Restic: Les restaurations pourraient être encore plus rapides
Grâce à la fusion de PR1719, les restaurations en restic sont _way_ plus rapides.
Ils pourraient être encore plus rapides, cependant.
À des fins de test, j'ai restauré à partir d'un compartiment AWS S3 restic dans la même région (us-west-1) qu'une instance i3.8xlarge EC2 dédiée. La restauration est allée à l'encontre du nvme 4x1,9 To dans l'instance, rayé RAID-0 via LVM avec un système de fichiers xfs en dessous. L'instance a une bande passante théorique de 10 gbit/s vers S3.
Avec workerCount dans filerestorer.go passé à 32 (par rapport à la limite compilée de 8), restic restaure un mélange de 228 Ko de fichiers avec une taille de fichier médiane de 8 Ko et une taille de fichier maximale de 364 Go à une moyenne de 160 mbit/s.
En comparaison, rclone avec --transfers=32 déplace les données du même compartiment à 5636 mbit/s, plus de 30 fois plus vite.
Ce n'est pas une comparaison de pommes à pommes. Les blobs de données Restic ont une taille de 4096 Ko, pas 8 Ko, et l'ouverture/fermeture des fichiers a certainement une surcharge _quelque_. Mais c'est toujours une différence suffisamment importante pour indiquer probablement un goulot d'étranglement dans restic.
Je suis heureux de tester des choses, de fournir de l'instrumentation ou d'aider de toute autre manière !
 pmkane
pmkane
Tous les 71 commentaires
160mbit/sec semble en effet lent. Je m'approchais de 200 Mbps sur un petit macbook pro téléchargeant à partir de onedrive via une connexion ftth 1 Gbps (rapide accordée). Je ne peux pas vraiment dire quoi que ce soit de spécifique sans accès à vos systèmes et à votre référentiel, mais voici quelques choses que je devrais faire pour réduire le problème, sans ordre particulier :
- Estimez le temps qu'il faut pour télécharger un fichier de pack unique sur un seul thread. Vous pouvez calculer cela à partir de votre test de téléchargement rclone 32x, mais je serais également curieux de connaître le temps nécessaire pour télécharger des packs individuels avec curl afin que nous puissions également estimer la surcharge de la demande http.
- Je vérifierais les statistiques du système d'exploitation sur la quantité de restic téléchargée à partir de S3 pendant la restauration. Cela nous dira si la restauration télécharge plusieurs fois les fichiers de packs individuels (ce qui est possible, mais ne devrait pas arriver très souvent, sauf si j'ai oublié quelque chose).
- Le niveau de concurrence S3 semble être limité à seulement 5 connexions . Cela peut-il expliquer la vitesse de restauration que vous voyez donnée par l'estimation de vitesse à thread unique ci-dessus ? Que se passe-t-il si vous augmentez la limite de connexion backend S3 pour correspondre à celle du restaurateur ?
- Graphique de l'utilisation du réseau pendant la restauration pour voir s'il y a des lacunes ou des ralentissements.
- Excluez ce fichier de 364 Go de la restauration et voyez ce qui se passe. Les fichiers individuels sont actuellement restaurés de manière séquentielle, de sorte que ce fichier peut considérablement fausser la vitesse de téléchargement moyenne.
 ifedorenko
le 7 nov. 2018
ifedorenko
le 7 nov. 2018
Salut!
Merci pour la réponse. C'était intéressant à creuser
tl;dr : augmenter les connexions s3 est la clé, mais les améliorations de performances qu'il fournit sont étrangement temporaires.
- Le transfert de la valeur d'un seul répertoire de packs (3062 fichiers totalisant 13 Go) / avec rclone --transfers 1 fonctionne à 233 mbit/sec. Confirmé avec lsof qu'il ne s'exécute qu'avec un seul thread et une seule connexion https dans ce mode. La vitesse de pointe est atteinte avec --transfers 32 (8,5 gbit/s, essentiellement la vitesse de ligne pour cette instance i3.8xlarge ec2). Dans les deux cas, nous écrivons dans le tableau nvme rayé.
- Heureux de collecter des statistiques, mais qu'aimeriez-vous voir en particulier ? (mais peut ne pas être requis, veuillez voir ci-dessous)
- Je vais faire d'une pierre deux coups ici ! Voici un graphique de l'utilisation du réseau pendant les restaurations avec :
- un stock stock restic avec ce PR fusionné (commit c0572ca15f946c622d9c4009347dc4d6c31cba4c)
- restic avec workerCount passé à 32 et filesWriterCount à 128
- restic avec les modifications précédentes + connexions s3 augmentées à 32.
- resitc avec les modifications précédentes + connexions s3 augmentées à 64.
- rclone avec --transfers 32 en déplaçant le répertoire data/
Les nombres de bande passante sont en kbps et ont été pris à des intervalles de 3 secondes sur 10 minutes. Pour les exécutions de restic, nous avons commencé à collecter des données _after_ restic avait déjà commencé à réellement restaurer les fichiers (c'est-à-dire qu'il exclut le temps de démarrage et le temps que restic passe au début de l'exécution à recréer la hiérarchie des répertoires. Pendant toutes les exécutions, l'utilisation du processeur sur le cas n'excédait pas 25 %.
Nous obtenons une légère bosse en augmentant le workerCount, mais la simultanéité S3 ressemble à l'endroit où se trouve le vrai gain. Mais alors qu'il démarre fort (approchant de la vitesse de reclonage, parfois !), les taux chutent brusquement et restent bas pour le reste de la course. restic renvoie également des erreurs qui ressemblent à « erreur d'ignorance pour [chemin expurgé] : capacité de cache insuffisante : demandé 2148380, disponible 872640 » qu'il ne renvoie pas avec une simultanéité s3 inférieure.
Comme vous pouvez le voir, les performances de rclone démarrent à un niveau élevé et restent élevées, il ne s'agit donc pas d'une situation dans laquelle les écritures vont dans le cache tampon de l'instance, puis se bloquent lorsqu'elles sont vidées sur le disque. Le tableau nvme est plus rapide que le canal réseau, en termes de débit.
- Je ne pense pas que le seul gros fichier soit un facteur, car je mesure les E/S disque/réseau pendant la restauration, donc le fait que cela puisse prendre un certain temps pour que ce fichier soit complètement restauré n'aura pas d'impact sur les nombres regarde ici.
Compte tenu de ce qui précède, il semble que l'augmentation de la simultanéité S3 soit ce qu'il faudra pour obtenir des taux raisonnables ici, mais il faut comprendre pourquoi les performances chutent (et si cela est lié ou non aux erreurs de cache).
Si rendre une instance i3 rapide et de l'espace et de la bande passante s3 disponibles pour vos tests serait utile, faites-le moi savoir, heureux de parrainer cela.
pmkane
le 7 nov. 2018
233mbit/sec fois 32 est 7456 et un peu moins de 8,5 gbit/sec. Ce qui est étrange. Je m'attendais à ce que le téléchargement monothread soit plus rapide que le débit par flux du téléchargement multithread. Je ne sais pas ce que cela signifie, cependant, si quelque chose.
Je cherchais à confirmer que restic ne retélécharge pas les mêmes packs encore et encore. Je pense que le graphique montre que les retéléchargements ne sont pas un problème, donc pas besoin de plus de statistiques, du moins pas maintenant.
Pouvez-vous confirmer l'échelle du graphique? rclone survole la ligne étiquetée "1000000", si c'est "1 000 000 kbps", ce qui, je pense, signifie "1gbps" et ne correspond pas au nombre "8,5 gbit/sec" que vous avez mentionné précédemment.
