Restic: Восстановление может быть еще быстрее
Благодаря слиянию PR1719 восстановление в restic происходит _way_ быстрее.
Однако они могли быть еще быстрее.
В целях тестирования я восстановил из рестайлингового ведра AWS S3 в том же регионе (us-west-1), что и выделенный экземпляр i3.8xlarge EC2. Восстановление выполнялось против nvme 4x1,9 ТБ в экземпляре, чередующегося RAID-0 через LVM с файловой системой xfs под ним. Экземпляр имеет теоретическую пропускную способность 10 Гбит / с для S3.
Если workerCount в filerestorer.go увеличен до 32 (с установленного лимита в 8), restic восстанавливает смесь из 228 КБ файлов со средним размером файла 8 КБ и максимальным размером файла 364 ГБ в среднем 160 Мбит / с.
Для сравнения, rclone с --transfers = 32 перемещает данные из того же сегмента со скоростью 5636 Мбит / с, что более чем в 30 раз быстрее.
Это не сравнение яблок с яблоками. Большие двоичные объекты данных имеют размер 4096 КБ, а не 8 КБ, и открытие / закрытие файлов, безусловно, вызывает некоторые перегрузки. Но это все еще достаточно большая разница, которая, вероятно, указывает на узкое место в restic.
Я счастлив протестировать, предоставить инструменты или помочь другим способом!
 pmkane
pmkane
Все 71 Комментарий
160 Мбит / сек действительно выглядит медленным. Я приближался к 200 Мбит / с на маленьком MacBook Pro, загружающемся с onedrive через (предоставленное быстрое) соединение ftth 1 Гбит / с. Я не могу сказать ничего конкретного без доступа к вашим системам и репозиторию, но вот несколько вещей, которые я бы сделал, чтобы сузить проблему, в произвольном порядке:
- Оцените время, необходимое для загрузки файла одного пакета в одном потоке. Вы можете рассчитать это из своего теста загрузки rclone 32x, но мне также было бы любопытно узнать время загрузки отдельных пакетов с помощью curl, чтобы мы также могли оценить накладные расходы на HTTP-запрос.
- Я бы проверил статистику ОС, сколько restic фактически загружается с S3 во время восстановления. Это сообщит нам, загружает ли восстановление отдельные файлы пакетов несколько раз (что возможно, но не должно происходить очень часто, если я что-то не упустил).
- Уровень параллелизма S3, по-видимому, ограничен всего 5 подключениями . Может ли это объяснить скорость восстановления, которую вы видите при оценке однопоточной скорости сверху? Что произойдет, если вы увеличите лимит подключения к серверу S3 до уровня реставратора?
- Изучите использование сети во время восстановления, чтобы увидеть, есть ли какие-либо пробелы или замедления.
- Исключите файл размером 364 ГБ из восстановления и посмотрите, что произойдет. В настоящее время отдельные файлы восстанавливаются последовательно, поэтому этот один файл может значительно повлиять на среднюю скорость загрузки.
 ifedorenko
7 нояб. 2018
ifedorenko
7 нояб. 2018
Всем привет!
Спасибо за ответ. Было интересно вникнуть
tl; dr: увеличение количества подключений s3 - это ключ, но, как ни странно, повышение производительности, которое оно обеспечивает, носит временный характер.
- Передача пакетов одного каталога (3062 файла общим объемом 13 ГБ) / с помощью rclone --transfers 1 выполняется со скоростью 233 Мбит / с. Подтверждено с помощью lsof, что он работает только с одним потоком и одним https-соединением в этом режиме. Пиковая скорость достигается с помощью --transfers 32 (8,5 Гбит / с, по существу линейная скорость для этого экземпляра i3.8xlarge ec2). В обоих случаях мы выполняем запись в полосатый массив nvme.
- Рад собрать некоторую статистику, но что бы вы хотели увидеть конкретно? (но может не потребоваться, см. ниже)
- Собираюсь убить двух зайцев здесь! Вот график использования сети во время восстановления с:
- сток остаток с этим PR объединен (commit c0572ca15f946c622d9c4009347dc4d6c31cba4c)
- restic с workerCount увеличен до 32, а filesWriterCount увеличен до 128
- restic с предыдущими изменениями + соединения s3 увеличились до 32.
- resitc с предыдущими изменениями + количество подключений s3 увеличилось до 64.
- rclone с --transfers 32 для перемещения каталога data /
Пропускная способность указывается в кбит / с с интервалом в 3 секунды в течение 10 минут. Для выполнения restic мы начали сбор данных, _after_ restic уже начал фактически восстанавливать файлы (т. Е. Не включает время запуска и время, которое restic тратит в начале цикла на воссоздание иерархии каталогов. Во время всех запусков загрузка ЦП на экземпляр не превышал 25%.
Мы получаем небольшой толчок от увеличения workerCount, но параллелизм S3 выглядит как реальная победа. Но в то время как он начинается хорошо (иногда приближаясь к скорости rclone!), Ставки резко падают и остаются на низком уровне до конца пробега. restic также выдает ошибки, которые выглядят как «ошибка игнорирования для [путь отредактирован]: недостаточно емкости кэша: запрошено 2148380, доступно 872640», которые он не генерирует при более низком параллелизме s3.
Как видите, производительность rclone начинается с высокой и остается высокой, поэтому это не та ситуация, когда записи идут в буферный кеш экземпляра, а затем останавливаются, когда они сбрасываются на диск. Массив nvme быстрее, чем сетевой канал, с точки зрения пропускной способности.
- Я не думаю, что один большой файл является важным фактором, поскольку я измеряю дисковый / сетевой ввод-вывод во время восстановления, поэтому тот факт, что для полного восстановления этого единственного файла может потребоваться время, не повлияет на цифры, которые мы Смотрим сюда.
Учитывая вышеизложенное, похоже, что увеличение параллелизма S3 - это то, что потребуется для получения здесь разумных показателей, но необходимо выяснить, почему падает производительность (и связано ли это с ошибками кеша или нет).
Если создание быстрого экземпляра i3 и некоторого пространства s3 и пропускной способности, доступных для вашего тестирования, было бы полезно, дайте мне знать, я буду счастлив спонсировать это.
pmkane
7 нояб. 2018
233 Мбит / с, умноженные на 32, составляют 7456 и немного меньше 8,5 Гбит / с. Что странно. Я ожидал, что однопоточная загрузка будет быстрее, чем потоковая загрузка многопоточной. Однако не уверен, что это означает, во всяком случае.
Я хотел убедиться, что restic не загружает одни и те же пакеты снова и снова. Я думаю, что график показывает, что повторные загрузки - это не проблема, поэтому нет необходимости в дополнительной статистике, по крайней мере, сейчас.
Вы можете подтвердить масштаб графика? rclone парит вокруг строки с пометкой «1000000», если это «1000000 кбит / с», что, я думаю, означает «1 гбит / с» и не совпадает с числом «8,5 гбит / с», которое вы упомянули ранее.
