Lorawan-stack: Grundlegende Stationsintegration: Die Race-Bedingung bei der erneuten Verbindungsbehandlung führt zu einem dauerhaften Ausfall der Uplink-Weiterleitung
Zusammenfassung
Das Basisstationsprotokoll basiert auf TCP. Gelegentlich kann es vorkommen, dass der Client diese Verbindung trennt, ohne eine saubere Sequenz zum Schließen der TCP-Verbindung auszuführen. Dies kann auftreten, wenn die Verbindung zwischen Verbindung und Netzschicht plötzlich verschwindet und die TCP-Schicht zurückgesetzt und erneut versucht wird (z. B. wechselt ein Gateway vom Ethernet-Backhaul zum 3G-Backhaul, weil das Ethernet weg ist, oder wenn das Gateway einen unerwarteten Stromzyklus sieht und schnell hochfährt - a häufiges Unplug / Plugin-Szenario für TTIG). Wenn die Basisstation innerhalb einer bestimmten Zeit nach der Weiterleitung des letzten Uplinks für die alte Verbindung eine neue Verbindung herstellt, beendet der LNS die Verarbeitung von Uplinks von diesem Gateway dauerhaft. Es sieht so aus, als ob diese Zeitüberschreitung etwa 60 Sekunden beträgt. Angesichts der Symptome und der Tatsache, dass dies auf dem v3-Stack nicht der Fall ist, sieht es so aus, als ob dieses Problem mit # 1729 zusammenhängt.
Dieses Problem wurde auch in den TTN-Foren erörtert
Schritte zum Reproduzieren
- Um die Beendigung einer unsauberen TCP-Verbindung zu simulieren, führen Sie eine iptables-Regel ein, die TCP-FIN-Pakete blockiert:
iptables -A OUTPUT -d 52.169.76.203 --protocol tcp --tcp-flags FIN FIN -j DROP - Starten Sie Basic auf dem Computer, auf dem die iptables-Regel aktiv ist. Stellen Sie sicher, dass Sie sich in einer Umgebung mit regelmäßigen Uplinks befinden (etwa alle 10 Sekunden). Beachten Sie
https://console.thethingsnetwork.org/gateways/<GATEWAYID>/trafficfür eingehenden Datenverkehr. - Nachdem einige Uplinks weitergeleitet wurden, stoppen Sie den Stationsprozess mit STRG + C (der Server sieht aufgrund des fehlenden FIN-Pakets eine unsaubere TCP-Beendigung). Definieren wir die Zeit
Tals die Zeit, zu der die letzte Uplink-Nachricht weitergeleitet wurde, bevor der Stationsprozess beendet wurde. - Starten Sie kurz darauf den Stationsprozess erneut (Basic Station stellt Uplinks her und leitet sie weiter).
- Zum Zeitpunkt
T + 60 stritt die Fehlerbedingung ein.
Was siehst du jetzt?
Die Fehlerbedingung: Die Gateway-Konsole https://console.thethingsnetwork.org/gateways/<GATEWAYID>/traffic zeigt keine Uplinks mehr an, während die Verbindung zwischen der Basisstation und dem Server als aktiv gehalten wird (TCP-Keep-Alive-Nachrichten werden ausgetauscht) und die Basisstation weiterhin Uplinks empfängt. Eine TCP / IP-Paketerfassung zeigt, dass die Uplinks tatsächlich über das Websocket übertragen werden und die TCP-Pakete vom Server bestätigt werden - dh der Server empfängt die Uplink-Nachrichten definitiv, zeigt sie jedoch nicht in der Gateway-Konsole an.
Was möchten Sie stattdessen sehen?
Uplink-Nachrichten sollten weiterhin vom LNS verarbeitet werden.
Umgebung
Basisstation (neueste Version), TTN-Community-Netzwerk.
(Auf dem v3-Stack passiert dies nicht - daher der Verdacht, dass dies etwas mit der Heuristik für die inaktive Verbindungsbeendigung zu tun hat).
Wie schlagen Sie vor, dies umzusetzen?