Comme je l'ai dit, les fichiers individuels sont restaurés séquentiellement. Le téléchargement de 364 Go à 233 mbit/s prendra environ 3,5 heures, et probablement plus longtemps en raison de la surcharge par pack et du déchiffrement, qui se produisent tous de manière séquentielle. Je ne peux pas dire si 3,5 heures est quelque chose que vous pouvez rejeter comme insignifiant sans savoir combien prend le reste de la restauration.
En ce qui concerne l'erreur not enough cache capacity , augmentez averagePackSize à la taille du plus gros fichier de pack de votre référentiel (quelle est sa taille, d'ailleurs?) Et je dois réfléchir à la meilleure façon de dimensionner le cache, je n'ai pas de répondre encore.
ifedorenko
le 7 nov. 2018
Salut!
Oups, je suis désolé. L'échelle du graphique est en KB/sec et non en kbit/sec. Ainsi, 1 012 995 dans la première ligne est de 8,1 gbit/s.
J'ai compris que les fichiers étaient restaurés séquentiellement, mais je n'avais pas compris qu'il n'y avait pas de parallélisme pour la récupération de pack pour un seul fichier. C'est certainement une pierre d'achoppement pour les sauvegardes avec des fichiers volumineux, car cela devient votre facteur limitant. Ce serait fantastique d'avoir un peu de parallélisme ici pour cette raison.
En échantillonnant 10 buckets aléatoires, notre taille de pack maximale est juste en dessous de 12 Mo et notre taille de pack moyenne est de 4,3 Mo.
Peut-être qu'avec plus de travailleurs et de connexions S3, nous dépassons le packCacheCapacity de (workerCount + 5) * averagePackSize. Je vais essayer d'augmenter cela et voir si les erreurs disparaissent.
pmkane
le 7 nov. 2018
Peut-être qu'avec plus de travailleurs et de connexions S3, nous dépassons le packCacheCapacity de (workerCount + 5) * averagePackSize. Je vais essayer d'augmenter cela et voir si les erreurs disparaissent.
La taille du cache est calculée en fonction de la taille du fichier du pack de 5 Mo et de workerCount . L'augmentation de workerCount augmente la taille du cache. Donc, soit il y a une fuite de mémoire, soit la restauration doit mettre en cache de nombreux fichiers de 12 Mo par pur hasard. Augmenter averagePackSize à 12 Mo devrait nous dire lequel.
ifedorenko
le 7 nov. 2018
Aucune erreur de cache avec averagePackSize défini sur 12.
S'il y a d'autres informations que nous pouvons fournir qui seraient utiles, faites-le moi savoir! Merci encore.
pmkane
le 8 nov. 2018
Il semble que nous perdions le parallélisme au fur et à mesure que la restauration progresse et cela ne semble pas être lié à des fichiers volumineux. Je vais monter un cas de test et faire rapport.
pmkane
le 8 nov. 2018
Salut!
J'ai essayé de reproduire les baisses de performances que je voyais avec mon mélange de fichiers de production avec trois mélanges de fichiers artificiels différents.
Pour tous les tests, j'ai utilisé c0572ca15f946c622d9c4009347dc4d6c31cba4c avec des connexions S3 augmentées à 128, workerCount augmenté à 128, filesWriterCount augmenté à 128 et averagePackSize augmenté à 12 * 1024 * 1024.
Tous les tests ont utilisé des fichiers avec des données aléatoires, pour éviter tout impact de la déduplication.
Pour le premier test, j'ai créé et sauvegardé 4 000 fichiers de 100 Mo, répartis uniformément sur 100 répertoires (environ 400 Go au total). Les sauvegardes et les restaurations ont été exécutées à partir de volumes nvme agrégés sur une instance i3.8xlarge. Le compartiment de sauvegarde était situé dans la même région que l'instance (us-west-1).
Avec ce mélange de fichiers, j'ai vu des vitesses moyennes de 9,7 gbit/s (!) Sans perte de parallélisme ou de vitesse tout au long de la restauration complète. Ces nombres sont égaux ou supérieurs aux nombres de rclone et sont essentiellement une vitesse de ligne, ce qui est fantastique.
J'ai ensuite créé et sauvegardé 400 000 fichiers de 1 Mo, répartis uniformément sur 100 répertoires (encore une fois, environ 400 Go au total).
Mêmes (excellents) résultats que ci-dessus.
Enfin, j'ai créé 40 répertoires avec 1 fichier de 10 Go par répertoire. Ici, les choses sont devenues intéressantes.
Je m'attendais à ce que cette restauration soit légèrement plus lente, car restic ne pourrait effectuer que 40 restaurations simultanées avec 40 connexions à S3.
Au lieu de cela, cependant, alors que Restic ouvre les 40 fichiers pour les écritures et écrit dans les 40 fichiers simultanément, il ne garde qu'une seule connexion TCP à S3 ouverte à la fois, pas 40.
Faites-moi savoir quelles statistiques ou instrumentation vous aimeriez voir.
pmkane
le 8 nov. 2018
Pouvez-vous confirmer qu'il y a eu 128 connexions S3 lors des tests "rapides" ?
ifedorenko
le 8 nov. 2018
Oui il y en avait.
pmkane
le 8 nov. 2018
Curieux... Pour être honnête, la prise en charge des fichiers volumineux n'est pas en haut de ma liste de priorités, mais je trouverai peut-être le temps d'examiner cela dans les prochaines semaines. Si quelqu'un veut creuser ça avant moi, merci de me le faire savoir.
ifedorenko
le 8 nov. 2018
J'ai fait d'autres tests et il semble en fait que la taille du fichier soit un faux-fuyant, c'est le nombre de fichiers qui détermine le nombre de connexions AWS.
Avec 128 fichiers de 10 Mo dans 4 répertoires, restic n'ouvre que 6 connexions à AWS, même s'il écrit dans les 128 fichiers.
Avec 512 fichiers de 10 Mo dans 4 répertoires, restic ouvre 18 connexions au cours de sa durée de vie, même s'il a 128 fichiers ouverts à la fois.
Avec 5 120 fichiers de 10 Mo dans 4 répertoires, restic n'ouvre que 75 connexions à AWS au cours de sa durée de vie, contenant à nouveau 128 fichiers ouverts à la fois.
Impair!
pmkane
le 8 nov. 2018
Je serais vraiment surpris si le client Go S3 ne mettait pas en commun et ne réutilisait pas les connexions http. Très probablement, il n'y a pas de corrélation un à un entre le nombre de travailleurs simultanés et les sockets TCP ouverts. Ainsi, par exemple, si la restauration est lente à traiter les packs téléchargés pour une raison quelconque, la même connexion S3 sera partagée par plusieurs travailleurs.
ifedorenko
le 8 nov. 2018
Il y a deux propriétés du restaurateur concurrent actuel qui sont responsables de la majeure partie de la complexité de l'implémentation et causent très probablement le ralentissement signalé ici :
- les fichiers individuels sont restaurés du début à la fin
- le nombre de dossiers en cours est réduit au minimum
La mise en œuvre sera beaucoup plus simple, utilisera moins de mémoire et sera très probablement plus rapide dans de nombreux cas si nous acceptons d'écrire des blobs de fichiers dans n'importe quel ordre et d'autoriser un nombre illimité de fichiers en cours.
L'inconvénient, il ne sera pas possible de dire combien de données ont déjà été restaurées dans un fichier donné jusqu'à la fin de la restauration. Ce qui peut être déroutant, surtout si la restauration se bloque ou est tuée. Ainsi, vous pouvez voir un fichier de 10 Go sur le système de fichiers, qui n'a en réalité que quelques octets écrits à la fin du fichier.