Как я уже сказал, отдельные файлы восстанавливаются последовательно. Загрузка 364 ГБ со скоростью 233 Мбит / с займет около 3,5 часов и, вероятно, больше из-за накладных расходов на пакет и дешифрования, которые происходят последовательно. Не могу сказать, можно ли отбросить 3,5 часа как незначительные, не зная, сколько времени займет остальная часть восстановления.
Что касается ошибки not enough cache capacity , увеличьте среднийPackSize до размера самого большого файла пакета в вашем репозитории (насколько он большой, кстати?) И мне нужно подумать, как лучше изменить размер кеша, у меня нет готового ответа пока нет.
ifedorenko
7 нояб. 2018
Всем привет!
Упс, мне очень жаль. Масштаб на графике - КБ / сек, а не кбит / сек. Итак, 1 012 995 в первой строке составляет 8,1 Гбит / с.
Я понимал, что файлы восстанавливаются последовательно, но не понимал, что нет параллелизма при извлечении пакетов для одного файла. Это определенно является камнем преткновения для резервного копирования с большими файлами, поскольку это становится вашим ограничивающим фактором. По этой причине было бы замечательно иметь здесь некоторый параллелизм.
При выборке 10 случайных сегментов максимальный размер нашего пакета составляет чуть менее 12 МБ, а средний размер пакета составляет 4,3 МБ.
Возможно, с большим количеством рабочих и подключений S3 мы превышаем packCacheCapacity (workerCount + 5) * averagePackSize. Я попробую увеличить это и посмотрю, исчезнут ли ошибки.
pmkane
7 нояб. 2018
Возможно, с большим количеством рабочих и подключений S3 мы превышаем packCacheCapacity (workerCount + 5) * averagePackSize. Я попробую увеличить это и посмотрю, исчезнут ли ошибки.
Размер кеша рассчитывается на основе размера файла пакета 5 МБ и workerCount . Увеличение workerCount увеличивает размер кеша. Таким образом, либо есть утечка памяти, либо при восстановлении необходимо кэшировать много файлов размером 12 МБ по чистой случайности. Увеличение averagePackSize до 12 МБ должно сказать нам, какой.
ifedorenko
7 нояб. 2018
Ошибок кеширования нет, если для параметра averagePackSize установлено значение 12.
Если есть какая-либо другая информация, которую мы можем предоставить, которая была бы полезна, дайте мне знать! Спасибо еще раз.
pmkane
8 нояб. 2018
Похоже, что мы теряем параллелизм по мере восстановления, и это не похоже на большие файлы. Я соберу тестовый пример и отчитаюсь.
pmkane
8 нояб. 2018
Всем привет!
Я попытался воспроизвести падение производительности, которое я наблюдал с моей производственной файловой смесью с тремя различными искусственными смесями файлов.
Для всех тестов я использовал c0572ca15f946c622d9c4009347dc4d6c31cba4c с увеличением количества подключений S3 до 128, workerCount до 128, filesWriterCount увеличился до 128, а среднийPackSize увеличился до 12 * 1024 * 1024.
Во всех тестах использовались файлы со случайными данными, чтобы избежать каких-либо последствий от дедупликации.
Для первого теста я создал и зарезервировал 4000 файлов по 100 МБ, равномерно распределенных по 100 каталогам (всего ~ 400 ГБ). Резервное копирование и восстановление выполнялись с чередующихся томов nvme на экземпляре i3.8xlarge. Резервная корзина находилась в том же регионе, что и экземпляр (us-west-1).
С этим набором файлов я получил среднюю скорость 9,7 Гбит / с (!) Без потери параллелизма или скорости при полном восстановлении. Эти числа совпадают с числами rclone или превышают их и, по сути, являются линейной скоростью, что фантастически.
Затем я создал и зарезервировал 400 000 файлов размером 1 МБ, равномерно распределенных по 100 каталогам (опять же, всего ~ 400 ГБ).
Те же (отличные) результаты, что и выше.
Наконец, я создал 40 каталогов с 1 файлом размером 10 ГБ на каталог. Здесь все стало интересно.
Я ожидал, что это восстановление будет немного медленнее, поскольку restic сможет выполнить только 40 одновременных восстановлений с 40 подключениями к S3.
Однако вместо этого, хотя Restic открывает все 40 файлов для записи и записывает все 40 файлов одновременно, он поддерживает только одно TCP-соединение с S3 за раз, а не 40.
Дайте мне знать, какую статистику или инструменты вы хотите увидеть.
pmkane
8 нояб. 2018
Можете ли вы подтвердить, что во время «быстрых» тестов было 128 подключений S3?
ifedorenko
8 нояб. 2018
Да там были.
pmkane
8 нояб. 2018
Любопытно ... Честно говоря, поддержка больших файлов не входит в число моих приоритетов, но, возможно, я найду время, чтобы взглянуть на это в ближайшие несколько недель. Если кто-то захочет разобраться в этом раньше, чем я, пожалуйста, дайте мне знать.
ifedorenko
8 нояб. 2018
Провел еще несколько тестов, и на самом деле похоже, что размер файла - отвлекающий маневр, именно количество файлов определяет количество подключений AWS.
Имея 128 файлов размером 10 МБ в 4 каталогах, restic открывает только 6 подключений к AWS, даже если он записывает все 128 файлов.
С 512 файлами по 10 МБ в 4 каталогах restic открывает 18 подключений за время своего существования, даже если одновременно открыто 128 файлов.
Имея 5120 файлов размером 10 МБ в 4 каталогах, restic открывает только 75 подключений к AWS за время своего существования, снова открывая 128 файлов одновременно.
Странный!
pmkane
8 нояб. 2018
Я был бы очень удивлен, если бы клиент Go S3 не объединял и не повторно использовал HTTP-соединения. Скорее всего, нет однозначной корреляции между количеством одновременно работающих рабочих и открытых сокетов TCP. Так, например, если восстановление - это медленная обработка загруженных пакетов по какой-либо причине, одно и то же соединение S3 будет совместно использоваться несколькими рабочими.
ifedorenko
8 нояб. 2018
Существуют два свойства текущего параллельного восстановителя, которые несут основную часть сложности реализации и, скорее всего, вызывают замедление, о котором здесь говорится:
- отдельные файлы восстанавливаются от начала до конца
- количество незавершенных файлов сведено к минимуму
Реализация будет намного проще, потребует меньше памяти и, скорее всего, будет быстрее во многих случаях, если мы согласимся записывать файловые BLOB-объекты в любом порядке и разрешить любое количество незавершенных файлов.
Обратной стороной является то, что невозможно определить, сколько данных уже было восстановлено в каком-либо конкретном файле до конца восстановления. Что может сбивать с толку, особенно если восстановление дает сбой или его убивают. Таким образом, вы можете увидеть файл размером 10 ГБ в файловой системе, который на самом деле имеет всего несколько байтов, записанных в конец файла.
