Thanks to the merge of PR1719, restores in restic are _way_ faster.
They could be faster still, however.
For test purposes, I restored from an restic AWS S3 bucket in the same region (us-west-1) as a dedicated i3.8xlarge EC2 instance. The restore went against the 4x1.9TB nvme in the instance, striped RAID-0 via LVM with an xfs filesystem underneath. The instance has a theoretical 10gbit/sec of bandwidth to S3.
With workerCount in filerestorer.go bumped to 32 (from the compiled-in limit of 8), restic restores a mix of 228k files with a median file size of 8KB and a maximum file size of 364GB at an average of 160mbit/sec.
By comparison, rclone with --transfers=32 moves data from the same bucket at 5636 mbit/sec, more than 30x's faster.
It's not an apples to apples comparison. Restic data blobs are 4096KB-ish in size, not 8KB, and opening/closing files certainly has _some_ overhea. But it's still a big enough difference that it likely points to a bottleneck in restic.
I'm happy to test things, provide instrumentation or help in any other way!
 pmkane
pmkane
All 71 comments
160mbit/sec does indeed look slow. I was getting close to 200Mbps on a puny macbook pro downloading from onedrive over (granted fast) 1Gbps ftth connection. I can't really say anything specific without access to your systems and repository, but here are few things I'd to do narrow down the problem, in no particular order:
- Estimate time it takes to download single pack file on single thread. You can calculate this from your rclone 32x download test, but I'd be also curious to know the time to download individual packs with curl so we can estimate http request overhead too.
- I'd check OS stats how much restic actually downloads from S3 during restore. This will tell us if restore downloads individual pack files multiple times (which is possible, but should not happen very often, unless I overlooked something).
- S3 concurrency level appears to be limited to just 5 connections. Can this explain the restore speed you see given single-threaded speed estimate from above? What happens if you increase S3 backend connection limit to match restorer's?
- Graph network utilization during restore to see if there are any gaps or slow downs.
- Exclude that 364GB file from restore and see what happens. Individual files are currently restored sequentially, so this one file can significantly skew average download speed.
 ifedorenko
on 7 Nov 2018
ifedorenko
on 7 Nov 2018
Hi there!
Thanks for the reply. This was interesting to dig into
tl;dr: bumping up s3 connections is the key, but the performance boosts it provides are temporary, oddly.
- Transferring a single directory's worth of packs (3062 files totaling 13GB) / with rclone --transfers 1 runs at 233mbit/sec. Confirmed with lsof that it is only running with a single thread and a single https connection in that mode. Peak speed is achieved with --transfers 32 (8.5 gbit/sec, essentially line speed for this i3.8xlarge ec2 instance). In both cases we are writing out to the striped nvme array.
- Happy to collect some stats, but what would you like to see, specifically? (but may not be required, please see below)
- Going to kill two birds with one stone here! Here's a graph of network utilization during restores with:
- a stock stock restic with this PR merged (commit c0572ca15f946c622d9c4009347dc4d6c31cba4c)
- restic with workerCount bumped to 32 and filesWriterCount bumped to 128
- restic with the previous changes + s3 connections increased to 32.
- resitc with the previous changes + s3 connections increased to 64.
- rclone with --transfers 32 moving the data/ directory
The bandwidth number are in kbps and were taken at 3 second intervals over 10 minutes. For the restic runs, we started collecting data _after_ restic had already begun to actually restore files (ie, it excludes startup time and the time that restic spends at the beginning of the run recreating the directory hierarchy. During all runs, CPU utilization on the instance did not exceed 25%.
We get a slight bump from increasing the workerCount, but the S3 concurrency looks like where the real win is. But while it starts out strong (approaching rclone speed, at times!), rates drop abruptly and stay down for the rest of the run. restic also throws errors that look like "ignoring error for [path redacted]: not enough cache capacity: requested 2148380, available 872640" that it does not throw with lower s3 concurrency.
As you can see, the rclone performance starts high and stays high, so it's not a situation where writes are going to the instance's buffer cache and then stalling when they get flushed to disk. The nvme array is faster than the network pipe, throughput-wise.
- I don't think the single large file is a factor, as I'm measuring disk/network IO during the restore, so the fact that it might take a while for that single file to be completely restored won't impact the numbers we're looking at here.
Given the above, it looks like bumping up the S3 concurrency is what it will take to get reasonable rates here, but need to figure out why the performance is dropping (and whether it's related to the cache errors or not).
If making a fast i3 instance and some s3 space and bandwidth available for your testing would be helpful, let me know, happy to sponsor that.
pmkane
on 7 Nov 2018
233mbit/sec times 32 is 7456 and quite a bit less than 8.5 gbit/sec. Which is odd. I expected single-threaded download to be faster than per-stream throughput of multi-threaded download. Not sure what this means, however, if anything.
I was looking to confirm restic does not redownload the same packs over and over again. I think the graph shows redownloads isn't a problem, so no need for more stats, at least not now.
Can you confirm the graph scale? rclone hovers around line labeled as "1000000", if that is "1,000,000 kbps", which I think means "1gbps" and does not align with "8.5 gbit/sec" number you mentioned in earlier.
Like I said, individual files are restored sequentially. 364 GB download at 233mbit/s will take about 3.5 hours, and probably longer due to per-pack overhead and decryption, all of which happens sequentially. Can't tell whether 3.5 hours is something you can discard as insignificant without knowing how much the rest of restore takes.
As for not enough cache capacity error, increase averagePackSize to the size of the largest pack file in your repository (how big is it, btw?) And I need to think how to size the cache better, don't have a ready answer yet.
ifedorenko
on 7 Nov 2018
Hi there!
Whoops, I'm sorry. The scale in the graph is KB/sec not kbit/sec. So 1,012,995 in the first row is 8.1gbit/sec.
I understood that files were restored sequentially, but didn't understand that there is no parallelism for pack retrieval for a single file. That's definitely a bit of a stumbling block for backups with large files, since that becomes your limiting factor. It would be fantastic to have some parallelism here for that reason.