Dies ist schwer zu beurteilen, ohne Zugriff auf den Code zu haben. Aus den Symptomen geht hervor, dass dieses Problem mit der Heuristik für die inaktive Verbindungsbeendigung zusammenhängt, wie in Problem Nr. 1729 erläutert. Wahrscheinlich sieht der Server zwei Verbindungen, weil eine neue Verbindung hergestellt wird, bevor die alte sauber geschlossen wird. Möglicherweise erkennt die Heuristik für die Verbindungsbeendigung eine inaktive Verbindung in der "toten" Verbindung und zerstört den mit dem Gateway verbundenen Kontext, ohne zu berücksichtigen, dass für eine zweite Verbindung dieser Kontext erforderlich ist, um Uplinks auf dem Stapel weiterzuleiten. Offensichtlich ist dies eine Vermutung, aber es könnte die Symptome erklären.
 beitler
beitler
Alle 16 Kommentare
Mit dem letzten Update wurde das Timeout anscheinend von 60 s auf 600 s geändert. Das zugrunde liegende Problem bleibt jedoch bestehen und kann mit den obigen Schritten zuverlässig reproduziert werden.
beitler
am 6. Feb. 2020
Ich werde versuchen, dies zu simulieren und die Proxy-Einstellungen zu optimieren, um festzustellen, wo das Problem liegt. Es muss jedoch beachtet werden, dass dies nur einen Prozentsatz der Gateways zu beeinflussen scheint.
In der folgenden Grafik entspricht die ansteigende Flanke der Spitze in Statusmeldungen dem 600s-Leerlauffenster. Jedes Mal, wenn das Gateway erneut eine Verbindung herstellt, protokollieren wir eine einzelne Statusmeldung (die diese Spitze berücksichtigt). Wenn Sie jedoch den Verkehr sehen, ist der Rückgang gering, aber nicht drastisch genug, um auf ein Problem mit allen Gateways hinzuweisen: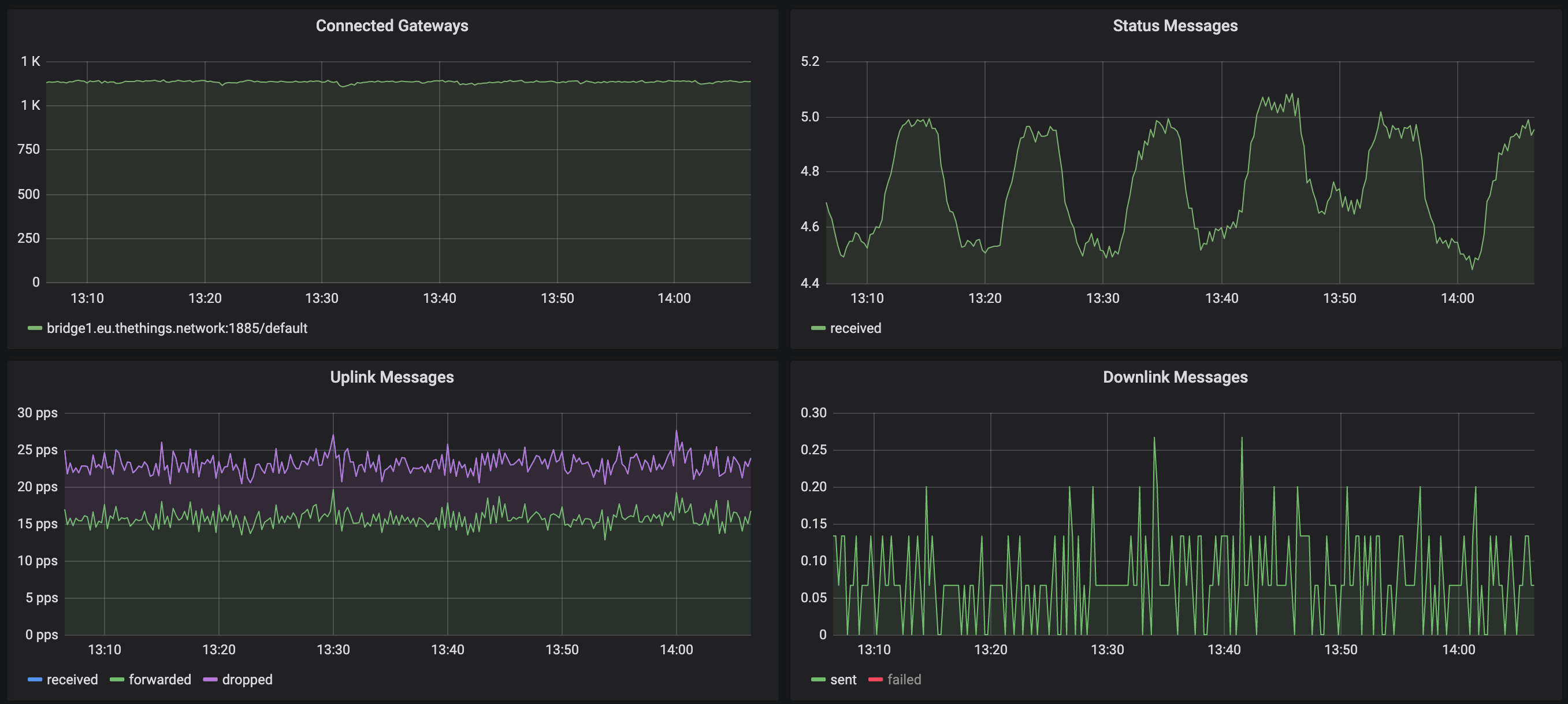
 KrishnaIyer
am 8. Feb. 2020
KrishnaIyer
am 8. Feb. 2020
Hallo Krishna, das Problem hängt nicht mit serverseitigen Verbindungsabbrüchen zusammen, sondern mit der Art und Weise, wie der Server unreine clientseitige Verbindungsabbrüche mit sofortigen erneuten Verbindungen behandelt. Das Problem betrifft alle auf Basisstationen basierenden Gateways und kann mit den obigen Anweisungen zuverlässig reproduziert werden.