@ fd0 как вы думаете, стоит ли улучшить текущее восстановление от начала до конца? Лично я готов признать, что с моей стороны это было слишком сложно, и если вы согласитесь, могу предложить более простую реализацию вне очереди.
ifedorenko
16 нояб. 2018
Я не помню, поддерживает ли Restic восстановление на стандартный вывод. Если это так, вам, очевидно, нужно сохранить для него восстановление от начала до конца (возможно, в качестве особого случая).
 pvgoran
16 нояб. 2018
pvgoran
16 нояб. 2018
@ifedorenko Я лично сторонник упрощения в целом, особенно если это
Обратной стороной является то, что невозможно определить, сколько данных уже было восстановлено в каком-либо конкретном файле до конца восстановления.
Если мы не говорим здесь о тысячах одновременно записываемых файлов, может быть, можно было бы использовать сопоставление имени файла с записанными байтами? Очевидно, что информация не станет доступной для файловой системы, но для отчета о ходе работы все еще можно сделать, не так ли? (И чтобы возобновить восстановление, которое было прервано, возможно, просто проверяя капли и смещения файла на ненулевые байты, возможно? Я не знаю.)
Я не помню, поддерживает ли Restic восстановление на стандартный вывод. Если это так, вам, очевидно, нужно сохранить для него восстановление от начала до конца (возможно, в качестве особого случая).
Я не думаю, что это так - не уверен, как это все равно будет работать, поскольку восстановление - это несколько файлов, вам нужно как-то их закодировать и как-то разделить, я думаю.
 mholt
16 нояб. 2018
mholt
16 нояб. 2018
Если мы не говорим здесь о тысячах одновременно записываемых файлов, может быть, можно было бы использовать сопоставление имени файла с записанными байтами?
Самая простая реализация - открывать и закрывать файлы для записи отдельных больших двоичных объектов. Если это окажется слишком медленным, то нам придется найти способ сохранить файлы открытыми для записи нескольких больших двоичных объектов, например, путем кэширования дескрипторов открытых файлов и упорядочивания загрузки пакетов в пользу уже открытых файлов.
Restore уже отслеживает, какие капли были записаны в какие файлы, а какие еще не обработаны. Я не ожидаю, что эта часть сильно изменится. Прогресс отслеживается в отдельной структуре данных, и я не ожидаю, что это изменится.
И чтобы возобновить восстановление, которое было прервано, возможно, просто проверив капли и смещения файла на ненулевые байты, возможно?
Resume необходимо проверить контрольные суммы файлов на диске, чтобы решить, какие капли еще нужно восстановить. Я считаю, что это верно независимо от того, идет ли восстановление последовательно или не по порядку. Например, если возобновление восстанавливается после сбоя питания, я не думаю, что можно предположить, что все файловые блоки были сброшены на диски до отключения питания, то есть файлы могут иметь пропуски или частично записанные блоки.
ifedorenko
16 нояб. 2018
@pmkane интересно, можно ли попробовать # 2101? в нем реализовано неупорядоченное восстановление, хотя запись в отдельные файлы по-прежнему сериализуется, и производительность восстановления больших файлов может быть неоптимальной. и вам нужно настроить количество рабочих, как и раньше.
ifedorenko
27 нояб. 2018
Абсолютно. На этой неделе я путешествую, но протестирую, как только смогу, и доложу.
pmkane
27 нояб. 2018
@ifedorenko Я пробовал этот PR, и он успешно создает структуру каталогов, но затем все восстановление файлов завершается неудачно с такими ошибками, как:
Нагрузка(, 3172070, 0) вернул ошибку, повторная попытка через 12.182749645 с: EOF
мастер восстанавливает нормально.
Моя команда восстановления:
/usr/local/bin/restic.outoforder -r s3: s3.amazonaws.com/ [отредактировано] -p /root/.restic_pass restore [snapshotid] -t.
Сообщите мне, какую дополнительную информацию я могу предоставить для отладки.
pmkane
1 дек. 2018
Сколько одновременных запросов на загрузку S3 вы разрешаете? Если это 128, можете ли вы ограничить его до 32 (что, как мы знаем, работает)?
Наполовину связанные ... знаете ли вы, сколько индексных файлов есть в вашем реальном репозитории? Пытаюсь прикинуть, сколько нужно восстановителю памяти.
ifedorenko
1 дек. 2018
Я не указывал ограничение на количество подключений, поэтому предполагаю, что по умолчанию он был равен 5.
Я получаю те же ошибки с -o s3.connections = 2 и -o s3.connections = 1.
В настоящее время у меня в папке index / 85 индексных блобов. Их общий размер составляет 745 МБ.
pmkane
1 дек. 2018
Хм. Я еще раз посмотрю, когда подойду к компьютеру сегодня же. Кстати, «возвращенная ошибка, повторная попытка» - это предупреждение, а не ошибка, поэтому это может быть связано с ошибкой восстановления или может быть просто отвлекающим маневром.
ifedorenko
1 дек. 2018
Не уверен, как я это пропустил ... в большинстве случаев реставратор не полностью считывал все файлы пакета из бэкэнда. Должен быть исправлен сейчас. @pmkane, можешь попробовать еще раз?
ifedorenko
2 дек. 2018
Я закружу!
pmkane
2 дек. 2018
Подтверждено, что файлы успешно восстанавливаются с помощью этого исправления. Сейчас тестирую производительность.
pmkane
2 дек. 2018
К сожалению, похоже, что он медленнее, чем мастер. Все тесты выполняются на экземпляре i3.8xlarge, описанном выше.
С workerCount, равным 8 (по умолчанию), выход из строя восстанавливается со скоростью 86 Мбит / с.
Когда workerCount был увеличен до 32, он показал себя немного лучше - в среднем 160 Мбит / с.
Загрузка ЦП в этой ветви значительно выше, чем в главной, но в любом случае она не исчерпывает возможности ЦП экземпляра.
Как ни странно, пользовательский интерфейс восстановления создает впечатление, что что-то «застревает», почти как будто оно конкурирует с самим собой за блокировку.
Рад предоставить более подробную информацию, профилирование или тестовый экземпляр для репликации.
pmkane
2 дек. 2018
Просто для подтверждения, у вас было установлено 32 подсчетов и реставратора, и бэкэнда s3, не так ли?
Пара мыслей, которые могут объяснить наблюдаемое вами поведение:
- Записи в отдельные файлы по-прежнему сериализуются. Я _ предполагал_, что это не будет проблемой с быстрыми целевыми файловыми системами, но никогда не измерял это.
- Открытие / закрытие файла вокруг каждого большого двоичного объекта, безусловно, увеличивает накладные расходы восстановителя. Когда я измерил это на macos, я смог «открыть файл; записать один байт; закрыть файл» 100 тыс. Раз за ~ 70 секунд, что приблизительно соответствует накладным расходам на запись 100 тыс. Блобов. Тест был действительно простым, а реальные накладные расходы могут быть значительно выше.
- В настоящее время у меня нет убедительного объяснения высокой загрузки ЦП. Реализация вне очереди расшифровывает каждый большой двоичный объект только один раз (мастер расшифровывает большие двоичные объекты для каждого целевого файла), и по сравнению с мастером ведение бухгалтерского учета намного меньше. Может быть, "разреженные" записи в файлы на самом деле не редкие и требуют, чтобы Go или ОС выполняли что-то, что сильно нагружает процессор. На самом деле не знаю.
ifedorenko
2 дек. 2018
Привет!