Sampling 10 random buckets, our maximum pack size is just below 12MB and our average pack size is 4.3MB.
Perhaps with more workers and S3 connections, we are exceeding the packCacheCapacity of (workerCount + 5) * averagePackSize. I'll try upping that and see if the errors go away.
pmkane
on 7 Nov 2018
Perhaps with more workers and S3 connections, we are exceeding the packCacheCapacity of (workerCount + 5) * averagePackSize. I'll try upping that and see if the errors go away.
Cache size is calculated based on 5MB pack file size and workerCount. Increasing workerCount increases cache size. So either there is a memory leak or restore needs to cache many 12MB files by pure chance. Upping averagePackSize to 12MB should tell us which.
ifedorenko
on 7 Nov 2018
No cache errors with averagePackSize set to 12.
If there's any other info we can provide that would be helpful, let me know! Thanks again.
pmkane
on 8 Nov 2018
It does look like we are losing parallelism as the restore progresses and it doesn't look to be related to large files. I'll put together a test case and report back.
pmkane
on 8 Nov 2018
Hi there!
I attempted to reproduce the performance drop offs that I was seeing with my production file mix with three different artificial file mixes.
For all tests, I used c0572ca15f946c622d9c4009347dc4d6c31cba4c with S3 connections increased to 128, workerCount increased to 128, filesWriterCount increased to 128 and averagePackSize increase to 12 * 1024 * 1024.
All tests used files with random data, to avoid any impacts from deduplication.
For the first test, I created and backed up 4,000 100MB files, split evenly across 100 directories (~400GB total). Backups and restores were run from striped nvme volumes on a i3.8xlarge instance. The backup bucket was location in the same region as the instance (us-west-1).
With this file mix, I saw average speeds of 9.7gbit/sec (!) with no loss of parallelism or speed across the full restore. These numbers are on par or above the rclone numbers and are essentially line speed, which is fantastic.
I then subsequently created and backed up 400,000 1MB files, split evenly across 100 directories (again, ~400GB total).
Same (excellent) results as above.
Finally, I created 40 directories with 1 10GB file per directory. Here, things got interesting.
I expected that this restore would be slightly slower, since restic would only be able to do 40 simultaneous restores with 40 connections to S3.
Instead, though, while Restic opens up all 40 files for writes and writes to all 40 files simultaneously, it only keeps a single TCP connection to S3 open at a time, not 40.
Let me know what stats or instrumentation you'd like to see.
pmkane
on 8 Nov 2018
Can you confirm there were 128 S3 connections during "fast" tests?
ifedorenko
on 8 Nov 2018
Yes, there were.
pmkane
on 8 Nov 2018
Curious... Large file support isn't high on my priority list to be honest, but I may find some time to look at this in the next few of weeks. If anyone wants to dig into this before I do, please let me know.
ifedorenko
on 8 Nov 2018
Did some more testing and it actually looks like file size is a red herring, it's file counts that is driving the AWS connection count.
With 128 10 MB files in 4 directories, restic only opens 6 connections to AWS, even though it's writing to all 128 files.
Wtih 512 10 MB files in 4 directories, restic opens 18 connections over its lifetime, even though it has 128 files open at a time.
With 5,120 10 MB files in 4 directories, restic opens only 75 connections to AWS over its lifetime, again holding 128 files open at a time.
Odd!
pmkane
on 8 Nov 2018
I'd be really surprised if Go S3 client didn't pool&reuse http connections. Most likely there is no one-to-one correlation between number of concurrent workers and open TCP sockets. So, for example, if restore is slow processing downloaded packs for whatever reason, the same S3 connection will be shared by multiple workers.
ifedorenko
on 8 Nov 2018
There are two properties of the current concurrent restorer that are responsible for the bulk of the implementation complexity and very likely cause the slowdown reported here:
- individual files are restored start-to-finish
- number of in-progress files is kept to the minimum
Implementation will be much simpler, use less memory and very likely be faster in many cases if we agree to write file blobs in any order and to allow any number of in-progress files.
The downside, it won't be possible to tell how much data was already restored in any given file until the end of restore. Which may be confusing, especially if restore crashes or gets killed. So you may see 10GB file on filesystem, which in reality has only few bytes written at the end of the file.
@fd0 do you think it's worth improving current start-to-finish restore? Personally, I am ready to admit it was over engineering on my part and can provide simpler out-of-order implementation if you agree.
ifedorenko
on 16 Nov 2018
I don't remember if Restic supports restoring to standard output. If it does, you'll obviously need to keep start-to-finish restore for it (possibly as a special case).
 pvgoran
on 16 Nov 2018
pvgoran
on 16 Nov 2018
@ifedorenko I personally am in favor of simplification, generally, especially if it comes with performance boosts. I'm trying to understand the tradeoffs though:
The downside, it won't be possible to tell how much data was already restored in any given file until the end of restore.
If we're not talking thousands of concurrently-written files here, maybe a map of file name to bytes written could be used? Obviously won't make the info available to the file system, but, for progress reporting, could still be done, no? (And to resume a restore that was interrupted, perhaps just checking the blobs and offsets of the file for non-null bytes, perhaps? I dunno.)
I don't remember if Restic supports restoring to standard output. If it does, you'll obviously need to keep start-to-finish restore for it (possibly as a special case).
I don't think it does -- not sure how that would work anyway, since restores are multiple files, you'd need to encode them somehow and separate them somehow I think.
 mholt
on 16 Nov 2018
mholt
on 16 Nov 2018
If we're not talking thousands of concurrently-written files here, maybe a map of file name to bytes written could be used?
The simplest implementation is to open and close files to write individual blobs. If this proves to be too slow, then we'll have to find a way to keep files open for multiple blob writes, for example by caching open file handles and ordering pack downloads to favour already open files.
