Lorawan-stack: Integração de estação básica: condição de corrida no manuseio de reconexão causa falha permanente de encaminhamento de uplink
Resumo
O protocolo Basic Station é baseado em TCP. Ocasionalmente, pode acontecer que o cliente interrompa esta conexão sem executar uma seqüência de fechamento de conexão TCP limpa. Isso pode ocorrer se a conectividade da camada de link / rede desaparecer repentinamente e fizer com que a camada TCP seja redefinida e tente novamente (por exemplo, um gateway está mudando de backhaul Ethernet para backhaul 3G porque a Ethernet foi embora; ou gateway está vendo um ciclo de energia inesperado e inicializa rapidamente - a cenário comum de desconexão / plug-in para TTIG). Se a Estação Básica estabelecer uma nova conexão dentro de um certo tempo após o último uplink para a conexão antiga ter sido encaminhado, o LNS para de processar os uplinks deste gateway permanentemente. Parece que o tempo limite é de cerca de 60 segundos. Dados os sintomas e o fato de que isso não acontece na pilha da v3, parece que esse problema está relacionado ao # 1729.
Este problema também foi discutido nos fóruns TTN
Passos para reproduzir
- Para simular o término da conexão TCP impuro, introduza uma regra iptables que bloqueia os pacotes TCP FIN:
iptables -A OUTPUT -d 52.169.76.203 --protocol tcp --tcp-flags FIN FIN -j DROP - Inicie o Basic na máquina onde a regra iptables está ativa. Certifique-se de estar em um ambiente de uplinks regulares (a cada 10 segundos ou mais). Observe
https://console.thethingsnetwork.org/gateways/<GATEWAYID>/trafficpara o tráfego de entrada. - Depois que alguns uplinks forem encaminhados, pare o processo da estação com CTRL + C (o servidor verá uma terminação TCP impura, por causa do pacote FIN ausente). Vamos definir a hora
Tcomo a hora em que a última mensagem de uplink foi enviada antes que o processo da estação fosse encerrado. - Pouco depois, inicie o processo da estação novamente (a Estação Básica conectará e encaminhará uplinks).
- No momento
T + 60 s, a condição de erro é ativada.
O que você vê agora?
A condição de erro: O console de gateway https://console.thethingsnetwork.org/gateways/<GATEWAYID>/traffic parará de mostrar uplinks enquanto a conexão entre a Estação Básica e o Servidor for mantida ativa (mensagens TCP keep alive são trocadas) e a Estação Basic continua a receber uplinks. Uma captura de pacote TCP / IP mostra que os uplinks são realmente transferidos pelo websocket e os pacotes TCP são reconhecidos pelo servidor - ou seja, o servidor definitivamente recebe as mensagens de uplink, mas não as mostra no console do gateway.
O que você quer ver em vez disso?
As mensagens de uplink devem continuar a ser processadas pelo LNS.
Meio Ambiente
Estação básica (versão mais recente), rede comunitária TTN.
(Na pilha v3 isso não acontece - daí a suspeita de que tem algo a ver com a heurística de encerramento de conexão inativa).
Como você pretende implementar isso?
Isso é difícil de julgar sem ter acesso ao código. Pelos sintomas, parece que esse problema está vinculado à heurística de encerramento de conexão inativa, conforme discutido no problema # 1729. Provavelmente, o servidor está vendo duas conexões porque uma nova conexão é estabelecida antes que a antiga seja totalmente fechada. Talvez, a heurística de término de conexão detecte uma conexão inativa na conexão 'morta' e destrua o contexto relacionado ao gateway sem considerar que uma segunda conexão requer este contexto para encaminhar uplinks para a pilha. Obviamente, isso é um palpite, mas pode explicar os sintomas.
 beitler
beitler
Todos 16 comentários
Com a atualização mais recente, o tempo limite aparentemente foi alterado de 60 s para 600 s. Mas o problema subjacente permanece e pode ser reproduzido de forma confiável com as etapas acima.
beitler
em 6 fev. 2020
Vou tentar simular isso e ajustar as configurações de proxy para ver onde está o problema. Mas deve-se notar que isso parece afetar apenas uma porcentagem dos gateways.