Верно. workerCount был установлен на 8 или 32 в файле internal / restorer / filerestorer.go, а -o s3.connections = 32 передавалось через restic cli в обоих случаях.
pmkane
3 дек. 2018
Вот общий вид данных трассировки, в то время как ветвь вне очереди восстанавливает файлы с 8 рабочими.
Похоже, что есть значительные (> 500-1000 мс) паузы, в которые рабочие часто попадают.
pmkane
3 дек. 2018
Я решил потратить на это еще немного времени и начал с написания простого автономного теста, который генерирует случайные байты 10 ГБ в блоках по 4 КиБ. Моей целью было оценить, насколько быстро моя система может перемещать байты. К моему большому удивлению, выполнение этого теста на моем MacBook Pro (2018 г., Intel Core i7 с тактовой частотой 2,6 ГГц) заняло 18,64 секунды. Это составляет ~ 4,29 Гбит / с или примерно половину того, что может сделать Ethernet 10G. И это без каких-либо криптографических, сетевых или дисковых операций ввода-вывода. И я использовал Xoshiro256 ** prng, math/rand был примерно в 2 раза медленнее, что, конечно, совершенно не относится к делу. Дело в том, что восстановитель должен обрабатывать капли в нескольких потоках, чтобы насыщать сеть 10G, многопоточного сетевого ввода-вывода недостаточно.
И просто для удовольствия, сопоставимый rust impl генерирует 10 ГБ случайных байтов за 3,1 секунды, а java за 10,77 секунды. Иди разберись :-)
ifedorenko
6 февр. 2019
Интересный тест!
Я понимаю, что скорость восстановления будет ограничена временем, необходимым для восстановления самого большого файла на данный момент.
Однако сейчас это не наш блокировщик, поскольку я знаю, что restic может восстановить один файл намного быстрее, чем 160 Мбит / с, которые мы видим здесь.
Я соберу тестовое репозиторий на 100 ГБ, состоящий из файлов размером 10 МБ на быстром SSD и в S3, и провожу несколько чисел, чтобы получить текущий лучший сценарий в главном и в этой ветке.
pmkane
6 февр. 2019
Привет всем, есть ли способ изменить количество рабочих с помощью параметра или это нужно делать прямо в коде? У нас также есть проблема медленного восстановления, и я хотел бы как-то улучшить то, что у нас есть ... Пожалуйста, дайте мне знать, могу ли я внести свой вклад с помощью тестов, чтобы помочь улучшить эту часть!
Спасибо!
 robvalca
19 февр. 2019
robvalca
19 февр. 2019
@robvalca какой бэкэнд вы используете? как быстро rclone копирует ваше репо в целевую систему? что такое скорость восстановления рестика?
Прямо сейчас я не уверен, что происходит, поэтому было бы действительно полезно, если бы вы могли предоставить тестовое репо и шаги, которые я мог бы использовать для локального воспроизведения проблемы (и под «тестовым репо» я имею в виду ненужные / случайные данные, не частные данные пожалуйста).
ifedorenko
22 февр. 2019
@ifedorenko мы используем S3 (ceph + radosgw) в качестве бэкэнда (управляемый нами). Я попытался скопировать репо с помощью rclone, и вот результаты:
rclone copy -P удаленный: cboxback-aabbcc / / var / tmp / restic / aabbcc /
Передано: 127,309 ГБ / 127,309 ГБ, 100%, 45,419 МБ / с, ETA 0 с
Ошибок: 0
Проверки: 0/0, -
Передано: 25435/25435, 100%
Затраченное время: 47 мин. 50,2 с
Восстановление репо с использованием "стокового" restic 0.9.4 заняло ~ 8 часов. В обоих случаях я использую 32 соединения S3 и один и тот же целевой хост. Я положил немного информации больше в этом форуме теме .
Я подготовлю репо для тестирования и сообщу, когда будет готов,
Большое спасибо за вашу помощь!
robvalca
25 февр. 2019
@robvalca, можешь попробовать восстановить с помощью моей восстановления ? ветка должна улучшить производительность восстановления очень больших файлов, с чем, похоже, вы столкнулись.
если ветка не улучшает для вас производительность восстановления, загрузите тестовое репо в публичную корзину s3 и разместите здесь имя корзины и пароль репо.
ifedorenko
26 февр. 2019
@pmkane можно ли восстановить большое количество идентичных или почти идентичных файлов? я думаю, это объяснило бы раздоры среди рабочих.
Изменить: на самом деле, можете ли вы повторить тест восстановления производительности, используя последнюю версию # 2101? Теперь он должен лучше обрабатывать одновременные записи в один и тот же файл и один и тот же большой двоичный объект в несколько файлов.
ifedorenko
26 февр. 2019
@ifedorenko действительно, с
- В обычном режиме покоя
0.9.4процесс запускается быстрее, с пиками200MB/secи мы получаем почти50 requestsв секунду на стороне S3. Спустя всего пару минут происходит деградация, и количество запросов снижается до 1 или около того, а скорость ~5MB/secв течение остальной части процесса. - В версии "ooo" скорость передачи примерно равна
40MB/secи ~8S3 запросов стабильно в течение всего процесса. - Еще я заметил, что я почти не вижу улучшений в увеличении количества подключений S3, это ожидается?
32 соединения:
Created 2197 directories, listed 171.141 GiB in 20930 files
Restored 171.136 GiB in 170258 files
real 57m54.588s
user 229m25.229s
sys 6m51.763s
64 контакта
real 53m13.876s
user 242m57.081s
sys 7m12.455s
- Наконец, провел тест с другим другим репозиторием (51 ГБ, 1,3 млн небольших файлов, много дубликатов), и он все еще быстрее, чем 0,9.4, с хорошим отрывом:
0.9.4
real 16m6.966s
user 25m4.116s
sys 4m19.424s
0.9.4-ооо:
real 8m14.375s
user 14m30.107s
sys 3m41.538s
Так что это не только улучшает работу с большими файлами, но и улучшает все случаи !!
И, кстати, новый просмотр прогресса восстановления хорош !! 8)
Дайте мне знать, если вы хотите, чтобы я провел еще несколько тестов.
Спасибо!