Restore already tracks what blobs were written to what files and what are still pending. I don't expect this part to change much. Progress is tracked in a separate data structure and I don't expect that to change either.
And to resume a restore that was interrupted, perhaps just checking the blobs and offsets of the file for non-null bytes, perhaps?
Resume needs to verify checksums of files on disk to decide what blobs still need to be restored. I believe this is true regardless whether restore is sequential or out of order. For example, if resume recovers from power failure, I don't think it can assume all file blocks were flushed to the disks before the power cut, i.e. files can have gaps or partially written blocks.
ifedorenko
on 16 Nov 2018
@pmkane wonder if you can try #2101? it implements out-of-order restore, although writes to individual files are still serialized and restore performance of large files may still be suboptimal. and you need to tweak number of workers as before.
ifedorenko
on 27 Nov 2018
Absolutely. I am traveling this week but will test as soon as I can and report back.
pmkane
on 27 Nov 2018
@ifedorenko I tried this PR and it succssfully creates the directory structure, but then all file restores fail with errors like:
Load(, 3172070, 0) returned error, retrying after 12.182749645s: EOF
master restores fine.
My restore command is:
/usr/local/bin/restic.outoforder -r s3:s3.amazonaws.com/[redacted] -p /root/.restic_pass restore [snapshotid] -t .
Let me know what additional info I can provide to help debug.
pmkane
on 1 Dec 2018
How many concurrent S3 download requests do you allow? If it's 128, can you limit it to 32 (which we know works)?
Semi-related... do you know how many index files does your real repository has? Trying to estimate how much memory restorer needs.
ifedorenko
on 1 Dec 2018
I didn't specify a connection limit, so I assume it was defaulting to 5.
I get the same errors with -o s3.connections=2 and -o s3.connections=1.
I currently have 85 index blobs in the index/ folder. They are 745MB in total size.
pmkane
on 1 Dec 2018
Hmm. I'll have another look when I get to my computer later today. Btw, "returned error, retrying" is a warning, not an error, so it may be related to the restore failure or it may be just a red herring.
ifedorenko
on 1 Dec 2018
Not sure how I missed it... the restorer didn't fully read all pack files from the backend in most cases. Should be fixed now. @pmkane can you try your test again?
ifedorenko
on 2 Dec 2018
I’ll give it a whirl!
pmkane
on 2 Dec 2018
Confirmed that files successfully restore with this fix. Testing performance now.
pmkane
on 2 Dec 2018
Unfortunately it looks like it's slower than master. All tests run on the i3.8xlarge instance described above.
With a workerCount of 8 (the default), the out of order branch restored at 86mbit/sec.
With a workerCount bumped to 32, it did a bit better -- averaging at 160mbit/sec.
CPU utilization with this branch is significantly higher than in master, but it is not maxing out the instance CPU in either case.
Anecdotally, the restore UI makes it seem like something is "sticking", almost like it's competing against itself for a lock somewhere.
Happy to provide more details, profiling or a test instance to replicate.
pmkane
on 2 Dec 2018
Just to confirm, you had both restorer and s3 backend worker count set to 32, right?
Couple of thoughts that may explain the behaviour your observed:
- Writes to individual files are still serialized. I _guessed_ this would not be a problem with fast target filesystems, but never measured it.
- File open/close around each blob certainly contributes to the restorer overhead. When I measured this on macos I was able to "open file; write one byte; close file" 100K times in ~70 second, which approximates overhead of writing 100K blobs. The test was really simple and real-life overhead may be significantly higher.
- I don't currently have plausible explanation for high CPU utilization. Out-of-order implementation decrypts each blob only once (master decrypts blobs for each target file), and there is lot less bookkeeping compared to master. Maybe "sparse" file writes aren't really sparse and require Go or OS do something CPU-heavy. Don't really know.
ifedorenko
on 2 Dec 2018
Hey there!
That's right. workerCount was set to 8 or 32 in internal/restorer/filerestorer.go and -o s3.connections=32 was passed via the restic cli in both cases.
pmkane
on 3 Dec 2018
Here's a top-level view of trace data while the out of order branch is restoring files with 8 workers.
It looks like there are significant (>500-1000ms) pauses that the workers hit frequently.

pmkane
on 3 Dec 2018
I decided to spend some more time on this and started by writing simple standalone test that generates 10GiB random bytes in 4KiB blocks. My goal was to assess how fast my system can move bytes around. Much to my surprise this test took 18.64 seconds to execute on my macbook pro (2018, 2.6 GHz Intel Core i7). Which translates to ~4.29 Gigabits/s or about half of what 10G ethernet can do. And this is without any crypto or net or disk i/o. And I was using Xoshiro256** prng, math/rand was about 2x slower, which is of course completely beside the point. The point is, restorer has to process blobs on multiple threads in order to saturate 10G network, multithreaded net i/o by itself is not enough.
And just for fun, comparable rust impl generates 10GiB of random bytes in 3.1 seconds, and java in 10.77s. Go figure :-)
ifedorenko
on 6 Feb 2019
Interesting test!
I understand that restic will be rate-limited by the amount of time it takes to restore the largest file, currently.
Right now, however, that's not our blocker, as I know that restic can restore a single file much faster than the 160mbit/sec that we see here.
I'll put together a 100GB test repo consisting of 10MB files on fast SSD and in S3 and run some numbers, to get the current best case scenario in master and in this branch.
pmkane
on 6 Feb 2019
Hi all, is there any way to change the number of workers using a parameter or has to be done directly on the code? We are also having the problem of slow restores and I would like to improve what we have somehow... Please let me know if I can contribute with tests to help improve this part!
Thanks!
 robvalca
on 19 Feb 2019
robvalca
on 19 Feb 2019
@robvalca what backend do you use? how fast does rclone copy your repo to the target system? what is restic restore speed?