No gráfico a seguir, a borda ascendente do pico nas mensagens de status corresponde à janela ociosa do 600s. Cada vez que o gateway se reconecta, registramos uma única mensagem de status (que é responsável por esse aumento). Mas se você vir o tráfego, a queda é leve, mas não drástica o suficiente para indicar um problema com todos os gateways: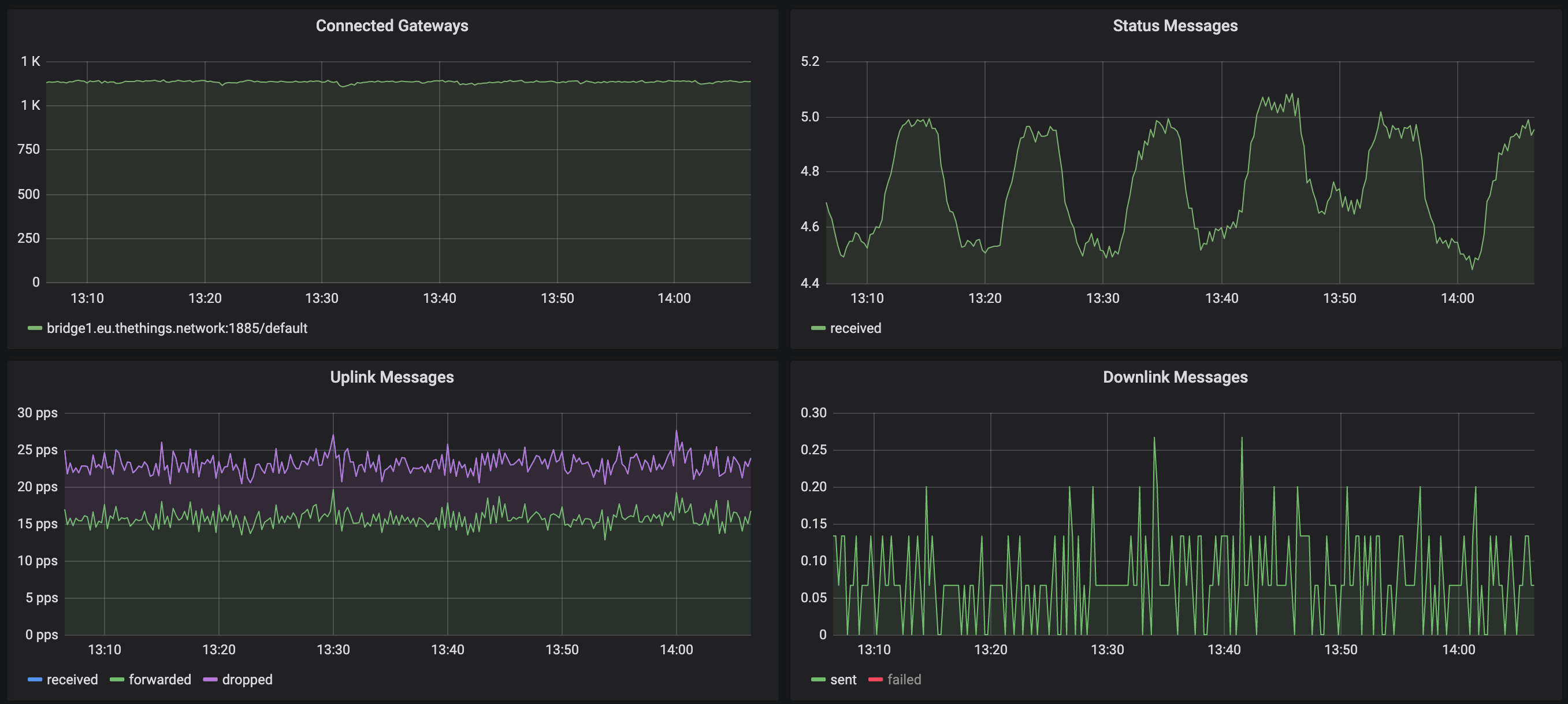
 KrishnaIyer
em 8 fev. 2020
KrishnaIyer
em 8 fev. 2020
Olá, Krishna, o problema não está relacionado às desconexões do lado do servidor, mas à maneira como o servidor lida com as desconexões impuras do lado do cliente com reconexões imediatas. O problema afeta todos os gateways baseados na Estação Básica e pode ser reproduzido de forma confiável com as instruções acima.