Das Fehlermuster ist wie folgt:
- Das Gerät beendet die Verbindung unsauber (Aus- und Wiedereinschalten, Hard-Reset, WiFi-Drop, TTIG-Stecker / Plugin usw.)
- Das Gerät stellt sofort wieder eine Verbindung her
- Für 600s nach dem Trennen (diese Nummer war früher 60s) werden die weitergeleiteten Pakete im LNS angezeigt
- Nach 600 s und darüber hinaus nach dem Trennen werden die weitergeleiteten Pakete NICHT im LNS angezeigt
Durch Erhöhen des Zeitlimits von 60 auf 600 Sekunden wurde das Problem schwerwiegender: Bei 60s musste der Benutzer, der sein TTIG aussteckt, nur 60 Sekunden warten, bevor er es wieder einsteckte, um nicht auf das Problem zu stoßen. Dies kann häufig genug geschehen sein, insbesondere wenn ein Werksreset durchgeführt wird. Jetzt mit 600s wird ein größerer Prozentsatz auf das Problem stoßen, was auch beobachtet werden kann.
Würde es weh tun, diese Zeitüberschreitung vollständig zu deaktivieren? Die Basisstation hält TCP standardmäßig am Leben (https://github.com/lorabasics/basicstation/blob/c29b8502f8c715daecec6666835da6e981dc820a/src/sys.c#L637). Reicht das nicht aus, um die Lebendigkeit der Verbindung zu überprüfen?
beitler
am 8. Feb. 2020
Für mich sieht es auch nach dem Fehler habbens aus, wenn der Provider Ihre Internetverbindung abbricht und Sie beim erneuten Verbinden eine neue IP erhalten :(
Momentan funktioniert mein TTIG-Gateway jeden Tag nicht mehr. Wenn ich in den Protokollen meiner App zeige, ist der letzte Wert, den ich erhalten habe, kurz, bevor die Verbindung getrennt und dann wieder verbunden wurde.
Um das Gateway wieder zum Laufen zu bringen, muss ich es ausstecken, etwas warten und dann wieder einstecken.
Dieses Verhalten tritt jedoch erst seit dem 29.01 auf, bevor dies nie ein Problem war.
