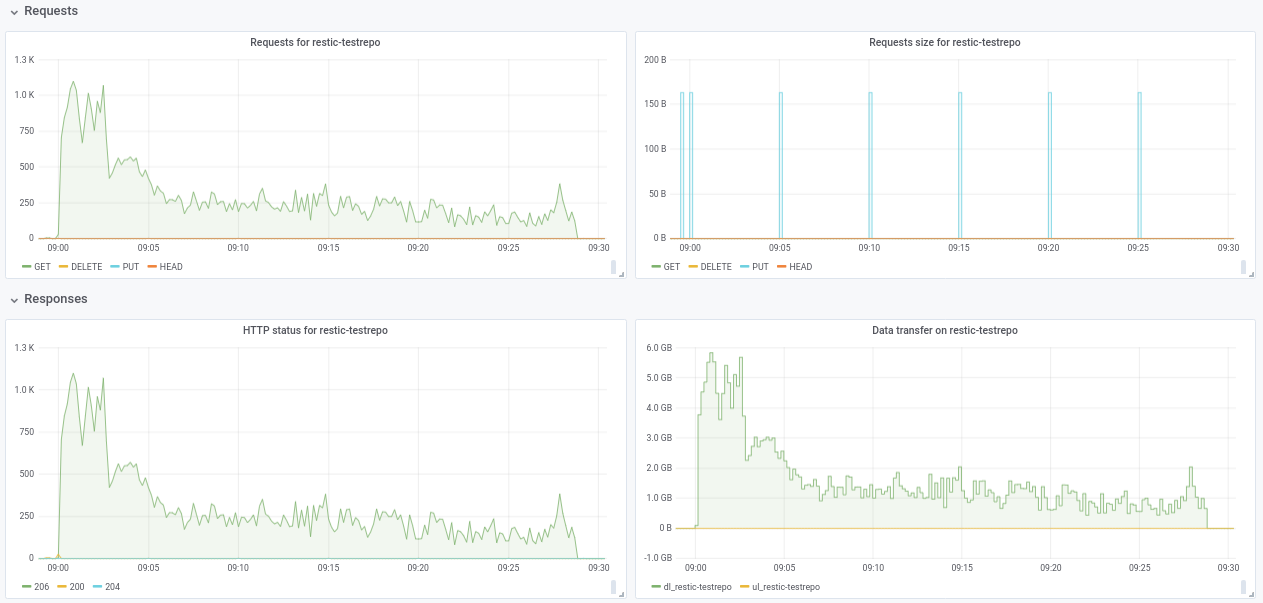
robvalca
في ٥ مارس ٢٠١٩
robvalca لا يمكنني i3.4xlarge 2x nvme raid0 هدف) أرى سرعة استعادة ثابتة تبلغ 0.68 جيجابايت / ثانية عند استخدام 32 عاملاً و 32 اتصالاً (إجمالي وقت الاستعادة 6 دقائق و 20 ثانية). لا يمكن أن يحافظ نظامك المستهدف على 10 غيغابايت / ثانية لفترة طويلة ، إذا كنت سأخمن ، على الأقل هذا ما سأفحصه أولاً إذا كنت سأستكشف هذا الأمر أكثر.
pmkane بشكل مثير للاهتمام ، لا يمكنني تأكيد ملاحظاتك أيضًا. كما ذكرت أعلاه ، أرى سرعة استعادة 0.68 جيجابايت / ثانية باستخدام أحدث فرع out-of-order-restore-no-progress (يبدو أن الاستعادة مرتبطة بوحدة المعالجة المركزية) ، و 0.81 جيجابايت / ثانية إذا قمت بتعطيل فحص blob المتكرر (الاستعادة لم تبدو وحدة المعالجة المركزية- مقيد). لا أعرف مدى السرعة التي يمكن أن تصل إليها شبكة "تصل إلى 10 جيجابت في الثانية" ، لكنني أعتقد أننا في منطقة "تناقص العوائد" بالفعل.
ifedorenko
في ٦ مارس ٢٠١٩
ifedorenko أوافق بصدق إعادة: تناقص العوائد. إنه سريع بما يكفي بالنسبة لنا كما هو.
pmkane
في ٦ مارس ٢٠١٩
ifedorenko مثير للاهتمام ،
robvalca
في ٧ مارس ٢٠١٩
فضوليًا بشأن حالة الحصول على هذا الدمج. هذا الفرع ، جنبًا إلى جنب مع عمل cbane على تسريع التقليم ، يجعله قابلاً للاستخدام للنسخ الاحتياطية الكبيرة للغاية.
pmkane
في ٢٢ أغسطس ٢٠١٩
قريبا ... 👀
 rawtaz
في ٢٦ فبراير ٢٠٢٠
rawtaz
في ٢٦ فبراير ٢٠٢٠
إغلاق هذا الآن بعد دمج # 2195. لا تتردد تمامًا في إعادة فتحه إذا لم يتم حل التفاصيل التي تتعلق بهذه المشكلة. إذا كان لا يزال هناك تحسينات يجب إجراؤها ليست من النوع الذي تمت مناقشته في هذه المشكلة ، فيرجى فتح مشكلة جديدة. شكرا!
rawtaz
في ٢٦ فبراير ٢٠٢٠
القضايا ذات الصلة
whereisaaron
·
3تعليقات
 viric
·
5تعليقات
viric
·
5تعليقات
 christian-vent
·
3تعليقات
christian-vent
·
3تعليقات
 McKael
·
4تعليقات
McKael
·
4تعليقات
 reallinfo
·
4تعليقات
reallinfo
·
4تعليقات
التعليق الأكثر فائدة
فضوليًا بشأن حالة الحصول على هذا الدمج. هذا الفرع ، جنبًا إلى جنب مع عمل cbane على تسريع التقليم ، يجعله قابلاً للاستخدام للنسخ الاحتياطية الكبيرة للغاية.