O padrão de erro é assim:
- O dispositivo encerra a conexão sem limpar (ciclo de energia, reinicialização de hardware, queda de WiFi, desconexão / plug-in TTIG, etc.)
- O dispositivo reconecta-se imediatamente
- Por 600s após a desconexão (este número costumava ser 60s), os pacotes encaminhados são vistos no LNS
- Após 600s e além, após a desconexão, os pacotes encaminhados NÃO são vistos no LNS
Aumentar o tempo limite de 60s para 600s tornou o problema mais grave: com 60s, o usuário, que desconectava seu TTIG, só tinha que esperar 60s antes de conectá-lo novamente para evitar o problema. Isso pode ter acontecido com bastante frequência, especialmente quando as pessoas fazem uma redefinição de fábrica. Já com 600s, uma porcentagem maior se deparará com o problema, que também pode ser observado.
Doeria desativar totalmente esse tempo limite? A Estação Básica TCP mantém viva por padrão (https://github.com/lorabasics/basicstation/blob/c29b8502f8c715daecec6666835da6e981dc820a/src/sys.c#L637). Isso não é suficiente para verificar a vitalidade da conexão?
beitler
em 8 fev. 2020
Para mim parece que o erro habbens também, quando o provedor desconecta sua conexão de internet e você obtém um novo IP na reconexão :(
No momento, todos os dias, meu TTIG Gateway não está mais funcionando e, quando eu mostro nos logs do meu aplicativo, o último valor que recebi é curto antes de a conexão ser desconectada e reconectada.
Para fazer o gateway funcionar novamente, tenho que desconectá-lo, esperar um pouco e conectá-lo novamente.
Mas esse comportamento ocorre apenas a partir de 29.01, antes isso nunca foi um problema.
 JackGruber
em 9 fev. 2020
JackGruber
em 9 fev. 2020
@JackGruber, você pode confirmar se também pode receber uplinks durante os primeiros 600 segundos após a conexão com a Internet ser desconectada? (Para ser exato: 600 segundos, menos o tempo que leva para o modem e o gateway serem totalmente reconectados.)
Ou se você não está vendo nenhum uplink nesses 600 segundos: com que frequência seus dispositivos transmitem? (Em outras palavras: você esperaria receber alguns uplinks durante esses 600 segundos?)
 avbentem
em 9 fev. 2020
avbentem
em 9 fev. 2020
O dispositivo que estou monitorando transmite a cada 5 minutos.
02:42 RX Frame
02:47 RX Frame
02:53 RX Frame
02:56 Reconectar
02:58 RX Frame
sem frames
07:30 Desconectar / reconectar TTIG
07:36 RX Frame
JackGruber
em 9 fev. 2020
Considerando 600 segundos após a reconexão de 2:56, acho que após o uplink de 2:58 também se pode esperar um uplink de 3:03 (que ainda é antes de 2:56 mais 600 segundos = 3:06). Mas talvez o tempo limite de 600 segundos seja redefinido após o uplink de 2:53 (em vez de depois de alguma mensagem keep-alive / status posterior), fazendo com que o TTN apague erroneamente o contexto / estado apenas quando o uplink de 3:03 deveria ser recebido. (E, claro, os uplinks também podem não ser recebidos por outros motivos.)
Além disso, tudo bem ao reiniciar o TTIG às 7:30, e não ter problemas novamente 600 segundos depois disso, parece confirmar a ( ótima ) análise de @beitler , que assume que o TTN
avbentem
em 9 fev. 2020
Hoje eu olhei mais de perto os tempos
Também anexei um arquivo de log do TTIG.
Infelizmente, não desde o momento da reconexão do ISP.
Se desejar, eu crio um registro de longo prazo, de modo que também a reconexão seja incluída
TTIG.log
Cronograma (UTC + 1)
02:46 Mensagens RX
02:51 Mensagens RX
02:56 Mensagens RX
02:58 Mensagens RX
02:58 ISP reconectar
03:01 Mensagens RX
03:03 Mensagens RX
03:06 Mensagens RX
não há mais mensagens recebidas
Console TTN
Status: não conectado
Visto pela última vez: 11/02/2020 03:05:04
06:46 Short Un- / Replug TTIG (sem energia por 10 segundos)
Console TTN
Status: conectado
Visto pela última vez: 11/02/2020 06:47:12
06:48 mensagens RX
....