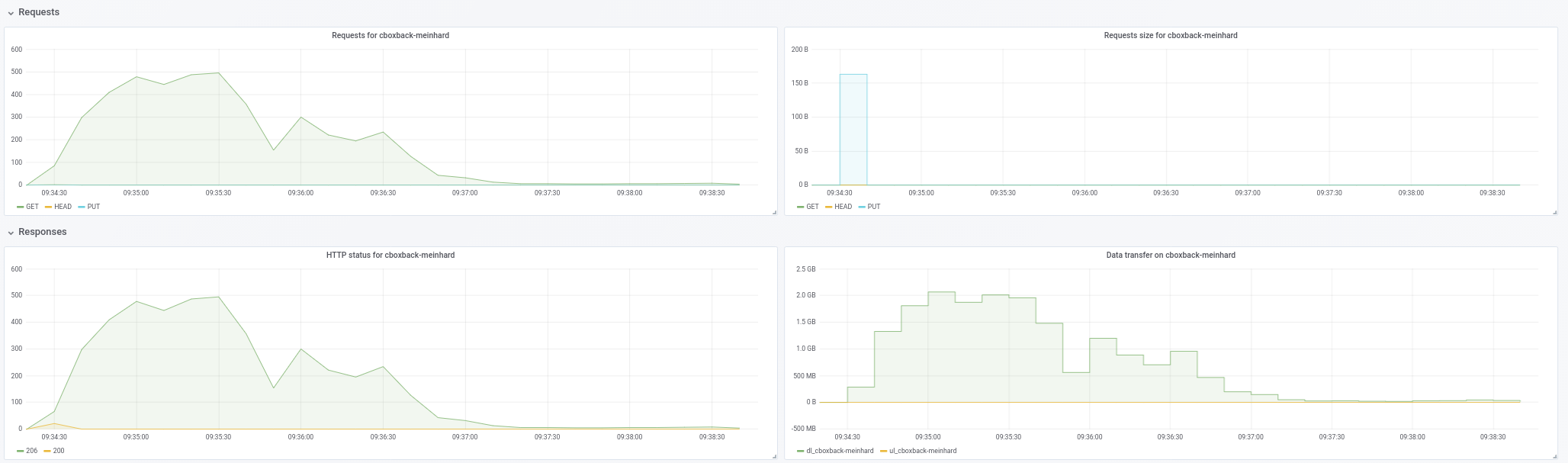
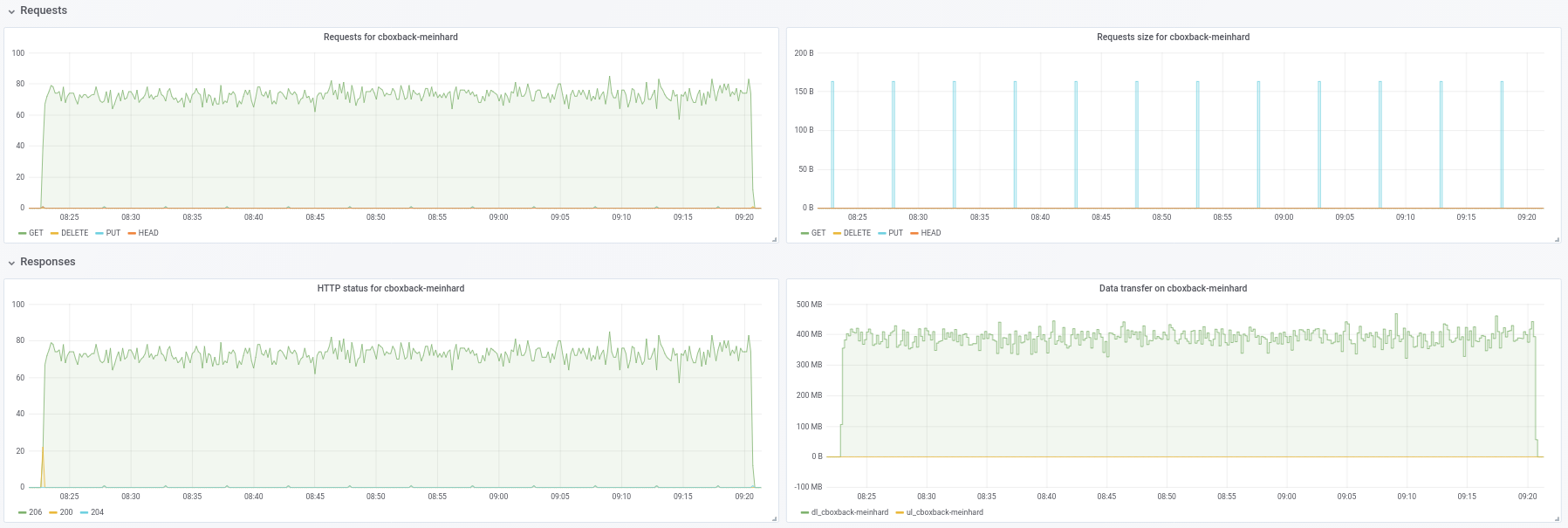
robvalca
26 февр. 2019
Спасибо за отзыв, @robvalca , это очень полезно.
- Еще я заметил, что я почти не вижу улучшений в увеличении количества подключений S3, это ожидается?
Извините, забыл упомянуть, что вам нужно изменить код, чтобы увеличить количество одновременных рабочих восстановления. На данный момент он жестко запрограммирован на 8:
https://github.com/ifedorenko/restic/blob/099f51c01c189a84b96be86ce6be61a45e3705fc/internal/restorer/filerestorer.go#L22
Дайте мне знать, если вы хотите, чтобы я провел еще несколько тестов.
Мы до сих пор не знаем, что вызывает явную конкуренцию рабочих во время восстановления вне очереди, упомянутого ранее в этом выпуске https://github.com/restic/restic/issues/2074#issuecomment -443759511. Можете ли вы протестировать эту конкретную фиксацию
https://github.com/ifedorenko/restic/commit/d410668ce3a8c7284d86a2b06bf42a0e654d43bc? Если вы наблюдаете конфликт с вашими репозиториями, это будет означать, что он не относится к данным pmkane и что мои недавние изменения устраняют конфликт.
Еще раз спасибо за вашу помощь.
ifedorenko
26 февр. 2019
Привет всем - все еще отслеживают это, но были абсолютно завалены. Я догоню в эти выходные и посмотрю, сможем ли мы воспроизвести с
pmkane
26 февр. 2019
@ifedorenko Спасибо, с 32 рабочими процесс намного быстрее, до 30 минут, что является отличным результатом. Я также пробовал увеличить количество рабочих / s3.connections до 64/64, 128/128, но я не вижу улучшений, получая почти те же результаты. В любом случае, я доволен текущими результатами.