@fd0 pensez-vous qu'il vaut la peine d'améliorer la restauration actuelle du début à la fin ? Personnellement, je suis prêt à admettre que c'était trop d'ingénierie de ma part et que je peux fournir une implémentation hors service plus simple si vous êtes d'accord.
ifedorenko
le 16 nov. 2018
Je ne me souviens pas si Restic prend en charge la restauration vers la sortie standard. Si c'est le cas, vous devrez évidemment conserver la restauration du début à la fin (peut-être comme cas particulier).
 pvgoran
le 16 nov. 2018
pvgoran
le 16 nov. 2018
@ifedorenko Personnellement, je suis favorable à la simplification, en général, surtout si elle s'accompagne d'améliorations des performances. J'essaie de comprendre les compromis cependant:
L'inconvénient, il ne sera pas possible de dire combien de données ont déjà été restaurées dans un fichier donné jusqu'à la fin de la restauration.
Si nous ne parlons pas ici de milliers de fichiers écrits simultanément, peut-être qu'une carte du nom de fichier aux octets écrits pourrait être utilisée ? De toute évidence, les informations ne seront pas disponibles pour le système de fichiers, mais pour les rapports d'avancement, cela pourrait toujours être fait, non ? (Et pour reprendre une restauration interrompue, peut-être en vérifiant simplement les blobs et les décalages du fichier pour les octets non nuls, peut-être? Je ne sais pas.)
Je ne me souviens pas si Restic prend en charge la restauration vers la sortie standard. Si c'est le cas, vous devrez évidemment conserver la restauration du début à la fin (peut-être comme cas particulier).
Je ne pense pas que ce soit le cas - je ne sais pas comment cela fonctionnerait de toute façon, puisque les restaurations sont plusieurs fichiers, vous auriez besoin de les encoder d'une manière ou d'une autre et de les séparer d'une manière ou d'une autre, je pense.
 mholt
le 16 nov. 2018
mholt
le 16 nov. 2018
Si nous ne parlons pas ici de milliers de fichiers écrits simultanément, peut-être qu'une carte du nom de fichier aux octets écrits pourrait être utilisée ?
L'implémentation la plus simple consiste à ouvrir et fermer des fichiers pour écrire des blobs individuels. Si cela s'avère trop lent, nous devrons alors trouver un moyen de garder les fichiers ouverts pour plusieurs écritures de blob, par exemple en mettant en cache les descripteurs de fichiers ouverts et en commandant les téléchargements de packs pour favoriser les fichiers déjà ouverts.
Restaurer suit déjà quels blobs ont été écrits dans quels fichiers et ce qui est encore en attente. Je ne m'attends pas à ce que cette partie change beaucoup. Les progrès sont suivis dans une structure de données distincte et je ne m'attends pas à ce que cela change non plus.
Et pour reprendre une restauration qui a été interrompue, peut-être en vérifiant simplement les blobs et les décalages du fichier pour les octets non nuls, peut-être ?
Resume doit vérifier les sommes de contrôle des fichiers sur le disque pour décider quels blobs doivent encore être restaurés. Je pense que cela est vrai, que la restauration soit séquentielle ou dans le désordre. Par exemple, si la reprise récupère après une panne de courant, je ne pense pas qu'elle puisse supposer que tous les blocs de fichiers ont été vidés sur les disques avant la coupure de courant, c'est-à-dire que les fichiers peuvent avoir des lacunes ou des blocs partiellement écrits.
ifedorenko
le 16 nov. 2018
@pmkane me demande si vous pouvez essayer #2101 ? il implémente une restauration dans le désordre, bien que les écritures sur des fichiers individuels soient toujours sérialisées et que les performances de restauration de fichiers volumineux puissent encore être sous-optimales. et vous devez modifier le nombre de travailleurs comme avant.
ifedorenko
le 27 nov. 2018
Absolument. Je voyage cette semaine mais je testerai dès que possible et je ferai un retour.
pmkane
le 27 nov. 2018
@ifedorenko J'ai essayé ce PR et il crée avec succès la structure de répertoires, mais toutes les restaurations de fichiers échouent avec des erreurs telles que :
Charge(, 3172070, 0) a renvoyé une erreur, réessayer après 12.182749645s : EOF
maître restaure bien.
Ma commande de restauration est :
/usr/local/bin/restic.outoforder -r s3:s3.amazonaws.com/[redacted] -p /root/.restic_pass restore [snapshotid] -t .
Faites-moi savoir quelles informations supplémentaires je peux fournir pour aider au débogage.
pmkane
le 1 déc. 2018
Combien de demandes de téléchargement S3 simultanées autorisez-vous ? Si c'est 128, pouvez-vous le limiter à 32 (dont nous savons qu'il fonctionne) ?
Semi-lié... savez-vous combien de fichiers d'index contient votre véritable référentiel ? Essayer d'estimer la quantité de mémoire dont le restaurateur a besoin.
ifedorenko
le 1 déc. 2018
Je n'ai pas spécifié de limite de connexion, donc je suppose qu'elle était par défaut à 5.
J'obtiens les mêmes erreurs avec -o s3.connections=2 et -o s3.connections=1.
J'ai actuellement 85 blobs d'index dans le dossier index/. Leur taille totale est de 745 Mo.
pmkane
le 1 déc. 2018
Hmm. J'y jetterai un autre coup d'œil quand j'arriverai à mon ordinateur plus tard dans la journée. Btw, "erreur renvoyée, nouvelle tentative" est un avertissement, pas une erreur, il peut donc être lié à l'échec de la restauration ou il peut s'agir simplement d'un faux-fuyant.
ifedorenko
le 1 déc. 2018
Je ne sais pas comment je l'ai raté... le restaurateur n'a pas lu complètement tous les fichiers de pack à partir du backend dans la plupart des cas. Devrait être corrigé maintenant. @pmkane peux-tu retenter ton test ?
ifedorenko
le 2 déc. 2018
Je vais lui donner un tourbillon !
pmkane
le 2 déc. 2018
Confirmé que les fichiers sont restaurés avec succès avec ce correctif. Tester les performances maintenant.
pmkane
le 2 déc. 2018
Malheureusement, il semble qu'il soit plus lent que le maître. Tous les tests s'exécutent sur l'instance i3.8xlarge décrite ci-dessus.
Avec un workerCount de 8 (valeur par défaut), la branche hors service est restaurée à 86 mbit/s.
Avec un workerCount passé à 32, il a fait un peu mieux, avec une moyenne de 160 mbit/s.
L'utilisation du processeur avec cette branche est nettement plus élevée que dans le maître, mais elle ne maximise pas le processeur de l'instance dans les deux cas.
Pour l'anecdote, l'interface utilisateur de restauration donne l'impression que quelque chose "colle", presque comme s'il était en compétition contre lui-même pour un verrou quelque part.
Heureux de fournir plus de détails, un profilage ou une instance de test à répliquer.
pmkane
le 2 déc. 2018
Juste pour confirmer, vous aviez à la fois le restaurateur et le nombre de travailleurs du backend s3 définis sur 32, n'est-ce pas ?
Quelques réflexions qui peuvent expliquer le comportement que vous avez observé :
- Les écritures dans des fichiers individuels sont toujours sérialisées. J'ai _deviné_ que ce ne serait pas un problème avec les systèmes de fichiers cibles rapides, mais je ne l'ai jamais mesuré.