Encontrei um erro na regra do meu firewall e a conexão primária do CUPS (rjs.sm.tc) não era permitida, apenas o CUPS-BACKUP (mh.sm.tc).
JackGruber
em 11 fev. 2020
Obrigado por relatar, identificamos o problema e o estamos corrigindo. Este problema reside em nossa base de código proprietário, mas será encerrado aqui.
 johanstokking
em 12 fev. 2020
johanstokking
em 12 fev. 2020
Algo mudou no back-end desde +/- 18h esta tarde?
Agora é quase impossível executar o TTN Indoor Gateway por mais de 10 minutos, enquanto ele estava funcionando bem, pelo que eu sei, por meses.
A mudança do endereço IP por meio do servidor DHCP oferece 10 minutos de conectividade com a rede TTN, mas depois ela é perdida novamente. (reconectar também funciona por 10 minutos)
 TD-er
em 13 fev. 2020
TD-er
em 13 fev. 2020
@ TD-er, você o deixou desconectado por mais de 10 minutos (600 segundos)?
Como explicado acima, isso é necessário desde a mudança de 6 de fevereiro. Antes de 7 de fevereiro, era necessário deixá-lo desconectado por 60 segundos. Não está claro para mim se a correção mesclada de hoje também foi implantada.
avbentem
em 13 fev. 2020
Não, não desconectado por tanto tempo.
Quando desconectado, ele foi desconectado apenas por alguns segundos.
Com a mudança do endereço IP do DHCP, a unidade nem mesmo foi desligada e ligada, apenas recebeu um novo IP do servidor DHCP e, assim, reconstruiu sua conexão de rede. Isso o fez funcionar por quase exatamente 10 minutos, até que ficou indisponível novamente.
Vou agora desconectá-lo por um tempo e ver o que acontece depois de reconectá-lo.
TD-er
em 13 fev. 2020
Ele desligou por cerca de 25 minutos e agora está conectado por cerca de 15 minutos e ainda está funcionando :) Vou ver se ainda funciona amanhã de manhã.
TD-er
em 14 fev. 2020
Estamos lançando a v3.5.3 hoje contendo a correção e provavelmente podemos implantá-la nos servidores aos quais o TTIG se conecta. Esperançosamente, isso será resolvido em breve.
johanstokking
em 14 fev. 2020
Esperemos que ele ainda não tenha sido implantado, já que meu gateway interno está off-line novamente por cerca de 3 horas.
TD-er
em 14 fev. 2020
Não ouvimos esse problema após a implantação das correções mais recentes. Sinta-se à vontade para reabrir se for observado novamente.
KrishnaIyer
em 24 fev. 2020
Questões relacionadas
johanstokking
·
8Comentários
johanstokking
·
8Comentários
 kschiffer
·
4Comentários
johanstokking
·
5Comentários
kschiffer
·
4Comentários
johanstokking
·
5Comentários
 adriansmares
·
9Comentários
adriansmares
·
9Comentários
Comentários muito úteis
Olá, Krishna, o problema não está relacionado às desconexões do lado do servidor, mas à maneira como o servidor lida com as desconexões impuras do lado do cliente com reconexões imediatas. O problema afeta todos os gateways baseados na Estação Básica e pode ser reproduzido de forma confiável com as instruções acima.
O padrão de erro é assim:
Aumentar o tempo limite de 60s para 600s tornou o problema mais grave: com 60s, o usuário, que desconectava seu TTIG, só tinha que esperar 60s antes de conectá-lo novamente para evitar o problema. Isso pode ter acontecido com bastante frequência, especialmente quando as pessoas fazem uma redefinição de fábrica. Já com 600s, uma porcentagem maior se deparará com o problema, que também pode ser observado.
Doeria desativar totalmente esse tempo limite? A Estação Básica TCP mantém viva por padrão (https://github.com/lorabasics/basicstation/blob/c29b8502f8c715daecec6666835da6e981dc820a/src/sys.c#L637). Isso não é suficiente para verificar a vitalidade da conexão?