Right now I am not sure what's going on, so it'd be really useful if you could provide a test repo and steps I can use to reproduce the problem locally (and by "test repo" I mean junk/random data, no private data please).
ifedorenko
on 22 Feb 2019
@ifedorenko we are using S3 (ceph+radosgw) as a backend (managed by us). I've tried to copy the repo using rclone and these are the results:
rclone copy -P remote:cboxback-aabbcc/ /var/tmp/restic/aabbcc/
Transferred: 127.309G / 127.309 GBytes, 100%, 45.419 MBytes/s, ETA 0s
Errors: 0
Checks: 0 / 0, -
Transferred: 25435 / 25435, 100%
Elapsed time: 47m50.2s
The restore of the repo using "stock" restic 0.9.4 took ~8 hours. In both cases I'm using 32 S3 connections and the same target host. I've put a little more information in this forum thread.
I will prepare a repo for you to test and let you know when ready,
Thank you a lot for your help!
robvalca
on 25 Feb 2019
@robvalca can you try restore using my out-order-restore branch? the branch is supposed to improve restore performance of very large files, which seems to be the problem you face.
if the branch does not improve restore performance for you, please upload the test repo to a public s3 bucket and post bucket name and repo password here.
ifedorenko
on 26 Feb 2019
@pmkane is it possible that you restore large number of identical or almost identical files? that would explain contention among workers, I think.
Edit: actually, can you retry your restore perf test using latest #2101? It should handle concurrent writes to the same file and same blob to multiple files better now.
ifedorenko
on 26 Feb 2019
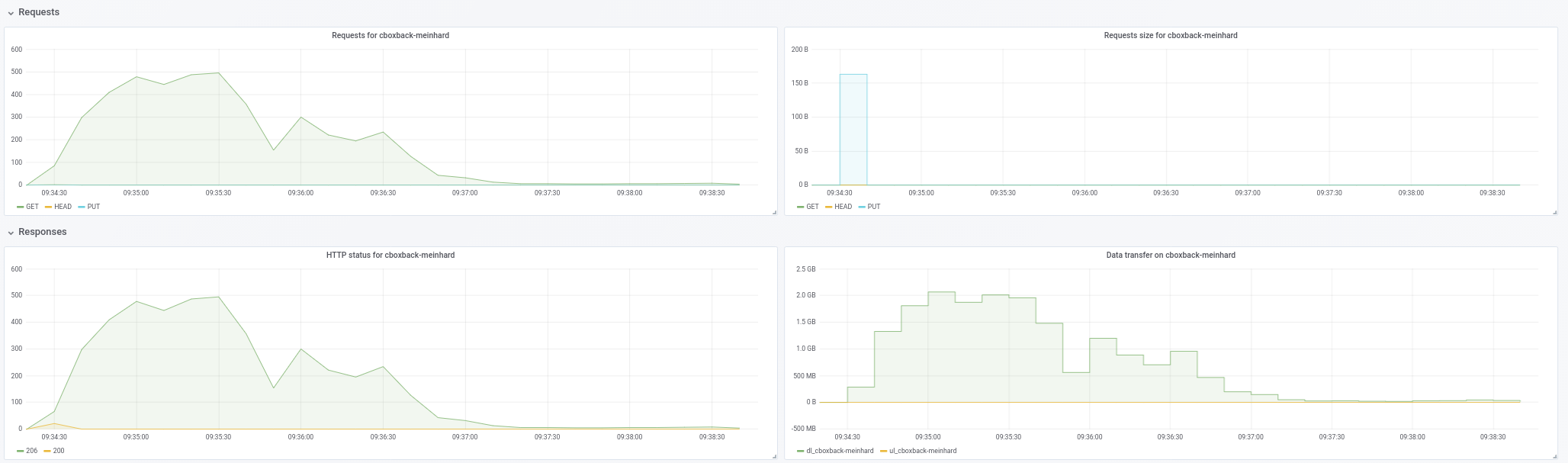
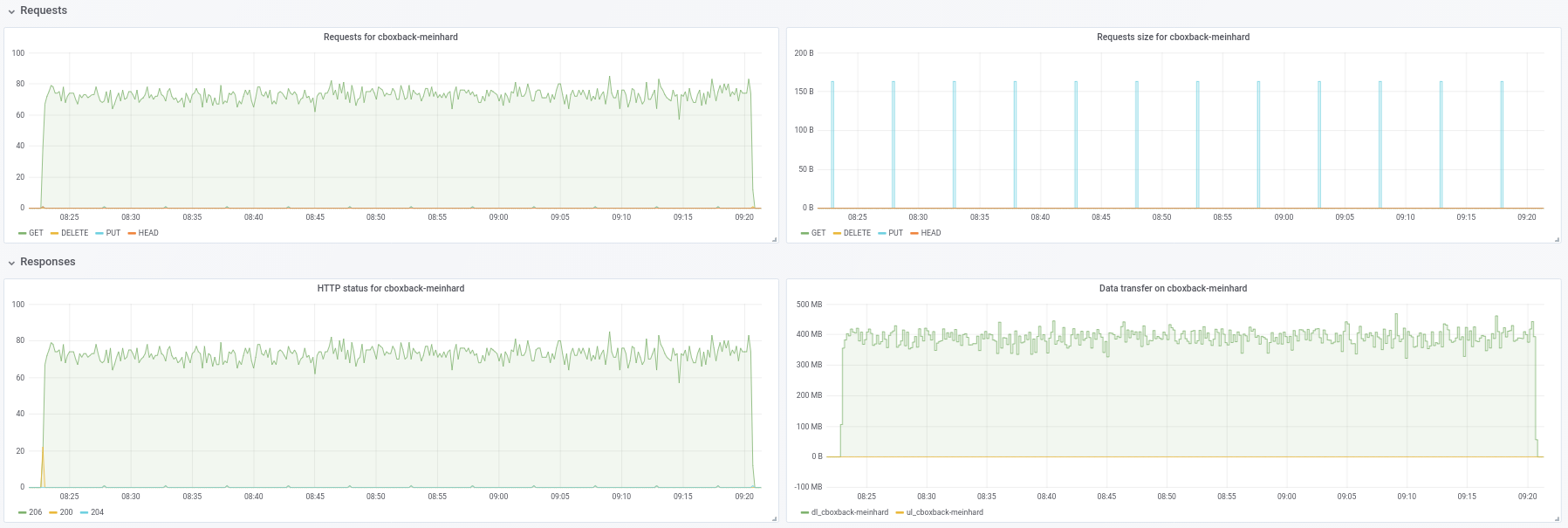
@ifedorenko indeed, with out-order version now is much better! It took less than one hour which is closer of what I've got with rclone. Some comments that I could extract from my tests so maybe you can find them usefu (see attached plots too!):
- On normal restic
0.9.4the process starts faster, with peaks of200MB/secand we are getting almost50 requestsper second on S3 side. After just a couple of minutes, the degradation happens and the requests go down to 1 or so and the speed ~5MB/secduring the rest of the process. - With the "o-o-o" version, the transfer speed is something like
40MB/secand ~8S3 requests steady during all the process. - Another thing that I've noticed is that I see almost no improvement on increasing the S3 connections, is this expected?