- L'ouverture/fermeture de fichier autour de chaque blob contribue certainement à la surcharge du restaurateur. Lorsque j'ai mesuré cela sur macos, j'ai pu "ouvrir un fichier ; écrire un octet ; fermer le fichier » 100 000 fois en environ 70 secondes, ce qui équivaut approximativement à la surcharge de l'écriture de 100 000 blobs. Le test était vraiment simple et les frais généraux réels peuvent être considérablement plus élevés.
- Je n'ai actuellement aucune explication plausible pour une utilisation élevée du processeur. L'implémentation dans le désordre ne déchiffre chaque blob qu'une seule fois (le maître déchiffre les blobs pour chaque fichier cible), et il y a beaucoup moins de comptabilité par rapport au maître. Peut-être que les écritures de fichiers "sparses" ne sont pas vraiment rares et nécessitent que Go ou OS fasse quelque chose de lourd en CPU. Je ne sais pas vraiment.
ifedorenko
le 2 déc. 2018
Salut!
C'est exact. workerCount a été défini sur 8 ou 32 dans internal/restorer/filerestorer.go et -o s3.connections=32 a été transmis via le restic cli dans les deux cas.
pmkane
le 3 déc. 2018
Voici une vue de haut niveau des données de trace pendant que la branche hors service restaure des fichiers avec 8 travailleurs.
Il semble qu'il y ait des pauses importantes (> 500-1000 ms) que les travailleurs effectuent fréquemment.
pmkane
le 3 déc. 2018
J'ai décidé de passer un peu plus de temps là-dessus et j'ai commencé par écrire un test autonome simple qui génère des octets aléatoires de 10 Gio dans des blocs de 4 Kio. Mon objectif était d'évaluer à quelle vitesse mon système peut déplacer des octets. À ma grande surprise, ce test a pris 18,64 secondes pour s'exécuter sur mon macbook pro (2018, Intel Core i7 à 2,6 GHz). Ce qui se traduit par environ 4,29 gigabits/s, soit environ la moitié de ce que l'Ethernet 10G peut faire. Et ceci sans aucune entrée/sortie de chiffrement, de réseau ou de disque. Et j'utilisais Xoshiro256** prng, math/rand était environ 2 fois plus lent, ce qui est bien sûr complètement hors de propos. Le fait est que le restaurateur doit traiter les blobs sur plusieurs threads afin de saturer le réseau 10G, les E/S réseau multithread en elles-mêmes ne suffisent pas.
Et juste pour le plaisir, Rust impl comparable génère 10 Go d'octets aléatoires en 3,1 secondes et Java en 10,77 secondes. Allez comprendre :-)
ifedorenko
le 6 févr. 2019
Essai intéressant !
Je comprends que restic sera limité par le temps qu'il faut pour restaurer le fichier le plus volumineux, actuellement.
Pour le moment, cependant, ce n'est pas notre bloqueur, car je sais que restic peut restaurer un seul fichier beaucoup plus rapidement que les 160 mbit/s que nous voyons ici.
Je vais créer un dépôt de test de 100 Go composé de fichiers de 10 Mo sur un SSD rapide et dans S3 et exécuter quelques chiffres, pour obtenir le meilleur scénario actuel dans le maître et dans cette branche.
pmkane
le 6 févr. 2019
Salut à tous, existe-t-il un moyen de modifier le nombre de travailleurs à l'aide d'un paramètre ou doit-il être fait directement sur le code ? Nous avons également le problème des restaurations lentes et j'aimerais améliorer ce que nous avons d'une manière ou d'une autre... Faites-moi savoir si je peux contribuer avec des tests pour aider à améliorer cette partie !
Merci!
 robvalca
le 19 févr. 2019
robvalca
le 19 févr. 2019
@robvalca quel backend utilisez-vous ? à quelle vitesse rclone copie votre référentiel sur le système cible ? quelle est la vitesse de restauration restic?
Pour le moment, je ne sais pas ce qui se passe, donc ce serait vraiment utile si vous pouviez fournir un référentiel de test et les étapes que je peux utiliser pour reproduire le problème localement (et par "test de référentiel", je veux dire des données indésirables/aléatoires, pas de données privées données s'il vous plaît).
ifedorenko
le 22 févr. 2019
@ifedorenko nous utilisons S3 (ceph+radosgw) comme backend (géré par nos soins). J'ai essayé de copier le dépôt à l'aide de rclone et voici les résultats :
rclone copy -P remote:cboxback-aabbcc/ /var/tmp/restic/aabbcc/
Transféré : 127,309 G / 127,309 Go, 100 %, 45,419 Mo/s, ETA 0s
Erreurs : 0
Chèques : 0 / 0, -
Transféré : 25435 / 25435, 100 %
Temps écoulé : 47m50,2s
La restauration du repo à l'aide de "stock" restic 0.9.4 a pris environ 8 heures. Dans les deux cas, j'utilise 32 connexions S3 et le même hôte cible. J'ai mis un peu plus d'informations dans ce fil de discussion .
Je vais préparer un repo pour que vous testiez et vous informerai quand je serai prêt,
Merci beaucoup pour votre aide !
robvalca
le 25 févr. 2019
@robvalca pouvez-vous essayer de restaurer à l'aide de ma branche de restauration hors commande ? la branche est censée améliorer les performances de restauration des fichiers très volumineux, ce qui semble être le problème auquel vous êtes confronté.
si la branche n'améliore pas les performances de restauration pour vous, veuillez télécharger le référentiel de test dans un compartiment s3 public et publier le nom du compartiment et le mot de passe du référentiel ici.
ifedorenko
le 26 févr. 2019
@pmkane est-il possible que vous restaurez un grand nombre de fichiers identiques ou presque identiques ? cela expliquerait les conflits entre les travailleurs, je pense.
Edit : en fait, pouvez-vous réessayer votre test de performances de restauration en utilisant le dernier #2101 ? Il devrait mieux gérer les écritures simultanées dans le même fichier et le même blob dans plusieurs fichiers maintenant.
ifedorenko
le 26 févr. 2019
@ifedorenko en effet, avec la version hors commande, c'est bien mieux maintenant ! Cela a pris moins d'une heure, ce qui est plus proche de ce que j'ai avec rclone. Quelques commentaires que j'ai pu extraire de mes tests pour que vous puissiez peut-être les trouver utiles (voir aussi les graphiques ci-joints !) :
- Sur des
0.9.4restic normaux, le processus démarre plus rapidement, avec des pics de200MB/secet nous obtenons presque50 requestspar seconde du côté S3. Après seulement quelques minutes, la dégradation se produit et les requêtes descendent à environ 1 et la vitesse ~5MB/secpendant le reste du processus. - Avec la version "ooo", la vitesse de transfert est quelque chose comme
40MB/secet ~8requêtes S3 stables pendant tout le processus. - Une autre chose que j'ai remarquée est que je ne vois presque aucune amélioration sur l'augmentation des connexions S3, est-ce attendu ?
32 connexions :
Created 2197 directories, listed 171.141 GiB in 20930 files
Restored 171.136 GiB in 170258 files
real 57m54.588s
user 229m25.229s
sys 6m51.763s
64 connexions
real 53m13.876s
user 242m57.081s
sys 7m12.455s
- Enfin fait un test avec un autre dépôt différent (51G, 1,3M de petits fichiers, beaucoup de doublons) et est toujours plus rapide que la 0.9.4 par une bonne marge :
0.9.4
real 16m6.966s
user 25m4.116s
sys 4m19.424s
0.9.4-ooo :
real 8m14.375s
user 14m30.107s
sys 3m41.538s
Donc, non seulement avec les gros fichiers, ça améliore tous les cas !!