Я пробовал также версию с https://github.com/ifedorenko/restic/commit/d410668, которую вы мне указали, и вот скриншот трассировки. У меня нет большого опыта работы с такими инструментами, но похоже на результаты @pmkane . Я запустил его с 8 воркерами и с -o s3.connections=32
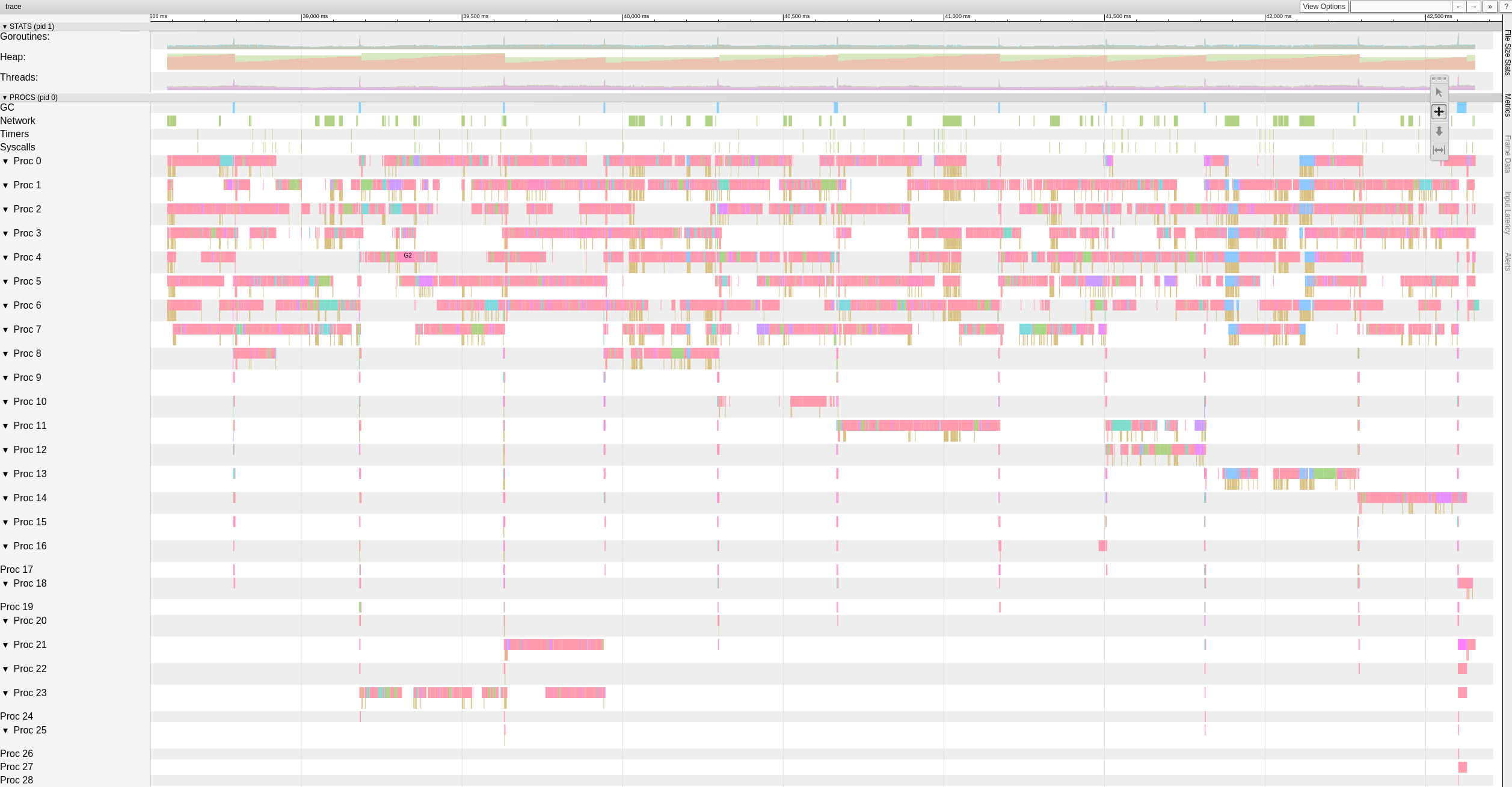
robvalca
27 февр. 2019
@robvalca, итак ifedorenko @ d410668 был значительно медленнее по сравнению с главой филиала, верно? это хорошая новость, значит, мы, вероятно, решили все известные проблемы. Спасибо за обновление.
ifedorenko
27 февр. 2019
@ifedorenko нет, забыл упомянуть, производительность более-менее такая же, как у главы ветки (вне очереди) с тем же количеством рабочих (8) и S3.connections (32). Оба заняли ~ 55 минут, что соответствует времени передачи репо с помощью rclone (~ 47 минут).
Дайте мне знать, если вы хотите, чтобы я протестировал с другими параметрами;)
robvalca
27 февр. 2019
Я обнаружил причину проблем с производительностью в моем варианте использования. Производительность восстановления для больших файлов нелинейна за пределами определенного размера файла.
Для тестирования я создал новое репо в S3, а затем скопировал в репо 6 файлов, содержащих случайные данные. Файлы имели размер 1, 5, 10, 20, 40 и 80 ГБ.
Как и в предыдущих тестах, тесты проводились на инстансах i3.8xlarge с резервным копированием и восстановлением на быстрых твердотельных накопителях с полосой пропускания.
Время резервного копирования, как и ожидалось, было линейным (8, 25, 46, 92, 177 и 345 секунд).
Однако время восстановления не было:
1 гб, 5 с
5гб, 17с
10гб, 33с
20гб, 85с
40 ГБ, 256 с
80гб, 807с
Так что с большими файлами и восстановлением производительности происходит что-то странное.
Корзина называется pmk-large-restic-test, и она и ее содержимое являются общедоступными. Он находится в us-west-1, а пароль для restic repo - пароль
Идентификаторы снимков для файлов:
1 гб: 0154ae25
5 гб: 3013e883
10 ГБ: 7463efa8
20 ГБ: 292650c6
40 ГБ: 5acb4bee
80 гб: d1b7e323
Дайте мне знать, если я могу предоставить больше данных!
pmkane
27 февр. 2019
@pmkane вы можете подтвердить , что вы использовали последнюю главу https://github.com/ifedorenko/restic/tree/out-order-restore филиала (https://github.com/ifedorenko/restic/commit/ead78b375f2efed6de57c99b6766edbe9322e009 быть конкретным) ?
ifedorenko
27 февр. 2019
Да. Извините, что не упомянул об этом.
pmkane
27 февр. 2019
(использовалось 32 рабочих и 32 s3-соединения для всех прогонов с ead78b3)
pmkane
27 февр. 2019
Вы знаете, нужно ли мне делать что-то особенное, чтобы получить доступ к этому ведру? Я никогда раньше не использовал публичные корзины, поэтому не уверен, что делаю что-то не так или у пользователя нет доступа. (Я могу получить доступ к корзинам моей команды очень хорошо, поэтому я знаю, что моя система может получить доступ к s3 в целом)
ifedorenko
27 февр. 2019
Эй, @ifedorenko ,
pmkane
27 февр. 2019
К сожалению, я применил политику общедоступной корзины, но не обновил объекты в самой корзине. Теперь у вас должен быть доступ к нему. Обратите внимание, что вам нужно будет использовать --no-lock, поскольку я предоставил разрешения только на чтение.
pmkane
27 февр. 2019
Ага. Теперь я могу получить доступ к репо. Поиграю с ним сегодня вечером.
ifedorenko
27 февр. 2019
И в случае, если это полезно / легче тестировать, мы видим аналогичные характеристики производительности при восстановлении одних и тех же файлов в / из репозитория на быстром SSD, что исключает S3 из уравнения.
pmkane
28 февр. 2019
@pmkane Я могу воспроизвести проблему локально, и мне больше не нужен доступ к этой корзине. это было очень полезно, спасибо.
ifedorenko
28 февр. 2019
@ifedorenko , фантастика. Удаляю ведро.
pmkane
28 февр. 2019
@pmkane, пожалуйста, ветку out-order-restore еще раз, когда у вас будет время. У меня не было времени проверить это в ec2, но на моем MacBook восстановление, похоже, ограничено скоростью записи на диск и теперь соответствует rclone.
ifedorenko
1 мар. 2019
@ifedorenko , звучит многообещающе. Я сейчас провожу тест.
pmkane
1 мар. 2019
@ifedorenko , лото.