 JackGruber
am 9. Feb. 2020
JackGruber
am 9. Feb. 2020
@JackGruber Können Sie bestätigen, dass Sie in den ersten 600 Sekunden nach dem Trennen der Internetverbindung auch Uplinks erhalten können? (Um genau zu sein: 600 Sekunden abzüglich der Zeit, die das Modem und das Gateway benötigen, um wieder vollständig verbunden zu sein.)
Oder wenn Sie in diesen 600 Sekunden keine Uplinks sehen: Wie oft senden Ihre Geräte? (Mit anderen Worten: Würden Sie in diesen 600 Sekunden einige Uplinks erwarten?)
 avbentem
am 9. Feb. 2020
avbentem
am 9. Feb. 2020
Das Gerät, das ich überwache, sendet alle 5 Minuten.
02:42 RX-Rahmen
02:47 RX Frame
02:53 RX Frame
02.56 Reconnect
02:58 RX Frame
keine Frames
07:30 TTIG ausstecken / wieder einstecken
07:36 RX Frame
JackGruber
am 9. Feb. 2020
Wenn man 600 Sekunden nach der 2:56-Wiederverbindung berücksichtigt, kann man nach dem 2:58-Uplink auch einen 3:03-Uplink erwarten (der immer noch vor 2:56 plus 600 Sekunden = 3:06 liegt). Aber vielleicht wird das 600-Sekunden-Timeout nach dem 2:53-Uplink zurückgesetzt (anstatt nach einer späteren Keep-Alive- / Statusmeldung), wodurch TTN fälschlicherweise den Kontext / Status löscht, wenn der 3:03-Uplink empfangen werden soll. (Und natürlich werden Uplinks möglicherweise auch aus anderen Gründen nicht empfangen.)
Außerdem scheint alles in Ordnung zu sein, wenn der TTIG um 7:30 neu gestartet wird und 600 Sekunden später keine Probleme mehr auftreten. Dies scheint die ( großartige ) Analyse von @beitler zu bestätigen, die davon ausgeht, dass TTN fälschlicherweise einen gemeinsamen Kontext / Status bei
avbentem
am 9. Feb. 2020
Heute habe ich mir die Zeiten genauer angesehen
Ich habe auch eine Protokolldatei von der TTIG angehängt.
Leider nicht ab dem Zeitpunkt der ISP-Wiederverbindung.
Wenn gewünscht, erstelle ich ein Langzeitprotokoll, so dass auch die Wiederverbindung enthalten ist
TTIG.log
Zeitplan (UTC + 1)
02:46 RX-Nachrichten
02:51 RX-Nachrichten
02:56 RX-Nachrichten
02:58 RX-Nachrichten
02:58 ISP stellt die Verbindung wieder her
03:01 RX-Nachrichten
03:03 RX-Nachrichten
03:06 RX-Nachrichten
Es wurden keine Nachrichten mehr empfangen
TTN-Konsole
Status: nicht verbunden
Zuletzt gesehen: 2/11/2020 03:05:04
06:46 Short Un- / Replug TTIG (10 Sekunden lang kein Strom)
TTN-Konsole
Status: verbunden
Zuletzt gesehen: 2/11/2020 06:47:12
06:48 Empfangsnachrichten
....
Ich habe einen Fehler in meiner Firewall-Regel gefunden und die primäre CUPS-Verbindung (rjs.sm.tc) war nicht zulässig, nur die CUPS-Sicherung (mh.sm.tc).
JackGruber
am 11. Feb. 2020
Vielen Dank für Ihre Meldung. Wir haben das Problem identifiziert und beheben es. Dieses Problem befindet sich in unserer proprietären Codebasis, wird jedoch hier geschlossen.
 johanstokking
am 12. Feb. 2020
johanstokking
am 12. Feb. 2020
Hat sich seit +/- 18 Uhr heute Nachmittag etwas im Backend geändert?
Es ist jetzt so gut wie unmöglich, das TTN Indoor Gateway länger als 10 Minuten zu betreiben, während es meines Wissens seit Monaten einwandfrei funktioniert hat.