Et d'ailleurs, la nouvelle vue d'avancement de la restauration est sympa !! 8)
Faites-moi savoir si vous voulez que je fasse d'autres tests.
Merci!
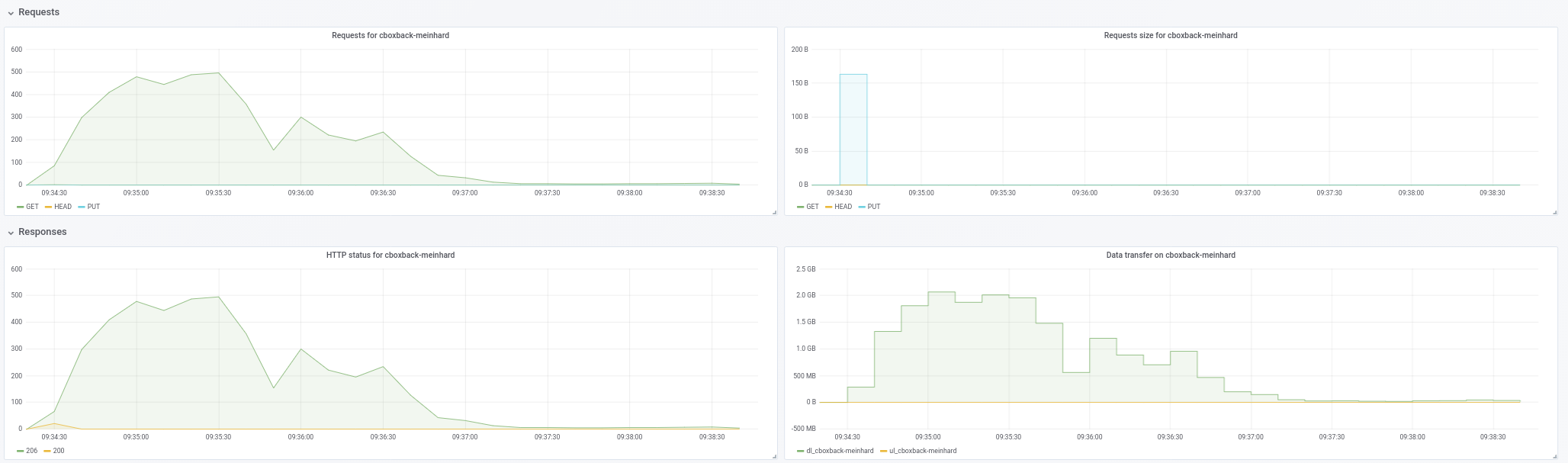
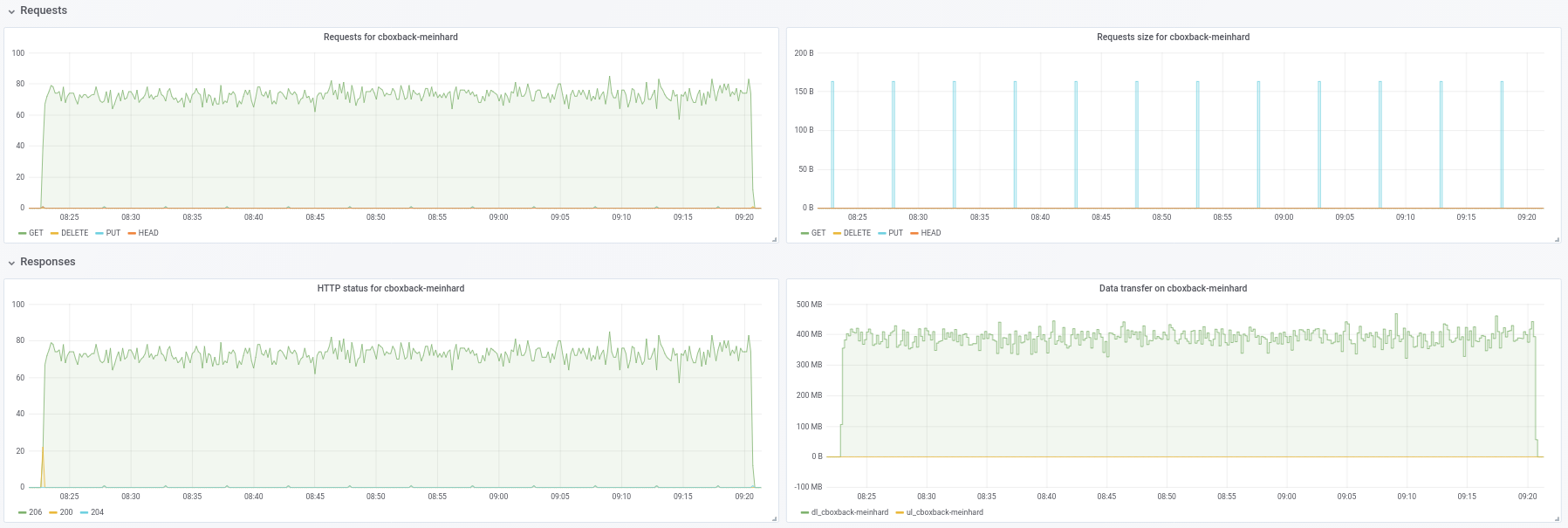
robvalca
le 26 févr. 2019
Merci pour le retour, @robvalca , c'est très utile.
- Une autre chose que j'ai remarquée est que je ne vois presque aucune amélioration sur l'augmentation des connexions S3, est-ce attendu ?
Désolé, j'ai oublié de mentionner que vous devez modifier le code pour augmenter le nombre de programmes de restauration simultanés. Il est codé en dur à 8 pour le moment :
https://github.com/ifedorenko/restic/blob/099f51c01c189a84b96be86ce6be61a45e3705fc/internal/restorer/filerestorer.go#L22
Faites-moi savoir si vous voulez que je fasse d'autres tests.
Nous ne savons toujours pas ce qui cause la contention apparente des travailleurs lors de la restauration hors service mentionnée plus haut dans ce problème https://github.com/restic/restic/issues/2074#issuecomment -443759511. Pouvez-vous tester ce commit spécifique
https://github.com/ifedorenko/restic/commit/d410668ce3a8c7284d86a2b06bf42a0e654d43bc? Si vous observez le conflit avec vos référentiels, cela signifierait qu'il n'est pas spécifique aux données de pmkane et que mes modifications récentes corrigent le conflit.
Merci encore pour votre aide.
ifedorenko
le 26 févr. 2019
Salut à tous -- je surveille toujours cela, mais j'ai été complètement submergé. Je vais me rattraper ce week-end et voir si on peut encore se reproduire avec ifedorenko@d410668. Nos données ne sont pas identiques/presque identiques, mais au cas où cela compte, une grande partie est compressée.
pmkane
le 26 févr. 2019
@ifedorenko Merci, avec 32 travailleurs, le processus est beaucoup plus rapide et descend à 30 minutes, ce qui est un excellent résultat. J'ai également essayé d'augmenter les workers/s3.connections à 64/64, 128/128 mais je ne vois aucune amélioration, obtenant presque les mêmes résultats. En tout cas, je suis content des résultats actuels.