32 connections:
Created 2197 directories, listed 171.141 GiB in 20930 files
Restored 171.136 GiB in 170258 files
real 57m54.588s
user 229m25.229s
sys 6m51.763s
64 connections
real 53m13.876s
user 242m57.081s
sys 7m12.455s
- Finally did a test with another different repository (51G, 1.3M small files, lot of duplicates) and is still faster than 0.9.4 by a good margin:
0.9.4
real 16m6.966s
user 25m4.116s
sys 4m19.424s
0.9.4-ooo:
real 8m14.375s
user 14m30.107s
sys 3m41.538s
So is not only improving with big files, it improves all cases!!
And btw, the new progress view of restore is nice!! 8)
Let me know if you want me to do some other tests.
Thanks!
robvalca
on 26 Feb 2019
Thank you for the feedback, @robvalca, it is very useful.
- Another thing that I've noticed is that I see almost no improvement on increasing the S3 connections, is this expected?
Sorry, forgot to mention you need to change the code to increase number of concurrent restore workers. It's hardcoded to 8 at the moment:
https://github.com/ifedorenko/restic/blob/099f51c01c189a84b96be86ce6be61a45e3705fc/internal/restorer/filerestorer.go#L22
Let me know if you want me to do some other tests.
We still don't know what is causing apparent worker contention during out-of-order restore mentioned earlier in this issue https://github.com/restic/restic/issues/2074#issuecomment-443759511. Can you test this specific commit
https://github.com/ifedorenko/restic/commit/d410668ce3a8c7284d86a2b06bf42a0e654d43bc? If you observe the contention with your repositories, that would mean it's not specific to pmkane's data and that my recent changes fix the contention.
Thank you again for your help.
ifedorenko
on 26 Feb 2019
Hi all -- still monitoring this, but have been absolutely swamped. I will catch up this weekend and see if we can still reproduce with ifedorenko@d410668. Our data is not identical/near identical, but in case it matters, much of it is compressed.
pmkane
on 26 Feb 2019
@ifedorenko Thanks, with 32 workers the process is much faster going down to 30min which is a great result. I've tried also increasing workers/s3.connections to 64/64, 128/128 but I see no improvements, getting almost the same results. Anyways, I'm happy with the current results.
I tried also the version with https://github.com/ifedorenko/restic/commit/d410668 you pointed me and here is a screenshot of the trace. I don't have too much experience with this kind of tools but seems similar to @pmkane results. I've run it with 8 workers and with -o s3.connections=32
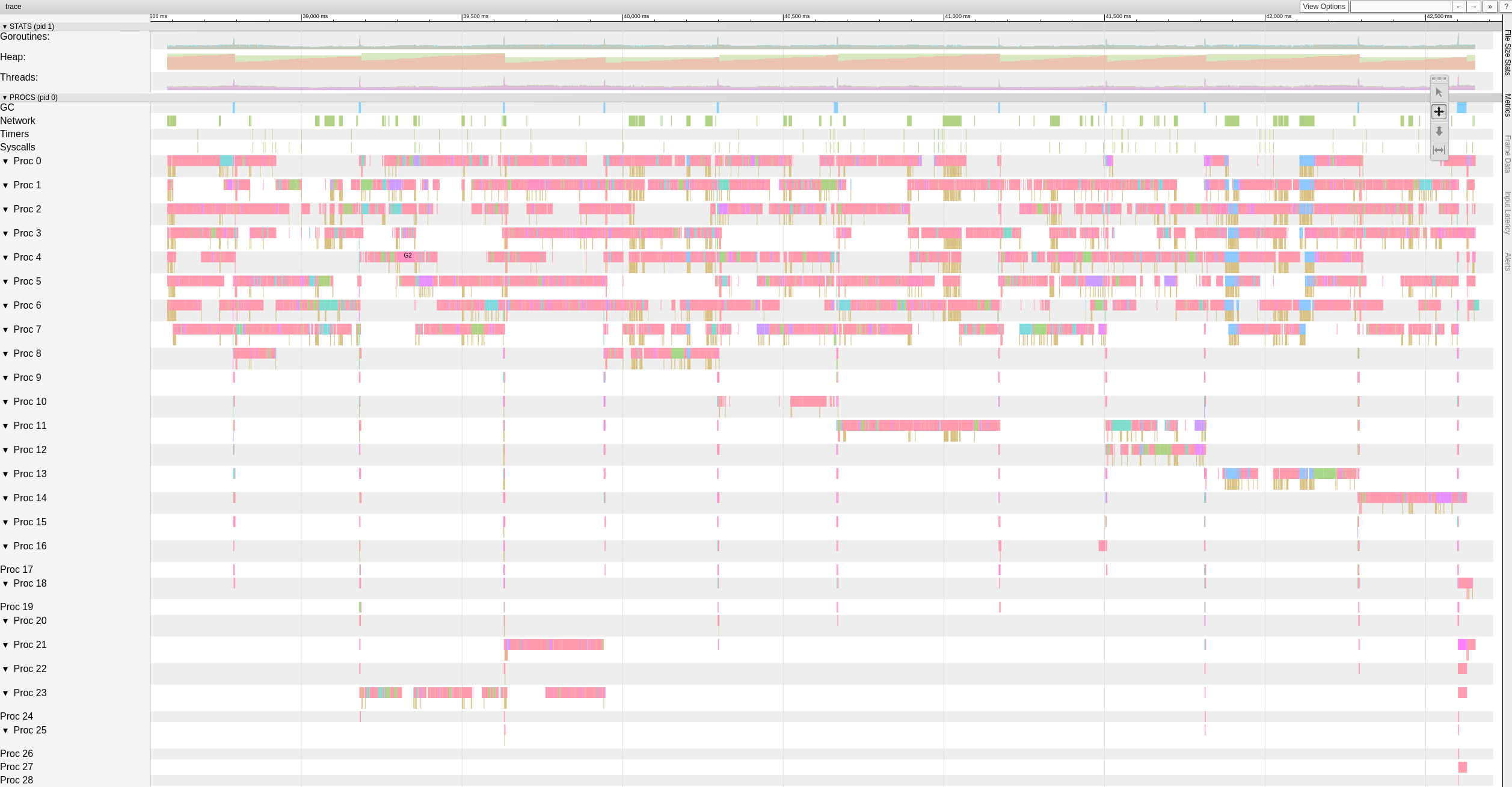
robvalca
on 27 Feb 2019
@robvalca so ifedorenko@d410668 was significantly slower compared to the head of the branch, right? this is a good news, means we've likely addressed all known problems. thank you for the update.
ifedorenko
on 27 Feb 2019
@ifedorenko no, I forgot to mention, the performance is more or less the same than the head of the branch (out-of-order) with the same number of workers(8) and S3.connections(32). Both took ~55m, which is is line with the time to transfer the repo with rclone (~47m)
Let me know if you want me to test with other parameters ;)
robvalca
on 27 Feb 2019
I found the trigger for performance issues in my use case. Restore performance for large files is non-linear beyond a certain file size.
To test, I created a new repo in S3 and then backed up 6 files containing random data to the repo. The files were 1, 5, 10, 20, 40 and 80GB in size.
As with previous tests, tests were run on i3.8xlarge instances with the backups and restores happening on fast, striped SSD.
The backup times were linear, as expected (8, 25, 46, 92, 177 and 345 seconds).