Восстановлено 133 ГБ BLOB-объектов, представляющих файлы разных размеров, самый большой из которых составляет 78 ГБ, всего за 16 минут. Раньше это восстановление занимало бы большую часть дня. Я подозреваю, что мы можем добиться этого еще быстрее, если поиграем с количеством restoreWorkers, но в нынешнем виде это достаточно быстро.
Спасибо за вашу тяжелую работу!
pmkane
1 мар. 2019
И для потомков: производительность нашего восстановления удваивается с 8-> 16 и снова с 16-> 32 рабочих восстановления. 32-> 64 годится только для увеличения ~ 50% по сравнению с 32, после чего мы восстанавливаем скорость около 3 Гбит / с. Почти на одном уровне с rclone.
Я знаю, что есть желание свести к минимуму объем конфигурации, необходимой для получения максимальной производительности от restic, но это достаточно большой скачок, особенно для пользователей с большими наборами файлов, и было бы неплохо иметь возможность указать количество рабочих во время выполнения.
pmkane
1 мар. 2019
Не уверен, почему восстановление по-прежнему не может обеспечить полную скорость передачи данных. Существует избыточная проверка хэша blob, которую вы можете прокомментировать, чтобы узнать, виновата ли она.
ifedorenko
2 мар. 2019
Я попробую.
pmkane
2 мар. 2019
Привет всем, я провел несколько тестов, используя последний запрос на перенос # 2195, и производительность продолжает улучшаться!
(20k маленьких файлов, 2x70G файлов, всего 170G)
8w_32c
real 27m46.185s
user 24m31.290s
sys 3m55.153s
32w_32c
real 15m30.904s
user 24m1.982s
sys 4m55.128s
64w_32c
real 18m37.566s
user 23m33.684s
sys 5m3.024s
64w_64c
real 17m12.314s
user 23m44.318s
sys 4m43.090s
Не уверен в падении производительности с 32 Вт до 64 Вт (проверено несколько раз и кажется нормальным). Прилагаю несколько графиков во время процесса, кажется, что есть какое-то ухудшение или ограничение, должно быть так? Например, с 64 рабочими процессами процесс начинается со скоростью 6 Гбит / сек, но после этого снижается до менее 1 Гбит / сек до конца процесса (что, я думаю, соответствует времени обработки этих больших файлов). Первый снимок экрана с 32w, 32c, а второй с 64w, 32c.
Я тоже согласен с @pmkane , было бы полезно изменить номер
В любом случае, я действительно впечатлен сделанными улучшениями! большое спасибо @ifedorenko
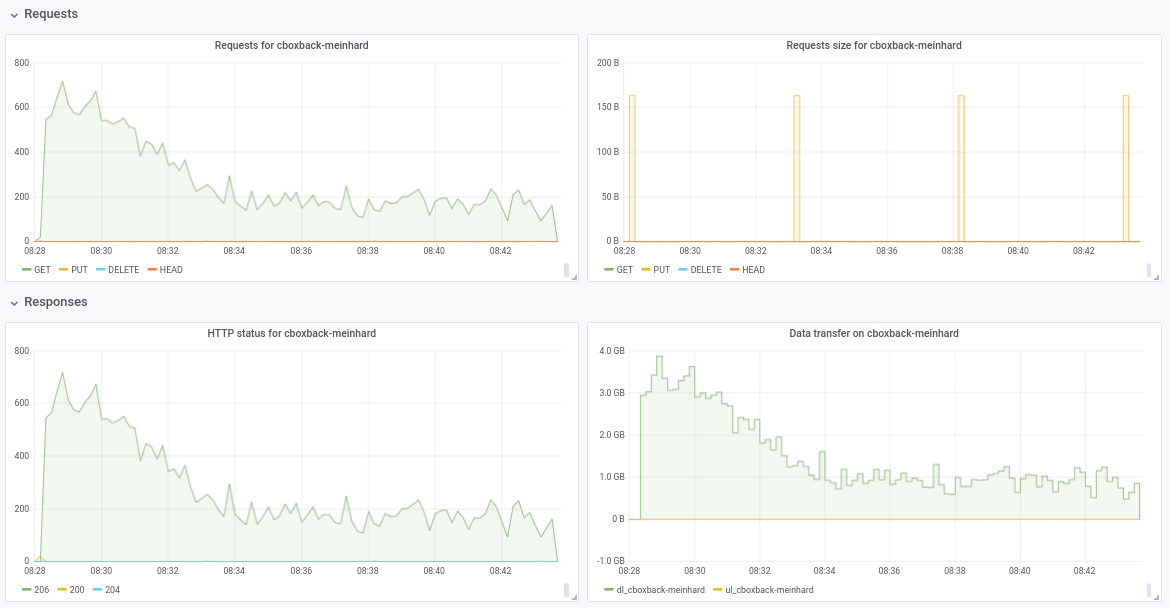
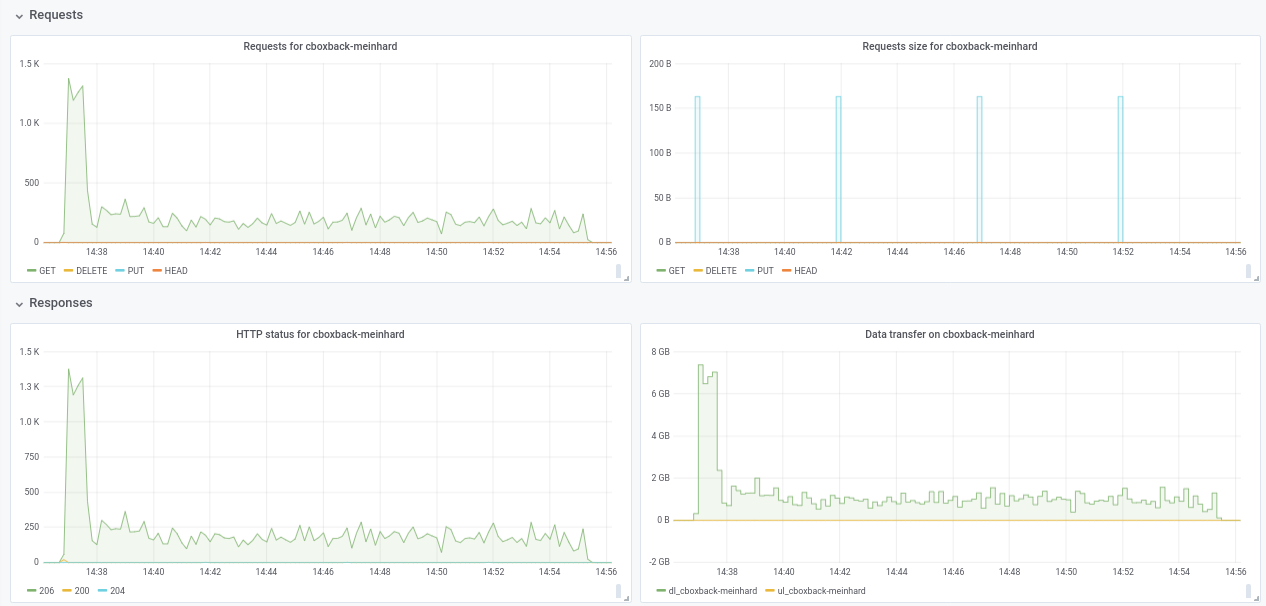
robvalca
4 мар. 2019
++. Спасибо @ifedorenko , это меняет правила игры для отдыха.