J'ai essayé aussi la version avec https://github.com/ifedorenko/restic/commit/d410668 tu m'as pointé et voici une capture d'écran de la trace. Je n'ai pas trop d'expérience avec ce genre d'outils mais semble similaire aux résultats de @pmkane . Je l'ai exécuté avec 8 travailleurs et avec -o s3.connections=32
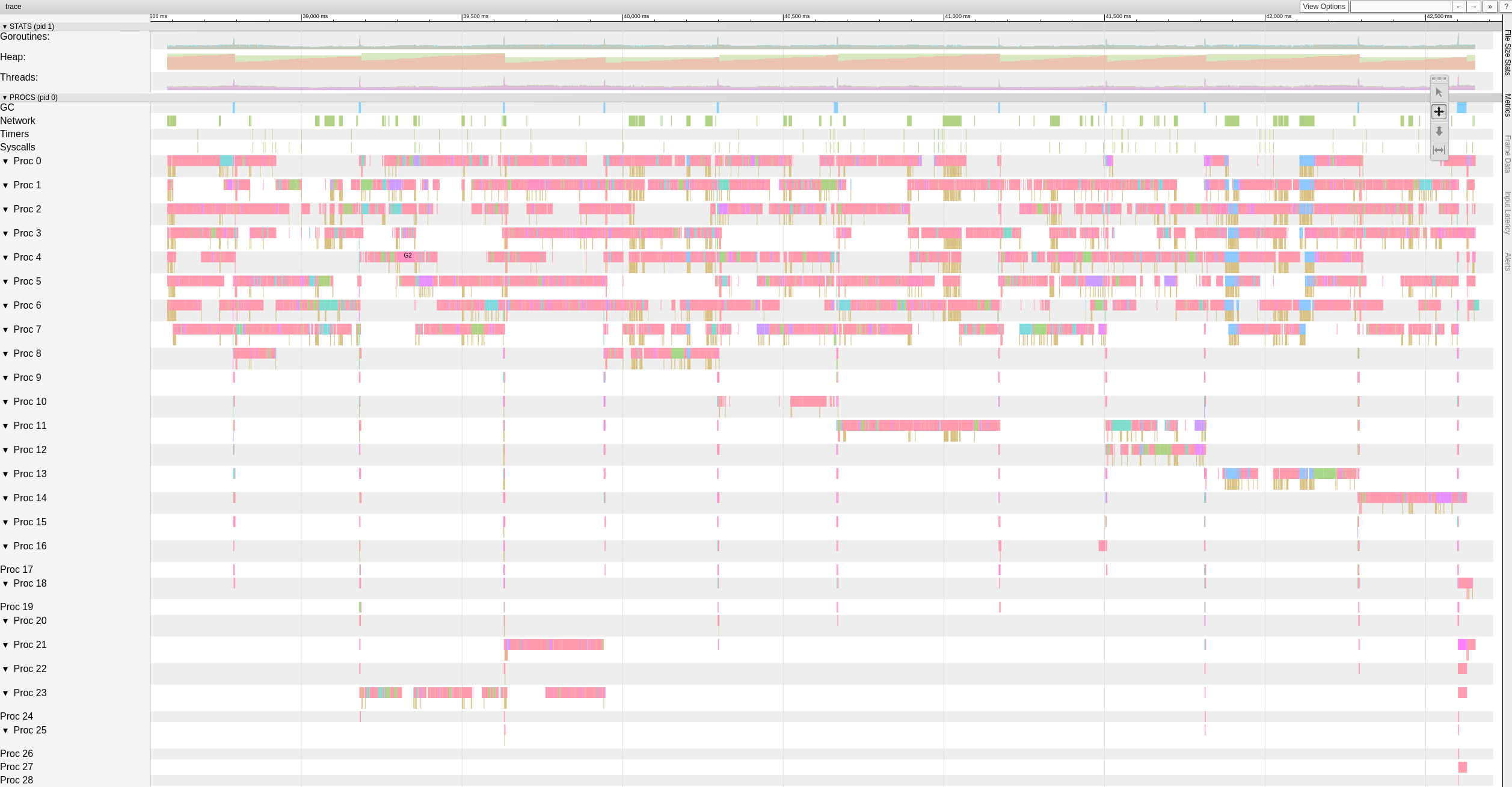
robvalca
le 27 févr. 2019
@robvalca donc ifedorenko@d410668 était nettement plus lent par rapport au chef de branche, non ? c'est une bonne nouvelle, cela signifie que nous avons probablement résolu tous les problèmes connus. Merci pour la mise à jour.
ifedorenko
le 27 févr. 2019
@ifedorenko non, j'ai oublié de préciser, la performance est plus ou moins la même que le chef d'agence (hors service) avec le même nombre d'ouvriers(8) et S3.connections(32). Les deux ont pris ~55m, ce qui correspond au temps de transfert du repo avec rclone (~47m)
Dites moi si vous voulez que je teste avec d'autres paramètres ;)
robvalca
le 27 févr. 2019
J'ai trouvé le déclencheur des problèmes de performances dans mon cas d'utilisation. Les performances de restauration des fichiers volumineux ne sont pas linéaires au-delà d'une certaine taille de fichier.
Pour tester, j'ai créé un nouveau référentiel dans S3, puis sauvegardé 6 fichiers contenant des données aléatoires dans le référentiel. Les fichiers avaient une taille de 1, 5, 10, 20, 40 et 80 Go.
Comme pour les tests précédents, les tests ont été exécutés sur des instances i3.8xlarge avec les sauvegardes et les restaurations effectuées sur un SSD rapide et agrégé.
Les temps de sauvegarde étaient linéaires, comme prévu (8, 25, 46, 92, 177 et 345 secondes).
Les temps de restauration, cependant, n'étaient pas :
1 Go, 5 s
5 Go, 17 s
10 Go, 33 secondes
20 Go, 85 s
40 Go, 256 s
80 Go, 807s
Il se passe donc quelque chose d'étrange avec les fichiers volumineux et les performances de restauration.
Le compartiment est nommé pmk-large-restic-test et le compartiment et son contenu sont publics. C'est dans us-west-1 et le mot de passe du dépôt restic est password
Les identifiants d'instantané des fichiers sont :
1 Go : 0154ae25
5 Go : 3013e883
10 Go : 7463efa8
20 Go : 292650c6
40 Go : 5acb4bee
80 Go : d1b7e323
Faites-moi savoir s'il y a plus de données que je peux fournir !
pmkane
le 27 févr. 2019
@pmkane pouvez - vous confirmer que vous avez utilisé le dernier chef de https://github.com/ifedorenko/restic/tree/out-order-restore branche (https://github.com/ifedorenko/restic/commit/ead78b375f2efed6de57c99b6766edbe9322e009 pour être précis) ?
ifedorenko
le 27 févr. 2019
Oui je l'ai fait. Désolé de ne pas le mentionner.
pmkane
le 27 févr. 2019
(utilisé 32 travailleurs et 32 connexions s3 sur toutes les exécutions avec ead78b3)
pmkane
le 27 févr. 2019
Savez-vous si je dois faire quelque chose de spécial pour accéder à ce compartiment ? Je n'ai jamais utilisé de buckets publics auparavant, donc je ne sais pas si je fais quelque chose de mal ou si l'utilisateur n'y a pas accès. (Je peux très bien accéder aux buckets de mon équipe, donc je sais que mon système peut accéder à s3 en général)
ifedorenko
le 27 févr. 2019
Hé @ifedorenko , accrochez-vous, laissez-moi aller dans un endroit sans privilège et essayez.
pmkane
le 27 févr. 2019
Désolé, j'avais appliqué une stratégie de compartiment public, mais je n'avais pas mis à jour les objets dans le compartiment lui-même. Vous devriez pouvoir y accéder maintenant. Notez que vous devrez utiliser --no-lock, car je n'ai accordé que des autorisations de lecture.
pmkane
le 27 févr. 2019
Ouais. Je peux accéder au dépôt maintenant. Je jouerai avec plus tard ce soir.
ifedorenko
le 27 févr. 2019
Et au cas où cela serait utile/plus facile à tester, nous constatons des caractéristiques de performances similaires lors de la restauration des mêmes fichiers vers/depuis un dépôt sur un SSD rapide, en retirant S3 de l'équation.
pmkane
le 28 févr. 2019
@pmkane Je peux reproduire le problème localement et je n'ai plus besoin d'accéder à ce seau. cela a été très utile, merci.
ifedorenko
le 28 févr. 2019
@ifedorenko , fantastique. Je vais supprimer le seau.
pmkane
le 28 févr. 2019
@pmkane, veuillez restauration hors commande lorsque vous en avez le temps. Je n'ai pas eu le temps de tester cela dans ec2, mais sur mon macbook, la restauration semble être limitée par la vitesse d'écriture du disque et correspond maintenant à rclone.
ifedorenko
le 1 mars 2019
@ifedorenko , cela semble très prometteur. Je lance un test maintenant.
pmkane
le 1 mars 2019
@ifedorenko , bingo.