The restore times, however, weren't:
1gb, 5s
5gb, 17s
10gb, 33s
20gb, 85s
40gb, 256s
80gb, 807s
So there's something strange going on with large files and restore performance.
The bucket is named pmk-large-restic-test and the bucket and its contents are public. It's in us-west-1 and the restic repo password is password
The snapshot ids for the files are:
1gb: 0154ae25
5gb: 3013e883
10gb: 7463efa8
20gb: 292650c6
40gb: 5acb4bee
80gb: d1b7e323
Let me know if there's more data I can provide!
pmkane
on 27 Feb 2019
@pmkane can you confirm you used latest head of https://github.com/ifedorenko/restic/tree/out-order-restore branch (https://github.com/ifedorenko/restic/commit/ead78b375f2efed6de57c99b6766edbe9322e009 to be specific)?
ifedorenko
on 27 Feb 2019
Yes, I did. Sorry for not mentioning that.
pmkane
on 27 Feb 2019
(used 32 workers and 32 s3 connections across all runs w/ ead78b3)
pmkane
on 27 Feb 2019
Do you know if I need to do anything special to access that bucket? I never used public buckets before, so not sure if I am doing anything wrong or by user does not have access. (I can access my team's buckets just fine, so I know my system can access s3 in general)
ifedorenko
on 27 Feb 2019
Hey @ifedorenko, hang on, let me get someplace unprivileged and try.
pmkane
on 27 Feb 2019
Sorry about that, I had applied a public bucket policy, but had not updated the objects in the bucket itself. You should be able to access it now. Note that you'll need to use --no-lock, as I've only granted read permissions.
pmkane
on 27 Feb 2019
Yup. I can access the repo now. Will play with it later tonight.
ifedorenko
on 27 Feb 2019
And in case it's helpful/easier to test, we see similar performance characteristics when doing restores of the same files to/from a repo on fast SSD, taking S3 out of the equation.
pmkane
on 28 Feb 2019
@pmkane I can reproduce the problem locally and don't need access to that bucket any more. this was very useful, thank you.
ifedorenko
on 28 Feb 2019
@ifedorenko, fantastic. I will delete the bucket.
pmkane
on 28 Feb 2019
@pmkane please give latest out-order-restore branch another try when you have time. I didn't have time to test this in ec2, but on my macbook restore seems to be limited by disk write speed and matches rclone now.
ifedorenko
on 1 Mar 2019
@ifedorenko, that sounds very promising. I'm firing up a test now.
pmkane
on 1 Mar 2019
@ifedorenko, bingo.
Restored 133GB worth of blobs representing a mixture of file sizes, the largest being 78GB, in just under 16 minutes. Previously, this restore would have taken the better part of a day. I suspect we can get this faster still by playing with the number of restoreWorkers, but it's plenty fast as it stands.
Thanks for your hard work on this!
pmkane
on 1 Mar 2019
And for posterity: our restore performance doubles from 8->16 and again from 16->32 restore workers. 32->64 is only good for a ~50% bump on top of 32, at which point we are restoring at around 3gbit/sec. Nearly on par with rclone.
I know that there is a desire to minimize the amount of configuration required to extract the best performance from restic, but this one is a big enough jump, especially for users with large file sets, that it would be nice to be able to specify the number of workers at runtime.
pmkane
on 1 Mar 2019
Not sure why restore still can't get full wire speed. There is redundant blob hash check you can comment out to see if it's responsible.
ifedorenko
on 2 Mar 2019
I'll give it a try.
pmkane
on 2 Mar 2019
Hi all, I ran some tests using the latest pull request #2195 and the performance continues to improve!