pmkane
4 мар. 2019
Спасибо за подробный отчет @robvalca. Есть ли шанс предоставить мне тестовый репозиторий в AWS (или GCP или Azure) или локально? В своих тестах я не заметил падения скорости восстановления больших файлов и хотел бы понять, что там происходит.
ifedorenko
4 мар. 2019
@pmkane Я тоже хотел бы настроить эти вещи во время выполнения . Мое предложение состояло в том, чтобы сделать их параметрами --option , чтобы они не загромождали обычные флаги или команды, но были доступны для «продвинутых» пользователей, которые хотят поэкспериментировать или настроиться на свою необычную ситуацию. Их даже не нужно документировать, и им можно дать имена, дающие понять, что вы не можете на них рассчитывать, например --option experimental.fooCount=32 .
 whereisaaron
4 мар. 2019
whereisaaron
4 мар. 2019
привет @ifedorenko , я создал публичное репо с нежелательными данными в s3.cern.ch/restic-testrepo . Это более или менее та же форма, что и та, которую я пробовал (много маленьких файлов и несколько очень больших), и я также мог воспроизвести то же поведение на этом (прикрепленный график). Пароль для репо: restic . Сообщите мне, если у вас возникнут проблемы с доступом к нему.
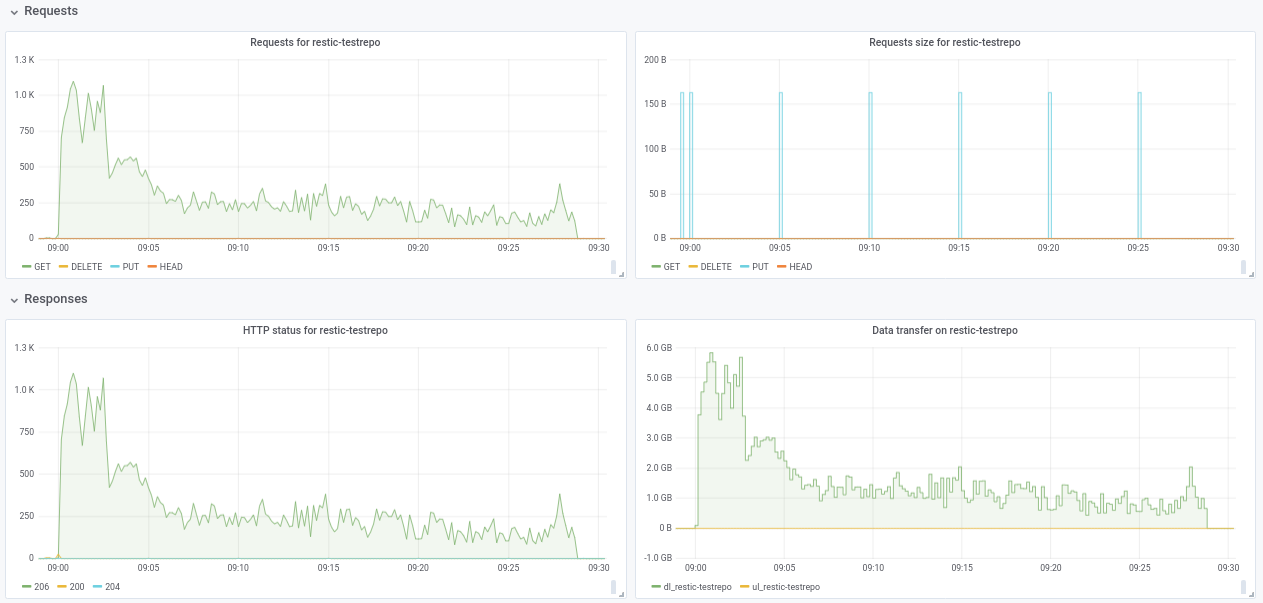
robvalca
5 мар. 2019
@robvalca Я не могу воспроизвести проблему с помощью вашего тестового репозитория. В AWS (us-east-2, s3 repo, i3.4xlarge 2x nvme raid0 target) я вижу стабильную скорость восстановления 0,68 ГБ / с при использовании 32 рабочих и 32 подключений (общее время восстановления 6 мин. 20 сек.). Ваша целевая система не может поддерживать скорость 10 ГБ / с в течение длительного времени, если я предполагаю, по крайней мере, это то, что я бы проверил в первую очередь, если бы я решил устранить эту неполадку дальше.
@pmkane интересно, я тоже не могу подтвердить ваши наблюдения. Как я упоминал выше, я вижу скорость восстановления 0,68 ГБ / с с использованием последней ветки out-of-order-restore-no-progress (восстановление выглядело с привязкой к ЦП) и 0,81 ГБ / с, если я отключил проверку хэша избыточных BLOB-объектов (восстановление не выглядело CPU- граница). Я не знаю, насколько быстрее может работать сеть «до 10 Гбит / с», но я думаю, что мы уже находимся в зоне «убывающей отдачи».
ifedorenko
6 мар. 2019
@ifedorenko Я полностью согласен с re: убывающая отдача. Для нас это и так достаточно быстро.
pmkane
6 мар. 2019
@ifedorenko интересно,
robvalca
7 мар. 2019
Интересно, как обстоят дела с объединением этой ветки. Эта ветка в сочетании с
pmkane
22 авг. 2019
Скоро ... 👀
 rawtaz
26 февр. 2020
rawtaz
26 февр. 2020
Закрытие теперь, когда # 2195 был объединен. Не стесняйтесь снова открыть его, если особенности, связанные с этой проблемой, не были решены. Если необходимо внести улучшения, которые не относятся к тому типу, который описан в этом выпуске, откройте новый выпуск. Спасибо!
rawtaz
26 февр. 2020
Смежные вопросы
 shibumi
·
3Комментарии
shibumi
·
3Комментарии
 jpic
·
3Комментарии
jpic
·
3Комментарии
 ikarlo
·
4Комментарии
ikarlo
·
4Комментарии
 cfbao
·
3Комментарии
cfbao
·
3Комментарии
 rakor
·
5Комментарии
rakor
·
5Комментарии
Самый полезный комментарий
Интересно, как обстоят дела с объединением этой ветки. Эта ветка в сочетании с