Restauration de 133 Go de blobs représentant un mélange de tailles de fichiers, la plus grande étant de 78 Go, en un peu moins de 16 minutes. Auparavant, cette restauration aurait pris la plus grande partie d'une journée. Je soupçonne que nous pouvons obtenir cela encore plus rapidement en jouant avec le nombre de restoreWorkers, mais c'est très rapide en l'état.
Merci pour votre travail acharné à ce sujet !
pmkane
le 1 mars 2019
Et pour la postérité : nos performances de restauration doublent de 8->16 et à nouveau de 16->32 restaurateurs. 32->64 n'est bon que pour une bosse d'environ 50 % au-dessus de 32, auquel cas nous restaurons à environ 3 gbit/s. Presque à égalité avec rclone.
Je sais qu'il y a un désir de minimiser la quantité de configuration requise pour extraire les meilleures performances de restic, mais celui-ci est un saut assez important, en particulier pour les utilisateurs avec de grands ensembles de fichiers, qu'il serait bien de pouvoir spécifier le nombre de travailleurs à l'exécution.
pmkane
le 1 mars 2019
Je ne sais pas pourquoi la restauration ne peut toujours pas obtenir la pleine vitesse du fil. Il existe une vérification de hachage de blob redondante que vous pouvez commenter pour voir si elle est responsable.
ifedorenko
le 2 mars 2019
Je vais essayer.
pmkane
le 2 mars 2019
Salut à tous, j'ai effectué quelques tests en utilisant la dernière pull request #2195 et les performances continuent de s'améliorer !
(20k petits fichiers, 2x70G fichiers, 170G au total)
8w_32c
real 27m46.185s
user 24m31.290s
sys 3m55.153s
32w_32c
real 15m30.904s
user 24m1.982s
sys 4m55.128s
64w_32c
real 18m37.566s
user 23m33.684s
sys 5m3.024s
64w_64c
real 17m12.314s
user 23m44.318s
sys 4m43.090s
Pas sûr de la baisse des performances de 32w à 64w (testé plusieurs fois et semble légitime). Je joins quelques graphiques pendant le processus, il semble qu'il y ait une dégradation ou une limite, devrait être comme ça? Par exemple, avec 64 travailleurs, le processus démarre à 6 gbit/s, mais tombe ensuite à moins de 1 gbit/s jusqu'à la fin du processus (ce qui, je pense, correspond au temps de traitement de ces gros fichiers). La première capture d'écran est en 32w, 32c et la seconde en 64w, 32c.
Je suis également d'accord avec @pmkane , il serait utile de changer le numéro de travailleur à partir de la ligne de commande. Ce serait très utile pour les scénarios de reprise après sinistre lorsque vous souhaitez restaurer vos données le plus rapidement possible. Il y a une pull request à ce sujet par mon collègue #2178
Quoi qu'il en soit, je suis vraiment impressionné par les améliorations apportées! merci beaucoup @ifedorenko
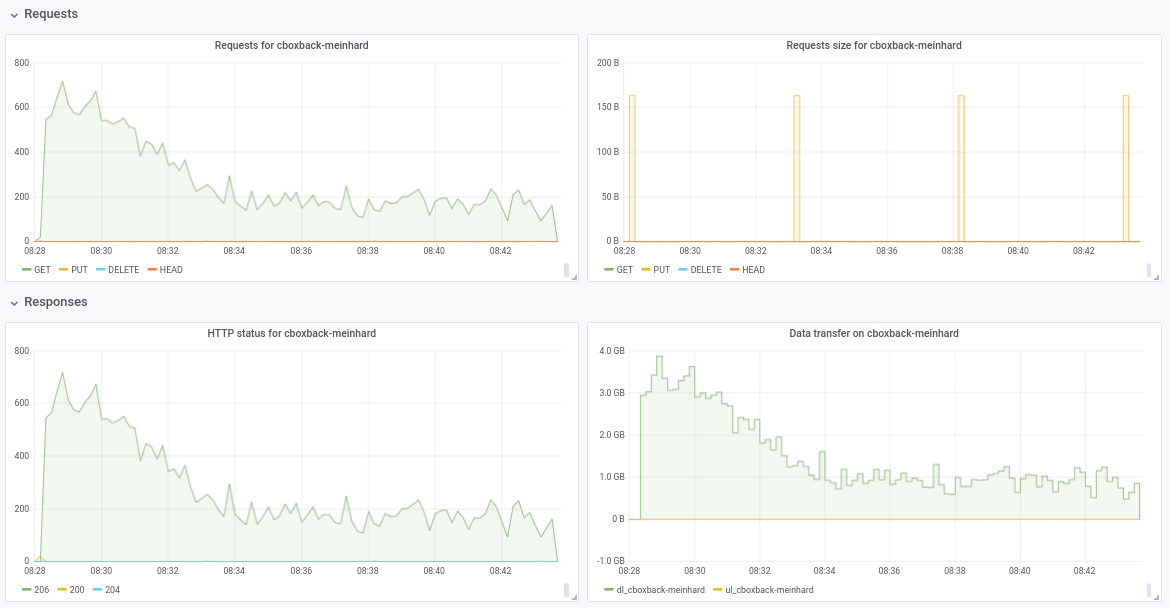
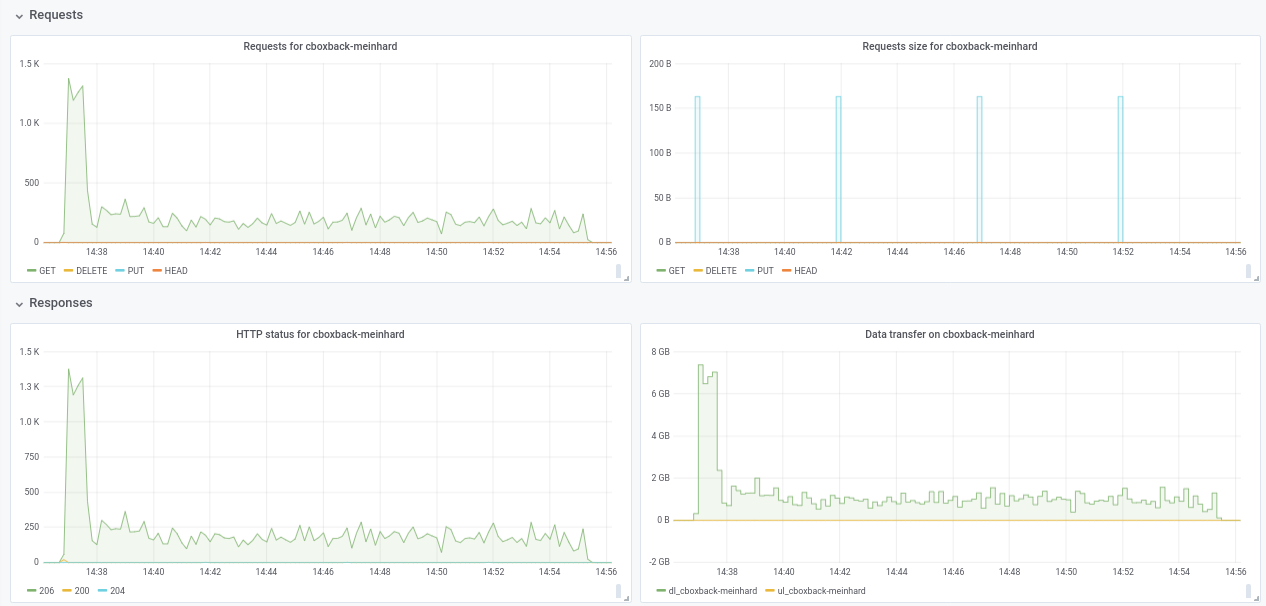
robvalca
le 4 mars 2019
++. Merci @ifedorenko , cela change la donne pour restic.