(20k small files, 2x70G files, 170G total)
8w_32c
real 27m46.185s
user 24m31.290s
sys 3m55.153s
32w_32c
real 15m30.904s
user 24m1.982s
sys 4m55.128s
64w_32c
real 18m37.566s
user 23m33.684s
sys 5m3.024s
64w_64c
real 17m12.314s
user 23m44.318s
sys 4m43.090s
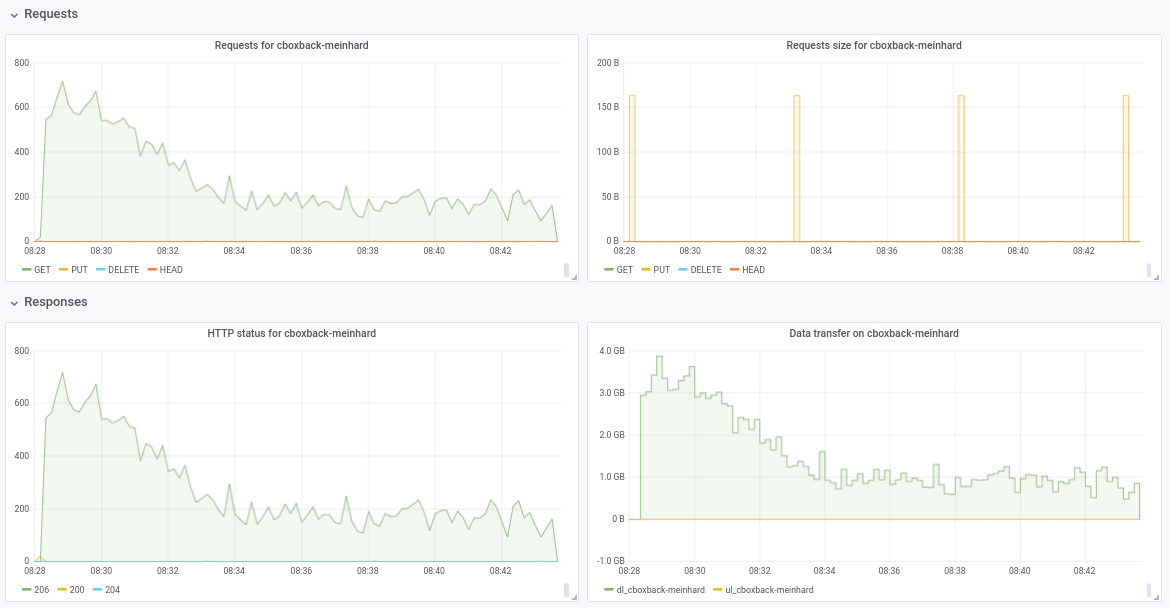
Not sure about the performance drop from 32w to 64w (tested several times and seems legit). I attach some graphs during the process, seems that there is some degradation or limit, should be like this? For example, with 64 workers the process starts at 6gbit/sec but after that drops to less than 1gbit/sec until the end of the process (which I think that correspond to the time to process those big files). The first screenshot is with 32w, 32c and the second with 64w, 32c.
I also agree with @pmkane , it would be useful to change the worker number from the command line. It would be very useful for disaster recovery scenarios when you want to restore your data as fast as possible. There is a pull request about this by my coworker #2178
Anyways I'm really impressed with the improvements done! thanks a lot @ifedorenko
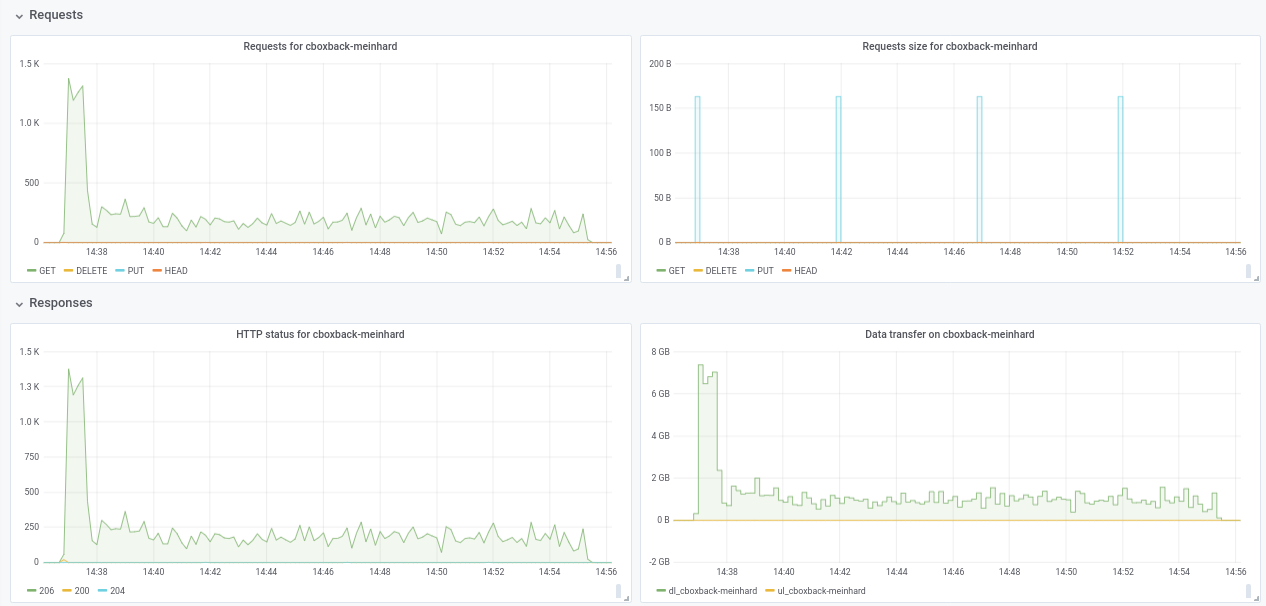
robvalca
on 4 Mar 2019
++. Thank you @ifedorenko, this is game changing stuff for restic.