Durch Ändern der IP-Adresse über den DHCP-Server wird zwar eine 10-minütige Verbindung zum TTN-Netzwerk hergestellt, diese geht jedoch wieder verloren. (Replug funktioniert auch für 10 Minuten)
 TD-er
am 13. Feb. 2020
TD-er
am 13. Feb. 2020
@ TD-er, hast du es länger als 10 Minuten (600 Sekunden) vom Stromnetz getrennt gelassen?
Wie oben erläutert, ist dies seit der Änderung am 6. Februar erforderlich. Vor dem 7. Februar musste man es 60 Sekunden lang vom Stromnetz trennen. Es ist mir unklar, ob der heutige zusammengeführte Fix auch bereitgestellt wurde.
avbentem
am 13. Feb. 2020
Nein, nicht so lange ausgesteckt.
Wenn der Netzstecker gezogen wurde, wurde er nur einige Sekunden lang vom Stromnetz getrennt.
Mit der DHCP-Änderung der IP-Adresse wurde das Gerät sogar nie aus- und wieder eingeschaltet. Es erhielt lediglich eine neue IP vom DHCP-Server und stellte so seine Netzwerkverbindung wieder her. Dadurch funktionierte es fast genau 10 Minuten lang, bis es wieder nicht verfügbar war.
Ich werde es jetzt für eine Weile ausstecken und dann sehen, was passiert, nachdem ich es wieder eingesteckt habe.
TD-er
am 13. Feb. 2020
Hatte es für ungefähr 25 Minuten ausgeschaltet und jetzt für ungefähr 15 Minuten angeschlossen und es funktioniert immer noch :) Mal sehen, ob es morgen früh noch läuft.
TD-er
am 14. Feb. 2020
Wir veröffentlichen heute Version 3.5.3 mit dem Fix und können diesen wahrscheinlich auf den Servern bereitstellen, auf denen TTIG eine Verbindung herstellt. Hoffentlich wird das sehr bald gelöst.
johanstokking
am 14. Feb. 2020
Hoffen wir, dass es noch nicht bereitgestellt wurde, da mein Indoor-Gateway jetzt bereits seit ca. 3 Stunden wieder offline ist.
TD-er
am 14. Feb. 2020
Wir haben dieses Problem nach der Bereitstellung der neuesten Fixes nicht gehört. Bitte öffnen Sie es erneut, wenn Sie es erneut beobachten.
KrishnaIyer
am 24. Feb. 2020
Verwandte Themen
 ecities
·
5Kommentare
ecities
·
5Kommentare
 ZeroSum24
·
3Kommentare
ZeroSum24
·
3Kommentare
 htdvisser
·
4Kommentare
johanstokking
·
8Kommentare
htdvisser
·
4Kommentare
johanstokking
·
8Kommentare
 adamsondelacruz
·
7Kommentare
adamsondelacruz
·
7Kommentare
Hilfreichster Kommentar
Hallo Krishna, das Problem hängt nicht mit serverseitigen Verbindungsabbrüchen zusammen, sondern mit der Art und Weise, wie der Server unreine clientseitige Verbindungsabbrüche mit sofortigen erneuten Verbindungen behandelt. Das Problem betrifft alle auf Basisstationen basierenden Gateways und kann mit den obigen Anweisungen zuverlässig reproduziert werden.
Das Fehlermuster ist wie folgt:
Durch Erhöhen des Zeitlimits von 60 auf 600 Sekunden wurde das Problem schwerwiegender: Bei 60s musste der Benutzer, der sein TTIG aussteckt, nur 60 Sekunden warten, bevor er es wieder einsteckte, um nicht auf das Problem zu stoßen. Dies kann häufig genug geschehen sein, insbesondere wenn ein Werksreset durchgeführt wird. Jetzt mit 600s wird ein größerer Prozentsatz auf das Problem stoßen, was auch beobachtet werden kann.
Würde es weh tun, diese Zeitüberschreitung vollständig zu deaktivieren? Die Basisstation hält TCP standardmäßig am Leben (https://github.com/lorabasics/basicstation/blob/c29b8502f8c715daecec6666835da6e981dc820a/src/sys.c#L637). Reicht das nicht aus, um die Lebendigkeit der Verbindung zu überprüfen?