pmkane
le 4 mars 2019
Merci pour le rapport détaillé @robvalca. Avez-vous la possibilité de fournir un référentiel de test que je puisse soit dans AWS (ou GCP ou Azure) soit localement ? Je n'ai pas vu de chute de vitesse de restauration de fichiers volumineux lors de mes tests et j'aimerais comprendre ce qui s'y passe.
ifedorenko
le 4 mars 2019
@pmkane J'aimerais moi aussi configurer ces choses au moment de l'exécution . Ma suggestion était de leur faire des options --option afin qu'elles n'encombrent pas les indicateurs ou les commandes ordinaires, mais soient là pour les utilisateurs «avancés» qui souhaitent expérimenter ou s'adapter à leur situation inhabituelle. Ils n'ont même pas besoin d'être documentés et peuvent recevoir des noms qui indiquent clairement que vous ne pouvez pas compter sur eux, comme --option experimental.fooCount=32 .
 whereisaaron
le 4 mars 2019
whereisaaron
le 4 mars 2019
salut @ifedorenko , j'ai créé un s3.cern.ch/restic-testrepo . C'est plus ou moins la même forme que celle que j'essayais (beaucoup de petits fichiers et quelques très gros) et aussi j'ai pu reproduire le même comportement sur celui-ci (tracé ci-joint). Le mot de passe du dépôt est restic . Faites-moi savoir si vous rencontrez des difficultés pour y accéder.
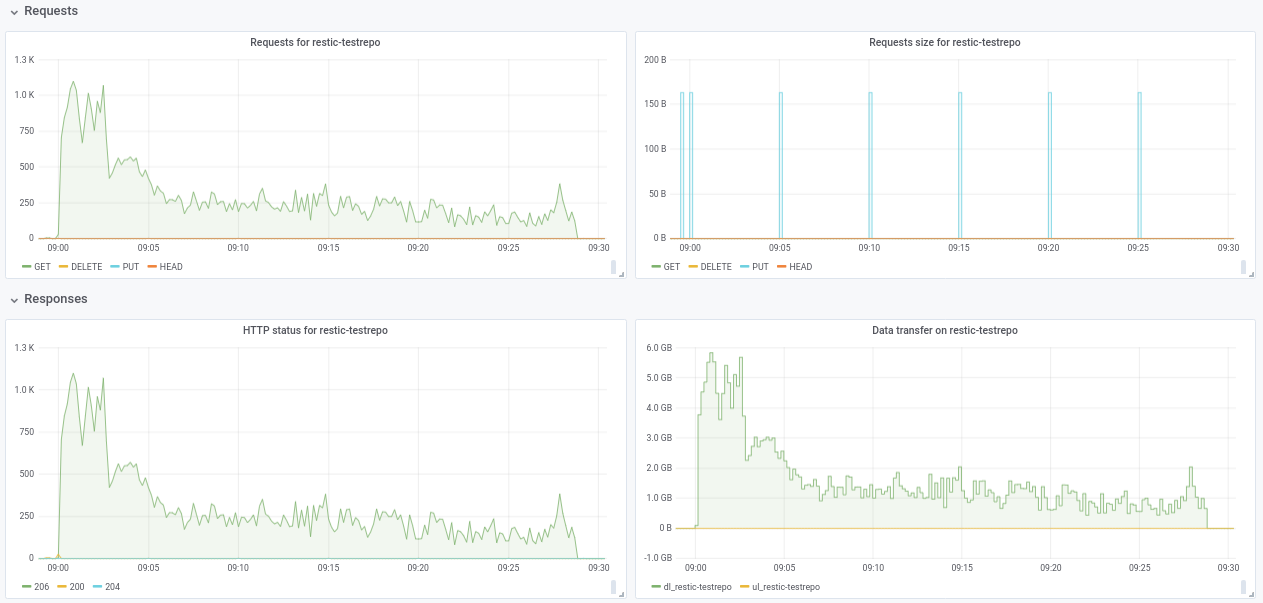
robvalca
le 5 mars 2019
@robvalca Je ne i3.4xlarge 2x nvme raid0 target), je vois une vitesse de restauration stable de 0,68 Go/s lors de l'utilisation de 32 travailleurs et 32 connexions (temps de restauration total 6m20s). Votre système cible ne peut pas supporter 10 Go/s pendant longtemps, si je devais deviner, c'est du moins ce que je vérifierais en premier si je devais résoudre ce problème davantage.
@pmkane fait intéressant, je ne peux pas non plus confirmer vos observations. Comme je l'ai mentionné ci-dessus, je vois une vitesse de restauration de 0,68 Go/s en utilisant la dernière branche out-of-order-restore-no-progress (la restauration semblait liée au processeur) et de 0,81 Go/s si je désactive la vérification de hachage de blob redondant (la restauration n'a pas l'air CPU- bondir). Je ne sais pas jusqu'à quel point un réseau "jusqu'à 10 Gbit/s" peut aller plus vite, mais je pense que nous sommes déjà sur le territoire des "rendements décroissants".
ifedorenko
le 6 mars 2019
@ifedorenko Je suis entièrement d'accord sur les rendements décroissants. C'est assez rapide pour nous comme ça.
pmkane
le 6 mars 2019
@ifedorenko intéressant, je vais enquêter à nos côtés. Quoi qu'il en soit, c'est assez rapide pour nous aussi, merci beaucoup pour vos efforts.
robvalca
le 7 mars 2019
Curieux de savoir où en est la fusion. Cette branche, combinée au travail de
pmkane
le 22 août 2019
Bientôt... 👀
 rawtaz
le 26 févr. 2020
rawtaz
le 26 févr. 2020
Fermeture maintenant que #2195 a été fusionné. N'hésitez pas à le rouvrir si les détails de ce problème n'ont pas été résolus. S'il reste des améliorations à apporter qui ne sont pas du type abordé dans ce numéro, veuillez ouvrir un nouveau numéro. Merci!
rawtaz
le 26 févr. 2020
Questions connexes
 ikarlo
·
4Commentaires
ikarlo
·
4Commentaires
 reallinfo
·
4Commentaires
reallinfo
·
4Commentaires
 McKael
·
4Commentaires
McKael
·
4Commentaires
 christian-vent
·
3Commentaires
christian-vent
·
3Commentaires
 cfbao
·
3Commentaires
cfbao
·
3Commentaires
Commentaire le plus utile
Curieux de savoir où en est la fusion. Cette branche, combinée au travail de