pmkane
on 4 Mar 2019
Thank you for the detailed report @robvalca. Any chance you can provide a test repository I can either in AWS (or GCP or Azure) or locally? I did not see large file restore speed drop in my tests and would like to understand what's going on there.
ifedorenko
on 4 Mar 2019
@pmkane I too would like to configure these things at run time. My suggestion was to make them --option options so they don't clutter the regular flags or commands, but are there for 'advanced' users who want to experiment or tune to their unusual situation. They don't even need to be documented and can be given names that make it clear you can't count on them, like --option experimental.fooCount=32.
 whereisaaron
on 4 Mar 2019
whereisaaron
on 4 Mar 2019
hi @ifedorenko, I've created a public repo with junk data at s3.cern.ch/restic-testrepo. It's more or less the same shape as the one that I was trying (a lot of small files and a few very big ones) and also I could reproduce the same behavior on this (attached plot). The password for the repo is restic. Let me know if you have any trouble accessing it.
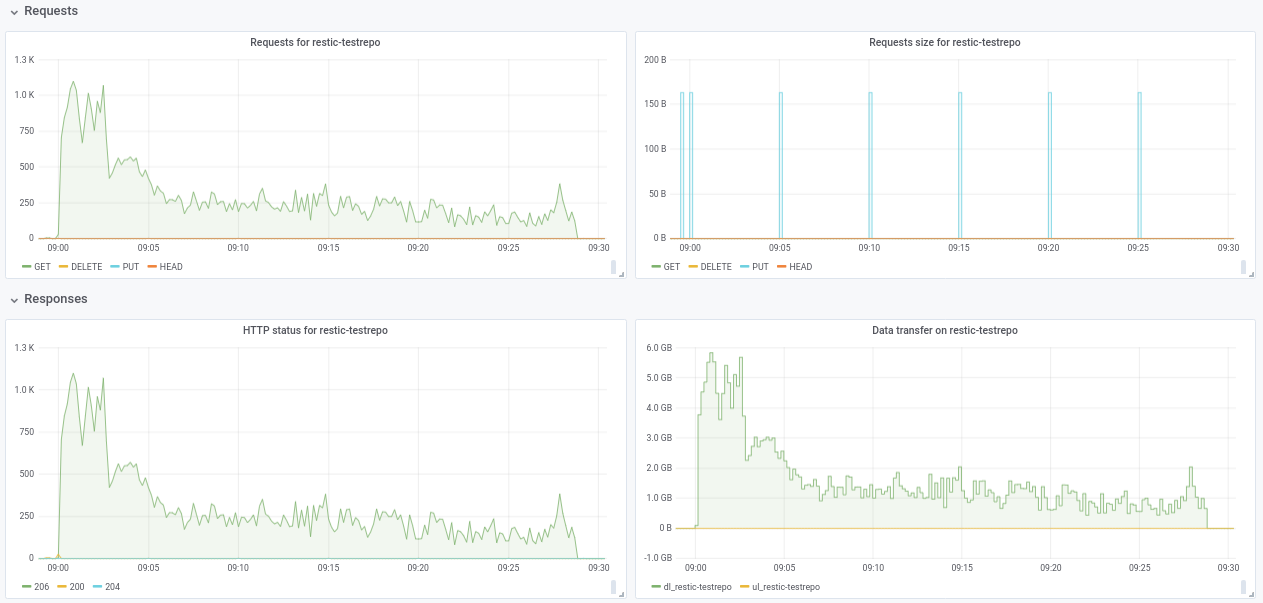
robvalca
on 5 Mar 2019
@robvalca I am unable to reproduce the problem using your test repository. In AWS (us-east-2, s3 repo, i3.4xlarge 2x nvme raid0 target) I see steady 0.68 GB/s restore speed when using 32 workers and 32 connections (total restore time 6m20s). Your target system can't sustain 10GB/s for long time, if I were to guess, at least that's what I'd check first if I were to troubleshoot this further.
@pmkane interestingly, I can't confirm your observations either. As I mentioned above, I see 0.68 GB/s restore speed using latest out-of-order-restore-no-progress branch (restore looked CPU-bound), and 0.81 GB/s if I disable redundant blob hash check (restore didn't look CPU-bound). I don't know how much faster "up to 10 Gbps" network can go, but I think we are very much in "diminishing returns" territory already.
ifedorenko
on 6 Mar 2019
@ifedorenko I agree wholeheartedly re: diminishing returns. It's plenty fast enough for us as it is.
pmkane
on 6 Mar 2019
@ifedorenko interesting, I will investigate this at our side. Anyways It's fast enough for us too, thanks a lot for your effort.
robvalca
on 7 Mar 2019
Curious about the status of getting this merged in. This branch, combined with @cbane's work on prune speed up, make restic usable for extremely large backups.
pmkane
on 22 Aug 2019
Soon... 👀
 rawtaz
on 26 Feb 2020
rawtaz
on 26 Feb 2020
Closing this now that #2195 has been merged. Feel perfectly free to reopen it if the specifics that this issue is about has not been resolved. If there's still improvements to be made that are not of the type discussed in this issue, please open a new issue. Thanks!
rawtaz
on 26 Feb 2020
Related issues
 fd0
·
4Comments
mholt
·
4Comments
fd0
·
4Comments
mholt
·
4Comments
 reallinfo
·
4Comments
reallinfo
·
4Comments
 axllent
·
4Comments
fd0
·
3Comments
axllent
·
4Comments
fd0
·
3Comments
Most helpful comment
Curious about the status of getting this merged in. This branch, combined with @cbane's work on prune speed up, make restic usable for extremely large backups.